GRAF: Generative Radiance Fields for 3D-Aware Image Synthesis
GRAF: Generative Radiance Fields for 3D-Aware Image Synthesis
Katja Schwarz, Yiyi Liao, Michael Niemeyer, Andreas Geiger
Abstract
2D 생성 적대적 네트워크는 고해상도 이미지 합성을 가능하게 했지만, 3D 세계와 이미지 형성 과정에 대한 이해가 크게 부족하다.
따라서 카메라 시점이나 물체 포즈를 정확하게 제어하지 못한다.
이 문제를 해결하기 위해 최근 몇 가지 접근법은 미분 가능한 렌더링과 함께 중간 복셀 기반 표현을 활용한다.
그러나 기존 방법은 낮은 이미지 해상도를 생성하거나 카메라 및 장면 속성을 분리하는 데 부족하다, 예를 들어 객체 ID는 관점에 따라 달라질 수 있다.
본 논문에서는 단일 장면의 새로운 뷰 합성에 최근 성공한 것으로 입증된 radiance fields에 대한 생성 모델을 제안한다.
복셀 기반 표현과 대조적으로, radiance fields는 3D 공간의 coarse 이산화로 제한되지 않지만 재구성 모호성이 있는 경우 우아하게 저하되면서 카메라 및 장면 속성을 분리할 수 있다.
다중 스케일 패치 기반 판별기를 도입하여, 우리는 제안되지 않은 2D 이미지만으로 모델을 학습시키면서 고해상도 이미지의 합성을 시연한다.
우리는 몇 가지 까다로운 합성 및 실제 데이터 세트에 대한 접근 방식을 체계적으로 분석한다.
우리의 실험은 radiance fields가 생성 이미지 합성을 위한 강력한 표현이며, 높은 충실도로 렌더링하는 3D 일관된 모델로 이어진다는 것을 보여준다.
1 Introduction
컨볼루션 생성 적대 네트워크는 비정형 이미지 컬렉션에서 고해상도 이미지[6, 26, 34, 53]를 합성하는 데 있어 인상적인 결과를 보여주었다.
그러나 이러한 성공에도 불구하고 SOTA 모델은 3D 모양과 관점을 포함한 기본 생성 요소를 적절하게 분리하기 위해 고군분투한다.
이는 세계의 3D 구조에 대해 추론하고 새로운 관점에서 사물을 상상하는 놀라운 능력을 가진 인간과 극명한 대조를 이룬다.
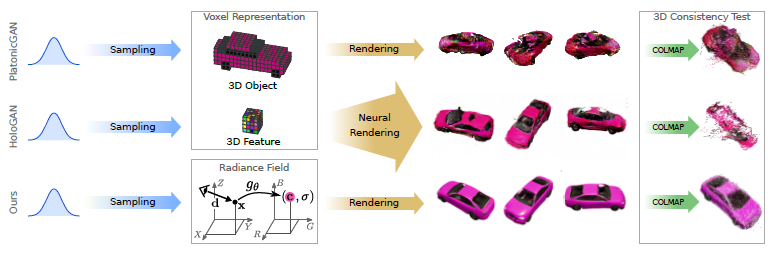
3D에서의 추론은 로봇 공학, 가상 현실 또는 데이터 증강의 애플리케이션에 기본적이기 때문에, 최근의 여러 연구는 카메라 포즈에 대한 명시적인 제어로 사진-사실적인 이미지 생성을 목표로 3D 인식 이미지 합성 작업을 고려한다[19, 39, 76].
2D 생성 적대적 네트워크와 대조적으로, 3D 인식 이미지 합성을 위한 접근 방식은 미분 가능한 렌더링 기술을 사용하여 이미지에 명시적으로 매핑되는 3D 장면 표현을 학습하므로 장면 콘텐츠와 관점 모두를 제어할 수 있다.
3D supervision 또는 포즈 이미지는 실제로 얻기 어려운 경우가 많기 때문에, 최근 연구에서는 2D supervision만을 사용하여 이 작업을 해결하려고 한다[19, 39].
이 목표를 위해, 기존 접근 방식은 이산화된 3D 표현, 즉 그림 1에 표시된 것처럼 전체 3D 객체[19] 또는 중간 3D 피쳐[39]를 나타내는 복셀 그리드를 생성한다.
색 공간에서 3D 객체를 모델링하면 미분 가능한 렌더링을 활용할 수 있지만, 복셀 기반 표현의 입방 메모리 증가는 [19] 해상도를 낮게 제한하고 가시적인 아티팩트를 초래한다.
중간 3D 피쳐[39]는 이미지 해상도로 더 작고 확장성이 좋습니다.
그러나 이를 위해서는 추상 피쳐를 RGB 값으로 디코딩하기 위한 3D-to-2D 매핑을 학습해야 하며, 이는 고해상도의 뷰에서 일관되지 않는 얽힌 표현을 초래한다.
본 논문에서, 우리는 coarse 출력과 얽힌 잠재 사이의 딜레마가 새로운 관점 합성을 위해 최근 제안된 연속 표현의 조건부 변형인 conditional radiance fields를 사용하여 해결될 수 있음을 보여준다[36].
보다 구체적으로, 우리는 다음과 같은 기여를 한다:
i) 우리는 제안되지 않은 이미지에서 고해상도 3D 인식 이미지 합성을 위한 radiance fields의 생성 모델인 GRAF를 제안한다.
관점 조작 외에도, 우리의 접근 방식은 생성된 물체의 모양과 외관을 수정할 수 있다.
ii) 우리는 이미지를 여러 척도로 샘플링하고 고해상도 생성 radiance fields를 효율적으로 학습하는 데 핵심인 패치 기반 판별기를 소개한다.
iii) 합성 및 실제 데이터 세트에 대한 접근 방식을 체계적으로 평가한다.
우리의 접근 방식은 높은 공간 해상도로 일반화하면서 시각적 충실도와 3D 일관성 측면에서 SOTA 방법에 비해 유리하다.
2 Related Work
Image Synthesis:
Generative Adversarial Networks (GAN)[16, 51]는 사진-사실적 이미지 합성의 SOTA 기술을 크게 발전시켰다.
이미지 합성 프로세스를 더 제어할 수 있도록 하기 위해 최근 몇 가지 연구에서 variation의 요인을 분리할 것을 제안했다[9, 25, 28, 41, 54, 74].
그러나 이러한 모든 방법은 2D 이미지가 3D 세계의 투영으로 획득된다는 사실을 무시한다.
일부 방법은 분리된 요소가 3D 속성을 캡처하여 [9, 28, 41]을 확장한다는 것을 보여주지만, 특히 객체 외관 및 정체성에서 관점 변화를 충실하게 분리하는 표현을 찾을 때 2D 컨볼루션 네트워크를 사용하여 이미지 메니폴드를 모델링하는 것은 여전히 어려운 작업으로 남아 있다.
따라서 2D 이미지 매니폴드를 직접 모델링하는 대신 3D 표현을 생성하고 이미지 형성 프로세스를 명시적으로 모델링하는 것을 목표로 하는 최근 작업[19, 30, 39]을 따른다.
3D-Aware Image Synthesis:
학습 기반 새로운 관점 합성은 문헌[14, 36, 56, 61–64, 69, 75]에서 집중적으로 조사되었다.
이러한 방법은 동일한 객체에서 보이지 않는 뷰를 생성하며 일반적으로 supervision으로 카메라 뷰 포인트가 필요하다.
일부 연구[14, 56, 62–64, 69]는 개체당 개별 네트워크를 학습시킬 필요 없이 서로 다른 개체에 걸쳐 일반화하지만, unconditional 랜덤 샘플을 그리기 위한 완전한 확률론적 생성 모델을 산출하지는 않는다.
대조적으로, 우리는 unposed 2D 이미지에서 3D 인식 생성 모델을 학습하여 여러 뷰에서 새로운 객체를 생성하는 데 관심이 있다.
최근의 여러 연구는 3D 인식 이미지 합성을 위해 생성적 3D 모델을 활용한다[4,30,39,45,68,76].
많은 방법들이 3D supervision[68, 76]을 요구하거나 3D 정보를 입력[4, 45]으로 가정합니다.
예: 텍스처 필드[45]는 특정 3D 모양을 조건으로 새로운 텍스처를 합성한다.
결과적으로 입력으로 3D 모양을, supervision으로 컬러 표면 점을 필요로 한다.
대신, 우리는 2D 이미지에서만 모양과 질감 모두에 대한 생성 모델을 배운다.
이것은 지금까지 시도한 작품이 거의 없는 어려운 작업이다: PLATONICGAN[19]은 미분 가능한 렌더링 기술을 사용하여 2D 이미지에서 질감이 있는 3D 복셀 표현을 학습한다.
그러나 이러한 복셀 기반 표현은 메모리 집약적이어서 높은 이미지 해상도에서 이미지 합성을 금지한다.
이 작업에서, 우리는 임의의 해상도로 이미지를 렌더링할 수 있는 연속 표현을 사용하여 이러한 메모리 제한을 피한다.
HoloGAN [39] 및 일부 관련 작업 [30, 40]은 학습 가능한 3D-to-2D 투영과 결합된 저차원 3D 피쳐를 학습한다.
그러나, 우리의 실험에서 증명되었듯이, 학습된 투영은 특히 고해상도에서, 얽힘 잠재(예: 객체 정체성 및 관점)를 초래할 수 있다.
추가 제약 조건을 사용하여 3D 일관성을 장려할 수 있지만 [44], 우리는 학습할 필요가 없는 미분 가능한 볼륨 렌더링 기술을 활용하여 설계에 의해 3D 일관성을 생성 모델에 통합한다.
Implicit Representations:
최근, 3D 기하학의 암시적 표현은 학습 기반 3D 재구성에서 인기를 얻고 있다[10, 15, 35, 42, 45, 48, 59].
복셀[7, 11, 55, 57, 70, 71] 또는 메시 기반 [17, 29, 47, 67] 방법에 비해 주요 이점은 공간을 이산화하지 않고 위상에 제한되지 않는다는 것입니다.
최근의 하이브리드 연속 그리드 표현[8, 22, 50]은 암시적 표현을 복잡하거나 대규모 장면으로 확장하지만 3D 입력이 필요하고 질감을 고려하지 않는다.
다른 일련의 작업[43, 62, 72]은 렌더링 프로세스를 미분 가능하여 포즈를 취한 다중 뷰 이미지에서만 연속적인 모양과 질감 표현을 학습할 것을 제안한다.
이러한 모델은 단일 물체 또는 작은 기하학적 복잡성의 장면으로 제한되므로, Mildenhall et al. [36]은 포즈를 취한 2D 이미지에서 보다 복잡한 실제 장면의 다중 뷰 일관된 새로운 뷰 합성을 가능하게 하는 neural radiance fields로 장면을 표현할 것을 제안한다.
그들은 이 작업에 대한 설득력 있는 결과를 보여주지만, 그들의 방법은 많은 포즈를 취한 뷰를 필요로 하고, 각 장면에 대해 재학습을 받아야 하며, 새로운 장면을 생성할 수 없다.
이 작업에서 영감을 받아, 우리는 이 표현의 conditional variant를 활용하고 unposed 2D 이미지 모음에서 풍부한 생성 모델을 입력으로 학습할 수 있는 방법을 보여준다.
3 Method
우리는 3D 인식 이미지 합성 문제, 즉 카메라 회전 및 이동에 대한 명시적인 제어를 제공하면서 높은 충실도의 이미지를 생성하는 작업을 고려한다.
우리는 물리적 기반과 매개 변수가 없는 투영 매핑을 허용하면서 이미지 해상도 및 메모리 소비와 관련하여 이러한 연속적인 표현이 잘 확장되기 때문에 radiance field로 장면을 표현해야 한다고 주장한다.
다음에서는 먼저 제안된 Generative Radiance Field (GRAF) 모델의 기초를 형성하는 Neural Radiance Fields (NeRF)[36]를 간략하게 검토한다.
3.1 Neural Radiance Fields
Neural Radiance Fields:
radiance field는 3D 위치 및 2D 뷰 방향에서 RGB 색상 값으로 연속 매핑되는 것입니다 [23, 33].
Mildenhall et al. [36]은 이 매핑을 표현하기 위해 신경망을 사용할 것을 제안했다.
보다 구체적으로, 그들은 먼저 x와 d의 세 가지 구성 요소 모두에 요소별로 적용되는 고정 위치 인코딩을 사용하여 3D 위치 x ∈ R^3과 뷰 방향 d ∈ S^2를 고차원 피쳐 표현에 매핑한다:
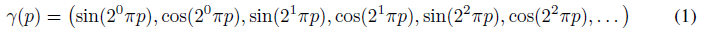
최근의 암시적 모델[10, 35, 48]에 따라, 그들은 결과적인 피쳐를 색상 값 c ∈ R^3 및 부피 밀도 σ ∈ R+에 매핑하기 위한 매개 변수 θ를 가진 다층 퍼셉트론 f_θ(·)를 적용한다:
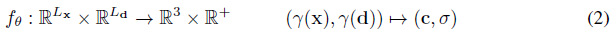
[36, 52]에서 입증된 바와 같이, 위치 인코딩 γ(·)는 다중 레이어 퍼셉트론 f_θ(·)에 대한 입력으로 x와 d를 직접 사용하는 것에 비해 고주파 신호의 더 나은 피팅을 가능하게 한다.
우리는 우리의 보충 자료의 ablation 연구를 통해 이것을 확인한다.
볼륨 컬러 c는 3D 위치보다 보는 방향에 따라 더 부드럽게 변화하므로, 일반적으로 보는 방향은 더 적은 구성 요소, 즉 L_d < L_x를 사용하여 인코딩된다.
Volume Rendering:
radiance field f_θ(·)에서 2D 이미지를 렌더링하기 위해 Mildenhall et al.[36]은 수치 적분을 사용하여 다루기 어려운 체적 투영 적분을 근사화한다.
보다 공식적으로, {(c_r^i, σ_r^i)}_(i=1)^N이 카메라 ray r을 따라 N개의 랜덤 샘플의 색상 및 부피 밀도 값을 나타낸다고 하자.
렌더링 연산자 π(·)는 이러한 값을 RGB 색 값 c_r에 매핑합니다:
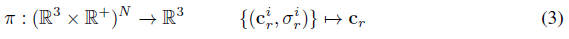
RGB 색상 값 c_r은 알파 합성
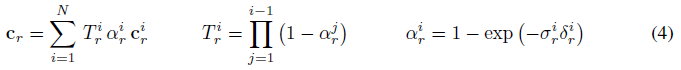
을 사용하여 구하는데, 여기서 T_r^i와 알파_r^i는 ray r을 따른 샘플 포인트 i의 투과도와 알파 값을 나타내고 δ_r^i = |x_r^(i+1) - x_r^i|는 인접 샘플 포인트 사이의 거리를 나타낸다.
Mildenhall et al. [36]은 단일 정적 장면의 포즈 2D 이미지 세트가 주어지면 관측치와 예측 사이의 재구성 loss(차이 제곱의 합)을 최소화하여 neural radiance field f_θ(·)의 매개 변수 θ를 최적화한다.
θ가 주어지면 각 pixel/ray에 대해 π(·)를 호출하여 새로운 뷰를 합성할 수 있다.
3.2 Generative Radiance Fields
본 연구에서, 우리는 3D 인식 이미지 합성을 위한 표현으로서 radiance fields에 관심이 있다.
[36]과 대조적으로, 우리는 단일 장면의 많은 포즈 이미지를 가정하지 않는다.
대신, 우리는 unposed 이미지에 대한 학습을 통해 새로운 장면을 합성하는 모델을 배우는 것을 목표로 한다.
보다 구체적으로, 우리는 적대적 프레임워크를 활용하여 radiance fields(GRAF)에 대한 생성 모델을 학습한다.
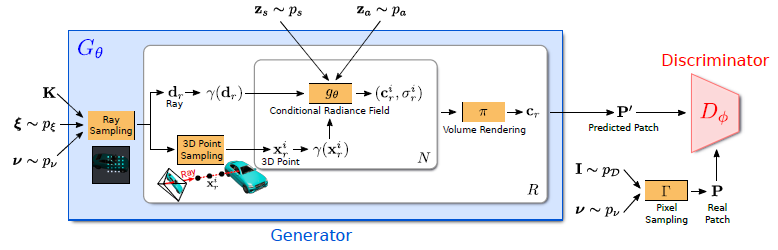
그림 2는 우리 모델에 대한 개요를 보여줍니다.
생성기 G_θ는 카메라 매트릭스 K, 카메라 포즈 ξ, 2D 샘플링 패턴 ν 및 형상/외관 코드 z_s ∈ R^m/z_a ∈ R^n을 입력으로 취하고 이미지 패치 P'를 예측한다.
판별기 D_ɸ는 합성된 패치 P'를 실제 이미지 I에서 추출된 패치 P와 비교한다.
추론 시, 우리는 모든 이미지 픽셀에 대해 하나의 색상 값을 예측한다.
하지만, 학습 시간에는 이것이 너무 비싸다.
따라서, 우리는 대신 전체 radiance field에 그레디언트를 제공하기 위해 랜덤으로 스케일링되고 회전되는 K x K 픽셀 크기의 고정 패치를 예측한다.
3.2.1 Generator
우리는 포즈 분포 p_ξ에서 카메라 포즈 ξ = [R|t]를 샘플링한다.
우리의 실험에서, 우리는 카메라가 좌표계의 원점을 향해 있는 카메라 위치에 대해 상반구의 균일한 분포를 사용한다.
데이터 세트에 따라 원점에서 카메라 거리도 균일하게 변경한다.
우리는 주요 지점이 이미지의 중앙에 오도록 K를 선택한다.
ν = (u, s)는 우리가 생성하고자 하는 가상 K x K 패치 P(u, s)의 중심 u = (u, v) ∈ R^2와 스케일 s ∈ R+를 결정한다.
이를 통해 이미지 해상도와 무관하게 컨볼루션 판별기를 사용할 수 있다.
이미지 도메인 Ω에 대한 uniform 분포에서 패치 중심 u ~ U(Ω)를 랜덤으로 그리고 패치 척도 s에서 패치 중심 s ~ U([1, S])를 랜덤으로 그린다, 여기서 S = min(W, H)/K는 타겟 이미지의 너비 W와 높이 H를 나타낸다.
또한 전체 패치가 이미지 도메인 Ω 내에 있는지 확인한다.
형상 및 외관 변수 z_s와 z_a는 형상 및 외관 분포 z_s ~ p_s와 z_a ~ p_a에서 각각 도출된다.
우리의 실험에서 우리는 p_s와 p_a 모두에 대해 표준 가우시안 분포를 사용한다.
Ray Sampling:
K x K 패치 P(u, s)는 그림 3과 같이 이미지 영역 Ω에서 패치의 모든 픽셀의 위치를 설명하는 2D 이미지 좌표 세트
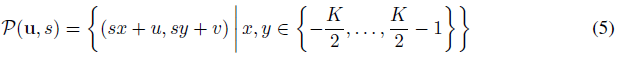
에 의해 결정됩니다.
이 좌표들은 우리가 지속적으로 radiance field를 평가할 수 있는 이산 정수가 아닌 실수입니다.
해당 3D rays는 P(u, s), 카메라 포즈 ξ 및 intrinsics K에 의해 고유하게 결정됩니다.
우리는 r로 pixel/ray 인덱스를, d_r로 정규화된 3D rays를, 학습 중 R = K^2로, 추론 중 R = WH로 rays 수를 나타낸다.
3D Point Sampling:
radiance field의 수치적 통합을 위해, 우리는 각 ray r을 따라 N개의 점 {x_r^i}을 샘플링한다.
우리는 [36]의 계층화된 샘플링 접근법을 사용한다, 자세한 내용은 보충 자료를 참조한다.
Conditional Radiance Field:
radiance field는 3D 위치 x ∈ R^3 및 뷰 방향 d ∈ S^2의 위치 인코딩(cf. 식(1))을 RGB 색상 값 c 및 볼륨 밀도 σ에 매핑하는 매개 변수 θ를 가진 deep fully-connected 신경망으로 표현된다:
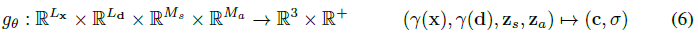
(2)와 대조적으로, g_θ는 두 개의 추가 잠재 코드, 즉 물체의 모양을 결정하는 모양 코드 z_s ∈ R^(M_s)와 외관을 결정하는 모양 코드 z_a ∈ R^(M_a)에 대해 조건화된다.
따라서 우리는 g_θ를 conditional radiance field라고 부른다.
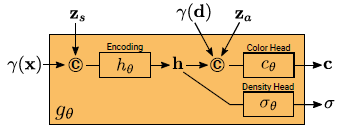
conditional radiance field g_θ의 네트워크 아키텍처는 그림 4에 설명되어 있다.
먼저 x의 위치 인코딩과 형상 코드 z_s로부터 형상 인코딩 h를 계산한다.
밀도 헤드 σ_θ는 이 인코딩을 볼륨 밀도 σ로 변환합니다.
3D 위치 x에서 색상 c를 예측하기 위해, 우리는 h를 d의 위치 인코딩 및 외관 코드 z_a와 연결하고 결과 벡터를 컬러 헤드 c_θ로 전달한다.
우리는 시각 d와 외관 코드 z_a와 독립적으로 σ를 계산하여 모양과 외관을 분리하면서 다중 뷰 일관성을 장려한다.
이는 네트워크가 각각 형상과 외관을 모델링하기 위해 잠재 코드 z_s와 z_a를 사용하도록 장려하고 추론 중에 이를 별도로 조작할 수 있게 한다.
좀 더 공식적으로, 우리는
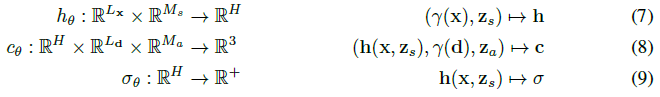
을 가지고 있다.
모든 매핑(h_θ, c_θ 및 σ_θ)은 ReLU 활성화와 함께 fully connected 네트워크를 사용하여 구현된다.
표기법이 복잡하지 않도록 각 네트워크의 매개 변수를 나타내기 위해 동일한 기호 θ를 사용한다.
Volume Rendering:
ray r을 따른 모든 점의 색상과 부피 밀도 {(c_r^i, σ_r^i)}가 주어지면, 우리는 식 (3)의 볼륨 렌더링 연산자를 사용하여 ray r에 해당하는 픽셀의 색상 c_r ∈ R^3을 얻는다.
모든 r rays의 결과를 결합하여, 우리는 그림 2와 같이 예측된 패치를 P'로 나타낸다.
3.2.2 Discriminator
판별기 D_ɸ는 예측된 패치 P'를 데이터 분포 p_D에서 그린 실제 이미지에서 추출된 패치 P와 비교하는 컨볼루션 신경망(자세한 내용은 보충자료 참조)으로 구현된다.
실제 이미지 I에서 K x K 패치를 추출하기 위해, 우리는 먼저 위의 생성기 패치를 그리는 데 사용하는 것과 동일한 분포 p_ν에서 ν = (u, s)를 도출한다.
그런 다음 이중선형 보간법을 사용하여 2D 이미지 좌표 P(u, s)에서 I를 쿼리하여 실제 패치 P를 샘플링한다.
다음에서는 Γ(I, ν)을 사용하여 이 이중선형 샘플링 작업을 나타냅니다.
우리의 판별기는 PatchGAN이 s = 1을 사용하는 동안 지속적인 변위 u와 스케일 s를 허용한다는 점을 제외하고는 PatchGAN[21]과 유사하다는 점에 유의하십시오.
s를 기반으로 실제 이미지 I를 다운샘플링하지 않고 희소 위치에서 I를 쿼리하여 고주파 세부 정보를 유지한다는 점에 유의해야 한다(그림 3 참조).
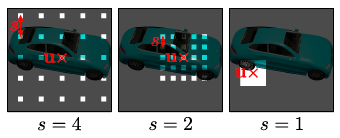
실험적으로, 우리는 가중치가 공유된 단일 판별기가 모든 패치에 대해 충분하다는 것을 발견했다.
비록 이것들이 서로 다른 척도를 가진 임의의 위치에서 샘플링된다 하더라도 말이다.
척도는 패치의 수용 필드를 결정합니다.
따라서 학습을 용이하게 하기 위해 전역 컨텍스트를 캡처하기 위해 더 큰 수용 필드의 패치로 시작한다.
그런 다음 더 작은 수용 필드가 있는 패치를 점진적으로 샘플링하여 로컬 세부 정보를 세분화한다.
3.2.3 Training and Inference
데이터 분포 p_D의 이미지를 나타내고 p_ν가 랜덤 패치에 대한 분포를 나타냅니다(섹션 3.2.1 참조).
우리는 R1 정규화[34]를 사용하여 비포화 GAN loss를 사용하여 모델을 학습한다:
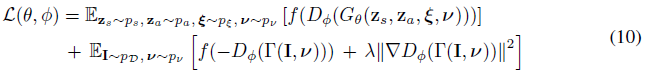
, 여기서 f(t) = -log(1 + exp(-t)) 및 λ는 정규화기의 강도를 제어합니다.
우리는 판별기에서 스펙트럼 정규화[37]와 인스턴스 정규화[65]를 사용하고, 각각 발생기와 판별기에 대해 배치 크기가 8이고 학습률이 0.0005와 0.0001인 RMSprop[27]을 사용하여 접근 방식을 학습한다.
추론 시, 우리는 z_s, z_a 및 ξ를 랜덤으로 샘플링하고 이미지의 모든 픽셀에 대한 색상 값을 예측한다.
네트워크 아키텍처에 대한 자세한 내용은 지원 자료에서 확인할 수 있습니다.
4 Experiments
Datasets:
우리는 실험에서 두 개의 합성 데이터 세트와 세 개의 실제 데이터 세트를 고려한다.
제어된 환경에서 우리의 접근 방식을 분석하기 위해 [46]의 렌더링 프로토콜에 따라 Photoshapes [49]에서 150,000개의 Chairs를 렌더링한다.
또한 Carla Driving simulator [12]를 사용하여 랜덤으로 샘플링된 색상과 사실적인 질감 및 반사 특성을 가진 18개 자동차 모델의 10k 이미지를 생성한다 (Cars).
우리는 또한 세 가지 실제 데이터 세트에 대한 접근 방식을 검증한다.
우리는 각각 최대 해상도 128^2 및 512^2픽셀의 이미지 합성을 위해 celebA[31]와 celebA-HQ[24]로 구성된 Faces 데이터 세트를 사용한다.
또한 Cats 데이터 세트[73]와 Caltech-UCSD Birds-200-2011 [66] 데이터 세트를 고려한다.
후자의 경우 사용 가능한 인스턴스 마스크를 사용하여 새를 흰색 배경에 합성한다.
Baselines:
저자의 구현을 사용하여 3D 인식 이미지 합성을 위한 두 가지 SOTA 모델과 우리의 접근 방식을 비교한다: PLATONICGAN [19]은 미분 가능한 볼륨 렌더링을 사용하여 이미지 평면에 투영된 3D 객체의 복셀 그리드를 생성한다.
HoloGAN[39]은 대신 추상 복셀화된 피쳐 표현을 생성하고 3D와 2D 컨볼루션의 조합을 사용하여 3D에서 2D로의 매핑을 학습한다.
학습된 투영의 결과를 분석하기 위해 3D 컨볼루션 레이어를 제거하여 학습된 매핑의 용량을 줄이는 HoloGAN(HoloGAN w/o 3D Conv)의 수정된 버전을 추가로 고려한다.
참고로, 우리는 또한 ResNet[18] 아키텍처가 있는 SOTA 2D GAN 모델[34]과 결과를 비교한다.
Evaluation Metrics:
우리는 Frechet Inception Distance(FID)[20]를 사용하여 이미지 충실도를 정량화하고 추가적으로 보충 자료에서 Kernel Inception Distance(KID)[5]를 보고한다.
3D 일관성을 평가하기 위해 COLMAP[60]를 사용하여 256^2픽셀 크기의 이미지에 대해 3D 재구성을 수행한다.
Minimum Matching Distance (MMD)[1]를 채택하여 정량적 비교를 위해 100개의 재구성된 형상과 실제에서 가장 가까운 형상 사이의 Chamfer Distance (CD)를 측정하고 재구성에 대한 정성적 결과를 보여준다.
우리는 이제 제안된 모델과 관련된 몇 가지 핵심 질문을 연구한다.
우리는 먼저 우리의 모델을 높은 충실도와 고해상도 출력을 생성하는 능력 측면에서 여러 베이스라인과 비교한다.
그런 다음 학습된 투영의 의미와 다중 스케일 판별기의 중요성을 분석한다.

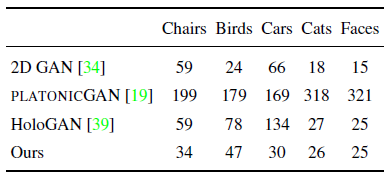
How do Generative Radiance Fields compare to voxel-based approaches?
먼저 64^2 픽셀의 이미지 해상도를 사용하여 모델을 베이스라인과 비교한다.
그림 5에 나타난 바와 같이, 모든 방법은 객체 ID와 카메라 시점을 분리할 수 있다.
그러나 PLATONICGAN은 얇은 구조를 표현하는 데 어려움이 있으며 PLATONICGAN과 HoloGAB 모두 제안된 모델에 비해 가시적인 아티팩트로 이어진다.
이는 표 1의 더 큰 FID 점수에도 반영된다.
HoloGAN은 Faces와 Cats에서 두 데이터 세트 모두 카메라의 방위각 변화가 거의 없는 반면 다른 데이터 세트는 더 큰 관점 변화를 다루기 때문에 우리의 접근 방식과 유사한 FID 점수를 달성한다.
이는 HoloGAN이 저차원 3D 피쳐 표현과 학습 가능한 투영으로 인해 다른 관점에서 물체의 외관을 정확하게 포착하기가 더 어렵다는 것을 시사한다.
대조적으로, 우리의 지속적인 표현은 학습된 투영을 필요로 하지 않으며 임의의 뷰에서 높은 충실도의 이미지를 렌더링한다.
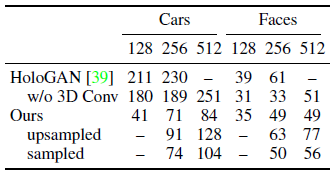
Do 3D-aware generative models scale to high-resolution outputs?
복셀 기반 표현으로 인해, PLATONICGAN은 더 높은 해상도로 확장될 때 메모리 집약적이 된다.
따라서, 우리는 이 분석을 위해 실험을 3D Conv를 사용하지 않는 HoloGAN과 HoloGAN으로 제한한다.
또한 128^2 픽셀에서 학습되었지만 추론 중에 더 높은 해상도로 샘플링된 모델에 대한 결과를 제공한다(샘플링된 ours).
표 2의 결과는 이것이 순수한 이중 선형 업샘플링(업샘플링된 ours)에 비해 크게 개선된다는 것을 보여주는데, 이는 우리의 학습된 표현이 더 높은 해상도로 잘 일반화된다는 것이다.
예상대로, 우리의 방법은 최대 해상도로 학습될 때 가장 작은 FID 값을 달성한다.
우리의 접근 방식은 Car 데이터 세트에서 HoloGAN과 HoloGAN without 3D Conv를 크게 능가하지만, HoloGAN without 3D Conv는 관점 변화가 더 작은 면에서 우리와 동등한 결과를 달성한다.
흥미롭게도, 우리는 3D Conv가 없는 HoloGAN이 모델 용량 감소에도 불구하고 [39]에서 원래 제안된 전체 HoloGAN 모델보다 낮은 FID 값을 달성한다는 것을 발견했다.
이는 HoloGAN을 고해상도로 학습할 때 관찰되는 학습 불안정성 때문이다.
심지어 우리는 결과를 보고할 수 없는 512^2의 해상도에서 모드 붕괴를 관찰한다.

Should learned projections be avoided?
그림 6에 도시된 바와 같이, HoloGAN(위)은 고해상도에서 외관으로부터 관점을 분리하는 데 실패하고, 얼굴 표정과 같은 다른 스타일 측면을 변화시키거나 심지어 포즈 입력을 완전히 무시한다.
우리는 학습 가능한 투영을 이러한 행동의 근본적인 원인으로 식별한다.
특히, 3D 컨볼루션 레이어를 제거하면 HoloGAN이 입력 포즈를 더 가깝게 고수할 수 있다는 것을 발견했다(그림 6(가운데) 참조).
그러나 3D Conv가 없는 HoloGAN의 이미지는 여전히 완전히 다중 뷰로 일관되지 않습니다.
이 관찰을 더 잘 조사하기 위해 우리는 3D Conv가 없는 HoloGAN과 우리의 접근 방식 모두에 대해 랜덤 관점에서 동일한 인스턴스의 여러 이미지를 생성하고 COLMAP[60]을 사용하여 고밀도 3D 재구성을 수행한다.
재구성은 뷰 간 일관성에 따라 달라지므로 재구성 정확도는 생성된 이미지의 다중 뷰 일관성에 대한 프록시로 간주할 수 있습니다.
표 3과 그림 7에서 분명히 알 수 있듯이, 멀티 뷰 스테레오는 우리 방법의 이미지를 입력으로 사용할 때 훨씬 더 잘 작동한다.
대조적으로, 업샘플링을 위해 학습된 2D 레이어를 사용하는 3D Conv가 없는 HoloGAN에 대해 더 적은 대응을 설정할 수 있다.
3D 컨볼루션이 있는 HoloGAN의 경우, 보충자료에 표시된 것처럼 성능이 훨씬 더 저하됩니다.
따라서 우리는 학습된 예측은 일반적으로 피해야 한다고 추측한다.

Are Generative Radiance Fields able to disentangle shape from appearance?
그림 8은 카메라와 장면 속성을 분리하는 것 외에도, 우리의 접근 방식이 z_s와 z_a를 통해 추론하는 동안 제어할 수 있는 모양과 외관을 분리하는 방법을 학습한다는 것을 보여준다.
Cars 및 Chairs의 경우 외관 코드가 객체의 색상을 제어하는 반면, Faces의 경우 피부 및 머리카락 색상을 인코딩합니다.

How important is the multi-scale patch discriminator?
제안된 다중 스케일 패치 판별기를 사용하여 이미지 품질을 희생하는지 조사하기 위해 다중 스케일 판별기(Patch)를 전체 이미지를 입력(Full)으로 받는 판별기와 비교한다.
이것은 메모리 집약적이기 때문에, 우리는 해상도 64^2의 이미지만 고려하고 h_θ와 c_θ(dim/2)에 숨겨진 차원의 절반을 사용한다.
표 4는 우리의 패치 판별기가 자동차의 전체 이미지 판별기와 유사한 성능을 달성하고 CelebA에서 훨씬 더 나은 성능을 발휘한다는 것을 보여준다.
이 현상에 대한 가능한 설명은 랜덤 패치 샘플링이 GAN 학습을 안정화하는 데 도움이 되는 데이터 증강 전략으로 작용한다는 것이다.
대조적으로, 로컬 패치(s=1)만 사용할 때, 우리는 우리의 생성기가 올바른 모양을 학습할 수 없어 표 4에서 높은 FID 값을 초래한다는 것을 관찰한다.
우리는 패치를 랜덤 규모로 샘플링하는 것이 강력한 성능을 위해 중요하다고 결론짓는다.
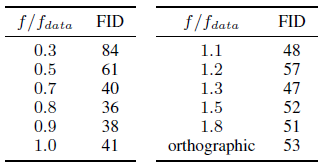
How important are the camera intrinsics?
우리는 표 5에서 모델의 민감도를 10의 고정 반지름 하에서 Cars에 대해 선택한 초점 길이로 축소한다.
우리 모델은 0.7 f_data 내에서 1.0 f_data로의 변경에 대해 매우 유사하게 수행되는데, 여기서 f_data는 학습 이미지를 렌더링하는 데 사용하는 초점 길이이다.
최대 1.8 f_data까지 초점 거리가 크고 직교 투영을 사용하여 좋은 성능을 관찰한다.
매우 작은 초점 거리의 경우에만 생성된 이미지가 이미지 경계에서 왜곡을 보여 더 높은 FID 값을 생성합니다.
5 Conclusion
우리는 고해상도 3D 인식 이미지 합성을 위해 Generative Radiance Fields (GRAF)를 도입했다.
우리는 우리의 프레임워크가 복셀 기반 접근법에 비해 더 나은 다중 뷰 일관성으로 고해상도 이미지를 생성할 수 있음을 보여주었다.
그러나 우리의 결과는 단일 객체가 있는 단순한 장면으로 제한된다.
우리는 depth 맵 또는 대칭과 같은 귀납적 편향을 통합하면 미래에 훨씬 더 어려운 실제 시나리오로 모델을 확장할 수 있다고 믿는다.