2022. 5. 23. 10:18ㆍ영상신호처리
Depth-Map Generation using Pixel Matching in Stereoscopic Pair of Images
Asra Aslam, Mohd. Samar Ansari
Abstract
현대 멀티미디어 콘텐츠 생성 및 보급은 점점 더 '현실적인' 시나리오를 제시하는 방향으로 나아가고 있다.
2차원(2D)에서 3차원(3D)으로의 전환은 이러한 방향으로의 주요 원동력이 되었습니다.
최근 들어 3D 이미지/비디오를 만들기 위한 수많은 접근 방식이 제안되었으며, 대부분은 depth 맵의 생성을 기반으로 한다.
이 논문은 사용 가능한 한 쌍의 입체 이미지에서 묘사된 장면과 관련된 depth 정보를 얻기 위한 새로운 알고리즘을 제시한다.
제안된 알고리즘은 depth 추정을 위해 스테레오 쌍의 두 이미지에 대한 픽셀 대 픽셀 매칭을 수행한다.
얻어진 depth 맵은 보고된 것에 비해 개선된 것을 보여준다.
Ⅰ. Introduction
최근 전 세계적으로 생성 및 배포되는 멀티미디어 데이터의 양이 엄청나게 증가했습니다 [1], [2].
이로 인해 보안 감시 및 보안, 군중 관리, 의료[3], 컴퓨터 비전 및 기타 많은 분야에 대한 애플리케이션과 솔루션이 지속적으로 개발됨에 따라 이미지 및 비디오 처리 분야에서 활발한 연구가 필요하게 되었습니다.
디지털 카메라의 출현은 사용자들이 사진을 찍는 방식에 혁명을 가져왔다.
아날로그 카메라와 비교하여 이러한 디지털 카메라(모바일 장치에 있는 카메라 포함)는 빠르고 쉬운 이미지 수집, 저장 및 검색을 제공합니다.
그러나 대부분의 인기 있는 디지털 카메라는 depth에 해당하는 구성 요소가 손실(기록되지 않음)되는 동안 장면의 2차원(2D) 투영을 캡처할 수 있다.
3차원(3D) 이미징은 depth의 추가 정보가 포함된 기존의 2D 기술의 발전으로 등장했다.
3D 카메라는 시장에 등장하기 시작했지만 엄청나게 비싸다.
2D 디지털 카메라를 사용하는 일반 사용자의 경우, 과거 [4]–[8]에서 제안한 다양한 기법을 사용하여 2D 이미지에서 depth 정보를 추출하여 3D 이미지를 구성할 수 있습니다.
이러한 방법 중 스테레오 이미지 쌍에서 depth 맵 생성은 [9]–[15]이 가장 인기 있다.
3D 이미징 [16], light field 이미지 디코딩 [17], 손 추적 [18] 등에서 많은 응용 프로그램을 찾습니다.
기본적으로 depth 맵은 색 강도에 의한 depth 인식을 제공하는 그레이 코딩된 2D 이미지입니다.
Depth-Map의 어두운 영역은 물체가 멀리 있다는 것을 나타내기 위해 생성되며, 이 어두운 색은 depth가 줄어들면서 점차 밝아지고 마침내 가까운 물체의 경우 하얗게 된다.
이 논문은 픽셀 대 픽셀 매칭을 수행하여 동일한 장면에 해당하는 왼쪽(L-) 및 오른쪽(R-) 이미지의 스테레오 쌍에서 시작하여 depth 맵을 생성하기 위한 알고리즘을 제시한다.
이 알고리즘은 L- 및 R- 이미지에서 픽셀의 RGB 구성 요소를 비교하여 일치하는 픽셀을 찾습니다.
만약 비교된 픽셀들 사이의 차이가 미리 지정된 허용오차(사용자 정의)보다 작다면, 그 픽셀들은 알고리즘에 의해 픽셀들의 '일치하는 쌍'으로 간주된다.
그런 다음 쌍안 시차를 일치된 픽셀에 대해 계산하여 depth 정보를 추정하는 데 추가로 활용한다.
그 논문의 나머지 부분은 다음과 같이 배열되어 있다.
depth 맵 작성 방법에 대한 간략한 개요는 섹션-Ⅱ에 제시되어 있다.
depth 맵과 제안된 알고리즘과 관련된 관련 이론적 정보는 섹션-Ⅲ에서 논의된다.
기존 작품과의 비교와 함께 IV에는 몇 가지 예와 파생된 depth맵이 표시된다.
마지막으로, 결론적인 언급은 섹션– V에 나타납니다.
Ⅱ. Related Work
이 섹션에서는 depth 맵 생성을 위한 다양한 접근 방식에 대해 설명합니다.
그들 중 몇몇은 감독되고 다른 것들은 감독되지 않는다.
MATLAB 알고리즘은 두 개의 정적 이미지를 사용하여 depth 마스크를 구성하기 위해 개발되었다[13].
알고리즘은 두 개의 영상을 표시하고 사용자는 두 영상의 해당 지점을 일치시킵니다.
선택한 영상 포인트의 변위로부터 알고리즘은 장면의 depth 표면을 추정합니다.
이것은 감독된 접근 방식이며, 여기서 포인트 매칭을 위해서는 사용자 상호작용이 필요하다[13].
depth를 추정하기 위해 단안 및 스테레오 단서에 기반한 접근법이 제안되었다[19].
연구에서 그들은 마르코프 랜덤 필드(MRF) 학습 알고리즘을 적용하여 단안 신호를 포착한 다음 스테레오 신호와 결합하여 depth 맵을 얻는다.
그러나 이러한 단안 단서 중 일부는 사전 지식을 기반으로 하므로 지도 학습이 필요하다[19].
스테레오 이미지 쌍에서 depth 불연속성을 감지하기 위해, 해당 스캔 라인 쌍의 개별 픽셀과 일치하는 동시에 폐색된 픽셀이 일치하지 않는 상태로 유지되도록 한 다음 스캔 라인 간에 정보를 전파하는 알고리즘이 제시되었다[20].
또 다른 접근 방식으로, 구조화된 빛을 사용하여 고정밀 depth 맵을 생성한다.
이 접근법은 한 쌍의 카메라와 구조화된 광 패턴을 현장에 투사하는 하나 이상의 광 투영기를 사용하는 것에 의존한다.
그들은 스테레오 이미지 쌍과 정확하게 정렬된 진실 disparity 측정을 얻기 위한 방법론을 개발했다[21].
픽셀별 좌우 이미지를 매칭하기 어려워 특정 크기 창을 선택하여 두 이미지를 매칭하는 접근법이 많이 제안된다.
강도 및 disparity의 로컬적 변화를 평가하여 적절한 창을 선택하는 방법이 제시된다.
이 방법은 이미지의 각 픽셀에 대해 불확실성이 가장 작은 disparity 추정치를 생성하는 창을 검색한 다음 이 적응형 창 방법을 스테레오 매칭 알고리즘에 포함시킨다[9].
위에 언급된 거의 모든 기술에서, 정확한 픽셀 대 픽셀 매칭이 수행되지 않아 생성된 depth 맵의 품질에 영향을 미친다.
본 논문에서는 픽셀 대 픽셀 매칭의 새로운 알고리즘을 제안하며, 이는 서로 다른 수준에서 다른 임계값을 고려한다.
제안된 알고리즘의 결과는 [22]에 거의 나타나지 않으며, 단점을 제거한다는 측면에서 그것보다 개선된 버전이다.
Ⅲ. Proposed Algorithm
depth map은 영상 좌표의 함수로서 물체의 depth를 제공하는 2D 이미지이다.
일반적으로 각 픽셀의 강도가 depth를 기록하는 그레이 레벨 이미지로 표시됩니다.
depth 맵을 만드는 데 필요한 작업은 (i) 이미지 캡처, (ii) 이미지 전처리, (iii) depth 추정 및 (iv) 모든 픽셀에 대한 색상 값 계산입니다.
A. Caturing Images
제안된 알고리즘은 동일한 장면의 두 이미지를 사용한다.
왼쪽과 오른쪽 이미지는 두 개의 디지털 카메라로 촬영할 수 있습니다.
그들은 같은 장면의 이미지를 동시에 캡처합니다.
이 카메라들은 수평으로 약간 변위되어 있다.
이 수평 거리는 두 눈 사이의 간격과 거의 같아야 한다.
각 이미지 세트에 대해 카메라 위치는 카메라의 고도 및 뷰 벡터에 대해 주의하여 제어해야 합니다.
B. Image Preprocessing
L- 및 R- 이미지의 헤더를 읽고 이미지의 높이 및 너비를 따라 픽셀 수를 찾습니다.
두 이미지를 바이트 단위로 읽고 저장합니다.
각 픽셀의 RGB(빨간색, 녹색 & 파란색) 구성 요소를 분리합니다.
C. Depth Estimation
depth estimation은 여러 뷰 또는 이미지에서 장면에 있는 여러 개체의 depth를 계산하는 것입니다.
서로 다른 뷰, 즉 동일한 3D 포인트를 식별하는 대응 지점을 찾는 것이 필요하다.
이러한 점을 찾아 depth 정보는 다음 세 가지 주요 단계를 통해 계산됩니다: (1) Pixel의 매칭 (2) 충돌 시 가장 좋은 것을 고르기. (3) 시차 계산.
1) Matching of Pixel:
일치 기준은 Sum of Absolute Differences (SAD)에 기초한다.
SAD는 일치 비용 함수이며, 세 개의 색상 채널에 대해 메트릭을 계산하고 결과 세 개의 절대 차이 값을 단순히 더한다.
이 값이 공차의 ±2.5%보다 작거나 같으면 오른쪽 이미지의 해당 픽셀만 왼쪽 이미지의 일치 픽셀로 간주합니다.
2) Resolving conflicts:
오른쪽 이미지의 다른 픽셀이 이미 다른 픽셀과 일치하는 왼쪽 이미지의 해당 픽셀과 유사한 상황이 발생하면 이전 픽셀의 허용오차를 현재 픽셀의 허용오차와 비교하여 모호성을 해결한다.
현재 픽셀의 허용오차 값이 더 많으면 무시하십시오.
그렇지 않으면 이전 픽셀을 버리고 현재 픽셀을 올바른 선택으로 간주하십시오.

3) Disparity Calculation:
depth 맵을 작성하기 위해 binocular disparity 방법이 사용됩니다.
binocular disparity은 그림 1과 같이 두 이미지 또는 두 눈의 차이이다.
· pl : 왼쪽 이미지의 픽셀 값
· pr: 왼쪽 이미지의 유사한 픽셀에 해당하는 오른쪽 영상의 픽셀 값
· f: 카메라의 초점 거리
· T: 두 카메라의 원점의 차이
· Z: depth 값
· xl: 왼쪽 이미지의 픽셀 거리
· xr: 오른쪽 이미지의 픽셀 거리
점의 disparity 값은 종종 관측된 물체에 대한 역 거리로 해석된다.
즉, disparity은 depth에 반비례합니다.
따라서 depth 맵을 구축하기 위해서는 disparity를 찾는 것이 필수적이다.


D. Calculate Pixel value
색상 값을 계산하려면 먼저 모든 픽셀의 depth에서 최대 depth를 계산하십시오.
최대 depth를 갖는 픽셀에 대해 0과 동일한 값(예: 검정색)을 부여한다.
그런 다음 각 픽셀에 대한 색상 값은 다음과 같이 계산됩니다:
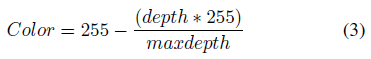
오른쪽 이미지에 일치하는 픽셀이 없는 왼쪽 이미지의 픽셀에 255(예: 흰색)와 동일한 값을 할당합니다.
이러한 픽셀 값을 제공함으로써 depth 맵을 만들 수 있다.
이 depth 맵에서 어두운 영역은 물체가 멀리 떨어져 있음을 나타내고 밝은 영역은 물체가 사용자에게 더 가깝다는 것을 나타냅니다.
그림 2는 제안된 알고리즘의 세부 사항을 보여준다.


Ⅳ. Results
알고리즘은 대규모 이미지 세트에 대해 테스트되었습니다.
다음 페이지의 그림 3에 이미지와 depth 맵이 거의 표시되지 않습니다.
그림 3(i)에서 나무는 카메라에 더 가까워서 더 밝고 배경 나무를 포함한 지면은 비교적 어두운 색을 띠는 것을 알 수 있다.
마찬가지로 그림 3(ii)에 표시된 방의 관점에서 옷과 가방은 카메라에 더 가까워서 색상은 흰색이고 창문, 랙, 의자 및 벽은 회색 픽셀이 더 많다.
그림 3(iii)의 경우 카메라와의 거리가 멀어짐에 따라 나무에서 농가까지의 깊이에 따라 어둠이 증가한다.
그림 3(iv)의 하늘은 거의 검은색인 반면 도르래와 다른 물체들은 회색과 흰색이다.
그림 3(v)의 3개의 병은 위치에 따라 색상이 다르며 벽은 검은색으로 보인다.
자동차는 그림 3(vi)에서 가장 가까운 물체이므로 집 벽이나 작은 나무들에 비해 색이 어두워서 흰색이다.

기존 알고리즘 [23]과의 비교를 위한 예가 그림 4에 나와 있습니다.
그것은 두 가지 depth 맵을 가지고 있는데, 하나는 기존 알고리즘에서 얻은 것이고, 두 번째 depth 맵은 이 논문에서 제안된 알고리즘에 의해 생성된다.
첫 번째 depth 맵은 이미지에서 멀리 있는 곳이 뚜렷한 가장자리가 없는 윤곽으로만 나타나기 때문에 많은 정보를 제공하지 못한다는 것을 알 수 있다.
Ⅴ. Conclusion
한 쌍의 입체(좌우) 이미지에서 depth 맵을 만드는 알고리즘이 제시되었다.
다양한 알려진 알고리즘과 다른 방식으로, 제안된 기술은 이미지 캡처에서 무작위 장애, 빛 효과 등으로 인해 유입될 수 있는 모든 종류의 차이를 처리하기 위해 최대 2.5%의 허용오차를 포함하는 RGB 구성 요소를 비교하여 두 이미지를 픽셀 대 픽셀로 일치시킨다.
얻어진 depth 맵은 보고된 맵보다 개선된 것으로 나타났다.