2022. 11. 8. 16:52ㆍDeep Learning
Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding
Chitwan Saharia, William Chan, Saurabh Saxenay, Lala Liy, Jay Whangy, Emily Denton, Seyed Kamyar Seyed Ghasemipour, Burcu Karagol Ayan, S. Sara Mahdavi, Rapha Gontijo Lopes, Tim Salimans, Jonathan Hoy, David J Fleety, Mohammad Norouzi
Abstract
우리는 전례 없는 수준의 사진사실주의와 깊은 언어 이해도를 가진 text-to-image 확산 모델인 Imagen을 제시한다.
Imagen은 텍스트를 이해하는 데 있어 대형 트랜스포머 언어 모델의 힘을 기반으로 하며, 충실도가 높은 이미지 생성에서 확산 모델의 강도에 의존한다.
우리의 핵심 발견은 텍스트 전용 corpora에서 사전 학습된 일반 대형 언어 모델(예: T5)이 이미지 합성을 위해 텍스트를 인코딩하는 데 놀라울 정도로 효과적이라는 것이다: Imagen에서 언어 모델의 크기를 늘리면 이미지 확산 모델의 크기를 늘리는 것보다 샘플 충실도와 image-text 정렬이 훨씬 더 향상된다.
Imagen은 COCO에 대한 학습 없이 COCO 데이터 세트에서 7.27이라는 새로운 SOTA FID 점수를 달성하고, 인간 평가자는 Imagen 샘플이 image-text 정렬에서 COCO 데이터 자체와 동등하다는 것을 발견한다.
text-to-image 모델을 보다 심층적으로 평가하기 위해 text-to-image 모델에 대한 포괄적이고 도전적인 벤치마크인 DrawBench를 소개한다.
DrawBench를 사용하여 Imagen을 VQ-GAN+CLIP, 잠재 확산 모델, GLIDE 및 DALL-E 2를 포함한 최근 방법과 비교한 결과 인간 평가자가 샘플 품질과 image-text 정렬 측면에서 다른 모델보다 Imagen을 선호한다는 것을 발견했다.
1 Introduction
멀티모달 학습은 최근 text-to-image 합성[53, 12, 57]과 image-text contrastive 학습[49, 31, 74]을 선두로 두각을 나타내고 있다.
이러한 모델은 창의적인 이미지 생성[22, 54] 및 편집 애플리케이션[21, 41, 34]으로 연구 커뮤니티를 변화시키고 광범위한 대중의 관심을 끌었다.
이러한 연구 방향을 더 추구하기 위해, 우리는 트랜스포머 언어 모델(LMs) [15, 52]의 힘을 충실도 높은 확산 모델 [28, 29, 16, 41]과 결합하여 text-to-image 합성에서 전례 없는 수준의 사진사실주의와 깊은 언어 이해를 제공하는 text-to-image 확산 모델인 Imagen을 소개한다.
모델 학습[예: 53, 41]에 image-text 데이터만 사용하는 이전 작업과 달리, Imagen 뒤의 핵심 발견은 텍스트 전용 corpora에서 사전 학습된 대형 LMs[52, 15]의 텍스트 임베딩이 text-to-image 합성에 현저하게 효과적이라는 것이다.
선택한 샘플은 그림 1을 참조하십시오.

Imagen은 입력 텍스트를 임베딩 시퀀스에 매핑하기 위한 동결 T5-XXL [52] 인코더와 64x64 이미지 확산 모델을 포함하며, 이어서 256x256 및 1024x1024 이미지를 생성하기 위한 두 개의 초해상도 확산 모델을 포함한다(그림 A.4 참조).
모든 확산 모델은 텍스트 임베딩 시퀀스를 조건으로 하며 classifier-free guidance를 사용한다[27].
Imagen은 이전 작업에서 관찰된 샘플 품질 저하 없이 큰 guidance 가중치를 사용할 수 있도록 새로운 샘플링 기술에 의존하여 이전에 가능한 것보다 더 높은 충실도와 더 나은 image-text 정렬을 가진 이미지를 생성한다.
개념적으로 단순하고 학습하기 쉽지만, Imagen은 놀랄 만큼 강력한 결과를 산출한다.
Imagen은 COCO [36]에서 제로샷 FID-30K가 7.27로 다른 방법을 능가하며, GLIDE [41] (12.4)와 DALL-E 2 [54] (10.4)의 동시 작업과 같은 이전 작업을 크게 능가한다.
우리의 제로샷 FID 점수는 또한 COCO에서 학습된 SOTA 모델보다 낫다, 예: Make-A-Scene [22] (7.6).
또한, 인간 평가자는 Imagen에서 생성된 샘플이 COCO 캡션의 참조 이미지에 대한 image-text 정렬에 동등한 것으로 나타낸다.
text-to-image 평가를 위한 새로운 텍스트 프롬프트 구조 세트인 DrawBench를 소개한다.
DrawBench는 모델의 다양한 의미적 특성을 조사하도록 설계된 텍스트 프롬프트를 통해 text-to-image 모델의 다차원 평가를 통해 더 깊은 통찰력을 가능하게 한다.
여기에는 구성성, 카디널리티, 공간 관계, 복잡한 텍스트 프롬프트 또는 희귀한 단어를 처리하는 능력, 그리고 학습 데이터의 범위를 훨씬 넘어 매우 신뢰할 수 없는 장면을 생성하는 모델의 능력의 한계를 밀어내는 창의적인 프롬프트가 포함된다.
DrawBench를 사용하여 광범위한 인간 평가는 Imagen이 다른 최신 방법[57, 12, 54]을 상당한 차이로 능가한다는 것을 보여준다.
우리는 또한 Imagen의 텍스트 인코더로 CLIP [49]와 같은 다중 모드 임베딩에 비해 사전 학습된 대규모 언어 모델 [52]의 사용의 몇 가지 분명한 이점을 보여준다.
이 논문의 주요 기여 사항은 다음과 같습니다:
1. 텍스트 데이터에만 대해 학습된 대규모 동결 언어 모델이 text-to-image 생성에 매우 효과적인 텍스트 인코더이며, 동결 텍스트 인코더의 크기를 조정하면 이미지 확산 모델의 크기를 조정하는 것보다 샘플 품질이 크게 향상된다는 것을 발견했다.
2. 우리는 높은 guidance 가중치를 활용하고 이전에 가능한 것보다 더 사진사실적이고 상세한 이미지를 생성하기 위한 새로운 확산 샘플링 기술인 dynamic thresholding를 소개한다.
3. 우리는 몇 가지 중요한 확산 아키텍처 설계 선택을 강조하고 더 단순하고 더 빠르게 수렴되며 메모리 효율성이 높은 새로운 아키텍처 변형인 Efficient U-Net을 제안한다.
4. 우리는 7.27의 새로운 SOTA COCO FID를 달성한다. 인간 평가자는 Imagen이 image-text 정렬 측면에서 참조 이미지와 동등하다는 것을 발견한다.
5. text-to-image 작업에 대한 새로운 종합적이고 도전적인 평가 벤치마크인 DrawBench를 소개한다. DrawBench 인간 평가에서, 우리는 Imagen이 DALL-E 2의 동시 작업을 포함한 다른 모든 작업을 능가한다는 것을 발견했다[54].
2 Imagen
Imagen은 텍스트를 임베딩 시퀀스에 매핑하는 텍스트 인코더와 이러한 임베딩을 해상도가 증가하는 이미지에 매핑하는 조건부 확산 모델의 계단식으로 구성된다(그림 A.4 참조).
다음 하위 섹션에서는 이러한 각 구성 요소에 대해 자세히 설명합니다.

2.1 Pretrained text encoders
text-to-image 모델은 임의의 자연어 텍스트 입력의 복잡성과 구성성을 포착하기 위해 강력한 의미론적 텍스트 인코더가 필요하다.
paired image-text 데이터에 대해 학습된 텍스트 인코더는 현재 text-to-image 모델에서 표준이다; 그들은 처음부터 학습[41, 53]되거나 image-text 데이터 [54]에 대해 사전 학습될 수 있다(예: CLIP [49]).
image-text 학습 목표는 이러한 텍스트 인코더가 특히 text-to-image 생성 작업과 관련된 시각적 의미와 의미 있는 표현을 인코딩할 수 있음을 시사한다.
대형 언어 모델은 text-to-image 생성을 위해 텍스트를 인코딩하는 또 다른 선택 모델이 될 수 있다.
최근 대규모 언어 모델(예: BERT [15], GPT [47, 48, 7], T5 [52])의 발전은 텍스트 이해와 생성 능력에서 비약적인 발전을 가져왔다.
언어 모델은 paired image-text 데이터보다 훨씬 큰 텍스트 corpus에 대해서만 학습되므로 매우 풍부하고 광범위한 텍스트 분포에 노출된다.
또한 이러한 모델은 현재 image-text 모델[49, 31, 80]에서 텍스트 인코더보다 훨씬 더 큽니다(예: PaLM [11]은 540B 매개 변수를 가지고 있는 반면 CoCa [80]는 ≒1B 매개 변수 텍스트 인코더).
따라서 text-to-image 작업을 위해 텍스트 인코더 제품군을 모두 탐색하는 것이 자연스러워진다.
Imagen은 사전 학습된 텍스트 인코더인 BERT [15], T5 [51] 및 CLIP [46]를 탐색합니다.
단순화를 위해, 우리는 이러한 텍스트 인코더의 가중치를 동결한다.
동결은 임베딩의 오프라인 계산과 같은 몇 가지 장점이 있어 text-to-image 모델 학습 중 계산 또는 메모리 풋프린트를 무시할 수 있다.
우리의 연구에서, 우리는 텍스트 인코더 크기를 조정하면 text-to-image 생성 품질이 향상된다는 확실한 확신이 있음을 발견했다.
우리는 또한 T5-XXL과 CLIP 텍스트 인코더가 MS-COCO와 같은 간단한 벤치마크에서 유사하게 수행되지만, 인간 평가자는 도전적이고 구성적인 프롬프트 세트인 DrawBench의 image-text 정렬과 이미지 충실도 모두에서 CLIP 텍스트 인코더보다 T5-XXL 인코더를 선호한다는 것을 발견했다.
우리는 독자들에게 우리의 발견에 대한 요약을 위해 섹션 4.4를, 상세한 ablation들을 위해 부록 D.1을 참조하라고 권한다.
2.2 Diffusion models and classifier-free guidance
여기서 우리는 확산 모델에 대한 간략한 소개를 한다; 정확한 설명은 부록 A에 있다.
확산 모델 [63, 28, 65]은 반복적인 디노이징 프로세스를 통해 학습된 데이터 분포에서 가우시안 노이즈를 샘플로 변환하는 생성 모델의 클래스이다.
이러한 모델은 예를 들어 클래스 레이블, 텍스트 또는 저해상도 이미지 [예: 16, 29, 59, 58, 75, 41, 54]에서 조건부일 수 있습니다.
확산 모델 ^x_θ는

형태의 디노이징 목표에 대해 학습된다, 여기서 (x, c)는 데이터 조절 쌍, t ~ U([0, 1]), ε ~ N(0, I) 및 α_t, σ_t, ω_t는 샘플 품질에 영향을 미치는 함수이다.
직관적으로, ^x_θ는 t의 특정 값을 강조하기 위해 가중된 제곱 오차 손실을 사용하여 z_t := α_t x + σ_t ε을 x로 디노이징하도록 학습된다.
조상 샘플러 [28] 및 DDIM [64]와 같은 샘플링은 순수 노이즈 z_1 ~ N(0, I)에서 시작하여 점 z_t_1, ..., z_t_T를 반복적으로 생성합니다, 여기서 1 = t_1 > ... > t_T = 0, 노이즈 함량이 점차 감소합니다.
이 점들은 x-predictions ^x_0^t := ^x_θ (z_t, c)의 함수이다.
Classifier guidance [16]은 샘플링 중에 사전 학습된 모델 p(c|z_t)의 그레디언트를 사용하여 조건부 확산 모델의 다양성을 줄이면서 샘플 품질을 향상시키는 기술이다.
Classifier-free guidance [27]은 학습 중 랜덤으로 c를 떨어뜨림(예: 10% 확률로)을 통해 조건부 및 무조건적인 목표에 대해 단일 확산 모델을 공동으로 학습함으로써 이 사전 학습된 모델을 피하는 대안 기법이다.
샘플링은 수정된 x-prediction (z_t - σ ~ε_θ) / α_t를 사용하여 수행됩니다, 여기서

여기서, ε_θ(z_t, c)와 ε_θ(z_t)는 ε_θ :=(z_t - α_t ^x_θ) / σ_t에 의해 주어지는 조건부 및 무조건적인 ε-predictions이며, ω는 guidance 가중치이다.
ω = 1을 설정하면 classifier-free guidance가 비활성화되고 ω > 1을 늘리면 guidance 효과가 강화됩니다.
Imagen은 효과적인 텍스트 조건을 위해 classifier-free guidance에 크게 의존한다.
2.3 Large guidance weight samplers
우리는 최근 text-guided 확산 작업[16, 41, 54]의 결과를 확증하고 classifier-free guidance 가중치를 증가시키면 image-text 정렬은 개선되지만 고도로 포화되고 부자연스러운 이미지를 생성하는 이미지 충실도는 손상된다는 것을 발견했다[27].
우리는 이것이 높은 guidance 가중치에서 발생하는 학습-테스트 불일치 때문이라는 것을 발견했다.
각 샘플링 단계 t에서 x-prediction ^x_0^t는 학습 데이터 x와 동일한 경계, 즉 [-1, 1] 내에 있어야 하지만, 우리는 경험적으로 높은 guidance 가중치가 x-prediction을 이러한 경계를 초과하게 한다는 것을 발견했다.
이것은 학습-테스트 불일치이며, 확산 모델은 샘플링 내내 자체 출력에 반복적으로 적용되기 때문에 샘플링 프로세스는 비정상적인 이미지를 생성하고 때로는 분기하기도 한다.
이 문제에 대처하기 위해 정적 임계값과 동적 임계값을 조사한다.
부록 그림 참조. A.31 기술 및 부록 그림 참조 구현 A.9 효과를 시각화한다.
Static thresholding:
우리는 [-1, 1]에 대한 x-prediction을 요소별로 클리핑하는 것을 정적 임계값이라고 한다.
이 방법은 실제로 사용되었지만 이전 연구[28]에서는 강조되지 않았으며, 우리가 아는 한 guided 샘플링의 맥락에서 그 중요성이 조사되지 않았다.
우리는 정적 임계값이 큰 guidance 가중치를 가진 샘플링에 필수적이며 빈 이미지의 생성을 방지한다는 것을 발견했다.
그럼에도 불구하고 정적 임계값은 guidance 가중치가 더 증가함에 따라 여전히 과포화 및 덜 상세한 이미지를 초래한다.
Dynamic thresholding:
우리는 새로운 동적 임계값 방법을 소개한다.
각 샘플링 단계에서 ^x_0^t에서 특정 백분위수 절대 픽셀 값으로 설정하고 s>1이면 ^x_0^t를 [-s,s] 범위로 임계값화한 다음 s로 나눈다.
동적 임계값은 포화 픽셀(-1 및 1에 가까운 픽셀)을 안쪽으로 밀어넣어 각 단계에서 픽셀이 포화되지 않도록 합니다.
우리는 동적 임계값이 특히 매우 큰 guidance 가중치를 사용할 때 image-text 정렬뿐만 아니라 훨씬 더 나은 사진사실주의를 가져온다는 것을 발견했다.
2.4 Robust cascaded diffusion models
Imagen은 기본 64x64 모델의 파이프라인과 두 개의 텍스트 조건 초해상도 확산 모델을 사용하여 64x64 생성 이미지를 256x256 이미지로 업샘플링한 다음 1024x1024 이미지로 업샘플링한다.
노이즈 조절 증강[29]이 있는 계단식 확산 모델은 충실도가 높은 이미지를 점진적으로 생성하는 데 매우 효과적이었다.
또한, 노이즈 수준 조절을 통해 초해상도 모델에 추가된 노이즈의 양을 인식시키면 샘플 품질이 크게 향상되고 저해상도 모델에 의해 생성된 아티팩트를 처리할 수 있는 초해상도 모델의 견고성이 향상된다[29].
Imagen은 초해상도 모델 모두에 대해 노이즈 조절 증강을 사용한다.
우리는 이것이 높은 충실도의 이미지를 생성하는 데 매우 중요하다는 것을 발견했다.
조건부 저해상도 이미지와 증강 수준(a.k.a aug_level)(예: 가우시안 노이즈 또는 블러의 강도)이 주어지면, 우리는 저해상도 이미지를 증강(aug_level에 해당)으로 손상시키고 확산 모델을 aug_level로 조정한다.
학습 중에 aug_level은 랜덤으로 선택되며, 추론 중에 우리는 최상의 샘플 품질을 찾기 위해 다른 값을 스위프한다.
우리의 경우, 우리는 가우시안 노이즈를 증강의 한 형태로 사용하고 확산 모델에 사용되는 순방향 프로세스와 유사한 가우시안 노이즈 확대를 보존하는 분산을 적용한다(부록 A).
증강 수준은 aug_level ∈ [0, 1]를 사용하여 지정됩니다.
참고 그림 A.32 참조 유사 코드.
2.5 Neural network architecture
Base model:
우리는 base 64x64 text-to-image 확산 모델을 위해 [40]의 U-Net 아키텍처를 채택한다.
네트워크는 [16, 29]에서 사용되는 클래스 임베딩 조건 방법과 유사한 확산 시간 단계 임베딩에 추가된 풀링 임베딩 벡터를 통해 텍스트 임베딩으로 조정된다.
우리는 여러 해상도에서 텍스트 임베딩에 교차 어텐션[57]을 추가하여 전체 텍스트 임베딩 시퀀스를 추가로 조건화한다.
우리는 부록 D.3.1의 다양한 텍스트 조건화 방법을 연구한다.
또한 어텐션 및 풀링 레이어에 텍스트 임베딩을 위한 레이어 정규화 [2]를 찾아 성능을 크게 향상시켰다.
Super-resolution models:
64x64 → 256x256 초해상도의 경우 [40, 58]에서 수정된 U-Net 모델을 사용한다.
우리는 메모리 효율성, 추론 시간 및 수렴 속도를 향상시키기 위해 이 U-Net 모델을 몇 가지 수정한다(우리의 변형은 [40, 58]에 사용된 U-Net보다 단계/초에서 2-3배 더 빠르다).
우리는 이 변형을 Efficient U-Net이라고 부른다(자세한 내용과 비교는 부록 B.1 참조).
우리의 256x256 → 1024x1024 초해상도 모델은 1024x1024 이미지의 64x64 → 256x256 크롭에 대해 학습한다.
이를 용이하게 하기 위해 셀프 어텐션 계층을 제거하지만 중요한 것으로 밝혀진 텍스트 교차 어텐션 계층을 유지한다.
추론하는 동안 모델은 전체 256x256 저해상도 영상을 입력으로 수신하고 업샘플링된 1024x1024 영상을 출력으로 반환합니다.
초해상도 모델 모두에 텍스트 교차 어텐션을 사용합니다.
3 Evaluating Text-to-Image Models
COCO [36] 검증 세트는 supervised [82, 22] 및 제로샷 설정 [53, 41] 모두에 대해 text-to-image 모델을 평가하기 위한 표준 벤치마크이다.
사용되는 주요 자동화된 성능 지표는 이미지 충실도를 측정하기 위한 FID [26]와 이미지 텍스트 정렬을 측정하기 위한 CLIP 점수 [25, 49]이다.
이전 작업과 일관되게, 우리는 제로샷 FID-30K를 보고하는데, 이 FID-30K는 검증 세트에서 랜덤으로 30K 프롬프트를 추출하고 이러한 프롬프트에서 생성된 모델 샘플을 전체 검증 세트의 참조 이미지와 비교한다.
지침 가중치는 이미지 품질과 텍스트 정렬을 제어하는 중요한 요소이기 때문에, 우리는 다양한 지침 가중치에 걸쳐 CLIP와 FID 점수 사이의 트레이드오프(또는 파레토) 곡선을 사용하여 대부분의 ablation 결과를 보고한다.
FID와 CLIP 점수 모두 한계가 있습니다, 예를 들어, FID가 지각 품질과 완전히 정렬되지 않았으며, CLIP는 계산에 효과적이지 않습니다 [49].
이러한 한계로 인해, 우리는 실제 참조 캡션-이미지 쌍을 기준으로 이미지 품질과 캡션 유사성을 평가하기 위해 인간 평가를 사용한다.
우리는 두 가지 실험 패러다임을 사용한다:
1. 이미지 품질을 조사하기 위해 평가자는 "어떤 이미지가 더 사진사실적(더 실제적으로 보이는)입니까?"라는 질문을 사용하여 모델 생성과 참조 이미지 중 하나를 선택하도록 요청받는다. 우리는 평가자가 참조 이미지보다 모델 생성을 선택하는 비율(선호도 비율)을 보고한다.
2. 정렬을 조사하기 위해 평가자는 이미지와 프롬프트를 보여주고 "자막이 위의 이미지를 정확하게 설명합니까?"라고 묻는다. 그들은 "예", "어느 정도" 또는 "아니오"로 응답해야 합니다. 이 응답은 각각 100, 50 및 0으로 점수가 매겨집니다. 이러한 등급은 모델 샘플 및 기준 영상에 대해 독립적으로 획득되며, 둘 다 보고됩니다.
두 경우 모두 COCO 유효성 검사 세트에서 랜덤으로 선택된 200개의 이미지 캡션 쌍을 사용한다.
피실험자들에게 50개의 이미지 묶음이 보여졌다.
또한 인터리빙된 "제어" 시험도 사용했으며, 제어 질문의 80% 이상을 정확하게 대답한 사람들의 평가 데이터만 포함합니다.
이는 이미지 품질과 image-text 정렬 평가에서 이미지당 각각 73과 51의 등급을 기록했다.
DrawBench:
COCO는 가치 있는 벤치마크이지만, 모델 간의 차이에 대한 통찰력을 쉽게 제공하지 못하는 제한된 범위의 프롬프트를 가지고 있다는 것이 점점 더 분명해지고 있다(예: 섹션 4.2 참조).
[10]의 최근 연구는 COCO를 넘어 시각적 추론 능력과 사회적 편견을 체계적으로 평가하기 위해 PaintSkills라는 새로운 평가 세트를 제안했다.
비슷한 동기로 텍스트와 이미지 모델의 평가 및 비교를 지원하는 포괄적이고 도전적인 프롬프트 세트인 DrawBench를 소개한다.
DrawBench에는 11가지 유형의 프롬프트가 포함되어 있으며, 서로 다른 색상, 개체 수, 공간 관계, 장면의 텍스트 및 개체 간의 비정상적인 상호 작용을 충실하게 렌더링하는 기능과 같은 모델의 다양한 기능을 테스트합니다.
범주는 또한 길고 복잡한 텍스트 설명, 희귀 단어 및 철자가 잘못된 프롬프트를 포함한 복잡한 프롬프트를 포함합니다.
또한 DALL-E [53], Gary Marcus et al. [38] 및 Reddit에서 수집된 프롬프트 세트를 포함한다.
이 11개 범주에서 DrawBench는 총 200개의 프롬프트로 구성되며, 크고 포괄적인 데이터 세트에 대한 욕구와 인간 평가가 실현 가능할 정도로 충분히 작은 것 사이에서 균형을 이룬다. (부록 C는 DrawBench에 대한 더 자세한 설명을 제공한다. 그림 2는 Imagen 샘플이 포함된 DrawBench의 프롬프트 예를 보여줍니다.)

우리는 다른 모델을 직접 비교하기 위해 DrawBench를 사용한다.
이를 위해 인간 평가자는 모델 A와 모델 B의 두 가지 이미지 세트를 제공하며, 각각 8개의 샘플을 가지고 있다.
평가자는 샘플 충실도와 image-text 정렬에 대해 모델 A와 모델 B를 비교해야 한다.
이들은 모델 A 선호, 무관심 또는 모델 B 선호의 세 가지 선택 중 하나로 응답합니다.
4 Experiment
섹션 4.1은 학습 세부 사항을 설명하고 섹션 4.2와 4.3은 MS-COCO 및 DrawBench에 대한 결과를 분석하며 섹션 4.4는 ablation 연구와 주요 결과를 요약합니다.
아래 모든 실험에서 이미지는 후처리 또는 재순위 지정 없이 Imagen의 공정한 랜덤 샘플입니다.
4.1 Training details
지정되지 않는 한, 64x64 text-to-image 합성을 위한 2B 매개 변수 모델과 64x64 → 256x256 및 256x256 → 1024x1024를 위한 600M 및 400M 매개 변수 모델을 각각 학습시킨다.
우리는 모든 모델에 대해 2048의 배치 크기와 250M의 학습 단계를 사용합니다.
우리는 base 64x64 모델에 256개의 TPU-v4 칩을 사용하고, 두 초해상도 모델 모두에 128개의 TPU-v4 칩을 사용한다.
우리는 과적합이 문제가 되지 않으며, 추가 학습이 전반적인 성능을 향상시킬 수 있다고 믿는다.
Adafactor를 base 64x64 모델에 사용합니다.
Adam과의 초기 비교에서 Adafactor에 대한 메모리 공간이 훨씬 작은 유사한 성능을 나타냈기 때문입니다.
초해상도 모델의 경우 Adafactor를 발견한 것처럼 Adam을 사용하여 초기 ablatiion에서 모델 품질을 손상시킨다.
classifier-free guidance를 위해, 우리는 세 모델 모두에 대해 10% 확률로 텍스트 임베딩을 영점화하는 것을 통해 무조건적으로 공동 학습을 한다.
우리는 ~460만 개의 image-text 쌍을 사용하는 내부 데이터 세트와 ~400만 개의 image-text 쌍을 사용하는 공개적으로 사용 가능한 Laion 데이터 세트[61]의 조합에 대해 학습한다.
학습 데이터에는 제한이 있으며, 자세한 내용은 섹션 6을 참조하십시오.
구현에 대한 자세한 내용은 부록 F를 참조하십시오.
4.2 Results on COCO
5 Related Work
확산 모델은 이미지 생성[28, 40, 59, 16, 29, 58]에서 광범위한 성공을 거두었으며, 학습 불안정성과 모드 붕괴 문제 없이 충실도와 다양성에서 GAN을 능가했다[6, 16, 29].
자동 회귀 모델 [37], GANs [76, 81], VQ-VAE Transformer 기반 방법 [53, 22] 및 확산 모델은 CLIP 텍스트 잠재성 및 계단식 확산 모델에 앞서 확산을 사용하여 고해상도 1024x1024 이미지를 생성하는 동시 DALL-E 2 [54]를 포함하여 text-to-image [57, 41, 57]에서 주목할 만한 발전을 이루었다; Imagen은 잠재된 사전 정보를 학습할 필요가 없지만 DrawBench에서 MS-COCO FID와 인간 평가 모두에서 더 나은 결과를 얻기 때문에 Imagen이 훨씬 단순하다고 믿는다.
GLIDE [41]는 text-to-image에도 계단식 확산 모델을 사용하지만, 이미지 충실도와 image-text 정렬 모두에 중요한 것으로 밝혀진 대규모 사전 학습된 동결 언어 모델을 사용한다.
XMC-GAN [81]은 BERT를 텍스트 인코더로 사용하지만 훨씬 더 큰 텍스트 인코더로 확장하여 그 효과를 입증한다.
계단식 모델의 사용은 문헌[14, 39] 전반에 걸쳐 인기가 있으며 고해상도 이미지를 생성하기 위해 확산 모델에서 성공적으로 사용되었다[16, 29].
6 Conclusions, Limitations and Social Impact
Imagen은 확산 모델을 사용하여 text-to-image 생성을 위한 텍스트 인코더로서 동결된 대규모 사전 학습된 언어 모델의 효과를 보여준다.
이러한 언어 모델의 크기를 확장하는 것이 전체 성능에 U-Net 크기를 확장하는 것보다 훨씬 더 큰 영향을 미친다는 우리의 관찰은 텍스트 인코더로 훨씬 더 큰 언어 모델을 탐색하는 향후 연구 방향을 장려한다.
또한 Imagen을 통해 분류기 없는 안내의 중요성을 다시 강조하고, 이전 작업에서 볼 수 있는 것보다 훨씬 더 높은 안내 가중치를 사용할 수 있는 동적 임계치를 도입하였다.
이러한 새로운 구성 요소로 Imagen은 전례 없는 사진사실주의와 텍스트와의 정렬을 가진 1024개의 샘플을 생산한다.
Imagen과의 주요 목표는 text-to-image 합성을 테스트 베드로 사용하여 생성 방법에 대한 연구를 발전시키는 것이다.
생성 방법의 최종 사용자 애플리케이션은 대부분 범위를 벗어나 있지만, 우리는 이 연구의 잠재적 다운스트림 애플리케이션이 다양하고 복잡한 방식으로 사회에 영향을 미칠 수 있다는 것을 인식한다.
한편, 생성 모델은 인간의 창의성을 보완, 확장 및 증강할 수 있는 큰 잠재력을 가지고 있다[30].
특히 text-to-image 생성 모델은 이미지 편집 기능을 확장하고 창의적인 실무자를 위한 새로운 도구의 개발로 이어질 수 있는 잠재력을 가지고 있다.
한편, 생성 방법은 괴롭힘과 잘못된 정보 확산을 포함한 악의적인 목적에 활용될 수 있으며 [20] 사회적, 문화적 배제와 편견에 대한 많은 우려를 제기할 수 있다[67, 62, 68].
이러한 고려 사항은 코드 또는 공개 데모를 공개하지 않기로 한 우리의 결정을 알려 줍니다.
향후 작업에서 우리는 외부 감사의 가치와 무제한 오픈 액세스의 위험 사이에서 균형을 이루는 책임 있는 외부화를 위한 프레임워크를 탐구할 것이다.
또 다른 윤리적 과제는 text-to-image 모델의 대규모 데이터 요구 사항과 관련이 있으며, 이로 인해 연구자들은 대부분 웹 스크래핑된 대규모 데이터 세트에 크게 의존하게 되었다.
이 접근 방식은 최근 몇 년 동안 알고리즘의 급속한 발전을 가능하게 했지만, 이러한 성격의 데이터 세트는 다양한 윤리적 차원을 따라 비판되고 논쟁되어 왔다.
예를 들어, 공공 데이터의 적절한 사용에 관한 공공 및 학술적 담론은 데이터 주제 인식과 동의에 대한 우려를 제기하고 있다[24, 18, 60, 43].
데이터 세트 감사는 이러한 데이터 세트가 사회적 고정관념, 억압적인 관점, 그리고 소외된 ID 그룹에 대한 경멸적이거나 해로운 연관성을 반영하는 경향이 있음을 밝혔다[44, 4].
이 데이터에 대한 text-to-image 모델을 학습하면 이러한 연관성을 재현하고 이미 사회 내에서 소외, 차별 및 배제를 겪고 있는 개인과 지역사회에 불균형적으로 영향을 미칠 수 있는 상당한 표현적 해를 초래할 위험이 있다.
이와 같이, Imagen과 같은 text-to-image 모델을 사용자 대면 애플리케이션에 안전하게 통합하기 전에 해결해야 하는 수많은 데이터 문제가 있다.
이 작업에서 이러한 과제를 직접 해결하지는 않지만, 학습 데이터의 한계에 대한 인식은 Imagen을 공개하지 않기로 하는 결정을 안내한다.
우리는 학습 데이터 세트의 내용에 대한 세심한 주의와 관심 없이 모든 사용자 대면 도구에 text-to-image 생성 방법을 사용하는 것을 강력히 경고한다.
Imagen의 학습 데이터는 이미지와 영어 alt-text 쌍의 몇 가지 기존 데이터 세트에서 도출되었다.
이 데이터의 하위 집합은 노이즈 및 포르노 이미지 및 독성 언어와 같은 바람직하지 않은 콘텐츠를 제거하기 위해 필터링되었습니다.
그러나 최근 데이터 소스 중 하나인 LAION-400M[61]에 대한 감사에서 포르노 이미지, 인종차별적 비방 및 유해한 사회적 고정관념을 포함한 광범위한 부적절한 콘텐츠가 발견되었습니다[4].
이 발견은 Imagen이 현재 공개 사용에 적합하지 않다는 우리의 평가를 알려주고 또한 모델의 적절하고 안전한 사용에 대한 후속 결정을 알리는 데 있어 엄격한 데이터 세트 감사와 포괄적인 데이터 세트 문서(예: [23, 45])의 가치를 보여준다.
Imagen은 또한 정리되지 않은 웹 스케일 데이터에 대해 학습된 텍스트 인코더에 의존하므로 대규모 언어 모델의 사회적 편견과 한계를 계승한다[5, 3, 50].
Imagen에 의해 인코딩된 사회적 및 문화적 편견에 대한 심층적인 경험적 분석을 향후 연구에 맡기지만, 소규모 내부 평가는 현재 Imagen을 출시하지 않기로 한 결정을 안내하는 몇 가지 한계를 드러낸다.
첫째, Imagen을 포함한 모든 생성 모델은 데이터 분포의 드롭 모드 위험에 직면할 수 있으며, 이는 데이터 세트 편향의 사회적 결과를 더욱 악화시킬 수 있다.
둘째, Imagen은 사람을 묘사하는 이미지를 생성할 때 심각한 한계를 보인다.
우리의 인간 평가는 Imagen이 사람을 묘사하지 않는 이미지에서 평가될 때 훨씬 더 높은 선호율을 얻어 이미지 충실도의 저하를 나타내는 것을 발견했다.
마지막으로, 우리의 예비 평가는 Imagen이 피부색이 밝은 사람들의 이미지를 생성하는 것에 대한 전반적인 편향과 서구 성별 고정관념과 일치하기 위해 다른 직업을 묘사하는 이미지의 경향을 포함하여 몇 가지 사회적 편견과 고정관념을 암호화한다는 것을 시사한다.
우리가 사람들로부터 몇 세대 떨어진 곳에 초점을 맞출 때에도, 우리의 예비 분석은 Imagen이 활동, 사건 및 사물의 이미지를 생성할 때 다양한 사회적, 문화적 편견을 암호화한다는 것을 보여준다.
사회적 편견의 형태(예: [8, 9, 68])에 대한 image-to-text 및 이미지 레이블링 모델을 감사하는 광범위한 작업이 있었지만, 최근 [10]을 제외하고 text-to-image 모델에 대한 사회적 편견 평가 방법에 대한 작업은 상대적으로 적었다.
우리는 이것이 미래 연구를 위한 중요한 방법이라고 믿고 향후 연구에서 사회 및 문화적 편향에 대한 벤치마크 평가를 탐구하고자 한다.
예를 들어 이미지 생성 모델의 편향 측정에 대해 표준화된 점별 상호 정보 메트릭 [1]을 일반화할 수 있는지 여부를 탐구한다.
또한 평가 메트릭의 개발을 안내하고 책임 있는 모델 릴리스에 알릴 수 있는 text-to-image 모델의 잠재적 해악에 대한 개념 어휘를 개발할 필요성이 크다.
우리는 향후 작업에서 이러한 과제를 해결하는 것을 목표로 한다.
A Background
확산 모델은 잠재 z = {z_t | t ∈ [0, 1]}를 갖는 잠재 변수 모델로, 데이터 x ~ p(x)에서 시작하는 순방향 프로세스 q(z|x)를 따른다.
이 순방향 과정은 마르코프 구조를 만족시키는 가우시안 과정이다:
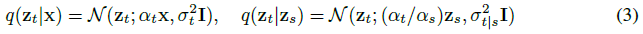
, 여기서 0 ≤ s < t ≤ 1, σ_(t|s)^2와 α_t, σ_t는 로그 신호 대 잡음 비율, 즉 λ_t가 q(z_1) ≒ N(0, I)까지 t와 함께 감소하는 미분 가능한 노이즈 스케줄을 지정합니다.
생성을 위해 확산 모델은 이 전진 프로세스를 역전시키는 방법을 학습한다.
'Deep Learning' 카테고리의 다른 글
| Learning bothWeights and Connections for Efficient Neural Networks (1) | 2023.05.03 |
|---|---|
| Segment Anything (0) | 2023.04.12 |
| [딥러닝] Multi-variable linear regression (0) | 2021.01.02 |
| [딥러닝] Describe the principle of cost minimization algorithm in Linear Regression (0) | 2021.01.02 |
| [딥러닝] Explanation of Hypothesis and cost of Linear Regression (0) | 2020.09.03 |