2022. 2. 16. 18:01ㆍ로봇 내비게이션
DROID-SLAM: Deep Visual SLAM for Monocular, Stereo, and RGB-D Cameras
Zachary Teed, Jia Deng
Abstract
새로운 딥러닝 기반 SLAM 시스템인 DROID-SLAM을 소개합니다.
DROID-SLAM은 밀도 번들 조정 레이어를 통해 카메라 포즈와 픽셀 단위 깊이의 반복적인 업데이트로 구성된다.
DROID-SLAM은 정확하여 이전 작업에 비해 크게 개선되었으며, 치명적인 고장이 훨씬 적습니다.
단안 영상 훈련에도 불구하고 스테레오나 RGB-D 영상을 활용해 테스트 시 성능 향상을 이룰 수 있다.
1. Introduction
동시 로컬라이제이션 및 매핑(SLAM)은 (1) 환경 맵을 작성하고 (2) 환경 내에서 에이전트를 로컬라이제이션하는 것을 목표로 한다.
이것은 장기 궤적의 정확한 추적에 초점을 맞춘 움직임으로부터의 구조(SfM)의 특별한 형태이다.
그것은 로봇 공학, 특히 자율 주행 자동차의 중요한 기능이다.
이 작업에서는 센서 기록이 단안, 스테레오 또는 RGB-D 카메라에서 캡처된 이미지의 형태로 제공되는 시각적 SLAM을 다룬다.
SLAM 문제는 다양한 각도에서 접근해 왔습니다.
초기 연구는 확률론적 및 필터링 기반 접근방식[12, 30]과 지도 및 카메라 포즈의 교대로 최적화를 사용하여 구축되었다[34, 16].
보다 최근에는 최신 SLAM 시스템이 최소 제곱 최적화를 활용했다.
정확성을 위한 핵심 요소는 단일 최적화 문제에서 카메라 포즈와 3D 맵을 공동으로 최적화하는 전체 번들 조정(BA)이었다.
최적화 기반 제형의 한 가지 장점은 SLAM 시스템을 쉽게 수정하여 서로 다른 센서를 활용할 수 있다는 것이다.
예를 들어, ORB-SLAM3 [5]은 단안, 스테레오, RGB-D 및 IMU 센서를 지원하며, 현대 시스템은 다양한 카메라 모델을 지원합니다 [5, 27, 43, 6].
상당한 진전에도 불구하고, 현재 SLAM 시스템은 많은 실제 애플리케이션에 요구되는 견고성이 부족하다.
실패는 손실된 특징 트랙, 최적화 알고리즘의 발산 및 드리프트 누적과 같은 많은 형태로 나타난다.
딥러닝은 이러한 많은 실패 사례에 대한 해결책으로 제안되었다.
이전 연구에서는 신경 3D 표현[47, 1, 9, 46, 45, 25, 22]을 사용하여 수작업으로 학습된 특징[13, 7, 29, 26, 35]을 대체하고 학습된 에너지 용어를 고전적 최적화 백엔드[59, 58]와 결합하는 것을 조사했다.
다른 연구에서는 SLAM 또는 VO 시스템을 종단 간 학습하려고 시도하였습니다 [60, 48, 54, 53, 47].
이러한 시스템은 때때로 더 강력하지만 공통 벤치마크에 대한 기존 시스템의 정확도에 크게 미치지 못한다.
본 연구에서는 딥러닝을 기반으로 하는 새로운 SLAM 시스템인 DROID-SLAM을 소개한다.
이 제품은 매우 큰 마진을 가진 까다로운 벤치마크에서 고전적이든 학습 기반이든 기존 SLAM 시스템을 능가하는 최첨단 성능을 갖추고 있다.
특히 다음과 같은 장점이 있습니다:
• 높은 정확도:
우리는 여러 데이터 세트 및 양식에 걸쳐 이전 작업에 비해 크게 개선된다.
TartanAir SLAM 대회[55]에서, 우리는 단안 트랙에서 최고의 이전 결과에 비해 오류를 62%, 스테레오 트랙에서 60% 줄였습니다.
우리는 ETH-3D RGB-D SLAM 리더보드[42]에서 1위를 차지했는데, 오류와 치명적인 실패율을 모두 고려하는 AUC 메트릭에서 2위를 35% 능가했다.
EuRoc [2]에서는 단안 입력으로 고장이 없는 방법 중 82%의 오류를 줄이고, 11개 시퀀스 중 10개만 성공하는 ORB-SLAM3에 비해 43%의 오류를 줄인다.
스테레오 입력을 통해 ORB-SLAM3에 비해 오류를 71% 줄입니다.
TUM-RGBD[44]에서는 고장이 없는 방법 중 오류를 83% 줄인다.
• 높은 견고성:
이전 시스템보다 치명적인 장애가 상당히 적습니다.
ETH-3D에서는 32개의 RGB-D 데이터 세트 중 30개를 성공적으로 추적하고 다음으로 가장 잘 추적하는 것은 19/32뿐이다.
Tartan Air, EuRoc, TUM-RGBD에서는 고장이 없습니다.
• 강력한 일반화:
단안 입력으로만 훈련된 우리 시스템은 스테레오 또는 RGB-D 입력을 직접 사용하여 재교육 없이 정확도를 높일 수 있다.
4개의 데이터 세 가지 양식에 걸친 모든 결과는 합성 TartanAir 데이터 세트에 대한 단안 입력만으로 한 번 훈련된 단일 모델에 의해 달성된다.
DROID-SLAM의 강력한 성능과 일반화는 고전적 접근 방식과 딥 네트워크의 장점을 모두 결합한 엔드 투 엔드 차별화 아키텍처인 "DROID(Differable Recurrent Optimization-Mensive Design)"가 가능하기 때문이다.
특히, 광학 흐름을 위해 RAFT[49]를 기반으로 하지만 두 가지 핵심 혁신을 소개하는 반복적인 업데이트로 구성된다.
첫째, 광학 흐름을 반복적으로 업데이트하는 RAFT와 달리 카메라 포즈와 깊이를 반복적으로 업데이트한다.
RAFT가 두 프레임에서 작동하는 반면, 우리의 업데이트는 임의의 수의 프레임에 적용되어 긴 궤적과 루프 폐쇄를 위한 드리프트를 최소화하는 데 필수적인 모든 카메라 포즈와 깊이 맵의 공동 전역 개선을 가능하게 한다.
둘째, DROID-SLAM에서 카메라 포즈와 깊이 맵의 각 업데이트는 차별화 가능한 DBA(Dense Bundle Adjustment) 레이어에 의해 생성되며, 이 레이어는 카메라 포즈와 픽셀당 밀도 업데이트를 계산하여 현재 광학 흐름 추정치와 호환성을 극대화한다.
이 DBA 계층은 기하학적 제약을 활용하고 정확성과 견고성을 향상시키며 단안 시스템이 재학습 없이 스테레오 또는 RGB-D 입력을 처리할 수 있도록 한다.
DROID-SLAM의 디자인은 참신하다.
가장 가까운 선행 딥 아키텍처는 DeepV2D [48]와 BA-Net [47]이며, 둘 다 깊이 추정에 초점을 맞추고 제한된 SLAM 결과를 보고했다.
DeepV2D는 번들 조정 대신 깊이 업데이트와 카메라 포즈 업데이트를 번갈아 한다.
BA-Net은 번들 조정 레이어를 가지고 있지만 그 레이어는 상당히 다르다: 깊이 베이스(사전 예측된 깊이 맵 세트)를 선형적으로 결합하는 데 사용되는 소수의 계수들을 최적화한다는 점에서 "밀도"가 아닌 반면, 우리는 깊이 베이스에 의해 방해받지 않고 픽셀당 깊이를 직접 최적화한다.
또한 BA-Net은 (피처 공간에서) 광도 재현 오차를 최적화하는 반면, 우리는 최첨단 흐름 추정을 활용하여 기하학적 오차를 최적화한다.
우리는 4개의 서로 다른 데이터 세트와 3개의 서로 다른 센서 양식에 대해 광범위한 평가를 수행하여 모든 경우에 최첨단 성능을 입증한다.
또한 중요한 설계 결정과 초 매개 변수를 밝히는 절제 연구도 포함되어 있다.
2. Related Work
최신 SLAM 시스템은 지역화 및 매핑을 공동 최적화 문제로 취급합니다 [4].
Visual SLAM은 단안, 스테레오 또는 RGB-D 영상의 형태로 관찰에 초점을 맞춘다.
이러한 접근방식은 일반적으로 직접 또는 간접으로 분류된다[15].
간접 접근법[31, 32, 5, 38]은 먼저 관심 지점을 감지하고 형상 설명자를 부착하여 이미지를 중간 표현으로 처리한다.
그런 다음 이미지 간에 피쳐가 일치합니다.
간접적인 접근 방식은 투영된 3D 지점과 이미지 내 위치 사이의 거리인 재투영 오류를 최소화하여 카메라 포즈와 3D 포인트 클라우드를 최적화합니다.
직접 접근방식은 이미지 형성 과정을 모델링하고 광도계 오류에 대한 목적 함수를 정의한다[16, 15, 61].
직접 접근법의 한 가지 장점은 간접 접근법이 사용하지 않는 선 및 강도 변화[15]와 같은 이미지에 대한 더 많은 정보를 모델링할 수 있다는 것이다.
그러나 광도 측정 오류는 일반적으로 더 어려운 최적화 문제를 초래하며, 직접적인 접근 방식은 롤링 셔터 아티팩트와 같은 기하학적 왜곡에 덜 강력하다.
이 접근 방식에는 로컬 최소값을 피하기 위해 거친 이미지 피라미드에서 미세한 이미지 피라미드와 같은 보다 정교한 최적화 기술이 필요하다.
우리의 방법은 어느 범주에도 확실히 들어맞지 않는다.
직접적인 접근 방식과 마찬가지로 이미지 간의 특징을 감지하고 일치시키기 위해 사전 처리 단계가 필요하지 않습니다.
대신 전체 이미지를 사용하여 일반적으로 모서리와 가장자리만 사용하는 간접 방법보다 광범위한 정보를 활용할 수 있습니다.
그러나 간접 방법과 유사한 재투영 오류를 최소화한다.
이것은 더 쉬운 최적화 문제이며 이미지 피라미드와 같은 더 복잡한 표현이 필요하지 않다.
이러한 의미에서, 우리의 접근법은 두 가지 접근법 중 가장 좋은 점: 즉 간접 접근법의 더 부드러운 객관적 기능과 간접 접근법의 더 큰 모델링 능력을 차용한다.
Deep Learning은 최근에 SLAM 문제에 적용되었다.
많은 연구는 특징 감지 [13, 7, 29, 26, 35], 특징 일치 및 이상치 거부 [39, 37], 그리고 지역화 [52, 40]와 같은 특정 하위 문제에 대한 훈련 시스템에 초점을 맞추고 있다.
SuperGlue [39]는 특징 일치 및 검증을 수행하고 2 뷰 포즈 추정치를 훨씬 더 견고하게 만들기 위해 설계되었다.
우리의 네트워크는 또한 키포인트 지역화 정확도를 향상시키기 위해 신경망을 SfM 파이프라인에 구축하는 Dusmanu 등[14]에서 영감을 얻는다.
다른 작업들은 SLAM 시스템의 엔드 투 엔드 훈련에 초점을 맞추고 있습니다 [60, 47, 8, 51, 24, 48, 54].
이 방법들은 완전한 SLAM 시스템은 아니지만, 대신 최대 12개의 프레임[8, 51, 54]까지 소규모 재구성에 초점을 맞춘다[60, 47, 48].
그들은 우리의 실험에서 증명된 바와 같이 대규모 재구성을 수행하는 능력을 저해하는 루프 폐쇄 및 글로벌 번들 조정과 같은 현대 SLAM 시스템의 많은 핵심 기능이 부족하다.
∇SLAM[23]은 몇 가지 기존 SLAM 알고리즘을 차별화 가능한 계산 그래프로 구현하여 재구성의 오류가 센서 측정으로 다시 전파되도록 한다.
이 접근 방식은 차별화할 수 있지만 훈련 가능한 매개 변수가 없으며, 이는 시스템의 성능이 에뮬레이트되는 고전적 알고리즘의 정확성에 의해 제한된다는 것을 의미한다.
DeepFactors[9]는 이전 CodeSLAM [1]을 기반으로 구축된 가장 완전한 deep SLAM 시스템입니다.
포즈와 깊이 변수의 공동 최적화를 수행하고 장단거리 루프 클로저가 가능하다.
BA-Net[47]과 유사하게 DeepFactors는 추론 중에 학습된 깊이 기준의 매개 변수를 최적화한다.
대조적으로, 우리는 학습된 기반에 의존하지 않고 대신 픽셀 단위 깊이를 최적화한다.
이를 통해 깊이 표현은 학습 데이터 세트에 연결되지 않기 때문에 네트워크가 새로운 데이터 세트로 더 잘 일반화할 수 있다.
3. Approach
우리는 두 가지 목적을 가진 비디오를 입력으로 받아들인다: 카메라의 궤적을 측정하고 환경의 3D 지도를 작성합니다.
먼저 단안 설정을 설명한다; 섹션 3.4에서는 시스템을 스테레오 및 RGB-D 비디오로 일반화하는 방법을 설명한다.
Representation:
우리의 네트워크는 순서화된 이미지 모음인 {I_t}^N _t=0에서 작동한다.
각 이미지 t에 대해 두 가지 상태 변수를 유지합니다: 카메라 포즈 G_t ≤ SE(3) 및 역 깊이 d_t ≤ R^(HxW) _+.
포즈 집합 {G_t}^N _(t=0) 및 역 깊이 {d_t}^N _(t=0)은 알려지지 않은 상태 변수이며, 새로운 프레임이 처리될 때 추론 중에 반복적으로 업데이트됩니다.
우리가 깊이를 참조할 때 논문을 상기시키기 위해, 우리는 역 깊이 매개 변수를 사용하고 있다는 것을 주목하라.
프레임 간의 공동 가시성을 나타내기 위해 프레임 그래프(Υ, Ε)를 채택한다.
가장자리(i, j) ∈ Ε는 이미지 I_i와 I_j가 겹치는 시야를 가지고 있다는 의미이며, 이는 점을 공유합니다.
프레임 그래프는 훈련 및 추론 중에 동적으로 구축된다.
각 포즈 또는 깊이 업데이트 후 가시성을 다시 계산하여 프레임 그래프를 업데이트할 수 있습니다.
카메라가 이전에 매핑된 영역으로 돌아가면 그래프에 장거리 연결을 추가하여 루프 닫기를 수행합니다.
3.1 Feature Extraction and Correlation
형상은 시스템에 추가된 각각의 새로운 영상에서 추출된다.
이 단계의 주요 구성요소는 RAFT[49]에서 차용된다.
Feature Extraction
각 입력 이미지는 형상 추출 네트워크에 의해 처리된다.
네트워크는 6개의 잔여 블록과 3개의 다운샘플링 레이어로 구성되며, 1/8 입력 이미지 해상도에서 조밀한 피처 맵을 생성한다.
RAFT[49]와 마찬가지로, 우리는 두 개의 별도 네트워크를 사용한다: 기능 네트워크 및 컨텍스트 네트워크.
기능 네트워크는 상관 관계 볼륨 세트를 구축하는 데 사용되며, 컨텍스트 기능은 업데이트 연산자를 적용할 때마다 네트워크에 주입됩니다.
Correlation Pyramid
프레임 그래프의 각 가장자리, (i, j) ∈ E에 대해 g_θ(I_i)와 g_θ(I_j)의 특징 벡터의 모든 쌍 사이의 도트 곱을 취하여 4D 상관 볼륨을 계산한다.
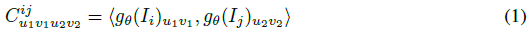
그런 다음 RAFT[49]에 이어 상관 볼륨의 마지막 2차원의 평균 풀링을 수행하여 4단계 상관 피라미드를 형성한다.
Correlation Lookup
반지름 r과 L_r: R^(H x W x H x W) x R^(H x W x 2) → R^(H x W x (r+1)^2)의 그리드를 사용하여 상관 볼륨을 색인화하는 조회 연산자를 정의한다.
룩업 연산자는 H x W 좌표 그리드를 입력으로 사용하고 이중 선형 보간을 사용하여 상관 관계 볼륨에서 값이 검색된다.
연산자는 피라미드의 각 상관 관계 볼륨에 적용되고 최종 특징 벡터는 각 수준의 결과를 연결하여 계산된다.
3.2 Update Operator
SLAM 시스템의 핵심 구성요소는 그림 2에 표시된 학습된 업데이트 연산자입니다.
업데이트 연산자는 히든 스테이트 h를 가진 3x3 컨볼루션 GRU이다.
연산자의 각 응용 프로그램은 히든 스테이트를 업데이트하고 포즈 업데이트 Δξ^(k) 및 깊이 업데이트 Δd^(k)를 추가로 생성합니다.
자세 및 깊이 업데이트는 SE3 매니폴드 및 벡터 추가를 통해 각각 현재 깊이 및 자세 추정치에 적용됩니다.
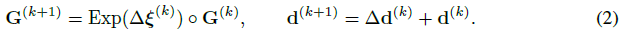
업데이트 연산자의 반복 애플리케이션은 실제 재구성을 반영하여 고정점 {G^(k)} → G*, {d^(k)} → d*로 수렴할 것으로 예상하는 일련의 포즈와 깊이를 생성한다.
Correspondence
각 반복을 시작할 때 포즈와 깊이의 현재 추정치를 사용하여 대응 관계를 추정한다.
프레임 i에서 픽셀 좌표의 격자 p_i ∈ R^(H x W x 2)가 주어지면 프레임 그래프의 각 가장자리 (i, j) ∈ E에 대해 밀도 대응 필드 p_ij를 계산한다.
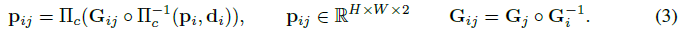
여기서 Π_c는 이미지에 3D 포인트 세트를 매핑하는 카메라 모델이고, Π_c^-1은 3D 포인트 클라우드에 대한 역투영 함수 매핑 d 및 좌표 그리드 p_i이다(우리는 공식과 야코비안을 부록에서 제공한다).
p_ij는 추정된 포즈와 깊이를 사용하여 프레임 j에 매핑된 픽셀 p_i의 좌표를 나타냅니다.
Inputs
대응 필드를 사용하여 상관 볼륨을 인덱싱합니다.
각 에지에 대해 (i, j) p E에 대해 p_ij를 사용하여 상관 볼륨 C_ij에서 조회를 수행하여 상관 기능을 검색합니다.
또한 대응 필드를 사용하여 카메라 움직임에 의해 유도된 광학 흐름을 p_ij - p_j 차이로 도출한다.
또한, 이전 BA 솔루션의 잔여물은 흐름 필드와 연결되어 네트워크가 이전 반복의 피드백을 사용할 수 있다.
상관관계 기능은 네트워크가 시각적으로 유사한 이미지 영역을 정렬하는 방법을 배울 수 있도록 p_ij 주변의 시각적 유사성에 대한 정보를 제공한다.
하지만, 관련성은 때때로 모호합니다.
이 흐름은 네트워크가 모션 필드의 부드러움을 활용하여 견고성을 얻을 수 있도록 보완적인 정보 소스를 제공한다.
Update
상관 관계 피처와 흐름 피처는 GRU에 주입되기 전에 각각 두 개의 컨볼루션 레이어를 통해 매핑된다.
또한 요소별 추가를 통해 컨텍스트 네트워크에 의해 추출된 컨텍스트 기능을 GRU에 주입한다.
ConvGRU는 작은 수용 필드를 가진 로컬 작업입니다.
이미지의 공간 차원에서 히든 스테이트를 평균화하여 전역 컨텍스트를 추출하고 이 기능 벡터를 GRU에 대한 추가 입력으로 사용한다.
예를 들어 움직이는 큰 물체로 인해 잘못된 대응이 시스템의 정확도를 저하시킬 수 있기 때문에 전역 컨텍스트는 SLAM에서 중요하다.
네트워크가 잘못된 대응을 인식하고 거부하는 것이 중요하다.
GRU는 업데이트된 히든 스테이트 h^(k+1)를 생성한다.
깊이나 포즈에 대한 업데이트를 직접 예측하는 대신, 밀도 높은 흐름 필드의 공간에서 업데이트를 예측한다.
우리는 두 개의 추가 컨볼루션 레이어를 통해 숨겨진 상태를 매핑하여 두 개의 출력을 생성한다: (1) 개정 흐름 필드 r_ij ∈ R^(H x W x 2) 및 (2) 관련 신뢰 맵 w_ij ∈ R^(H x W x 2)_+.
개정판 r_ij는 밀집된 대응 분야의 오류를 수정하기 위해 네트워크가 예측하는 수정 항이다.
우리는 수정된 대응관계를 p*_ij = rij + pj로 나타낸다.
그런 다음 동일한 소스 뷰 i를 공유하고 픽셀 단위 댐핑 계수 λ를 예측하는 모든 기능에 대해 숨겨진 상태를 풀링한다.
우리는 감쇠 조건이 양수인지 확인하기 위해 소프트플러스 오퍼레이터를 사용합니다.
또한 풀링된 기능을 사용하여 역 깊이 추정치를 업샘플링하는 데 사용할 수 있는 8x8 마스크를 예측한다.
Dense Bundle Adjustment Layer (DBA)
DBA(Dense Bundle Adjustment Layer)는 흐름 수정기호 집합을 포즈 집합 및 픽셀 단위 깊이 업데이트로 매핑합니다.
전체 프레임 그래프에서 비용 함수를 정의합니다
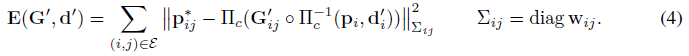
여기서 |·|_∑는 신뢰 가중치 w_ij에 기초한 오차항 가중치를 갖는 마할라노비스 거리이다.
식 (4)는 재투사된 점이 업데이트 연산자가 예측한 수정된 대응 p*_ij와 일치하도록 업데이트된 포즈 G'와 깊이 d'를 원한다고 명시한다.
우리는 식 (4)를 선형화하기 위해 로컬 매개 변수화를 사용하고 업데이트에 대해 가우스-뉴턴 알고리즘 해결(Δξ, Δd)을 사용한다.
식 (4)의 각 항은 하나의 깊이 변수만 포함하므로 헤시안 행렬은 블록 대각선 구조를 가집니다.
포즈와 깊이 변수를 분리하여 깊이 블록에 픽셀 단위 댐핑 계수 λ를 추가하여 Schur 보어를 사용하여 시스템을 효율적으로 해결할 수 있습니다.
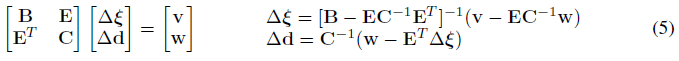
여기서 C는 대각선이며 C^-1 = 1/C로 저렴하게 반전될 수 있다.
DBA 계층은 계산 그래프의 일부로 구현되며 학습 중에 계층을 통해 역전파가 수행됩니다.
3.3 Training
SLAM 시스템은 PyTorch에서 구현되며 LieTorch 확장 [50]을 사용하여 모든 그룹 요소의 접선 공간에서 역전파를 수행한다.
Removing gauge freedom
단안 설정에서 네트워크는 유사성 변환까지의 카메라 궤적만 복구할 수 있다.
한 가지 해결책은 유사성 변환에 변하지 않는 손실을 정의하는 것이다.
그러나 학습 중에는 게이지 자유도가 여전히 존재하여 선형 시스템의 컨디셔닝과 기울기의 안정성에 좋지 않은 영향을 미친다.
우리는 처음 두 포즈를 각 학습 시퀀스의 실제 ground-truth 포즈에 고정함으로써 이 문제를 해결한다.
첫 번째 포즈를 고정하면 6도프 게이지의 자유도가 제거됩니다.
두 번째 포즈를 수정하면 스케일 자유도가 결정됩니다.
Constructing training video
각 학습 예는 7프레임 비디오 시퀀스로 구성됩니다.
안정적인 훈련과 좋은 다운스트림 성능을 보장하기 위해 너무 쉽지도 않고 어렵지 않은 영상을 샘플로 제작하고자 합니다.
학습 세트는 비디오 모음으로 구성되어 있습니다.
길이가 N_i인 각 비디오 i에 대해, 우리는 각 프레임 쌍 사이의 평균 광학 흐름 크기를 저장하는 N_i x N_i 거리 매트릭스를 미리 계산한다.
그러나 모든 프레임이 함께 보이는 것은 아니며, 50% 미만의 겹치는 프레임 쌍에는 무한대의 거리가 할당된다.
학습 중에, 우리는 인접한 비디오 프레임 사이의 평균 흐름이 8px와 96px 사이가 되도록 거리 매트릭스에서 경로를 샘플링하여 동적으로 비디오를 생성한다.
Supervision
우리는 포즈 손실과 흐름 손실의 조합을 사용하여 네트워크를 감독합니다.
흐름 손실은 인접한 프레임 쌍에 적용됩니다.
예측된 깊이와 포즈에 의해 유도된 광학 흐름과 ground-truth의 깊이와 포즈에 의해 유도된 흐름을 계산한다.
손실은 두 흐름 필드 사이의 평균 l2 거리로 간주합니다.
ground-truth 포즈 {T}^N_i와 예측 포즈 {G}^N_i가 주어지면, 포즈 손실은 ground-truth와 예측 포즈 사이의 거리로 간주된다,
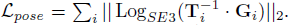
γ = 0.9를 사용하여 기하급수적으로 가중치가 증가하는 모든 반복의 출력에 손실을 적용한다.
3.4 SLAM System
추론하는 동안 네트워크를 전체 SLAM 시스템으로 구성한다.
SLAM 시스템은 비디오 스트림을 입력으로 받아 실시간으로 재구성 및 현지화를 수행합니다.
우리 시스템에는 비동기식으로 실행되는 두 개의 스레드가 있습니다.
프런트 엔드 스레드는 새로운 프레임을 도입하고, 기능을 추출하고, 키 프레임을 선택하고, 로컬 번들 조정을 수행합니다.
백엔드 스레드는 키 프레임의 전체 기록에 대해 글로벌 번들 조정을 동시에 수행합니다.
여기에 시스템에 대한 개요와 자세한 내용은 부록을 참조하십시오.
Initialization
DROID-SLAM을 사용하면 초기화가 간단합니다.
우리는 12개 세트를 가질 때까지 프레임을 수집합니다.
프레임을 누적할 때 광학 흐름이 16px(한 번의 업데이트 반복 적용으로 추정)보다 큰 경우에만 이전 프레임을 유지합니다.
12개의 프레임이 누적되면 3개의 시간 단계 내에 있는 키 프레임 사이에 에지를 만들어 프레임 그래프를 초기화한 다음 업데이트 연산자를 10회 반복 실행한다.
Frontend
프런트 엔드는 들어오는 비디오 스트림에서 직접 작동합니다.
키 프레임의 모음과 함께 볼 수 있는 키 프레임 사이의 가장자리를 저장하는 프레임 그래프를 유지합니다.
키프레임 포즈와 깊이가 적극적으로 최적화되고 있다.
먼저 들어오는 프레임에서 피쳐가 추출됩니다.
그런 다음 새로운 프레임이 프레임 그래프에 추가되어 평균 광학 흐름에 의해 측정된 3개의 가장 가까운 이웃으로 가장자리를 추가한다.
포즈는 선형 모션 모델을 사용하여 초기화됩니다.
그런 다음 키 프레임 포즈와 깊이를 업데이트하기 위해 업데이트 연산자의 여러 반복을 적용한다.
처음 두 가지 포즈를 수정하여 게이지 자유를 제거하지만 모든 깊이를 자유 변수로 취급한다.
새 프레임을 추적한 후 제거할 키 프레임을 선택합니다.
평균 광학 흐름 크기를 계산하여 프레임 쌍 사이의 거리를 계산하고 중복 프레임을 제거한다.
제거하기에 좋은 프레임이 없으면 가장 오래된 키 프레임을 제거합니다.
Backend
백엔드는 전체 키 프레임 기록에 대해 글로벌 번들 조정을 수행합니다.
각 반복 중에 N x N 거리 매트릭스로 표현되는 모든 키 프레임 쌍 사이의 흐름을 사용하여 프레임 그래프를 재구성한다.
먼저 일시적으로 인접한 키 프레임 사이에 가장자리를 추가합니다.
그런 다음 흐름이 증가하는 순서대로 거리 행렬에서 새로운 가장자리를 샘플링한다.
선택된 각 에지에서, 우리는 2의 거리 내에서 이웃 에지를 억제한다, 여기서 거리는 인덱스 쌍 ||(i, j) - (k, l)||_∞ = max(|i-k|, |j-l|) 사이의 체비셰프 거리로 정의된다.
그런 다음 업데이트 연산자를 종종 수천 개의 프레임과 가장자리로 구성된 전체 프레임 그래프에 적용한다.
전체 상관 관계 볼륨 세트를 저장하면 비디오 메모리를 빠르게 초과할 수 있습니다.
대신에, 우리는 RAFT [49]에서 제안된 메모리 효율적인 구현을 사용한다.
학습 중에, 우리는 자동 미분 엔진을 활용하기 위해 PyTorch에서 고밀도 번들 조정을 구현한다.
추론 시간에, 우리는 문제의 블록 스파스 구조를 이용하는 사용자 지정 CUDA 커널을 사용한 다음 축소된 카메라 블록에서 희소 콜레스키 분해를 수행한다.
우리는 키프레임 이미지에 대해서만 전체 번들 조정을 수행합니다.
non-키 프레임의 자세를 복구하기 위해 각 키 프레임과 인접 non-키 프레임 사이의 흐름을 반복적으로 추정하여 모션 전용 번들 조정을 수행한다.
테스트하는 동안 우리는 키 프레임뿐만 아니라 전체 카메라 궤적을 평가한다.
Stereo and RGB-D
우리 시스템은 스테레오와 RGB-D 비디오로 쉽게 수정할 수 있습니다.
RGB-D의 경우, 센서 깊이는 노이즈가 있을 수 있고 관측치가 누락될 수 있으므로, 우리는 깊이를 여전히 변수로 취급하고, 단순히 측정 깊이와 예측 깊이 사이의 제곱 거리를 벌하는 최적화 목표(식 (4))에 항을 추가한다.
스테레오의 경우 위에서 설명한 것과 동일한 시스템을 사용하며 프레임만 두 배로 늘리고 DBA 계층에서 왼쪽과 오른쪽 프레임 사이의 상대적인 자세를 고정합니다.
그래프의 교차 카메라 엣지는 스테레오 정보를 활용할 수 있게 해줍니다.
4. Experiment
5. Conclusion
시각적 SLAM을 위한 엔드 투 엔드 신경 아키텍처인 DROID-SLAM을 소개한다.
DROID-SLAM은 정확하고 강력하며 다재다능하며 단안, 스테레오 및 RGB-D 비디오에 사용할 수 있습니다.
까다로운 벤치마크에서 이전 작업을 큰 폭으로 능가한다.