2022. 2. 22. 17:35ㆍComputer Vision
NEURAL ARCHITECTURE SEARCH WITH REINFORCEMENT LEARNING
Barret Zoph, Quoc V. Le
Abstract
신경망은 이미지, 음성 및 자연어 이해에서 많은 어려운 학습 과제에 잘 작동하는 강력하고 유연한 모델이다.
그들의 성공에도 불구하고, 신경망은 여전히 설계하기 어렵다.
본 논문에서, 우리는 반복 네트워크를 사용하여 신경망의 모델 설명을 생성하고 검증 세트에서 생성된 아키텍처의 예상 정확도를 최대화하기 위한 강화 학습으로 이 RNN을 훈련시킨다.
CIFAR-10 데이터 세트에서, 우리의 방법은 처음부터 시작하여 테스트 세트 정확도 측면에서 인간이 발명한 최고의 아키텍처에 필적하는 새로운 네트워크 아키텍처를 설계할 수 있다.
우리의 CIFAR-10 모델은 3.65의 테스트 오류율을 달성하는데, 이는 유사한 아키텍처 체계를 사용한 이전의 최첨단 모델보다 0.09% 더 낫고 1.05배 더 빠르다.
Penn Treebank 데이터 세트에서, 우리의 모델은 널리 사용되는 LSTM 셀과 다른 최첨단 기준선을 능가하는 새로운 반복 셀을 구성할 수 있다.
우리 셀은 Penn Treebank에서 62.4의 테스트 세트 복잡도를 달성하는데, 이것은 이전 최신 모델보다 3.6 더 나은 복잡도이다.
셀은 또한 PTB의 문자 언어 모델링 작업으로 전송될 수 있으며 1.214의 최첨단 복잡성을 달성한다.
1. Introduction
지난 몇 년간 음성 인식(Hinton 등, 2012), 이미지 인식(LeCun 등, 1998; Krizhevsky 등, 2012) 및 기계 번역(Sutskever 등, 2014; Bahdanau 등, 2015년; Wu 등, 2016년)과 같은 많은 도전적인 애플리케이션에서 심층 신경망이 크게 성공했다.
이러한 성공과 함께 기능 설계에서 아키텍처 설계, 즉 SIFT(Lowe, 1999), HOG(Dalal & Triggs, 2005), AlexNet(Krizhevsky et al., 2012), VGGGNet(Simony & Zisserman, 2014), GoogleNet (Szegedy et al., 2015), 그리고 ResNet (He et al., 2016a)으로 패러다임이 변화하고 있다.
건축물을 설계하는 것은 쉬워졌지만, 여전히 많은 전문 지식을 필요로 하고 충분한 시간이 필요합니다.

본 논문은 좋은 아키텍처를 찾기 위한 그레이디언트 기반 방법인 NAS를 제시한다(그림 1 참조).
우리의 연구는 신경망의 구조와 연결성이 일반적으로 가변 길이 문자열에 의해 지정될 수 있다는 관찰을 기반으로 한다.
그러므로 이러한 문자열을 생성하기 위해 컨트롤러라는 반복 네트워크를 사용하는 것이 가능하다.
문자열로 지정된 네트워크("하위 네트워크")를 실제 데이터에 대해 훈련시키면 검증 집합에서 정확성을 얻을 수 있습니다.
이 정확도를 보상 신호로 사용하여 제어기를 업데이트하는 정책 기울기를 계산할 수 있다.
결과적으로, 다음 반복에서, 제어기는 높은 정확도를 수신하는 아키텍처에 더 높은 확률을 줄 것이다.
즉, 컨트롤러는 시간이 지남에 따라 검색을 개선하는 방법을 배웁니다.
우리의 실험은 신경 구조 검색이 처음부터 좋은 모델을 설계할 수 있다는 것을 보여주는데, 이는 다른 방법으로는 불가능한 성과이다.
CIFAR-10을 사용한 이미지 인식에서 NAS는 인간이 만든 대부분의 아키텍처보다 더 나은 새로운 ConvNet 모델을 찾을 수 있다.
우리의 CIFAR-10 모델은 현재 최상의 모델보다 1.05배 빠른 3.65 테스트 세트 오류를 달성한다.
펜 트리뱅크를 사용한 언어 모델링에서 신경 아키텍처 검색은 이전 RNN 및 LSTM 아키텍처보다 더 나은 새로운 반복 셀을 설계할 수 있다.
우리 모델이 발견한 셀은 Penn Treebank 데이터 세트에서 62.4의 테스트 세트 복잡도를 달성했는데, 이는 이전의 SOTA 기술보다 3.6 더 나은 복잡도이다.
2. Related Work
하이퍼파라미터 최적화는 기계 학습에서 중요한 연구 주제이며 실제로 널리 사용된다(Bergstra et al., 2011; Bergstra & Bengio, 2012; Snoek et al., 2012; 2015; Saxena & Verbek, 2016).
이러한 방법의 성공에도 불구하고, 이러한 방법은 고정된 길이 공간에서 모델만 검색한다는 점에서 여전히 제한적이다.
즉, 그들에게 네트워크의 구조와 연결성을 명시하는 가변 길이 구성을 생성하도록 요구하기는 어렵다.
실제로 이러한 방법은 좋은 초기 모델이 제공되는 경우 더 잘 작동한다(Bergstra & Bengio, 2012; Snoek 등, 2012; 2015).
고정되지 않은 길이 아키텍처를 검색할 수 있는 베이지안 최적화 방법(Bergstra 등, 2013; Mendoza 등, 2016)이 있지만, 본 논문에서 제안된 방법보다 일반적이지 않고 유연성이 떨어진다.
현대 신경 진화 알고리즘, 예를 들어비어스트라 외 연구진 (2005); 플로리아노 외 연구진. (2008); 스탠리 외. 반면에 2009년은 새로운 모델을 구성하기 위해 훨씬 더 유연하지만 일반적으로 대규모에서는 덜 실용적이다.
이들의 한계는 검색 기반 방법이기 때문에 속도가 느리거나 많은 휴리스틱이 필요하다는 데 있다.
NAS는 프로그램 합성 및 유도 프로그래밍과 유사하며, 예제 (1977년 서머스; 1978년 비어만)에서 프로그램을 검색하는 아이디어이다.
기계 학습에서 확률론적 프로그램 유도는 간단한 Q&A를 해결하는 학습(Liang 등, 2010년; Neelakantan 등, 2015년; Andreas 등, 2016년), 숫자 목록을 정렬(Red & de Freitas, 2015년)하고 매우 적은 예로 학습(Lake 등, 2015년)과 같은 많은 환경에서 성공적으로 사용되어 왔다.
신경 아키텍처 검색의 컨트롤러는 자동 회귀적이어서 이전 예측에 따라 한 번에 한 번씩 하이퍼 파라미터를 예측한다.
이 아이디어는 종단 간 시퀀스의 디코더에서 시퀀스 학습으로 차용된다(Sutskever 등, 2014).
시퀀스 간 학습과 달리, 우리의 방법은 하위 네트워크의 정확성인 미분 불가능한 메트릭을 최적화한다.
따라서 그것은 신경 기계 번역의 BLEU 최적화 작업과 유사하다(Ranzato 등, 2015; Shen 등, 2016).
이러한 접근 방식과 달리, 우리의 방법은 감독되는 부트스트래핑 없이 보상 신호에서 직접 학습한다.
또한 학습 또는 메타 학습(Thrun & Pratt, 2012)에 대한 아이디어도 우리의 작업과 관련이 있다. 이는 미래 과제를 개선하기 위해 한 과제에서 학습한 정보를 사용하는 일반적인 프레임워크이다.
신경망을 사용하여 다른 네트워크에 대한 경사 강하 업데이트를 학습하는 아이디어(Andrychowicz 등, 2016)와 강화 학습을 사용하여 다른 네트워크에 대한 업데이트 정책을 찾는 아이디어(Li & Malik, 2016)가 더 밀접하게 관련되어 있다.
3. Methods
다음 절에서는 먼저 반복 네트워크를 사용하여 컨볼루션 아키텍처를 생성하는 간단한 방법을 설명할 것이다.
우리는 샘플링된 아키텍처의 예상 정확도를 최대화하기 위해 정책 그라데이션 방법을 사용하여 반복 네트워크를 어떻게 훈련할 수 있는지 보여줄 것이다.
모델 복잡성을 높이기 위한 스킵 연결 형성, 학습 속도를 높이기 위한 매개 변수 서버 접근 방식 사용 등 핵심 접근 방식의 몇 가지 개선 사항을 제시하겠다.
이 절의 마지막 부분에서는 논문의 또 다른 주요 기여인 반복 아키텍처를 생성하는 데 초점을 맞출 것이다.
3.1 Generate Model Descriptions with a Controller Recurrent Neural Network
NAS에서는 컨트롤러를 사용하여 신경망의 구조적 하이퍼 파라미터를 생성한다.
유연성을 위해 컨트롤러는 RNN으로 구현된다.
컨볼루션 레이어만을 사용하여 피드포워드 신경망을 예측하고 싶다고 가정하자, 컨트롤러를 사용하여 하이퍼 파라미터를 토큰 시퀀스로 생성할 수 있다:
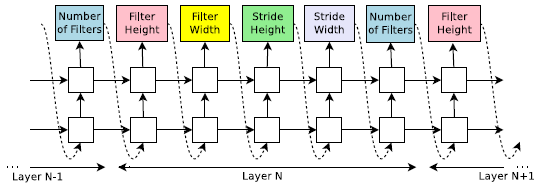
우리의 실험에서, 계층 수가 특정 값을 초과하면 아키텍처를 생성하는 과정이 중단된다.
이 값은 교육이 진행됨에 따라 증가하는 일정에 따릅니다.
컨트롤러 RNN이 아키텍처 생성을 마치면 이 아키텍처를 가진 신경 네트워크가 구축되고 훈련된다.
수렴 시 홀드아웃 유효성 검사 세트의 네트워크 정확도가 기록됩니다.
그런 다음 컨트롤러 RNN의 매개 변수 θ_c는 제안된 아키텍처의 예상 유효성 검사 정확도를 최대화하기 위해 최적화된다.
다음 섹션에서는 컨트롤러 RNN이 시간이 지남에 따라 더 나은 아키텍처를 생성하도록 매개 변수 θ_c를 업데이트하는 데 사용하는 정책 그레이디언트 방법에 대해 설명할 것이다.
3.2 Training with REINFORCE
컨트롤러가 예측하는 토큰 목록은 하위 네트워크의 아키텍처를 설계하기 위한 작업 a_(1:T) 목록으로 볼 수 있습니다.
수렴 시 이 하위 네트워크는 홀드아웃 데이터 세트에서 정확도 R을 달성한다.
우리는 이 정확도 R을 보상 신호로 사용하고 강화 학습을 사용하여 제어기를 훈련시킬 수 있다.
보다 구체적으로, 최적의 아키텍처를 찾기 위해, 우리는 컨트롤러에게 J(θ_c)로 표현되는 예상 보상을 최대화할 것을 요청한다:
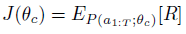
보상 신호 R은 미분이 불가능하기 때문에 정책 기울기 방법을 사용하여 θ_c를 반복적으로 업데이트해야 한다.
이 연구에서는 윌리엄스(1992)의 강화 규칙을 사용한다:

위의 수량에 대한 경험적 근사치는 다음과 같다:
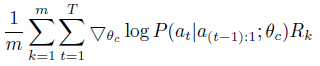
여기서 m은 컨트롤러가 한 배치에서 샘플링하는 서로 다른 아키텍처의 수이고 T는 컨트롤러가 신경망 아키텍처를 설계하기 위해 예측해야 하는 하이퍼 파라미터의 수입니다.
k번째 신경망 아키텍처가 훈련 데이터 세트에 대해 훈련한 후 달성하는 검증 정확도는 R_k이다.
위의 업데이트는 우리의 그라데이션에 대한 편향되지 않은 추정치이지만, 매우 큰 편차를 가지고 있습니다.
이 추정치의 분산을 줄이기 위해 기준 함수를 사용합니다:
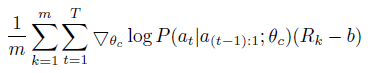
기준선 함수 b가 현재 동작에 의존하지 않는 한, 이것은 여전히 편향되지 않은 기울기 추정치이다.
이 작업에서 기준선 b는 이전 아키텍처 정확도의 지수 이동 평균이다.
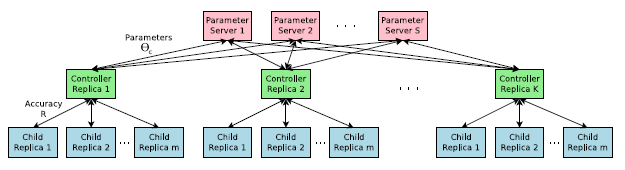
Accelerate Training with Parallelism and Asynchronous Updates:
NAS에서 컨트롤러 매개 변수 θ_c에 대한 각 그라데이션 업데이트는 하나의 하위 네트워크를 수렴으로 학습시키는 것에 해당한다.
하위 네트워크를 학습하는 데 몇 시간이 걸릴 수 있으므로 컨트롤러의 학습 프로세스 속도를 높이기 위해 분산 학습 및 비동기 매개 변수 업데이트를 사용한다(Dean 등, 2012).
우리는 K 컨트롤러 복제본에 대한 공유 매개 변수를 저장하는 S 샤드의 매개 변수 서버가 있는 매개 변수-서버 체계를 사용한다.
각 컨트롤러 복제본은 병렬로 학습된 서로 다른 하위 아키텍처를 샘플링합니다.
그런 다음 컨트롤러는 수렴 시 m 아키텍처의 미니배치의 결과에 따라 그레이디언트를 수집하여 매개 변수 서버로 전송하여 모든 컨트롤러 복제본의 가중치를 업데이트한다.
우리의 구현에서 각 하위 네트워크의 융합은 학습이 특정 epochs를 초과할 때 도달한다.
이 병렬화 계획은 그림 3에 요약되어 있습니다.
3.3 Increase Architecture Complexity with Skip Connections and Other Layer Types
섹션 3.1에서 검색 공간은 GoogleNet (Szegedy 등, 2015) 및 Residual Net (He 등, 2016a)과 같은 현대 아키텍처에서 사용되는 스킵 연결 또는 분기 계층을 가지고 있지 않다.
이 절에서는 컨트롤러가 스킵 연결 또는 branching 레이어를 제안하여 검색 공간을 넓힐 수 있는 방법을 소개한다.
컨트롤러가 그러한 연결을 예측할 수 있도록 하기 위해, 우리는 Attention 메커니즘(Bahdanau 등, 2015; Vinyals 등, 2015)을 기반으로 구축된 세트 선택 유형 Attention(Neelakantan 등, 2015)를 사용한다.
계층 N에서 N-1 콘텐츠 기반 시그모이드가 있는 앵커 포인트를 추가하여 연결해야 하는 이전 계층을 나타낸다.
각 시그모이드는 컨트롤러의 현재 은닉 상태와 이전 N-1 앵커 포인트의 이전 은닉 상태의 함수이다:

여기서 h_j는 j번째 레이어의 앵커 포인트에 있는 컨트롤러의 숨겨진 상태를 나타냅니다, 여기서 j는 0에서 N-1 사이의 범위입니다.
그런 다음 이러한 시그모이드에서 샘플을 추출하여 현재 레이어에 대한 입력으로 사용할 이전 레이어를 결정한다.
행렬 W_prev, W_curr 및 v는 학습 가능한 파라미터입니다.
이러한 연결들은 확률 분포에 의해서도 정의되기 때문에, REPORINCE 방법은 큰 수정 없이 여전히 적용됩니다.
그림 4는 컨트롤러가 스킵 연결을 사용하여 현재 계층에 대한 입력으로 원하는 계층을 결정하는 방법을 보여줍니다.

우리의 프레임워크에서, 한 레이어에 많은 입력 레이어가 있다면, 모든 입력 레이어는 깊이 차원에서 연결된다.
연결 스킵은 한 계층이 다른 계층과 호환되지 않거나 한 계층이 입력이나 출력을 갖지 못하는 "컴파일 실패"를 일으킬 수 있다.
이러한 문제를 피하기 위해 우리는 세 가지 간단한 기술을 사용한다.
첫째, 레이어가 입력 레이어에 연결되어 있지 않으면 이미지가 입력 레이어로 사용됩니다.
둘째, 최종 계층에서 우리는 이 최종 은닉 상태를 분류기로 보내기 전에 연결되지 않은 모든 계층 출력을 취하여 연결한다.
마지막으로 연결할 입력 레이어의 크기가 다르면 작은 레이어를 0으로 패딩하여 연결된 레이어의 크기가 같도록 합니다.
마지막으로 섹션 3.1에서는 학습률을 예측하지 않으며 아키텍처가 컨볼루션 계층으로만 구성된다고 가정하는데, 이는 또한 상당히 제한적이다.
예측 중 하나로 학습률을 추가하는 것이 가능하다.
또한 아키텍처에서 풀링, local contrast 정규화(Jarrett et al., 2009; Krizhevsky et al., 2012) 및 batchnorm(Ioffe & Szegedy, 2015)을 예측할 수도 있다.
더 많은 유형의 계층을 추가하려면 컨트롤러 RNN에서 계층 유형을 예측하는 단계를 추가한 다음 계층 유형과 관련된 다른 하이퍼 파라미터를 추가해야 합니다.
3.4 Generate Recurrent Cell Architecture
이 섹션에서는 반복 세포를 생성하기 위해 위의 방법을 수정할 것입니다.
모든 단계 t에서 컨트롤러는 x_t와 h_(t-1)를 입력으로 하는 h_t 함수 형태를 찾아야 한다.
가장 간단한 방법은 h_t=tanh(W_1*x_t+W_2*h_(t-1))를 갖는 것이다, 이것은 기본적인 반복 세포의 공식화이다.
더 복잡한 공식은 널리 사용되는 LSTM 순환 셀이다(Hochreiter & Schmidhuber, 1997).
기본 RNN 및 LSTM 셀에 대한 계산은 x_t와 h_(t-1)를 입력으로 사용하고 최종 출력으로 h_t를 생성하는 단계의 트리로 일반화할 수 있다.
컨트롤러 RNN은 트리의 각 노드에 두 입력을 병합하고 하나의 출력을 생성하기 위한 결합 방법(추가, 요소 곱셈 등)과 활성화 함수(tahn, 시그모이드 등)로 레이블을 지정해야 한다.
그런 다음 두 개의 출력이 트리의 다음 노드에 입력으로 공급됩니다.
컨트롤러 RNN이 이러한 방법과 기능을 선택할 수 있도록 컨트롤러 RNN이 각 노드를 하나씩 방문하고 필요한 하이퍼 파라미터에 레이블을 지정할 수 있도록 트리의 노드를 순서대로 인덱싱합니다.
LSTM 셀의 구성(Hochreiter & Schmidhuber, 1997)에서 영감을 받아 메모리 상태를 나타내기 위해 c_(t-1)와 c_t 세포 변수도 필요하다.
이러한 변수를 통합하려면 이 두 변수를 연결할 트리의 노드를 예측하는 컨트롤러 RNN이 필요하다.
이러한 예측은 컨트롤러 RNN의 마지막 두 블록에서 수행할 수 있다.

이 과정을 더 명확하게 하기 위해, 우리는 2개의 리프 노드와 1개의 내부 노드가 있는 트리 구조의 예를 그림 5에 보여준다.
리프 노드는 0과 1로 인덱싱되며 내부 노드는 2로 인덱싱됩니다.
컨트롤러 RNN은 먼저 각 트리 인덱스에 대한 조합 방법과 활성화 함수를 지정하는 블록 3개를 예측해야 한다.
그 후에 트리 내부의 임시 변수들에 c_t와 c_(t-1)를 연결하는 방법을 지정하는 마지막 두 블록을 예측할 필요가 있다.
특히 이 예에서 컨트롤러 RNN의 예측에 따라 다음과 같은 계산 단계가 발생합니다:
'Computer Vision' 카테고리의 다른 글
| Feature Pyramid Networks for Object Detection (0) | 2022.04.05 |
|---|---|
| An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale (0) | 2022.03.03 |
| EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks (0) | 2022.02.10 |
| MobileNetV2: Inverted Residuals and Linear Bottlenecks (0) | 2022.02.08 |
| FaceNet, A Unified Embedding for Face Recognition and Clustering (0) | 2021.11.19 |