2025. 2. 7. 14:53ㆍDeep Learning
Depth Anything: Unleashing the Power of Large-Scale Unlabeled Data
Lihe Yang, Bingyi Kang, Zilong Huang, Xiaogang Xu, Jiashi Feng, Hengshuang Zhao
Abstract
이 연구는 강력한 단안 뎁스 추정을 위한 매우 실용적인 솔루션인 Depth Anything을 제시합니다.
새로운 기술 모듈을 추구하지 않고, 우리는 어떤 상황에서도 모든 이미지를 처리하는 간단하면서도 강력한 파운데이션 모델을 구축하는 것을 목표로 합니다.
이를 위해 데이터 엔진을 설계하여 대규모 비라벨 데이터 (~62M)를 수집하고 자동으로 주석을 달게 함으로써 데이터 범위를 크게 확장하고 일반화 오류를 줄일 수 있습니다.
우리는 데이터 확장을 유망하게 만드는 두 가지 간단하면서도 효과적인 전략을 조사합니다.
첫째, 데이터 증강 도구를 활용하여 더 도전적인 최적화 목표를 만듭니다.
이는 모델이 추가적인 시각적 지식을 적극적으로 찾고 견고한 표현을 획득하도록 강제합니다.
둘째, 모델이 사전 학습된 인코더로부터 풍부한 시맨틱 priors를 상속받도록 하기 위해 보조 supervision을 개발했습니다.
우리는 6개의 공개 데이터셋과 랜덤으로 캡처된 사진을 포함하여 제로샷 기능을 광범위하게 평가했습니다.
이는 인상적인 일반화 능력을 입증했습니다 (그림 1).
또한, NYUv2와 KITTI의 메트릭 뎁스 정보를 사용하여 파인튜닝을 통해 새로운 SOTA를 설정했습니다.
우리의 더 나은 뎁스 모델은 더 나은 뎁스 조건 제어 네트워크를 제공합니다.

1. Introduction
컴퓨터 비전 및 자연어 처리 분야는 현재 다양한 다운스트림 시나리오에서 강력한 제로/퓨 샷 성능을 보여주는 "foundation models" [6]의 등장으로 혁명을 겪고 있습니다 [45, 59].
이러한 성공은 주로 데이터 분포를 효과적으로 커버할 수 있는 대규모 학습 데이터에 의존합니다.
로봇 공학 [66], 자율 주행 [64, 80], 가상 현실 [48] 등의 광범위한 응용 분야에서 근본적인 문제인 Monocular Depth Estimation (MDE)도 단일 이미지에서 뎁스 정보를 추정하기 위해 파운데이션 모델이 필요합니다.
그러나 수천만 개의 뎁스 레이블로 데이터셋을 구축하는 어려움으로 인해 이 문제는 충분히 탐구되지 않았습니다.
MiDaS [46]는 혼합 레이블 데이터셋 컬렉션에서 MDE 모델을 학습하여 이 방향을 따라 선구적인 연구를 수행했습니다.
일정 수준의 제로 샷 능력을 입증했음에도 불구하고 MiDaS는 데이터 커버리지에 한계가 있어 일부 시나리오에서는 치명적인 성능을 발휘합니다.
이 연구에서 우리의 목표는 어떤 상황에서도 모든 이미지에 대해 고품질의 뎁스 정보를 생성할 수 있는 MDE 파운데이션 모델을 구축하는 것입니다.
우리는 이 목표를 데이터셋 확장의 관점에서 접근합니다.
전통적으로 뎁스 데이터셋은 주로 센서 [18, 55], 스테레오 매칭 [15], 또는 SfM [33]으로부터 뎁스 데이터를 획득하여 생성되며, 이는 비용이 많이 들고 시간이 많이 소요되며 특정 상황에서는 다루기 어렵습니다.
대신 처음으로 대규모 라벨이 없는 데이터에 주목합니다.
뎁스 센서의 스테레오 이미지나 라벨이 붙은 이미지와 비교했을 때, 우리가 사용하는 단안 라벨이 없는 이미지는 세 가지 장점을 보입니다:
(i) (단순하고 저렴하게 구입할 수 있음) 단안 이미지는 거의 모든 곳에 존재하므로 전문 장치 없이 쉽게 수집할 수 있습니다.
(ii) (다양한) 단안 이미지는 모델 일반화 능력과 확장성에 중요한 더 넓은 범위의 장면을 다룰 수 있습니다.
(iii) (주석 작성이 용이함) 사전 학습된 MDE 모델을 사용하여 라벨이 없는 이미지에 대해 뎁스 레이블을 할당할 수 있으며, 이는 피드포워드 단계만 수행할 수 있습니다.
효율적일 뿐만 아니라 LiDAR [18]보다 뎁스 맵이 더 밀집되어 있어 계산 집약적인 스테레오 매칭 과정을 생략할 수 있습니다.
우리는 라벨이 없는 이미지에 대한 뎁스 주석을 자동으로 생성하여 임의의 스케일로 데이터를 확장할 수 있도록 데이터 엔진을 설계합니다.
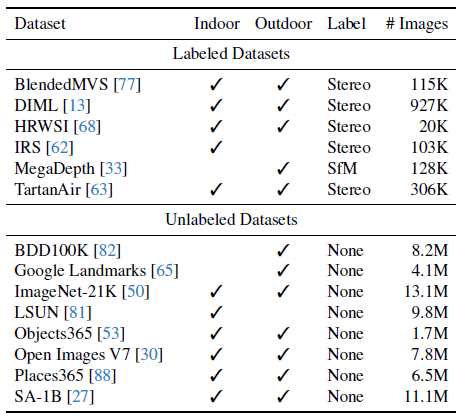
SA-1B [27], Open Images [30], BDD100K [82]와 같은 8개의 공개 대규모 데이터셋에서 62M 개의 다양하고 유익한 이미지를 수집합니다.
라벨이 없는 raw 라벨 이미지를 사용합니다.
그런 다음 라벨이 없는 이미지에 대한 신뢰할 수 있는 주석 도구를 제공하기 위해 6개의 공개 데이터셋에서 1.5M 개의 라벨이 있는 이미지를 수집하여 초기 MDE 모델을 학습합니다.
그런 다음 라벨이 없는 이미지에 자동으로 주석을 달고 라벨이 있는 이미지와 함께 자가 학습 방식으로 공동 학습합니다 [31].
앞서 언급한 단안 비라벨 이미지의 모든 장점에도 불구하고, 특히 충분한 라벨 이미지와 강력한 사전 학습 모델의 경우 이러한 대규모 비라벨 이미지를 긍정적으로 활용하는 것은 결코 쉬운 일이 아닙니다 [73, 90].
우리의 예비 시도에서 라벨 이미지와 pseudo 라벨 이미지를 직접 결합하는 것은 라벨 이미지만을 사용하는 베이스라인을 개선하는 데 실패했습니다.
우리는 이러한 나이브한 셀프 학습 방식으로 습득한 추가 지식이 다소 제한적이라고 추측합니다.
이 딜레마를 해결하기 위해, 우리는 pseudo 라벨을 학습할 때 더 어려운 최적화 목표를 가진 student 모델에 도전할 것을 제안합니다.
student 모델은 추가적인 시각적 지식을 찾고 다양한 강한 교란 하에서 견고한 표현을 학습하여 보이지 않는 이미지를 더 잘 처리하도록 강제됩니다.
또한, MDE를 위한 보조 시맨틱 세그멘테이션 작업의 이점을 입증하는 몇 가지 연구 [9, 21]가 있었습니다.
우리는 또한 이 연구 방향을 따르며, 모델에 더 나은 고수준 장면 이해 능력을 갖추는 것을 목표로 합니다.
그러나 MDE 모델이 이미 충분히 강력할 때, 이러한 보조 작업이 추가적인 이득을 가져다주기 어렵다는 것을 관찰했습니다.
우리는 이미지를 이산 클래스 공간으로 디코딩할 때 시맨틱 정보가 심각하게 손실되기 때문이라고 추측합니다.
따라서 시맨틱 관련 작업에서 DINOv2의 뛰어난 성능을 고려하여, 간단한 피쳐 정렬 loss를 통해 풍부한 시맨틱 priors를 유지할 것을 제안합니다.
이는 MDE 성능을 향상시킬 뿐만 아니라 중간 수준 및 고수준 인식 작업 모두를 위한 멀티-태스크 인코더를 제공합니다.
우리의 기여는 다음과 같이 요약됩니다:
• 우리는 MDE를 위한 방대하고 저렴하며 다양한 라벨이 없는 이미지의 데이터 확장의 가치를 강조합니다.
• 우리는 대규모 라벨링된 이미지와 라벨링되지 않은 이미지를 공동으로 학습하는 주요 관행을 지적합니다. 라벨링되지 않은 raw 이미지를 직접 학습하는 대신, 추가 지식을 얻기 위해 더 어려운 최적화 목표를 가진 모델에 도전합니다.
• 우리는 보조 시맨틱 세그멘테이션 작업을 사용하는 대신, 장면을 더 잘 이해하기 위해 사전 학습된 인코더로부터 풍부한 시맨틱 priors를 상속할 것을 제안합니다.
• 우리 모델은 MiDaS-BEiTL-512 [5]보다 더 강력한 제로샷 기능을 보여줍니다. 또한, 메트릭 뎁스로 파인튜닝되어 ZoeDepth [4]를 크게 능가합니다.
2. Related Work
Monocular depth estimation (MDE).
초기 작품 [23, 37, 51]은 주로 수작업으로 제작된 피쳐와 전통적인 컴퓨터 비전 기법에 의존했습니다.
이 작품들은 명확한 뎁스 단서에 의존하는 한계가 있었고, 가려짐과 질감 없는 영역이 있는 복잡한 장면을 처리하는 데 어려움을 겪었습니다.
딥러닝 기반 방법은 섬세하게 주석이 달린 데이터셋으로부터 뎁스 표현을 효과적으로 학습함으로써 단안 뎁스 추정에 혁명을 일으켰습니다 [18, 55].
Eigen et al. [17]은 뎁스를 회귀하기 위해 멀티스케일 융합 네트워크를 처음 제안했습니다.
이후, 많은 연구들이 회귀 작업을 분류 작업으로 신중하게 설계하여 뎁스 추정 정확도를 지속적으로 향상시켰습니다 [3, 34], 더 많은 priors [32, 54, 76, 83], 그리고 더 나은 objective 함수 [68, 78] 등을 도입했습니다.
유망한 성능에도 불구하고, 이를 보이지 않는 영역으로 일반화하기는 어렵습니다.
Zero-shot depth estimation.
우리의 연구는 이 연구 분야에 속합니다.
우리는 다양한 학습 세트를 사용하여 MDE 모델을 학습시키는 것을 목표로 하고 있으며, 따라서 주어진 이미지의 뎁스를 예측할 수 있습니다.
일부 선구적인 연구 [10, 67]는 더 많은 학습 이미지를 수집하여 이 방향을 탐구했지만, 그들의 supervision은 매우 드물고 제한된 포인트 쌍에만 적용됩니다.
효과적인 멀티-데이터셋 공동 학습을 가능하게 하기 위해, 이정표 작업인 MiDaS [46]은 아핀 불변 loss를 활용하여 다양한 데이터셋 간의 잠재적으로 다른 뎁스 스케일과 이동을 무시합니다.
따라서 MiDaS는 상대적인 뎁스 정보를 제공합니다.
최근에는 일부 작업 [4, 22, 79]이 메트릭 뎁스를 추정하기 위해 한 걸음 더 나아갔습니다.
그러나 실제로는 이러한 방법들이 MiDaS, 특히 최신 버전 [5]보다 일반화 능력이 떨어지는 것을 관찰했습니다.
ZoeDepth [4]에서 입증한 바와 같이, 강력한 상대적 뎁스 추정 모델은 메트릭 뎁스 정보를 파인튜닝하여 일반화 가능한 메트릭 뎁스 추정에서도 잘 작동할 수 있습니다.
따라서 우리는 여전히 상대적 뎁스 추정에서 MiDaS를 따르지만, 대규모 단안 비라벨 이미지의 가치를 강조함으로써 이를 더욱 강화합니다.
Leveraging unlabeled data.
이는 다양한 응용 분야에서 인기 있는 semi-supervised 학습 [31, 56, 90]의 연구 분야에 속합니다 [71, 75].
그러나 기존 연구들은 일반적으로 제한된 이미지만 제공된다고 가정합니다.
이들은 이미 충분한 라벨링된 이미지뿐만 아니라 더 큰 규모의 라벨링되지 않은 이미지가 있는 도전적이지만 현실적인 시나리오도 거의 고려하지 않습니다.
우리는 제로샷 MDE에 대해 이 도전적인 방향을 취합니다.
우리는 라벨링되지 않은 이미지가 데이터 커버리지를 크게 향상시켜 모델의 일반화와 견고성을 향상시킬 수 있음을 입증합니다.
3. Depth Anything
우리의 연구는 라벨링된 이미지와 라벨링되지 않은 이미지를 모두 활용하여 더 나은 monocular depth estimation (MDE)을 가능하게 합니다.
공식적으로 라벨링된 세트와 라벨링되지 않은 세트는 각각 D^l = {(x_i, d_i)} 및 D^u = {u_i}로 표시됩니다.
우리는 D^l로부터 teacher 모델 T를 학습하는 것을 목표로 합니다.
그런 다음 T를 활용하여 D^u에 대한 pseudo 뎁스 레이블을 할당합니다.
마지막으로, 라벨링된 세트와 pseudo 라벨링된 세트의 조합에 대해 student 모델 S를 학습합니다.
간단한 예시는 그림 2에 나와 있습니다.
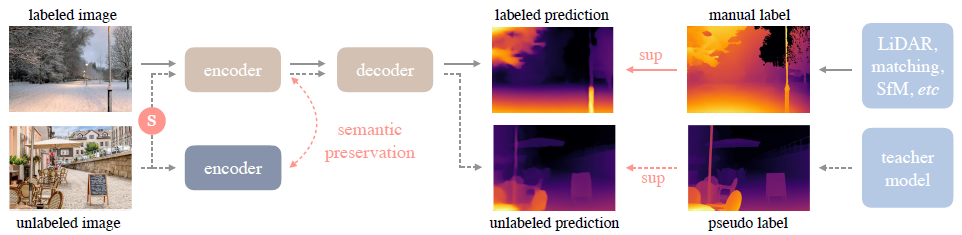
3.1. Learning Labeled Images
이 과정은 MiDaS [5, 46]의 학습과 유사합니다.
그러나 MiDaS는 코드를 공개하지 않았기 때문에 먼저 이를 재현했습니다.
구체적으로, 뎁스 값은 먼저 d = 1/t만큼 차이 공간으로 변환된 후 각 뎁스 맵에서 0~1로 정규화됩니다.
멀티 dataset 공동 학습을 가능하게 하기 위해, 우리는 각 샘플의 알려지지 않은 스케일과 이동을 무시하기 위해 아핀-불변 loss를 채택합니다:
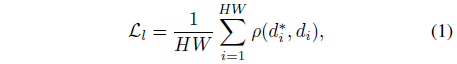
, 여기서 d_i*와 d_i는 각각 예측값과 ground truth입니다.
그리고 ρ은 아핀 불변 mean absolute error loss입니다: ρ(d_i*, d_i) = |ˆd_i* - ˆd_i|, 여기서 ˆd_i*와 ˆd_i는 예측 d_i*와 ground truth d_i의 스케일 및 시프트 버전입니다:
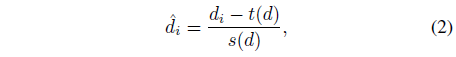
, t(d)와 s(d)를 사용하여 예측과 ground truth를 이동 및 단위 척도가 0이 되도록 정렬합니다:
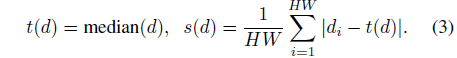
견고한 단안 뎁스 추정 모델을 얻기 위해, 우리는 6개의 공개 데이터셋에서 150만 개의 라벨링된 이미지를 수집합니다.
이러한 데이터셋의 세부 사항은 표 1에 나와 있습니다.
우리는 MiDaS v3.1 [5] (12개의 학습 데이터셋)보다 적은 수의 라벨링된 데이터셋을 사용합니다, 왜냐하면 1) NYUv2 [55] 및 KITTI [18] 데이터셋을 사용하여 제로샷 평가를 보장하지 않기 때문입니다, 2) 일부 데이터셋은 (더 이상) 이용할 수 없습니다, 예를 들어, Movies [46] 및 WSVD [61], 그리고 3) 일부 데이터셋은 품질이 좋지 않습니다, 예를 들어, RedWeb (저해상도) [67].
라벨링된 이미지를 적게 사용함에도 불구하고, 획득하기 쉽고 다양한 라벨링되지 않은 이미지는 데이터 커버리지를 이해하고 모델의 일반화 능력과 견고성을 크게 향상시킬 것입니다.
또한, 이러한 라벨링된 이미지로부터 학습된 teacher 모델 T를 강화하기 위해, 우리는 사전 학습된 DINOv2 [43] 가중치를 채택하여 인코더를 초기화합니다.
실제로, 우리는 sky 영역을 감지하기 위해 사전 학습된 시맨틱 세그멘테이션 모델 [70]을 적용하고, 그 차이 값을 0 (가장 먼)으로 설정합니다.
3.2. Unleashing the Power of Unlabeled Images
이것이 우리 연구의 주요 요점입니다.
다양한 라벨링된 데이터셋을 힘들게 구축한 이전 연구들과 달리, 우리는 라벨링되지 않은 이미지가 데이터 커버리지를 향상시키는 데 중요한 역할을 한다는 점을 강조합니다.
오늘날 우리는 인터넷이나 다양한 작업의 공개 데이터셋을 통해 다양하고 대규모의 라벨링되지 않은 이미지 세트를 실질적으로 구축할 수 있습니다.
또한, 사전에 학습된 잘 수행된 MDE 모델로 전달하는 것만으로도 단안 라벨링되지 않은 이미지의 밀집 뎁스 맵을 쉽게 얻을 수 있습니다.
이는 스테레오 이미지나 비디오에 대해 스테레오 매칭이나 SfM 재구성을 수행하는 것보다 훨씬 더 편리하고 효율적입니다.
우리는 다양한 장면에 대해 8개의 대규모 공개 데이터셋을 라벨링되지 않은 소스로 선택했습니다.
이 데이터셋에는 총 62만 개 이상의 이미지가 포함되어 있습니다.
자세한 내용은 표 1의 하단 절반에 나와 있습니다.
기술적으로, 이전에 얻어진 MDE teacher 모델 T가 주어졌을 때, 우리는 라벨이 없는 집합 D^u에 대한 예측을 수행하여 pseudo 라벨이 붙은 집합 ˆD^u를 얻습니다:
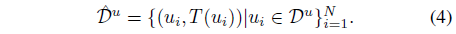
레이블이 지정된 이미지와 pseudo 레이블이 지정된 이미지의 조합 집합 D^l ∪ ^d^u를 사용하여 studoent 모델 S를 학습시킵니다.
이전 연구 [74]에 따르면, T에서 S를 파인튜닝하는 대신, 더 나은 성능을 위해 S를 다시 초기화합니다.
안타깝게도 파일럿 연구에서는 이러한 셀프 학습 파이프라인을 통해 개선을 얻는 데 실패했으며, 이는 라벨링된 이미지가 몇 개밖에 없을 때의 관찰 결과와 실제로 모순됩니다 [56].
우리의 경우 이미 충분한 라벨링된 이미지를 가지고 있기 때문에 추가적인 라벨링되지 않은 이미지로부터 얻은 추가 지식은 다소 제한적이라고 추측합니다.
특히 teacher와 student가 동일한 사전 학습과 아키텍처를 공유한다는 점을 고려할 때, 명시적인 셀프 학습 절차 없이도 라벨링되지 않은 집합 D^u에 대해 유사한 정확하거나 잘못된 예측을 하는 경향이 있습니다.
딜레마를 해결하기 위해, 우리는 라벨이 없는 이미지에 대한 추가적인 시각적 지식을 얻기 위해 student에게 더 어려운 최적화 목표를 제시할 것을 제안합니다.
우리는 학습 중에 라벨이 없는 이미지에 강한 교란을 가합니다.
이는 student 모델이 추가적인 시각적 지식을 적극적으로 추구하고 이러한 라벨이 없는 이미지로부터 불변 표현을 얻도록 합니다.
이러한 장점들은 우리 모델이 열린 세계를 더 견고하게 다루는 데 도움을 줍니다.
우리는 두 가지 형태의 교란을 소개합니다: 하나는 색상 지터링과 가우시안 블러링을 포함한 강한 색상 왜곡이고, 다른 하나는 CutMix [84]라는 강력한 공간 왜곡입니다.
두 가지 수정 사항은 단순함에도 불구하고 라벨이 없는 대규모 이미지의 베이스라인을 크게 향상시킵니다.
CutMix에 대한 자세한 내용을 제공합니다.
원래 이미지 분류를 위해 제안되었으며, 단안 뎁스 추정에서는 거의 탐구되지 않습니다.
먼저 라벨이 없는 랜덤 이미지 쌍 u_a와 u_b를 공간적으로 보간합니다:
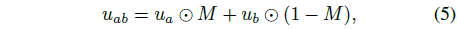
, M은 직사각형 영역이 1로 설정된 이진 마스크입니다.
라벨이 없는 loss L_u는 각각 M과 1 - M으로 정의된 유효 영역에서 아핀 불변 loss를 먼저 계산하여 얻습니다:
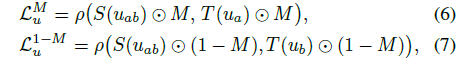
, 단순화를 위해 ∑와 픽셀 첨자 i를 생략합니다.
그런 다음 가중 평균을 통해 두 loss들을 합산합니다:
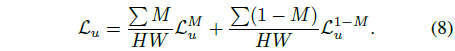
우리는 50% 확률로 CutMix를 사용합니다.
CutMix의 라벨이 없는 이미지는 이미 색상이 크게 왜곡되어 있지만, pseudo 라벨링을 위해 teacher 모델 T에 입력된 라벨이 없는 이미지는 왜곡 없이 깨끗합니다.
3.3. Semantic-Assisted Perception
보조 시맨틱 세그멘테이션 작업을 통해 뎁스 추정을 개선하는 몇 가지 연구 [9, 21, 28, 72]가 있습니다.
우리는 뎁스 추정 모델에 이러한 높은 수준의 시맨틱 관련 정보를 제공하는 것이 유익하다고 믿습니다.
또한, 라벨이 없는 이미지를 활용하는 특정 맥락에서, 다른 작업에서 나오는 이러한 보조 supervision 신호는 pseudo 뎁스 레이블의 잠재적인 노이즈를 방지할 수도 있습니다.
따라서, 우리는 RAM [86] + GroundDINO [38] + HQ-SAM [26] 모델의 조합으로 라벨이 없는 이미지에 시맨틱 세그멘테이션 레이블을 신중하게 할당하는 초기 시도를 했습니다.
후처리를 통해 4K 클래스를 포함하는 클래스 공간을 확보할 수 있습니다.
공동 학습 단계에서는 모델이 공유 인코더와 두 개의 개별 디코더를 사용하여 뎁스와 세그멘테이션 예측을 모두 생성하도록 강제됩니다.
불행히도 시행착오 끝에 원래의 MDE 모델의 성능을 향상시키지 못했습니다.
우리는 이미지를 이산 클래스 공간으로 디코딩하는 것이 실제로 너무 많은 시맨틱 정보를 잃는다고 추측했습니다.
이러한 시맨틱 마스크의 제한된 정보는 특히 뎁스 모델이 매우 경쟁력 있는 결과를 얻었을 때 뎁스 모델을 더욱 향상시키기 어렵습니다.
따라서 우리는 뎁스 추정 작업의 보조 supervision 역할을 하기 위해 더 유익한 시맨틱 신호를 찾고자 합니다.
이미지 retrieval 및 시맨틱 세그멘테이션과 같은 시맨틱 관련 작업에서 DINOv2 모델 [43]의 강력한 성능에 크게 놀랐습니다.
이러한 단서에 영감을 받아, 우리는 보조 피쳐 정렬 loss를 가진 뎁스 모델에 강력한 시맨틱 능력을 전이할 것을 제안합니다.
피쳐 공간은 고차원적이고 연속적이어서 이산 마스크보다 더 풍부한 시맨틱 정보를 포함합니다.
피쳐 정렬 loss는
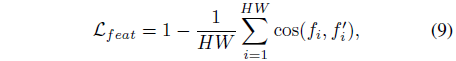
로 공식화되며, 여기서 cos(·, ·)는 두 피쳐 벡터 간의 코사인 유사성을 측정합니다.
f는 뎁스 모델 S에 의해 추출된 피쳐이고, f′는 고정된 DINOv2 인코더의 피쳐입니다.
우리는 온라인 피쳐 f를 정렬을 위한 새로운 공간으로 투영하는 일부 연구 [19]를 따르지 않습니다, 왜냐하면 랜덤으로 초기화된 프로젝터가 초기 단계에서 큰 정렬 loss를 전체 loss를 지배하기 때문입니다.
피쳐 정렬에서 또 다른 중요한 점은 DINOv2와 같은 시맨틱 인코더가 객체의 앞뒤 부분에 대해 유사한 피쳐를 생성하는 경향이 있다는 것입니다.
그러나 뎁스 추정에서는 동일한 부분 내의 다른 부분이나 픽셀이 뎁스가 다를 수 있습니다.
따라서 우리의 뎁스 모델이 고정된 인코더와 정확히 동일한 피쳐를 생성하도록 철저히 강제하는 것은 유익하지 않습니다.
이 문제를 해결하기 위해 피쳐 정렬에 대한 허용 오차 범위 α를 설정합니다.
f_i와 f′_i의 코사인 유사도가 α를 초과하면 이 픽셀은 L_feat에서 고려되지 않습니다.
이를 통해 우리의 방법은 DINOv2의 시맨틱 인식 표현과 뎁스 supervision의 부분 수준 차별 표현을 모두 즐길 수 있습니다.
부수적인 효과로, 우리가 생산한 인코더는 다운스트림 MDE 데이터셋에서 우수한 성능을 발휘할 뿐만 아니라 시맨틱 세그멘테이션 작업에서도 강력한 결과를 달성합니다.
또한, 중간 수준 및 고수준 인식 작업 모두를 위한 범용 멀티태스크 인코더로서의 잠재력을 나타냅니다.
마지막으로, 우리의 전체 loss는 L_l, L_u, 그리고 L_feat의 세 가지 loss의 평균 조합입니다.
4. Experiment
4.1. Implementation Details
우리는 피쳐 추출을 위해 DINOv2 인코더 [43]를 채택합니다.
MiDaS [5, 46]에 이어 뎁스 회귀를 위해 DPT [47] 디코더를 사용합니다.
모든 라벨링된 데이터셋은 재샘플링 없이 간단히 결합됩니다.
첫 번째 단계에서는 라벨링된 이미지에 대해 20 에포크 동안 teacher 모델을 학습시킵니다.
두 번째 공동 학습 단계에서는 student 모델이 라벨링되지 않은 모든 이미지를 한 번에 걸쳐 스윕하도록 학습합니다.
라벨링되지 않은 이미지는 ViT-L 인코더를 사용하여 가장 성능이 뛰어난 teacher 모델에 의해 주석이 달립니다.
라벨링된 이미지와 라벨링되지 않은 이미지의 비율은 각 배치에서 1:2로 설정됩니다.
두 단계 모두 사전 학습된 인코더의 기본 학습률은 5e-6으로 설정되며, 랜덤으로 초기화된 디코더는 10배 더 큰 학습률을 사용합니다.
우리는 AdamW 최적화기를 사용하고 선형 스케줄로 학습률을 감소시킵니다.
라벨링된 이미지의 데이터 증강은 수평 뒤집기만 적용합니다.
피쳐 정렬 loss에 대한 허용 오차 범위 α는 0.85로 설정됩니다.
자세한 내용은 부록을 참조하세요.
4.2. Zero-Shot Relative Depth Estimation
앞서 언급한 바와 같이, 본 연구는 모든 이미지에 대한 정확한 뎁스 추정을 제공하는 것을 목표로 합니다.
따라서 우리는 KITTI [18], NYUv2 [55], Sintel [7], DDAD [20], ETH3D [52], 및 DIODE [60]의 여섯 가지 대표적인 보이지 않는 데이터셋에서 Depth Anything 모델의 제로샷 뎁스 추정 능력을 종합적으로 검증합니다.
우리는 최신 MiDaS v3.1 [5]의 최고의 DPT-BEiTL-512 모델과 비교했으며, 이 모델은 우리보다 더 많은 라벨링된 이미지를 사용합니다.
표 2에서 볼 수 있듯이, ViT-L 인코더를 사용할 때, 우리의 Depth Anything은 AbsRel (absolute relative error: |d* - d|/d) 및 δ_1(percentage of max(d*/d, d/d*) < 1.25) 메트릭 측면에서 광범위한 장면에서 가장 강력한 MiDaS 모델을 압도합니다.
예를 들어, 잘 알려진 자율주행 데이터셋 DDAD [20]에서 테스트했을 때, AbsRel(↓)을 0.251 → 0.230에서 개선하고, δ_1(↑)을 0.766 → 0.789에서 개선했습니다.

게다가, 우리의 ViT-B 모델은 훨씬 더 큰 ViT-L을 기반으로 한 MiDaS보다 이미 확실히 우수합니다.
게다가, 규모가 MiDaS 모델의 1/10 미만인 우리의 ViT-S 모델은 Sintel, DDAD, ETH3D를 포함한 여러 보이지 않는 데이터셋에서도 MiDaS를 능가합니다.
이러한 소규모 모델의 성능 이점은 계산적으로 제약된 시나리오에서 큰 잠재력을 보여줍니다.
가장 널리 사용되는 MDE 벤치마크인 KITTI와 NYUv2에서는 MiDaS v3.1이 더 이상 제로샷이 아닌 해당 학습 이미지를 사용하지만, 우리의 Depth Anything은 여전히 KITTI나 NYUv2 이미지를 사용하지 않고도 여전히 그보다 뛰어나다는 점도 주목할 만합니다, 예를 들어, AbsRel에서는 0.127 vs. 0.076, KITTI에서는 δ_1에서 0.850 vs. 0.947과 같은 경우입니다.
4.3. Fine-tuned to Metric Depth Estimation
제로샷 상대 뎁스 추정에서 인상적인 성능 외에도, 우리는 다운스트림 메트릭 뎁스 추정을 위한 유망한 가중치 초기화로서 Depth Anything 모델을 추가로 검토합니다.
우리는 사전 학습된 인코더 매개변수를 사용하여 다운스트림 MDE 모델의 인코더를 초기화하고 디코더를 랜덤으로 초기화합니다.
모델은 해당 메트릭 뎁스 정보로 파인튜닝됩니다.
이 부분에서는 ViT-L 인코더를 사용하여 파인튜닝합니다.
우리는 두 가지 대표적인 시나리오를 검토합니다: 1) 동일한 도메인에서 모델을 학습하고 평가하는 도메인 내 메트릭 뎁스추정 (섹션 4.3.1), 그리고 2) 제로샷 메트릭 뎁스 추정은 모델이 하나의 도메인 (예: NYUv2 [55])에서 학습되지만, 다른 도메인 (예: SUN RGB-D [57])에서 평가되는 경우입니다 (섹션 4.3.2).
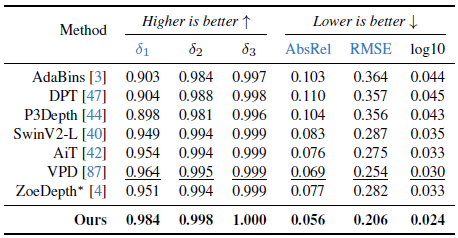
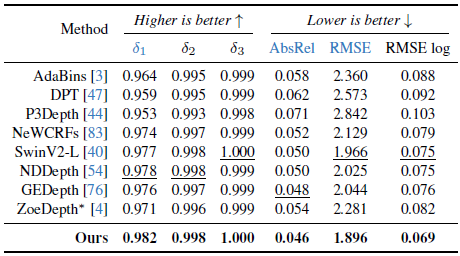
4.3.1. In-Domain Metric Depth Estimation
NYUv2 [55]의 표 3에서 볼 수 있듯이, 우리의 모델은 이전 최고의 방법인 VPD [87]을 현저히 능가하여 δ_1(↑)을 0.964 → 0.984에서 AbsRel (↓)을 0.069에서 0.056으로 개선했습니다.
유사한 개선 사항은 KITTI 데이터셋 [18]의 표 4에서도 관찰할 수 있습니다.
우리는 KITTI에서 δ_1 (↑)을 0.978 → 0.982에서 개선했습니다.
이 시나리오에 대해 비교적 기본적인 뎁스 모델을 사용하여 ZoeDepth 프레임워크를 채택했다는 점에 주목할 필요가 있으며, 더 고급 아키텍처를 갖춘다면 우리의 결과가 더욱 향상될 수 있다고 믿습니다.
4.3.2. Zero-Shot Metric Depth Estimation
ZoeDepth [4]를 따라 제로샷 메트릭 뎁스 추정을 수행합니다.
ZoeDepth는 사전 학습된 MiDaS 인코더를 NYUv2 [55] (실내 장면의 경우) 또는 KITTI [18] (야외 장면의 경우)의 메트릭 뎁스 정보로 파인튜닝합니다.
따라서 MiDaS 인코더를 더 나은 Depth Anything 인코더로 교체하기만 하면 다른 구성 요소는 변경되지 않습니다.
표 5에서 볼 수 있듯이 실내 및 실외 장면의 보이지 않는 다양한 데이터셋에서 우리의 Depth Anything은 MiDaS 기반의 원래 ZoeDepth보다 더 나은 메트릭 뎁스 추정 모델을 제공합니다.

4.4. Fine-tuned to Semantic Segmentation
우리의 방법에서는 간단한 피쳐 정렬 제약을 통해 사전 학습된 인코더로부터 풍부한 시맨틱 priors를 상속받도록 우리의 MDE 모델을 설계합니다.
여기서 우리는 MDE 인코더의 시맨틱 능력을 검토합니다.
구체적으로, 우리는 MDE 인코더를 다운스트림 시맨틱 세그멘테이션 데이터셋으로 파인튜닝합니다.
Cityscapes 데이터셋 [15]의 표 7에 나타난 바와 같이, 대규모 MDE 학습 (86.2 mIoU)의 인코더는 Swin-L [39] (84.3) 및 ConvNeXt-XL [41] (84.6)과 같은 대규모 ImageNet-21K 사전 학습의 기존 인코더보다 우수합니다.
유사한 관찰 결과는 표 8의 ADE20K 데이터셋 [89]에서도 유효합니다.
우리는 58.3→59.4에서 이전 최고의 결과를 개선했습니다.
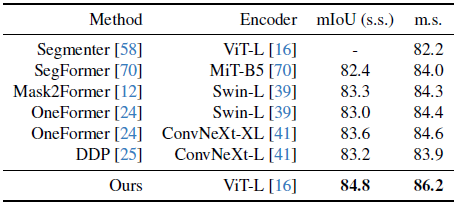
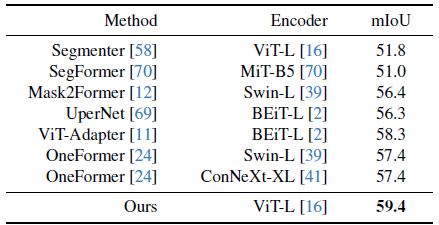
우리는 우리의 사전 학습된 인코더가 단안 뎁스 추정 및 시맨틱 세그멘테이션 작업 모두에서 우수함을 목격함으로써, 중간 수준 및 고수준 시각 인식 시스템 모두에서 일반적인 멀티 태스크 인코더로서 큰 잠재력을 가지고 있다고 생각한다는 점을 강조하고자 합니다.
4.5. Ablation Studies
달리 명시되지 않는 한, 우리는 여기서 ablation 연구를 위해 ViT-L 인코더를 사용합니다.
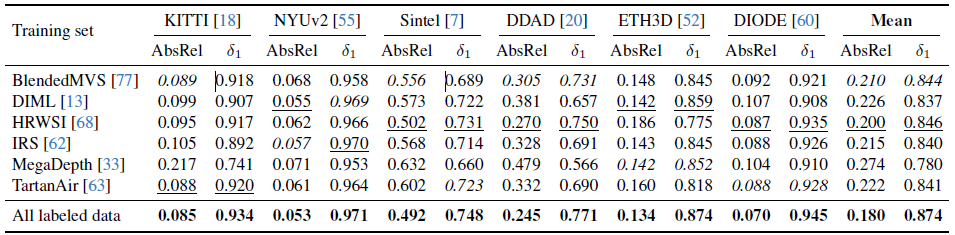
Zero-shot transferring of each training dataset.
표 6에서 우리는 각 학습 데이터셋의 제로샷 전송 성능을 제공합니다.
이는 하나의 학습 데이터셋에서 상대적인 MDE 모델을 학습시키고, 이를 여섯 개의 보이지 않는 데이터셋에서 평가한다는 것을 의미합니다.
이러한 결과를 바탕으로, 일반적인 단안 뎁스 추정 시스템을 구축하는 것을 목표로 하는 향후 연구에 더 많은 통찰을 제공할 수 있기를 바랍니다.
여섯 개의 학습 데이터셋 중 HRWSI [68]는 20,000개의 이미지만 포함하고 있음에도 불구하고 모델에 가장 강력한 일반화 능력을 부여합니다.
이는 데이터 다양성이 많이 중요하다는 것을 나타내며, 이는 라벨이 없는 이미지를 활용하려는 우리의 동기와도 잘 일치합니다.
예를 들어, 일부 라벨이 지정된 데이터셋은 성능이 좋지 않을 수 있지만, MegaDepth [33]은 이 여섯 개의 테스트 데이터셋에 반영되지 않은 고유한 선호도를 가지고 있습니다.
예를 들어, MegaDepth 데이터로 학습된 모델은 초원격 건물의 거리를 추정하는 데 특화되어 있으며 (그림 1), 이는 항공기에 매우 유용할 것입니다.
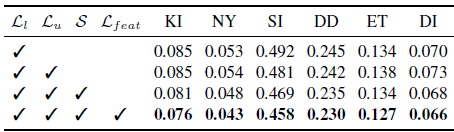
Effectiveness of 1) challenging the student model when learning unlabeled images, and 2) semantic constraint.
표 9에서 볼 수 있듯이, 라벨이 없는 이미지에 pseudo 라벨을 추가한다고 해서 반드시 모델에 이득을 가져다주는 것은 아닙니다, 왜냐하면 라벨이 없는 이미지는 이미 충분하기 때문입니다.
그러나 재학습 중에 라벨이 없는 이미지에 강한 섭동 (S)을 가하기 때문에 student 모델은 추가적인 시각적 지식을 찾고 더 견고한 표현을 학습하는 데 어려움을 겪습니다.
따라서 대규모 라벨이 없는 이미지는 모델 일반화 능력을 크게 향상시킵니다.
또한 사용된 시맨틱 제약 조건 L_feat을 통해 뎁스 추정 작업에서 라벨이 없는 이미지의 성능을 더욱 강화할 수 있습니다.
더 중요한 것은 섹션 4.4에서 강조했듯이 이 보조 제약 조건을 통해 학습된 인코더가 중간 수준 및 고수준 인식을 위한 멀티-태스크 시각 시스템의 핵심 구성 요소로 사용될 수 있다는 점입니다.
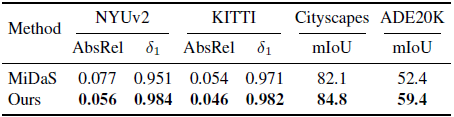
Comparison with MiDaS trained encoder in downstream tasks.
우리의 Depth Anything 모델은 MiDaS [5, 46]보다 더 강력한 제로샷 기능을 보여주었습니다.
여기서 우리는 학습된 인코더와 MiDaS v3.1 [5] 학습된 인코더를 다운스트림 파인튜닝 성능 측면에서 추가로 비교합니다.
표 10에서 보여준 바와 같이, 다운스트림 뎁스 추정 작업과 시맨틱 세그멘테이션 작업 모두에서 우리가 생성한 인코더는 NYUv2에서 δ_1 메트릭에서 0.951 vs. 0.984로, ADE20K에서 mIoU 메트릭에서 52.4 vs. 59.4로 MiDaS 인코더를 현저하게 능가합니다.
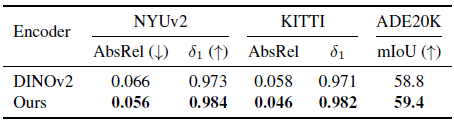
Comparison with DINOv2 in downstream tasks.
우리는 학습된 인코더가 다운스트림 작업에 파인튜닝될 때 우수함을 입증했습니다.
최종적으로 생성된 인코더 (대규모 MDE 학습에서 얻은)는 DINOv2 [43]에서 파인튜닝되었기 때문에, 우리는 표 11의 원래 DINOv2 인코더와 우리의 인코더를 비교합니다.
다운스트림 메트릭 뎁스 추정 작업과 시맨틱 세그멘테이션 작업 모두에서 우리의 인코더가 원래 DINOv2 인코더보다 더 나은 성능을 보인다는 것을 알 수 있습니다.
비록 DINOv2 가중치가 매우 강력한 초기화를 제공했지만, 우리의 대규모 및 고품질 MDE 학습은 다운스트림 전송 성능을 더욱 향상시킬 수 있습니다.


4.6. Qualitative Results
우리는 그림 3에 있는 여섯 개의 보이지 않는 데이터셋에서 모델 예측을 시각화합니다.
우리의 모델은 다양한 도메인의 이미지를 테스트하는 데 견고합니다.
또한, 우리는 그림 4의 MiDaS와 모델을 비교합니다.
또한, 예측된 뎁스 맵을 기반으로 한 새로운 이미지를 ControlNet [85]으로 합성하려고 시도합니다.
우리의 모델은 MiDaS보다 더 정확한 뎁스 추정과 더 나은 합성 결과를 제공합니다.
더 정확한 합성을 위해, 우리는 이미지 합성 및 비디오 편집을 위한 더 나은 제어 신호를 제공하기 위해 Depth Anything을 기반으로 한 더 나은 뎁스 조건 제어 네트워크를 재학습했습니다.
우리의 Depth Anything을 사용한 비디오 편집 [35]에 대한 보다 질적인 결과는 프로젝트 페이지를 참조해 주세요.
5. Conclusion
이 연구에서는 견고한 단안 뎁스 추정을 위한 매우 실용적인 솔루션인 Depth Anything을 소개합니다.
기존 기술과 달리, 특히 저렴하고 다양한 라벨이 없는 이미지의 가치를 강조합니다.
우리는 그 가치를 최대한 활용하기 위해 두 가지 간단하면서도 매우 효과적인 전략을 설계합니다: 1) 라벨이 없는 이미지를 학습할 때 더 어려운 최적화 목표를 제시하고, 2) 사전 학습된 모델로부터 풍부한 시맨틱 priors를 보존합니다.
그 결과, 우리의 Depth Anything 모델은 뛰어난 제로샷 뎁스 추정 능력을 보이며, 다운스트림 메트릭 뎁스 추정 및 시맨틱 세그멘테이션 작업을 위한 유망한 초기화 역할도 합니다.
'Deep Learning' 카테고리의 다른 글
| YOLOv12: Attention-Centric Real-Time Object Detectors (0) | 2025.02.24 |
|---|---|
| Depth Anything V2 (0) | 2025.02.12 |
| DINO-X: A Unified Vision Model for Open-World Object Detection and Understanding (0) | 2024.12.26 |
| YOLOv11: An Overview of the Key Architectural Enhancements (0) | 2024.11.27 |
| Fast Segment Anything (0) | 2024.11.07 |