2024. 12. 26. 11:30ㆍDeep Learning
DINO-X: A Unified Vision Model for Open-World Object Detection and Understanding
IDEA Research Team
Abstract
이 논문에서는 IDEA Research에서 개발한 통합 객체 중심 비전 모델인 DINO-X를 소개합니다, 이 모델은 현재까지 최고의 오픈 월드 객체 탐지 성능을 자랑합니다.
DINO-X는 Grounding DINO 1.5 [47]와 동일한 트랜스포머 기반 인코더-디코더 아키텍처를 사용하여 오픈 월드 객체 이해를 위한 객체 수준 표현을 추구합니다.
긴 꼬리 객체 탐지를 쉽게 하기 위해 DINO-X는 입력 옵션을 확장하여 텍스트 프롬프트, 시각 프롬프트, 맞춤형 프롬프트를 지원합니다.
이러한 유연한 프롬프트 옵션을 통해 프롬프트-프리 오픈 월드 탐지를 지원하는 범용 객체 프롬프트를 개발하여 사용자가 프롬프트를 제공할 필요 없이 이미지에서 모든 것을 탐지할 수 있게 합니다.
모델의 핵심 grounding 능력을 향상시키기 위해, 우리는 모델의 오픈 어휘 탐지 성능을 향상시키기 위해 1억 개 이상의 고품질 grounding 샘플을 포함한 대규모 데이터셋인 Grounding-100M을 구축했습니다.
이러한 대규모 grounding 데이터셋에 대한 사전 학습을 통해 DINO-X는 여러 인식 헤드를 통합하여 탐지, 세그멘테이션, 포즈 추정, 객체 캡셔닝, 객체 기반 QA 등 여러 객체 인식 및 이해 작업을 동시에 지원할 수 있습니다.
DINO-X는 두 가지 모델을 포함합니다: 다양한 시나리오에 대해 향상된 인식 능력을 제공하는 Pro 모델과 더 빠른 추론 속도에 최적화되고 엣지 장치에 배포하기에 더 적합한 Edge 모델.
실험 결과는 DINO-X의 우수한 성능을 입증합니다.
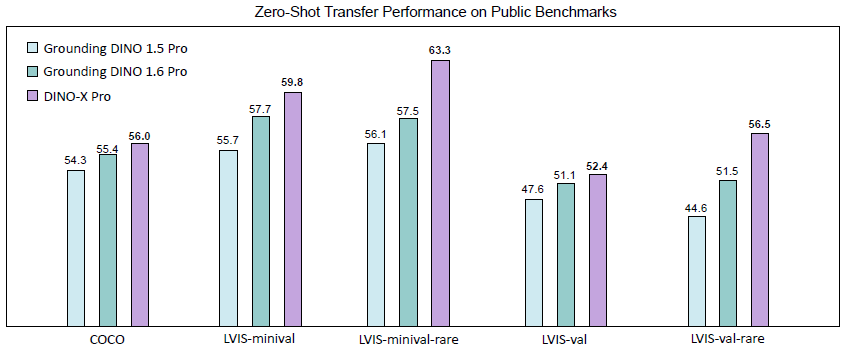
구체적으로, DINO-X Pro 모델은 COCO, LVIS-minival, LVIS-val 제로샷 객체 탐지 벤치마크에서 각각 56.0 AP, 59.8 AP, 52.4 AP를 달성했습니다.
특히, 희귀 클래스의 LVIS-minival 및 LVIS-val 벤치마크에서 63.3 AP와 56.5 AP를 획득하여 이전 SOTA 성능을 5.8 AP 및 5.0 AP 향상시켰습니다.
이러한 결과는 긴 꼬리 객체 인식 능력을 크게 강조합니다.
1 Introduction
최근 몇 년 동안 객체 감지는 closed-set detection models [74, 28, 4]에서 사용자가 제공한 프롬프트에 해당하는 객체를 식별할 수 있는 open-set detection models [33, 29, 76]로 점차 발전하고 있습니다.
이러한 모델은 동적 환경에서 로봇의 적응력을 향상시키고, 자율 주행 차량이 새로운 객체를 신속하게 찾고 반응할 수 있도록 지원하며, multimodal large language models (MLLM)의 지각 능력을 향상시키고, 환각을 줄이고, 응답의 신뢰성을 높이는 등 다양한 실용적인 응용 분야를 가지고 있습니다.
이 논문에서는 IDEA Research에서 개발한 통합 객체 중심 비전 모델인 DINO-X를 소개합니다, 이 모델은 현재까지 최고의 오픈 월드 객체 탐지 성능을 자랑합니다.
Grounding DINO 1.5 [47]을 기반으로, DINO-X는 동일한 트랜스포머 인코더-디코더 아키텍처를 사용하며 오픈셋 탐지를 핵심 학습 과제로 채택하고 있습니다.
긴 꼬리 객체 탐지를 쉽게 하기 위해, DINO-X는 모델의 입력 단계에서 보다 포괄적인 프롬프트 설계를 통합합니다.
전통적인 텍스트 프롬프트 전용 모델 [33, 47, 29]은 큰 진전을 이루었지만, 다양한 응용 프로그램을 다룰 수 있을 만큼 충분히 다양한 학습 데이터를 수집하는 어려움 때문에 여전히 충분한 범위의 긴 꼬리 탐지 시나리오를 다루기 어렵습니다.
이러한 부족을 극복하기 위해, DINO-X에서는 모델 아키텍처를 확장하여 다음 세 가지 유형의 프롬프트를 지원합니다.
(1) 텍스트 프롬프트: 이는 사용자가 제공한 텍스트 입력을 기반으로 원하는 객체를 식별하는 것을 포함하며, 이는 대부분의 탐지 시나리오를 포괄할 수 있습니다.
(2) 비주얼 프롬프트: 텍스트 프롬프트 외에도, DINO-X는 T-Rex2 [18]에서와 같이 시각적 프롬프트도 지원하며, 텍스트만으로는 잘 설명할 수 없는 탐지 시나리오를 더 포괄합니다.
(3) 맞춤형 프롬프트: 더 긴 꼬리 탐지 문제를 해결하기 위해, 우리는 특히 DINO-X에서 맞춤형 프롬프트를 도입합니다, 이 프롬프트는 맞춤형 필요에 맞게 미리 정의되거나 사용자 조정된 프롬프트 임베딩으로 구현될 수 있습니다.
프롬프트 튜닝을 통해 다양한 도메인에 대한 도메인 맞춤형 프롬프트나 기능별 프롬프트를 생성하여 다양한 기능적 요구를 해결할 수 있습니다.
예를 들어, DINO-X에서는 프롬프트-프리 오픈 월드 객체 감지를 지원하는 범용 객체 프롬프트를 개발하여 사용자가 프롬프트를 제공할 필요 없이 특정 이미지에서 객체를 감지할 수 있도록 합니다.
강력한 grounding 성능을 달성하기 위해 다양한 출처에서 1억 개 이상의 고품질 grounding 샘플을 수집하고 큐레이션했습니다.
이러한 대규모 grounding 데이터셋에 대한 사전 학습을 통해 기본적인 객체 수준의 프레젠테이션을 제공하며, 이를 통해 DINO-X는 여러 인식 헤드를 통합하여 여러 객체 인식 및 이해 작업을 동시에 지원할 수 있습니다.
객체 감지를 위한 박스 헤드 외에도 DINO-X는 세 가지 헤드를 추가로 구현했습니다: (1) 탐지된 객체에 대한 세그멘테이션 마스크를 예측하기 위한 마스크 헤드, (2) 특정 카테고리에 대해 보다 시맨틱적으로 의미 있는 키포인트를 예측하기 위한 키포인트 헤드, (3) 각 탐지된 객체에 대해 세밀한 설명 캡션을 생성하기 위한 언어 헤드.
이러한 헤드를 통합함으로써 DINO-X는 입력 이미지에 대한 객체 수준의 더 자세한 이해를 제공할 수 있습니다.
그림 1에서는 DINO-X가 지원하는 객체 수준 비전 작업을 설명하기 위한 다양한 예제를 나열합니다.

Grounding DINO 1.5와 마찬가지로, DINO-X도 두 가지 모델을 포함합니다: 다양한 시나리오에서 향상된 인식 기능을 제공하는 DINO-X Pro 모델과 더 빠른 추론 속도에 최적화되어 엣지 디바이스에 배포하기에 더 적합한 DINO-X Edge 모델.
실험 결과는 DINO-X의 우수한 성능을 입증합니다.
그림 2에서 볼 수 있듯이, 우리의 DINO-X Pro 모델은 COCO, LVIS-minival, LVIS-val 제로샷 전송 벤치마크에서 각각 56.0 AP, 59.8 AP, 52.4 AP를 달성하여 롱테일 객체 인식 능력이 크게 향상되었음을 보여줍니다.
특히, LVIS-minival 및 LVIS-val 벤치마크의 희귀 클래스에서 63.3 AP와 56.5 AP를 기록하여 Grounding DINO 1.6 Pro보다 5.8 AP, Grounding DINO 1.5 Pro보다 7.2 AP와 11.9 AP의 개선된 성능을 보여줍니다.

2 Approach
2.1 Model Architecture
DINO-X의 전체 프레임워크는 그림 3에 나와 있습니다.
Ground DINO 1.5에 이어, 우리는 또한 두 가지 변형된 DINO-X 모델을 개발했습니다: 더 강력하고 포괄적인 "Pro" 버전인 DINO-X Pro와 더 빠른 "Edge" 버전인 DINO-X Edge가 개발되었으며, 이는 각각 섹션 2.1.1과 2.1.2에서 자세히 소개될 예정입니다.
2.1.1 DINO-X Pro
DINO-X Pro 모델의 핵심 아키텍처는 Grounding DINO 1.5 [47]과 유사합니다.
우리는 사전 학습된 ViT [12] 모델을 주요 비전 백본으로 활용하고, 피쳐 추출 단계에서 심층 초기 융합 전략을 사용합니다.
Grounding DINO 1.5와는 달리, 긴 꼬리 객체를 감지하는 모델의 능력을 더욱 확장하기 위해 입력 단계에서 DINO-X Pro의 프롬프트 지원을 확대했습니다.
텍스트 프롬프트 외에도, 우리는 시각적 프롬프트와 다양한 감지 요구를 충족하는 맞춤형 프롬프트를 지원하기 위해 DINO-X Pro를 확장했습니다.
텍스트 프롬프트는 일상 생활에서 흔히 접할 수 있는 대부분의 객체 감지 시나리오를 포괄할 수 있으며, 시각적 프롬프트는 데이터 부족과 설명적 제한으로 인해 텍스트 프롬프트가 부족한 상황에서 모델의 감지 능력을 향상시킵니다 [18].
맞춤형 프롬프트는 프롬프트 조정 [26] 기술을 통해 모델의 객체 감지 능력을 확장할 수 있는 일련의 특수 프롬프트로 정의되며, 이는 다른 기능을 손상시키지 않고 더 긴 꼬리, 도메인별 또는 기능별 시나리오에서 객체를 감지하는 능력을 확장합니다.
대규모 grounding 사전 학습을 수행함으로써, 우리는 DINO-X의 인코더 출력으로부터 기초적인 객체 수준 표현을 얻습니다.
이러한 견고한 표현은 다양한 인식 헤드를 도입하여 여러 객체 인식 또는 이해 작업을 원활하게 지원할 수 있게 합니다.
그 결과, DINO-X는 바운딩 박스와 같은 대략적인 레벨부터 마스크, 키포인트, 객체 캡션을 포함한 더 세밀한 레벨까지 다양한 시맨틱 레벨에서 출력을 생성할 수 있습니다.
다음 단락에서는 먼저 DINO-X에서 지원되는 프롬프트를 소개하겠습니다.
Text Prompt Encoder:
Grounding DINO [33]와 Grounding DINO 1.5 [47] 모두 텍스트 인코더로 BERT [9]를 사용합니다.
그러나 BERT 모델은 텍스트 데이터만을 기반으로 학습되므로 오픈 월드 감지와 같은 멀티모달 정렬이 필요한 인식 작업에 대한 효과가 제한됩니다.
따라서 DINO-X Pro에서는 광범위한 멀티모달 데이터에 대해 사전 학습된 CLIP [65] 모델을 텍스트 인코더로 사용하여 다양한 오픈 월드 벤치마크에서 모델의 학습 효율성과 성능을 더욱 향상시킵니다.
Visual Prompt Encoder:
우리는 T-Rex2 [18]의 시각적 프롬프트 인코더를 채택하여 사용자 정의 시각적 프롬프트를 박스 형식과 포인트 형식 모두에서 활용하여 객체 감지를 향상시킵니다.
이러한 프롬프트는 사인-코사인 레이어를 사용하여 위치 임베딩으로 변환된 후 통합된 피쳐 공간에 투영됩니다.
모델은 서로 다른 선형 투영을 사용하여 박스 프롬프트와 포인트 프롬프트를 분리합니다.
그런 다음 T-Rex2에서와 동일한 멀티 스케일 변형 가능한 크로스-어텐션 레이어를 사용하여 사용자가 제공한 시각적 프롬프트를 조건으로 멀티 스케일 피쳐 맵에서 시각적 프롬프트 피쳐를 추출합니다.
Customized Prompt:
실제 사용 사례에서는 맞춤형 시나리오를 위한 파인튜닝 모델이 필요한 경우가 흔합니다.
DINO-X Pro에서는 맞춤형 프롬프트라고 불리는 일련의 특수 프롬프트를 정의합니다, 이 프롬프트는 리소스 효율적이고 비용 효율적인 방식으로 더 긴 꼬리, 도메인별 또는 기능별 시나리오를 다루기 위해 [26] 기술을 통해 파인튜닝될 수 있습니다.
예를 들어, 프롬프트-프리 오픈 월드 감지를 지원하기 위해 범용 객체 프롬프트를 개발하여 이미지 내의 모든 객체를 감지할 수 있게 함으로써 screen parsing [35] 등과 같은 분야에서 잠재적인 응용 가능성을 확장했습니다.
입력 이미지와 사용자가 제공한 프롬프트가 주어지면, 텍스트, 시각적 또는 맞춤형 프롬프트 임베딩이든 상관없이, DINO-X는 프롬프트와 입력 이미지에서 추출한 시각적 피쳐 간의 깊은 피쳐 융합을 수행한 다음 서로 다른 인식 작업에 서로 다른 헤드를 적용합니다.
보다 구체적으로, 구현된 헤드는 다음 단락에서 소개됩니다.
Box Head:
Grounding DINO [33] 이후, 우리는 언어 기반 쿼리 선택 모듈을 채택하여 입력 프롬프트와 가장 관련성이 높은 피쳐를 디코더 객체 쿼리로 선택합니다.
그런 다음 각 쿼리는 트랜스포머 디코더에 입력되어 레이어별로 업데이트되며, 간단한 MLP 레이어가 각 객체 쿼리에 대한 해당 바운딩 박스 좌표를 예측합니다.
Grounding DINO와 유사하게, 우리는 바운딩 박스 회귀를 위해 L1 loss와 G-IoU [49] loss를 사용하며, 대조 loss를 사용하여 각 객체 쿼리를 분류를 위한 입력 프롬프트와 정렬합니다.
Mask Head:
Mask2Former [4]와 Mask DINO [28]의 핵심 설계에 따라, 우리는 트랜스포머 인코더의 1/4 해상도 백본 피쳐와 업샘플링된 1/8 해상도 피쳐를 융합하여 픽셀 임베딩 맵을 구성합니다.
그런 다음 트랜스포머 디코더의 각 객체 쿼리와 픽셀 임베딩 맵 간의 내적 곱을 수행하여 쿼리의 마스크 출력을 얻습니다.
학습 효율성을 향상시키기 위해 백본의 1/4 해상도 피쳐 맵은 마스크 예측에만 사용되었습니다.
또한, 최종 마스크 loss 계산에서 샘플링된 포인트에 대해서만 마스크 loss를 계산하기 위해 [24, 4]를 따릅니다.
Keypoint Head:
키포인트 헤드는 사람이나 손과 같은 DINO-X의 키포인트 관련 검출 출력을 입력으로 받아 별도의 디코더를 사용하여 객체 키포인트를 디코딩합니다.
각 검출 출력은 쿼리로 처리되어 여러 개의 키포인트로 확장되며, 이는 여러 변형 가능한 트랜스포머 디코더 레이어로 전송되어 원하는 키포인트 위치와 가시성을 예측합니다.
이 과정은 객체 검출 작업을 고려할 필요 없이 키포인트 검출에만 집중하는 단순화된 ED-Pose [68] 알고리즘으로 간주될 수 있습니다.
DINO-X에서는 사람과 손의 두 개의 키포인트 헤드를 인스턴스화하며, 각각 17개와 21개의 미리 정의된 키포인트를 가집니다.

Language Head:
언어 헤드는 DINO-X가 지역 맥락을 이해하고 객체 인식, 지역 캡셔닝, 텍스트 인식, 지역 기반 visual question answering (VQA)과 같은 지역화를 넘어 인식 작업을 수행하는 능력을 향상시키기 위한 작업 촉진형 생성형 작은 언어 모델입니다.
우리 모델의 아키텍처는 그림 4에 나와 있습니다.
DINO-X에서 감지된 객체에 대해, 먼저 RoIAlign [15] 연산자를 사용하여 DINO-X 백본 피쳐에서 지역 피쳐를 추출하고, 쿼리 임베딩과 결합하여 객체 토큰을 형성합니다.
그런 다음 간단한 선형 투영을 적용하여 텍스트 임베딩과 일치하는 차원을 보장합니다.
경량 언어 디코더는 이러한 지역 표현을 작업 토큰과 통합하여 자동 회귀 방식으로 출력을 생성합니다.
학습 가능한 작업 토큰은 언어 디코더가 다양한 작업을 처리할 수 있도록 지원합니다.
2.1.2 DINO-X Edge
Ground DINO 1.5 Edge [47] 이후, DINO-X Edge는 효율적인 피쳐 추출을 위해 EfficientViT [1]을 백본으로 사용하고 유사한 트랜스포머 인코더-디코더 아키텍처를 통합합니다.
DINO-X Edge 모델의 성능과 계산 효율성을 더욱 향상시키기 위해, 우리는 다음과 같은 측면에서 모델 아키텍처와 학습 기법에 몇 가지 개선 사항을 적용합니다:
Stronger Text Prompt Encoder:
더 효과적인 지역 수준 멀티모달 정렬을 달성하기 위해, DINO-X Edge는 Pro 모델과 동일한 CLIP 텍스트 인코더를 채택합니다.
실제로 텍스트 프롬프트 임베딩은 대부분의 경우에 대해 사전 계산이 가능하며 시각적 인코더와 디코더의 추론 속도에 영향을 미치지 않습니다.
더 강력한 텍스트 프롬프트 인코더를 사용하면 일반적으로 더 나은 결과를 얻을 수 있습니다.
Knowledge Distillation:
DINO-X Edge에서는 Pro 모델의 성능을 향상시키기 위해 Pro 모델의 지식을 distill합니다.
구체적으로, 우리는 Edge 모델과 Pro 모델 간의 피쳐 및 예측 로짓을 각각 정렬하는 피쳐 기반 distillation과 응답 기반 distillation을 모두 활용합니다.
이러한 지식 전달을 통해 DINO-X Edge는 Ground DINO 1.6 Edge에 비해 더 강력한 제로샷 기능을 달성할 수 있습니다.
Improved FP16 Inference:
부동 소수점 곱셈을 위한 정규화 기법을 사용하여 정확도를 저하시키지 않으면서 FP16으로 모델 양자화를 가능하게 합니다.
그 결과 추론 속도는 20.1 FPS로, Ground DINO 1.6 Edge에 비해 15.1 FPS에서 33% 증가했으며, Ground DINO 1.5 Edge에 비해 10.7 FPS에서 87% 향상되었습니다.
3 Dataset Construction and Model Training
Data Collection:
핵심 오픈 어휘 객체 탐지 능력을 보장하기 위해, 우리는 웹에서 수집된 1억 개 이상의 이미지로 구성된 고품질의 시맨틱-풍부한 grounding 데이터셋인 Grounding-100M을 개발했습니다.
T-Rex2의 학습 데이터와 시각적 프롬프트 기반 grounding 사전 학습을 위한 추가 산업 시나리오 데이터를 사용했습니다.
SAM [23] 및 SAM2 [46]과 같은 오픈 소스 세그멘테이션 모델을 사용하여 Grounding-100M 데이터셋의 일부에 대한 pseudo 마스크 주석을 생성했으며, 이는 마스크 헤드의 주요 학습 데이터로 사용됩니다.
우리는 Grounding-100M 데이터셋에서 고품질 데이터의 일부를 샘플링하고 그들의 박스 주석을 프롬프트 없는 탐지 학습 데이터로 활용했습니다.
또한 객체 인식, 지역 캡셔닝, OCR 및 언어 헤드 학습을 위한 지역 수준 QA 시나리오를 포함한 1천만 개 이상의 지역 이해 데이터를 수집했습니다.
Model Training:
여러 비전 과제를 학습하는 문제를 극복하기 위해 우리는 두 단계 전략을 채택했습니다.
첫 번째 단계에서는 텍스트 프롬프트 기반 탐지, 시각 프롬프트 기반 탐지, 객체 세그멘테이션을 위한 공동 학습을 실시했습니다.
이 학습 단계에서는 COCO [32], LVIS [14], V3Det [57] 데이터셋의 이미지나 주석을 통합하지 않아 이러한 벤치마크에서 모델의 제로샷 탐지 성능을 평가할 수 있었습니다.
이러한 대규모 사전 학습은 DINO-X의 뛰어난 오픈 어휘 grounding 성능을 보장하며, 기본적인 객체 수준 표현을 제공합니다.
두 번째 단계에서는 DINO-X 백본을 동결하고 두 개의 키포인트 헤드(사람과 손을 위한)와 언어 헤드를 추가하여 각각 별도로 학습했습니다.
헤드를 더 추가함으로써 포즈 추정, 지역 캡셔닝, 객체 기반 QA 등과 같은 보다 세밀한 인식 및 이해 작업을 수행할 수 있는 DINO-X의 능력을 크게 확장했습니다.
그 후, 프롬프트 튜닝 기법을 활용하여 범용 객체 프롬프트를 학습하여 모델의 다른 기능을 유지하면서도 프롬프트-프리 모든 객체 탐지를 가능하게 했습니다.
이러한 두 단계 학습 접근 방식에는 여러 가지 장점이 있습니다: (1) 모델의 핵심 grounding 능력이 새로운 능력을 도입해도 영향을 받지 않도록 보장하며, (2) 대규모 grounding 사전 학습이 객체 중심 모델의 견고한 기반이 되어 다른 오픈 월드 이해 작업으로 원활하게 전환될 수 있음을 검증합니다.
4 Evaluation
이 섹션에서는 DINO-X 시리즈 모델의 다양한 기능을 관련 작업과 비교합니다.
가장 좋은 결과와 두 번째로 좋은 결과는 굵은 글씨와 밑줄로 표시되어 있습니다.

4.1 DINO-X Pro
4.1.1 Open-World Detection and Segmentation
Evaluation on Zero-Shot Object Detection and Segmentation Benchmarks:
Grounding DINO 1.5 Pro [47]에 이어, 80개의 공통 카테고리를 포함하는 COCO [32] 벤치마크와 카테고리의 더 풍부하고 광범위한 롱테일 분포를 특징으로 하는 LVIS 벤치마크에서 DINO-X Pro의 제로샷 객체 검출 및 세그멘테이션 능력을 평가했습니다.
표 1에서 볼 수 있듯이, DINO-X Pro는 이전의 SOTA 방법들과 비교했을 때 상당한 성능 향상을 보였습니다.
구체적으로, COCO 벤치마크에서 DINO-X Pro는 Ground DINO 1.5 Pro와 Ground DINO 1.6 Pro에 비해 각각 1.7 box AP와 0.6 box AP 증가를 달성했습니다.
LVIS-minival 벤치마크와 LVIS-val 벤치마크에서 DINO-X Pro는 각각 59.8 box AP와 52.4 box AP를 달성하여 이전에 최고 성능을 보였던 Ground DINO 1.6 Pro 모델을 각각 2.0 AP와 1.1 AP 차이로 능가했습니다.
특히, LVIS 희귀 클래스에서의 검출 성능에서 DINO-X는 LVIS-minival에서 63.3 AP, LVIS-val에서 56.5 AP를 달성하여 이전 SOTA Ground DINO 1.6 Pro 모델을 각각 5.8 AP와 5.0 AP 차이로 크게 능가하며, 롱테일 객체 검출 시나리오에서 DINO-X의 뛰어난 능력을 입증했습니다.
세그멘테이션 지표 측면에서, 우리는 COCO와 LVIS 제로샷 인스턴스 세그멘테이션 벤치마크에서 DINO-X를 가장 일반적으로 사용되는 일반 세그멘테이션 모델인 Ground SAM [48] 시리즈와 비교했습니다.
제로샷 감지를 위해 Grounding DINO 1.5 Pro를 사용하고 세그멘테이션을 위해 SAM-Huge [23]를 사용하는 Grounded SAM은 LVIS 인스턴스 세그멘테이션 벤치마크에서 최고의 제로샷 성능을 달성합니다.
DINO-X는 COCO, LVIS-minival, LVIS-val 제로샷 인스턴스 세그멘테이션 벤치마크에서 각각 37.9, 43.8, 38.5의 mask AP 점수를 달성했습니다.
Grounded SAM과 비교했을 때, DINO-X가 따라잡기에는 여전히 주목할 만한 성능 격차가 존재하며, 이는 여러 작업을 위한 통합 모델을 학습하는 데 어려움이 있음을 보여줍니다.
그럼에도 불구하고, DINO-X는 여러 복잡한 추론 단계 없이 각 영역에 해당하는 마스크를 생성하여 세그멘테이션 효율성을 크게 향상시킵니다.
향후 작업에서 마스크 헤드의 성능을 더욱 최적화할 것입니다.
Evaluation on Visual-Prompt Based Detection Benchmarks:
DINO-X의 시각적 프롬프트 객체 감지 능력을 평가하기 위해 퓨샷 객체 카운팅 벤치마크에 대한 실험을 수행합니다.
이 작업에서는 각 테스트 이미지가 타겟 객체를 나타내는 세 개의 시각적 예시 박스와 함께 제공되며, 모델은 타겟 객체의 개수를 출력해야 합니다.
우리는 작은 물체들이 밀집된 장면을 특징으로 하는 FSC147 [45] 및 FSCD-LVIS [40] 데이터셋을 사용하여 성능을 평가합니다.
구체적으로, FSC147은 주로 단일 대상 장면으로 구성되며, 이미지당 하나의 유형의 객체만 존재하는 반면, FSCD-LVIS는 여러 객체 카테고리를 포함하는 다중 대상 장면에 초점을 맞춥니다.
FSC147의 경우 Mean Absolute Error (MAE) 지표를 보고하고, FSCD-LVIS의 경우 Average Precision (AP) 지표를 사용합니다.
이전 연구 [17, 18]에 이어, 시각적 예제 박스들이 인터랙티브 시각적 프롬프트로 사용됩니다.
표 2에 나타난 바와 같이, DINO-X는 SOTA 성능을 달성하여 실질적인 시각적 프롬프트 객체 탐지에서 강력한 능력을 입증했습니다.


4.1.2 Keypoint Detection
Evaluation on Human 2D Keypoint Benchmarks:
우리는 표 3에 나타난 바와 같이, DINO-X를 COCO [32], CrowdPose [52], 그리고 Human-Art [20] 벤치마크에서 다른 관련 작업들과 비교한 결과를 제시합니다.
우리는 주요 지표로 OKS 기반의 Average Precision (AP) [52]를 사용합니다.
포즈 헤드는 MSCOCO, CrowdPose, 그리고 Human-Art에서 공동으로 학습되었습니다.
따라서 평가는 제로샷 설정이 아닙니다.
그러나 우리는 DINO-X의 백본을 동결하고 포즈 헤드만 학습시켰기 때문에 객체 감지 및 세그멘테이션에 대한 평가는 여전히 제로샷 설정을 따릅니다.
여러 포즈 데이터셋에서 학습하면, 우리의 모델은 일상적인 시나리오, 혼잡한 환경, 가려짐, 예술적 표현 등 다양한 사람 스타일에서 중요한 점들을 효과적으로 예측할 수 있습니다.
우리의 모델은 ED-Pose보다 1.6 낮은 AP를 달성했지만 (주로 포즈 헤드의 학습 가능한 매개변수 수가 제한적이기 때문에), CrowdPose와 Human-Art에서 기존 모델들을 각각 3.4 AP와 1.8 AP 차이로 능가하여 더 다양한 시나리오에서 놀라운 일반화 능력을 보여줍니다.
Evaluation on Human Hand 2D Keypoint Benchmarks:
인간 포즈를 평가하는 것 외에도, 우리는 HINt 벤치마크 [42]에서 Percentage of Correctly Localized Keypoints (PCK)을 측정값으로 사용하여 손 포즈 결과를 제시합니다.
PCK는 키포인트 위치 추정의 정확성을 평가하는 데 사용되는 지표입니다.
키포인트는 예측된 위치와 실제 위치 사이의 거리가 지정된 임계값 이하일 경우 올바른 것으로 간주됩니다.
우리는 0.05 박스 크기의 임계값, 즉 PCK@0.05를 사용합니다.
학습 중에 HINt, COCO, 그리고 OneHand10K [59] 학습 데이터셋 (비교 방법 HamMeR [42]의 하위 집합)을 결합하고, HINt 테스트 세트에서 성능을 평가합니다.
표 4에 나타난 바와 같이, DINO-X는 PCK@0.05 지표에서 가장 우수한 성능을 보이며, 이는 매우 정확한 손 포즈 추정에서 강력한 능력을 나타냅니다.


4.1.3 Object-Level Vision-Language Understanding
Evaluation on Object Recognition:
우리는 이미지의 특정 영역에서 객체의 범주를 인식해야 하는 객체 인식 벤치마크에 대한 관련 작업을 통해 언어 헤드의 효과를 검증합니다.
Osprey [73]에 이어, 우리는 Semantic Similarity (SS)과 Semantic IoU (S-IOU) [8]을 사용하여 객체 수준 LVIS-val [14] 및 부분 수준 PACO-val [44] 데이터셋에서 언어 헤드의 객체 인식 능력을 평가합니다.
표 5에서 볼 수 있듯이, 우리의 모델은 SS에서 71.25%, S-IoU에서 41.15%를 달성하여 LVIS-val 데이터셋에서 Osprey를 6.01%, S-IoU에서 2.06% 초과 달성했습니다.
PACO 데이터셋에서 우리의 모델은 Osprey보다 열등합니다.
LVIS와 PACO를 우리의 언어 헤드 학습에 포함하지 않았으며, 모델의 성능은 제로 샷 방식으로 달성되었습니다.
PACO에서 성능이 낮은 이유는 학습 데이터와 PACO 간의 불일치 때문일 수 있습니다.
그리고 우리의 모델은 Osprey에 비해 학습 가능한 매개변수가 1%에 불과합니다.

Evaluation on Region Captioning:
우리는 Visual Genome [25]과 RefCOCOg [37]에서 모델의 지역 캡션 품질을 평가했습니다.
평가 결과는 표 6에 제시되어 있습니다.
놀랍게도, 동결된 DINO-X 백본으로 추출된 객체 수준의 피쳐를 기반으로 하며, Visual Genome 학습 데이터를 전혀 활용하지 않고 Visual Genome 벤치마크에서 제로샷 방식으로 142.1 CIDEr 점수를 달성했습니다.
또한, Visual Genome 데이터셋을 파인튜닝한 후, 경량 언어 헤드만으로 201.8 CIDEr 점수로 새로운 SOTA 결과를 세웠습니다.
4.2 DINO-X Edge
Evaluation on Zero-Shot Object Detection Benchmarks:
DINO-X Edge의 제로샷 객체 탐지 능력을 평가하기 위해, 우리는 Grounding-100M에 대한 사전 학습 후 COCO 및 LVIS 벤치마크에서 테스트를 수행합니다.
표 7에 나타난 바와 같이, DINO-X Edge는 COCO 벤치마크에서 기존의 실시간 오픈셋 검출기보다 큰 차이로 우수한 성능을 보였습니다.
또한, DINO-X Edge는 LVIS-minival 및 LVIS-val에서 각각 48.3 AP와 42.0 AP를 달성하여 긴 꼬리 탐지 시나리오에서 뛰어난 제로샷 탐지 능력을 입증했습니다.
우리는 NVIDIA Orin NX에서 FP32 및 FP16 TensorRT 모델을 사용하여 추론 속도 DINO-X Edge를 평가하고, frames per second (FPS)로 성능을 측정했습니다.
PyTorch 모델과 A100 GPU에서 FP32 TensorRT 모델의 FPS 결과도 포함되었습니다.
†는 YOLO-World 결과가 최신 공식 코드를 사용하여 재현되었음을 언급합니다.
부동 소수점 곱셈의 정규화 기법을 활용하면 성능을 희생하지 않고도 모델을 FP16으로 양자화할 수 있습니다.
입력 크기가 640×640인 DINO-X Edge는 20.1FPS의 추론 속도를 달성하여 Grounding DINO 1.6 Edge에 비해 33% 향상된 성능을 보였습니다 (15.1FPS에서 20.1FPS로 증가).
5 Case Analysis and Qualitative Visualization
이 섹션에서는 다양한 실제 시나리오에서 DINO-X 모델의 다양한 기능을 시각화합니다.
이미지는 주로 COCO [32], LVIS [14], V3Det [57], SA-1B [23] 및 기타 공개된 리소스에서 제공됩니다.
커뮤니티에 큰 도움이 된 그들의 기여에 깊이 감사드립니다.

5.1 Open-World Object Detection
그림 5에서 볼 수 있듯이 DINO-X는 주어진 텍스트 프롬프트를 기반으로 모든 객체를 감지할 수 있는 기능을 보여줍니다.
일반적인 카테고리부터 긴 꼬리 클래스, 밀집된 객체 시나리오에 이르기까지 다양한 객체를 식별할 수 있어 강력한 오픈 월드 객체 감지 기능을 보여줍니다.

5.2 Long Caption Phrase Grounding
그림 6에서 볼 수 있듯이 DINO-X는 긴 캡션의 명사구를 기반으로 이미지에서 해당 영역을 찾는 인상적인 능력을 보여줍니다.
자세한 캡션의 각 명사구를 이미지의 특정 객체에 매핑하는 기능은 이미지 이해의 상당한 발전을 의미합니다.
이 기능은 multimodal large language models (MLLM)이 보다 정확하고 신뢰할 수 있는 응답을 생성할 수 있도록 하는 등 실질적인 가치가 있습니다.

5.3 Open-World Object Segmentation and Visual Prompt Counting
그림 7에서 볼 수 있듯이, Grounding DINO 1.5 [47]을 넘어서, DINO-X는 텍스트 프롬프트를 기반으로 오픈 월드 객체 감지를 가능하게 할 뿐만 아니라 각 객체에 해당하는 세그멘테이션 마스크를 생성하여 더 풍부한 시맨틱 출력을 제공합니다.
또한, DINO-X는 타겟 객체에 바운딩박스나 포인트를 그려 사용자 정의 시각적 프롬프트를 기반으로 한 감지를 지원합니다.
이 기능은 객체 카운팅 시나리오에서 탁월한 사용성을 보여줍니다.

5.4 Prompt-Free Object Detection and Recognition
DINO-X에서는 프롬프트를 제공하지 않고도 입력 이미지의 모든 객체를 감지할 수 있는 프롬프트-프리 객체 감지라는 매우 실용적인 기능을 개발했습니다.
그림 8과 같이, 이 기능은 DINO-X의 언어 헤드와 결합하면 사용자 입력 없이 이미지 내 모든 객체를 원활하게 감지하고 식별할 수 있습니다.

5.5 Dense Region Caption
그림 9에서 볼 수 있듯이 DINO-X는 특정 지역에 대해 더 세분화된 캡션을 생성할 수 있습니다.
또한 DINO-X의 언어 헤드를 사용하면 지역 기반 QA 및 기타 지역 이해 작업과 같은 작업도 수행할 수 있습니다.
현재 이 기능은 아직 개발 단계에 있으며 다음 버전에서 출시될 예정입니다.

5.6 Human Body and Hand Pose Estimation
그림 10에서 볼 수 있듯이, DINO-X는 텍스트 프롬프트를 기반으로 키포인트 헤드를 통해 특정 카테고리의 키포인트를 예측할 수 있습니다.
COCO, CrowdHuman, Human-Art 데이터셋을 결합하여 학습된 DINO-X는 다양한 시나리오에서 인체 및 손 키포인트를 예측할 수 있습니다.

5.7 Side-by-side comparison with Grounding DINO 1.5 Pro
우리는 DINO-X를 이전 SOTA 모델인 Grounding DINO 1.5 Pro 및 Grounding DINO 1.6 Pro와 나란히 비교했습니다.
그림 11에서 볼 수 있듯이, Grounding DINO 1.5를 기반으로 구축된 DINO-X는 언어 이해 능력을 더욱 향상시키면서도 밀집된 객체 탐지 시나리오에서 놀라운 성능을 발휘합니다.
6 Conclusion
이 논문은 오픈셋 객체 탐지 및 이해 분야를 발전시키기 위한 강력한 객체 중심 비전 모델인 DINO-X를 제시했습니다.
주력 모델인 DINO-X Pro는 COCO 및 LVIS 제로샷 벤치마크에서 새로운 기록을 세우며 탐지 정확도와 신뢰성 면에서 놀라운 향상을 보여주었습니다.
긴 꼬리 객체 탐지를 쉽게 하기 위해, DINO-X는 텍스트 프롬프트를 기반으로 한 오픈 월드 탐지를 지원할 뿐만 아니라 시각적 프롬프트와 맞춤형 시나리오를 위한 맞춤형 프롬프트를 통해 객체 탐지를 가능하게 합니다.
또한, DINO-X는 탐지에서 세분화, 포즈 추정, 객체 수준 이해 작업을 포함한 더 넓은 범위의 인식 작업으로 기능을 확장합니다.
엣지 디바이스에서 더 많은 애플리케이션을 위한 실시간 객체 탐지를 가능하게 하기 위해, 우리는 DINO-X Edge 모델을 개발하여 DINO-X 시리즈 모델의 실용적인 유용성을 더욱 확장했습니다.
'Deep Learning' 카테고리의 다른 글
| Depth Anything V2 (0) | 2025.02.12 |
|---|---|
| Depth Anything: Unleashing the Power of Large-Scale Unlabeled Data (0) | 2025.02.07 |
| YOLOv11: An Overview of the Key Architectural Enhancements (0) | 2024.11.27 |
| Fast Segment Anything (0) | 2024.11.07 |
| Depth Pro: Sharp Monocular Metric Depth in Less Than a Second (0) | 2024.11.07 |