2021. 2. 25. 16:58ㆍComputer Vision
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun
Abstract
최첨단 물체 탐지 네트워크는 물체 위치를 가설하기 위해 지역 제안 알고리즘에 의존합니다.
SPPnet[1] 및 Fast R-CNN[2]과 같은 발전으로 인해 이러한 탐지 네트워크의 실행 시간이 단축되어 지역 제안 계산이 병목 현상으로 드러났습니다.
이 작업에서는 감지 네트워크와 전체 이미지 컨볼루션 기능을 공유하여 거의 비용이 들지 않는 지역 제안을 가능하게 하는 RPN(Region Proposal Network)을 소개합니다.
RPN은 각 위치에서 객체 경계와 객체성 점수를 동시에 예측하는 완전 컨벌루션 네트워크입니다.
RPN은 탐지를 위해 Fast R-CNN에서 사용되는 고품질 지역 제안을 생성하도록 종단 간 훈련되었습니다.
또한 컨볼루션 기능을 공유하여 RPN과 Fast R-CNN을 단일 네트워크로 병합합니다, 최근 인기있는 "주의" 메커니즘이 있는 신경망 용어를 사용하여 RPN 구성 요소는 통합 네트워크에 찾을 위치를 알려줍니다.
매우 깊은 VGG-16 모델[3]의 경우 감지 시스템은 GPU에서 5fps(모든 단계 포함)의 프레임 속도를 제공하는 동시에 PASCAL VOC 2007, 2012 및 2012 그리고 이미지 당 300개의 제안만 있는 MS COCO 데이터 세트에서 최첨단 물체 감지 정확도를 달성합니다.
ILSVRC 및 COCO 2015 대회에서 Faster R-CNN 및 RPN은 여러 트랙에서 1위를 차지한 항목의 기반입니다.
코드가 공개되었습니다.
1. Introduction
최근 객체 탐지의 발전은 지역 제안 방법 (예 : [4])과 지역 기반 컨볼루션 신경망 (R-CNN)[5]의 성공에 의해 주도되었습니다.
지역 기반 CNN은 원래 [5]에서 개발된 것처럼 계산 비용이 많이 들었지만 제안 [1], [2]간에 회선을 공유하여 비용이 크게 감소했습니다.
최신 버전인 Fast R-CNN[2]은 지역 제안에 소요되는 시간을 무시할 때 매우 딥 네트워크 [3]를 사용하여 거의 실시간 속도를 달성합니다.
이제 제안은 최첨단 탐지 시스템의 테스트 시간 계산 병목 현상입니다.
지역 제안 방법은 일반적으로 저렴한 기능과 경제적인 추론 체계에 의존합니다.
가장 많이 사용되는 방법 중 하나인 선택적 검색[4]은 엔지니어링된 저수준 기능을 기반으로 슈퍼 픽셀을 탐욕스럽게 병합합니다.
그러나 효율적인 탐지 네트워크[2]와 비교할 때 선택적 검색은 CPU 구현에서 이미지 당 2초로 훨씬 느립니다.
EdgeBoxes[6]는 현재 이미지 당 0.2초로 제안 품질과 속도 사이에서 최상의 균형을 제공합니다.
그럼에도 불구하고 지역 제안 단계는 여전히 탐지 네트워크만큼 많은 실행 시간을 소비합니다.
빠른 지역 기반 CNN은 GPU를 활용하는 반면 연구에 사용되는 지역 제안 방법은 CPU에서 구현되어 이러한 런타임 비교가 불공평하다는 것을 알 수 있습니다.
제안 계산을 가속화하는 분명한 방법은 GPU에 대해 다시 구현하는 것입니다.
이것은 효과적인 엔지니어링 솔루션일 수 있지만 재구현은 다운 스트림 탐지 네트워크를 무시하므로 계산 공유를 위한 중요한 기회를 놓칩니다.
이 논문에서는 알고리즘 변경 (심층 컨볼루션 신경망을 사용한 제안 계산)이 탐지 네트워크의 계산을 고려할 때 제안 계산이 거의 비용이 들지 않는 우아하고 효과적인 솔루션으로 이어진다는 것을 보여줍니다.
이를 위해 첨단 객체 감지 네트워크 [1], [2]와 컨볼루션 레이어를 공유하는 새로운 지역 제안 네트워크(RPN)를 소개합니다.
테스트 시간에 컨볼루션을 공유하면 제안 계산을 위한 한계 비용이 적습니다(예 : 이미지 당 10ms).
우리의 관찰은 Fast R-CNN과 같은 지역 기반 탐지기가 사용하는 컨볼루션 피쳐 맵을 지역 제안 생성에 사용할 수도 있다는 것입니다.
이러한 컨벌루션 기능 외에도 일반 그리드의 각 위치에서 영역 경계와 객체성 점수를 동시에 회귀시키는 몇 가지 추가 컨볼루션 레이어를 추가하여 RPN을 구성합니다.
따라서 RPN은 일종의 완전 컨볼루션 네트워크 (FCN)[7]이며 특히 탐지 제안을 생성하기 위한 작업을 위해 종단 간 훈련 될 수 있습니다.

RPN은 광범위한 스케일 및 종횡비로 지역 제안을 효율적으로 예측하도록 설계되었습니다.
이미지 피라미드 (그림 1, a) 또는 필터 피라미드 (그림 1, b)를 사용하는 일반적인 방법 [8], [9], [1], [2]와는 달리, 우리는 여러 스케일 및 종횡비에서 참조 역할을 하는 새로운 "앵커" 상자를 소개합니다.
우리의 계획은 회귀 참조의 피라미드(그림 1, c)로 생각할 수 있으며, 여러 스케일 또는 종횡비의 이미지 또는 필터를 열거하지 않습니다.
이 모델은 단일 스케일 이미지를 사용하여 훈련 및 테스트할 때 잘 작동하므로 실행 속도가 향상됩니다.
RPN을 Fast R-CNN[2] 객체 감지 네트워크와 통합하기 위해 제안을 고정된 상태로 유지하면서 지역 제안 작업을 위한 미세 조정과 객체 감지를 위한 미세 조정을 번갈아 가며 훈련 체계를 제안합니다.
이 체계는 빠르게 수렴하고 두 작업 간에 공유되는 컨볼루션 기능을 사용하여 통합 네트워크를 생성합니다.
우리는 Fast R-CNN을 사용하는 RPN이 Fast R-CNN을 사용하는 선택적 검색의 강력한 기준보다 더 나은 탐지 정확도를 생성하는 PASCAL VOC 탐지 벤치 마크[11]에서 방법을 종합적으로 평가합니다.
한편, 우리의 방법은 테스트시 선택적 검색의 거의 모든 계산 부담을 덜어줍니다- 제안서의 효과적인 실행 시간은 10ms입니다.
[3]의 값 비싼 매우 딥 모델을 사용하는 우리의 감지 방법은 GPU에서 여전히 5fps(모든 단계 포함)의 프레임 속도를 가지고 있으므로 속도와 정확성 측면에서 실용적인 물체 감지 시스템입니다.
또한 MS COCO 데이터 세트[12]에 대한 결과를 보고하고 COCO 데이터를 사용하여 PASCAL VOC의 개선 사항을 조사합니다.
이 원고의 예비 버전은 이전에 출판되었습니다 [10].
그 이후로 RPN 및 Faster R-CNN의 프레임 워크는 3D 객체 감지 [13], 부품 기반 감지 [14], 인스턴스 분할 [15] 및 이미지 캡션 [16]과 같은 다른 방법으로 채택되고 일반화되었습니다. .
빠르고 효과적인 물체 감지 시스템은 Pinterests [17]와 같은 상용 시스템에도 구축되었으며 사용자 참여 개선이보고되었습니다.
ILSVRC 및 COCO 2015 대회에서 Faster R-CNN 및 RPN은 ImageNet 탐지, ImageNet 현지화, COCO 탐지 및 COCO 세분화 트랙에서 여러 1위 항목 [18]의 기초입니다.
RPN은 데이터에서 영역을 제안하는 방법을 완전히 학습하므로 더 깊고 표현력이 풍부한 기능 (예 : [18]에서 채택한 101 레이어 잔여 그물)을 쉽게 활용할 수 있습니다.
Faster R-CNN 및 RPN은 이 대회의 다른 주요 출품작에서도 사용됩니다.
이러한 결과는 우리의 방법이 실제 사용을 위한 비용 효율적인 솔루션일 뿐만 아니라 물체 감지 정확도를 향상시키는 효과적인 방법임을 시사합니다.
2. Related Work
Object Proposals.
객체 제안 방법에 대한 많은 문헌이 있습니다.
객체 제안 방법에 대한 포괄적인 조사 및 비교는 [19], [20], [21]에서 찾을 수 있습니다.
널리 사용되는 객체 제안 방법에는 수퍼 픽셀 그룹화 (예 : 선택적 검색[4], CPMC[22], MCG[23]) 및 슬라이딩 창 (예 : 창에서의 객체성[24], EdgeBoxes[6]).
객체 제안 방법은 감지기와는 독립적인 외부 모듈로 채택되었습니다 (예 : 선택적 검색[4] 객체 감지기, R-CNN[5] 및 Fast R-CNN[2]).
Deep Networks for Object Detection.
R-CNN 방법[5]은 제안 영역을 객체 범주 또는 배경으로 분류하기 위해 CNN을 종단 간 훈련합니다.
R-CNN은 주로 분류기 역할을 하며 객체 경계를 예측하지 않습니다 (경계 상자 회귀에 의한 정제 제외).
정확도는 지역 제안 모듈의 성능에 따라 다릅니다 ([20]의 비교 참조).
여러 논문에서 객체 경계 상자를 예측하기 위해 딥 네트워크를 사용하는 방법을 제안했습니다 [25], [9], [26], [27].
OverFeat 방법[9]에서는 단일 객체를 가정하는 지역화 작업에 대한 상자 좌표를 예측하도록 완전 연결 계층이 훈련됩니다.
그런 다음 완전 연결 계층은 여러 클래스 별 객체를 감지하기 위한 컨벌루션 계층으로 바뀝니다.
MultiBox 방법[26], [27]은 마지막 완전 연결 계층이 동시에 여러 클래스에 구애받지 않는 상자를 예측하여 OverFeat의 "단일 상자"방식을 일반화하는 네트워크에서 지역 제안을 생성합니다.
이러한 클래스에 구애받지 않는 상자는 R-CNN[5]에 대한 제안으로 사용됩니다.
멀티 박스 제안 네트워크는 완전한 컨볼루션 방식과 달리 단일 이미지 자르기 또는 여러 큰 이미지 자르기 (예 : 224x224)에 적용됩니다.
MultiBox는 제안 네트워크와 탐지 네트워크간에 기능을 공유하지 않습니다.
OverFeat 및 MultiBox는 나중에 우리의 방법과 관련하여 더 자세히 논의합니다.
우리 작업과 동시에 DeepMask 방법[28]은 분할 제안을 학습하기 위해 개발되었습니다.
컨볼루션의 공유 계산[9], [1], [29], [7], [2]는 효율적이면서도 정확한 시각적 인식을 위해 점점 더 많은 관심을 끌고 있습니다.
OverFeat 논문[9]은 분류, 위치 파악 및 감지를 위해 이미지 피라미드에서 합성곱 특징을 계산합니다.
공유된 컨볼루션 피쳐 맵에 대한 적응형 크기 풀링 (SPP)[1]은 효율적인 영역 기반 객체 감지 [1], [30] 및 시맨틱 분할 [29]을 위해 개발되었습니다.
Fast R-CNN[2]는 공유된 컨볼루션 기능에 대한 엔드-투-엔드 감지기 훈련을 가능하게 하고 뛰어난 정확성과 속도를 보여줍니다.
3. Faster R-CNN

Faster R-CNN이라고 하는 우리의 물체 감지 시스템은 두 개의 모듈로 구성됩니다.
첫 번째 모듈은 지역을 제안하는 깊은 완전 컨벌루션 네트워크이고 두 번째 모듈은 제안된 지역을 사용하는 Fast R-CNN 검출기[2]입니다.
전체 시스템은 물체 감지를 위한 단일 통합 네트워크입니다 (그림 2).
최근 인기있는 신경망 용어인 '주의'[31] 메커니즘을 사용하여 RPN 모듈은 Fast R-CNN 모듈에 어디를 볼 것인지 알려줍니다.
섹션 3.1에서는 지역 제안을 위한 네트워크의 디자인과 속성을 소개합니다.
섹션 3.2에서는 공유된 기능을 사용하여 두 모듈을 교육하기 위한 알고리즘을 개발합니다.
3.1. Region Proposal Networks
RPN (Region Proposal Network)은 이미지(모든 크기)를 입력으로 가져와 각각 객관성 점수가 있는 일련의 직사각형 개체 제안을 출력합니다.
우리는 이 섹션에서 설명하는 완전 컨볼루션 네트워크[7]로 이 프로세스를 모델링합니다.
우리의 궁극적인 목표는 Fast R-CNN 객체 탐지 네트워크[2]와 계산을 공유하는 것이기 때문에 두 네트워크 모두 공통된 컨벌루션 레이어 집합을 공유한다고 가정합니다.
실험에서 우리는 공유 가능한 컨볼루션 레이어가 5개있는 Zeiler 및 Fergus 모델[32](ZF)과 공유 가능한 컨벌루션 레이어가 13개있는 Simonyan 및 Zisserman 모델[3](VGG-16)을 조사했습니다.

지역 제안을 생성하기 위해 마지막 공유 컨벌루션 레이어가 출력한 컨볼루션 피쳐 맵에 작은 네트워크를 슬라이드합니다.
이 작은 네트워크는 입력 컨벌루션 피쳐 맵의 n x n 공간 창을 입력으로 사용합니다.
각 슬라이딩 윈도우는 저차원 피쳐에 매핑됩니다 (ZF의 경우 256-d, VGG의 경우 512-d, ReLU [33] 다음).
이 피쳐는 상자 회귀 계층(reg)과 상자 분류 계층(cls)의 두 형제 완전 연결 계층에 제공됩니다.
이 논문에서 n=3을 사용하여 입력 이미지의 유효 수용 필드가 크다는 점에 주목합니다 (ZF 및 VGG의 경우 각각 171 및 228 픽셀).
이 미니 네트워크는 그림 3(왼쪽)의 단일 위치에 나와 있습니다.
미니 네트워크는 슬라이딩 윈도우 방식으로 작동하기 때문에 완전히 연결된 레이어는 모든 공간 위치에서 공유됩니다.
이 아키텍처는 자연스럽게 n x n 컨벌루션 레이어와 2개의 형제 1x1 컨볼루션 레이어(각각 reg 및 cls 용)로 구현됩니다.
3.1.1. Anchors
각 슬라이딩 윈도우 위치에서 동시에 여러 지역 제안을 예측하며, 각 위치에 대해 가능한 최대 제안 수는 k로 표시됩니다.
따라서 reg 레이어에는 k개의 상자 좌표를 인코딩하는 4k 출력이 있고 cls 레이어는 각 제안에 대한 개체의 확률을 추정하는 2k 점수를 출력합니다.
k개의 제안은 우리가 앵커라고 부르는 k개의 참조 상자를 기준으로 매개 변수화됩니다.
앵커는 해당 슬라이딩 윈도우의 중앙에 있으며 배율 및 종횡비와 연결됩니다 (그림 3, 왼쪽).
기본적으로 3개의 스케일과 3개의 종횡비를 사용하여 각 슬라이딩 위치에서 k=9개의 앵커를 생성합니다.
크기가 W x H (일반적으로 ~2,400)인 컨벌루션 피쳐 맵의 경우 총 W H k 앵커가 있습니다.
Translation-Invariant Anchors
우리 접근 방식의 중요한 속성은 앵커와 앵커와 관련된 제안을 계산하는 함수 측면에서 번역이 불변한다는 것입니다.
이미지의 개체를 번역하는 경우 제안서는 번역 되어야하며 동일한 기능이 어느 위치에서나 제안을 예측할 수 있어야합니다.
이 번역 불변 속성은 우리의 방법에 의해 보장됩니다.
비교를 위해 MultiBox 방법[27]은 k-means를 사용하여 변환 불변이 아닌 800개의 앵커를 생성합니다.
따라서 MultiBox는 객체가 번역된 경우 동일한 제안이 생성 된다는 것을 보장하지 않습니다.
변환 불변 속성은 또한 모델 크기를 줄입니다.
MultiBox에는 (4+1)x800차원 완전 연결 출력 레이어가 있는 반면, 우리의 방법에는 k=9 앵커의 경우 (4+2)x9차원 컨볼루션 출력 레이어가 있습니다.
결과적으로 출력 레이어에는 2.8x10^4 매개 변수 (VGG-16의 경우 512x(4+2)x9)가 있으며, 6.1x10^6 매개 변수가 있는 MultiBox의 출력 레이어 (1536x(MultiBox[27]의 GoogleNet[34]의 경우 4+1)x800).
피처 프로젝션 레이어를 고려한다면 제안 레이어는 여전히 MultiBox보다 훨씬 적은 매개 변수를 갖습니다.
우리의 방법은 PASCAL VOC와 같은 작은 데이터 세트에서 과적합 위험이 적을 것으로 기대합니다.
Multi-Scale Anchors as Regression References
우리의 앵커 디자인은 다중 스케일 (및 종횡비)을 처리하기위한 새로운 방식을 제시합니다.
그림 1에서 볼 수 있듯이 다중 규모 예측에는 두 가지 인기있는 방법이 있습니다.
첫 번째 방법은 이미지 / 특징 피라미드를 기반으로 합니다, 예를 들어 DPM[8] 및 CNN 기반 방법 [9], [1], [2]에서.
이미지는 여러 축척으로 크기가 조정되고 각 축척에 대해 피쳐 맵 (HOG [8] 또는 깊은 컨볼루션 특징 [9], [1], [2])이 계산됩니다 (그림 1 (a)).
이 방법은 종종 유용하지만 시간이 많이 걸립니다.
두 번째 방법은 피쳐 맵에서 여러 배율 (and / or 종횡비)의 슬라이딩 창을 사용하는 것입니다.
예를 들어, DPM[8]에서 서로 다른 종횡비의 모델은 서로 다른 필터 크기(예 : 5x7 및 7x5)를 사용하여 개별적으로 학습됩니다.
이 방법을 사용하여 여러 척도를 처리하는 경우 "필터 피라미드"로 생각할 수 있습니다 (그림 1 (b)).
두 번째 방법은 일반적으로 첫 번째 방법과 공동으로 채택됩니다[8].

비교하자면, 앵커 기반 방법은 앵커 피라미드를 기반으로 구축되어 비용 효율적입니다.
우리의 방법은 여러 스케일 및 종횡비의 앵커 상자를 참조하여 경계 상자를 분류하고 회귀합니다.
단일 축척의 이미지 및 피쳐 맵에만 의존하고 단일 크기의 필터(기능 맵의 슬라이딩 창)를 사용합니다.
우리는 여러 규모와 크기를 처리하기 위한 이 계획의 효과를 실험을 통해 보여줍니다 (표 8).
앵커를 기반으로 하는 이 다중 스케일 설계로 인해 Fast R-CNN 검출기[2]에서도 수행되는 것처럼 단일 스케일 이미지에서 계산된 컨볼루션 기능을 간단히 사용할 수 있습니다.
다중 스케일 앵커의 디자인은 스케일을 처리하기 위한 추가 비용 없이 기능을 공유하기 위한 핵심 구성 요소입니다.
3.1.2. Loss Function
RPN 학습을 위해 각 앵커에 이진 클래스 레이블(객체 여부)을 할당합니다.
두 종류의 앵커에 양수 레이블을 할당합니다: (i) 가장 높은 IoU (Intersection-over-Union)가 있는 앵커 / 앵커가 ground-truth 상자와 겹치거나 (ii) IoU가 0.7보다 높게 겹치는 앵커가 Ground-Truth Box와 겹칩니다.
단일 ground-truth 상자는 여러 앵커에 양의 레이블을 할당할 수 있습니다.
일반적으로 두 번째 조건은 양성 샘플을 결정하기에 충분합니다; 그러나 드물게 두 번째 조건이 양성 샘플을 찾지 못할 수 있다는 이유로 여전히 첫 번째 조건을 채택합니다.
모든 Ground-Truth Box에 대해 IoU 비율이 0.3보다 낮으면 음수가 아닌 앵커에 음수 레이블을 할당합니다.
긍정적이거나 부정적이지 않은 앵커는 학습 목표에 기여하지 않습니다.
이러한 정의를 통해 Fast R-CNN[2]에서 다중 작업 손실에 따른 목적 함수를 최소화합니다.
이미지에 대한 손실 함수는 다음과 같이 정의됩니다:
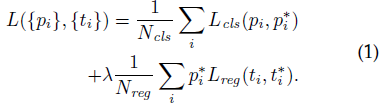
여기서 i는 미니 배치에서 앵커의 인덱스이고 pi는 앵커 i가 객체가 될 것으로 예상되는 확률입니다.
실측 레이블 p^*i는 앵커가 양수이면 1이고 앵커가 음수이면 0입니다.
ti는 예측된 경계 상자의 매개 변수화된 4개의 좌표를 나타내는 벡터이고, t^*i는 양의 앵커와 관련된 정답 상자의 좌표입니다.
분류 손실 Lcls는 두 클래스(객체 vs. 객체 아님)에 대한 로그 손실입니다.
회귀 손실의 경우 Lreg (ti, t^*i) = R (ti-t^*i)를 사용합니다, 여기서 R은 [2]에 정의된 로버스트 손실 함수 (평활한 L1)입니다.
p^*i Lreg 항은 회귀 손실이 양의 앵커에 대해서만 활성화되고 (p^*i=1) 그렇지 않으면 비활성화 됨 (p^*i=0)을 의미합니다.
cls 및 reg 레이어의 출력은 각각 {pi} 및 {ti}로 구성됩니다.

두 항은 Ncl과 Nreg에 의해 정규화되고 균형 매개 변수 λ에 의해 가중치가 부여됩니다.
현재 구현에서 (출시된 코드에서와 같이) 식 (1)의 cls항은 미니 배치 크기 (즉, Ncls = 256)로 정규화되고 reg항은 앵커 위치 수 (즉, Nreg ~ 2, 400).
기본적으로 λ=10으로 설정하므로 cls 및 reg 항 모두 대략 동일한 가중치가 적용됩니다.
우리는 실험을 통해 결과가 넓은 범위의 λ값에 민감하지 않음을 보여줍니다 (표 9).
또한 위와 같은 정규화는 필요하지 않으며 단순화할 수 있습니다.
경계 상자 회귀의 경우 [5]에 따라 4개의 좌표를 매개 변수화합니다:

여기서 x, y, w 및 h는 상자의 중심 좌표와 너비 및 높이를 나타냅니다.
변수 x, xa 및 x^*는 각각 예측 상자, 앵커 상자 및 groundtruth 상자에 대한 것입니다 (예 : y, w, h의 경우).
이것은 앵커 박스에서 근처의 실측 박스로의 경계 상자 회귀로 생각할 수 있습니다.
그럼에도 불구하고 우리의 방법은 이전 RoI 기반 (관심 영역) 방법 [1], [2]와 다른 방식으로 경계 상자 회귀를 달성합니다.
[1], [2]에서는 임의의 크기의 RoI에서 풀링된 특성에 대해 경계 상자 회귀가 수행되며 회귀 가중치는 모든 영역 크기에서 공유됩니다.
공식화에서 회귀에 사용되는 기능은 피쳐 맵에서 동일한 공간 크기 (3x3)입니다.
다양한 크기를 설명하기 위해 k 경계 상자 회귀 변수 집합을 학습합니다.
각 회귀자는 하나의 척도와 하나의 종횡비를 담당하며 k 회귀자는 가중치를 공유하지 않습니다.
따라서 앵커 설계 덕분에 피처가 고정된 크기/스케일 임에도 불구하고 다양한 크기의 상자를 예측할 수 있습니다.
3.1.3. Training RPNs
RPN은 역전파 및 확률적 경사 하강 법 (SGD)[35]에 의해 종단 간 훈련 될 수 있습니다.
이 네트워크를 훈련하기 위해 [2]의 "이미지 중심" 샘플링 전략을 따릅니다.
각 미니 배치는 다수의 긍정 및 부정 예제 앵커가 포함된 단일 이미지에서 발생합니다.
모든 앵커의 손실 함수를 최적화할 수 있지만, 이는 우세한 음의 샘플로 편향됩니다.
대신 이미지에서 256개의 앵커를 무작위로 샘플링하여 미니 배치의 손실 함수를 계산합니다, 여기서 샘플링된 positive 앵커와 negative 앵커의 비율은 최대 1:1입니다.
이미지에 positive 샘플이 128개 미만인 경우 미니 배치를 negative 샘플로 채웁니다.
표준 편차가 0.01인 zero-mean 가우시안 분포에서 가중치를 그려 모든 새 레이어를 무작위로 초기화합니다.
다른 모든 계층 (즉, 공유된 컨벌루션 계층)은 표준 관행[5]과 같이 ImageNet 분류[36]를 위한 모델을 사전 훈련하여 초기화됩니다.
우리는 ZF 네트워크의 모든 레이어를 조정하고 메모리를 절약하기 위해 VGG 네트워크에 대해 conv3_1 이상을 조정합니다[2].
우리는 PASCAL VOC 데이터 세트에서 60k 미니 배치에 대해 0.001의 학습률을 사용하고 다음 20k 미니 배치에 대해 0.0001을 사용합니다.
우리는 0.9의 운동량과 0.0005의 무게 감소를 사용합니다 [37].
우리의 구현은 Caffe를 사용합니다 [38].
3.2. Sharing Features for RPN and Fast R-CNN
지금까지 이러한 제안을 활용할 지역 기반 객체 감지 CNN을 고려하지 않고 지역 제안 생성을 위해 네트워크를 훈련하는 방법을 설명했습니다.
탐지 네트워크의 경우 Fast R-CNN[2]을 채택합니다.
다음으로 공유 컨볼루션 레이어를 사용하여 RPN 및 Fast R-CNN으로 구성된 통합 네트워크를 학습하는 알고리즘을 설명합니다(그림 2).
독립적으로 훈련된 RPN과 Fast R-CNN은 서로 다른 방식으로 컨벌루션 레이어를 수정합니다.
따라서 두 개의 개별 네트워크를 학습하는 대신 두 네트워크 간에 컨볼루션 계층을 공유할 수있는 기술을 개발해야 합니다.
공유된 기능으로 네트워크를 훈련시키는 세 가지 방법에 대해 설명합니다:
(i) Alternating training.
이 솔루션에서는 먼저 RPN을 학습하고 제안을 사용하여 Fast R-CNN을 학습합니다.
그런 다음 Fast R-CNN에 의해 조정된 네트워크를 사용하여 RPN을 초기화하고 이 프로세스를 반복합니다.
이것이 이 논문의 모든 실험에 사용되는 솔루션입니다.
(ii) Approximate joint training.
이 솔루션에서 RPN 및 Fast R-CNN 네트워크는 그림 2와 같이 훈련 중에 하나의 네트워크로 병합됩니다.
각 SGD 반복에서 순방향 패스는 Fast R-CNN 감지기를 훈련할 때 고정된 사전 계산된 제안처럼 취급되는 지역 제안을 생성합니다.
역방향 전파는 평소와 같이 발생하며, 공유 레이어의 경우 RPN 손실과 고속 R-CNN 손실 모두에서 역방향 전파된 신호가 결합됩니다.
이 솔루션은 구현하기 쉽습니다.
그러나 이 솔루션은 미분 w.r.t. 네트워크 응답이기도 한 제안 상자의 좌표이므로 근사치입니다.
실험에서 우리는 이 solver가 근접한 결과를 생성하지만 alternating training에 비해 훈련 시간을 약 25-50% 단축한다는 것을 경험적으로 발견했습니다.
이 solver는 릴리스된 Python 코드에 포함되어 있습니다.
(iii) Non-approximate joint training.
위에서 설명한 것처럼 RPN에 의해 예측되는 경계 상자도 입력의 함수입니다.
Fast R-CNN의 RoI 풀링 레이어[2]는 컨볼루션 기능과 예측된 경계 상자를 입력으로 받아들이므로 이론적으로 유효한 역 전파 solver는 기울기 w.r.t 상자 좌표도 포함해야합니다.
이러한 기울기는 위의 approximate joint training에서 무시됩니다.
Non-approximate joint training 솔루션에서는 w.r.t. 상자 좌표와 차별화할 수 있는 RoI 풀링 레이어가 필요합니다.
이것은 사소한 문제이며 [15]에서 개발된 "RoI warping"레이어에 의해 해결책이 제공될 수 있습니다, 이는 이 논문의 범위를 벗어납니다.
4-Step Alternating Training.
이 논문에서는 대체 최적화를 통해 공유 기능을 학습하기 위해 실용적인 4단계 학습 알고리즘을 채택합니다.
첫 번째 단계에서는 섹션 3.1.3에 설명된대로 RPN을 학습합니다.
이 네트워크는 ImageNet 사전 학습 모델로 초기화되고 지역 제안 작업을 위해 종단 간 미세 조정됩니다.
두 번째 단계에서는 1단계 RPN에서 생성된 제안을 사용하여 Fast R-CNN에 의해 별도의 탐지 네트워크를 훈련합니다.
이 감지 네트워크는 ImageNet 사전 학습 모델에 의해 초기화됩니다.
이 시점에서 두 네트워크는 컨볼루션 레이어를 공유하지 않습니다.
세 번째 단계에서는 검출기 네트워크를 사용하여 RPN 훈련을 초기화하지만 공유된 회선 계층을 수정하고 RPN에 고유 한 계층만 미세 조정합니다.
이제 두 네트워크는 컨벌루션 계층을 공유합니다.
마지막으로 공유된 컨볼루션 레이어를 고정된 상태로 유지하면서 Fast R-CNN의 고유 레이어를 미세 조정합니다.
따라서 두 네트워크는 동일한 컨볼루션 레이어를 공유하고 통합 네트워크를 형성합니다.
더 많은 반복을 위해 유사한 alternating training을 실행할 수 있지만, 우리는 미미한 개선을 관찰했습니다.
3.3. Implementation Details
우리는 단일 스케일의 이미지에 대해 지역 제안 네트워크와 객체 감지 네트워크를 모두 훈련하고 테스트합니다 [1], [2].
짧은 면이 s=600 픽셀이 되도록 이미지 크기를 다시 조정합니다 [2].
다중 스케일 특징 추출 (이미지 피라미드 사용)은 정확도를 향상 시킬 수 있지만 좋은 속도-정확성 트레이드 오프를 나타내지 않습니다 [2].
크기가 조정된 이미지에서 마지막 컨볼루션 레이어의 ZF 및 VGG 네트에 대한 총 stride은 16픽셀이므로 크기를 조정하기 전에 일반적인 PASCAL 이미지에서 ~10픽셀입니다 (~500x375).
stride가 클수록 정확도가 더 향상될 수 있지만 이러한 큰 stride도 좋은 결과를 제공합니다.

앵커의 경우 상자 영역이 128^2, 256^2 및 512^2 픽셀인 3개의 배율과 1:1, 1:2 및 2:1의 3가지 종횡비를 사용합니다.
이러한 하이퍼 매개 변수는 특정 데이터 세트에 대해 신중하게 선택되지 않으며 다음 섹션에서 그 효과에 대한 절제 실험을 제공합니다.
논의한 바와 같이, 우리의 솔루션은 여러 스케일의 영역을 예측하기 위해 이미지 피라미드 또는 필터 피라미드가 필요하지 않으므로 상당한 실행 시간이 절약됩니다.
그림 3 (오른쪽)은 광범위한 스케일 및 종횡비에 대한 방법의 기능을 보여줍니다.
표 1은 ZF net을 사용하여 각 앵커에 대해 학습된 평균 제안 크기를 보여줍니다.
우리의 알고리즘은 기본 수용 필드보다 더 큰 예측을 허용합니다.
이러한 예측은 불가능하지 않습니다-물체의 중간만 보이면 물체의 범위를 대략적으로 추측할 수 있습니다.
이미지 경계를 가로 지르는 앵커 박스는 주의해서 다루어야 합니다.
훈련 중에는 모든 교차 경계 앵커를 무시하므로 손실에 기여하지 않습니다.
일반적인 1000x600 이미지의 경우 총 약 20000 (≒ 60x40x9) 앵커가 있습니다.
교차 경계 앵커를 무시하면 학습용 이미지 당 약 6000개의 앵커가 있습니다.
경계 교차 이상값이 훈련에서 무시되지 않으면 목표에 크고 수정하기 어려운 오류 항이 도입되고 훈련이 수렴되지 않습니다.
그러나 테스트 중에 전체 이미지에 완전 컨볼루션 RPN을 적용합니다.
이렇게하면 이미지 경계에 클리핑되는 교차 경계 제안 상자가 생성될 수 있습니다.
일부 RPN 제안은 서로 매우 겹칩니다.
중복성을 줄이기 위해 cls 점수를 기반으로 제안 영역에 NMS (non-maximum suppression)를 채택합니다.
NMS에 대한 IoU 임계값을 0.7로 고정하여 이미지 당 약 2000개의 제안 영역을 남깁니다.
우리가 보여줄 것처럼 NMS는 궁극적인 탐지 정확도에 해를 끼치지 않지만 제안 수를 크게 줄입니다.
NMS 이후, 우리는 탐지를 위해 상위 N개의 제안 영역을 사용합니다.
다음에서는 2000개의 RPN 제안을 사용하여 Fast R-CNN을 훈련하지만 테스트 시간에 서로 다른 수의 제안을 평가합니다.
4. Experiments
4.1. Experiments on PASCAL VOC
PASCAL VOC 2007 탐지 벤치 마크[11]에서 방법을 종합적으로 평가합니다.
이 데이터 세트는 약 5k trainval 이미지와 20개 개체 범주에 대한 5k 테스트 이미지로 구성됩니다.
또한 일부 모델에 대한 PASCAL VOC 2012 벤치 마크 결과를 제공합니다.
ImageNet 사전 훈련된 네트워크의 경우 5개의 컨볼루션 레이어와 3개의 완전 연결 레이어가있는 ZF net[32]의 "빠른" 버전과 13개의 컨벌루션 레이어와 3개의 완전 연결 레이어가 있는 공개 VGG-16 모델[3]을 사용합니다.
우리는 주로 탐지 mAP를 평가합니다, 왜냐하면 이것은 개체 제안 프록시 메트릭에 초점을 맞추기보다는 개체 탐지를 위한 실제 메트릭이기 때문입니다.

표 2 (위)는 다양한 지역 제안 방법을 사용하여 훈련 및 테스트한 경우의 Fast R-CNN 결과를 보여줍니다.
이 결과는 ZF net을 사용합니다.
선택적 검색 (SS)[4]의 경우 "빠른" 모드로 약 2000개의 제안을 생성합니다.
EdgeBoxes (EB)[6]의 경우 0.7 IoU로 조정된 기본 EB 설정으로 제안을 생성합니다.
Fast R-CNN 프레임워크에서 SS의 mAP는 58.7%이고 EB의 mAP는 58.6%입니다.
Fast R-CNN이 포함된 RPN은 최대 300개의 제안을 사용하면서 59.9%의 mAP로 경쟁력 있는 결과를 달성합니다.
RPN을 사용하면 공유 컨볼루션 계산으로 인해 SS 또는 EB를 사용하는 것보다 훨씬 빠른 감지 시스템이 생성됩니다; 제안이 적을수록 지역별 완전 연결 계층의 비용도 감소합니다 (표 5).
Ablation Experiments on RPN.
제안 방법으로서 RPN의 동작을 조사하기 위해 몇 가지 절제 연구를 수행했습니다.
먼저 RPN과 Fast R-CNN 탐지 네트워크 사이에 convolutional layer를 공유하는 효과를 보여줍니다.
이를 위해 4단계 교육 과정의 두 번째 단계 이후에 중단합니다.
별도의 네트워크를 사용하면 결과가 58.7%로 약간 감소합니다 (RPN+ZF, 비공유, 표 2).
검출기 조정 기능을 사용하여 RPN을 미세 조정하는 세 번째 단계에서는 제안 품질이 향상되기 때문입니다.
다음으로 Fast R-CNN 탐지 네트워크 훈련에 대한 RPN의 영향을 분리합니다.
이를 위해 2000 SS 제안과 ZF net을 사용하여 Fast R-CNN 모델을 훈련합니다.
이 감지기를 수정하고 테스트시 사용되는 제안 영역을 변경하여 감지 mAP를 평가합니다.
이러한 절제 실험에서 RPN은 검출기와 기능을 공유하지 않습니다.
테스트 시간에 SS를 300개의 RPN 제안으로 대체하면 mAP가 56.8%가 됩니다.
mAP의 손실은 교육/테스트 제안 사이의 불일치 때문입니다.
이 결과는 다음 비교의 기준으로 사용됩니다.
다소 놀랍게도 RPN은 테스트 시간에 상위 100개 제안을 사용할 때 여전히 경쟁 결과 (55.1%)로 이어지며, 이는 상위 RPN 제안이 정확함을 나타냅니다.
다른 극단적으로, 최상위 6000 RPN 제안 (NMS 제외)을 사용하면 비슷한 mAP (55.2%)가 있어 NMS가 탐지 mAP에 해를 끼치지 않으며 오경보를 줄일 수 있음을 시사합니다.
다음으로 테스트시 RPN의 cls 및 reg 출력 중 하나를 꺼서 역할을 개별적으로 조사합니다.
테스트 시간에 cls 레이어가 제거되면 (따라서 NMS / 순위가 사용되지 않음) 채점되지 않은 지역에서 N개의 제안을 무작위로 샘플링합니다.
mAP는 N=1000 (55.8%)에서는 거의 변하지 않지만 N=100에서는 44.6%로 상당히 저하됩니다.
이것은 cls 점수가 가장 높은 순위의 제안의 정확성을 설명한다는 것을 보여줍니다.
반면에 reg 계층이 테스트 시간에 제거되면 (따라서 제안이 앵커 상자가 됨) mAP는 52.1%로 떨어집니다.
이는 고품질 제안이 주로 회귀된 상자 경계로 인한 것임을 시사합니다.
앵커 박스는 여러 스케일과 종횡비를 가지고 있지만 정확한 감지에는 충분하지 않습니다.
또한 RPN만의 제안 품질에 대한 보다 강력한 네트워크의 효과를 평가합니다.
우리는 VGG-16을 사용하여 RPN을 훈련하고 여전히 위의 SS+ZF 감지기를 사용합니다.
mAP는 56.8% (RPN+ZF 사용)에서 59.2% (RPN+VGG 사용)로 향상됩니다.
이는 RPN+VGG의 제안 품질이 RPN+ZF보다 우수하다는 것을 보여주기 때문에 유망한 결과입니다.
RPN+ZF의 제안은 SS와 경쟁하기 때문에 (훈련 및 테스트에 지속적으로 사용되는 경우 둘 다 58.7%), RPN+VGG가 SS보다 더 좋을 것으로 예상할 수 있습니다.
다음 실험은 이 가설을 정당화합니다.
Performance of VGG-16.

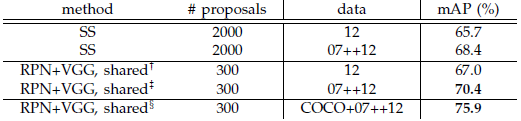


표 3은 제안 및 탐지에 대한 VGG-16의 결과를 보여줍니다.
RPN+VGG를 사용하면 공유되지 않은 기능의 경우 결과는 68.5%로 SS 기준선보다 약간 높습니다.
위와 같이 RPN+VGG에서 생성된 제안이 SS보다 정확하기 때문입니다.
미리 정의된 SS와 달리 RPN은 적극적으로 훈련되고 더 나은 네트워크의 이점을 얻습니다.
기능 공유 변형의 경우 결과는 69.9%로 강력한 SS 기준보다 우수하지만 거의 비용이 들지 않습니다.
PASCAL VOC 2007 trainval 및 2012 trainval의 조합 세트에서 RPN 및 탐지 네트워크를 추가로 훈련합니다.
mAP는 73.2%입니다.
그림 5는 PASCAL VOC 2007 테스트 세트의 일부 결과를 보여줍니다.
PASCAL VOC 2012 테스트 세트 (표 4)에서 우리의 방법은 VOC 2007 trainval+test 및 VOC 2012 trainval의 조합 세트에 대해 훈련된 70.4%의 mAP를 가지고 있습니다.
표 6 및 표 7은 자세한 번호를 보여줍니다.

표 5에는 전체 물체 감지 시스템의 실행 시간이 요약되어 있습니다.
SS는 콘텐츠에 따라 1~2 초 (평균 약 1.5초), VGG-16이 포함된 Fast R-CNN은 2000 SS 제안에서 320ms (또는 완전 연결된 레이어에서 SVD를 사용하는 경우 223ms[2])가 걸립니다.
VGG-16을 사용하는 시스템은 제안 및 감지 모두에 총 198ms가 걸립니다.
컨볼루션 기능을 공유하면 RPN만으로 추가 레이어를 계산하는 데 10ms만 걸립니다.
더 적은 제안 (이미지 당 300 개) 덕분에 지역별 계산도 더 낮습니다.
우리 시스템의 프레임 속도는 ZF net에서 17fps입니다.
Sensitivities to Hyper-parameters.
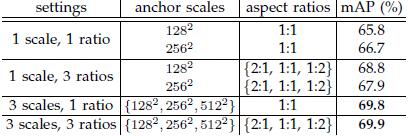
표 8에서는 앵커 설정을 조사합니다.
기본적으로 3개의 스케일과 3개의 종횡비를 사용합니다 (표 8에서 69.9% mAP).
각 위치에서 하나의 앵커만 사용하는 경우 mAP는 3-4%의 상당한 마진으로 떨어집니다.
3개의 배율 (1개의 종횡비 포함) 또는 3개의 종횡비 (1개의 배율 포함)를 사용하는 경우 mAP가 더 높으므로 회귀 참조로 여러 크기의 앵커를 사용하는 것이 효과적인 솔루션임을 보여줍니다.
가로 세로 비율이 1개인 (69.8%) 3개의 스케일을 사용하는 것은이 데이터 세트에서 가로 세로 비율이 3개인 3개의 스케일을 사용하는 것만큼 좋습니다, 이는 스케일과 가로 세로 비율이 감지 정확도를 위해 얽히지 않은 차원이 아님을 시사합니다.
그러나 우리는 시스템을 유연하게 유지하기 위해 디자인에 이 두 가지 차원을 여전히 채택하고 있습니다.

표 9에서 우리는 식 (1)에서 λ의 다른 값을 비교합니다.
기본적으로 λ=10을 사용하여 정규화 후 식 (1)의 두 항에 대략 동일한 가중치를 부여합니다.
표 9는 λ가 약 2 자릿수 (1~100)의 척도 내에 있을 때 결과가 미미하게 (~1%) 영향을 받는다는 것을 보여줍니다.
이것은 결과가 넓은 범위에서 λ에 둔감하다는 것을 보여줍니다.
Analysis of Recall-to-IoU.
다음으로 우리는 Groundtruth Box를 사용하여 서로 다른 IoU 비율에서 제안의 회수를 계산합니다.
Recall-to-IoU 메트릭이 궁극적인 감지 정확도와 거의 [19], [20], [21] 관련되어 있다는 점은 주목할 만합니다.
제안 방법을 평가하는 것보다 진단하기 위해 이 메트릭을 사용하는 것이 더 적절합니다.

그림 4에서는 300, 1000 및 2000 제안을 사용한 결과를 보여줍니다.
SS 및 EB와 비교하여 N개의 제안이 이러한 방법에 의해 생성된 신뢰도를 기반으로 상위 N개 순위의 제안입니다.
플롯은 제안 수가 2000개에서 300개로 떨어질 때 RPN 방법이 정상적으로 작동함을 보여줍니다.
이것은 RPN이 300개의 제안을 사용할 때 우수한 최종 검출 mAP를 갖는 이유를 설명합니다.
이전에 분석했듯이 이 속성은 주로 RPN의 cls 항에 기인합니다.
SS 및 EB의 회수는 제안이 적을 때 RPN보다 더 빨리 떨어집니다.
One-Stage Detection vs. Two-Stage Proposal+Detection.
OverFeat 논문[9]은 컨볼루션 피쳐 맵의 슬라이딩 윈도우에서 회귀자와 분류기를 사용하는 탐지 방법을 제안합니다.
OverFeat는 1단계, 클래스 별 감지 파이프 라인이며, 우리는 클래스에 구애받지 않는 제안과 클래스 별 감지로 구성된 2단계 캐스케이드입니다.
OverFeat에서 영역 별 기능은 스케일 피라미드 위에 한 종횡비의 슬라이딩 윈도우에서 나옵니다.
이러한 기능은 개체의 위치와 범주를 동시에 결정하는 데 사용됩니다.
RPN에서 기능은 정사각형 (3x3) 슬라이딩 윈도우에서 제공되며 배율 및 종횡비가 다른 앵커와 관련된 제안을 예측합니다.
두 방법 모두 슬라이딩 윈도우를 사용하지만 지역 제안 작업은 Faster R-CNN의 첫 번째 단계일 뿐입니다-다운 스트림 Fast R-CNN 감지기가 제안에 참여하여 이를 개선합니다.
캐스케이드의 두 번째 단계에서 지역별 기능은 지역의 기능을 보다 충실하게 다루는 제안 상자에서 적응적으로 풀링됩니다 [1], [2].
이러한 기능이 더 정확한 탐지로 이어진다고 믿습니다.
1단계 및 2단계 시스템을 비교하기 위해 1단계 Fast R-CNN을 통해 OverFeat 시스템을 에뮬레이션하여 구현 세부 사항의 다른 차이점을 피합니다.
이 시스템에서 "제안"은 3가지 스케일 (128, 256, 512) 및 3가지 종횡비 (1:1, 1:2, 2:1)의 조밀한 슬라이딩 윈도우입니다.
Fast R-CNN은 이러한 슬라이딩 윈도우에서 클래스 별 점수와 회귀 상자 위치를 예측하도록 훈련되었습니다.
OverFeat 시스템은 이미지 피라미드를 채택하기 때문에 5개의 스케일에서 추출한 컨볼루션 기능을 사용하여 평가합니다.
우리는 [1], [2]에서와 같이 5개의 스케일을 사용합니다.

표 10은 2단계 시스템과 1단계 시스템의 두 가지 변형을 비교합니다.
ZF 모델을 사용하면 1단계 시스템의 mAP는 53.9%입니다.
이는 2단계 시스템 (58.7%)보다 4.8% 낮습니다.
이 실험은 계단식 지역 제안 및 물체 감지의 효과를 정당화합니다.
유사한 관찰이 [2], [39]에서 보고 되었으며 SS 영역 제안을 슬라이딩 윈도우로 대체하면 두 논문에서 ~6% 저하가 발생합니다.
또한 1단계 시스템은 처리할 제안이 상당히 많기 때문에 속도가 느립니다.
4.2. Experiments on MS COCO
~~~
5. Conclusion
효율적이고 정확한 지역 제안 생성을 위해 RPN을 제시했습니다.
컨볼루션 기능을 다운 스트림 탐지 네트워크와 공유함으로써 지역 제안 단계는 거의 비용이 들지 않습니다.
이 방법을 사용하면 통합된 딥러닝 기반 객체 감지 시스템을 거의 실시간 프레임 속도로 실행할 수 있습니다.
학습된 RPN은 또한 영역 제안 품질을 개선하여 전체적인 물체 감지 정확도를 향상시킵니다.
'Computer Vision' 카테고리의 다른 글
| Mask R-CNN (번역) (0) | 2021.03.02 |
|---|---|
| SPPnet: Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition (번역) (0) | 2021.02.26 |
| Fast R-CNN (번역) (0) | 2021.02.24 |
| OverFeat: Integrated Recognition, Localization and Detection using Convolutional Networks (번역) (0) | 2021.02.23 |
| R-CNN, Rich feature hierarchies for accurate object detection and semantic segmentation (번역) (0) | 2021.02.22 |