2021. 3. 4. 12:17ㆍComputer Vision
Densely Connected Convolutional Networks
Gao Huang, Zhuang Liu, Laurens van der Maaten, Kilian Q. Weinberger
Abstract
최근 연구에 따르면 컨볼루션 네트워크는 입력에 가까운 레이어와 출력에 가까운 레이어 사이에 더 짧은 연결을 포함할 경우 훨씬 더 깊고 정확하며 효율적으로 훈련할 수 있습니다.
이 논문에서는 이러한 관찰을 수용하고 피드 포워드 방식으로 각 레이어를 다른 모든 레이어에 연결하는 DenseNet (Dense Convolutional Network)을 소개합니다.
L계층이 있는 기존의 컨볼루션 네트워크에는 각 계층과 후속 계층 사이에 하나씩 L연결이 있는 반면, 우리 네트워크에는 L(L+1)/2 직접 연결이 있습니다.
각 레이어에 대해 모든 이전 레이어의 피처 맵이 입력으로 사용되고 자체 피처 맵이 모든 후속 레이어의 입력으로 사용됩니다.
DenseNets에는 몇 가지 강력한 장점이 있습니다: 즉, 소실 기울기 문제를 완화하고, 기능 전파를 강화하고, 기능 재사용을 장려하고, 매개 변수 수를 크게 줄입니다.
우리는 경쟁이 치열한 4가지 객체 인식 벤치 마크 작업 (CIFAR-10, CIFAR-100, SVHN 및 ImageNet)에 대해 제안된 아키텍처를 평가합니다.
DenseNets는 고성능을 달성하기 위해 더 적은 계산을 필요로 하는 동시에 대부분의 최신 기술보다 크게 개선되었습니다.
1. Introduction
컨볼루션 신경망(CNN)은 시각적 객체 인식을 위한 지배적인 머신러닝 접근 방식이 되었습니다.
20년 전에 처음 소개되었지만 [18] 컴퓨터 하드웨어 및 네트워크 구조의 개선으로 인해 최근에야 진정한 심층 CNN의 훈련이 가능해졌습니다.
원래 LeNet5[19]는 5개의 레이어로 구성되었고 VGG는 19[29]를 특징으로 했으며 작년에만 Highway Networks[34]와 Residual Networks (ResNets)[11]가 100개 레이어 장벽을 넘어 섰습니다.
CNN이 점점 더 깊어짐에 따라 새로운 연구 문제가 나타납니다: 입력 또는 기울기에 대한 정보가 여러 계층을 통과하면 네트워크의 끝(또는 시작)에 도달할 때 사라져서 사라질 수 있습니다.
최근의 많은 출판물에서 이 문제 또는 관련 문제를 다룹니다.
ResNets[11]와 Highway Networks[34]는 신원 연결을 통해 한 레이어에서 다음 레이어로 신호를 우회합니다.
확률적 깊이[13]는 더 나은 정보와 기울기 흐름을 허용하기 위해 훈련 중에 레이어를 무작위로 삭제하여 ResNets를 단축합니다.
FractalNets[17]는 네트워크에서 많은 짧은 경로를 유지하면서 큰 공칭 깊이를 얻기 위해 여러 개의 병렬 계층 시퀀스를 다른 수의 컨볼루션 블록과 반복적으로 결합합니다.
이러한 서로 다른 접근 방식은 네트워크 토폴로지 및 훈련 절차에 따라 다르지만 모두 핵심 특성을 공유합니다: 즉, 초기 계층에서 이후 계층으로의 짧은 경로를 만듭니다.
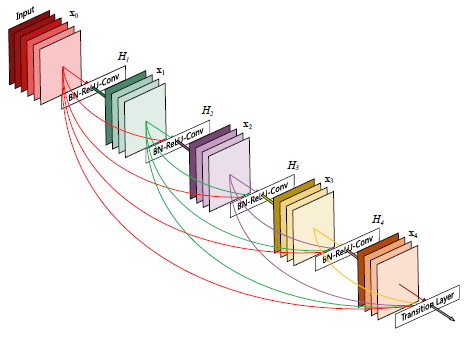
이 논문에서는 이러한 통찰력을 간단한 연결 패턴으로 추출하는 아키텍처를 제안합니다: 네트워크의 레이어 간 정보 흐름을 극대화하기 위해 모든 레이어(피처 맵 크기가 일치)를 서로 직접 연결합니다.
피드-포워드 특성을 유지하기 위해 각 레이어는 이전의 모든 레이어에서 추가 입력을 얻고 자체 피처 맵을 모든 후속 레이어로 전달합니다.
그림 1은 이 레이아웃을 개략적으로 보여줍니다.
결정적으로 ResNets와 달리, 우리는 계층으로 전달되기 전에 합산을 통해 기능을 결합하지 않습니다; 대신 기능을 연결하여 결합합니다.
따라서 l번째 레이어에는 이전의 모든 컨벌루션 블록의 피처 맵으로 구성된 l개의 입력이 있습니다.
자체 특성 맵은 모든 L-1 후속 레이어로 전달됩니다.
이것은 전통적인 아키텍처에서와 같이 L계층 네트워크에서 L(L+1)/2 연결을 도입합니다.
조밀한 연결 패턴 때문에 우리는 우리의 접근 방식을 DenseNet (Dense Convolutional Network)이라고 합니다.
이 조밀한 연결 패턴의 반직관적인 효과는 중복 특성 맵을 다시 배울 필요가 없기 때문에 기존의 컨볼루션 네트워크보다 더 적은 매개 변수가 필요하다는 것입니다.
전통적인 피드-포워드 아키텍처는 계층 간에 전달되는 상태가 있는 알고리즘으로 볼 수 있습니다.
각 계층은 이전 계층에서 상태를 읽고 후속 계층에 씁니다.
상태를 변경하지만 보존해야하는 정보도 전달합니다.
ResNets[11]는 부가적인 신원 변환을 통해 이러한 정보 보존을 명시적으로 만듭니다.
ResNets의 최근 변형[13]은 많은 레이어가 거의 기여하지 않으며 실제로 훈련 중에 무작위로 삭제될 수 있음을 보여줍니다.
이것은 ResNets의 상태를 (언롤링된) 반복 신경망[21]과 유사하게 만들지만, ResNets의 매개 변수 수는 각 레이어가 자체 가중치를 가지고 있기 때문에 상당히 더 큽니다.
우리가 제안한 DenseNet 아키텍처는 네트워크에 추가되는 정보와 보존되는 정보를 명시적으로 구분합니다.
DenseNet 레이어는 매우 좁아 (예 : 레이어 당 12개의 필터), 네트워크의 "집단 지식"에 작은 피쳐 맵 세트만 추가하고 나머지 피쳐 맵은 변경하지 않습니다.-그리고 최종 분류자는 네트워크의 모든 피쳐 맵을 기반으로 결정을 내립니다.
더 나은 매개 변수 효율성 외에도 DenseNets의 큰 장점 중 하나는 네트워크 전체에서 정보 흐름과 기울기가 개선되어 쉽게 학습할 수 있다는 것입니다.
각 레이어는 손실 함수 및 원래 입력 신호의 기울기에 직접 액세스할 수 있으므로 암시적 심층 감시가 수행됩니다[20].
이를 통해 더 깊은 네트워크 아키텍처를 학습할 수 있습니다.
또한 조밀한 연결이 정규화 효과를 가져와서 훈련 세트 크기가 작은 작업에 대한 과적합을 줄이는 것도 관찰합니다.
경쟁이 치열한 4개의 벤치 마크 데이터 세트 (CIFAR-10, CIFAR-100, SVHN 및 ImageNet)에서 DenseNet을 평가합니다.
우리 모델은 비슷한 정확도로 기존 알고리즘보다 훨씬 적은 매개 변수를 요구하는 경향이 있습니다.
또한, 우리는 대부분의 벤치 마크 작업에서 현재의 최신 결과를 훨씬 능가합니다.
2. Related Work
네트워크 아키텍처 탐색은 초기 발견 이후 신경망 연구의 일부였습니다.
최근 신경망의 인기가 다시 상승하면서 이 연구 영역도 부활했습니다.
현대 네트워크에서 증가하는 계층의 수는 아키텍처 간의 차이를 증폭시키고 서로 다른 연결 패턴을 탐색하고 오래된 연구 아이디어를 재검토하도록 동기를 부여합니다.
우리가 제안한 고밀도 네트워크 레이아웃과 유사한 캐스케이드 구조는 이미 1980년대에 신경망 문헌에서 연구되었습니다[3].
그들의 선구적인 작업은 레이어 단위 방식으로 훈련된 완전히 연결된 다층 퍼셉트론에 중점을 둡니다.
최근에는 배치 경사 하강법으로 훈련할 완전히 연결된 캐스케이드 네트워크가 제안되었습니다 [40].
이 접근 방식은 작은 데이터 세트에 효과적이지만 수백 개의 매개 변수가 있는 네트워크로만 확장됩니다.
[9, 23, 31, 41]에서는 스킵 연결을 통해 CNN의 다단계 기능을 활용하는 것이 다양한 비전 작업에 효과적인 것으로 밝혀졌습니다.
우리 작업과 병행하여 [1]은 우리와 유사한 교차 계층 연결을 가진 네트워크에 대한 순수 이론적 프레임 워크를 도출했습니다.
Highway Networks[34]는 100개 이상의 레이어로 종단 간 네트워크를 효과적으로 훈련할 수있는 수단을 제공한 최초의 아키텍처 중 하나였습니다.
게이팅 장치와 함께 우회 경로를 사용하면 수백 개의 레이어가 있는 Highway Networks를 어려움 없이 최적화할 수 있습니다.
우회 경로는 이러한 매우 깊은 네트워크의 훈련을 용이하게 하는 핵심 요소로 추정됩니다.
이 지점은 ResNets[11]에 의해 추가로 지원되며, 여기서 순수 ID 매핑이 우회 경로로 사용됩니다.
ResNets는 ImageNet 및 COCO 물체 감지[11]와 같은 많은 까다로운 이미지 인식, 위치 파악 및 감지 작업에서 인상적이고 기록적인 성능을 달성했습니다.
최근에, 1202-layer ResNet을 성공적으로 훈련시키기 위한 방법으로 확률적 깊이가 제안되었습니다[13].
확률적 깊이는 훈련 중에 계층을 무작위로 삭제하여 깊은 잔차 네트워크의 훈련을 개선합니다.
이것은 모든 계층이 필요하지 않을 수 있음을 나타내며 딥(잔류) 네트워크에 많은 양의 중복성이 있음을 강조합니다.
우리 논문은 그 관찰에서 부분적으로 영감을 받았습니다.
사전 활성화 기능이 있는 ResNet은 1000개 이상의 레이어를 포함하는 최첨단 네트워크의 훈련을 용이하게 합니다[12].
네트워크를 더 깊게 만들기 위한 직교 접근 방식(예 : 연결 건너 뛰기 사용)은 네트워크 너비를 늘리는 것입니다.
GoogLeNet[36, 37]은 다양한 크기의 필터로 생성된 피쳐 맵을 연결하는 "Inception 모듈"을 사용합니다.
[38]에서는 넓은 일반화 잔차 블록을 가진 ResNet의 변형이 제안되었습니다.
사실 ResNets의 각 레이어에서 필터 수를 늘리는 것만으로도 깊이가 충분하다면 성능을 향상시킬 수 있습니다 [42].
FractalNets는 또한 광범위한 네트워크 구조를 사용하여 여러 데이터 세트에서 경쟁력 있는 결과를 얻습니다 [17].
DenseNets는 매우 깊거나 넓은 아키텍처에서 표현력을 끌어내는 대신 피쳐 재사용을 통해 네트워크의 잠재력을 활용하여 학습하기 쉽고 매개 변수 효율이 높은 압축 모델을 생성합니다.
다른 레이어에서 학습한 피처 맵을 연결하면 후속 레이어 입력의 변동이 증가하고 효율성이 향상됩니다.
이것은 DenseNets와 ResNets의 주요 차이점을 구성합니다.
다른 계층의 기능도 연결하는 Inception 네트워크[36, 37]와 비교하여 DenseNet은 더 간단하고 효율적입니다.
경쟁 결과를 낳은 다른 주목할만한 네트워크 아키텍처 혁신이 있습니다.
NIN (Network in Network) [22]구조는 더 복잡한 특징을 추출하기 위해 컨볼루션 레이어의 필터에 마이크로 다층 퍼셉트론을 포함합니다.
DSN (Deeply Supervised Network)[20]에서 내부 계층은 보조 분류기에 의해 직접 감독되며, 이는 이전 계층에서 받은 기울기를 강화할 수 있습니다.
Ladder Networks[27, 25]는 autoencoder에 측면 연결을 도입하여 준지도 학습 작업에서 인상적인 정확도를 제공합니다.
[39]에서는 서로 다른 기본 네트워크의 중간 계층을 결합하여 정보 흐름을 개선하기 위해 DFN (Deeply-Fused Nets)이 제안되었습니다.
재구성 손실을 최소화하는 경로를 가진 네트워크의 증가는 또한 이미지 분류 모델을 개선하는 것으로 나타났습니다[43].
3. DenseNets
컨벌루션 네트워크를 통해 전달되는 단일 이미지 x0을 고려하십시오.
네트워크는 L 계층으로 구성되며, 각 계층은 비선형 변환 Hl(·)을 구현하며, 여기서 l은 계층을 인덱싱합니다.
Hl(·)은 배치 정규화 (BN)[14], 정류 선형 단위 (ReLU)[6], 풀링[19] 또는 컨볼루션 (Conv)과 같은 연산의 복합 함수일 수 있습니다.
l번째 레이어의 출력을 xl로 표시합니다.
ResNets.
전통적인 컨벌루션 피드-포워드 네트워크는 l번째 레이어의 출력을 (l+1)번째 레이어에 입력으로 연결하여 다음 레이어 전환을 발생시킵니다 : xl=Hl(xl-1).
ResNets[11]은 항등 함수를 사용하여 비선형 변환을 우회하는 스킵 연결을 추가합니다:

ResNets의 장점은 그라데이션이 identity 함수를 통해 이후 계층에서 이전 계층으로 직접 흐를 수 있다는 것입니다.
그러나 identity 함수와 Hl의 출력은 합산으로 결합되어 네트워크의 정보 흐름을 방해할 수 있습니다.
Dense connectivity.
레이어 간의 정보 흐름을 더욱 개선하기 위해 다른 연결 패턴을 제안합니다: 모든 레이어에서 모든 후속 레이어로의 직접 연결을 도입합니다.
그림 1은 결과 DenseNet의 레이아웃을 개략적으로 보여줍니다.
결과적으로 l번째 레이어는 모든 선행 레이어 x0, ..., xl-1의 특징 맵을 입력으로 받습니다:
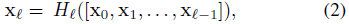
여기서 [x0, x1, ..., xl-1]은 레이어 0, ..., l-1에서 생성된 피쳐 맵의 연결을 나타냅니다.
고밀도 연결로 인해 이 네트워크 아키텍처를 DenseNet (Dense Convolutional Network)이라고 합니다.
구현의 용이성을 위해 식 (2)에서 Hl(·)의 여러 입력을 단일 텐서로 연결합니다.
Composite function.
[12]에 동기를 부여하여 Hl(·)을 3개의 연속 연산의 복합 함수로 정의합니다: 배치 정규화 (BN)[14], ReLU (rectified linear unit)[6] 및 3x3 convolution (Conv)이 뒤 따릅니다.

Pooling layers.
식 (2)에서 사용된 연결 연산은 피쳐 맵의 크기가 변경될 때 실행되지 않습니다.
그러나 컨볼루션 네트워크의 필수 부분은 피쳐 맵의 크기를 변경하는 다운 샘플링 레이어입니다.
아키텍처에서 다운 샘플링을 용이하게 하기 위해 네트워크를 조밀하게 연결된 여러 개의 조밀 블록으로 나눕니다; 그림 2를 참조하십시오.
블록 사이의 레이어를 컨볼루션과 풀링을 수행하는 전환 레이어라고합니다.
실험에 사용된 전환 레이어는 배치 정규화 레이어와 1x1 컨벌루션 레이어와 2x2 평균 풀링 레이어로 구성됩니다.
Growth rate.
각 함수 Hl이 k개의 특징 맵을 생성하는 경우, l번째 계층에는 k0 + k x (l-1) 입력 특징 맵이 있으며, 여기서 k0은 입력 계층의 채널 수입니다.
DenseNet과 기존 네트워크 아키텍처의 중요한 차이점은 DenseNet이 매우 좁은 계층 (예 : k=12)을 가질 수 있다는 것입니다.
하이퍼 파라미터 k를 네트워크의 성장률이라고합니다.
섹션 4에서는 상대적으로 작은 성장률로 테스트 한 데이터 세트에 대한 최신 결과를 얻을 수 있음을 보여줍니다.
이에 대한 한 가지 설명은 각 레이어가 해당 블록의 모든 선행 피쳐 맵에 액세스할 수 있으므로 네트워크의 "집단 지식"에 액세스할 수 있다는 것입니다.
피쳐 맵을 네트워크의 글로벌 상태로 볼 수 있습니다.
각 레이어는 이 상태에 고유한 특성 맵을 k개 추가합니다.
성장률은 각 계층이 글로벌 상태에 기여하는 새로운 정보의 양을 규제합니다.
글로벌 상태는 일단 기록되면 네트워크 내의 모든 곳에서 액세스할 수 있으며 기존 네트워크 아키텍처와 달리 계층 간에 복제할 필요가 없습니다.
Bottleneck layers.
각 레이어는 k개의 출력 피처 맵만 생성하지만 일반적으로 더 많은 입력이 있습니다.
[37, 11]에서는 각 3x3 컨볼루션 이전에 1x1 컨볼루션을 병목 계층으로 도입하여 입력 특징 맵의 수를 줄여 계산 효율을 높일 수 있음을 알 수 있습니다.
우리는 이 디자인이 DenseNet에 특히 효과적이라는 것을 알고 있으며 이러한 병목 계층이있는 네트워크, 즉 DenseNet-B와 같은 Hl의 BN-ReLU-Conv(1x1)-BN-ReLU-Conv(3x3) 버전을 참조합니다.
실험에서 각 1x1 컨볼루션이 4k 피처 맵을 생성하도록 했습니다.
Compression.
모델 간결함을 더욱 향상시키기 위해 전환 레이어에서 피쳐 맵의 수를 줄일 수 있습니다.
조밀한 블록에 m개의 피처 맵이 포함된 경우 다음 전환 레이어가 [θm] 출력 피처 맵을 생성하도록합니다, 여기서 0 <θ≤1은 압축 계수라고 합니다.
θ=1이면 전환 레이어 전체의 피처 맵 수가 변경되지 않은 상태로 유지됩니다.
θ<1인 DenseNet을 DenseNet-C라고 하며, 실험에서 θ=0.5로 설정했습니다.
θ<1인 병목 및 전이 레이어를 모두 사용하는 경우 모델을 DenseNet-BC라고 합니다.
Implementation Details.
ImageNet을 제외한 모든 데이터 세트에서 실험에 사용된 DenseNet에는 각각 동일한 수의 레이어가 있는 세 개의 조밀한 블록이 있습니다.
첫 번째 조밀 블록에 들어가기 전에 16개 (또는 DenseNet-BC의 경우 성장 속도의 두 배) 출력 채널을 가진 컨볼루션이 입력 이미지에서 수행됩니다.
커널 크기가 3x3인 컨벌루션 레이어의 경우, 입력의 각면에 피쳐 맵 크기를 고정하기 위해 1픽셀씩 0으로 채워집니다.
우리는 1x1 컨볼루션과 2x2 평균 풀링을 두 개의 연속된 조밀한 블록 사이의 전환 레이어로 사용합니다.
마지막 조밀 블록의 끝에서 글로벌 평균 풀링이 수행된 다음 소프트 맥스 분류기가 연결됩니다.
세 개의 조밀한 블록의 피쳐 맵 크기는 각각 32x32, 16x16 및 8x8입니다.
{L=40, k=12}, {L=100, k=12} 및 {L=100, k=24} 구성을 사용하여 기본 DenseNet 구조를 실험합니다.
DenseNet-BC의 경우 구성이 {L=100, k=12}, {L=250, k=24} 및 {L=190, k=40}인 네트워크가 평가됩니다.
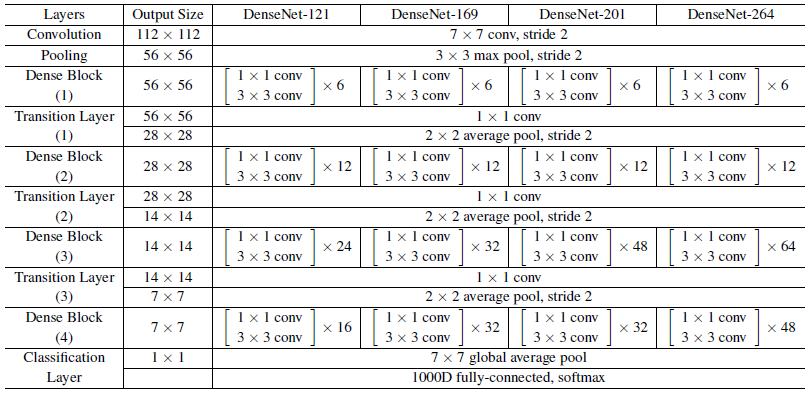
ImageNet 실험에서 224x224 입력 이미지에 4개의 조밀한 블록이 있는 DenseNet-BC 구조를 사용합니다.
초기 컨볼루션 레이어는 stride 2와 함께 7x7 크기의 2k 컨볼루션으로 구성됩니다; 다른 모든 레이어의 피처 맵 수도 설정 k에서 따릅니다.
ImageNet에서 사용한 정확한 네트워크 구성은 표 1에 나와 있습니다.
4. Experiments
우리는 여러 벤치 마크 데이터 세트에서 DenseNet의 효과를 경험적으로 입증하고 최첨단 아키텍처, 특히 ResNet 및 그 변형과 비교합니다.
4.1. Datasets
CIFAR.
두 개의 CIFAR 데이터 세트[15]는 32x32 픽셀의 컬러 자연 이미지로 구성됩니다.
CIFAR-10(C10)은 10개에서 가져온 이미지와 100개 클래스에서 가져온 CIFAR-100(C100)으로 구성됩니다.
훈련 및 테스트 세트에는 각각 50,000개와 10,000개의 이미지가 포함되며 5,000개의 훈련 이미지를 유효성 검사 세트로 보유합니다.
우리는 이 두 데이터 세트에 널리 사용되는 표준 데이터 증가 체계 (미러링/이동)를 채택합니다[11, 13, 17, 22, 28, 20, 32, 34].
이 데이터 증가 체계는 데이터 세트 이름 끝에 "+"표시로 표시됩니다 (예 : C10+).
전처리를 위해 채널 평균과 표준 편차를 사용하여 데이터를 정규화합니다.
최종 실행을 위해 50,000개의 훈련 이미지를 모두 사용하고 훈련이 끝날 때 최종 테스트 오류를 보고합니다.
SVHN.
SVHN (Street View House Numbers) 데이터 세트[24]에는 32x32 색상의 숫자 이미지가 포함되어 있습니다.
훈련 세트에는 73,257개의 이미지, 테스트 세트에는 26,032개의 이미지, 추가 훈련에는 531,131개의 이미지가 있습니다.
일반적인 관행[7, 13, 20, 22, 30]에 따라 데이터 증가없이 모든 훈련 데이터를 사용하며, 6,000개의 이미지가 있는 검증 세트가 훈련 세트에서 분리됩니다.
학습 중 검증 오류가 가장 낮은 모델을 선택하고 테스트 오류를 보고합니다.
[42]에 따라 픽셀 값을 255로 나누어 [0,1] 범위에 있게 합니다.
ImageNet.
ILSVRC 2012 분류 데이터 세트[2]는 1,000개의 클래스에서 학습용 120만 이미지와 검증용 이미지 50,000개로 구성됩니다.
훈련 이미지에 대해 [8, 11, 12]에서와 동일한 데이터 증가 체계를 채택하고 테스트 시간에 크기가 224x224인 단일 자르기 또는 10 자르기를 적용합니다.
[11, 12, 13]에 따라 검증 세트에 대한 분류 오류를 보고합니다.
4.2. Training
모든 네트워크는 확률적 경사 하강 법(SGD)을 사용하여 훈련됩니다.
CIFAR 및 SVHN에서 우리는 각각 300 및 40 epoch에 대해 배치 크기 64를 사용하여 훈련합니다.
초기 학습률은 0.1로 설정되어 있으며 총 학습 세대 수의 50%와 75%에서 10으로 나뉩니다.
ImageNet에서는 배치 크기가 256인 90 에포크 모델을 훈련합니다.
학습률은 초기에 0.1로 설정되어 있으며, 30 및 60기에는 10배 낮아집니다.
DenseNet의 순진한 구현에는 메모리 비효율성이 포함될 수 있습니다.
GPU에서 메모리 소비를 줄이려면 DenseNets[26]의 메모리 효율적인 구현에 대한 기술 보고서를 참조하십시오.
[8]에 따라 우리는 감쇠없이 10^-4의 가중치 감쇠와 0.9의 Nesterov 운동량[35]을 사용합니다.
[10]에서 소개한 가중치 초기화를 채택합니다.
데이터 증가가 없는 세 개의 데이터 세트, 즉 C10, C100 및 SVHN의 경우 각 컨벌루션 레이어 (첫 번째 레이어 제외) 뒤에 드롭아웃 레이어[33]를 추가하고 드롭아웃 비율을 0.2로 설정합니다.
테스트 오류는 각 작업 및 모델 설정에 대해 한 번만 평가되었습니다.
4.3. Classification Results on CIFAR and SVHN
깊이, L 및 성장률 k가 다른 DenseNet을 훈련합니다.
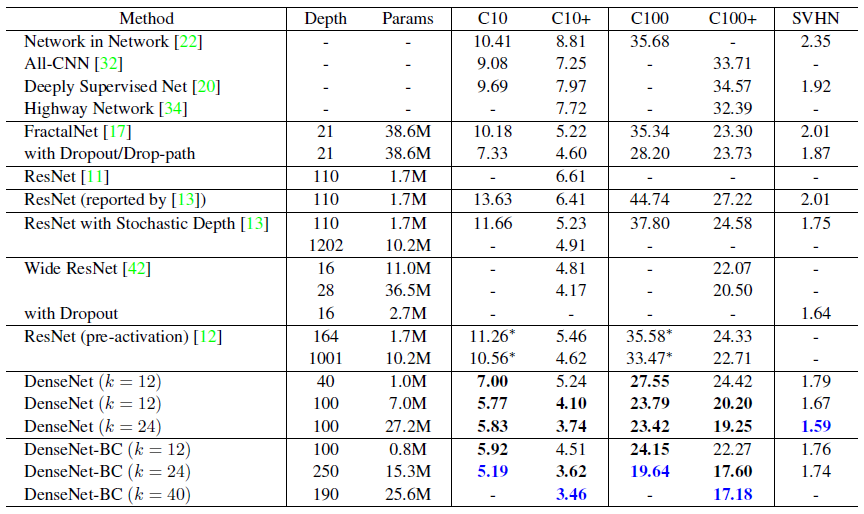
CIFAR 및 SVHN의 주요 결과는 표 2에 나와 있습니다.
일반적인 트렌드를 강조하기 위해 기존의 최신 기술을 능가하는 모든 결과를 굵은 글씨로 표시하고 전반적으로 최상의 결과를 파란색으로 표시합니다.
Accuracy.
아마도 가장 눈에 띄는 추세는 표 2의 맨 아래 행에서 비롯될 수 있습니다, 이는 L=190 및 k=40인 DenseNet-BC가 모든 CIFAR 데이터 세트에서 일관되게 기존의 최신 기술을 능가한다는 것을 보여줍니다.
C10+에서 3.46%, C100+에서 17.18%의 오류율은 광범위한 ResNet 아키텍처에서 달성한 오류율보다 훨씬 낮습니다[42].
C10 및 C100(데이터 증가 없음)에 대한 최상의 결과는 훨씬 더 고무적입니다: 둘 다 드롭 경로 정규화를 사용하는 Fractal-Net보다 30%에 가깝습니다[17].
SVHN에서 드롭아웃이 있는 DenseNet(L=100 및 k=24)도 광범위한 ResNet에서 달성한 현재 최상의 결과를 능가합니다.
그러나 250 계층 DenseNet-BC는 짧은 제품에 비해 성능을 더 향상시키지 않습니다.
이것은 SVHN이 상대적으로 쉬운 작업이고 매우 깊은 모델이 훈련 세트에 과적합할 수 있다는 점에 의해 설명될 수 있습니다.
Capacity.
압축 또는 병목 레이어가 없으면 L 및 k가 증가함에 따라 DenseNets의 성능이 향상되는 일반적인 추세가 있습니다.
이는 주로 모델 용량의 증가에 기인합니다.
이것은 C10+ 및 C100+ 컬럼에서 가장 잘 입증됩니다.
C10+에서는 매개 변수 수가 1.0M에서 7.0M에서 27.2M으로 증가함에 따라 오류가 5.24%에서 4.10%로, 마지막으로 3.74%로 떨어집니다.
C100+에서도 비슷한 경향이 있습니다.
이것은 DenseNets가 더 크고 더 깊은 모델의 증가된 표현력을 활용할 수 있음을 시사합니다.
또한 과적합이나 잔여 네트워크의 최적화 어려움을 겪지 않는다는 것을 나타냅니다 [11].
Parameter Efficiency.
표 2의 결과는 DenseNet이 대체 아키텍처(특히 ResNets)보다 매개 변수를 더 효율적으로 활용함을 나타냅니다.
병목 구조와 전이 계층에서 치수 감소가 있는 DenseNet-BC는 특히 매개 변수 효율적입니다.
예를 들어, 250-레이어 모델에는 1530만 개의 매개 변수만 있지만 3천만 개 이상의 매개 변수가있는 FractalNet 및 Wide ResNet과 같은 다른 모델보다 지속적으로 성능이 뛰어납니다.
또한 L=100 및 k=12인 DenseNet-BC는 90을 사용하는 1001-계층 사전 활성화 ResNet과 유사한 성능 (예 : C10+에서 4.51% vs. 4.62% 오류, C100+에서 22.27% vs. 22.71% 오류)을 달성합니다.
그림 4(오른쪽 패널)는 C10+에서 이 두 네트워크의 훈련 손실 및 테스트 오류를 보여줍니다.
1001 계층 심층 ResNet은 더 낮은 학습 손실값으로 수렴되지만 유사한 테스트 오류입니다.
이 효과를 아래에서 자세히 분석합니다.
Overfitting.
보다 효율적인 매개 변수 사용의 긍정적인 부작용 중 하나는 DenseNet이 과적합을 덜 일으키는 경향이 있다는 것입니다.
데이터 증가가 없는 데이터 세트에서 이전 작업에 비해 DenseNet 아키텍처의 개선이 특히 두드러집니다.
C10에서 개선은 7.33%에서 5.19%로 29%의 상대적 오류 감소를 나타냅니다.
C100에서 감소는 28.20%에서 19.64%로 약 30%입니다.
실험에서 단일 설정에서 잠재적인 과적합을 관찰했습니다: C10에서 k=12를 k=24로 증가시켜 생성된 매개 변수의 4배 증가는 5.77%에서 5.83%로 약간의 오차 증가로 이어집니다.
DenseNet-BC 병목 현상 및 압축 계층은 이러한 추세에 대응하는 효과적인 방법으로 보입니다.
4.4. Classification Results on ImageNet
ImageNet 분류 작업에서 다양한 깊이와 성장률로 DenseNet-BC를 평가하고 최첨단 ResNet 아키텍처와 비교합니다.
두 아키텍처 간의 공정한 비교를 보장하기 위해 [8]까지 ResNet에 대해 공개적으로 사용 가능한 Torch 구현을 채택하여 데이터 전처리 및 최적화 설정의 차이와 같은 다른 모든 요소를 제거합니다.
ResNet 모델을 DenseNet-BC 네트워크로 간단히 교체하고 모든 실험 설정을 ResNet에 사용된 것과 동일하게 유지합니다.
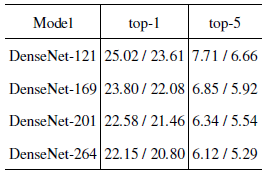

표 3의 ImageNet에서 DenseNets의 단일 자르기 및 10-자르기 유효성 검사 오류를 보고합니다.
그림 3은 매개 변수 수 (왼쪽) 및 FLOP (오른쪽)의 함수로서 DenseNets 및 ResNets의 단일 자르기 top-1 검증 오류를 보여줍니다.
그림에 제시된 결과는 DenseNet이 최첨단 ResNet과 동등한 성능을 발휘하는 반면 비교 가능한 성능을 달성하기 위해 훨씬 적은 매개 변수와 계산이 필요하다는 것을 보여줍니다.
예를 들어, 매개 변수가 20M인 DenseNet-201 모델은 매개 변수가 40M 이상인 101 계층 ResNet과 유사한 유효성 검사 오류를 생성합니다.
유사한 경향이 오른쪽 패널에서 관찰될 수 있으며, 이는 FLOP 수의 함수로 유효성 검사 오류를 표시합니다: ResNet-50이 수행하는 계산만큼 많은 계산이 필요한 DenseNet은 ResNet-101과 동등하며 두 배 더 많이 필요합니다.
실험 설정은 ResNet에 최적화 되었지만 DenseNet에는 최적화되지 않은 하이퍼 파라미터 설정을 사용한다는 것을 의미합니다.
보다 광범위한 하이퍼 매개 변수 검색은 ImageNet에서 DenseNet의 성능을 더욱 향상시킬 수 있습니다.
5. Discussion
표면적으로 DenseNets는 ResNets와 매우 유사합니다: 식 (2)는 Hl(·)에 대한 입력이 합산되는 대신 연결된다는 점에서만 식 (1)과 다릅니다.
그러나 이러한 작은 수정의 의미로 인해 두 네트워크 아키텍처의 동작이 크게 달라집니다.
Model compactness.
입력 연결의 직접적인 결과로 DenseNet 계층에서 학습한 피쳐 맵은 모든 후속 계층에서 액세스할 수 있습니다.
이는 네트워크 전체에서 기능 재사용을 장려하고 더 컴팩트한 모델로 이어집니다.
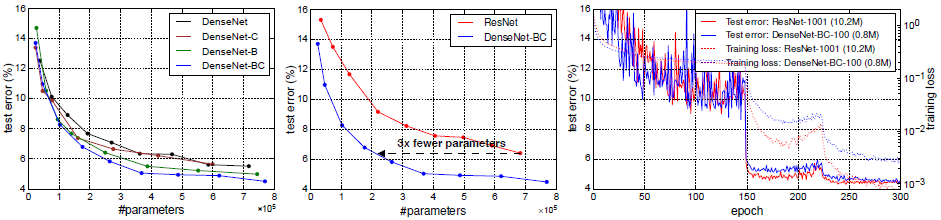
그림 4의 왼쪽 두 플롯은 DenseNet의 모든 변형(왼쪽)과 비슷한 ResNet 아키텍처(중간)의 매개 변수 효율성을 비교하는 것을 목표로하는 실험의 결과를 보여줍니다.
C10+에서 다양한 깊이로 여러 소규모 네트워크를 훈련하고 네트워크 매개 변수의 함수로 테스트 정확도를 플로팅합니다.
AlexNet [16] 또는 VGG-net [29]과 같은 다른 널리 사용되는 네트워크 아키텍처와 비교할 때, 사전 활성화된 ResNet은 일반적으로 더 나은 결과를 달성하면서 더 적은 매개 변수를 사용합니다 [12].
따라서 DenseNet (k=12)을 이 아키텍처와 비교합니다.
DenseNet의 훈련 설정은 이전 섹션과 동일하게 유지됩니다.
그래프는 DenseNet-BC가 일관되게 DenseNet의 가장 매개 변수 효율적인 변형임을 보여줍니다.
또한 동일한 수준의 정확도를 달성하기 위해 DenseNet-BC는 ResNets (중간 플롯) 매개 변수의 약 1/3만 필요합니다.
이 결과는 그림 3에 제시된 ImageNet의 결과와 일치합니다.
그림 4의 오른쪽 플롯은 훈련 가능한 매개 변수가 0.8M에 불과한 DenseNet-BC가 10.2M 매개 변수를 사용하는 1001 계층 (사전 활성화) ResNet [12]과 비슷한 정확도를 달성할 수 있음을 보여줍니다.
Implicit Deep Supervision.
조밀한 컨벌루션 네트워크의 향상된 정확도에 대한 한 가지 설명은 개별 계층이 더 짧은 연결을 통해 손실 함수로부터 추가 감독을 받는다는 것입니다.
DenseNets를 해석하여 일종의 "심층 감독"을 수행할 수 있습니다.
심층 감독의 이점은 이전에 심층 감독 네트워크 (DSN; [20])에서 나타났습니다, 이 네트워크에는 모든 은닉 계층에 분류 기가 부착되어 있어 중간 계층이 차별적 특징을 학습하도록 합니다.
DenseNets는 암시적 방식으로 유사한 심층 감독을 수행합니다: 네트워크 상단의 단일 분류기는 최대 2개 또는 3개의 전환 계층을 통해 모든 계층에 직접 감독을 제공합니다.
그러나 DenseNets의 손실 함수와 기울기는 모든 레이어 간에 동일한 손실 함수가 공유되기 때문에 훨씬 덜 복잡합니다.
Stochastic vs. deterministic connection.
조밀한 컨볼루션 네트워크와 잔여 네트워크의 확률적 깊이 정규화 사이에는 흥미로운 연관성이 있습니다 [13].
확률적 깊이에서는 잔여 네트워크의 레이어가 무작위로 삭제되어 주변 레이어 간에 직접 연결이 생성됩니다.
풀링 레이어가 삭제되지 않기 때문에 네트워크는 DenseNet과 유사한 연결 패턴을 생성합니다: 모든 중간 레이어가 무작위로 삭제되는 경우 동일한 풀링 레이어 사이의 두 레이어가 직접 연결될 가능성이 적습니다.
방법은 궁극적으로 매우 다르지만 확률적 깊이에 대한 DenseNet 해석은 이 정규화 프로그램의 성공에 대한 통찰력을 제공할 수 있습니다.
Feature Reuse.
설계 상 DenseNets는 모든 이전 레이어의 피처 맵에 대한 레이어 액세스를 허용합니다 (때로는 전환 레이어를 통해).
훈련된 네트워크가 이 기회를 활용하는지 조사하기 위해 실험을 수행합니다.
먼저 L=40 및 k=12로 C10+에서 DenseNet을 훈련합니다.
블록 내의 각 컨벌루션 레이어 l에 대해 레이어 s와의 연결에 할당된 평균 (절대) 가중치를 계산합니다.
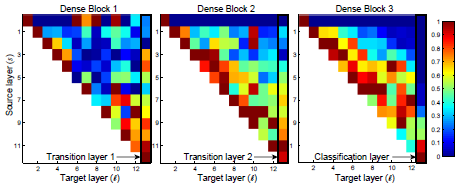
그림 5는 세 개의 고밀도 블록 모두에 대한 히트 맵을 보여줍니다.
평균 절대 가중치는 이전 레이어에 대한 컨벌루션 레이어의 종속성에 대한 대리 역할을 합니다.
(l, s) 위치의 빨간색 점은 레이어 l이 평균적으로 이전에 s-레이어가 생성된 피처 맵을 강력하게 사용함을 나타냅니다.
플롯에서 몇 가지 관찰을 할 수 있습니다:
1. 모든 계층은 동일한 블록 내의 여러 입력에 가중치를 분산합니다.
이것은 매우 초기 계층에서 추출한 특징이 실제로 동일한 조밀한 블록 전체에서 깊은 계층에서 직접 사용됨을 나타냅니다.
2. 트랜지션 레이어의 가중치는 이전 조밀 블록 내의 모든 레이어에 가중치를 분산하여 몇 가지 간접을 통해 DenseNet의 첫 번째 레이어에서 마지막 레이어로 정보 흐름을 나타냅니다.
3. 두 번째 및 세 번째 조밀한 블록 내의 레이어는 전환 레이어(삼각형의 맨 위 행)의 출력에 최소 가중치를 지속적으로 할당하여 전환 레이어가 많은 중복 피처를 출력함을 나타냅니다(평균 가중치가 낮음).
이는 이러한 출력이 정확히 압축된 DenseNet-BC의 강력한 결과와 일치합니다.
4. 맨 오른쪽에 표시된 최종 분류 계층도 전체 조밀 블록에 대한 가중치를 사용하지만 최종 피쳐 맵에 대한 집중이 있는 것 같습니다, 이는 후반부에 생성된 네트워크에 일부 고급 기능이 있을 수 있음을 시사합니다.
6. Conclusion
우리는 DenseNet (Dense Convolutional Network)이라고 하는 새로운 convolutional 네트워크 아키텍처를 제안했습니다.
피처 맵 크기가 동일한 두 레이어 간에 직접 연결을 도입합니다.
우리는 DenseNets가 최적화 어려움 없이 자연스럽게 수백 개의 레이어로 확장된다는 것을 보여주었습니다.
우리의 실험에서 DenseNets는 성능 저하 또는 과적합의 징후 없이 증가하는 매개 변수로 정확도를 일관되게 개선하는 경향이 있습니다.
여러 설정에서 경쟁이 치열한 여러 데이터 세트에서 최첨단 결과를 얻었습니다.
또한 DenseNets는 최첨단 성능을 달성하기 위해 훨씬 더 적은 수의 매개 변수와 더 적은 계산을 필요로 합니다.
연구에서 잔여 네트워크에 최적화된 초 매개 변수 설정을 채택했기 때문에 초 매개 변수 및 학습률 일정을 보다 세부적으로 조정하면 DenseNet의 정확도를 더욱 높일 수 있다고 생각합니다.
간단한 연결 규칙을 따르는 동안 DenseNets는 자연스럽게 identity 매핑, 심층 감독 및 다양한 깊이의 속성을 통합합니다.
이를 통해 네트워크 전체에서 기능을 재사용할 수 있으며 결과적으로 더 간결하게 학습할 수 있으며 실험에 따르면 더 정확한 모델을 훈련할 수 있습니다.
콤팩트한 내부 표현과 감소된 기능 중복으로 인해 DenseNets는 컨볼루션 기능을 기반으로 하는 다양한 컴퓨터 비전 작업에 적합한 기능 추출기가 될 수 있습니다 (예 : [4, 5]).
향후 작업에서 DenseNets로 이러한 기능 이전을 연구할 계획입니다.
'Computer Vision' 카테고리의 다른 글
| FaceNet, A Unified Embedding for Face Recognition and Clustering (0) | 2021.11.19 |
|---|---|
| Deeper Depth Prediction with Fully Convolutional Residual Networks (번역) (0) | 2021.04.19 |
| ResNeXt: Aggregated Residual Transformations for Deep Neural Networks (번역) (0) | 2021.03.03 |
| GAN : Generative Adversarial Nets (번역) (1) | 2021.03.02 |
| Mask R-CNN (번역) (0) | 2021.03.02 |