2021. 4. 19. 16:36ㆍComputer Vision
Deeper Depth Prediction with Fully Convolutional Residual Networks
Iro Laina, Christian Rupprecht, Vasileios Belagiannis, Federico Tombari, Nassir Navab
Abstract
이 논문은 하나의 RGB 이미지가 주어진 장면의 깊이 맵을 추정하는 문제를 다룹니다.
우리는 단안 이미지와 깊이 맵 사이의 모호한 매핑을 모델링 하기 위해 잔차 학습을 포함하는 완전 컨볼루션 아키텍처를 제안합니다.
출력 해상도를 개선하기 위해 네트워크 내에서 피쳐 맵 업샘플링을 효율적으로 학습할 수 있는 새로운 방법을 제시합니다.
최적화를 위해 우리는 특히 당면한 작업에 적합하고 깊이 맵에 일반적으로 존재하는 값 분포에 의해 구동되는 역 Huber 손실을 도입합니다.
우리의 모델은 엔드-투-엔드 훈련된 단일 아키텍처로 구성되며 CRF 또는 기타 추가 개선 단계와 같은 후처리 기술에 의존하지 않습니다.
결과적으로 이미지 또는 비디오에서 실시간으로 실행됩니다.
평가에서 우리는 제안된 모델이 깊이 추정에 대한 모든 접근 방식을 능가하는 동시에 최신 기술보다 더 적은 매개 변수를 포함하고 더 적은 훈련 데이터를 필요로 함을 보여줍니다.
코드와 모델은 공개적으로 사용할 수 있습니다.
1. Introduction
단일 관점에서의 깊이 추정은 컴퓨터 비전만큼 오래된 학문이며 수년 동안 개발된 여러 기술을 포함합니다.
이러한 기술 중 가장 성공적인 기술 중 하나는 SfM (Structure-from-Motion) [34]입니다; 카메라 모션을 활용하여 서로 다른 시간 간격을 통해 카메라 포즈를 추정하고 연속적인 뷰 쌍에서 삼각 측량을 통해 깊이를 추정합니다.
모션 대신 조명 [39] 또는 초점 [33]의 변화와 같은 깊이를 추정하기 위해 다른 작업 가정을 사용할 수 있습니다.
이러한 환경적 가정이 없는 경우 일반적인 장면의 단일 이미지에서 깊이를 추정하는 것은 강도 또는 색상 측정 값을 깊이 값으로 매핑하는 고유한 모호성으로 인해 잘못된 문제입니다.
이것은 또한 인간의 두뇌 제한이지만 깊이 지각은 단안시에서 나타날 수 있습니다.
따라서 단안 신호를 활용하여 깊이 맵를 추정할 수 있는 컴퓨터 비전 시스템을 개발하는 것은 어려운 작업일 뿐만 아니라 직접 깊이 감지를 사용할 수 없거나 불가능한 시나리오에서도 필요한 작업입니다.
더욱이, 합리적으로 정확한 깊이 정보의 가용성은 예를 들어 재구성[23], 인식[26], 의미 분할[5] 또는 사람 포즈 추정[35]에서 RGB 전용 대응물과 관련하여 많은 컴퓨터 비전 작업을 개선하는 것으로 잘 알려져 있습니다.
이러한 이유로 단안 깊이 추정 문제를 다루는 여러 작품이 있습니다.
첫 번째 접근법 중 하나는 슈퍼 픽셀을 MRF(Markov Random Fields)를 통해 평면 계수를 통해 평면 및 추론된 깊이로 가정했습니다 [30].
[16, 20, 37]에서는 깊이 맵의 정규화를 위해 CRF(Conditional Random Fields)가 배포되는 슈퍼 픽셀도 고려되었습니다.
[10, 13]과 같은 데이터 기반 접근 방식은 주어진 쿼리 이미지에 대한 훈련 세트의 가장 유사한 후보를 검색하기 위해 손으로 만든 기능을 기반으로 이미지 매칭을 수행하도록 제안했습니다.
그런 다음 최종 결과를 생성하기 위해 해당 깊이 후보를 뒤틀고 병합합니다.
최근에는 컬러 픽셀과 깊이 사이의 암시적 관계를 학습하기 위해 CNN(Convolutional Neural Networks)이 사용되었습니다[5, 6, 16, 19, 37].
CNN 접근법은 종종 후처리 단계 [16, 37] 또는 구조화된 딥러닝 [19] 및 랜덤 포레스트 [27]를 통해 CRF 기반 정규화와 결합되었습니다.
이러한 방법은 심층 네트워크 [5, 6, 19] 또는 CNN과 CRF의 공동 사용[16, 37]에 관련된 많은 매개 변수로 인해 더 높은 복잡성을 포함합니다.
그럼에도 불구하고 딥러닝은 표준 벤치 마크 데이터세트의 정확도를 크게 향상시켜 이러한 방법을 최첨단 기술에서 1위로 평가했습니다.
이 작업에서는 CNN을 사용하여 단일 RGB 이미지와 해당 깊이 맵 간의 매핑을 학습할 것을 제안합니다.
우리 작업의 기여는 다음과 같습니다.
먼저, 새로운 업샘플링 블록이 부여된 깊이 예측에 완전 컨볼루션 아키텍처를 도입하여 더 높은 해상도의 고밀도 출력 맵을 허용하고 동시에 상태보다 10배 적은 데이터에 대해 더 적은 매개 변수와 훈련을 필요로 합니다, 표준 벤치 마크 데이터세트에서 기존의 모든 방법을 능가합니다[23, 29].
우리는 더 효율적인 업 컨볼루션 기법을 제안하고 이를 잔여 학습 개념과 결합하여 피쳐 맵의 효과적인 업샘플링을 위한 업 프로젝션 블록을 생성합니다.
마지막으로, 우리는 역 Huber 함수(berHu)[40]를 기반으로 손실을 최적화하여 네트워크를 훈련시키고 이론적으로나 실험적으로 왜 이것이 당면한 작업에 더 유익하고 더 적합한지 보여줍니다.
네트워크의 깊이, 손실 함수 및 업샘플링에 사용된 특정 레이어의 영향을 철저히 평가하여 이점을 분석합니다.
마지막으로 방법의 정확도를 추가로 평가하기 위해 3D 재구성 시나리오 내에서 훈련된 모델을 사용합니다, 여기서는 일련의 RGB 프레임과 SLAM(Simultaneous Localization and Mapping)에 대한 예측된 깊이 맵을 사용합니다.
2. Related Work
이미지 데이터의 깊이 추정은 원래 스테레오 비전[22, 32]에 의존하여 동일한 장면의 이미지 쌍을 사용하여 3D 모양을 재구성했습니다.
단일 뷰의 경우 대부분의 접근 방식은 모션 (모션 구조 [34]) 또는 다양한 촬영 조건 (셰이프에서 셰이딩 [39], 디 포커스에서 셰이프 [33])에 의존했습니다.
이러한 정보가 부족하여 발생하는 모호함에도 불구하고 단안 신호에서 인간의 깊이 인식에 대한 비유에서 영감을 얻었음에도 불구하고 단일 RGB 이미지에서 깊이 맵 예측도 조사되었습니다.
아래에서는 우리의 방법과 유사한 단일 RGB 입력에 대한 관련 작업에 중점을 둡니다.
단안 깊이 추정에 대한 고전적인 방법은 주로 손으로 만든 기능에 의존하고 확률적 그래픽 모델을 사용하여 문제를 해결하고 [8, 17, 29, 30] 일반적으로 장면 형상에 대해 강력한 가정을 합니다.
첫 번째 작품 중 하나, Saxena et al. [29]는 MRF를 사용하여 이미지에서 추출된 로컬 및 글로벌 특징에서 깊이를 추론하는 반면, 수퍼 픽셀[1]은 인접 제약을 적용하기 위해 MRF 공식에 도입되었습니다.
그들의 작업은 나중에 3D 장면 재구성으로 확장되었습니다 [30].
이 작품에서 영감을 얻은 Liu et al. [17] 의미론적 분할 작업을 깊이 추정과 결합합니다, 여기서 예측된 레이블은 최적화 작업을 용이하게 하기 위한 추가 제약으로 사용됩니다.
Ladicky et al. [15] 대신 분류 접근법에서 레이블과 깊이를 공동으로 예측합니다.
관련 작업의 두 번째 클러스터는 깊이 전송을 위한 비모수적 접근 방식을 포함합니다 [10, 13, 18, 20]; 일반적으로 주어진 RGB 이미지와 해당 RGB 이미지 사이의 특징 기반 매칭 (예 : GIST [24], HOG [3])을 수행합니다; 가장 가까운 이웃을 찾기 위한 RGB-D 저장소의 이미지; 검색된 깊이 대응물은 뒤틀리고 결합되어 최종 깊이 맵을 생성합니다.
Karsch et al. [10] SIFT 흐름을 사용하여 워핑을 수행합니다 [18], 글로벌 최적화 체계가 뒤따르는 반면 Konrad et al. [13] 검색된 깊이 맵에 대한 중앙값을 계산한 다음 평활화를 위한 교차 양방향 필터링을 수행합니다.
후보자를 뒤틀는 대신 Liu et al. [20], 최적화 문제를 연속 및 불연속 가변 전위를 갖는 조건부 랜덤 필드(CRF)로 공식화합니다.
특히, 이러한 접근 방식은 RGB 이미지에서 영역 간의 유사성이 유사한 깊이 단서를 의미한다는 가정에 의존합니다.
최근에는 딥러닝 분야의 눈부신 발전으로 깊이 추정을 위해 CNN을 사용하는 연구가 진행되었습니다.
작업이 의미론적 라벨링과 밀접하게 관련되어 있기 때문에 대부분의 작품은 ImageNet 대규모 시각 인식 도전(ILSVRC) [28]의 가장 성공적인 아키텍처를 기반으로 구축되었으며, 종종 AlexNet[14] 또는 더 깊은 VGG[31]로 네트워크를 초기화합니다.
Eigen et al. [6]은 2 스케일 아키텍처의 단일 이미지에서 고밀도 깊이 맵을 회귀하기 위해 CNN을 처음으로 사용했습니다, 첫 번째 단계(AlexNet 기반)는 대략적인 출력을 생성하고 두 번째 단계는 원래 예측을 개선합니다.
그들의 작업은 나중에 VGG를 기반으로 하는 더 깊고 더 차별적인 모델과 추가 개선을 위한 3 스케일 아키텍처를 사용하여 노멀과 레이블을 추가로 예측하도록 확장됩니다[5].
[5, 6]의 딥 아키텍처와 달리 Roy와 Todorovic [27]은 각 트리 노드에서 매우 얕은 아키텍처를 사용하여 CNN을 회귀 포레스트와 결합하여 빅데이터의 필요성을 제한합니다.
예측된 깊이 맵의 품질을 개선하기 위한 또 다른 방향은 CNN과 그래픽 모델을 함께 사용하는 것입니다 [16, 19, 37].
Liu et al. [19] CNN 훈련 동안 CRF 손실의 형태로 단항 및 쌍별 전위를 학습하도록 제안하는 반면 Li et al. [16] 및 Wang et al. [37] 계층적 CRF를 사용하여 패치 방식의 CNN 예측을 슈퍼 픽셀에서 픽셀 수준까지 세분화합니다.
우리의 방법은 깊이 추정을 위해 CNN을 사용하며 효율적인 잔여 업샘플링 블록을 통합하는 완전 컨볼루션 모델을 사용하여 매개 변수 수와 관련하여 비용이 많이 드는 일반적인 완전 연결 계층을 개선한다는 점에서 이전 작업과 다릅니다, 우리는 상향 투영이라고 하며 이는 고차원 회귀 문제를 다룰 때 더 적합하다는 것을 증명합니다.
3. Methodology
이 섹션에서는 단일 RGB 이미지에서 깊이 예측을 위한 모델을 설명합니다.
먼저 채택된 아키텍처를 제시한 다음이 작업에서 제안된 새로운 구성 요소를 분석합니다.
이어서 주어진 작업의 최적화에 적합한 손실 함수를 제안합니다.
3.1. CNN Architecture
현재 거의 모든 CNN 아키텍처에는 일련의 컨볼루션 및 풀링 작업을 통해 입력 이미지 해상도를 점진적으로 감소시켜 더 높은 수준을 제공하는 축소 부분이 포함되어 있습니다, 뉴런은 수용 필드가 커서 더 많은 글로벌 정보를 캡처합니다.
원하는 출력이 고해상도 이미지인 회귀 문제에서는 더 큰 출력 맵을 얻기 위해 어떤 형태의 업샘플링이 필요합니다.
Eigen et al. [5, 6], 일반적인 분류 네트워크에서처럼 완전히 연결된 레이어를 사용하여 완전한 수용 필드를 생성합니다.
결과는 출력 해상도로 재구성됩니다.
깊이 예측을 위한 완전 컨벌루션 네트워크를 소개합니다.
여기서 수용 필드는 명시적인 완전한 연결이 없기 때문에 건축 설계의 중요한 측면입니다.
특히, 304x228 픽셀의 입력을 설정하고 ([6]에서와 같이) 입력 해상도의 약 절반이 될 출력 맵을 예측한다고 가정합니다.
사전 훈련된 가중치가 수렴을 촉진하기 때문에 인기 있는 아키텍처(AlexNet [14], VGG-16 [31])를 축소 부분으로 조사합니다.
AlexNet의 마지막 컨볼루션 레이어의 수용 필드는 151x151 픽셀이며, 완전히 연결된 레이어 없이 네트워크에서 진정한 글로벌 정보(예 : 단안 큐)를 캡처해야할 때 매우 낮은 해상도의 입력 이미지만 허용합니다.
276x276의 더 큰 수용 필드는 VGG-16에 의해 달성되지만 여전히 입력 해상도에 대한 제한을 설정합니다.
Eigen과 Fergus[5]는 AlexNet에서 VGG로 전환할 때 상당한 개선을 보여주지만 두 모델 모두 완전 연결 계층을 사용하기 때문에 VGG의 더 높은 차별력 때문입니다.
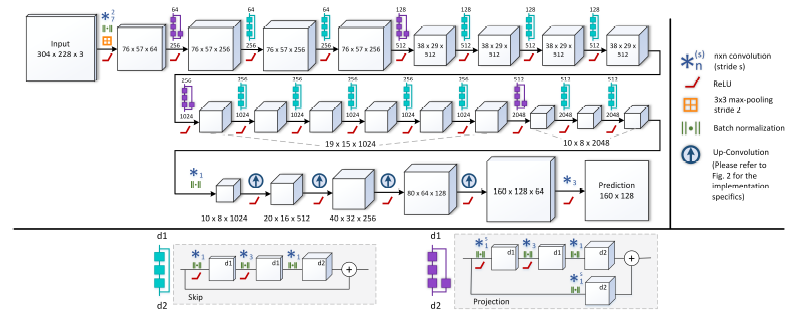
최근 ResNet[7]은 두 개 이상의 컨볼루션을 우회하고 출력에 합산되는 스킵 레이어를 도입했습니다, 여기에는 매 컨볼루션 후 배치 정규화[9]가 포함됩니다 (그림 1 참조).
이 디자인에 따라 저하되거나 그라디언트가 사라지지 않고 훨씬 더 깊은 네트워크를 만들 수 있습니다.
이러한 매우 깊은 아키텍처의 또 다른 유익한 속성은 넓은 수용 영역입니다, ResNet-50은 더 높은 해상도에서도 입력 이미지를 완전히 캡처할 수 있을 만큼 큰 483x483의 입력 크기를 캡처합니다.
입력 크기와 이 아키텍처를 고려할 때, 마지막 풀링 레이어를 제거할 때 마지막 컨볼루션 레이어는 공간 해상도 10x8 픽셀의 2048 피처 맵을 생성합니다.
나중에 보여 주듯이, 잔여 상향 회선을 사용하는 제안된 모델은 160x128 픽셀의 출력을 생성합니다.
대신 동일한 크기의 완전히 연결된 레이어를 추가하면 33억개의 매개 변수가 도입되어 12.6GB의 메모리에 해당하므로 현재 하드웨어에서는 이 접근 방식이 불가능합니다.
이는 더 적은 가중치를 포함하는 업샘플링 블록을 사용하는 완전 컨볼루션 아키텍처 제안에 동기를 부여하는 동시에 예측된 깊이 맵의 정확도를 향상시킵니다.
우리가 제안한 아키텍처는 그림 1에서 볼 수 있습니다.
기능 맵 크기는 NYU Depth v2 데이터 세트[23]의 경우 입력 크기 304x228에 대해 훈련된 네트워크에 해당합니다.
네트워크의 첫 번째 부분은 ResNet-50을 기반으로 하며 사전 훈련된 가중치로 초기화됩니다.
아키텍처의 두 번째 부분은 일련의 풀링 및 컨볼루션 계층을 통해 업 스케일링을 학습하도록 네트워크를 안내합니다.
이러한 업샘플링 블록 세트 다음에 드롭아웃이 적용되고 예측을 생성하는 최종 컨볼루션 레이어가 이어집니다.
Up-Projection Blocks.
Unpooling Layer[4, 21, 38]는 풀링의 역 동작을 수행하여 피처 맵의 공간 해상도를 높입니다.
우리는 각 항목을 2x2 (제로) 커널의 왼쪽 상단 모서리에 매핑하여 크기를 두 배로 늘리기 위해 풀링 해제 계층의 구현에 대해 [4]에 설명된 접근 방식을 적용합니다.
이러한 각 레이어 뒤에는 5x5 컨볼루션이 이어지므로 각 위치에서 하나 이상의 0이 아닌 요소에 적용되고 연속적으로 ReLU 활성화가 적용됩니다.
이 블록을 상향 회선이라고합니다.
경험적으로, 우리는 이러한 업 컨볼루션 블록 4개를 스택합니다. 즉, 가장 작은 피쳐 맵의 16배 업 스케일링을 통해 메모리 소비와 해상도 간의 최상의 균형을 이룹니다.
다섯번째 블록을 추가할 때 성능이 향상되지 않음을 발견했습니다.
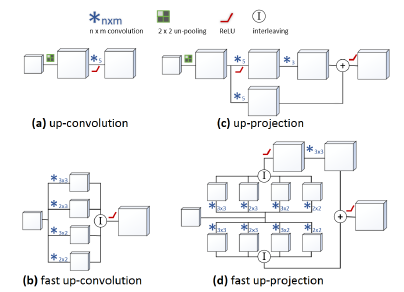
유사하지만 역의 개념을 사용하여 간단한 업 컨볼루션을 [7]로 확장하여 업 샘플링 res-블록을 생성합니다.
이 아이디어는 그림 2 (c)와 같이 업 컨볼루션 후에 간단한 3x3 컨볼루션을 도입하고 저해상도 피쳐 맵의 투영 연결을 결과에 추가하는 것입니다.
크기가 다르기 때문에 작은 크기의 맵은 투영 브랜치에서 또 다른 업 컨볼루션을 사용하여 업 샘플링해야 하지만 풀링 해제는 두 브랜치에 한 번만 적용하면 되므로 두 브랜치에 5x5 컨볼루션을 개별적으로 적용합니다. .
우리는 이 새로운 업샘플링 블록 업 프로젝션이라고 부릅니다, 이는 투영 연결 [7]의 아이디어를 업 컨볼루션으로 확장하기 때문입니다.
상향 프로젝션 블록을 연결하면 피쳐 맵 크기를 점진적으로 늘리면서 높은 수준의 정보를 네트워크에서 보다 효율적으로 전달할 수 있습니다.
이를 통해 깊이 예측을 위한 일관된 완전 컨볼루션 네트워크를 구성할 수 있습니다.
그림 2는 up-convolutional 블록과 upprojection 블록의 차이점을 보여줍니다, 또한 다음 섹션에서 설명할 해당 빠른 버전을 보여줍니다.

Fast Up-Convolutions.
이 작업의 또 다른 기여는 업 컨볼루션 작업을 재구성하여 더 효율적으로 만들어 전체 네트워크의 훈련 시간을 약 15% 단축하는 것입니다.
이것은 새로 도입된 상향 프로젝션 작업에도 적용됩니다.
주요 직관은 다음과 같습니다, 풀링을 해제한 후 결과 피쳐 맵의 75%에 0이 포함되어 있으므로 다음 5x5 컨볼루션은 대부분 수정된 공식에서 피할 수 있는 0에서 작동합니다.
이것은 그림 3에서 볼 수 있습니다.
왼쪽 상단에서 원래 피쳐 맵은 풀링(상단 중간)된 다음 5x5 필터로 컨볼루션됩니다.
풀링되지 않은 피쳐 맵에서 5x5 필터의 위치 (빨간색, 파란색, 보라색, 주황색 경계 상자)에 따라 특정 가중치만 잠재적으로 0이 아닌 값으로 곱해지는 것을 관찰합니다.
이러한 가중치는 서로 다른 색상과 그림에서 A, B, C, D로 표시된 4개의 겹치지 않는 그룹으로 나뉩니다.
필터 그룹을 기반으로 원래 5x5 필터를 (A) 3x3, (B) 3x2, (C) 2x3 및 (D) 2x2 크기의 새 필터 4개로 정렬합니다.
이제 그림 3에서와 같이 4개의 결과 피쳐 맵의 요소를 인터리빙하여 원래 작업(풀링 해제 및 컨볼루션)과 정확히 동일한 출력을 얻을 수 있습니다.
간단한 상향 컨볼루션 블록에서 제안된 상향 프로젝션으로의 해당 변경 사항이 그림 2 (d)에 나와 있습니다.
3.2. Loss Function
회귀 문제에서 최적화를 위한 표준 손실 함수는 L2 손실로, 예측 y~와 Ground Truth y : L2 (y~ - y) = ||y~ - y||_2^2 사이의 제곱된 유클리드 노름을 최소화합니다.
이것이 우리의 테스트 케이스에서 좋은 결과를 만들어 내지만, 손실 함수 B로 역 Huber (berHu) [25, 40]를 사용하면 L2보다 더 나은 최종 오류가 생성된다는 것을 발견했습니다.
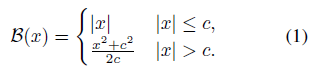
'Computer Vision' 카테고리의 다른 글
| MobileNetV2: Inverted Residuals and Linear Bottlenecks (0) | 2022.02.08 |
|---|---|
| FaceNet, A Unified Embedding for Face Recognition and Clustering (0) | 2021.11.19 |
| DenseNet: Densely Connected Convolutional Networks (번역) (0) | 2021.03.04 |
| ResNeXt: Aggregated Residual Transformations for Deep Neural Networks (번역) (0) | 2021.03.03 |
| GAN : Generative Adversarial Nets (번역) (1) | 2021.03.02 |