2022. 3. 31. 17:25ㆍ3D Object Detection
PointPillars: Fast Encoders for Object Detection from Point Clouds
Alex H. Lang, Sourabh Vora, Holger Caesar, Lubing Zhou, Jiong Yang, Oscar Beijbom
Abstract
포인트 클라우드에서 물체 감지는 자율 주행과 같은 많은 로봇 애플리케이션의 중요한 측면입니다.
이 논문에서는 포인트 클라우드를 다운스트림 감지 파이프라인에 적합한 형식으로 인코딩하는 문제를 고려한다.
최근의 문헌에 의하면, 고정 인코더는 고속이지만 정확도가 저하되는 경향이 있는 반면, 데이터에서 학습한 인코더는 정확도가 향상되지만 속도가 저하되는 경향이 있습니다.
본 연구에서는 PointNets를 활용하여 수직 열(필러)로 구성된 포인트 클라우드의 표현을 학습하는 새로운 인코더인 PointPillars를 제안한다.
인코딩된 피쳐는 모든 표준 2D 컨볼루션 검출 아키텍처와 함께 사용할 수 있지만, lean 다운스트림 네트워크를 추가로 제안합니다.
광범위한 실험에 따르면 PointPillars는 속도와 정확성 모두에서 이전 인코더보다 훨씬 뛰어난 성능을 발휘합니다.
라이다만 사용해도 3D 및 조감도 KITTI 벤치마크에서 퓨전 방식에서도 우리의 전체 탐지 파이프라인이 SOTA 성능을 크게 능가합니다.
이 탐지 성능은 62Hz로 실행 중일 때 달성됩니다: 즉, 실행 시간이 2-4배 향상됩니다.
이 방법의 더 빠른 버전은 105Hz의 SOTA와 일치합니다.
이러한 벤치마크를 통해 PointPillars는 포인트 클라우드 내의 객체 검출에 적합한 부호화임을 알 수 있습니다.
1. Introduction
도시 환경에 자율 차량(AVs)을 배치하는 것은 어려운 기술적 문제를 야기한다.
무엇보다도 AVs는 차량, 보행자 및 자전거 이용자와 같은 움직이는 물체를 실시간으로 감지하고 추적해야 합니다.
이를 달성하기 위해 자율 주행 차량은 여러 센서에 의존하며, 그중에서도 라이다가 가장 중요합니다.
라이다는 레이저 스캐너를 사용하여 환경과의 거리를 측정함으로써 희소 포인트 클라우드 표현을 생성한다.
전통적으로 라이다 로보틱스 파이프라인은 이러한 포인트 클라우드를 배경 감산을 포함한 상향식 파이프라인을 통해 물체 탐지로 해석하고 시공간 클러스터링과 분류가 뒤따른다[12, 9].
컴퓨터 비전에 대한 딥러닝 방법의 엄청난 진보에 따라, 많은 문헌들이 이 기술이 라이다 포인트 클라우드에서 물체 탐지에 어느 정도까지 적용될 수 있는지를 조사했다[33, 31, 32, 11, 2, 21, 15, 30, 26, 25].
양식 사이에는 많은 유사점이 있지만, 두 가지 주요 차이점이 있다:
1) 포인트 클라우드는 희박한 표현인 반면, 이미지는 밀도가 높고
2) 포인트 클라우드는 3D인 반면, 이미지는 2D이다.
그 결과, 포인트 클라우드로부터의 오브젝트 검출은 표준 화상 컨볼루션 파이프라인에 충분히 도움이 되지 않는다.
일부 초기 연구는 3D 컨볼루션[3]을 사용하거나 이미지에 포인트 클라우드를 투영하는 데 초점을 맞추고 있습니다[14].
최근의 방법에서는 라이다 포인트 클라우드를 조감도(BEV)에서 보는 경향이 있습니다[2, 11, 33, 32].
이러한 오버헤드의 관점에서는 몇 가지 이점이 있습니다.
첫째, BEV는 객체 축척을 유지합니다.
둘째, BEV의 컨볼루션은 로컬 범위 정보를 유지합니다.
대신 이미지 뷰에서 컨볼루션을 수행하면 depth 정보가 흐려집니다([28]의 그림 3).
그러나 조감도에서는 극히 희박한 경향이 있어 컨볼루션 신경망의 직접 적용이 실용적이지 않고 비효율적이다.
이 문제에 대한 일반적인 회피책은 그라운드 플레인을 예를 들어 10 x 10 cm의 일반 그리드로 분할한 후 각 그리드 셀의 포인트에서 수작업으로 피쳐 부호화 방법을 실행하는 것입니다[2, 11, 26, 32].
다만, 하드 코드화된 피쳐 추출 방법은, 엔지니어링의 큰 노력이 없으면, 새로운 설정으로 일반화되지 않는 경우가 있기 때문에, 이러한 방법은 최적이라고는 할 수 없습니다.
이러한 문제를 해결하고 Qi et al. [22]에 의해 개발된 PointNet 설계를 기반으로 한 VoxelNet[33]은 이 영역에서 진정으로 엔드 투 엔드 학습을 수행할 수 있는 최초의 방법 중 하나였습니다.
VoxelNet은 공간을 복셀로 나누고 각 복셀에 PointNet을 적용한 후 3D 컨볼루션 중간층을 적용하여 수직축을 통합한 후 2D 컨볼루션 검출 아키텍처를 적용합니다.
VoxelNet의 성능은 강력하지만 추론 시간은 4.4Hz로 너무 느려서 실시간으로 전개할 수 없습니다.
최근 SECOND [30]는 VoxelNet의 추론 속도를 개선했지만 3D 컨볼루션은 여전히 병목 현상으로 남아 있습니다.
본 연구에서는 2D 컨볼루션 레이어만으로 엔드 투 엔드 학습을 가능하게 하는 3D 객체 감지 방법인 PointPillars를 제안한다.
PointPillars는 포인트 클라우드의 기둥(수직 열)에 있는 피쳐를 학습하는 새로운 인코더를 사용하여 객체의 3D 지향 상자를 예측합니다.
이 접근법에는 몇 가지 장점이 있습니다.
첫째, PointPillars는 고정된 인코더를 사용하는 대신 피쳐를 학습함으로써 포인트 클라우드가 나타내는 모든 정보를 활용할 수 있습니다.
또, 복셀이 아닌 기둥을 조작하는 것으로써, 수직 방향의 비닝을 수작업으로 조정할 필요가 없어진다.
마지막으로 모든 주요 작업을 GPU에서 매우 효율적인 2D 컨볼루션으로 구성할 수 있기 때문에 기둥은 매우 빠릅니다.
학습 피쳐의 또 다른 장점은 PointPillars가 여러 개의 라이다 스캔이나 레이더 포인트 클라우드와 같은 다른 포인트 클라우드 구성을 사용하기 위해 수동 조정이 필요하지 않다는 것입니다.
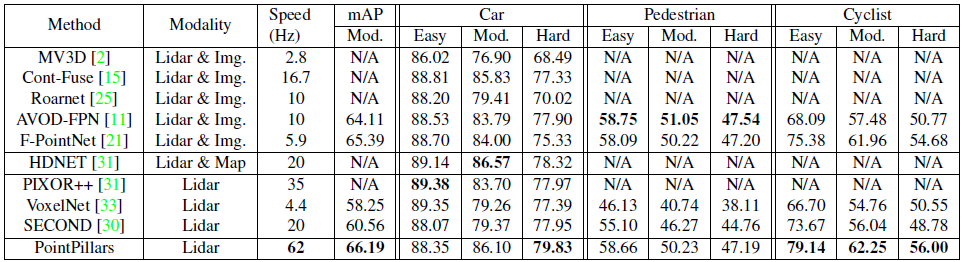

BEV 또는 3D에서 자동차, 보행자 및 자전거 이용자를 감지해야 하는 공공 KITI 감지 과제에 대해 PointPillars 네트워크를 평가했습니다[5].
우리의 PointPillars 네트워크는 라이다 포인트 클라우드만을 사용하여 학습되지만 라이다와 이미지를 사용하는 방법을 비롯한 SOTA 기술을 지배하고 있으며, 이에 따라 BEV와 3D 검출에 대한 새로운 성능 표준을 확립하고 있습니다(표 1 및 표 2).
동시에 PointPillars는 62Hz로 동작하며, 이는 이전 기술보다 2-4배 빠른 속도입니다(그림 1).
또한 PointPillars는 속도와 정확도 간의 균형을 가능하게 합니다; 한 가지 설정에서는 100Hz 이상의 SOTA 성능과 일치합니다(그림 5).
또, 결과를 재현하기 위한 코드도 공개했습니다.


1.1. Related Work
1.1.1 Object detection using CNNs
Girshick et al. [6]의 주요 연구에서 시작하여, 컨볼루션 뉴럴 네트워크(CNN) 아키텍처가 영상에서 검출을 위한 SOTA이라는 것이 확인되었다.
[24, 7] 뒤에 나온 일련의 논문은 이 문제에 대한 2 stage 접근법을 지지한다.
1 stage에서는 Region Proposal Network(RPN)가 후보 제안을 제안하며, 후보 제안들은 2 stage 네트워크에 의해 분류되기 전에 잘라지고 크기가 조정됩니다.
2 stage 방법은 원래 Liu et al. [18]이 제안한 1 stage 아키텍처보다 COCO[17]와 같은 중요한 비전 벤치마크 데이터 세트를 지배했다.
1 stage 아키텍처에서는 앵커 박스의 조밀도가 높은 세트를 1 stage로 회귀시켜 예측 세트로 분류하여 빠르고 단순한 아키텍처를 제공한다.
최근에 Lin et al. [16]이 제안된 초점 손실 함수에서 1 stage 방법이 정확도와 실행 시간 면에서 2 stage 방법보다 우수하다고 설득력 있게 주장했다.
이 작업에서는 1 stage 방법을 사용합니다.
1.1.2 Object detection in lidar point clouds
포인트 클라우드에서의 객체 검출은 본질적으로 3차원적인 문제입니다.
따라서, 여러 초기 연구 [3, 13]의 패러다임인 탐지를 위한 3D 컨볼루션 네트워크를 배치하는 것은 자연스러운 일입니다.
이러한 방법은 간단한 아키텍처를 제공하지만 속도가 느립니다; Engelcke et al. [3]은 단일 포인트 클라우드에 대한 추론을 위해 0.5s가 필요하다.
가장 최근의 방법은 3D 포인트 클라우드를 지면[11, 2] 또는 이미지 평면[14]에 투영하여 실행 시간을 개선합니다.
가장 일반적인 패러다임에서 포인트 클라우드는 복셀로 구성되며, 각 수직 컬럼의 복셀 세트는 고정 길이의 수작업으로 특징 부호화로 부호화되어 표준 화상 검출 아키텍처에 의해 처리될 수 있는 의사 화상을 형성한다.
주목할 만한 작품으로는 MV3D [2], AVOD [11], PIXOR [32] 및 Complex YOLO [26]이 있습니다, 이것들은 모두 아키텍처의 첫 번째 단계와 동일한 고정 부호화 패러다임으로 변형을 사용하고 있습니다.
처음 두 가지 방법에서는 라이더 피쳐와 영상 피쳐를 추가로 통합하여 멀티모달 디텍터를 만듭니다.
MV3D 및 AVOD에서 사용되는 퓨전스텝에서는 2단계 검출 파이프라인을 사용해야 하며 PIXOR 및 Complex YOLO는 1단계 파이프라인을 사용합니다.
그들의 중요한 작품에서 Qi et al. [22, 23]은(는) 완전한 엔드 투 엔드 학습을 위한 경로를 제공한 무질서한 포인트 집합에서 학습하기 위한 단순한 아키텍처인 PointNet을 제안했습니다.
VoxelNet [33]은 라이다 포인트 클라우드에서 객체 감지를 위해 PointNet을 최초로 배포한 방법 중 하나입니다.
이들의 방법에서 PointNets는 복셀에 적용되며, 복셀은 3D 컨볼루션 레이어 세트에 이어 2D 백본과 검출 헤드로 처리된다.
이를 통해 엔드 투 엔드 학습이 가능하지만, 3D 컨볼루션에 의존했던 이전 작업과 마찬가지로 VoxelNet은 속도가 느려서 단일 포인트 클라우드에 225ms의 추론 시간(4.4Hz)이 필요합니다.
또 다른 최신 방법인 Frustum Point-Net[21]은 PointNets를 사용하여 이미지에 대한 탐지를 투영하여 생성된 Frustum의 포인트 클라우드를 3D로 분할하고 분류합니다.
Frustum PointNet은 다른 퓨전 방식에 비해 높은 벤치마크 성능을 달성했지만, 멀티 stage 설계로 인해 엔드 투 엔드 학습이 실용적이지 않습니다.
매우 최근에 SECOND[30]는 VoxelNet에 일련의 개선 사항을 제공하여 성능이 더욱 향상되고 속도가 20Hz로 크게 향상되었습니다.
그러나 값비싼 3D 컨볼루션 레이어를 제거할 수 없었습니다.
1.2. Contributions
• 포인트 클라우드에서 작동하는 새로운 포인트 클라우드 인코더 및 네트워크 PointPillars를 제안하여 3D 객체 감지 네트워크의 엔드 투 엔드 훈련을 가능하게 합니다.
• 기둥에 대한 모든 연산이 62Hz에서 추론을 가능하게 하는 밀도 높은 2D 컨볼루션으로 어떻게 배치될 수 있는지 보여준다; 다른 방법보다 2-4배 빠른 계수이다.
• KITTI 데이터 세트에 대한 실험을 수행하고 BEV와 3D 벤치마크 모두에서 자동차, 보행자 및 자전거에 대한 최신 결과를 시연합니다.
• 강력한 검출 성능을 가능하게 하는 주요 요인을 조사하기 위해 여러 ablation 연구를 수행합니다.
2. PointPillars Network
PointPillars는 포인트 클라우드를 입력으로 받아들이고 자동차, 보행자 및 자전거 전용 3D 박스를 추정합니다.
3개의 주요 스테이지(그림 2)로 구성되어 있다: (1) 포인트 클라우드를 희박한 pseudo 이미지로 변환하는 피쳐 인코더 네트워크; (2) pseudo 이미지를 높은 레벨의 표현으로 처리하는 2D 컨볼루션 백본; 그리고 (3) 3D 박스를 검출해 회귀시키는 검출 헤드.
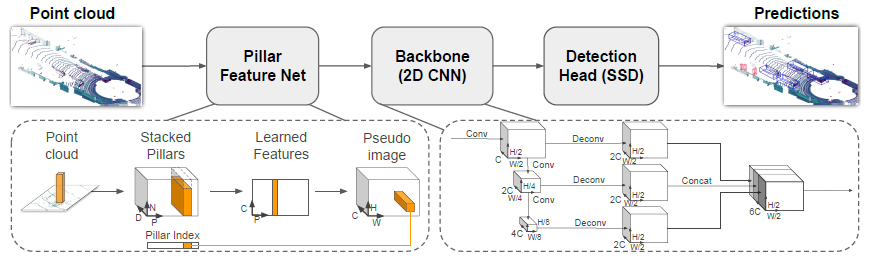
2.1. Pointcloud to Pseudo-Image
2D 컨볼루션 아키텍처를 적용하기 위해 먼저 포인트 클라우드를 pseudo 이미지로 변환합니다.
x, y 및 z 좌표를 가진 포인트 클라우드의 점을 l로 나타냅니다.
첫 번째 단계로 포인트 클라우드를 x-y 평면 내에서 균일한 간격의 그리드로 이산하여 |P| = B의 한 쌍의 기둥 P를 생성한다.
기둥은 z 방향으로 공간 범위가 무제한인 복셀이므로 z 치수의 빈을 제어하기 위해 하이퍼 파라미터가 필요하지 않습니다.
그런 다음 각 기둥의 점을 r, x_c, y_c, z_c, x_p, y_p로 장식(증가)합니다, 여기서 r은 반사율이고, c 첨자는 기둥의 모든 점의 산술 평균까지의 거리를 나타내며, p 첨자는 기둥 x, y 중심으로부터의 오프셋을 나타냅니다(설계 세부 사항은 섹션 7.3 참조).
장식된 라이다 포인트 ^l은 D = 9차원입니다.
라이다 포인트 클라우드에 초점을 맞추고 있지만, 각 포인트의 장식을 변경하여 레이더나 RGB-D[27]와 같은 다른 포인트 클라우드를 PointPillars와 함께 사용할 수 있습니다.
포인트 클라우드의 희소성으로 인해 기둥 세트는 대부분 비어 있으며 비어 있지 않은 기둥에는 일반적으로 포인트가 거의 없습니다.
예를 들어 0.16^2 ㎡ 빈에서 HDL-64E Velodyne Lidar의 포인트 클라우드는 약 ~97%의 희소성에 대해 KITI에서 일반적으로 사용되는 범위의 6k-9k의 비어 있지 않은 기둥을 가진다.
이 희소성은 표본당 비어 있지 않은 기둥의 수(P)와 기둥당 포인트의 수(N) 모두에 제한을 가하여 조밀한 크기 텐서(D, P, N)를 생성함으로써 이용된다.
표본 또는 기둥에 너무 많은 데이터가 들어 있어서 이 텐서에 적합하지 않으면 데이터가 랜덤하게 추출됩니다.
반대로 샘플 또는 필러가 텐서를 채우기에는 데이터가 너무 적으면 제로 패딩이 적용됩니다.
다음으로, 우리는 (C, P, N) 크기의 텐서를 생성하기 위해 각 포인트에 대해 선형 레이어를 적용한 후 Batch-Norm [10] 및 ReLU [19]를 적용하는 PointNet의 단순화된 버전을 사용한다.
그런 다음 채널에서 최대 연산을 수행하여 크기(C, P)의 출력 텐서를 생성합니다.
선형 레이어는 텐서 전체에 걸쳐 1x1 회전으로 공식화될 수 있으며, 그 결과 매우 효율적인 연산을 할 수 있습니다.
부호화가 완료되면 피쳐가 원래 기둥 위치로 산란되어 크기(C, H, W)의 pseudo 이미지가 생성됩니다, 여기서 H와 W는 캔버스의 높이와 폭을 나타냅니다.
복셀 대신 기둥을 사용하여 [33]의 Convolutional Middle Layer에서 고가의 3D Convolution을 생략할 수 있습니다.
2.2. Backbone
[33]과 같은 백본을 사용하고 있으며 구조는 그림 2와 같습니다.
백본에는 다음 2개의 서브네트워크가 있습니다: 공간 해상도가 점점 작아지는 피쳐를 생성하는 하향식 네트워크와 하향식 기능을 업샘플링 및 연결하는 두 번째 네트워크입니다.
하향식 백본은 일련의 블록(S, L, F)으로 특징지을 수 있습니다.
각 블록은 스트라이드 S(원래 입력 pseudo 이미지에 대해 측정)로 동작한다.
블록에는 각각 BatchNorm과 ReLU가 이어지는 F 출력 채널을 가진 L 3x3 2D 컨벤션 레이어가 있습니다.
층내의 제1의 회전은 스트라이드 S_in의 입력 블록을 받아 스트라이드 S 상에서 블록이 동작하도록 스트라이드 S/S_in을 가진다.
블록 내의 모든 후속 컨볼루션은 스트라이드1을 가집니다.
각 하향식 블록의 최종 피쳐는 업샘플링과 연결을 통해 다음과 같이 결합됩니다.
우선 F 최종 피쳐와의 치환된 2D 컨볼루션에 의해 초기 스트라이드 S_in에서 최종 스트라이드 S_out(양쪽 모두 원래의 pseudo 이미지에 대해 재측정)까지 업샘플링한다.
다음으로 업샘플링된 기능에 BatchNorm 및 ReLU가 적용됩니다.
최종 출력 피쳐는 다른 단계에서 모든 피쳐를 연결한 것입니다.
2.3. Detection Head
Single Shot Detector(SSD) [18] 설정을 사용하여 3D 물체 탐지를 수행합니다.
다른 작업(예: 분할)에 관심이 있는 경우, 검출 헤드를 원하는 작업에 특화된 헤드로 교환하기만 하면 된다.
SSD와 마찬가지로 2D Intersection over Union(IoU)를 사용하여 이전 상자를 실제 정보와 일치시킵니다[4].
바운딩 박스 높이와 표고는 일치에 사용되지 않았습니다; 대신 2D 일치를 지정하면 높이와 표고가 추가 회귀 표적이 됩니다.
3. Implementation Details
3.1. Network
네트워크를 사전 훈련하는 대신, 모든 가중치는 [8]에서와 같이 균일한 분포를 사용하여 무작위로 초기화되었습니다.
인코더 네트워크에는 C = 64 출력 피쳐가 있습니다.
자동차와 보행자/자전거 백본은 첫 번째 블록의 stride를 제외하고 동일하다(자동차의 경우 S=2, 보행자/자전거 선수의 경우 S=1).
양쪽 네트워크는 Block1(S, 4, C), Block2(2S, 6, 2C) 및 Block3(4S, 6, 4C)의 3개의 블록으로 구성됩니다.
각 블록은 Up1(S, S, 2C), Up2(2S, S, 2C) 및 Up3(4S, S, 2C)의 업샘플링 스텝에 의해 업샘플링됩니다.
그런 다음 Up1, Up2 및 Up3의 기능을 연결하여 검출 헤드에 대한 6C 피쳐를 만듭니다.
3.2. Loss
우리는 SECOND [30]에 소개된 것과 동일한 손실 함수를 사용한다.
Ground-truth 상자 및 앵커는 (x, y, z, w, l, h, θ)로 정의됩니다.
Ground-truth와 앵커 사이의 로컬 회귀 잔차는 다음과 같이 정의됩니다:
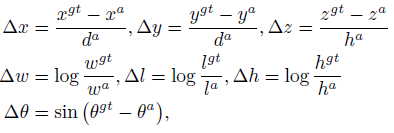
여기서 x^gt 및 x^a는 각각 ground-truth 및 앵커 박스이며 d^a = ((w^a)^2 + (l^a)^2)^1/2이다.
로컬화 손실의 합계는 다음과 같습니다:
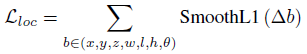
각도 로컬화 손실은 플립 박스를 구별할 수 없기 때문에, 헤딩은 이산화된 방향에서 소프트맥스 분류 손실 L_dir로 학습된다[30].
물체 분류 손실은 초점 손실을 사용합니다 [16]:
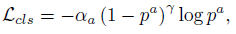
여기서 p^a는 앵커의 클래스 확률입니다.
α = 0.25, γ = 2 의 원래 논문의 설정을 사용합니다.
따라서 총 손실은 다음과 같습니다:
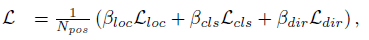
여기서 N_pos는 양의 앵커 수이고 β_loc = 2, β_cls = 1, β_cls = 0.2이다.
손실 함수는 Adam을 사용하여 최적화되며, 초기 학습률은 2 * 10^-4로 15에폭마다 0.8배 감소한다.
에폭의 수는 160과 320이며, 배치 사이즈는 각각 2와 4입니다.
4. Experimental setup
5. Results
6. Realtime Inference
7. Ablation Studies
8. Conclusion
이 논문에서는 라이다 포인트 클라우드에서 엔드 투 엔드로 학습할 수 있는 새로운 딥 네트워크 및 인코더인 PointPillars를 소개한다.
KITTI 과제에서는 PointPillars가 더 빠른 속도로 더 높은 감지 성능(BEV 및 3D mAP)을 제공함으로써 기존의 모든 방법을 지배한다는 것을 보여준다.
우리의 결과에 따르면 PointPillars는 라이다에서 3D 객체 감지를 위한 지금까지 최고의 아키텍처를 제공합니다.
'3D Object Detection' 카테고리의 다른 글
| Center-based 3D Object Detection and Tracking (0) | 2022.04.06 |
|---|---|
| DeepFusion: Lidar-Camera Deep Fusion for Multi-Modal 3D Object Detection (0) | 2022.03.22 |