2022. 4. 6. 14:50ㆍ3D Object Detection
Center-based 3D Object Detection and Tracking
Tianwei Yin, Xingyi Zhou, Philipp Kr¨ahenb¨uhl
Abstract
3차원 객체는 일반적으로 포인트 클라우드에서 3D 박스로 표현된다.
이 표현은 잘 연구된 이미지 기반 2D 바운딩 박스 탐지를 모방하지만 추가 과제를 수반한다.
3D 월드의 객체는 특정 방향을 따르지 않으며, 박스 기반 검출기는 모든 방향을 열거하거나 회전하는 객체에 축 정렬 바운딩 박스를 장착하는 데 어려움을 겪는다.
본 논문에서는 대신 3D 객체를 포인트로 표현, 감지 및 추적할 것을 제안한다.
우리의 프레임워크인 CenterPoint는 먼저 키포인트 검출기를 사용하여 물체의 중심을 감지하고 3D 크기, 3D 방향 및 속도를 포함한 다른 속성으로 회귀한다.
두 번째 단계에서는 객체의 추가 포인트 피쳐를 사용하여 이러한 추정치를 세분화합니다.
CenterPoint에서 3D 객체 추적은 탐욕스러운 가장 가까운 포인트 일치를 단순화한다.
결과 탐지 및 추적 알고리즘은 간단하고 효율적이며 효과적이다.
CenterPoint는 단일 모델의 경우 65.5 NDS와 63.8 AMOTA로 3D 감지와 추적 모두를 위한 nuScene 벤치마크에서 SOTA 성능을 달성했습니다.
Waymo Open Dataset에서 CenterPoint는 이전의 모든 단일 모델 방법을 큰 폭으로 능가하며 모든 라이다 전용 제출물 중 1위를 차지한다.
1. Introduction
강력한 3D 인식은 많은 첨단 주행 시스템의 핵심 요소입니다 [1, 48].
잘 연구된 2D 감지 문제와 비교하여, 포인트 클라우드의 3D 감지는 다음과 같은 흥미로운 과제를 제공한다:
첫째, 포인트 클라우드는 희박하며 3D 물체의 대부분은 측정이 없다[22].
둘째, 결과 출력은 종종 전역 좌표 프레임과 잘 정렬되지 않는 3차원 상자이다.
셋째, 3D 물체는 다양한 크기, 모양 및 가로 세로 비율로 나타난다, 예를 들어, 교통 영역에서 자전거는 평면 가까이에 있고, 버스와 리무진은 길쭉하며, 보행자는 키가 크다.
2D와 3D 검출 사이의 이러한 현저한 차이는 두 영역 사이의 아이디어 전달을 더 어렵게 만들었다[43, 45, 58].
축 정렬 2D 박스 [16, 17]는 자유 형식 3D 객체의 잘못된 프록시입니다.
한 가지 해결책은 각 객체 방향에 대해 서로 다른 템플릿(앵커)을 분류하는 것일 수 있지만 [56, 57] 이는 계산 부담을 불필요하게 증가시키고 많은 수의 잠재적 거짓 양성 탐지를 도입할 수 있다.
우리는 2D 도메인과 3D 도메인을 연결하는 데 있어 주요 근본적인 과제는 이러한 객체의 표현에 있다고 주장한다.

본 논문에서는 객체를 포인트로 표현하는 방법(그림 1)이 3D 인식을 크게 단순화하는 방법을 보여준다.
우리의 2단계 3D 검출기인 CenterPoint는 키포인트 검출기[62]를 사용하여 물체의 중심과 그 특성을 찾고, 2단계는 모든 추정치를 정밀하게 한다.
특히, CenterPoint는 표준 라이다 기반 백본 네트워크, 즉 VoxelNet[54, 64] 또는 PointPillars[27]를 사용하여 입력 포인트 클라우드의 표현을 구축한다.
그런 다음 이 표현을 오버헤드 맵 뷰로 평탄하게 만들고 표준 이미지 기반 키포인트 검출기를 사용하여 객체 중심을 찾는다[62].
탐지된 각 중심에 대해 중심 위치의 포인트 피쳐에서 3D 크기, 방향 및 속도와 같은 다른 모든 객체 특성으로 회귀합니다.
또한 경량화된 두 번째 단계를 사용하여 개체 위치를 세분화한다.
이 두 번째 단계는 추정된 객체 3D 바운딩 박스의 각 면의 3D 중심에서 포인트 피쳐를 추출한다.
스트라이딩과 제한된 수용 분야로 인해 손실된 로컬 기하학적 정보를 복구하고 적은 비용으로 상당한 성능 향상을 가져온다.
중심 기반 표현에는 몇 가지 주요 이점이 있습니다:
첫째, 바운딩 박스와 달리 포인트에는 고유한 방향이 없습니다.
이것은 객체 검출기의 검색 공간을 극적으로 줄이고 백본이 객체의 회전 불변성과 동등성을 학습할 수 있게 한다.
둘째, 센터 기반 표현은 추적과 같은 다운스트림 작업을 단순화한다.
객체가 포인트일 경우 트랙렛은 공간과 시간의 경로입니다.
CenterPoint는 연속적인 프레임과 링크 객체 간의 상대적 오프셋(속도)을 예측합니다.
셋째, 포인트 기반 피쳐 추출을 통해 이전 접근 방식보다 훨씬 빠른 효과적인 2단계 개선 모듈을 설계할 수 있다[42–44].
우리는 두 가지 인기 있는 대규모 데이터 세트에서 모델을 테스트한다: Waymo Open [46] 및 nuScene [6]
박스 표현에서 중앙 기반 표현으로 단순 전환하면 서로 다른 백본에서 3D 검출이 3-4mAP 증가한다는 것을 보여준다[27, 54, 64, 65].
2단계 개선은 적은 계산 오버헤드로 2mAP를 추가로 향상시킨다.
우리의 최고의 단일 모델은 Waymo에서 차량 및 보행자 감지를 위해 71.8 및 66.4 레벨 2 mAPH를 달성하고 nuScene에서 58.0 mAP 및 65.5 NDS를 달성하여 두 데이터 세트에서 게시된 모든 방법을 능가한다.
특히 NeurIPS 2020 nuScene 3D Detection 챌린지에서 CenterPoint는 상위 4개 수상 항목 중 3개의 기초를 형성한다.
3D 추적의 경우, 우리 모델은 63.8 AMOTA에서 nuScene에서 이전 최신 기술을 8.8 AMOTA만큼 능가한다.
Waymo 3D tracking 벤치마크에서, 우리의 모델은 차량과 보행자 추적에 대해 각각 59.4와 56.6 레벨 2 MOTA를 달성하여 이전 방법을 최대 50% 능가한다.
우리의 엔드 투 엔드 3D 감지 및 추적 시스템은 거의 실시간으로 실행되며, Waymo에 11 FPS, nuScene에 16 FPS가 있다.
2. Related work
2D object detection
2D 객체 감지는 이미지 입력에서 축 정렬 바운딩 박스를 예측한다.
RCNN 계열[16,17,20,41]은 범주와 무관한 바운딩 박스 후보를 찾은 다음 분류하고 세분화한다.
YOLO [40], SSD [32], RetinaNet [31]은 범주별 박스 후보를 직접 찾으며, 이후 분류 및 세분화는 생략합니다.
CenterNet[62] 또는 CenterTrack[61]과 같은 센터 기반 검출기는 후보 박스 없이 암시적 객체 중심 포인트를 직접 검출한다.
많은 3D 검출기[19, 43, 45, 58]는 이러한 2D 검출기에서 진화했다.
우리는 센터 기반 표현[61, 62]이 3D 응용에 이상적이라는 것을 보여준다.
3D object detection
3D 물체 감지는 3차원 회전 바운딩 박스 [11,15,27,30,37,54,58,59]를 예측하는 것을 목표로 한다.
입력 인코더의 2D 디텍터와 다릅니다.
Vote3Deep[12]는 피쳐 중심 voting [49]을 활용하여 동일한 간격의 3D 복셀에서 희소 3D 포인트 클라우드를 효율적으로 처리한다.
VoxelNet[64]은 각 복셀 내부의 PointNet[38]을 사용하여 3D 희소 컨볼루션 [18]과 2D 컨볼루션을 가진 헤드가 탐지를 생성하는 통일된 피쳐 표현을 생성한다.
SECOND [54]는 VoxelNet을 단순화하고 희소 3D 컨볼루션을 가속화한다.
PIXOR [55]는 값비싼 3D 컨볼루션을 제거하기 위해 3D 점유율과 포인트 강도 정보가 있는 2D 피쳐 맵에 모든 포인트를 투영한다.
PointPillars [27]는 모든 복셀 계산을 지도 위치당 하나의 키가 큰 길쭉한 복셀인 기둥 표현으로 대체하여 백본 효율성을 향상시킨다.
MVF[63]와 Pillar-od[50]는 여러 뷰 피쳐를 결합하여 보다 효과적인 필러 표현을 학습한다.
우리의 기여는 출력 표현에 초점을 맞추고 모든 3D 인코더와 호환되며 모든 것을 개선할 수 있다.
VoteNet[36]은 포인트 피쳐 샘플링 및 그룹화를 사용하여 투표 클러스터링을 통해 객체를 감지한다.
대조적으로, 우리는 투표하지 않고 중앙 포인트의 특징을 통해 3D 바운딩 박스로 직접 회귀한다.
Wong et al. [53]과 Chen et al. [8]은 객체 중심 영역(즉, 포인트 앵커)에서 유사한 다중 포인트 표현을 사용했으며 다른 속성으로 회귀했다.
우리는 각 개체에 대해 하나의 양의 셀을 사용하고 키포인트 추정 손실을 사용한다.
Two-stage 3D object detection.
최근 연구는 3D 도메인에 RCNN 스타일 2D 검출기를 직접 적용하는 것을 고려했다[9, 42–44, 59].
대부분 PointNet 기반 포인트 [43] 또는 복셀 [42] 형상 추출기를 사용하여 3D 공간에서 RoI 관련 형상을 집계하기 위해 RoIPool[41] 또는 RoIAign[20]을 적용한다.
이러한 접근 방식은 3D 라이다 측정(포인트 및 복셀)에서 영역 피쳐를 추출하여 대량 포인트로 인한 엄청난 런타임을 초래한다.
대신 중간 형상 맵에서 5개의 표면 중심 포인트의 희소 형상을 추출한다.
이것은 우리의 두 번째 단계를 매우 효율적이고 지속적으로 효과적으로 만든다.
3D object tracking.
많은 2D 추적 알고리즘[2, 4, 26, 52]은 3D 객체를 즉시 추적합니다.
그러나 3D Kalman filters [10, 51]를 기반으로 하는 전용 3D 추적기는 장면에서 3차원 모션을 더 잘 활용하기 때문에 여전히 우위를 가지고 있다.
여기서는 CenterTrack [61]에 따라 훨씬 더 간단한 접근 방식을 채택합니다.
우리는 속도 추정치를 포인트 기반 감지와 함께 사용하여 여러 프레임을 통해 물체의 중심을 추적한다.
이 추적기는 전용 3D 추적기 [10, 51]보다 훨씬 빠르고 정확합니다.
3. Preliminaries
2D CenterNet
2D CenterNet[62]은 객체 탐지를 키포인트 추정으로 다시 표현한다.
입력 이미지를 가져와서 각 K 클래스에 대한 w × h 히트맵 ^Y ∈ [0, 1]^(w × h × K)를 예측한다.
출력 히트맵에서 각 로컬 최대값(즉, 값이 이웃 8개보다 큰 픽셀)은 감지된 물체의 중심에 해당합니다.
2D 박스를 검색하기 위해 CenterNet은 모든 범주 간에 공유되는 크기 맵 ^S ∈ R^(w×h×2)로 회귀한다.
크기 맵은 각 탐지 객체의 너비와 높이를 중앙 위치에 저장합니다.
CenterNet 아키텍처는 표준 완전 컨볼루션 이미지 백본을 사용하고 위에 고밀도 예측 헤드를 추가합니다.
학습 중에 CenterNet은 각 클래스 c_i ∈ {1. . .K}에 대해 주석이 달린 각 객체 센터 q_i에서 렌더링된 가우스 커널로 히트 맵을 예측하고 주석이 달린 바운딩 박스의 중심에 있는 객체 크기 S로 회귀하는 방법을 학습한다.
백본 아키텍처의 스트라이딩에 의해 야기된 양자화 오류를 보완하기 위해, CenterNet은 또한 로컬 오프셋 ^O로 회귀한다.
테스트 시 검출기는 K 히트맵과 고밀도 클래스 무관 회귀 지도를 생성한다.
히트맵의 각 로컬 최대값(피크)은 피크의 히트맵 값에 비례하는 신뢰도로 객체에 해당합니다.
검출된 각 객체에 대해 디텍터는 해당 피크 위치의 회귀 맵에서 모든 회귀 값을 검색합니다.
응용 프로그램 도메인에 따라 NMS(Non-Maxima Suppression)가 보증될 수 있습니다.
3D Detection
P = {(x, y, z, r)_i}를 3D 위치(x, y, z) 및 반사율 측정값의 순서 없는 포인트 클라우드라고 합니다.
3D 객체 감지는 이 포인트 클라우드에서 조감도에서 3D 객체 바운딩 박스 B = {b_k} 세트를 예측하는 것을 목표로 한다.
각 바운딩 박스 b = (u, v, d, w, l, h, α)는 물체 지면에 상대적인 중심 위치 (u, v, d)와 3D 크기 (w, l, h) 그리고 yaw α로 표현되는 회전으로 구성된다.
일반성을 잃지 않고 센서가 (0, 0, 0)이고 yaw = 0인 자기중심 좌표계를 사용한다.
현대의 3D 객체 검출기[19, 27, 54, 64]는 포인트 클라우드를 일반 빈으로 양자화하는 3D 인코더를 사용한다.
그런 다음 포인트 기반 네트워크 [38]는 빈 내부의 모든 포인트에 대한 피쳐를 추출한다.
그런 다음 3D 인코더는 이러한 피쳐를 기본 피쳐 표현에 풀링합니다.
대부분의 계산은 이러한 양자화 및 풀링된 피쳐 표현에서만 작동하는 백본 네트워크에서 발생한다.
백본 네트워크의 출력은 맵뷰 참조 프레임에서 F 채널이 있는 폭 W와 길이 L의 맵뷰 피쳐 맵 M ∈ R^(W×L×F)이다.
폭과 높이는 모두 개별 복셀 빈의 해상도와 백본 네트워크의 보폭과 직접 관련이 있다.
일반적인 백본에는 VoxelNet[54, 64] 및 PointPillars[27]가 있습니다.
맵 뷰 피쳐 맵 M을 사용하는 경우, 감지 헤드는 일반적으로 1단계 [31] 또는 2단계 [41] 바운딩 박스 검출기이며, 그런 다음 이 오버헤드 피쳐 맵에 고정된 일부 사전 정의된 바운딩 박스에서 물체 탐지를 생성한다.
3D 바운딩 박스는 다양한 크기와 방향을 가지고 있기 때문에 앵커 기반 3D 검출기는 축 정렬된 2D 박스를 3D 물체에 장착하는 데 어려움을 겪는다.
더욱이, 학습 동안 이전의 앵커 기반 3D 검출기는 목표 할당[42, 54]을 위해 2D Box IoU에 의존하므로 다른 클래스 또는 다른 데이터 세트에 대한 양의/음성의 임계값을 선택하는 데 불필요한 부담이 발생한다.
다음 섹션에서는 포인트 표현을 기반으로 원칙적인 3D 객체 감지 및 추적 모델을 구축하는 방법을 보여 준다.
새로운 센터 기반 감지 헤드를 도입하지만 기존 3D 백본(VoxelNet 또는 PointPillars)에 의존한다.
4. CenterPoint
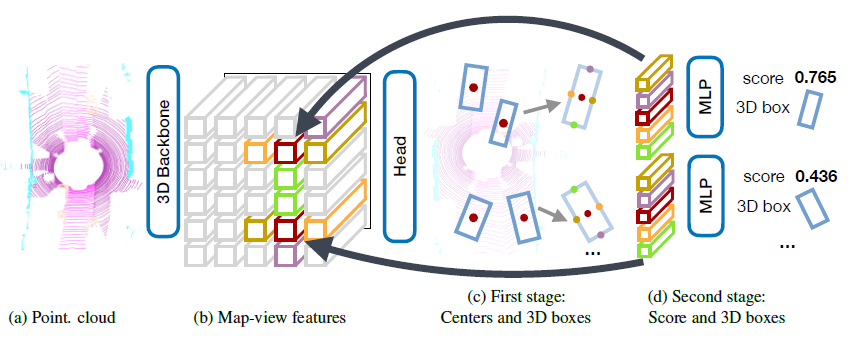
그림 2는 CenterPoint 모델의 전체 프레임워크를 보여줍니다.
M ∈ R^(W×H×F)를 3D 백본의 출력으로 하자.
CenterPoint의 첫 번째 단계에서는 클래스별 히트맵, 개체 크기, 하위 복셀 위치 미세화, 회전 및 속도를 예측합니다.
모든 출력은 밀도 예측입니다.
Center heatmap head.
센터 헤드의 목표는 감지된 물체의 중심 위치에 히트맵 피크를 생성하는 것이다.
이 헤드는 각 K 클래스에 대해 하나의 채널인 K 채널 히트맵 ^Y를 생성합니다.
학습 중에, 그것은 주석이 달린 바운딩 박스의 3D 중심을 맵 뷰에 투영하여 생성된 2D 가우스를 목표로 한다.
우리는 초점 손실을 사용한다[28, 62].
하향식 맵 뷰의 객체는 이미지보다 더 희박합니다.
맵 뷰에서 거리는 절대적인 반면 이미지 뷰는 원근법에 의해 거리를 왜곡합니다.
맵 뷰에서는 차량이 차지하는 면적이 작지만 이미지 뷰에서는 몇 개의 큰 물체가 화면의 대부분을 차지할 수 있다.
또한 투시 투영에서 깊이 치수의 압축은 자연스럽게 이미지 뷰에서 객체 중심을 서로 훨씬 더 가깝게 배치한다.
CenterNet[62]의 표준 감독을 따르면 대부분의 위치가 백그라운드로 간주되는 매우 희박한 감독 신호가 발생한다.
이에 대응하기 위해, 우리는 각 ground-truth 객체 센터에서 렌더링되는 가우스 피크를 확대하여 대상 히트맵 Y에 대한 긍정적인 감독을 증가시킨다.
구체적으로, 우리는 가우스 반경을 σ = max(f(wl), τ)로 설정했다, 여기서 τ = 2는 허용되는 가장 작은 가우스 반지름이고 f는 CornerNet[28]에 정의된 반지름 함수이다.
이러한 방식으로 CenterPoint는 중앙 기반 대상 할당의 단순성을 유지합니다; 모델은 근처의 픽셀로부터 더 밀도 높은 감독을 받습니다.
Regression heads.
우리는 물체의 중심 피쳐에 몇 가지 물체 특성을 저장한다: 하위 복셀 위치 미세화 o ∈ R^2, 지상 높이 h_g ∈ R, 3D 크기 s ∈ R^3 및 yaw 회전 각도(sin(θ), cos(θ) ∈ [-1, 1]^2이다.
하위 복셀 위치 미세화는 백본 네트워크의 복셀화 및 스트라이딩에서 양자화 오류를 감소시킨다.
지면 위 높이 h_g는 객체를 3D로 위치시키는 데 도움이 되며 맵 뷰 투영에 의해 제거된 표고 정보를 추가합니다.
방향 예측에서는 yaw 각도의 사인 및 코사인을 연속 회귀 분석 대상으로 사용합니다.
이러한 회귀 헤드는 박스 크기와 결합하여 3D 바운딩 박스의 전체 상태 정보를 제공합니다.
각 출력은 자체 헤드를 사용합니다.
우리는 ground-truth 센터 위치에서 L1 손실을 사용하여 모든 출력을 학습한다.
우리는 다양한 모양의 박스를 더 잘 다루기 위해 로그 크기로 회귀한다.
추론 시, 우리는 각 객체의 피크 위치에서 고밀도 회귀 헤드 출력으로 인덱싱하여 모든 속성을 추출한다.
Velocity head and tracking.
시간을 통해 물체를 추적하기 위해, 우리는 탐지된 각 물체에 대한 2차원 속도 추정 v ∈ R^2를 추가 회귀 출력으로 예측하는 것을 배운다.
속도 추정에는 시간적 포인트 클라우드 시퀀스 [6]가 필요하다.
우리의 구현에서, 우리는 이전 프레임의 포인트를 변환하고 현재 참조 프레임으로 병합하고 시간 차이(속도)로 정규화된 현재 프레임과 과거 프레임 사이의 객체 위치 차이를 예측한다.
다른 회귀 대상과 마찬가지로 현재 시간 단계에서 ground-truth 천체의 위치에서 L1 손실을 사용하여 속도 추정도 감독한다.
추론 시, 우리는 이 오프셋을 사용하여 현재 탐지를 탐욕스러운 방식으로 과거의 탐지와 연관시킨다.
구체적으로, 우리는 음의 속도 추정치를 적용한 다음 가장 가까운 거리 매칭을 통해 추적된 물체와 일치시킴으로써 현재 프레임의 물체 중심을 이전 프레임으로 다시 투영한다.
SORT [4]에 따라, 우리는 T=3 프레임까지 일치하지 않는 트랙을 삭제하기 전에 유지합니다.
우리는 마지막으로 알려진 속도 추정으로 일치하지 않는 각 트랙을 업데이트한다.
자세한 추적 알고리즘 다이어그램은 부록을 참조하십시오.
CenterPoint는 모든 히트맵 및 회귀 손실을 하나의 공통 목표에서 결합하고 공동으로 최적화합니다.
이전의 앵커 기반 3D 디텍터를 단순화하고 개선합니다(실험 참조).
그러나 모든 객체 속성은 현재 객체의 중심 피쳐에서 유추되어 정확한 객체 위치 파악을 위한 충분한 정보를 포함하지 않을 수 있다.
예를 들어, 자율 주행에서 센서는 물체의 측면만 볼 뿐 중심은 볼 수 없는 경우가 많습니다.
다음으로, 우리는 경량 포인트-피처 추출기와 함께 두 번째 정제 단계를 사용하여 CenterPoint를 개선한다.
4.1. Two-Stage CenterPoint
첫 번째 단계로 변경되지 않은 CenterPoint를 사용합니다.
두 번째 단계는 백본의 출력에서 추가 포인트 피쳐를 추출한다.
우리는 예측 바운딩 박스의 각 면의 3D 중심에서 하나의 포인트 피쳐를 추출한다.
바운딩 박스 중심, 상단 및 하단 면 중심은 모두 맵 뷰에서 동일한 포인트에 투영됩니다.
따라서 우리는 예측된 객체 중심과 함께 네 개의 바깥쪽을 향한 박스 표면만 고려한다.
각 점에 대해 백본 맵 뷰 출력 M에서 이중 선형 보간을 사용하여 형상을 추출한다.
다음으로, 우리는 추출된 포인트 피쳐를 연결하고 MLP를 통과시킨다.
두 번째 단계는 첫 번째 단계 CenterPoint의 예측 결과 위에 클래스 무관 신뢰 점수 및 박스 미세화를 예측한다.
등급에 구애받지 않는 신뢰도 점수 예측을 위해 [25, 29, 42, 44]를 따르고 해당하는 ground-truth 바운딩 박스와 함께 박스의 3D IoU에 의해 안내된 점수 목표를 사용한다:
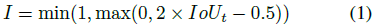
여기서 IoU_t는 t번째 제안 박스와 실측값 사이의 IoU이다.
이진 교차 엔트로피 손실을 사용하여 학습한다:
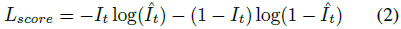
여기서 ^I_t는 예측 신뢰 점수입니다.
추론하는 동안, 우리는 첫번째 단계 CenterPoint의 클래스 예측을 직접 사용하고 최종 신뢰 점수를 두 점수의 기하학적 평균 ^Q_t = (^Y_t * ˆI_t)^1/2로 계산한다, 여기서 ^Q_t는 객체 t의 최종 예측 신뢰도이고 ^Y_t = max_(0≤k≤K) ^Y_(p,k) 및 ^I_t는 객체 t의 첫 번째 단계 및 두 번째 단계 신뢰도이다.
박스 회귀 분석의 경우, 모델은 첫 번째 단계 제안 위에 개선을 예측하고, 우리는 L1 손실로 모델을 학습시킨다.
우리의 두 번째 단계 CenterPoint는 값비싼 PointNet 기반 피쳐 추출기 또는 RoIAlign 작업 [42,43]을 사용하는 이전의 두 번째 단계 3D 디텍터를 단순화하고 가속화한다.
4.2. Architecture
모든 첫 번째 단계 출력은 첫 번째 3×3 컨볼루션 레이어, 배치 정규화 [24] 및 ReLU를 공유한다.
각 출력은 batch norm과 ReLU로 분리된 두 개의 3×3 컨볼루션의 자체 분기를 사용한다.
우리의 두 번째 단계는 batch norm, ReLU 및 드롭률이 0.3인 Dropout [21]을 가진 공유 2계층 MLP를 사용하고, 신뢰도 예측 및 박스 회귀를 위해 별도의 3계층 MLP를 사용한다.
5. Experiments
Conclusion
우리는 라이다 포인트 클라우드에서 동시에 3D 객체 감지 및 추적을 위한 센터 기반 프레임워크를 제안했다.
우리의 방법은 헤드에 몇 개의 컨볼루션 레이어가 있는 표준 3D 포인트 클라우드 인코더를 사용하여 조감도 히트맵과 다른 고밀도 회귀 출력을 생성한다.
탐지는 정교함이 있는 간단한 로컬 피크 추출이며, 추적은 가장 가까운 거리 매칭이다.
CenterPoint는 단순하고 거의 실시간이며 Waymo 및 nuScene 벤치마크에서 SOTA 성능을 달성합니다.
'3D Object Detection' 카테고리의 다른 글
| PointPillars: Fast Encoders for Object Detection from Point Clouds (0) | 2022.03.31 |
|---|---|
| DeepFusion: Lidar-Camera Deep Fusion for Multi-Modal 3D Object Detection (0) | 2022.03.22 |