2022. 4. 12. 08:08ㆍView Synthesis
Block-NeRF: Scalable Large Scene Neural View Synthesis
Matthew Tancik, Vincent Casser, Xinchen Yan, Sabeek Pradhan, Ben Mildenhall, Pratul Srinivasan, Jonathan T.Barron, Henrik Kretzschmar
Abstract
대규모 환경을 나타낼 수 있는 Neural Radiance Fields의 변형인 Block-NeRF를 제시한다.
특히, 우리는 여러 블록에 걸쳐 도시 규모의 장면을 렌더링하기 위해 NeRF를 스케일링할 때, 장면을 개별적으로 학습된 NeRF로 분해하는 것이 중요하다는 것을 보여준다.
이 분해를 통해 렌더링 시간을 장면 크기에서 분리하고 렌더링을 임의로 큰 환경으로 확장할 수 있으며, 환경을 블록 단위로 업데이트할 수 있습니다.
우리는 서로 다른 환경 조건에서 몇 달 동안 캡처된 데이터에 대해 NeRF를 견고하게 만들기 위해 몇 가지 아키텍처 변경을 채택한다.
우리는 외관 임베딩, 학습된 포즈 개선 및 각 개별 NeRF에 대한 제어 가능한 노출을 추가하고, 인접 NeRF 간에 외관을 정렬하여 원활하게 결합할 수 있는 절차를 소개한다.
우리는 280만 개의 이미지로부터 Block-NeRF의 그리드를 구축하여 샌프란시스코의 전체 이웃을 렌더링할 수 있는 현재까지 가장 큰 신경 장면 표현을 생성한다.
1. Introduction
Neural Radiance Fields [42]와 같은 신경 렌더링의 최근 발전은 포즈를 취한 카메라 이미지 세트 [3, 40, 45]를 감안할 때 사진 사실적인 재구성 및 새로운 뷰 합성을 가능하게 했다.
초기 작업은 소규모 및 객체 중심 재구성에 초점을 맞추는 경향이 있었다.
비록 일부 방법들은 현재 단일 방이나 건물 크기의 장면을 다루지만, 이것들은 일반적으로 여전히 제한적이며 도시 규모의 환경에 나이브하게 확장되지 않는다.
이러한 방법을 대규모 환경에 적용하면 일반적으로 모델 용량이 제한되어 상당한 아티팩트와 시각적 충실도가 떨어진다.
대규모 환경을 재구성하면 자율 주행 [32, 44, 68] 및 항공 측량 [14, 35]과 같은 영역에서 몇 가지 중요한 사용 사례가 가능하다.
한 가지 예는 매핑으로, 로봇 위치 지정, 탐색 및 충돌 회피와 같은 다양한 문제에 대한 강력한 사전 작업으로 작용하기 위해 전체 운영 도메인의 높은 충실도 맵이 생성된다.
또한 대규모 장면 재구성은 폐쇄 루프 로봇 시뮬레이션에 사용될 수 있다[13].
자율 주행 시스템은 일반적으로 이전에 접했던 시나리오를 다시 시뮬레이션하여 평가합니다; 그러나 기록된 접촉으로부터의 편차는 차량의 궤적을 변화시킬 수 있으므로 변경된 경로를 따라 고화질의 새로운 뷰 렌더링을 필요로 한다.
기본 뷰 합성 외에도 장면 조건화 NeRF는 카메라 노출, 날씨 또는 하루 중 시간과 같은 환경 조명 조건을 변경할 수 있으며, 시뮬레이션 시나리오를 더욱 강화하는 데 사용할 수 있다.
이러한 대규모 환경을 재구성하면 일시적인 물체(자동차와 보행자), 모델 용량의 제한, 메모리 및 계산 제약 등의 추가 문제가 발생한다.
또한 이러한 대규모 환경에 대한 학습 데이터는 일관된 조건에서 단일 캡처로 수집될 가능성이 매우 낮다.
오히려 환경의 다른 부분에 대한 데이터는 서로 다른 데이터 수집 노력에서 소스화하여 장면 형상(예: 건설 작업 및 주차 차량)과 외관(예: 날씨 조건 및 하루 중 시간) 모두에 차이를 도입해야 할 수 있다.
우리는 환경 변화와 수집된 데이터의 오류를 해결하기 위해 외관 임베딩과 학습된 포즈 개선으로 NeRF를 확장한다.
추론 중에 노출을 수정할 수 있는 기능을 제공하기 위해 노출 조건을 추가로 추가한다.
우리는 이 수정된 모델을 Block-NeRF라고 부른다.
Block-NeRF의 네트워크 용량을 확장하면 점점 더 큰 장면을 표현할 수 있습니다.
그러나 이 접근 방식에는 여러 가지 제약이 따른다; 렌더링 시간은 네트워크 크기에 따라 확장되며, 네트워크는 더 이상 단일 컴퓨팅 장치에 맞지 않으며, 환경을 업데이트하거나 확장하려면 전체 네트워크를 재학습해야 합니다.

이러한 과제를 해결하기 위해 대규모 환경을 개별적으로 학습된 Block-NeRF로 분할한 다음 추론 시간에 동적으로 렌더링되고 결합할 것을 제안한다.
이러한 Block-NeRF를 독립적으로 모델링하면 최대 유연성을 확보할 수 있으며, 임의의 대규모 환경까지 확장할 수 있으며, 그림 1과 같이 전체 환경을 재학습하지 않고도 단계별로 새로운 영역을 업데이트하거나 도입할 수 있습니다.
타켓 뷰를 계산하기 위해 Block-NeRF의 하위 집합만 렌더링된 다음 카메라와 비교한 지리적 위치를 기준으로 합성된다.
보다 매끄러운 합성을 위해, 우리는 외관 임베딩을 최적화하여 다양한 Block-NeRF를 시각적 정렬로 가져오는 외관 매칭 기법을 제안한다.
2. Related Work
2.1. Large Scale 3D Reconstruction
연구자들은 수십 년 동안 대형 이미지 컬렉션에서 3D 재구성을 위한 기술을 개발하고 정제해 왔으며 [1, 16, 33, 47, 57, 77] 현재 많은 작업은 이 작업을 수행하기 위해 COLMAP과 같은 성숙하고 강력한 소프트웨어 구현에 의존한다 [55: SfM].
거의 모든 재구성 방법은 공통 파이프라인을 공유합니다.
2D 이미지 피쳐(예: SIFT [39])를 추출하고, 다른 이미지에 걸쳐 이러한 피쳐를 일치시키고, 이러한 일치와 일치하도록 3D 포인트와 카메라 포즈 세트를 공동으로 최적화한다(번들 조정의 잘 탐구된 문제 [23, 65]).
이 파이프라인을 도시 규모 데이터로 확장하는 것은 Photo Tourism [57]과 Building Rome in a Day [1]와 같은 작업에서 탐구한 바와 같이 이러한 알고리즘의 매우 강력하고 병렬화된 버전을 구현하는 데 크게 문제가 된다.
핵심 그래픽 연구는 또한 빠른 고품질 렌더링을 위한 분해 장면을 탐구했습니다 [38].
이러한 접근 방식은 일반적으로 각 입력 이미지와 희소 3D 포인트 클라우드에 대한 카메라 포즈를 출력한다.
완전한 3D 장면 모델을 얻으려면 이러한 출력을 고밀도 다중 뷰 스테레오 알고리즘(예: PMVS [18])으로 추가로 처리하여 고밀도 포인트 클라우드 또는 삼각형 메시를 생성해야 한다.
이 프로세스는 자체적인 확장 문제를 제기합니다[17].
결과적인 3D 모델은 이미지 간에 삼각 측량이 어렵기 때문에 텍스처나 경면 반사가 제한된 영역에 아티팩트나 구멍을 포함하는 경우가 많다.
따라서 설득력 있는 이미지를 렌더링하는 데 사용할 수 있는 모델을 만들기 위해 추가 후처리가 필요한 경우가 많습니다 [56].
그러나 이 작업은 주로 새로운 뷰 합성 영역이며 3D 재구성 기술은 주로 기하학적 정확도에 중점을 둔다.
대조적으로, 우리의 접근 방식은 카메라 포즈를 생성하기 위해 대규모 SfM에 의존하지 않고, 이미지가 수집될 때 차량의 다양한 센서를 사용하여 주행 거리 측정을 수행한다[64].
2.2 Novel View Synthesis
주어진 장면의 입력 이미지 세트와 카메라 포즈가 주어지면, 새로운 뷰 합성은 이전에 관찰되지 않은 시점에서 관찰된 장면 콘텐츠를 렌더링하여 사용자가 높은 시각적 충실도로 재현된 환경을 탐색할 수 있도록 한다.
Geometry-based Image Reprojection.
뷰 합성에 대한 많은 접근 방식은 기존의 3D 재구성 기법을 적용하여 장면을 나타내는 포인트 클라우드 또는 삼각형 메시를 구축하는 것으로 시작한다.
이 기하학적 "프록시"는 입력 이미지에서 새로운 카메라 뷰로 픽셀을 재투영하는데 사용되며, 여기서 heuristic [6] 또는 학습 기반 방법 [24, 52, 53]에 의해 혼합된다.
이 접근 방식은 1인칭 비디오 [31], 시내 거리를 따라 수집된 파노라마 [30] 및 Photo Tourism 데이터 세트의 단일 랜드마크로 확장되었다[41].
지오메트리 프록시에 의존하는 방법은 초기 3D 재구성의 품질에 의해 제한되므로 복잡한 지오메트리 또는 반사 효과가 있는 장면에서 성능이 저하된다.
Volumetric Scene Representations.
최근의 뷰 합성 작업은 재구성 및 렌더링을 통합하고 일반적으로 체적 장면 표현을 사용하여 이 파이프라인을 종단 간 학습하는 데 초점을 맞추고 있다.
작은 베이스라인 뷰 보간을 렌더링하는 방법은 종종 피드포워드 네트워크를 사용하여 입력 이미지에서 출력 볼륨에 대한 매핑을 직접 학습한다[15, 76], 반면 더 큰 베이스라인 뷰 합성을 목표로 하는 Neural Volumes [37]와 같은 방법은 기존의 번들 조정과 유사하게 모든 새로운 장면을 재구성하기 위해 모든 입력 이미지에 대해 전역 최적화를 실행한다.
Neural Radience Fields (NeRF) [42]는 이 단일 장면 최적화 설정을 이산 3D 복셀 그리드보다 복잡한 장면을 훨씬 더 효율적으로 표현할 수 있는 신경 장면 표현과 결합한다; 그러나 렌더링 모델은 컴퓨팅 측면에서 대규모 장면으로 매우 저조한 확장성을 보인다.
후속 작업은 공간을 자체 경량 NeRF 네트워크를 포함하는 더 작은 영역으로 분할하여 NeRF를 더욱 효율적으로 만들 것을 제안했다 [48: DeRF, 49: Kilo-NeRF].
우리의 방법과 달리, 이러한 네트워크 앙상블은 공동으로 학습되어야 하며, 유연성을 제한한다.
또 다른 접근 방식은 잠재 코드의 coarse 3D 그리드 형태로 추가 용량을 제공하는 것이다 [36: NSVF].
이 접근법은 또한 상세한 3D 모양을 신경 부호 거리 함수 [62]로 압축하고 occupancy network [46]를 사용하여 큰 장면을 나타내는 데 적용되었다.
우리는 입력 이미지가 다양한 거리에서 장면을 관찰하는 장면에서 NeRF의 성능을 손상시키는 앨리어싱 문제를 개선하는 mipNeRF [3] 위에 Block-NeRF 구현을 구축한다.
우리는 NeRF in the Wild (NeRF-W) [40]의 기법을 통합하는데, 이는 Photo Tourism 데이터 세트의 랜드마크에 NeRF를 적용할 때 일관되지 않은 장면 외관을 처리하기 위해 학습 이미지당 잠재 코드를 추가한다.
NeRF-W는 수천 개의 이미지에서 각 랜드마크에 대해 별도의 NeRF를 생성하는 반면, 우리의 접근 방식은 많은 NeRF를 결합하여 수백만 개의 이미지에서 일관된 대규모 환경을 재구성한다.
또한 우리의 모델은 이전 연구에서 탐구된 학습된 카메라 포즈 개선 사항을 통합한다[34, 59, 66, 69, 70].
일부 NeRF 기반 방법은 세그먼테이션 데이터를 사용하여 비디오 시퀀스에 걸쳐 정적[67] 또는 움직이는 물체(사람 또는 자동차 등)를 분리하고 재구성한다[44, 73].
우리는 주로 환경 자체를 재구성하는 데 중점을 두기 때문에 학습 중에 동적 개체를 간단히 마스크하는 것을 선택한다.
2.3. Urban Scene Camera Simulation
카메라 시뮬레이션은 대화형 플랫폼에서 자율 주행 시스템을 학습하고 검증하는 데 인기 있는 데이터 소스가 되었다[2,28].
초기 작업[13,19,51,54]은 스크립트로 작성된 시나리오의 데이터를 합성하고 3D 자산을 수동으로 생성했습니다.
이러한 방법은 도메인 불일치와 제한된 장면 수준 다양성으로 어려움을 겪었다.
최근 몇 가지 연구는 시뮬레이션 및 렌더링 파이프라인의 분포 이동을 최소화하여 시뮬레이션과 현실 간의 격차를 해결한다.
Kar et al. [26]과 Devaranjan et al. [12]은 학습된 시나리오 생성 프레임워크를 통해 렌더링된 출력에서 실제 카메라 센서 데이터로 장면 수준 분포 이동을 최소화할 것을 제안했다.
Richter et al. [50]은 그래픽 파이프라인에서 중간 렌더링 버퍼를 활용하여 합성적으로 생성된 카메라 이미지의 사진사실주의를 개선했다.
사진 사실적이고 확장 가능한 카메라 시뮬레이션을 구축하기 위해 이전 방법[9, 32, 68]은 단일 드라이브 동안 수집된 풍부한 멀티 센서 구동 데이터를 활용하여 2D 신경 렌더링을 위한 이미지 GAN을 포함한 최신 머신러닝 기술을 사용하여 객체 주입[9]과 새로운 뷰 합성[68]을 위해 3D 장면을 재구성한다.
정교한 Surfel 재구성 파이프라인에 의존하는 SurfelGAN [68]은 여전히 그래픽 재구성 오류에 취약하며 LiDAR 스캔의 제한된 범위와 수직 시야에 시달릴 수 있다.
기존 노력과 달리, 우리의 작업은 3D 렌더링 문제를 해결하고 대규모 지역을 재구성하기 위한 필수 조건인 날씨와 시간 등 다양한 환경 조건에서 여러 드라이브에서 캡처한 실제 카메라 데이터를 모델링할 수 있다.
3. Background
우리는 NeRF[42]와 그 확장 mip-NeRF[3]를 기반으로 한다.
여기서는 이러한 방법의 관련 부분을 요약한다.
자세한 내용은 원본 문서를 참조하십시오.
3.1. NeRF and mip-NeRF Preliminaries
Neural Radience Fields (NeRF) [42]는 알려진 카메라 포즈에서 입력 이미지 세트의 외관을 재현하기 위해 미분 가능한 렌더링 손실을 통해 최적화된 좌표 기반 신경 장면 표현이다.
최적화 후 NeRF 모델을 사용하여 이전에 보이지 않는 관점을 렌더링할 수 있습니다.
NeRF 장면 표현은 한 쌍의 MLP(다층 퍼셉트론)입니다.
첫 번째 MLP f_σ는 3D 위치 x를 취하여 체적 밀도 σ 및 피쳐 벡터를 출력합니다.
이 피쳐 벡터는 2D 뷰 방향 d와 연결되어 RGB 색상 c를 출력하는 두 번째 MLP f_c로 공급된다.
이 아키텍처는 다른 각도에서 관찰할 때 출력 색상이 달라질 수 있으므로 NeRF가 반사 및 광택 물질을 나타낼 수 있지만 σ로 표현되는 기본 지오메트리는 위치의 함수일 뿐이다.
영상의 각 픽셀은 3D 공간을 통해 레이 r(t) = o + td에 해당합니다.
r의 색상을 계산하기 위해 NeRF는 랜덤으로 ray를 따라 거리 {t_i}^N_(i=0)를 샘플링하고 MLP를 통해 r(t_i) 및 방향 점들을 통과하여 σ_i와 c_i를 계산한다.
결과 출력 색상은
입니다.
NeRF의 완전한 구현은 (w_i 가중치를 확률 분포로 처리함으로써) 고밀도 영역에 샘플을 더 잘 집중시키기 위해 점 t_i를 반복적으로 재샘플링한다.
NeRF MLP가 더 높은 주파수 세부 정보를 나타낼 수 있도록 [63] 입력 x와 d는 각각 성분별 사인파 위치 인코딩
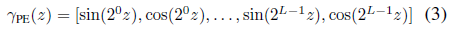
에 의해 사전 처리된다: 여기서 L은 위치 인코딩 레벨의 수입니다.
NeRF의 MLP f_σ는 단일 3D 포인트를 입력으로 사용합니다.
그러나 이는 해당 이미지 픽셀의 상대적 풋프린트와 점을 포함하는 레이를 따라 간격 [t_(i-1), t_i]의 길이를 모두 무시하여 새로운 카메라 궤적을 렌더링할 때 아티팩트를 앨리어싱한다.
Mip-NeRF[3]는 투영된 픽셀 풋프린트를 사용하여 간격이 아닌 레이를 따라 원뿔형 frustum을 샘플링함으로써 이 문제를 해결한다.
이러한 frustum을 MLP에 공급하기 위해, mip-NeRF는 매개 변수 μ_i, Σ_i를 가진 가우스 분포로 각각 근사하고, 통합 위치 인코딩이라고 하는 입력 가우시안
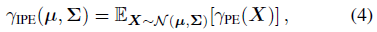
에 대한 기대치로 위치 인코딩 PE를 대체한다.
4. Method
단일 NeRF 학습은 도시만큼 큰 장면을 표현하려고 할 때 확장되지 않는다.
우리는 대신 환경을 독립적으로 병렬로 학습하고 추론하는 동안 합성할 수 있는 Block-NeRF 집합으로 분할할 것을 제안한다.
이러한 독립성을 통해 전체 환경을 재학습하지 않고도 추가 Block-NeRF 또는 업데이트 블록으로 환경을 확장할 수 있습니다(그림 1 참조).
렌더링을 위해 관련 Block-NeRF를 동적으로 선택한 다음 장면을 횡단할 때 부드러운 방식으로 합성한다.
이 합성을 돕기 위해, 우리는 조명 조건에 일치하도록 외관 코드를 최적화하고 새로운 뷰에 대한 각 Block-NeRF의 거리를 기반으로 계산된 보간 가중치를 사용한다.
4.1. Block Size and Placement
개별 Block-NeRF는 타겟 환경의 전체 적용 범위를 전체적으로 보장하도록 배치되어야 한다.
일반적으로 각 교차로에 Block-NeRF를 하나씩 배치하여 교차로 자체와 다음 교차로로 수렴될 때까지 연결된 거리의 75%를 커버합니다(그림 1 참조).
따라서 연결 거리 세그먼트에서 인접한 두 블록이 50% 중첩되어 둘 사이의 모양 정렬이 쉬워집니다.
이 절차를 따르는 것은 블록 크기가 가변적이라는 것을 의미하며, 필요한 경우 교차로 사이의 커넥터로 추가 블록을 도입할 수 있습니다.
우리는 지리적 필터를 적용하여 각 블록에 대한 학습 데이터가 의도한 범위 내에서 정확히 유지되도록 한다.
이 절차는 자동화가 가능하며 OpenStreetMap [22]과 같은 기본 지도 데이터에만 의존한다.
전체 환경이 적어도 하나의 Block-NeRF로 덮여 있는 한 다른 배치 휴리스틱도 가능하다는 점에 유의하십시오.
예를 들어, 일부 실험의 경우, 우리는 대신 단일 거리 세그먼트를 따라 블록을 배치하고 블록 크기를 Block-NeRF Origin 주변의 구체로 정의한다(그림 2 참조).
4.2. Training Individual Block-NeRFs
4.2.1 Appearance Embeddings
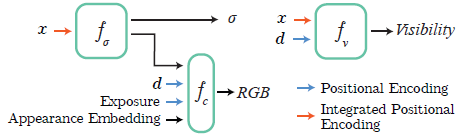
다른 환경 조건에서 데이터의 다른 부분이 캡처될 수 있다는 점을 감안할 때, 우리는 NeRF-W [40]를 따르고 그림 3과 같이 이미지별 모양 임베딩 벡터를 최적화하기 위해 Generative Latent Optimization [5]를 사용한다.
이를 통해 NeRF는 다양한 날씨 및 조명과 같은 여러 가지 외관 변화 조건을 설명할 수 있습니다.
우리는 또한 이러한 외관 임베딩을 조작하여 학습 데이터에서 관찰된 다른 조건(예: 흐림 vs 맑은 하늘 또는 낮과 밤) 사이에 보간할 수 있다.
다양한 외관을 가진 렌더링의 예는 그림 4에서 확인할 수 있습니다.
§ 4.3.3에서, 우리는 이러한 임베딩에 대한 테스트 시간 최적화를 사용하여 인접한 Block-NeRF의 외관과 일치시키는데, 이는 여러 렌더링을 결합할 때 중요하다.

4.2.2 Learned Pose Refinement
카메라 포즈가 제공된다고 가정하지만, 추가 정렬을 위해 정규화된 포즈 오프셋을 배우는 것이 유리하다.
포즈 개선은 이전 NeRF 기반 모델[34,59,66,70]에서 탐구되었다.
이러한 오프셋은 운전 세그먼트별로 학습되며 변환 및 회전 구성요소를 모두 포함한다.
우리는 이러한 오프셋을 NeRF 자체와 공동으로 최적화하여 네트워크가 포즈를 수정하기 전에 먼저 대략적인 구조를 학습할 수 있도록 학습 초기 단계에서 오프셋을 상당히 정규화한다.
4.2.3 Exposure Input
학습 이미지는 광범위한 노출 수준에 걸쳐 캡처될 수 있으며, 이를 고려하지 않은 채로 두면 NeRF 학습에 영향을 미칠 수 있다.
우리는 카메라 노출 정보를 모델의 외관 예측 부분에 제공하면 NeRF가 시각적 차이를 보상할 수 있다는 것을 발견했다(그림 3 참조).
특히, 노출 정보는 γ_PE(셔터 속도 x 아날로그 gain/t)로 처리된다, 여기서 γ_PE는 4 레벨의 사인파 위치 인코딩이고 t는 스케일링 계수이다(실제로 1,000을 사용한다).
다양한 학습된 노출의 예는 그림 5에서 확인할 수 있다.

4.2.4 Transient Objects
우리의 방법은 외관 임베딩을 사용하여 외관의 변화를 설명하지만, 우리는 장면 형상이 학습 데이터 전반에 걸쳐 일관성이 있다고 가정한다.
이동 가능한 물체(예: 자동차, 보행자)는 일반적으로 이 가정을 위반한다.
따라서 우리는 세맨틱 세그멘테이션 모델[10]을 사용하여 일반적인 이동 물체의 마스크를 생산하고 학습 중에 마스크된 영역을 무시한다.
이는 환경의 정적 부분(예: 건축)의 변화를 설명하지는 않지만, 가장 일반적인 유형의 기하학적 불일치를 수용한다.
4.2.5 Visibility Prediction
여러 Block-NeRF를 병합할 때 특정 공간의 영역이 학습 중에 특정 NeRF에 보이는지 여부를 아는 것이 유용할 수 있다.
우리는 샘플링된 포인트의 가시성의 근사치를 학습하도록 학습된 추가 작은 MLP f_v로 모델을 확장한다(그림 3 참조).
학습 레이를 따라 각 샘플에 대해 f_v는 위치와 뷰 방향을 취하며 점의 해당 투과도를 회귀시킵니다(식 (2)의 T_i).
모델은 supervision을 제공하는 f_σ와 함께 학습된다.
투과율은 특정 입력 카메라에서 점을 얼마나 볼 수 있는지를 나타냅니다: 자유 공간이나 첫 번째 교차된 물체의 표면에 있는 점들은 1에 가까운 투과율을 가질 것이고, 첫 번째 가시적인 물체의 내부 또는 뒤에 있는 점들은 0에 가까운 투과율을 가질 것이다.
어떤 점이 다른 관점에서는 보이지 않지만 다른 관점에서는 보이지 않는 경우, 회귀된 투과율 값은 모든 학습 카메라의 평균이 되고 0과 1 사이에 위치하며, 그 점이 부분적으로 관찰되었음을 나타낸다.
우리의 가시성 예측은 Srinivasan et al. [58]이 제안한 가시성 필드와 유사하다.
그러나, 우리는 학습 레이에 대한 가시성을 예측하는 반면, 그들은 재조명 가능한 NeRF 모델을 복구하기 위해 환경 조명에 대한 가시성을 예측하기 위해 MLP를 사용했다.
가시성 네트워크는 작으며 색상 및 밀도 네트워크와 독립적으로 실행할 수 있습니다.
이는 § 4.3.1에서 설명한 바와 같이 특정 NeRF가 특정 위치에 대해 의미 있는 출력을 생성하는지 여부를 결정하는 데 도움이 될 수 있기 때문에 여러 NeRF를 병합할 때 유용합니다.
가시성 예측은 또한 § 4.3.3에서 자세히 설명한 바와 같이 두 NeRF 사이의 외관 일치를 수행할 위치를 결정하는 데 사용될 수 있다.
4.3. Merging Multiple Block-NeRFs
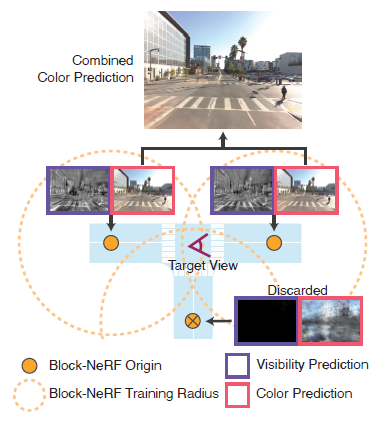
4.3.1 Block-NeRF Selection
환경은 임의의 수의 Block-NeRF로 구성될 수 있습니다.
효율성을 위해 두 가지 필터링 메커니즘을 사용하여 지정된 타겟 관점과 관련된 블록만 렌더링한다.
우리는 타겟 관점의 설정된 반경 내에 있는 Block-NeRF만 고려한다.
또한 이러한 각 후보에 대해 관련 가시성을 계산한다.
평균 가시성이 임계값보다 낮으면 Block-NeRF를 폐기합니다.
가시성 필터링의 예는 그림 2에 나와 있습니다.
가시성은 네트워크가 컬러 네트워크와 독립적이며 타겟 이미지 해상도로 렌더링할 필요가 없기 때문에 빠르게 계산될 수 있다.
필터링 후 일반적으로 1개에서 3개의 Block-NeRF가 병합될 때까지 남아 있습니다.
4.3.2 Block-NeRF Compositing
우리는 필터링된 각 Block-NeRF에서 컬러 이미지를 렌더링하고 카메라 원점 c와 각 Block-NeRF의 중심 x_i 사이의 역거리 가중치를 사용하여 그들 사이를 보간한다.
구체적으로, 우리는 각각의 가중치를 w_i ∝ distance(c, x_i)^-p로 계산하는데, 여기서 p는 Block-NeRF 렌더 간의 혼합 속도에 영향을 미친다.
보간은 2D 영상 공간에서 수행되며 Block-NeRF 간에 원활한 전환을 생성합니다.
우리는 또한 § 5.4에서 다른 보간 방법을 탐구한다.
4.3.3 Appearance Matching
학습된 모델의 외관은 Block-NeRF가 학습된 후 외관 잠재 코드에 의해 제어될 수 있다.
이러한 코드는 학습 중에 랜덤으로 초기화되므로 동일한 코드가 다른 Block-NeRF에 공급될 때 일반적으로 다른 모습을 나타낸다.
이것은 합성할 때 뷰 간의 불일치를 초래할 수 있기 때문에 바람직하지 않습니다.
Block-NeRF 중 하나에서 타겟 외관이 주어지면 나머지 블록에서 외관을 일치시키는 것을 목표로 한다.
이를 위해 먼저 인접한 Block-NeRF 쌍 간의 3D matching location을 선택한다.
이 위치의 가시성 예측은 두 Block-NeRF 모두에 대해 높아야 합니다.
일치하는 위치가 주어지면 Block-NeRF 네트워크 가중치를 동결하고 각 영역 렌더링 간의 l2 손실을 줄이기 위해 타겟의 외관 코드만 최적화한다.
이 최적화는 빠르게 진행되어 100 iterations 이내에 수렴됩니다.
반드시 완벽한 정렬을 만들지는 않지만, 이 절차는 성공적인 컴포지팅을 위한 필수 조건인 시간, 색상 균형 및 날씨와 같은 장면의 대부분의 전역 및 저주파 속성을 정렬한다.
그림 6은 외관 매칭이 인접한 Block-NeRF와 일치하도록 주간 장면을 야간으로 바꾸는 최적화의 예를 보여준다.

최적화된 모양은 장면을 통해 반복적으로 전파됩니다.
하나의 루트 Block-NeRF에서 시작하여, 우리는 인접한 루트들의 외관을 최적화하고 거기서부터 프로세스를 계속한다.
타겟 Block-NeRF를 둘러싼 여러 블록이 이미 최적화되어 있는 경우 손실을 계산할 때 각각을 고려한다.
5. Results and Experiments
이 섹션에서는 데이터 세트와 실험에 대해 설명합니다.
아키텍처 및 최적화 세부 사항은 부록에 나와 있습니다.
이 부록은 또한 전통적인 Structure from Motion 접근 방식인 COLMAP[55]의 재구성과의 비교를 제공한다.
이 재구성은 희박하며 반사 표면과 하늘을 나타내지 못한다.
5.1. Datasets
우리는 대규모 장면의 새로운 뷰 합성 작업을 위해 특별히 수집하는 데이터 세트에 대한 실험을 수행한다.
우리의 데이터 세트는 데이터 수집 차량을 사용하여 공공 도로에서 수집된다.
여러 대규모 주행 데이터 세트가 이미 존재하지만, 뷰 합성 작업을 위해 설계되지 않았다.
예를 들어, 일부 데이터 세트는 충분한 카메라 커버리지(예: KITTI [21], Cityscapes [11])가 없거나 타겟 영역의 반복적인 관찰(예: NuScenes [7], Waymo Open Dataset [61], Argoverse [8])보다 시각적 다양성을 우선시한다.
대신 일반적으로 드라이브 간에 유사한 관찰이 일반화 문제로 이어질 수 있는 개체 감지 또는 추적과 같은 작업을 위해 설계되었습니다.
우리는 장기 시퀀스 데이터(100초 이상)와 특정 타겟 영역에서 수개월 동안 반복적으로 캡처된 별개의 시퀀스를 모두 캡처한다.
우리는 12개의 카메라에서 캡처한 이미지 데이터를 사용하여 360° 뷰를 제공한다.
8개의 카메라가 차량 지붕에서 완벽한 서라운드 뷰를 제공하며, 차량 전방에 위치한 4개의 카메라가 전방과 측면을 가리키고 있습니다.
각 카메라는 10Hz에서 이미지를 캡처하고 스칼라 노출 값을 저장합니다.
차량 pose가 알려져 있고 모든 카메라가 보정되어 있습니다.
이 정보를 사용하여 카메라의 롤링 셔터를 설명하는 공통 좌표 시스템에서 해당 카메라 레이의 원점과 방향을 계산한다.
§ 4.2.4에 설명된 바와 같이, 우리는 이동 가능한 물체를 감지하기 위해 의미론적 분할 모델[10]을 사용한다.
San Francisco Alamo Square Dataset.
우리는 확장성 실험의 타겟 지역으로 San Francisco Alamo Square 지역을 선택한다.
데이터 세트는 약 960m x 570m의 영역에 걸쳐 있으며 2021년 6월, 7월, 8월에 기록되었다.
우리는 이 데이터 세트를 35개의 Block-NeRF로 나눈다.
그림 1에서 예시적인 렌더링 및 Block-NeRF 배치를 볼 수 있습니다.
재구성의 규모를 가장 잘 이해하기 위해서는 보충 비디오를 참조하십시오.
각 Block-NeRF는 38~48개의 서로 다른 데이터 수집 실행 데이터에 대해 학습을 받았으며, 총 주행 시간은 각각 18~28분이었다.
일부 중복 이미지 캡처(예: 고정 캡처)를 필터링한 후 각 Block-NeRF는 64,575에서 108,216개의 이미지에 대해 학습된다.
전체 데이터 세트는 1,330개의 서로 다른 데이터 수집 실행에서 13.4시간의 주행 시간으로 구성되며, 총 2,818,745개의 학습 이미지가 있다.
San Francisco Mission Bay Dataset.
우리는 베이스라인, 블록 크기 및 배치 실험의 타겟 지역으로 San Francisco Mission Bay District를 선택한다.
Mission Bay는 도전적인 기하학과 반사적인 외관을 가진 도시 환경이다.
우리는 3번가에서 원거리 가시성을 가진 긴 구간을 확인하여 흥미로운 테스트 사례로 만들었다.
특히, 이 데이터 세트는 2020년 11월에 단일 캡처에 기록되었으며, 일관된 환경 조건을 통해 간단한 평가가 가능하다.
이 데이터 세트는 데이터 수집 차량이 1.08km를 이동하고 12개 카메라에서 총 12,000개의 이미지를 캡처한 100초에 걸쳐 기록되었다.
우리는 재현성을 돕기 위해 이 단일 캡처 데이터 세트를 출시할 것이다.
5.2. Model Ablations
우리는 Alamo Square 데이터 세트의 단일 교차로에서 모델 수정을 ablation한다.
표 1의 테스트 이미지 재구성에 대한 PSNR, SSIM 및 LPIPS [75] 메트릭을 보고한다.
테스트 이미지는 수직으로 절반으로 분할되며, 외관 임베딩은 한 쪽에서 최적화되고 다른 쪽에서 테스트된다.
우리는 또한 그림 7에 질적인 예를 제공한다.
Mip-NeRF만 해도 장면을 제대로 재구성하지 못하고 외관의 차이를 설명하기 위해 존재하지 않는 기하학적 구조와 흐린 아티팩트를 추가하는 경향이 있다.

우리의 방법이 외관 임베딩으로 학습되지 않은 경우에도 이러한 아티팩트는 여전히 존재한다.
우리의 방법이 포즈 최적화로 학습되지 않은 경우, 결과 장면은 블러해지고 포즈 정렬 오류로 인해 중복된 객체를 포함할 수 있다.
마지막으로, 노출 입력은 재구성을 약간 개선하지만, 더 중요한 것은 추론 중에 노출을 변경할 수 있는 기능을 제공한다.
5.3. Block-NeRF Size and Placement
우리는 Mission Bay 데이터 세트의 성능과 사용된 Block-NeRF의 수를 비교한다.
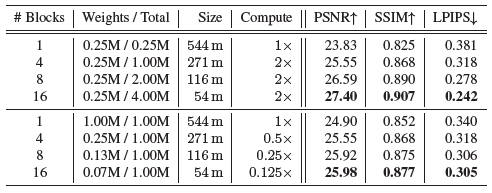
우리는 표 2에서 세부 사항을 보여주는데, 여기서 세분성에 따라 Block-NeRF 크기는 최대 54m에서 최대 544m까지 다양하다.
우리는 인접한 블록의 각 쌍이 50%까지 겹치도록 보장하고 supplement의 다른 겹침 비율을 비교한다.
모든 것은 전체 궤적에 걸쳐 동일한 held-out 테스트 이미지 세트에서 평가되었다.
우리는 두 가지 체제를 고려한다, 하나는 각 Block-NeRF가 동일한 수의 가중치를 포함하는 체제(상단 섹션)이고 다른 하나는 모든 Block-NeRF에 걸친 총 가중치 수가 고정되는 체제(하단 섹션)이다.
두 경우 모두 모델 수를 늘리면 재구성 메트릭이 향상된다는 것을 관찰한다.
계산 비용 측면에서, 각 모델은 장치 간에 독립적으로 최적화될 수 있기 때문에 학습 중 병렬화는 사소한 것이다.
추론에서, 우리의 방법은 타겟 뷰 근처에 Block-NeRF를 렌더링하는 것만 필요로 한다.
장면과 NeRF 레이아웃에 따라 일반적으로 1~3개의 NeRF를 렌더링한다.
우리는 병렬화를 가정하지 않고 각 설정의 상대적인 계산 비용을 보고하지만, 이는 가능하며 추가 속도 향상으로 이어질 수 있다.
우리의 결과는 장면을 여러 개의 더 낮은 용량 모델로 분할하면 모든 모델을 평가할 필요가 없기 때문에 전체 계산 비용을 줄일 수 있음을 의미한다(표 2의 하단 섹션 참조).
5.4. Interpolation Methods
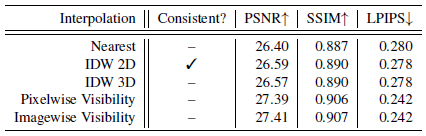
우리는 표 3에서 서로 다른 보간 방법을 탐구한다.
카메라에 가장 가까운 Block-NeRF만 렌더링하는 간단한 방법은 최소한의 계산을 요구하지만 블록 간 전환 시 거친 점프를 초래한다.
이러한 전환은 § 4.3.2에 설명된 바와 같이 카메라와 Block-NeRF 중심 사이의 역 거리 가중치(IDW)를 사용하여 원활하게 이루어질 수 있습니다.
우리는 또한 예상 Block-NeRF depth에 의해 예측된 예상 3D 지점에 대해 보간이 수행된 IDW의 변형을 탐구했다.
이 방법은 depth 예측이 잘못되면 아티팩트와 시간적 불일치로 이어진다.
마지막으로 픽셀당 및 이미지당 예측 가시성을 기반으로 Block-NeRF의 가중치를 측정하는 실험을 한다.
이는 더 멀리 있는 영역을 더 선명하게 재구성하지만 시간적 불일치를 일으키기 쉽다.
따라서 이러한 방법은 정지 이미지를 렌더링할 때만 사용하는 것이 가장 좋습니다.
자세한 내용은 부록에 나와 있습니다.
6. Limitations and Future Work
제안된 방법은 분할 알고리즘을 사용하여 마스킹을 통해 학습 중에 일시적인 개체를 필터링하여 처리한다.
객체가 제대로 마스킹되지 않으면 결과 렌더링에 아티팩트가 발생할 수 있습니다.
예를 들어, 자동차 자체가 올바르게 제거되어도 자동차의 그림자가 남아 있는 경우가 많습니다.
초목은 또한 계절에 따라 잎이 변하고 바람에 움직이면서 이러한 가정을 깨뜨린다.
마찬가지로, 건설 작업과 같은 학습 데이터의 시간적 불일치는 자동으로 처리되지 않으며 영향을 받는 블록의 수동 재학습이 필요하다.
또한 동적 객체를 포함하는 장면을 렌더링할 수 없기 때문에 현재 로봇 공학에서 폐쇄 루프 시뮬레이션 작업에 대한 Block-NeRF의 적용 가능성이 제한된다.
향후 이러한 문제는 최적화 중에 일시적인 개체를 학습하거나 동적 개체를 직접 모델링하여 해결할 수 있다[40].
특히, 장면은 환경의 여러 Block-NeRF와 개별 제어 가능한 객체 NeRF로 구성될 수 있다.
분할 마스크 또는 바운딩 박스를 사용하여 분리를 용이하게 할 수 있습니다.
우리 모델에서 장면의 먼 물체는 근처 물체와 동일한 밀도로 샘플링되지 않아 블러 재구성으로 이어진다.
이것은 무제한 볼륨 표현 샘플링과 관련된 문제이다.
NeRF++[74]와 동시에 Mip-NeRF 360[4]에서 제안된 기술은 멀리 있는 물체의 더 선명한 렌더링을 생성하는 데 잠재적으로 사용될 수 있다.
많은 애플리케이션에서 실시간 렌더링이 핵심이지만 NeRF는 렌더링하는 데 계산 비용이 많이 든다(이미지당 최대 몇 초).
여러 NeRF 캐싱 기술[20, 25, 72] 또는 희소 복셀 그리드[36]를 사용하여 실시간 Block-NeRF 렌더링을 가능하게 할 수 있다.
마찬가지로, 여러 동시 작업은 NeRF 스타일 표현의 학습 속도를 몇 배 더 빠르게 하는 기술을 입증했다[43, 60, 71].
7. Conclusion
본 논문에서는 NeRF를 사용하여 임의로 대규모 환경을 재구성하는 방법인 Block-NeRF를 제안한다.
우리는 2.8M개의 이미지로 샌프란시스코에 전체 이웃을 구축하여 현재까지 가장 큰 신경 장면 표현을 형성함으로써 이 방법의 효과를 입증한다.
우리는 표현을 독립적으로 최적화할 수 있는 여러 블록으로 분할하여 이 규모를 달성한다.
이러한 규모에서 수집된 데이터는 필연적으로 일시적인 개체와 외관의 변화를 가질 것이며, 이는 기본 NeRF 아키텍처를 수정하여 설명한다.
우리는 이것이 현대적인 신경 렌더링 방법을 사용하는 대규모 장면 재구성에서 향후 작업에 영감을 줄 수 있기를 바란다.
A. Model Parameters / Optimization Details
우리의 네트워크는 mip-NeRF 구조를 따른다.
네트워크 f_σ는 폭이 512(Mission Bay 실험) 또는 1024(다른 모든 실험)인 8개의 레이어로 구성됩니다.
f_c는 폭 128을 가진 3개의 레이어를 가지고 있고 f_v는 폭 128을 가진 4개의 레이어를 가지고 있다.
외관 임베딩은 32차원이다.
우리는 배치 크기가 16384인 300K 반복에 대해 Adam [29] 최적화를 사용하여 각 Block-NeRF를 학습한다.
mip-NeRF와 유사하게, 학습 속도는 2x10^-3에서 2x10^-5까지 로그로 소둔되며, 처음 1024회 반복 동안 warm up 단계를 갖는다.
coarse-to-fine 네트워크는 학습 중 256회, 비디오를 렌더링할 때 512회 샘플링된다.
가시성은 MSE loss로 supervise되며 10^-6으로 스케일링된다.
학습된 포즈 보정은 위치 오프셋과 3x3 잔류 회전 매트릭스로 구성되며, 이는 아이덴티티 매트릭스에 추가되고 직교 여부를 확인하기 위해 적용되기 전에 정규화된다.
포즈 수정은 0으로 초기화되고 학습 중 요소별 l2 규범이 정규화된다.
이 정규화는 학습을 시작할 때 10^5 규모로 조정되며 5000회 반복 후에는 10^-1로 선형적으로 감소한다.
이를 통해 네트워크는 포즈 오프셋을 적용하기 전에 초기 지오메트리를 학습할 수 있다.
각 Block-NeRF는 (하이퍼 매개 변수에 따라) 학습하는 데 9시간에서 24시간이 걸린다.
우리는 구글 클라우드 컴퓨팅을 통해 사용 가능한 32개의 TPU v3 코어에서 각 Block-NeRF를 학습한다, 이 코어는 총 1680 TFLOPS와 512GB 메모리를 제공한다.
단일 Block-NeRF에 대해 1200 x 900px 이미지를 렌더링하는 데 약 5.9초가 걸립니다.
다중 Block-NeRF는 추론 중에 병렬로 처리될 수 있다(일반적으로 단일 프레임에 대해 3개 미만의 Block-NeRF를 렌더링해야 함).

B. Block-NeRF Size and Placement
우리는 (§ 5.3, 표 2)의 정량적 비교를 보완하기 위해 Mission Bay 데이터 세트의 그림 9에 정성적 비교를 포함한다.
이 그림에서, 우리는 두 가지 체제에 대한 비교를 제공하는데, 하나는 각 Block-NeRF가 동일한 수의 가중치(왼쪽 섹션)를 포함하는 것이고, 다른 하나는 모든 Block-NeRF에 걸친 총 가중치 수(오른쪽 섹션)가 고정된 것이다.
C. Block-NeRF Overlap Comparison
본 논문에서는 Block-NeRF 크기 및 배치(§5.3)에 대한 실험을 포함한다.
이러한 실험을 위해, 우리는 외관 정렬에 도움이 되는 각 Block-NeRF 쌍 사이의 상대적인 중첩을 50%로 가정했다.
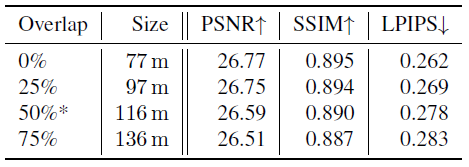
표 4는 본 논문에서 표 2를 직접 확장한 것으로 8블록 시나리오에서 다양한 블록 오버랩의 효과를 보여준다.
겹침을 변경하면 공간 블록 크기가 변경됩니다.
메인 논문의 원래 설정은 별표로 표시됩니다.
메트릭은 중복을 줄이는 것이 이미지 품질 메트릭에 도움이 된다는 것을 의미합니다.
그러나 이는 블록 크기의 감소에 기인할 수 있다.
실제로 Block-NeRF 사이를 보간할 때 시간적 아티팩트를 피하기 위해 블록 사이에 중첩을 갖는 것이 중요하다.
D. Block-NeRF Interpolation Details
우리는 Block-NeRF 사이를 보간하기 위해 여러 가지 방법을 실험하고 이미지 공간의 단순한 역 거리 가중치(IDW)가 시간적 부드러움으로 인해 가장 매력적인 비디오를 생성한다는 것을 발견했다.
Alamo Square 렌더링에는 IDW power p of 4, Mission Bay 렌더링에는 power of 1을 사용합니다.
우리는 타겟 뷰에 가장 가까운 Block-NeRF에서 예상되는 레이 종단 depth를 사용하여 렌더링된 픽셀을 3D 공간에 투영하여 각 개별 픽셀에 대한 3D 역 거리 가중치를 실험한다.
그런 다음 투영된 픽셀의 색상 값은 가장 가까운 Block-NeRF와의 역 거리 가중치를 사용하여 결정된다.
depth 예측의 노이즈로 인해 합성된 렌더링에서 아티팩트가 발생합니다.
우리는 또한 보간을 위해 Block-NeRF 예측 가시성을 사용하는 실험을 한다.
우리는 전체 이미지의 평균 가시성을 취하는 이미지별 가시성과 픽셀당 가시성 예측을 직접 활용하는 픽셀별 가시성을 고려한다.
이 두 가지 방법 모두 더 날카로운 결과를 가져오지만 시간적 불일치를 희생한다.
마지막으로 우리는 Block-NeRF를 타겟 뷰에 가장 가깝게 렌더링하는 가장 가까운 이웃 보간과 비교한다.
이로 인해 Block-NeRF 간을 통과할 때 심한 점프가 발생합니다.
E. Structure from Motion (COLMAP)
우리는 COLMAP[3]를 사용하여 Mission Bay 데이터 세트를 재구성한다.
먼저 카메라 위치를 기준으로 데이터 세트를 각각 97m 반경의 8개의 중첩 블록으로 분할한다(각 블록은 인접 블록과 대략 25% 중첩됨).
번들 조정 단계는 재구성에 대부분의 시간이 소요되며 블록당 반지름을 증가시킬 경우 크게 개선되지 않습니다.
우리는 Block-NeRF와 동일한 분할 모델을 사용하여 매칭을 위해 피처 포인트를 추출할 때 이동 가능한 객체를 마스킹한다.
우리는 핀홀 카메라 모델을 가정하고 움직임에서 구조를 실행하기 위한 사전 단계로 카메라 intrinsics과 카메라 포즈를 제공한다.
그런 다음 각 블록 내에서 멀티 뷰 스테레오를 실행하여 밀도 높은 depth와 일반 맵을 3D로 생성하고 장면의 밀도 높은 포인트 클라우드를 생성한다.
우리의 예비 실험에서, 우리는 텍스처가 있는 메시를 재구성하기 위해 융합된 조밀한 포인트 클라우드에서 포아송 메시[27]를 실행했지만, 이 방법이 반사 표면과 하늘에 의해 도입된 도전적인 기하학과 depth 오류로 인해 합리적으로 보이는 결과를 생성하지 못한다는 것을 발견했다.
대신, 우리는 융합된 포인트 클라우드를 활용하고 두 가지 대안, 즉 각각 포인트 렌더링과 surfel 렌더링을 탐구한다.
테스트 뷰를 렌더링하기 위해 가장 가까운 장면을 선택하고 램버트 모델과 단일 광원을 가정하여 OSMesa 오프스크린 렌더링을 사용한다.

표 5에서는 조밀하게 재구성된 포인트 클라우드에 대한 두 가지 렌더링 옵션을 비교한다.
우리는 두 가지 방법 모두에 대해 PSNR을 계산할 때 보이지 않는 픽셀을 폐기하여 정량적 결과를 BlockNeRF 설정과 유사하게 만든다.

그림 8에서는 해당 이미지에서 PSNR을 사용한 두 렌더링 옵션 간의 질적 비교를 보여준다.
이 재구성은 희박하며 반사 표면과 하늘을 나타내지 못한다.

F. Examples from our Datasets
그림 10에서는 Mission Bay 데이터 세트의 카메라 이미지를 보여준다.
그림 11에서는 Alamo Square 데이터 세트의 카메라 이미지와 해당 분할 마스크를 모두 보여준다.

G. Societal Impact
G.1. Methodological
우리의 방법은 NeRF 모델의 무거운 컴퓨팅 공간을 상속하며 전례 없는 규모로 적용할 것을 제안한다.
우리의 방법은 또한 환경(매핑)의 상세한 지도를 구축하는 것과 같은 신경 렌더링을 위한 새로운 사용 사례를 공개하는데, 이는 계산적으로 덜 관련된 대안을 선호하여 더 광범위한 사용을 야기할 수 있다.
이 작업이 적용되는 규모에 따라 계산에 사용되는 에너지가 탄소 배출량 증가로 이어질 경우 계산 수요가 환경 피해를 초래하거나 악화시킬 수 있습니다.
논문에서 언급한 바와 같이, 우리는 컴퓨팅 요구를 줄이고 환경 피해를 완화할 수 있는 캐싱 방법과 같은 추가 작업을 예상한다.
G.2. Application
우리는 실제 도시 환경에 우리의 방법을 적용한다.
본 논문을 위한 자체 데이터 수집 노력 동안, 우리는 얼굴과 번호판과 같은 민감한 정보를 블러 하는 것에 주의했고, 운전을 공공 도로로 제한했다.
이 작업의 향후 적용은 훨씬 더 큰 데이터 수집 노력을 수반할 수 있으며, 이는 개인 정보 보호 문제를 더 제기한다.
공공 도로에 대한 자세한 이미지는 이미 구글 스트리트 뷰와 같은 서비스에서 찾을 수 있지만, 우리의 방법론은 환경에 대한 반복적이고 더 정기적인 스캔을 촉진할 수 있다.
자율 주행 차량 공간의 여러 회사는 차량을 사용하여 정기적인 영역 스캔을 수행하는 것으로 알려져 있지만, 일부 회사는 카메라 이미지를 수집하는 것보다 덜 민감할 수 있는 LiDAR 스캔만 사용할 수 있다.