2022. 4. 28. 13:26ㆍView Synthesis
MVSNeRF: Fast Generalizable Radiance Field Reconstruction from Multi-View Stereo
Anpei Chen, Zexiang Xu, Fuqiang Zhao, Xiaoshuai Zhang, Fanbo Xiang, Jingyi Yu, Hao Su
Abstract
우리는 뷰 합성을 위해 neural radiance fields를 효율적으로 재구성할 수 있는 새로운 신경 렌더링 접근법인 MVSNeRF를 제시한다.
조밀하게 캡처된 이미지에서 장면당 최적화를 고려하는 neural radiance fields에 대한 이전 연구와 달리, 우리는 빠른 네트워크 추론을 통해 근처의 세 가지 입력 뷰에서만 radiance fields를 재구성할 수 있는 일반적인 심층 신경망을 제안한다.
우리의 접근 방식은 기하학 인식 장면 추론을 위해 평면 스위프 비용 볼륨(멀티 뷰 스테레오에서 널리 사용됨)을 활용하고, 이를 neural radiance field 재구성을 위해 물리적 기반 볼륨 렌더링과 결합한다.
우리는 DTU 데이터 세트의 실제 개체에 대해 네트워크를 학습시키고, 세 가지 다른 데이터 세트에서 네트워크를 테스트하여 효과와 일반화 가능성을 평가한다.
우리의 접근 방식은 여러 장면(심지어 실내 장면, 객체의 학습 장면과는 완전히 다른)을 일반화하고 세 개의 입력 이미지만 사용하여 현실적인 뷰 합성 결과를 생성하여 일반화 가능한 radiance field 재구성에 대한 동시 작업을 크게 능가한다.
또한, 고밀도 이미지가 캡처되면 추정된 radiance field 표현을 쉽게 미세 조정할 수 있으며; 이는 NeRF보다 렌더링 품질이 높고 최적화 시간이 상당히 짧아서 장면당 재구성이 빠르다.
1. Introduction
새로운 뷰 합성은 컴퓨터 비전과 그래픽에서 오랫동안 지속된 문제이다.
최근 신경 렌더링 접근법이 이 영역의 발전을 크게 진전시켰다.
Neural radiance fields (NeRF)와 그 다음 연구[34, 31, 27]는 이미 사진 사실적인 새로운 뷰 합성 결과를 생성할 수 있다.
그러나 이러한 이전 연구의 한 가지 중요한 단점은 고품질의 radiance fields를 얻기 위해 매우 긴 장면 최적화 프로세스가 필요하다는 것인데, 이는 비용이 많이 들고 실용성을 크게 제한한다.
우리의 목표는 매우 효율적인 radiance field 추정을 가능하게 하여 신경 장면 재구성 및 렌더링을 보다 실용적으로 만드는 것이다.
우리는 구조화되지 않은 여러 개의 다중 뷰 입력 이미지에서만 radiance field를 재구성하는 작업을 위해 장면 전반에 걸쳐 잘 일반화하는 새로운 접근 방식인 MVSNeRF를 제안한다.
강력한 일반화 가능성으로 지루한 장면별 최적화를 피하고 빠른 네트워크 추론을 통해 새로운 시점에서 사실적인 이미지를 직접 회귀시킬 수 있다.
짧은 기간(5-15분)으로 더 많은 이미지에서 더 최적화되면 재구성된 radiance fields는 몇 시간의 최적화로 NeRF[34]를 능가할 수 있다(그림 1 참조).

우리는 딥 멀티 뷰 스테레오(MVS)의 최근 성공을 활용한다[50, 18, 10].
이 작업 라인은 비용 볼륨에 3D 컨볼루션을 적용하여 3D 재구성 작업을 위한 일반화 가능한 신경망을 학습시킬 수 있다.
[50]과 유사하게, 우리는 근처의 입력 뷰에서 2D 이미지 피쳐 (2D CNN에 의해 추론됨)을 참조 뷰의 frustum에 있는 스위핑 평면으로 왜곡하여 입력 참조 뷰에서 비용 볼륨을 구축한다.
이러한 비용 볼륨에 대해 depth 추론만 수행하는 MVS 방법[50, 10]과 달리, 우리 네트워크는 장면 지오메트리와 외관 모두에 대해 추론하고 neural radiance field(그림 2 참조)를 출력하여 뷰 합성을 가능하게 한다.
특히, 3D CNN을 활용하여 로컬 장면 지오메트리 및 외관에 대한 정보를 인코딩하는 복셀별 신경 피쳐로 구성된 신경 장면 인코딩 볼륨을 (비용 볼륨에서) 재구성한다.
그런 다음, 우리는 다층 퍼셉트론(MLP)을 사용하여 인코딩 볼륨 내에서 3차 보간 신경 피쳐를 사용하여 임의의 연속 위치에서 볼륨 밀도와 radiance를 디코딩한다.
본질적으로, 인코딩 볼륨은 radiance fields의 로컬적인 신경 표현이다; 일단 추정되면, 이 볼륨을 미분 가능한 ray marching에 의해 최종 렌더링을 위해 직접(3D CNN을 드롭) 사용할 수 있다([34]에서처럼).
우리의 접근 방식은 학습 기반 MVS와 신경 렌더링이라는 두 가지 세계를 최대한 활용한다.
기존 MVS 방법과 비교하여, 우리는 추가적인 품질 개선을 위해 3D supervision 및 추론 시간 최적화 없이 학습이 가능한 미분 가능한 신경 렌더링을 가능하게 한다.
기존 신경 렌더링 작업과 비교하여 MVS와 같은 아키텍처는 교차 뷰 대응 추론을 수행하는 것이 자연스러워서 보이지 않는 테스트 장면으로 일반화를 용이하게 하고 또한 더 나은 신경 장면 재구성 및 렌더링으로 이어진다.
따라서 우리의 접근 방식은 명시적인 기하학 인식 3D 구조 없이 주로 2D 이미지 피쳐를 고려하는 최근의 동시 일반화 가능한 NeRF 작업[54, 46]을 크게 능가할 수 있다(표 1 및 그림 4 참조).
우리는 세 개의 입력 이미지만 사용하여 DTU 데이터 세트에서 학습된 우리의 네트워크가 테스트 DTU 장면에서 사진 사실적인 이미지를 합성할 수 있고 심지어 장면 분포가 매우 다른 다른 데이터 세트에서 합리적인 결과를 생성할 수 있음을 보여준다.
또한, NeRF보다 훨씬 적은 최적화 시간이 걸리지만, 우리의 추정된 3개 이미지 radiance field(신경 인코딩 볼륨)는 새로운 테스트 장면에서 더 쉽게 최적화되어 장면당 비교 가능하거나 심지어 더 나은 이미지가 NeRF에 적합할 경우 신경 재구성을 개선할 수 있다(그림 1 참조).


이러한 실험은 우리의 기술이 캡처된 이미지가 거의 없을 때 현실적인 뷰 합성을 위해 radiance field를 재구성할 수 있는 강력한 재구성기로 또는 고밀도 이미지를 사용할 수 있을 때 장면별 radiance field 최적화를 상당히 용이하게 하는 강력한 초기화기로 사용될 수 있음을 보여준다.
우리의 접근 방식은 현실적인 신경 렌더링을 실용적으로 만드는 데 중요한 단계를 밟는다.
2. Related Work
Multi-view stereo.
다중 뷰 스테레오(MVS)는 여러 관점에서 캡처한 이미지를 사용하여 고밀도 지오메트리 재구성을 달성하는 것을 목표로 하는 고전적인 컴퓨터 비전 문제로, 다양한 전통적인 방법[12, 24, 23, 14, 39, 16, 38]에 의해 광범위하게 탐구되었다.
최근 MVS 문제를 해결하기 위해 딥러닝 기술이 도입되었다[50, 19].
MVSNet[50]은 depth 추정을 위한 참조 뷰에서 평면 스윕 비용 볼륨에 3D CNN을 적용하여 기존의 방법을 능가하는 고품질 3D 재구성을 달성한다[16, 38].
다음 작업은 반복 평면 스위핑 [51], 점 기반 밀도화 [8], 신뢰 기반 집계 [30] 및 여러 비용 볼륨 [10, 18]으로 이 기법을 확장하여 재구성 품질을 향상시켰다.
우리는 비용-볼륨 기반 deep MVS 기술을 미분 가능한 볼륨 렌더링과 결합하여 신경 렌더링을 위한 radiance fields를 효율적으로 재구성할 것을 제안한다.
직접 depth supervision을 사용하는 MVS 접근 방식과 달리, 우리는 새로운 뷰 합성만을 위해 이미지 loss를 가진 네트워크를 학습시킨다.
이를 통해 네트워크는 다중 뷰 일관성을 충족하고 자연스럽게 고품질 지오메트리 재구성을 가능하게 한다.
보조 제품으로서, MVSNeRF는 MVSNet[50]에 필적하는 정확한 depth 재구성을 달성할 수 있다.
이것은 잠재적으로 unsupervised 지오메트리 재구성 방법을 개발하는 향후 작업에 영감을 줄 수 있다.
View synthesis.
뷰 합성은 수십 년 동안 라이트 필드[17, 25, 47, 21, 42, 7], 이미지 기반 렌더링[13, 3, 40, 5, 4] 및 기타 최근의 딥러닝 기반 방법[56, 55, 49, 15]을 포함한 다양한 접근법으로 연구되어 왔다.
평면 스위프 볼륨은 뷰 합성에도 사용되었습니다 [35, 55, 15, 33, 49].
딥러닝을 통해 MPI 기반 방법 [55, 11, 33, 41]은 참조 뷰에서 평면 스위프 볼륨을 작성하는 반면, 다른 방법 [15, 49]은 새로운 시점에서 평면 스위프를 구성한다; 이러한 이전 작업은 일반적으로 이산 스위프 평면의 색상을 예측하고 알파 블렌딩 또는 학습된 가중치를 사용하여 평면당 색상을 집계한다.
평면당 직접 색상 예측 대신, 우리의 접근 방식은 평면 스위프의 복셀당 신경 피쳐를 장면 인코딩 볼륨으로 추론하고 임의의 3D 위치에서 볼륨 렌더링 속성을 회귀시킬 수 있다.
이는 연속적인 neural radiance field를 모델링하여 물리적 기반 볼륨 렌더링을 통해 현실적인 뷰 합성을 달성할 수 있다.
Neural rendering.
최근에는 뷰 합성 및 기하학적 재구성 작업을 달성하기 위해 다양한 신경 장면 표현이 제시되고 있다[55, 45, 28, 2, 34].
특히, NeRF[34]는 MLP와 미분 가능한 볼륨 렌더링을 결합하고 사진 사실적인 뷰 합성을 달성한다.
다음 작업은 뷰 합성[31, 27]에 대한 성능을 향상시키려고 노력했으며, 다른 관련 작업은 동적 뷰 합성[26, 36, 43], 도전 장면[29, 52], 포즈 추정 [32], 실시간 렌더링 [53], 재조명 [37, 1, 9] 및 편집 [48, 6]과 같은 다른 신경 렌더링 작업을 지원하기 위해 확장했다.
우리는 신경 렌더링에 대한 포괄적인 검토를 위해 독자들을 [44]를 참조한다.
그러나 대부분의 이전 작업은 여전히 원래의 NeRF를 따르며 값비싼 장면별 최적화 프로세스가 필요하다.
우리는 대신 deep MVS 기술을 활용하여 적은 이미지만 입력으로 사용하여 뷰 합성을 위한 장면 간 neural radiance field 추정을 달성한다.
우리의 접근 방식은 기하학적 인식 장면 이해를 위해 평면 스윕 3D 비용 볼륨을 활용하여 radiance field 재구성의 일반화를 위해 2D 이미지 피쳐만 고려하는 동시 작업[54, 46]보다 훨씬 나은 성능을 달성한다.
3. MVSNeRF
이제 MVSNeRF를 발표하겠습니다.
장면당 "network memorization"을 통해 radiance field를 재구성하는 NeRF[34]와 달리, MVSNeRF는 radiance field 재구성을 위한 일반 네트워크를 학습한다.
실제 장면의 M 입력 캡처 이미지 I_i (i = 1, ..., M)와 알려진 카메라 매개 변수 Φ_i를 감안할 때, 우리는 radiance field를 신경 인코딩 볼륨으로 재구성하고 이를 사용하여 뷰 합성을 위해 임의의 장면 위치에서 볼륨 렌더링 특성(밀도 및 뷰 의존적 radiance)을 회귀시킬 수 있는 새로운 네트워크를 제시한다.
일반적으로, 우리의 전체 네트워크는 다음

으로 표현되는 radiance field의 함수로 볼 수 있다, 여기서 x는 3D 위치를 나타내고, d는 뷰 방향, σ는 x에서의 부피 밀도, r은 뷰 방향 d에 따라 x에서의 출력 radiance (RGB 색상)를 나타낸다.
우리 네트워크의 출력 볼륨 속성은 미분 가능한 ray marching을 통해 새로운 타겟 시점 Φ_t에서 새로운 이미지 I_t를 합성하는 데 직접 사용될 수 있다.
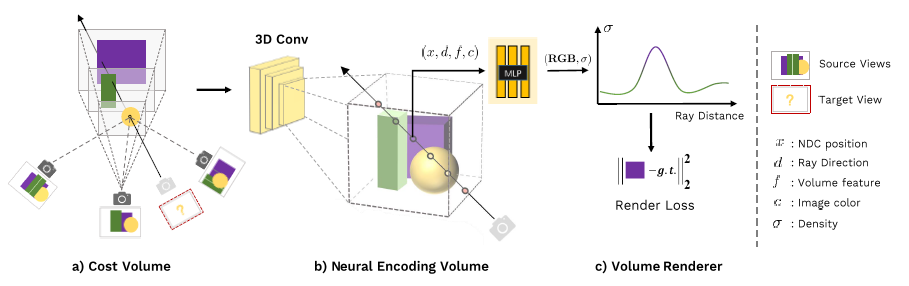
본 논문에서는 효율적인 radiance field 재구성을 위해 근처의 입력 뷰의 희소 집합을 고려한다.
실제로 우리는 실험에 M = 3 뷰를 사용하는 반면, 우리의 접근 방식은 비정형 뷰를 처리하고 다른 수의 입력을 쉽게 지원할 수 있다.
MVSNeRF의 개요는 그림 2에 나와 있습니다.
먼저 2D 신경 피쳐를 여러 스위핑 평면에 왜곡하여 참조 뷰(뷰 i=1을 참조 뷰로 표시)에서 비용 볼륨을 구축한다(섹션 3.1).
그런 다음 3D CNN을 활용하여 신경 인코딩 볼륨을 재구성하고, MLP를 사용하여 볼륨 렌더링 속성을 회귀하여 radiance field를 표현한다(섹션 3.2).
우리는 네트워크에 의해 모델링된 radiance field를 사용하여 새로운 시점에서 이미지를 회귀시키기 위해 미분 가능한 ray marching을 활용한다, 이것은 렌더링 loss(섹션 3.3)로 전체 프레임워크의 종단 간 학습을 가능하게 한다.
우리의 프레임워크는 몇 개의 이미지에서 radiance field 재구성을 달성한다.
한편, 고밀도 이미지가 캡처될 때 재구성된 인코딩 볼륨과 MLP 디코더도 독립적으로 빠르게 미세 조정하여 렌더링 품질을 더욱 향상시킬 수 있다(섹션 3.4).
3.1. Cost volume construction.
최근의 심층 MVS 방법[50]에서 영감을 받아, 우리는 참조 뷰(i=1)에서 비용 볼륨 P를 구축하여 지오메트리 인식 장면 이해를 가능하게 한다.
이는 입력 이미지의 2D 이미지 피쳐를 참조 뷰의 frustum에 있는 평면 스위프 볼륨으로 왜곡해 달성됩니다.
Extracting image features.
우리는 심층 2D CNN T를 사용하여 개별 입력 뷰에서 2D 이미지 피쳐를 추출하여 로컬 이미지 외관을 나타내는 2D 신경 피쳐를 효과적으로 추출한다.
이 하위 네트워크는 다운샘플링 컨볼루션 레이어로 구성되며 입력 이미지 I_i ∈ R^(H_i × W_i × 3)을 2D 피쳐 맵 F_i ∈ R^(H_i/4 × W_i/4 × C),

로 변환한다, 여기서 H와 W는 이미지 높이와 너비이고 C는 결과 피쳐 채널의 수이다.
Warping feature maps.
카메라 intrinsic 및 extrinsic 매개 변수 Φ = [K, R, t]를 고려할 때, 우리는 homographic 왜곡
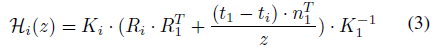
을 고려한다, 여기서 H_i(z)는 뷰 i에서 depth z의 참조 뷰로 행렬 왜곡, K는 intrinsic 행렬, R과 t는 카메라 회전 및 변환이다.
각 피쳐 맵 F_i는 다음을 통해 참조 뷰로 비틀 수 있다:
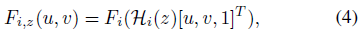
, 여기서 F_(i,z)는 depth z에서 뒤틀린 피쳐 맵이고, (u,v)는 참조 뷰에서 픽셀 위치를 나타냅니다.
본 연구에서는 참조 뷰에서 정규화된 장치 좌표(NDC)를 사용하여 매개 변수화(u, v, z)한다.
Cost volume.
비용 볼륨 P는 D 스위핑 평면의 뒤틀린 피쳐 맵에서 생성된다.
우리는 분산 기반 메트릭을 활용하여 비용을 계산하는데, MVS [50, 10]에서 기하학 재구성을 위해 널리 사용되어 왔다.
특히 (u, v, z)에 중심을 둔 P의 각 복셀에 대해 비용 피쳐 벡터는
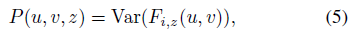
에 의해 계산된다, 여기서 Var는 M 뷰에 대한 분산을 계산한다.
3.2. Radiance field reconstruction.
우리는 심층 신경망을 사용하여 실제 뷰 합성을 위해 구축된 비용 볼륨을 radiance field의 재구성으로 효과적으로 변환할 것을 제안한다.
우리는 3D CNN B를 사용하여 raw 2D 이미지 피쳐 비용의 비용 볼륨 P로부터 신경 인코딩 볼륨 S를 재구성한다; S는 로컬 장면 지오메트리 및 외관을 인코딩하는 복셀당 피쳐로 구성된다.
MLP 디코더 A는 이 인코딩 볼륨에서 볼륨 렌더링 속성을 회귀하는 데 사용됩니다.
Neural encoding volume.
이전 MVS 작품 [50, 18, 10]은 일반적으로 장면 형상만을 표현하는 비용 볼륨에서 직접 depth 확률을 예측한다.
우리는 비용 볼륨에서 더 많은 외관 인식 정보를 유추해야 하는 고품질 렌더링을 달성하는 것을 목표로 한다.
따라서, 우리는 구축된 이미지 피쳐 비용 볼륨을 새로운 C 채널 신경 피쳐 볼륨 S로 변환하기 위해 심층 3D CNN B를 학습하는데, 여기서 피쳐 공간은 다음 볼륨 속성 회귀를 위해 네트워크 자체에 의해 학습되고 발견된다.
이 과정은

로 표현된다.
3D CNN B는 다운 샘플링 및 업샘플링 컨볼루션 레이어와 스킵 연결이 있는 3D UNet으로 장면 모양 정보를 효과적으로 추론하고 전파하여 볼륨 S를 인코딩하는 의미 있는 장면으로 이어질 수 있다.
이 인코딩 볼륨은 unsupervised 방식으로 예측되며 볼륨 렌더링을 사용한 종단 간 학습에서 유추된다(섹션 3.3 참조).
우리의 네트워크는 복셀별 신경 피쳐에서 의미 있는 장면 지오메트리 및 외관을 인코딩하는 것을 배울 수 있다; 이러한 피쳐는 나중에 지속적으로 보간되고 볼륨 밀도 및 뷰 의존적 radiance로 변환된다.
장면 인코딩 볼륨은 2D 피쳐 추출의 다운샘플링으로 인해 상대적으로 저해상도이다; 이 정보만으로 고주파 외관을 회귀시키는 것은 어렵다.
따라서 우리는 또한 다음 볼륨 회귀 단계에 대한 원본 이미지 픽셀 데이터를 통합하지만, 나중에 이 고주파수가 빠른 장면당 미세 조정 최적화(섹션 3.4)를 통해 증강 볼륨에서도 복구할 수 있음을 보여준다.
Regressing volume properties.
임의의 3D 위치 x와 뷰 방향 d가 주어지면, 우리는 MLP A를 사용하여 신경 인코딩 볼륨 S에서 해당하는 볼륨 밀도 σ와 뷰 의존적 radiance r을 회귀시킨다.
앞서 언급한 바와 같이, 우리는 또한 원본 이미지 I_i의 픽셀 색상 c = [I(u_i, v_i)]를 추가 입력으로 간주한다; 여기서 (u_i, v_i)는 뷰 i에 3D 포인트 x를 투영할 때의 픽셀 위치이며, 모든 뷰에서 색상 I(u_i, v_i)를 3M 채널 벡터로 연결한다.
MLP는
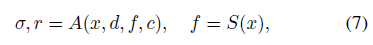
로 표현된다, 여기서 f = S(x)는 x 위치의 볼륨 S에서 3차 보간된 신경 피쳐이다.
특히, x는 참조 뷰의 NDC 공간에서 매개 변수화되고 참조 뷰의 좌표에서 단위 벡터로 표시된다.
NDC 공간을 사용하면 서로 다른 데이터 소스에 걸쳐 장면 척도를 효과적으로 정규화할 수 있어 우리 방법의 좋은 일반화 가능성에 기여할 수 있다.
또한 NeRF[34]에서 영감을 받아 위치 및 방향 벡터(x 및 d)에 위치 인코딩을 적용하여 결과의 고주파 세부 정보를 더욱 강화한다.
Radiance field.
결과적으로, 우리의 전체 프레임워크는 몇 개의 입력 이미지에서 장면의 볼륨 밀도와 뷰 의존적 radiance를 회귀시키는 neural radiance field를 모델링한다.
또한 장면 인코딩 볼륨 S가 재구성되면 MLP 디코더 A와 결합된 이 볼륨을 2D 및 3D CNN을 추가하지 않고도 독립적으로 사용할 수 있다.
이들은 radiance field의 독립적 신경 표현으로 볼 수 있으며, 볼륨 속성을 출력하여 볼륨 렌더링을 지원한다.
3.3. Volume rendering and end-to-end training.
우리의 MVSNeRF는 신경 인코딩 볼륨을 재구성하고 장면의 임의 지점에서 볼륨 밀도와 뷰 의존적 radiance를 회귀시킨다.
이를 통해 이미지 색상을 회귀시키기 위해 미분 가능한 볼륨 렌더링을 적용할 수 있습니다.
Volume rendering.
물리적 기반 볼륨 렌더링 방정식은 뷰 합성을 위해 (NeRF [34]에서와 같이) 미분 가능한 ray marching을 통해 수치적으로 평가할 수 있다.
특히, 픽셀의 radiance 값(색상)은 다음과 같이 주어진 픽셀을 통해 ray를 marching하고 ray의 샘플링된 음영 지점에서 radiance를 누적함으로써 계산된다:
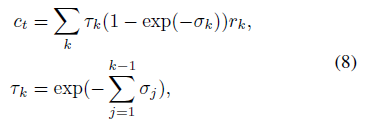
여기서 c_t는 최종 픽셀 색 출력이고 τ는 볼륨 전송률을 나타냅니다.
radiance field 함수으로서의 MVSNeRF는 기본적으로 ray marching을 위한 볼륨 렌더링 속성 σ_k 및 r_k를 제공한다.
End-to-end training.
이 ray marching 렌더링은 완전히 미분 가능하므로, 우리의 프레임워크가 종단 간 세 개의 입력 뷰를 사용하여 새로운 시점에서 최종 픽셀 색상을 회귀시킬 수 있다.
우리는 L2 렌더링 loss

을 사용하여 전체 프레임워크를 ground truth 픽셀 색상으로 supervise한다, 여기서 ~c_t는 새로운 관점에서 타겟 이미지 I_t에서 샘플링된 ground truth 픽셀 색이다.
이것이 우리가 전체 시스템을 supervise하는데 사용하는 유일한 loss이다.
물리적으로 기반을 둔 볼륨 렌더링과 종단 간 학습 덕분에 렌더링 supervision은 모든 네트워크 구성 요소를 통해 장면 모양과 대응 정보를 전파하고 최종 뷰 합성을 위해 이를 정규화할 수 있다.
장면별 학습에 주로 초점을 맞춘 이전의 NeRF 작업[34, 31, 27]과 달리, 우리는 DTU 데이터 세트의 서로 다른 장면에서 전체 네트워크를 학습시킨다.
우리의 MVSNeRF는 비용 볼륨 처리에서 기하학적 인식 장면 추론의 이점을 얻고 고품질 뷰 합성을 가능하게 하는 새로운 테스트 장면에서 radiance fields를 신경 인코딩 볼륨으로 재구성할 수 있는 일반적인 함수를 효과적으로 학습할 수 있다.
3.4. Optimizing the neural encoding volume.
여러 장면에서 학습할 때, MVSNeRF는 세 개의 입력 이미지에서만 여러 장면에서 radiance field를 재구성하는 강력한 일반화 함수를 이미 배울 수 있다.
그러나 입력이 제한되어 있고 다른 장면과 데이터 세트에 걸쳐 다양성이 높기 때문에, 그러한 일반적인 솔루션을 사용하여 다른 장면에서 완벽한 결과를 얻는 것은 매우 어렵다.
반면, NeRF는 고밀도 입력 이미지에 대해 장면당 최적화를 수행하여 이러한 하드 일반화 문제를 방지한다; 이는 사실적인 결과를 가져오지만 비용이 매우 많이 든다.
대조적으로, 우리는 신경 인코딩 볼륨을 미세 조정할 것을 제안한다 – 네트워크를 통해 즉시 재구성할 수 있는 몇 가지 이미지 – 고밀도 이미지가 캡처될 때 빠른 데이터당 최적화를 달성할 수 있습니다.
Appending colors.
언급한 바와 같이, 우리의 신경 인코딩 볼륨은 MLP 디코더(식 (7))로 전송될 때 픽셀 색상과 결합된다.
미세 조정을 위해 이 설계를 유지하는 것은 여전히 작동하지만 항상 세 가지 입력에 의존하는 재구성을 초래한다.
우리는 대신 복셀 센터의 뷰별 색상을 인코딩 볼륨에 추가 채널로 추가하여 독립적인 신경 재구성을 달성한다; 이러한 색상은 장면별 최적화에서도 학습할 수 있다.
이 간단한 첨부는 처음에 렌더링에 모호함을 초래하지만 미세 조정 프로세스에서 매우 빠르게 해결된다.
Optimization.
색을 추가한 후, MLP를 사용한 신경 인코딩 볼륨은 합리적인 이미지를 이미 합성할 수 있는 괜찮은 초기 radiance field이다.
우리는 고밀도 이미지를 사용할 수 있을 때 빠른 장면당 최적화를 수행하기 위해 MLP 디코더와 함께 복셀 피쳐를 추가로 미세 조정할 것을 제안한다.
전체 네트워크 대신 인코딩 볼륨과 MLP만 최적화합니다.
이는 최적화에 따라 복셀별 로컬 신경 피쳐를 독립적으로 조정할 수 있는 신경 최적화에 더 많은 유연성을 부여한다; 이는 복셀 간에 공유 컨볼루션 연산을 최적화하려고 시도하는 것보다 더 쉬운 작업이다.
또한 이 미세 조정은 2D CNN, 평면 스위프 왜곡 및 3D CNN의 값비싼 네트워크 처리를 방지한다.
따라서 그림 3에서 보는 바와 같이, 우리의 최적화는 매우 빠를 수 있으며, 처음부터 NeRF를 최적화하는 것보다 훨씬 적은 시간이 소요됩니다.

우리의 장면별 최적화는 [34, 27]과 유사한 입력 이미지 데이터(색상 채널 추가 덕분에)와 독립적으로 깨끗한 신경 재구성을 유도한다; 따라서 고밀도 입력 이미지는 최적화 후에 드롭될 수 있다.
이와는 대조적으로, 동시 작업[54, 46]에서는 렌더링을 위해 입력 이미지를 유지해야 합니다.
우리의 인코딩 볼륨은 또한 Sparse Voxel fields [27]와 유사하지만, 우리의 네트워크는 처음에 [27]의 순수한 장면별 최적화 대신 빠른 추론을 통해 예측된다.
반면에, 우리는 [27]에서 수행한 것처럼 더 나은 성능을 위해 미세 조정에서 볼륨 그리드를 잠재적으로 세분화할 수 있다.
4. Implementation details
Dataset.
우리는 일반화 가능한 네트워크를 학습하기 위해 DTU[20] 데이터 세트에 대한 프레임워크를 학습한다.
우리는 PixelNeRF[54]를 따라 88개의 학습 장면과 16개의 테스트 장면으로 데이터를 분할하고 512×640의 이미지 해상도를 사용한다.
또한 학습 세트와 장면 및 뷰 분포가 다른 Realistic Synthetic NeRF 데이터[34] 및 Forward-Facing 데이터[33]에 대해 모델(DTU에 대해서만 학습됨)을 테스트한다.
각 테스트 장면에 대해 20개의 주변 뷰를 선택한 다음, 3개의 중앙 뷰를 입력으로, 13개의 장면별 미세 조정을 위한 추가 입력을 선택하고 나머지 4개를 테스트 뷰로 선택합니다
Network details.
피처 추출에 f = 32 채널을 사용하며, 이는 비용 볼륨 및 신경 인코딩 볼륨(색상 채널을 추가하기 전)의 피처 채널 수이기도 하다.
우리는 평면 스위프 볼륨을 지정하기 위해 근방에서 먼 곳까지 균일하게 샘플링된 D = 128 depth 가설을 채택한다.
우리의 MLP 디코더는 NeRF[34]의 MLP와 유사하지만 6개의 레이어로 구성된 더 컴팩트하다.
NeRF가 두 개의 (coarse 및 fine) radiance fields를 별도의 네트워크로 재구성하는 것과 달리, 우리는 하나의 단일 radiance field만 재구성하고 이미 좋은 결과를 얻을 수 있다.
동일한 초기화로 두 개의 개별 인코딩 볼륨을 최적화하여 미세 조정 시 coarse하고 fine한 radiance field로 확장할 수 있다.
ray marching의 경우 각 marching ray에서 128개의 음영 점을 샘플링한다.
우리는 보충 자료에서 상세한 네트워크 구조를 보여준다.
우리는 하나의 RTX 2080 Ti GPU를 사용하여 네트워크를 학습한다.
DTU에 대한 장면 횡단 학습을 위해 하나의 새로운 관점에서 랜덤으로 1024픽셀을 샘플링하고, 초기 학습 속도가 5e-4인 Adam [22] 최적화 도구를 사용한다.
5. Experiments
이제 방법을 평가하고 결과를 보여준다.
Comparisons on results with three-image input.
우리는 또한 radiance field 재구성의 일반화를 달성하는 것을 목표로 하는 PixelNeRF[54]와 IBRNet[46]이라는 두 개의 최근 동시 작업과 비교한다.
우리는 공개된 코드와 PixelNeRF의 학습된 모델을 사용하고 DTU 데이터에 대한 IBRNet 재학습(섹션 4 참조)을 사용한다.
우리는 논문에서 사용된 3개의 입력 뷰를 사용하여 이러한 방법을 학습하고 테스트한다.
우리는 동일한 입력 뷰로 3개의 데이터 세트[34, 20, 33]의 모든 방법을 비교하고 4개의 추가 이미지를 사용하여 각 장면을 테스트한다.
우리는 표 1의 정량적 결과와 그림 4의 시각적 비교를 보여준다.
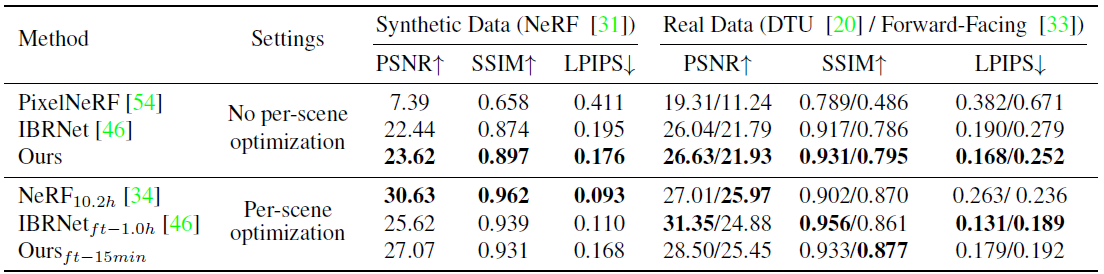

그림 4에서 보듯이, 우리의 접근 방식은 서로 다른 데이터 세트에 걸쳐 세 개의 이미지만 입력으로 사용하여 현실적인 뷰 합성 결과를 달성할 수 있다.
우리 모델은 DTU에서만 학습되지만, 장면과 뷰 분포가 매우 다른 두 데이터 세트로 잘 일반화될 수 있다.
대조적으로, PixelNeRF[54]는 DTU의 학습 설정을 과적합시키는 경향이 있다.
DTU 테스트 장면에서 합리적으로 작동하지만, Realistic Synthetic 장면에서 명백한 아티팩트를 포함하고 심지어 Forward-Facing 장면에서 완전히 실패한다.
IBRNet[46]은 다른 데이터세트에서 테스트할 때 pixelNeRF보다 더 나은 작업을 수행할 수 있지만, 부록 비디오에서 보여지는 것처럼 깜박임 아티팩트는 여전히 관찰될 수 있고 우리 데이터세트보다 훨씬 더 명백하다.
이러한 시각적 결과는 표 1에 표시된 정량적 결과를 명확하게 반영한다.
세 가지 방법은 모두 DTU 테스트 세트에서 합리적인 PSNR, SSIM 및 LPIP를 얻을 수 있다.
그러나 우리의 접근 방식은 세 가지 메트릭 모두에 대해 동일한 입력으로 PixelNeRF 및 IBRNet을 지속적으로 능가한다.
더 인상적이게도, 다른 두 테스트 데이터 세트에 대한 우리의 결과는 비교 방법보다 훨씬 더 뛰어나 우리 기술의 좋은 일반화 가능성을 분명히 보여준다.
일반적으로 두 가지 비교 방법은 모두 radiance field 추론을 위해 ray marching 지점에서 교차 뷰 2D 이미지 피처를 직접 집계한다.
우리의 접근 방식은 대신 평면 스위프 비용 볼륨에서 지오메트리 인식 장면 추론을 위한 MVS 기술을 활용하고, 로컬화된 radiance field 표현을 명시적인 3D 구조를 가진 신경 인코딩 볼륨으로 재구성한다.
따라서 다양한 테스트 장면에서 최상의 일반성과 최고의 렌더링 품질로 이어집니다.
Per-scene fine-tuning results.
또한 네트워크에서 예측한 신경 인코딩 볼륨(섹션 3.4)을 미세 조정하여 생성된 표 1과 그림 4의 16개의 추가 입력 이미지를 사용하여 장면당 최적화 결과를 보여준다.
우리의 네트워크에서 얻은 강력한 초기화 때문에, 우리는 신경 재구성을 15분(10k 반복)의 짧은 기간 동안만 미세 조정할 수 있으며, 이는 이미 사실적인 결과로 이어질 수 있다.
우리는 빠른 미세 조정 결과를 훨씬 더 긴 최적화 시간(최대 10.2시간)으로 생성된 NeRF의 [34] 결과와 비교한다.
초기 렌더링 결과는 15분 미세 조정만으로도 크게 향상될 수 있으며, 이는 30배 더 긴 최적화 시간으로 NeRF 결과보다 동등하거나 더 나은 고품질 결과(Realistic Synthetic) 또는 더 나은 결과(DTU 및 Forward-Facing)로 이어진다.
우리는 또한 그림 3에서 방법과 NeRF의 최적화 진행률을 다른 최적화 시간과 비교하는 하나의 예시 장면에서 결과를 보여주는데, 이는 우리 기술의 훨씬 빠른 수렴을 명확하게 보여준다.
일반 네트워크를 사용하여 강력한 초기 radiance field를 달성함으로써, 우리의 접근 방식은 밀도가 높은 이미지를 사용할 수 있을 때 장면당 radiance field를 매우 실용적인 재구성할 수 있다.

Depth reconstruction.
우리의 접근 방식은 장면 지오메트리를 볼륨 밀도로 나타내는 radiance field를 재구성한다.
우리는 부피 밀도에서 생성된 depth 재구성 결과를 marching된 ray에 샘플링된 점의 depth 값의 가중 합으로 비교함으로써 기하학적 재구성 품질을 평가한다([34]에서 수행됨).
우리는 우리의 접근 방식을 DTU 테스트 세트에서 두 가지 비교 radiance field 방법[54, 46] 및 고전적인 심층 MVSNet[50]과 비교한다.
비용 볼륨 기반 재구성 덕분에, 우리의 접근 방식은 다른 신경 렌더링 방법보다 훨씬 더 정확한 depth를 달성한다[54, 46].
우리의 네트워크는 렌더링 supervision만으로 학습되고 depth supervision은 없지만, 우리 접근 방식은 직접적인 depth supervision이 있는 MVS 방법에 필적하는 높은 재구성 정확도를 달성할 수 있다.
이는 사실적인 렌더링을 이끄는 중요한 요소 중 하나인 지오메트리 재구성의 높은 품질을 보여준다.
6. Conclusion
고품질 radiance field 재구성 및 현실적인 신경 렌더링을 위한 새로운 일반화 접근 방식을 제시한다.
우리의 접근 방식은 심층 MVS와 신경 렌더링의 주요 이점을 결합하여 비용 볼륨 기반 장면 추론을 물리적 기반 신경 볼륨 렌더링에 성공적으로 통합한다.
우리의 접근 방식은 세 개의 입력 뷰에서만 고품질 radiance field 재구성을 가능하게 하고 재구성의 현실적인 뷰 합성 결과를 얻을 수 있다.
우리의 방법은 다양한 테스트 데이터 세트에 걸쳐 잘 일반화되며 일반화 가능한 radiance field 재구성에 대한 동시 작업[54, 46]을 크게 능가할 수 있다.
우리의 신경 재구성은 고밀도 입력 이미지를 사용할 수 있는 경우 장면당 최적화를 위해 쉽게 미세 조정될 수 있어 최적화 시간을 크게 줄이면서 NeRF보다 나은 사실적 렌더링을 달성할 수 있다.
우리 작업은 적은 수 또는 조밀한 이미지를 입력으로 사용하여 실용적인 신경 렌더링 기술을 제공한다.