2022. 4. 30. 10:36ㆍView Synthesis
IBRNet: Learning Multi-View Image-Based Rendering
Qianqian Wang, Zhicheng Wang, Kyle Genova, Pratul Srinivasan, Howard Zhou, Jonathan T. Barron, Ricardo Martin-Brualla, Noah Snavely, Thomas Funkhouser
Abstract
우리는 가까운 뷰의 희박한 세트를 보간하여 복잡한 장면의 새로운 뷰를 합성하는 방법을 제시한다.
우리 방법의 핵심은 연속된 5D 위치(3D 공간 위치 및 2D 뷰 방향)에서 radiance와 부피 밀도를 추정하는 다층 퍼셉트론과 ray 트랜스포머를 포함하는 네트워크 아키텍처로, 여러 소스 뷰에서 즉시 외관 정보를 그린다.
렌더링 시 소스 뷰에 그림을 그리면 image-based rendering (IBR)에 대한 고전적인 작업을 다시 듣고 고해상도 이미지를 렌더링할 수 있다.
렌더링을 위해 장면별 피쳐를 최적화하는 신경 장면 표현 작업과 달리, 우리는 새로운 장면으로 일반화하는 일반적인 뷰 보간 함수를 학습한다.
우리는 완전히 미분 가능하고 다중 뷰 포즈된 이미지만을 supervision으로 사용하여 학습할 수 있는 고전적인 볼륨 렌더링을 사용하여 이미지를 렌더링한다.
실험에 따르면 우리의 방법은 새로운 장면으로 일반화를 추구하는 최근의 새로운 뷰 합성 방법을 능가한다.
또한, 각 장면에서 미세 조정될 경우, 우리의 방법은 SOTA 단일 장면 신경 렌더링 방법과 경쟁력이 있다.
1. Introduction
장면의 포즈된 이미지 세트가 주어지면, 새로운 뷰 합성의 목표는 새로운 시점에서 동일한 장면의 사진 사실적 이미지를 생성하는 것이다.
새로운 뷰 합성에 대한 초기 연구는 image-based rendering (IBR)에 초점을 맞췄다.
Chen과 Williams의 뷰 보간에 대한 선구적인 연구[6]에서 시작하여, 라이트 필드 렌더링[3, 15, 28], 뷰 의존적 텍스처링[8] 및 보다 현대적인 학습 기반 방법[17]을 통해 IBR 방법은 일반적으로 소스 뷰를 타겟 뷰로 왜곡, 재샘플링 및/또는 혼합하여 작동한다.
이러한 방법들은 고해상도 렌더링을 가능케 하지만 일반적으로 매우 조밀한 입력 뷰나 명시적인 프록시 지오메트리를 필요로 하는데, 이는 렌더링 시 아티팩트로 이어지는 높은 품질로 추정하기 어렵다.
보다 최근에, 새로운 뷰 합성을 위한 가장 유망한 연구 방향 중 하나는 장면을 신경망의 가중치로 나타내는 신경 장면 표현이다.
이 연구 분야는 Neural Radience Fields (NeRF)의 사용을 통해 상당한 진전을 보았다[40].
NeRF는 위치 인코딩과 결합된 multi-layer perceptron (MLP)을 사용하여 장면의 연속 5D radiance field를 나타낼 수 있어 복잡한 실제 장면에서 사진-사실적 새로운 뷰 합성이 가능하다는 것을 보여준다.
명시적 이산화된 볼륨[56] 또는 다중 평면 이미지[12, 70]와 달리 NeRF는 MLP를 통한 연속 장면 모델링을 사용하여 보다 콤팩트한 표현과 더 큰 뷰 볼륨으로 스케일링할 수 있다.
NeRF와 같은 신경 장면 표현은 장면을 충실하고 간결하게 표현할 수 있지만, 일반적으로 각 새로운 장면의 새로운 뷰를 합성하기 전에 각 새로운 장면에 대한 긴 최적화 프로세스가 필요하며, 이는 많은 실제 응용 분야에서 이러한 방법의 가치를 제한한다.
본 연구에서는 IBR과 NeRF의 아이디어를 새로운 뷰를 렌더링하기 위해 여러 소스 뷰에서 연속적인 장면 radiance field를 즉시 생성하는 새로운 학습 기반 방법에 활용한다.
우리는 ray를 렌더링하는 동안 밀도/폐색/가시성 추론과 색상 블렌딩을 동시에 수행하는 일반 뷰 보간 함수를 학습한다.
이를 통해 우리 시스템은 장면별 최적화나 사전 계산된 프록시 지오메트리 없이 작동할 수 있다.
우리 방법의 핵심은 IBRNet이라고 하는 경량 MLP 네트워크로, 주어진 ray를 따라 소스 뷰의 정보를 집계하여 최종 색상을 계산한다.
ray를 따라 샘플링된 3D 위치의 경우, 네트워크는 먼저 공간 컨텍스트를 인코딩하는 인근 소스 뷰에서 파생된 잠재적 2D 피쳐를 가져온다.
그런 다음 IBRNet은 샘플링된 각 위치에 대해 이러한 2D 피쳐를 집계하여 해당 피쳐가 표면에 있는 것처럼 보이는지 여부에 대한 정보를 캡처하는 밀도 피쳐를 생성한다.
그런 다음 ray 트랜스포머 모듈은 전체 ray를 따라 이러한 밀도 피쳐를 고려하여 각 샘플에 대한 스칼라 밀도 값을 계산하여 더 큰 공간 스케일에서 가시성 추론을 가능하게 한다.
이와는 별도로, 색상 블렌딩 모듈은 소스 뷰의 2D 피쳐와 뷰 방향 벡터를 사용하여 소스 뷰의 투영된 색상의 가중 조합으로 계산된 각 샘플에 대한 뷰 종속 색상을 도출한다.
그런 다음 볼륨 렌더링을 사용하여 각 ray에 대한 최종 색상 값을 계산합니다.
우리의 접근 방식은 완전히 미분 가능하므로 멀티 뷰 이미지를 사용하여 종단 간 학습을 할 수 있다.
우리의 실험은 많은 양의 데이터에 대해 학습될 때, 우리의 방법이 복잡한 기하학과 재료를 포함하는 보이지 않는 장면에 대해 고해상도 사진 사실적 새로운 뷰를 렌더링할 수 있다는 것을 보여주며, 우리의 정량적 평가는 그것이 한 번의 샷으로 일반화하도록 설계된 SOTA 새로운 뷰 합성 방법을 개선한다는 것을 보여준다.
정경 또한 특정 장면에 대해 NeRF[40]와 같은 SOTA 신경 장면 표현 방법의 성능과 일치하도록 IBRNet을 미세 조정할 수 있다.
요약하면, 우리의 기여는 다음과 같습니다:
– 새로운 장면에서 기존의 원샷 뷰 합성 방법을 능가하는 새로운 학습 기반 멀티 뷰 이미지 기반 렌더링 접근 방식,
– IBRNet이라고 불리는 새로운 모델 아키텍처는 여러 뷰에서 공간의 색과 밀도를 지속적으로 예측할 수 있게 합니다.
– 단일 스탬프 추론을 위해 설계된 SOTA 새로운 뷰 합성 방법과 동등한 성능을 달성하는 스탬프별 미세 조정 절차.
2. Related work
Image based rendering.
IBR에 대한 초기 연구는 참조 픽셀의 가중 혼합을 통해 일련의 참조 이미지에서 새로운 뷰를 합성하는 아이디어를 도입했다[9, 15, 28].
혼합 가중치는 ray 공간 근접성 [28] 또는 근사 프록시 지오메트리 [3, 9, 19]를 기반으로 계산되었다.
보다 최근의 연구에서, 연구자들은 프록시 기하학[5, 18], optical flow 보정[4, 10, 11] 및 소프트 블렌딩[46, 51]을 위한 개선된 방법을 제안했다.
예를 들어, Hedman et al. [17]은 두 가지 유형의 다중 뷰 스테레오[22, 53]를 사용하여 뷰 종속 메시 표면을 생성한 다음 CNN을 사용하여 혼합 가중치를 계산한다.
다른 것들은 메쉬 표면[8, 21, 62] 또는 포인트 클라우드 [1, 38, 47]에서 직접 radiance field를 합성한다.
이러한 방법은 다른 접근 방식보다 더 희박한 뷰를 처리하고 경우에 따라 유망한 결과를 얻을 수 있지만, 3D 재구성 알고리즘의 성능에 의해 근본적으로 제한된다[22, 53].
이들은 스테레오 재구성이 실패하는 경향이 있는 저질감 또는 반사 영역에서 어려움을 겪으며 부분적으로 반투명 표면을 다룰 수 없다.
대조적으로, 우리의 방법은 합성 품질에 최적화된 종단 간 방식으로 연속 볼륨 밀도를 학습하여 까다로운 시나리오에서 더 나은 성능을 제공한다.
Volumetric Representations.
다른 작업 라인은 이산 체적 표현을 사용하여 사진 사실적 렌더링을 달성한다.
최근의 방법은 컨볼루션 신경망(CNN)을 활용하여 복셀 그리드[20, 25, 26, 46, 64] 또는 다중 평면 이미지(MPI)[12, 13, 31, 39, 59, 70]에 저장된 체적 표현을 예측한다.
테스트 시, 알파 합성[48]을 통해 이러한 표현으로부터 새로운 뷰를 렌더링할 수 있다.
대규모 데이터 세트에 대해 학습된 이러한 방법은 종종 저해상도 복셀 그리드의 이산화 아티팩트를 보상하는 방법을 배우고 다른 장면으로 합리적으로 일반화할 수 있다.
고품질 뷰 합성 결과를 달성하지만, 많은 샘플을 명시적으로 처리 및 저장해야 하므로 출력의 해상도가 제한된다.
출력의 해상도가 제한된다.
대조적으로, 우리의 방법은 전체 장면 표현을 저장하지 않고 연속적인 3D 위치와 2D 뷰 방향에서 색과 불투명도를 쿼리할 수 있으며 고해상도 이미지를 렌더링하도록 크기를 조정할 수 있다.
우리의 방법은 또한 MPI 기반 방법보다 더 큰 뷰 볼륨을 처리할 수 있다.
Neural scene representations.
최근 유망한 연구 방향은 장면의 외관과 모양을 나타내기 위해 신경망을 사용하는 것이다.
이전 연구[2, 14, 23, 37, 42, 44, 66]는 MLP의 가중치가 연속 공간 좌표를 부호 있는 거리 또는 점유 값에 매핑하는 암묵적 형상 표현으로 사용될 수 있음을 보여주었다.
미분 가능한 렌더링 방법[7, 24, 29, 33, 34, 41]의 진보와 함께, 많은 방법[32, 35, 41, 52, 54, 56, 57, 61, 67]은 단순한 기하학과 확산 재료에 대한 멀티 뷰 관찰로부터 장면 지오메트리와 외관을 모두 학습하는 능력을 보여주었다.
보다 최근의 NeRF[40]는 장면에 대한 5D 신경 radiance field를 최적화하여 새로운 뷰 합성에 매우 인상적인 결과를 달성하며, 복셀 그리드 또는 메시와 같은 이산적 표현에 비해 연속적인 표현의 이점을 제시한다.
NeRF는 많은 새로운 연구 기회를 열어주지만 [30, 36, 43, 45, 55, 58] 새로운 장면마다 최적화되어야 하며, 수렴하는 데 몇 시간 또는 며칠이 걸린다.
동시 작업[63, 68]은 이 문제를 해결하고 NeRF를 일반화하기 위해 노력한다(매우 희박한 입력 뷰에 중점을 둔다).
그러나 직접적인 네트워크 입력으로 절대 위치를 사용하는 것은 임의의 새로운 장면으로 일반화하는 능력을 제한한다.
대조적으로, 우리의 방법은 고품질의 새로운 실제 장면으로 일반화할 수 있다.
3. Method
주변 소스 뷰가 주어지면, 우리의 방법은 볼륨 렌더링을 사용하여 새로운 카메라 포즈에서 타겟 뷰를 합성한다.
우리가 해결하려고 하는 핵심 문제는 소스 뷰에 존재하는 정보를 집계하여 연속적인 공간에서 색과 밀도를 얻는 것이다.
우리의 시스템 파이프라인(그림 1)은 세 부분으로 나눌 수 있습니다:
1) 주변 소스 뷰 집합을 입력으로 식별하고 각 소스 뷰에서 조밀한 피쳐를 추출합니다.
2) 볼륨 밀도 σ 및 색상 예측 연속 5D 위치(3D 공간 위치 및 2D 뷰 방향),
그리고 3) 볼륨 렌더링을 통해 각 카메라 ray를 따라 색상과 밀도를 합성하여 합성된 이미지를 생성합니다.

3.1. View selection and feature extraction
전체 장면을 단일 네트워크로 인코딩하려고 시도하는 신경 장면 표현과 달리, 우리는 가까운 소스 뷰를 보간하여 새로운 타겟 뷰를 합성한다.
우리의 네트워크(다음 섹션에서 설명)는 임의의 수의 인접 뷰를 처리할 수 있지만, 제한된 GPU 메모리가 주어지면 새로운 뷰를 렌더링하기 위한 "working set"로 적은 수의 소스 뷰를 선택한다.
효과적인 작업 세트를 얻기 위해, 우리는 공간적으로 가까운 후보 뷰를 식별한 다음, 뷰 방향이 타겟 뷰와 가장 유사한 N개의 뷰의 하위 세트를 선택한다.
I_i ∈ [0, 1]^(H_i x W_i x 3) 및 P_i ∈ R^(3x4)가 각각 i번째 소스 뷰에 대한 컬러 이미지 및 카메라 투영 행렬을 나타내도록 합니다.
우리는 공유 U-Net 기반 컨볼루션 신경망을 사용하여 각 이미지 I_i에서 조밀한 피쳐 F_i ∈ R^(H_i x W_i x d)을 추출한다.
튜플 집합 {(I_i,P_i,F_i)}_(i=1)^N은 타겟 뷰를 렌더링하기 위한 입력을 형성한다.

3.2. RGB-σ prediction using IBRNet
우리의 방법은 고전적인 볼륨 렌더링을 기반으로 이미지를 합성하여 3D 장면에서 색과 밀도를 누적하여 2D 이미지를 렌더링한다.
우리는 여러 소스 뷰의 정보를 집계하고 ray를 따라 장거리 컨텍스트를 통합하여 연속적인 5D 위치에서 색과 밀도를 예측하는 IBRNet(그림 2에 그림)을 제안한다.
우리가 제안한 IBRNet은 순열 불변이며 가변적인 수의 소스 뷰를 받아들인다.
먼저 단위 길이 뷰 방향이 d ∈ R^3인 ray r ∈ R^3의 단일 쿼리 지점 위치 x ∈ R^3에 대한 IBRNet에 대한 입력을 설명한다.
우리는 카메라 매개 변수를 사용하여 x를 모든 소스 뷰에 투영하고, 쌍선형 보간을 통해 투영된 픽셀 위치의 색상과 피쳐를 추출한다.
{C_i}_(i=1)^N ∈ [0, 1]^3 및 {f_i}_(i=1)^N ∈ R^d가 각각 점 x에 대해 추출된 색상과 이미지 피쳐를 나타내도록 하자.
우리는 또한 {d_i}_(i=1)^N으로 표시되는 모든 소스 뷰에서 x에 대한 뷰 방향을 고려한다.
3.2.1 Volume density prediction
점(x, d)에서의 밀도 예측은 두 단계를 포함한다.
먼저 (x, d)에서 다중 뷰 피쳐를 집계하여 밀도 피쳐를 얻는다.
그런 다음, 우리가 제안한 ray 트랜스포머는 ray의 모든 샘플에 대한 밀도 피쳐를 취하고 (x, d)를 포함한 각 샘플에 대한 밀도를 예측하기 위해 장거리 상황 정보를 통합한다.
Multi-view feature aggregation.
우리는 표면의 3D 점이 여유 공간의 3D 점보다 여러 뷰에서 일관된 로컬 모양을 가질 가능성이 더 높다는 것을 관찰한다.
따라서 밀도를 추론하는 효과적인 방법은 주어진 점에 대해 피쳐 {f_i}_(i=1)^N 사이의 일관성을 확인하는 것이며, 가능한 구현은 멀티 뷰 피쳐를 취하고 분산을 전역 풀링 연산자로 사용하는 PointNet과 유사한 [49] 아키텍처가 될 것이다.
구체적으로, 우리는 먼저 전역 정보를 포착하기 위해 피쳐 {f_i}_(i=1)^N에서 제곱당 평균 μ ∈ R^d 및 분산 v ∈ R^d를 계산하고, 각 f_i를 μ 및 v와 연결한다.
연결된 각 피처는 로컬 및 전역 정보를 모두 통합하기 위해 작은 공유 MLP로 공급되어 멀티 뷰 인식 피처 f_i'와 가중치 벡터 w_i ∈ [0, 1]을 생성한다.
MLP를 사용하여 밀도 피쳐 f_σ ∈ R^(d_σ)에 매핑된 가중치 {w_i}_(i=1)^N을 사용하여 가중 평균 및 분산을 계산하여 이러한 새로운 피쳐 {f_i'}_(i=1)^N을 풀링한다.
PointNet[49]의 직접 평균 또는 최대 풀링과 비교하여, 가중 풀링이 네트워크의 폐색 처리 능력을 향상시킨다는 것을 발견했다.
Ray transformer.
밀도 피쳐 f_σ를 얻은 후, 다른 MLP와 함께 이를 단일 밀도 σ로 직접 바꿀 수 있다.
그러나 이러한 접근 방식은 복잡한 기하학이 있는 새로운 장면에 대한 정확한 밀도를 예측하는 데 실패한다는 것을 발견했다.
우리는 이를 단일 지점에 대한 피쳐를 단독으로 보는 것은 밀도를 정확하게 예측하는 데 불충분하며, 특정 픽셀의 depth를 결정하기 전에 평면 스위프 스테레오 방법이 전체 ray를 따라 점수를 일치시키는 방법을 고려하는 것과 유사하게 더 많은 상황 정보가 필요하다는 사실로 돌렸다.
따라서 우리는 새로운 ray 트랜스포머 모듈을 도입하여 ray의 샘플이 밀도를 예측하기 전에 서로 대응할 수 있도록 한다.
ray 트랜스포머는 고전적인 트랜스포머의 두 가지 핵심 부품으로 구성됩니다 [65] : 위치 인코딩 및 셀프 어텐션.
ray를 따라 M개의 샘플이 주어지면, 우리 ray 트랜스포머는 가까운 곳부터 먼 곳까지의 샘플을 시퀀스로 처리하고, 위치 인코딩 및 다중 헤드 셀프 어텐션을 밀도 피쳐 시퀀스에 적용한다(f_σ(x_1), · · ·, f_σ(x_M)).
그런 다음 각 샘플에 대한 최종 밀도 값 σ는 참석한 피쳐에서 예측된다.
ray 트랜스포머 모듈은 가변적인 수의 입력을 허용하고 매개 변수와 계산 오버헤드의 작은 증가만을 도입하는 동시에 ablation 연구에서 보여 주듯이 예측된 밀도와 최종 합성 이미지의 품질을 극적으로 향상시킨다.
Improving temporal visual consistency.
우리의 방법은 타겟 뷰를 합성할 때 근처 소스 뷰만 작업 세트로 간주한다.
따라서 매끄러운 카메라 경로를 따라 비디오를 생성할 때, 우리의 방법은 카메라가 이동함에 따라 작업 세트의 갑작스러운 변화로 인해 일시적으로 일관성 없는 밀도 예측과 깜박임 아티팩트의 영향을 받을 수 있다.
이 문제를 완화하기 위해 Sun et al. [60]의 풀링 기법을 채택한다.
우리는 작업 세트에서 가장 먼 이미지의 영향을 줄이기 위해 가중 평균 μ_w와 분산 v_w로 {f_i}_(i=1)^N의 평균 μ와 분산 v_w를 교체한다.
가중 함수는 다음과 같이 정의된다:

, 여기서 s는 학습 가능한 매개 변수입니다.
이 기술은 두 가지 방법으로 우리의 방법을 개선한다:
1) 인접 프레임 간의 전역 피쳐의 변화를 부드럽게 한다.
그리고 2) 작업 세트에서 더 가까운 뷰를 상향 조정하고 더 먼 뷰를 하향 조정하여 더 합리적인 전역 피쳐를 생성한다.
우리는 이 기술이 합성 안정성과 품질을 경험적으로 향상시킨다는 것을 관찰한다.
3.2.2 Color prediction
우리는 5D 지점에 해당하는 소스 뷰에서 이미지 색상 {C_i}_(i=1)^N에 대한 혼합 가중치를 예측하여 5D 지점에서 색상을 얻는다.
절대 뷰 방향을 사용하는 NeRF [40]와 달리, 우리는 소스 뷰의 뷰 방향, 즉 d와 d_i의 차이에 상대적인 뷰 방향을 고려한다.
d와 d_i의 차이가 작다는 것은 일반적으로 타겟 뷰에서 i의 해당 색과 유사한 색상의 가능성이 크다는 것을 의미하며, 그 반대의 경우도 마찬가지이다.
각 소스 색상 C_i에 대한 혼합 가중치를 예측하기 위해 피쳐 f_i'를 Δd_i = d - d_i로 연결하고 각 연결된 피쳐를 작은 네트워크에 입력하여 혼합 가중치 w_i^c를 산출한다.
이 5D 위치의 최종 색상은 soft-argmax 최대 연산자 c = ∑[C_i exp(w_i^c)/∑ exp(w_j^c)]를 통해 혼합됩니다.
혼합 가중치를 예측하는 대안은 c를 직접 회귀시키는 것이다.
그러나 c의 직접적인 회귀가 성능 저하로 이어진다는 것을 발견했다.
3.3. Rendering and training
이전 섹션에서 소개한 접근 방식을 통해 연속 5D 위치에서 색상과 밀도 값을 계산할 수 있습니다.
장면을 통과하는 ray r의 색상을 렌더링하기 위해 먼저 ray에 있는 M 샘플의 색상과 밀도를 쿼리한 다음 밀도로 변조된 ray를 따라 색상을 축적한다:

여기서는 1부터 M까지의 샘플이 오름차순 depth 값을 가지도록 정렬됩니다.
c_k와 σ_k는 각각 ray 상의 k번째 샘플의 색과 밀도를 나타낸다.
Hierarchical volume rendering.
연속 RGB-σ 예측이 가능한 한 가지 이점은 공간에서 보다 적응적이고 효율적인 샘플링을 할 수 있다는 것이다.
NeRF[40]에 이어, 우리는 계층적 볼륨 샘플링을 수행하고 동일한 네트워크 아키텍처로 두 개의 네트워크, 즉 coarse IBRNet과 fine IBRNet을 동시에 최적화한다.
대략적인 규모에서, 우리는 픽셀 공간의 인접한 점 투영 간에 동일한 간격을 초래하는 등거리 disparity(inverse depth)에서 M_c 위치 세트를 샘플링한다.
coarse 네트워크의 예측을 고려할 때, 우리는 각 ray를 따라 더 많은 정보를 얻은 포인트 샘플링을 수행하는데, 여기서 샘플은 렌더링을 위해 관련 영역에 위치할 가능성이 더 높다.
추가 M_f 위치를 샘플링하고 모든 M_c+M_f 위치를 사용하여 NeRF [40]와 같이 fine 결과를 렌더링한다.
우리의 네트워크에서, 우리는 M_c와 M_f를 모두 64로 설정했다.
Training objective.
우리는 coarse 샘플 세트와 fine 샘플 세트를 모두 사용하여 각 ray의 색상을 렌더링하고 학습을 위해 렌더링된 색상과 ground-truth 픽셀 색 사이의 평균 제곱 오차를 최소화한다:
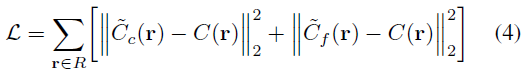
, 여기서 R은 각 학습 배치의 ray 세트이다.
이를 통해 피쳐 추출 네트워크뿐만 아니라 coarse하고 fine한 IBRNet을 동시에 학습할 수 있다.
Fine-tuning.
대량의 데이터에 대해 학습된 우리의 방법은 새로운 장면으로 잘 일반화할 수 있다.
우리의 방법은 또한 학습 시간에 동일한 목표(식 4)를 사용하여 장면당 미세 조정될 수 있으며, 이는 특정 장면에서만 가능하기 때문에 해당 장면에서 합성 성능을 향상시킨다.
3.4. Implementation details
Source and target view sampling.
장면의 여러 뷰가 주어지면 먼저 타겟 뷰를 랜덤으로 선택한 다음 N개의 인근 뷰를 소스 뷰로 샘플링하여 소스 뷰와 타겟 뷰의 학습 쌍을 구성한다.
소스 뷰를 선택하기 위해 먼저 n · N개의 주변 뷰 풀을 식별한 다음(n은 [1, 3]에서 균일하게 샘플링됨) 풀에서 N개의 뷰를 랜덤으로 샘플링한다.
이 샘플링 전략은 학습 중에 다양한 뷰 밀도를 시뮬레이션하므로 네트워크가 뷰 밀도에 걸쳐 일반화하는 데 도움이 된다.
학습 중에, 우리는 [8, 12]에서 N을 무작위로 균일하게 표본화한다.
Network details.
레이어 3 뒤에 잘린 ResNet34[16]를 인코더로 사용하고, 컨볼루션과 스킵 연결을 가진 두 개의 추가 업샘플링 레이어를 디코더로 사용하여 이미지 피쳐 추출 네트워크를 구현한다.
우리는 최종 디코딩 레이어에서 두 세트의 피처 맵을 디코딩하여 각각 coarse하고 fine한 IBRNet에 대한 입력으로 사용된다.
coarse 피처 맵과 fine 피처 맵은 모두 d = 32 차원으로 원래 이미지 크기의 1/4입니다.
IBRNet의 경우, 밀도 피쳐 f_σ의 차원은 16이며, 우리는 셀프 어텐션 모듈인 ray 트랜스포머를 위해 4개의 헤드를 사용한다.
자세한 네트워크 정보는 보충 자료를 참조하십시오.
Training details.
Adam[27]을 사용하여 다중 뷰 포즈 이미지의 데이터 세트에서 피쳐 추출 네트워크와 IBRNet을 종단 간으로 학습한다.
피쳐 추출 네트워크와 IBRNet의 기본 학습률은 각각 10^-3과 5×10^-4이며, 최적화와 함께 기하급수적으로 감소한다.
미세 조정 중에 더 작은 기본 학습 속도(5×10^-4 및 2×10^-4)를 사용하여 2D 피쳐 추출기와 IBRNet 자체를 최적화한다.
사전 학습을 위해 이미지 해상도와 소스 뷰 수에 따라 배치 크기가 3,200~9,600선인 8개의 V100 GPU에서 학습하는데, 완료하는 데 약 하루가 걸린다.
4. Experiments
우리는 두 가지 방법으로 우리의 방법을 평가한다:
a) 미세 조정(Ours) 없이 모든 테스트 장면에서 사전 학습된 모델을 직접 평가한다.
우리는 하나의 모델만 학습하고 모든 테스트 장면에서 평가한다는 점에 유의한다.
그리고 b) NeRF와 유사하게 평가 전 각 테스트 장면(Ours_ft)에서 사전 학습된 모델을 미세 조정한다.
4.1. Experimental Settings
Training datasets.
우리의 학습 데이터는 합성 데이터와 실제 데이터로 구성된다.
합성 데이터의 경우 Google Scanned Objects [50]에서 1,023개 모델의 개체 중심 렌더링을 생성한다.
실제 데이터의 경우 RealEstate10K[70], Spaces dataset[12] 및 휴대 전화 캡처의 102개 실제 장면(LLFF[39]의 35개, 우리 자신의 67개)을 사용한다.
RealEstate10K는 카메라 포즈가 있는 실내 장면의 대규모 비디오 데이터 세트이다.
Spaces 데이터 세트에는 16개 카메라 장비로 캡처한 100개의 장면이 포함되어 있습니다.
휴대전화에서 캡처한 각 장면은 대략 2D 그리드에 분산된 전방 카메라로 캡처한 20-60개의 이미지를 가지고 있다[39].
우리는 COLMAP[53]를 사용하여 캡처에 대한 카메라 매개 변수와 장면 경계를 추정한다.
우리의 학습 데이터에는 다양한 카메라 설정과 장면 유형이 포함되어 있어 우리의 방법이 보이지 않는 시나리오로 잘 일반화될 수 있다.
Evaluation datasets.
NeRF[40]에서와 같이 평가를 위해 객체의 합성 렌더링과 복잡한 장면의 실제 이미지를 모두 사용한다.
합성 데이터는 DeepVoxels[56] 데이터 세트의 간단한 기하학을 가진 4개의 Lambertian 객체와 NeRF 합성 데이터 세트의 복잡한 기하학 및 현실적인 재료를 가진 8개의 객체로 구성된다.
DeepVoxels의 각 객체는 상위 반구에서 샘플링된 512x512 해상도에서 479개의 학습 뷰와 1,000개의 테스트 뷰를 가지고 있다.
NeRF 합성 데이터 세트의 객체는 상부 반구 또는 전체 구에서 샘플링된 800x800 해상도에서 100개의 학습 뷰와 200개의 테스트 뷰를 갖는다.
실제 데이터 세트에는 NeRF의 대략적인 전방 이미지로 캡처된 8개의 복잡한 실제 장면이 포함되어 있다.
각 장면은 1008x756 해상도에서 20~62개의 이미지로 캡처됩니다.
이미지의 1/8은 테스트를 위해 유지됩니다.
Baselines.
우리는 우리의 방법을 두 클래스의 현재 최상의 뷰 합성 방법과 비교한다: MPI 기반 방법 및 신경 렌더링 방법.
MPI 기반 방법의 경우, 우리는 Ours를 각 입력 이미지에 대한 이산화된 그리드를 예측하기 위해 3D 컨볼루션 신경망을 사용하고 근처 MPI를 새로운 관점으로 혼합하는 SOTA 방법 LLFF[39]와 비교한다.
Ours와 LLFF는 모두 새로운 장면으로 일반화하도록 설계되었다.
우리는 Ours_ft를 신경 렌더링 방법과 비교한다: Neural Volumes (NV) [35], Scene Represetation Networks (SRN) [57] 및 NeRF [40].
이러한 방법은 각 장면 또는 각 장면 클래스에 대해 별도의 네트워크를 학습시키고, 전혀 일반화하지 않거나 개체 범주 내에서만 일반화한다.
이러한 신경 장면 표현 방법에 대해 평가할 때 베이스라인과 마찬가지로 장면별 모델을 미세 조정한다.
4.2. Results
각 테스트 뷰를 렌더링하기 위해 모든 평가 데이터 세트에 대한 학습 세트에서 10개의 소스 뷰를 샘플링한다.
PSNR, SSIM 및 LPIPS를 사용하여 방법과 베이스라인을 평가한다[69].
그 결과는 표 1 및 그림 3에서 확인할 수 있다.


표 1은 사전 학습된 모델이 새로운 장면으로 잘 일반화되고 모든 테스트 장면에서 LLFF[39]를 지속적으로 능가한다는 것을 보여준다.
미세 조정 후, 우리 모델의 성능은 NeRF[40]와 같은 SOTA 신경 렌더링 방법과 경쟁력이 있다: 우리는 Diffuse Synthetic 360˚와 Real Forward-Facing [39] 모두에서 NeRF를 능가하고 현실 합성 360˚에서 PSNR과 SSIM이 더 낮다.
Realistic Synthetic 360˚에서 NeRF를 제대로 수행하지 못하는 한 가지 이유는 이 데이터가 매우 복잡한 기하학적 장면에 대한 학습 뷰가 매우 희박하기 때문이다.
따라서 제한된 로컬 소스 뷰 세트에 포함된 정보는 새로운 뷰를 합성하기에 불충분할 수 있으며, 이 경우 NeRF와 같은 모든 뷰를 사용하여 전역 radiance field를 최적화하는 방법이 더 적합할 수 있다.
Real Forward-Facing [39] 데이터에서 Ours_ft는 NeRF[40]보다 훨씬 더 나은 SSIM 및 LPIPS를 달성하여 합성된 이미지가 더 사실적으로 보인다는 것을 나타낸다.
NeRF의 핵심 구성 요소는 고주파 세부 정보를 생성하는 데 도움이 되는 위치 인코딩 [61]의 사용이다.
그러나 위치 인코딩은 또한 이미지에서 원치 않는 고주파 아티팩트를 유발하여 지각 품질을 저하시킬 수 있다(그림 3 orchid 참조).
대조적으로, 우리의 모델은 색상을 회귀시키기 위해 위치 인코딩을 사용하지 않고 소스 뷰의 색상을 혼합하여 합성된 이미지를 더 자연스러운 이미지처럼 보이도록 편향시킨다.
우리의 방법은 합리적인 프록시 지오메트리를 생성하고 일시적으로 일관된 비디오를 생성하는 데 사용될 수 있다.
자세한 내용은 보충 자료를 참조하십시오.

4.3. Ablations and analysis
Ablation studies.
Real Forward-Facing [39] 데이터에 대한 사전 학습된 모델을 사용하여 우리 방법의 주요 측면의 개별 기여도를 조사하기 위해 ablation 연구(표 2)를 수행한다.
"No ray transformer"의 경우, 우리는 각 ray의 샘플에 대한 밀도 예측이 독립적이고 로컬적이 되도록 ray 트랜스포머를 제거한다.
이 모듈을 제거하면 네트워크가 정확한 밀도를 예측하지 못해 "블랙홀" 아티팩트와 블러가 발생합니다(질적 비교를 위한 보충 자료 참조).
"No view directions"의 경우 네트워크에서 뷰 방향 입력을 제거합니다.
여기에는 식 1에서 가중 풀링을 제거하고 색상 예측을 위한 네트워크 입력으로 보는 방향을 제거하는 것이 포함된다.
이는 우리 모델이 스펙타일과 같은 뷰 의존적 효과를 재현하는 능력을 감소시키지만, 우리 모델이 근처의 입력 이미지(뷰 의존적 효과 자체를 포함)를 혼합하기 때문에 NeRF에서 보는 것만큼 성능을 크게 감소시키지는 않는다.
"Direct color regression"의 경우 혼합 가중치 대신 각 5D 위치에서 RGB 값을 직접 예측한다.
이것은 소스 뷰에서 이미지 색상을 혼합하는 것보다 약간 더 나쁘다.
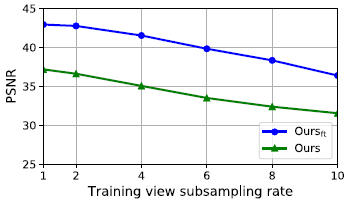
Senstivity to source view density.
우리는 Diffuse Synthetic 360˚[56]에서 소스 뷰가 더 희박해짐에 따라 우리의 방법이 어떻게 저하되는지 조사한다.
원래 데이터의 각 장면은 상위 반구에 랜덤으로 분포된 479개의 학습 뷰를 제공합니다.
우리는 다양한 뷰 밀도를 생성하기 위해 학습 뷰를 2, 4, 6, 8, 10의 요소별로 균일하게 하위 샘플링한다.
우리는 그림 4에서 사전 학습된 모델 Ours와 미세 조정된 모델 Ours_ft 모두에 대한 PSNR을 보고한다.
우리의 방법은 입력 뷰가 더 희박해짐에 따라 합리적으로 저하된다.
Computational overhead at inference.
여기서 우리는 IBRNet이 다른 방법과 비교하여 요구하는 계산을 조사한다.
타겟 뷰를 렌더링하기 위한 추론 파이프라인은 두 단계로 나눌 수 있다: 우리는 먼저 모든 관심 소스 뷰에서 이미지 피쳐를 추출하는데, 이는 렌더링에 피쳐를 반복적으로 사용할 수 있기 때문에 한 번만 수행해야 한다.
이러한 사전 계산된 피쳐를 고려하여 제안된 IBRNet을 사용하여 각 카메라 ray를 따라 샘플의 색상과 밀도를 생성한다.
이미지 피쳐는 사전 계산될 수 있기 때문에 추론 시 주요 계산 비용은 IBRNet에 의해 발생한다.
우리의 방법은 소스 뷰 세트에서 새로운 뷰를 보간하기 때문에 IBRNet의 #FLOPs는 로컬 작업 세트의 크기, 즉 소스 뷰의 수에 따라 달라진다(#Src.Views).
우리는 표 3에서 다양한 수의 소스 뷰에서 단일 픽셀을 렌더링하는 데 필요한 IBRNet 및 #FLOP의 크기를 보고한다.
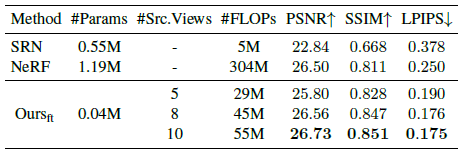
IBRNet은 비슷한 성능을 달성하면서 NeRF가 요구하는 것보다 #FLOPs의 20% 미만을 필요로 한다는 것을 알 수 있다.
IBRNet의 효율성 증가에 대한 두 가지 설명을 고려한다.
첫째, NeRF는 단일 MLP를 사용하여 전체 장면을 인코딩한다.
장면의 임의의 포인트를 쿼리하려면 MLP의 모든 매개 변수를 터치해야 합니다.
장면이 복잡해짐에 따라 NeRF는 더 많은 네트워크 용량을 필요로 하며, 이는 각 쿼리에 대해 더 큰 #FLOP로 이어진다.
대조적으로, 우리의 방법은 주변 뷰를 로컬로 보간하므로 #FLOP는 장면의 규모에 따라 증가하지 않고 로컬 작업 세트의 크기에만 따라 증가한다.
또한 이 속성은 큰 장면을 스트리밍하고 장치에 맞게 계산 비용을 즉시 조정하는 것과 같은 애플리케이션을 가능하게 하여 우리의 접근 방식을 더욱 동적으로 만든다.
둘째, NeRF에 사용되는 MLP보다 더 구조적이고 해석 가능한 표현인 포즈 이미지 및 피쳐로 장면을 인코딩한다.
간단한 투영 작업을 통해 공간의 한 지점에서 radiance를 추정하기 위해 소스 뷰에서 가장 관련성이 높은 정보를 가져올 수 있다.
IBRNet은 해당 정보를 처음부터 통합하는 방법이 아니라 결합하는 방법만 배워야 합니다.
5. Conclusion
우리는 MLP 및 ray 트랜스포머로 구성된 네트워크에서 추론한 가중치와 부피 밀도와 근처 이미지의 픽셀을 혼합하여 새로운 장면 뷰를 합성하는 학습 기반 멀티 뷰 이미지 기반 렌더링 프레임워크를 제안했다.
이 접근 방식은 IBR과 NeRF의 장점을 결합하여 사전 계산된 지오메트리를 요구하지 않고(많은 IBR 방법과 달리), 값비싼 이산화된 볼륨을 저장하거나(신경 복셀 표현과 달리), 각 새로운 장면에 대한 값비싼 학습(NeRF와 달리) 없이 복잡한 장면에서 SOTA 렌더링 품질을 생성한다.