2022. 5. 3. 17:24ㆍView Synthesis
SinNeRF: Training Neural Radiance Fields on Complex Scenes from a Single Image
Dejia Xu, Yifan Jiang, Peihao Wang, Zhiwen Fan, Humphrey Shi, Zhangyang Wang

Abstract
Neural Radience Field (NeRF)의 빠른 개발에도 불구하고, 고밀도 커버의 필요성은 더 넓은 적용을 크게 금지한다.
최근 몇 가지 작업이 이 문제를 해결하려고 시도했지만, 희소 뷰(그래도 일부) 또는 간단한 객체/장면에서 작동한다.
이 연구에서 우리는 보다 야심찬 작업을 고려한다: "looking only once"를 통해 현실적으로 복잡한 시각적 장면에서 신경 방사장을 학습하는 것이다.
이 목표를 달성하기 위해, 우리는 신중하게 설계된 의미 및 기하학 정규화로 구성된 Single View NeRF (SinNeRF) 프레임워크를 제시한다.
특히, SinNeRF는 준지도 학습 프로세스를 구성하며, 여기서 geometry pseudo labels과 semantic pseudo labels을 도입하고 전파하여 점진적 학습 프로세스를 안내한다.
NeRF synthetic 데이터 세트, Local Light Field Fusion 데이터 세트 및 DTU 데이터 세트를 포함한 복잡한 장면 벤치마크에 대해 광범위한 실험이 수행된다.
우리는 다중 뷰 데이터 세트에 대한 사전 학습 없이도 SinNeRF가 사진-사실적인 새로운 뷰 합성 결과를 낼 수 있음을 보여준다.
단일 이미지 설정에서 SinNeRF는 모든 경우에 현재 SOTA NeRF 베이스라인을 크게 능가한다.
1. Introduction
사진 사실적인 이미지를 합성하는 것은 컴퓨터 비전 분야에서 가장 필수적인 목표 중 하나였다.
최근 새로운 뷰 합성 분야는 좌표 기반 신경망의 성공과 함께 엄청난 인기를 얻고 있다.
효과적인 중간 장면 표현으로서 Neural Radiance Field (NeRF)[24]는 최근 이미지 기반 렌더링 접근 방식에서 우세하다.
성공에도 불구하고, NeRF는 신뢰할 수 있는 카메라 포즈는 말할 것도 없고, 잘 보정된 여러 카메라에서 캡처된 조밀한 뷰의 엄격한 요구 사항으로 인해 방해 받는다.
결과적으로, 충분한 뷰 없이 neural radiance field를 직접 학습하면 최근 문헌에서 암시하는 바와 같이 잘못된 지오메트리와 흐릿한 외관을 포함한 급격한 성능 저하가 초래될 것이다[26].
실제 시나리오에서는 AR/VR 또는 자율 주행과 같은 특정 애플리케이션에 대해 충분히 조밀한 시야 범위를 수집하는 것이 어렵거나 불가능할 수 있다.
따라서 많은 연구자[47: PixelNeRF, 26: RegNeRF, 15: DietNeRF, 18: InfoNeRF, 8: DSNeRF, 6: MVSNeRF]는 희소 뷰 설정에서 이 취약성을 해결하려고 시도한다.
한 연구 라인[47: PixelNeRF, 6: MVSNeRF]은 대규모 데이터 세트에 대한 적절한 사전 학습에서 얻은 사용 가능한 학습 이전 사항을 집계한다.
다른 접근법은 서로 다른 관점의 색상과 기하학에 대한 다양한 정규화를 제안한다[8: DSNeRF, 15: DietNeRF, 18: InfoNeRF, 26: RegNeRF].
그러나 앞서 언급한 대부분의 작업에는 여전히 최소 3개의 뷰가 필요한 다중 뷰 입력이 필요하다[26: RegNeRF, 8: DSNeRF].
이전 연구와 대조적으로, 우리는 하나의 뷰에서만 neural radiance field를 학습시킴으로써 희소 뷰의 설정을 극단적으로 밀어붙인다.
우리가 아는 한, 이전에 이 상황을 탐구하기 위한 노력은 거의 없었다.
PixelNeRF[47]는 대규모 데이터 세트에 대한 피처 추출기를 사전 학습하여 첫 번째 시도를 한다.
간단한 객체(예: ShapeNet 데이터 세트 [5])에서 인상적인 결과를 보고하지만 복잡한 장면[16]에서 성능은 만족스럽지 못하다.
다른 연구[19: Mine, 33: 3D Photography]는 새로운 뷰 합성에서 좋은 성능을 보여주지만, 그들의 플랫폼은 다른 기술(예: 멀티플레인 이미지)을 기반으로 한다.
이전의 연구와는 달리, 우리의 연구는 복잡한 장면의 광학적 새로운 뷰를 생성하기 위해 종과 휘파람 없이 neural radiance field를 처음부터 학습시키는 것을 목표로 한다.
그럼에도 불구하고, 단일 이미지로 neural radiance field를 학습하는 것은 답답할 정도로 어렵다.
무엇보다도, 단일 이미지에서 정확한 3D 모양을 재구성하면 몇 가지 장애물이 발생한다.
이전 연구는 단일 이미지에서 다른 유형의 물체를 재구성하는 것을 다루었다[44: Pixel2Mesh, 29: PIFu].
특히 Pixel2Mesh[44]는 단일 이미지에서 3D 모양을 재구성하여 삼각형 메시로 표현할 것을 제안한다.
PIFu [29]는 고해상도 인간 표면을 복구하기 위해 3D occupancy field를 채택한다.
그러나 이러한 모든 접근 방식은 특정 객체 클래스 또는 인스턴스에 특정된 사전 지식에 의존하므로 복잡한 장면 재구성에는 작동하지 않는다.
더욱이, 더 단순한 2D 사례에서도, 단일 이미지에 대한 학습 탐구는 지금까지도 열린 문제로 많은 관심을 받고 있다[32: SinGAN, 34: InGAN, 36: SIREN, 41: Deep Image Prior].
SIREN [36]은 단일 이미지에 더 잘 맞도록 implicit 함수에 대한 주기적 activation을 도입한다.
SinGAN[32]과 InGAN[34]은 단일 이미지를 참조로 하여 generative adversarial network(GAN)를 학습시킬 것을 제안한다.
그들의 모델은 유사한 콘텐츠를 가진 이미지의 시각적 만족스러운 결과를 생성할 수 있지만, 그들의 결과는 종종 주어진 이미지에서 패치 또는 텍스처 패턴을 대략적으로 복제하거나 재구성하는 것으로 요약되어 정교한 3D 뷰 변환을 모델링하는 목적을 수행할 수 없다.
우리의 영감은 사용 가능한 단일 뷰에 따라 pseudo labels를 생성하는 것으로부터 도출되며, 이를 통해 학습된 radiance field를 제약하기 위한 준지도 학습 전략을 설계할 수 있다.
특히, 우리는 보완적인 숨겨진 정보를 포착하기 위해 두 가지 범주의 pseudo labels를 설계한다.
첫 번째 pseudo label 범주는 이미지 왜곡[14]을 통해 참조 뷰와 보이지 않는 뷰 간에 depth 정보를 전송하여 학습된 radiance field의 다중 뷰 지오메트리 일관성을 보장하는 radiance field의 지오메트리에 중점을 둔다.
두 번째 pseudo label 범주는 보이지 않는 뷰의 semantic fidelity에 초점을 맞춘다.
discriminator와 사전 학습된 Vision Transformer (ViT [9])를 모두 사용하여 보이지 않는 뷰를 제한한다: 전자는 보이지 않는 각 뷰의 로컬 텍스처에 대한 adversarial loss를 통해, 후자는 전역 구조의 지각 품질에 초점을 맞춘다.
우리의 주요 기여는 다음과 같이 요약할 수 있습니다:
– 우리는 단일 참조 뷰를 사용하여 복잡한 장면에서 neural radiance field를 효과적으로 학습하기 위한 새로운 준지도 프레임워크인 SinNeRF를 제안한다.
– 우리는 geometry 및 semantic pseudo labels를 소개하고 전파하여 점진적 학습 과정을 공동으로 안내한다.
전자는 다중 뷰 지오메트리 일관성을 보장하기 위해 이미지 왜곡에서 영감을 받았고, 후자는 전역 구조뿐만 아니라 로컬 텍스처의 지각 품질을 강화한다.
– 우리는 복잡한 장면 벤치마크에 대한 광범위한 실험을 수행하고 SinNeRF가 종과 휘파람 없이 사진 사실적인 새로운 뷰 합성 결과를 낼 수 있다는 것을 보여준다.
단일 이미지 설정에서 SinNeRF는 모든 경우에서 SOTA NeRF 베이스라인을 크게 능가한다.
2. Related Works
2.1 Neural Radiance Field
Neural Radiance Fields (NeRF)[24]은 신경 장면 표현을 학습하여 새로운 뷰 합성을 위한 흥미로운 진전을 보여주었다.
희소 뷰 설정에서 NeRF의 데이터 요구 사항을 줄이기 위한 여러 작업이 시도되었다.
한 연구 라인[47,6]은 유사한 객체 또는 장면의 다중 뷰 데이터 세트에 사전 학습된 피쳐 추출기를 채택한다.
PixelNeRF [47]는 CNN을 활용하고 로컬 CNN 피쳐를 사용하여 radiance field를 학습시킨다.
MVSNeRF [6]는 3D 비용 볼륨을 획득하고 MVS 3D CNN을 처리합니다.
이러한 방법은 뛰어난 성능에도 불구하고 여러 장면의 다중 뷰 이미지 데이터 세트에 대한 사전 학습이 필요하며, 이는 많은 실제 시나리오(예: AR/VR 또는 자율 주행)에 이상적인 경우가 아니다.
또 다른 방향은 새로운 뷰의 모양이나 기하학에 대한 다양한 정규화를 통해 radiance field를 학습하는 것이다.
DS-NeRF [8]는 재구성 품질을 개선하기 위해 추가 depth 감독을 채택한다.
RegNeRF [26]는 정규화 흐름과 depth smoothness 정규화를 제안한다.
InfoNeRF [18]는 rays에 대한 엔트로피 정규화를 제안한다.
그리고 DietNeRF [15]는 보이지 않는 뷰를 위한 CLIP [27] 임베딩을 감독으로 활용한다.
그러나 CLIP 임베딩은 장면의 낮은 해상도에서만 얻을 수 있으므로 높은 수준의 정보만 제공한다.
또한 이러한 방법들은 적어도 두 개 또는 세 개의 입력 뷰에서만 잘 수행될 수 있습니다.
본 연구에서는 다중 뷰 데이터 세트에 대한 사전 학습 없이 단일 뷰만 사용하는 까다로운 설정에 중점을 둔다.
NeRF의 렌더링 품질 또는 속도를 개선하기 위한 다른 노력[3,2,28]이 있다.
MipNeRF [2]는 안티앨리어싱 설계를 도입했습니다.
MipNeRF-360 [3]은 무한 장면에서 작동하도록 설계를 더욱 확장합니다.
KiloNeRF [28]는 여러 개의 작은 mlp 네트워크를 채택하여 NeRF 속도를 높입니다.
우리의 SinNeRF는 조밀한 뷰 학습 설정에서 NeRF의 렌더링 품질을 향상시키는 방법과 직교한다.
SinNeRF와 이러한 기술 중 하나를 결합하는 것은 유망하다.
2.2 Single View 3D Reconstruction
단일 뷰 3D 재구성은 오랜 문제입니다.
초기 방법은 shape-from-shading [10]을 사용하거나 texture [20] 및 defocus [12] 단서들을 채택한다.
이러한 기술은 depth 단서를 사용하여 이미지의 기존 영역에 의존한다.
더 최근의 접근법은 학습된 선행 기술을 사용하여 보이지 않는 부분을 환각시킨다.
Johnston et al. [17]은 역 이산 코사인 변환 디코더를 채택한다.
Fan et al. [11]은 포인트 클라우드를 직접 회귀시킵니다.
Wu et al. [45]은 입력 이미지에서 2.5D 스케치에 대한 매핑을 학습하고 중간 표현을 최종 3D 모양에 매핑한다.
그러나 3D 주석을 위해 사용할 수 있는 데이터 세트는 매우 적으며 이러한 방법의 대부분은 단순한 모양의 개체를 포함하는 ShapeNet[5]을 사용한다.
특정 물체(예: 인간)의 3D 모양을 재구성하려는 시도도 있다.
PiFU [29]는 3D occupancy field를 사용하여 옷을 입은 인간의 3D 형상을 복구한다.
DeepHuman [50]은 image-guided volume-to-volume translation 프레임워크를 채택한다.
NormalGAN [43]은 참조 뷰의 정규 맵에서 generative adversarial network를 조건화한다.
또 다른 연구 라인은 뷰 합성을 위한 3D 표현을 학습하는 데 초점을 맞추고 있다.
Explicit 표현은 체적 표현 [31: Photorealistic scene representation, 13: Learning a neural 3d texture space, 37: DeepVoxels], Layer Depth Image (LDI) [39: Layer-structured 3d scene inference, 33: 3d photography using context] 및 멀티플레인 이미지(MPI) [23: LLFF]를 포함한다.
Implicit 표현은 좌표 기반 네트워크를 사용하여 단일 뷰에서 신경 장면 표현을 학습한다.
PixelNeRF [47]는 대규모 데이터 세트에서 사전 학습된 피쳐 추출기를 활용하여 첫 번째 시도를 한다.
복잡한 장면에 대한 그들의 결과는 ShapeNet[5]의 단순한 객체에 대한 인상적인 결과와 비교할 때 만족스럽지 못하다.
GRF [38]는 2D 이미지의 피쳐를 3D 포인트에 투영하여 3D 지오메트리를 모델링하는 generative radiance field를 제안한다.
MINE [19]은 연속 depth MPI를 학습하고 볼륨 렌더링을 사용하여 새로운 뷰를 합성한다.
우리의 작업은 다음과 같은 점에서 기존 작업과 근본적으로 다릅니다:
1) 우리는 사전 학습된 피쳐 추출기 또는 다중 평면 이미지에 의존하지 않고 처음부터 신경 장면 표현을 학습한다;
2) 우리는 복잡한 3D 환경에 대한 실험을 수행하고 사진 현실적 렌더링 결과를 산출한다.
2.3 Single Image Training
단일 이미지 학습은 또한 2D 컴퓨터 비전에 큰 관심 분야이다.
SinGAN [32]과 InGAN [34]은 단일 이미지를 참조로 학습된 generative adversarial network를 제안한다.
그들의 모델은 이미지의 유사한 내용을 포함하는 시각적으로 만족스러운 결과를 생성할 수 있지만, 다양성이 제한되고 결과가 종종 원래 이미지와 다른 패치를 복사하여 붙여넣는다.
Dmitry et al. [41]은 컨볼루션 네트워크보다 먼저 심층 이미지를 조사하고 이미지 복구에서 우수한 결과를 보여준다.
보다 최근에 SIREN [36]은 네트워크의 그레이디언트를 감독하여 단일 이미지에 맞도록 implicit 함수에 대한 주기적 activation을 제안한다.
이 연구에서, 우리는 단일 이미지를 사용하여 radiance field를 adversarially 학습시키기 위한 추가 시도를 한다.
3. Method
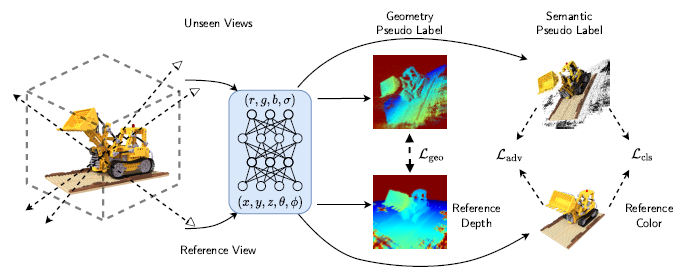
3.1 Overview
사용 가능한 뷰에 대한 학습이 참조 뷰에 과적합으로 이어지고 neural radiance field가 붕괴되기 때문에 사용 가능한 단일 뷰만 설정하는 것은 NeRF에 어려운 일이다.
이 문제를 해결하기 위해, 우리는 보이지 않는 뷰에 필요한 제약을 제공하기 위해 SinNeRF를 준지도 프레임워크로 구축한다.
우리는 RGB와 사용 가능한 depth가 있는 참조 뷰를 레이블링된 세트로 처리하는 반면, 보이지 않는 뷰는 레이블링되지 않은 세트로 간주한다.
neural radiance field가 보이지 않는 뷰에서 합리적인 결과를 도출할 수 있도록 geometry 및 semantic 제약의 관점에서 두 가지 유형의 감독 신호를 소개한다.
우리는 먼저 neural radiance field의 preliminary와 준지도 학습 프레임워크를 소개한 다음, 점진적 학습 전략을 소개할 것이다.
3.2 Preliminary
Neural Radiance Fields (NeRFs)[24]는 카메라 ray를 따라 5D 좌표(위치(x, y, z)와 뷰 방향(θ, ϕ))을 샘플링한 이미지를 합성하여 색상(r, g, b)과 부피 밀도 σ에 매핑한다.
Mildenhall et al. [24]은 먼저 좌표 기반 multi-layer perception networks (MLPs)를 사용하여 이 함수를 매개 변수화한 다음 볼륨 렌더링 기술을 사용하여 각 위치의 값을 알파 합성하고 최종 렌더링 이미지를 얻을 것을 제안한다.
여기서 o는 카메라 원점이고 d는 ray 방향인 픽셀 r(t) = o + td가 주어졌을 때 픽셀의 예측 색상은 다음과 같이 정의됩니다:
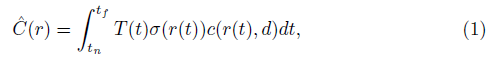
여기서 T(t) = exp(-∫σ(r(s))ds), σ(·), 그리고 c(·,·)는 네트워크의 밀도 및 색 예측이다.
계산 비용 때문에 연속 적분은 quadrature [24]를 사용하여 수치적으로 추정됩니다.
NeRF [24]는 렌더링된 색과 ground truth 색 사이의 평균 제곱 오차를 최소화하여 radiance field를 최적화합니다,
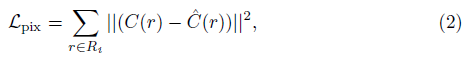
여기서 R_i는 학습 중 입력 rays의 집합이다.
3.3 Geometry Pseudo Label
참조 이미지에 직접 과적합하면 손상된 neural radiance field가 제공된 뷰 쪽으로 붕괴된다.
이 문제는 학습 이미지가 하나만 있을 때 훨씬 더 심각합니다.
다중 뷰 감독의 도움이 없으면 NeRF는 장면의 고유한 geometry를 학습할 수 없으므로 뷰 일관적인 표현을 구축하지 못한다.
단일 이미지에서 3D 모양을 재구성하기 위한 이전 작업[46: LeReS]과 유사하게, 우리는 합리적인 3D geometry를 재구성하기 전에 depth를 채택하는 것으로 시작한다.
[8: DS-NeRF]이 제안한 대로, depth 감독을 하나 더 추가하면 학습된 geometry를 크게 향상시킬 수 있다.
그러나, 우리의 설정에서 단 하나의 학습 뷰만 사용할 수 있기 때문에, 단순히 depth 감독을 채택하는 것은 그림 4와 같이 합리적인 3D 모양을 만들 수 없다.

참조 뷰에서 사용 가능한 정보를 가장 잘 활용하기 위해 이미지 왜곡 [14]을 통해 다른 뷰로 전파할 것을 제안한다.
참조 뷰 I_ref의 픽셀 p_i(x_i, y_i)에 대해, 보이지 않는 j번째 뷰 I_unsee의 해당 픽셀 p_j(x_j, y_j)는 다음과 같이 공식화될 수 있다:
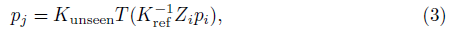
여기서 Z_i는 참조 뷰의 사용가능한 depth이고, T는 I_ref에서 I_unsee까지의 카메라 extrinsic 행렬 사이의 관계를 의미하며, K_ref와 K_unseen은 카메라 intrinsic 행렬을 의미한다.
또한 참조 뷰의 여러 점이 보이지 않는 뷰의 동일한 지점에 투영될 때 Painter's 알고리즘[25]을 채택하고 가장 depth가 작은 점을 왜곡 결과로 선택한다.
이미지 왜곡을 통해 보이지 않는 뷰의 depth 맵을 얻을 수 있으며, 이는 pseudo ground truth 역할을 할 수 있다.
그럼에도 불구하고, 예측된 depth 맵의 작은 정렬 오류는 다른 뷰에 투영될 때 큰 오류를 일으킬 수 있기 때문에 이러한 pseudo ground truth와 실제 대응 사이에는 여전히 피할 수 없는 차이가 있다.
더욱이, 예상 결과에 폐색 때문에 불확실한 영역이 포함되어 있는 것은 꽤 흔한 일이다.
왜곡된 결과의 불확실한 영역을 정규화하기 위해 RGB 픽셀 값의 2차 그레이디언트를 사용하여 예측 depth의 smoothness를 장려하는 self-supervised inverse depth smoothness loss [42]을 활용한다:
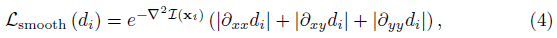
여기서 d_i는 depth 맵이며, ∇^2L(x_i)는 위치 x_i에서 픽셀 값의 라플라시안을 나타낸다.
[42]와 유사하게, 우리는 축소된 해상도에서 이 손실을 계산한다.
또한 지오메트리 일관성을 적용하기 위해 보이지 않는 뷰를 참조 뷰에 다시 투영한다.
요약하면, geometry pseudo label은 다음과 같이 활용된다,
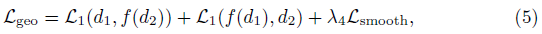
여기서 λ_4는 경험적으로 0.1로 설정되며, d_1과 d_2는 두 뷰의 depth를 의미하며, f(·)는 현재 뷰의 depth 정보를 이용한 다른 뷰의 이미지 왜곡 결과를 의미한다.
3.4 Semantic Pseudo Label
렌더링된 색상과 텍스처가 서로 다른 뷰에서 여전히 일정하지 않을 수 있으므로 이미지 왜곡은 depth 정보만 투영할 수 있습니다.
우리는 학습된 외관 표현을 정규화하기 위해 semantic pseudo labels를 채택할 것을 제안한다.
3D 공간에서 일관성을 적용하는 geometry pseudo labels와 달리 semantic pseudo labels는 2D 이미지 충실도를 정규화하기 위해 채택된다.
구체적으로 말하면, 우리는 adversarial 학습에 의해 구현된 Local Texture Guidance loss와 사전 학습된 ViT 네트워크에 의해 이전에 지원되는 전역 구조를 소개한다.
두 가지 보완 지침은 SinNeRF가 각 뷰에서 시각적으로 만족스러운 결과를 제공하는 데 공동으로 도움이 된다.
Local Texture Guidance
Local Texture Guidance는 패치 discriminator를 통해 구현된다.
NeRF의 출력은 가짜 샘플로 간주되며, 참조 뷰에서 랜덤하게 잘라낸 패치는 실제 샘플로 간주됩니다.
사용 가능한 학습 데이터가 너무 제한적이기 때문에 discriminator는 전체 학습 세트를 기억하는 경향이 있다.
이 문제를 극복하기 위해 discriminator에 미분 가능한 증강[49]을 채택하여 데이터 효율성을 향상시킨다:
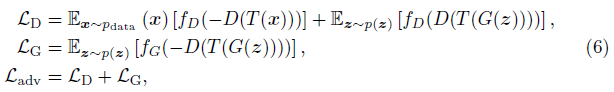
여기서 T는 실제 샘플과 가짜 샘플 모두에 적용되는 증강을 의미한다.
우리는 Hinge loss [21], 즉 f_D(x) = max(0, 1+x) 및 f_G(x) = x를 사용하여 GAN 프레임워크를 학습한다.
우리의 discriminator의 아키텍처는 cascade 컨볼루션 레이어이다.
discriminator 설계에 대한 자세한 내용은 보충 자료에 나와 있습니다.
Global Structure Prior
Vision Transformers (ViT)는 잘못 정렬된 이미지 사이에서도 표현적 semantic prior로 입증되었다[40,1].
[15]와 유사하게, 우리는 보이지 않는 뷰와 참조 뷰 사이의 semantic 일관성을 강제하는 global structure guidance를 위해 사전 학습된 ViT를 채택할 것을 제안한다.
뷰 사이에 픽셀 단위의 정렬 불량이 존재하지만, 우리는 ViT의 추출된 표현이 이러한 정렬 불량에 견고하며 그림 3과 같이 semantic level에서 감독을 제공하는 것을 관찰한다.
직관적으로, 이것은 두 관점의 내용과 스타일이 비슷하고, 심층 네트워크가 불변 표현을 학습할 수 있기 때문이다.

여기서는 ImageNet[7] 데이터 세트에 대해 학습된 self-supervised Vision Transformer인 DINO-ViT[4]를 채택한다.
CLIP-ViT [27]를 활용하고 투영된 이미지 임베딩을 피쳐로 채택하는 DietNeRF [15]와 달리, 우리는 DINO-ViT의 출력에서 직접 [CLS] 토큰을 추출한다.
[CLS] 토큰이 전체 이미지를 표현하는 역할을 하기 때문에 이 접근법은 더 간단하다[9].
직관은 또한 [40]의 최근 발견과 일치하며, 여기서 ViT 아키텍처는 self-supervised pre-training 후 semantic 외관을 포착할 수 있다.
우리는 추출된 피쳐들 사이의 L_2 거리를 계산한다
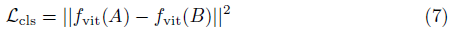
, 여기서 f_vit(·)는 추출된 [CLS] 토큰을 참조한다.
A와 B는 각각 참조 뷰와 보이지 않는 뷰의 패치입니다.
3.5 Progressive Training Strategy
GAN 프레임워크의 학습을 안정화하기 위해 단일 뷰 radiance field의 효율적이고 안정적인 학습을 위한 점진적인 샘플링 전략을 제안한다.
Progressive Strided Ray Sampling:
첫째, 우리는 ray 생성의 스트라이드 샘플링 [30: Graf]을 활용하고 학습 중 스트라이드 크기를 점진적으로 줄인다.
이 설계를 통해 SinNeRF는 제한된 양의 ray로 훨씬 더 큰 영역을 커버할 수 있습니다.
특히, 점 (u, v)을 포함하는 스트라이드의 K × K 패치 P는 2D 이미지 좌표 세트
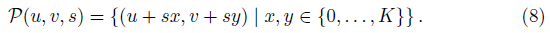
로 정의된다.
이러한 방식으로, NeRF는 장면의 큰 측면을 나타내는 K × K 패치를 생성할 수 있다.
학습 중에, 우리는 각 반복에서 2개의 패치를 무작위로 샘플링하는데, 하나는 참조 뷰에서, 다른 하나는 보이지 않는 랜덤 뷰에서 샘플링한다.
그 후, 협업 local texture guidance과 global structure prior loss는 이러한 패치를 입력으로 사용하여 보이지 않는 뷰에 대한 semantic guidance를 제공한다.
한편, 우리는 이미지 왜곡을 통해 geometry pseudo labels를 얻고 해당 패치의 왜곡된 결과와 각 패치의 교차점에 정규화를 추가한다.
학습이 후반 단계로 진행됨에 따라 스트라이드가 감소하여 프레임워크가 더 많은 지역에 초점을 맞추기 시작한다.
스트라이드 크기를 줄인 후 랜덤하게 discriminator를 초기화합니다.
이를 통해 discriminator가 고정 해상도에 집중하여 학습을 보다 안정적으로 수행할 수 있다.
Progressive Gaussian Pose Sampling:
둘째, 학습 중 시야 각을 점진적으로 확대할 것을 제안한다.
학습 중, 우리는 참조 뷰의 로컬 이웃에서 시작하여 학습이 진행됨에 따라 카메라 포즈를 더 점진적으로 회전시킨다.
이는 카메라 포즈가 참조 뷰와 약간 다를 때 출력 이미지 패치가 좋은 품질을 가지므로 네트워크가 자신 있는 영역을 처리하는 데 집중하고 학습을 안정시키는 데 도움이 된다.
구체적으로, 우리는 보이지 않는 뷰와 참조 뷰 사이의 거리를 오일러 각도로 표현한다.
(α, β, ϕ)가 참조 뷰의 카메라 좌표에 있는 축과 보이지 않는 뷰의 카메라 좌표에 있는 축 사이의 부호화된 각도를 나타내도록 합니다.
각 반복에서, 우리는 가우스 분포 N(0, ω^2)을 기반으로 각각 α, β, ϕ를 샘플링하는데, 여기서 ω는 반복 횟수가 많을수록 증가한다.
우리는 전체 손실 함수를 다음과 같이 보여준다:
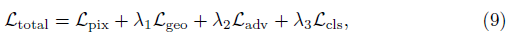
여기서 λ_1, λ_2, λ_3은 가중 요인이다.
우리는 학습 중에 가중치 감소를 하지 않는다.
우리가 큰 스트라이드를 사용하고 패치가 원본 이미지의 주요 영역을 덮는 초기 단계에서, 그 global structure prior는 local texture guidance의 가중치 λ_2에 비해 큰 가중치 λ_3이 주어진다.
학습이 진행됨에 따라, 우리는 고주파 세부 사항을 재구성하는 데 초점을 맞추기 위해 스트라이드를 줄인다.
결과적으로, 우리는 global structure prior λ_3의 가중치를 줄이고 local texture guidance의 가중치를 λ_2 증가시킨다.
우리의 모든 실험에서 λ_1, λ_2 및 λ_3은 각각 8, 0.1, 0으로 초기화된다.
학습 과정 동안, 우리는 선형 함수로 λ_2를 0으로 점진적으로 줄이고 λ_3을 0.1로 증가시킨다.
4. Experiment
4.1 Implementation Details
우리는 원래의 NeRF 논문에서 소개된 것과 동일한 것으로 multi-layer perceptron 아키텍처를 구축한다[24].
학습 반복 동안, 우리는 참조 뷰와 랜덤 샘플링된 보이지 않는 뷰 모두에서 두 개의 ray 패치를 랜덤하게 샘플링한다.
NeRF synthetic 데이터 세트, Local Light Field Fusion 데이터 세트 및 DTU 데이터 세트의 패치 크기는 각각 64×64, 84×63 및 70×56으로 설정된다.
그런 다음 렌더링된 패치는 discriminator 및 ViT 네트워크에 공급된다.
ViT 아키텍처의 요구사항을 충족하기 위해 입력 패치의 크기를 추가로 224x224 해상도로 조정했습니다.
초기 학습 속도가 1e^-3인 RAdam 옵티마이저 [22]를 사용하여 프레임워크를 학습한다.
우리는 10k회 반복 후 학습 속도를 절반으로 감소시킨다.
discriminator의 학습 속도는 NeRF의 1/5로 유지된다.
패치를 샘플링하기 위한 스트라이드는 6에서 시작되며 10k회 반복할 때마다 점차 2씩 감소한다.
SinNeRF의 모든 실험은 NVIDIA RTX A6000 GPU에서 수행된다.
전체 학습 과정은 각 장면마다 몇 시간이 걸린다.
자세한 구현 세부 정보와 시각적 결과는 부록에 나와 있습니다.
4.2 Evaluation Protocol
우리는 NeRF synthetic 데이터 세트[24], Local Light Field Fusion (LLFF) 데이터 세트[23] 및 DTU 데이터 세트[16]에 대한 실험을 수행한다.
NeRF synthetic 데이터 세트는 360° 뷰의 복잡한 객체를 포함한다.
LLFF는 복잡한 정면 장면을 제공합니다.
DTU는 테이블 위에 놓인 다양한 객체들로 구성된다.
우리는 PSNR, 구조적 유사성 지수 (SSIM) 및 LPIPS 지각 메트릭을 포함한 메트릭을 보고한다 [48].
우리는 우리의 방법을 SOTA neural radiance field 방법인 DietNeRF[15], PixelNeRF[47] 및 DS-NeRF[8]와 비교한다.
DietNeRF와 DS-NeRF는 테스트 시간 최적화 방법이기 때문에 각 장면별로 학습한다.
PixelNeRF의 경우 공정한 비교를 위해 평가 전에 각 장면에서 모델을 미세 조정한다.
4.3 View synthesis on NeRF Synthetic Dataset
NeRF synthetic 데이터 세트의 경우 각 장면은 Blender를 통해 렌더링된다.
100개의 카메라 포즈의 ground truth 렌더링 이미지와 원본 blender 파일이 모두 제공됩니다.
단일 뷰를 참조 뷰로 랜덤하게 선택하고 주변 뷰를 보이지 않는 뷰로 참조한다.
그런 다음 우리는 world-to-camera 행렬을 회전시킴으로써 보이지 않는 뷰의 ground truth를 렌더링하기 위해 blender를 사용한다.
특히 [-30˚, 30˚]에서 Y축을 중심으로 카메라를 균일하게 회전시켜 60개의 테스트 세트 이미지를 생성한다.
정량적 결과는 표 1에 나와 있다.
우리의 방법은 픽셀 단위 오류와 지각 품질 모두에서 최상의 결과를 달성한다.


우리는 그림 4의 처음 두 행에서 새로운 뷰 합성 결과를 보여준다.
각 행은 고정된 카메라 포즈에 해당하며, 각 열은 방법의 결과를 포함합니다.
우리의 방법이 지각적 품질뿐만 아니라 최고의 geometry를 보존한다는 것을 알 수 있다.
DS-NeRF의 출력에는 lego 상단에 잘못된 지오메트리가 포함되어 있습니다.
이는 DS-NeRF가 참조 뷰에 대한 감독만 활용하고 다른 뷰에 대한 뒤틀림을 수행하지 않기 때문이다.
PixelNeRF의 결과는 geometry를 explicitly 정규화하지 않기 때문에 "ghost" 핫도그를 포함한다.
보이지 않는 뷰에 최적화하여 DietNeRF는 매력적인 결과를 생성하지만 안타깝게도 새로운 뷰의 geometry에 결함이 있다(예: 객체가 더 이상 중심에 있지 않다).
CLIP 임베딩은 낮은 해상도로 획득되기 때문에 결과도 흐릿하다.
4.4 View synthesis on LLFF Dataset
local light field fusion 데이터 세트의 경우 이미지와 colmap의 SfM 결과가 제공된다.
우리는 단일 뷰를 참조 뷰로 랜덤하게 선택하고 학습 중에 주변 뷰를 보이지 않는 뷰로 사용한다.
정량적 평가를 위해, 우리는 ground truth 이미지를 사용할 수 있는 데이터 세트의 다른 뷰를 렌더링한다.
그림 4의 마지막 두 행에 시각적 결과를 제공하고 표 1에 정량적 결과를 제공한다.
우리의 방법은 시각적으로 가장 만족스러운 결과를 생성하는 반면, 다른 방법은 새로운 견해에 대해 불명확한 추정치를 만드는 경향이 있다.
DS-NeRF는 사실적인 형상을 보여주지만 렌더링된 이미지는 흐릿하다.
PixelNeRF와 DietNeRF는 좋은 구조를 나타내지만 local texture guidance 및 geometry pseudo label이 없기 때문에 잘못된 geometry를 나타낸다.
4.5 View synthesis on DTU Dataset
DTU 데이터 세트의 각 장면에는 고정 카메라 포즈뿐만 아니라 49개의 이미지가 제공된다.
카메라 2의 이미지가 장면의 대부분을 포함하기 때문에 우리는 카메라 2를 참조 뷰로 사용한다.
우리는 학습 중에 데이터 세트에서 10개의 인근 카메라를 보이지 않는 뷰로 사용한다.
이러한 인근 뷰의 ground truth가 제공되기 때문에 정량적 평가를 위해 이러한 뷰를 렌더링한다.
우리는 그림 5의 시각적 결과와 표 2의 정량적 결과를 제공한다.
우리의 방법은 가장 시각적으로 만족스러운 결과뿐만 아니라 최고의 정량적 성능을 보여준다.
DS-NeRF는 사실적인 형상을 생성하지만 결과에는 심각한 아티팩트가 포함되어 있습니다.
PixelNeRF와 DietNeRF는 전체적으로 보기 좋지만 잘못된 형상으로 인해 어려움을 겪는다.


4.6 Ablation Study
Variants of pseudo labels.
이 섹션에서는 제안된 방법의 각 구성 요소의 효과를 연구한다.
우리는 lego 장면을 평가하고 그 결과를 그림 6과 표 3에 제공한다.
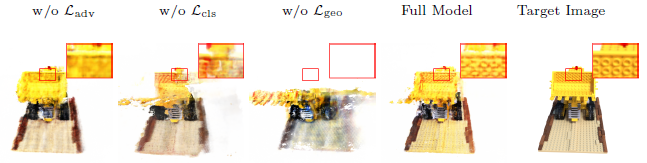

adversarial 학습을 제거하면 아티팩트가 흐릿해진다.
이는 L_cls가 추출된 패치가 이미지의 주요 구조를 덮을 만큼 충분히 큰 수용 필드를 가질 때에만 유익하기 때문이다.
global structure prior가 없는 변형은 새로운 관점에 잘못된 구조를 포함하는데, 이는 전체 semantic 구조에 대한 guidance가 누락되었기 때문이다.
여전히 사용할 수 있는 geometry pseudo label이 있지만, 투영된 depth 정보는 부분적인 guidance만 제공하고 폐쇄된 영역을 제약하지 않는다.
마지막으로, geometry pseudo label이 없는 변형은 잘못된 geometry로 인해 어려움을 겪는다.
참조 뷰에 대한 depth 감독만 있을 뿐 보이지 않는 뷰는 제대로 정규화되지 않습니다.
Different choices of the global structure prior.
우리는 이 섹션에서 우리의 global structure prior에 대한 다양한 모델 선택을 연구한다.
global structure prior는 픽셀 정렬 오류와 관계없이 보이지 않는 뷰와 참조 뷰 사이의 전반적인 의미 일관성에 초점을 맞추도록 설계되었다.
이 방향에 따라 ConvNets와 ViT를 포함한 다양한 아키텍처를 평가한다.
표 4에 표시된 바와 같이, 우리는 보이지 않는 뷰와 참조 뷰 사이의 사전 학습된 VGG 네트워크에서 콘텐츠, 스타일 및 셀프 유사성 손실을 채택하거나 DINO-ViT [4] 아키텍처의 [CLS] 토큰 출력 사이의 거리를 최소화하는 것을 포함하여 "lego" 장면에서 실험을 수행하여 다양한 종류의 global structure prior를 평가한다.
정량적 결과는 DINO-ViT가 더 강력한 global structure prior를 보여주며, 픽셀 정렬 오류에 더 강하다는 것을 보여준다.

5. Conclusion
복잡한 장면으로부터 단일 뷰에서 neural radiance field를 학습하는 프레임워크인 SinNeRF를 제시한다.
SinNeRF는 준지도 프레임워크를 기반으로 하며, 여기서 geometry pseudo label과 semantic pseudo label을 합성하여 학습 과정을 안정화한다.
포괄적인 실험은 NeRF synthetic 데이터 세트, Local Light Field Fusion (LLFF) 데이터 세트 및 DTU 데이터 세트를 포함하여 복잡한 장면 데이터 세트에 대해 수행되며, 여기서 SinNeRF는 최신 NeRF 프레임워크를 능가한다.
그러나 대부분의 NeRF 접근 방식과 유사하게, SinNeRF의 한 가지 한계는 학습 효율성 문제이며, 이는 향후 탐색해야 할 방향 중 하나가 될 수 있다.