2023. 2. 22. 13:03ㆍView Synthesis
GAUDI: A Neural Architect for Immersive 3D Scene Generation
Miguel Angel Bautista, Pengsheng Guo, Samira Abnar, Walter Talbott, Alexander Toshev, Zhuoyuan Chen, Laurent Dinh , Shuangfei Zhai, Hanlin Goh, Daniel Ulbricht, Afshin Dehghan, Josh Susskind
Abstract
우리는 움직이는 카메라에서 몰입적으로 렌더링할 수 있는 복잡하고 현실적인 3D 장면의 분포를 캡처할 수 있는 생성 모델인 GAUDI를 소개한다.
우리는 확장 가능하면서도 강력한 접근 방식으로 이 어려운 문제를 해결한다, 여기서 우리는 먼저 radiance 필드와 카메라 포즈를 분리하는 잠재 표현을 최적화한다.
그런 다음 이 잠재적 표현은 3D 장면의 unconditional 및 conditional 생성을 가능하게 하는 생성 모델을 학습하는 데 사용된다.
우리 모델은 카메라 포즈 분포가 샘플 간에 공유될 수 있다는 가정을 제거하여 단일 물체에 초점을 맞춘 이전 작업을 일반화한다.
우리는 GAUDI가 여러 데이터 세트에 걸쳐 unconditional 생성 설정에서 SOTA 성능을 얻고 희소 이미지 관찰 또는 장면을 설명하는 텍스트와 같은 조건화 변수가 주어지면 3D 장면의 조건부 생성을 허용한다는 것을 보여준다.
1 Introduction
학습 시스템이 3D 공간을 이해하고 만들 수 있으려면 3D 생성 모델의 진전이 절실하다.
"창조는 인간의 매체를 통해 끊임없이 계속된다."라는 인용구는 종종 Antoni Gaudí가 우리 방법의 이름과 함께 경의를 표하기 때문이다.
우리는 3D 장면의 분포를 캡처한 다음 학습된 분포에서 샘플링된 장면에서 뷰를 렌더링할 수 있는 생성 모델에 관심이 있다.
이러한 생성 모델을 조건부 추론 문제로 확장하면 머신러닝 및 컴퓨터 비전의 광범위한 작업에 엄청난 영향을 미칠 수 있다.
예를 들어, 이미지 관찰 또는 텍스트 설명과 일치하는 그럴듯한 장면 완성을 샘플링할 수 있다(GAUDI에서 샘플링한 3D 장면의 경우 그림 1 참조).
또한, 이러한 모델은 모델 기반 강화 학습 및 planning[12], SLAM[39] 또는 3D 콘텐츠 제작에 큰 실용적인 용도가 될 것이다.

3D 객체 또는 장면에 대한 생성 모델링에 대한 최근 연구[56, 5, 7]는 생성기가 radiance 필드를 명시적으로 인코딩하는 Generative Adversarial Network (GAN)을 사용한다 - 이는 3D 공간과 카메라 포즈의 한 지점의 좌표를 입력으로 취하고 해당 3D 지점에 대한 밀도 스칼라 및 RGB 값을 출력하는 매개 변수 함수이다.
쿼리된 3D 포인트를 볼륨 렌더링 방정식을 통해 전달하여 모델이 생성한 radiance 필드에서 이미지를 렌더링하여 임의의 2D 카메라 뷰에 투영할 수 있습니다.
GAN은 소규모 또는 단순한 3D 데이터 세트(예: 단일 객체 또는 소수의 실내 장면)에서는 학습 pathologies에 시달리며, 3D 장면의 경우처럼 표준 좌표계가 존재하지 않는 데이터에 대해 학습하기 어렵다[57].
또한 3D 객체 vs. 장면의 모델링 분포 사이의 한 가지 주요 차이점은 객체를 모델링할 때 카메라 포즈가 객체 간에 공유되는 분포(즉, 일반적으로 SO(3)를 통해)에서 샘플링된다고 가정하는 경우가 많다는 것이다, 이는 장면에는 해당되지 않는다.
이것은 유효한 카메라 포즈의 분포가 각각의 특정 장면에 독립적으로(벽과 다른 물체의 구조와 위치에 기초하여) 의존하기 때문이다.
또한 장면의 경우 이 분포는 SE(3) 그룹의 모든 포즈를 포함할 수 있습니다.
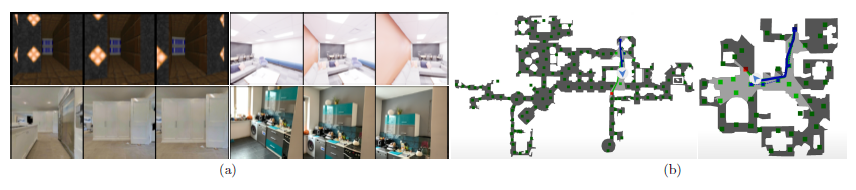
이 사실은 카메라 포즈를 장면을 통과하는 궤적으로 생각할 때 더 명확해진다(cf. 그림 3(b)).
GAUDI에서 우리는 각 궤적(즉, 3D 장면의 포즈 이미지 시퀀스)을 완전히 분리된 방식으로 radiance 필드(예: 3D 장면)와 카메라 경로를 인코딩하는 잠재 표현으로 매핑한다.
우리는 이러한 잠재 표현을 자유 매개 변수로 해석하고 재구성 목표를 통해 각 궤적에 대한 잠재 표현이 최적화되는 최적화 문제를 공식화함으로써 찾는다.
이 간단한 학습 과정은 수천 개의 궤적으로 확장할 수 있다.
각 궤적의 잠재적 표현을 자유 매개 변수로 해석하면 정교한 인코더 아키텍처가 다수의 뷰에 걸쳐 풀링되어야 하는 것보다 각 궤적에 대해 크고 가변적인 수의 뷰를 쉽게 처리할 수 있다.
관측된 궤적의 경험적 분포에 대한 잠재 표현을 최적화한 후, 우리는 잠재 표현 집합에 대한 생성 모델을 학습한다.
unconditional인 경우, 모델은 모델이 학습한 사전 분포에서 전체적으로 radiance 필드를 샘플링할 수 있으므로 잠재 공간 내에서 보간하여 장면을 합성할 수 있다.
conditional의 경우, 학습 시간에 모델이 사용할 수 있는 조건부 변수(예: 이미지, 텍스트 프롬프트 등)를 사용하여 해당 변수와 일치하는 radiance 필드를 생성할 수 있다.
우리의 기여는 다음과 같이 요약할 수 있습니다:
- 우리는 3D 장면 생성을 학습 중 모드 붕괴 또는 표준 방향 문제로 고생하지 않고 수십만 개의 이미지가 포함된 수천 개의 실내 장면으로 확장한다.
- 우리는 radiance 필드와 카메라가 분리된 방식으로 공동으로 모델화하는 잠재 표현을 찾기 위한 새로운 디노이징 최적화 objective를 소개한다.
- 우리의 접근 방식은 여러 데이터 세트에서 SOTA 생성 성능을 얻는다.
- 우리의 접근 방식은 다양한 생성 설정을 허용한다: 이미지 또는 텍스트에 대한 conditional 생성뿐 아니라 unconditional 생성도 가능합니다.
2 Related Work
최근 몇 년 동안 이 분야는 2D 이미지 영역에 대한 생성 모델링에서 뛰어난 발전을 목격했으며, 대부분의 접근 방식은 적대적 모델[19, 20] 또는 자동 회귀 모델[64, 42, 9]에 초점을 맞추고 있다.
최근에는 score-matching 기반 접근법[16, 58]이 인기를 얻고 있다.
특히 Denoising Diffusion Probabilistic Models (DDPMs)[15, 33, 48, 63]은 적대적 접근법과 자동 회귀 접근법 모두에 대한 강력한 경쟁자로 떠올랐다.
DDPM에서 목표는 경험적 데이터 분포를 일반적으로 등방성 가우시안 분포의 형태를 취하는 고정된 후방으로 점진적으로 변환하는 고정 확산 마르코프 체인의 단계별 반전을 배우는 것이다.
이와 병행하여, 지난 몇 년 동안 신경망 내에서 3D 데이터가 표현되는 방식에 혁명이 있었다.
NeRF[29]는 3D 장면을 radiance 필드로 표현함으로써 주어진 RGB 이미지 세트의 시야 안에 있는 3D 포인트의 radiance를 나타내기 위해 MLP의 가중치를 최적화하는 접근 방식을 도입한다.
주어진 카메라 포즈에서 레이 샷에 놓여 있는 3D 포인트 세트에 대한 radiance를 고려할 때, NeRF[29]는 볼륨 렌더링을 사용하여 해당 픽셀의 색상을 계산하고 이미지 공간의 재구성 loss를 통해 MLP 가중치를 최적화한다.
또한 생성 모델 내에 radiance 필드 표현을 통합하려는 몇 가지 시도가 있었다.
대부분의 접근 방식은 데이터 세트의 샘플에 걸쳐 공유 카메라 포즈 분포가 있는 얼굴 또는 ShapeNet 객체와 같은 알려진 표준 방향을 가진 단일 객체의 문제에 초점을 맞추었다[56, 5, 34, 22, 4, 10, 70, 43].
이러한 접근 방식을 단일 객체에서 완전히 제한되지 않은 3D 장면으로 확장하는 것은 해결되지 않은 문제이다.
이 공간에서 언급할 가치가 있는 논문 중 하나는 GSN[7]인데, 이는 radiance 필드를 장면을 집합적으로 나타내는 로컬 radiance 필드 그리드로 나눈다.
이러한 radiance 필드의 분해는 높은 표현 용량으로 모델을 허용하지만, GSN은 여전히 제한되지 않은 3D 장면이 표준 방향을 갖지 않는다는 사실로 인해 악화되는 모드 붕괴[61]와 같은 GAN의 표준 학습 pathodologies로 인해 어려움을 겪는다.
우리의 실험에서 보여주듯이 (cf. 섹션 4), 이러한 문제는 학습 세트 크기가 증가함에 따라 두드러져 복잡한 분포를 캡처하는 생성 모델의 용량에 영향을 미친다.
이와는 별도로, 최근의 일련의 접근법은 또한 radiance 필드를 사용하지 않고 장면의 생성 모델을 학습하는 문제를 연구했다[36, 65, 47].
이러한 연구는 모델이 학습 중에 룸 레이아웃과 객체 CAD 모델의 데이터베이스에 액세스할 수 있다고 가정하여 데이터베이스에서 객체 선택 및 각 객체에 대한 포즈 예측으로 장면 생성 문제를 단순화한다.
마지막으로, 단일(또는 다중) 소스 뷰와 상대적 포즈 변환이 주어졌을 때 타겟 뷰를 예측하는 방법을 배우는 접근법이 최근 제안되었다[24, 69, 53, 8, 11].
이러한 접근법에 의해 채택된 순수 재구성 objective는 소스 이미지와 상대 카메라 변환을 타겟 이미지에 매핑하는 결정론적 조건 함수를 학습하도록 강요한다.
첫 번째는 이 장면 완료 문제가 ill-posed라는 것이다(예: 장면의 단일 소스 뷰가 주어지면 동일하게 가능성이 있는 여러 타겟 완료가 있다).
확률론적 방식으로 문제를 모델링하려는 시도가 제안되었다[49, 45].
그러나 이러한 접근 방식은 radiance 필드와 같은 3D 일관된 표현을 명시적으로 모델링하지 않기 때문에 예측된 장면에서 불일치로 어려움을 겪는다.
3 GAUDI
우리의 목표는 3D 장면에 대한 궤적의 경험적 분포가 주어진 생성 모델을 배우는 것이다.
X = {x_(i∈{0, ..., n})}가 경험적 분포를 정의하는 예제의 모음을 나타내도록 하자, 여기서 각 예제 x_i는 궤적이다.
모든 궤적 x_i는 대응하는 RGB, depth 이미지 및 6DOF 카메라 포즈의 가변 길이 시퀀스로 정의된다(그림 3 참조).
우리는 생성 모델을 학습하는 작업을 두 단계로 분해한다.
먼저, 우리는 장면 radiance 필드를 나타내며 별도의 분리된 벡터에 포즈를 취하는 각 예 x ∈ X에 대한 잠재적 표현 z = [z_model, z_model]을 얻는다.
둘째, 잠재력 집합 Z = {z_(i∈{0, ..., n}}}이 주어지면 분포 p(Z)를 학습한다.
3.1 Optimizing latent representations for radiance fields and camera poses
이제 각 예제 x ∈ X(즉, 경험적 분포의 각 궤적에 대한)에 대한 잠재 표현 z ∈ Z를 찾는 작업으로 넘어간다.
이 잠재적 표현을 얻기 위해 우리는 인코더가 없는 관점을 취하고 z를 최적화 문제를 통해 찾을 수 있는 자유 매개 변수로 해석한다[2, 35].
잠재 z를 궤적 x에 매핑하기 위해 카메라 포즈와 radiance 필드 매개 변수화를 분리하는 네트워크 아키텍처(즉, 디코더)를 설계한다.
우리의 디코더 아키텍처는 3개의 네트워크로 구성된다(그림 2 참조):
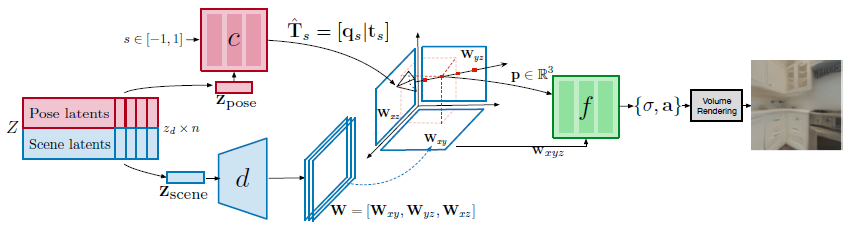
● 카메라 포즈 디코더 네트워크 c(θ_c에 의해 매개 변수화됨)는 전체 궤적에 대한 카메라 포즈를 나타내는 z 포즈에 따라 궤적의 정규화된 시간 위치 s ∈ [-1, 1]에서 카메라 포즈를 예측하는 역할을 한다.
c의 출력이 유효한 카메라 포즈(예: SE(3)의 요소)인지 확인하기 위해, 우리는 방향에 대한 정규화된 쿼터니언 q_s를 나타내는 3D 벡터와 3D 변환 벡터 t_s를 출력한다.
● 장면 디코더 네트워크 d(θ_d에 의해 매개 변수화됨)는 radiance 필드 네트워크 f에 대한 조건 변수를 예측하는 역할을 한다.
이 네트워크는 장면 z_scene을 나타내는 잠재 코드를 입력으로 받아들이고 W ∈ R^(3xSxSxF)를 예측한다.
이는 공간 차원 SxS 및 F 채널의 3가지 피쳐 맵 [W_xy, W_xz, W_yz]에 해당하며, 각 축 정렬 평면 xy, xz 및 yz에 대해 하나씩이다.
● radiance 필드 디코더 네트워크 f(θ_f로 매개 변수화됨)는 식 1의 볼륨 렌더링 방정식을 사용하여 이미지 레벨 타겟을 재구성하는 작업을 수행한다.
f에 대한 입력은 p ∈ R^3이고 삼면 표현 W= [W_xy, W_xz, W_yz]이다.
radiance를 예측해야 하는 3D 지점 p = [i, j, k]가 주어지면, 우리는 수직으로 W의 각 평면에 p를 투영하고 이중 선형 샘플링을 수행한다.
우리는 3개의 이중 스펙트럼 샘플링 벡터를 w_xyz = [W_xy(i, j), W_xz(j, k), W_yz(i, k)] ∈ R^3F로 연결하는데, 이는 radiacne 필드 함수 f를 조건화하는 데 사용된다.
우리는 밀도 값 σ와 신호 a를 출력하는 MLP로 f를 구현한다.
픽셀의 값 v를 예측하기 위해 볼륨 렌더링 방정식이 사용됩니다(cf. 식 1), 여기서 3D 포인트는 특정 depth u에서 ray 방향 r(픽셀 위치에 해당)로 표현된다.

우리는 식 2에 표시된 θ_d, θ_c, θ_f 및 {z}_(i={0, ..., n)}에 대해 공동으로 최적화하기 위해 디노이징 재구성 objective를 공식화한다.
잠재 z는 각 예 x에 대해 독립적으로 최적화되지만 네트워크의 매개 변수 θ_d, θ_c, θ_f는 모든 예 x에 걸쳐 상각된다.
이전의 자동 측정 접근법[2, 35]과는 달리, 각 잠재 z는 모든 잠재적 요소에 걸친 경험적 표준 편차인 z = z+β N(0, std(Z))에 비례하는 가산 노이즈로 학습 중 교란되어 수축 표현을 유도한다[46].
이 설정에서 β는 분포 z ∈ Z의 엔트로피와 재구성 항 사이의 균형을 제어하며, β = 0인 경우 z의 분포는 지시 함수의 집합이 되는 반면, 잠재 공간의 비결정 구조는 β > 0에 대해 발생한다.
작은 β > 0 값을 사용하여 보간된 샘플(또는 후속 생성 모델을 샘플링하여 얻을 수 있는 샘플처럼 경험적 분포에서 작은 편차를 포함하는 샘플)이 디코더 지원에 포함되는 잠재 공간을 시행한다.

우리는 매개 변수 θ_d, θ_f, θ_c를 최적화하고 두 가지 다른 loss로 z ∈ Z를 잠재시킨다.
첫 번째 loss 함수 L_scene은 렌더링에 필요한 ground truth 카메라 포즈 T_s가 주어지면 z_scene으로 인코딩된 radiance 필드와 궤적 x_s^im(여기서 s는 궤적에서 프레임의 정규화된 시간적 위치를 나타낸다)의 이미지 사이의 재구성을 측정한다.
우리는 RGB에는 l_2 loss를, depth에는 l_1을 사용한다.
두 번째 loss 함수 L_pose는 z_pose로 인코딩된 포즈 ^T_s와 ground truth 포즈 사이의 카메라 포즈 재구성 오류를 측정한다.
우리는 카메라 포즈의 정규화된 4분의 1 부분에 대해 이동 시 l_2 loss와 l_1 loss를 사용한다.
이론적으로 정규화된 쿼터니언이 반드시 고유한 것은 아니지만(예: q 및 -q) 학습 중에 경험적으로 문제를 관찰하지는 않는다.
3.2 Prior Learning
식 2에서 objective를 최소화한 결과로 인한 잠재 z ∈ Z 집합을 고려할 때, 우리의 목표는 그들의 분포를 포착하는 생성 모델 p(Z)를 학습하는 것이다(즉, 식 2에서 objective를 최소화한 후 우리는 z ∈ Z를 잠재 공간의 경험적 분포의 예로 해석한다).
p(Z)를 모델링하기 위해 우리는 Denoising Diffusion Probabilistic Model (DDPM)[15]을 사용하는데, 이는 크지만 유한한 시간 단계로 diffusion 마르코프 체인을 역전시키는 방법을 배우는 최근의 score-matching[16] 기반 모델이다.
DDPM [15]에서 이 역 프로세스는 가중치가 묶인 오토인코더의 디노이징 시퀀스를 학습하는 것과 동일한 것으로 나타났다.
DDPM의 supervised 디노이징 objective는 학습 p(Z)를 간단하고 확장 가능하게 한다.
이를 통해 3D 장면의 unconditional 생성과 conditional 생성을 모두 가능하게 하는 강력한 생성 모델을 학습할 수 있다.
prior p_θ_p (Z)를 학습하기 위해 우리는 식 3에 정의된 [15]의 목적 함수를 취한다.
식 3의 t는 시간 단계를 나타내며, ε ~ N(0, I)은 노이즈이고 α_t는 일정이 고정된 노이즈 크기 매개 변수입니다.
마지막으로, ε_θ_p는 디노이징 모델을 나타냅니다.
추론 시간에, 우리는 DDPM의 추론 과정을 따라 z ~ p_θ_p(Z)를 샘플링한다.
우리는 z_T ~ N(0, I)을 샘플링하는 것으로 시작하고 ε_θ_p를 반복적으로 적용하여 z_T를 점진적으로 노이즈 제거함으로써 diffusion 마르코프 체인을 역전시켜 z_0을 얻는다.
그런 다음 우리는 디코더 아키텍처에 입력으로 z_0을 공급하고(cf. 그림 2) radiance 필드와 카메라 경로를 재구성한다.
쌍을 이룬 데이터 {z ∈ Z, y ∈ Y}가 주어졌을 때 잠재 p(Z|Y)의 조건부 분포를 학습하는 것이 목표인 경우 디노이징 모델 ε_θ는 조건부 변수 y로 증강되어 결과적으로 ε_θ_p(z, t, y)가 디노이징 아키텍처에서 어떻게 사용되는지에 대한 구현 세부 정보를 부록 C에서 찾을 수 있다.
4 Experiments
이 섹션에서는 여러 문제에 대한 GAUDI의 적용 가능성을 보여준다.
첫째, 재구성 단계의 재구성 품질과 성능을 평가한다.
그런 다음 이미지 또는 텍스트 프롬프트에 해당하는 조건화 변수에서 radiance 필드가 생성되는 unconditional 및 conditional 추론을 포함한 생성 작업에서 모델의 성능을 평가한다.
전체 실험 설정 및 세부 정보는 부록 B에서 확인할 수 있습니다.
4.1 Data
우리는 4개의 데이터 세트에 대한 결과를 보고한다: Vizdoom [21], Replica [60], VLN-CE [23] 및 ARKit Scene [1]은 장면 수와 복잡성에 따라 달라집니다(그림 3 및 표 1 참조).

Vizdoom [21]: Vizdoom은 단순한 질감과 기하학적 구조를 가진 합성 시뮬레이션 환경이다.
[7]에서 제공한 데이터를 사용하여 모델을 학습한다.
텍스처뿐만 아니라 장면 수와 궤적 측면에서 가장 간단한 데이터 세트로, 가장 간단한 설정에서 GAUDI를 검사하는 테스트 베드 역할을 한다.
Replica [60]: Replica는 Habitat [55]를 통해 궤적이 렌더링되는 18개의 사실적인 장면으로 구성된 데이터 세트이다.
[7]에서 제공한 데이터를 사용하여 모델을 학습했습니다.
VLN-CE [23]: VLN-CE는 원래 지속적인 환경에서 비전 및 언어 탐색을 위해 설계된 데이터 세트이다.
이 데이터 세트는 3D 데이터 세트에서 3D 장면의 두 지점 사이를 이동하는 에이전트의 3.6K 궤적으로 구성된다[6].
우리는 Habitat [55]를 통해 관찰을 제공한다.
특히, 이 데이터 세트에는 에이전트가 취한 궤적에 대한 텍스트 설명도 포함되어 있다.
섹션 4.5에서 우리는 설명이 주어진 3D 장면을 생성하기 위해 conditional 방식으로 GAUDI를 학습한다.
ARKitScenes [1]: ARKitScenes는 실내 공간 스캔의 데이터 세트입니다.
이 데이터 세트에는 약 160,000개의 서로 다른 실내 공간에 대한 5,000개 이상의 스캔이 포함되어 있다.
시뮬레이션에서 렌더링을 통해 RGB, depth 및 카메라 포즈를 얻는 이전 데이터 세트(즉, Vizdoom [21] 또는 Habitat [55])와 달리, ARKitScenes는 ARKit SLAM을 사용하여 추정된 스캔 및 카메라 포즈의 raw RGB 및 depth를 제공한다.
또한 이전 데이터 세트의 궤적은 일반적으로 내비게이션에서 수행하는 것처럼 포인트 투 포인트인 반면, ARKitScenes에 대한 카메라 궤적은 전체 실내 공간의 자연스러운 스캔과 유사하다.
우리의 실험에서 우리는 모델을 학습시키기 위해 ARKitScenes의 1K 스캔의 하위 집합을 사용한다.

4.2 Reconstruction
우리는 먼저 식 2에 설명된 최적화 문제가 경험적 분포에서 궤적을 만족스러운 방식으로 재구성할 수 있는 잠재 코드 z를 찾을 수 있다는 가설을 검증한다.
표 1에서 우리는 모든 데이터 세트에서 모델의 재구성 성능을 보고한다.
그림 4는 각 데이터 세트에 대한 랜덤 궤적의 재구성을 보여준다.
우리의 모든 실험에 대해 우리는 달리 언급되지 않는 한 z_scene와 z_pose의 차원을 2048로 설정하고 β = 0.1로 설정한다.
학습 중에 궤적의 중간 프레임이 좌표계의 원점이 되도록 각 궤적에 대한 카메라 포즈를 표준화한다.
ablation 실험은 부록 E를 참조하십시오.

4.3 Interpolation
또한, 식 2의 최적화 문제를 최소화하여 얻은 잠재 표현의 구조를 평가하기 위해, 우리는 그림 5의 잠재 쌍(z_i, z_j) 사이의 보간 결과를 보여준다.
장면을 보간하는 동안 이미지를 렌더링하기 위해 좌표계의 원점에 고정 카메라를 배치합니다.
우리는 기하학(벽, 천장)과 질감(계단, 카펫) 모두에서 장면의 원활한 전환을 관찰한다.
더 많은 시각화는 부록 E.1에 포함되어 있다.
4.4 Unconditional generative modeling
섹션 4.2와 같이 샘플 x ∈ X를 높은 정확도로 재구성할 수 있는 잠재 표현 z ∈ Z를 고려하여, 이제 잠재 z_i ∈ Z의 분포를 학습하여 경험적 분포 x ∈ X를 캡처하는 이전 p_θ_p(Z)의 용량을 평가한다.
이를 위해 DDPM의 추론 프로세스를 따라 z ~ p_θ_p(Z)를 샘플링한 다음 디코더 네트워크를 통해 z를 공급하여 RGB 이미지의 궤적을 생성하여 평가에 사용한다.
우리는 우리의 접근 방식을 다음과 같은 베이스라인과 비교한다: GRAF [56], π-GAN [5] 및 GSN [7].
우리는 각 모델과 데이터 세트에 대한 예측 분포와 타겟 분포에서 5k 이미지를 샘플링하고 FID[14]와 SwAV-FID[31] 점수를 모두 보고한다.
우리는 정량적 결과를 표 2에 보고하는데, 여기서 GAUDI가 모든 데이터 세트와 메트릭에 걸쳐 SOTA 성능을 얻는 것을 알 수 있다.
우리는 GAUDI가 장면을 모델링할 때 핵심적인 radiance 필드와 카메라 포즈에 대해 풀렸지만 해당하는 잠재력을 학습하기 때문에 이러한 성능 향상이 가능하다고 본다(부록 E의 ablation 참조).
우리는 이러한 훌륭한 경험적 결과를 얻기 위해 GAUDI가 재구성 충실도가 높은 잠재자를 동시에 찾는 동시에 분포를 효율적으로 학습해야 한다는 점에 주목한다.

그림 6에서 우리는 GAUDI가 서로 다른 데이터 세트에 대해 학습한 unconditional 분포의 샘플을 보여준다.
우리는 GAUDI가 샘플링된 카메라 포즈에서 렌더링될 수 있는 경험적 분포에서 다양하고 현실적인 3D 장면을 생성할 수 있음을 관찰한다.

4.5 Conditional Generative Modeling
분포 p(Z)를 모델링하는 것 외에도 GAUDI를 사용하여 p(Z)를 변조하기 위해 조건부 변수 y ∈ Y가 주어진 조건부 생성 문제 p(Z|Y)도 해결할 수 있습니다.
모든 조건 변수 y에 대해 조건 모델을 학습하기 위해 쌍을 이룬 데이터 {z, y}의 존재를 가정한다[42, 9, 41].
이 섹션에서는 조건부 추론 문제에 대한 양적 및 질적 결과를 모두 보여준다.
우리가 고려하는 첫 번째 조건화 변수는 궤적에 대한 텍스트 설명이다.
둘째, 궤적에서 랜덤 샘플링된 RGB 이미지가 조건 변수로 작용하는 조건부 모델을 고려한다.
마지막으로, 우리는 각 궤적이 획득된 3D 환경(즉, 특정 실내 공간)을 나타내는 범주형 변수(즉, 원핫 벡터)를 사용한다.
표 3은 다양한 조건부 추론 문제에 대한 정량적 결과를 보여준다.

4.5.1 Text Conditioning
우리는 3D 장면 생성을 위한 텍스트 conditional 모델을 학습하는 어려운 작업을 다룬다.
우리는 VLN-CE[23]에 제공된 탐색 텍스트 설명을 사용하여 모델을 조건화한다.
이러한 텍스트 설명에는 탐색 경로뿐만 아니라 장면에 대한 높은 수준의 정보가 포함되어 있습니다(즉, "침실에서 나와 거실로 걸어가십시오", "흔들리는 문을 통해 방을 나간 다음 침실로 들어가십시오").
우리는 사전 학습된 RoBERTA 기반 [26] 텍스트 인코더를 사용하고 diffusion 모델을 조건화하기 위해 중간 표현을 사용한다.
그림 7은 이 과제에 대한 GAUDI의 정성적 결과를 보여준다.
우리가 아는 한, 이것은 텍스트에서 조건부 3D 장면 생성을 상각 방식으로(즉, 비용이 많이 드는 최적화 문제[17, 28]를 통해 CLIP[40]를 증류하지 않고) 허용하는 첫 번째 모델이다.

4.5.2 Image Conditioning
이제 GAUDI가 Z에 대한 분포를 예측하기 위해 RGB 이미지에서 정보를 가져올 수 있는지 분석한다.
이 실험에서 우리는 궤적 x ∈ X에서 이미지를 랜덤으로 선택하고 조건 변수 y로 사용한다.
이 실험을 위해 우리는 VLN-CE 데이터 세트의 궤적을 사용한다[23].
각 학습 반복 동안 우리는 각 궤적 x에 대해 랜덤 이미지를 샘플링하고 이를 조건 변수로 사용한다.
우리는 이미지 인코더로 사전 학습된 ResNet-18[13]을 사용한다.
추론하는 동안, 결과적인 conditional GAUDI 모델은 주어진 이미지가 확률적 관점에서 관찰되는 radiance 필드를 샘플링할 수 있다.
그림 8에서 우리는 다른 RGB 이미지에서 조건화된 모델의 샘플을 보여준다.

4.5.3 Categorical Conditioning
마지막으로, 우리는 각 궤적이 기록된 기본 3D 실내 환경을 나타내는 범주형 변수를 조건으로 GAUDI가 어떻게 수행되는지 분석한다.
우리는 VLN-CE [23] 데이터 세트에서 실험을 수행하며, 여기서 학습 가능한 임베딩 계층을 사용하여 각 환경을 나타내는 범주형 변수의 표현을 학습한다.
conditional 모델의 환경별 FID 점수를 unconditional 모델과 비교한다.
이 환경별 FID 점수는 모델이 조건화된 동일한 실내 환경의 실제 이미지에서만 계산된다.
우리의 가설은 모델이 조건화 변수의 정보를 효율적으로 포착한다면 동일한 데이터에 대해 학습된 unconditional 상대보다 환경 특정 분포를 더 잘 포착해야 한다는 것이다.
표 3에서 마지막 열은 VLN-CE 데이터 세트의 conditional 모델과 unconditional 모델 간 환경별 평균 FID 점수의 차이(예: Δ)를 보여준다.
우리는 conditional 모델이 모든 실내 환경에서 unconditional 모델보다 지속적으로 더 나은 FID 점수를 획득하여 평균 FID 및 SwAV-FID 점수가 급격히 감소하는 것을 관찰한다.
또한, 그림 9에서는 주어진 범주형 변수에 따라 조정된 모델의 샘플을 보여준다.

5 Conclusion
우리는 복잡하고 현실적인 3D 장면의 분포를 포착하는 생성 모델인 GAUDI를 소개했다.
GAUDI는 확장 가능한 2단계 접근 방식을 사용하는데, 먼저 radiance 필드와 카메라 포즈를 분리하는 잠재 표현 학습을 포함한다.
그런 다음 분리된 잠재 표현의 분포는 강력한 prior로 모델링된다.
우리 모델은 여러 3D 데이터 세트 및 메트릭에 걸친 최근 베이스라인과 비교할 때 SOTA 성능을 얻는다.
GAUDI는 conditional 및 unconditional 문제에 모두 사용할 수 있으며 텍스트 설명에서 3D 장면을 생성하는 것과 같은 새로운 작업을 가능하게 한다.
A Limitations, Future Work and Social Impact
GAUDI는 3D 장면의 생성 모델에서 한 단계 발전한 것이지만, 우리는 그 한계에 대해 명확하게 논의하고 싶다.
우리 모델의 현재 한계 중 하나는 추론이 실시간이 아니라는 사실이다.
그 이유는 두 가지입니다: (i) 전체 3D 장면에 대해 상각되더라도 이전 DDPM에서 샘플링하는 것은 느립니다.
DDPM에서 추론 효율성을 향상시키기 위한 기술이 최근 제안되었으며 GAUDI를 보완할 수 있다.
(ii) radiance 필드에서 렌더링하는 것은 메시와 같은 다른 3D 구조를 렌더링하는 것만큼 효율적이지 않다.
최근의 연구는 또한 이 문제를 다루었으며 [25, 68, 44] 우리의 접근 방식에 적용될 수 있다.
또한, 많은 최신 이미지 생성 모델[41, 32, 52]은 고해상도 이미지를 렌더링하기 위해 diffusion 모델을 통한 여러 단계의 업샘플링을 사용한다.
이러한 업샘플 단계는 GAUDI에 직접 적용될 수 있다.
또한 잠재를 찾기 위한 최적화 과정을 대체할 효율적인 인코더 연구를 고려할 수 있다.
짧은 궤적(5-10 프레임)에 트랜스포머[53]를 사용하려는 시도가 있었지만, [1]의 것처럼 궤적당 수천 개의 이미지로 확장하는 방법은 불분명하다.
마지막으로, GAUDI와 같은 모델이 개선된 생성 및 일반화 능력을 발휘하기 위한 주요 한계는 대규모 개방형 도메인 3D 데이터 세트가 없다는 것이다.
특히 텍스트 설명과 같은 다른 관련 양식과 함께.
생성 모델의 사회적 영향을 고려할 때 주의가 필요한 몇 가지 측면은 불성실한 데이터 생성을 위한 사용 생성 모델, 예를 들어 "DeepFakes"[30], 학습 데이터 유출 및 개인 정보 보호 [62], 학습 데이터에 존재하는 편향의 증폭[18]이다.
GAUDI에 적용되는 한 가지 구체적인 윤리적 고려 사항은 몰입형 3D 장면을 쉽게 만들 수 있는 모델이 미래 세대와 현실 분리에 미칠 수 있는 영향이다[3].
생성 모델링의 윤리적 고려 사항에 대한 심층적인 검토는 [51]을 참조하도록 한다.
B Experimental Settings and Details
이 섹션에서는 데이터 및 모델 하이퍼 파라미터에 대한 자세한 내용을 설명합니다.
모든 실험에서 우리의 잠재 z_scene과 z_pose는 2048차원을 갖는다.
첫 번째 단계에서, 잠재가 식 2를 통해 최적화되면, z_scene은 장면 디코더 네트워크에 공급하기 전에 8x8x32 피처 맵으로 재구성된다.
두 번째 단계에서는 DDPM prior를 학습할 때 z_scene과 z_pose를 8x8x64 잠재 상태로 재구성하고 UNet[50] 디노이징 아키텍처의 힘을 활용한다.
각 데이터 세트에 대해 궤적은 렌더링을 위한 근거리 및 원거리 평면뿐만 아니라 길이, 물리적 스케일이 다르다, 이에 따라 모델에서 조정한다.
Vizdoom [21]: Vizdoom에서 궤도는 평균 600개의 계단을 포함한다. 각 단계에서 카메라는 0.5 게임 단위 앞으로 이동하거나 왼쪽 또는 오른쪽으로 30도 회전할 수 있습니다. 우리는 삼면 표현에서 요소의 단위 길이를 0.05 게임 단위로 설정한다(각 잠재 코드 w_xyz는 0.05 큐빅 게임 단위의 공간 부피를 나타낸다). 근거리 평면은 0.0 게임 단위, 원거리 평면은 800 게임 단위이다. 우리는 [7]에서 제공하는 데이터와 분할을 사용한다.
Replica [60]: Replica에서 모든 궤적에는 100개의 단계가 포함됩니다. 각 단계에서 카메라는 왼쪽이나 오른쪽으로 25도 회전하거나 15센티미터 앞으로 움직일 수 있다. 우리는 삼면 표현에서 요소의 단위 길이를 25센티미터로 설정한다(즉, 각 잠재 코드 w_xyz는 0.25세제곱센티미터의 공간 부피를 나타낸다). 근접 평면은 0.0m, 원거리 평면은 6m다. 우리는 [7]에서 제공하는 데이터와 분할을 사용한다.
VLN-CE [23]: VLN-CE 궤도는 대략 30에서 150 사이의 다양한 수의 단계를 포함한다. 각 단계에서 카메라는 왼쪽이나 오른쪽으로 25도 회전하거나 15센티미터 앞으로 움직일 수 있다. 우리는 삼면 표현에서 요소의 단위 길이를 50센티미터로 설정한다. 근거리 평면은 0.0미터, 원거리 평면은 12미터입니다. 우리는 [23]에서 제공하는 데이터와 학습 분할을 사용한다.
ARKitScenes [1]: ARKitScenes에서 궤적은 평균적으로 약 1000개의 단계를 포함한다. 이러한 궤적에서 카메라는 모든 방향과 방향으로 연속적으로 이동할 수 있습니다. 우리는 삼면 표현에서 요소의 단위 길이를 20센티미터로 설정한다. 근거리 평면은 0.0미터, 원거리 평면은 8미터입니다. [1]에서 제공하는 데이터의 3DOD 분할을 사용합니다
C Decoder Architecture Design and Details
이 섹션에서 우리는 본 논문의 그림 2에 있는 디코더 모델을 설명한다.
디코더 네트워크는 3개의 모듈로 구성됩니다: 장면 디코더, 카메라 포즈 디코더 및 radiance field 디코더.

• 장면 디코더 네트워크는 각 블록의 끝에 셀프 어텐션 레이어를 포함하는 컨볼루션 아키텍처로 매개 변수화된 VQGAN 디코더의 아키텍처[9]를 따른다. 장면 디코더의 출력은 형상 64x64x768의 피쳐 맵입니다. 3면 표현 W = [W_xy, W_xz, W_yz]를 얻기 위해 출력 피처 맵의 채널 차원을 동일한 크기의 64x64x256의 3개 청크로 나눈다.
• 카메라 포즈 디코더는 [27]에서와 같이 잔여 연결과 숨겨진 크기가 256인 4개의 conditional batch normalization (CBN) 블록을 갖는 MLP로 구현된다. 조건부 배치 정규화 파라미터는 z_pose로부터 예측된다. 카메라 포즈 인코더 입력에 위치 인코딩을 적용한다(s ∈ [-1, 1]). 그림 10(a)는 카메라 포즈 디코더 모듈의 구조를 나타낸다.
• radiance 필드 디코더는 숨겨진 차원 512 및 LeakyReLU 활성화를 가진 8개의 선형 레이어를 가진 MLP로 구현된다. 우리는 입력에 위치 인코딩을 적용하고 (p ∈ R^3) 입력 레이어에서 시작하는 MLP의 다른 모든 레이어(예: 레이어 0, 2, 4, 6)의 출력에 조건 변수 w_xyz를 연결한다. 효율성을 향상시키기 위해 RGB 이미지 대신 512 채널(출력 해상도보다 2배 작은)의 작은 해상도 피쳐 맵을 렌더링하고 추가 디콘볼루션 레이어가 있는 UNet[50]을 사용하여 최종 이미지[7,34]를 예측한다. 그림 10(b)는 radiance 필드 디코더 모듈의 구조를 보여준다.
학습을 위해 모든 잠재 z = 0을 초기화하고 3개 모듈의 매개 변수와 공동으로 학습한다.
우리는 Adam 옵티마이저와 잠재적인 경우 0.001, 모델 매개 변수의 경우 0.0001의 학습률을 사용한다.
우리는 (데이터 세트 크기에 따라) 8개의 A100 NVIDIA GPU에서 2-7일 동안 모델을 학습하며, 궤적당 2개의 이미지를 랜덤으로 샘플링하는 16개의 궤적 배치 크기를 사용한다.
D Prior Architecture Design and Details
분포 p(Z)를 학습하기 위해 Denoising Diffusion Probabilistic Model (DDPM)[15]을 사용한다.
구체적으로, 우리는 [33]의 UNet 아키텍처를 채택하여 각 시간 단계에서 잠재적인 노이즈를 제거한다.
학습 중에 t ∈ {1, ..., T}를 균일하게 샘플링하고 식 3에서 θ_p에 대한 그레디언트 강하 단계를 수행한다.
[33]과는 달리 고정된 시간 의존적 공분산 행렬과 선형 노이즈 스케줄이 있는 원래 DDPM 학습 체계를 유지한다.
추론하는 동안, 우리는 제로 평균 단위 분산 가우시안 분포에서 잠재된 샘플링부터 시작하여 디노이징 단계를 반복적으로 수행한다.
샘플링 효율을 가속화하기 위해 DDIM[59]을 활용하여 결정론적 비마르코비안 diffusion 프로세스를 모델링하여 50단계만 노이즈를 제거한다.
conditional 생성 모델링 작업의 경우, 다양한 양식(즉, 텍스트, 이미지, 범주형 클래스 등)의 조건화 입력을 지원하기 위해 조건화 메커니즘이 일반적이어야 한다.
이 요구 사항을 충족하기 위해 먼저 양식별 인코더를 통해 conditional 입력을 임베딩 표현 c에 투영한다.
텍스트 조건화를 위해 사전 학습된 RoBERTA 기반을 사용한다[26].
이미지 조건화를 위해 ImageNet에서 사전 학습된 ResNet-18[13]을 사용한다.
범주형 조건화를 위해 학습 가능한 환경별 임베딩 계층을 사용한다.
우리는 과적합 문제를 피하기 위해 텍스트 및 이미지 입력에 대한 인코더를 동결한다.
우리는 LDM[48]에서 크로스 어텐션 모듈을 빌려 조건 표현 c를 UNet[50]의 여러 수준에서 중간 활성화와 융합한다.
크로스 어텐션 모듈은 UNet 아키텍처의 중간 활성화에서 생성된 쿼리가 [48]을 참조하는 동안 c에서 생성된 키와 값으로 어텐션 메커니즘을 구현한다.
DDPM을 사전에 학습하기 위해 Adam 옵티마이저와 4.0e^-06의 학습률을 사용한다.
우리는 1개의 A100 NVIDIA GPU에서 (데이터 세트 크기에 따라) unconditional prior 학습 1-3일, conditional prior 학습 실험 3-5일 동안 모델을 각각 256 및 32 배치 크기로 학습한다.
DDPM 모델의 하이퍼 파라미터의 경우, 우리는 숫자 diffusion 단계를 1000으로, 노이즈 스케줄을 0.0195에서 0.0015로 선형적으로 감소시키는 것으로, 기본 채널 크기를 224로, 어텐션 해상도를 [8, 4, 2, 1]로, 어텐션 헤드 수를 8로 설정한다.
'View Synthesis' 카테고리의 다른 글
| GRAF: Generative Radiance Fields for 3D-Aware Image Synthesis (0) | 2023.03.07 |
|---|---|
| Putting NeRF on a Diet: Semantically Consistent Few-Shot View Synthesis (4) | 2023.03.03 |
| Decomposing NeRF for Editing via Feature Field Distillation (0) | 2023.01.22 |
| Depth-supervised NeRF: Fewer Views and Faster Training for Free (v2) (0) | 2022.12.08 |
| Reinforcement Learning with Neural Radiance Fields (0) | 2022.12.06 |