2023. 1. 22. 15:44ㆍView Synthesis
Decomposing NeRF for Editing via Feature Field Distillation
Sosuke Kobayashi, Eiichi Matsumoto, Vincent Sitzmann
Abstract
새로운 neural radiance fields (NeRF)는 컴퓨터 그래픽의 유망한 장면 표현으로 이미지 관찰에서 고품질 3D 재구성과 새로운 뷰 합성을 가능하게 한다.
그러나 MLP 또는 복셀 그리드와 같은 기본 연결주의적 표현은 객체 중심적이거나 구성적이지 않기 때문에 NeRF로 대표되는 장면을 편집하는 것은 어렵다.
특히 특정 영역이나 객체를 선택적으로 편집하는 것이 어려웠다.
본 연구에서는 NeRF의 semantic 장면 분해 문제를 해결하여 표현된 3D 장면의 쿼리 기반 로컬 편집을 가능하게 한다.
CLIP-LSeg 또는 DINO와 같은 기성품, supervised 및 self-supervised 2D 이미지 피처 추출기의 knowledge를 radiance 분야와 병렬로 최적화된 3D 피처 분야로 distill할 것을 제안한다.
텍스트, 이미지 패치 또는 포인트 앤 클릭 선택과 같은 다양한 양식에 대한 사용자 지정 쿼리가 주어지면 3D 피처 필드는 재학습 없이 3D 공간을 semantically 분해하고 radiance 필드에서 영역을 semantically 선택하고 편집할 수 있다.
우리의 실험은 distilled 피처 필드가 2D 비전 및 언어 기반 모델의 최근 진전을 3D 장면 표현으로 전송하여 설득력 있는 3D segmentation과 신흥 신경 그래픽 표현의 선택적 편집을 가능하게 할 수 있음을 검증한다.
1 Introduction
새로운 신경 implict 표현 또는 신경 필드는 다양한 신호를 표현하기 위한 유망한 접근법으로 나타났다[82, 53, 65, 106, 56].
특히 제한된 수의 컨텍스트 이미지에서 3D 장면 재구성 및 새로운 뷰 합성에 중요한 역할을 한다.
Neural radiance fields (NeRF)[56]는 제한된 수의 관측치에서 연속적인 볼륨 밀도와 radiance 필드를 복구하여 컴퓨터 그래픽의 유망한 응용 프로그램으로 볼륨 렌더링을 통해 임의의 뷰에서 고품질 이미지를 생성할 수 있도록 했다.
그러나 NeRF에 의해 재구성된 장면을 편집하는 것은 장면이 객체 중심이 아니며 MLP[56] 또는 복셀그리드[23]와 같은 연결주의적 표현의 가중치로 implicitly 인코딩되기 때문에 명확하지 않다.
입력 또는 출력 공간에서 또는 최적화 기반 편집을 통해 장면을 변환할 수 있지만 [37, 97], 이것은 단일 객체 이동과 같은 선택적인 객체 중심 또는 semantic 로컬 편집을 가능하게 하지 않는다.
이전 연구는 NeRF의 일부를 선택적으로 이동, 변형, 도장 또는 최적화할 수 있는 좌표-레벨의 semantic 분해를 통해 이 문제를 해결했지만, 인스턴스 segmentation에 대한 비용이 많이 드는 주석과 인스턴스별 네트워크 학습에 의존한다[104].
이는 사전 학습된 segmentation 모델[25, 41]로 완화될 수 있지만, 그러한 모델은 사전 정의된 폐쇄 레이블 세트와 도메인(예: 트래픽 장면)을 필요로 하므로 분해 및 편집이 제한된다.
NeRF의 로컬 편집은 이상적으로 좌표-레벨 분해를 위한 효율적이고 개방적인 방법을 필요로 한다.
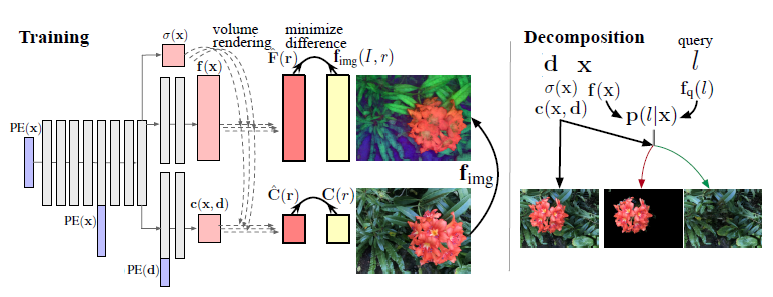
본 연구에서는 NeRF의 로컬 대화형 편집을 위한 쿼리 기반 장면 분해에 대한 새로운 접근 방식인 distilled feature fields (DFFs)를 제시한다.
우리는 모든 3D 좌표를 해당 좌표의 semantic 피처 설명자에 매핑하는 3D 신경 피처 필드에 초점을 맞춘다.
텍스트 또는 이미지 패치와 같은 사용자 쿼리에 따라 이 3D 피처 필드는 재학습 없이 장면의 분해를 계산할 수 있다.
우리는 이미지 도메인에서 사전 학습된 피처 인코더의 supervision을 사용하여 teacher-student distillation [34]을 통해 장면별 DFF를 학습한다.
3D 장면의 영역과 달리, 이미지 도메인은 대규모 고품질 데이터 세트와 효과적인 피처 추출 모델의 self-supervised 및 supervised 학습에 대한 풍부한 사전 작업을 자랑한다.
특히, 최근 제안된 트랜스포머 기반 모델[96, 22]은 다양한 비전 및 텍스트 기반 작업(예: CLIP [69], LSeg [44], DINO [12])에 걸쳐 인상적인 기능을 보여주었다.
이러한 피처 공간은 영역의 semantic 속성을 캡처하고 텍스트, 이미지 쿼리 또는 클러스터링으로 잘 대응하고 세분화할 수 있도록 한다.
우리는 이러한 모델을 teacher 네트워크로 사용하고 볼륨 렌더링을 통해 3D 피처 필드로 distill한다.
학습된 피처 필드를 사용하면 3D NeRF 장면에서 특정 영역을 semantically 선택 및 편집하고 로컬로 편집된 장면에서 다중 뷰 일관된 이미지를 렌더링할 수 있다.
광범위한 실험에서, 우리는 (1) CLIP에서 영감을 받은 언어 기반 semantic segmentation 네트워크인 LSeg[44]와 (2) 다양한 객체 경계와 대응을 인식하는 self-supervised 네트워크인 DINO[12, 3]의 두 가지 다른 사전 학습된 teacher 네트워크를 가진 신경 피처 분야의 응용을 조사한다.
LSeg 및 DINO 피처를 사용하면 각각 간단한 텍스트 쿼리 또는 이미지 패치로 3D 영역을 선택할 수 있습니다.
먼저 레이블 쿼리가 있는 LSeg 기반 DFF가 supervised 포인트 클라우드 데이터 세트인 ScanNet[20]에서 학습된 기존 포인트 클라우드 기반 3D segmentation 베이스라인과 비교하여 높은 3D segmentation 성능을 가질 수 있음을 정량적으로 보여준다.
그런 다음 segmentation 주석이 없는 실제 NeRF 장면에 걸쳐 다양한 3D 모양 및 기하학적 편집을 시연하고 텍스트, 이미지, 픽셀 또는 클러스터 선택에 대한 단일 쿼리로 영역을 편집할 수 있음을 보여준다.
2 Related Work
Neural Implicit Representations.
신경 implicit 표현 또는 신경 필드는 최근 3D 데이터 및 다중 뷰 2D 이미지에 대한 신경 처리가 발전하고 있다[82, 53, 65, 106, 56].
이 신흥 공간을 검토하기 위해 우리는 독자들에게 Kato et al. [39], Tewari et al. [90], and Xie et al. [102]의 보고서를 지적한다.
특히, neural radiance field (NeRF)는 포즈를 취한 2D 이미지 세트에 장착될 수 있으며 3D 포인트 좌표와 뷰 방향을 RGB 색상 및 밀도에 매핑한다.
관측치가 제한적일 때 NeRF는 종종 과적합하며 정확한 기하학적 구조와 외관으로 새로운 뷰를 합성하지 못한다.
사전 학습된 비전 모델은 flows [62], 다중 뷰 일관성[35], perceptual loss [110] 또는 depth 추정[100, 77]을 통해 NeRF를 정규화하는 데 사용되었다.
일부 사전 학습된 모델은 시각적 세계뿐만 아니라 언어와 같은 다른 양식에서도 작동한다.
최근 제안된 CLIP 모델[69]은 다양한 텍스트 및 시각적 개념에 대한 강력한 일반화와 함께 이미지와 텍스트 정렬에서 인상적인 성능을 보여주었다.
Wang et al. [97], Jain et al. [36], and Poole et al. [68]은 CLIP 또는 Imagen[79]을 사용하여 NeRF 매개 변수를 최적화하여 텍스트 프롬프트 쿼리와 함께 단일 개체 NeRF를 편집하거나 생성합니다.
이러한 방법은 유망하지만 특정 장면 영역의 정확한 선택적 편집을 가능하게 하지는 않는다.
예를 들어, "노란 꽃"이라는 프롬프트는 식물의 잎과 같은 의도하지 않은 장면 영역에 영향을 미칠 수 있다.
제안된 분해 방법은 사전 학습된 기초 모델을 활용하여 실제 NeRF 장면을 선택적으로 편집할 수 있다.
신경 설명자 필드[80]는 로봇 객체 파악을 효율적으로 가르치기 위해 3D occupancy 필드 네트워크[53]에서 나타나는 중간 피처를 사용한다.
사전 학습된 객체 중심 3D 모델 대신, 우리는 distillation을 통해 2D 비전 모델을 teacher 네트워크로 사용하여 사전 학습된 기초 모델의 최근 발전을 활용한다[7].
Geometric Decomposition of Neural Scene Representations
Kohli et al. [40] and Zhi et al. [112]은 신경 implicit 표현이 semantic 레이블의 supervision과 결합될 수 있음을 보여준다.
Yang et al. [104]은 학습 중에 뷰 일관성 있는 ground-truth 인스턴스 segmentation 마스크가 주어지면 실제로 그러한 주석이 비싸지만 NeRF가 각 객체를 다른 볼륨으로 표현하도록 학습될 수 있음을 보여준다.
동시에, Benaim et al. [6]도 다른 매개 변수화를 실험한다.
조건부 [49, 37, 21, 63] 및 생성 모델 [60, 61, 31]은 대규모 데이터 세트가 있는 제한된 도메인에서 어느 정도의 범주별 분해(예: 인체 부위) 및 편집을 가능하게 한다.
복셀그리드 또는 옥트리[13, 48, 14, 88, 94, 89, 43, 81, 107, 59, 60] 또는 unsupervised 분해[73, 85, 109, 83]와 같은 정규 구조는 로컬화된 매개 변수의 조작을 통해 편집 가능성을 가능하게 한다.
그러나 장면에 대한 유연하지 않은 구조화된 경계 또는 강력한 가정으로 인해 분해가 제한된다; self-supervised 객체 중심 학습은 어려운 작업이다.
다른 연구들은 또한 도메인에 특화된 파이프라인(예: 트래픽 장면)[64, 25, 41] 또는 상황(예: 각 객체 데이터는 독립적으로 액세스 가능)을 통해 더 구조화된 하이브리드 표현으로 재구성을 탐구했다[28, 27, 105].
이 작업 라인은 학습 중 또는 학습 전에 도메인 또는 segmentation 유형을 정의하고 제한하므로 편집 가능한 장면 및 객체에 대한 자유도를 제한한다는 점에 유의하십시오.
대조적으로, 우리의 방법은 텍스트 및 이미지 쿼리를 통해 장면별 NeRF를 임의의 semantic 단위로 분해하여 재학습 없이 다양한 장면 편집을 가능하게 한다.
Tschernezki et al. [93]의 동시 논문도 동일한 학습 프레임워크를 탐구하고, 특히 2D teacher 네트워크에서 융합된 피쳐가 어떻게 개선되는지 조사한다.
또한 다른 teacher 모델(MoCo-v3[17] 및 DeiT[91]), PCA를 통한 차원 축소 및 NeuralDiff[92] 기반 신경 필드를 사용하여 결과를 보완적으로 보여준다.
다른 동시 연구는 click 또는 scribble 주석에 의해 supervise되는 장면별 segmentation 필드[113] 또는 3DCNN[76]을 학습하여 분해를 탐구한다.
마지막으로, 다르지만 관련된 작업인 비디오 편집에서, Kasten et al.[38]은 시간 일관성 있는 로컬 편집을 위해 전경 배경 분해 및 아틀라스 표현을 사용한다; Loeschcke et al. [51]과 Bar-Tal et al. [5]은 편집을 위해 CLIP를 추가로 사용한다.
Zero-shot Semantic Segmentation.
제로샷 semantic segmentation은 모델이 범주의 사전 정보 없이 이미지에서 픽셀의 semantic 레이블을 예측해야 하는 어려운 작업[24, 2, 10]이다.
일반적인 해결책은 비전 및 언어 cross-modal 인코더를 사용하는 것이다.
이미지(픽셀)와 텍스트 레이블을 동일한 semantic 공간으로 인코딩하고 두 입력의 유사성 또는 정렬을 기반으로 제로샷 예측을 수행하도록 학습된다.
최근 이미지 인코더 아키텍처[96, 22, 71]와 대규모 학습[69, 12]의 개발로 제로샷 모델[44, 52, 99, 103, 114, 72]을 포함한 비전 모델의 능력과 일반화가 향상되었다.
반면, 3D에서 제로샷 인식에 대한 진행 중인 연구는 여전히 효과적이고 효율적이며 고해상도 아키텍처와 주석이 달린 대규모 데이터 세트의 부족으로 어려움을 겪고 있다[54, 33, 29, 101, 78, 30].
우리의 방법은 semantic 3D supervision 없이 이미지 도메인의 진행 상황을 활용하여 장면별 3D 필드에서 제로샷 semantic segmentation을 수행하는 새로운 접근 방식이다.
우리는 이 논문의 목표가 3D semantic segmentation 작업에서 SOTA 성능을 달성하는 것이 아니라는 점에 주목한다.
대신, 우리의 목표는 편집을 위한 신경 장면 표현의 분해이며, 이는 이산 포인트 클라우드 또는 복셀 그리드의 segmentation보다 연속적인 3D 공간에서 원활한 segmentation 결과를 필요로 한다.
3 Preliminaries
3.1 Neural Radiance Feidls (NeRF)
3.2 Pre-trained Models and Zero-shot Segmentation of Images
대부분의 semantic segmentation 모델은 닫힌 레이블 세트를 사전 정의하며, supervised 학습 없이 segmentation 범주 또는 경계를 유연하게 변경할 수 없다.
대조적으로, 제로샷 semantic segmentation은 개방형 쿼리가 주어진 타겟 영역을 예측한다.
Li et al. [44]은 픽셀-레벨 피쳐와 텍스트 쿼리 피처를 정렬하여 제로샷 semantic segmentation을 수행하는 모델인 LSeg를 제안한다.
LSeg는 대규모 언어-이미지 대조 학습을 통해 학습된 DPT 아키텍처[71]와 CLIP 기반 텍스트 레이블 피처 인코더[69]를 사용한다.
이미지 I에서 픽셀 r이 주어진 텍스트 레이블 l의 확률은 픽셀 레벨 이미지 피처 f_img(I, r)와 쿼리 텍스트 피처 f_q(l) 다음 소프트맥스를 통해 계산된다:

, 여기서 L은 가능한 레이블의 집합입니다.
음수 레이블을 사용할 수 없는 경우 임계값 코사인 유사성과 같은 다른 점수를 사용하여 레이블의 확률을 직접 계산할 수 있습니다.
학습 중에 LSeg는 supervised semantic segmentation 데이터 세트에서 교차 엔트로피를 최소화하여 이미지 인코더 f_img(I, r)만 최적화한다.
텍스트 인코더 f_q(l)는 사전 학습된 CLIP 모델[69]에서 얻는다.
최근에는 사전 학습된 CLIP이 다양한 작업의 백본으로 활용되고 있으며 동일한 잠재 공간을 공유하는 추가 모듈로 확장되었다.
예를 들어, Reimers and Gurevych[74, 75]는 다국어(50개 이상의 언어) 텍스트 인코더를 학습하여 CLIP 및 CLIP에서 영감을 받은 변형이 일본어와 같이 영어가 아닌 쿼리를 사용할 수 있도록 한다.
마찬가지로 distillation을 통해 LSeg에 대해 사전 학습된 CLIP의 잠재 공간을 사용하여 영어 쿼리와 영어 이외의 쿼리 모두로 NeRF를 분해할 수 있다.
sementation은 식.2에서와 유사한 내적곱 유사성 공식을 사용하여 이미지, 패치 또는 픽셀 쿼리 피쳐 f_q와 같은 다른 양식으로 추가로 수행될 수 있다.
특히, self-supervesed 비전 모델인 DINO[12]는 인접 프레임의 피처 간 유사성을 계산하여 비디오 인스턴스 segmentation 및 추적을 해결한다.
Amir et al. [3]은 또한 DINO 피처가 유사성 및 클러스터링에 의한 co-segmentation 및 포인트 대응에서 잘 작동한다는 것을 보여준다.
우리의 실험에서, 우리는 3D 분해를 위한 이미지와 텍스트의 피처를 얻기 위해 공개적으로 사용 가능한 두 가지 모델인 LSeg와 DINO를 사용한다.
4 Distilled Feature Fields
4.1 Distilling Foundation Modules into 3D Feature Fields via Volume Rendering
NeRF는 밀도와 뷰 의존적인 색상, σ(x)와 c(x,d)를 계산하기 위해 신경 필드를 학습한다.
우리는 다른 관심 수량에 대한 디코더를 추가하여 NeRF를 확장할 수 있다.
예를 들어, SemanticNeRF [112]는 ground truth semantic 레이블이 있는 이미지를 통해 supervision으로 학습된 폐쇄 세트 semantic 레이블의 확률 분포를 출력하는 가지를 추가한다.
이를 통해 새로운 뷰에서 RGB 및 semantic segmentation 마스크 쌍을 예측할 수 있어 데이터 확대에 유용하다.
그러나 ground truth 정보 주석은 비용이 많이 들기 때문에, 이 방법은 장면 편집의 수단으로는 비효율적이다[104].
교통 장면[25, 41]과 같은 특정 도메인의 경우, 우리는 대신 폐쇄 세트 segmentation 모델을 학습하고 객체 인식 신경 필드를 학습하기 위해 그 예측을 사용할 수 있다.
그러나 이 접근 방식은 객체 유형이 제한되고 도메인별 supervision 데이터 세트를 사용할 수 있는 경우에만 가능하며, 도메인 및 분해의 유연성 측면에서 장면 편집의 적용을 제한한다.
우리는 이러한 아이디어를 기반으로 구축하고 열린 세트 텍스트 레이블 또는 기타 피처 쿼리를 사용하여 NeRF의 3D 제로샷 segmentation을 수행한다.
닫힌 세트 분류를 수행하는 가지 대신, 피처 벡터 자체를 출력하는 피처 가지를 추가할 것을 제안한다.
이 가지는 각 공간 점의 의미를 설명하는 3D 피쳐 필드를 모델링합니다.
우리는 teacher 네트워크로서 사전 학습된 픽셀 레벨 이미지 인코더 f_img에 의해 피쳐 필드를 supervise한다.
그림 1과 같이, 3차원 좌표 x가 주어지면, 피쳐 필드는 밀도 σ(x)와 c(x,d) 외에 피처 벡터 f(x)를 출력한다.
피처 필드의 볼륨 렌더링은
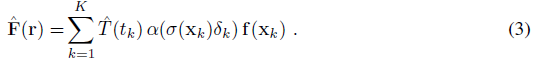
을 통해 유사하게 수행된다.
렌더링된 피쳐 ^F(r)와 teacher의 피쳐 f_img(I,r) 사이의 차이를 최소화하여 f를 최적화할 수 있다.
효과적으로, 우리는 미분 가능한 렌더링을 통해 [34] 2D teacher 네트워크를 3D student 네트워크로 distill하고 있으므로 이 모델을 distilled feature field (DFF)라고 부른다.
렌더링된 피처 ^F(r)와 teacher 출력 f_img(I, r) 사이의 차이를 처벌하는 피처 목표 L_f를 원래 NeRF의 photometric loss에 추가한다.
우리는 coarse and fine 계층적 샘플링을 사용하여 볼륨 렌더링을 위해 두 개의 네트워크를 사용한다.
따라서 photometric loss L_p와 피처 loss L_f의 합을 총 L
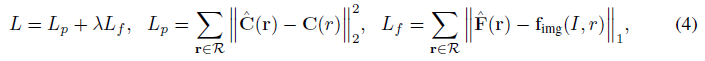
를 최소화한다, 여기서 R은 샘플링된 레이, C(r)는 레이의 ground truth 픽셀 색상, λ는 피쳐 loss의 가중치이며 loss의 균형을 맞추기 위해 0.04로 설정된다[112].
우리는 teacher의 피쳐 f_img(I, r)가 완전히 다중 뷰로 일관되지 않아 재구성된 기하학의 품질을 해칠 수 있기 때문에 식 3의 피쳐 ^F(r) 렌더링 밀도에 정지 그레이디언트를 적용한다.
4.2. Query-based Decomposition and Editing
학습된 DFF 모델은 피쳐 필드 f와 쿼리 인코더 f_q에 의해 3D 제로샷 segmentation을 수행할 수 있다.
3D 공간에서 점 x의 레이블 l의 확률 p(l|x)는 3D 피쳐 f(x)와 텍스트 레이블 피쳐 f_q(l) 다음 소프트맥스의 내적 곱으로 계산됩니다:
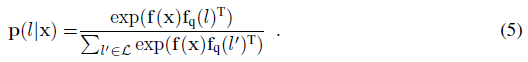
이 쿼리 기반 segmentation 필드는 제안된 방법의 핵심이다.
해상도를 제한하지 않고 임의의 3D 지점에서 계산할 수 있으며, 자연스럽게 radiance 필드 및 볼륨 렌더링과 함께 사용됩니다.
segmentation은 3D 좌표와 쿼리에만 의존합니다.
오리지널 NeRF로서 멀티뷰 일관성이 있다.
또한 대화형 편집에서 중요한 것은 재학습 없이 쿼리를 통해 segmentation을 변경할 수 있으며, 이는 semantic [112] 또는 인스턴스 segmentation 주석[104]을 사용하는 닫힌 집합 방법으로는 실현될 수 없다.
이제 이 쿼리 조건부 분할을 사용하여 편집할 특정 3D 영역을 식별할 수 있습니다.
혼합을 위해 segmentation 필드 p를 사용하는 두 가지 NeRF 장면 σ_1(x); c_1(x; d) 및 σ_2(x); c_2(x; d)의 병합으로 다양한 편집이 일반화될 수 있다.
실험 섹션에서, 우리는 α의 비율을 기반으로 두 장면의 혼합으로 식.1을 수정합니다:
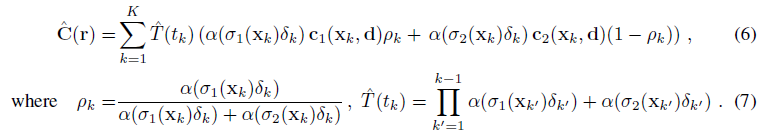
예를 들어, NeRF 장면(σ, c)에서 쿼리 l의 영역에 기하학적 변환 g를 적용하려는 경우, (6)을 설정하여 식 6과 7을 통해 변환된 장면을 렌더링할 수 있다.
색상화, translation 및 삭제를 위한 편집에 대한 자세한 내용은 부록 B에 나와 있습니다.
CLIPNeRF[97]와 같은 최적화 기반 방법을 포함하여 이를 더 복잡한 편집과 결합할 수 있다.
CLIPNeRF 자체는 다중 객체 장면에서 특정 영역을 선택적으로 편집할 수 없지만, 우리의 분해 방법을 사용하면 의도하지 않은 영역을 파괴하지 않고 원하는 객체만 업데이트할 수 있다.
5 Experiments
우리는 먼저 DFF에 의해 달성된 분해에 대한 정량적 평가를 수행한다.
우리는 DFF가 인간 주석 semantic segmentation 레이블이 있는 스캔된 포인트 클라우드를 사용하여 벤치마크 데이터 세트에서 3D semantic segmentation을 가능하게 한다는 것을 보여준다.
그런 다음 실제 데이터 세트에서 편집 및 후속 새로운 뷰 합성을 위한 DFF의 기능을 조사한다.
우리는 사전 학습을 받고 공개적으로 이용 가능한 두 가지 teacher 네트워크인 LSeg[44]와 DINO[12]를 사용한다.
각 학습 이미지는 네트워크의 이미지 인코더에 의해 인코딩되며 식 4에 정의된 대상 피처 맵 f_img(I, r)로 사용된다.
피쳐 맵은 네트워크의 제한으로 인해 크기가 줄어들기 때문에 먼저 원래 이미지 크기로 크기를 조정합니다.
달리 명시되지 않은 한 NeRF의 구현과 설정은 Zhi et al. [112]에 따른다.
200K 반복 학습 중, 식 4의 loss L은 선형 붕괴 학습 속도(5e-4~8e-5)로 Adam에 의해 최소화된다.
학습 중에는 밀도에 대한 가우시안 노이즈도 적용된다.
coarse 샘플과 fine 샘플의 수는 각각 64개와 128개이다.
neural radiance field의 MLP는 그림 1과 같이 256차원의 8개의 ReLU 층으로 구성되며, 밀도를 위한 선형 층, 색상을 위한 3개의 층, 피쳐을 위한 3개의 층으로 구성되며, 입력 좌표와 스킵 연결을 위해 길이 10의 위치 인코딩이 사용되며, 길이 4의 위치 인코딩은 뷰 방향을 위한 것이다.
독립적인 MLP가 피쳐 필드를 위해 준비된 경우, 그것은 4개의 레이어(위치 인코딩이 사용되는 경우 세 번째 레이어에서 스킵 연결이 있음)로 구성된다.
학습 이미지의 크기는 Replica 데이터 세트의 경우 320x240이고 다른 데이터 세트의 경우 1008x756입니다.
학습 레이의 배치 크기는 Replica의 경우 1024, 기타의 경우 2048이다.
피처 필드 또는 radiance 필드의 미세 조정 중에 가우시안 노이즈가 제거되고 학습 속도가 1e-4로 설정됩니다.
자세한 학습 내용은 부록 A 및 C를 참조하십시오.
5.1 3D Semantic Segmentation
[112]에서 제공하는 데이터 분할 및 포즈 이미지를 사용하여 Replica 데이터 세트 [86]의 4개 장면에서 3D semantic segmentation 벤치마크를 구성한다.
데이터 세트에 대한 자세한 내용은 부록 D를 참조하십시오.
우리는 DFF를 학습 이미지의 광채와 피쳐 필드로 각 장면을 재구성하도록 학습하고 주석이 달린 포인트 클라우드의 새로운 뷰 합성 및 3D segmentation 품질을 평가한다.
우리는 LSeg를 teacher 네트워크로 사용한다.
LSeg 텍스트 인코더는 각 레이블을 인코딩하며, 각 점의 확률은 식 2에 의해 계산됩니다.
학습은 측광학적 및 피쳐 loss(식 4)만 사용하고 semantic 레이블을 통해 supervision에 액세스하지 않는다는 점에 유의한다.
Semantic Segmentation Results.
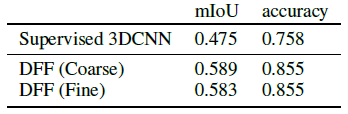
먼저 표 1에서 3D semantic segmentation, 평균 교차 결합(mIoU) 및 정확도의 평가 지표를 보여준다.
비교를 위해, 우리는 또한 색이 있는 포인트 클라우드를 입력으로 하는 희소 3D 컨볼루션 기반 segmentation 모델인 MinkowskiNet42[18]로 실험한다.
포인트 클라우드 segmentation을 위한 표준 SOTA 아키텍처를 가지고 있으며 3D semantic segmentation의 최대 주석이 달린 학습 데이터 세트인 ScanNet 데이터 세트[20]에서 학습된다.
결과는 LSeg에 의해 학습된 DFF가 supervised 모델보다 훨씬 더 나은 유망한 성능을 달성한다는 것을 보여준다.
이는 DFF가 2D teacher 네트워크에서 3D semantic segmentation을 distilling하는 데 성공했음을 나타낸다.

Impact of Sampling on Semantic Segmentation.
NeRF는 계층적 샘플링을 위해 두 개의 MLP를 사용하는데, 여기서 coarse MLP는 계층화 샘플링을 사용하여 더 적은 포인트(64)로 볼륨 렌더링을 수행하고, fine MLP는 중요도 샘플링(총 192)과 함께 작동한다.
따라서 피쳐 필드를 학습하기 위한 두 가지 샘플링 옵션이 있습니다.
정밀한 샘플링은 정확한 radiance 필드를 학습하는 데 중요하지만 segmentation은 텍스처보다 공간 주파수가 현저히 낮다.
따라서 우리는 그림 2에서 coarse하고 fine한 학습의 영향을 분석한다.
예상대로, coarse 모델은 부드러운 segmentation을 생성하는 반면, fine한 버전은 고주파 아티팩트를 도입한다.
이 평활도 속성은 자연 편집 가능한 새로운 뷰 합성에 중요하며 나중에 다시 논의된다.

Compatibility with View Synthesis.
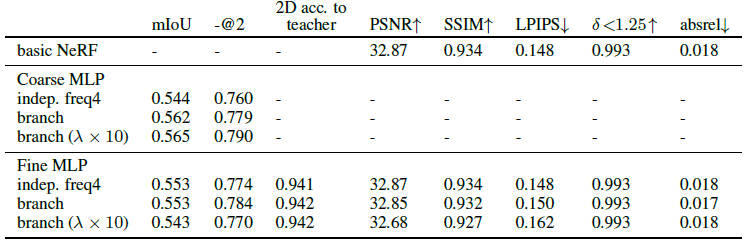
또한 피처 필드를 학습하지 않는 NeRF와 새로운 뷰 합성의 품질을 확인하고 비교한다.
피처 브랜치는 (그림 1에 표시된 것처럼) radiance 필드와 레이어를 부분적으로 공유하기 때문에, 학습 피처 필드는 radiance 필드에 해를 끼칠 수 있다.
이러한 우려에도 불구하고, 표 2에서 보는 바와 같이, 뷰 합성의 성능은 저하되지 않는다.
따라서 원래 NeRF에 비해 작은 계산 및 매개 변수 오버헤드로 분기 기반 DFF를 학습하고 사용할 수 있다.
피쳐 loss λ x 10의 가중치를 과도하게 늘리면 segmentation 성능이 더 향상되지 않으면서 뷰 합성에 손상을 입힌다.
우리는 또한 radiance 필드 MLP의 분기 대신 독립적인 경량 피처 필드 MLP를 학습하면 분기 기반 접근법과 경쟁력 있는 semantic segmentation 결과를 달성할 수 있음을 확인한다(모든 변형의 결과는 부록 표 3 참조).
이 옵션은 특히 radiance 필드의 재학습 없이 기성 NeRF 모델, 동적 NeRF[26, 66, 45] 또는 메시를 포함한 임의의 3D 장면 표현에 DFF 분해를 도입하려는 경우에 유용하다.
5.2 Editable Novel View Synthesis
이전 섹션에서는 DFF가 semantic 분해를 수행하는 능력을 정량적으로 검증했다.
이제 LLFF 데이터 세트[55]와 자체 데이터 세트를 포함하여 실제 장면에서 편집 가능한 뷰 합성 기능에 대해 논의한다.
우리의 방법은 정규화된 장치 좌표를 기반으로 하는 LLFF 장면에도 사용될 수 있다.
비디오를 포함한 추가 결과는 추가 웹 페이지를 참조하십시오.
텍스트 쿼리를 사용하는 LSeg 외에도 이미지 패치 쿼리를 사용하여 쿼리 기반 분해를 가능하게 하기 위해 다른 teacher 네트워크로 self-supervised DINO[12]를 실험한다.
여기서, 우리는 임계값 코사인 유사성을 사용하여 Eq.5의 음수 쿼리를 가진 소프트맥스 대신 쿼리의 확률을 직접 계산하고 유사성이 임계값을 초과하면 p = 1로 설정하고, 그렇지 않으면 하드 분해를 위해 p = 0으로 설정한다.
피쳐 loss가 photometric loss보다 훨씬 빠르게 수렴되고 짧은 학습이 충분하다는 것을 발견했기 때문에 먼저 200K 반복(L_p)에 대해 각 장면에 대해 피쳐 분기가 없는 NeRF를 학습한 다음 5K 반복(L_p + λL_f)에 대해 distillation을 통해 피쳐 분기로 미세 조정한다.
우리는 피쳐 분기를 학습하기 위해 coarse 샘플링을 사용하고 fine 샘플링이 있는 편집된 렌더링에 사용한다.
자세한 내용은 부록 A를 참조하십시오.


Appearance Editing, Deletion, Extraction.
우리는 그림 3과 그림 4에서 새로운 관점 합성에 대한 정성적 평가를 보여준다.
이러한 장면의 특정 3D 영역은 다양한 쿼리 양식에 따라 분해를 통해 식별되고 로컬로 편집된다.
이러한 실험에서, 우리는 섹션 5.1에서와 같이 LSeg-DFF에 대한 텍스트 쿼리를 사용하고 DINO-DFF에 대한 이미지 패치 쿼리를 사용한다.
DINO 피쳐는 self-supervised 학습[12, 3] 덕분에 지역의 유사성과 대응성을 잘 포착하기 때문에 이미지 패치 쿼리는 의미적으로 유사한 모든 영역을 한 번에 선택하는 데 도움이 된다.
그런 다음 패치에 포함된 모든 픽셀의 피쳐를 평균하여 패치 피쳐를 계산합니다.

그림 3에서, 우리는 DFF가 설득력 있는 선택적 외관 편집을 가능하게 한다는 것을 보여준다.
우리의 초점은 분해를 통한 영역 선택이기 때문에 여기서는 명확성을 위해 간단한 색상 변환을 사용한다(예: RGB를 BGR로 플립, 색상 혼합).
원래 NeRF에 의한 radiance 필드의 MLP도 숨겨진 층을 가지고 있으며, 그 피쳐는 분해에 사용될 수 있다고 생각할 수 있다.
우리는 특히 복잡한 다중 객체 장면에서 그림 5에 나타난 것처럼 NeRF 피쳐의 나이브한 사용이 분해에 강하지 않다는 것을 확인한다.
우리는 fine radiance 필드 네트워크의 8번째 숨겨진 레이어(즉, 그림 1의 분기 직전 레이어)를 사용한다.
NeRF 피쳐는 단순한 모양과 색상으로는 물체도 명확하게 분해할 수 없다.
영역 선택은 색상, 지오메트리 또는 위치가 유사한 다른 부품으로 유출되지만 대상을 완전히 포함하지는 않습니다.
예를 들어 바닥 선택이 벽, 테이블, 빈 또는 천장으로 누출됩니다.
의자 선택은 텔레비전, 케이블, 조명 장비 또는 그림자와 같은 관련이 없는 검은 부분으로 유출됩니다.
이는 원래 NeRF의 피쳐 공간이 semantic 유사성을 잘 학습하지 못하고 색상 또는 공간 인접과 같은 예측 불가능하고 더 낮은 수준의 요인과 얽혀 있음을 나타낸다.
그림 4에서, 우리는 DFF가 두 개의 패치 쿼리(잎과 땅에 대한 쿼리-1, 꽃에 대한 쿼리-2)와 텍스트 쿼리-3 "꽃"을 사용하여 객체의 삭제 또는 추출에도 잘 작동한다는 것을 보여준다.
베이스라니 편집 방법과의 비교를 위해, 우리는 SOTA 이미지 인페인팅 모델인 LaMa[87]에 의한 결과를 보여준다.
모델에는 인페인팅 영역에 마스크가 필요하기 때문에 평가를 위해 뷰에 수동으로 주석을 달았다.
그림과 같이 이미지 인페인팅 모델은 선명하고 사실적인 이미지를 생성할 수 없으며, 서로 다른 뷰가 일관성이 없습니다.
반면, DFF는 특히 전경 객체를 추출하는 데 성공하면서 다중 뷰 일관된 그럴듯한 결과를 생성한다.
전경 객체를 삭제하는 성능은 높지만, 삭제된 객체 뒤의 먼 거리에 떠다니는 아티팩트와 블러 볼륨이 존재하는 것이 남은 단점이다.
Priors for Smooth Decomposition
편집 가능한 NeRF의 과제를 몇 가지 범주로 구성할 수 있습니다: 표면 분해, 부피 분해, 조명 분해, 관찰되지 않은 부품의 추정 등이 있습니다.
우리가 외관만 편집한다면, 레이의 색은 대부분 표면 주위의 응축된 간격으로 결정되기 때문에 실질적으로 물체 표면 근처의 분해 영역, 즉 표면 분해만 필요하다.
반면에 기하학적 변환은 종종 더 높은 수준의 분해를 필요로 한다.
삭제 예에서 보는 바와 같이, 기하학적 변환은 일부 표면을 이동하거나 제거하고 그 뒤의 공간을 노출시킬 수 있다.
이는 모델이 물체의 내부를 포함하여 폐색으로 인해 알려지지 않은 영역을 더 적게 또는 전혀 관찰되지 않도록 한다.
따라서, 부피의 내부와 후면을 합성하면서 부드럽게 부피를 분해하는 것이 바람직하다.
여기에는 새로운 뷰 합성 태클과 동일한 과제가 포함되지만 편집 가능성은 그 중요성을 더욱 강조한다.
이전 연구[8, 9, 111]에서 논의된 조명 분해 외에도, 우리는 다양한 DFF 설정을 실험하여 부드러운 볼륨 분해의 새로운 과제를 추가로 조사한다.
섹션 5.1에서 논의한 바와 같이, DFF에는 피쳐 필드를 학습하기 위한 두 가지 샘플링 옵션이 있다.
coarse 학습은 평활도 정규화를 도입하고 응집력 있는 분해와 관찰되지 않은 영역의 원활한 인페인팅을 도울 수 있다.
또 다른 합리적인 평활도 정규화는 고주파 위치 인코딩(PE)을 제거하는 것이다.
따라서 PE가 없는 피처 필드에 대해 독립적인 MLP 네트워크를 학습한다.
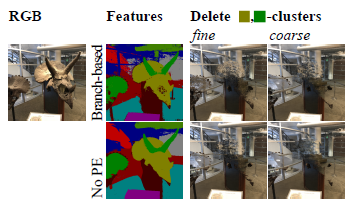
우리는 그림 6에서 네 가지 렌더링 조합을 비교한다.
그들의 행동을 더 잘 이해하기 위해, 우리는 DINO-DFF를 사용하고, 렌더링된 피처 맵의 k-평균 클러스터를 표시하고, 해당 클러스터를 선택하는 쿼리에 의해 트리케라톱스의 머리를 삭제한다.
예상대로, coarse 학습된 모델과 no-PE 모델은 더 부드러운 볼륨 분해에 성공하고, 이 조합은 고주파 부동 아티팩트를 최소화할 수 있다.
부작용으로는 고주파 표현력이 부족하여 때로는 이질적인 배경 영역을 삭제하고 복잡한 구조의 특징을 표현하지 못한다(예: 창의 얇은 프레임의 클러스터 시각화 참조).
두 세계의 최고를 향해, 적절한 사전 또는 귀납적 편향을 개발하는 것은 향후 연구를 위한 중요한 방향이다[70].
그렇지 않으면 IDR [106, 98]과 같은 표면 인식 표현을 통해 부동 아티팩트의 문제를 방지할 수 있습니다.
모든 기하학적 편집이 이러한 문제를 겪는 것은 아닙니다.
예를 들어, 그림 7에서와 같이, 카메라에 더 가까이 물체를 이동시키거나, 확대하거나, 다른 장면으로 왜곡시키는 것이 종종 덜 문제가 된다.

Localizing Optimization-based Editing.
마지막으로, 우리는 최적화 기반 편집 방법과의 조합을 보여준다.
CLIPNeRF[97]는 렌더링된 이미지가 CLIP를 통해 텍스트 프롬프트와 일치하도록 radiacne 필드의 파라미터를 최적화합니다.
주로 특정 범주의 단일 객체 장면을 위해 설계되었지만 다른 실제 NeRF에 적용할 수 있다.
다만 편집 범위를 통제할 수 없기 때문에 '하얀 꽃'과 같은 프롬프트가 나뭇잎처럼 의도하지 않은 대상의 색을 바꿀 수 있다.
우리의 DFF 기반 분해는 CLIP에 최적화된 NeRF 장면과 원래 NeRF 장면의 구성을 통해 장면을 렌더링하기 위해 그러한 최적화 기반 방법을 업그레이드할 수 있다.
우리는 그 결과를 그림 8에 보여준다.
나이브한 CLIPNeRF는 의도하지 않은 부분을 편집하지만, 우리의 방법은 의도적인 부분만 로컬로 편집하는 데 도움이 된다.
렌더링 전환 외에도 역전파 중 학습 신호를 제어하기 위해 분해를 사용할 수 있다.
추가 실험은 부록 F에 나와 있다.
이러한 확장은 CLIPNeRF 또는 다른 최적화 기반 편집 방법의 적용을 복잡한 장면으로 확장한다.

6 Discussion, Limitations, and Conclusions
본 연구에서는 선택적 편집을 위한 NeRF 장면 분해의 새로운 방법인 distilled feature field (DFF)를 제안한다.
우리는 segmentation에 대한 정량적 평가와 편집 가능한 새로운 관점 합성에 대한 광범위한 정성적 평가를 제시한다.
이러한 유망한 결과 외에도, DFF 기반 모델은 self-supervised 2D 기초 모델의 향후 개선으로부터 이익을 얻을 것이다.
또한 실험을 통해 편집 가능한 뷰 합성에 대한 향후 방향을 명확히 하며, 특히 관찰되지 않은 영역의 평활도를 추정한다.
또한, 이 작업은 편집 가능한 뷰 합성에 초점을 맞추고 있지만, DFF를 텍스트 쿼리의 3D 등록[16, 1, 47, 4] 또는 로봇 티칭[32, 80]을 포함한 다른 응용 프로그램으로 전송하는 것도 흥미롭다.
DFF 프레임워크의 한계는 두 가지이다.
첫 번째는 distillation으로 인한 성능의 상위 bdurround입니다.
distillation의 student 모델은 teacher 모델을 크게 능가할 수 없다.
teacher 인코더의 해상도가 낮으면 해당 DFF도 coarse-grained가 된다.
LSeg가 텍스트 쿼리를 이해할 수 없으면 LSeg-DFF도 이해할 수 없습니다.
둘째, DFF는 NeRF에 의한 3D 재구성에 따라 볼륨 렌더링을 사용한다.
NeRF 모델은 때때로 기하학적으로 잘못된 솔루션(예: 부유물)에 최적화된다.
radiance 필드의 이러한 기하학적 오류는 DFF에 대한 supervision을 노이즈로 만들 것이다.
사회적으로 부정적인 영향을 미칠 수 있으므로 NeRF를 원하는 대로 편집하여 현실적이지만 가짜 콘텐츠를 만드는 방법을 사용할 수 있다.
자동 가짜 검출 방법은 이러한 오용을 방지하는 데 도움이 될 수 있다.
NeRF는 더 계산 집약적이어서 높은 전기 사용으로 이어진다.
효율적인 NeRF[23, 57, 15]에 대한 최근의 연구는 이러한 우려를 완화시킬 수 있다.
A Training and Model Architectures
B Editing Procedure
색상화, 변환 및 삭제를 위한 편집은 다음과 같이 진행됩니다:
(1) NeRF에서 일반적으로 레이의 포인트 [..., x_i, ...]를 샘플한다.
(2) 각 포인트에 대해 DFF를 쿼리합니다.
이제 좌표가 일련의 쿼리와 일치할 확률을 p ∈ [0, 1]로 계산할 수 있다.
이제 p가 사용자 정의 임계값 이상이면 "쿼리에 의해 좌표가 선택됨"을 정의하고, 그렇지 않으면 "선택되지 않음"을 정의합니다.
또한 분계점이 없는 p의 비율로 선택된 결과와 선택되지 않은 결과를 혼합하여 사용할 수 있습니다.
(3) 선택하지 않으면 vanilla NeRF를 통해 x에서 밀도 σ(x)와 색상 c(x)를 계산합니다.
(4) 선택한 경우 다음 변환을 적용할 수 있습니다:
(4-A) 삭제 (그림 4): 점의 밀도 σ(x)를 0으로 설정합니다.
(4-B) 색상 편집: NeRF를 쿼리하여 밀도 σ(x)와 색상 c(x)에 대해 NeRF를 쿼리합니다.
그런 다음 색상은 색상화 함수 b에 의해 편집됩니다, 즉, b(c(x))로 변환됩니다.
(4'-C) 변환/크기 조정: 기하학적 변환은 (2)를 수행하기 전에 다른 단계가 필요합니다.
먼저 변형된 점 좌표 x'를 계산합니다: x'는 편집 변환의 역을 적용하여 계산된다, 즉, x' = g^-1(x). 번역의 경우, g는 벡터가 있는 단순한 덧셈일 것이다.
쿼리에서 x'를 선택하면 색과 밀도를 계산하기 위해 x 대신 x'가 사용됩니다.
만약 x와 x'가 모두 선택되고 0이 아닌 밀도(예를 들어, 그림 7의 변형 사과와 다른 사과의 경계)를 가진다면, 우리는 단순성을 위해 그들의 알파의 비율로 그들의 색 c(x)와 c(x')를 혼합한다.
(5) 마지막으로, 평소와 같이 일련의 (밀도, 색상) 튜플로 볼륨 렌더링을 수행한다.
'View Synthesis' 카테고리의 다른 글
| Putting NeRF on a Diet: Semantically Consistent Few-Shot View Synthesis (1) | 2023.03.03 |
|---|---|
| GAUDI: A Neural Architect for Immersive 3D Scene Generation (0) | 2023.02.22 |
| Depth-supervised NeRF: Fewer Views and Faster Training for Free (v2) (0) | 2022.12.08 |
| Reinforcement Learning with Neural Radiance Fields (0) | 2022.12.06 |
| Mip-NeRF 360: Unbounded Anti-Aliased Neural Radiance Fields (0) | 2022.11.03 |