2022. 12. 6. 17:22ㆍView Synthesis
Reinforcement Learning with Neural Radiance Fields
Danny Driess, Ingmar Schubert, Pete Florence, Yunzhu Li, Marc Toussaint
Abstract
강화 학습(RL) agent를 학습하기 위한 효과적인 표현을 찾는 것은 오랜 문제이다.
이 논문은 Neural Radiance Fields (NeRFs)의 supervision을 통해 state 표현을 학습하면 다른 학습된 표현이나 심지어 저차원 수동 엔지니어링 state 정보에 비해 RL의 성능을 향상시킬 수 있음을 보여준다.
구체적으로, 우리는 장면의 물체를 설명하는 latent space에 여러 이미지 관찰을 매핑하는 encoder를 학습시킬 것을 제안한다.
latent-conditioned NeRF로 구축된 decoder는 latent space를 학습하는 supervision 신호 역할을 한다.
그런 다음 RL 알고리즘은 학습된 latent space에서 state 표현으로 작동한다.
우리는 이것을 NeRF-RL이라고 부릅니다.
우리의 실험은 supervision으로서의 NeRF가 후크에 머그컵을 걸고, 물체를 밀거나, 문을 여는 것과 같은 로봇 물체 조작을 포함하는 downstream RL 작업에 더 적합한 latent space로 이어진다는 것을 나타낸다.
1 Introduction
강화 학습(RL) 알고리즘의 샘플 효율성은 알고리즘이 작동하는 기본 시스템 state의 표현에 결정적으로 의존한다[1, 2, 3, 4, 5, 6, 7].
때때로, 환경 내 객체의 위치와 같은 state의 저차원(직접) 표현은 결과적인 RL 문제를 가장 효율적으로 만드는 것으로 간주된다[2].
그러나 이러한 저차원의 직접 state 표현에는 몇 가지 단점이 있을 수 있다.
한편, 인식 모듈, 예를 들어 포즈 추정은 raw 관찰에서 표현을 얻기 위해 실제 세계에서 필요하며, 이는 종종 충분한 견고성으로 실제적으로 달성하기 어렵다.
반면에, 목표가 다른 객체 모양에 대해 일반화하는 policy를 학습하는 것이라면 [8], 저차원 state 표현을 사용하는 것은 종종 비현실적이다.
이러한 시나리오는 RL에 도전적이지만 로봇 조작 작업 등에서 일반적이다.
따라서 이미지와 같은 raw 고차원 관측에서 직접 RL을 고려하는 접근 방식의 역사가 크다(예: [9, 10]).
일반적으로 encoder는 고차원 입력을 가져와 state의 저차원 latent 표현에 매핑한다.
그런 다음 RL 알고리즘(예: Q-function 또는 policy 네트워크)은 state 입력으로 latent vector에서 작동한다.
이렇게 하면 별도의 인식 모듈이 필요하지 않으며, 프레임워크는 작업과 관련된 raw 관찰에서 정보를 추출할 수 있으며, 원칙적으로 RL agent는 객체 모양이 다양한 경우와 같은 까다로운 환경에 대해 일반화할 수 있다.
원칙적으로 이러한 장점이 있지만, RL 신호만으로 고차원 입력을 처리할 수 있는 encoder를 공동으로 학습하는 것은 어렵다.
이를 해결하기 위해 한 가지 접근 방식은 이미지 reconstruction[1, 4, 11], 다중 뷰 consistency[6] 또는 시간-contrastive 작업[3]과 같은 다른 작업에서 encoder를 사전 학습하는 것이다.
또는 RL 절차 동안 latent encoding에 대한 auxiliary loss를 추가할 수 있다[5].
두 경우 모두, 실제 (auto-) encoder 아키텍처와 관련 (auxiliary) loss 함수의 선택은 downstream RL 작업에 대한 결과 latent space의 유용성에 상당한 영향을 미친다.
특히 이미지 데이터의 경우, encoder에 일반적으로 convolutional neural network (CNNs)이 사용된다[12].
그러나 2D CNN은 2D(등분산) bias가 있는 반면, 많은 RL 작업의 경우 우리 세계의 3D 구조가 필수적이다.
Vision Transformers[13, 14]와 같은 아키텍처는 그러한 2D bias 없이 이미지를 처리할 수 있지만, 대규모 데이터가 필요할 수 있으며, 이는 RL 애플리케이션에서 어려울 수 있습니다.
또한, 보정되지 않은 여러 2D 이미지 입력을 일반 이미지 encoder와 함께 사용할 수 있지만[15], 3D 유도 bias의 이점을 얻지 못하며, 이는 예를 들어 occlusion 및 객체 영구성과 같은 2D 이미지의 모호성을 해결하는 데 도움이 될 수 있다.
최근, Neural Radiance Fields (NeRFs)[16]는 새로운 관점에서 장면을 렌더링할 수 있는 신경망으로 장면을 표현하는 학습에 큰 성공을 거두었고, 컴퓨터 비전[17]에 대한 광범위한 관심을 불러일으켰다.
NeRF는 강력한 3D 유도 bias를 보여 일반 이미지 encoder로 구성된 방법(예: [18])보다 더 나은 장면 재구성 기능을 제공한다.
본 연구에서는 NeRF의 이러한 3D 유도 bias를 state 표현 학습에 통합할 수 있는지 여부를 조사한다.
구체적으로, 우리는 auto-encoder 구조를 통해 장면의 여러 RGB 이미지 뷰를 latent 표현에 매핑하는 encoder를 학습시킬 것을 제안한다, 여기서 (compositional) NeRF decoder는 각 뷰에 대한 이미지 reconstruction loss를 사용하여 self-supervision 신호를 제공한다.
실험에서, 우리는 NeRF의 supervision이 2D CNN decoder를 통한 supervision에 비해 downstream RL 절차를 더 효율적으로 샘플로 만드는 latent 표현, latent space에 대한 contrastive loss 또는 심지어 키포인트로 제공된 수작업으로 설계된 완벽한 낮은 수준의 state 정보로 이어진다는 것을 보여준다.
일반적으로 RL은 객체의 모양이 동일한 환경에서 학습된다.
우리의 환경에는 후크에 머그잔 걸기, 테이블 위의 물체 밀기, 문 열기 시나리오가 포함된다.
이 모든 것에서 객체의 모양은 고정되지 않으며 agent가 분포의 모든 모양에 대해 일반화해야 한다.
우리의 주요 기여를 요약하면 다음과 같습니다:
(i) NeRF supervision을 통해 RL에 대한 state 표현을 학습할 것을 제안하며, (ii) 특히 object-compositional NeRF decoder를 사용하여 latent-conditioned NeRF decoder로 학습된 encoder가 표준 2D CNN auto-encoder, contrastive learning 또는 expert 키포인트에 비해 RL 성능을 향상시킨다는 것을 경험적으로 입증한다.
2 Related Work
Neural Scene/Object Representations in Computer Vision, and Applications.
우리가 아는 한, NeRF와 같은 신경 장면 표현이 RL에 도움이 될 수 있는지를 탐구하는 것은 현재 연구가 처음이다.
그러나 RL 외부에서는 표현 자체[19, 20, 21, 22]와 그 응용 분야 모두에서 신경 장면 표현 분야에서 매우 활발한 연구 분야가 있었다; 최근 리뷰는 [23, 24, 17]을 참조하라.
NeRF 및 관련 방법군 내에서, 연구의 주요 추진력은 다음과 같다: 모델링 공식 개선 [25, 26], 더 큰 장면 모델링 [26, 27],(re-) lighting 다루기 [28, 29, 30], 특히 활발한 연구 분야는 훈련과 추론 시간 렌더링 모두 속도를 향상시키는 것이다 [31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41].
우리의 경우, 우리는 이미지를 렌더링할 필요가 없고 latent space encoder(RTX3090에서 런타임이 약 7ms)만 실행하면 되기 때문에 추론 시간 계산 문제에 의해 제약을 받지 않는다.
특별한 관련성 외에도, 다양한 방법들이 NeRF[45, 46, 47, 48, 49, 50, 51, 52, 53]에 대한 latent-conditioned 접근법 또는 compositional/객체 지향 접근법을 개발했다, 그러나 우리가 아는 다른 NeRF 스타일의 방법들은 RL에 적용되지 않았다.
신경 장면 표현은 많은 분야(즉, 증강 현실 및 의료 영상 [54])에 걸쳐 적용되었으며 NeRF[55, 56, 57, 58]와 다른 신경 장면 접근법[59, 60, 61, 62] 모두 포즈 추정[55], 궤적 계획[56], 시각적 선견지명[11, 53], 파악 [59, 57] 및 재배열 작업[60, 61, 58]을 포함한 로봇의 다양한 문제에 사용되기 시작했다.
Learning State Representations for Reinforcement Learning.
심층 RL의 성공을 가능하게 하는 핵심 요소 중 하나는 고차원 관측 데이터에서 환경의 효과적인 표현을 찾을 수 있는 능력이다[10, 63].
광범위한 연구는 다양한 보조 목적 함수를 사용하여 더 나은 state 표현을 학습하는 다양한 방법을 조사하는 데 착수했다.
contrastive learning은 일반적인 목표이며 컴퓨터 비전 애플리케이션에서 unsupervised 표현 학습에서 성공을 보여주었다[64, 65].
이러한 성공을 바탕으로 구축된 연구원들은 이러한 학습 목표가 실제 로봇 작업에 적용되는 시간 정렬[68, 3], 카메라 시점[69] 및 다른 감각 양식[70]에서 대비 신호가 올 수 있는 심층 RL[66, 67]에서 더 나은 성능과 샘플 효율성으로 이어질 수 있음을 보여주었다.
광범위한 노력이 RL[72]에서 표현 학습의 역할을 조사하고, 다양한 시각적 표현 사전 학습 방법의 중요성에 대한 상세한 분석을 제공했으며, 다중 auxiliary loss에 직면하여 학습 안정성을 개선할 수 있는 방법을 보여주었다[74].
또한 새로운 목적 함수(예: 이중 시뮬레이션 메트릭[75] 및 시간 주기 일관성 loss[76])와 덜 탐색된 데이터 소스(예: 야생 이미지[77] 및 액션 프리 비디오[78])를 사용한 사전 학습 방법에 대한 다양한 추가 탐색이 있다.
이 방향[79]의 더 많은 관련 작업에 대해서는 survey를 확인하십시오.
우리의 방법은 NeRF가 제공하는 강력한 3D 유도 bias를 포함하는 decoder를 explicitly 활용한다는 점에서 다르다, 이는 객체의 기하학에 의존하는 작업에 대한 RL 개선을 경험적으로 보여준다.
3 Background
3.1 Reinforcement Learning
이 연구는 이산 시간 마르코프 의사 결정 프로세스(MDP) M = <S, A, T, γ, R, P_0>으로 설명될 수 있는 의사 결정 문제를 고려한다.
S와 A는 각각 모든 state와 action의 집합입니다.
action a를 사용하여 s에서 s'로의 transition 확률(밀도)은 T(s'|s,a)이다.
agent는 각 단계 후에 실제 값의 reward R(s, a, s')을 받는다.
discount factor γ ∈ [0, 1)는 즉시 reward와 미래 reward를 교환한다.
P_0: S → R_0+은 시작 state의 분포입니다.
RL 알고리즘은 최적의 policy π*: S x A → R_0+를 찾으려고 한다, 여기서 π* = argmax_π ∑γ^t E[R(s_t, a_t, s_(t+1))]이다.
중요한 것은, 이 작업에서, 우리는 state s가 장면에서 물체의 위치와 모양을 모두 encoding하는 RL 문제를 고려한다는 것이다.
우리는 RL agent가 테스트 시 이러한 모든 모양에 대해 일반화할 것을 요구한다.
따라서 우리는 state를 튜플 s = (s_p, s_s)로 생각할 수 있는데, 여기서 s_p는 위치 정보를 encoding하고 s_s는 관련된 모양을 encoding한다.
우리는 실험을 희소 reward 설정에 초점을 맞춘다, 즉, s' ∈ S_g의 경우 R(s, a, s') = R_0 > 0이고 s ∈ S/S_g의 경우 R(s, a, s') = 0으로 S_g ⊂ S의 볼륨보다 훨씬 작다.
state 공간 S는 일반적으로 시스템의 자유도에 대한 저차원 또는 최소 설명이다.
이 작업에서, 우리는 RL 알고리즘이 장면의 (고차원) 관찰 y ∈ Y에만 액세스할 수 있다고 고려한다(예: RGB 이미지).
특히 이는 policy에 a ~ π(·|y) 입력으로 관측치가 있음을 의미합니다.
기본 state s = (s_p, s_s)가 y에서 완전히 관측 가능하다고 가정하기 때문에, 우리는 y를 MDP의 상태처럼 다룰 수 있다.
Reinforcement Learning with Learned Latent Scene Representations.
학습된 latent 장면 표현이 있는 RL의 일반적인 아이디어는 관찰 y ∈ Y를 장면의 k차원 latent vector z = Ω(y) ∈ Z ⊂ R^k에 매핑하는 encoder Ω를 학습하는 것이다.
실제 RL 구성 요소, 예를 들어 Q-function 또는 policy는 state 설명으로 z에서 작동합니다.
policy π의 경우, 이것은 action a ~ π(·|z) = π(·|Ω(y))가 관찰 y 대신 latent vector z에 직접 조건부임을 의미한다.
latent vector의 차원 k는 일반적으로 관측 공간 Y의 차원보다 작지만 state 공간 S의 차원보다 크다.
3.2 Neural Radiance Fields (NeRFs)
4 Learning State Representations for RL with NeRF Supervision
이 섹션에서는 NeRF supervision에서 학습한 RL에 대한 latent state space를 사용하는 제안된 프레임워크에 대해 설명한다.
latent space를 학습하기 위해, 우리는 decoder가 latent-conditioned NeRF인 encoder-decoder를 사용하는데, 이는 global [42, 43, 44] 또는 compositional NeRF decoder일 수 있다.
우리가 아는 한, RL에 대해 NeRF에서 파생된 supervision을 사용한 이전 작업은 없었다.
섹션 4.1에서 우리는 이 제안을 설명하고, 섹션 4.2는 encoder-decoder 학습의 개요를 제공하며, 섹션 4.3과 섹션 4.4는 각각 NeRF decoder와 encoder에 대한 옵션을 소개한다.

4.1 Using Latent-Conditioned NeRF for RL
우리는 RL 알고리즘이 여러 뷰의 이미지를 latent z로 매핑하는 encoder에 의해 생성된 latent vector로 작동하는 state 표현 z를 제안한다, encoder는 (compositional) latent-conditioned NeRF decoder로 학습된다.
실험에서 검증될 것처럼, 우리는 이 프레임워크가 장면에서 객체의 실제 3D 기하학을 나타내는 latent vector를 생성하고, 여러 객체를 잘 처리할 수 있을 뿐만 아니라, 형상 완성을 제공하여 occlusion을 처리하기 위해 일관된 방식으로 여러 뷰를 융합할 수 있기 때문에 downstream RL 작업에 이롭다고 가정한다, 이 모든 것은 기하학이 중요한 과제를 해결하는 것과 관련이 있다.
그림 1과 같이 프레임워크에는 두 가지 단계가 있다.
첫째, 환경과의 랜덤 상호 작용에 의해 수집된 데이터 세트에서 encoder + decoder를 학습시킨다, 즉, 아직 학습된 policy가 필요하지 않다.
둘째, 첫 번째 단계에서 학습된 encoder를 사용하여 동결하고 latent space를 사용하여 RL policy를 학습한다.
우리는 전체 장면이 하나의 latent vector로 표현되는 global인 것과 객체가 자체 latent vector로 표현되는 compositional 것의 두 가지 변형인 auto-encoder 프레임워크를 조사한다는 점에 유의한다.
후자의 경우 뷰에서 마스크로 객체를 식별합니다.
4.2 Overview: Auto-Encoder with Latent-Conditioned NeRF Decoder
장면의 관찰 y = (I^(1:V), K^(1:V), M^(1:V))가 V 많은 카메라 뷰에서 가져온 RGB 이미지 I^i ∈ R^(3 x h x w), i = 1, ..., V, 각각의 카메라 투영 행렬 K^i ∈ R^(3x4) (intrinsics 및 extrinsics 포함) 및 뷰당 이미지 마스크 M^(1:V)로 구성된다고 가정한다.
global NeRF decoder의 경우, 이것들은 global 비배경 마스크 M_tot^i ∈ {0, 1}^(h x w)이고, [53]에서와 같은 compositional NeRF decoder의 경우, 이것들은 뷰 i의 장면에서 객체 j = 1, ..., m을 식별하는 이진 마스크 M_j^i ∈ {0, 1}^(h x w) 세트이다.
global인 경우는 m = 1, M_(j=1)^i = M_tot^i에 해당한다.
encoder Ω는 다중 뷰에서 이러한 포즈를 취한 이미지 관측치를 latent vector z_(1:m) 집합으로 매핑하며, 여기서 각 z_j는 compositional 사례에서 장면의 각 객체를 개별적으로 나타내거나 장면의 단일 z_1 모든 객체를 나타낸다.
이것은 마스크 M_j^(1:V), 즉

에서 객체 j에 대해 Ω를 쿼리함으로써 달성된다.
encoder를 학습시키기 위한 supervision 신호는 decoder D가 latent vector z_(1:m) 집합에서 카메라 행렬 K에 의해 지정된 임의의 뷰에 대한 이미지 I = D(z_(1:m), K)를 렌더링하는 입력 뷰 i의 이미지 reconstruction loss

이다.
encoder와 decoder 모두 동시에 종단 간 학습을 받는다.
decoder의 타겟 이미지는 global 및 compositional 사례 모두에서 동일합니다: global 마스크 이미지 I^i o M_tot^i (o는 요소별 곱입니다.)
compositional 경우 이것은 M_tot^i로 계산할 수 있다.
객체의 여러 뷰의 정보를 decoder가 여러 뷰에서 장면을 렌더링할 수 있어야 하는 latent vector에 융합함으로써, 이 auto-encoder 프레임워크는 장면에서 객체의 3D 구성(모양 및 포즈)을 나타내는 latent vector를 학습할 수 있다.
4.3 Latent-Conditioned NeRF Decoder Details
Global.
원래 NeRF 공식 [16]은 하나의 단일 장면을 나타내는 완전히 연결된 네트워크 f를 학습한다(섹션 3.2).
latent space를 학습하기 위해 auto-encoder 내에서 NeRF에서 decoder를 생성하기 위해, 우리는 latent vector z ∈ R^k [42, 43, 44]에 NeRF f(·,z)를 조건화한다.
[42, 43, 44]와 같은 접근 방식은 lighting 또는 범주 수준 일반화와 같은 요소를 나타내기 위해 latent 코드를 사용하지만, 우리의 경우 latent 코드는 장면 변화, 즉 객체의 모양과 구성을 나타내도록 의도되어 downstream RL agent가 이를 state 표현으로 사용할 수 있다.
Compositional.
compositional 경우, encoder는 각 객체 j = 1, ..., m을 개별적으로 설명하는 latent vector 세트 z_(1:m)를 생성하며, 이는 관련 부피 밀도 σ_j 및 색상 값 c_j와 함께 많은 NeRF(σ_j(x), c_j(x)) = f_j(x) = f(x, z_j), j = 1, ..., m로 이어진다.
각 개체에 대해 고유한 네트워크 가중치를 가진 서로 다른 네트워크 f_j를 사용할 수 있지만, 모든 개체에 대해 단일 네트워크 f를 가지고 있습니다.
이것은 물체의 포즈뿐만 아니라 모양과 종류 모두 latent 코드 z_j를 통해 표현된다는 것을 의미한다.
조건화된 NeRF가 각 객체의 3D 구성을 개별적으로 학습하도록 강제하기 위해, 우리는 compositional 공식(예: [80, 81]에 의해 제안됨)을 가진 global NeRF 모델로 구성한다: σ(x) = ∑σ_j(x), c(x) = 1/σ(x) ∑σ_j(x) c_j(x).
이 composition이 3D 공간에서 발생하기 때문에 latent vector는 다른 객체에 대한 장면에서 객체의 실제 모양과 포즈를 정확하게 나타내도록 학습될 것이며, 이는 downstream RL agent에 유용할 수 있다고 가정한다.
4.4 Encoder Details
encoder Ω는 RL 작업에 대한 latent vector를 추정하기 위해 여러 뷰를 함께 융합하여 작동한다.
이 연구의 과학적 질문은 encoder를 종단 간 학습시키기 위해 NeRF로 구축된 decoder가 RL에 유익한지 조사하는 것이기 때문에, 우리는 두 가지 다른 encoder 아키텍처를 고려한다.
첫 번째는 다양한 뷰에서 featur encoding을 평균화하는 2D CNN이며, 각 encoding은 해당 뷰의 카메라 행렬에 추가로 조건화된다.
두 번째는 3D convolution과 카메라 투영을 통해 3D 공간에서 서로 다른 카메라 뷰를 융합하여 3D bias를 통합하는 학습된 3D neural vector field를 기반으로 한다.
이러한 방식으로, 우리는 encoder와 decoder에 통합된 3D priors의 중요성을 구별할 수 있다.
Per-image CNN Encoder ("Image encoder").
global 버전의 경우, encoder 선택으로 [11]의 네트워크 아키텍처를 활용한다.
compositional 사례에서 여러 객체를 작업하기 위해 다음과 같이 객체 마스크를 고려하여 [11]에서 아키텍처를 수정한다.
각 객체 j에 대해 2D CNN encoder는

를 계산한다.
E_CNN은 ResNet-18 [82] CNN 피쳐 추출기로, 각 뷰 i에 대한 객체 j의 마스킹된 입력 이미지 I^i ㅇ M_j^i에서 피쳐를 결정한 다음 (flattened) 카메라 행렬과 연결된다.
따라서 네트워크 g_MLP의 출력은 카메라 정보를 포함한 각 뷰의 encoding이며, 이는 평균화된 다음 h_MLP로 처리되어 최종 latent vector를 생성한다.
global인 경우, 우리는 Ω_CNN이 단일 latent vector를 생성하도록 m = 1, M_j^i = 1 = M_tot^i를 설정한다.
Neural Field 3D CNN Encoder ("Field encoder").
여러 저자[43]는 장면의 쿼리된 3D 위치에서 픽셀 정렬 피쳐를 계산하여 다른 카메라 뷰의 정보를 3D 공간에서 직접 융합하여 encoder를 학습하는 데 3D bias을 통합하는 것을 고려했다.
우리는 [53]의 encoder 아키텍처를 활용하는데, 여기서 아이디어는 입력 뷰와 마스크에 따라 3D 공간을 통해 neural vector field ɸ[I^(1:V), M_j^(1:V)] : R^3 → R^E를 학습하는 것이다.
ɸ의 피쳐는 각각의 뷰에서 카메라 좌표계에 쿼리 포인트를 투영하여 계산된다.
ɸ를 latent vector로 바꾸기 위해 작업 공간 세트 X_h ∈ R^(d_X x h_X x w_X) (3D 그리드)에서 쿼리한 다음 3D convolution 네트워크, 즉 z_j = E_(3D CNN) (ɸ[I^(1:V), M_j^(1:V)](X_h))에 의해 처리된다.
이 방법은 픽셀 정렬 피쳐에서 latent vector를 계산함으로써 [43, 83, 60]과 다르다.
5 Baselines / Alternative State Representations
이 섹션에서는 RL에 대한 encoder를 학습하는 대안적인 방법을 간략하게 설명하며, 이를 베이스라인 및 ablations로서 실험에서 조사할 것이다.
Conv. Autoencoder.
이 베이스라인은 NeRF 대신 deconvolution 기반의 표준 CNN decoder를 사용하여 [1]과 유사한 latent 표현에서 이미지를 재구성한다.
따라서 이 베이스라인을 사용하여 CNN decoder에 대한 NeRF decoder의 영향을 조사한다.
우리는 global 사례의 deconvolution 부분에 대해 [11]의 아키텍처를 따른다.
compositional 경우, 우리는 단일 global 벡터 대신 개별 latent vector 세트를 처리할 수 있도록 아키텍처를 수정한다.
이미지 I = D_deconv(g_MLP(1/m ∑z_j), K)은 먼저 latent vector를 평균화한 다음 완전히 연결된 네트워크 g_MLP로 평균화된 벡터를 처리하여 z_(1:m)에서 렌더링되어 집계된 피쳐로 이어진다.
이 집계된 피쳐는 원하는 뷰를 설명하는 (flattened) 카메라 행렬 K와 연결된 다음 D_deconv를 사용하여 이미지로 렌더링된다.
실험에서, 우리는 이 decoder를 supervision 신호로 사용하여 섹션 4.4의 2D CNN encoder에 의해 생성된 latent space를 학습시킨다.
compositional버전에서 2D CNN encoder (4)는 compositional NeRF-RL 변형과 동일한 객체 마스크를 사용한다.
Contrastive Learning.
reconstruction loss를 통해 encoder를 학습하는 대안으로, contrastive learning [84]의 아이디어는 동일한 구성을 설명하는 latent vector (positive 샘플이라고 함)를 함께 끌어오려는 latent space에서 loss 함수를 직접 정의하는 동시에 다른 시스템 state (negative 샘플이라고 함)를 나타내는 것이다.
이를 달성하기 위한 일반적인 접근법은 InfoNCE loss를 사용하는 것입니다 [85, 64].
y_i와 ~y_i를 같은 state의 서로 다른 관측치라고 하자.
여기서 ~는 perturbed/augmented 버전의 관측치를 나타냅니다.
관측치 {(y_i, ~y_i)}_(i=1)^n의 mini--batch의 경우, encoder Ω와 함께 각각의 latent vector z_i = Ω(y_i), ~z_i = Ω(~y_i)로 encoding한 후, 해당 배치에 대한 loss는 (z_i, ~z_i)를 positive 쌍으로 사용하고 (z_i, ~z_≠i)를 negative 쌍 또는 유사한 변형으로 사용할 것이다.
contrastive learning에서 중요한 질문은 어떻게 관찰 y가 ~y로 perturbed/augmented되어 positive 및 negative 학습 쌍을 생성하는지에 대한 것이다, 다음에서 설명한다.
CURL.
CURL [5]에서는 입력 이미지가 랜덤으로 잘라져 y 및 ~y가 생성됩니다.
우리는 [5]의 초 매개변수와 설계를 면밀히 따른다.
CURL은 단일 입력 뷰에서 작동하며 환경 state를 최대한 잘 추론할 수 있는 이 베이스라인에 대한 뷰를 신중하게 선택한다.
Multi-View CURL.
이 베이스라인은 neural field 3D encoder(섹션 4.4)를 contrastive loss로 학습할 수 있는지 조사한다.
이 encoder는 여러 입력 뷰에서 작동하므로 사용 가능한 카메라 뷰의 양이 두 배가 됩니다.
뷰의 절반은 다른 실험과 동일하며, 나머지 절반은 시각적으로 perturbed 카메라 각도에서 캡처됩니다.
우리는 CURL과 동일한 loss를 사용하지만, 다른 contrastive 쌍을 사용한다 - augmentation에서가 아니라, contrastive style은 TCN에서 취한다 [68]: positive 쌍들은 다른 시각에서 동시에 오는 반면, negative 쌍들은 다른 시간에서 온다.
따라서 이 베이스라인은 CURL[5]의 다중 뷰 적응으로 볼 수 있다.

Direct State / Keypoint Representations.
마지막으로, 우리는 또한 state의 직접적이고 저차원적인 표현을 고려한다.
우리는 다양한 물체 모양에 대한 일반화에 관심이 있기 때문에, 전문 지식에 의해 물체의 관련 위치에 부착되고 완벽한 키포인트 검출기로 관찰되는 여러 3D 키포인트를 고려한다[8].
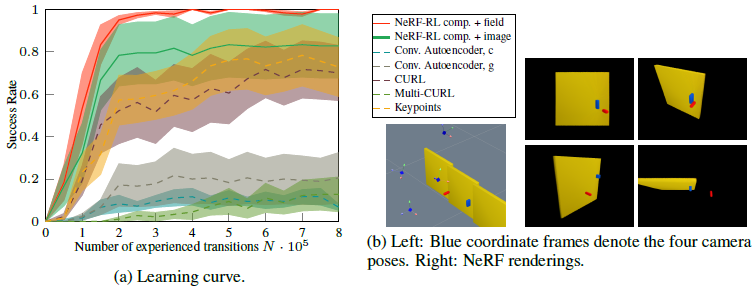
이러한 핵심 사항에 대한 시각화는 그림 2b를 참조하십시오.
키포인트는 둘 다 객체 모양과 포즈에 대한 정보를 제공합니다.
또한, 그림 2b에서 보는 바와 같이, 과제 해결과 관련된 환경에서 이러한 위치를 반영하도록 선택되었다.
또한 state가 객체의 포즈로 표현되는 결과를 보고한다.
이는 객체 모양을 나타낼 수 없기 때문에 이 경우 학습과 테스트를 위해 일정한 객체 모양을 사용한다.
6 Experiments
우리는 작업을 성공적으로 해결하기 위해 장면에서 객체의 기하학적 구조가 중요한 다른 환경에서 제안된 방법을 평가한다.
일반적으로 RL은 포즈만 변경되지만 관련된 객체 모양은 일정하게 유지되는 단일 환경에서 학습되고 평가된다.
latent-conditioned NeRF는 기하학에 걸쳐 일반화할 수 있는 것으로 나타났기 때문에 [43], 우리는 RL agent가 일부 분포 내의 객체 모양에 대해 일반화할 것을 요구하는 실험을 고려한다.
이 연구의 과학적 질문에 답하려면 다중 뷰 관찰이 있는 환경이 필요하며 - compositional 버전의 경우 객체 마스크도 필요하다.
이것들은 표준 RL 벤치마크에 제공되지 않으며, 이는 본 연구에서 조사된 환경을 선택하는 이유이다.
우리는 모든 실험에서 PPO[86]를 RL 알고리즘과 4개의 카메라 뷰로 사용한다.
환경, 매개 변수 선택 및 학습 시간에 대한 자세한 내용은 부록을 참조하십시오.
6.1 Environments
Mug on Hook.
[87]에서 채택되고 그림 2b에 시각화된 이러한 환경에서, 과제는 머그컵을 후크에 거는 것이다.
머그컵과 후크 모양은 모두 랜덤화되어 있다.
actions은 머그잔에 적용된 작은 3D translations입니다.
RL agent가 머그와 후크 모양을 일반화해야 하고 핸들 개방과 후크 사이의 tolerance가 상대적으로 작기 때문에 이러한 환경은 어렵다.
또한, agent는 머그잔이 안정적으로 걸려 있는 경우에만 희소 reward를 받는다.
이 reward는 각 action 후 머그 드롭을 가상으로 시뮬레이션하여 계산됩니다.
머그가 현재 state에서 바닥으로 떨어지지 않을 경우, 1의 reward가 할당되고, 그렇지 않을 경우 0이 할당됩니다.

Planar Pushing.
이러한 환경에서의 과제는, 그림 3b에 도시된 바와 같이, 평면 내에서 이동할 수 있는 빨간색 pusher, 즉 2차원적인 action을 갖는, 노란색 박스 형상의 물체를 테이블의 좌측 영역으로, 파란색 물체를 우측 영역으로 밀어 넣는 것이다.
이는 동일한 네 가지 카메라 뷰를 가진 [53]에서와 동일한 환경입니다.
각 런에는 테이블 위의 개체(pusher 포함)가 하나씩 포함됩니다.
상자를 각 영역 안으로 밀어넣으면 1의 희소 reward가 수신되고, 그렇지 않으면 0이 수신됩니다.
환경에 있는 상자들은 두 가지 색상으로 크기가 다르며 임의로 초기화됩니다.
이 환경에서는 reward가 객체 색상에 따라 다르기 때문에 다중 형상 설정에 키포인트를 사용할 수 없습니다; 단일 형상 사례에서만 키포인트 베이스라인을 평가합니다(부록).
Door Opening.
그림 4b는 door 환경을 보여주는데, 여기서 작업은 3DoF로 translate할 수 있는 빨간색 엔드-이펙터를 action으로 하여 슬라이딩 도어를 여는 것이다.
이 작업을 해결하려면 agent가 도어 핸들을 눌러야 합니다.
핸들 위치와 크기가 랜덤화되므로 agent는 그에 따라 핸들 지오메트리와 상호 작용하는 방법을 배워야 합니다.
흥미롭게도, 비디오에서 볼 수 있듯이, agent는 종종 처음에만 핸들을 누르는 것을 선택하는데, 그 후에는 문 자체를 옆으로 밀기에 충분하기 때문이다.
agent는 문이 충분히 열린 경우 희소 reward를 받고, 그렇지 않은 경우에는 0 보상이 할당된다.
6.2 Results
그림 2a, 3a, 4a는 학습 단계의 함수로서 성공률(시간 단계당 6개 이상의 독립적인 실험 반복과 반복당 30개 이상의 시험 롤아웃 평균)을 보여준다.
68% 신뢰 구간도 표시됩니다.
이러한 성공률은 랜덤 객체 모양과 초기 조건을 사용하여 평가되었으며, 따라서 이에 대한 agent의 일반화 능력을 반영한다.
이러한 모든 실험에서, decoder로 compositional NeRF supervision으로 학습된 latent space는 샘플 효율성과 asymptotic 성능 측면에서 다른 모든 학습된 표현을 지속적으로 능가했다.
또한 compositional NeRF를 사용하여 제안된 프레임워크는 expert 키포인트 표현을 능가한다.
door 환경의 경우 3D neural field encoder와 NeRF decoder (NeRF-RL comp. + field)가 거의 완벽한 성공률에 도달한다.
다른 두 환경의 경우 compositional 2D CNN encoder와 NeRF decoder (NeRF-RL comp. + image)가 neural field encoder보다 약간 낫지만 크게 향상되지는 않았다.
이는 compositional NeRF로 구축된 decoder가 encoder의 선택이 아니라 성능과 관련이 있음을 보여준다.
서로 다른 카메라 뷰에 대한 supervision 신호로서 contrastive loss를 가진 3D neural field encoder를 positive/negative 학습 쌍으로 학습시키는 것은 이러한 시나리오에서 상당한 학습 진전을 달성할 수 없다(Multi-CURL).
그러나 다른 contrastive 베이스라인인 CURL은 다른 encoder를 가지고 있으며 추가 카메라 뷰 대신 이미지 cropping을 데이터 확대로 사용하여 door 환경에서 적절한 성능과 샘플 효율성을 달성할 수 있지만 pushing 환경에서는 그렇지 않다.
mug 환경에서 CURL은 처음에는 우리의 프레임워크에 필적하는 학습 진전을 이룰 수 있지만 59% 이상의 성공률에 도달하지 못하고 불안정해진다.
마찬가지로, global CNN autoencoder 베이스라인은 처음에는 mug와 pushing 시나리오(door가 아님)에서 적절한 학습 진전을 보여주지만, 그 후에는 불안정해지거나(mug) 성공률(pushing) 50%를 절대 초과하지 않는다.
다양한 환경에서 이러한 성능의 변화나 불안정한 학습은 모든 경우에 안정적인 우리의 방법으로 관찰되지 않았다.
우리 프레임워크의 compositional variation (NeRF-RL comp.)은 최고의 성능을 달성한다.
conv. comp. autoencoder 베이스라인은 global variant보다 성능이 좋지 않으며, compositionality만으로 state 표현이 더 나은 유일한 이유는 아닙니다.
실제로 pushing 환경의 global NeRF-RL+ 이미지 variant도 다른 모든 베이스라인보다 낫다.
7 Discussion
Why NeRF provides better supervision.
NeRF 학습 목표 (1)는 각 f(·, z_j)가 실제 3D 구성에서 각 객체를 나타내도록 강하게 강요하며, 형상을 포함한 장면의 다른 객체(compositional 사례)와 상대적이다.
이는 latent vectors z_j가 이 정보를 포함해야 한다는 것을 의미한다, 즉, 장면에서 물체 유형, 모양 및 포즈를 결정하도록 학습된다.
global의 경우, z_1은 전체 장면의 기하학적 구조를 나타내야 한다.
우리가 고려하는 작업은 객체의 기하학적 구조를 고려하는 policy를 필요로 하기 때문에, 3D 공간에서 장면을 재구성하기 위해 NeRF를 매개 변수화할 수 있는 latent vectors는 policy가 성공하기 위해서도 객체의 관련 3D 정보를 충분히 포함해야 한다고 가정한다.
Masks.
auto-encoder 프레임워크가 compositional이기 위해서는 객체 마스크가 필요하다.
우리는 instance segmentation이 공정한 가정이 되는 성숙도[88]에 도달했다고 생각한다.
우리는 또한 좋은 성능을 보여주지 않는 compositional conv. autoencoder와 다중 뷰 CURL 베이스라인에 개별 마스크를 활용하기 때문에, 이는 마스크가 우리의 state 표현이 더 높은 성능을 달성하는 주요 이유가 아님을 나타낸다.
pushing 시나리오에서 개별 객체 마스크에 의존하지 않는 global NeRF-RL 변형이 모든 베이스라인보다 높은 성능을 달성했다는 사실, 즉 마스크가 compositional 버전을 활성화하므로 NeRF-RL의 성능을 향상시키지만 필수적인 것 같지는 않다.
Offline/Online.
이 연구에서는 랜덤 action에 의해 수집된 데이터 세트에서 오프라인으로 latent 표현을 사전 학습하는 데 중점을 두었다.
RL 동안 encoder는 고정되고 policy 네트워크만 학습된다.
이는 다른 RL 작업에 동일한 표현을 사용할 수 있으며 표현을 학습하기 위한 데이터 세트가 반드시 동일한 분포에서 올 필요는 없다는 장점이 있다.
그러나 state 공간의 합리적인 영역을 탐색하기 위한 policy가 필요한 경우, state 공간을 충분히 커버하는 latent space를 학습하기 위해 데이터 세트를 오프라인으로 수집하는 것은 오프라인 접근 방식에 더 어려울 수 있다.
이것은 랜덤 action으로 데이터를 수집하는 것으로 충분했던 우리의 실험에는 문제가 되지 않았다.
실제로, 우리는 동일한 환경의 다른 시작 state와 다른 모양(분포 내)과 관련하여 일반화를 보여준다.
향후 연구는 온라인 설정에서 NeRF supervision을 조사할 수 있다.
NeRF를 통한 reconstruction loss는 2D CNN deconv. decoder이나 contrastive 항을 통한 것보다 계산적으로 더 까다로워 각 RL 학습 단계에서 auxiliary loss로서의 NeRF supervision이 비용이 많이 든다는 점에 유의한다.
이를 위한 한 가지 잠재적 해결책은 auxiliary loss를 모든 RL 학습 단계가 아니라 더 낮은 빈도로 적용하는 것이다.
계산 효율성과 관련하여, NeRF auto-encoder가 우리의 환경을 위해 학습하는 데 최대 2일이 걸린 반면, CURL을 사용한 encoding은 반나절 이내에 학습될 수 있기 때문에 contrastive learning이 우리가 제안한 NeRF 기반 decoder보다 유리하다.
그러나 RL에 encoder를 사용할 때는 추론 시간에 차이가 없다.
Multi-View.
우리가 제안하는 auto-encoder 프레임워크는 여러 카메라 뷰의 정보를 장면의 물체를 설명하는 latent vector로 융합할 수 있다.
이러한 방식으로 occlusions을 해결할 수 있으며 agent는 다른 카메라 각도에서 장면을 더 잘 3D로 이해할 수 있다.
여러 카메라 뷰와 카메라 행렬에 액세스할 수 있다는 것은 이 정보를 활용할 수 있는 기능이 우리 방법의 장점이라고 생각하지만 우리가 제시하는 추가적인 가정이다.
8 Conclusion
이 연구에서, 우리는 RL에 대한 latent space를 학습하기 위해 Neural Radiance Fields (NeRFs)를 활용하는 아이디어를 제안했다.
우리의 환경은 장면에서 객체의 기하학적 구조가 작업을 성공적으로 해결하는 데 관련이 있는 작업에 초점을 맞춘다.
장면의 여러 뷰를 latent space에 매핑하는 사전 학습된 encoder를 사용하여 RL agent를 학습하면 state 표현을 학습하는 다른 방법과 전문 지식에 의해 선택된 키포인트를 지속적으로 능가한다.
우리의 결과는 decoder로서 compositional NeRF에 존재하는 3D prior가 encoder의 priors보다 더 중요하다는 것을 보여준다.
Broader Impacts.
우리의 주요 기여는 자동화에 영향을 미칠 수 있는 비전 기반 RL의 효율성을 향상시키는 표현을 학습하는 방법이다.
이와 같이, 우리의 연구는 사회에서 증가하는 자동화의 잠재력을 어떻게 해결할 것인가 하는 문제와 같은 AI의 일반적인 윤리적 위험을 계승한다.