2023. 3. 3. 16:17ㆍView Synthesis
Putting NeRF on a Diet: Semantically Consistent Few-Shot View Synthesis
Ajay Jain, Matthew Tancik, Pieter Abbeel
Abstract
우리는 몇 가지 이미지에서 추정된 3D 신경 장면 표현인 DietNeRF를 제시한다.
Neural Radiance Fields (NeRF)는 다중 뷰 일관성을 통해 장면의 연속적인 체적 표현을 학습하고, 레이 캐스팅을 통해 새로운 관점에서 렌더링할 수 있다.
NeRF는 360˚의 까다로운 장면을 위해 최대 100개의 이미지를 포함한 많은 이미지를 통해 기하학적 구조와 세부 사항을 재구성할 수 있는 인상적인 능력을 가지고 있지만, 종종 몇 개의 입력 뷰만 사용할 수 있을 때 이미지 재구성 목표에 대한 퇴행 솔루션을 찾는다.
퓨샷 품질을 향상시키기 위해 DietNeRF를 제안한다.
우리는 새로운 포즈에서 현실적인 렌더링을 장려하는 보조 semantic 일관성 loss를 소개한다.
DietNeRF는 (1) 동일한 포즈에서 주어진 입력 뷰를 올바르게 렌더링하기 위해 개별 장면에서 학습되며, (2) 서로 다른 랜덤 포즈에서 높은 수준의 semantic 속성을 일치시킨다.
우리의 semantic loss는 임의의 포즈로부터 DietNeRF를 supervise할 수 있게 한다.
우리는 자연어 supervision으로 웹에서 채굴된 수억 개의 다양한 단일 뷰, 2D 사진에 대해 학습된 비전 트랜스포머인 CLIP와 같은 사전 학습된 시각적 인코더를 사용하여 이러한 semantics를 추출한다.
실험에서 DietNeRF는 처음부터 학습할 때 퓨샷 뷰 합성의 지각 품질을 향상시키고, 다중 뷰 데이터 세트에 대해 사전 학습되었을 때 관찰된 이미지 하나만으로 새로운 뷰를 렌더링할 수 있으며, 완전히 관찰되지 않은 영역의 그럴듯한 완성을 생성한다.

1. Introduction
새로운 관점 합성 문제에서, 우리는 희박하게 샘플링된 관점 세트가 주어진 임의의 관점에서 장면을 렌더링하려고 한다.
뷰 합성은 고주파 텍스처 합성 외에도 어느 정도의 3D 재구성이 필요한 까다로운 문제이다.
최근 많은 관찰이 가능한 고품질 뷰 합성에 큰 진전이 있었다.
널리 사용되는 접근법은 Neural Radiance Fields (NeRF)[30]를 사용하여 이미지 관찰에서 연속적인 신경 장면 표현을 추정하는 것이다.
특정 장면에 대한 학습 중에 재구성 loss를 계산하기 위해 체적 ray casting을 사용하여 관찰된 관점에서 표현이 렌더링됩니다.
테스트 시, NeRF는 동일한 절차에 의해 새로운 관점에서 렌더링될 수 있다.
개념적으로 매우 간단하지만 NeRF는 고품질 렌더링을 가능하게 하는 고주파 뷰 의존적 장면 외관과 정확한 기하학적 구조를 학습할 수 있다.
그럼에도 불구하고 NeRF는 장면별로 추정되며 다른 이미지 및 객체에서 얻은 prior 지식의 혜택을 받을 수 없다.
peior 지식이 부족하기 때문에 NeRF는 주어진 장면을 고품질로 재구성하기 위해 많은 입력 뷰를 필요로 한다.
8개의 뷰가 주어졌을 때, 그림 2B는 최적화가 관찰된 포즈에서만 정확한 퇴화 솔루션을 찾기 때문에 전체 NeRF 모델로 렌더링된 새로운 뷰에 많은 아티팩트가 포함되어 있음을 보여준다.
우리는 렌더링 loss를 기반으로 하는 이전의 3D 재구성 시스템이 알려진 포즈에서만 supervise되므로 포즈가 거의 관찰되지 않을 때 과적합된다는 것을 발견했다.
아키텍처를 단순화하여 NeRF를 정규화하면 최악의 아티팩트를 피할 수 있지만 세밀한 세부 사항을 희생해야 한다.
또한 장면 재구성 문제가 과소 결정될 때 prior 지식이 필요하다.
3D 재구성 시스템은 물체의 영역이 관찰되지 않을 때 어려움을 겪는다.
이는 객체를 상당히 다른 포즈로 렌더링할 때 특히 문제가 된다.
극단적인 베이스라인 변경으로 장면을 렌더링하면 학습 중에 관찰되지 않은 영역이 표시됩니다.
뷰 합성 시스템은 공백을 메우기 위해 누락된 세부 정보를 그럴듯하게 생성해야 한다.
정규화된 NeRF조차도 prior 지식이 부족하기 때문에 보이지 않는 영역에 대한 잘못된 외삽법을 학습한다(그림 2D).
최근 연구는 NeRF를 유사한 장면[52, 44, 38, 43, 49]의 다중 뷰 데이터 세트에 대해 학습시켜 새로운 장면의 재구성을 편향시켰다.
불행히도 이러한 모델은 불확실성으로 인해 블러 이미지를 생성하거나, 크고 다양한 다중 뷰 데이터를 캡처하는 것이 어렵기 때문에 ShapeNet 클래스와 같은 단일 개체 범주로 제한되는 경우가 많다.
이 연구에서, 우리는 "a bulldozer is a bulldozer from any perspective"라는 일관성 원칙을 활용한다: 개체는 뷰 간에 높은 수준의 semantic 속성을 공유합니다.
이미지 인식 모델은 객체 ID를 포함한 많은 높은 레벨의 semantic 피쳐를 추출하는 방법을 배운다.
우리는 매우 다양한 2D 단일 뷰 이미지 데이터에 대해 학습된 사전 학습된 이미지 인코더에서 뷰 합성 문제로 prior 지식을 이전한다.
단일 뷰 설정에서 이러한 인코더는 ImageNet[7]과 같은 수백만 개의 사실적인 이미지에 대해 자주 학습된다.
CLIP는 400M 이미지를 포함하는 대규모 웹 스크래치에서 이미지를 캡션과 일치시키도록 학습된 최근의 다중 모드 인코더이다[33].
데이터의 다양성으로 인해 CLIP는 이미지 인식 작업에 대한 유망한 제로샷 및 퓨샷 전이 성능을 보여주었다.
CLIP 및 ImageNet 모델에도 새로운 뷰 합성에 유용한 prior 지식이 포함되어 있음을 발견했다.
우리는 몇 장의 사진에서만 추정할 수 있고 관찰되지 않은 영역으로 뷰를 생성할 수 있는 NeRF를 기반으로 하는 신경 장면 표현인 DietNeRF를 제안한다.
픽셀 공간에서 알려진 포즈에서 NeRF의 평균 제곱 오차 loss를 최소화하는 것 외에도 DietNeRF는 semantic 일관성 loss에 불이익을 준다.
이 loss는 ground truth 이미지와 다른 포즈에서 렌더링된 이미지 사이에서 CLIP의 비전 트랜스포머[9]의 최종 활성화와 일치하므로 임의 포즈에서 radiance field를 supervise할 수 있다.
실험에서, 우리는 DietNeRF가 기본 볼륨 표현을 단순화하지 않고 8개의 뷰로 객체의 현실적인 재구성을 학습하고, 심지어 완전히 닫힌 영역의 합리적인 재구성을 생성할 수 있음을 보여준다.
최소 1개의 관찰로 새로운 뷰를 생성하기 위해 일반화 가능한 장면 표현인 pixelNeRF[52]를 미세 조정하고 지각 품질을 향상시킨다.
2. Background on Neural Radiance Fields
플렌옵틱 함수 또는 라이트 필드는 경계가 있는 장면과 같은 볼륨에서 모든 방향의 모든 지점에서 방사되는 빛을 설명하는 5차원 함수이다.
입력의 차원성으로 인해 고해상도에서 플렌옵틱 함수를 명시적으로 저장하거나 추정하는 것은 비현실적이지만, Neural Radiance Fields [30]는 다층 퍼셉트론(MLP)과 같은 연속 신경망으로 함수를 매개 변수화한다.
Neural Radiance Field (NeRF) 모델은 공간 위치 x = (x, y, z)와 뷰 방향 (θ, ɸ)의 5차원 함수 f_θ(x, d) = (c, σ)이며, 3D 단위 벡터 d로 표현된다.
NeRF는 이러한 입력으로부터 RGB 색상 c와 차등 볼륨 밀도 σ를 예측한다.
뷰 일관성을 장려하기 위해 볼륨 밀도는 x에만 의존하는 반면, 색상은 또한 스펙타클 반사와 같은 관점 의존적 효과를 포착하기 위해 뷰 방향 d에 의존한다.
볼륨 렌더링에 따라 관찰자가 보낸 ray를 따라 색상을 통합하여 모든 위치의 가상 카메라에서 이미지를 렌더링합니다 [22]:
, 여기서 카메라 원점에서 발생하는 ray는 경로 r(t) = o + td를 따르며, 투과율 T(t) = exp(-∫σ(r(s)ds)는 ray가 t_n의 이미지 평면에서 t로 방해받지 않고 이동할 확률에 의해 radiance의 가중치를 부여한다.
적분을 근사하기 위해 NeRF는 계층적 샘플링 알고리즘을 사용하여 각 ray를 따라 물체 표면 근처의 함수 평가 지점을 선택한다.
NeRF는 두 개의 MLP, 즉 coarse 네트워크와 fine 네트워크를 별도로 추정하고, coarse 네트워크를 사용하여 (1)을 보다 정확하게 추정하기 위해 ray를 따라 샘플링을 안내한다.
네트워크는 다양한 관점에서 수십에서 수백 장의 사진이 주어진 각 장면에서 처음부터 학습된다.
한 장면의 관찰된 다중 뷰 학습 이미지 {I_i}가 주어지면 NeRF는 COLMAP SfM[37]을 사용하여 카메라 extrinsics (회전 및 원점) {p_i}를 추정하여 포즈된 데이터 세트 D = {(I_i; p_i)}을 생성한다.
3. NeRF Struggles at Few-Shot View Synthesis
뷰 합성은 장면이 드문드문 관찰될 때 어려운 문제이다.
개별 장면에서 학습하는 NeRF와 같은 시스템은 특히 유사한 장면에서 얻은 prior 지식 없이 어려움을 겪는다.
우리는 NeRF가 몇 가지 설정에서 퓨샷 새로운 뷰 합성에 실패한다는 것을 발견했다.
NeRF overfits to training views
개념적으로 NeRF는 관찰된 포즈에서 이미지 형성 프로세스를 모방하여 학습된다.
radiance field는 학습 이미지와 포즈(I, p_i)를 반복적으로 샘플링하고 볼륨 통합 (1)에 의해 동일한 포즈에서 이미지 ^I_p_i를 렌더링한 다음 픽셀 단위로 정렬해야 하는 이미지 사이의 평균 제곱 오차(MSE)를 최소화할 수 있다:
실제로 NeRF는 학습 중 전체 이미지를 렌더링하는 데 드는 계산 비용을 피하기 위해 모든 학습 이미지에 걸쳐 더 작은 ray 배치를 샘플링한다.
학습 카메라에서 주조된 하위 샘플 rays R이 주어지면 NeRF는
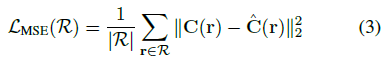
을 최소화한다.
많은 학습 뷰에서 L_MSE는 볼륨에서 f_θ에 학습 신호를 조밀하게 제공하며 개별 학습 뷰에 과적합하지 않는다.
대신 MLP는 정확한 텍스처와 점유율을 복구하여 새로운 뷰에 보간할 수 있습니다(그림 2A).
사인파 위치 임베딩이 있는 radiance field는 MLP가 미세한 세부 사항을 표현하는 데 도움이 되는 고주파 함수를 학습하는 데 상당히 효과적이다[43].
불행하게도, 이 고주파 표현 용량은 NeRF가 소수만 사용할 수 있을 때 각 입력 뷰에 지나치게 적합하도록 한다.
L_MSE는 학습 뷰 (I, p)의 재구성을 카메라 가까이에 패킹하여 최소화할 수 있습니다.
기본적으로, 플레놉틱 함수 표현은 원거리 카메라가 다른 카메라가 관찰하지 않는 공간의 중요한 영역을 각각 관찰하는 근거리 모호성[53]으로 어려움을 겪는다.
이 경우 최적의 장면 표현은 충분히 결정되지 않습니다.
퇴화 솔루션은 또한 radiance field의 뷰 의존성을 이용할 수 있다.
그림 2B는 8개의 뷰에 대해 학습된 동일한 NeRF의 새로운 뷰를 보여준다.
학습 이미지 근처의 포즈에서 렌더링된 뷰는 적절한 질감을 가지지만, 왜곡이 잘못되고 잘못된 지오메트리로 인해 블러 아티팩트가 있습니다.
지오메트리가 올바르게 추정되지 않기 때문에 원거리 뷰에는 정확한 정보가 거의 없습니다.
불투명도가 높은 영역이 카메라를 차단합니다.
주변 카메라의 supervision이 없으면 불투명도는 랜덤 초기화에 민감하다.
Regularization fixes geometry, but hurts fine-detail
NeRF를 정규화함으로써 가짜 불투명도 및 빠르게 변화하는 색상과 같은 고주파 아티팩트를 피할 수 있다.
계층적 샘플링을 제거하고 단일 MLP만 학습하고 입력 계층에 최대 주파수 위치 임베딩을 줄임으로써 NeRF 아키텍처를 단순화한다.
이는 NeRF를 학습 카메라에서 더 멀리 떨어진 장면의 중심에 콘텐츠를 배치하는 것과 같은 저주파 솔루션으로 편향시킨다.
또한 초기 수렴을 개선하기 위해 학습 속도를 낮춤으로써 몇 가지 몇 가지 최적화 문제를 해결할 수 있다, 렌더링이 퇴화된 경우 수동으로 학습을 다시 시작합니다.
그림 2C는 이러한 정규화를 통해 NeRF가 그럴듯한 객체 지오메트리를 성공적으로 복구할 수 있음을 보여준다.
그러나 2A에 비해 고주파의 미세한 세부 정보가 손실됩니다.
No prior knowledge, no generalization to unseen views
NeRF는 장면별로 처음부터 추정되므로 공통 대칭 및 객체 부분과 같은 자연 객체에 대한 prior 지식이 없다.
그림 2D에서, 우리는 Lego 차량의 오른쪽 절반의 14개 뷰로 학습된 NeRF가 왼쪽으로 잘 일반화되지 않음을 보여준다.
NeRF를 정규화하여 원래 왼쪽을 완전히 차단한 고불투명도 영역을 제거했다.
그럼에도 불구하고, 본질적인 과제는 NeRF가 L_MSE에서 관찰되지 않은 영역으로 supervision 신호를 수신하지 않고 대신 모든 인페인팅에 MLP의 유도 편향에 의존한다는 것이다.
NeRF가 그럴듯한 완성을 위해 양자 대칭을 활용할 수 있도록 하는 prior 지식을 소개하고자 한다.
4. Semantically Consistent Radiance Fields
이러한 과제에 자극을 받아 DietNeRF 장면 표현을 소개한다.
DietNeRF는 사전 학습된 이미지 인코더의 prior 지식을 사용하여 퓨샷 설정에서 NeRF 최적화 프로세스를 안내한다.
4.1. Semantic consistency loss
DietNeRF는 semantic loss가 있는 학습 중 임의의 카메라 포즈에서 f_θ를 supervise한다.
ground truth 관측 이미지와 L_MSE를 사용한 렌더링 이미지 간의 픽셀 단위 비교는 렌더링된 이미지가 관찰된 포즈와 정렬될 때만 유용하지만, 인간은 semantic 단서에서 두 이미지가 동일한 객체의 뷰인지 여부를 쉽게 감지할 수 있다.
일반적으로 서로 다른 관점에서 캡처한 이미지의 표현을 비교할 수 있습니다:
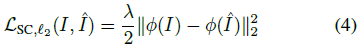
ɸ(x) = x인 경우, 식 (4)는 스케일링 계수까지 L_full로 감소합니다.
그러나 identity 매핑은 뷰 의존적입니다.
우리는 동일한 객체의 뷰에서 유사하고 객체 클래스와 같은 중요한 높은 레벨의 semantic 속성을 캡처하는 표현이 필요하다.
우리는 표현 학습을 위한 두 가지 supervision 소스의 유용성을 평가한다.
첫째, 멀티 모달 언어 및 비전 추론을 위해 사전 학습된 최근 CLIP 모델을 contrastive learning으로 실험한다[33].
그런 다음 레이블이 지정된 ImageNet 이미지에 대해 사전 학습된 시각적 분류기를 평가한다[9].
두 경우 모두 유사한 Vision Transformer(ViT) 아키텍처를 사용합니다.
Vision Transformer는 성능이 대량의 2D 데이터로 매우 잘 확장되기 때문에 매력적입니다.
다양한 이미지에 대한 학습을 통해 네트워크는 명시적인 다중 뷰 데이터 캡처 없이 학습 과정에서 객체 클래스의 여러 뷰를 만날 수 있다.
또한 동종 데이터 세트에 의존하는 이전의 클래스별 재구성 작업과 달리 그래픽 애플리케이션의 다양한 관심 대상으로 시각적 인코더를 전송할 수 있다[3, 23].
ViT는 첫 번째 계층에서 겹치지 않는 이미지 패치에서 피쳐를 추출한 다음 전역 셀프 어텐션[48]을 기반으로 점점 더 추상적인 표현을 트랜스포머 블록과 집계하여 단일 전역 임베딩 벡터를 생성한다.
ViT는 초기 실험에서 CNN 인코더를 능가했다.
실제로 CLIP는 정규화된 이미지 임베딩을 생성한다.
ɸ(·)가 단위 벡터일 때, 식 (4)는 loss 가중치 λ에 흡수될 수 있는 상수와 스케일링 계수까지 코사인 유사성을 단순화한다:
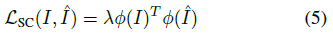
L_SC (5)는 관찰된 뷰와 렌더링된 뷰 사이의 높은 수준의 semantic 피쳐의 유사성을 측정하기 때문에 semantic 일관성 loss라고 한다.
원칙적으로 semantic 일관성은 미분 가능한 렌더링을 기반으로 하는 모든 3D 재구성 시스템에 적용할 수 있는 매우 일반적인 loss이다.
4.2. Interpreting representations across views
우리가 사용하는 사전 학습된 CLIP 모델은 다양한 세부 정보의 캡션이 있는 수억 개의 이미지에 대해 학습된다.
이미지 캡션은 이미지 표현에 대한 풍부한 supervision을 제공합니다.
한편, 짧은 캡션은 레이블을 표현하는 유연한 방법으로 의미론적으로 희박한 학습 신호를 표현한다[8].
예를 들어, "A photo of hotdogs"라는 캡션은 그림 2A를 설명한다.
언어는 또한 "Two hotdogs on a plate with ketchup and mustard"라는 캡션과 같은 객체 속성, 관계 및 외관을 설명함으로써 의미론적으로 조밀한 학습 신호를 제공한다.
이러한 캡션을 예측하기 위해 이미지 표현은 관점에서 안정적인 일부 높은 레벨의 의미론을 캡처해야 한다.
동시에 [12]는 CLIP 표현이 예술 스타일과 색상과 같은 이미지의 시각적 속성뿐만 아니라 객체 태그와 범주, 얼굴 표정, 타이포그래피, 지리 및 브랜드를 포함한 높은 수준의 의미 속성을 포착한다는 것을 발견했다.
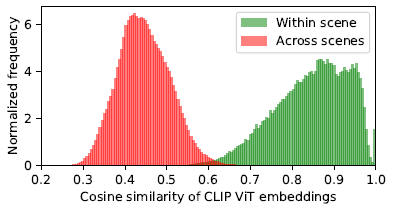
그림 3에서, 우리는 물체 주위를 도는 뷰의 CLIP 표현 사이의 쌍별 코사인 유사성을 측정한다.
우리는 뷰 쌍이 정반대의 카메라에 대해서도 매우 유사한 CLIP 표현을 가지고 있다는 것을 발견했다.
이는 크고 다양한 단일 뷰 데이터 세트가 다중 뷰 애플리케이션에 유용한 표현을 유도할 수 있음을 시사한다.
4.3. Pose sampling distribution
우리는 L_SC 최소화로 NeRF 학습 루프를 강화한다.
각 반복마다, 우리는 관찰 데이터 세트 I ~ D에서 샘플링된 랜덤 학습 이미지와 랜덤 포즈 p ~ π에서 렌더링된 이미지 ^I_p 사이에서 L_SC를 계산한다.
360˚ 뷰 합성에 관심이 있는 NeRF의 Realistic Synthetic 장면과 같은 경계가 있는 장면의 경우, 우리는 포즈 샘플링 분포 π를 경계 범위에서 균일하게 샘플링된 반지름을 가진 상반구에 대한 균일한 분포로 정의한다.
포즈 샘플링 분포를 정의하기 어려운 무한 전방 장면 또는 장면의 경우, 우리는 쌍별 보간 가중치 α_1, α_2 ~ U(0, 1)로 랜덤으로 샘플링된 알려진 세 개의 포즈 p_1, p_2, p_3 ~ D 사이를 보간한다.
4.4. Improving efficiency and quality
볼륨 렌더링은 계산 집약적입니다.
픽셀의 색상을 계산하면 NeRF의 MLP f_θ가 ray를 따라 여러 지점에서 평가됩니다.
학습 중 DietNeRF의 효율성을 향상시키기 위해, 우리는 전체 해상도 학습 이미지로 ray의 15-20%만 필요로 하는 낮은 해상도로 의미론적 일관성을 위한 이미지를 렌더링한다.
ray는 이미지 평면의 전체 범위에 걸쳐 스트라이드 그리드에서 샘플링되어 각 렌더링에서 객체를 대부분 볼 수 있도록 한다.
우리는 연속 분포에서 포즈를 샘플링하는 것이 낮은 해상도에서 학습할 때 앨리어싱 아티팩트를 피하는 데 도움이 된다는 것을 발견했다.
실험에서, 우리는 많은 장면에서 L_SC가 L_MSE보다 더 빨리 수렴한다는 것을 발견했다.
우리는 의미론적 일관성 loss가 DietNeRF가 학습 초기에 그럴듯한 장면 기하학을 복구하도록 장려하지만 ViT 표현 ɸ(·)의 차원이 상대적으로 낮기 때문에 세분화된 세부 정보를 재구성하는 데는 덜 도움이 된다고 가정한다.
우리는 k마다 반복되는 L_SC를 최소화함으로써 L_SC의 빠른 수렴을 활용한다.
DietNeRF는 k의 선택에 강하지만 10과 16 사이의 값이 우리의 실험에서 잘 작동했다.
StyleGAN2[24]는 loss의 주기적 적용을 게으른 정규화라고 언급하면서 효율성에 대해 유사한 전략을 사용했다.
렌더링을 통한 역 전파는 역 모드 자동 미분으로 메모리 집약적이기 때문에 혼합 정밀 계산으로 L_SC에 대한 이미지를 렌더링하고 ɸ(·)를 절반 정밀도로 평가한다.
렌더링하는 동안 중간 MLP 활성화를 삭제하고 역방향 패스 동안 다시 구체화합니다 [6, 19].
모든 실험은 단일 16GB NVIDIA V100 또는 11GB 2080 Ti GPU를 사용한다.
L_MSE 이전에 L_SC가 수렴하기 때문에 20-70k 반복에 대해 L_MSE만으로 DietNeRF를 미세 조정하여 세부 사항을 세분화하는 것이 도움이 된다는 것을 알았다.
알고리즘 1은 우리의 전반적인 학습 과정을 상세히 설명한다.

5. Experiments
실험에서, 우리는 합성적으로 렌더링된 객체와 다중 객체 장면의 실제 사진 모두에 대해 DietNeRF와 베이스라인에 의해 합성된 새로운 뷰의 품질을 평가한다.
(1) 섹션 5.1에서 8개의 뷰를 가진 특정 장면에 대한 학습을 처음부터 평가한다.
(2) 우리는 섹션 5.2에서 DietNeRF가 단일 실제 사진에서만 시각 합성의 지각 품질을 향상시킨다는 것을 보여준다.
(3) 우리는 DietNeRF가 섹션 5.3에서 절대 관찰되지 않는 영역을 재구성할 수 있으며, 마지막으로 (4) 섹션 6에서 ablations를 실행할 수 있다는 것을 발견했다.
Datasets
[29]의 Realistic Synthetic 벤치마크에는 뷰에 의존적인 광 전송 효과를 가진 8개의 현실적인 객체의 상세한 다중 뷰 렌더링이 포함되어 있다.
또한 pixelNeRF[52]에서 사용하는 DTU 멀티 뷰 스테레오(MVS) 데이터 세트[20]를 벤치마킹한다.
DTU는 드문드문 샘플링된 물리적 물체의 실제 사진을 포함하는 까다로운 데이터 세트이다.
Low-level full reference metrics
과거 연구는 Peak Signal-to-Noise Ratio (PSNR) 및 Structural Simily Index Measure (SSIM)을 사용하여 동일한 포즈에서 ground truth와 관련하여 새로운 뷰 품질을 평가한다[41].
PSNR은 로그 공간에서 평균 제곱 오차를 나타냅니다.
그러나 SSIM은 종종 유사성에 대한 인간의 판단에 동의하지 않는다[54].
Perceptual metrics
심층 CNN 활성화는 인간 인식의 측면을 반영한다.
NeRF는 사전 학습된 VGG 인코더의 모든 계층에서 정규화된 피쳐 사이의 MSE를 계산하는 LPIPS[54]를 사용하여 지각 이미지 품질을 측정한다[39].
생성 모형은 또한 피쳐 공간 거리를 사용하여 샘플 품질을 측정합니다.
Frechet Inception Distance (FID) [15]는 실제 이미지와 가짜 이미지에 대한 마지막 Inception v3 [42] 피쳐의 가우시안 추정치 사이의 Frechet 거리를 계산한다.
그러나 FID는 낮은 샘플 크기에서 편향된 메트릭이다.
우리는 개념적으로 유사한 Kernel Inception Distance (KID)를 채택하는데, 이는 인셉션 피쳐 사이의 MMD를 측정하고 편향되지 않은 추정기를 가지고 있다[2, 31].
모든 메트릭은 CLIP ViT 인코더와 다른 아키텍처와 데이터를 사용합니다.
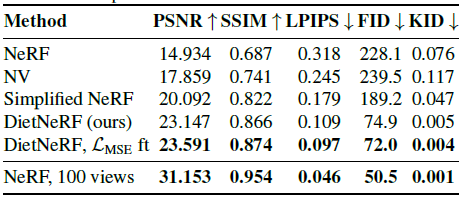
5.1. Realistic Synthetic scenes from scratch
NeRF의 Realistic Synthetic 데이터 세트에는 가상 카메라의 렌더링 100개가 안쪽을 가리키는 반구에 랜덤으로 배열된 8개의 세부 합성 개체가 포함되어 있다.
퓨샷 성능을 테스트하기 위해 각 장면에서 8개 이미지의 학습 하위 세트를 랜덤으로 샘플링한다.
표 1은 결과를 보여줍니다.
원래 NeRF 모델은 전체 100개의 이미지 데이터 세트보다 8개의 이미지로 훨씬 낮은 정량적 품질을 달성한다.
Neural Volumes [28]는 장면의 바운딩 박스 크기를 엄격하게 제한하고 복셀 불투명도의 공간 그레디언트에 대한 페널티와 이미지 불투명도에 대한 Beta prior를 사용하여 장면 표현을 명시적으로 정규화하기 때문에 성능이 더 좋다.
이렇게 하면 최악의 아티팩트는 피할 수 있지만 재구성은 여전히 낮은 품질입니다.
NeRF를 단순화하고 각 개별 장면에 맞게 조정하면 표현이 정규화되고 전체 NeRF에 대한 수렴(+5.1 PSNR)이 도움이 된다.
최고의 성능은 DietNeRF의 L_SC loss로 정규화함으로써 달성된다.
또한 L_MSE를 사용한 미세 조정은 NeRF보다 +8.5 PSNR, -0.2 LPIPS 및 -156 FID의 총 개선을 위해 품질을 더욱 향상시킨다.
이는 의미론적 일관성이 고품질 퓨샷 뷰 합성에 앞서 중요하다는 것을 보여준다.
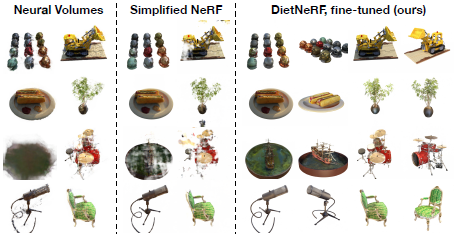
그림 4는 결과를 시각화합니다.
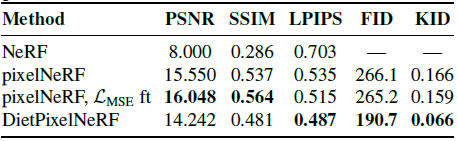
5.2. Single-view synthesis by fine-tuning
NeRF는 학습 중에 관찰만 사용하고 추론은 사용하지 않으며 보조 데이터는 사용하지 않는다.
단일 뷰에서 정확한 3D 재구성은 순전히 L_MSE에서 가능하지 않으므로 NeRF는 단일 뷰 설정에서 성능이 좋지 않습니다(표 2).
단일 또는 퓨샷 뷰 합성을 수행하기 위해 pixelNeRF[52]는 유사한 장면의 다중 뷰 데이터 세트에서 ResNet-34 인코더와 피처 조건 neural radiance field를 학습한다.
인코더는 새로운 단일 뷰 장면으로 일반화하는 priors를 학습한다.
표 2는 held-out 장면의 단일 사진을 고려할 때 pixelNeRF가 NeRF를 크게 능가한다는 것을 보여준다.
그러나 새로운 관점은 블러하고 비현실적이다(그림 5).
우리는 L_MSE만을 사용하거나 L_MSE와 L_SC를 모두 사용하여 단일 장면에서 pixelNeRF를 미세 조정할 것을 제안한다.
MSE를 사용하여 장면별 미세 조정은 로컬 이미지 품질 메트릭을 향상시키지만 지각 메트릭에 약간만 도움이 된다.
그림 6은 한 뷰에서 픽셀 공간 MSE 미세 조정이 대부분 해당 뷰의 품질만 향상시킨다는 것을 보여준다.


우리는 단기간 동안 두 loss를 모두 가진 미세 조정을 DietPixelNeRF라고 부른다.
질적으로, DietPixelNeRF는 훨씬 더 샤프한 새로운 관점을 가지고 있다(그림 5, 6).
DietPixelNeRF는 지각 LPIPS, FID 및 KID 메트릭의 베이스라인을 능가한다(표 2).
매우 까다로운 단일 뷰 설정의 경우 ground truth 새로운 뷰는 입력에서 완전히 차단된 콘텐츠를 포함할 것이다.
불확실성 때문에 블러 렌더링은 MSE 및 PSNR과 같은 평균 오류 메트릭에서 날카롭지만 부정확한 렌더링보다 성능이 뛰어나다.
논쟁의 여지가 있지만, 사진 편집 및 가상 현실과 같은 그래픽 응용 프로그램의 경우 신뢰성이 강조되기 때문에 지각 품질과 선명도가 픽셀 오류보다 더 나은 메트릭이다.
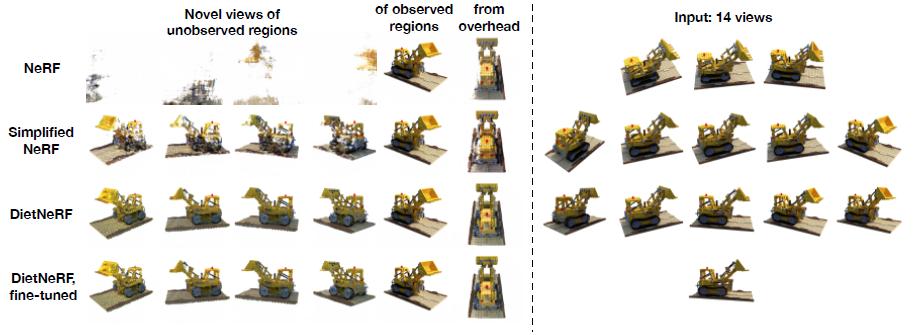
5.3. Reconstructing unobserved regions
재구성 문제가 충분히 결정되지 않았을 때 DietNeRF가 그럴듯한 완료를 생성하는지 평가한다.
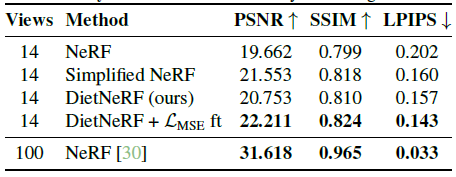
학습을 위해, 우리는 Realistic Synthetic Lego 장면의 오른쪽 측면의 주변 뷰 14개를 샘플링한다(그림 7, 오른쪽).
좁은 베이스라인 다중 뷰 캡처 장치는 360˚ 캡처보다 비용이 적게 들고 무한 장면을 지원한다.
그러나 좁은 베이스라인 관측치는 폐색으로 인해 어려움을 겪는다: Lego bulldozer의 왼쪽이 보이지 않는다.
NeRF는 장면의 이쪽을 재구성하지 못하는 반면, Simplified NeRF는 비현실적인 변형과 잘못된 색상을 학습한다(그림 7, 왼쪽).
놀랍게도, DietNeRF는 누락된 영역에서 정량적(표 3) 및 질적으로 더 정확한 색상을 학습하여 희소 재구성 문제에 대한 의미론적 이미지의 가치를 제안한다.
단일 장면에 정확한 추정을 위해 샘플이 너무 적기 때문에 FID 및 KID는 제외합니다.
6. Ablations
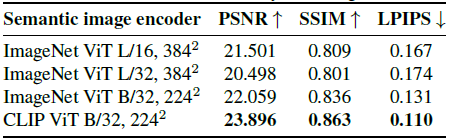
Choosing an image encoder
표 4는 다양한 의미 인코더 아키텍처와 사전 학습 데이터 세트가 있는 품질 메트릭을 보여준다.
우리는 8개의 뷰로 Lego 장면을 평가한다.
Large ViT 모델(ViTL)은 base ViTB보다 결과를 향상시키지 않는다.
아키텍처를 수정하면 CLIP는 ImageNet 모델보다 +1.8 PSNR 향상을 제공하여 데이터 다양성과 언어 supervision이 3D 작업에 도움이 된다는 것을 시사한다.
그럼에도 불구하고, 둘 다 뷰 합성으로 전달되는 유용한 표현을 유도한다.
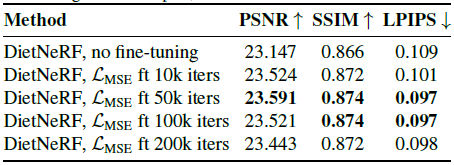
Varying L_MSE fine-tuning duration
L_MSE를 사용하여 DietNeRF를 미세 조정하면 미세한 세부 정보를 더 잘 재구성하여 품질을 향상시킬 수 있다.
표 5에서, 우리는 8개의 뷰로 Realistic Synthetic 장면에 대한 미세 조정의 반복 횟수를 변경한다.
최대 50,000회까지 미세 조정하는 것이 도움이 되지만, 최적화 시간이 길어지면 성능이 저하됩니다.
8개의 입력 뷰에 모형이 과적합되기 시작할 수 있습니다.
7. Related work
Few-shot radiance fields
몇몇 연구는 장면당 NeRF를 추정하는 대신 장면 기하학 또는 외관을 설명하는 잠재 코드에 따라 NeRF를 조건으로 한다[38, 44, 52].
이미지 인코더 및 radiance field 디코더는 유사한 물체 또는 장면의 다중 뷰 데이터 세트에서 미리 학습된다.
테스트 시, 새로운 장면에서, 새로운 관점은 몇 개의 관찰된 이미지의 인코딩에 따라 조정된 디코더를 사용하여 렌더링된다.
GRAF는 매 반복마다 장면의 패치를 렌더링하여 판별기로 네트워크를 supervuse한다[38].
우리 연구와 동시에 IBRNet[49]은 NeRF의 재구성 loss를 사용하여 특정 장면에서 잠재 조건 radiance field를 미세 조정하지만 적어도 50개의 뷰가 필요했다.
[43, 11] 공유 인코더와 디코더를 통해 장면 간을 일반화하는 대신, 몇 가지 그레디언트 단계에서 특정 장면에 적응할 수 있는 메타 학습 radiance field 가중치를 사용한다.
메타 학습은 퓨 뷰 설정에서 성능을 향상시킨다.
마찬가지로, 부호 있는 거리 필드는 형상 표현 문제에 대해 메타 학습할 수 있다[40].
많은 문헌은 다른 명시적인 3D 표현으로 단일 뷰 재구성을 연구한다.
최근의 주목할 만한 예로는 복셀[45], 메시[16] 및 포인트 클라우드[50] 접근법이 있다.
Novel view synthesis, image-based rendering
Neural Volumes [28]는 포즈 이미지 관찰에서 장면의 볼륨 표현을 예측하기 위해 VAE [26, 34] 인코더-디코더 아키텍처를 제안한다.
NV는 DietNeRF와 같은 보조 objective로 priors를 사용하지만 RGB 이미지 의미론이 아닌 기하학적 직관을 기반으로 불투명도를 처벌한다.
TBN[32]은 단일 범주에 대한 새로운 관점을 렌더링하기 위해 회전할 수 있는 3차원 잠재력을 가진 오토인코더를 학습한다.
SRN[41]은 장면에 연속 표현을 적합시키고 대규모 다중 뷰 데이터 세트에서 학습된 경우 새로운 단일 범주 개체로 일반화한다.
그것은 포인트당 의미 segmentation 맵을 예측하도록 확장할 수 있다[27].
Local Light Field Fusion [29]는 각 장면에 대해 여러 MPI 표현을 추정하고 혼합합니다.
Free View Synthesis [35]는 기하학적 접근법을 사용하여 무한한 야생 장면에서 뷰 합성을 개선합니다.
NeRF++[53]는 또한 여러 NeRF 모델을 사용하고 NeRF의 매개 변수화를 변경하여 무한 장면을 개선한다.
Semantic representation learning
심층 supervised 및 unsupervised 접근법을 사용한 표현 학습은 오랜 역사를 가지고 있다[1].
레이블이 없으면 생성 모델은 인식을 위한 유용한 표현을 학습할 수 있지만 [4] CPC와 같은 self-supervised 모델이 매개 변수 효율성이 더 높은 경향이 있다.
CLIP를 포함한 대조적 방법은 캡션 및 이미지[33, 21], 이미지의 확대 변형 [5] 또는 프레임에 걸친 비디오 패치와 같은 유사한 항목 쌍을 일치시켜 시각적 표현을 학습한다[18].
8. Conclusions
우리의 결과는 단일 뷰 2D 표현이 볼륨 새로운 뷰 합성과 같은 어렵고 제한되지 않은 3D 재구성 문제로 효과적으로 전달된다는 것을 시사한다.
사전 학습된 이미지 인코더 표현은 미세 조정을 통해 과거에 3D 비전 애플리케이션으로 확실히 이전되었지만, 최근 CLIP와 같은 거대한 100M 이상의 이미지 데이터 세트에 대해 학습된 시각적 모델의 등장으로 놀라울 정도로 효과적인 퓨샷 전이가 가능해졌다.
우리는 이 전달 가능한 prior 지식을 활용하여 최적화 문제를 해결하고 NeRF 장면 표현 제품군의 부분적인 관찰 가능성에 대처하여 지각 품질의 눈에 띄는 개선을 제공하였다.
향후, 우리는 "diet-friendly" 퓨샷 전이가 광범위한 3D 애플리케이션에서 더 큰 역할을 할 것이라고 믿는다.