2023. 3. 8. 17:29ㆍView Synthesis
GIRAFFE: Representing Scenes as Compositional Generative Neural Feature Fields
Michael Niemeyer, Andreas Geiger
Abstract
심층 생성 모델은 고해상도에서 사진사실적인 이미지 합성을 가능하게 한다.
그러나 많은 애플리케이션의 경우 이만으로는 충분하지 않습니다: 콘텐츠 제작 또한 제어 가능해야 합니다.
최근 여러 연구에서 데이터 변동의 근본적인 요인을 분리하는 방법을 조사하고 있지만 대부분 2D로 작동하므로 우리 세계가 3차원이라는 것을 무시한다.
또한 장면의 구성적 특성을 고려한 작품은 거의 없다.
우리의 핵심 가설은 구성적인 3D 장면 표현을 생성 모델에 통합하면 더 제어 가능한 이미지 합성으로 이어진다는 것이다.
장면을 구성 생성 신경 피쳐 필드로 표현하면 별도의 supervision 없이 비정형 및 unposed 이미지 컬렉션에서 학습하면서 배경뿐만 아니라 개별 개체의 모양과 모양에서 하나 또는 여러 개체를 분리할 수 있다.
이 장면 표현을 신경 렌더링 파이프라인과 결합하면 빠르고 현실적인 이미지 합성 모델이 생성된다.
우리의 실험에서 증명되었듯이, 우리의 모델은 개별 물체를 분리할 수 있고 카메라 포즈를 변경할 뿐만 아니라 장면에서 그것들을 이동하고 회전시킬 수 있다.
1. Introduction
사진 사실적인 이미지 콘텐츠를 생성하고 조작하는 능력은 컴퓨터 비전과 그래픽스의 오랜 목표이다.
현대의 컴퓨터 그래픽 기술은 인상적인 결과를 달성하고 게임과 영화 제작에서 업계 표준입니다.
그러나 하드웨어 비용이 많이 들고 3D 콘텐츠를 만들고 배열하는 데 상당한 인력이 필요하다.
최근 몇 년 동안 컴퓨터 비전 커뮤니티는 매우 사실적인 이미지 생성을 향해 큰 발전을 이루었다.
특히, Generative Adversarial Networks (GANs)[24]는 강력한 생성 모델 클래스로 부상했다.
그들은 1024^2 픽셀의 해상도와 [6,14,15,39,40] 이상의 사진 사실적인 이미지를 합성할 수 있다.
이러한 성공에도 불구하고, 현실적인 2D 이미지를 합성하는 것이 생성 모델의 응용에서 필요한 유일한 측면은 아니다.
생성 프로세스도 간단하고 일관된 방식으로 제어할 수 있어야 합니다.
이를 위해 많은 연구[9, 25, 39, 43, 44, 48, 54, 71, 74, 97, 98]에서는 명시적인 supervision 없이 데이터에서 분리된 표현을 학습할 수 있는 방법을 조사한다.
분리의 정의는 다양하지만 [5, 53], 일반적으로 다른 속성을 변경하지 않고 관심 있는 속성(예: 물체 모양, 크기 또는 포즈)을 제어할 수 있는 것을 의미한다.
그러나 대부분의 접근 방식은 장면의 구성적 특성을 고려하지 않으며 우리의 세계가 3차원이라는 것을 무시하고 2D 영역에서 작동한다.
이는 종종 복잡한 표현으로 이어지며(그림 2) 제어 메커니즘은 내장되어 있지 않지만, 후방의 잠재 공간에서 발견될 필요가 있다.
그러나 이러한 속성은 복잡한 객체 궤적이 일관된 방식으로 생성되어야 하는 영화 제작과 같은 성공적인 응용 프로그램에 중요하다.

따라서 최근의 여러 연구는 복셀[32,63,64], primitives [46] 또는 radiance fields [77]와 같은 3D 표현을 생성 모델에 직접 통합하는 방법을 조사한다.
이러한 방법은 제어 기능이 내장된 인상적인 결과를 허용하지만, 대부분 단일 객체 장면으로 제한되며 결과는 더 높은 해상도와 더 복잡하고 사실적인 이미지(예: 가운데에 없는 물체가 있거나 배경이 어수선한 장면)에 대해 덜 일관적이다.
Contribution:
본 연구에서는 raw 비정형 이미지 컬렉션에서 학습하는 동안 제어 가능하고 사진 사실적인 방식으로 장면을 생성하는 새로운 방법인 GIRAFFE를 소개한다.
우리의 핵심 통찰력은 두 가지입니다:
첫째, 구성적 3D 장면 표현을 생성 모델에 직접 통합하면 보다 제어 가능한 이미지 합성이 가능해진다.
둘째, 이 명시적인 3D 표현을 신경 렌더링 파이프라인과 결합하면 추론이 더 빨라지고 더 사실적인 이미지를 얻을 수 있다.
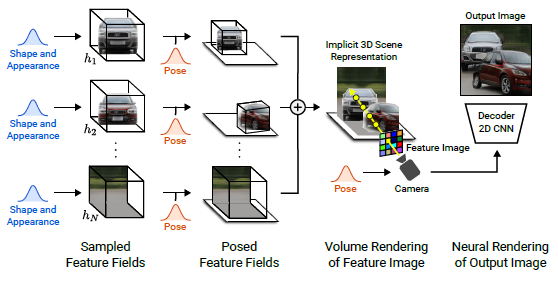
이를 위해 장면을 구성 생성 신경 피쳐 분야로 표현한다(그림 1).
우리는 시간과 계산을 절약하기 위해 장면을 비교적 낮은 해상도의 피처 이미지로 볼륨 렌더링한다.
신경 렌더러는 이러한 피쳐 이미지들을 처리하고 최종 렌더링을 출력한다.
이러한 방식으로, 우리의 접근 방식은 고품질 이미지를 달성하고 실제 장면으로 확장된다.
우리는 우리의 방법이 raw 비정형 이미지 컬렉션에 대해 학습될 때 다중 객체 장면뿐만 아니라 단일 객체의 제어 가능한 이미지 합성을 허용한다는 것을 발견했다.
2. Related Work
GAN-based Image Synthesis:
Generative Adversarial Networks (GANs) [24]는 1024^2 픽셀 해상도와 [6, 14, 15, 39, 40] 이상에서 사진 사실적인 이미지 합성을 허용하는 것으로 나타났다.
합성 과정에 대한 더 나은 제어를 얻기 위해, 많은 연구는 명시적인 supervision 없이 변동 요인이 어떻게 분리될 수 있는지 조사한다.
그들은 학습 objective [9, 40, 71] 또는 네트워크 아키텍처[39]를 수정하거나 잘 설계되고 사전 학습된 생성 모델의 잠재 공간을 조사한다[1, 16, 23, 27, 34, 78, 96].
그러나 이 모든 작품이 장면의 구성적 특성을 명시적으로 모델링하지는 않는다.
따라서 최근 연구는 합성 프로세스가 객체 수준에서 어떻게 제어될 수 있는지 조사한다[3,4,7,18,19,26,45,86,90].
앞서 언급한 모든 작품은 사진 사실적인 결과를 달성하면서도 우리 세계의 3차원 구조를 무시하고 이미지 형성 과정을 2D로 모델링한다.
이 연구에서, 우리는 더 나은 분리와 더 제어 가능한 합성을 위해 형성 과정을 3D로 직접 모델링하는 것을 지지한다.
Implicit Functions:
암시적 함수를 사용하여 3D 기하학을 표현하는 것은 학습 기반 3D 재구성[11, 12, 22, 59, 60, 65, 67, 69, 76]에서 인기를 얻었으며 장면 수준 재구성[8, 13, 35, 72, 79]으로 확장되었다.
3D supervision의 필요성을 극복하기 위해 여러 연구[50, 51, 66, 81, 92]에서 미분 가능한 렌더링 기술을 제안한다.
Mildenhall et al.[61]은 복잡한 장면의 새로운 뷰 합성을 위해 암시적 신경 모델과 볼륨 렌더링을 결합하는 Neural Radiance Fields (NeRF)를 제안한다.
표현력 때문에 NeRF의 생성적 변형을 객체 수준 표현으로 사용한다.
우리의 방법과 달리, 논의된 작업은 카메라 포즈를 supervision으로 하는 다중 뷰 이미지를 필요로 하며, 장면당 단일 네트워크를 학습시키고, 새로운 장면을 생성할 수 없다.
대신, 우리는 생성된 장면의 제어 가능하고 사진 사실적인 이미지 합성을 가능하게 하는 비정형 이미지 컬렉션에서 생성 모델을 학습한다.
3D-Aware Image Synthesis:
여러 연구는 3D 표현이 어떻게 생성 모델에 귀납적 편향으로 통합될 수 있는지 조사한다[21,29–32,46,55,63,64,75,77].
많은 접근 방식이 추가적인 supervision[2, 10, 87, 88, 99]을 사용하지만, 우리는 우리의 접근 방식과 같은 raw 이미지 컬렉션에 대해 학습된 작업에 초점을 맞춘다.
Henzler et al. [32]은 미분 가능한 렌더링을 사용하여 복셀 기반 표현을 학습한다.
결과는 3D 제어가 가능하지만 입방 메모리 성장으로 인한 복셀 해상도 제한으로 인한 아티팩트를 보여준다.
Nguyen-Phuoc et al. [63, 64]은 재구성 작업을 통해 2D로 렌더링되는 복셀화된 피처 그리드 표현을 제안한다.
인상적인 결과를 달성하는 동안, 학습은 안정성이 떨어지고 고해상도에서는 일관성이 떨어진다.
Liao et al. [46]은 추상적인 피쳐를 원시적이고 미분 가능한 렌더링과 결합하여 사용한다.
다중 객체 장면을 처리하는 동안 실제 장면에서는 얻기 어려운 순수 배경 이미지 형태의 추가 supervision이 필요하다.
Schwarz et al. [77]은 Generative Neural Radiances Fields (GRAF)을 제안한다.
고해상도에서 제어 가능한 이미지 합성을 달성하는 동안, 이 표현은 단일 객체 장면으로 제한되며 더 복잡한 실제 이미지에서 결과가 저하된다.
대조적으로, 우리는 구성적 3D 장면 구조를 생성 모델에 통합하여 다중 객체 장면을 자연스럽게 처리한다.
또한 신경 렌더링 파이프라인[20, 41, 42, 49, 62, 80, 81, 83, 84]을 통합하여 모델을 보다 복잡한 실제 데이터로 확장한다.
3. Method
우리의 목표는 추가 supervision 없이 raw 이미지 컬렉션에서 학습할 수 있는 제어 가능한 이미지 합성 파이프라인이다.
다음에서는 우리 방법의 주요 구성 요소에 대해 논의한다.
먼저, 우리는 개별 객체를 신경 피쳐 필드로 모델링한다(섹션 3.1).
다음으로, 피처 필드의 추가 속성을 활용하여 여러 개별 객체의 합성 장면을 만든다(섹션 3.2).
렌더링을 위해 볼륨 및 신경 렌더링 기술의 효율적인 조합을 탐구한다(섹션 3.3).
마지막으로 raw 이미지 컬렉션에서 모델을 학습하는 방법에 대해 논의한다(섹션 3.4).
그림 3은 우리의 방법에 대한 개요를 포함한다.
3.1. Objects as Neural Feature Fields
Neural Radiance Fields:
radiance field는 3D 점 x ∈ R^3과 뷰 방향 d ∈ S^2를 체적 밀도 σ ∈ R+와 RGB 색 값 c ∈ R^3에 매핑하는 연속 함수 f이다.
[61, 82]의 핵심적인 관찰은 f가 신경망으로 매개변수화될 때 복잡한 신호를 표현할 수 있도록 저차원 입력 x와 d가 고차원 피쳐에 매핑될 필요가 있다는 것이다.
더 구체적으로, 사전 정의된 위치 인코딩은 x와 d의 각 구성 요소에 요소별로 적용된다:
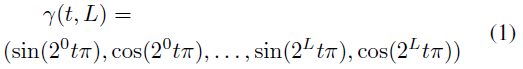
, 여기서 t는 스칼라 입력이며, 예를 들어 x 또는 d의 성분이며, L은 주파수 옥타브의 개수이다.
생성 모델의 맥락에서, 우리는 이 표현의 추가적인 이점을 관찰한다: 그것은 귀납적 편향을 도입하여, 그렇지 않으면 임의적일 수 있는 표준 방향으로 3D 형상 표현을 학습한다(그림 11 참조).
암묵적인 형태 표현[12, 59, 69]에 이어, Mildenhall et al. [61]은 다층 퍼셉트론(MLP)으로 f를 매개 변수화하여 Neural Radiance Fields (NeRFs)를 학습할 것을 제안한다:
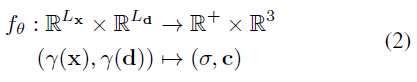
, 여기서 θ는 네트워크 매개 변수와 위치 인코딩의 출력 차원을 나타낸다.
Generative Neural Feature Fields:
[61]이 θ를 단일 장면의 여러 포즈 이미지에 적합한 반면, Schwarz et al. [77]은 unposed 이미지 컬렉션에서 학습된 a generative model for Neural Radiance Fields (GRAF)를 제안한다.
NeRF의 잠재 공간을 학습하기 위해, 그들은 MLP를 형상 및 외관 코드 z_s, z_a ~ N(0, I)에 조건을 붙인다:
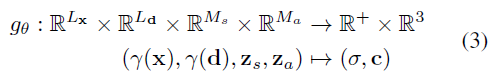
, 여기서 M_s, M_a는 잠재 코드의 차원이다.
이 작업에서 우리는 볼륨과 신경 렌더링의 보다 효율적인 조합을 탐구한다.
우리는 3차원 색상 출력 c에 대한 GRAF의 공식을 보다 일반적인 M_f 차원 피쳐 f로 대체하고 객체를 Generative Neural Feature Fields로 나타낸다:
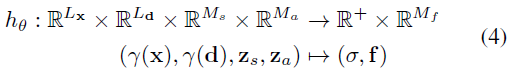
Object Representation:
NeRF와 GRAF의 주요 한계는 전체 장면이 단일 모델로 표현된다는 것이다.
장면에서 서로 다른 개체를 분리하는 데 관심이 있으므로 개별 개체의 포즈, 모양 및 외관에 대한 제어가 필요합니다(배경도 개체로 간주).
따라서 우리는 아핀 변환

과 함께 별도의 피쳐 필드를 사용하여 각 객체를 표현한다, 여기서 s, t ∈ R^3은 척도 및 변환 매개 변수를 나타내고, R ∈ SO(3)는 회전 행렬을 나타낸다.
이 표현을 사용하여 다음과 같이 객체에서 장면 공간으로 점을 변환한다:
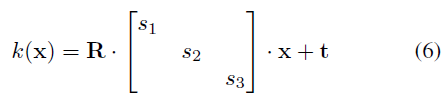
실제로 우리는 장면 공간에서 볼륨 렌더링을 하고 표준 객체 공간에서 피쳐 필드를 평가한다(그림 1 참조):
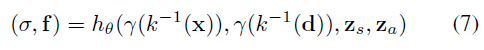
이를 통해 한 장면에 여러 개체를 배열할 수 있습니다.
모든 객체 피처 필드는 가중치를 공유하며 T는 데이터 세트 종속 분포에서 샘플링된다(섹션 3.4 참조).
3.2. Scene Compositions
위에서 논의한 바와 같이, 우리는 첫 번째 N - 1이 장면의 객체이고 마지막 N이 배경을 나타내는 N개의 엔티티의 구성으로 장면을 설명한다.
우리는 두 가지 경우를 고려한다:
첫째, N은 이미지에 항상 N - 1 개체와 배경이 포함되도록 데이터 세트에 걸쳐 고정된다.
둘째, N은 데이터 세트 전체에 걸쳐 변화한다.
실제로, 우리는 전체 장면에 걸쳐지고 장면 공간 원점에서 중심이 되도록 스케일 및 변환 매개 변수 s_N, t_N을 고정하는 것을 제외하고 객체의 경우와 동일한 배경 표현을 사용한다.
Composition Operator:
합성 연산자 C를 정의하기 위해, 단일 엔티티 h_(θ_i)^i의 피처 필드가 주어진 점 x와 뷰 방향 d에 대한 밀도 σ_i ∈ R+와 피처 벡터 f_i ∈ R^(M_f)를 예측한다는 것을 상기하자.
비고체 물체를 결합할 때, x에서 전체 밀도에 대한 자연스러운 선택[17]은 개별 밀도를 합하고 밀도 가중 평균을 사용하여 (x; d)에서 모든 피쳐를 결합하는 것이다:
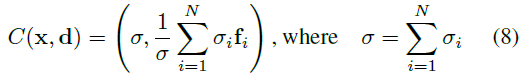
C에 대한 이 선택은 간단하고 직관적이지만 다음과 같은 추가적인 이점이 있습니다: 밀도가 0보다 큰 모든 엔티티에 그레디언트 flow를 보장합니다.
3.3. Scene Rendering
3D Volume Rendering:
이전 연구[47, 57, 61, 77] 볼륨이 RGB 색상 값을 렌더링하는 동안, 우리는 이 공식을 M_f 차원 피처 벡터 f를 렌더링하는 것으로 확장한다.
주어진 카메라 extrinsics ξ의 경우, {x_j}_(j=1)^가 주어진 픽셀에 대해 카메라 ray를 따라 샘플 포인트가 되고 (σ_j, f_j) = C(x_j, d) 해당 밀도와 필드의 피쳐 벡터가 된다고 가정하자.
볼륨 렌더링 연산자 π_vol [37]은 이러한 평가를 픽셀의 최종 피쳐 벡터 f에 매핑합니다:
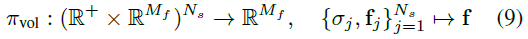
[61]에서와 같이 수치적 통합을 사용하여 f를
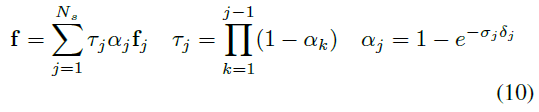
로 구합니다, 여기서 τ_j는 투과율, α_j는 x_j의 알파 값, δ_j = |x_(j+1) - x_j| 인접한 샘플 포인트 사이의 거리.
모든 픽셀에서 π_vol을 평가하여 전체 피쳐 이미지를 얻는다.
효율성을 위해 64^2 또는 256^2 픽셀의 출력 해상도보다 낮은 해상도 16^2로 피처 이미지를 렌더링한다.
그런 다음 2D 신경 렌더링을 사용하여 저해상도 피쳐 맵을 고해상도 RGB 이미지로 업샘플링한다.
우리의 실험에서 증명되었듯이, 이것은 두 가지 이점이 있다: 렌더링 속도 향상 및 이미지 품질 향상.
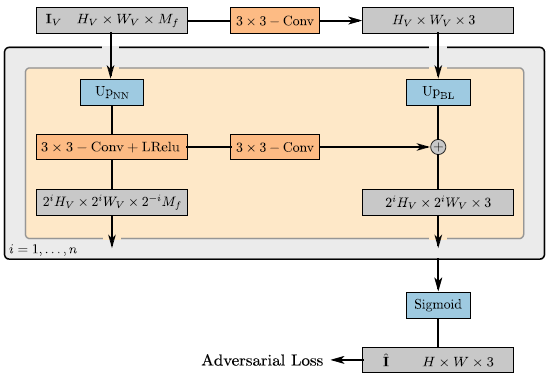
2D Neural Rendering:
가중치 θ를 가진 신경 렌더링 연산자
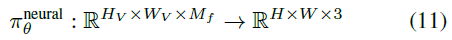
는 피처 이미지 I_V ∈ R^(H_V x W_V x M_f)를 최종 합성 이미지 ^I ∈ R^(H x W x 3)에 매핑한다.
우리는 π_θ^neural을 leaky ReLU[56, 89] 활성화(그림 4)가 있는 2D 컨볼루션 신경망(CNN)으로 매개 변수화하고 가장 가까운 이웃 업샘플링을 3x3 컨볼루션과 결합하여 공간 해상도를 높인다.
우리는 작은 커널 크기와 중간 계층이 없는 것을 선택하여 이미지 합성 중에 전역 장면 속성이 얽히지 않도록 공간적으로 작은 정교함만 허용하는 동시에 출력 해상도를 증가시킨다.
[40]에서 영감을 받아 모든 공간 해상도에서 피쳐 이미지를 RGB 이미지에 매핑하고 이중 선형 업샘플링을 통해 이전 출력을 다음 출력에 추가한다.
이러한 건너뛰기 연결은 피쳐 필드에 대한 강력한 그래디언트 flow를 보장한다.
우리는 마지막 RGB 레이어에 시그모이드 활성화를 적용하여 최종 이미지 예측 ^I를 얻는다.
우리는 ablation 연구(표 4)에서 우리의 설계 선택을 검증한다.
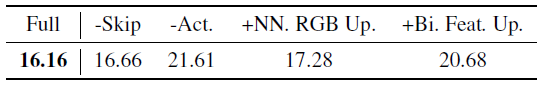
3.4. Training
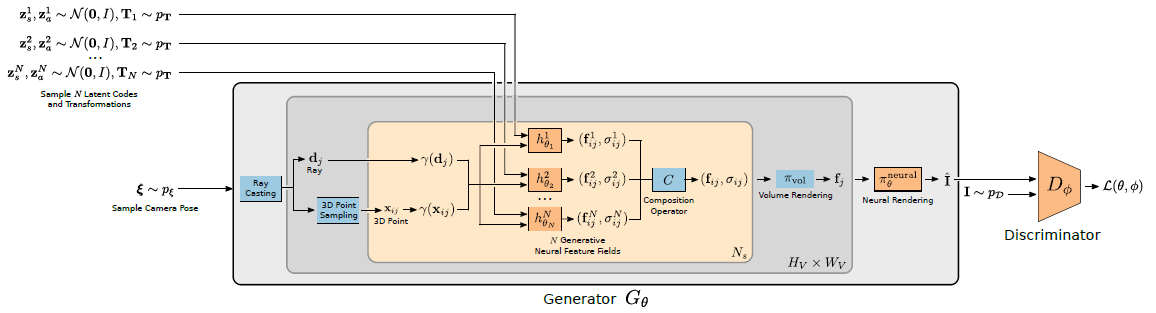
Generator:
우리는 공식적으로 전체 생성 프로세스를
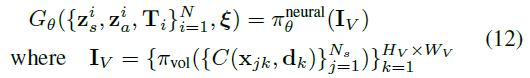
로 나타내며 N은 장면의 엔티티 수, N_s는 각 ray를 따르는 샘플 포인트 수, d_k는 k번째 픽셀에 대한 ray, x_jk는 k번째 pixel/ray에 대한 j번째 샘플 포인트이다.
Discriminator:
우리는 판별기 D_ɸ를 Leaky ReLU 활성화가 있는 CNN[73]으로 매개 변수화한다.
Training:
학습 중, 우리는 장면 N ~ p_N의 엔티티 수, 잠재 코드 z_s^i, z_a^i ~ N(0, I), 카메라 포즈 ξ ~ p_ξ 및 객체 수준 변환 T_i ~ p_T를 샘플링한다.
실제로, 우리는 p_ξ와 p_T를 각각 데이터 세트 의존 카메라 고도 각도와 유효한 객체 변환에 대한 균일한 분포로 정의한다.
이러한 선택의 동기는 대부분의 실제 장면에서 물체가 임의로 회전하지만 중력 때문에 기울어지지 않기 때문이다.
대조적으로 관찰자(우리의 경우 카메라)는 장면에 대한 고도 각도를 자유롭게 변경할 수 있다.
우리는 비포화 GAN objective [24]와 R1 그레디언트 페널티[58]로 모델을 학습한다:
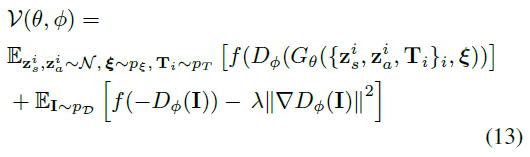
, 여기서 f(t) = -log(1 + exp(-t)), λ = 10, p_D는 데이터 분포를 나타냅니다.
3.5. Implementation Details
모든 객체 피처 필드 {h_(θ_i)^i}_(i=1)^N는 가중치를 공유하며 ReLU 활성화를 통해 MLP로 매개 변수화한다.
우리는 숨겨진 차원이 128이고 밀도와 피쳐 헤드가 각각 차원 1과 M_f = 128인 8개의 레이어를 사용한다.
배경 피처 필드 h_(θ_N)^N의 경우, 우리는 절반의 레이어와 숨겨진 차원을 사용한다.
위치 인코딩에는 L_x = 2·3·10 및 L_d = 2·3·4를 사용합니다.
우리는 각 ray를 따라 M_s = 64 포인트를 샘플링하고 16^2 픽셀에서 피처 이미지 I_V를 렌더링한다.
우리는 생성기의 가중치에 대해 감쇠가 0.999인 지수 이동 평균[93]을 사용한다.
우리는 판별기와 생성기에 각각 배치 크기가 32이고 학습률이 1x10^-4와 5x10^-4인 RMSprop 최적화기[85]를 사용한다.
256^2 픽셀에서의 실험을 위해, 우리는 M_f = 256과 생성기 학습률의 절반을 2.5x10^-4로 설정한다.
4. Experiments
Datasets:
우리는 일반적으로 사용되는 단일 객체 데이터 세트 Chairs[68], Cats[95], CelebA[52] 및 CelebA-HQ[38]에 대한 결과를 보고한다.
첫 번째는 Photoshape Chairs[70]의 합성 렌더링으로 구성되며, 다른 것들은 각각 Cats와 human face의 이미지 컬렉션이다.
배경이 순수하게 흰색이거나 이미지의 작은 부분만 차지하기 때문에 데이터 복잡성이 제한됩니다.
우리는 더 까다로운 단일 객체, 실제 데이터 세트 CompCars[91], LSUN Churchs[94] 및 FFHQ[39]에 대한 결과를 추가로 보고한다.
CompCars의 경우 이미지에서 개체의 위치를 더 다양하게 만들기 위해 이미지를 랜덤으로 자른다.
이러한 데이터 세트의 경우 객체가 항상 중앙에 있는 것은 아니며 배경이 더 어수선하고 이미지의 더 큰 부분을 차지하기 때문에 객체를 분리하는 것이 더 복잡하다.
다중 객체 장면에서 모델을 테스트하기 위해 [36]의 스크립트를 사용하여 2, 3, 4 또는 5개의 랜덤 원시 요소(Clevr-N)가 있는 장면을 렌더링한다.
다양한 수의 객체가 있는 장면에서 모델을 테스트하기 위해, 우리는 또한 그들의 조합에서 모델을 실행한다(Clevr-2345).
Baselines:
우리는 복셀 기반 PlatonicGAN[32], BlockGAN[64], HoloGAN[63] 및 radiance field 기반 GRAF[77]와 비교한다(방법에 대한 논의는 섹션 2 참조).
우리는 또한 더 높은 해상도를 위해 [77]에서 제안된 [63]의 변형인 3D Conv가 없는 HoloGAN과 비교한다.
참고를 위해 ResNet 기반 [28] 2D GAN [58]을 추가로 보고한다.
Metrics:
우리는 이미지 품질을 정량화하기 위해 Frechet Inception Distance (FID) 점수[33]를 보고한다.
우리는 FID 점수를 계산하기 위해 20,000개의 실제 샘플과 가짜 샘플을 사용한다.
4.1. Controllable Scene Generation
Disentangled Scene Generation:
우리는 먼저 우리 모델이 어느 정도까지 엉킨 장면 표현을 학습하는지 분석한다.
특히, 우리는 배경에서 물체가 분리되는지 여부에 관심이 있다.
이 목표를 위해, 우리는 우리의 구성 연산자가 단순한 추가 연산(식 8)이라는 사실을 활용하고 개별 구성 요소와 객체 알파 맵(식 10)을 렌더링한다.
우리는 학습 중에 항상 피쳐 이미지를 16^2로 렌더링하지만, 테스트 시간에 임의의 해상도를 선택할 수 있다.

그림 5는 우리의 방법이 배경에서 객체를 분리하는 것을 제안한다.
이 분리는 아무런 supervision 없이 나타나며, 모델은 순수한 배경 이미지를 보지 않고 그럴듯한 배경을 생성하는 법을 학습하여 암묵적으로 인페인팅 작업을 해결한다.
우리는 또한 우리의 모델이 고정되거나 다양한 수의 객체가 있는 다중 객체 장면에서 학습될 때 개별 객체를 올바르게 분리한다는 것을 관찰한다.
우리는 또한 unsupervised 분리가 학습의 맨 처음에 이미 나타나는 우리 모델의 속성이라는 것을 발견한다(그림 6).
우리 모델이 배경을 표현하는 데 용량을 소비하기 전에 개별 객체를 합성하는 방법에 주목하십시오.

Controllable Scene Generation:
장면의 개별 구성 요소가 올바르게 분리되어 있기 때문에, 우리는 그것들이 얼마나 잘 제어될 수 있는지 분석한다.
더 구체적으로, 우리는 개별 물체가 회전하고 이동될 수 있는지뿐만 아니라 모양과 외관을 얼마나 잘 제어할 수 있는지도 관심이 있다.
그림 7에서는 이미지 합성 시 장면을 제어하는 예를 보여준다.
우리는 개별 물체를 회전시키거나, 3D 공간에서 그것들을 번역하거나, 카메라 고도를 변경한다.
서로 다른 잠재 코드로 각 엔티티의 모양과 외관을 모델링하여 모양을 변경하지 않고 개체의 모양을 추가로 변경할 수 있다.

Generalization Beyond Training Data:
학습된 구성 장면 표현을 통해 학습 분포 외부에서 일반화할 수 있다.
예를 들어, 우리는 객체의 이동 범위를 늘리거나 학습 데이터에 존재했던 것보다 더 많은 객체를 추가할 수 있다(그림 8).

4.2. Comparison to Baseline Methods
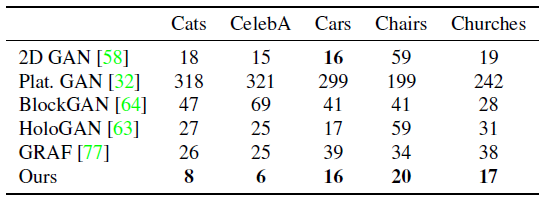
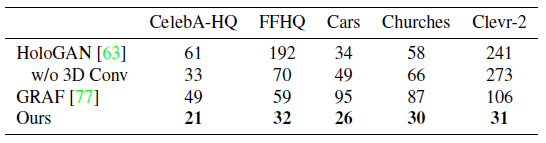
베이스라인 방법과 비교하여, 우리의 방법은 64^2(표 1) 및 256^2(표 2) 픽셀 해상도 모두에서 유사하거나 더 나은 FID 점수를 달성한다.
질적으로, 우리는 모든 접근 방식이 제한된 복잡성의 데이터 세트에서 제어 가능한 이미지 합성을 허용하지만, 배경이 어수선한 더 복잡한 장면에서 베이스라인 방법에 대한 결과는 덜 일관적이라는 것을 관찰한다.
또한, 우리의 모델은 배경에서 객체를 분리하여 배경과 독립적으로 객체를 제어할 수 있다(그림 9).

또한 우리는 우리 모델이 더 적은 네트워크 매개 변수(1.69m에 비해 0.41m)에도 불구하고 ResNet 기반 2D GAN[58]과 유사하거나 더 나은 FID 점수를 달성한다는 점에 주목한다.
이것은 3D 표현을 귀납적 편향으로 사용하는 것이 더 나은 출력을 낳는다는 우리의 초기 가설을 확인시켜준다.
공정한 비교를 위해 네트워크 크기 및 학습 시간과 관련하여 유사한 방법만 보고합니다(표 3 참조).

4.3. Ablation Studies
Importance of Individual Components:
표 4의 ablation 연구는 RGB 스킵 연결, 최종 활성화 함수 및 선택된 업샘플링 유형의 설계 선택이 결과를 향상시키고 더 높은 FID 점수로 이어진다는 것을 보여준다.
Effect of Neural Renderer:
[77]과의 주요 차이점은 볼륨을 신경 렌더링과 결합한다는 것입니다.
양적 비교(표 1과 2)와 질적 비교(그림 9)는 우리의 접근 방식이 특히 복잡한 실제 데이터의 경우 더 나은 결과로 이어진다는 것을 나타낸다.
우리의 모델은 더 표현력이 풍부하고 실제 장면의 복잡성을 더 잘 처리할 수 있다.
예를 들어 신경 렌더러가 어떻게 물체의 모습을 배경에 현실적으로 적용하는지 주목한다(그림 10).
또한 렌더링 속도가 빨라지는 것을 관찰할 수 있습니다:
[77]과 비교하여, 64^2 및 256^2 픽셀의 총 렌더링 시간은 각각 110.1ms에서 4.8ms로, 1595.0ms에서 5.9ms로 단축됩니다.

Positional Encoding:
입력 지점 및 뷰 방향에 대해 축 정렬 위치 인코딩을 사용합니다(식 1).
놀랍게도, 이것은 모델이 가장 높은 대칭을 가진 객체 축을 표준 축과 정렬하는 편향을 도입하여 모델이 객체 대칭을 활용할 수 있도록 하기 때문에 표준 표현을 학습하도록 장려한다(그림 11).

4.4. Limitations
Dataset Bias:
우리의 방법은 데이터에 고유한 편향이 있는 경우 변동 요인을 분리하는 데 어려움을 겪는다.
우리는 그림 12에 예시를 보여준다: celebA-HQ 데이터 세트에서 눈과 머리 방향은 얼굴 회전에 관계없이 주로 카메라를 향하고 있다.
물체를 회전할 때 생성된 이미지의 눈과 머리카락은 고정된 상태를 유지하지 않고 데이터 세트 편향을 충족하도록 조정된다.

Object Transformation Distributions:
우리는 때때로 분리 실패를 관찰한다, 예를 들어 배경에 교회가 포함된 교회 또는 전경에 배경 요소가 포함된 CompCar의 경우이다(보충 자료 참조).
우리는 이것들이 카메라 포즈와 객체 수준 변환에 대한 가정된 균일한 분포와 실제 분포 사이의 불일치 때문이라고 본다.
5. Conclusion
우리는 제어 가능한 이미지 합성을 위한 새로운 방법인 GIRAFFE를 제시한다.
우리의 핵심 아이디어는 구성적인 3D 장면 표현을 생성 모델에 통합하는 것이다.
장면을 구성 생성 신경 피쳐 필드로 표현함으로써, 우리는 명시적인 supervision 없이 개별 객체뿐만 아니라 모양과 외관을 배경에서 분리한다.
이것을 신경 렌더러와 결합하면 빠르고 제어 가능한 이미지 합성이 가능해진다.
향후, 우리는 데이터에서 객체 수준 변환과 카메라 포즈에 대한 분포를 어떻게 학습할 수 있는지 조사할 계획이다.
또한, 예측된 객체 마스크와 같이 얻기 쉬운 supervision을 통합하는 것은 더 복잡한 다중 객체 장면으로 확장하는 유망한 접근법이다.