2023. 3. 10. 12:10ㆍView Synthesis
DiffRF: Rendering-Guided 3D Radiance Field Diffusion
Norman M¨uller, Yawar Siddiqui, Lorenzo Porzi, Samuel Rota Bul`o, Peter Kontschieder, Matthias Nießner
Abstract
denoising diffusion probabilistic models을 기반으로 한 3D radiance field 합성을 위한 새로운 접근법인 DiffRF를 소개한다.
기존 diffusion 기반 방법은 이미지, 잠재 코드 또는 포인트 클라우드 데이터에서 작동하지만, 부피 radiance fields를 직접 생성한 것은 우리가 처음이다.
이를 위해 명시적 복셀 그리드 표현에서 직접 작동하는 3D 디노이징 모델을 제안한다.
그러나 포즈 이미지 세트에서 생성된 radiance fields는 모호하고 아티팩트를 포함할 수 있으므로 ground truth radiance fields 샘플을 얻는 것은 중요하지 않다.
디노이징 공식을 렌더링 loss와 결합하여 이 문제를 해결하여 모델이 부동 아티팩트와 같은 적합 오류를 복제하는 대신 양호한 이미지 품질을 선호하는 편향된 사전 학습을 가능하게 한다.
2D diffusion 모델과 달리, 우리 모델은 다중 뷰 일관성 있는 priors를 학습을 통해 자유 뷰 합성과 정확한 형상 생성을 가능하게 한다.
3D GAN에 비해 우리의 diffusion 기반 접근 방식은 추론 시 마스크 완료 또는 단일 뷰 3D 합성과 같은 조건부 생성을 자연스럽게 가능하게 한다.
1. Introduction
최근 몇 년 동안, Neural Radiance Fields (NeRFs)[34]는 포즈를 취한 2D 입력 이미지에서 개별 3D 장면을 맞추기 위한 강력한 표현으로 등장했다.
기본 3D 장면 기하학을 존중하면서 임의의 관점에서 새로운 뷰를 사진 사실적으로 합성할 수 있는 능력은 AR/VR, 게임, 매핑, 탐색 등과 같은 애플리케이션을 중단하고 변형시킬 수 있는 잠재력을 가지고 있다.
최근의 많은 연구는 NeRF를 더 정교하게 만들기 위한 확장을 도입했다, 예를 들어, 장면 의미론을 통합하는 방법을 보여준다[15, 27], 이기종 데이터 소스의 학습 모델을 보여준다[32], 또는 대규모 장면을 나타내도록 확장한다[57, 59].
이러한 발전은 ML 기반 장면 표현의 다용성에 대한 증거이다; 그러나 여전히 입력 학습 데이터 이상으로 일반화하기보다는 특정 개별 장면에 적합하다.
대조적으로, 단일 이미지 3D 객체 생성[5, 36, 46, 60, 65] 및 제한되지 않은 장면 탐색과 같은 응용 프로그램을 가능하게 함에도 불구하고, 여러 객체 범주로 일반화하거나 데이터 세트에 걸쳐 장면에 대한 prior를 학습하는 신경 필드 표현은 현재까지 훨씬 제한적으로 보인다.
이러한 방법은 물체를 모양 및 외관 기반 구성 요소로 분리하거나, 장면 생성 품질을 향상시키기 위해 radiance fields를 여러 개의 작고 로컬적인 radiance fields로 분해하는 방법을 탐구한다; 그러나 그 결과는 여전히 사진 사실적 및 기하학적 정확도와 관련하여 상당한 격차를 두고 있다.
2D 도메인에서 3D 인식 신경 필드 생성으로 확장된 generative adversarial networks (GAN)와 관련된 방향은 인상적인 합성 결과를 보여주고 있다[6].
일반 2D GAN과 마찬가지로 학습 objective는 합성된 3D radiance field를 렌더링하여 얻은 2D 이미지를 식별하는 것을 기반으로 한다.
동시에 diffusion 기반 모델[48]은 최근 컴퓨터 비전 연구 커뮤니티를 강타하여 여러 2D 벤치마크에서 동등하거나 심지어 GAN을 능가하는 성능을 발휘하고 있으며 실제 사진과 거의 구별할 수 없는 사진 사실적인 이미지를 생성하고 있다.
text-to image 합성과 같은 멀티 모달 또는 조건부 설정의 경우, 우리는 현재 diffusion 기반 접근법에서 전례 없는 출력 품질과 다양성을 관찰한다.
몇몇 연구는 순전히 기하학적 표현[30, 68]을 다루지만, denoising-diffusion 공식을 3D 부피 radiance fields로 직접 올리는 것은 여전히 어려운 일이다.
주된 이유는 노이즈 벡터와 해당 ground truth 샘플 간의 일대일 매핑이 필요한 diffusion 모델의 특성에 있다.
radiance fields의 맥락에서, 그러한 체적 ground truth 데이터는 비용이 많이 드는 샘플당 NeRF 최적화를 실행하더라도 불완전하고 불완벽한 radiance fields 재구성을 초래하기 때문에 실제로 얻기가 불가능하다.
본 연구에서는 3D radiance fields를 직접 합성하여 모양과 외관 모두에 대한 고품질 3D 자산 생성을 잠금 해제하는 최초의 diffusion 기반 생성 모델을 제시한다.
우리의 목표는 각 샘플이 포즈된 RGB 이미지 세트에 의해 제공되는 객체에 걸쳐 학습된 생성 모델을 배우는 것이다.

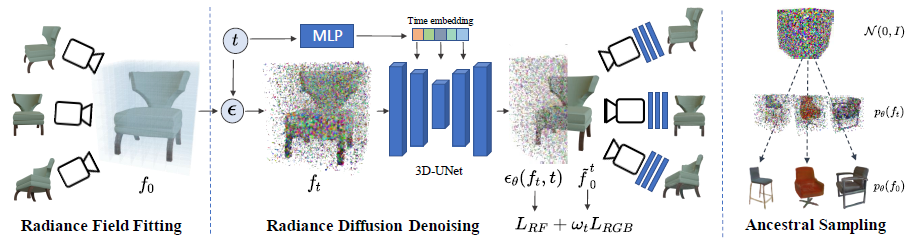
이를 위해 고주파 노이즈 추정치를 생성하는 명시적 복셀 그리드 표현(그림 1, 왼쪽)에서 직접 작동하는 3D 디노이징 모델을 제안한다.
각 학습 샘플에 대한 모호하고 불완전한 radiance fields 표현을 해결하기 위해 노이즈 예측 공식을 Denoising Diffusion Probabilistic Models(DDPM)에서 추정치에 대한 추가 볼륨 렌더링 loss에 의해 더 높은 이미지 품질을 합성하는 쪽으로 편향시킬 것을 제안한다.
이를 통해 우리의 방법은 샘플링 프로세스 중에 적합 아티팩트 또는 노이즈 축적이 덜 발생하기 전에 radiance field priors를 학습할 수 있다.
우리는 우리의 공식이 효율적이고 현실적이며 일관된 렌더링을 생성하는 다양하고 기하학적으로 정확한 radiance field 합성으로 이어진다는 것을 보여준다.
우리가 학습한 diffusion prior는 3D 객체 합성이 다중 뷰 일관된 방식으로 획득되어 고정밀 3D 모양을 생성하고 자유 뷰 합성이 가능한 unconditional 환경에서 적용될 수 있다.
우리는 추론 시간에 radiance field 완료를 위한 conditional masked completion - analog to shape completopm -라는 새로운 작업을 추가로 소개한다.
이 설정에서, 우리는 작업별 모델 적응 또는 학습 없이 부분적으로 마스킹된 객체의 현실적인 3D 완료를 허용한다(그림 1, 오른쪽 참조).
우리는 우리의 기여를 다음과 같이 요약한다:
• 우리가 아는 한, 우리는 3D radiance fields에서 직접 작동하는 최초의 diffusion 모델을 도입하여 고품질의 진실한 3D 기하학 및 이미지 합성을 가능하게 한다.
• 우리는 3D radiance field 마스킹 완료의 새로운 적용을 소개하는데, 이는 이미지 인페인팅을 볼륨 영역으로 자연스럽게 확장한 것으로 해석될 수 있다.
• 우리는 도전적인 PhotoShape Chairs 데이터 세트[41]에서 이미지 품질(FID에서 27.03에서 25.64로)과 기하학적 합성(MMD를 5.86에서 4.26으로 개선)에 대한 GAN 기반 접근 방식을 개선하여 unconditional이고 conditional 설정에서 설득력 있는 결과를 보여준다.
2. Related work
Diffusion models.
생성 diffusion 모델링에 대한 Sohl-Dickstein et al. [48]의 주요 연구 이후, diffusion 과정의 반전을 수행하는 두 가지 클래스의 생성 모델이 제안되었다: Denoising Score Matching (DSM) [49,52,53] 및 Denoising Diffusion Probablistic Models (DDPMs) [20].
Song et al. 의 연구에서 두 가지 접근 방식 모두 Score SDE라는 단일 프레임워크의 맛으로 나타났다[54].
"Diffusion models"이라는 용어는 현재 이 방법들의 모든 것을 포괄하는 이름으로 사용되고 있다.
연구 중인 몇 가지 주요 방향에는 서로 다른 샘플링 체계 [25, 50] 및 노이징 모델 [12, 22], 대체 공식 및 학습 알고리즘[23, 38, 51], 효율성 향상[44]이 포함된다.
현재 연구 결과의 개요는 Karas et al. 이 제공한다[25].
diffusion 모델은 text-to-image 합성 및 guided 합성[33, 37, 42, 44], 3D 형상 생성[4, 30, 67, 68], 분자 예측[31, 58, 62], 비디오 생성[21, 64]과 같은 많은 영역에서 SOTA 결과를 얻기 위해 사용되었다.
흥미롭게도, diffusion 모델은 고해상도 이미지 생성 작업[14, 44]에서 Generative Adversarial Networks (GAN)를 능가하여 conditional 이미지 생성에서 전례 없는 결과를 달성하는 것으로 나타났다[43].
또한, 종종 prone 및 모드 붕괴가 발생하기 쉬운 GAN에 비해 [3,35], 학습 시간이 아직 상대적으로 길지만 diffusion 모델은 학습하기 훨씬 더 쉬운 것으로 관찰되었다.
3D generation.
초기에 2D 이미지 합성을 위해 개발된 적대적 접근법은 3D에서도 성공을 거두었다, 예를 들어 메시[16, 61], 3D 텍스처[47], 복셀화된 표현[8, 18] 또는 Neural Radiance Fields (NeRFs)[5, 6, 17, 39, 46, 69].
특히, 이 마지막 범주의 방법은 최근 몇 년 동안 많은 관심을 받아왔는데, 그 이유는 3D supervision의 어떤 형태도 없이 순수하게 2D 이미지 모음에서 학습될 수 있고, 처음으로 생성된 3D 객체의 사진 사실적인 새로운 뷰 합성을 가능하게 하기 때문이다.
Pi-GAN [5] 및 GRAF [46]는 적대적 loss로 학습된 확률적 조건화의 형태를 추가하여 표준 NeRF [34] 모델이 GAN 설정에서 주조되는 유사한 접근 방식을 제안한다.
이러한 접근 방식은 NeRF 스타일 볼륨 렌더링의 높은 학습 시간 메모리 비용으로 인해 부분적으로 제한되어 저해상도 이미지 패치를 사용해야 한다.
CIPS-3D[69] 및 GIRAFFE[39]는 볼륨 렌더링 구성 요소가 저해상도 2D 피쳐 맵을 출력하도록 하여 이 문제를 해결한 다음 효율적인 컨볼루션 네트워크에 의해 업샘플링되어 최종 이미지를 생성한다.
이 접근 방식은 렌더링된 이미지의 품질과 해상도를 획기적으로 향상시키지만 컨볼루션 단계가 동일한 개체의 다른 뷰를 임의로 다른 방식으로 처리할 수 있기 때문에 3D 불일치도 발생시킨다.
StyleNeRF[17]는 불일치를 최소화하기 위해 컨볼루션 단계를 신중하게 설계하여 부분적으로 이 문제를 해결하는 반면, EG3D[6]는 MLP 기반 NeRF를 컨볼루션 네트워크에서 생성된 경량 3면 체적 모델로 대체하여 학습 효율성을 더욱 향상시킨다.
우리의 방법과 달리, 이러한 GAN 기반 접근 방식은 조건부 합성 또는 완료를 자연스럽게 지원하지 않는다.
GAN에 비해 diffusion 모델은 3D 합성을 위한 도구로서 상대적으로 충분히 탐구되지 않지만, 지난 2년 동안 몇 가지 연구가 등장했다.
일부 diffusion 기반 생성기는 조건부 합성, 완료 및 기타 관련 작업에 대한 유망한 결과를 보여주는 3D 포인트 클라우드에 대해 제안되었다[4, 30, 67, 68].
DreamFusion [42] 및 GAUDI [2]는 우리의 연구와 마찬가지로 조건부(텍스트 및 이미지) 및 무조건적 3D 생성 모두에 적용되는 radiance field와 함께 diffusion 모델을 사용한다.
DreamFusion [42]은 사전 학습된 2D 텍스트 조건부 diffusion 모델에 의해 정의된 loss를 최적화하여 조명 구성 요소로 증강된 NeRF를 생성하는 알고리즘을 제시한다.
GAUDI[2]는 먼저 조건부 NeRF를 학습시켜 장면별 잠재력이 주어진 실내 비디오 세트를 재구성한 다음 학습된 잠재 공간을 포착하기 위해 diffusion 모델을 적합시킴으로써 3D 장면 생성기를 구축한다.
대조적으로, 우리의 diffusion 모델은 형상 완성과 같은 3D 조건부 작업에 사용될 수 있는 강력한 체적 priors를 학습하면서 radiance fields의 공간에서 직접 작동한다(섹션 4.2 참조).
3. Method
우리의 방법은 최신 SOTA diffusion probabilistic 모델을 기반으로 하는 3D 객체에 대한 생성 모델로 구성된다[20].
다양한 스케일의 노이즈를 주입하여 3D 객체를 서서히 손상시키는 프로세스를 되돌리도록 학습된다.
우리의 경우, 3D 객체는 radiance fields [34]로 표현되므로, 학습된 디노이징 프로세스를 통해 노이즈로부터 객체 radiance fields를 생성할 수 있다.
우리는 3D 객체의 생성을 radiance fields로 타겟으로 하기 때문에, 우리는 우리의 방법의 세부 사항을 탐구하기 전에 이 표현에 대한 간략한 개요로 시작한다.
3.1. Radiance Fields
radiance field (σ, ξ)은 3D 영역 X ⊂ R^3에 걸쳐 정의된 밀도 필드 σ : X → R+ 및 RGB 색상 필드 ξ : X → R^3의 관점에서 주어진 3D 객체의 암시적, 부피 표현이다.
밀도 필드는 공간의 특정 지점에 있는 물체의 존재에 대한 정보를 제공하는 반면, 색상 필드는 궁극적으로 해당하는 RGB 색을 제공한다.
ray casting 논리에 따라, radiance field는 주어진 ray r을 따라 렌더링될 수 있으며, RGB 색상 c_r을 생성할 수 있다 [34]
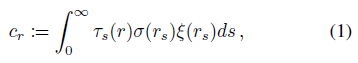
, 여기서, ray r은 단위 속도를 갖는 s에 의해 매개변수화된 선형 곡선이고, r_s ∈ X는 s에서 ray를 따라가는 점을, τ_s(r)는
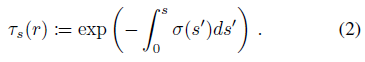
에 의해 주어진 s에서 투과율 확률을 나타낸다.
위의 ray 렌더링 방정식을 사용하여 주어진 카메라에서 radiance field를 렌더링하여 새로운 뷰의 이미지를 생성할 수 있습니다.
카메라를 월드 좌표로 표현된 적절한 ray 세트로 바꾸는 것으로 충분하다.
radiance field를 구현하는 방법은 신경망[34]에서 명시적 복셀 그리드[24,55]에 이르기까지 다양하다.
이 작업에서, 우리는 후자를 선택하는데, 이는 그것이 더 빠른 학습과 추론과 함께 좋은 렌더링 품질을 가능하게 하기 때문이다.
명시적 그리드는 복셀 정점의 이중 선형 보간을 통해 연속적인 위치에서 쿼리할 수 있다.
명시적 표현 하에서, radiance field은 4D 텐서가 되는데, 여기서 처음 3차원은 X에 걸쳐 있는 그리드를 색인화하는 반면, 마지막 차원은 밀도와 색상 채널을 색인화한다.
3.2. Generating Radiance Fields
디노이징 기반 생성 방법의 맥락에서 최근 발전에 따라 [20], 우리는 denoising diffusion probabilistic model 모델로 radiance fields의 생성 모델을 공식화한다.
Generation process.
생성(일명 디노이징) 프로세스는 고정된 크기의 평평한 4D 텐서로 표현되는 모든 가능한 사전 활성화 radiance fields의 상태 공간 F에 정의된 이산 시간 마르코프 체인에 의해 제어된다.
체인에는 제한된 수의 시간 단계 {0, ..., T}가 있습니다.
디노이징 프로세스는 표준 다변량 정규 분포 p(f_T) := N(f_T|0, I)에서 state f_T를 샘플링하는 것으로 시작하고 학습된 매개 변수 θ를 가진 가우시안인 역 transition 확률 p_θ(f_(t-1)|f_t)를 활용하여 f_t에서 state f_(t-1)를 생성한다.
구체적으로
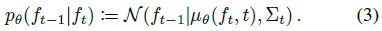
가 있습니다.
생성 프로세스는 최종 상태 f_0까지 반복되며, 이는 우리의 방법에 의해 생성된 3D 객체의 radiance field를 나타낸다.
(3)의 가우시안 평균은 신경망으로 직접 모델링할 수 있다.
그러나 나중에 알게 되겠지만, 다음과 같은 재매개변수화를 고려하는 것이 더 편리하다
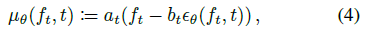
, 여기서 ε_θ(f_t, t)는 신경망에 의해 예측된 f_(t-1)를 손상시키는 데 사용된 노이즈인 반면, a_t와 b_t는 사전 정의된 계수이다.
또한 공분산 ∑_t는 사전 정의된 값을 갖지만 데이터에 종속될 수 있습니다.
사전 정의된 변수가 취하는 값에 대한 자세한 내용은 섹션 3.3에 나와 있습니다.
Diffusion process.
생성 프로세스는 완전히 랜덤 radiance field를 반복적으로 디노이징하는 방식으로 작동하는 반면, diffusion 프로세스는 반대로 작동하며 우리가 모델링하려는 3D 객체의 분포에서 샘플을 반복적으로 손상시킨다.
우리는 그것이 생성 과정의 학습 체계에서 근본적인 역할을 하기 때문에 그것을 소개한다.
diffusion 과정은 생성 과정에서 언급된 것과 동일한 상태 공간과 시간 경계를 가지고 있지만
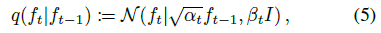
에 의해 미리 정의되고 주어진 가우시안 transition 확률을 가진 이산 시간 마르코프 체인에 의해 지배된다, 여기서 α_t := 1 - β_t 및 0 ≤ β_t ≤ 1은 주입된 노이즈 분산에 대한 스케쥴을 구현하는 사전 정의된 계수이다.
이 프로세스는 모델링하려는 3D 객체 radiance fields의 분포 q(f_0)에서 f_0을 선택하는 것으로 시작하고, 후자의 크기가 조정되고 노이즈로 손상된 버전을 산출하는 f_t를 반복적으로 샘플링하며, 구현된 노이즈 분산 스케줄에 따라 f_T가 일반적으로 완전 랜덤에 가까운 상태로 중지된다.
가우시안 분포의 특성을 활용하여 f_0에서 조건화된 f_t의 분포를 가우시안 분포로 편리하게 표현할 수 있으며
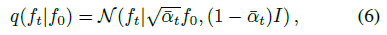
, 여기서 α_t := ∏ α_i를 산출한다.
이 관계는 임의의 시간 단계에서 diffusion 데이터 포인트를 빠르게 생성하는 데 유용합니다.
3.3. Training Objective
우리의 학습 objective는 두 가지 보완적 loss로 구성된다: i) 데이터 분포에 맞지 않는 radiance fields의 생성에 불이익을 주는 loss L_RF와 ii) 생성된 radiance fields의 렌더링 품질을 개선하기 위한 RGB loss L_RGB.
Radiance field generation loss.
[20]에 이어 Negative Log-Likelihood (NLL)의 변동 상한에서 시작하여 모델에 대한 학습 objective를 도출한다.
이 상한은 실제로 diffusion 과정을 지배하는 분포 q에 해당하기 때문에 q라고 부르는 surrogate 분포를 지정하여 생성 과정과 예상되는 기본 연결을 설정해야 한다.
우리는 여기서 경계 도출의 몇 가지 주요 단계를 제공하고 중간 단계에 대한 자세한 내용은 [20]을 참조한다.
Jensen 부등식에 의해, 데이터 점 f_0 ∈ F의 NLL은 다음과 같이 q를 이용하여 상한을 가질 수 있다:
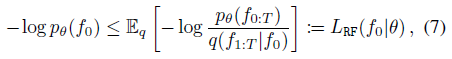
, 여기서 f_(t_1:t_2)는 (f_t_1, ..., f_t_2)를 나타냅니다.
NLL을 경계로 하는 L_RF(f_0|θ) loss는 θ와 독립적인 상수까지 다음 합계로 더 분해될 수 있다
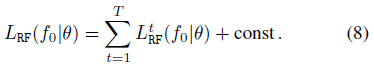
여기서 L_RF^t(f_0|θ)는 (4)에서 a_t := 1/√(α_t)와 b_t := β_t /√(1-α_t)를 설정하고 ∑_t := β_t^2 / (2 α_t) I를 선택하면 간단하고 직관적인 형태를 취한다.
실제로, 이것은
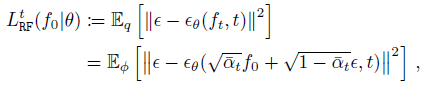
를 산출하는데, 여기서 ɸ(ε) := N(ε|0, I)은 ε의 확률 분포, 즉 정규 다변량이며, 마지막 등식은 (6)부터이다.
Radiance field rendering loss.
생성된 radiance fields에서 렌더링 품질을 향상시키는 것을 목표로 하는 추가 RGB loss L_RGB(f_0|θ)로 이전 loss를 보완한다.
실제로, 생성된 radiance fields의 품질을 평가하기 위해 이전 loss에서 암시적으로 사용되는 표현에 대한 유클리드 메트릭은 일단 radiance fields를 렌더링하려고 하면 아티팩트의 부재를 반드시 보장하지는 않는다.
L_RGB(f_0|θ)를 (8)과 유사한 시간별 항 L_RGB^t(f_0|θ)의 합으로 정의하여
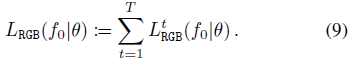
를 산출한다.
radiance field f ∈ F와 시점 v가 주어지면, 우리는 식 (1)을 사용하여 시점 v에서 f를 렌더링한 후 얻은 이미지를 R(v, f)로 나타낸다.
우리는 또한 radiance fields f와 f', 즉
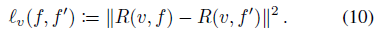
를 사용하여 시점 v에서 렌더링된 이미지 사이의 유클리드 거리를 l_v(f, f')로 나타낸다.
이 아이디어는 데이터 분포에서 샘플링된 주어진 radiance field f_0의 렌더링을 t diffusion 단계로 손상된 동일한 radiance field와 비교한 다음 완전히 디노이즈되는 것이다.
이론적으로, 이것은 q(f_t|f_0)에서 f_t를 먼저 샘플링한 다음 p_θ(f_0|f_t)에서 f_0을 다시 샘플링하는 것을 의미한다.
그러나 이것은 계산적으로 요구되며 우리는 더 간단한 근사치에 의존한다.
L_RF^t의 정의에서, loss는 우리가 ~f_0^t(ε, θ) := f_0 + (1-α_t) / (α_t) (ε - ε_θ(f_t, t))의 근사치를 도출할 수 있는 ε ~ ε_θ(f_t, t)을 갖는 쪽으로 밀어붙인다.
그런 다음 렌더링 loss를 (11)로 정의할 수 있으며, 여기서 v 시점과 ε ~ ɸ(ε)에 대한 이전 분포 ψ에 대한 기대치가 취해진다.
스텝 t가 0에 가까운 경우에만 근사치가 합리적이기 때문에 스텝 값이 증가함에 따라 감소하는 가중치 ω_t를 도입한다(예: ω_t := α_t^2를 사용한다).
우리는 근사치임에도 불구하고 제안된 loss가 결과를 크게 개선하는 데 기여한다는 증거를 실험 섹션에서 제공한다.
Final loss.
요약하면, 데이터 포인트 f_0 당 최종 학습 loss는 이전에 소개된 radiance field 생성 및 렌더링 loss의 가중 조합에 의해 주어지며, 균일한 분포 κ(t)에서 단계 t를 확률적으로 샘플링할 수 있는 작은 변동이 있다:
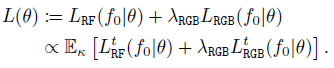
Implementation details.
우리는 2D 컨볼루션과 어텐션 계층을 해당 3D 연산자로 대체하여 [14]에서 소개된 2D-UNET 아키텍처를 기반으로 하는 3D-UNet으로 구현한다.
또한 렌더링된 이미지를 세분화하기 위해 작은 CNN을 배치하여 뷰 일관성에 영향을 미치지 않고 이미지 품질을 향상시킨다.
학습을 위해, 우리는 β_1 = 0.0015에서 β_T = 0.05까지 선형적으로 증가하는 diffusion 과정의 분산을 가진 모든 실험에 대해 시간 단계 t = 1, ..., T = 1000을 균일하게 샘플링하고, 렌더링 loss L_RGB^t에 ω_t = α_t^2의 가중치를 부여하도록 선택한다.
우리는 추가적인 세부 사항을 위해 보충 자료를 참조한다.
4. Experiments
이 섹션에서는 무조건적 및 조건적 radiance field 생성에 대한 방법의 성능을 평가한다.
Datasets.
우리는 PhotoShape Chairs [41]와 Amazon Berkeley Objects(ABO) Tables 데이터 세트[9]에 대한 실험을 실행한다.
PhotoShape Chairs의 경우 아르키메데스 나선의 200개 뷰에서 Blender Cycles [10]를 사용하여 제공된 15,576개의 의자를 렌더링한다.
ABO Tables의 경우 객체당 2-3개의 서로 다른 환경 맵 설정으로 제공된 91개의 렌더링을 사용하여 1676개의 테이블을 생성한다.
두 데이터 세트 모두 3D 객체의 radiance field 표현을 제공하지 않기 때문에 다중 뷰 렌더링에서 32^3의 해상도로 복셀 기반 접근법을 사용하여 생성한다.
Metrics.
Fréchet Inception Distance [19](FID)와 Inception Score [45](IS)를 사용하여 이미지 품질을 평가한다.
기하학적 품질의 비교를 위해 [1]을 따르고 Chamfer Distance (CD)를 사용하여 Coverage Score (COV)와 Minimum Matching Distance (MMD)를 계산한다.
Coverage Score는 생성된 샘플의 다양성을 측정하는 반면, MMD는 생성된 샘플의 품질을 평가합니다.
모든 메트릭은 128x128의 해상도로 평가됩니다.
4.1. Unconditional Radiance Field Synthesis
Comparison against state of the art.
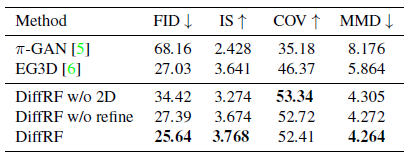
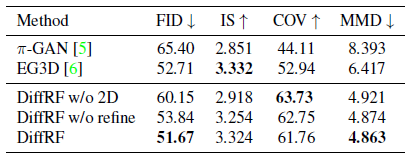
우리는 표 1의 PhotoShape[41]와 표 2의 ABO Tables [9]에 대한 무조건적인 3D 합성 작업에 대한 접근 방식을 정량적으로 평가한다.
우리는 3Daware 이미지 합성을 위한 주요 방법과 비교한다: π-GAN [5] 및 EG3D [6].
우리의 방법과 GAN 기반 접근 방식 모두 학습을 위해 동일한 렌더링된 이미지 세트를 사용한다.
렌더링된 이미지를 사전 처리하여 각 형상 샘플에 대한 radiance field 표현을 생성하는 동안 GAN 기반 방법은 렌더링된 이미지에 대해 직접 학습된다.


이러한 접근 방식에 비해, 우리의 방법은 기하학적 품질과 다양성에서 상당한 개선을 달성하면서 전반적으로 더 나은 이미지 품질을 산출한다.
그림 3과 그림 4는 우리의 방법을 π-GAN 및 EG3D와 정성적으로 비교한 것이다.
EG3D는 좋은 이미지 품질을 달성하지만, 팔걸이를 추가하거나 제거하거나 지지 구조를 변경하는 것과 같은 부정확한 모양과 뷰 의존적인 이미지 아티팩트를 생성하는 경향이 있다.
학습 objective (섹션 3.3 참조)는 diffusion 과정을 반전시켜 상세한 체적 표현을 위해 노이즈를 제거하는 것이기 때문에, 우리는 DiffRF가 미세한 광도 및 기하학적 세부 사항을 가진 radiance field를 안정적으로 생성하는 것을 관찰한다.
Contribution of the rendering loss.
표 1과 표 2는 radiance 합성에 대한 2D supervision의 영향을 평가하는 ablation 결과를 보여준다.
예상대로 2D supervision("DiffRF w/o 2D", 표의 3행)을 제거하면 FID에 큰 영향을 미치며, PhotoShape의 경우 ≒ 8.8, ABO Tables의 경우 ≒8.5가 증가합니다.
이는 볼륨 렌더링 loss에 의해 DDPM의 노이즈 예측 공식을 편향시키면 이미지 품질이 향상된다는 것을 보여준다.
렌더링 loss가 디노이징 모델을 더 적은 아티팩트로 학습 radiance field로 안내하여 다양하지만 가짜 모양의 양을 줄인다는 사실로 설명하는 Coverage Score의 감소를 알 수 있다.
Contribution of the refinement CNN.
CNN 기반 이미지 개선("DiffRF w/o refine", 표의 4행)의 제거는 유사하지만 덜 두드러지는 효과가 있다: 이미지 및 형상 품질 저하, 형상 다양성 증가.
4.2. Conditional Generation
diffusion 모델은 테스트 시 효과적으로 조건화될 수 있는 반면, GAN은 특정 작업에 대해 학습되어야 한다[14, 29, 54].
우리는 마스킹된 radiance field 완성이라는 새로운 작업에 이 속성을 활용한다.
Masked Radiance Field Completion.
형상 완성과 이미지 인페인팅은 각각 기하학적 표현 또는 이미지 내의 누락된 영역을 채우는 것을 목표로 하는 잘 연구된 작업[56, 63, 66, 68]이다.
우리는 마스킹된 radiance field 완성이라는 새로운 작업에서 이 두 가지를 결합할 것을 제안한다: radiance field와 3D 마스크가 주어지면 마스크되지 않은 영역과 조화를 이루는 마스크된 영역의 완성도를 합성합니다.
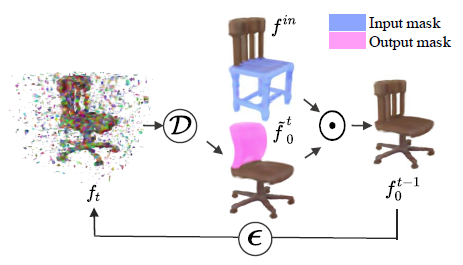
RePaint[29]에서 영감을 받아 알려진 영역의 무조건적 샘플링 프로세스를 입력 f^in으로 점진적으로 안내하여 조건적 완료를 수행한다
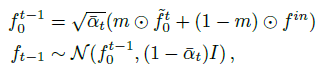
, 여기서 m은 입력에 적용된 이진 마스크(그림 6의 연한 파란색)이며 복셀 그리드의 요소별 곱셈을 나타낸다.
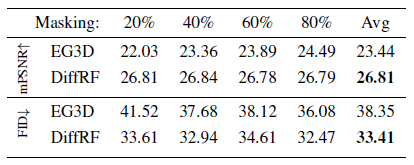
마스킹 성능에 대한 정량적 분석은 표 3에 나와 있으며, 여기서 우리는 다양한 마스킹 수준에서 우리의 방법을 EG3D와 비교한다.
각 수준에서 200개의 샘플을 랜덤으로 마스킹하고 (10개의 랜덤 뷰에서 렌더링하여) FID와 마스크되지 않은 영역(mPSNR)의 광 측정 정확도 측면에서 완료 성능을 평가한다.
EG3D의 경우, 우리는 마스크된 GAN 반전을 사용하며, 여기서 우리는 Global Latent Optimization (GLO)를 수행하여 다시 투영된 마스크되지 않은 영역에서 광 메트릭 오류를 최소화한다.
단일 잠재 코드 표현으로 인해 EG3D는 입력 샘플의 마스킹되지 않은 영역을 충실하게 재구성하기 위해 고군분투하고 있으며, 전체 표현을 손상시키지 않기 위해 정규화가 필요하다는 것을 알 수 있다.
그림 5는 EG3D에 대한 마스킹 성능의 정성적 비교를 더 보여준다.

Image-to-Volume Synthesis.
DiffRF는 볼륨 렌더링을 사용하여 샘플링 프로세스를 스티어링하여 싱글 뷰 이미지에서 3D radiance field를 얻는 데 사용할 수 있습니다.
이를 위해 [14]의 Classifer Guidance 공식을 채택하여 디노이징 프로세스를 해당 객체 마스크(예: 기성 분할 네트워크로 획득)가 있는 포즈된 RGB 이미지에 대해 렌더링 오류를 최소화하도록 안내한다.
그림 7은 ScanNet의 의자에 대한 이 단일 이미지 재구성 작업에 대한 정성적 결과를 보여준다[11].
우리의 상세한 prior를 사용하면 이 ill-posed 설정에서도 합리적인 radiance field를 재구성할 수 있다.

4.3. Limitations
우리의 방법은 조건적 및 무조건적 radiance field 합성 작업에 대해 유망한 결과를 보여주지만, 몇 가지 한계가 남아 있다.
GAN 기반 접근 방식에 비해 샘플링 시간이 상당히 길다.
이러한 맥락에서, 더 빠른 샘플링 방법을 활용하는 방법을 탐구하는 것은 흥미로울 것이다[26].
마지막으로, 우리의 모델은 학습 시간 메모리 제한에 의해 최대 그리드 해상도에서 제약을 받는다.
이것들은 [7]의 것과 같은 인수분해 신경 필드 표현을 탐색함으로써 해결될 수 있다.
5. Conclusions
DiffRF를 소개합니다 – denoising diffusion probabilistic models 모델을 기반으로 한 3D radiance field 합성을 위한 새로운 접근 방식.
우리가 아는 한, DiffRF는 체적 radiance fields에서 직접 작동하는 최초의 생성 diffusion 기반 방법이다.
우리 모델은 포즈 이미지 컬렉션에서 다중 뷰 일관성을 학습하여 자유 뷰 이미지 합성과 정확한 형상 생성을 가능하게 한다.
우리는 여러 객체 클래스에서 DiffRF를 평가하여 SOTA GAN 기반 접근 방식과 성능을 비교하고 조건적 및 무조건적 3D 생성 작업 모두에서 효과를 입증했다.