2023. 3. 15. 15:46ㆍView Synthesis
RenderDiffusion: Image Diffusion for 3D Reconstruction, Inpainting and Generation
Titas Anciukeviˇcius, Zexiang Xu, Matthew Fisher, Paul Henderson, Hakan Bilen, Niloy J. Mitra, Paul Guerrero
Abstract
Diffusion 모델은 현재 조건적 및 무조건적 이미지 생성 모두에서 SOTA 성능을 달성한다.
그러나 지금까지 이미지 diffusion 모델은 뷰 일관성 있는 3D 생성 또는 단일 뷰 객체 재구성과 같은 3D 이해에 필요한 작업을 지원하지 않는다.
본 논문에서는 단안 2D supervision만을 사용하여 학습할 수 있는 3D 생성 및 추론을 위한 첫 번째 diffusion 모델로 RenderDiffusion을 제시한다.
우리 방법의 핵심은 각 디노이징 단계에서 장면의 중간 3차원 표현을 생성하고 렌더링하는 새로운 이미지 디노이징 아키텍처이다.
이것은 (단안) 2D supervision만 필요로 하면서 3D 일관된 표현을 제공하는 강력한 유도 구조를 diffusion 과정에 강제한다.
결과적인 3D 표현은 임의의 관점에서 렌더링될 수 있다.
ShapeNet 및 Clevr 데이터 세트에서 RenderDiffusion을 평가하고 3D 장면 생성 및 2D 이미지에서 3D 장면 추론을 위한 경쟁력 있는 성능을 보여준다.
또한, 우리의 diffusion 기반 접근법을 사용하여 2D 인페인팅을 사용하여 3D 장면을 편집할 수 있다.
우리는 우리의 작업이 대규모 이미지 컬렉션에 대해 학습될 때 규모에 맞게 완전한 3D 생성을 가능하게 할 것을 약속하며, 따라서 supervision을 위해 대규모 3D 모델 컬렉션을 가질 필요가 없다고 믿는다.
1. Introduction
이미지에 대한 diffusion 모델은 이제 생성 및 추론 작업 모두에서 SOTA 성능을 달성한다.
대안적 접근법(예: GAN 및 VAE)과 비교하여, 학습 데이터의 가능성을 명시적으로 최대화함으로써 특히 긴 꼬리 분포에 대한 복잡한 데이터 세트를 보다 충실하게 모델링할 수 있다.
text-to-image 생성[40, 46], 인페인팅[45], 객체 삽입[4] 및 개인화[44]를 포함한 많은 흥미로운 애플리케이션이 지난 몇 달 동안 등장했다.
그러나 3D 생성과 이해에서 그들의 성공은 지금까지 결과의 품질과 다양성 측면에서 제한적이었다.
일부 방법은 diffusion 모델을 포인트 클라우드 또는 복셀 데이터에 직접 적용하거나 [30, 57], 사전 학습된 diffusion 모델을 사용하여 NeRF를 최적화했다[1].
3D에서의 이러한 제한적인 성공은 두 가지 문제 때문입니다: 첫째, 명시적인 3D 표현(예: 복셀)은 상당한 메모리 요구를 초래하고 수렴 속도에 영향을 미친다; 그리고 더 중요한 것은 3D 모델 저장소가 이미지 저장소에 비해 데이터를 훨씬 적게 포함하기 때문에 명시적인 3D superrvision에 액세스해야 하는 설정이 문제이다.
이는 GAN 또는 VAE보다 데이터를 많이 필요로 하는 경향이 있는 대규모 diffusion 모델의 경우 특히 문제가 된다.
본 연구에서는 2D 이미지만을 사용하여 학습된 3D 콘텐츠의 첫 번째 diffusion 방법인 RenderDiffusion을 제시한다.
이전 diffusion 모델과 마찬가지로, 우리는 2D 이미지를 디노이즈하도록 모델을 학습시킨다.
우리의 핵심 통찰력은 잠재된 3D 표현을 노이즈 제거기에 통합하는 것이다.
이는 명시적인 3D supervision 없이 2D에서 디노이즈하도록 학습하는 동안 3D 객체를 복구할 수 있는 유도 편향을 생성한다.
이 잠재적 3D 구조는 인코더에 의해 노이즈가 있는 이미지에서 생성되는 3면 표현[8]과 3D 표현을 (노이즈된) 2D 이미지로 다시 렌더링하는 볼륨 렌더러[31]로 구성된다.
삼면 표현을 사용하여 볼륨 데이터에 대한 입방 메모리 증가를 피하고 2D 이미지에 직접 작업함으로써 3D supervision의 필요성을 피한다.
사전 학습된 잠재 공간에서 작동하는 잠재 diffusion 모델[6,41]과 비교하여 2D 이미지에서 직접 작업하면 더 샤프한 생성 및 추론 결과를 얻을 수 있다.
RenderDiffusion은 학습 시간에 사용할 수 있는 intrinsic 및 extrinsic 카메라 매개 변수가 있다고 가정합니다.

우리는 CLEVR 및 ShapeNet 데이터 세트에서 파생된 장면에서 RenderDiffusion을 평가하고 그럴듯하고 다양한 3D 일관된 장면을 생성한다는 것을 보여준다(그림 1 참조).
또한, 우리는 그것이 그러한 작업에 대한 특별한 학습 없이도 마스크된 2D 이미지에서 단안 3D 재구성 및 3D 장면을 그리는 것과 같은 어려운 추론 작업을 성공적으로 수행한다는 것을 보여준다.
우리는 단안 3D 재구성에서도 단안 supervision으로만 학습된 최근의 SOTA 방법[8]에 비해 향상된 재구성 정확도를 보여준다.
간단히 말해서, 우리의 주요 기여는 명시적인 잠재 3D 표현을 가진 디노이징 아키텍처로, 2D 이미지에서 순수하게 학습될 수 있는 최초의 3D 인식 diffusion 모델을 구축할 수 있다.
2. Related Work
Generative models.
고품질 이미지 합성을 달성하기 위해 GAN[2, 15, 23], VAE[26, 52], 독립 성분 추정[14], 자기 회귀 모델[51]을 포함한 다양한 생성 모델이 제안되었다.
최근 diffusion 모델[18, 49]은 이미지 생성 및 다른 많은 이미지 합성 작업[13, 19, 25, 29, 47]에 대한 SOTA 결과를 달성했다.
독특하게, diffusion 모델은 모드 붕괴(GAN의 공통 과제)를 피할 수 있고, 다른 likelihood 기반 방법보다 더 나은 밀도 추정을 달성하며, 이미지를 생성할 때 높은 샘플 품질로 이어질 수 있다.
우리는 이러한 강력한 이미지 diffusion 모델을 2D 이미지 합성에서 3D 콘텐츠 생성 및 추론으로 확장하는 것을 목표로 한다.
(GAN과 같은) 많은 생성 모델이 3D 생성 작업[17, 33, 34]을 위해 확장되었지만, 3D 장면에 diffusion 모델을 적용하는 것은 여전히 비교적 미개척 영역이다.
최근의 몇 가지 연구는 3D(기하학) supervision에 의존하여 포인트, 복셀 또는 SDF 기반 표현[20, 30, 57]을 사용하여 3D diffusion 모델을 구축한다.
이러한 방법은 형상 생성에만 초점을 맞추고 결과 형상을 렌더링하는 데 중요한 표면 색상이나 질감을 모델링하지 않습니다.
대신, 우리는 diffusion 모델을 고급 신경 필드 표현과 결합하여 완전한 3D 콘텐츠 생성으로 이어집니다; 우리 모델은 모양과 외관을 모두 생성할 수 있으므로 임의의 관점에서 현실적인 이미지 합성이 가능합니다.
Neural field representations.
컴퓨터 비전 커뮤니티에서 3D 장면을 신경 분야로 표현하는 데 있어 기하급수적인 진전이 있었다[5,11,31,32,50,54].
이를 통해 다양한 재구성 및 이미지 합성 작업에서 높은 충실도의 렌더링이 가능해졌다[3,28,37,39,56].
우리는 diffusion 모델에서 최근의 3면 기반 표현[8, 11]을 활용하여 볼륨 렌더링을 통해 작고 효율적인 3D 모델링을 가능하게 한다.
최근 NeRF 기반 방법은 효율적인 퓨샷 3D 재구성을 위해 장면 간에 학습된 일반화 가능한 네트워크[12, 55]를 개발했다.
우리의 모델은 단일 뷰 이미지에 대해서만 학습되지만, 우리의 방법은 학습 중에 다중 뷰 데이터가 필요한 PixelNeRF[55]와 같은 방법에 필적하는 높은 추론 품질을 달성할 수 있다.
신경 필드 표현은 또한 대부분의 방법이 GAN을 기반으로 하는 3D 생성 모델 구축[9, 27]으로 확장되었다[8, 16, 36].
동시 작업 중 하나인 DreamFields [21]을 확장한 DreamFusion [1]은 NeRF 최적화를 추진하기 전에 미리 학습된 2D diffusion 모델을 활용하여 유망한 텍스트 기반 3D 생성을 달성한다.
대신 우리는 3D diffusion 모델을 구축하고 샘플링을 통해 직접 객체 생성을 달성하려고 한다.
또 다른 동시 작업인 GAUDI[6]는 다중 뷰 데이터를 사용하여 먼저 3면 기반 잠재 공간을 학습한 다음 이 잠재 공간에 대한 diffusion 모델을 구축하는 3D 생성 모델을 소개한다.
대조적으로, 우리의 접근 방식은 단일 뷰 2D 이미지만 필요하며 3D 잠재 공간을 사전 학습하지 않고 이미지 diffusion에서 종단 간 3D 생성을 가능하게 한다.
3. Method
우리의 방법은 다양한 양의 추가 노이즈가 있는 입력 이미지를 디노이즈하도록 학습된 2D 이미지 diffusion 모델의 성공적인 학습 및 생성 설정을 기반으로 한다[18].
테스트 시 모델을 여러 단계로 적용하여 순수 노이즈 샘플에서 시작하는 이미지를 점진적으로 복구하여 새로운 이미지를 생성한다.
우리는 이 학습과 생성 설정을 유지하지만 노이즈가 많은 입력 이미지를 볼륨적으로 렌더링된 장면의 3D 표현으로 인코딩하여 노이즈가 있는 출력 이미지를 얻도록 메인 디노이저의 아키텍처를 수정한다.
이는 3D 장면 일관성을 선호하는 귀납적 편향을 도입하고, 새로운 관점에서 3D 표현을 렌더링할 수 있게 한다.
그림 2는 아키텍처의 개요를 보여줍니다.
다음에서는 먼저 2D 이미지 diffusion 모델을 간략하게 검토한 다음(섹션 3.1), 3D 인식 노이즈 제거기를 얻기 위해 도입하는 새로운 아키텍처 변화를 설명한다(섹션 3.2).

3.1. Image Diffusion Models
diffusion 모델은 가우시안 노이즈에서 샘플링된 이미지 샘플 x_T ~ N(0, I)을 여러 작은 디노이징 단계 x_(T-1), ..., x_0을 통해 데이터 매니폴드에 점진적으로 더 가까이 이동하여 이미지를 생성하여 결국 디노이즈된 이미지 x_0을 생성한다.
Forward process.
모델을 학습하기 위해 학습 이미지 x_0에서 시작하는 가우시안 노이즈를 반복적으로 추가하여 노이즈 이미지 x_1, ..., x_T를 생성한다:
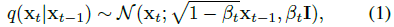
, 여기서 β_t는 β_0 = 0에서 β_T = 1까지 증가하는 분산 스케줄이며 각 단계에서 추가되는 노이즈의 양을 제어합니다.
우리는 실험에서 코사인 스케줄[35]을 사용한다.
불필요한 반복을 피하기 위해 닫힌 형식을 사용하여 단일 단계에서 x_0에서 x_t를 직접 얻을 수 있습니다:
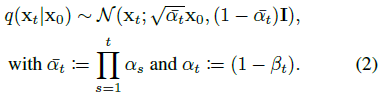
Reverse process.
역 프로세스는 노이즈가 더 많은 이미지 x_t가 주어졌을 때 노이즈가 덜한 이미지 x_(t-1)에 대한 posterior 분포를 찾아 전진 프로세스의 단계를 역전시키는 것을 목표로 한다:
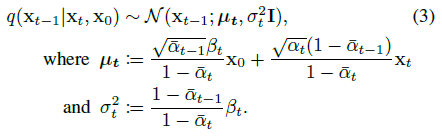
x_0은 알 수 없으므로(생성하려는 이미지) 이 분포를 직접 계산할 수 없으며, 대신 매개 변수 θ를 사용하여 디노이저 g_θ를 근사화합니다.
분산은 알 수 없는 이미지 x_0에 의존하지 않기 때문에 일반적으로 평균 μ_t만 디노이저에 의해 근사화되어야 한다.
도출은 Ho et al. [18]을 참조하십시오.
우리는 평균 μ_t를 예측하기 위해 디노이저를 직접 학습할 수 있지만, Ho et al. [18]은 디노이저 g_θ가 노이즈 이미지 x_t에 추가된 총 노이즈 x_t - x_0을 직접 예측함으로써 더 안정적이고 효율적으로 학습될 수 있음을 보여준다.
우리는 Ho et al. 을 따르지만 디노이저 g_θ는 중간 표현으로 x_0에 표시된 장면의 3D 버전을 재구성하는 임무도 맡게 되기 때문에, 우리는 노이즈 x_t - x_0 대신 x_0을 예측하도록 g_θ를 학습시킨다:
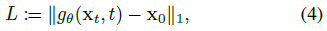
, 여기서 L은 학습 loss를 나타낸다.
일단 학습되면, 생성 시점에 모델 g_θ는 posterior q(x_(t-1)|x_t, x_0) = N(x_(t-1), μ_t, σ_t^2 I)의 평균 μ_t를
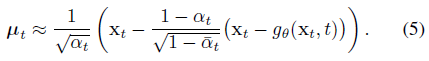
로 근사할 수 있다.
이 대략적인 posterior는 각 생성 단계에서 샘플링되어 더 노이즈가 많은 이미지 x_t에서 점진적으로 더 노이즈가 적은 이미지 x_(t-1)를 얻는다.
3.2. 3D-Aware Denoiser
디노이저 g_θ는 노이즈가 있는 이미지 x_t를 입력으로 받아 디노이즈된 이미지 ~x_0을 출력합니다.
기존 방법[18, 42]에서, 디노이저 g_θ는 일반적으로 UNet[43]의 유형에 의해 구현된다.
이것은 2D 설정에서는 잘 작동하지만 디노이저가 장면의 3D 구조에 대해 추론하도록 권장하지는 않습니다.
우리는 삼중 평면을 기반으로 한 디노이저에 잠재적인 3D 표현을 도입한다[8, 38].
이를 위해 디노이저의 아키텍처를 수정하여 다음과 같은 두 가지 추가 구성 요소를 통합한다: 카메라 뷰 v를 사용하여 포즈를 취한 입력 이미지 x_t를 3D 삼면 표현으로 변환하는 삼면 인코더 e_ɸ 및 3D 삼면 표현을 노이즈가 있는 이미지 ~x_0으로 다시 변환하는 삼면 렌더러 r_ψ, 즉
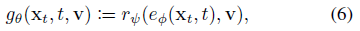
, 여기서 θ는 인코더와 렌더러의 연결 매개변수 ɸ와 ψ를 나타낸다.
출력 이미지는 입력 이미지의 디노이즈된 버전이므로 동일한 관점에서 렌더링해야 합니다.
우리는 입력 이미지의 시점 v를 사용할 수 있다고 가정한다.
노이즈는 소스/렌더링된 이미지에 직접 적용됩니다.
Triplane representation.
삼면 표현 P는 전체 3D 피쳐 그리드를 세 개의 (표준) 좌표 평면을 따라 배치된 세 개의 2D 피쳐 맵으로 분해하여 훨씬 더 간결한 표현을 제공한다[8, 38].
각 피쳐 맵의 해상도는 N x N x n_f이며, 여기서 n_f는 피쳐 채널의 개수이다.
그런 다음 주어진 3D 점 p에 대한 피쳐는 각 좌표 평면에 점을 투영하고, 각 피쳐 맵을 이중으로 보간하고, 크기 n_f의 단일 피쳐 벡터를 얻기 위해 세 가지 결과를 합산하여 얻는다.
우리는 P에서 이 선형 샘플링 과정을 P[p]로 나타낸다.
Triplane encoder.
삼면 인코더 e_ɸ는 크기가 M x M x 3인 입력 이미지 x_t를 크기가 N x N x 3n_f인 삼면 표현으로 변환한다, 여기서 N ≥ M.
우리는 diffusion 모델[18]에 일반적으로 사용되는 U-Net 아키텍처를 기본으로 사용하지만, 삼중 평면의 크기로 피처 맵을 출력하기 위해 (스킵 연결 없이) 추가 레이어를 추가한다.
추가 자료에 더 많은 아키텍처 세부 사항이 나와 있습니다.
Triplane renderer.
삼면 렌더러 r_psi는 삼면 피쳐를 사용하여 볼륨 렌더링을 수행하고 크기가 M x M x 3인 이미지 x_(t-1)를 출력합니다.
이미지에서 주조된 ray를 따라 각 3D 샘플 포인트 p에서 MLP를 (γ, c) = s_ψ(p, P[p])로 갖는 밀도 γ와 색상 c를 얻는다.
픽셀의 최종 색상은 MipNeRF와 동일한 명시적 볼륨 렌더링 접근법을 사용하여 ray를 따라 색상과 밀도를 통합하여 생성됩니다[5].
우리는 NeRF[31]의 2-패스 중요도 샘플링 접근법을 사용한다; 첫 번째 패스는 계층화된 샘플링을 사용하여 각 ray를 따라 샘플을 배치하고, 두 번째 패스 중요도는 첫 번째 패스의 결과를 샘플링한다.
3.3. 3D Reconstruction
기존 2D diffusion 모델과 달리 RenderDiffusion을 사용하여 2D 이미지에서 3D 장면을 재구성할 수 있습니다.
입력 이미지 x_0에 표시된 장면을 재구성하기 위해 t_r ≤ T 단계에 대한 순방향 프로세스를 통과한 다음 학습된 디노이저 g_θ를 사용하여 역방향 프로세스에서 디노이즈한다.
마지막 디노이징 단계에서 삼면은 새로운 관점에서 렌더링할 수 있는 3D 장면을 인코딩한다.
t_r을 선택하면 기존 3D 재구성 방법에서는 사용할 수 없는 흥미로운 제어가 도입된다.
이를 통해 재구성 충실도와 일반화 사이에서 분포를 벗어난 입력 이미지로 전환할 수 있습니다: t_r = 0에서는 입력 이미지에 노이즈가 추가되지 않으며 3D 재구성은 입력 이미지에 표시된 장면을 최대한 정확하게 재현합니다; 그러나 분포를 벗어난 이미지는 처리할 수 없습니다.
t_r 값이 클수록 디노이저가 입력 이미지를 학습된 분포 쪽으로 이동할 수 있기 때문에 점점 더 분포를 벗어난 입력 이미지를 처리할 수 있다.
노이즈가 추가되면 입력 이미지에서 일부 세부 정보가 제거되므로 재구성 충실도가 저하됩니다, 디노이저는 이를 생성된 콘텐츠로 채웁니다.
4. Experiments
우리는 세 가지 작업에서 RenderDiffusion을 평가한다: 단안 3D 재구성, 무조건적 생성 및 3D 인식 인페인팅.
Datasets.
우리는 학습과 평가를 위해 CLEVR[22]과 ShapeNet[10]의 맞춤형 장면을 사용한다.
CLEVR 장면은 평면에 배열된 다양한 색상의 큐브, 실린더, 구와 같은 원시 요소로 구성된다.
우리는 CLEVR1 데이터 세트라고 하는 CLEVR 데이터 세트의 변형을 생성하는데, 여기서 각 장면은 원점의 평면에 서 있는 단일 개체를 포함한다.
우리는 다른 장면의 물체를 랜덤으로 추출하여 다른 색상, 모양 및 크기를 가지며 900개의 장면을 생성한다, 여기서 400개는 학습에 사용되고 나머지는 테스트에 사용된다.
보다 복잡한 모양에 대한 방법을 평가하기 위해 ShapeNet 데이터 세트의 세 가지 범주의 개체를 사용한다.
ShapeNet에는 질감이 있는 메시로 표현되는 다양한 범주의 인공 개체가 포함되어 있습니다.
우리는 car, plane 및 chair 범주에서 각각 지상 평면에 배치된 모양을 사용한다.
각 범주에서 총 3200개의 개체를 사용합니다: 2700개는 학습용이고 500개는 시험용이다.
장면을 렌더링하기 위해 먼저 원점 중심의 반구에서 균일하게 100개의 시점을 랜덤으로 샘플링한다.
너무 얕은 시야각(12˚ 미만)은 재샘플링됩니다.
이러한 관점 중 70개는 학습을 위해 사용되고 30개는 테스트를 위해 예약되어 있습니다.
Blender [7]을 사용하여 100개의 관점에서 각 객체를 렌더링합니다.
4.1. Monocular 3D Reconstruction
우리는 세 가지 ShapeNet 범주의 테스트 장면에서 3D 재구성을 평가한다.
이러한 이미지는 학습 데이터와 동일한 분포에서 그려지기 때문에 노이즈를 추가하지 않는다, 즉, t_r = 0을 설정한다.
디노이저 g_θ를 한 번 반복하여 비 노이즈 이미지에 대해 재구성이 수행된다.
우리의 방법은 입력으로 이미지의 카메라 시점을 요구하지 않는다.
Baselines.
우리는 3D supervision 없이도 학습된 두 가지 SOTA 방법과 비교한다.
EG3D[8]는 삼중 평면을 3D 표현으로 사용하는 생성 모델이며, 우리의 방법과 마찬가지로 단일 이미지만 supervision으로 학습한다.
인코더가 없으므로 GAN 반전을 수행하여 3D 재구성을 얻는다[58].
구체적으로, 우리는 ground truth 관점에서 렌더링될 때 입력 이미지와 일치하도록 StyleGAN2 [24] 디코더 및 EG3D의 초해상도 블록의 잠재 벡터 z 및 잠재 노이즈 맵 n을 최적화한다.
우리는 4개의 랜덤 초기화 각각에 대해 1000단계에 대해 EG3D를 최적화하여 생성된 이미지와 타겟 이미지 간의 VGG16 피쳐[48] 차이를 최소화한 다음 최상의 결과를 선택한다.
두 번째 베이스라인으로 우리는 희소 뷰에서 새로운 뷰 합성을 위한 최근 접근법인 PixelNeRF[55]를 사용한다.
우리의 방법과 달리, 이것은 다중 뷰 supervision으로 학습되어 우리와 EG3D 모두에 비해 상당한 이점을 제공한다.
따라서 우리는 이 베이스라인을 능가할 것으로 예상하지 않는 참조로 취급한다.
EG3D와 PixelNeRF는 모두 데이터 세트에서 신중하게 조정되고 재학습되었다.
Metrics.
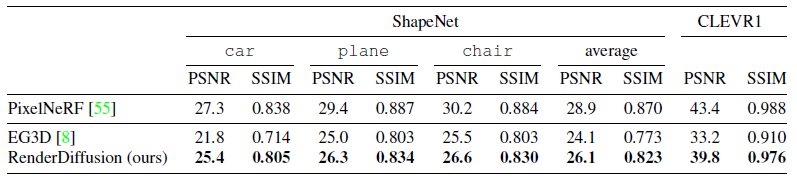
재구성된 장면의 모든 held-out 테스트 세트 뷰를 두 가지 메트릭을 사용하여 ground truth 렌더링과 비교하여 3D 재구성 성능을 평가한다: PSNR 및 SSIM [53].
우리는 모든 테스트 이미지에 대한 결과를 평균화한다.
여러 뷰에서 이미지 공간에서 평가하는 것은 모양뿐만 아니라 모든 포인트에서 표면의 (뷰에 의존적일 수 있는) 색상의 정확도를 측정한다는 장점이 있다.

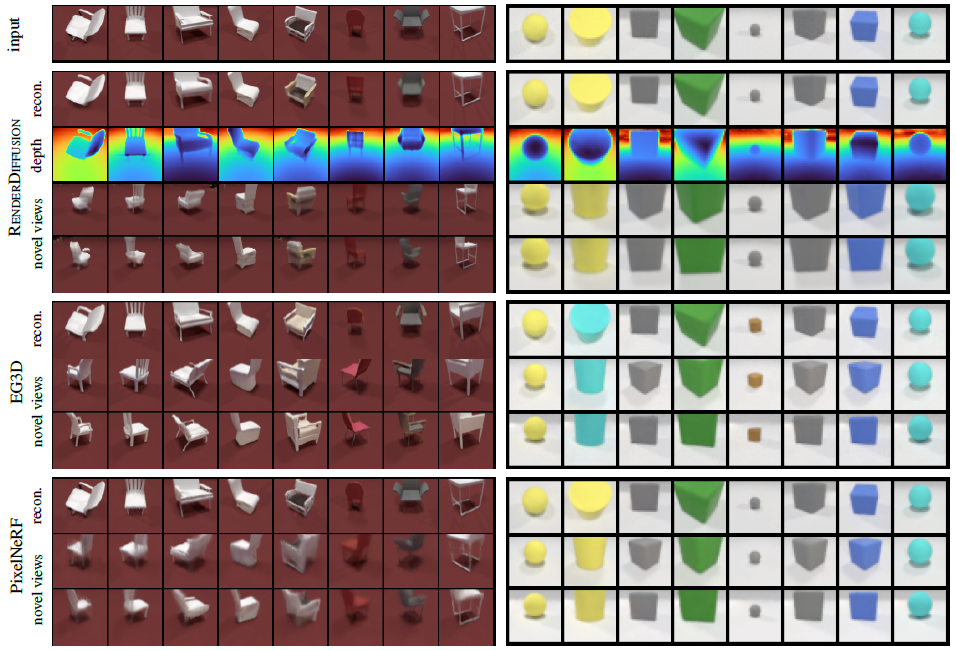
Results.
우리의 방법과 베이스라인의 정성적 결과는 그림 3과 4에 나와 있다.
우리는 EG3D가 거의 항상 모든 각도에서 현실적으로 보이는 모양을 예측한다는 것을 알 수 있다.
그러나 이들은 종종 입력 이미지와 모양이나 색상이 다소 다르며, 때로는 극적으로(예: 4번째와 5번째 car)도 있다.
대조적으로, PixelNeRF는 입력 뷰의 충실한 재구성을 생성한다.
그러나 입력 뷰에서 회전하면 이미지가 블러해지거나 세부 정보가 부족한 경우가 많습니다.
우리의 RenderDiffusion은 모양의 정체성을 보존하면서 두 가지 사이의 균형을 달성하지만 뒷면 영역에서 샤프하고 그럴듯한 세부 정보를 산출한다.
세 가지 방법 모두 색상과 모양을 정확하게 재구성하여 더 단순한 CLEVR1 데이터 세트에서 좋은 결과를 산출한다.
정량적 결과는 표 1과 같다.
정성적 결과에 동의하여, 모든 방법은 세 가지 ShapeNet 클래스보다 간단한 CLEVR1 데이터 세트에서 더 잘 수행된다.
RenderDiffusion은 모든 데이터 세트에서 EG3D를 능가하여 ShapeNet에서 평균 PSNR을 26.1로 달성했으며 EG3D의 경우 24.1을 능가한다.
학습 중 멀티뷰 supervision을 받기 때문에 직접 비교할 수 없는 PixelNeRF는 ShapeNet의 평균 PSNR이 28.9로 여전히 더 높은 성능을 달성한다.
Reconstruction on out-of-distribution images.
3D 인식 디노이저를 사용하면 노이즈가 있는 이미지에서 3D 장면을 재구성할 수 있으며, 노이즈로 인해 손실된 정보가 생성된 콘텐츠로 채워진다.
노이즈를 더 추가함으로써 재구성 충실도를 희생하면서 점점 더 분포를 벗어난 이미지를 입력하도록 일반화할 수 있다.
그림 6에서는 학습 시간에 본 이미지와 배경 및 재료가 크게 다른 사진에서 3D 재구성을 보여준다.
우리는 재구성된 모델의 덜 정확한 모양과 포즈를 대가로 추가된 노이즈(t_r = 0)가 없는 결과보다 추가된 노이즈(t_r = 40)가 있는 결과가 더 잘 일반화된다는 것을 알 수 있다.
또한, 보충 자료에서, 우리는 다양한 노이즈 t_r의 양에 따라 결과가 어떻게 변하는지 보여준다.
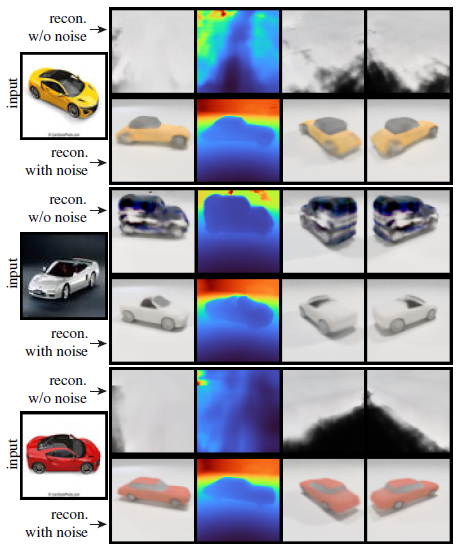
4.2. Unconditional Generation
무조건적 생성에 대한 정성적 결과를 보여줍니다; 정량적 결과에 대해서는 보충 자료를 참조하십시오.
Baselines.
우리는 EG3D[8]와 비교하는데, EG3D는 3D 장면에 대한 삼면 표현과 유사한 렌더링 접근 방식을 사용하기 때문이다.
그러나 EG3D는 diffusion을 디노이징하기보다는 적대적 학습을 사용한다.

Results.
두 방법의 정성적인 예는 그림 5에 나와 있다.
우리는 두 모델에 의해 생성된 장면이 모든 관점에서 사실적으로 보이며 3D로 일관된다는 것을 알 수 있다.
이는 우리의 방법이 단일 관점(그림 5의 상단 행)에서만 디노이징 프로세스를 수행하기 때문에 RenderDiffusion에서 특히 주목할 만하다.
우리는 EG3D의 샘플보다 우리 모델의 샘플에서 색상과 모양의 다양성이 다소 더 높다는 것을 관찰한다.
그러나 두 방법 모두 복잡한 구조(예: 슬랫드 의자 등받이)를 생성하고 지상 평면에 드리워진 물리적으로 그럴듯한 그림자를 합성할 수 있다.
4.3. 3D-Aware Inpainting
마지막으로, 우리는 학습된 모델을 이미지의 마스킹된 2D 영역을 그리는 작업에 적용하는 동시에 이미지가 보여주는 3D 모양을 재구성한다.
RePaint[29]와 유사한 접근 방식을 따르지만 2D 아키텍처 대신 3D 디노이저를 사용한다.
구체적으로, 우리는 알려진 영역의 x_(t-1)을 노이즈가 있는 타겟 픽셀로 설정하고 x_t를 기반으로 평소처럼 알 수 없는 영역을 샘플링하여 이미지의 알려진 영역에서 디노이징 반복을 조건화한다.
따라서 모델은 3D 인식 인페인팅을 수행하여 이미지의 관찰된 부분과 일치하는 잠재된 3D 구조를 찾으며 마스킹된 부분에서도 그럴듯하다.
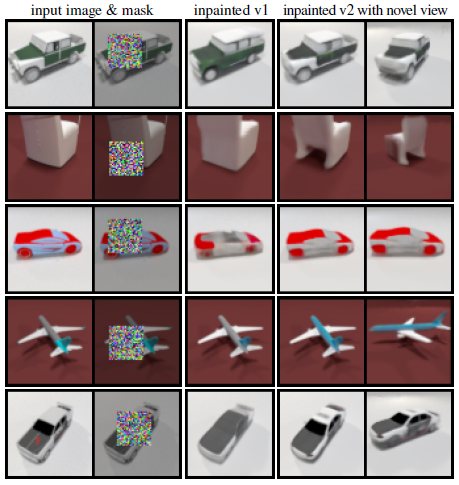
Results.
정성적 결과는 그림 7과 같다.
각각의 마스킹된 이미지에 대해, 우리는 두 개의 다른 노이즈 샘플로 인한 장면을 보여준다.
우리의 모델은 이 작업에 대해 명시적으로 학습되지 않았지만, 우리는 그것이 이미지의 관찰된 부분과 일치하는 다양하고 그럴듯한 영역을 생성한다는 것을 알 수 있다.
보충 자료에서, 우리는 각 입력에 대해 여러 완료를 샘플링하고 그들이 ground truth에 얼마나 근접할 수 있는지 측정함으로써 이 작업에 대한 정량적 결과를 제공한다.
5. Conclusion
우리는 명시적인 3D supervision 없이 포즈를 취한 2D 이미지에서 순수하게 학습될 수 있는 최초의 3D diffusion 모델인 RenderDiffusion을 제시했다.
디노이징 아키텍처는 강력한 유도 편향을 적용하고 3D 일관된 생성을 생성하는 3면 렌더링 모델을 통합한다.
RenderDiffusion은 이미지에서 3D 장면을 유추하고, 2D 인페인팅을 사용한 3D 편집 및 3D 장면 생성에 사용할 수 있습니다.
우리는 결과의 품질과 다양성 측면에서 샘플링 및 추론 작업에서 경쟁력 있는 성능을 보여주었다.
우리의 방법은 현재 몇 가지 한계가 있다.
우리는 학습 이미지가 알려진 카메라 매개 변수와 함께 제공되어야 하며 삼면은 전역 좌표 시스템에 배치되어 객체 배치 전반에 걸쳐 일반화를 제한한다.
이는 카메라 매개 변수와 객체 바운딩 박스를 동시에 추정하고 객체 중심 좌표 시스템에서 작업함으로써 완화될 수 있다.
이것은 구성성을 활성화하고 여러 객체가 있는 장면을 생성하는 단계가 될 것이다.
우리의 인코더 모듈은 또한 이미지의 영역을 삼면의 해당 영역에 연결하는 스킵 연결로 3D 장면 구조에 대한 정보를 주입함으로써 이익을 얻을 수 있다.
마지막으로, 우리는 객체 편집과 재료 편집을 지원하여 보다 표현적인 3D 인식 2D 이미지 편집 워크플로우를 가능하게 하고 싶다.