2023. 4. 10. 17:26ㆍView Synthesis
Infinite Nature: Perpetual View Generation of Natural Scenes from a Single Image
Andrew Liu, Richard Tucker, Varun Jampani, Ameesh Makadia, Noah Snavely, Angjoo Kanazawa
Abstract
지속적인 뷰 생성 문제를 소개합니다—단일 이미지가 주어진 임의의 긴 카메라 궤적에 해당하는 새로운 뷰의 장거리 생성.
이는 큰 카메라 모션으로 제시되면 빠르게 퇴화하는 현재 뷰 합성 방법의 기능을 훨씬 뛰어넘는 어려운 문제입니다.
비디오 생성 방법도 긴 시퀀스를 생성하는 데 한계가 있으며 종종 장면 지오메트리에 구애받지 않습니다.
우리는 기하학과 이미지 합성을 모두 반복적인 '렌더, 정제 및 반복' 프레임워크에 통합하는 하이브리드 접근 방식을 취하여 수백 프레임 후에 먼 거리를 커버하는 장거리 생성을 가능하게 됩니다.
우리의 접근 방식은 일련의 단안 비디오 시퀀스로부터 학습될 수 있습니다.
우리는 해안 장면의 항공 영상 데이터 세트를 제안하고, 우리의 방법을 최근의 뷰 합성 및 조건적 비디오 생성 베이스라인과 비교하여 기존 방법에 비해 큰 카메라 궤적에서 훨씬 긴 시간 동안 그럴듯한 장면을 생성할 수 있음을 보여줍니다.

1. Introduction
그림 1의 해안선 입력 이미지를 생각해 보십시오.
새처럼 이 장면을 비행한다고 상상해 보십시오.
처음에는 물체에 접근함에 따라 물체가 시야에서 성장하는 것을 볼 수 있습니다.
그 너머에서, 우리는 넓은 바다나 새로운 섬을 발견할 수도 있습니다.
해안에서, 우리는 절벽이나 해변을 볼 수 있고, 내륙에는 산이나 숲이 있을 수 있습니다.
인간으로서, 우리는 우리 자신의 경험을 바탕으로 한 하나의 그림에서 그럴듯한 세계를 상상하는 데 능숙합니다.
우리가 어떻게 컴퓨터에서 이 능력을 모방할 수 있습니까?
한 가지 접근 방식은 단일 이미지에서 고해상도 세부 정보로 전체 3D 행성을 생성하는 것입니다.
하지만, 이것은 매우 비싸고 현재의 기술을 훨씬 뛰어넘을 것입니다.
따라서, 우리는 영구적인 뷰 생성의 더 다루기 쉬운 문제를 제기합니다: 장면의 단일 이미지가 주어지면, 작업은 임의의 카메라 궤적에 해당하는 비디오를 합성하는 것입니다.
이 문제를 해결하면 콘텐츠 생성, 새로운 사진 상호 작용 및 모델 기반 강화 학습과 같은 학습된 세계 모델을 사용하는 방법에 응용될 수 있습니다.
지속적인 뷰 생성은 단순하지만 매우 어려운 작업입니다.
관점이 이동함에 따라 보이지 않는 영역에서 새로운 콘텐츠를 추정하고 카메라에 더 가까운 기존 영역에서 새로운 세부 정보를 합성해야 합니다.
비디오 합성과 뷰 합성이라는 두 가지 활성 연구 분야는 모두 다른 이유로 이 문제에 맞게 확장하지 못합니다.
최근의 비디오 합성 방법은 이미지 합성의 발전을 시간 영역에 적용하거나 반복 모델에 의존합니다 [10].
그러나 제한된 수의 새로운 프레임(예: 25 [41] 또는 48 프레임 [9])만 생성할 수 있습니다.
또한 이러한 방법은 종종 비디오 구조의 중요한 요소를 무시합니다—장면 형상이나 카메라 움직임을 모델링하지 않습니다.
대조적으로, 많은 뷰 합성 방법은 고품질의 새로운 뷰를 합성하기 위해 지오메트리를 활용합니다.
그러나 이러한 접근 방식은 카메라 모션의 제한된 범위 내에서만 작동할 수 있습니다.
그림 6과 같이 카메라가 이 범위를 벗어나면 이러한 방법은 치명적으로 실패합니다.

우리는 이러한 과제를 해결하기 위해 기하학과 이미지 합성 기술을 모두 활용하는 하이브리드 프레임워크를 제안합니다.
우리는 disparity 맵을 사용하여 장면의 지오메트리를 표현하고 지속적 뷰 생성 작업을 렌더-정제-반복의 프레임워크로 분해합니다.
먼저, 우리는 장면 콘텐츠가 기하학적으로 올바른 방식으로 이동하도록 disparity를 사용하여 현재 프레임을 새로운 관점에서 렌더링합니다.
그런 다음, 우리는 결과 이미지와 기하학을 정제합니다.
이 단계에서는 인페인팅 또는 아웃페인팅이 필요한 영역에서 세부 정보를 추가하고 새로운 콘텐츠를 합성합니다.
이미지와 disparity를 모두 개선하기 때문에 전체 프로세스가 반복적으로 반복될 수 있으므로 임의의 궤적으로 지속적인 생성이 가능합니다.
우리의 시스템을 학습시키기 위해, 우리는 2백만 프레임에 이르는 700개 이상의 비디오에서 자연과 해안 장면의 대규모 드론 영상 데이터 세트를 큐레이션했습니다.
3D 카메라 궤적을 복구하기 위해 모션 파이프라인에서 구조를 실행하고 이를 항공 해안선 이미지 데이터 세트(ACID)라고 부릅니다.
우리의 학습된 모델은 항공 해안 비디오의 미적 느낌을 유지하면서 수백 프레임의 시퀀스를 생성할 수 있습니다.
비록 몇 프레임 후에 카메라가 초기 뷰에 묘사된 장면의 한계를 벗어났지만 말입니다.
우리의 실험은 disparity 맵을 통한 기하학적 전파를 통한 새로운 렌더링-정제-반복 프레임워크가 이 문제를 해결하는 데 핵심적이라는 것을 보여줍니다.
최근의 뷰 합성 및 비디오 생성 베이스라인과 비교하여, 우리의 접근 방식은 훨씬 더 긴 시간 동안 그럴듯한 프레임을 생성할 수 있습니다.
이 작품은 환각 세계에서 전역 일관성이 부족하다는 한계가 있지만 지속적인 뷰 생성을 향한 중요한 단계를 나타냅니다.
우리는 우리의 방법과 데이터 세트가 대규모 장면에 대한 생성 방법의 추가적인 발전으로 이어질 것이라고 믿습니다.
2. Related Work
Image extrapolation.
우리의 연구는 2D 변환된 이미지를 스티칭하여 'infinite' 이미지를 생성하기 위한 비모수적 접근법과 이미지 확장을 위한 패치 기반 비모수적 접근법을 제안한 Kaneva et al. [19]의 중요한 작업에서 영감을 받았습니다 [29, 1].
우리는 각 이미지 뒤에 있는 3D 지오메트리에 대해서도 추론하는 학습 프레임워크에서 'infinite image' 개념을 다시 검토합니다.
또한 우리의 작업과 관련이 있는 것은 아웃페인팅 문제에 대한 최근의 딥러닝 접근법, 즉 이미지 경계 밖에서 보이지 않는 콘텐츠를 추론하는 작업이다[44, 46, 36], 또한 인페인팅은 이미지 내에서 누락된 콘텐츠를 채우는 작업입니다 [15, 50].
이러한 접근 방식은 인/아웃페인팅을 위해 적대적 프레임워크와 의미 정보를 사용합니다.
우리의 문제는 또한 초고해상도의 측면을 통합합니다 [14, 22].
이미지별 GAN 방법은 또한 텍스처와 자연 이미지의 이미지 외삽과 초고해상도의 형태를 보여줍니다 [53, 34, 30, 33].
위의 방법과 대조적으로, 우리는 각 이미지 뒤의 3D 기하학에 대해 추론하고 시간적 이미지 시퀀스 생성의 맥락에서 이미지 외삽을 연구합니다.
View synthesis.
많은 뷰 합성 방법은 장면의 여러 뷰[23, 3, 24, 12, 7] 사이를 보간함으로써 작동하지만, 최근의 작업은 우리 작업에서와 같이 단일 입력 이미지로부터 새로운 뷰를 생성할 수 있습니다 [5, 39, 25, 38, 31, 6].
그러나 두 설정 모두에서 대부분의 방법은 매우 제한된 범위의 출력 관점만 허용합니다.
(보간뿐만 아니라) 뷰 외삽을 명시적으로 허용하는 방법도 일반적으로 카메라 모션을 참조 뷰 주변의 작은 영역으로 제한합니다 [52, 35, 8].
카메라 움직임을 제한하는 한 가지 요인은 레이어 depth 이미지 [39, 32], 다중 평면 이미지 [52, 38], 포인트 클라우드 [25, 45] 또는 radiance 필드 [48, 37]와 같은 많은 방법이 정적 장면 표현을 구성하고 페인트가 분리된 영역을 구성한다는 것입니다.
이러한 표현은 빠른 렌더링을 허용할 수 있지만, 실행 가능한 카메라 위치의 범위는 장면 표현의 유한한 경계에 의해 제한됩니다.
일부 방법은 이 장면 표현 패러다임을 확장하여 출력 뷰 범위를 제한적으로 늘릴 수 있습니다.
Niklaus et al.은 렌더링 후 페인팅을 수행합니다 [25], 반면 SynSin은 렌더링 후 정제 네트워크를 사용하여 피처 포인트 클라우드에서 현실적인 이미지를 생성합니다 [45].
우리는 출력을 렌더링한 다음 정제함으로써 이러한 방법에서 영감을 얻습니다.
그러나 이와 대조적으로, 우리의 시스템은 장면의 단일 3D 표현을 구성하지 않습니다.
대신, 우리는 반복적으로 진행하여 이전의 출력 뷰를 생성하고 각 프레임에 대한 disparity 맵 형태의 기하학적 장면 표현을 생성합니다.
일부 방법은 비디오를 학습 데이터로 사용합니다.
단안 depth는 3D 영화 좌우 카메라 쌍[27] 또는 모션 기술에서 구조로 분석한 비디오 시퀀스[4]에서 학습할 수 있습니다.
비디오는 또한 뷰 합성에 직접 사용될 수 있습니다 [38, 45].
이러한 방법은 이미지 쌍을 사용하는 반면, 우리의 모델은 장거리 비디오를 생성하기 위해 여러 개의 넓은 공간 프레임 시퀀스에 대해 학습됩니다.
Video synthesis.
우리의 작업은 하나 이상의 이미지에서 비디오 시퀀스를 생성하는 방법과 관련이 있습니다 [42, 11, 43, 10, 40, 47].
이러한 접근 방식의 대부분은 정적 카메라로 동적 물체의 미래를 예측하는 데 중점을 두었으며, 종종 인간이 걷는 간단한 비디오[2] 또는 로봇 팔[11]을 사용합니다.
대조적으로, 우리는 자연의 실제 항공 비디오를 사용하여 움직이는 카메라로 대부분 정적인 장면에 초점을 맞춥니다.
최근의 일부 연구는 움직이는 카메라가 있는 야생 비디오의 비디오 합성을 다루지만 [9, 41], 기하학적 구조를 명시적으로 고려하지 않고 생성된 비디오의 길이에 엄격한 제한을 두고 있습니다.
대조적으로, 우리 작업에서 카메라 모션에서 픽셀의 움직임은 3D 지오메트리를 사용하여 명시적으로 모델링됩니다.
3. Perceptual View Generation
RGB 이미지 I_0과 임의 길이의 카메라 궤적(P_0, P_1, P_2, ...)이 주어지면, 우리의 작업은 초기 뷰에 의해 캡처된 장면의 flythrough를 묘사하는 비디오를 구성하는 새로운 이미지 시퀀스(I_0, I_1, I_2, ...)를 출력하는 것입니다.
궤적은 일련의 3D 카메라 포즈 P_t = (R_0^(3×3) t_1^(3×1))이며, 여기서 R과 t는 각각 3D 회전과 변환입니다.
또한 각 카메라에는 intrinsic 행렬 K가 있습니다.
학습 시간에 카메라 데이터는 [52]와 같이 structure-from-motion을 통해 비디오 클립에서 얻습니다.
테스트 시 카메라 궤적은 사전 지정되거나 자동 파일럿 알고리즘에 의해 생성되거나 사용자 인터페이스를 통해 제어될 수 있습니다.
3.1. Approach: Render, Refine, Repeat
우리의 프레임워크는 새로운 조합으로 확립된 기술(3D 렌더링, image-to-image 변환, auto-regressive 학습)을 적용합니다.
그림 2와 같이 지속적인 뷰 생성을 세 단계로 구분합니다:
1. 미분 가능한 렌더러를 이용하여 disparity 맵에 따라 이미지를 워핑하여 기존의 관점에서 새로운 뷰를 렌더링하고,
2. 렌더링된 뷰와 지오메트리를 정제하여 누락된 내용을 채우고 필요한 경우 세부 정보를 추가합니다,
3. 이 과정을 반복하여 이미지와 disparity를 모두 전파하여 이전의 뷰에서 각각의 새 뷰를 생성합니다.
우리의 접근 방식에는 몇 가지 바람직한 특성이 있습니다.
기하학적 구조를 disparity 맵으로 표현하면 픽셀을 한 프레임에서 다음 프레임으로 이동시키는 작업의 상당 부분을 미분 가능한 렌더링으로 처리할 수 있어 로컬 시간적 일관성을 보장합니다.
그런 다음 합성 작업은 다음과 같이 구성되는 이미지 정제 작업 중 하나가 됩니다: 1) 인페인팅 불연속 영역 2) 새 이미지 영역의 아웃페인팅 및 3) 초정밀 이미지 콘텐츠.
모든 단계는 완전히 미분될 수 있기 때문에 여러 뷰 합성 반복을 통해 역 전파를 통해 세분화 네트워크를 학습할 수 있습니다.
우리의 auto-regressive 프레임워크는 학습 데이터의 길이가 유한하더라도 명시적인 뷰 제어를 통해 새로운 뷰가 무한히 생성될 수 있음을 의미합니다.
형식적으로 포즈 P_t가 있는 이미지 I_t의 경우 연관된 disparity(즉, inverse depth) 맵 D_t ∈ R^(H×W)를 가지며, 다음 프레임 I_(t+1)과 disparity D_(t+1)를
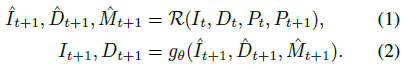
로 계산합니다.
여기서, ^I_(t+1)와 ^D_(t+1)은 새로운 카메라 P_(t+1)로부터 이미지 I_t와 disparity D_t를 이분 가능한 렌더러 R[13]를 사용하여 렌더링한 결과입니다.
이 함수는 또한 이미지의 어느 영역이 누락되어 있고 채워야 하는지를 나타내는 마스크 ^M_(t+1)을 반환합니다.
그런 다음 정제 네트워크 g_θ는 이러한 입력을 인페인트, 아웃페인트 및 초분해하여 다음 프레임 I_(t+1)과 그 disparity D_(t+1)를 생성합니다.
이 과정은 학습 중에 그리고 임의로 긴 카메라 궤적에 대한 테스트 시간에 T 단계에 대해 반복적으로 반복됩니다.
다음으로 각 단계에 대해 자세히 설명합니다.
Geometry and Rendering.
렌더 단계 R은 미분 가능한 메쉬 렌더러를 사용합니다 [13].
먼저 I_t의 각 픽셀 좌표(u, v)와 D_t의 해당 disparity d를 카메라 좌표계의 3D 포인트로 변환합니다: (x, y, z) = K^-1(u, v, 1)/d.
그런 다음 이미지를 3D 삼각형 메시로 변환하여 각 픽셀이 렌더링 준비가 된 이웃에 연결된 정점으로 처리됩니다.
depth 불연속성에서 늘어난 삼각형 아티팩트를 피하고 인페인트할 영역을 식별하여 정제 네트워크를 지원하기 위해, 우리는 소벨 필터로 계산된 disparity 이미지 ∇^D_t의 그래디언트를 임계값으로 하여 픽셀당 이진 마스크 M_t ∈ R^(H×W)를 계산합니다:
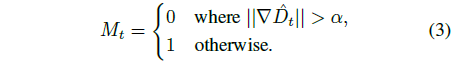
3D 메시를 사용하여 새 뷰 P_(t+1)에서 이미지와 마스크를 렌더링하고 렌더링된 이미지에 요소별로 렌더링된 마스크를 곱하여 ^I_(t+1)을 제공합니다.
렌더러는 또한 새 카메라에서 볼 수 있는 depth 맵을 출력합니다, 이 맵을 뒤집고 렌더링된 마스크에 곱하여 ^D_(t+1)을 얻습니다.
마스크를 사용하면 I_t에 포함된 ^I_(t+1) 및 ^D_(t+1)의 영역이 마스크되어 0으로 설정됩니다(이전 카메라의 시야 밖에 있던 영역과 함께).
이러한 영역은 정제 단계에서 인페인트(또는 아웃페인트)해야 하는 영역입니다.
분홍색으로 표시된 누락 영역의 예는 그림 2와 3을 참조하십시오.

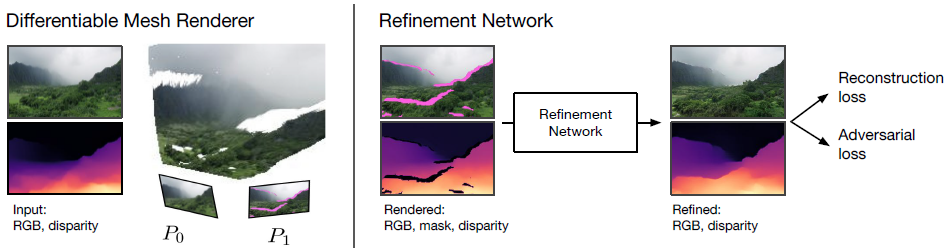
Refinement and Synthesis.
렌더링된 이미지 ^I_(t+1), disparity ^D_(t+1) 및 마스크 ^M_(t+1)을 고려할 때, 우리의 다음 작업은 블러 영역과 누락된 픽셀을 포함하는 이 이미지를 개선하는 것입니다.
이전의 인페인팅 작업[49, 36]과 달리, 정제 네트워크는 또한 초해상도를 수행해야 하므로 렌더링된 이미지를 정제하는 데 합성 작업을 사용할 수 없습니다.
대신 정제 단계를 생성 image-to-image 변환 작업으로 보고, SOTA SPADE 네트워크 아키텍처[26]를 채택하여 I_(t+1), D_(t+1)를 직접 출력합니다.
이 아키텍처에 필요한 추가 GAN 노이즈 입력을 제공하기 위해 I_0을 인코딩합니다.
자세한 내용은 보충 자료를 참조하십시오.
Rinse and Repeat.
이전 단계를 통해 단일 새로운 뷰를 생성할 수 있습니다.
우리 접근 방식의 중요한 측면은 RGB뿐만 아니라 disparity도 개선하여 장면 기하학이 프레임 간에 전파되도록 하는 것입니다.
이 설정을 통해 우리는 정제된 이미지와 disparity를 다음 입력으로 사용하여 여러 단계에 걸쳐 loss가 역 전파되는 auto-regressive 방식으로 학습할 수 있습니다.
이러한 방식으로 설계되지는 않았지만 다른 뷰 합성 방법도 반복적인 환경에서 학습되고 평가될 수 있지만, 우리가 하는 것처럼 기하학을 전파하지 않고 이러한 방법을 나이브하게 반복하려면 모든 단계에서 기하학을 처음부터 다시 추론해야 합니다.
섹션 6에서 보여주듯이, 반복 단계를 통해 이러한 베이스라인을 학습하고 평가하는 것은 지속적인 뷰 생성에 여전히 충분하지 않습니다.
Geometric Grounding to Prevent Drift.
긴 시퀀스를 생성하는 데 있어 핵심적인 과제는 오류의 누적을 처리하는 것입니다 [28].
현재 예측이 미래 출력에 영향을 미치는 시스템에서 각 반복의 작은 오류가 복합적으로 발생하여 결국 학습 중에 보이는 분포 외부에서 예측을 생성하고 예기치 않은 동작을 유발할 수 있습니다.
학습 과정에서 생성 루프를 반복하고 자체 출력을 네트워크에 공급하면 ablation 연구(섹션 6.2)에 나온 것처럼 드리프트가 개선되고 시각적 품질이 향상됩니다.
그러나, 우리는 특히 학습 중에 보이는 것보다 훨씬 더 긴 시간 범위에서 특히 테스트 시간에 disparity가 여전히 표류할 수 있다는 것을 알아챘습니다.
따라서 우리는 disparity 맵의 명시적인 기하학적 재접지를 추가합니다.
구체적으로, 우리는 렌더링 프로세스가 이전 프레임의 가시적인 영역에 대한 새로운 관점 ^D_(t+1)에서 정확한 범위의 disparity를 제공한다는 사실을 활용합니다.
미세화 네트워크는 구멍과 블러 영역을 미세화할 때 이러한 값을 수정할 수 있으며, 이는 전체 disparity가 예상보다 점차 크거나 작아짐에 따라 표류로 이어질 수 있습니다.
그러나 우리는 해결
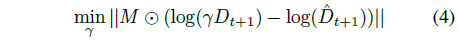
을 통해 스케일 팩터 γ를 계산하여 정제된 disparity 맵을 올바른 범위로 재조정함으로써 이를 기하학적으로 수정할 수 있습니다.
우리의 접근 방식은 세분화된 disparity를 γ로 조정함으로써 disparity 맵이 일관된 규모로 유지되도록 보장하며, 이는 섹션 6.3에 나와 있는 것처럼 테스트 시 드리프트를 크게 줄입니다.
4. Aerial Coastline Imagery Dataset
긴 시퀀스를 생성하는 방법을 배우는 것은 학습을 위해 실제 이미지 시퀀스를 필요로 합니다.
뷰 합성을 위한 기존의 많은 데이터 세트는 시퀀스를 사용하지 않고 약간 다른 카메라 위치의 뷰 세트만 사용합니다.
시퀀스가 있는 경우 길이가 제한됩니다: 예를 들어, RealEstate 10K는 주로 카메라 움직임이 제한된 실내 장면을 가지고 있습니다 [52].
움직이는 카메라와 몇 가지 동적인 물체로 긴 시퀀스를 얻기 위해, 우리는 인터넷에서 이용할 수 있는 아름다운 자연 장면의 항공 영상으로 눈을 돌립니다.
GAN이 자연 질감에 대한 유망한 결과를 보여주었기 때문에 자연 장면은 우리의 어려운 문제에 대한 좋은 출발점입니다 [30, 33].
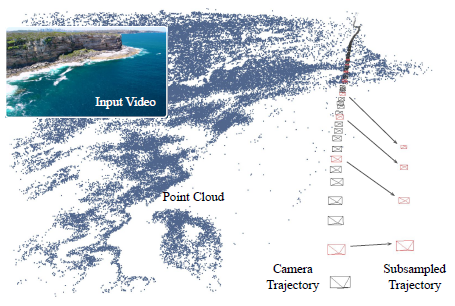
우리는 'coastal' 및 'aerial footage'와 같은 키워드를 사용하여 765개의 비디오를 수집했고, Zhou et al. [52]의 접근 방식에 따라 SLAM과 구조로 이러한 비디오를 처리하여 총 210만 프레임의 13,000개 이상의 시퀀스를 생성했습니다.
우리는 비디오 목록과 SfM 카메라 궤적을 공개했습니다.
해안선 비디오에서 실행되는 SfM 파이프라인의 예는 그림 4를 참조하십시오.
모든 프레임에 대한 disparity 맵을 얻기 위해 기성 MiDaS 단일 뷰 depth 예측 방법을 사용합니다 [27].
우리는 MiDaS가 매우 강력하고 우리의 방법에 대해 충분히 정확한 disparity 맵을 생성한다는 것을 발견했습니다.
MiDaS disparity는 최대 확장 및 이동까지만 예측되므로 먼저 데이터에 맞게 조정해야 합니다.
이를 달성하기 위해, 우리는 모션 구조 중 각 장면에 대해 계산된 희소 포인트 클라우드를 사용합니다.
각 프레임에 대해 우리는 해당 프레임에서 추적된 포인트만 고려하고 최소 제곱을 사용하여 이러한 포인트에서 disparity 오류를 최소화하는 척도와 이동을 계산합니다.
우리는 이 스케일을 적용하고 MiDaS 출력으로 전환하여 각 시퀀스에 대한 SfM 카메라 궤적(P_i)과 스케일이 일치하는 disparity 맵(D_i)을 얻습니다.
비디오 간 카메라 모션의 차이로 인해 학습 시퀀스에서 일관된 카메라 속도를 보장하기 위해 전략적으로 프레임을 하위 샘플링합니다.
자세한 내용은 보충 자료를 참조하십시오.
5. Experimental Setup
Losses.
우리는 해당 카메라 포즈 {P_t}^T_(t=0)와 각 프레임 {D_t}^T_(t=0)에 대한 disparity 맵이 있는 이미지 시퀀스 {I_t}^T_(t=0) 모음에 대한 접근 방식을 학습합니다.
조건적 생성 모델에 대한 문헌에 따라, 우리는 학습 중 합성하는 T 프레임에 대해 RGB 및 disparity에 대한 L_1 재구성 loss, RGB [18]에 대한 VGG 지각 loss, 판별기(및 피쳐 매칭 loss)와 힌지 기반 적대적 loss를 사용합니다.
또한 초기 이미지 인코더 L_KLD = D_KL(q(z|x)|N(0, 1))에서 KL-divergence loss [21]을 사용합니다.
우리의 완전한 loss 함수는
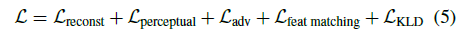
입니다.
loss는 미니 배치의 모든 반복 및 모든 샘플에 대해 계산됩니다.
Metrics.
인간의 판단과 상관되는 방식으로 생성된 이미지의 품질을 평가하는 것은 어려운 일입니다.
우리는 이미지의 생성 모델을 평가하는 데 사용되는 공통 메트릭인 Fréchet inception distance (FID)를 사용합니다.
FID는 사전 학습된 Inception 네트워크[17]를 통해 실제 및 가짜 이미지 임베딩의 평균과 공분산 간의 차이를 계산하여 생성된 이미지의 다양성뿐만 아니라 실제 이미지의 현실성을 측정합니다.
우리는 데이터 세트에서 20,000개의 실제 이미지 샘플을 사용하여 실제 통계를 사전 계산합니다.
시간에 따른 생성된 품질의 변화를 측정하기 위해 슬라이딩 윈도우를 통해 FID를 보고합니다: 우리는 t에 FID-w를 써서 시간 t 중심의 w 폭 창 내에서 모든 이미지 출력에 대해 계산된 FID 값을 나타냅니다, 즉, t - w/2 < i ≤ t + w/2에 대해 {I_i}.
ground truth 이미지를 사용할 수 있는 단거리 궤적의 경우 PSNR 및 SSIM과 같은 기존 메트릭보다 인간의 지각 판단과 더 잘 상관되는 지각 유사성 메트릭인 평균 제곱 오차(MSE) 및 LPIPS [51]도 보고합니다.
Implementation Details.
우리는 160x256의 이미지 해상도에서 T = 5단계의 렌더-정제-반복으로 모델을 학습합니다(대부분의 항공 비디오는 16:9의 가로 세로 비율을 가지고 있기 때문입니다).
T의 선택은 메모리와 사용 가능한 학습 시퀀스 길이 모두에 의해 제한됩니다.
정제 네트워크 아키텍처는 [26]의 SPADE 생성기와 동일하며, 동일한 다중 스케일 판별기도 사용합니다.
TensorFlow에서 모델을 구현하고 약 8일이 소요되는 7M 반복을 위해 10개 이상의 GPU 4개의 배치 크기로 학습합니다.
그런 다음 검증 세트에 대한 FID 점수가 가장 좋은 모델 체크포인트를 식별합니다.
6. Evaluation
우리는 우리의 접근 방식을 SVG-LP 비디오 합성 방법 [10]뿐만 아니라 세 가지 최신 단일 이미지 뷰 합성 방법—3D 사진 촬영 방법(이후 '3D Photos') [32], SynSin [45] 및 단일 뷰 MPI [38]—과 비교합니다 [10].
우리는 야생 이미지에 대해 학습되고 우리의 방법과 마찬가지로 MiDaS disparity를 입력으로 사용하는 3D Photos를 제외하고, 우리의 ACID 학습 데이터에 대해 각 방법을 재학습합니다.
SynSin과 단일 뷰 MPI는 256x256 해상도로 학습되었습니다.
SVG-LP는 컨텍스트를 위해 두 개의 입력 프레임을 사용하며 128x128의 낮은 해상도로 작동합니다.
뷰 합성 베이스라인 방법은 긴 카메라 궤적을 위해 설계되지 않았습니다.
충분한 카메라 이동 후 둘 사이에 겹치는 부분이 거의 없을 수도 있지만 생성되는 모든 새로운 프레임은 초기 프레임 I_0에서 나옵니다.
따라서 우리는 또한 이러한 각 방법의 두 가지 변형과 비교합니다.
첫째, 평가가 반복되는 변형(Synsin -Iterated, MPI-Iterated): 이러한 방법은 기본 모델과 동일한 학습된 모델을 사용하지만, 테스트 시에 반복적으로 적용하여 초기 프레임이 아닌 이전 프레임에서 각각의 새 프레임을 생성합니다.
둘째, 반복으로 학습된 변형(Synsin-Repeat, MPI-Repeat): 이러한 방법은 전체 모델에서와 같이 T = 5단계에 걸쳐 loss가 역 전파되면서 자동 회귀적으로 학습됩니다.
(3D 사진 방법에 대해서는 이러한 변형을 생략했는데, 안타깝게도 너무 느려서 반복적으로 적용할 수 없었고, 재학습할 수도 없었습니다.)
6.1. Short-to-medium range view synthesis
단거리에서 중거리 합성을 평가하기 위해, 우리는 카메라가 최대 45˚ 각도로 앞으로 이동하면서 입력 프레임과 10개의 후속 ground truth 프레임(보조에서 설명한 대로 서브샘플링)이 있는 ACID 테스트 시퀀스를 선택합니다.
우리의 방법은 모든 유형의 카메라 모션에 대해 학습되었지만, 이 전진 모션은 극단적인 카메라 모션을 처리하도록 설계되지 않은 뷰 합성 방법과 비교하는 데 적합합니다.
그런 다음 각 시퀀스의 마지막 두 프레임에서 카메라 모션을 추정하여 추가로 40 프레임의 궤적을 확장합니다.
카메라가 장면과 충돌하는 것을 방지하기 위해 마지막 ground truth 프레임의 disparity 맵에 대해 최종 카메라 위치를 확인하고 이미지 외부에 있거나 장면에 의해 가려질 정도로 큰 depth에 있는 시퀀스를 폐기합니다.
이것은 50단계의 카메라 궤적과 첫 10단계의 ground truth 이미지를 가진 279개의 시퀀스 세트를 산출합니다.
단거리 평가의 경우, 우리는 처음 10단계의 ground truth와 비교합니다.
중간 범위 평가를 위해, 우리는 모든 50 프레임에 대한 FID 점수를 계산합니다.
우리는 각 방법을 이러한 시퀀스에 적용하여 각 시퀀스의 카메라 포즈에 해당하는 새로운 뷰를 생성합니다(SVG-LP는 카메라 포즈를 고려하지 않는다는 점에서 예외입니다).
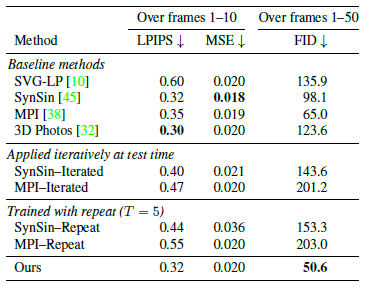
표 1의 결과를 참조하십시오.
우리의 목표는 지속적인 뷰 생성이지만, 우리의 접근 방식은 LPIPS 및 MSE 메트릭에 대한 단거리 합성을 위한 최근의 뷰 합성 접근 방식과 경쟁력이 있다는 것을 발견했습니다.
중간 범위 평가의 경우 생성된 50개 프레임에 대한 FID-50을 보고합니다.
우리의 접근 방식은 다른 방법보다 FID-50 점수가 현저히 낮아 출력의 자연스러운 모습을 반영합니다.
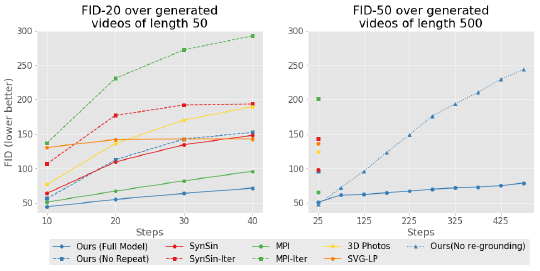
시간에 따른 각 방법의 성능 저하를 정량화하기 위해 t = 10 ~ 40에서 계산된 슬라이딩 윈도우 FID-20을 보고합니다.
그림 5(왼쪽)에서 볼 수 있듯이, 기본 방법의 이미지 품질(FID-20으로 측정)은 우리의 접근 방식에 비해 t가 증가함에 따라 더 빠르게 악화됩니다.
이러한 방법의 질적 비교는 그림 6과 각 방법의 출력 품질이 시간이 지남에 따라 어떻게 변화하는지 보여주는 보충 비디오에 나와 있습니다.
여기서 주목할 만한 것은 SVG-LP의 블러와 카메라 움직임을 전혀 예측할 수 없는 능력, 3D Photos 출력물의 점점 늘어나는 질감, MPI 기반 방법의 개별 레이어가 눈에 띄게 되는 방식입니다.
SynSin은 그럴듯한 질감을 생성하는 것을 가장 잘하지만, 시간이 지나도 구멍이 생성되고 새로운 세부 사항을 추가하지 않습니다.
–Iterated and–반복 변형은 원래의 SynSin 및 MPI 방법보다 지속적으로 더 나쁘며, 이는 단순히 기존 방법을 반복적으로 적용하거나 자동으로 재학습하는 것만으로는 대규모 카메라 이동을 처리하기에 충분하지 않다는 것을 시사합니다.
이러한 변형은 (우리의 방법과 달리) 기하학적 구조를 단계별로 전파하지 않기 때문에 원래 버전보다 표류하는 아티팩트를 더 많이 보여줍니다.
MPI 방법은 세부 사항을 추가할 수 없기 때문에 반복적으로 적용할 때 추가적으로 매우 블러하게 되며, 우리의 개선 단계가 부족합니다.
요약하자면, 렌더-정제-반복의 사려 깊은 조합은 이러한 기존 방법과 변형보다 더 나은 결과를 보여줍니다.
그림 7은 다양한 입력을 사용하여 15개 및 30개 프레임을 생성한 결과의 추가적인 질적 결과를 보여줍니다.

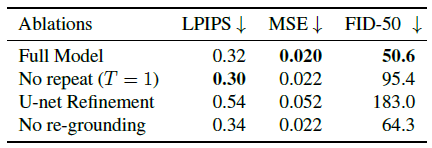
6.2. Ablations
우리는 T = 1('No repeat')로 모델을 학습함으로써 렌더-정제-반복 루프의 여러 반복에 대한 학습의 이점을 조사합니다.
표 2에서 볼 수 있듯이, LPIPS 및 MSE에서 측정된 단거리 생성 성능은 전체 모델과 유사하지만 FID를 보면 이 방법이 낮은 품질의 이미지를 생성하고 t가 증가함에 따라 상당히 악화된다는 것을 알 수 있습니다(그림 5, 왼쪽 참조).
이것은 우리의 방법에 반복적인 학습 설정을 사용하는 것의 중요성을 보여줍니다.
다음으로 정제 단계를 고려합니다.
이 단계를 완전히 생략하면 증가함에 따라 이미지의 점점 더 많은 부분이 완전히 누락됩니다.
그림 6의 'Ours (no refine)'과 같은 예가 있으며, 여기서 누락된 픽셀은 분홍색으로 강조 표시됩니다.
전체 모델에서 이러한 영역은 각 단계에서 정제 네트워크에 의해 인페인트되거나 아웃페인트됩니다.
또한 정제 단계를 생략하면 이미지의 마스킹되지 않은 영역도 훨씬 블러되어 초해상도 이미지 콘텐츠에서 정제 네트워크의 이점을 보여줍니다.
표 2는 또한 정제 단계의 두 가지 추가 변형에 대한 결과를 보여줍니다.
첫째, 정제 네트워크를 더 단순한 U-Net 아키텍처로 대체하면 상당히 더 나쁜 결과('U-Net refinement')를 얻을 수 있습니다.
둘째, 기하학적 접지(섹션 3.1)를 비활성화하면 이 short-to-medium 범위 뷰 합성 작업('No regrounding')에서도 품질이 약간 저하됩니다.
6.3. Preceptual view generation
우리는 또한 지상, 하늘 또는 산과 같은 장애물로 직접 비행하는 것을 피하는 온라인 카메라 궤적을 만들기 위해 자동 조종 알고리즘을 사용하여 500 프레임의 비디오를 합성하여 지속적인 뷰 생성을 수행하는 모델의 능력을 평가합니다.
이 알고리즘은 이미지 생성과 함께 반복적으로 작동하여 장면에서 하늘과 전경 장애물의 비율을 측정하는 휴리스틱을 기반으로 카메라를 제어합니다.
자세한 내용은 보충 자료를 참조하십시오.
우리는 이 작업이 예외적으로 어렵고 현재 생성 및 뷰 합성 방법의 기능을 완전히 벗어난다는 점에 주목합니다.
난이도를 더욱 높이기 위해, 우리의 정제 네트워크는 학습 중에 길이 5의 비디오만 보았지만, 우리는 각 테스트 시퀀스에 대해 500 프레임을 생성합니다.
그림 5(오른쪽)에서 볼 수 있듯이, 생성된 프레임에 대한 FID-50 점수는 매우 강력합니다: 500 프레임 이후에도 FID는 50 프레임 이상의 모든 베이스라인 방법보다 낮습니다.
그림 5는 또한 제안된 기하학적 접지의 이점을 보여줍니다: 생략하면 이미지 품질이 점차 저하되어 드리프트를 해결하는 것이 중요한 역할을 한다는 것을 알 수 있습니다.

그림 8은 긴 시퀀스 생성의 질적인 예를 보여줍니다.
먼 거리에 걸쳐 프레임을 생성하는 것의 본질적인 어려움에도 불구하고, 우리의 접근 방식은 해안선의 미적인 외관을 유지하여 세계를 비행하면서 새로운 섬, 바위, 해변 및 파도를 생성합니다.
자동 파일럿 알고리즘은 추가 입력(사용자가 지정한 궤적 또는 랜덤 요소 등)을 수신하여 단일 이미지에서 다양한 비디오를 생성할 수 있습니다.
추가 예제와 생성된 flythrough 비디오의 전체 효과는 보충 비디오를 참조하십시오.
6.4. User-controlled video generation
렌더링 단계는 카메라 포즈를 입력으로 사용하기 때문에 루프에서 사용자가 제어하는 궤적을 포함하여 테스트 시간에 임의의 카메라 궤적에 대한 프레임을 렌더링할 수 있습니다.
우리는 사용자가 이 상상의 세계를 비행할 때 자동 조종 알고리즘을 조종할 수 있는 HTML 인터페이스를 만들었습니다.
이 데모는 인터넷을 통해 실행되며 초당 몇 개의 프레임을 생성할 수 있습니다.
데모는 보충 비디오를 참조하십시오.
7. Discussion
지속적인 뷰 생성의 새로운 문제를 소개하고 이를 해결하기 위한 첫 단계로 기하학적 기법과 생성 기법을 모두 결합한 새로운 프레임워크를 제시합니다.
우리의 시스템은 수백 개의 프레임에 걸쳐 비디오 시퀀스를 생성할 수 있으며, 우리가 아는 한 이전의 비디오 또는 뷰 합성 방법에는 나타나지 않았습니다.
결과는 하이브리드 접근 방식이 유망한 단계임을 나타냅니다.
그럼에도 불구하고, 많은 도전들이 남아있습니다.
첫째, 우리의 렌더-정제-반복 루프는 유한 길이 비디오에 대해 학습하면서 유한 메모리 및 계산 예산을 사용하여 임의로 긴 출력을 생성할 수 있는 의도적인 선택인 무메모리 설계에 의한 것입니다.
결과적으로, 그것은 가까운 프레임 간의 지역적 일관성을 목표로 하지만, 장기적 일관성이나 전역 대표성의 문제를 직접 다루지는 않습니다.
이러한 시스템에 장기 기억을 통합하는 방법은 향후 연구에 있어 흥미로운 질문입니다.
둘째, 우리의 정제 네트워크는 다른 GAN과 마찬가지로 현실적으로 보이지만 인식할 수 없는 이미지를 생성할 수 있습니다 [16].
기하학을 통합하는 영상, 비디오 합성 생성 방법의 추가적인 발전은 흥미로운 미래 방향이 될 것입니다.
마지막으로 동적 장면을 모델링하지 않습니다: 우리의 기하학적 인식 접근법을 객체 역학에 대해 추론할 수 있는 방법과 결합하는 것은 또 다른 유익한 방향이 될 수 있습니다.