2023. 4. 21. 11:52ㆍView Synthesis
MobileNeRF: Exploiting the Polygon Rasterization Pipeline for Efficient Neural Field Rendering on Mobile Architectures
Zhiqin Chen, Thomas Funkhouser, Peter Hedman, Andrea Tagliasacchi
Abstract
Neural Radiance Fields (NeRF)는 새로운 관점에서 3D 장면의 이미지를 합성하는 놀라운 능력을 보여주었습니다.
그러나 광범위하게 배치된 그래픽 하드웨어의 기능과 일치하지 않는 ray marching 기반의 전문 볼륨 렌더링 알고리즘에 의존합니다.
이 논문은 표준 렌더링 파이프라인으로 새로운 이미지를 효율적으로 합성할 수 있는 질감 처리된 다각형을 기반으로 하는 새로운 NeRF 표현을 소개합니다.
NeRF는 이진 불투명도 및 피쳐 벡터를 나타내는 텍스처를 가진 다각형 집합으로 표시됩니다.
z-버퍼를 사용하여 다각형을 전통적으로 렌더링하면 모든 픽셀에 피쳐가 있는 이미지가 생성되며, 이는 프래그먼트 셰이더에서 실행되는 작은 뷰 의존적 MLP로 해석되어 최종 픽셀 색상을 생성합니다.
이 접근 방식을 통해 NeRF를 기존의 폴리곤 래스터화 파이프라인으로 렌더링할 수 있습니다, 이 파이프라인은 엄청난 픽셀 수준의 병렬 처리를 제공하여 휴대 전화를 포함한 광범위한 컴퓨팅 플랫폼에서 대화형 프레임 속도를 달성합니다.

1. Introduction
Neural Radiance Fields (NeRF) [33]는 3D 장면의 새로운 뷰 합성에 대한 인기 있는 표현이 되었습니다.
이들은 모든 방향의 모든 위치에서 방출되는 밀도와 radiance를 추정하는 5D 암시적 함수를 평가하는 다층 퍼셉트론(MLP)을 사용하는 장면을 나타내며, 이는 볼륨 렌더링 프레임워크에서 새로운 이미지를 생성하는 데 사용될 수 있습니다.
포즈를 취한 사진 세트에 대해 다중 뷰 색상 일관성 loss를 최소화하도록 최적화된 NeRF 표현은 새로운 뷰에 대해 미세한 이미지 세부 정보를 재현하는 놀라운 능력을 보여주었습니다.
NeRF의 광범위한 채택에 대한 주요 장애물 중 하나는 일반적으로 사용할 수 있는 하드웨어와 일치하지 않는 전문 렌더링 알고리즘이 필요하다는 것입니다.
기존의 NeRF 구현에서는 밀도와 radiance를 추정하고 통합하기 위해 각 픽셀에 대해 ray를 따라 수백 개의 샘플 위치에서 대규모 MLP를 평가하는 볼륨 렌더링 알고리즘을 사용합니다.
이 렌더링 프로세스는 대화형 시각화에 비해 너무 느립니다.
최근의 연구는 NeRF를 희소한 3D 복셀 그리드에 "baking"함으로써 이 문제를 해결했습니다 [21, 51].
예를 들어, Hedman et al.은 각 활성 복셀이 불투명, 확산 색상 및 학습된 피쳐 벡터를 포함하는 Sparse Neural Radiance Grids (SNeRG) [21]를 도입했습니다.
SNeRG에서 이미지 렌더링은 두 단계로 나뉩니다: 첫 번째는 ray marching을 사용하여 각 ray를 따라 사전 계산된 확산 색상과 피쳐 벡터를 축적하고, 두 번째는 축적된 피쳐 벡터에서 작동하는 경량 MLP를 사용하여 누적된 확산 색상에 추가된 뷰 의존적 잔차를 생성합니다.
이러한 사전 계산 및 지연된 렌더링 접근 방식은 NeRF의 렌더링 속도를 3배까지 향상시킵니다.
그러나 각 픽셀에 대한 피쳐를 생성하기 위해 희소 복셀 그리드를 통한 ray marching에 여전히 의존하므로 상용 그래픽 처리 장치(GPU)에서 사용할 수 있는 병렬을 완전히 활용할 수 없습니다.
또한 SNeRG는 볼륨 텍스처를 저장하기 위해 상당한 양의 GPU 메모리가 필요하므로 일반적인 모바일 장치에서 실행할 수 없습니다.
본 논문에서는 다양한 일반 모바일 장치에서 대화형 프레임 속도로 실행할 수 있는 NeRF인 MobileNeRF를 소개합니다.
NeRF는 폴리곤이 대략 장면의 표면을 따르는 텍스처 폴리곤 세트로 표현되며 텍스처 아틀라스는 불투명도와 피쳐 벡터를 저장합니다.
이미지를 렌더링하기 위해 Z 버퍼링이 있는 고전적인 폴리곤 래스터화 파이프라인을 사용하여 각 픽셀에 대한 피쳐 벡터를 생성하고 GLSL 단편 셰이더에서 실행되는 경량 MLP로 전달하여 출력 색상을 생성합니다.
이 렌더링 파이프라인은 ray를 샘플링하거나 다각형을 depth 순서대로 정렬하지 않으므로 이진 불투명도만 모델링할 수 있습니다.
그러나 최신 그래픽 하드웨어에서 z 버퍼와 프래그먼트 셰이더가 제공하는 병렬성을 최대한 활용하므로 표준 테스트 장면에서 동일한 출력 품질로 SNeRG보다 10배 더 빠릅니다.
또한 거의 모든 컴퓨팅 플랫폼에서 구현되고 가속화되는 표준 폴리곤 렌더링 파이프라인만 필요하므로 이전에는 대화형 속도로 NeRF 시각화를 지원할 수 없었던 휴대 전화 및 기타 장치에서 실행됩니다.
Contributions.
요약하자면, MobileNeRF:
• 동일한 출력 품질로 SOTA(SNeRG)보다 10배 더 빠릅니다;
• 볼륨 텍스처 대신 표면 텍스처를 저장하여 메모리 소비를 줄여 메모리와 전력이 제한된 통합 GPU에서 실행할 수 있습니다;
• 웹 브라우저에서 실행되며 뷰어가 HTML 웹 페이지이기 때문에 테스트한 모든 장치와 호환됩니다;
• 단순한 삼각망이므로 재구성된 객체/장면을 실시간으로 조작할 수 있습니다.
2. Related work
우리의 연구는 라이트 필드, 이미지 기반 렌더링 및 신경 렌더링 등 많은 연구 영역을 포괄하는 뷰 합성 분야에 있습니다.
범위를 좁히기 위해 출력 뷰를 실시간으로 렌더링하는 방법에 중점을 둡니다.
라이트 필드 [27] 및 Lumigraphs [19]는 이미지의 조밀한 그리드를 저장하여 카메라 자유도가 제한되고 상당한 스토리지 오버헤드가 있지만 고품질 장면의 실시간 렌더링을 가능하게 합니다.
optical flow [5]를 가진 중간 이미지를 보간하거나, 라이트 필드를 신경망[1]으로 표현하거나, 장면의 다중 평면 이미지(MPI) 표현을 재구성하여 저장 공간을 줄일 수 있습니다 [15,32,37,47,54].
다중 구 이미지는 더 큰 시야[2,6]를 가능하게 하지만 이러한 표현은 여전히 제한된 출력 카메라 모션만 지원합니다
다른 접근 방식은 명시적인 3D 지오메트리를 활용하여 더 많은 카메라 자유를 가능하게 합니다.
초기 방법은 3D 메시[7, 12, 13]에 뷰 의존적 텍스처링을 적용했지만, 이후 방법은 품질을 개선하기 위한 사후 처리 단계로 컨볼루션 신경망을 통합했습니다[20, 31, 44].
또는 입력 지오메트리를 알파[28]를 사용하여 질감이 있는 평면 집합으로 단순화할 수 있습니다.
포인트 기반 표현은 사후 처리 네트워크를 학습하는 동안 장면 형상을 공동으로 개선하여 품질을 더욱 향상시킵니다 [24, 25, 40].
그러나 이 컨볼루션 후 처리는 출력 프레임별로 독립적으로 실행되므로 3D 일관성이 부족한 경우가 많습니다.
또한 우리의 작업과 달리 강력한 데스크톱 GPU가 필요하며 모바일 장치에서 실행되는 것으로 입증되지 않았습니다.
마지막으로, 위의 대부분의 방법과 달리, 우리의 방법은 재구성된 3D 기하학을 입력으로 필요로 하지 않습니다.
또한 미분 가능한 역 렌더링을 통해 명시적인 삼각망을 추출할 수 있습니다 [11, 16, 35].
DefTet [16]은 각 꼭짓점에서 점유율과 색상이 있는 사면체 그리드를 미분적으로 렌더링한 다음 ray를 따라 교차된 모든 면에서 보간된 값을 합성합니다.
NVDiffRec [35]는 미분 가능한 marching tetrahedra [42]를 미분 가능한 래스터화와 결합하여 전체 역 렌더링을 수행하고 이미지에서 삼각망, 재료 및 조명을 추출합니다.
이 표현을 사용하면 정교한 편집 및 장면 재조명이 가능합니다.
그러나 뷰 합성 품질에서 상당한 loss가 발생합니다.
또한 간단한 조명으로 실시간 렌더링이 가능하지만 모바일 하드웨어에서는 전역 조명(GI)이 계산적으로 불가능합니다.
대조적으로, 우리의 방법은 GI 효과를 모델링하기 위해 값비싼 계산이 필요하지 않고 더 높은 뷰 합성 품질을 초래하는 나가는 radiance를 단순히 캐시합니다.
NeRF [33]은 장면을 불투명도 및 뷰 의존적인 색상의 연속 필드로 나타내며 볼륨 렌더링으로 이미지를 생성합니다.
이 표현은 3D 일관성이 있으며 고품질 결과에 도달합니다[3,45].
그러나 NeRF를 렌더링하려면 픽셀당 여러 3D 위치에서 대규모 신경망을 평가하여 실시간 렌더링을 방지해야 합니다.
최근의 연구는 NeRF의 학습 속도를 향상시켰습니다.
예를 들어, 포인트[29] 대신 전체 ray 세그먼트의 불투명도와 색상을 모델링하거나 장면을 세분화하고 더 작은 신경망으로 각 하위 영역을 모델링합니다[38].
최근에는 작은 신경망으로 3D 임베딩에서 가져온 피쳐를 디코딩하여 상당한 속도 향상을 달성했습니다.
이 임베딩은 고밀도 복셀 그리드 [23, 43], 희소 복셀 그리드 [41], 복셀 그리드 [9]의 낮은 순위 분해, 포인트 기반 표현 [50] 또는 다중 해상도 해시 맵 [34]일 수 있습니다.
이러한 3D 임베딩은 학습된 디코더 없이도 사용될 수 있습니다, 예를 들어, 확산 색상을 직접 저장하거나 뷰 의존 색상을 구면 고조파로 인코딩합니다 [41].
이러한 접근 방식은 학습 속도를 크게 향상시키지만 렌더링에는 여전히 대규모 소비자 GPU가 필요합니다.
학습된 NeRF를 후처리하여 렌더링 성능을 더욱 향상시킬 수 있습니다.
예를 들어, 학습된 샘플링을 사용하여 픽셀당 네트워크 쿼리를 줄이고 [36], 더 큰 ray 세그먼트에 대한 네트워크를 평가하거나 [48] 장면을 더 작은 네트워크로 세분화합니다 [38, 39, 49].
또는 사전 계산은 장면 불투명도와 뷰 의존적 색상에 대한 잠재 표현을 그리드에 저장하여 렌더링 속도를 높일 수 있습니다.
FastNeRF [17]은 고밀도 복셀 그리드를 사용하며 전역 구면 기반 함수로 뷰 의존성을 나타냅니다.
PlenOctree [51]에서는 각 잎 노드가 색상에 대한 불투명도와 구면 고조파를 모두 저장하는 8진수 표현을 사용합니다.
SNeRG[21]는 희소 그리드 표현을 사용하며, 작은 신경망을 가진 사후 프로세스로서 뷰 의존성을 평가합니다.
이러한 실시간 방법 중에서 SNeRG만 CUDA에 액세스하지 않고 저전력 장치에서 작동하는 것으로 나타났습니다.
우리의 방법은 저전력 하드웨어에서 렌더링을 직접 타겟으로 하기 때문에 주로 실험에서 SNeRG와 비교합니다.
3. Method
(보정된) 이미지 모음이 주어지면 효율적인 새로운 뷰 합성을 위해 표현을 최적화하려고 합니다.
우리의 표현은 다각형 메시(그림 2a)로 구성되어 있으며 텍스처 맵(그림 2b)은 피쳐와 불투명도를 저장합니다.
렌더링 시 카메라 포즈가 주어지면 2단계 지연 렌더링 프로세스를 채택합니다:
• 렌더링 단계 1 – 메쉬를 래스터화하여 스크린 공간을 만들고 피쳐 이미지(그림 2c)를 구성합니다, 즉, GPU 메모리에 지연 렌더링 버퍼를 생성합니다;
• 렌더링 단계 2 – 우리는 프래그먼트 셰이더에서 실행되는 (신경) 지연 렌더러, 즉 작은 MLP를 통해 이러한 피쳐를 컬러 이미지로 변환하여 피쳐 벡터와 뷰 방향을 수신하고 픽셀 색상을 출력합니다(그림 2d).
우리의 표현은 세 가지 학습 단계로 구성되어 고전적인 NeRF와 같은 연속 표현에서 이산적인 표현으로 점차 이동합니다:
• 학습 단계 1 (섹션 3.1) – 볼륨 렌더링 직교점이 다각형 메시에서 파생되는 연속 불투명도를 가진 NeRF-like 모델을 학습합니다;
• 학습 단계 2 (섹션 3.2) – 불투명도를 이진화합니다, 고전적 래스터화는 조각을 쉽게 폐기할 수 있지만 반투명 조각은 우아하게 처리할 수 없습니다.
• 학습 단계 3 (섹션 3.3) – 희소 다각형 메시를 추출하고 불투명도와 피쳐를 텍스처 맵에 굽고 신경 지연 셰이더의 가중치를 저장합니다.
메시는 OBJ 파일로 저장되고 텍스처 맵은 PNG로 저장되며 지연된 셰이더 가중치는 (작은) JSON 파일에 저장됩니다.
표준 GPU 래스터화 파이프라인을 사용하기 때문에 실시간 렌더러는 HTML 웹 페이지에 불과합니다.
이산 표현으로 연속 신호를 표현하면 앨리어싱을 도입할 수 있기 때문에 슈퍼 샘플링에 기반한 간단하지만 계산적으로 효율적인 안티앨리어싱 솔루션도 자세히 설명합니다(섹션 3.4).

3.1. Continuous training (Training Stage 1)
그림 3에서 볼 수 있듯이, 우리의 학습 설정은 다각형 메시 M=(T, V)와 3개의 MLP로 구성됩니다.
메시 토폴로지 T는 고정되어 있지만 NeRF와 유사하게 정점 위치 V 및 MLP는 학습 이미지에서 픽셀의 예측 색상과 ground truth 색상 사이의 평균 제곱 오차를 최소화하여 자동 디코딩 방식으로 최적화됩니다:
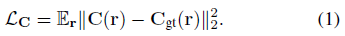
, 여기서 예측 색상 C(.)는 (depth 정렬된) 직교점 K={t_k}_(k =1)^K에서 ray r(t)=o + td를 따라 알파 결합하여 얻을 수 있습니다:
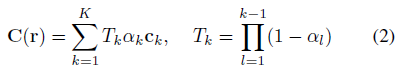
, 여기서 불투명도 α_k와 뷰 의존도 c_k는 위치 p_k=r(t_k)에서 MLP를 평가하여 제공됩니다:
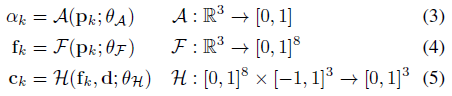
작은 네트워크 H는 우리의 deferred neural shader로, 조각 피쳐와 뷰 방향이 주어진 각 조각의 색상을 출력합니다.
마지막으로, (2)는 체적 밀도[33]로 합성하지 않고 불투명도 [1, Eq.8]로 합성합니다.
Polygonal mesh.
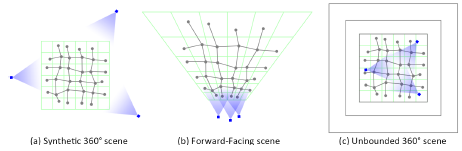
일반성의 loss 없이 Synthetic 360˚ 장면에 사용되는 다각형 메시에 대해 설명하고, 보충자료(섹션 G)에서 Forward-Facing 및 Unbounded 360˚ 장면에 대한 구성을 제공합니다.
2D 그림은 그림 4에서 찾을 수 있습니다.
먼저 원점 중심의 단위 입방체에서 PxPxP 크기의 정규 그리드 G를 정의합니다; 그림 4a를 참조하십시오.
Dual Contouring [10, 22]과 같이 복셀당 하나의 정점을 생성하고, 인접한 네 개의 복셀의 정점을 연결하는 그리드 에지당 하나의 사각형(두 개의 삼각형)을 생성하여 T를 인스턴스화합니다.
복셀 중심(및 크기)과 관련하여 정점 위치를 로컬적으로 매개 변수화하여 V ∈ [-.5,+.5]^(PxPxPx3) 자유 변수를 생성합니다.
최적화하는 동안, 우리는 정점 위치를 정규 유클리드 격자에 해당하는 V=0으로 초기화하고, 정점이 복셀에서 빠져나가는 것을 방지하고 최적화 문제가 충분히 제한될 때마다 중립 위치로 복귀하도록 정규화합니다:
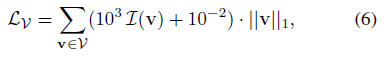
, 여기서 v가 해당 복셀 외부에 있을 때마다 표시기 피쳐 I(v)=1.
Quadrature.
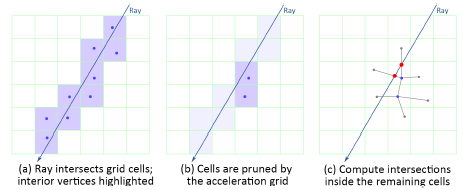
표현의 MLP를 평가하는 것은 계산 비용이 많이 들기 때문에 가속도 그리드에 의존하여 직교점의 카디널리티 |K|를 제한합니다.
우선, 직교 점은 ray와 교차하는 복셀 세트에 대해서만 생성됩니다; 그림 5a: 그러면 InstantNGP [34]처럼 가속 그리드 G를 사용하여 기하학적 구조를 포함할 가능성이 없는 복셀을 제거합니다; 그림 5b를 참조하십시오.
마지막으로, 우리는 복셀의 꼭짓점에 입사하는 M의 면과 ray 사이의 교차점을 계산하여 최종 직교점 세트를 얻습니다; 그림 5c를 참조하십시오.
우리는 무게 중심 보간법을 사용하여 교차점에서 교차 삼각형의 세 꼭짓점까지의 그래디언트를 역전파합니다.
교차로 계산에 대한 자세한 기술적 세부 사항은 독자에게 보충 자료(섹션 F)를 참조하도록 합니다.
요약하면, 각 입력 ray r:
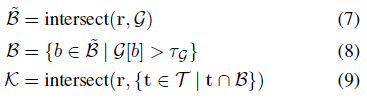
, 여기서 a가 b와 교차하는 경우 (a ∩ b)=true이고, 가속 그리드는 학습 중 시점에 알파 교차 가시성 T_k α_k를 상한으로 하도록 supervise됩니다.
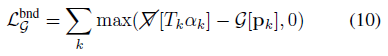
, 여기서 ∇/[.]은 가속 그리드가 이미지 재구성 품질에 (부정적인) 영향을 미치지 않도록 하는 스탑-그래디언트 연산자입니다.
이는 nerf2nerf[18]에서와 같이 학습 후가 아니라 NeRF 학습 중에 소위 "surface field"를 계산하는 방법으로 해석될 수 있습니다.
Plenoxels [41]와 마찬가지로, 우리는 점별 희소성(즉, lasso)과 공간적 부드러움을 촉진하여 그리드의 내용을 추가로 정규화합니다:
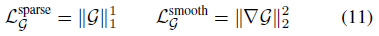
3.2. Binarized training (Training Stage 2)
일반적인 하드웨어에 구현된 렌더링 파이프라인은 기본적으로 반투명 메쉬를 지원하지 않습니다.
반투명 메쉬를 렌더링하려면 프레임별로 번거로운 정렬이 필요하므로 올바른 알파 합성을 보장하기 위해 back-to-front 순서로 렌더링을 실행해야 합니다.
우리는 매끄러운 불투명도 α_k ∈ [0, 1]를 (3)에서 이산/범주 불투명도 ^α_k ∈ {0, 1}로 변환하여 이 문제를 극복합니다.
photometric supervision을 통해 이산 불투명도를 최적화하기 위해 직선 추정기[4]를 사용합니다:
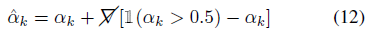
그래디언트는 α_k 값과 결과 ^α_k ∈ {0,1}에 관계없이 이산화 작업(즉, ∇^α ≡ ∇α)을 통해 투명하게 전달됩니다.
그런 다음 학습을 안정화하기 위해 연속 모델과 이산 모델을 함께 학습합니다:
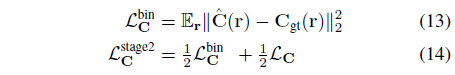
여기서 ^C(r)는 이산 불투명도 모델 ^α에 해당하는 출력 radiance입니다:
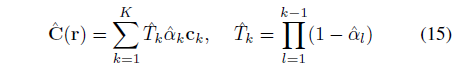
(14)가 수렴되면 다른 가중치를 고정하면서 L_C^bin을 최소화하여 F와 H의 가중치에 미세 조정 단계를 적용할 것입니다.
3.3. Discretization (Training Stage 3)
이진화 및 미세 조정 후 표현을 명시적 다각형 메쉬(OBJ 형식)로 변환합니다.
학습 카메라 포즈에서 쿼드가 적어도 부분적으로 보이는 경우에만 쿼드를 저장합니다(즉, 비선택적 쿼드는 버려집니다).
그런 다음 눈에 보이는 쿼드의 수에 비례하는 크기의 텍스처 이미지를 생성하고 각 쿼드에 대해 디즈니의 Ptex [8]과 유사하게 텍스처에 K x K 패치를 할당합니다.
실험에서 K=17을 사용하여 쿼드는 16x16 텍스처에 0.5픽셀 경계 패딩을 사용합니다.
그런 다음 텍스처의 픽셀에서 반복하여 픽셀 좌표를 3D 좌표로 변환하고 이산 불투명도 (예, (3) 및 (12))와 피쳐 (예, (4))의 값을 텍스처 맵에 굽습니다.
[0, 1] 범위를 8비트 정수로 양자화하고 텍스처를 (손실 없이 압축된) PNG 이미지에 저장합니다.
실험 결과 [0, 1] 범위를 역변환 시 설명되지 않는 8비트 정밀도로 양자화해도 렌더링 품질에 큰 영향을 미치지 않는 것으로 나타났습니다.
3.4. Anti-aliasing
고전적인 래스터화 파이프라인에서 앨리어싱은 고품질 렌더링을 얻기 위해 고려되어야 하는 문제입니다.
고전적인 NeRF는 반투명 볼륨을 통해 매끄러운 에지를 환영하지만, 앞서 논의한 바와 같이 반투명은 프레임별 다각형 정렬을 필요로 할 것입니다.
우리는 슈퍼 샘플링에 의한 안티 앨리어싱을 사용하여 이 문제를 극복합니다.
(5)를 단순히 4회 실행하고 결과 색상을 평균할 수 있지만, 지연 신경 셰이더 H의 실행은 우리 기술의 계산 병목 현상입니다.
우리는 출력을 평균화하는 대신 피쳐, 즉 지연 신경 셰이더의 입력을 평균화함으로써 이 문제를 극복할 수 있습니다.
먼저 피쳐를 (2배 해상도로) 래스터화합니다:
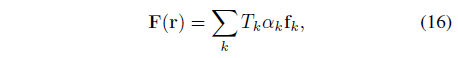
그런 다음 신경 지연 쉐이더에 공급되는 안티 앨리어싱 표현을 생성하기 위한 평균 하위 픽셀 피쳐:
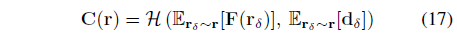
여기서 E_(r_δ~r)는 하위 픽셀(즉, 구현의 4개) 사이의 평균을 계산하고, d_δ는 ray r_δ의 방향입니다.
이 변경에서 H는 출력 픽셀당 한 번만 쿼리하는 방법에 주목하십시오.
마지막으로, 이 프로세스는 이산 점유 ^α에 대해 (15)에 유사하게 적용됩니다.
안티 앨리어싱을 위한 이러한 변경 사항은 학습 2 단계(14)에서 적용됩니다.
3.5. Rendering
최적화 프로세스의 결과는 텍스처링된 다각형 메시(텍스쳐 맵이 색상이 아닌 피쳐를 저장하는 경우)와 작은 MLP(뷰 방향과 피쳐를 색상으로 변환하는 경우)입니다.
이 표현은 지연된 렌더링 파이프라인을 사용하여 두 번의 패스로 수행됩니다:
1. 텍스처링된 메시의 모든 면을 z-버퍼로 래스터화하여 픽셀당 12개 채널로 2M x 2N 피처 이미지를 생성합니다.
학습된 피처의 8개 채널, 이진 불투명도 및 3D 뷰 방향으로 구성됩니다;
2. 피쳐 이미지를 텍스처로 사용하는 텍스처링된 직사각형을 렌더링하여 M x N 출력 RGB 이미지를 합성하고, 선형 필터링을 통해 안티앨리어싱을 위한 피쳐를 평균화합니다.
0이 아닌 알파를 가진 픽셀에 대해 작은 MLP를 적용하여 피쳐를 RGB 색상으로 변환합니다.
작은 MLP는 GLSL 조각 쉐이더로 구현됩니다.
이러한 렌더링 단계는 고전적인 래스터화 파이프라인 내에서 구현됩니다.
이진 투명도를 갖는 z-버퍼링은 순서에 독립적이기 때문에 새로운 뷰마다 깊이 순서로 다각형을 정렬할 필요가 없으므로 실행을 시작할 때 한 번 GPU의 버퍼에 로드할 수 있습니다.
피쳐를 색상으로 변환하기 위한 MLP가 매우 작기 때문에 모든 픽셀에 대해 병렬로 실행되는 GLSL 프래그먼트 쉐이더[21]에 구현될 수 있습니다.
이러한 고전적인 렌더링 단계는 GPU에서 매우 최적화되어 있으므로 렌더링 시스템은 다양한 장치에서 대화형 프레임 속도로 실행될 수 있습니다.
표 2를 참조하십시오.
프래그먼트 쉐이더를 사용한 표준 다각형 렌더링만 필요하기 때문에 구현하기도 쉽습니다.
대화형 뷰어는 WebGL이 threejs 라이브러리를 통해 렌더링한 Javascript가 있는 HTML 웹 페이지입니다.
4. Experiments
우리는 다양한 장면과 장치에서 MobileNeRF의 성능을 테스트하기 위해 일련의 실험을 실행합니다.
우리는 세 가지 데이터 세트에서 테스트합니다: NeRF[33]의 8개의 synthetic 360˚ 장면, LLFF[32]의 8개의 전향 장면, Mip-NeRF 360[3]의 5개의 무한 360˚ 야외 장면을 비교합니다.
우리가 아는 한, NeRF는 일반적인 장치에서 실시간으로 실행될 수 있는 유일한 NeRF 모델이기 때문입니다.
또한 다양한 설계 선택의 영향을 조사하기 위한 광범위한 ablation 연구도 포함되어 있습니다.
4.1. Comparisons
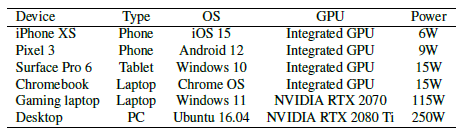
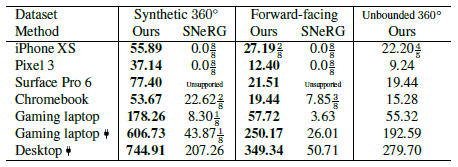
이 방법의 우수한 성능과 호환성을 보여주기 위해 표 1과 같이 다양한 장치에서 방법 및 SNeRG를 테스트합니다.
표 2에 렌더링 속도를 보고합니다.
렌더링 해상도는 학습 이미지와 동일합니다: synthetic의 경우 800x800, 전방의 경우 1008x756, 경계가 없는 경우 1256x828입니다.
우리는 크롬 브라우저에서 모든 방법을 테스트하고 카메라를 전체 원으로 회전/패닝하여 360 프레임을 렌더링합니다.
SNeRG는 정기적인 그리드 표현으로 인해 경계가 없는 360˚ 장면을 표현할 수 없으며 호환성 또는 메모리 부족 문제로 인해 전화나 태블릿에서 실행되지 않습니다.
또한 표 3에 GPU 메모리 소비 및 저장 비용을 보고합니다.
MobileNeRF는 SNeRG보다 5배 적은 GPU 메모리를 필요로 합니다.

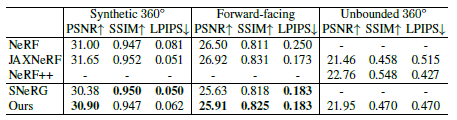
Rendering quality.
우리는 표 4에 렌더링 품질을 보고하는 한편 일반적인 PSNR, SSIM [46] 및 LPIPS [53] 메트릭을 사용하는 다른 방법과 비교합니다.
우리의 방법은 SNeRG와 거의 동일한 화질을 가지며 NeRF보다 우수합니다.
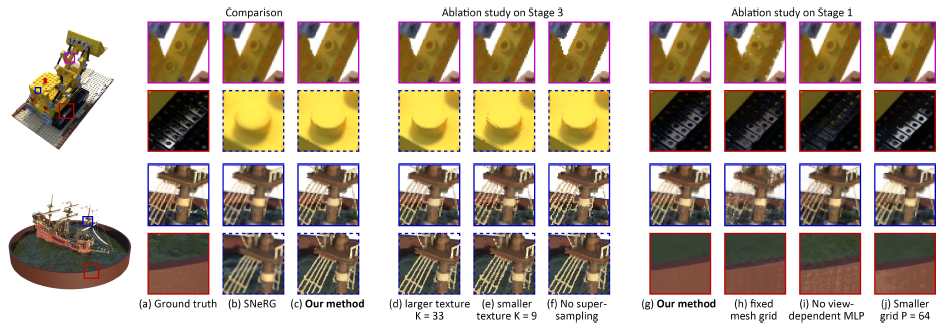
시각적 결과는 그림 6(a-c)에 나와 있습니다.
우리의 방법은 카메라가 적절한 거리에 있을 때 SNeRG와 유사한 화질을 달성합니다.
카메라가 줌인되면 SNeRG는 오버 스무트된 이미지를 렌더링하는 경향이 있습니다.

Polygon count.
표 5는 우리의 방법으로 생성된 정점과 삼각형의 평균 수와 초기 메시에서 사용 가능한 모든 정점/삼각형과 비교한 백분율을 보여줍니다.
우리는 가시적인 삼각형만 유지하기 때문에, 최종 메시에서 대부분의 정점/삼각형이 제거됩니다.

Shading mesh.
그림 2a 및 그림 7에서 우리는 추출된 삼각형 메쉬를 텍스처 없이 보여줍니다.
대부분의 삼각형 면은 실제 객체 표면과 정렬되지 않습니다.
이는 삼각형이 정렬된 방식에도 불구하고 좋은 렌더링 품질을 달성할 수 있다는 모호성 때문일 수 있습니다.
예를 들어 표 6의 단계 1 이후 방법의 결과는 표 4의 다른 방법과 유사합니다.
따라서 더 나은 표면 품질을 가지기를 원한다면 더 나은 정규화 loss 또는 training objective를 고안해야 합니다.
그러나 그림 6h와 같이 정점을 최적화하면 렌더링 품질이 향상됩니다.
4.2. Ablation studies
표 6에서는 각 단계에서 방법의 렌더링 품질을 보여주고 ablation 연구를 보고합니다.
각 단계가 모델에 더 많은 제약을 가하기 때문에 렌더링 품질은 각 단계 후에 점차 떨어집니다.
1단계에서는 최적화된 메쉬 정점을 갖는 대신 고정된 일반 그리드 메쉬를 사용하거나 각 점의 색상과 알파를 직접 예측하여 뷰 의존적 효과를 포기하는 경우 성능이 크게 떨어집니다.
그리드가 더 작으면 성능이 약간 떨어집니다(P=64 vs. 128).
가속 그리드를 제거하면 학습 중 배치 크기를 4배로 늘릴 수 없습니다; 이 모델을 학습시킬 때 이 방법과 동일한 횟수의 반복을 수행하면 성능이 떨어집니다.
이 모델의 PSNR은 전방 장면에서 더 높습니다.
이는 가속 그리드가 학습 이미지에 보이지 않는 셀을 제거하므로 객체를 "inpaint"할 수 없고 구멍을 남길 수 있기 때문입니다.
2단계에서 F와 H만 최적화하고 다른 사람의 가중치를 고정하는 미세 조정 단계를 수행하지 않으면 성능이 떨어집니다.
식 14 대신 L_C^stage2 = L_C^bin을 적용하여 pseudo-그래디언트가 있는 이진법만 사용하면 성능이 떨어집니다.
예측된 불투명도에서 이진 loss를 사용하면 ^C(r)가 있는 pseudo-gradients를 사용하는 대신 L_binary = -∑ |α_k-0.5|를 사용하면 성능이 약간 떨어집니다.
3단계에서 식 17 대신 더 큰 텍스처 크기 K=33을 사용하면 성능은 향상되지만 텍스처 크기는 4배가 됩니다; 작은 텍스쳐 크기 K=9를 사용하면 성능이 떨어집니다.
초정밀 단계를 제거하면 성능이 크게 떨어집니다.
시각적인 결과는 그림 6에 나와 있습니다.
일부 모델은 방법과 비교하여 시각적으로 큰 차이가 없기 때문에 생략합니다.
텍스쳐 이미지의 제곱 픽셀은 (e)의 점선 상자에서 분명히 보이고 (d)에는 거의 보이지 않습니다.
앨리어싱 아티팩트는 (f)의 실선 상자에서 두드러집니다.
1단계에서 격자 정점을 최적화할 수 없으면 (h)와 같이 결과가 상당히 나빠질 것입니다.
작은 MLP가 없으면 (i)와 같이 모델은 반사를 처리할 수 없습니다.
작은 격자 크기로 변경하면 (j)에 약간의 작은 아티팩트가 추가됩니다. 표 7에서 렌더링 속도와 공간 비용을 보여줍니다.
우리는 더 크거나 작은 텍스쳐 크기를 사용하거나 초정밀 단계를 제거하거나 뷰 의존적인 색상을 예측하기 위해 작은 MLP를 사용하지 않고 래스터화만 수행하는 경우입니다.
초정밀 단계와 작은 MLP가 가장 큰 영향을 미친다는 것을 알 수 있습니다.
5. Conclusions
기존 래스터화 파이프라인(즉, z-버퍼 및 조각 쉐이더)을 활용하여 광범위한 컴퓨팅 플랫폼에서 표면 기반 신경 필드의 효율적인 렌더링을 수행하는 아키텍처인 MobileNeRF를 소개합니다.
이전의 SOTA (SNeRG)보다 더 빠른 프레임 레이트를 달성하는 동시에 동등한 품질의 이미지를 생성합니다.

Limitations.
추정 표면은 특히 정반사 표면 및/또는 희소 뷰가 있는 장면의 경우 부정확할 수 있습니다(그림 8a); 폴리곤 정렬을 피하기 위해 이진 불투명도를 사용하므로 반투명도가 있는 장면을 처리할 수 없습니다(그림 8b); 고정 메쉬 및 텍스처 해상도를 사용합니다, 이 해상도는 근접 신규 뷰 합성에 너무 거칠 수 있습니다(그림 8c); 조명과 반사율을 명시적으로 분해하지 않고 래디언스 필드를 모델링하므로 최근 방법뿐만 아니라 광택이 있는 표면도 처리하지 않습니다 [45].
효율적인 부분 정렬, 세부 수준, mipmap 및 표면 음영으로 폴리곤 렌더링 파이프라인을 확장하면 이러한 문제 중 일부를 해결할 수 있습니다.
또한, NeRF의 MLP 백본 때문에 MobileNeRF의 현재 학습 속도가 느립니다.
MobileNeRF를 빠른 학습 아키텍처(예: Instant NGP [34])로 확장하는 것은 향후 작업을 위한 흥미로운 길을 구성합니다.
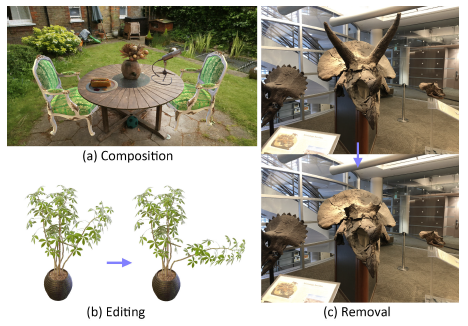
MobileNeRF에서 제공하는 명시적인 메쉬 표현은 복잡한 아키텍처 변경 없이 NeRF 모델을 직접 편집할 수 있지만(예: Control-Nerf [26]), 본 논문에서는 이러한 가능성에 대해 피상적으로만 조사했습니다.
그림 9 및 부록의 비디오(섹션 B)를 참조하십시오.