2023. 6. 5. 17:36ㆍView Synthesis
MEIL-NeRF:
Memory-Efficient Incremental Learning of Neural Radiance Fields
Jaeyoung Chung, Kanggeon Lee, Sungyong Baik, Kyoung Mu Lee
Abstract
신경망의 표현력에 의존하는 neural radiance fields (NeRF)는 최근 3D 객체 및 장면 표현에 대해 유망하고 널리 적용 가능한 방법 중 하나로 부상했습니다.
그러나 NeRF는 데이터를 순차적으로 처리해야 하는 대규모 장면 및 메모리 양이 제한된 에지 장치와 같은 실용적인 응용 분야에서 과제에 직면해 있습니다.
이러한 점진적인 학습 시나리오에서 신경망은 치명적인 망각을 겪는 것으로 알려져 있습니다: 새로운 데이터로 학습을 받은 후 이전에 본 데이터를 쉽게 잊어버립니다.
우리는 이전의 incremental learning 알고리즘이 낮은 성능 또는 메모리 확장성 문제에 의해 제한된다는 것을 관찰합니다.
따라서 Memory-Efficient Incremental Learning algorithm for NeRF (MEIL-NeRF)를 개발합니다.
MEIL-NeRF는 신경망이 쿼리로 ray가 주어진 픽셀 RGB 값을 제공하는 메모리 역할을 할 수 있다는 점에서 NeRF 자체에서 영감을 얻습니다.
동기 부여에 따라 프레임워크는 NeRF를 쿼리하여 이전 픽셀 값을 추출할 ray를 학습합니다.
그런 다음 추출된 픽셀 값은 치명적인 망각을 방지하기 위해 self-distillation 방식으로 NeRF를 학습하는 데 사용됩니다.
그 결과, MEIL-NeRF는 지속적인 메모리 소비와 경쟁력 있는 성능을 보여줍니다.
1. Introduction
3D 객체 및 장면의 표현 및 재구성은 가상 현실 [5,16], 자율 주행 [21,30] 및 로봇 공학 [2,14,40]과 같은 광범위한 응용 분야에서 중요한 컴퓨터 비전 및 컴퓨터 그래픽 작업입니다.
최근 neural radiance fields (NeRF)[36]는 신경망의 표현력을 활용하여 상당한 개선을 가져왔습니다.
그들은 카메라 ray를 따라 공간 위치와 뷰 방향을 쿼리하고 볼륨 렌더링 기술을 사용하여 출력 색상과 밀도를 통합하여 MLP 네트워크로 정적 장면을 나타냅니다.
그러나 이러한 뛰어난 성능을 달성하기 위해 NeRF는 모든 데이터(즉, 모든 관점에서 본 장면의 RGB 값)에 한 번에 액세스한다고 가정합니다.
이러한 제약으로 인해 NeRF가 순차적으로 데이터를 처리해야 하는 실제 애플리케이션—예: 메모리 양이 제한된 대규모 장면 및 에지 장치—에 적용되지 않습니다.
즉, NeRF는 그림 1과 같이 장면을 점진적으로 학습하며, 그 부분적인 정보는 매번 몇 가지 관점에서 볼 수 있습니다.

이러한 점진적인 학습 시나리오에서 신경망은 치명적인 망각을 겪는 것으로 알려져 있습니다 [15]: 오래된 지식은 새로운 지식을 배우는 동안 잊혀집니다.
분류 문제에 대한 치명적인 망각[11]의 부작용을 완화하기 위해 다양한 incremental learning 알고리즘이 개발되었습니다.
그 중에서도 재생을 위해 메모리에 소량의 데이터를 저장하는 방식이 간편하고 성능이 뛰어나 주목을 받고 있습니다.
일부 연구[50,62]는 동시 로컬화 및 매핑(SLAM)에 대해 NeRF와 함께 이러한 재생 방법을 사용했습니다.
단순성과 주목할 만한 성능에도 불구하고 이러한 재생 기반 방법은 실제 응용 분야에서 사용해야 하는 중요한 단점이 있습니다: 메모리의 단조로운 증가로 인한 확장성 문제.

NeRF의 incremental learning 문제에 대한 연구 부족을 고려하여, 먼저 카메라가 이전에 본 장면의 부분을 다시 방문하지 않는 새로운 벤치마크를 소개합니다(그림 2a).
그런 다음, 우리는 NeRF를 몇 가지 대표적인 incremental learning 알고리즘으로 학습시켜 3D 표현의 맥락에서 효과를 평가합니다.
낮은 성능 또는 메모리 확장성 문제를 겪고 있는 것으로 확인되었습니다.
낮은 성능은 주로 이전 데이터에 대한 액세스 권한이 없기 때문인 반면 메모리 확장성 문제는 이전 데이터를 저장하기 위해 메모리를 늘려야 하기 때문입니다.
균형을 맞추기 위해 Memory-Efficient Incremental Learning of NeRF (MEIL-NeRF)를 도입합니다.
메모리를 늘리지 않고 치명적인 망각을 방지하기 위해 신경망 자체에 관심을 돌립니다.
NeRF에서 신경망은 ray 또는 관점이 입력으로 제공될 때 픽셀 RGB 값을 생성합니다.
따라서, 우리는 신경 네트워크를 장면의 픽셀 RGB 값에 대한 메모리 저장소로 간주합니다.
제안된 관점은 다음과 같은 질문을 제기합니다: 이전에 본 장면의 픽셀 RGB 값이 검색되도록 NeRF에 어떤 ray를 제공해야 합니까?
ray가 장면을 향할 때만 네트워크에서 장면의 픽셀 RGB 값을 추출할 수 있습니다.
이 작업에서, 우리는 이전에 본 장면을 향하는 ray를 생성하도록 학습된 Ray Generator Network (RGN)이라는 또 다른 작은 네트워크를 소개함으로써 질문에 답합니다.
그런 다음 생성된 ray를 NeRF에 공급하여 장면의 이전 RGB 값을 얻습니다, 이전의 RGB 값을 잊어버리는 것을 방지하기 위해 self-distillation[61] 방식으로 NeRF를 학습하는 데 사용됩니다.
실험 결과는 제안된 프레임워크가 그림 2b에 표시된 것처럼 메모리를 늘리지 않고 NeRF에서 치명적인 망각의 악영향을 크게 줄인다는 것을 보여줍니다.
메모리 효율적인 incremental learning 알고리즘은 NeRF를 메모리 저장소로 고려하고 이전 RGB 값을 추출하기 위해 NeRF를 공급할 ray를 기억하기 위해 RGN을 사용하여 실현 가능합니다.
2. Related Works
Neural Radiance Fields.
signed distance function [42], occupancy probability [35] 또는 공간 위치에서 색상 정보 [36, 47]를 학습하여 3D 기하학을 암시적으로 표현하는 시도가 여러 번 있었습니다.
이러한 시도 중에서 neural radiance fields (NeRF)[36]는 높은 재구성 품질에 대한 유망한 방법 중 하나로 부상하여 [3, 4, 9, 18, 22, 27, 28, 33, 37, 44, 52-55, 57-59] 및 광범위한 응용 분야에 대한 많은 연구에 박차를 가했습니다: 제어 가능한 인간 아바타 [10, 29, 43], 현실 게임 [17], 로봇 공학 [20, 41, 50, 62], 3D 인식 이미지 생성 [6, 7], 데이터 압축 [13].
주어진 이미지와 해당 카메라 포즈가 주어지면 NeRF는 카메라 ray를 캐스팅하고 샘플 포인트와 뷰 방향을 쿼리한 다음 마지막으로 카메라 ray를 따라 출력 색상과 밀도를 누적하여 이미지를 합성합니다.
NeRF는 학습을 위해 모든 데이터(예: 관점 및 해당 장면 색상)에 대한 액세스를 가정하기 때문에, NeRF는 그러한 가정이 유지되지 않는 실제 애플리케이션(예: 메모리 양이 제한된 에지 장치)에서 과제에 직면합니다.
따라서 NeRF는 이전에 관찰된 데이터에 액세스하지 않고 온라인 데이터 스트림으로 장면을 학습해야 합니다.
Incremental learning.
위에서 설명한 것과 같은 incremental learning 시나리오에서 신경망은 새로운 지식을 학습하는 동안 이전에 학습한 지식을 잊어버리는 것으로 알려져 있으며, 이를 재앙적 망각이라고 합니다 [15].
분류 작업에 대한 치명적인 망각을 완화하기 위한 많은 연구가 있었습니다.
incremental learning 알고리즘은 세 가지 방법론으로 나눌 수 있습니다: regularization, parameter isolation 및 replay [11].
regularization 기반 방법은 새로운 데이터(새로운 지식)에 대한 매핑을 학습하면서 과거 데이터(이전 지식)에 대한 학습된 매핑을 유지하는 것을 목표로 합니다.
이를 위해 여러 연구[1, 8, 23, 60]는 오래된 지식에 중요한 매개 변수를 찾고 새로운 지식을 배우는 동안 그러한 중요한 매개 변수의 변화를 정규화하려고 노력합니다.
대조적으로, 다른 연구는 분류의 맥락에서 새로운 클래스를 학습하면서 이전에 학습된 클래스[12, 26]에 대한 출력의 변화를 정규화하는 것을 목표로 합니다.
한편, parameter isolation 방법 [19,31,32,45]은 각 데이터 유형(즉, 작업)에 대해 별도의 하위 네트워크를 학습하려고 시도합니다.
마지막으로, replay 기반 방법은 학습 중에 새로운 데이터와 함께 사용되는 과거 데이터의 선택된 샘플을 저장하여 오래된 지식을 보존하는 것을 목표로 합니다.
Incremental Learning for Neural Radiance Fields.
simultaneous localization and mapping (SLAM)과 같은 특정 애플리케이션에 맞게 조정된 incremental learning과 NeRF를 통합하려는 연구는 거의 없었습니다.
iMAP [50]은 각 키 프레임에서 소수의 데이터를 지속적으로 선택하여 저장합니다.
반면, NICE-SLAM[62]과 NeRF-SLAM[46]은 각각 피쳐 표현과 다른 NeRF로 다중 스케일 공간 그리드 위치를 예약하여 계층적 볼륨 구조를 사용합니다.
그러나 이러한 방법은 대부분 공간의 규모에 따라 필요한 메모리 양(모델 또는 데이터)이 증가함에 따라 메모리 확장성 문제를 겪습니다.
이 작업에서, 우리는 이전 작업이 낮은 성능 또는 메모리 비효율성을 겪는 것을 관찰합니다.
균형을 맞추기 위해 NeRF가 스토리지 역할을 할 수 있다는 새로운 관점을 제안합니다: 장면을 향한 적절한 ray가 주어지면, 그것은 상응하는 RGB 값을 제공합니다.
따라서 프레임워크가 어떤 ray가 장면을 향하는지 학습하는 경우, NeRF에 ray를 공급하여 과거 데이터(과거 관점에서 본 RGB 값)를 쉽게 검색할 수 있습니다.
그런 다음 NeRF는 검색된 과거 데이터와 함께 새로운 데이터에 대해 학습하여 잊어버리는 것을 방지할 수 있습니다.
동기 부여에 따라, 우리는 주어진 장면과 관련된 ray를 학습하는 다른 네트워크를 소개합니다.
결과적으로, 우리의 프레임워크는 incremental learning 시나리오에서 일정한 메모리로 NeRF에 대한 치명적인 망각을 완화합니다.
3. Problem Statement
제안된 프레임워크의 세부 사항을 탐구하기 전에 incremental learning 시나리오에서 neural radiance fields (NeRF)의 문제 문을 정의하는 것으로 시작합니다.
특히, 우리는 일련의 데이터(즉, 태스크)가 순차적으로 들어오는 task incremental learning 시나리오[11, 26]를 고려합니다.
NeRF의 맥락에서 각 태스크 T는 N개의 이미지와 해당 카메라 포즈로 구성되며, 여기서 N > 1은 각 태스크에서 기하학적 정보를 얻을 수 있도록 보장합니다.
구체적으로, t번째 태스크 T_t는 쌍을 이룬 데이터 세트(X^(t), Y^(t))로 구성됩니다, 여기서 X^(t)는 주어진 N개의 카메라 뷰에서 방출되는 ray 세트이고 Y^(t)는 해당 RGB 색상 세트입니다.
incremental learning을 적용하려면 이전 태스크에 액세스할 수 없는 동안 최신 태스크만 사용할 수 있습니다.
전반적으로, 공식을 고려할 때, incremental learning의 목표는 치명적인 망각을 방지하고 보이는 모든 태스크에서 잘 수행되는 최적의 매개 변수 Θ_opt를 찾는 것입니다:
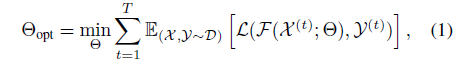
, 여기서 T는 보이는 태스크의 수입니다; L은 loss 함수입니다; F는 X^(t)에서 Y^(t)로의 forward 매핑(NeRF 네트워크 및 볼륨 렌더링으로 구성됨)입니다; 및 Θ는 네트워크의 매개 변수를 나타냅니다.
4. Method
이 섹션에서는 섹션 4.1의 neural radiance fields (NeRF) 공식화로 시작합니다.
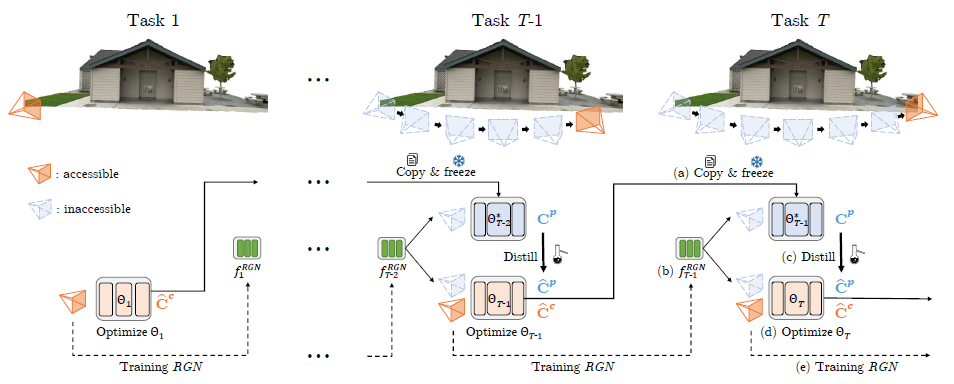
그런 다음 제안된 프레임워크인 MEIL-NeRF를 설명합니다, 이 프레임워크는 새로 도입된 ray generator network (섹션 4.3)에서 발생한 ray와 함께 NeRF 자체(섹션 4.2)에서 검색된 과거 태스크 정보를 사용하여 치명적인 망각을 방지합니다.
전체 파이프라인은 그림 3에 나와 있습니다.
4.1. Preliminaries
NeRF [36]은 3D 좌표 p와 뷰 방향 r_d를 입력으로 하고 RGB 색 c와 부피 밀도 σ를 출력으로 하는 MLP 네트워크로 장면을 표현하는 것을 목표로 합니다.
주어진 카메라 ray r의 해당 픽셀 색상 C는 볼륨 렌더링 [25]에 의해 추정되며, 주어진 카메라 ray r = (r_o, r_d)의 뷰 방향 r_d를 따라 샘플링된 3D 포인트에 대한 직교 규칙 [34]과 합산됩니다, 여기서 각 샘플링된 점은 p_i = r_o + z_i ∗ r_d로 구하며; r_o는 카메라의 좌표이며, z_i는 카메라에서 샘플링된 점 p_i까지의 거리입니다.
따라서, (2)에 의해 ray r의 추정 픽셀 색상 ^C를 구하며, 여기서 α_i = 1 - exp(-σ_i(z_(i+1) - z_i)) 및 P는 샘플링된 포인트의 수입니다.
표기법 혼란을 피하기 위해 ray에서 픽셀 색상으로의 포워드 매핑을 ^C = F(r; Θ)라고 합니다. 여기서 Θ는 MLP 네트워크의 매개 변수입니다.
4.2. MEIL-NeRF
제안된 프레임워크의 핵심 아이디어는 네트워크에 과거 ray를 쿼리하여 과거 카메라 ray의 픽셀 색상을 검색하는 것입니다.
이 섹션에서는 제안된 프레임워크가 치명적인 망각을 방지하기 위해 과거 카메라 ray의 검색된 픽셀 색상을 사용하는 방법을 설명하는 반면, 섹션 4.3에서는 과거 ray가 생성되는 방법에 대해 설명합니다.
네트워크에서 정확한 과거 태스크 정보를 검색할 수 있도록 현재 T번째 태스크에 대한 네트워크 학습 전에 네트워크의 매개 변수를 복사하고 해제합니다.
네트워크는 T-1 이전 태스크에 대해 학습되었기 때문에 Θ_(T-1)*을 사용하여 고정 매개 변수를 나타냅니다.
T번째 태스크에 대한 각 학습 반복에서, 우리는 Θ_(T-1)*을 가진 네트워크에서 과거 카메라 ray의 픽셀 색상을 과거 ray r^p와 함께 공급하여 얻습니다:
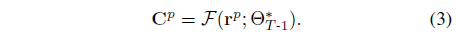
C^p를 pseudo ground truth로 취급하여, 우리는 Θ_T를 최적화하여 self-distillation [61] 방식으로 과거의 태스크를 기억합니다.
따라서 네트워크는 현재 태스크 (r^c, C^c)과 과거 태스크(r^p, C^p)을 학습하도록 학습됩니다:
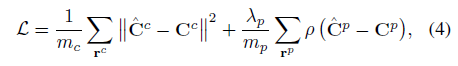
, 여기서 ρ(x) = √(x^2 + ϵ^2)는 Charbonnier페널티 함수입니다; λ_p는 학습 현재 태스크와 과거 태스크 간의 균형을 제어하는 하이퍼 파라미터입니다; m_c 및 m_p는 현재 및 과거 ray의 배치 크기입니다; 및 ˆC^c 및 ˆC^p는 학습 중인 네트워크에 의해 추정되는 색상입니다:
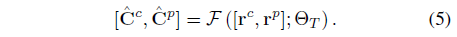
표준 NeRF 학습[36]에서와 같이 현재 데이터를 학습하기 위해 L2 loss를 사용하는 반면, 과거 데이터를 학습하기 위해 Charbonnier 페널티 함수[51]를 채택합니다.
Charbonnier는 L1 거리의 미분 가능한 변형이므로 L2 loss가 다르게 사용될 경우 발생할 수 있는 블러 없이 과거 데이터를 더 잘 보존할 수 있습니다.
각 태스크를 학습할 때 처음에는 λ_p를 작게 설정하고 점차 늘려갑니다.
이러한 스케줄링은 네트워크가 먼저 현재 태스크를 학습한 다음 치명적인 망각을 방지함으로써 학습을 용이하게 합니다.
4.3. Ray Generator Network
따라서, 나이브한 랜덤 ray 생성은 관심 있는 장면을 가리키지 않을 가능성이 높으며, 과거 태스크의 데이터를 제공하지 못합니다.
또 다른 가능한 대안은 과거 태스크와 관련된 카메라 ray를 저장하는 것이지만 메모리 확장성 문제가 있습니다.
대신 관심 있는 장면으로 향하는 과거 카메라 ray를 생성하도록 학습된 ray generator network (RGN)를 소개합니다.
RGN은 실수 x ∈ [0, 1]에서 원점 r_o∗ 및 단위 길이의 ray 방향 r_d∗로 매핑하는 방법을 학습는 작은 MLP 네트워크 f^RGN에 의해 구현됩니다:
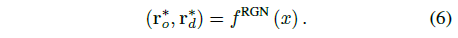
각 태스크에 대해 N개의 카메라와 그에 상응하는 principal ray가 있기 때문에, (T-1)N개의 등간격 숫자 x^(T-1) = [0, 1/((T-1)N-1), 2/((T-1)N-1), ····, 1]은 해당 과거 principal ray에 할당되며, 여기서 x = 0 및 x = 1은 각각 초기 및 최신 principal ray에 해당합니다.
생성된 principal ray(r_o∗, r_d∗)을 중심으로 카메라 intrinsic을 사용하여 principal 주위에 m_p non-principal ray(r_o, r_d)을 생성하지만 원래 r_o = r_o∗:
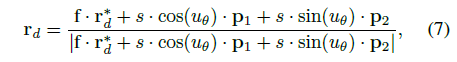
, 여기서 p1, p2는 Gram-Schmidt 프로세스에 의해 얻어진 principal ray에 수직인 단위 벡터입니다; f는 초점 거리입니다; 그리고 s, u_θ은 s ~ U[0,√(W^2 + H^2)/2] 및 u_θ ~ U[0,2π]와 같이 분포가 균일한 랜덤 변수입니다.
이러한 공식화를 통해 RGN의 학습 복잡성을 줄이면서 상당한 양의 ray를 생성할 수 있습니다.
전반적으로, 과거 ray는 식 (7)에 의한 non-principal ray와 함께 x ~ U[0,1]를 공급하여 RGN에서 검색할 수 있습니다.
마찬가지로 새로운 ray가 순차적으로 들어오기 때문에 self-distillation을 통해 RGN의 incremental learning을 수행합니다.
각 태스크의 마지막에 x^(T-1) 조건의 RGN에서 검색된 현재 principal ray (r_o∗, r_d∗)_T와 과거 principal ray (r_o∗, r_d∗)_(1:T-1)을 사용하여 RGN을 업데이트합니다.
그런 다음 MSE loss를 통해 T·N 등간격 숫자 x^T ∈ [0, 1]을 (r_o∗, r_d∗)_(1:T)에 매핑하도록 RGN을 학습합니다:
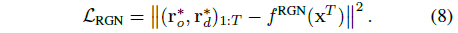
5. Experiment
섹션 5.1의 실험 설정; 섹션 5.2의 incremental learning을 위한 데이터 세트 구성; 섹션 5.3 및 5.4의 실험 결과 및 ablation 연구를 각각 보고합니다.
5.1. Experiment Settings
우리는 incermental 시나리오 하에서 vanilla NeRF를 베이스라인으로 설정하고 NeRF-Incre로 이름을 지정합니다.
NeRF-Incre는 현재 태스크 데이터만 사용하여 incrementally 학습되므로 치명적인 망각에 취약하고 하한 역할을 합니다.
또한 모든 데이터를 항상 사용할 수 있는 표준 joint 학습으로 vanilla NeRF를 학습합니다.
우리는 그것을 NeRF-Joint로 분류하고 상한으로 간주합니다.
또한 NeRF의 대표적인 incremental learning 알고리즘(regularization, parameter isolation 및 replay)과 비교하여 분류 작업을 위해 개발된 알고리즘이 incremental 시나리오에서 NeRF로 일반화되는 방식을 관찰합니다.
regularization의 대표로 선택된 Elastic Weight Consolidation (EWC) [23]은 과거 태스크에 중요한 매개 변수의 변경을 처벌합니다.
parameter isolation을 위해 덜 중요한 매개 변수를 잘라내고 다음 태스크를 위한 공간을 만들기 위해 재학습하는 Pack-Net [32] 아이디어를 채택합니다.
replay에 대해서는 SLAM에 맞게 replay 알고리즘을 조정한 iMAP [50]의 일반적인 구현을 따릅니다.
각 태스크가 끝날 때마다 loss에 가중치를 둔 랜덤 예제를 저장하고, 새로운 태스크를 학습하는 동안 반복합니다.
replay 기반 알고리즘의 성능은 각 태스크에 예약된 메모리 양에 따라 다르기 때문에 메모리 크기를 변경하고 두 가지 버전을 구현합니다: 우리 방법과 비슷한 메모리 사용량을 가진 iMAP와 메모리 사용량을 제한하지 않고 우리와 비슷한 성능을 가진 iMAP*.
각 태스크에 대해 기본적으로 이미지 수 N = 5를 설정하고 태스크당 3000 * N 반복을 실행합니다.
우리는 모든 반복에서 현재 태스크를 학습하기 위해 m_c = 4096 rays를 사용합니다.
우리의 방법과 iMAP는 또한 m_p = m_c / 2 과거 ray에 대해 학습함으로써 망각을 방지합니다, 이는 우리의 방법으로 생성되거나 메모리 버퍼(iMAP)에서 샘플링됩니다.
5.2. Datasets
Tanks and Temples [24], Replica[48] 및 TUM-RGBD [49]를 기반으로 incremental 시나리오에 대한 데이터 세트를 구성합니다.
incremental 시나리오를 시뮬레이션하기 위해 카메라의 순서를 순서대로 다시 정렬하고 이전 이미지가 다시 방문되지 않도록 데이터 세트의 일부를 선택합니다.
Tanks and Temples은 관심 있는 장면이나 물체를 이동하는 동안 찍은 사진으로 구성됩니다.
데이터 세트는 큰 장면(예: Barn)에서 작은 물체(예: Family)에 이르는 다양한 크기의 장면으로 구성됩니다.
우리는 카메라가 한 방향으로 돌아가도록 다시 정렬하고, 첫 번째 장면에 도달하기 전에 시퀀스를 다시 정렬합니다.
Replica 데이터 세트는 정확한 카메라 포즈와 렌더링된 이미지가 있는 합성 실내 데이터 세트입니다.
카메라가 부드럽게 움직이기 때문에, 우리는 태스크 간에 충분한 정도의 변화가 있도록 이미지를 서브샘플링합니다.
TUM-RGBD 데이터 세트는 Tanks and Temple과 마찬가지로 카메라 시퀀스의 일부를 잘라내어 네트워크가 과거 이미지를 검토하지 않습니다.
TUM-RGBD 데이터 세트는 SLAM을 위해 만들어진 데이터 세트로, 휴대용 카메라 또는 로봇에 장착된 카메라로 촬영되었습니다.
이미지는 이동 중에 촬영되기 때문에 대부분의 시퀀스에는 심하게 블러 사진이 있습니다.
치명적인 망각을 더 잘 평가하기 위해 블러 정도가 낮은 시퀀스를 선택합니다.
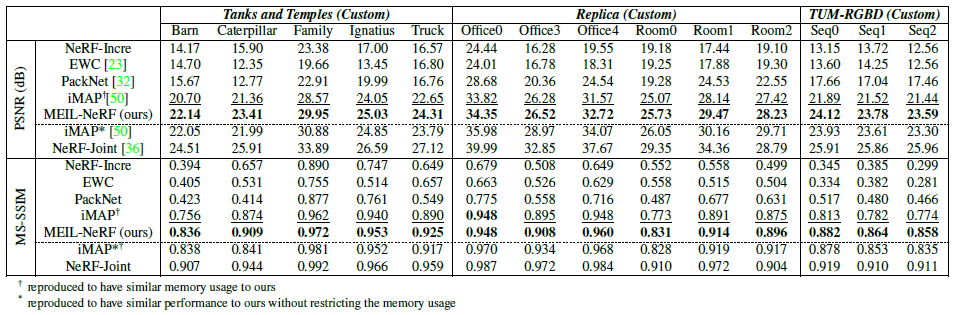
5.3. Results
우리는 Peak Signal-to-Noise Ratio (PSNR) 및 MultiScale Structural Simility Measure (MS-SSIM)과 관련하여 모델을 평가합니다.
표 1의 모든 태스크의 평균 성능과 랜덤으로 선택된 세 개의 장면에 대한 각 태스크의 성능을 그림 5에 보여줍니다.
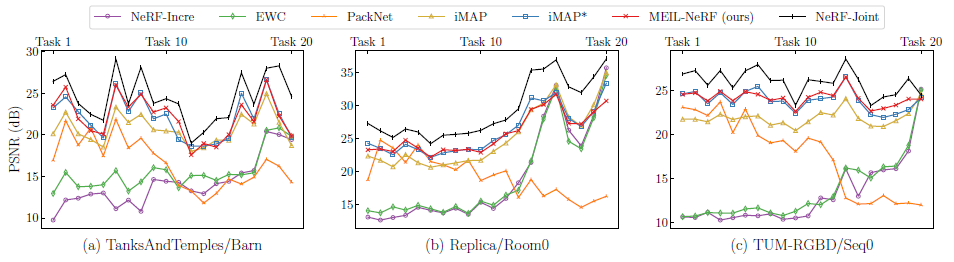
그림 6은 또한 모델이 시간이 지남에 따라 새로운 태스크를 학습하여 치명적인 망각을 보여줌에 따라 첫 번째 태스크(태스크 1)의 성능이 어떻게 변화하는지를 보여줍니다.
NeRF-Incre에서 예상한 대로, 치명적인 망각으로 인해 초기 태스크의 성능이 심각하게 저하됩니다.
EWC는 치명적인 망각의 부작용을 줄이는 데 실패했습니다.
실제로 EWC는 새로운 태스크의 학습을 방해하여 모든 태스크의 평균 성능을 저하시키는 것으로 나타났습니다.
새 태스크에 할당된 매개 변수 수가 점차 줄어들기 때문에 PackNet은 새 태스크에서 성능이 저하됩니다.
반면에 PackNet은 pruning 후 첫 번째 태스크에 대한 매개 변수가 고정되므로 초기 태스크에 대한 성능을 유지합니다.
iMAP는 과거 태스크 데이터를 직접 저장함에도 불구하고 비슷한 양의 메모리를 사용하는 MEIL-NeRF보다 성능이 낮습니다.
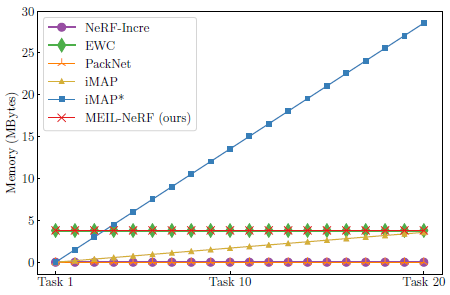
지속적인 메모리 사용으로 MEIL-NeRF는 그림 4와 같이 치명적인 망각을 효과적으로 완화하고 메모리 사용량이 우리 방법보다 상당히 큰 iMAP*과 동등한 성능을 발휘합니다.
이는 NeRF를 메모리 저장소로 사용하고 NeRF 자체에서 과거 정보를 검색하는 효율성과 효과를 보여줍니다.

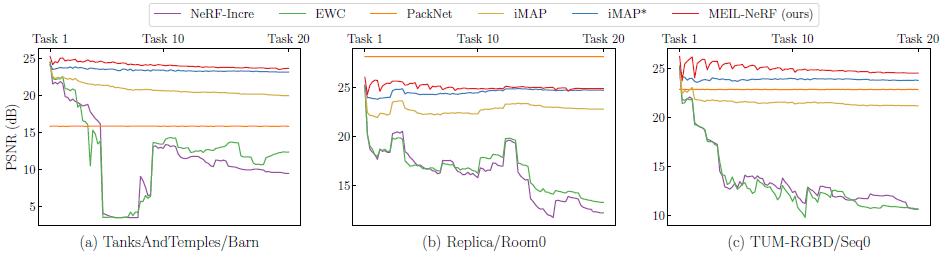
우리는 그림 7에 나타난 질적 결과를 관찰함으로써 더 많은 통찰력을 얻을 수 있습니다.
그림은 incremental learning이 완료된 후(즉, 모든 태스크가 순차적으로 학습됨) 초기 태스크에 대한 이미지 재구성을 보여줍니다.
replay 기반 방법 iMAP*은 비교적 선명한 이미지를 보여주지만 일부 왜곡 아티팩트가 있습니다.
선택한 샘플만 저장되고 반복적으로 사용되기 때문에 iMAP*는 특정 ray에 과적합하여 멀티뷰 일관성을 손상시킵니다.
반대로, MEIL-NeRF는 아티팩트 없이 더 부드러운 재구성을 보여줍니다.
우리의 방법은 RGN과 NeRF를 사용하여 다양한 샘플을 생성할 수 있기 때문에 아티팩트가 적습니다.
MEIL-NeRF에 의한 재구성은 반복 distillation 과정에서 누적된 오류의 영향을 받는 평활화 효과를 얻을 수 있습니다.
NeRF를 학습하기 위해 생성된 중요한 샘플을 선택하여 더 날카롭고 정확한 재구성을 얻는 것은 향후 흥미로운 연구 방향 중 하나가 될 수 있습니다.

5.4. Ablations
표 2는 현재 태스크 배치 크기 m_c에 따라 성능이 어떻게 변화하는지 보여줍니다.
iMAP*에 비해 배치 크기가 작아질수록 우리의 방법은 상대적으로 빠르게 악화됩니다.
배치 크기가 작으면 각 태스크가 부족하게 됩니다.
따라서 네트워크에서 검색된 과거 태스크 정보가 더 부정확해져 성능이 저하될 수 있습니다.
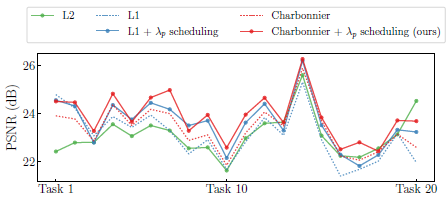
우리는 또한 그림 8과 같이 Charbonnier loss 함수의 선택을 정당화하기 위해 과거 태스크에 사용된 loss 함수에 대한 ablation 연구를 수행합니다.
L1과 Charbonnier loss는 L2 loss보다 더 높은 성능을 나타내며, λ_p 스케줄링은 추가적인 개선을 제공합니다.
L1 loss 및 재구성된 이미지의 가장자리와 선명도를 보존하기 위해 네트워크 학습을 용이하게 하는 것으로 알려진 변형(예: Charbonnier)은 보조 자료에 표시된 것처럼 MS-SSIM에서 훨씬 더 많은 성능 향상을 보여줍니다.
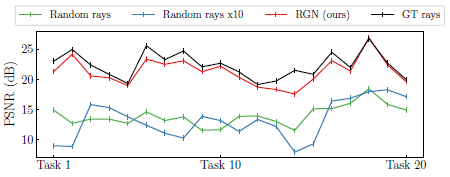
그림 9는 ray generator network (RGN)에 대한 ablation 실험을 보고합니다.
결과는 랜덤 ray가 사용되는 경우(10배 더 많은 ray라도) NeRF에서 과거의 색상 정보를 검색할 수 없음을 보여줌으로써 장면을 가리키는 바람직한 ray 사용의 중요성을 강조합니다.
과거 ray를 기억하는 RGN의 효과를 보여주기 위해 GT 과거 ray를 사용하는 것과 비교합니다.
RGN은 GT 과거 ray를 사용하는 것과 유사한 성능을 현저하게 제공하여 지속적인 메모리 사용으로 과거 ray를 기억하는 데 있어 RGN의 효과를 강조합니다.
6. Limitation
MEIL-NeRF는 NeRF를 메모리 저장소로 사용하고 NeRF를 쿼리하여 과거 정보를 찾기 때문에 NeRF와 유사한 높은 지연 시간 제한이 있습니다.
NeRF는 점을 샘플링하고 카메라 ray를 따라 통합하는 절차로 인해 대기 시간이 높습니다.
우리는 NeRF의 지연 시간을 개선하기 위해 시도한 최근 연구[38, 39]를 사용함으로써 지연 시간 문제를 극복할 수 있다고 믿습니다.
7. Conclusion
본 연구에서, 우리는 NeRF를 incremental 시나리오에 초점을 맞춘 실제 시나리오로 더욱 추진하는 것을 목표로 합니다.
공식화된 incremental 시나리오에서 이전의 incremental learning 알고리즘은 NeRF 또는 대용량 메모리에 대한 요구에 대해 작동하지 않았습니다.
따라서 Memory-Efficient Incremental Learning(MEIL-NeRF) 알고리즘을 제안합니다.
MEIL-NeRF는 네트워크 자체를 과거 정보를 저장하는 수단으로 취급하여 지속적인 메모리 사용으로 치명적인 망각을 완화합니다.
우리는 이 연구가 incremental learning 시나리오에서 NeRF에 대한 향후 연구 작업에 영감을 줄 수 있기를 바랍니다.