2023. 7. 13. 11:51ㆍView Synthesis
DynIBaR: Neural Dynamic Image-Based Rendering
Zhengqi Li, Qianqian Wang, Forrester Cole, Richard Tucker, Noah Snavely
Abstract
우리는 복잡한 동적 장면을 묘사하는 단안 비디오에서 새로운 뷰를 합성하는 문제를 해결합니다.
시간적으로 변화하는 Neural Radiance Fields(일명 dynamic NeRFs)를 기반으로 하는 SOTA 방법은 이 작업에서 인상적인 결과를 보여주었습니다.
그러나 복잡한 객체 모션과 제어되지 않은 카메라 궤적이 있는 긴 비디오의 경우 이러한 방법은 블러하거나 부정확한 렌더링을 생성하여 실제 응용 프로그램에서 사용을 방해할 수 있습니다.
MLP의 가중치 내에서 전체 동적 장면을 인코딩하는 대신, 장면 모션 인식 방식으로 인근 뷰의 피쳐를 집계하여 새로운 뷰를 합성하는 볼륨 이미지 기반 렌더링 프레임워크를 채택하여 이러한 한계를 해결하는 새로운 접근 방식을 제시합니다.
우리 시스템은 복잡한 장면과 뷰 의존적 효과를 모델링할 수 있다는 점에서 이전 방법의 장점을 유지하지만, 제한되지 않은 카메라 궤적으로 복잡한 장면 역학을 특징으로 하는 긴 비디오에서 사진처럼 사실적인 새로운 뷰를 합성할 수도 있습니다.
동적 장면 데이터 세트에서 SOTA 방법에 비해 상당한 개선을 보여주며, 이전 방법으로는 고품질 렌더링을 생성하지 못하는 까다로운 카메라 및 객체 모션을 사용하는 야생 내 비디오에도 접근 방식을 적용합니다.
1. Introduction
컴퓨터 비전 방법은 이제 정적 3D 장면의 자유 시점 렌더링을 놀라운 품질로 생성할 수 있습니다.
사람이나 애완동물이 등장하는 것과 같은 움직이는 장면은 어떻습니까?
동적 장면의 단안 비디오에서 새로운 뷰 합성은 훨씬 더 어려운 동적 장면 재구성 문제입니다.
최근 연구는 좌표 기반 다층 퍼셉트론(MLP) 내에서 시공간적으로 변화하는 장면 콘텐츠를 볼륨적으로 인코딩하는 HyperNeRF [50] 및 Neural Scene Flow Fields (NSFF)[35)와 같은 새로운 시간 변동 신경 부피 표현 덕분에 공간과 시간 모두에서 새로운 뷰를 합성하는 방향으로 진전되었습니다.
그러나 이러한 dynamic NeRF 방법은 일반적인 야생 비디오에 적용하는 것을 방해하는 한계가 있습니다.
NSFF와 같은 로컬 장면 흐름 기반 방법은 제한되지 않은 카메라 모션으로 캡처한 비디오를 더 길게 입력하도록 확장하는 데 어려움을 겪습니다: NSFF 논문은 1초의 전방 지향 비디오에 대해서만 우수한 성능을 주장합니다 [35].
표준 모델을 구성하는 HyperNeRF와 같은 방법은 대부분 제어된 카메라 경로가 있는 객체 중심 장면으로 제한되며 복잡한 객체 모션이 있는 장면에서 실패할 수 있습니다.
본 연구에서는 1) 긴 시간 지속, 2) 제한 없는 장면, 3) 제어되지 않는 카메라 궤적, 4) 빠르고 복잡한 객체 모션으로 캡처된 동적 비디오로 확장 가능한 새로운 접근 방식을 제시합니다.
우리의 접근 방식은 그림 1과 같이 복잡한 장면 형상을 뷰 의존적 효과로 모델링할 수 있는 볼륨 장면 표현의 이점을 유지하는 동시에 정적 및 동적 장면 콘텐츠 모두에 대한 렌더링 충실도를 최근 방법[35, 50]에 비해 크게 향상시킵니다.

우리는 에피폴라 라인[39, 64, 70]을 따라 가까운 뷰에서 로컬 이미지 피쳐를 집계하여 새로운 이미지를 합성하는 정적 장면을 렌더링하는 최근 방법에서 영감을 얻습니다.
그러나 동작 중인 장면은 이러한 방법에 의해 가정된 에피폴라 제약 조건을 위반합니다.
대신 장면 모션 조정된 ray 공간에서 다중 뷰 이미지 피쳐를 집계할 것을 제안합니다.
이를 통해 시공간적으로 변화하는 기하학적 구조와 모양에 대해 올바르게 추론할 수 있습니다.
또한 집계 기반 방법을 동적 장면으로 확장하는 과정에서 많은 효율성 및 견고성 문제에 직면했습니다.
여러 뷰에서 장면 모션을 효율적으로 모델링하기 위해 학습된 기초 함수로 표현되는 여러 프레임에 걸쳐 있는 모션 궤적 필드를 사용하여 이 모션을 모델링합니다.
또한 동적 장면 재구성에서 시간적 일관성을 달성하기 위해 움직임 조정 ray 공간에서 작동하는 새로운 시간적 photometric loss를 도입합니다.
마지막으로, 새로운 뷰의 품질을 향상시키기 위해 베이지안 학습 프레임워크 내에서 새로운 IBR 기반 모션 분할 기술을 통해 장면을 정적 및 동적 구성 요소로 분해할 것을 제안합니다.
두 가지 동적 장면 벤치마크에서 우리의 접근 방식이 매우 상세한 장면 콘텐츠를 렌더링하고 SOTA 기술을 크게 향상시켜 동적 객체에 해당하는 영역뿐만 아니라 전체 장면 모두에서 LPIPS 오류를 평균 50% 이상 줄일 수 있음을 보여줍니다.
우리는 또한 우리의 방법이 이전의 SOTA 방법이 고품질 렌더링을 생성하지 못하는 긴 지속 시간, 복잡한 장면 모션 및 제어되지 않는 카메라 궤적을 가진 야생 내 비디오에 적용될 수 있음을 보여줍니다.
우리는 우리의 연구가 동적 뷰 합성 방법의 실제 비디오에 대한 적용 가능성을 발전시키기를 바랍니다.
2. Related Work
Novel view synthesis.
고전적인 image-based rendering (IBR) 방법은 입력 이미지[58]의 픽셀 정보를 통합하여 새로운 뷰를 합성하며, 명시적 기하학에 대한 의존성에 따라 분류할 수 있습니다.
라이트 필드 또는 lumigraph 렌더링 방법 [9, 21, 26, 32]은 명시적인 기하학적 모델을 사용하지 않고 샘플링된 ray를 필터링하고 보간하여 새 뷰를 생성합니다.
희소 입력 뷰를 처리하기 위해 많은 접근 방식[7, 14, 18, 23, 24, 26, 30, 52, 54, 55]은 깊이 맵 또는 메시와 같은 사전 계산된 프록시 지오메트리를 활용하여 새로운 뷰를 렌더링합니다.
최근, 신경 표현은 고품질의 새로운 뷰 합성을 보여주었습니다 [12, 17, 38, 40, 46, 48, 59–62, 72, 81].
특히, Neural Radiance Fields (NeRF)[46]는 multi-layer perceptrons (MLP) 내에서 연속 장면 radiance 필드를 인코딩하여 전례 없는 수준의 충실도를 달성합니다.
NeRF에 구축된 모든 방법 중 IBRNet [70]은 우리 작업과 가장 관련이 있습니다.
IBRNet은 고전적인 IBR 기법과 볼륨 렌더링을 결합하여 장면별 최적화 없이 고품질 뷰를 렌더링할 수 있는 일반화된 IBR 모듈을 생성합니다.
우리의 연구는 정적 장면[11, 64, 70]을 위해 설계된 이러한 종류의 체적 IBR 프레임워크를 더 도전적인 동적 장면으로 확장합니다.
우리의 초점은 장면 간의 일반화보다는 복잡한 카메라와 객체 모션으로 긴 비디오에 대한 고품질의 새로운 뷰를 합성하는 데 있습니다.
Dynamic scene view synthesis.
우리의 연구는 RGBD [5, 15, 25, 47, 68, 83] 또는 단안 비디오 [31, 44, 78, 80]의 동적 장면의 기하학적 재구성과 관련이 있습니다.
그러나 깊이 또는 메시 기반 표현은 복잡한 기하학적 구조와 뷰 의존적 효과를 모델링하기 어렵습니다.
동적 장면에 대한 새로운 뷰 합성에 대한 대부분의 이전 작업에는 여러 개의 동기화된 입력 비디오[1, 3, 6, 27, 33, 63, 69, 76, 82]가 필요하여 실제 적용 가능성이 제한됩니다.
일부 방법[8, 13, 22, 51, 71]은 고품질 결과를 얻기 위해 템플릿 모델과 같은 도메인 지식을 사용하지만 특정 범주로 제한됩니다 [41, 56].
더 최근에, 많은 작품들이 하나의 카메라에서 역동적인 장면의 새로운 뷰를 합성할 것을 제안합니다.
Yoon et al. [75]은 단일 뷰 깊이 및 다중 뷰 스테레오를 통해 얻은 깊이 맵을 사용하여 명시적인 뒤틀림을 통해 새로운 뷰를 렌더링합니다.
그러나 이 방법은 복잡한 장면 형상을 모델링하고 분리 시 현실적이고 일관된 내용을 채우지 못합니다.
신경 렌더링의 발전으로 NeRF 기반 동적 뷰 합성 방법은 SOTA 결과를 보여주었습니다 [16, 35, 53, 66, 74].
Nerfies [49] 및 HyperNeRF [50]와 같은 일부 접근 방식은 각 로컬 관찰을 표준 장면 표현에 매핑하는 변형 필드를 사용하는 장면을 나타냅니다.
이러한 변형은 시간 [53] 또는 프레임별 잠재 코드 [49, 50, 66]에 따라 조정되며 변환 [53, 66] 또는 강체 운동 필드 [49, 50]로 매개 변수화됩니다.
이러한 방법은 긴 비디오를 처리할 수 있지만, 대부분 상대적으로 작은 객체 모션과 제어된 카메라 경로가 있는 객체 중심 장면으로 제한됩니다.
다른 방법은 장면을 시간 변동 NeRF로 표현합니다 [19, 20, 35, 67, 74].
특히 NSFF는 야생 내 비디오에 대해 빠르고 복잡한 3D 장면 모션을 캡처할 수 있는 신경 장면 흐름 필드를 사용합니다 [35].
그러나 이 방법은 짧은(1-2초) 정방향 비디오에만 잘 작동합니다.
3. Dynamic Image-Based Rendering
프레임(I_1, I_2, ..., I_N)과 알려진 카메라 매개 변수(P_1, P_2, ..., P_N)가 있는 동적 장면의 단안 비디오를 고려할 때, 우리의 목표는 비디오 내에서 원하는 시간에 새로운 관점을 합성하는 것입니다.
다른 많은 접근 방식과 마찬가지로, 우리는 비디오당 학습을 하는데, 먼저 입력 프레임을 재구성하기 위해 모델을 최적화한 다음, 이 모델을 사용하여 새로운 뷰를 렌더링합니다.
최근의 동적 NeRF 방법처럼 MLP의 가중치로 직접 3D 색상과 밀도를 인코딩하는 대신, 고전적인 IBR 아이디어를 볼륨 렌더링 프레임워크에 통합합니다.
명시적 표면에 비해 볼륨 표현은 뷰 의존적 효과로 복잡한 장면 형상을 보다 쉽게 모델링할 수 있습니다.
다음 섹션에서는 장면 모션 조정 다중 뷰 피쳐 집계(섹션 3.1) 및 모션 조정 ray 공간(섹션 3.2)에서 교차 시간 렌더링을 통해 시간적 일관성을 강화하는 방법을 소개합니다.
우리의 전체 시스템은 정적 모델과 동적 모델을 결합하여 각 픽셀에서 색상을 생성합니다.
정확한 장면 인수분해는 베이지안 학습 프레임워크 내에서 별도로 학습된 모션 세그멘테이션 모듈에서 파생된 세그멘테이션 마스크를 통해 달성됩니다(섹션 3.3).
3.1. Motion-adjusted feature aggregation
우리는 시간적으로 가까운 소스 뷰에서 추출한 피쳐를 집계하여 새로운 뷰를 합성합니다.
시간 i에서 이미지를 렌더링하기 위해 먼저 i, j ∈ N(i) = [i-r, i+r]의 시간 반지름 r 프레임 내에서 소스 뷰 I_j를 식별합니다.
각 소스 뷰에 대해 공유 컨볼루션 인코더 네트워크를 통해 2D 피처 맵 F_i를 추출하여 입력 튜플 {I_j,P_j,F_j}을 형성합니다.
타겟 ray r을 따라 샘플링된 각 점의 색상과 밀도를 예측하려면 장면 모션을 고려하면서 소스 뷰 피쳐를 집계해야 합니다.
정적 장면의 경우, 타겟 ray를 따라 있는 점은 인접한 소스 뷰에서 해당 에피폴라 라인을 따라 있으므로, 우리는 단순히 인접한 에피폴라 라인을 따라 샘플링함으로써 잠재적 대응을 집계할 수 있습니다 [64, 70].
그러나 움직이는 장면 요소는 에피폴라 제약 조건을 위반하여 모션이 설명되지 않으면 일관성 없는 피쳐 집계로 이어집니다.
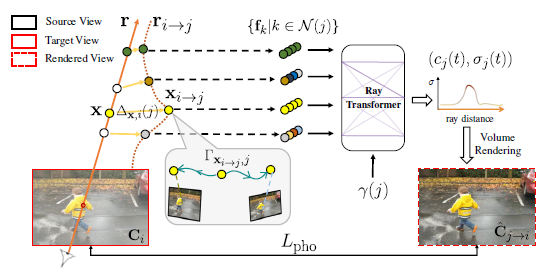
따라서, 우리는 그림 3과 같이 움직임 조정 피쳐 집계를 수행합니다.
동적 장면에서의 대응을 결정하기 위해, 한 가지 간단한 아이디어는 MLP[35]를 통해 장면 흐름 필드를 추정하여 주어진 포인트의 움직임 조정 3D 위치를 가까운 시간에 결정하는 것입니다.
그러나 이 전략은 MLP의 재귀적인 롤링으로 인해 볼륨 IBR 프레임워크에서 계산이 불가능합니다.
Motion trajectory fields.
대신 학습된 기본 함수의 관점에서 설명된 모션 궤적 필드를 사용하여 장면 모션을 나타냅니다.
시간 i에서 타겟 ray r을 따라 주어진 3D 포인트 x에 대해 MLP G_MT로 궤적 계수를 인코딩합니다:
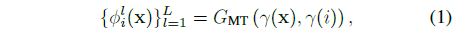
, 여기서 ɸ_i^l ∈ R^3은 기저 계수(아래에 설명된 움직임 기저를 사용하여 x, y, z에 대한 별도의 계수)이며 γ는 위치 인코딩을 나타냅니다.
장면 움직임이 저주파인 경향이 있다는 가정에 기초하여 인코딩 γ에 대해 L = 6개의 기저와 16개의 선형 증가 주파수를 선택합니다 [80].
또한 MLP와 함께 최적화된 입력 비디오의 모든 단계 i에 걸쳐 전역적으로 학습 가능한 모션 기반 {h_i^l}_(l=1)^L, h_i^l ∈ R을 소개합니다.
그런 다음 x의 운동 궤적은 Γ_(x,i)(j) = ∑ h_j^l p_i^l(x)로 정의되며, 따라서 x와 시간 j에서 x의 3D 대응 x_(i→j) 사이의 상대적 변위는
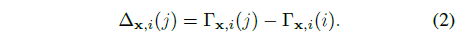
로 계산됩니다.
이 모션 궤적 표현을 사용하면 인접 뷰에서 쿼리 포인트 x에 대한 3D 대응을 찾는 데 단일 MLP 쿼리만 필요하므로 볼륨 렌더링 프레임워크 내에서 효율적인 다중 뷰 피쳐 집계가 가능합니다.
Wang et al. [67]이 제안한 DCT 기반으로 기반 {h_i^l}_(l=1)^L을 초기화하지만, 고정된 DCT 기반이 광범위한 실제 움직임을 모델링하지 못할 수 있다는 것을 관찰하기 때문에 최적화 중에 다른 구성 요소와 함께 미세 조정합니다(그림 4의 세 번째 열 참조).

시간 i에서 x의 추정된 움직임 궤적을 사용하여 시간 j에서 x의 해당 3D 지점을 x_(i→j) = x + Δ_(x,i)(j)로 나타냅니다.
카메라 매개 변수 P_j를 사용하여 각 뒤틀린 점 x_(i→j)를 소스 뷰 I_j로 투영하고, 투영된 2D 픽셀 위치에서 색상 및 피쳐 벡터 f_j를 추출합니다.
인접 뷰 j에 걸친 소스 피처 결과 세트는 가중 평균 풀링 [70]을 통해 출력 피처가 집계된 공유 MLP에 공급되어 ray r을 따라 각 3D 샘플 포인트에서 단일 피처 벡터를 생성합니다.
그런 다음 시간 임베딩 γ(i)가 있는 ray 트랜스포머 네트워크는 ray를 따라 집계된 피쳐의 시퀀스를 처리하여 샘플당 색상과 밀도(c_i, σ_i)를 예측합니다(그림 2 참조).
그런 다음 표준 NeRF 볼륨 렌더링 [4]를 사용하여 이 색상 및 밀도 시퀀스에서 ray에 대한 최종 픽셀 색상 ^C_i(r)를 얻습니다.
3.2. Cross-time rendering for temporal consistency
^C_i와 C_i만 비교하여 동적 장면 표현을 최적화하면 표현이 입력 이미지에 너무 적합할 수 있습니다: 이러한 뷰를 완벽하게 재구성할 수는 있지만 올바른 새로운 뷰를 렌더링하는 데 실패합니다.
이는 표현이 장면 모션을 활용하거나 정확하게 재구성하지 않고 각 시간 인스턴스에 대해 완전히 별개의 모델을 재구성할 수 있는 용량을 갖기 때문에 발생할 수 있습니다.
따라서 물리적으로 그럴듯한 모션으로 일관된 장면을 복구하기 위해 장면 표현의 시간적 일관성을 강제합니다.
이러한 맥락에서 시간적 일관성을 정의하는 한 가지 방법은 장면 모션을 고려할 때 인접한 두 시간 i 및 j에서의 장면이 일관되어야 한다는 것입니다 [19, 35, 67].
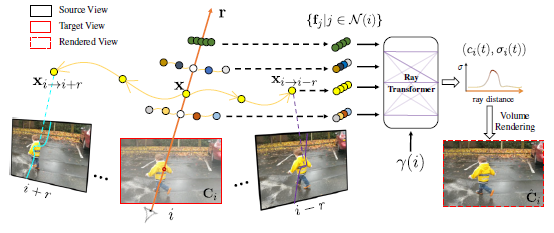
특히, 우리는 그림 3과 같이 움직임이 조정된 ray 공간에서 교차 시간 렌더링을 통해 최적화된 표현에 시간 photometric 일관성을 적용합니다.
이 아이디어는 i 시점에 뷰를 렌더링하지만 우리가 교차 시간 렌더링이라고 부르는 가까운 시간 j를 통해 뷰를 렌더링하는 것입니다.
각 근처 시간 j ∈ N(i)에 대해 ray r을 따라 점 x_(i→j)를 직접 사용하는 대신 움직임이 조정된 ray r_(i→j)를 따라 점 x_(i→j)를 고려하고 시간 j에서 ray를 따라 있는 것처럼 처리합니다.
구체적으로, 움직임 조정된 점 x_(i→j)를 계산한 후 MLP를 쿼리하여 새로운 궤적 {ϕ^l_j (x_(i→j)}_(l=1)^L = G_MT(x_(i→j), γ(j))의 계수를 예측하고, 이를 사용하여 식 2를 사용하여 시간 창 N(j)의 이미지 k에 대한 해당 3D 점 (x_(i→j)_(j→k)을 계산합니다.
그런 다음 이 새로운 3D 대응은 곡선의 움직임 조정 ray r_(i→j)를 따라 지금을 제외하고 섹션 3.1에서 "straight" ray r_i에 대해 설명한 대로 픽셀 색상을 정확하게 렌더링하는 데 사용됩니다.
즉, 각 포인트 (x_(i→j)_(j→k)는 소스 뷰 I_k에 투영되고 카메라 매개 변수 P_k와 피처 맵 F_k를 투영하여 RGB 색상 및 이미지 피처 f_k를 추출한 다음 이러한 피처는 시간 임베딩 γ(j)와 함께 집계되고 ray 트랜스포머에 입력됩니다.
그 결과 시간 j에서 r_(i→j)를 따라 색상과 밀도 (c_j, σ_j)의 시퀀스가 생성되며, 이는 볼륨 렌더링을 통해 합성되어 색상 ^C_(j→i)을 형성할 수 있습니다.
그런 다음 움직임 폐색 인식 RGB 재구성 loss를 통해 ^C_(j→i)(r)을 타겟 픽셀 C_i(r)와 비교할 수 있습니다:
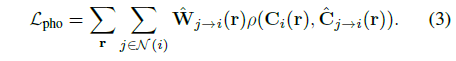
우리는 RGB loss ρ를 위해 일반화된 Charbonnier loss [10]를 사용합니다.
^W_(j→i)(r)은 NSFF [35]에 의해 설명된 운동 폐색 모호성을 해결하기 위해 시간 i와 j 사이의 누적 알파 가중치의 차이로 계산된 운동 폐색 가중치입니다(자세한 내용은 부록 참조).
j = i일 때, 장면 운동 유도 변위가 없으며, 이는 ^C_(j→i) = ^C_i 및 폐색 가중치가 관련되지 않음을 의미합니다 (^W_(j→i) = 1).
우리는 그림 4의 첫 번째 열에서 시간적 일관성을 시행하는 방법과 시행하지 않는 방법을 비교합니다.
3.3. Combining static and dynamic models
NSFF에서 관찰된 바와 같이, 콘텐츠는 제어되지 않은 카메라 경로로 인해 공간적으로 멀리 떨어진 프레임에서만 관찰될 수 있기 때문에 작은 시간 창을 사용하여 새로운 뷰를 합성하는 것은 정적 장면 영역에 대한 완전하고 고품질의 콘텐츠를 복구하기에 불충분합니다.
따라서 NSFF [35]의 아이디어를 따르고 두 개의 분리된 표현을 사용하여 전체 장면을 모델링합니다.
동적 콘텐츠 (c_i, σ_i)는 위와 같이 시간 가변 모델로 표현됩니다 (최적화 중 시간 교차 렌더링에 사용).
정적 콘텐츠 (c, σ)는 시간 가변 모델과 동일한 방식으로 렌더링되지만 장면 모션 조정 없이(즉, 에피폴라 라인을 따라) 멀티뷰 피쳐를 집계하는 시간 불변 모델로 표현됩니다.
NeRF-W [45]의 정적 및 일시적 모델을 결합하는 방법을 사용하여 동적 및 정적 예측이 결합되고 단일 출력 색상 ^C_i^full(또는 교차 시간 렌더링 동안 ^C_(j→i)^full)으로 렌더링됩니다.
각 모델의 색상 및 밀도 추정치도 별도로 렌더링되어 정적 콘텐츠의 경우 ^C^st, 동적 콘텐츠의 경우 ^C_i^dy 색상을 제공할 수 있습니다.
두 표현을 결합할 때, 우리는 ^C_(j→i)^full(r)과 타겟 픽셀 C_i(r)을 비교하는 loss로서 식 3의 photometric 일관성 항을 다시 씁니다:
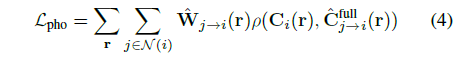
Image-based motion segmentation.
우리의 프레임워크에서, 우리는 초기화 없이 장면 요인화가 시간 불변 또는 시간 가변 표현에 의해 지배되는 경향이 있다는 것을 관찰했습니다 [28, 42].
요인화를 용이하게 하기 위해, Gao et al. [19]는 모든 움직이는 객체가 후보 시멘틱 세그멘테이션 레이블 세트에 의해 캡처되고 세그멘테이션 마스크가 시간적으로 정확하다는 가정에 의존하여 시멘틱 세그멘테이션에서 마스크를 사용하여 시스템을 초기화합니다.
그러나 이러한 가정은 Zhang et al. [79]에서 관찰된 바와 같이 많은 실제 시나리오에서는 성립되지 않습니다.
대신, 우리는 주요 2개 구성 요소 장면 표현을 supervised하기 위한 세그멘테이션 마스크를 생성하는 새로운 모션 세그멘테이션 모듈을 제안합니다.
우리의 아이디어는 최근 연구 [45, 79]에서 제안된 베이지안 학습 기술에서 영감을 얻었지만 동적 비디오의 볼륨 IBR 표현에 통합되었습니다.
특히 주요 2개 구성 요소 장면 표현을 학습하기 전에 두 개의 경량 모델을 공동으로 학습하여 각 입력 프레임 I_i에 대한 모션 세그멘테이션 마스크 M_i를 얻습니다.
장면 모션을 고려하지 않고 근처 소스 뷰에서 에피폴라 라인을 따라 피쳐 집계를 통해 각 ray를 따라 볼륨 렌더링을 사용하여 픽셀 색상 ^B^st를 렌더링하는 IBRNet [70]으로 정적 장면 콘텐츠를 모델링합니다.
입력 프레임에서 2D 불투명 맵 α_i^dy, 신뢰 맵 β_i^dy 및 RGB 이미지 ^B_i^dy를 예측하는 2D 컨볼루션 인코더-디코더 네트워크 D로 동적 장면 콘텐츠를 모델링합니다:
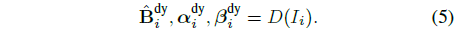
그런 다음 두 모델의 출력에서 전체 복원 이미지가 픽셀 단위로 합성됩니다:
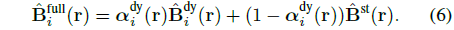
움직이는 물체를 세그먼트하기 위해, 우리는 관찰된 픽셀 색상이 이질적인 격변식으로 불확실하다고 가정하고, 시간에 의존하는 신뢰도 β_i^dy를 가진 코시 분포로 비디오의 관측치를 모델링합니다.
관측치의 음의 log-likelihood를 취함으로써, 우리의 세그멘테이션 loss는 가중치 재구성 loss로 기록됩니다:
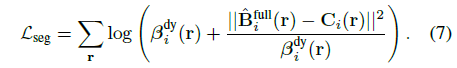
식 7을 사용하여 두 모델을 최적화함으로써 α_i^dy를 0.5로 임계함으로써 모션 세그멘테이션 마스크 M_i를 얻습니다.
퇴행을 피하기 위해 NeRF-W [45]에서와 같은 알파 정규화 loss가 필요하지 않습니다.
네트워크 D에서 스킵 연결을 제외함으로써 자연스럽게 그러한 유도 기반을 포함하므로 D가 정적 IBR 모델보다 더 느리게 수렴합니다.
그림 5에서 입력 이미지에 겹쳐진 추정된 모션 세그멘테이션 마스크를 보여줍니다.

Supervision with segmentation masks.
동적 영역에서 시간 변동 모델의 렌더링과 정적 영역에서 시간 변동 모델의 렌더링에 재구성 loss를 적용하여 마스크 M_i로 주요 시간 변동 및 시간 변동 모델을 초기화합니다:
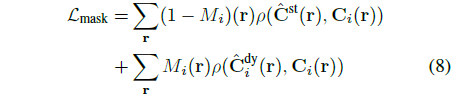
우리는 마스크 경계 근처의 loss를 끄기 위해 M_i에 대해 형태학적 침식과 확장을 수행하여 동적 영역과 정적 영역의 마스크를 각각 얻습니다.
우리는 L_mask로 시스템을 supervise하고 50K 최적화 단계마다 동적 영역에 대해 가중치를 5배 감소시킵니다.
3.4. Regularization
이전 연구에서 언급된 바와 같이, 복잡한 동적 장면의 단안 재구성은 매우 부적절하며, photometric 일관성을 사용하는 것만으로는 최적화 중 나쁜 로컬 최소화를 피하기에 충분하지 않습니다 [19, 35].
따라서 이전 연구에서 사용된 정규화 체계를 채택합니다 [2, 35, 73, 75], 이는 L_reg = L_data + L_MT + L_cpt의 세 가지 주요 부분으로 구성됩니다.
L_data는 Zhang et al. [80] 및 RAFT [65]의 추정치를 사용하는 L1 monocular depth 및 optical flow 일관성 priors로 구성된 데이터 기반 항입니다.
L_MT는 추정된 궤적 필드가 주기 독립적이고 공간-시간적으로 매끄럽도록 장려하는 운동 궤적 정규화 항입니다.
L_cpt는 엔트로피 loss를 통해 장면 분해가 이진화되도록 장려하고 왜곡 loss를 통해 플로팅을 완화하는 컴팩트성 prior입니다 [2].
자세한 내용은 부록을 참조하십시오.
요약하면, 시공간 뷰 합성을 위한 주요 표현을 최적화하는 데 사용된 최종 결합 loss는 다음과 같습니다:
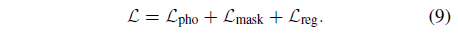
4. Implementation details
Data.
Nvidia Dynamic Scene Dataset [75] 및 UCSD Dynamic Scene Dataset [37]에 대해 수치 평가를 수행합니다.
각 데이터 세트는 동기화된 멀티뷰 카메라에 의해 녹화된 8개의 전방 동적 장면으로 구성됩니다.
우리는 선행 연구 [35]를 따라 각 시퀀스에서 단안 비디오를 도출하며, 각 비디오에는 100~250 프레임이 포함됩니다.
우리는 움직이는 객체의 큰 영역이 부족한 프레임을 제거했습니다.
평가를 위해 한 번의 인스턴스당 보류된 이미지를 사용하는 선행 연구 [35]의 프로토콜을 따릅니다.
또한 보다 도전적인 카메라 및 객체 움직임이 특징인 야생 단안 비디오에서 방법을 테스트했습니다.
View selection.
시간 변동 동적 모델의 경우 모든 실험에 대해 r = 3의 프레임 윈도우 반경을 사용합니다.
정적 장면 콘텐츠를 나타내는 시간 변동 모델의 경우 동적 장면 벤치마크와 야생 비디오에 대해 별도의 전략을 사용합니다.
카메라 시점이 이산 카메라 장치 위치에 위치한 벤치마크의 경우 시간 단계가 목표 시간의 12 프레임 이내인 모든 인근 고유 시점을 선택합니다.
야생 비디오의 경우 가장 가까운 소스 시점을 나이브하게 선택하면 카메라 베이스라인이 충분하지 않아 재구성이 잘 되지 않을 수 있습니다.
따라서 렌더링된 픽셀에 대해 색상을 계산하기에 충분한 소스 시점을 확보하기 위해 먼 프레임에서 소스 시점을 선택합니다.
시간 변동 모델에 대해 N^vs 소스 시점을 선택하려면 입력 비디오에서 2r^max/N^vs 프레임마다 서브샘플링하여 후보 풀을 구축하고, 주어진 목표 시간 i에 대해 [i - r^max, i + r^max] 프레임 내에서 소스 시점만 검색합니다.
SfM 포인트 공시성 및 카메라 상대 베이스라인에 기초한 Li et al. [34]의 방법을 사용하여 r^max를 추정합니다.
그런 다음 카메라 베이스라인 측면에서 타겟 뷰에 가장 가까운 후보 풀에서 상위 N^vs 프레임을 선택하여 모델에 대한 최종 소스 시점 집합을 구성합니다.
N^vs = 16을 설정합니다.
Global spatial coordinate embedding.
로컬 이미지 피쳐 집계만으로는 NeuRay [39]에 설명된 것처럼 서로 다른 소스 뷰의 일관되지 않은 피쳐로 인해 지표면 또는 폐색 표면 점에서 밀도를 정확하게 결정하기가 어렵습니다.
따라서 밀도 예측을 위한 전역 추론을 개선하기 위해 [64]의 아이디어와 유사하게 시간 임베딩 외에 전역 공간 좌표 임베딩을 ray 트랜스포머에 입력으로 추가합니다.
자세한 내용은 부록을 참조하십시오.
Handling degeneracy through virtual views.
이전 연구 [35]에서는 카메라 및 객체 모션이 공선에 가깝거나 객체 모션이 너무 빨라서 추적할 수 없는 경우 최적화가 나쁜 로컬 최소로 수렴될 수 있음을 관찰했습니다.
[36]에서 영감을 받아 [80]에 의해 추정된 모든 입력 비아 깊이에 대해 랜덤으로 샘플링된 8개의 근처 시점에서 이미지를 합성합니다.
렌더링하는 동안 가상 뷰를 추가 소스 이미지로 랜덤으로 샘플링합니다.
이러한 입력에 대한 최적화 안정성과 렌더링 품질을 향상시키므로 이 기술을 야생 비디오에만 적용하는 반면 [20]에서 설명한 것처럼 카메라-객체 모션이 흐트러짐으로 인해 벤치마크에서 개선되는 것을 관찰하지 않습니다.
Time interpolation.
또한 우리의 접근 방식은 NSFF [35]에 의해 도입된 것처럼 장면 모션 기반 스플랫을 수행하여 시간 보간을 허용합니다.
지정된 목표 분수 시간에 렌더링하기 위해, 우리는 해당 소스 뷰 세트에서 로컬 이미지 피쳐를 집계하여 두 개의 근처 입력 시간에서 체적 밀도와 색상을 예측합니다.
그런 다음 예측된 색상과 밀도는 움직임 궤적에서 파생된 장면 흐름을 통해 스플랫되고 선형적으로 혼합되며 타겟 분수 시간 지수에 따라 가중치가 부여됩니다.
Setup.
우리는 COLMAP[57]을 사용하여 카메라 포즈를 추정합니다.
각 ray에 대해 Wang et al. [70]에서와 같이 128개의 ray별 샘플로 대략적인 미세 샘플링 전략을 사용합니다.
별도의 모델이 Adam Optimizer[29]를 사용하여 각 장면에 대해 처음부터 학습됩니다.
두 개의 주요 표현에 대한 네트워크 아키텍처는 IBRNet[70]의 변형입니다.
우리는 특별한 장면 매개 변수화 없이 유클리드 공간에서 전체 장면을 재구성합니다.
10초 비디오에서 전체 시스템을 최적화하는 데는 8개의 Nvidia A100을 사용하여 약 이틀이 걸리며, 렌더링은 768 × 432 프레임의 경우 약 20초가 걸립니다.
우리는 독자들에게 네트워크 아키텍처, 하이퍼 파라미터 설정 및 추가 세부 정보에 대한 보충 자료를 참조합니다.
5. Evaluation
5.1. Baselines and error metrics
우리는 최신 단안 뷰 합성 방법과 우리의 접근 방식을 비교합니다.
구체적으로, 우리는 최근의 세 가지 표준 공간 기반 방법인 Nerfies [49] 및 HyperNeRF [50]와 비교하고, Gao et al. 의 두 가지 장면 흐름 기반 방법인 NSFF [35] 및 DVS(Dynamic View Synthesis)와 비교합니다.
공정한 비교를 위해, 우리는 우리의 접근 방식에 사용되는 것과 동일한 depth, optical flow 및 모션 세그멘테이션 마스크를 다른 방법에 대한 입력으로 사용합니다.
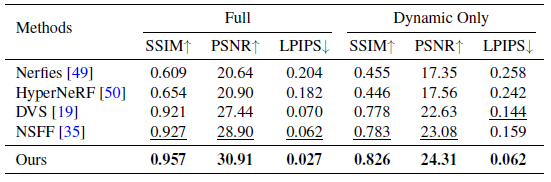
선행 연구 [35]에 따라 우리는 세 가지 표준 오류 메트릭을 사용하여 각 방법의 렌더링 품질을 보고합니다: 최대 신호 대 잡음비(PSNR), 구조 유사성(SSIM) 및 LPIPS [77]를 통해 지각 유사성을 계산하고 전체 장면(Full) 및 이동 영역에 대한 오류를 계산합니다(Dynamic Only).
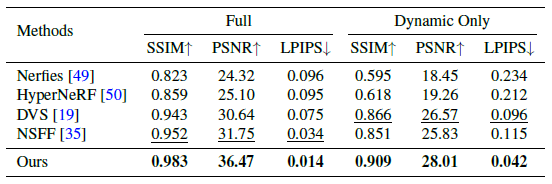
5.2. Quantitative evaluation
두 벤치마크 데이터 세트에 대한 정량적 결과는 표 1과 표 2에 나와 있습니다.
우리의 접근 방식은 모든 오류 메트릭 측면에서 이전의 SOTA 방법보다 크게 향상됩니다.
특히, 우리의 접근 방식은 두 데이터 세트 각각에 대해 차선의 방법에서 전체 장면에 대한 PSNR을 2dB 및 4dB 개선합니다.
우리의 접근 방식은 또한 실제 이미지 [77]과 비교하여 지각 품질의 주요 지표인 LPIPS 오류를 50% 이상 줄입니다.
이러한 결과는 우리의 프레임워크가 매우 상세한 장면 콘텐츠를 복구하는 데 훨씬 더 효과적임을 시사합니다.
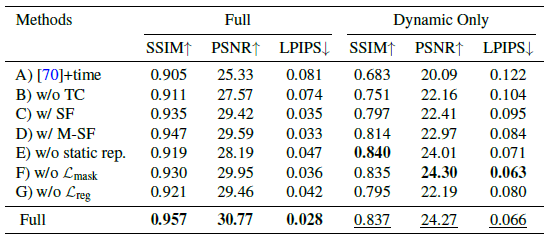
Ablation study.
우리는 제안된 다양한 시스템 구성 요소의 효과를 검증하기 위해 Nvidia Dynamic Scene Dataset에 대한 ablation 연구를 수행합니다.
우리는 표 3에서 우리의 전체 시스템과 변형을 비교합니다: A) 추가 시간 임베딩이 포함된 베이스라인 IBRNet [70]; B) 교차 시간 렌더링을 통해 시간적 일관성을 적용하지 않고; C) 장면 흐름 필드를 사용하여 한 번의 단계로 이미지 피쳐를 집계합니다; D) 각 샘플에서 2r개의 가까운 시간을 가리키는 복수의 3D 장면 흐름 벡터 예측; E) 시간 변동 정적 장면 모델을 사용하지 않음; F) 추정 움직임 세그멘테이션 마스크를 통한 마스크 재구성 loss 없음; 그리고 G) 정규화 loss 없이.
이 ablation 연구의 경우 ray당 64개의 샘플로 각 모델을 학습합니다.
움직임 궤적 표현과 시간적 일관성이 없으면 표 3의 처음 세 행에서 볼 수 있듯이 뷰 합성 품질이 크게 저하됩니다.
전역 공간 좌표 임베딩을 통합하면 렌더링 품질이 더욱 향상됩니다.
정적 모델과 동적 모델을 결합하면 전체 장면에 대한 메트릭에서 볼 수 있듯이 정적 요소에 대한 품질이 향상됩니다.
마지막으로, 모션 분할 또는 정규화에서 supervision을 제거하면 전체 렌더링 품질이 저하되어 최적화 중 불량 로컬 최소화를 방지하기 위해 제안된 loss의 가치를 입증합니다.


5.3. Qualitative evaluation
Dynamic scenes dataset.
우리는 그림 6과 그림 7의 두 데이터 세트에서 테스트 뷰에 대한 우리의 접근 방식과 세 가지 이전의 SOTA 방법 [19, 35, 50]을 정성적으로 비교합니다.
이전의 dynamic-NeRF 방법은 풍선의 질감, 사람의 얼굴 및 옷을 포함하여 지나치게 블러된 동적 콘텐츠에서 볼 수 있듯이 움직이는 객체의 세부 정보를 렌더링하는 데 어려움이 있습니다.
이와는 대조적으로, 우리의 접근 방식은 정적 및 동적 장면 콘텐츠 모두와 ground truth 이미지에 가장 가까운 사진 현실적인 새로운 뷰를 합성합니다.


In-the-wild videos.
복잡한 동적 장면의 야생 이미지에 대한 정성적인 비교를 보여줍니다.
그림 8에서 Dynamic-NeRF 기반 방법과 비교를 보여주고, 그림 9는 depth [80]를 사용한 포인트 클라우드 렌더링과 비교를 보여줍니다.
우리의 접근 방식은 사진 현실적인 새로운 뷰를 합성하는 반면, 이전의 Dynamic-Nerf 방법은 그림 8에서 셔츠 주름과 개의 털과 같은 정적인 장면과 움직이는 장면 콘텐츠 모두의 고품질 세부 사항을 복구하지 못합니다.
반면, 명시적인 depth 왜곡은 돌출부 근처와 시야 밖의 영역에 구멍을 생성합니다.
완전한 비교를 위해 독자를 보충 비디오를 참조합니다.

6. Discussion and conclusion
Limitations.
우리의 방법은 정적 또는 준정적 장면을 위해 설계된 방법에 비해 상대적으로 작은 관점 변화로 제한됩니다; 우리의 방법은 잘못된 초기 깊이와 optical flow 추정치로 인해 빠르게 움직이는 작은 물체를 처리할 수 없습니다(왼쪽, 그림 10).
또한, 이전의 dynamic NeRF 방법과 비교하여, 합성된 뷰는 엄격하게 다중 뷰 일관성이 없으며, 정적 콘텐츠의 렌더링 품질은 어떤 소스 뷰를 선택하느냐에 따라 달라집니다(가운데, 그림 10).
우리의 접근 방식은 또한 물체와 카메라 움직임이 대부분 동일한 것인 야생 내 비디오의 퇴화된 움직임 패턴에 민감하지만, 우리는 보충에서 그러한 경우를 처리하기 위한 휴리스틱을 보여줍니다.
게다가, 우리의 방법은 먼 시간에만 나타나는 동적인 콘텐츠를 합성할 수 있습니다(오른쪽, 그림 10)
Conclusion.
우리는 복잡한 동적 장면을 묘사하는 단안 비디오에서 시공간 뷰 합성을 위한 새로운 접근법을 제시했습니다.
볼륨 IBR 프레임워크 내에서 동적 장면을 표현함으로써 우리의 접근 방식은 복잡한 카메라와 객체 모션으로 긴 비디오를 모델링할 수 없는 최근 방법의 한계를 극복합니다.
우리는 우리의 방법이 야생의 동적 비디오에서 사진 사실적인 새로운 뷰를 합성할 수 있으며 동적 장면 벤치마크에서 이전의 SOTA 방법보다 상당한 개선을 달성할 수 있음을 보여주었습니다.