2023. 5. 9. 11:34ㆍView Synthesis
AligNeRF: High-Fidelity Neural Radiance Fields via Alignment-Aware Training
Yifan Jiang, Peter Hedman, Ben Mildenhall, Dejia Xu, Jonathan T. Barron, Zhangyang Wang, Tianfan Xue
Abstract
Neural Radiance Fields (NeRF)는 3D 장면을 연속 함수로 모델링하기 위한 강력한 표현입니다.
NeRF는 뷰 의존적 효과로 복잡한 3D 장면을 렌더링할 수 있지만, 고해상도 설정에서 한계를 탐색하기 위한 노력은 거의 없습니다.
특히, 기존 NeRF 기반 방법은 매우 많은 수의 매개 변수, 잘못 정렬된 입력 데이터 및 지나치게 매끄러운 세부 정보를 포함하여 고해상도 실제 장면을 재구성할 때 몇 가지 제한에 직면합니다.
이 연구에서, 우리는 고해상도 데이터로 NeRF를 학습하는 것에 대한 첫 번째 시범 연구를 수행하고 해당 솔루션을 제안합니다:
1) 전체 매개 변수 수를 줄이면서 더 많은 이웃 정보를 인코딩할 수 있는 컨볼루션 레이어와 다층 퍼셉트론(MLP)을 결합합니다;
2) 움직이는 물체나 작은 카메라 보정 오류로 인한 정렬 오류를 해결하기 위한 새로운 학습 전략;
3) 고주파 인식 loss.
우리의 접근 방식은 명백한 학습/테스트 비용을 도입하지 않고도 거의 자유로운 반면, 다른 데이터 세트에 대한 실험은 현재의 SOTA NeRF 모델에 비해 더 많은 고주파 세부 사항을 복구할 수 있음을 보여줍니다.
1. Introduction
Neural Radiance Field (NeRF [24])와 그 변형 [1-3, 7, 19, 20]은 최근 이미지에서 기하학적 3D 표현을 학습하는 데 인상적인 성능을 보여주었습니다.
결과적으로 고품질 장면 표현은 복잡한 기하학적 구조와 뷰 의존적 외관으로 몰입형 새로운 뷰 합성 경험을 가능하게 합니다.
NeRF의 기원 이후, 품질과 효율을 개선하기 위해 엄청난 양의 작업이 이루어졌으며, "in-the-wild"로 캡처된 데이터[15,20] 또는 제한된 수의 입력[7, 11, 26, 32, 44]에서 재구성하고 여러 장면에서 일반화할 수 있었습니다 [4, 41, 45].
그러나 고해상도 재구성에는 상대적으로 거의 관심이 없습니다.
mip-NeRF[1]는 다른 해상도로 렌더링할 때 과도하게 블러되거나 앨리어싱된 이미지를 다루며, 무한히 작은 3D 포인트 대신 3D 원추형 frustum으로 ray 샘플을 모델링합니다.
mip-NeRF 360[2]은 이 접근 방식을 더 복잡한 모양과 기하학을 포함하는 경계가 없는 장면으로 확장합니다.
그럼에도 불구하고, 이 두 작품에 사용된 최고 해상도 데이터는 1280x840 픽셀에 불과하며, 이는 현대의 스마트폰 카메라(4032x3024)는 말할 것도 없고, 표준 HD 모니터(1920x1080)의 해상도와는 아직 거리가 먼 것입니다.
본 논문에서는 고해상도 이미지를 입력으로 사용하여 고충실도 설정에서 neural radiance fields를 학습하는 첫 번째 파일럿 연구를 수행합니다.
여기에는 몇 가지 장애물이 있습니다.
첫째, 고해상도 학습 이미지를 사용할 때의 주요 과제는 모든 고주파 세부 정보를 인코딩하는 데 훨씬 더 많은 매개 변수가 필요하다는 것이며, 이로 인해 학습 시간이 훨씬 길어지고 메모리 비용이 높아지며, 때로는 문제를 다루기 어렵게 만들기도 합니다 [2, 20, 30].
둘째, 고주파 세부 사항을 학습하기 위해 NeRF는 캡처 중 정확한 카메라 포즈와 움직임이 없는 장면이 필요합니다.
그러나 실제로 Structure-from-Motion (SfM) 알고리즘으로 복구된 카메라 포즈에는 픽셀 수준의 부정확성이 불가피하게 포함됩니다 [18].
이러한 부정확성은 다운샘플링된 저해상도 이미지에서 학습할 때는 눈에 띄지 않지만, 고해상도 입력으로 NeRF를 학습할 때는 블러 결과를 초래합니다.
게다가, 포착된 장면에는 구름과 식물이 움직이는 것과 같은 피할 수 없는 움직임도 포함될 수 있습니다.
이는 정적 장면 가정을 깨뜨릴 뿐만 아니라 추정된 카메라 포즈의 정확도를 저하시킵니다.
부정확한 카메라 포즈와 장면 모션으로 인해 NeRF의 렌더링된 출력이 그림 2에 표시된 것처럼 ground truth 이미지와 약간 어긋나는 경우가 많습니다.
우리는 섹션 4.3에서 이 현상을 조사하여 NeRF를 반복적으로 학습하고 입력 이미지를 NeRF의 추정 형상에 다시 정렬함으로써 이미지 품질을 크게 향상시킬 수 있음을 보여줍니다.
분석에 따르면 NeRF는 렌더링된 프레임과 ground truth 이미지 간의 차이를 최소화하도록 학습되기 때문에 정렬이 잘못되면 왜곡된 텍스처를 학습하게 됩니다.
이전 연구에서는 NeRF와 카메라 포즈[5, 17, 23, 43]를 공동으로 최적화하여 이 문제를 완화하지만, 이러한 방법은 미묘한 객체 움직임을 처리할 수 없으며 종종 섹션 4.6에서 입증된 것처럼 사소한 학습 오버헤드를 초래합니다.

이러한 문제를 해결하기 위해 고주파 세부 정보를 더 잘 보존할 수 있는 정렬 인식 학습 전략인 AligNeRF를 제시합니다.
우리의 솔루션은 두 가지 방식으로 제공됩니다: NeRF의 표현력을 효율적으로 증가시키는 접근법 및 오정렬을 교정하는 효과적인 방법.
고해상도 입력으로 NeRF를 효율적으로 학습하기 위해 로컬 패치에서 ray chunk를 샘플링하고 후 처리를 위해 ConvNets를 적용하여 NeRF의 MLP와 컨볼루션을 결합합니다.
관련 아이디어는 NeRF-SR[40]에서 논의되지만, 그 설정은 학습 세트보다 높은 해상도로 테스트 이미지를 렌더링하는 것을 기반으로 합니다.
또 다른 작업 라인은 볼륨 렌더링과 생성 모델링[27, 34]을 결합하여 ConvNets는 많은 입력 이미지의 역 문제를 해결하는 대신 효율적인 업샘플링 및 생성 텍스처 합성에 주로 사용됩니다.
대조적으로, 우리의 접근 방식은 작은 ConvNet의 유도 prior가 상당한 계산 비용을 초래하지 않고 고해상도 학습 데이터에서 NeRF의 성능을 향상시킨다는 것을 보여줍니다.
이 새로운 파이프라인에서는 학습 중에 이미지 패치를 렌더링합니다.
이를 통해 사소한 포즈 오류나 움직이는 물체로 인해 발생했을 수 있는 렌더링된 패치와 실제 사이의 불일치를 추가로 해결할 수 있습니다.
먼저 렌더링된 프레임과 해당 ground truth 이미지 사이의 추정된 optical flow를 활용하여 비정렬이 이미지 품질에 어떤 영향을 미치는지 분석합니다.
우리는 이전의 정렬 오류 인식 loss의 한계에 대해 논의하고 [22, 48], 우리의 작업에 맞게 조정된 새로운 정렬 전략을 제안합니다.
또한 패치 기반 렌더링 전략은 단순한 평균 제곱 오차를 넘어 패치별 loss 함수도 지원합니다.
이는 새로운 주파수 인식 loss를 설계하도록 동기를 부여하여 오버헤드 없이 렌더링 품질을 더욱 향상시킵니다.
결과적으로 AligNeRF는 추가 비용이 거의 들지 않으면서 고해상도 3D 재구성 작업에 대한 현재의 최상의 방법을 크게 능가합니다.
요약하자면, 우리의 기여는 다음과 같습니다:
• 고해상도 학습 데이터의 정렬 오류로 인한 성능 저하를 보여주는 분석입니다.
• 약간의 추가 비용으로 렌더링된 이미지의 품질을 향상시키는 새로운 컨볼루션 지원 아키텍처.
• NeRF를 카메라 포즈 오류 및 미묘한 객체 모션에 더욱 견고하게 만드는 새로운 패치 정렬 loss와 고주파 세부 정보를 개선하기 위한 패치 기반 loss가 함께 발생합니다.
2. Preliminaries
vanilla NeRF [24] 방법은 해당 카메라 포즈를 학습 세트로 하여 수백 개의 이미지를 촬영하여 합성 렌더링된 객체 또는 실제 전방 장면에서 작업합니다.
이후의 연구는 NeRF를 제한되지 않은 사진 모음 [20]으로 확장하고, 학습 입력을 희박하게 샘플링된 뷰로만 줄이고, [7, 11, 26, 32], 재조명 작업에 적용하고, 학습/추측 시간을 단축하고, [9, 19, 25, 37], 보이지 않는 장면으로 일반화합니다[4, 41, 45].
대조적으로, 우리는 이 작업에서 고해상도 입력 데이터에 대한 학습 문제를 탐구합니다.
2.1. NeRF
NeRF는 3D 위치 x = (x, y, z) 및 2D 뷰 방향 d = (θ, ɸ)를 입력으로 사용하고 방출된 색상 c = (r, g, b) 및 볼륨 밀도 σ를 출력합니다.
이 연속적인 5D 장면 표현은 MLP 네트워크 F_θ : (x, d) → (c, σ)에 의해 근사됩니다.
픽셀의 출력 색상을 계산하기 위해, NeRF는 숫자 직교를 사용하여 볼륨 렌더링 적분을 근사화합니다 [21].
각 카메라 ray r(t) = o + td에 대해, 여기서 o는 카메라 원점이고 d는 ray 방향이며, 근접 및 원거리 경계 t_n 및 t_f를 갖는 r(t)의 예상 색상 ^C(r)는
로 공식화될 수 있으며, 여기서 {t_k}_(k=1)^K는 카메라의 근접 및 원거리 평면 사이에서 샘플링된 3D 포인트 세트를 나타내며, τ는 추정 부피 밀도 σ를 나타냅니다.
신경망은 대략적인 낮은 주파수 함수[28]에 편향된 것으로 알려져 있기 때문에, NeRF는 다중 주파수에서 sinusoid로 구성된 위치 인코딩 함수 γ(·)를 사용하여 네트워크 입력에 고주파 변동을 도입합니다.
2.2. mip-NeRF 360
렌더링된 뷰의 해상도가 학습 이미지와 다를 때 앨리어싱 문제를 해결하기 위해, mip-NeRF[1]는 무한히 작은 3D 포인트를 샘플링하는 대신 ray를 둘러싼 원뿔에서 부피 frustum을 샘플링할 것을 제안합니다.
mip-NeRF 360[2]은 임의로 멀리 있는 장면 콘텐츠를 경계 영역(NeRF++[46]과 유사)으로 왜곡하는 "contraction" 함수를 채택하여 이 통합된 위치 인코딩을 경계 없는 실제 장면으로 확장합니다.
학습의 효율성을 높이기 위해 mip-NeRF 360도 온라인 distillation 전략을 채택합니다.
coarse NeRF("Proposal MLP"라고도 함)는 더 이상 photometric 재구성 loss에 의해 supervise되지 않고, 대신 fine NeRF ("NeRF MLP"라고도 함)에서 구조에 대한 distill된 지식을 학습합니다.
그렇게 함으로써, Proposal MLP의 매개 변수 수는 최종 RGB 색상에 기여하지 않기 때문에 크게 줄일 수 있습니다.
ray 샘플은 Proposal MLP에 의해 더 잘 안내되기 때문에, 최종 NeRF MLP에 대한 쿼리 수를 크게 줄일 수도 있습니다.
따라서 고정된 계산 예산을 재할당하여 이 NeRF MLP를 크게 확장하여 mip-NeRF와 동일한 총 비용으로 렌더링된 이미지 품질을 향상시킬 수 있습니다.
3. Method
이 섹션에서는 섹션 1에서 논의되고 섹션 4.3에서 분석된 장애물을 해결하기 위한 정렬 인식 학습 전략인 AligNeRF를 소개합니다.
AligNeRF는 포인트 샘플링 접근법과 frustum 기반 접근법을 모두 포함하여 NeRF와 유사한 모델을 위한 플러그인이 용이한 구성 요소입니다.
AligNeRF는 단계별 학습을 사용합니다: 초기 "normal" 사전 학습 단계부터 시작하여 정렬 인식 미세 조정 단계까지입니다.
우리는 mip-NeRF 360을 베이스라인으로 선택하는데, 이것은 복잡한 경계 없는 실제 장면을 위한 SOTA NeRF 방법이기 때문입니다.
다음으로 컨볼루션 증강 아키텍처를 소개한 다음 정렬 오류 인식 학습 절차와 고주파 loss를 제시합니다.
3.1. Marrying Coordinate-Based Representations with Convolutions
비전 트랜스포머[6]에서 유도 priors 암호화의 최근 성공에 영감을 받아, 우리의 첫 번째 단계는 NeRF와 같은 좌표 기반 표현에 대한 로컬 유도 prior를 효과적으로 인코딩하는 방법을 탐구하는 것입니다.
NeRF와 유사한 모델은 일반적으로 좌표-to-값 매핑 함수를 구성하고 해당 매개 변수를 최적화하기 위해 ray 배치를 랜덤으로 샘플링하므로 패치 기반 처리를 수행할 수 없습니다.
따라서 첫 번째 수정은 카메라 ray와 관련하여 랜덤 샘플링에서 패치 기반 샘플링으로 전환하는 것입니다(실험에서 32x32 패치를 사용함).
이 패치 기반 샘플링 전략을 사용하면 각 반복 동안 작은 로컬 이미지 영역을 수집하여 각 픽셀을 렌더링할 때 2D 로컬 이웃 정보를 사용할 수 있습니다.
우선 MLP에서 마지막 레이어의 출력 채널 수를 3개에서 더 큰 N개로 변경하고 RGB 공간이 아닌 이 피처 공간에서 ray를 따라 수치 통합을 적용합니다.
이를 통해 각 카메라 ray에서 보다 풍부한 표현을 수집할 수 있습니다.
다음으로 볼륨 렌더링 함수에 따라 ReLU 활성화 및 3x3 커널이 포함된 간단한 3층 컨볼루션 네트워크를 추가합니다.
각 컨볼루션의 입력에 대해 "reflectance" 패딩을 채택하고 출력에서 패딩 값을 제거하여 체커보드 아티팩트를 방지합니다.
이 네트워크의 끝에서, 우리는 피드포워드 퍼셉트론 레이어를 사용하여 표현을 피쳐 공간에서 RGB 공간으로 변환합니다.
결과적으로 각 픽셀의 렌더링 프로세스는 해당 방향을 따라 개별 ray/cone에 의존할 뿐만 아니라 인접 영역에도 의존하므로 더 나은 텍스처 세부 정보를 생성하는 데 도움이 됩니다.
CNN은 매우 얕고 업샘플링을 수행하지 않기 때문에 이미지 출력에서 결과적으로 발생하는 멀티뷰 불일치를 관찰하지 않습니다.
3.2. Alignment-Aware Loss
NeRF는 렌더링 함수 F_Θ : (x, d) → (c, σ)를 사용하여 3D 포인트의 좌표를 장면의 속성에 매핑하여 3D 장면을 모델링합니다.
이 프레임워크에서 카메라 포즈의 정확도는 NeRF 학습에 중요합니다.
그렇지 않으면 다른 관점에서 동일한 3D 포인트를 관찰하는 ray가 공간의 동일한 위치로 수렴되지 않을 수 있습니다.
vanilla NeRF [24]는 매우 짧은 시간에 걸쳐 (장면 움직임과 조명 변화를 방지하기 위해) 이미지를 캡처하여 이 문제를 해결하고 COLMAP [33]을 채택하여 카메라 매개 변수를 계산합니다.
이 데이터 준비 파이프라인은 1) 이전 연구에서 지적한 것처럼 ground truth 카메라 포즈와 COLMAP의 카메라 포즈 사이에 간격이 있습니다 [10, 29]; 그리고 2) 통제되지 않은 야외 장면에서 흔들리는 식물과 다른 견고하지 않은 물체가 있는 이미지를 피하는 것은 보통 어렵습니다, 이로 인해 COLMAP의 성능이 더욱 저하됩니다.
고해상도 재구성 설정에서 픽셀 공간 비정렬이 해상도에 따라 선형으로 확장되기 때문에 카메라 포즈와 움직이는 물체로 인한 비정렬 문제가 더욱 증폭될 수 있습니다.
우리는 섹션 4.3에서 이러한 정렬 오류가 렌더링된 이미지의 품질에 얼마나 영향을 미치는지 살펴봅니다.
이 문제를 해결하기 위해 렌더링된 이미지의 품질을 개선하기 위해 채택할 수 있는 정렬 인식 학습 전략을 제안합니다.

왜곡된 텍스처에도 불구하고, 우리는 NeRF가 그림 3의 두 번째 열에 표시된 것처럼 잘못 정렬된 이미지로부터 거친 구조를 여전히 학습한다는 것을 관찰합니다.
이를 활용하여 정렬된 ground truth와 렌더링된 패치 사이의 loss를 제안했습니다.
G가 ground truth 패치를 나타내고 R이 렌더링된 패치를 나타냅니다.
우리는 각 반복 동안 더 큰 크기의 ground truth 패치 G를 샘플링하고 더 작은 렌더링된 패치 R과 가장 잘 일치하기 위해 가능한 모든 하위 패치 G_i를 검색합니다.
NeRF는 ground truth 집합에서 가능한 많은 패치 G_i와 동일하게 잘 정렬된 것처럼 보이는 매우 블러한 패치 R을 렌더링할 수 있기 때문에, 우리는 이 검색 공간에 대한 페널티로 유클리드 거리를 기반으로 정규화 항을 추가로 설정합니다.
최종 loss 함수는
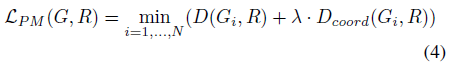
이며, 여기서 D(G_i, R) = |G_i - R| 및 D_cord(G_i, R) = √(Δx^2 + Δy^2), Δx/Δy는 G_i와 R 사이의 수평/직렬 오프셋입니다.
정규화 항을 제어하기 위해 λ를 채택하고 경험적으로 0.01로 설정합니다.
모든 실험에서 G에 대한 48x48 패치를 샘플링하고 각 반복 내에서 R에 대한 32x32 패치를 렌더링합니다.
유사한 loss는 이미지 초해상도 [48] 또는 style transfer [22]에도 사용됩니다.
그러나 이러한 loss는 단일 픽셀에서 정의되는 반면, 정렬 인식 loss는 정렬 벡터(Δx, Δy)를 보다 강력하게 추정할 수 있는 패치에서 정의됩니다.
3.3. High-frequency aware Loss
평균 제곱 오차(MSE) loss는 NeRF 학습을 supervise하기 위해 일반적으로 사용되지만 MSE가 종종 블러 출력 이미지로 이어진다는 것은 이미지 처리 문헌에 잘 알려져 있습니다 [12, 16].
패치 샘플링 전략을 고려할 때, 우리는 높은 빈도의 세부 정보를 더 잘 보존하는 지각 loss를 채택할 수 있습니다.
우리는 먼저 사전 학습된 VGG 피쳐의 L2 loss를 사용하려고 시도했습니다 [35].
그러나 다른 이미지 복원 작업[16]과 유사하게 지각 loss는 더 높은 빈도의 세부 사항을 생성하지만 때때로 물체의 실제 질감을 왜곡한다는 것을 발견했습니다.
대신, 우리는 최대 풀링 전에 첫 번째 블록의 출력만 사용하여 Johnson et al. [12]이 제안한 원래 지각 loss를 수정합니다:
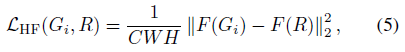
, 여기서 G_i는 정렬 후의 ground truth 패치를 나타내고 R은 렌더링된 패치를 나타내며, F는 사전 학습된 VGG-19 모델의 첫 번째 블록을 나타내며, C, W, H는 추출된 피처 맵의 차원입니다.
이러한 변화로, 제안된 loss는 실제 텍스처를 여전히 보존하면서 고주파 세부 사항을 개선합니다.
요약하자면, AligNeRF와 이전 작업의 주요 차이점은 픽셀당 MSE loss에서 패치 기반 MSE loss(오정렬 설명)와 고주파 세부 사항을 개선하기 위한 얕은 VGG 피쳐 공간 loss의 조합으로 전환한다는 것입니다:
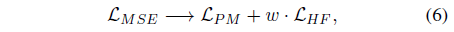
, 여기서 w는 경험적으로 0.05로 설정됩니다.
비교를 용이하게 하고 간단한 플러그 앤 플레이 수정으로 AligNeRF를 사용하는 것을 입증하기 위해 mip-NeRF 360의 다른 정규화 loss는 기본적으로 동일하게 유지됩니다.
4. Experiments
4.1. Dataset
우리 실험의 주요 테스트 베드는 mip-NeRF 360[2]의 야외 장면입니다.
이것은 제한 없는 실제 장면, 복잡한 텍스처 세부 사항 및 미묘한 장면 모션으로 가장 까다로운 벤치마크이기 때문입니다.
[2] "bicycle", "flowers", "treehill", "garden", "stump"을 포함한 5개의 야외 장면을 캡처했습니다.
그러나 이러한 캡처된 이미지는 크기가 4배 더 작아져 해상도가 약 1280x840입니다.
정렬 오류를 더 잘 조사하기 위해 이러한 장면의 고해상도 버전(2560x1680)에 대한 실험도 수행합니다.
마지막으로, 우리는 또한 섹션 4.3에 설명된 바와 같이 잘못 정렬된 데이터로부터 편향된 결론을 도출하지 않기 위해 더 잘 정렬된 새로운 테스트 세트를 생성합니다.
4.2. Training Details
Standard Training Setting.
베이스라인 알고리즘은 mip-NeRF 360의 표준 학습 절차에 따라 최적화됩니다.
배치 크기는 16384, β1 = 0.9 및 β2 = 0.999인 Adam [13] 최적화기, 1e-3의 표준으로 그래디언트 클리핑.
초기 및 최종 학습 속도는 2x10^-3 및 2x10^-5로 설정되며, 어닐된 로그 선형 감쇠 전략을 사용합니다.
처음 512회 반복은 학습 속도 준비 단계에 사용됩니다.
Alignment-aware Training Setting.
AligNeRF의 학습 과정을 사전 학습 단계(MLP만 해당)와 미세 조정 단계(ConvNets와 함께 MLP)의 두 단계로 나눕니다.
첫 번째 단계에서는 일반적으로 표준 학습 절차를 따르지만 반복 횟수는 60%입니다.
다음 단계에서는 섹션 3.1-3.3에 설명된 정렬 인식 학습 전략을 사용하여 개별 픽셀 대신 각 배치에서 32x32 패치를 샘플링하고 배치 크기를 32개 패치로 설정합니다.
총 ray 수가 사전 학습 단계보다 2배 더 많기 때문에, 우리는 학습 중에 보이는 총 ray 수를 동일하게 하기 위해 두 번째 단계에 대해 20%의 반복만 사용합니다.
이를 통해 두 단계의 총 학습 비용은 표준 학습과 거의 동일하게 됩니다.
또한 다음 두 가지 설정에 대한 벤치마크를 보고합니다: mip-NeRF 360[2]에 사용되는 표준 250k 반복과 1000k 단계에 대해 학습된 4배 더 긴 버전.
이는 2배 더 큰 해상도 학습 이미지를 사용하려면 동일한 총 에포크 수에 대해 4배 더 많은 반복이 필요하기 때문입니다.
모든 실험은 32개 코어의 TPU v2 가속기에서 수행됩니다.
4.3. Misalignment Analysis
우리는 NeRF를 고해상도로 확장할 때 품질 저하의 원인을 분석하는 것으로 시작합니다.
특히, 학습 이미지 정렬 오류가 NeRF에 의해 렌더링되는 이미지 품질에 어떻게 영향을 미치는지 보여줍니다.
이를 설명하기 위해 움직임 추정 기법을 사용하여 정렬 오류를 수정하는 ablation 연구를 수행합니다.
[50]에서 영감을 받아, 우리는 운동 추정을 사용하여 학습 뷰를 NeRF로 재구성된 기하학과 정렬합니다.
4.3.1 Re-generating Training/Testing Data with Iterative Alignment
여기서는 optical flow를 사용하여 입력 이미지를 NeRF에 의해 추정된 형상과 정렬함으로써 데이터 세트의 정렬 오류를 수정합니다.
이를 달성하기 위해 고품질이지만 값비싼 모션 추정기(PWC-Net [38])를 사용하여 NeRF에 의해 렌더링된 이미지와 해당 ground truth 뷰 사이의 optical flow를 계산합니다.
그러나 우리는 우리의 사례가 일반적으로 두 개의 샤프한 이미지를 쌍 입력으로 예상하는 일반 optical flow 추정기의 가정을 부분적으로 위반한다는 것을 관찰합니다.
그러나 실제로 NeRF에 의해 생성된 렌더링된 이미지는 정렬 오류로 인해 대부분 블러입니다.
그림 3의 두 번째 열에 나타난 바와 같이, 현재 최상의 NeRF 변형(mip-NeRF 360[2])은 샤프한 세부사항을 생성하지 못하여 PWC-Net에서 추정한 optical flow 결과에 손상을 줍니다.
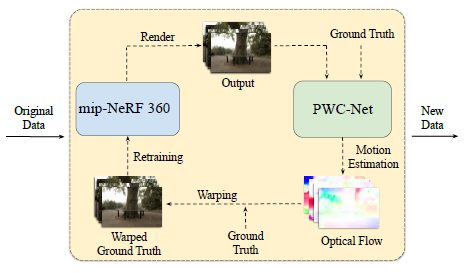
이 문제를 해결하기 위해 그림 4에 표시된 반복 정렬 전략을 제안합니다.
즉, 모든 선형 반복에서 다음을 수행합니다:
1) 원본 ground truth 이미지를 사용하여 mip-NeRF 360을 학습하고 각 학습 뷰에 대한 출력 이미지를 렌더링합니다.
2) 그런 다음 PWC-Net을 사용하여 렌더링된 뷰에서 ground truth 뷰로의 flow를 계산합니다.
블러 NeRF 이미지로 인해 flow 필드에 약간의 부정확성이 포함될 수 있지만, PWC-Net은 일반적으로 전역 구조와 모양을 기반으로 합리적인 결과를 생성할 수 있습니다.
3) 마지막으로, 우리는 이러한 추정된 optical flow를 사용하여 NeRF에 의해 추정된 기하학적 구조와 더 잘 정렬된 새로운 학습 세트를 구축하여 ground truth 이미지를 왜곡합니다.
각 정렬 반복에서 mip-NeRF 360은 더 잘 정렬된 데이터를 활용하여 더 샤프한 이미지를 생성할 수 있습니다.
그런 다음 이러한 더 샤프한 이미지는 추정된 optical flow의 정확도를 더욱 향상시킵니다.
그리고 더 정확한 optical flow를 통해 다음 학습을 위해 더 잘 정렬된 학습 이미지를 생성할 수 있습니다.
우리는 최상의 품질에 도달하는 데 일반적으로 2-3번의 반복이 필요하다는 것을 관찰합니다.
이 정렬 전략을 사용하여 정렬이 더 나은 테스트 이미지 세트를 새로 생성하여 원래 정렬이 잘못된 테스트 세트에서 편향된 결론을 도출하는 것을 방지할 수 있습니다.
4096개 채널의 최고 품질 mip-NeRF 360 모델을 사용하여 생성한 동일한 정렬 테스트 세트를 모든 방법에 사용합니다.
다음 실험에서 우리는 두 테스트 세트 모두에 대한 결과를 보고합니다.
4.3.2 Qualitative Analysis of Misalignment Issue
그림 3에서 우리는 반복적인 정렬 전략의 중간 시각적 예를 비교합니다.
먼저 기본 매개 변수(1024 채널)를 가진 mip-NeRF 360 모델을 학습합니다.
이로 인해 이미지가 블러해지고 추정된 optical flow에 왜곡된 영역(첫 번째 열)의 아티팩트가 포함됩니다.
다음으로, 우리는 mip-NeRF 360 매개 변수를 4배 증가시켜 결과의 시각적 품질을 약간 향상시킬 뿐입니다.
또한 이 강력한 모델의 결과를 개선하기 위해 반복 정렬 전략을 적용합니다.
세 번째 열과 네 번째 열을 비교함으로써, 우리는 재생된 데이터로 학습된 모델이 잘못 정렬된 데이터로 학습된 모델(처음 두 열)에 비해 훨씬 더 샤프한 세부 정보를 복구한다는 것을 알 수 있습니다.
이 관찰은 현재 최고의 NeRF 모델이 잘못 정렬된 학습 예제의 영향을 강하게 받는다는 것을 의미합니다.
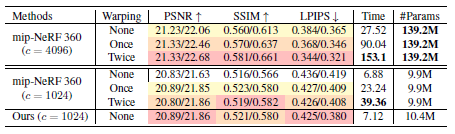
4.3.3 Quantitative Analysis of Misalignment Issue
다음으로 세 가지 공통 메트릭(PSNR, SSIM [42] 및 LPIPS [47])을 사용하여 이러한 모델에 대한 정량적 평가를 수행합니다.
표 1에 나타난 바와 같이, 더 큰 MLP(4096 채널)를 가진 mip-NeRF 360은 더 잘 정렬된 학습 데이터에 의해 지속적으로 개선되며, PSNR 점수가 큰 차이(warped test set에서 +0.62dB)로 증가했습니다.
더 작은 모델(1024 채널)과 관련하여, 매개 변수 부족으로 인해 더 작지만 반복 정렬 전략은 여전히 약간의 개선을 가져옵니다(+0.23dB PSNR).
이 정렬 전략은 좋은 결과를 낳지만, mip-NeRF 360을 처음부터 재학습하고 전체 학습 데이터 세트를 여러 번 다시 렌더링해야 하기 때문에 시간이 매우 많이 걸립니다.
대조적으로, 섹션 3에서 제안된 솔루션은 추가 비용을 거의 들이지 않고 warped 테스트 세트에서 베이스라인을 +0.23dB PSNR만큼 개선합니다.
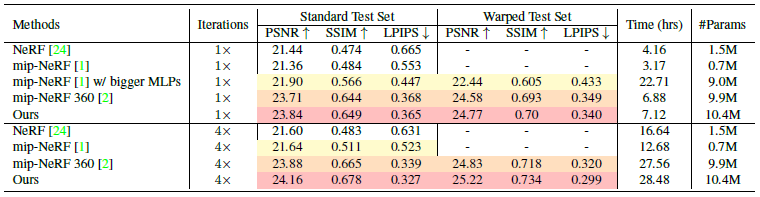
4.4. Comparing with Previous Methods
먼저 [2]에서 수집한 고해상도(2560x1680) "outdoor" 장면에 대한 방법과 이전 작업을 평가합니다.
공정한 비교를 위해 제안된 AligNeRF 기술을 mip-NeRF 360에 적용하고, 단계별 학습(사전 학습 + 미세 조정)으로 학습 시간이 늘지 않도록 주의합니다.
기본적으로 mip-NeRF 360은 250k 반복에 대해 학습됩니다.
그러나 이 실험은 고해상도 이미지를 사용하기 때문에 동일한 수의 학습 기간을 유지하기 위해 학습 시간을 4배 늘리는 결과도 살펴봅니다.
표 2에 나타난 바와 같이, NeRF[24]와 mip-NeRF[1]는 360도 경계가 없는 장면을 위해 설계되지 않았기 때문에 낮은 성능을 보입니다.
mip-NeRF의 매개 변수를 증가시키면 작은 개선이 이루어지지만 학습 시간이 길어집니다.
mip-NeRF 360[2]은 standard 및 warped 테스트 세트에서 23.88dB 및 24.83dB PSNR에 도달하는 강력한 베이스라인 역할을 합니다.
제안된 방법은 상당한 학습 오버헤드를 초래하지 않고 두 그룹 모두에서 베이스라인 방법을 능가합니다.
우리는 또한 그림 5와 보충 자료에 시각적인 예를 포함하는데, 여기서 우리의 방법은 다른 모든 접근법보다 더 선명하고 선명한 질감을 만들어냅니다.

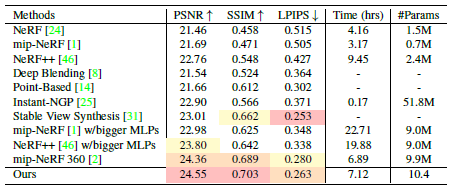
표 3에서는 [2]에서 사용한 것과 동일한 해상도(1280x840)로 "outdoor" 장면에서 실행함으로써 우리의 방법이 저해상도 데이터에서 어떻게 작동하는지 분석합니다.
이전 접근법의 점수는 대부분 [2]에서 직접 얻습니다.
그러나 비교를 위해 최근의 instant-NGP [25] 방법도 포함합니다.
우리는 저자들에게 연락을 취했고 해시 그리드(2^21), 학습 배치(2^20) 및 장면의 바운딩 박스(32)의 크기를 늘려 큰 장면에 대해 instant-NGP[25]를 조정했습니다.
Stable View Synthesis (SVS) [31]가 최고 LPIPS 점수에 도달하지만, [2]에서 입증된 것처럼 시각적 결과는 다른 방법보다 품질이 낮습니다.
이러한 접근 방식 중에서, 우리의 방법은 저해상도 이미지에서 정렬 오류 문제가 훨씬 덜 심각하지만 세 가지 메트릭 중에서 최고의 성능을 보여줍니다.
4.5. Ablation Study
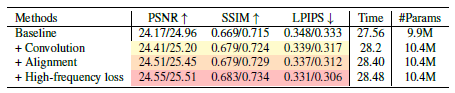
표 4에서 "outdoor" 데이터 세트의 "bicycle" 장면(해상도 2560x1680)에 대한 방법의 ablation 연구를 수행합니다[2].
우리는 먼저 1000k 반복에 대한 기본 mip-NeRF 360 모델을 학습합니다.
다음으로, 우리는 600k번의 반복을 위해 또 다른 mip-NeRF 360 모델을 학습하고, 그 위에 컨볼루션 증강 아키텍처를 적용합니다.
패치별 샘플링 전략을 사용하여 200,000회 반복으로 이 새로운 아키텍처를 추가로 미세 조정합니다.
이를 통해 컨볼루션 증강 모델은 학습 시간을 크게 늘리지 않고도 훨씬 높은 품질(standard/warped 테스트 세트에서 +0.24dB/0.24dB)에 도달할 수 있습니다.
한편, 정렬 인식 loss를 이 컨볼루션 증강 아키텍처에 추가하면 품질이 더욱 향상됩니다.
특히, 제안된 정렬 인식 학습을 적용한 후 warped 테스트 세트(+0.25dB PSNR)의 개선이 standard 테스트 세트(+0.10dB PSNR)보다 커서 장면의 잘못 정렬된 부분에서 더 많은 개선을 가져온다는 것을 알 수 있습니다.
마지막으로, 제안된 고주파 loss는 최신 결과를 약간 개선합니다.
다른 메트릭을 희생하여 LPIPS 점수를 향상시키는 경향이 있는 이전의 다른 지각 loss[12]과는 달리, 우리의 loss는 세 가지 메트릭을 모두 향상시킵니다.
4.6. Evaluating Pose-free NeRFs on Non-still Scenes
bundle-adjustment NeRF[17]를 사용하여 카메라 포즈를 공동으로 최적화함으로써 비정렬 문제를 해결할 수 있는지 의문을 가질 수 있습니다.
이 전략은 정적 장면에 실제로 도움이 되지만, 우리는 객체의 포즈 최적화를 위해서는 객체가 피처 매칭을 위해 정적이어야 하기 때문에 객체의 미묘한 움직임이 성능을 해칠 수도 있다고 주장합니다.
이를 입증하기 위해 미묘한 움직임이 포함된 정지하지 않은 장면에서 포즈가 없는 NeRF-like [17] 모델의 성능을 측정하는 toy 실험을 수행합니다.
이 현상을 시뮬레이션하기 위해 Blender 소프트웨어를 채택하여 100개의 학습 뷰와 200개의 테스트 뷰를 가진 새로운 "lego" 예제 세트를 렌더링합니다, 여기서 팔은 랜덤으로 0.5 확률로 두 가지 다른 조건으로 설정됩니다.
따라서 우리는 수동으로 비정렬을 만들 수 있습니다.
우리는 그림 6의 첫 번째 행에서 두 조건의 차이가 잘못 정렬된 영역을 나타내는 시각적 예를 보여줍니다.
고충실도 설정에 맞게 더 높은 해상도(1200x1200)를 렌더링합니다.
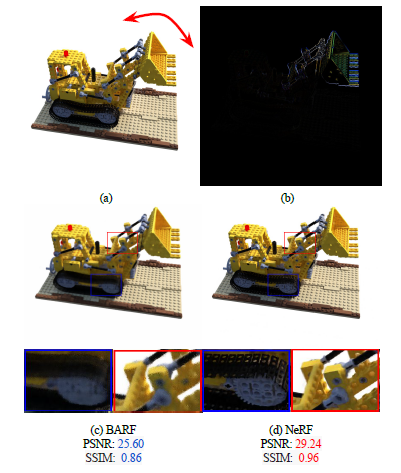
우리는 이 새로운 데이터 세트에서 BARF [17] 모델을 평가합니다, 여기서 초기 포즈는 실제 포즈에서 섭동됩니다.
한편, 우리는 비교를 위해 vanilla NeRF[24]를 학습합니다.
그림 6에 나타난 바와 같이, NeRF는 정렬된 영역에 대한 샤프한 세부 정보와 잘못 정렬된 영역에 대한 블러 질감을 생성하며, BARF는 두 영역에 대해 블러한 결과를 만듭니다.
정량적 및 정성적 실험은 움직이는 물체가 포함될 때 NeRF와 카메라 포즈를 공동으로 최적화하는 것이 심각한 문제에 직면할 수 있음을 보여줍니다.
5. Conclusion
이 연구에서, 우리는 고해상도 데이터에 대한 neural radiance field 학습에 대한 파일럿 연구를 수행했습니다.
NeRF의 성능을 향상시키는 효과적인 정렬 인식 학습 전략인 AligNeRF를 제시했습니다.
또한 모션 추정을 사용하여 정렬된 데이터를 다시 생성하여 잘못 정렬된 데이터로 인한 성능 저하를 정량적 및 정성적으로 분석합니다.
이 분석은 또한 NeRF를 더 높은 해상도로 확장하는 현재 병목 현상을 이해하는 데 도움이 됩니다.
우리는 여전히 매개 변수의 수를 크게 늘리고 학습 시간을 더 늘림으로써 NeRF를 더욱 향상시킬 수 있다는 것을 관찰합니다.
향후 이 격차를 해소하는 방법을 조사할 것입니다.