2023. 10. 29. 15:33ㆍView Synthesis
3D Gaussian Splatting for Real-Time Radiance Field Rendering
BERNHARD KERBL, GEORGIOS KOPANAS, THOMAS LEIMKÜHLER, GEORGE DRETTAKIS
Radiance Field 방법은 최근 여러 사진 또는 비디오로 캡처된 장면의 새로운 뷰 합성에 혁신을 일으키고 있습니다.
그러나 높은 시각적 품질을 달성하려면 학습 및 렌더링에 비용이 많이 드는 신경망이 여전히 필요하며, 최근의 더 빠른 방법은 필연적으로 품질과 속도를 맞바꾸어야 합니다.
(분리된 객체가 아닌) 경계가 없고 완전한 장면 및 1080p 해상도 렌더링의 경우 현재 방법으로는 실시간 디스플레이 속도를 달성할 수 없습니다.
경쟁력 있는 학습 시간을 유지하면서 SOTA 시각적 품질을 달성하고 1080p 해상도에서 고품질 실시간 (≥ 30fps) 새로운 뷰 합성을 중요하게 허용하는 세 가지 주요 요소를 소개합니다.
첫째, 카메라 보정 중에 생성된 희소 점에서 시작하여 빈 공간에서 불필요한 계산을 방지하면서 장면 최적화를 위해 연속 체적 래디언스 필드의 바람직한 속성을 보존하는 3D 가우시안으로 장면을 표현합니다; 둘째, 3D 가우시안의 인터리브 최적화/밀도 제어를 수행하며, 특히 장면의 정확한 표현을 달성하기 위해 anisotropic 공분산을 최적화합니다; 셋째, anisotropic splatting을 지원하고 학습을 가속화하고 실시간 렌더링을 허용하는 빠른 가시성 인식 렌더링 알고리즘을 개발합니다.
우리는 여러 확립된 데이터 세트에 대한 SOTA 시각적 품질과 실시간 렌더링을 입증합니다.
1 INTRODUCTION
메시와 포인트는 명시적이고 빠른 GPU/CUDA 기반 래스터화에 적합하기 때문에 가장 일반적인 3D 장면 표현입니다.
이와 대조적으로, 최근의 Neural Radiance Field (NeRF) 방법은 연속 장면 표현을 기반으로 하며, 일반적으로 캡처된 장면의 새로운 뷰 합성을 위해 체적 ray-marching을 사용하여 Multi-Layer Perceptron (MLP)을 최적화합니다.
마찬가지로, 현재까지 가장 효율적인 radiance field 솔루션은 복셀 [Fridovich-Keil and Yu et al. 2022] 또는 해시 [Müler et al. 2022] 그리드 또는 포인트 [Xu et al. 2022]에 저장된 값을 보간하여 연속 표현을 기반으로 합니다.
이러한 방법의 연속적인 특성은 최적화에 도움이 되지만, 렌더링에 필요한 확률적 샘플링은 비용이 많이 들고 노이즈가 발생할 수 있습니다.
우리는 두 세계의 최상의 것을 결합한 새로운 접근 방식을 소개합니다: 3D 가우시안 표현은 SOTA 시각 품질과 경쟁력 있는 학습 시간으로 최적화를 허용하는 반면, 타일 기반 splatting 솔루션은 이전에 발표된 여러 데이터 세트에서 1080p 해상도의 SOTA 품질로 실시간 렌더링을 보장합니다 [Barron et al. 2022; Hedman et al. 2018; Knapitsch et al. 2017] (그림 1 참조).

우리의 목표는 여러 사진으로 촬영된 장면에 대해 실시간 렌더링을 허용하고 일반적인 실제 장면에 대해 가장 효율적인 이전 방법만큼 빠르게 최적화 시간으로 표현을 만드는 것입니다.
최근의 방법은 빠른 학습을 달성하지만[Fridovich-Keil and Yu et al. 2022; Müller et al. 2022], 최대 48시간의 학습 시간이 필요한 현재의 SOTA NeRF 방법, 즉 Mip-NeRF360 [Barron et al. 2022]에 의해 얻어진 시각적 품질을 달성하기 위해 어려움을 겪고 있습니다.
빠른 - 그러나 품질이 낮은 - 래디언스 필드 방식은 장면에 따라 대화형 렌더링 시간(초당 10~15프레임)을 달성할 수 있지만 고해상도의 실시간 렌더링에는 미치지 못합니다.
우리의 솔루션은 세 가지 주요 구성 요소를 기반으로 구축됩니다.
먼저 유연하고 표현적인 장면 표현으로 3D 가우시안을 소개합니다.
이전 NeRF-like 방법, 즉 Structure-from-Motion (SfM) [Snavely et al. 2006]으로 보정된 카메라와 동일한 입력으로 시작하여 SfM 프로세스의 일부로 무료로 생성된 희소 포인트 클라우드로 3D 가우시안 세트를 초기화합니다.
Multi-View Stereo (MVS) 데이터 [Aliev et al. 2020; Kopanas et al. 2021; Rückert et al. 2022]가 필요한 대부분의 포인트 기반 솔루션과는 대조적으로 SfM 포인트만 입력하면 고품질의 결과를 얻을 수 있습니다.
NeRF-synthetic 데이터 세트의 경우, 우리의 방법은 랜덤 초기화로도 높은 품질을 달성합니다.
3D 가우시안은 미분 가능한 부피 표현이지만 NeRF와 같은 동등한 이미지 형성 모델을 사용하여 2D로 투사하고 표준 𝛼-블렌딩을 적용함으로써 매우 효율적으로 래스터화할 수 있기 때문에 우수한 선택임을 보여줍니다.
우리 방법의 두 번째 구성 요소는 적응형 밀도 제어 단계와 인터리빙된 3D 가우시안의 속성-3D 위치, 불투명도 𝛼, anisotropic 공분산 및 spherical harmonics (SH) 계수-을 최적화하는 것이며, 최적화하는 동안 3D 가우시안을 추가하고 때때로 제거합니다.
최적화 절차는 상당히 압축적이고 비구조적이며 정확한 장면 표현을 생성합니다(테스트된 모든 장면의 경우 100만-500만 가우시안).
우리 방법의 세 번째이자 마지막 요소는 최근 연구 [Lassner and Zollhofer 2021]에 이어 빠른 GPU 정렬 알고리즘을 사용하고 타일 기반 래스터화에서 영감을 얻은 실시간 렌더링 솔루션입니다.
그러나 3D 가우시안 표현 덕분에 가시성 순서 -정렬 및 𝛼-블렌딩 덕분에- 를 존중하는 anisotropic splatting을 수행하고 필요한 만큼 정렬된 splats의 횡단을 추적하여 빠르고 정확한 역방향 패스를 가능하게 할 수 있습니다.
요약하자면, 우리는 다음과 같은 기여를 제공합니다:
• anisotropic 3D 가우시안을 고품질의 비구조화된 래디언스 필드 표현으로 소개합니다.
• 캡처된 장면에 대해 고품질 표현을 생성하는 적응형 밀도 제어와 인터리브된 3D 가우시안 특성의 최적화 방법.
• 가시성 인식 GPU를 위한 빠르고 미분 가능한 렌더링 방식은 anisotropic splatting과 빠른 역전파를 통해 고품질의 새로운 뷰 합성을 달성할 수 있습니다.
이전에 게시된 데이터 세트에 대한 결과는 다중 뷰 캡처로부터 3D 가우시안을 최적화하고 최고 품질의 이전 암시적 래디언스 필드 접근 방식과 동일하거나 더 나은 품질을 달성할 수 있음을 보여줍니다.
또한 가장 빠른 방법과 유사한 학습 속도와 품질을 달성할 수 있으며 중요하게도 새로운 뷰 합성을 위한 고품질의 첫 번째 실시간 렌더링을 제공할 수 있습니다.
2 RELATED WORK
먼저 기존 재구성에 대해 간략하게 설명한 다음 포인트 기반 렌더링 및 래디언스 필드 작업에 대해 논의하고 유사성에 대해 논의합니다; 래디언스 필드는 광범위한 영역이므로 직접 관련된 작업에만 초점을 맞춥니다.
해당 분야의 완벽한 취재를 위해서는 우수한 최근 surveys [Tewari et al. 2022; Xie et al. 2022]를 참고하시기 바랍니다.
2.1 Traditional Scene Reconstruction and Rendering
최초의 새로운 뷰 합성 접근법은 라이트 필드를 기반으로 했으며, 처음에는 조밀하게 샘플링된 [Gortler et al. 1996; Levoy and Hanrahan 1996] 그 후 비정형 캡처를 허용했습니다 [Buehler et al. 2001].
Structure-from-Motion (SfM) [Snavely et al. 2006]의 출현은 사진 모음을 사용하여 새로운 뷰를 합성할 수 있는 전체 도메인을 가능하게 했습니다.
SfM은 카메라 보정 동안 희소 포인트 클라우드를 추정하며, 처음에는 3D 공간을 단순하게 시각화하는 데 사용되었습니다.
이후 멀티뷰 스테레오 (MVS)는 수년에 걸쳐 인상적인 완전한 3D 재구성 알고리즘을 생산하여 [Goesle et al. 2007], 여러 뷰 합성 알고리즘을 개발할 수 있게 했습니다 [Chaurasia et al. 2013; Eisemann et al. 2008; Hedman et al. 2018; Kopanas et al. 2021].
이 모든 방법은 입력 이미지를 새로운 뷰 카메라에 재투영 및 혼합하고 지오메트리를 사용하여 이 재투영을 안내합니다.
이 방법은 많은 경우 우수한 결과를 얻었지만, 일반적으로 MVS가 존재하지 않는 지오메트리를 생성할 때 재구성되지 않은 영역이나 "over-reconstruction"에서는 완전히 복구할 수 없습니다.
최근의 신경 렌더링 알고리즘 [Tewari et al. 2022]은 이러한 아티팩트를 크게 줄이고 모든 입력 이미지를 GPU에 저장하는 막대한 비용을 방지하여 대부분의 분야에서 이 방법을 능가합니다.
2.2 Neural Rendering and Radiance Fields
딥러닝 기법은 새로운 뷰 합성을 위해 초기에 채택되었다 [Flynn et al. 2016; Zhou et al. 2016]; CNN은 블렌딩 가중치 [Hedman et al. 2018]를 추정하거나 텍스처 공간 솔루션 [Riegler and Koltun 2020; Thies et al. 2019]에 사용되었다.
MVS 기반 지오메트리의 사용은 대부분의 이러한 방법의 주요 단점입니다; 또한 최종 렌더링을 위해 CNN을 사용하면 시간적 깜박임이 자주 발생합니다.
새로운 뷰 합성을 위한 볼륨 표현은 Soft3D [Penner and Zhang 2017]에 의해 시작되었습니다; 볼륨 ray-marching과 결합된 딥러닝 기술은 지오메트리를 표현하기 위해 연속 미분 가능한 밀도 필드에 [Henzler et al. 2019; Sitzmann et al. 2019]를 구축하는 것이 후속적으로 제안되었습니다.
볼륨 ray-marching을 사용하는 렌더링은 볼륨을 쿼리하는 데 필요한 샘플 수가 많기 때문에 상당한 비용이 듭니다.
Neural Radiance Fields (NeRF) [Mildenhall et al. 2020]는 품질을 향상시키기 위해 중요 샘플링 및 위치 인코딩을 도입했지만 속도에 부정적인 영향을 미치는 대규모 다층 퍼셉트론을 사용했습니다.
NeRF의 성공은 종종 정규화 전략을 도입하여 품질과 속도를 다루는 후속 방법의 폭발적인 증가를 초래했습니다; 새로운 뷰 합성을 위한 이미지 품질의 현재 SOTA 기술은 Mip-NeRF360 [Barron et al. 2022]입니다.
렌더링 품질이 탁월하지만 학습 및 렌더링 시간은 매우 높습니다; 빠른 학습 및 실시간 렌더링을 제공하면서 이 품질과 동등하거나 능가할 수 있습니다.
가장 최근의 방법은 주로 다음과 같은 세 가지 설계 선택 사항을 활용하여 보다 빠른 학습 및/또는 렌더링에 초점을 맞추고 있습니다: 공간 데이터 구조를 사용하여 체적 ray-marching 중에 보간되는 (신경) 피쳐를 저장하는 것, 다양한 인코딩 및 MLP 용량.
이러한 방법에는 공간 이산화의 다양한 변형이 포함됩니다 [Chen et al. 2022b,a; Fridovich-Keil and Yu et al. 2022; Garbin et al. 2021; Hedman et al. 2021; Reiser et al. 2021; Takikawa et al. 2021; Wu et al. 2022; Yu et al. 2021], 코드북 [Takikawa et al. 2022], 해시 테이블과 같은 인코딩 [Müler et al. 2022], 더 작은 MLP 또는 앞서 설명한 신경망을 완전히 사용할 수 있습니다 [Fridovich-Keil and Yu et al. 2022; Sun et al. 2022].
이러한 방법 중 가장 눈에 띄는 것은 해시 그리드와 점유 그리드를 사용하여 계산을 가속화하고 밀도와 외관을 나타내기 위해 MLP를 더 작게 사용하는 InstantNGP [Müler et al. 2022]와 희소 복셀 그리드를 사용하여 연속 밀도 필드를 보간하고 신경망을 완전히 포기할 수 있는 Plenoxels [Fridovich-Keil and Yu et al. 2022]입니다.
둘 다 Spherical Harmonics에 의존합니다: 전자는 방향 효과를 직접적으로 표현하고 후자는 컬러 네트워크에 입력을 인코딩합니다.
둘 다 뛰어난 결과를 제공하지만, 이러한 방법은 여전히 빈 공간을 효과적으로 표현하는 데 어려움을 겪을 수 있으며, 장면/캡처 유형에 부분적으로 의존합니다.
또한 이미지 품질은 가속에 사용되는 구조화된 그리드의 선택에 의해 상당 부분 제한되며, 주어진 ray-marching 단계를 위해 많은 샘플을 쿼리해야 하기 때문에 렌더링 속도가 방해됩니다.
우리가 사용하는 비구조화되고 명시적인 GPU 친화적인 3D 가우시안은 신경 구성 요소 없이 더 빠른 렌더링 속도와 더 나은 품질을 달성합니다.
2.3 Point-Based Rendering and Radiance Fields
포인트 기반 방법은 연결되지 않은 및 비구조화된 지오메트리 샘플(즉, 포인트 클라우드)을 효율적으로 렌더링합니다 [Gross and Pfister 2011].
포인트 샘플 렌더링 [Grossman and Dally 1998]은 고정된 크기의 비구조화된 포인트 세트를 래스터화하며, 이를 위해 기본적으로 지원되는 그래픽 API의 포인트 유형 [Sainz and Pajarola 2004] 또는 GPU의 병렬 소프트웨어 래스터화를 활용할 수 있습니다 [Lain and Karras 2011; Schütz et al. 2022].
포인트 샘플 렌더링은 기본 데이터에 충실하지만 구멍이 발생하고 앨리어싱이 발생하며 엄격하게 불연속적입니다.
고품질 포인트 기반 렌더링에 대한 중요한 작업은 픽셀보다 큰 범위(예: 원형 또는 타원형 디스크, 타원체 또는 서펠)로 포인트 프리미티브를 "splatting"함으로써 이러한 문제를 해결합니다 [Botsch et al. 2005; Pfister et al. 2000; Ren et al. 2002; Zwicker et al. 2001b].
최근, 미분 가능한 포인트 기반 렌더링 기법에 대한 관심이 증가하고 있습니다[Wiles et al. 2020; Yifan et al. 2019].
포인트는 신경 피쳐로로 증강되고 CNN [Alliev et al. 2020; Rückert et al. 2022]을 사용하여 렌더링되어 빠른 또는 심지어 실시간 뷰 합성이 가능합니다; 그러나 초기 지오메트리를 위해 여전히 MVS에 의존하며, 특히 피쳐가 없는/빛나는 영역이나 얇은 구조와 같은 딱딱한 경우에 과도하거나 재구성 중인 아티팩트를 상속합니다.
포인트 기반 𝛼-블렌딩 및 NeRF 스타일 볼륨 렌더링은 본질적으로 동일한 이미지 형성 모델을 공유합니다.
구체적으로, 컬러 𝐶는 ray를 따른 볼륨 렌더링에 의해 제공됩니다:
, 여기서 밀도 𝜎, 투과율 𝑇, 컬러 c의 샘플은 간격 𝛿_𝑖와 함께 ray를 따라 추출됩니다.
이것은 𝛼_i와 함께
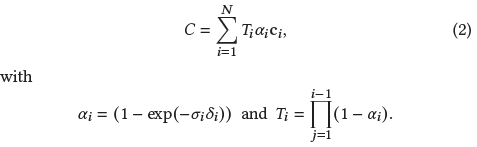
로 다시 쓸 수 있습니다.
일반적인 신경 포인트 기반 접근법(예를 들어, [Kopanas et al. 2022, 2021])은 픽셀에 중첩되는 N개의 순서 포인트를 블렌딩하여 픽셀의 색상 𝐶를 계산합니다:
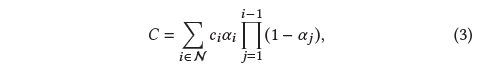
, 여기서 c_𝑖는 각 포인트의 색상이고 𝛼_𝑖는 공분산 ∑에 학습된 포인트당 불투명도를 곱한 2D 가우시안을 평가함으로써 주어진다 [Yifan et al. 2019].
식 2와 식 3을 통해, 우리는 이미지 형성 모델이 동일하다는 것을 분명히 알 수 있습니다.
그러나 렌더링 알고리즘은 매우 다릅니다.
NeRF는 빈 공간/점유 공간을 암시적으로 표현하는 연속적인 표현입니다; 결과적인 노이즈 및 계산 비용으로 식 2의 샘플을 찾기 위해서는 값비싼 랜덤 샘플링이 필요합니다.
대조적으로 포인트는 NeRF와 유사한 지오메트리의 생성, 파괴 및 변위를 허용할 수 있을 정도로 충분히 유연한 비구조화된 이산 표현입니다.
이는 이전 작업 [Kopanas et al. 2021]에서 볼 수 있듯이 불투명도와 위치를 최적화하면서 전체 부피 표현의 단점을 방지함으로써 달성됩니다.
Pulsar [Lassner and Zollhofer 2021]은 타일 기반 및 정렬 렌더러에 영감을 준 빠른 sphere 래스터화를 달성합니다.
그러나 위의 분석을 고려할 때, 우리는 부피 표현의 이점을 가지기 위해 정렬된 splats에서 기존의 𝛼-블렌딩을 (대략) 유지하고 싶습니다: 우리의 래스터화는 순서 독립적인 방법과 대조적으로 가시성 순서를 존중합니다.
또한 픽셀의 모든 splats에서 그래디언트를 역전파하고 anisotropic splats를 래스터화합니다.
이러한 요소는 모두 결과의 높은 시각적 품질에 기여합니다(섹션 7.3 참조).
또한 위에서 언급한 이전 방법도 렌더링에 CNN을 사용하므로 시간적 불안정을 초래합니다.
그럼에도 불구하고 Pulsar [Lassner and Zollhofer 2021]와 ADOP [Rückert et al. 2022]의 렌더링 속도는 빠른 렌더링 솔루션을 개발하는 동기가 되었습니다.
추측 효과에 초점을 맞추는 동안 Neural Point Catacastics [Kopanas et al. 2022]의 diffuse 포인트 기반 렌더링 트랙은 MLP를 사용하여 이러한 시간적 불안정성을 극복하지만 입력으로 MVS 지오메트리를 필요로 했습니다.
이 범주의 가장 최근 방법 [Zhang et al. 2022]은 MVS가 필요하지 않고 방향을 위해 SH를 사용하지만, 한 객체의 장면만 처리할 수 있으며 초기화를 위한 마스크가 필요합니다.
해상도가 작고 포인트 수가 적지만 일반적인 데이터 세트의 장면으로 어떻게 확장할 수 있는지는 불분명합니다 [Barron et al. 2022; Hedman et al. 2018; Knapitsch et al. 2017].
우리는 보다 유연한 장면 표현을 위해 3D 가우시안을 사용하며, 투영된 가우시안에 대한 타일 기반 렌더링 알고리즘 덕분에 MVS 지오메트리의 필요성을 피하고 실시간 렌더링을 달성합니다.
최근의 접근법 [Xu et al. 2022]은 radial basis 함수 접근법을 갖는 래디언스 필드를 나타내기 위해 점들을 사용하고, 최적화 동안 포인트 pruning 및 densification 기법을 사용하지만, 체적 ray-marching을 사용하고, 실시간 디스플레이 레이트를 달성할 수 없습니다.
인간 성능 캡처 영역에서 3D 가우시안은 캡처된 인체를 나타내는 데 사용되어 왔습니다 [Rhodin et al. 2015; Stoll et al. 2011]; 최근에는 비전 작업을 위한 체적 ray-marching과 함께 사용되었습니다 [Wang et al. 2023].
신경 체적 프리미티브는 유사한 맥락에서 제안되었습니다 [Lombardi et al. 2021].
이러한 방법은 장면 표현으로 3D 가우시안을 선택하는 데 영감을 주었지만, 단일 고립된 물체(사람의 신체 또는 얼굴)를 재구성하고 렌더링하는 특정 경우에 초점을 맞추어서 depth 복잡성이 작은 장면을 생성합니다.
이와는 대조적으로, anisotropic 공분산의 최적화, 인터리브 최적화/밀도 제어 및 렌더링을 위한 효율적인 depth 정렬은 실내 및 실외 모두에서 배경을 포함한 완전하고 복잡한 장면을 처리할 수 있도록 해줍니다.
3 OVERVIEW
우리의 방법에 대한 입력은 부작용으로 희소한 포인트 클라우드를 생성하는 SfM [Schönberger and Frahm 2016]에 의해 보정된 해당 카메라와 함께 정적 장면의 이미지 세트입니다.
이 점에서 우리는 매우 유연한 최적화 체제를 허용하는 위치(평균), 공분산 행렬 및 불투명도 𝛼에 의해 정의되는 3D 가우시안 세트(섹션 4)를 만듭니다.
이는 부분적으로 높은 anisotropic 체적 splats를 사용하여 fine 구조를 압축적으로 표현할 수 있기 때문에 3D 장면을 합리적으로 압축적으로 표현합니다.
래디언스 필드의 방향성 외관 구성 요소 (색상)는 표준 관행 [Fridovich-Keil and Yu et al. 2022; Müller et al. 2022]에 따라 spherical harmonics (SH)를 통해 표현됩니다.
우리의 알고리즘은 가우시안 밀도의 적응적 제어를 위한 연산과 인터리빙된 위치, 공분산, 𝛼 및 SH 계수와 같은 3D 가우시안 매개변수의 일련의 최적화 단계를 통해 래디언스 필드 표현(섹션 5)을 생성합니다.
이 방법의 효율성의 핵심은 타일 기반 래스터라이저(섹션 6)로, 빠른 정렬 덕분에 가시성 순서를 존중하여 anisotropic splats를 𝛼로 혼합할 수 있습니다.
우리의 빠른 래스터화는 그래디언트를 수신할 수 있는 가우시안의 수에 제한 없이 누적된 𝛼값을 추적하여 빠른 역방향 패스도 포함됩니다.
방법의 개요는 그림 2에 나와 있습니다.
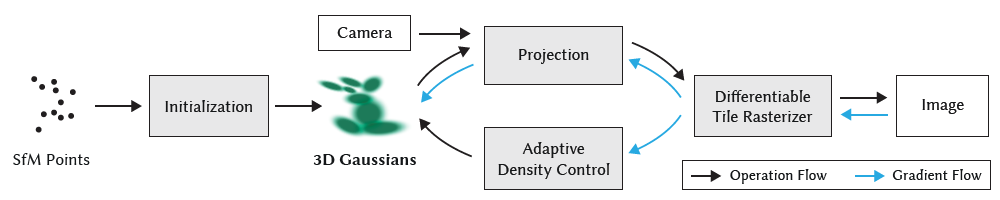
4 DIFFERENTIABLE 3D GAUSSIAN SPLATTING
우리의 목표는 normals 없이 희박한 (SfM) 포인트 집합에서 시작하여 고품질의 새로운 뷰 합성을 가능하게 하는 장면 표현을 최적화하는 것입니다.
이를 위해서는 미분 가능한 부피 표현의 특성을 계승하는 동시에 매우 빠른 렌더링을 허용하기 위해 비구조화되고 명시적인 프리미티브가 필요합니다.
우리는 미분 가능하고 렌더링을 위해 빠른 𝛼-블렌딩을 가능하게 하는 2D splats에 쉽게 투영될 수 있는 3D 가우시안을 선택합니다.
우리의 표현은 2D 포인트를 사용하고 [Kopanas et al. 2021; Yifan et al. 2019] 각 포인트가 normal을 가진 작은 평면 원이라고 가정하는 이전의 방법과 유사합니다.
SfM 포인트의 극단적인 희소성을 고려할 때 normal을 추정하는 것은 매우 어렵습니다.
마찬가지로, 그러한 추정에서 매우 노이즈한 normal을 최적화하는 것은 매우 어려울 것입니다.
대신 normal이 필요 없는 3D 가우시안 집합으로 지오메트리를 모델링합니다.
우리의 가우시안은 점(평균) 𝜇 중심의 세계 공간 [Zwicker et al. 2001a]에 정의된 전체 3D 공분산 행렬 ∑에 의해 정의됩니다:
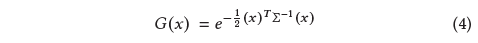
이 가우시안은 우리의 블렌딩 과정에서 𝛼을 곱한 것입니다.
그러나 렌더링을 위해 3D 가우시안을 2D로 투영해야 합니다.
Zwicker et al. [2001a]는 이 투영을 이미지 공간에 투영하는 방법을 보여줍니다.
뷰 변환 𝑊가 주어지면 카메라 좌표에서 공분산 행렬 ∑'는 다음
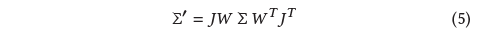
과 같이 주어지며, 여기서 𝐽는 투영 변환의 아핀 근사치의 자코비안입니다.
Zwicker et al. [2001a]는 또한 ∑'의 세 번째 행과 열을 건너뛰면 이전 연구 [Kopanas et al. 2021]에서와 같이 normals를 가진 평면 점에서 시작하는 것처럼 동일한 구조와 특성을 가진 2×2 분산 행렬을 얻을 수 있음을 보여줍니다.
명백한 접근법은 공분산 행렬 ∑를 직접 최적화하여 래디언스 필드를 나타내는 3D 가우시안을 얻는 것입니다.
그러나 공분산 행렬은 양의 반정형일 때만 물리적 의미를 갖습니다.
모든 매개 변수를 최적화하기 위해 그러한 유효 행렬을 생성하기 위해 쉽게 제한할 수 없는 그래디언트 하강을 사용하고 업데이트 단계와 그래디언트는 매우 쉽게 유효하지 않은 공분산 행렬을 생성할 수 있습니다.
그 결과 최적화를 위해 보다 직관적이면서도 동등하게 표현하는 표현을 선택했습니다.
3D 가우시안의 공분산 행렬 ∑는 타원체의 구성을 설명하는 것과 유사합니다.
스케일링 행렬 𝑆와 회전 행렬 𝑅이 주어지면, 우리는 상응하는 ∑을 찾을 수 있습니다:
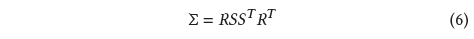
두 요인을 독립적으로 최적화할 수 있도록 다음과 같이 별도로 저장합니다: 스케일링을 위한 3D 벡터 𝑠와 회전을 표현하기 위한 quaternion 𝑞.
이것들은 각각의 행렬로 조금씩 변환되고 조합될 수 있고, 유효한 단위 quaternion을 얻기 위해 𝑞을 정규화할 수 있습니다.
학습 중 자동 미분으로 인한 상당한 오버헤드를 방지하기 위해 모든 매개변수에 대한 그래디언트를 명시적으로 도출합니다.
정확한 미분 계산에 대한 자세한 내용은 부록 A에 있습니다.
–최적화에 적합한– 이 anisotropic 공분산의 표현은 캡처된 장면에서 다른 모양의 지오메트리에 적응하기 위해 3D 가우시안을 최적화하여 상당히 압축된 표현을 할 수 있게 해줍니다.
그림 3은 그러한 경우를 보여줍니다.

5 OPTIMIZATION WITH ADAPTIVE DENSITY CONTROL OF 3D GAUSSIANS
우리 접근 방식의 핵심은 자유 뷰 합성을 위해 장면을 정확하게 표현하는 밀집된 3D 가우시안 세트를 만드는 최적화 단계입니다.
위치 𝑝, 𝛼 및 공분산 ∑ 외에도 각 가우시안의 색상 𝑐을 나타내는 SH 계수를 최적화하여 장면의 뷰 의존적 모양을 정확하게 캡처합니다.
이러한 매개 변수의 최적화는 장면을 더 잘 표현하도록 가우시안의 밀도를 제어하는 단계와 연동됩니다.
5.1 Optimization
최적화는 결과 이미지를 캡처된 데이터 세트의 학습 뷰와 렌더링 및 비교의 연속적인 반복을 기반으로 합니다.
필연적으로 3D에서 2D 투영의 모호성으로 인해 지오메트리가 잘못 배치될 수 있습니다.
따라서 최적화는 지오메트리를 생성하고 잘못 배치된 경우 지오메트리를 파괴하거나 이동할 수 있어야 합니다.
3D 가우시안의 공분산의 매개 변수의 품질은 큰 homogeneous 영역이 적은 수의 큰 anisotropic 가우시안으로 캡처될 수 있기 때문에 표현의 압축성에 중요합니다.
우리는 최적화를 위해 Stochastic Gradient Descent 기법을 사용하며, 표준 GPU 가속 프레임워크의 이점을 최대한 활용하고 최근 모범 사례에 따라 일부 작업에 대해 사용자 지정 CUDA 커널을 추가할 수 있습니다 [Fridovich-Keil and Yu et al. 2022; Sun et al. 2022].
특히, 우리의 빠른 래스터화(섹션 6 참조)는 최적화의 주요 계산 병목 현상이기 때문에 최적화의 효율성에서 매우 중요합니다.
𝛼에 대한 시그모이드 활성화 함수를 사용하여 [0, - 1) 범위에서 제한하고 부드러운 그래디언트를 얻으며, 유사한 이유로 공분산의 스케일에 대한 지수 활성화 함수를 사용합니다.
우리는 초기 공분산 행렬을 가장 가까운 세 점까지의 거리의 평균과 같은 축을 가진 isotropic 가우시안으로 추정합니다.
우리는 Plenoxels [Fridovich-Keil and Yu et al. 2022]과 유사한 표준 지수 붕괴 스케줄링 기술을 사용하지만 위치에 대해서만 사용합니다.
loss 함수는 D-SSIM 항과 결합된 L1입니다:
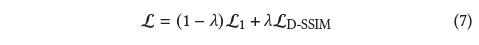
우리는 모든 테스트에 λ = 0.2를 사용합니다.
섹션 7.1의 학습 일정 및 기타 요소에 대한 세부 정보를 제공합니다.
5.2 Adaptive Control of Gaussians
우리는 SfM의 초기 희소 포인트 세트로 시작한 다음 우리 방법을 적용하여 단위 볼륨에 대한 가우시안 수와 밀도를 적응적으로 제어하여 초기 희소 가우시안 세트에서 장면을 더 잘 표현하고 올바른 매개변수를 사용하는 더 밀도 높은 세트로 이동할 수 있습니다.
최적화 워밍업(섹션 7.1 참조) 후 100번의 반복마다 밀도를 높이고 본질적으로 투명한 가우시안을 제거합니다, 즉, 𝛼가 임계 ϵ_𝛼 미만인 경우.
가우시안에 대한 적응적 제어는 빈 영역을 채워야 합니다.
그것은 누락된 지오메트릭 피쳐("under-reconstruction")가 있는 영역에 초점을 맞추지만, 가우시안이 장면에서 넓은 영역을 커버하는 영역(종종 "over-reconstruction"에 해당)에도 초점을 맞춥니다.
우리는 둘 다 큰 뷰-공간 위치 그래디언트를 가지고 있음을 관찰합니다.
직관적으로, 이는 아직 잘 재구성되지 않은 영역에 해당하고, 최적화는 이를 수정하기 위해 가우시안을 이동시키려 하기 때문일 가능성이 있습니다.
두 경우 모두 밀도화에 적합한 후보이기 때문에 테스트에서 0.0002로 설정한 임계 τ_pos 이상의 뷰 공간 위치 그래디언트의 평균 크기로 가우시안을 밀도화합니다.
다음으로 이 과정에 대한 자세한 내용을 그림 4에 제시합니다.
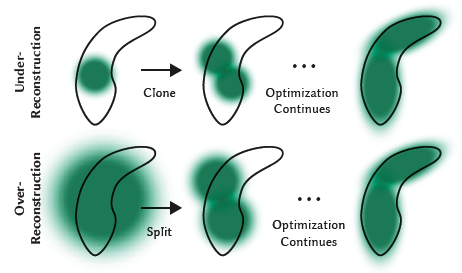
under-reconstruction 영역에 있는 작은 가우시안의 경우, 우리는 생성되어야 하는 새로운 지오메트리를 다룰 필요가 있습니다.
이를 위해서는 단순히 같은 크기의 복제본을 만들어 위치 그래디언트 방향으로 이동함으로써 가우시안을 복제하는 것이 좋습니다.
반면 분산이 큰 영역의 큰 가우시안들은 작은 가우시안들로 나눌 필요가 있습니다.
우리는 그러한 가우시안들을 두 개의 새로운 것으로 대체하고, 그들의 규모를 실험적으로 결정한 ɸ = 1.6의 인자로 나눕니다.
우리는 또한 원래의 3D 가우시안을 샘플링을 위한 PDF로 사용하여 그들의 위치를 초기화합니다.
첫 번째 경우에는 시스템의 전체 부피와 가우시안의 수를 모두 증가시킬 필요를 감지하고 처리하는 반면, 두 번째 경우에는 전체 부피를 보존하지만 가우시안의 수를 증가시킵니다.
다른 체적 표현과 마찬가지로, 우리의 최적화는 입력 카메라에 가까운 부유물에 갇힐 수 있습니다; 우리의 경우 가우시안 밀도가 부당하게 증가할 수 있습니다.
이 경우 가우시안 수의 증가를 완화하는 효과적인 방법은 N = 3000번 반복할 때마다 𝛼값을 0에 가깝게 설정하는 것입니다.
그런 다음 최적화는 위에서 설명한 것처럼 𝛼가 ϵ_𝛼보다 작은 𝛼를 가진 가우시안을 제거할 수 있도록 하는 동시에 필요한 가우시안에 대한 𝛼를 증가시킵니다.
가우시안은 축소되거나 성장하여 다른 사람들과 상당히 겹칠 수 있지만, 세계 공간에서 매우 큰 가우시안과 시야 공간에서 큰 발자국을 가진 가우시안을 주기적으로 제거합니다.
이 전략은 전체 가우시안 수에 대한 전반적인 양호한 제어를 초래합니다.
우리 모델의 가우시안은 항상 유클리드 공간에서 원시적인 존재로 남아 있습니다; 다른 방법 [Barron et al. 2022; Fridovich-Keil and Yu et al. 2022]과 달리 멀리 있거나 큰 가우시안을 위한 공간 압축, 뒤틀림 또는 투영 전략이 필요하지 않습니다.
6 FAST DIFFERENTIABLE RASTERIZER FOR GAUSSIANS
우리의 목표는 대략적인 𝛼-블렌딩(anisotropic splats 포함)을 허용하고 이전 작업에 존재하는 그래디언트를 받을 수 있는 splats 수에 대한 엄격한 제한을 피하기 위해 전체적으로 빠른 렌더링과 빠른 정렬을 하는 것입니다 [Lassner and Zollhofer 2021].
이러한 목표를 달성하기 위해 최근의 소프트웨어 래스터화 접근법 [Lassner and Zollhofer 2021]에서 영감을 받은 가우시안 splats용 타일 기반 래스터라이저를 설계하여 한 번에 전체 이미지에 대한 프리미티브를 사전 정렬함으로써 이전 𝛼-블렌딩 솔루션을 방해했던 픽셀당 정렬 비용을 방지했습니다 [Kopanas et al. 2022, 2021].
우리의 빠른 래스터라이저는 추가 메모리 소비가 적은 임의의 수의 블렌디드 가우시안에 대해 효율적인 역전파를 허용하여 픽셀당 일정한 오버헤드만 필요합니다.
우리의 래스터화 파이프라인은 완전히 미분 가능하며, 2D(섹션 4)로의 투영을 고려할 때 이전의 2D splatting 방법과 유사하게 anisotropic splats를 래스터화할 수 있습니다 [Kopanas et al. 2021].
우리의 방법은 화면을 16x16개의 타일로 분할하는 것으로 시작하여 뷰 frustum과 각 타일에 대해 3D 가우시안을 선별하는 것으로 진행합니다.
특히 뷰 frustum과 교차하는 99% 신뢰 구간의 가우시안만 유지합니다.
또한 예상 2D 공분산을 계산하는 것이 불안정하기 때문에 보호 밴드를 사용하여 극단적인 위치(즉, 뷰 frustum에 가까운 평면에 가깝고 멀리 떨어진 평균을 가진 것들)에서 가우시안을 사소한 것으로 거부합니다.
그런 다음 중첩되는 타일 수에 따라 각 가우시안을 인스턴스화하고 각 인스턴스에 뷰 공간 depth와 타일 ID를 결합한 키를 할당합니다.
그런 다음 단일 빠른 GPU Radix sort [Merrill and Grimshaw 2010]을 사용하여 이러한 키를 기반으로 가우시안을 정렬합니다.
포인트의 픽셀당 추가 순서가 없으며 이 초기 정렬을 기반으로 블렌딩이 수행됩니다.
결과적으로 𝛼-블렌딩은 일부 구성에서 근사할 수 있습니다.
그러나 이러한 근사치는 splats이 개별 픽셀 크기에 접근함에 따라 무시할 수 있습니다.
이 선택은 수렴 장면에서 가시적인 아티팩트를 생성하지 않고 학습 및 렌더링 성능을 크게 향상시킨다는 것을 발견했습니다.
가우시안 정렬 후, 주어진 타일에 분할되는 첫 번째와 마지막 depth 정렬 항목을 식별하여 각 타일에 대한 목록을 생성합니다.
래스터화를 위해 각 타일에 대해 하나의 스레드 블록을 시작합니다.
각 블록은 먼저 가우스 패킷을 공유 메모리에 공동으로 로드한 다음 주어진 픽셀에 대해 목록을 앞뒤로 이동하여 색상 및 𝛼 값을 누적하므로 데이터 로드/공유 및 처리에 대해 병렬로 이득을 최대화합니다.
픽셀에서 𝛼의 목표 포화 상태에 도달하면 해당 스레드가 중지됩니다.
일정한 간격으로 타일의 스레드가 쿼리되고 모든 픽셀이 포화 상태가 되면(즉, 𝛼가 1로 이동) 타일 전체의 처리가 종료됩니다.
정렬에 대한 자세한 내용과 전체 래스터화 접근법에 대한 개요는 부록 C에 나와 있습니다.
래스터화 동안 𝛼의 포화가 유일한 정지 기준입니다.
이전 연구와 달리 그레디언트 업데이트를 받는 혼합된 프리미티브의 수를 제한하지 않습니다.
우리는 이 속성을 적용하여 장면별 하이퍼 파라미터 튜닝에 의존하지 않고 임의의 다양한 depth 복잡성을 가진 장면을 처리하고 정확하게 학습할 수 있습니다.
따라서 역방향 패스 동안 순방향 패스에서 픽셀당 블렌디드 포인트의 전체 시퀀스를 복구해야 합니다.
한 가지 해결책은 픽셀당 블렌디드 포인트의 임의로 긴 목록을 전역 메모리에 저장하는 것입니다 [Kopanas et al. 2021].
암시된 동적 메모리 관리 오버헤드를 피하기 위해 대신 타일당 목록을 다시 횡단하기로 선택합니다; 순방향 패스의 정렬된 가우시안 배열과 타일 범위를 재사용할 수 있습니다.
그래디언트 계산을 용이하게 하기 위해, 우리는 이제 그것들을 앞뒤로 횡단합니다.
순회는 타일의 픽셀에 영향을 준 마지막 점에서 시작되며, 공유 메모리로 점을 다시 로드하는 작업이 다시 공동으로 수행됩니다.
또한 각 픽셀은 순방향 패스 동안 색상에 기여한 마지막 점의 depth 이하인 경우에만 포인트의 중첩 테스트 및 처리를 시작(비용이 많이 듭니다).
섹션 4에서 설명한 그래디언트 계산은 원래 블렌딩 과정 중 각 단계에서 누적된 불투명도 값을 필요로 합니다.
역방향 패스에서 점진적으로 축소되는 불투명도의 명시적인 목록을 통과하지 않고 순방향 패스의 끝에 총 누적 불투명도만 저장하여 이러한 중간 불투명도를 복구할 수 있습니다.
특히 각 포인트는 순방향 프로세스에서 최종 누적 불투명도 𝛼를 저장합니다; 이를 앞뒤 횡단에서 각 포인트의 𝛼로 나누어 그래디언트 계산에 필요한 계수를 얻습니다.
7 IMPLEMENTATION, RESULTS AND EVALUATION
다음으로 이전 작업 및 ablation 연구와 비교하여 구현, 현재 결과 및 알고리즘 평가에 대한 몇 가지 세부 사항에 대해 논의합니다.
7.1 Implementation
PyTorch 프레임워크를 사용하여 Python에 방법을 구현하고 이전 방법의 확장 버전인 래스터화를 위한 맞춤형 CUDA 커널을 작성했으며[Kopanas et al. 2021], 빠른 Radix sort [Merrill and Grimshaw 2010]을 위한 NVIDIA CUB 정렬 루틴을 사용했습니다.
또한 대화형 보기에 사용되는 오픈 소스 SIBR [Bonopera et al. 2020]을 사용하여 대화형 뷰어를 구축했으며, 이 구현을 통해 달성된 프레임 속도를 측정했습니다.
Optimization Details.
안정성을 위해 낮은 해상도에서 계산을 "warm-up"합니다.
특히 4배 작은 이미지 해상도를 사용하여 최적화를 시작하고 250번과 500번을 반복한 후 두 번 샘플을 업샘플링합니다.
SH 계수 최적화는 각도 정보의 부족에 민감합니다.
중심 물체가 주변의 전체 반구에서 찍은 사진에 의해 관찰되는 일반적인 "NeRF-like" 캡처의 경우 최적화가 잘 작동합니다.
그러나 캡처에 각도 영역이 누락된 경우(예: 장면의 모서리를 캡처하거나 "inside-out" [Hedman et al. 2016] 캡처) SH의 0차 성분(즉, 베이스 또는 확산 색상)에 대해 완전히 잘못된 값을 최적화에 의해 생성할 수 있습니다.
이 문제를 극복하기 위해 0차 성분만 최적화하는 것으로 시작한 다음 SH의 모든 4개 대역이 표시될 때까지 1000번의 반복 후 SH의 한 대역을 도입합니다.
7.2 Results and Evaluation
Results.
이전에 게시된 데이터 세트와 합성 블렌더 데이터 세트에서 가져온 총 13개의 실제 장면에 대해 알고리즘을 테스트했습니다 [Mildenhall et al. 2020].
특히 NeRF 렌더링 품질의 최신 기술인 Mip-Nerf360 [Barron et al. 2022]에 제시된 전체 장면 세트, Tanks&Temples 데이터 세트 [2017]의 두 장면 및 Hedman et al. [Hedman et al. 2018]에서 제공된 두 장면에 대한 접근 방식을 테스트했습니다.
우리가 선택한 장면은 매우 다른 캡처 스타일을 가지며 경계가 있는 실내 장면과 경계가 없는 대규모 실외 환경을 모두 포함합니다.
우리는 평가의 모든 실험에 동일한 하이퍼 파라미터 구성을 사용합니다.
Mip-NeRF360 방법(아래 참조)을 제외한 모든 결과는 A6000 GPU에서 실행되는 것으로 보고되었습니다.
보충적으로 입력된 사진에서 멀리 떨어진 뷰를 포함하는 장면 선택을 위해 렌더링된 비디오 경로를 보여줍니다.
Real-World Scenes.
품질 측면에서 현재 SOTA 기술은 Mip-Nerf360 [Barron et al. 2021]입니다.
품질 벤치마크로서 이 방법과 비교합니다.
또한 InstantNGP [Müler et al. 2022] 및 Plenoxels [Fridovich-Keil and Yu et al. 2022]의 두 가지 최신 빠른 NeRF 방법과 비교합니다.

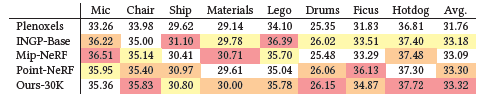
문헌에서 가장 자주 사용되는 표준 PSNR, L-PIPS 및 SSIM 메트릭을 사용하여 일관되고 의미 있는 비교를 위해 Mip-NeRF360에서 제안한 방법론을 사용하여 데이터셋에 대한 학습/테스트 분할을 사용합니다; 표 1을 참조하십시오.
표의 모든 숫자는 데이터셋에 있는 Mip-NeRF360의 경우를 제외하고 모든 이전 방법에 대한 저자 코드의 자체 실행에서 가져온 것이며, 데이터셋의 경우 현재 SOTA에 대한 혼동을 피하기 위해 원본 출판물에서 숫자를 복사했습니다.
그림의 이미지의 경우 Mip-NeRF360의 자체 실행을 사용했습니다.
이러한 실행에 대한 숫자는 부록 D에 있습니다.
또한 최적화된 파라미터를 저장하는 데 사용되는 평균 학습 시간, 렌더링 속도 및 메모리를 보여줍니다.
저자(Big)가 제안한 약간 더 큰 네트워크뿐만 아니라 35K 반복에 대해 실행되는 InstantNGP(Base)의 기본 구성과 7K 및 30K 반복의 두 가지 구성에 대한 결과를 보고합니다.
그림 6에서 두 구성에 대한 시각적 품질의 차이를 보여줍니다.
많은 경우 7K 반복의 품질은 이미 상당히 우수합니다.

학습 시간은 데이터셋에 따라 다르며 별도로 보고합니다.
이미지 해상도 또한 데이터셋에 따라 달라집니다.
프로젝트 웹 사이트에서는 모든 장면에 대한 모든 방법(당사 및 이전 작업)에 대한 통계를 계산하는 데 사용한 모든 테스트 뷰 렌더링을 제공합니다.
모든 렌더링에 대해 기본 입력 해상도를 유지했습니다.
표는 완전 수렴 모델이 SOTA Mip-NeRF360 방법보다 동등하고 때로는 약간 더 나은 품질을 달성한다는 것을 보여줍니다; 동일한 하드웨어에서 평균 학습 시간은 35-45분에 비해 48시간^2이며 렌더링 시간은 10초/프레임입니다.
우리는 5-10m의 학습 후 InstantNGP 및 Plenoxels와 동등한 품질을 달성하지만, 추가 학습 시간을 통해 다른 빠른 방법에는 해당되지 않는 SOTA 품질을 달성할 수 있습니다.
Tanks & Temple의 경우 유사한 학습 시간(우리의 경우 약 7분)에 기본 InstantNGP와 유사한 품질을 달성합니다.
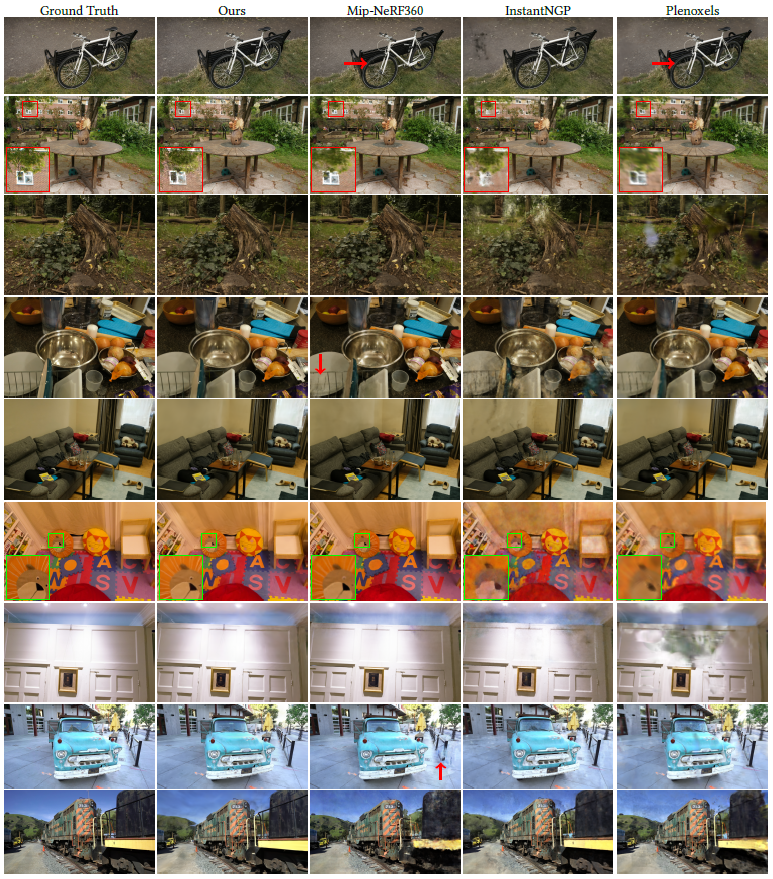
우리는 또한 그림 5에서 비교를 위해 선택된 이전 렌더링 방법과 우리의 테스트 뷰에 대한 시각적 결과를 보여줍니다.
우리의 방법의 결과는 30K 반복 학습에 대한 것입니다.
우리는 일부 경우 Mip-NeRF360조차도 우리의 방법이 피할 수 있는 남아있는 아티팩트(예: 식물의 블러 – 자전거, 그루터기 – 또는 방의 벽)을 가지고 있음을 알 수 있습니다.
보충 비디오 및 웹 페이지에서 우리는 멀리서 경로를 비교합니다.
우리의 방법은 이전 방법의 경우에는 항상 그렇지 않은 먼 곳에서도 잘 덮인 영역의 시각적 세부 사항을 보존하는 경향이 있습니다.
Synthetic Bounded Scenes.
현실적인 장면 외에도 합성 블렌더 데이터 세트에 대한 접근 방식도 평가합니다 [Mildenhall et al. 2020].
해당 장면은 포괄적인 뷰 세트를 제공하고 크기가 제한되며 정확한 카메라 매개 변수를 제공합니다.
이러한 시나리오에서는 랜덤 초기화로도 SOTA 결과를 얻을 수 있습니다.
장면 경계를 둘러싸는 볼륨 내에서 100K의 균일하게 랜덤 가우시안으로부터 학습을 시작합니다.
우리의 접근 방식은 빠르고 자동으로 약 6-10K의 의미 있는 가우시안으로 가지치기합니다.
30K 반복 후 학습된 모델의 최종 크기는 장면당 약 200-500K의 가우시안에 도달합니다.
호환성을 위해 흰색 배경을 사용하여 달성된 PSNR 점수를 표 2의 이전 방법과 보고하고 비교합니다.
예는 그림 10(왼쪽에서 두 번째 이미지)과 보충 자료에서 볼 수 있습니다.
학습된 합성 장면은 180-300FPS에서 렌더링됩니다.

Compactness.
이전의 명시적인 장면 표현과 비교하여, 최적화에 사용된 anisotropic 가우시안은 더 적은 수의 매개 변수로 복잡한 모양을 모델링할 수 있습니다.
우리는 [Zhang et al. 2022]에서 얻은 매우 작은 포인트 기반 모델에 대한 접근 방식을 평가함으로써 이를 보여줍니다.
우리는 전경 마스크로 공간을 조각하여 얻은 초기 포인트 클라우드에서 시작하여 보고된 PSNR 점수로도 깨질 때까지 최적화합니다.
이는 일반적으로 2-4분 이내에 발생합니다.
우리는 포인트 수의 약 4분의 1을 사용하여 보고된 메트릭을 능가하여 9MB와 대조적으로 평균 모델 크기가 3.8MB입니다.
우리는 이 실험에서 그들의 spherical harmonics와 유사한 2도만 사용했다는 것에 주목합니다.
7.3 Ablations
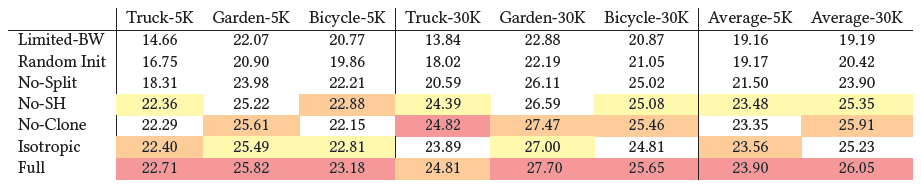
우리는 우리가 한 다양한 기여와 알고리즘 선택을 분리하고 그 효과를 측정하기 위한 일련의 실험을 구성했습니다.
구체적으로 우리는 우리 알고리즘의 다음 측면을 테스트합니다: SfM에서 초기화, 밀도화 전략, anisotropic 공분산, 무제한의 스플릿 수에 그래디언트와 spherical harmonics 사용을 허용한다는 사실.
각 선택의 정량적 효과는 표 3에 요약되어 있습니다.
Initialization from SfM.
저희는 또한 SfM 포인트 클라우드에서 3D 가우시안을 초기화하는 것의 중요성을 평가합니다.
이 ablation을 위해 입력 카메라의 바운딩 박스 범위의 3배와 같은 크기의 큐브를 균일하게 샘플링합니다.
저희 방법은 SfM 포인트가 없어도 완전한 실패를 피하면서 비교적 잘 수행된다는 것을 관찰했습니다.
대신 주로 배경에서 성능이 저하됩니다, 그림 7을 참조하십시오.
학습 뷰에서 잘 다루지 않는 영역에서도 랜덤 초기화 방법에는 최적화로 제거할 수 없는 더 많은 플로터가 있는 것으로 보입니다.
반면 합성 NeRF 데이터 세트는 배경이 없고 입력 카메라의 제약을 잘 받기 때문에 이러한 동작이 없습니다(위의 논의 참조).

Densification.
다음으로 저희는 두 가지 밀도화 방법, 특히 섹션 5에 설명된 clone 및 split 전략을 평가합니다.
저희는 각 방법을 개별적으로 비활성화하고 나머지 방법은 변경되지 않은 상태로 사용하여 최적화합니다.
결과는 그림 8에서 볼 수 있듯이 배경을 잘 재구성할 수 있도록 큰 가우시안을 분할하는 것이 중요한 반면, 작은 가우시안을 분할하는 대신 복제하면 특히 장면에 얇은 구조가 나타날 때 더 나은 및 더 빠른 수렴이 가능함을 보여줍니다.

Unlimited depth complexity of splats with gradients.
Pulsar [Lassner and Zollhofer 2021]에서 제안한 바와 같이 𝑁 최전단 지점 이후 그래디언트 계산을 생략하면 품질을 희생하지 않고 속도를 낼 수 있는지 평가합니다.
본 테스트에서는 Pulsar의 기본값보다 2배 높은 N=10을 선택하지만 그래디언트 계산에서 근사치가 심해 불안정한 최적화를 수행했습니다.
Truck 장면의 경우 PSNR에서 11dB만큼 품질이 저하되었으며(표 3, Limited-BW 참조), Garden의 경우 시각적 결과는 그림 9와 같습니다.

Anisotropic Covariance.
저희 방법에서 중요한 알고리즘 선택은 3D 가우시안에 대한 전체 공분산 행렬을 최적화하는 것입니다.
이 선택의 효과를 입증하기 위해 저희는 세 축 모두에서 3D 가우시안의 반경을 제어하는 단일 스칼라 값을 최적화하여 anisotropic을 제거하는 ablation을 수행합니다.
이 최적화의 결과는 그림 10에 시각적으로 나와 있습니다.
저희는 anisotropic이 3D 가우시안의 표면 정렬 능력의 품질을 크게 향상시키고, 이를 통해 동일한 수의 점을 유지하면서 훨씬 더 높은 렌더링 품질을 얻을 수 있음을 관찰했습니다.
Spherical Harmonics.
마지막으로, spherical harmonics를 사용하면 뷰 종속 효과를 보상하기 때문에 전체 PSNR 점수가 향상됩니다(표 3).

7.4 Limitations
우리의 방법에 한계가 없는 것은 아닙니다.
현장이 잘 관찰되지 않는 지역에서는 아티팩트가 있습니다; 그러한 지역에서는 다른 방법도 어려움을 겪습니다(예: 그림 11의 Mip-NeRF360).
anisotropic 가우시안은 위에서 설명한 것과 같은 많은 이점이 있지만, 우리의 방법은 길쭉한 아티팩트 또는 "splotchy" 가우시안을 만들 수 있습니다(그림 12 참조); 이전 방법도 이러한 경우 어려움을 겪습니다.

또한 최적화를 통해 큰 가우시안을 생성할 때 가끔 팝핑 아티팩트가 발생하는데, 이는 뷰에 의존적인 모양을 가진 지역에서 발생하는 경향이 있습니다.
이러한 팝핑 아티팩트의 한 가지 이유는 래스터라이저의 가드 밴드를 통해 가우시안이 사소한 거부를 했기 때문입니다.
보다 원칙적인 컬링 접근 방식을 통해 이러한 아티팩트를 완화할 수 있습니다.
또 다른 요인은 간단한 가시성 알고리즘으로 가우시안이 갑자기 depth/블렌딩 순서를 전환할 수 있다는 것입니다.
이 문제는 안티앨리어싱을 통해 해결할 수 있으며, 이는 향후 작업으로 남겨두겠습니다.
또한 현재 최적화에 정규화를 적용하지 않고 있으며, 이렇게 하면 보이지 않는 영역과 팝핑 아티팩트 모두에 도움이 될 것입니다.
완전한 평가를 위해 동일한 하이퍼파라미터를 사용했지만, 초기 실험은 매우 큰 장면(예: 도시 데이터 세트)에 수렴하기 위해 위치 학습률을 줄이는 것이 필요할 수 있음을 보여줍니다.
이전의 포인트 기반 접근 방식에 비해 매우 컴팩트하지만 메모리 소비량은 NeRF 기반 솔루션보다 훨씬 높습니다.
대규모 장면을 학습하는 동안 최적화되지 않은 프로토타입에서 최대 GPU 메모리 소비량이 20GB를 초과할 수 있습니다.
그러나 이 수치는 최적화 로직(InstantNGP와 유사)을 신중하게 저수준으로 구현하면 크게 감소할 수 있습니다.
학습된 장면을 렌더링하려면 장면 크기와 이미지 해상도에 따라 전체 모델(대규모 장면의 경우 수백 메가바이트)을 저장할 수 있는 충분한 GPU 메모리와 래스터라이저를 위해 추가로 30-500MB가 필요합니다.
저희 방법의 메모리 소비량을 더욱 줄일 수 있는 기회가 많다는 점에 주목합니다.
포인트 클라우드에 대한 압축 기술은 잘 연구된 분야이며 [De Qeiroz and Chou 2016]; 이러한 접근 방식을 어떻게 우리의 표현에 맞게 조정할 수 있는지 보는 것은 흥미로울 것입니다.
8 Discussion
다양한 장면과 캡처 스타일로 실시간 고품질의 래디언스 필드 렌더링을 가능하게 하는 동시에 가장 빠른 이전 방법과 경쟁력 있는 학습 시간이 필요한 첫 번째 접근 방식을 제시했습니다.
저희의 3D 가우시안 프리미티브 선택은 빠른 스플릿 기반 래스터화를 직접적으로 허용하면서 최적화를 위한 볼륨 렌더링 특성을 보존합니다.
저희의 연구는 -일반적으로 받아들여지는 의견과는 달리- 빠르고 고품질의 래디언스 필드 학습을 허용하기 위해 연속적인 표현이 엄격하게 필요하지 않다는 것을 보여줍니다.
저희 방법을 다른 사람들이 쉽게 사용할 수 있도록 PyTorch에 솔루션을 구축했기 때문에 학습 시간의 대부분(~80%)을 PyTorch에서 사용합니다.
래스터화 루틴만 최적화된 CUDA 커널로 구현됩니다, 예를 들어 InstantNGP [Müler et al. 2022]에서 수행된 것처럼 남은 최적화를 CUDA로 완전히 이식하면 성능이 필수적인 애플리케이션에 대해 훨씬 더 빠른 속도를 제공할 수 있을 것으로 기대합니다.
또한 GPU의 성능과 소프트웨어 래스터화 파이프라인 아키텍처의 속도를 활용하여 실시간 렌더링 원리를 기반으로 구축하는 것이 중요하다는 것을 입증했습니다.
이러한 설계 선택은 학습 및 실시간 렌더링 모두에서 성능의 핵심이며, 이전의 체적 ray-marching에 비해 성능에서 경쟁 우위를 제공합니다.
우리의 가우시안이 캡처된 장면의 메쉬 재구성을 수행하는 데 사용될 수 있는지 확인하는 것은 흥미로울 것입니다.
메쉬의 광범위한 사용을 고려할 때 실용적인 의미 외에도, 이를 통해 부피 및 표면 표현 사이의 연속체에서 우리의 방법이 정확히 어디에 있는지 더 잘 이해할 수 있습니다.
결론적으로, 우리는 가장 빠른 기존 솔루션과 경쟁력 있는 학습 시간을 가지고 가장 비싼 이전 방법과 일치하는 렌더링 품질을 가진 래디언스 필드를 위한 최초의 실시간 렌더링 솔루션을 제시했습니다.
'View Synthesis' 카테고리의 다른 글
| Mip-Splatting: Alias-free 3D Gaussian Splatting (0) | 2024.06.22 |
|---|---|
| Instruct-NeRF2NeRF: Editing 3D Scenes with Instructions (0) | 2023.09.29 |
| D-NeRF: Neural Radiance Fields for Dynamic Scenes (1) | 2023.09.04 |
| Instant Neural Graphics Primitives with a Multiresolution Hash Encoding (0) | 2023.08.16 |
| DynIBaR: Neural Dynamic Image-Based Rendering (0) | 2023.07.13 |