2023. 11. 23. 19:03ㆍtext-to-3D
One-2-3-45++: Fast Single Image to 3D Objects with Consistent Multi-View Generation and 3D Diffusion
Minghua Liu, Ruoxi Shi, Linghao Chen, Zhuoyang Zhang, Chao Xu, Xinyue Wei, Hansheng Chen, Chong Zeng, Jiayuan Gu, Hao Su
Abstract
image-to-3D 방법은 text-to-3D 대응물에 대한 탁월한 세밀한 제어를 제공하며 open-world 3D 객체 생성의 최근 발전은 두드러졌습니다.
그러나 대부분의 기존 모델은 빠른 생성 속도와 입력 이미지에 대한 높은 충실도를 동시에 제공하는 데 부족합니다 - 실제 적용에 필수적인 두 가지 기능.
본 논문에서는 단일 이미지를 약 1분 만에 상세한 3D 텍스처 메쉬로 변환하는 혁신적인 방법인 One-2-3-45++를 제시합니다.
저희의 접근 방식은 2D 디퓨전 모델에 내장된 광범위한 지식과 가치 있지만 제한적인 3D 데이터의 priors를 완전히 활용하는 것을 목표로 합니다.
이는 일관된 멀티뷰 이미지 생성을 위한 2D 디퓨전 모델을 초기에 파인튜닝한 후 멀티뷰 조건 3D 네이티브 디퓨전 모델을 사용하여 이러한 이미지를 3D로 높임으로써 달성됩니다.
광범위한 실험 평가를 통해 저희의 방법이 원래 입력 이미지와 밀접하게 유사한 고품질의 다양한 3D 자산을 생성할 수 있음을 알 수 있습니다.
1. Introduction
단일 이미지 또는 텍스트 프롬프트에서 3D 모양을 생성하는 것은 컴퓨터 비전의 오랜 문제이며 다양한 응용 분야에서 필수적인 요소입니다.
발전된 생성 방법과 대규모 이미지-텍스트 데이터 세트로 인해 2D 이미지 생성 분야에서 괄목할 만한 발전을 이루었지만 3D 학습 데이터의 제한된 가용성으로 인해 이러한 성공을 3D 도메인으로 이전하는 것이 방해됩니다.
많은 작업에서 정교한 3D 생성 모델을 소개하지만 [8, 16, 38, 87], 대부분은 학습을 위해 3D 모양 데이터 세트에만 의존합니다.
이러한 방법은 공개적으로 사용 가능한 3D 데이터 세트의 제한된 크기를 고려할 때 open-world 시나리오에서 보이지 않는 범주에 걸쳐 일반화하는 데 어려움을 겪는 경우가 많습니다.
DreamFusion [50], Magic3D [31]로 대표되는 또 다른 작업 라인은 CLIP [52] 및 Stable Diffusion [57]과 같은 2D prior 모델의 광범위한 지식 또는 강력한 생성 잠재력을 활용합니다.
이들은 일반적으로 입력 텍스트 또는 이미지마다 3D 표현(예: NeRF 또는 메쉬)을 처음부터 최적화합니다.
최적화 프로세스 동안 3D 표현은 2D 이미지로 렌더링되고 2D prior 모델을 사용하여 해당 모델에 대한 그래디언트를 계산합니다.
이러한 방법은 인상적인 결과를 얻었지만, 모양별 최적화는 매우 시간 집약적이어서 각 입력에 대해 단일 3D 모양을 생성하는 데 수십 분 또는 심지어 몇 시간이 소요될 수 있습니다.
또한 "multi-face" 또는 Janus 문제에 자주 직면하고 NeRF 또는 삼중면 표현에서 상속된 과포화 색상 및 아티팩트로 결과를 생성하며 다양한 랜덤 시드에서 다양한 결과를 생성하는 데 어려움을 겪습니다.
최근 연구인 One-2-3-45 [34]는 3D 콘텐츠 생성을 위해 풍부한 2D 디퓨전 모델의 priors를 활용하는 혁신적인 방법을 제시했습니다.
처음에는 뷰 조건적 2D 디퓨전 모델인 Zero123 [35]를 통해 멀티뷰 이미지를 예측합니다.
이러한 예측 이미지는 이후 3D 재구성을 위해 일반화 가능한 NeRF 방법 [39]을 통해 처리됩니다.
One-2-3-45는 단일 피드 포워드 패스에서 3D 모양을 생성할 수 있지만, 그 효과는 종종 Zero123의 일관성 없는 멀티뷰 예측에 의해 제한되어 3D 재구성 결과가 손상됩니다.
본 논문에서는 One-2-3-45의 단점을 효과적으로 극복하고 견고성과 품질을 크게 향상시킨 새로운 방법인 One-2-3-45++를 소개합니다.
개체의 단일 이미지를 입력으로 사용하면 One-2-3-45++에도 두 가지 주요 단계가 포함됩니다: 2D 멀티뷰 생성 및 3D 재구성.
초기 단계에서 One-2-3-45++는 Zero123을 사용하여 각 뷰를 개별적으로 예측하는 대신 일관된 멀티뷰 이미지를 동시에 예측합니다.
이는 간결한 6개 뷰 이미지 세트를 단일 이미지로 타일링한 다음 2D 디퓨전 모델을 핀셋 조정하여 입력된 참조 이미지에 조건화된 이 결합 이미지를 생성함으로써 실현됩니다.
이러한 방식으로 2D 디퓨전 네트워크는 생성 중에 각 뷰에 참여할 수 있으므로 뷰 간에 보다 일관된 결과를 보장합니다.
두 번째 단계에서는 One-2-3-45++는 멀티뷰 조건 3D 디퓨전 기반 모듈을 사용하여 텍스처 메쉬를 coarse-to-fine 방식으로 예측합니다.
일관된 멀티뷰 조건 이미지는 3D 재구성의 청사진 역할을 하여 제로샷 환각 기능을 촉진합니다.
동시에 3D 디퓨전 네트워크는 3D 데이터 세트에서 추출된 광범위한 priors 스펙트럼을 활용할 수 있어 멀티뷰 이미지를 리프팅하는 데 탁월합니다.
궁극적으로 One-2-3-45++는 경량 최적화 기법을 사용하여 일관된 멀티뷰 이미지를 supervision할 수 있습니다.
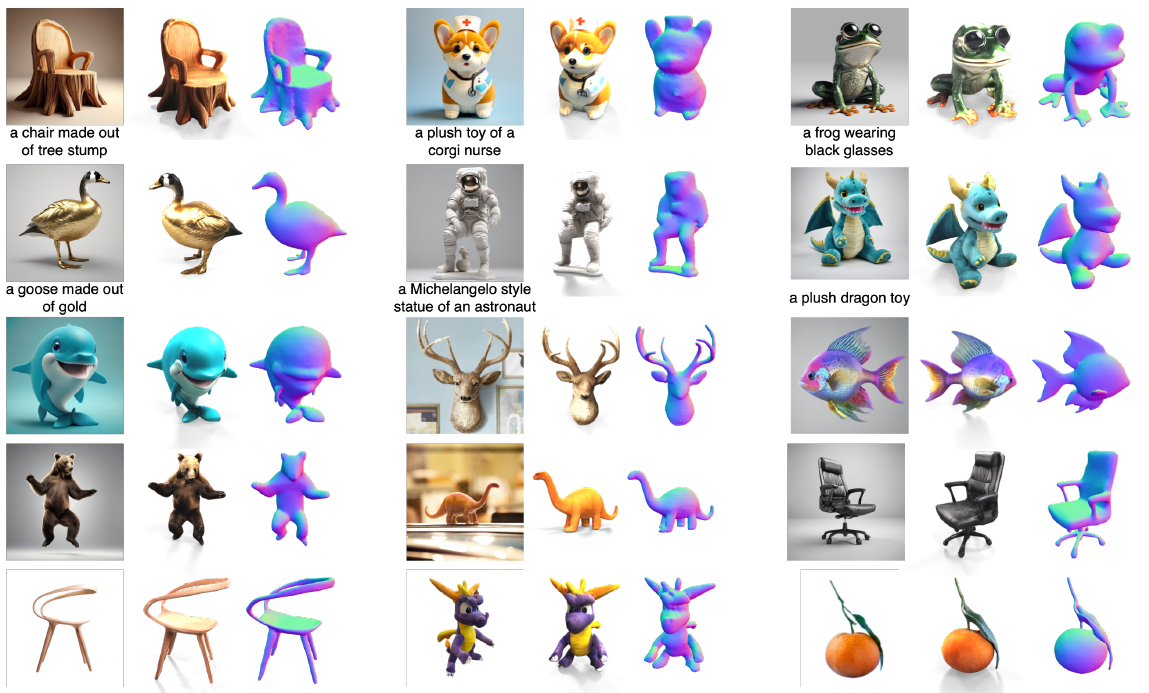
그림 1에 표시된 것처럼 One-2-3-45++는 실제 텍스쳐를 가진 3D 메쉬를 1분 이내에 효율적으로 생성하여 정밀한 fine-grained 기능을 제공합니다.
광범위한 테스트 세트에 걸친 사용자 연구 및 객관적인 메트릭을 포함한 우리의 종합적인 평가는 견고성, 시각적 품질 및 가장 중요한 입력 이미지에 대한 충실도 측면에서 One-2-3-45++의 우수성을 강조합니다.
2. Related Work
2.1. 3D Generation
최근 몇 년 동안 3D 생성은 상당한 관심을 받고 있습니다.
대규모 사전 학습된 2D 모델이 등장하기 전에 연구자들은 종종 3D 합성 데이터 또는 실제 스캔에서 직접 학습하고 포인트 클라우드 [1, 15, 42, 48, 83], 3D 복셀 [9, 60, 74, 75], 폴리곤 메쉬 [16, 17, 26, 33, 38, 47, 68], 파라메트릭 모델 [21] 및 암시적 필드 [8, 14, 19, 25, 30, 43, 49, 73, 78, 82, 86, 87]와 같은 다양한 3D 표현을 생성하는 3D 네이티브 생성 모델을 탐구했습니다.
그러나 3D 데이터의 제한된 가용성을 고려할 때, 이러한 모델은 개방 세계에서 볼 수 없는 범주로 일반화하기 위해 고군분투하는 선택된 수의 범주(예: chairs, cars, planes, humans, etc.)에 초점을 맞추는 경향이 있었습니다.
최근의 2D 생성 모델(예: DALL-E [54], Imagen [59], Stable Diffusion [58])과 비전 언어 모델(예: CLIP [52])의 등장은 우리에게 3D 세계에 대한 강력한 priors를 제공했으며, 결과적으로 3D 생성에서 연구의 급증을 촉진했습니다.
특히, DreamFusion [50], Magic3D [31] 및 ProlificDreamer [71]와 같은 모델은 모양별 최적화를 위한 접근 방식을 개척했습니다 [6, 7, 12, 23, 29, 41, 44–46, 51, 53, 61, 63, 64, 67, 76, 77, 81].
이 모델들은 그라디언트 가이던스를 위한 2D prior 모델을 기반으로 각 고유한 입력 텍스트 또는 이미지에 대한 3D 표현을 최적화하도록 설계되었습니다.
인상적인 결과를 얻었지만, 이러한 방법은 장기간의 최적화 시간, "다중 얼굴 문제", 과포화 색상 및 결과의 다양성 부족으로 어려움을 겪는 경향이 있습니다.
일부 작업은 또한 2D 모델의 priors를 활용하여 입력 메시를 위한 텍스처 또는 재료를 만드는 데 집중합니다 [5, 56].
Zero123 [35]와 같은 연구에서 강조된 새로운 연구 물결은 단일 이미지 또는 텍스트에서 새로운 뷰를 합성하기 위해 사전 학습된 2D 디퓨전 모델을 사용하여 3D 생성을 위한 새로운 문을 열 수 있는 가능성을 보여주었습니다.
예를 들어, Zero123이 예측한 멀티뷰 이미지를 사용하는 One-2-3-45 [34]는 단 45초 만에 텍스처링된 3D 메쉬를 생성할 수 있습니다.
그럼에도 불구하고 Zero123이 생성한 멀티뷰 이미지는 3D 일관성이 부족합니다.
우리의 연구는 여러 동시 연구와 함께 이러한 멀티뷰 이미지의 일관성을 향상시키는 데 전념하고 있습니다[32, 37, 40, 62, 72, 80] – 후속 3D 재구성 애플리케이션을 위한 필수 단계.
2.2. Sparse View Reconstruction
멀티뷰 스테레오 또는 NeRF 기반 기술과 같은 기존의 3D 재구성 방법은 정확한 지오메트릭 추론을 위해 입력 이미지의 조밀한 모음을 요구하는 경우가 많지만, 최신 일반화 가능한 NeRF 솔루션 [3, 24, 28, 36, 39, 55, 66, 69, 70, 79]은 장면 전반에 걸쳐 사전 학습을 위해 노력합니다.
이를 통해 희소한 이미지 세트에서 NeRF를 추론하고 새로운 장면으로 일반화할 수 있습니다.
이러한 방법은 일반적으로 2D 네트워크를 활용하여 2D 피쳐를 추출하는 데 몇 가지 소스 뷰를 입력으로 수집합니다.
그런 다음 이러한 픽셀 피쳐는 투영되지 않고 3D 공간으로 집계되어 밀도 (또는 SDF) 및 색상의 추론을 용이하게 합니다.
그러나 이러한 방법은 정확한 대응을 가진 일관된 멀티뷰 이미지에 의존하거나 학습 데이터 세트를 넘어 일반화하기에는 제한된 사전 정보를 가질 수 있습니다.
최근 일부 방법 [2, 27, 65, 88]은 희소 뷰 재구성 작업을 돕기 위해 디퓨전 모델을 사용했습니다.
그러나 일반적으로 문제를 새로운 뷰 합성으로 프레임화하므로 3D 콘텐츠를 생성하기 위해 3D 표현을 사용한 distillation과 같은 추가 처리가 필요합니다.
저희의 작업은 3D 생성을 위해 다중 뷰 조건부 3D 디퓨전 모델을 활용합니다.
이 모델은 3D 데이터에서 priors를 직접 학습하고 추가 사후 처리의 필요성을 제거합니다.
또한 일부 동시 작업 [37, 40, 62]은 특수 loss 함수를 활용하여 재구성을 위해 NeRF 기반 장면별 최적화를 사용합니다.
3. Method
전통적인 게임 스튜디오에서 3D 콘텐츠 제작에는 컨셉 아트, 3D 모델링, 텍스처링 등 일련의 단계가 포함됩니다.
각 단계는 서로 다른 상호 보완적인 전문 지식을 필요로 합니다.
예를 들어 컨셉 아티스트는 창의력, 생생한 상상력, 3D 자산을 시각화하는 능력을 갖춰야 합니다.
반면, 도면에 불일치나 오류가 포함된 경우에도 3D 모델러는 3D 모델링 도구에 능숙해야 하며 멀티뷰 개념 도면을 실제와 같은 모델로 해석하고 번역할 수 있어야 합니다.
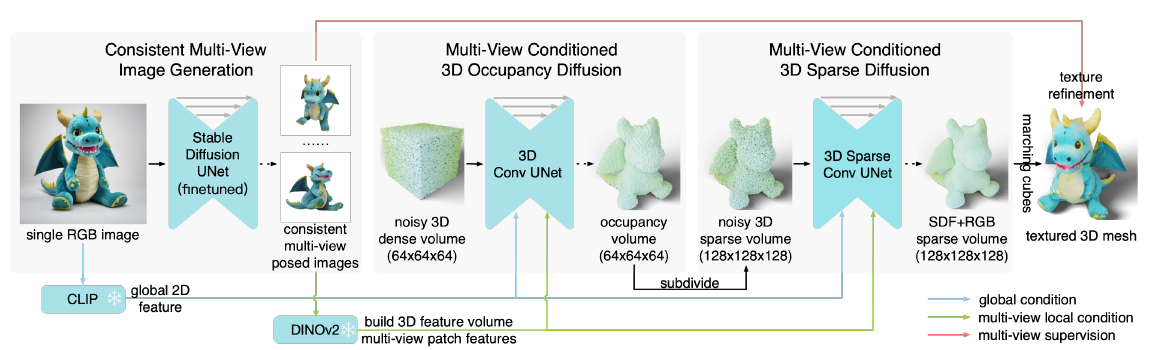
One-2-3-45++는 유사한 철학을 따라 풍부한 2D priors 및 가치 있지만 제한된 3D 데이터를 활용하는 것을 목표로 합니다.
그림 2와 같이 객체의 단일 입력 이미지로 One-2-3-45+는 객체의 일관된 멀티뷰 이미지를 생성하는 것으로 시작합니다.
이는 사전 학습된 2D 디퓨전 모델을 파인튜닝함으로써 달성되며 개념 아티스트의 역할과 유사하게 작용합니다.
생성된 이미지는 그런 다음 3D 모델링을 위해 멀티뷰 조건부 3D 디퓨전 모델에 입력됩니다.
광범위한 멀티뷰 및 3D 페어링으로 학습된 3D 디퓨전 모듈은 멀티뷰 이미지를 3D 메쉬로 변환하는 데 탁월합니다.
마지막으로 생성된 메쉬는 멀티뷰 이미지의 가이드에 따라 경량 정제 모듈을 거쳐 텍스처 품질을 더욱 향상시킵니다.
3.1. Consistent Multi-View Generation
최근 Zero123은 카메라 뷰 제어를 통합하기 위해 사전 학습된 2D 디퓨전 네트워크를 파인튜닝하여 단일 참조 이미지에서 객체의 새로운 뷰를 합성할 수 있는 가능성을 입증했습니다.
이전 연구에서는 Zero123을 사용하여 멀티뷰 이미지를 생성했지만, 종종 서로 다른 뷰에서 불일치로 인해 어려움을 겪습니다.
이러한 불일치는 Zero123이 멀티뷰 생성 중에 내부 뷰간 커뮤니케이션을 고려하지 않고 각 뷰에 대한 조건부 한계 분포를 개별적으로 모델링하기 때문에 발생합니다.
이 작업에서는 일관된 멀티뷰 이미지를 생성하여 다운스트림 3D 재구성에 크게 도움이 되는 혁신적인 방법을 제시합니다.
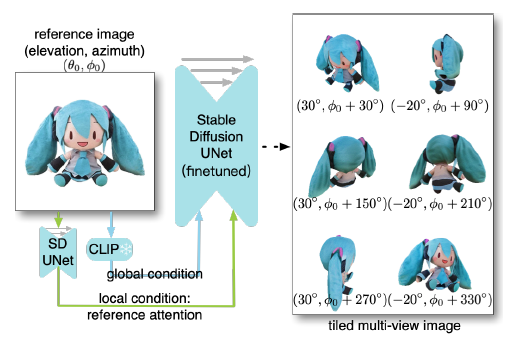
Multi-View Tiling
단일 디퓨전 과정에서 여러 뷰를 생성하기 위해 그림 3과 같이 6개의 뷰로 구성된 희소 집합을 3x2 레이아웃의 단일 이미지로 타일링하여 간단한 전략을 채택했습니다.
그런 다음 단일 입력 이미지를 기반으로 합성 이미지를 생성하기 위해 사전 학습된 2D 디퓨전 네트워크를 파인튜닝합니다.
이 전략을 사용하면 디퓨전 중에 여러 뷰가 서로 상호 작용할 수 있습니다.
멀티뷰 이미지의 카메라 포즈를 정의하는 것은 쉬운 일이 아닙니다.
학습 데이터 세트 내의 3D 형상에 정렬된 표준 포즈가 부족하다는 점을 감안할 때, 멀티뷰 이미지에 절대 카메라 포즈를 사용하면 생성 모델에 대한 모호성이 발생할 수 있습니다.
또는 Zero123과 같이 입력 뷰에 대해 카메라 포즈를 설정하는 경우 다운스트림 애플리케이션이 멀티뷰 이미지의 카메라 포즈를 추론하기 위해 입력 이미지의 고도 각도를 추론해야 합니다.
이 추가 단계는 파이프라인에 오류를 발생시킬 수 있습니다.
이를 해결하기 위해 상대 azimuth 각과 쌍을 이루는 고정된 절대 elevation 각도를 선택하여 멀티뷰 이미지의 포즈를 정의하여 추가 elevation 추정 없이도 방향 모호성을 효과적으로 해결합니다.
더 정확하게는 그림 3과 같이 30˚에서 시작하는 azimuth 각과 30˚와 -20˚의 elevation을 번갈아 가며 6개의 포즈를 결정하고 각 후속 포즈에 대해 60˚씩 증가시킵니다.
Network and Training Details
이미지 컨디셔닝을 추가하고 일관된 멀티뷰 합성 이미지를 생성하기 위해 Stable Diffusion을 파인튜닝하기 위해 세 가지 중요한 네트워크 또는 학습 설계를 사용합니다:
(a) 로컬 조건: 저희는 로컬 조건을 통합하기 위해 참조 어텐션 기법 [85]을 채택합니다.
구체적으로, 저희는 디노이징 UNet 모델로 참조 입력 이미지를 처리하고 조건부 참조 이미지의 셀프 어텐션 키 및 값 행렬을 디노이징 멀티뷰 이미지의 해당 어텐션 레이어에 추가합니다.
(b) 전역 조건: 저희는 CLIP 이미지 임베딩을 전역 조건으로 활용하여 원래 Stable Diffusion에서 사용되었던 텍스트 토큰 피쳐를 대체합니다.
이러한 전역 이미지 임베딩에는 학습 가능한 가중치 세트가 곱해져서 네트워크가 객체에 대한 전반적인 의미론적 이해를 제공합니다.
(c) 노이즈 스케줄: 원래의 Stable Diffusion 모델은 스케일링된 선형 노이즈 스케줄을 사용하여 학습되었습니다.
우리는 파인튜닝 과정에서 선형 노이즈 방식으로 전환하는 것이 필요하다는 것을 발견했습니다.
저희는 Objaverse 데이터 세트 [11]의 3D 형상을 사용하여 Stable Diffusion2 v-모드를 파인튜닝합니다.
각 형상에 대해 지정된 범위에서 입력 이미지의 카메라 포즈를 랜덤으로 샘플링하고 균일한 조명을 제공하는 큐레이팅된 세트에서 랜덤 HDRI 환경 조명을 선택하여 세 개의 데이터 포인트를 생성합니다.
초기에는 LoRA [22]를 사용하여 크로스 어텐션 레이어의 키 및 값 행렬과 함께 셀프 어텐션 레이어만 파인튜닝했습니다.
이후 보수적인 학습 속도를 사용하여 전체 UNet을 파인튜닝했습니다.
파인튜닝 프로세스는 16개의 GPU를 사용하여 수행되었으며 약 10일이 소요되었습니다.
3.2. 3D Diffusion with Multi-View Condition
이전 작업은 3D 재구성을 위해 일반화 가능한 NeRF 방법을 사용하지만, 주로 멀티뷰 이미지의 정확한 로컬 대응에 의존하며 3D 생성을 위한 priors 조건이 제한됩니다.
이는 2D 디퓨전 네트워크에서 생성된 복잡하고 일관성이 없는 멀티뷰 이미지를 리프팅하는 데 효과적이지 못한 제약을 미칩니다.
대신 멀티뷰 조건부 3D 생성 모델을 활용하여 생성된 멀티뷰 이미지를 3D로 리프팅하는 혁신적인 방법을 제안합니다.
광범위한 3D 데이터에 대한 표현형 3D 네이티브 디퓨전 네트워크를 학습하여 멀티뷰 이미지에 조건부된 그럴듯한 3D 형상의 매니폴드를 학습하고자 합니다.
3D Volume Representations
그림 2와 같이 텍스처링된 3D 형상을 두 개의 이산 3D 볼륨, 즉 signed distance function (SDF) 볼륨 및 색상 볼륨으로 표현합니다.
SDF 볼륨은 각 그리드 셀의 중심에서 가장 가까운 형상 표면까지의 부호화된 거리를 측정하고 색상 볼륨은 그리드 셀의 중심에 대해 가장 가까운 표면 지점의 색상을 캡처합니다.
또한 SDF 볼륨은 각 그리드 셀이 사전 정의된 임계값 미만인지 여부에 따라 이진 점유를 저장하는 이산 점유 볼륨으로 변환될 수 있습니다.
Two-Stage Diffusion
3D 형상의 세분화된 디테일을 캡처하려면 고해상도 3D 그리드를 사용해야 하며, 이는 불행히도 상당한 메모리 및 계산 비용을 수반합니다.
결과적으로, 저희는 LAS-Diffusion [87]을 따라 coarse-to-fine 두 단계 방식으로 고해상도 볼륨을 생성합니다.
구체적으로, 초기 단계는 3D 형상의 쉘을 근사화하기 위해 저해상도 (예: n = 64) 전체 3D 점유 볼륨 F ∈ R^(n x n x n x 1)을 생성하는 반면, 두 번째 단계는 점유된 영역 내에서 세분화된 SDF 값과 색상을 예측하는 고해상도(예: N = 128) 희소 볼륨 S ∈ R^(N x N x N x 4)를 생성합니다.
저희는 각 단계에 대해 별도의 디퓨전 네트워크를 사용합니다.
첫 번째 단계의 경우 normal 3D 컨볼루션을 사용하여 전체 3D 점유 볼륨 F를 생성하는 반면, 두 번째 단계의 경우 3D 희소 컨볼루션을 UNet에 통합하여 3D 희소 볼륨 S를 생성합니다.
두 디퓨전 네트워크는 디노이징 loss [20]을 사용하여 학습됩니다:
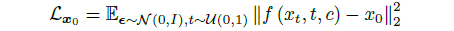
, 여기서 ϵ 및 t는 노이즈 샘플링 및 시간 단계이며, x_0는 데이터 포인트(F 또는 S)이고 x_t는 노이즈가 있는 버전이고, c는 멀티뷰 조건이고, f는 UNet입니다.
N과 U는 각각 가우시안 및 균일 분포를 나타냅니다.
Multi-View Condition
기존의 3D 네이티브 디퓨전 네트워크를 학습하는 것은 3D 데이터의 제한된 가용성으로 인해 일반화하기 어려울 수 있습니다.
그러나 생성된 멀티뷰 이미지를 사용하면 포괄적인 가이드를 제공할 수 있어 3D 생성의 상상력 어려움을 크게 단순화할 수 있습니다.
저희는 멀티뷰 이미지를 통합하여 초기에 로컬 이미지 피쳐를 추출한 다음 C로 표시된 조건부 3D 피쳐 볼륨을 구성하여 디퓨전 과정을 가이드합니다.
이 전략은 로컬 선행이 일반화를 더 쉽게 한다는 근거를 따릅니다 [87].
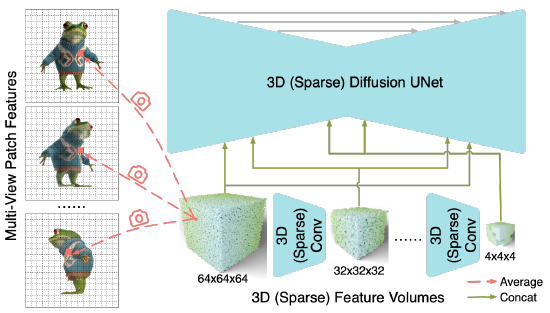
그림 4와 같이 m개의 멀티뷰 이미지가 주어지면 먼저 사전 학습된 2D 백본인 DINOv2를 사용하여 각 이미지에 대한 로컬 패치 피처 세트를 추출합니다.
그런 다음 알려진 카메라 포즈를 사용하여 볼륨 내의 각 3D 복셀을 m개의 멀티뷰 이미지에 투영하여 3D 피처 볼륨 C를 구축합니다.
각 3D 복셀에 대해 공유 가중치 MLP를 통해 m개의 연관된 2D 패치 피처를 집계한 다음 맥스 풀링을 수행합니다.
이렇게 집계된 피처는 피처 볼륨 C를 집합적으로 형성합니다.
디퓨전 네트워크에서 UNet은 여러 레벨로 구성됩니다.
예를 들어, 초기 단계의 점유 UNet은 5개의 레벨로 구성됩니다: 64^3, 32^3, 16^3, 8^3 및 4^3.
처음에는 앞서 설명한 대로 시작 해상도와 일치하는 조건부 피처 볼륨 C를 구성합니다.
그런 다음 3D 컨볼루션 네트워크를 C에 적용하여 후속 해상도의 볼륨을 생성합니다.
결과적인 조건부 볼륨은 디퓨전 과정을 가이드하기 위해 UNet 내부의 볼륨과 연결됩니다.
두 번째 단계에서는 희소 조건부 볼륨을 구성하고 3D 희소 컨볼루션을 활용합니다.
색상 볼륨의 디퓨전을 돕기 위해 2D 픽셀 단위로 투영된 색상도 디퓨전 UNet의 최종 레이어에 연결합니다.
또한 입력 이미지의 CLIP 피쳐를 전역 조건으로 통합합니다.
자세한 설명은 보충 자료를 참조하십시오.
Training and Inference Details
저희는 Objaverse 데이터 세트의 3D 형상을 사용하여 두 디퓨전 네트워크를 학습합니다 [11].
각 3D 형상에 대해 SDF 볼륨을 추출하기 전에 먼저 방수 매니폴드로 변환합니다.
저희는 색상 볼륨을 구축하는 데 사용되는 3D 색상의 포인트 클라우드를 얻기 위해 모양의 멀티뷰 렌더링을 투영하지 않습니다.
학습하는 동안 ground truth 렌더링을 활용하여 멀티뷰 조건으로 사용합니다.
두 디퓨전 네트워크가 별도로 학습되기 때문에 견고성을 높이기 위해 카메라 포즈에 랜덤 섭동을 도입하고 두 번째 단계의 초기 점유에 랜덤 노이즈를 주입했습니다.
저희는 각 단계에 대해 약 10일 동안 8xA100 GPU를 사용하여 두 디퓨전 네트워크를 학습합니다.
자세한 내용은 보충 자료를 참조하십시오.
추론하는 동안 64^3 그리드는 먼저 가우시안 노이즈로 초기화된 다음 첫 번째 디퓨전 네트워크에 의해 디노이즈됩니다.
각 예측된 점유 복셀은 8개의 더 작은 복셀로 다시 세분화되어 고해상도 희소 볼륨을 구성하는 데 사용됩니다.
희소 볼륨은 가우시안 노이즈로 초기화된 다음 두 번째 디퓨전 네트워크로 디노이즈되어 각 복셀의 SDF 및 색상을 예측할 수 있습니다.
Marching Cubes 알고리즘은 최종적으로 텍스처 메시를 추출하기 위해 적용됩니다.
3.3. Texture Refinement
멀티뷰 이미지가 3D 컬러 볼륨보다 해상도가 높기 때문에 경량 최적화 프로세스를 통해 생성된 메쉬의 텍스처를 정제할 수 있습니다.
이를 위해 TensoRF [4]로 표현되는 컬러 필드를 최적화하면서 생성된 메쉬의 지오메트리를 수정합니다.
각 반복에서 메쉬는 래스터화 및 컬러 네트워크 쿼리를 통해 2D로 렌더링됩니다.
저희는 생성된 일관된 멀티뷰 이미지를 활용하여 l2 loss를 사용하여 텍스처 최적화를 가이드합니다.
마지막으로 표면 노멀이 뷰 방향 역할을 하는 최적화된 컬러 필드를 메쉬에 굽습니다.
4. Experiments
4.1. Comparison on Image to 3D
Baselines: 저희는 최적화 기반 및 피드포워드 방법 모두에 대해 One-2-3-45++를 평가합니다.
최적화 기반 접근 방식 내에서 저희의 베이스라인에는 Zero123 XL [35]을 백본으로 하는 DreamFusion [50]과 SyncDreamer [37] 및 DreamGaussian [63]이 포함됩니다.
피드포워드 접근 방식의 경우 One-2-3-45 [34] 및 Shap-E [25]와 비교합니다.
저희는 Zero123 XL [18]에 대해 ThreeStudio [18] 구현을 사용하고 다른 방법에는 원래 공식 구현을 사용합니다.
Dataset and Metrics: 우리는 GSO 데이터 세트 [13]의 전체 1,030개 형상 세트를 사용하여 방법의 성능을 평가하며, 이는 우리가 아는 한 학습 중에 어떤 방법도 노출되지 않았습니다.
각 형상에 대해 입력 역할을 할 정면 뷰 이미지를 생성합니다.
One-2-3-45 [34]에 따라 F-Score 및 CLIP similarity를 평가 메트릭으로 사용합니다.
F-Score는 예측된 메쉬와 ground truth 메쉬 사이의 지오메트릭 유사성을 평가합니다.
CLIP similarity 메트릭의 경우 각 예측된 메쉬와 ground truth 메쉬에 대해 24개의 다른 뷰를 렌더링하고 해당 이미지 쌍별로 CLIP similarity를 계산한 다음 모든 뷰에서 이 값을 평균화합니다.
메트릭 계산 전에 선형 검색과 ICP 알고리즘의 조합을 사용하여 예측된 메쉬를 ground truth 메쉬와 정렬합니다.
User Study: 사용자 연구도 수행되었습니다.
각 참가자에 대해 전체 GSO 데이터 세트에서 45개의 형상을 랜덤으로 선택하고 각 형상에 대해 두 가지 방법을 랜덤으로 샘플링했습니다.
참가자는 우수한 품질을 나타내고 입력된 이미지와 더 잘 일치하는 각 비교 결과 쌍에서 결과를 선택하도록 요청 받았습니다.
그런 다음 이러한 선택을 기반으로 모든 방법에 대한 선호도 비율을 집계했습니다.
53명의 참가자로부터 총 2,385개의 평가된 쌍이 수집되었습니다.
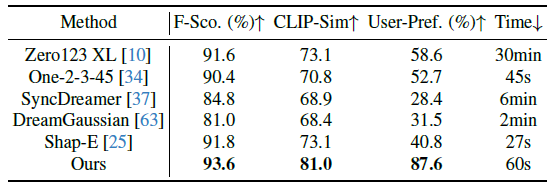
Results: 표 1에 제시된 바와 같이, One-2-3-45++는 F-Score 및 CLIP similarity에 관한 모든 베이스라인 방법을 능가합니다.
사용자 선호도 점수는 상당한 성능 차이를 더욱 강조하며, 우리의 방법은 경쟁 접근 방식을 상당한 차이로 능가합니다.
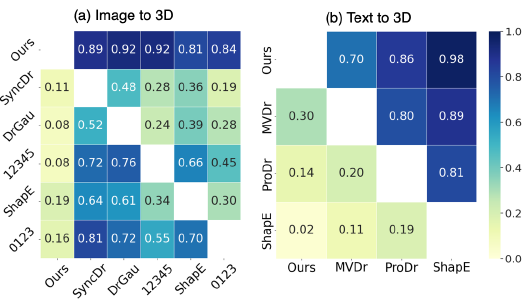
One-2-3-45++가 One-2-3-45 92%의 성능을 발휘한다는 것을 보여주는 in-depth confision 행렬은 그림 6을 참조하십시오.
또한 최적화 기반 방법과 비교할 때, 우리의 접근 방식은 현저한 런타임 이점을 보여줍니다.
그림 5와 7은 정성적 결과를 보여줍니다.


4.2. Comparison on Text-to-3D
Baselines: 저희는 One-2-3-45++를 최적화 기반 방법, 특히 ProlificDreamer [71] 및 MVDream [62]과 피드 포워드 접근 방식인 Shap-E [25]와 비교했습니다.
ProlificDreamer의 경우 ThreeStudio 구현 [18]을 활용했고, 나머지 방법은 각각의 공식 구현을 사용했습니다.
Dataset and Metrics: 많은 기본 접근 방식이 단일 3D 형상을 생성하는 데 몇 시간이 필요하다는 점을 감안할 때, 평가는 DreamFusion [50]에서 샘플링된 50개의 텍스트 프롬프트에 대해 수행되었습니다.
저희는 예측된 메시의 24개의 렌더링된 뷰를 입력된 텍스트 프롬프트와 비교한 다음 모든 뷰에서 유사성 점수를 평균화하여 계산된 CLIP similarity를 활용합니다.
User Study: 사용자 연구는 image-to-3D 평가와 마찬가지로 각 참가자에 대해 랜덤으로 선택된 30쌍의 결과를 포함했습니다.
53명의 참가자로부터 총 1,590쌍의 평가 쌍이 수집되었습니다.
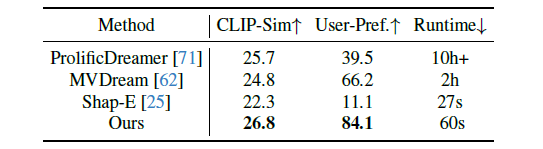
Results: 표 2에서 볼 수 있듯이 One-2-3-45++는 CLIP similarity 측면에서 모든 베이스라인 방법보다 성능이 뛰어납니다.
이는 사용자 선호도 점수에 의해 더욱 입증되며, 우리의 방법은 경쟁사 기술보다 훨씬 뛰어납니다.
심층 분석은 그림 6을 참조하십시오.
One-2-3-45++와 두 번째로 좋은 방법인 MVDream [62]을 직접 비교할 때, 우리의 접근 방식은 70%의 사용자 선호도 비율을 명령합니다.
또한 우리의 방법은 신속한 결과를 제공하지만 MVDream [62]은 단일 모양을 생성하는 데 약 2시간이 필요합니다.
그림 8은 정성적인 결과를 보여줍니다.

4.3. Analyses
Ablation Studies of Overall Pipeline
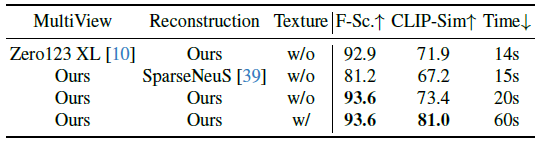
One-2-3-45++는 일관된 멀티뷰 생성, 멀티뷰 조건부 3D 디퓨전 및 텍스처 정제의 세 가지 핵심 모듈로 구성됩니다.
저희는 전체 GSO 데이터 세트 [13]를 사용하여 이러한 모듈에 대한 ablation 연구를 수행했으며, 그 결과는 표 3에 자세히 설명되어 있습니다.
일관된 멀티뷰 생성 모듈을 Zero123XL [10]로 교체하면 성능이 눈에 띄게 저하되었습니다.
또한 3D 디퓨전 모듈을 One-2-3-45 [34]에 사용된 일반화 가능한 NeRF로 대체하면 성능이 훨씬 더 크게 저하되었습니다.
그러나 텍스처 정제 모듈을 포함하면 텍스처 품질이 현저하게 향상되어 더 높은 CLIP similarity 점수를 얻을 수 있습니다.
Ablation Studies of 3D Diffusion
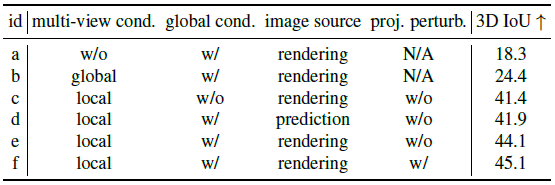
표 4는 3D 디퓨전 모듈의 ablation 연구 결과를 보여줍니다.
이 연구는 모듈의 효율성을 위해 멀티뷰 이미지의 중요성을 강조합니다.
모듈이 단일 입력 뷰(행 a 및 f)의 전역 CLIP 피쳐에만 의존하여 멀티뷰 조건 없이 작동하면 성능이 크게 저하됩니다.
반대로 One-2-3-45++ 접근 방식은 알려진 투영 행렬로 3D 피쳐 볼륨을 구성하여 멀티뷰 로컬 피쳐를 활용합니다.
여러 뷰에서 전역 CLIP 피쳐를 연결하기만 해도 성능이 저하되어 멀티뷰 로컬 조건의 가치가 강조됩니다.
그러나 입력 뷰의 전역 CLIP 피쳐는 전역 모양 의미론을 제공하며, 이를 제거하면 성능이 저하됩니다(행 c 및 e).
One-2-3-45++는 3D 재구성을 위해 예측된 멀티뷰 이미지를 사용하지만, 3D 디퓨전 모듈을 학습하는 동안 이러한 예측 이미지를 통합하면 예측된 멀티뷰 이미지와 실제 3D ground truth 메쉬 간의 잠재적 불일치로 인해 성능이 저하될 수 있습니다(행 d 및 e).
모듈을 효과적으로 학습하기 위해 ground truth 렌더링을 활용합니다.
예측된 멀티뷰 이미지에 결함이 있을 수 있음을 인식하고 학습 중에 투영 행렬에 랜덤 섭동을 도입하여 예측된 멀티뷰 이미지(행 e 및 f)를 처리할 때 견고성을 향상시킵니다.
Comparison on Multi-View Generation
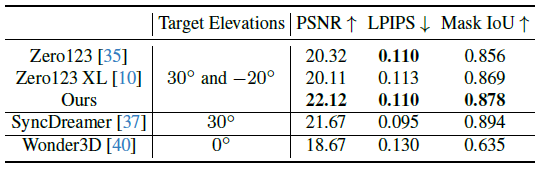
우리는 또한 두 가지 동시 작업과 함께 기존 접근 방식, 즉 Zero123 [35] 및 그 확장된 변형 [10]에 대해 일관된 멀티뷰 생성 모듈을 평가합니다: SyncDreamer [37] 및 Wonder3D [40].
저희의 비교는 GSO [13] 데이터 세트를 활용하는데, 여기서 각 객체에 대해 단일 입력 이미지를 렌더링하고 다중 뷰 이미지를 생성하는 방법을 작업합니다.
Zero123 및 Zero123 XL의 경우 저희는 접근 방식과 동일한 대상 포즈를 사용합니다.
그러나 Wonder3D 및 SyncDreamer의 경우 추론 중 카메라 위치를 변경하는 것을 지원하지 않기 때문에 이러한 방법으로 미리 설정된 대상 포즈를 사용합니다.
표 5에 제시된 바와 같이 저희의 접근 방식은 PSNR, LPIPS 및 전경 마스크 IoU의 현재 방법론을 능가합니다.
특히 Wonder3D [40]는 학습 단계에서 정형 투영을 사용하여 추론 중에 원근 이미지를 다룰 때 견고성을 손상시킵니다.
SyncDreamer [37]는 30˚의 elevaiton에서만 뷰를 생성하는데, 이는 저희보다 간단한 설정입니다.
또한 이러한 메트릭은 뷰 간의 3D 일관성을 평가하지 않기 때문에 추가적인 질적 비교 및 논의에 대한 보완 사항을 참조하십시오.
5. Conclusion
본 논문에서는 모든 물체의 단일 이미지를 3D 텍스처 메쉬로 변환하는 혁신적인 방법인 One-2-3-45++를 소개했습니다.
이 방법은 기존의 text-to-3D 모델에 비해 더 정밀한 제어 기능을 제공하여 고품질의 메쉬를 빠르게 전달할 수 있습니다—일반적으로 60초 이내입니다.
또한 생성된 메시는 원래 입력 이미지에 대해 높은 충실도를 나타냅니다.
미래에는 RGB 이미지와 함께 2D 디퓨전 모델의 추가 가이딩 조건을 통합하여 지오메트리의 견고성과 디테일을 향상시킬 수 있습니다.