2023. 12. 21. 18:02ㆍtext-to-3D
4D-fy: Text-to-4D Generation Using Hybrid Score Distillation Sampling
Sherwin Bahmani, Ivan Skorokhodov, Victor Rong, Gordon Wetzstein, Leonidas Guibas, Peter Wonka, Sergey Tulyakov, Jeong Joon Park, Andrea Tagliasacchi, David B. Lindell
Abstract
최근 text-to-4D 생성의 획기적인 발전은 사전 학습된 text-to-image 및 text-to-video 모델에 의존하여 동적 3D 장면을 생성합니다.
그러나 현재의 text-to-4D 방법은 장면 외관의 품질, 3D 구조 및 모션 사이에서 3자 균형에 직면해 있습니다.
예를 들어, text-to-image 모델과 그들의 3D 인식 변형은 인터넷 규모의 이미지 데이터 세트에서 학습되어 실제적인 외관과 3D 구조를 가진 장면을 생성하는 데 사용될 수 있지만 모션은 없습니다.
text-to-video 모델은 비교적 작은 비디오 데이터 세트에서 학습되어 모션이 있는 장면을 생성할 수 있지만 외관과 3D 구조는 열악합니다.
이러한 모델은 보완적인 강점을 가지고 있지만 반대되는 약점도 있으므로 이러한 3자 균형을 완화하는 방식으로 결합하기가 어렵습니다.
여기에서는 사전 학습된 여러 디퓨전 모델의 supervision 신호를 혼합하고 각각에 대한 높은 충실도의 text-to-4D 생성의 이점을 통합하는 교대 최적화 절차인 hybrid score distillation sampling을 소개합니다.
hybrid SDS를 사용하여 매력적인 외관, 3D 구조 및 모션으로 4D 장면의 합성을 시연합니다.
1. Introduction
인터넷 규모의 이미지-텍스트 데이터 세트 [52]의 출현과 디퓨전 모델 [20, 56, 58]의 발전으로 인해 텍스트 프롬프트에서 안정적이고 높은 충실도의 이미지 생성에 대한 새로운 기능이 등장했습니다 [6, 49, 50].
최근 방법들은 또한 대규모 text-to-image 또는 text-to-video [54] 디퓨전 모델이 3D [25, 43] 및 4D 장면 생성에 대한 유용한 priors를 학습한다는 것을 보여주었습니다.
저희의 연구는 text-to-4D 장면 생성에 초점을 맞추고 있으며, 이는 증강 및 가상 현실, 컴퓨터 애니메이션 및 산업 디자인에 적용하기 위한 흥미로운 새로운 기능을 약속합니다(그림 1).
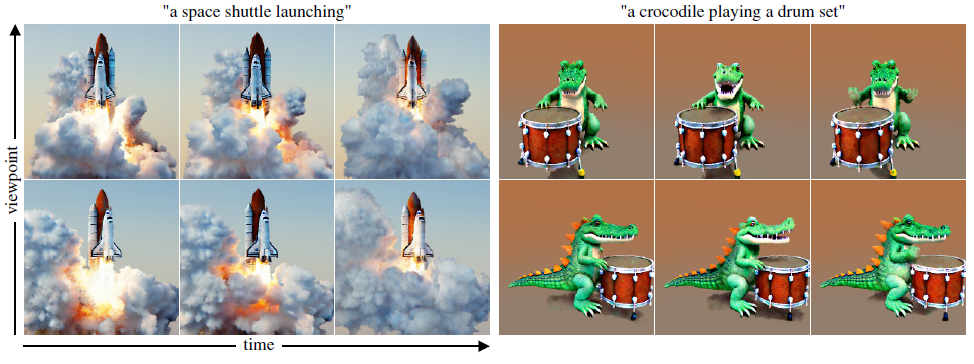
텍스트 프롬프트에서 3D 또는 4D 장면을 생성하는 현재의 기술은 일반적으로 디퓨전 모델의 supervision 신호를 사용하여 장면의 표현을 반복적으로 최적화합니다 [43, 65, 69].
특히, 이러한 방법은 3D 장면의 이미지를 렌더링하고 렌더링된 이미지에 노이즈를 추가하며 렌더링된 이미지를 노이즈 제거하기 위해 사전 학습된 디퓨전 모델을 사용하며 3D 표현을 업데이트하는 데 사용되는 그래디언트를 추정합니다 [43, 65].
score distillation sampling (SDS)[43]으로 알려진 이 절차는 텍스트 조건 장면 생성을 위한 가장 최근의 방법을 뒷받침합니다.
text-to-4D 생성을 위해 SDS를 사용하려면 외관의 품질, 3D 구조, 모션 사이의 3방향 트레이드오프를 탐색해야 합니다(표 1 참조); 기존의 기술들은 이러한 범주 중 하나 또는 두 개에서만 만족스러운 결과를 얻을 수 있습니다.
예를 들어, SDS는 특정 시점에서 생성된 장면을 렌더링할 때 실제와 같은 이미지를 생성하지만 여러 시점을 검사하면 해당 장면에 여러 개의 얼굴이나 머리, 복제된 부속물 또는 잘못 반복된 3D 구조가 있음을 알 수 있습니다—현재 "Janus problem"라고 불리는 문제[53].
3D 구조를 개선하는 한 가지 방법은 SDS를 3D 인식 디퓨전 모델과 함께 사용하는 것이며, 이 모델은 다양한 카메라 시점에서 이미지를 생성하도록 학습되어 있습니다[33].
그러나 3D 인식 모델은 포즈 이미지의 합성 데이터 세트에 대한 파인튜닝을 필요로 하기 때문에 외관 품질을 희생시킵니다[53].
text-to-video 모델과 함께 SDS를 사용하는 장면에 모션을 통합하면 일반적으로 text-to-image 모델로 생성된 정적 장면에 비해 외관이 더 사실적으로 저하됩니다(그림 2 참조).
따라서 다양한 유형의 디퓨전 모델은 상호 보완적인 특성을 갖지만 반대되는 단점도 있습니다(표 1).
따라서 고품질 외관, 3D 구조 및 모션으로 text-to-4D 생성을 생성하는 방식으로 이들을 결합하는 것은 사소한 일이 아닙니다.


여기서는 사전 학습된 여러 디퓨전 모델의 그래디언트 업데이트를 혼합하고 각각의 최상의 품질을 사용하여 4D 장면을 합성하는 교대 최적화 방식인 hybrid SDS를 사용하여 이러한 3방향 트레이드오프를 완화하는 text-to-4D 장면 생성 방법을 제안합니다.
방법은 세 단계의 최적화로 구성됩니다: (1) 저희는 3D 인식 text-to-image 모델 [53]을 사용하여 (Janus problem 없이) 초기 정적 3D 장면을 생성하고; (2) 외관을 개선하기 위해 변형 SDS [69] 및 text-to-image 모델과 교대 supervision을 혼합하여 최적화를 계속하고, (3) 비디오 SDS를 사용한 교대 supervision과 text-to-video 모델 [67]과 혼합하여 장면에 모션을 추가합니다.
학습 과정 전반에 걸쳐 이러한 세 가지 디퓨전 모델의 supervision 신호를 원활하게 통합함으로써 외관, 3D 구조 및 모션 측면에서 SOTA 품질을 갖춘 텍스트 기반 4D 장면 생성을 달성합니다.
전반적으로 저희는 다음과 같은 기여를 제공합니다.
• 사전 학습된 여러 디퓨전 모델에서 바람직한 특성을 추출하고 text-to-4D 장면 생성에서 외관, 3D 구조 및 모션 사이의 트레이드오프를 완화하는 기술인 hybrid SDS를 소개합니다.
• 저희는 방법에 대한 정량적, 정성적 평가를 제공하며, 향후 연구를 촉진하기 위해 ablation 연구를 통해 3자 절충 공간을 탐색합니다.
• 오픈 소스 사전 학습 모델을 기반으로 text-to-4D로의 생성을 시연하고 모든 코드와 평가 절차를 공개적으로 제공할 것입니다.
• text-to-4D로 생성하는 작업에 대한 SOTA 결과를 제시합니다.
2. Related Work
저희의 방법은 text-to-image, text-to-video 및 text-to-3D 모델을 포함한 생성 모델링의 여러 영역의 기술과 관련이 있습니다.
관련 작업에 대한 보다 광범위한 논의를 위해 독자들은 디퓨전 모델에 대한 최신 보고서를 참조하십시오 [42].
Text-to-image generation.
텍스트 프롬프트에서 이미지를 생성하는 방법은 비교적 새로운 혁신이며, 처음에는 생성 적대 네트워크를 사용하여 입증되었습니다 [48, 71, 77].
문제 자체는 텍스트 기반 이미지 retrieval [34] 또는 이미지 조건 텍스트 생성 [59, 74]을 위한 다른 방법과도 관련이 있습니다.
보다 최근에는 수십억 개의 샘플을 가진 텍스트-이미지 데이터 세트에서 학습된 모델이 이 작업의 최신 기술이 되었습니다 [49].
디퓨전 모델 [20, 57]은 대규모 데이터 세트에서 생성 모델링을 위한 인기 있는 아키텍처이며, autoregressive 모델도 유망한 결과를 보여주었습니다 [46, 75].
일반적으로 이러한 방법은 CLIP [45]와 같은 사전 학습된 텍스트 인코더를 활용하여 텍스트 프롬프트를 디퓨전 모델 [40, 47]을 조정하는 데 사용되는 피쳐 벡터로 인코딩합니다.
디퓨전 모델에서 고해상도(예, 메가픽셀) 이미지 생성은 반복 업샘플링 레이어 [22, 47]를 적용하거나 오토인코더의 저해상도 잠재 공간에서 디퓨전을 수행한 다음 결과를 디코딩하여 명목 해상도 [16, 49]로 이미지를 복구함으로써 달성됩니다.
저희의 연구는 두 가지 오픈 소스 text-to-image 디퓨전 모델을 통합합니다: 4D 장면 생성을 가능하게 하는 Stable Diffusion [49] 및 MVDream [53](최근 3D 인식 디퓨전 모델).
Text-to-video generation.
저희의 작업은 비디오 데이터 세트의 제한된 규모에 의해 다소 제약을 받는 분야인 디퓨전 모델을 통한 급성장하는 비디오 생성 분야에 의존합니다.
이에 대응하기 위해 방법은 종종 WebVid-10M[5], HD-VG-130M[67] 또는 HD-VILA-100M[72]와 같은 이미지 및 비디오 데이터 세트 모두에서 하이브리드 학습 접근 방식을 활용합니다.
이 분야의 최근 접근 방식은 일반적으로 공간 및 시간 해상도를 향상시키기 위해 픽셀 공간 업샘플링 [21] 또는 잠재 공간 업샘플링의 변형을 사용합니다 [17, 18, 68, 78].
autoregressive 모델은 다양한 길이의 비디오를 생성하는 능력으로 구별됩니다 [63].
비디오 데이터에 대해 사전 학습된 text-to-image 디퓨전 모델을 파인튜닝하거나 초기 이미지 프레임을 시작점으로 사용하여 콘텐츠 및 모션 생성 프로세스를 분리함으로써 비디오 합성이 더욱 향상되었습니다 [7, 54, 70].
최근 text-to-video 합성의 발전에도 불구하고 생성된 비디오의 충실도는 정적 이미지 생성(그림 2 참조)보다 여전히 뒤처져 있으므로 text-to-4D 생성에 SDS와 직접 사용할 때 성능이 좋지 않습니다.
대신 저희의 작업은 hybrid SDS를 사용하여 사전 학습된 다른 오픈 소스 디퓨전 모델과 함께 Zeroscope [3](Modelscope 아키텍처[66]에서 확장)라는 오픈 소스 잠재 공간 text-to-video 디퓨전 모델을 활용합니다.
Text-to-3D generation.
text-to-3D로 생성하는 초기 방법은 입력 텍스트를 의미 표현으로 변환하기 위해 parsers에 의존했고 객체 데이터베이스에서 장면을 합성했습니다[4, 10, 12].
이후 자동화된 데이터 기반 방법은 입력 3D 메쉬 [14, 27] 또는 radiance field [64]를 편집하거나 스타일화하기 위해 멀티 모달 데이터 세트 [11]와 사전 학습된 모델 (CLIP [45])을 사용했습니다.
보다 최근에는 CLIP 기반 supervision을 통해 전체 3D 장면을 합성할 수 있었고, 이러한 기술은 SDS supervision을 기반으로 메쉬 또는 radiance field를 최적화하는 최신 접근 방식으로 발전했습니다 [31, 43, 69].
여러 관점을 고려하는 디퓨전 모델을 적용하여 3D 구조의 품질을 향상시켰습니다 [32, 33, 53].
또는 최근의 발전은 새로운 시점 합성을 위해 입력 2D 이미지를 3D 표현으로 변환하기 위해 디퓨전 또는 트랜스포머 모델을 사용하는 방향으로 변화하고 있습니다 [9, 15, 35, 44, 60, 61, 73].
그러나 이러한 기술은 아직 4D 장면 생성을 지원하지 않습니다.
저희의 작업은 Make-A-Video3D (MAV3D) [55]와 가장 밀접한 관련이 있습니다, 이는 text-to-4D로 생성하기 위한 최근의 방법으로, SDS 기반 supervision을 두 개의 개별 단계로 통합합니다: 먼저 text-to-image 모델을 사용하고 이후 text-to-video 모델을 사용합니다.
MAV3D와 마찬가지로 동적 3D 장면을 생성하는 것을 목표로 하지만 저희의 접근 방식은 hybrid SDS를 사용하여 여러 모델의 그래디언트 업데이트를 교대 최적화에서 원활하게 혼합할 수 있습니다.
저희의 접근 방식은 고품질의 동적 3D 장면을 생성하고 Janus 문제를 겪지 않습니다.
3. Method
text-to-4D 생성을 위한 저희의 접근 방식은 장면을 정적 및 동적 피쳐 그리드로 암시적으로 분해하는 해시 인코딩 기반 신경 표현 [39]을 기반으로 합니다.
이 섹션에서는 4D 신경 렌더링에 대한 저희의 표현을 개관하고 hybrid SDS를 기반으로 한 최적화 절차를 설명합니다(그림 3 참조).
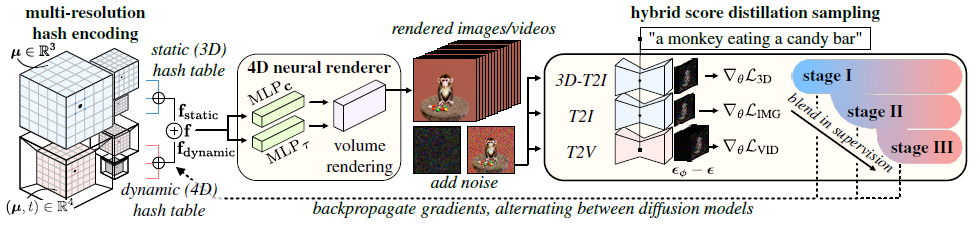
3.1. 4D Neural Rendering
체적 신경 렌더링 방법은 3D 공간의 모든 지점에서 빛의 감쇠와 방출을 매개변수화하기 위해 신경 표현을 사용하여 장면을 나타냅니다 [36, 38].
이러한 표현을 사용하여 카메라 투영 중심에서 각 픽셀 위치를 통해 장면에 ray를 캐스팅하여 이미지를 렌더링할 수 있습니다.
ray μ ∈ R^3을 따라 샘플링된 지점의 경우 신경 표현을 쿼리하여 특정 지점에서 빛의 감쇠와 방출을 각각 설명하는 체적 밀도 τ ∈ R_+ 및 색상 c ∈ R^3_+를 검색합니다.
그런 다음 결과 밀도와 색상 샘플을 알파 합성하여 렌더링된 픽셀 C의 색상을
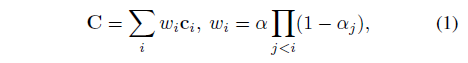
로 복구합니다, 여기서 α_i = 1 - e^(-τ_i ∥μ_i-μ_(i+1)∥).
저희는 time-varying 밀도와 색상 모델링을 가능하게 하는 추가 입력 시간 변수 t를 사용하여 신경 표현을 쿼리합니다.
우리는 그림 3의 신경 표현을 보여줍니다; 정적 및 동적 장면 모델링을 분리하기 위해 두 개의 다중 해상도 해시 테이블로 구성됩니다.
Müller et al. [39]에 따르면, 정적 해시 테이블은 복셀-lookup 및 해싱 작업으로 인덱싱되고 두 개의 작은 다층 퍼셉트론 (MLP)을 사용하여 밀도와 색상으로 디코딩된 학습 가능한 피쳐 벡터를 저장합니다.
구체적으로, 저희는 정적 및 동적 해시 테이블과 MLP에서 학습할 수 있는 모든 매개변수를 나타내는 θ = {θ_static, θ_dynamic, θ_MLP}와 함께 신경 표현
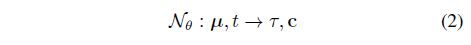
를 고려합니다.
주어진 μ에 대해 각 스케일 1≤s≤S에서 가장 가까운 복셀을 식별하여 정적 해시 테이블을 쿼리합니다.
그런 다음, 저희는 해시 테이블에서 피쳐 값을 검색한 후 복셀 정점에서 3중 보간합니다.
각 스케일에서 검색된 특징은 f_static = f_static^(1) ⊕ · · · ⊕ f_static^(S)로 concatenate됩니다.
저희는 피쳐 값을 보간하기 위해 쿼드릴선형 보간법을 사용하는 것을 제외하고는 주어진 동적 해시 테이블 (μ, t)을 쿼리하는 동일한 절차를 따릅니다.
정적 및 동적 해시 테이블의 결과 피쳐는 f = f_static + f_dynamic으로 추가됩니다.
저희는 피쳐 인코딩에서 뷰 종속 효과를 모델링하지 않습니다.
마지막으로 밀도와 색상을 각각 MLP_τ(f) 및 MLP_c(f)로 디코딩합니다.
3.2. Hybrid Score Distillation Sampling
저희는 텍스트 프롬프트에서 동적 3D 장면을 생성하기 위해 SDS와 함께 4D 표현을 활용합니다.
저희의 하이브리드 접근 방식은 교대 최적화 과정에서 원활하게 병합되는 세 가지 다른 맛의 SDS를 통합하여 4D 모델의 구조와 품질을 향상시킵니다:
1. SDS는 Janus 문제 없이 정적 장면을 최적화하기 위해 3D 인식 text-to-image 간 디퓨전 모델에 적용했습니다.
2. 정적 장면의 외관을 개선하기 위해 표준 text-to-image 모델을 사용하는 variational score distillation sampling (VSD; SDS의 수정된 버전 [69]).
3. text-to-video 모델을 사용한 Video SDS [67], SDS를 여러 비디오 프레임으로 확장하고 장면에 모션을 추가합니다.
다음에서는 SDS의 각 유형과 text-to-4D 생성에 사용되는 방법에 대해 설명합니다.
3D-aware scene optimization.
저희는 먼저 3D-aware text-to-image 디퓨전 모델 [53]과 함께 SDS를 사용하여 정적 장면을 최적화하는 것을 고려합니다.
디퓨전 모델은 0 ≤ t_d ≤ T_d 시간 단계에 걸쳐 멀티뷰 이미지 x에 가우시안 노이즈를 천천히 추가하는 stochastic 포워드 프로세스를 사용하여 사전 학습됩니다.
t_d가 증가하면 프로세스는 t_d = T_d에서 가우시안에 가까운 노이즈 이미지 z_t_d를 생성합니다.
학습 후 모델은 이 프로세스를 반전하여 노이즈 이미지에 구조를 추가합니다.
텍스트 임베딩 y [47, 49, 50]와 각 이미지에 해당하는 카메라 extrinsicx T를 조건으로 각 시간 단계 t_d에서 최적의 디노이저 출력을 근사하는 ˆx_ϕ(z_t_d; t_d, y, T)를 예측합니다.
실제로 text-to-image 디퓨전 모델은 일반적으로 디노이즈된 이미지 ˆx_ϕ 대신 노이즈 콘텐츠 ϵ_ϕ를 예측합니다.
그러나 노이즈 이미지에서 예측 노이즈를 빼서 디노이즈된 이미지를 여전히 ˆx_ϕ(z_t_d; t_d, y, T) ∝ z_t_d - ϕ(z_t_d; t_d, y, T)로 얻을 수 있습니다 [20].
저희는 신경 표현에서 여러 이미지 x_θ를 렌더링하고 노이즈 ϵ를 추가하며 3D-aware 디퓨전 모델 [53]을 사용하여 classifier-free guidance [19]를 사용하여 노이즈 ϵ_ϕ를 예측함으로써 3D-aware SDS를 구현합니다.
신경 표현의 매개 변수 θ을 업데이트하기 위해 3D-aware SDS 그래디언트를 사용합니다:
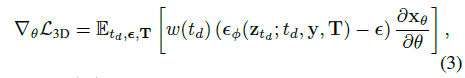
, 여기서 ω(t_d)는 디퓨전 시간 단계에 따라 달라지는 가중 함수이며, 저희는 디퓨전 모델의 출력에 스탑 그래디언트를 추가합니다 [53].
직관적으로 SDS loss는 디퓨전 모델에 구조를 추가하는 방법을 쿼리한 다음 이 정보를 사용하여 장면 표현에 그래디언트를 역전파합니다.
Improving appearance using VSD.
저희는 장면에서 렌더링된 이미지의 모양을 개선하기 위해 VSD[69]를 기반으로 한 추가 loss 항을 통합합니다.
이 항은 3D-aware text-to-image 모델 단독에 비해 화질을 개선하는 파인튜닝 체계와 함께 사전 학습된 text-to-image 모델[49]을 사용합니다.
저희는 Wang et al. [69]를 따라 장면 최적화 중에 low-rank adaptation [24]을 사용하여 파인튜닝된 추가 text-to-image 디퓨전 모델의 출력으로 표준 SDS 그래디언트를 증가시킵니다.
특히
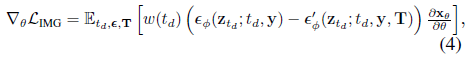
가 있는데, 여기서 ϕ'_θ는 카메라 extrinsics T에서 추가 컨디셔닝을 통합한 파인튜닝 버전의 디퓨전 모델을 사용하여 예측된 노이즈이며, 여기서 z_t_d는 N_ ϵ에서 렌더링된 단일 이미지의 노이즈 버전을 나타냅니다.
모델은 표준 디퓨전 objective
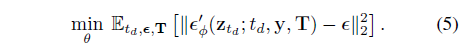
를 사용하여 파인튜닝됩니다.
VSD [69]의 원래 설명과 달리 여러 장면 샘플(즉, [69]의 변형 구성 요소)에 대한 동시 최적화를 생략할 수 있으며, 이는 외관을 크게 저하시키지 않으면서 메모리 요구 사항을 줄일 수 있습니다.
Adding motion with Video SDS.
마지막으로 text-to-video 디퓨전 모델[67]의 supervision을 사용하여 생성된 장면에 모션을 추가합니다.
이 절차는 디퓨전 모델에 의해 추가된 구조를 모든 노이즈 비디오 프레임 [55]에 통합하여 원래 SDS 그래디언트를 확장합니다.
video SDS 그래디언트는
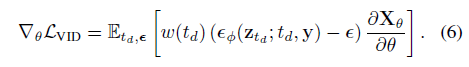
과 같이 제공됩니다.
표기를 단순화하기 위해 여기에 ϵ_ϕ와 ϵ를 재사용하여 각 비디오 프레임의 예측된 노이즈와 실제 노이즈를 나타내고 X_θ를 표현에서 렌더링된 V 비디오 프레임 X_θ = [x_θ^(1), ..., x_θ^(V)]^T의 모음으로 지정합니다.

Optimization procedure - Algorithm 1.
우리는 (1) 3D-aware SDS, (2) VSD 및 (3) video SDS의 교대 단계에서 supervision을 원활하게 혼합하는 3단계로 4D 표현을 최적화합니다.
Stage 1.
최적화의 첫 번째 단계에서는 수렴할 때까지 3D-aware SDS의 그래디언트를 사용하여 N_θ를 업데이트합니다.
이 단계는 정적 장면을 최적화하는 데 중점을 두기 때문에 동적 해시 테이블 f_dynamic의 매개 변수를 동결(업데이트하지 않음)하고 정적 해시 테이블과 디코더 MLP만 업데이트합니다.
저희는 Shi et al. [53]과 일치하도록 첫 번째 단계 반복의 총 수 N_(stage-1)를 설정했으며, 이를 통해 한 번의 반복에서 다음 반복으로 렌더링된 장면에 구별할 수 있는 변경 사항이 없을 때까지 최적화를 진행할 수 있습니다.
Stage 2.
다음으로, 교대 최적화 절차를 사용하여 VSD 그래디언트를 추가합니다.
각 반복에서 ∇_θ L_3D 또는 ∇_θ L_IMG를 사용하여 P_3D 및 P_IMG 확률로 모델을 업데이트하도록 랜덤으로 선택합니다.
저희는 수렴할 때까지 N_(stage-2) 반복에 대해 교대 최적화를 계속합니다.
다음 섹션에서 보여드릴 수 있듯이, 이 최적화 단계는 Janus 문제가 없는 ∇_θ L_3D 단독을 사용하는 것에 비해 개선된 외관을 제공합니다.
Stage 3.
마지막으로, 저희는 모든 그래디언트 업데이트의 조합을 사용하여 표현을 업데이트합니다.
구체적으로, 저희는 ∇_θ L_3D, ∇_θ L_IMG 또는 ∇_θ L_VID를 각각 확률 P_3D, P_3D · P_IMG 및 1 - P_3D · P_IMG를 사용하여 각 반복에서 모델을 업데이트하도록 랜덤으로 선택합니다.
이제 모션을 표현에 통합하는 것을 목표로 하기 때문에, 저희는 ∇_θ L_VID로 업데이트하는 동안 동적 해시 테이블의 매개 변수를 풀지만 text-to-image 모델을 사용한 업데이트를 위해 고정 상태로 유지합니다.
또한 이전 단계의 고품질 외관을 유지하기 위해 정적 해시 테이블의 학습률을 낮춥니다.
저희는 마지막 단계에서 수렴될 때까지 교대 최적화를 반복하며, 이는 N_(stage-3) 반복 내에서 일관되게 발생한다는 것을 발견했습니다.
전반적으로 hybrid SDS는 각 모델의 그래디언트를 순수하게 결합함으로써 발생하는 품질 저하를 방지하면서 사전 학습된 각 디퓨전 모델의 강점을 효과적으로 결합합니다.
3.3. Implementation
저희는 MVDream [53](3D-aware text-to-image 디퓨전 및 SDS의 경우), Stable Diffusion을 가진 ProlificDreamer [69](text-to-image 디퓨전 및 VSD)의 구현을 포함하는 threestudio 프레임워크 [2]를 기반으로 hybrid SDS를 구현하고, Zeroscope [3, 67]를 사용하여 video SDS 업데이트를 구현합니다.
Hyperparameter values.
저희는 [31, 43]에 이어 4D 신경 표현을 초기화하고 객체 중심 재구성을 촉진하기 위해 장면 중앙의 네트워크에서 예측한 밀도에 오프셋을 추가합니다.
저희는 정적 해시 맵의 학습 속도를 0.01, 동적 해시 맵의 학습 속도를 0.01, MLP의 학습 속도를 0.001로 설정했습니다.
저희는 동적 해시 맵에 그래디언트 업데이트를 집중하기 위해 마지막 단계 전에 정적 해시 맵의 학습 속도를 0.0001로 떨어뜨립니다.
N_(stage-1), N_(stage-2) 및 N_(stage-3)의 값은 각각 10000, 10000 및 100000으로 설정됩니다.
hybrid SDS의 확률을 P_3D = 0.5 및 P_IMG = 0.5로 설정하여 외관, 3D 구조 및 모션과 관련하여 합리적인 균형을 제공합니다.
Rendering.
사전 학습된 디퓨전 모델은 각각 다른 기본 해상도를 가지고 있으므로 N_θ에서 이미지를 렌더링합니다.
저희는 3D-aware text-to-image 모델의 기본(256x256 픽셀) 해상도에서 3D-aware SDS 업데이트를 위해 서로 다른 카메라 위치에서 4개의 이미지를 렌더링합니다.
VSD 업데이트는 256x256 이미지를 렌더링하고 Stable Diffusion (512x512)의 기본 해상도로 이미지를 이중 선형 업샘플링하여 계산됩니다.
마지막으로 video SDS 업데이트는 160x288 해상도에서 16개의 비디오 프레임을 렌더링하고 Zeroscope의 기본 320x576 해상도로 업샘플링하여 계산됩니다.
이미지의 배경을 렌더링하기 위해 ray 방향을 취하고 배경 색상을 반환하는 두 번째 작은 MLP를 최적화합니다.
저희는 이 배경 색상 위에 N_θ에서 렌더링된 ray 색상 C를 합성합니다.
Computation.
NVIDIA A100 GPU에서 모델을 최적화했습니다.
전체 절차에는 약 80GB의 VRAM이 필요하고 3개의 최적화 단계에는 각각 약 2, 2, 19시간의 컴퓨팅 시간이 필요합니다.
4. Experiments
4.1. Metrics
저희는 CLIP Score [41]와 사용자 연구를 사용하여 저희의 방법을 평가합니다.
이 분야의 향후 연구를 촉진하기 위해 저희는 사용자 연구를 위한 평가 프로토콜을 오픈 소스화할 것입니다.
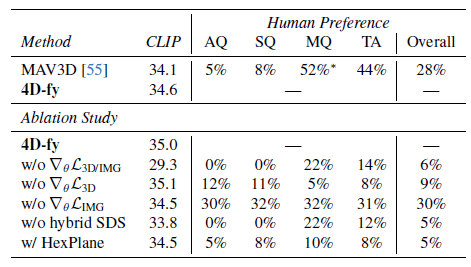
저희는 17개의 프롬프트에 대해 MAV3D와 모델을 비교하고 5개의 프롬프트의 하위 집합에 대해 ablation과 비교합니다.
이러한 비교에 사용된 프롬프트는 MAV3D에서 사용한 28개의 텍스트 프롬프트에서 가져온 것입니다.
현재 text-to-4D 모델은 학습 비용이 많이 들고 학계의 많은 연구자들이 대규모 기술 회사에서 사용할 수 있는 리소스 규모에 액세스하지 못합니다.
따라서 계산 제한으로 인해 하위 집합만 사용했습니다.
CLIP Score.
CLIP Score [41]는 텍스트 프롬프트와 이미지 사이의 상관 관계를 평가합니다.
특히, 이는 textual CLIP [45] 임베딩과 visual CLIP [45] 임베딩 사이의 코사인 유사성에 해당합니다.
점수는 0과 100 사이에 속하며, 100이 가장 좋습니다.
저희는 방법에 사용하는 것과 동일한 절차를 사용하여 MAV3D에 대한 CLIP score를 계산합니다.
특히, 각 입력 텍스트 프롬프트에 대해 MAV3D와 동일한 카메라 궤적을 사용하여 비디오를 렌더링합니다.
이후, 저희는 CLIP ViT-B/32로 각 비디오 프레임을 점수화하고 모든 프레임과 텍스트 프롬프트에서 평균을 내 최종 CLIP score를 도출합니다.
User study.
저희는 26명의 인간 평가자를 조사하여 저희의 방법과 베이스라인인 MAV3D 간의 정성적 비교를 수행합니다.
저희는 MAV3D에서 수행한 사용자 설문조사와 동일한 정면 비교 모델을 사용합니다.
특히 저희는 방법과 베이스라인 방법의 해당 출력과 함께 텍스트 프롬프트를 랜덤 순서로 제시합니다.
평가자는 비디오에 대한 전반적인 선호도를 지정하고 다음과 같은 네 가지 특정 속성을 평가해야 합니다: 외관 품질, 3D 구조 품질, 모션 품질, 텍스트 정렬 등이 있습니다.
표 2에는 4가지 속성에 기초하여 전체적으로 각 방법을 선호하는 사용자의 비율을 보고합니다.
p < 0.05 수준에서 통계적 유의성을 평가하기 위해 χ^2-test를 실시합니다.
사용자 연구에 대한 자세한 내용은 부록에 수록되어 있습니다.

4.2. Results
저희는 그림 4의 MAV3D와 비교하여 depth 맵과 함께 시공간 렌더링을 시각화합니다.
두 방법 모두 4D 장면을 합성할 수 있지만 MAV3D는 디테일이 현저히 부족합니다.
이에 반해 저희 방법은 공간과 시간에 걸쳐 사실적인 렌더링을 생성합니다.
표 2에 정량적 메트릭을 보고합니다.
사용자 연구에서 4D-fy는 CLIP Score 및 전체 선호도 측면에서 MAV3D를 능가합니다.
사용자는 외관 품질, 3D 구조 품질, 텍스트 정렬 및 전체 선호도 측면에서 MAV3D에 비해 4D-fy에 대해 통계적으로 유의한 선호도를 나타냈습니다.
그들은 적절한 text-to-video 모델을 사용한 MAV3D와 동등하게 모션 품질을 평가했습니다.
예를 들어, 전체적으로 72%의 사용자가 MAV3D에 대해 28%보다 우리 방법을 선호합니다.
4.3. Ablations
저희는 각 구성 요소를 ablating하고 MAV3D와 더 유사한 4D 신경 표현의 사용을 평가함으로써 hybrid SDS 학습 계획에 동기를 부여하는 심층 분석을 제공합니다.
저희는 표 2와 그림 5에 ablations를 제공합니다.

Image guidance (w/o ∇_θ L_3D/IMG).
기술적으로 text-to-image의 가이던스 없이 text-to-video 모델만으로 동적 3D 장면을 학습할 수 있습니다.
이 접근 방식의 단점을 입증하기 위해 처음 두 단계를 건너뛰고 text-to-video의 가이던스만으로 모델을 직접 학습하는 결과를 제시합니다.
이는 P_3D = 0 및 P_IMG = 0 설정에 해당합니다.
저희의 실험은 text-to-video 모델이 동적 3D 장면을 생성하기 위한 실제적인 3D 구조와 고품질 외관을 제공하지 못한다는 것을 보여줍니다.
3D-aware guidance (w/o ∇_θ L_3D).
현실적인 3D 구조를 생성하기 위해서는 3D-aware 디퓨전 모델을 사용하는 것이 중요하다는 것을 알게 되었습니다.
3D-aware 디퓨전 모델을 제거하면 P_3D = 0을 설정하여 유사한 모션과 고품질의 장면을 생성할 수 있지만 3D 구조는 저하됩니다.
이는 그림 5의 두 장면 모두에서 잘 드러납니다.
VSD guidance (w/o ∇_θ L_IMG).
우리는 VSD가 사실적인 장면 모습을 제공하는 데 도움이 된다는 것을 발견했습니다; 장면 생성 중에 비활성화하는 경우(P_IMG = 0), 일부 부정적인 영향이 있습니다.
예를 들어, 그림 5에서 버킷(위 행)의 아이스크림 콘은 더 상세하고 개의 얼굴(아래 행)은 더 날카롭습니다(줌인하십시오).
Hybrid SDS.
hybrid SDS 접근 방식의 영향을 설명하기 위해 저희는 세 번째 단계에 대해서만 P_3D = 0 및 P_IMG = 0을 설정하여 두 번째 단계 이후에 이미지 가이던스를 비활성화합니다.
이는 정적 모델이 text-to-image 사전 학습된 후 text-to-video 파인튜닝하는 MAV3D 학습 방식과 일치합니다.
저희의 정량적 및 정성적 분석은 이 접근 방식이 저하된 외관과 3D 구조를 초래한다는 것을 보여줍니다.
저희는 최종 최적화 단계에서 hybrid SDS를 통해 text-to-image, 3D-aware text-to-image, text-to-video를 통합하면 실제와 같은 외관과 고품질의 3D 구조가 유지된다는 것을 발견했습니다.
Backbone architecture.
마지막으로, 저희는 해시 그리드 기반 4D 표현을 HexPlane [8, 13] 아키텍처로 대체하여 축소합니다.
이 표현은 유사하게 정적 및 동적 장면 구성 요소를 분리하고 우리의 파이프라인에 쉽게 통합할 수 있습니다.
HexPlane 접근 방식은 해시 그리드 기반 표현의 외관 품질과 일치하지 않습니다.
MAV3D는 HexPlane을 사용하지만 128개의 히든 유닛을 피쳐로 하는 대규모 5-레이어 디코딩 MLP로 다중 스케일 변형을 구현합니다.
모델이 80GB A100 GPU에 맞지 않아 이 접근 방식을 다시 구현할 수 없었습니다.
공정한 비교를 위해 대신 해시 그리드 기반 표현의 메모리 소비량에 맞게 HexPlane의 용량을 늘렸습니다.
HexPlane의 용량을 늘리고 학습 시간을 늘리면 표현과 유사한 결과가 나올 수 있을 것으로 예상합니다.
5. Conclusion
저희의 방법은 새로운 hybrid score distillation sampling 절차를 사용하여 텍스트 프롬프트에서 고품질의 4D 장면을 합성합니다.
저희의 작업은 외관, 3D 구조 및 모션 사이의 3방향 트레이드오프를 완화하고 오픈 소스 모델을 기반으로 한 최초의 작업입니다.
향후 text-to-4D 생성에 대한 연구를 용이하게 하기 위해 코드를 공개할 것입니다.
Limitations.
저희 방법이 강력한 동적 3D 장면을 생성하지만, 향후 작업을 위한 몇 가지 제한 사항과 방법이 있습니다.
첫째, 장면에서 모션의 복잡성은 단순한 모션으로 제한됩니다.
현재 text-to-video의 모델이 저품질 렌더링과 비현실적인 모션으로 인해 어려움을 겪기 때문에 저희 방법이 text-to-video 생성의 향후 발전으로부터 직접적인 이점을 얻을 수 있다고 믿습니다.
모션을 개선하는 또 다른 방법은 최근 제안된 동적 표현, 예를 들어 동적 3D 가우시안 [37]을 활용하는 것일 수 있습니다.
또한 text-to-3D 생성의 현재 메트릭은 이미지 기반 메트릭과 사용자 연구에 주로 의존하기 때문에 충분하지 않습니다.
보다 정교한 3D 및 4D 메트릭을 설계하는 것은 향후 작업을 위한 중요한 방향입니다.
마지막으로 각 장면을 생성하는 데 상당한 시간이 걸립니다.
동시 text-to-3D 작업 [23, 28]은 3D 데이터에 대한 대규모 모델을 학습하여 몇 초 이내에 생성할 수 있도록 함으로써 이 문제를 완화합니다.
2D, 3D 및 비디오 데이터에 대한 대규모 사전 학습 간에 혼합하기 위해 하이브리드 최적화 절차를 통합하면 빠른 text-to-4D 생성이 가능해질 수 있습니다.