2024. 1. 2. 20:24ㆍtext-to-3D
LucidDreamer: Towards High-Fidelity Text-to-3D Generation via Interval Score Matching
Yixun Liang, Xin Yang, Jiantao Lin, Haodong Li, Xiaogang Xu, Yingcong Chen
Abstract
text-to-3D 생성의 최근 발전은 다양한 실제 시나리오에서 상상력이 풍부한 3D 자산을 생성할 수 있는 새로운 가능성을 열어주면서 생성 모델의 중요한 이정표를 세웠습니다.
text-to-3D 생성의 최근 발전은 가능성을 보여주었지만, 상세하고 고품질의 3D 모델을 렌더링하는 데는 종종 부족합니다.
이 문제는 특히 많은 방법이 Score Distillation Sampling (SDS)을 기반으로 하기 때문에 널리 발생합니다.
본 논문에서는 3D 모델에 대한 일관되지 않고 낮은 품질의 업데이트 방향을 가져와 오버 스무팅 효과를 유발한다는 SDS의 현저한 결함을 식별합니다.
이를 해결하기 위해 저희는 Interval Score Matching (ISM)이라는 새로운 접근 방식을 제안합니다.
ISM은 결정론적 diffusing 궤적을 채택하고 interval 기반 score matching을 활용하여 오버 스무팅에 대응합니다.
또한 저희는 text-to-3D 생성 파이프라인에 3D Gaussian Splatting을 통합합니다.
광범위한 실험에 따르면 저희 모델은 품질과 학습 효율성에서 SOTA 모델을 크게 능가합니다.
1. Introduction
디지털 3D는 우리의 실제 경험을 반영하는 복잡한 물체와 환경과의 시각화, 이해 및 상호 작용을 가능하게 하며 우리의 디지털 시대에 필수적인 것이 되었습니다.
그들의 영향은 건축, 애니메이션, 게임, 가상 및 증강 현실을 포함한 광범위한 영역에 걸쳐 있으며 소매, 온라인 회의, 교육 등에서 널리 사용됩니다.
3D 기술의 광범위한 사용은 중대한 도전을 가져오고, 즉 고품질의 3D 콘텐츠를 생성하는 것은 많은 시간, 노력 및 숙련된 전문 지식을 필요로 하는 과정입니다.
이는 3D 콘텐츠 생성 접근 방식 [5, 14, 16, 21–24, 29, 31, 34, 35, 41, 47]의 빠른 발전을 자극합니다.
그 중 text-to-3D 생성 [5, 14, 21, 29, 31, 34, 47, 52]은 단순한 텍스트 설명에서 상상력 있는 3D 모델을 만드는 능력이 돋보입니다.
이는 신경 매개 변수화된 3D 모델의 학습을 supervise하기 전에 미리 학습된 text-to-image 디퓨전 모델을 강력한 이미지 prior로 사용하여 텍스트와 일치하는 3D 이미지를 렌더링할 수 있도록 함으로써 달성됩니다.
이 놀라운 기능은 기본적으로 Score Distillation Sampling (SDS)을 사용하는 데 기반이 있습니다.
SDS는 2D 결과를 디퓨전 모델에서 3D 세계로 lift하는 핵심 메커니즘으로 작용하여 이미지 없이 3D 모델을 학습할 수 있습니다 [4, 5, 16, 21, 29, 34, 50].
그 인기에도 불구하고 경험적 관찰에 따르면 SDS는 종종 오버 스무딩과 같은 문제에 직면하며, 이는 고충실도 3D 생성의 실제 적용을 크게 방해합니다.
본 논문에서는 이러한 문제의 근본적인 원인을 철저히 조사합니다.
특히, 저희는 SDS 뒤에 있는 메커니즘이 3D 모델에 의해 렌더링된 이미지와 디퓨전 모델에 의해 생성된 pseudo Ground-Truth (pseudo-GT)을 일치시키는 것임을 밝힙니다.
그러나 그림 2에서 볼 수 있듯이 생성된 pseudo-GT는 일반적으로 일관성이 없고 시각적 품질이 낮습니다.
결과적으로 이러한 pseudo-GT가 제공하는 모든 업데이트 방향은 이후에 동일한 3D 모델에 적용됩니다.
평균 효과로 인해 최종 결과가 오버-스무스하고 디테일이 부족한 경향이 있습니다.

본 논문은 앞서 언급한 한계를 극복하는 것을 목표로 합니다.
저희는 불만족스러운 pseudo-GT가 두 가지 측면에서 비롯되었음을 보여줍니다.
첫째, 이러한 pseudo-GT는 높은 재구성 오류를 가진 디퓨전 모델의 한 단계 재구성 결과입니다.
또한, 디퓨전 궤적의 intrinsic 랜덤성은 이러한 pseudo-GT를 시맨틱적으로 변형시켜 평균화 효과를 유발하고 결국 오버스무딩 결과로 이어지게 합니다.
이러한 문제를 해결하기 위해 저희는 Interval Score Matching (ISM)이라는 새로운 접근 방식을 제안합니다.
ISM은 두 가지 효과적인 메커니즘으로 SDS를 개선합니다.
첫째, DDIM inversion을 사용하여 ISM은 가역적인 디퓨전 궤적을 생성하고 pseudo-GT 불일치로 인한 평균화 효과를 완화합니다.
둘째, ISM은 3D 모델로 렌더링된 이미지와 pseudo-GT를 일치시키는 대신 디퓨전 궤적의 두 간격 단계 사이에서 일치를 수행하여 높은 재구성 오류를 산출하는 한 단계 재구성을 방지합니다.
저희는 ISM loss가 매우 현실적이고 상세한 결과로 SDS를 지속적으로 능가한다는 것을 보여줍니다.
마지막으로, 저희의 ISM이 보다 고급 모델인 3D Gaussian Splatting [20]을 활용하여 [34]에 도입된 원래 3D 모델과 호환될 뿐만 아니라 저희 모델은 Magic3D [21], Fantasia3D [5] 및 ProlificDreamer [47]를 포함한 SOTA 접근 방식에 비해 우수한 결과를 달성한다는 것을 보여줍니다.
특히 이러한 경쟁 모델은 모델에서 필요하지 않은 다단계 학습이 필요합니다.
이를 통해 학습 비용을 절감할 뿐만 아니라 간단한 학습 파이프라인을 유지할 수 있습니다.
전반적으로 저희의 기여는 다음과 같이 요약할 수 있습니다.
• 저희는 text-to-3D 생성의 기본 구성 요소인 Score Distillation Sampling (SDS)에 대한 심층 분석을 제공하고 일관되지 않고 낮은 품질의 pseudo-GT를 제공하기 위한 주요 한계를 확인합니다.
이는 많은 접근 방식에서 존재하는 오버 스무딩 효과에 대한 설명을 제공합니다.
• 저희는 SDS의 한계에 대응하여 Interval Score Matching (ISM)을 제안합니다.
ISM은 가역적 디퓨전 궤적과 인터벌 기반 매칭을 통해 현실성이 높고 세부적인 결과로 SDS를 크게 능가합니다.
• 저희 모델은 3D Gaussian Splatting과 통합하여 더 적은 학습 비용으로 기존 방법을 능가하는 SOTA 성능을 달성합니다.
2. Related Works
Text-to-3D Generation.
하나의 작업은 text-to-3D 생성[2, 5–7, 12, 17, 21, 30, 34, 38, 39, 41, 45, 48]으로 분류할 수 있습니다.
선구자로서 DreamField [17]는 먼저 text-to-3D distillation을 달성하기 위해 CLIP [37] 가이던스로 NeRF [32]를 학습시킵니다.
그러나 CLIP loss에 대한 supervision이 약해 결과는 만족스럽지 않습니다.
디퓨전 모델의 발전으로 Dreamfusion [34]은 사전 학습된 2D text-to-image 디퓨전 모델에서 3D 자산을 distill하기 위해 Score Distillation Sampling (SDS)을 도입합니다.
SDS는 텍스트-가이드 디퓨전 모델에서 특정 모드를 찾아 3D distillation을 용이하게 하여 디퓨전 모델의 2D 지식을 기반으로 3D 모델을 학습할 수 있습니다.
이는 빠르게 많은 다음 작업 [5, 16, 21, 30, 34, 36, 50]에 동기를 부여하고 이들의 중요한 통합이 됩니다.
이러한 작업은 다양한 방식으로 text-to-3D 성능을 향상시킵니다.
예를 들어, 그 중 일부 [5, 12, 21, 30, 45, 48]는 NeRF를 수정하거나 다른 고급 3D 표현을 도입하여 text-to-3D distillation의 시각적 품질을 향상시킵니다.
다른 일부 [2, 6, 41]는 Janus 문제를 해결하는 데 중점을 두고 있습니다, 예를 들어, MVDream [41]은 사전 학습된 디퓨전 모델을 3D가 인식할 수 있도록 파인튜닝할 것을 제안하고, GSGEN [6]은 공동 최적화를 위해 3D 디퓨전 모델을 도입하여 새로운 접근 방식을 제안합니다.
그러나 이러한 모든 방법은 Score Distillation Sampling에 크게 의존합니다.
유망하지만 SDS는 많은 문헌 [21, 31, 34, 50]에서 오버스무딩 효과를 보여주었습니다.
또한 대규모 조건적 가이던스 [12]와의 결합이 필요하여 과포화 결과를 초래합니다.
SDS 개선을 목표로 하는 매우 최근의 작업 [18, 47, 49, 52]도 있습니다.
ProlificDreamer [47]는 3D 표현을 분포로 모델링하기 위해 VSD를 제안합니다.
HiFA [52]는 더 나은 반복 추정을 제안합니다.
상당한 개선이 이루어졌지만 이러한 작업은 훨씬 더 긴 학습 단계를 필요로 합니다.
CSD [49]와 NFSD [18]는 오리지널 SDS를 개선하기 위한 경험적 솔루션을 얻기 위해 SDS의 구성 요소를 분석하는 두 가지 동시 작업입니다.
저희 작업은 SDS의 불일치와 저품질 pseudo ground truth에 대한 체계적인 분석을 제공한다는 점에서 본질적으로 다릅니다.
그리고 Interval Score Matching을 도입하여 계산 부담을 늘리지 않으면서 우수한 결과를 달성합니다.
Differentiable 3D Representations.
미분 가능한 3D 표현은 텍스트 가이드된 3D 생성의 중요한 통합입니다.
학습 가능한 매개 변수 θ가 있는 3D 표현이 주어지면, 해당 3D 표현의 카메라 포즈 c에서 이미지를 렌더링하는 미분 가능한 렌더링 방정식 g(θ, c)가 사용됩니다.
프로세스를 미분할 수 있기 때문에 3D 표현을 역전파로 조건에 맞게 학습시킬 수 있습니다.
이전에는 text-to-3D 생성 [3, 8, 32, 40, 46]에 다양한 표현이 도입되었습니다.
그 중 NeRF [21, 32, 41]는 text-to-3D 생성 작업에서 가장 일반적인 표현입니다.
암시적 표현의 과도한 렌더링 프로세스로 인해 NeRF는 distillation 중 디퓨전 해상도와 일치하는 고해상도 이미지를 생성하기가 어렵습니다.
결과적으로 이러한 제한은 차선의 결과로 이어집니다.
이를 해결하기 위해 효율적인 명시적 렌더링으로 알려진 텍스트 메쉬 s [40]을 이 필드에서 사용하여 자세한 3D 자산 [5, 21, 47]을 생성하여 더 나은 성능을 제공합니다.
한편, 또 다른 효과적인 명시적 표현인 3D Gaussian Splatting [19]은 재구성 작업에서 현저한 효율성을 보여줍니다.
본 논문에서는 저희 프레임워크에서 3D 표현으로 3D Gaussian Splatting [19]을 조사합니다.
Diffusion Models.
text-to-3D로 생성하는 또 다른 핵심 구성 요소는 3D 모델에 대한 supervision을 제공하는 디퓨전 모델입니다.
저희는 몇 가지 개념을 다루기 위해 여기에서 그것을 간략하게 소개합니다.
Denoising Diffusion Probabilistic Model (DDPM) [13, 39, 43]은 포괄적인 기능으로 텍스트 기반 2D 이미지 생성에 널리 채택되었습니다.
DDPM은 p(x_t|x_(t-1))를 시간 t에서 미리 정의된 일정 β_t에 따른 디퓨전 프로세스로 가정합니다:
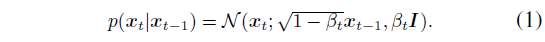
그리고 posterior p_ϕ(x_(t-1)|x_t)는 신경망 ϕ으로 모델링되며,
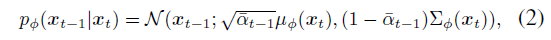
, 여기서 ¯α_t := (∏1 - β_t) 및 μ_ϕ(x_t), ∑_ϕ(x_t)는 각각 x_t에 주어진 예측 평균과 분산을 나타냅니다.
3. Methodology
3.1. Revisiting the SDS
섹션 2에서 언급한 바와 같이, SDS [34]는 DDPM 잠재 공간의 조건부 post prior에 대한 모드를 탐색함으로써 text-to-3D로의 생성을 개척합니다.
θ에서 렌더링된 2D 뷰로 x_0 := g(θ, c)를 표시하면 노이즈가 많은 잠재 x_t의 posterior는
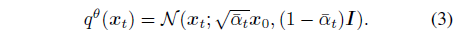
으로 정의됩니다.
한편, SDS는 사전 학습된 DDPM을 채택하여 p_ϕ(x_t|y)의 조건부 posterior를 모델링합니다.
그런 다음, SDS는 모든 t에 대해 다음과 같은 KL 발산을 최소화하여 달성할 수 있는 이러한 조건부 posterior에 대한 모드를 탐색하여 3D 표현 θ을 distill하는 것을 목표로 합니다:
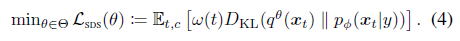
또한 DDPM 학습을 위해 가중된 디노이징 score 매칭 objective [13, 43]를 재사용하여 식 (4)를
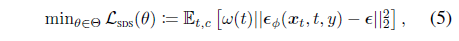
로 다시 매개변수화하고, 여기서 ϵ ~ N(0, I)는 시간 t 단계에서 x_t의 ground truth 디노이징 방향입니다.
그리고 ϵ_ϕ(x_t, t, y)는 주어진 조건 y에서 예측된 디노이징 방향입니다.
UNet Jacobian [34]를 무시하고 θ에서 SDS loss의 그래디언트는
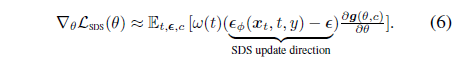
으로 제공됩니다.
Analysis of SDS.
향후 논의를 위한 보다 명확한 기반을 마련하기 위해 γ(t) = √1-α ¯t / √¯αt로 표기하고 식 (5)를 다음과 같이 대체 형태로 동등하게 변환합니다:
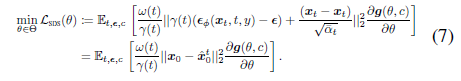
, 여기서 x_t ~ q^θ(x_t) 및 ˆx_0^t = x_t - √(1-¯α_t ϵ_ϕ(x_t,t,y)) / √¯α_t.
결과적으로 SDS loss의 그래디언트를 다음과 같이 다시 쓸 수도 있습니다:
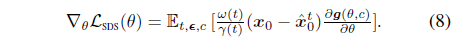
이러한 의미에서 SDS objective는 3D 모델의 뷰 x_0와 DDPM이 x_t에서 추정하는 ˆx_0^t(즉, pseudo-GT)를 단일 단계로 일치시키는 것으로 볼 수 있습니다.
그러나 저희는 이 distillation 패러다임이 DDPM의 특정 중요한 측면을 간과한다는 것을 발견했습니다.
그림 2에서 저희는 사전 학습된 DDPM이 distillation 과정에서 간혹 품질이 낮은 피쳐 불일치 pseudo-GT를 예측하는 경향이 있음을 보여줍니다.
그러나 이러한 바람직하지 않은 상황에서 식 (8)에 의해 산출된 모든 업데이트 방향은 θ으로 업데이트되며 필연적으로 오버스무스된 결과로 이어집니다.
저희는 두 가지 주요 측면에서 이러한 현상의 이유를 결론지었습니다.
첫째, SDS의 핵심 직관에 주목하는 것이 중요합니다: 입력 뷰 x_0을 참조하여 2D DDPM으로 pseudo-GT를 생성합니다.
그리고 그 후 SDS는 x_0 최적화를 위해 이러한 pseudo-GT를 활용합니다.
식 (8)에 의해 공개된 바와 같이, SDS는 먼저 x_0에서 x_t를 랜덤 노이즈로 교란한 다음 ˆx_0^t를 pseudo-GT로 추정하여 이 목표를 달성합니다.
그러나 저희는 DDPM이 입력에 매우 민감하며, 여기서 x_t의 작은 변동은 pseudo-GT의 피쳐를 크게 변경합니다.
한편, 저희는 x_t의 노이즈 성분의 랜덤성뿐만 아니라 x_0의 카메라 포즈의 랜덤성도 이러한 변동에 기여할 수 있음을 발견했으며, 이는 distillation 중에 피할 수 없습니다.
일관되지 않은 pseudo-GT 방향으로 x_0을 최적화하면 그림 2의 마지막 열에 표시된 것과 같이 궁극적으로 피쳐 평균화된 결과를 얻을 수 있습니다.
둘째, 식 (8)은 SDS가 모든 t에 대해 단일 단계 예측으로 이러한 pseudo-GT를 얻음을 의미하며, 이는 일반적으로 고품질 결과를 생성할 수 없는 단일 단계 DDPM의 제한을 무시합니다.
그림 2의 중간 열에서도 볼 수 있듯이 이러한 단일 단계 예측 pseudo-GT는 간혹 세부 사항이 없거나 블러하여 distillation을 분명히 방해합니다.
결과적으로 저희는 SDS 목표로 3D 자산을 distilling하는 것이 덜 이상적일 수 있다고 생각합니다.
이러한 관찰에 동기를 부여하여 더 나은 결과를 달성하기 위해 앞서 언급한 문제를 해결하는 것을 목표로 합니다.
3.2. Interval Score Matching
앞서 언급한 문제는 x_0 = g(θ, c)와 일치하는 pseudo-ground-truth 역할을 하는 ^x_0^t가 일관되지 않고 때로는 낮은 품질이라는 사실에서 비롯됩니다.
이 섹션에서는 이러한 문제를 상당히 완화하는 SDS에 대한 대안 솔루션을 제공합니다.
우리의 핵심 아이디어는 두 가지 폴드에 있습니다.
첫째, 노이즈와 카메라 포즈의 랜덤성에 관계없이 distillation 중에 보다 일관된 pseudo GT를 얻는 것을 추구합니다.
그런 다음 높은 시각적 품질로 이러한 pseudo GT를 생성합니다.
DDIM Inversion.
위에서 논의한 바와 같이, 저희는 x_0에 정렬된 보다 일관된 pseudo-GT를 생성하고자 합니다.
따라서 식 (3)을 사용하여 x_t를 확률적으로 생성하는 대신 DDIM inversion을 사용하여 노이즈 잠재 x_t를 예측합니다.
특히 DDIM inversion은 반복적인 방식으로 가역 노이즈 잠재 궤적 {x_δ_T, x_2δ_T, ..., x_t}을 예측합니다:
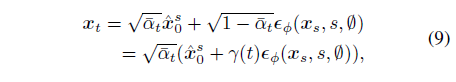
, 여기서 s = t − δ_T , ^x_0^s = 1/√¯α_s (x_s − γ(s)ϵ_ϕ(x_s, s, ∅)).
간단한 계산을 통해 ^x_0^s를 다음과 같이 구성합니다:
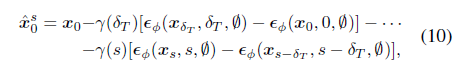
DDIM inversion의 가역성 덕분에 모든 t에 대해 pseudo-GT(즉, ^x_0^t)와 x_0의 일관성을 크게 높였으며, 이는 이후 작업에 중요합니다.
공간을 절약하기 위해 분석을 위해 우리의 부록을 참조하십시오.
Inversion Score Matching.
SDS의 또 다른 한계는 모든 t에 대해 x_t에서 단일 단계 예측으로 pseudo-GT를 생성하여 고품질 pseudo-GT를 보장하기 어렵다는 것입니다.
이를 기반으로 pseudo-GT의 시각적 품질을 더욱 개선하고자 합니다.
직관적으로 단일 단계 추정 pseudo-GT ^x_0^t = 1/√¯α_t를 대체하여 이를 달성할 수 있습니다
직관적으로 단일 단계 추정 pseudo-GT ^x_0^t = 1/√¯α_t(x_t - γ(t)ϵ_ϕ(x_t, t, y)))를 ˜x_0^t : = ˜x_0, 즉 다단계 DDIM 디노이징 프로세스를 따라 ˜x_0까지 반복
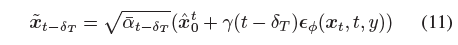
합니다.
이 디노이징 프로세스는 DDIM inversion (식. (9))과 달리 y에 대해 조건부로 지정됩니다.
이는 SDS(식. (6))의 동작과 일치하며, 즉, SDS는 전달 중에 무조건적인 노이즈 ϵ을 부과하고 노이즈 잠재력을 조건부 모델 ϵ_ϕ(x_t, t, y)로 디노이즈합니다.
직관적으로, 식 (8)의 ^x_0^t를 ˜x_0^t로 대체함으로써, 우리는 SDS의 나이브한 대안을 결론짓습니다, 여기서:
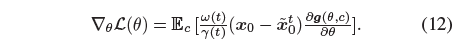
˜x_0^t는 더 좋은 품질의 가이던스를 제공할 수 있지만, 계산하는 데 시간이 너무 많이 소요되어 알고리즘의 실용성이 크게 제한됩니다.
이는 우리가 문제를 더 깊이 파고들어 더 효율적인 방법을 모색하도록 동기를 부여합니다.
먼저, 우리는 ˜x_0^t의 디노이징 과정을 inversion 과정과 공동으로 조사합니다.
우리는 먼저 식 (11)의 반복 과정을
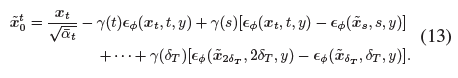
으로 통일합니다.
그런 다음 식 (9)를 식 (13)과 결합하여 식 (12)를 다음과 같이 변환할 수 있습니다:
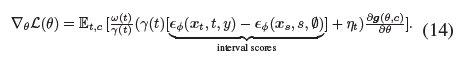
, 여기서 바이어스 항 η_t를 요약합니다:
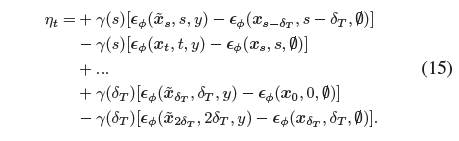
특히 η_t에는 척도가 서로 반대인 일련의 neighboring interval score가 포함되어 있으며, 이는 서로 상쇄되는 것으로 간주됩니다.
또한 η_t를 최소화하는 것은 3D 표현과 무관한 하이퍼파라미터인 δ_T와 더 관련이 있는 일련의 score 잔차를 포함하기 때문에 우리의 의도를 뛰어 넘는 것입니다.
따라서 distillation 품질을 손상시키지 않고 학습 효율을 높이기 위해 η_t를 무시할 것을 제안합니다.
η_t에 대한 자세한 분석 및 실험은 부록을 참조하십시오.
결과적으로 바이어스 항 η_t를 무시하고 interval score를 최소화하는 데 초점을 맞추어 식 (12)에 대한 효율적인 대안을 제안하며, 이를 Interval Score Matching (ISM)이라고 불렀습니다.
구체적으로, 주어진 프롬프트 y와 x_0에서 DDIM inversion을 통해 생성된 노이즈 잠재 x_s 및 x_t에서 ISM loss는
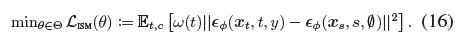
으로 정의됩니다.
[34]에 이어 θ에 따른 ISM loss의 그래디언트는

에 의해 제공됩니다.
식 (19)에서 η_t를 생략했음에도 불구하고 ISM objective를 최적화하는 핵심은 여전히 피쳐 일관성이 있으면서도 고품질이면서도 계산 친화적인 pseudo-GT를 향해 x_0을 업데이트하는 것을 중심으로 합니다.
따라서 ISM은 더 정제된 방식이지만 SDS-like objective [9, 34, 47]의 기본 원칙과 일치합니다.
결과적으로, ISM은 이전 방법론에 비해 몇 가지 이점을 제시합니다.
첫째, ISM은 일관된 고품질 pseudo-GT를 제공하기 때문에 풍부한 디테일와 fine 구조를 가진 고충실도 distillation 결과를 생성하여 대규모 조건부 가이던스 스케일 [12]이 필요하지 않고 3D 콘텐츠 생성을 위한 유연성을 향상시킵니다.
둘째, 다른 작업 [26, 47]과 달리 SDS에서 ISM으로 전환하는 데는 한계 계산 오버헤드가 발생합니다.
한편, ISM은 DDIM inversion을 위해 추가 계산 비용이 필요하지만, ISM을 사용한 3D distillation은 일반적으로 더 적은 반복으로 수렴하기 때문에 전체 효율성을 손상시키지 않습니다.
자세한 논의는 우리의 부록을 참조하십시오.
한편, 표준 DDIM inversion은 일반적으로 고정된 보폭을 채택하기 때문에 t가 커질수록 궤적 추정 비용이 선형적으로 증가합니다.
그러나 일반적으로 더 큰 시간 단계에서 θ을 supervise하는 것이 좋습니다.
따라서 균일한 보폭으로 잠재 궤적을 추정하는 대신 더 큰 단계 크기의 δ_S로 x_s를 예측하여 프로세스를 가속화할 것을 제안합니다.
저희는 이러한 솔루션이 distillation 품질을 손상시키지 않고 학습 시간을 극적으로 단축한다는 것을 발견했습니다.
또한 저희는 섹션 4.1에서 δ_T와 δ_S의 영향에 대한 정량적 분석을 제시합니다.
전반적으로 저희는 그림 3과 알고리즘 1에서 제안한 ISM을 요약합니다.
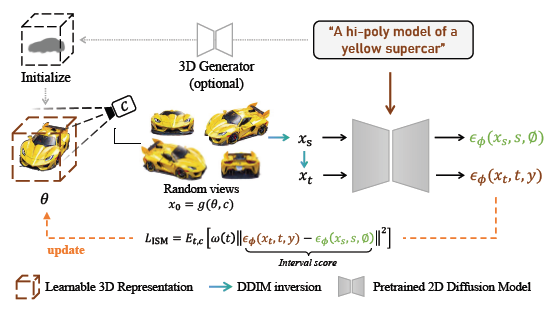

3.3. The Advanced Generation Pipeline
또한 text-to-3D 생성의 시각적 품질에 영향을 미칠 요인을 살펴보고 ISM과의 고급 파이프라인을 제안합니다.
구체적으로, 초기화를 위한 3D 표현 및 3D 포인트 클라우드 생성 모델로 3D Gaussian Splatting (3DGS)을 소개합니다.
3D Gaussian Splatting.
기존 연구에 대한 경험적 관찰에 따르면 학습을 위한 렌더링 해상도와 배치 크기를 높이면 시각적 품질이 크게 향상될 것으로 나타났습니다.
그러나 text-to-3D 생성에서 채택된 대부분의 학습 가능한 3D 표현은 상대적으로 시간과 메모리가 많이 듭니다.
이와 대조적으로 3D Gaussian Splatting [19]은 렌더링과 최적화 모두에서 매우 효율적입니다.
이를 통해 더 제한된 계산 리소스로도 고해상도 렌더링과 큰 배치 크기를 달성할 수 있습니다.
Initialization.
대부분의 이전 방법 [5, 34, 41, 47]은 일반적으로 상자, 구 및 실린더와 같은 제한된 지오메트릭 구조로 3D 표현을 초기화하므로 비축 대칭 개체에서 원하지 않는 결과를 초래할 수 있습니다.
3DGS를 3D 표현으로 도입하기 때문에 여러 text-to-point 생성 모델 [33]을 자연스럽게 채택하여 이전에 사람과 대략적인 초기화를 생성할 수 있습니다.
이 초기화 접근 방식은 섹션 4.1에서 볼 수 있듯이 수렴 속도를 크게 향상시킵니다.
4. Experiments
Text-to-3D Generation.
저희는 원래의 stable diffusion [38](점선 아래)과 다양한 파인튜닝한 체크포인트 [1, 27, 53] (점선 위)를 사용하여 그림 1에서 LucidDreamer의 생성된 결과를 보여줍니다.
결과는 LucidDreamer가 입력 텍스트의 의미적 단서와 매우 일치하는 3D 콘텐츠를 생성할 수 있음을 보여줍니다.
캐릭터 초상화나 머리카락 질감의 디테일과 같은 과도한 스무딩이나 과포화 문제를 피하면서 현실적이고 복잡한 모양을 생성하는 데 탁월합니다.
또한 저희 프레임워크는 공통 객체를 정확하게 생성하는 데 능숙할 뿐만 아니라 "Iron Man with white hair"과 같은 고유한 개념을 상상하는 것과 같은 창의적인 창작물을 지원합니다(그림 1).

Generalizability of ISM.
ISM의 일반화 가능성을 평가하기 위해 명시적 표현 (3DGS [20])과 암시적 표현 (NeRF [32]) 모두에서 ISM 및 SDS와의 비교를 수행합니다.
특히, 저희는 NeRF 비교에서 ProlificDreamer의 하이퍼파라미터 설계를 따릅니다.
그림 5에서 볼 수 있듯이, 저희 ISM은 NeRF [32] 및 3D Gaussian Splatting [20](3DGS) 모두에서 일반 CFG(7.5)에서도 세분화된 세부 정보를 제공하며, 이는 SDS보다 훨씬 우수합니다.
이는 저희 ISM의 일반화 가능성을 명확하게 보여주는 것입니다.
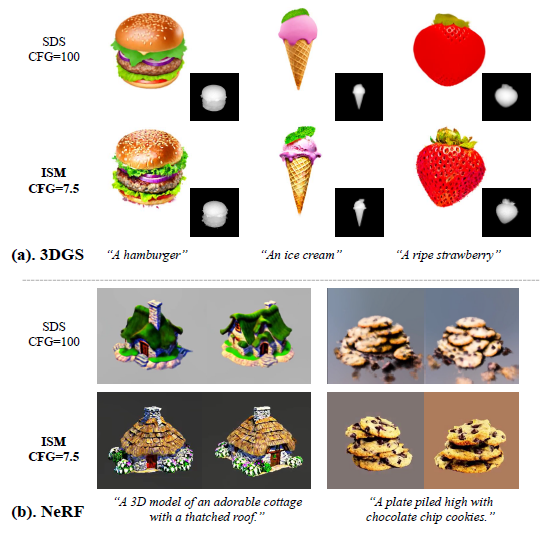

Qualitative Comparison.
저희는 저희 모델을 Three-studio [11]로 재구현된 현재 SoTA 베이스라인 [5, 21, 34, 47]과 비교합니다.
저희는 모두 distillation을 위해 stable diffusion 2.1을 사용하고 공정한 비교를 위해 모든 실험을 A100에서 수행했습니다.
그림 4에서 볼 수 있듯이 저희의 방법은 더 적은 시간과 자원 소비로 높은 충실도와 지오메트리 일관성에 관한 결과를 달성합니다.
예를 들어, 저희 프레임워크에서 생성된 Crown은 더 정확한 지오메트릭 구조와 현실적인 색상을 나타내며, 이는 다른 기본 방법에 널리 퍼져 있는 지오메트릭 모호성과 극명한 대조를 이룹니다.
다른 방법으로 생성된 Schnauzer에 비해 저희의 접근 방식은 현실에 더 가까운 머리카락 텍스쳐와 전체적인 체형을 가진 Schnauzer를 생성하여 분명한 이점을 보여줍니다.
한편, 포인트 제너레이터가 지오메트리 prior를 도입하기 때문에 저희 프레임워크에서는 Janus 문제가 줄어듭니다.
User study.
저희는 종합적인 평가를 제공하기 위해 사용자 연구를 수행합니다.
구체적으로, 저희는 28개의 프롬프트를 선택하고 각 프롬프트에 대해 서로 다른 text-to-3D 생성 방법을 사용하여 객체를 생성합니다.
사용자는 충실도와 주어진 텍스트 프롬프트와의 정렬 정도를 기반으로 순위를 매길 것을 요청 받았습니다.
저희는 사용자의 선호도를 평가하기 위해 평균 순위를 보여줍니다.
표 1에서 볼 수 있듯이, 저희 프레임워크는 6가지 선택적 방법에서 가장 높은 평균 순위를 받습니다.
사용자가 프레임워크에서 생성한 3D 모델을 지속적으로 선호했음을 나타냅니다.
사용자 연구에 대한 자세한 내용과 더 많은 시각적 결과는 저희 부록을 참조하십시오.

4.1. Ablation Studies
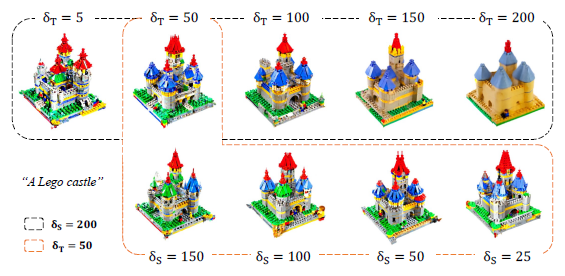
Effect of Interval Length.
저희는 이 섹션에서 학습하는 동안 간격 길이 δ_T와 δ_S의 영향을 살펴봅니다.
그림 6에서 저희는 δ_T와 δ_S의 영향을 시각화합니다.
고정된 δ_T의 경우 δ_S가 증가하면 결과에 약간의 영향이 걸리지만 DDIM inversion의 계산 비용이 크게 절약됩니다.
한편 매개 변수 δ_T가 증가함에 따라 결과는 더 자연스러운 색상과 더 간단한 구조를 채택합니다.
그러나 이는 세부 사항을 희생하는 것입니다.
따라서 저희는 δ_T를 선택하는 데 있어 절충점을 맺습니다.
예를 들어, 더 높은 δ_T에서는 성벽이 더 매끄럽게 나타납니다.
반대로, 더 낮은 δ_T 값은 세부 사항을 향상시키지만 지나치게 포화된 색상 및 성 탑 위에 떠다니는 아티팩트의 부유물과 같은 불필요한 시각적 이상을 초래할 수 있습니다.
저희는 이러한 관찰이 더 자세한 피쳐를 포함하지만 구조적 supervision이 덜한 작은 간격에 의해 제공되는 그래디언트로 인해 발생한다고 가정합니다.
따라서 저희는 처음에 전체 구조를 구성한 다음 세분화된 피쳐를 통합하는 직관적인 프로세스로 간격을 어닐링할 것을 제안합니다.
또한 이 하이퍼파라미터를 사용하면 사용자가 선호도에 따라 다른 수준의 평활성을 가진 객체를 생성할 수 있습니다.
Initialization with Point Generators.
저희는 이 섹션에서 Point Generator를 ablate합니다.
구체적으로, 저희는 랜덤 초기화에서 생성된 raw 포인트 클라우드에서 각각 주어진 프롬프트로 시작하여 두 개의 3D 가우시안을 학습합니다.
그림 7에서 저희는 distillation 결과를 동일한 프롬프트로 비교하지만 서로 다릅니다.
매개 변수와 랜덤 시드가 일정하게 보장되면 포인트 초기화가 있는 3D 가우시안이 지오메트리에서 더 나은 결과를 가져옵니다.

5. Applications
이 섹션에서는 LucidDreamer의 응용 프로그램에 대해 자세히 살펴봅니다.
특히, 우리는 프레임워크를 고급 조건화 기술과 결합하고 몇 가지 실제 응용 프로그램을 달성합니다.
Zero-shot Avatar Generation.
저희는 3D 가우시안 포인트 클라우드를 초기화하기 위한 지오메트리 prior로 Skinned Multi-Person Linear Model (SMPL) [25]을 사용하여 포즈별 아바타를 생성하기 위해 프레임워크를 확장합니다.
그런 다음 DensePose [10] 신호를 조건으로 하는 ControlNet [51]에 의존하여 보다 강력한 supervision을 제공합니다.
구체적으로, 저희는 샘플링된 카메라 파라미터를 기반으로 pytorch3d를 사용하여 3D 인간 메쉬를 2D 이미지로 렌더링한 다음 사전 학습된 DensePose 모델에 입력하여 DensePose 조건으로 인체 부위 분할 맵을 얻습니다.
더 자세한 프레임워크는 부록에 나와 있습니다.
이러한 고급 제어 신호에 따라 그림 8과 같이 높은 충실도의 아바타를 달성할 수 있습니다.

Personalized Text-to-3D.
우리는 또한 프레임워크를 개인화된 기술인 LoRA [15]와 결합합니다.
이러한 기술을 사용하여 모델은 피사체 또는 스타일을 식별자 문자열에 묶고 피사체 또는 스타일의 이미지를 생성하는 방법을 배울 수 있습니다.
text-to-3D 생성을 위해 식별자 문자열을 사용하여 특정 피사체 및 스타일을 3D로 생성할 수 있습니다.
그림 8과 같이, 우리의 방법은 세분화된 세부 정보를 가진 개인화된 인간 또는 사물을 생성할 수 있습니다.
이것은 또한 고급 개인화된 기술과 결합하여 제어 가능한 text-to-3D 생성에서 우리 방법의 큰 잠재력을 보여줍니다.
Zero-shot 2D and 3D Editing.
우리의 프레임워크는 주로 text-to-3D 생성 작업을 위해 설계되었지만, 두 작업의 유사성으로 인해 ISM을 편집으로 확장하는 것이 가능합니다.
ISM은 그림 8과 같이 입력 이미지를 기반으로 일관된 업데이트 방향을 제공하여 목표 조건으로 가이딩하기 때문에 조건부 distillation 방식으로 쉽게 2D 이미지 또는 3D 표현을 편집할 수 있습니다.
공간 제한으로 인해 향후 탐색을 위해 2D/3D 편집 작업을 위한 ISM의 추가 사용자 지정을 예약합니다.
6. Conclusions
이 논문에서는 Score Distillation Sampling (SDS)에 내재된 오버 스무딩 효과에 대한 포괄적인 분석을 제시하여 pseudo ground truth의 불일치와 낮은 품질에 대한 근본적인 원인을 파악했습니다.
이 문제를 해결하기 위해 일관되고 신뢰할 수 있는 가이던스를 제공하는 새로운 접근 방식인 Interval Score Matching (ISM)을 도입했습니다.
저희의 연구 결과는 ISM이 오버 스무딩 문제를 효과적으로 극복하여 추가 계산 비용 없이 매우 상세한 결과를 산출한다는 것을 보여줍니다.
특히 ISM의 호환성은 3D 생성 및 편집을 위한 NeRF 및 3D Gaussian Splatting뿐만 아니라 2D 편집 작업을 포함한 다양한 응용 분야로 확장되어 탁월한 다용도성을 보여줍니다.
이를 기반으로 저희는 ISM과 3D Gaussian Splatting을 결합한 프레임워크인 LucidDreamer를 개발했습니다.
광범위한 실험을 통해 LucidDreamer가 현재의 SOTA 방법론을 훨씬 능가한다는 것을 확인했습니다.
그 우수한 성능은 text-to-3D 생성 및 편집, 제로샷 아바타 생성 및 개인화된 text-to-3D 변환에 이르기까지 광범위한 실제 응용 분야의 길을 열어줍니다.