2024. 5. 7. 11:06ㆍtext-to-3D
LGM: Large Multi-View Gaussian Model for High-Resolution 3D Content Creation
Jiaxiang Tang, Zhaoxi Chen, Xiaokang Chen, Tengfei Wang, Gang Zeng, Ziwei Liu
Abstract
3D 콘텐츠 제작은 품질과 속도 모두에서 상당한 발전을 이루었습니다.
현재 피드포워드 모델은 몇 초 만에 3D 객체를 생성할 수 있지만, 해상도는 학습 중에 필요한 집중적인 계산으로 인해 제한됩니다.
이 논문에서는 텍스트 프롬프트 또는 단일 뷰 이미지에서 고해상도 3D 모델을 생성하도록 설계된 새로운 프레임워크인 Large Multi-View Gaussian Model (LGM)을 소개합니다.
저희의 주요 통찰력은 두 가지입니다:
1) 3D 표현: 멀티뷰 가우시안 피쳐를 효율적이면서도 강력한 표현으로 제안하며, 이를 융합하여 미분가능한 렌더링을 구현할 수 있습니다.
2) 3D 백본: 저희는 멀티뷰 디퓨전 모델을 활용하여 텍스트 또는 단일 뷰 이미지 입력에서 생성할 수 있는 멀티뷰 이미지에서 작동하는 고처리량 백본으로 비대칭 U-Net을 제시합니다.
광범위한 실험을 통해 저희 접근 방식의 높은 충실도와 효율성을 입증했습니다.
특히 저희는 빠른 속도를 유지하여 5초 이내에 3D 객체를 생성하는 동시에 학습 해상도를 512로 높임으로써 고해상도 3D 콘텐츠 생성을 달성했습니다.
1 Introduction
자동 3D 콘텐츠 제작은 디지털 게임, 가상 현실 및 영화와 같은 다양한 분야에서 큰 잠재력을 가지고 있습니다.
image-to-3D 및 text-to-3D와 같은 기본 기술은 전문 3D 아티스트의 육체 노동 요구 사항을 현저하게 줄여 전문 지식이 없는 사람들이 3D 자산 제작에 참여할 수 있도록 함으로써 상당한 이점을 제공합니다.
3D 생성에 대한 이전 연구는 주로 2D 디퓨전 priors를 3D로 리프팅하기 위해 score distillation sampling (SDS) [22,24,36,47] 에 중점을 두었습니다.
이러한 최적화 기반 방법은 텍스트 또는 단일 뷰 이미지 입력에서 매우 상세한 3D 객체를 생성할 수 있지만, 종종 느린 생성 속도 및 제한된 다양성과 같은 문제에 직면합니다.
최근의 발전으로 인해 단일 뷰 또는 퓨샷 이미지에서 대규모 재구성 모델을 사용하여 3D 객체를 생성하는 데 필요한 시간이 크게 단축되었습니다[15,19,52,55,57].
이러한 방법은 트랜스포머를 사용하여 triplane-기반 [2] nerual radiance fields (NeRF) [32]를 직접 회귀합니다.
그러나 이러한 방법은 저해상도 학습으로 인해 세부적인 텍스처와 복잡한 지오메트리를 생성할 수 없습니다.
저희는 병목 현상이 1) 비효율적인 3D 표현과 2) 심하게 매개변수화된 3D 백본이라고 주장합니다.
예를 들어, 고정된 계산 예산이 주어지면 LRM [15]의 triplane 표현은 해상도 32로 제한되는 반면, 렌더링된 이미지의 해상도는 온라인 볼륨 렌더링으로 인해 128로 제한됩니다.
그럼에도 불구하고 이러한 방법은 계산 집약적인 트랜스포머 기반 백본으로 인해 학습 해상도가 제한됩니다.
이러한 문제를 해결하기 위해 저희는 triplane-기반 볼륨 렌더링 또는 트랜스포머에 의존하지 않고 퓨 샷 3D 재구성 모델을 학습하는 새로운 방법을 제시합니다 [15].
대신 저희의 접근 방식은 3D Gaussian Splatting [17]을 사용하며, 이 중 비대칭 U-Net에 의해 예측되는 피쳐는 고처리량 백본 [40,46]입니다.
이 설계의 동기는 고해상도 3D 생성을 달성하기 위한 것이며, 이를 위해서는 표현력 있는 3D 표현과 고해상도로 학습할 수 있는 능력이 필요합니다.
Gaussian splatting은 1) 단일 triplane에 비해 장면을 압축적으로 표현하는 표현력과 2) 무거운 볼륨 렌더링에 비해 렌더링 효율성이 뛰어나 고해상도 학습이 용이합니다.
그러나 자세한 3D 정보를 정확하게 표현하려면 충분한 수의 3D Gaussians이 필요합니다.
splatter 이미지 [46]에서 영감을 받아 U-Net이 멀티뷰 픽셀에서 충분한 수의 Gaussians을 생성하는 데 효과적이며, 이는 고해상도 학습을 위한 용량을 동시에 유지합니다.
주목할 점은 이전 방법 [15,62]과 비교할 때 저희의 기본 모델은 최대 65,536개의 Gaussians로 3D 모델을 생성할 수 있으며 512의 해상도로 학습할 수 있는 동시에 피드 포워드 회귀 모델의 빠른 생성 속도를 유지합니다.
그림 1에서 볼 수 있듯이 저희 모델은 image-to-3D 작업과 text-to-3D 작업을 모두 지원하여 약 5초 만에 고해상도의 풍부한 세부 3D Gaussians를 생성할 수 있습니다.

저희의 방법은 Instant3D [19]와 유사한 멀티뷰 재구성 설정을 채택합니다.
이 과정에서 각 입력 뷰의 이미지와 카메라 임베딩은 피쳐 맵으로 변환되며, 이는 Gaussians 집합으로 디코딩되고 융합될 수 있습니다.
융합된 3D Gaussians에서 새로운 뷰를 렌더링하기 위해 미분가능한 렌더링이 적용되어 고해상도로 종단간 이미지 레벨 supervision이 가능합니다.
모든 입력 뷰에서 정보 공유를 향상시키기 위해 어텐션 블록이 U-Net의 더 깊은 레이어에 통합됩니다.
이를 통해 회귀 objective만 사용하여 멀티뷰 이미지 데이터 세트에 대한 네트워크를 학습할 수 있습니다[12].
추론하는 동안 저희의 방법은 기존 이미지 또는 텍스트를 멀티뷰 디퓨전 모델에 활용하여 Gaussian 융합 네트워크의 입력으로 멀티뷰 이미지를 생성합니다[27, 43, 44, 51].
실제 3D 개체에서 렌더링되고 디퓨전 모델을 사용하여 합성된 멀티뷰 이미지 간의 도메인 격차를 극복하기 위해 강력한 학습을 위한 두 가지 적절한 데이터 증강을 추가로 제안합니다.
마지막으로 다운스트림 작업에서 다각형 메시를 선호하는 점을 고려하여 생성된 3D Gaussians을 부드럽고 텍스처가 있는 메시로 변환하는 일반 알고리즘을 설계합니다.
요약하면, 우리의 기여는 다음과 같습니다:
1. 텍스트 프롬프트 또는 단일 뷰 이미지에서 생성할 수 있는 멀티 뷰 이미지의 정보를 융합하여 고해상도 3D Gaussians을 생성하는 새로운 프레임워크를 제안합니다.
2. 훨씬 더 높은 해상도로 효율적인 종단 간 학습을 위한 비대칭 U-Net 기반 아키텍처를 설계하고, 강력한 학습을 위한 데이터 증강 기술을 조사하며, 3D Gaussians에서 일반적인 메시 추출 접근 방식을 제안합니다.
3. 광범위한 실험을 통해 text-to-3D 및 image-to-3D 작업 모두에서 우리 방법의 우수한 품질, 해상도 및 효율성을 입증했습니다.
2 Related Work
High-Resolution 3D Generation.
고충실도 3D 모델을 생성하기 위한 현재 접근 방식은 대부분 SDS 기반 최적화 기술에 의존합니다.
2D 디퓨전 모델에서 세부 정보를 3D로 효과적으로 distill하려면 표현형 3D 표현과 고해상도 supervision이 모두 필요합니다.
NeRF의 고해상도 렌더링과 관련된 상당한 메모리 소비로 인해 Magic3D [22]는 먼저 NeRF를 DMTet [42]으로 변환한 다음 더 fine한 해상도 개선을 위해 두 번째 단계를 학습합니다.
DMTet 지오메트리 및 해시 그리드 [34] 텍스처의 하이브리드 표현을 통해 고품질 3D 정보를 캡처할 수 있으며, 이는 미분 가능한 래스터화 [18]를 사용하여 효율적으로 렌더링할 수 있습니다.
Fantasia3D [6]는 분리된 지오메트리 및 외관 생성으로 DMTet을 직접 학습하는 방법을 살펴봅니다.
후속 연구 [8,20,21,47,49,54]에서도 유사한 메쉬 기반 단계를 사용하여 디테일을 향상시키는 고해상도 supervision이 가능합니다.
또 다른 유망한 3D 표현은 표현력과 효율적인 렌더링 기능을 위해 Gaussian splatting [17]입니다.
그럼에도 불구하고 이 방법으로 풍부한 디테일을 달성하려면 최적화 중에 적절한 초기화와 신중한 밀도화가 필요합니다[10,59].
이와는 대조적으로, 우리의 작업은 충분한 수의 3D Gaussians을 직접 생성하기 위한 피드포워드 접근 방식을 조사합니다.
Efficient 3D Generation.
SDS 기반 최적화 방법과 달리 피드포워드 3D 기본 방법은 대규모 3D 데이터 세트에 대한 학습 후 몇 초 안에 3D 자산을 생성할 수 있습니다 [11, 12].
일부 작업은 포인트 클라우드 및 볼륨 [1, 5, 9, 16, 26, 33, 35, 53, 58, 61]과 같은 3D 표현에 대해 텍스트 조건 디퓨전 모델을 학습하려고 시도합니다.
그러나 이러한 방법은 대규모 데이터 세트로 잘 일반화할 수 없거나 간단한 텍스처의 저품질 3D 자산만 생성합니다.
최근 LRM [15]은 먼저 회귀 모델이 단 5초 만에 단일 뷰 이미지에서 NeRF를 강력하게 예측하도록 학습할 수 있으며, 이는 메시로 추가로 내보낼 수 있음을 보여줍니다.
Instant3D [19]는 텍스트를 멀티뷰 이미지 디퓨전 모델과 다시점 LRM으로 학습하여 빠르고 다양한 text-to-3D 생성을 수행합니다.
다음 작업은 LRM을 확장하여 멀티뷰 이미지 [52]가 주어진 포즈를 예측하고, 디퓨전 [57]과 결합하고, 인간 데이터를 전문화합니다 [55].
이러한 피드포워드 모델은 간단한 회귀 objective로 학습할 수 있으며, 3D 객체 생성 속도를 크게 가속화합니다.
그러나 triplane NeRF 기반 표현은 상대적으로 낮은 해상도로 제한되며 최종 생성 충실도를 제한합니다.
대신 저희 모델은 Gaussian splatting 및 U-Net을 사용하여 고충실도 피드포워드 모델을 학습하려고 합니다.
Gaussian Splatting for Generation.
저희는 특히 Gaussian splatting [4,7,23,38,56]을 사용하는 생성 작업의 최근 방법에 대해 논의합니다.
DreamGaussian [47]은 먼저 3D Gaussians을 SDS 기반 최적화 접근 방식과 결합하여 생성 시간을 줄입니다.
GSGen [10]과 Gaussian Dreamer [59]는 텍스트에서 3D Gaussians를 생성을 위한 다양한 densification 및 initialization 전략을 살펴봅니다.
가속화가 달성되었음에도 불구하고, 이러한 최적화 기반 방법을 사용하여 고충실도 3D Gaussians을 생성하는 데는 여전히 몇 분이 걸립니다.
TriplaneGaussians [62]은 LRM의 프레임워크에 Gaussian splatting을 도입합니다.
이 방법은 Gaussians 중심을 포인트 클라우드로 예측한 다음 다른 피쳐를 위해 triplane에 투영하는 것으로 시작합니다.
그럼에도 불구하고 Gaussians의 수와 triplane의 해상도는 여전히 제한되어 생성된 Gaussians의 품질에 영향을 미칩니다.
Splatter image [46]는 단일 뷰 이미지의 U-Net을 사용하여 출력 피처 맵의 픽셀로 3D Gaussians을 예측할 것을 제안합니다.
이 접근 방식은 주로 단일 뷰 또는 2-뷰 시나리오에 초점을 맞추어 일반화를 대규모 데이터 세트로 제한합니다.
유사하게 PixelSplat [3]은 장면 데이터 세트에서 두 개의 포즈 이미지의 각 픽셀에 대한 Gaussians 매개 변수를 예측합니다.
저희는 일반 텍스트 또는 이미지에서 고충실도 3D 객체 생성을 위해 기존의 멀티 뷰 디퓨전 모델과 결합된 4-뷰 재구성 모델을 설계합니다.
3 Large Multi-View Gaussian Model
먼저 Gaussian splatting 및 멀티뷰 디퓨전 모델에 대한 배경 정보를 제공합니다 (섹션 3.1).
그런 다음 고해상도 3D 콘텐츠 생성 프레임워크를 소개합니다 (섹션 3.2), 여기서 핵심 부분은 비대칭 U-Net 백본으로 멀티뷰 이미지에서 3D Gaussians을 예측하고 융합합니다 (섹션 3.3).
저희는 견고성과 안정성을 향상시키기 위해 신중한 데이터 증강 및 학습 파이프라인을 설계합니다 (섹션 3.4).
마지막으로 생성된 3D Gaussians에서 원활한 텍스처 메시 추출을 위한 효과적인 방법을 설명합니다 (섹션 3.5).
3.1 Preliminaries
Gaussian Splatting.
[17]에 소개된 바와 같이, Gaussian splatting은 3D 데이터를 표현하기 위해 3D Gaussians 컬렉션을 사용합니다.
구체적으로, 각 Gaussian은 중심 x ∈ R^3, 스케일링 인자 ∈ R^3 및 회전 쿼터니언 q ∈ R^4로 정의됩니다.
또한 렌더링을 위해 불투명도 α ∈ R과 컬러 피쳐 c ∈ R^C가 유지되며, 여기서 구형 고조파를 사용하여 뷰 종속 효과를 모델링할 수 있습니다.
이러한 매개변수는 i번째 Gaussian에 대한 매개변수를 나타내는 θ_i = {x_i, s_i, q_i, α_i, c_i}를 사용하여 θ로 집합적으로 표시할 수 있습니다.
3D Gaussians의 렌더링은 2D Gaussians으로 이미지 평면에 투영하고 각 픽셀에 대해 전후 depth 순서로 알파 구성을 수행하여 최종 색상과 알파를 결정하는 것을 포함합니다.
Multi-View Diffusion Models.
원래의 2D 디퓨전 모델 [39,41]은 주로 단일 뷰 이미지를 생성하는 데 중점을 두며 3D 시점 조작을 지원하지 않습니다.
최근 몇 가지 방법 [20, 27, 43, 44, 51]은 카메라 포즈를 추가 입력으로 통합하기 위해 3D 데이터 세트에서 멀티뷰 디퓨전 모델을 파인튜닝할 것을 제안합니다.
이러한 접근 방식을 통해 텍스트 프롬프트 또는 단일 뷰 이미지에서 동일한 객체의 멅키뷰 이미지를 생성할 수 있습니다.
그러나 실제 3D 모델이 없기 때문에 생성된 뷰에서 여전히 불일치가 발생할 수 있습니다.
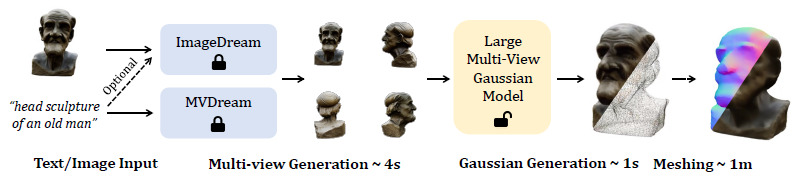
3.2 Overall Framework
그림 2에 도시된 바와 같이, 저희는 추론 시 2단계 3D 생성 파이프라인을 채택합니다.
먼저, 저희는 멀티뷰 이미지를 생성하기 위해 기성 텍스트 또는 이미지를 멀티뷰 디퓨전 모델에 활용합니다.
구체적으로, 저희는 텍스트 입력에 MVDream [44]을 채택하고 이미지(및 선택적으로 텍스트) 입력에 ImageDream [51]을 채택합니다.
두 모델 모두 4개의 직교 azimuth 각과 고정된 elevation 각에서 멀티뷰 이미지를 생성하도록 설계되었습니다.
두 번째 단계에서는 U-Net 기반 모델을 사용하여 이러한 희소 뷰 이미지에서 3D Gaussians을 예측합니다.
구체적으로, 저희 모델은 카메라 포즈 임베딩을 입력으로 하는 4개의 이미지를 촬영하고 이를 융합하여 최종 3D Gaussians을 형성하는 4개 세트를 예측하도록 학습되었습니다.
생성된 Gaussians은 추가 변환 단계를 사용하여 선택적으로 다각형 메시로 변환할 수 있으며, 이는 다운스트림 작업에 더 적합합니다.
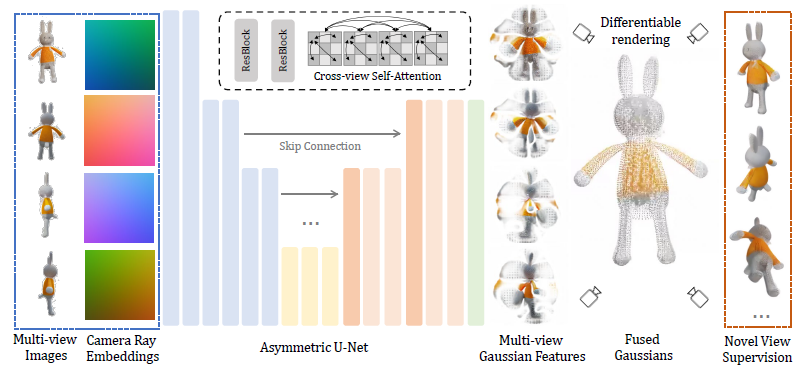
3.3 Asymmetric U-Net for 3D Gaussians
프레임워크의 핵심에는 멀티뷰 이미지에서 Gaussians을 예측하고 융합하는 비대칭 U-Net이 있습니다.
네트워크 아키텍처는 그림 3에 나와 있습니다.
저희는 4개의 이미지와 해당 카메라 포즈를 입력으로 사용합니다.
이전 작업 [57]에 이어 Plücker ray 임베딩을 사용하여 카메라 포즈를 조밀하게 인코딩합니다.
RGB 값과 ray 임베딩은 첫 번째 레이어에 대한 입력으로 9채널 피처 맵으로 연결됩니다: (1), 여기서 f_i는 픽셀 i의 입력 피쳐, c_i는 RGB 값, d_i는 ray 방향, o_i는 ray 원점입니다.
U-Net은 이전 작업 [14, 31, 46]과 유사한 잔차 레이어 [13]와 셀프 어텐션 레이어 [50]로 구축되었습니다.
저희는 메모리를 절약하기 위해 피쳐 맵 해상도가 다운 샘플링되는 더 깊은 레이어에서만 셀프 어텐션을 추가합니다.
여러 뷰에 걸쳐 정보를 전파하기 위해 이전의 멀티뷰 디퓨전 모델과 유사하게 셀프 어텐션을 적용하기 전에 4개의 이미지 피쳐를 평평하게 하고 연결합니다 [44, 51].
출력 피쳐 맵의 각 픽셀은 splatter image [46]에서 영감을 받은 3D Gaussians로 처리됩니다.
다르게, 저희의 U-Net은 입력에 비해 더 작은 출력 해상도로 비대칭적으로 설계되어 더 높은 해상도의 입력 이미지를 사용하고 출력 Gaussians의 수를 제한할 수 있습니다.
저희는 [46]에서 명시적인 ray별 카메라 투영에 필요한 depth 예측을 폐기합니다.
출력 피쳐 맵에는 각 Gaussians θ_i의 원래 속성에 해당하는 14개의 채널이 포함되어 있습니다.
학습을 안정화하기 위해 저희는 원래 Gaussian Splatting [17]과 비교하여 몇 가지 다른 활성화 함수를 선택합니다.
저희는 예측된 위치 x_i를 [-1, 1]^3으로 클램핑하고 softplus-활성화 척도 s_i에 0.1을 곱하여 학습 초기에 생성된 Gaussians이 장면 중심에 가깝습니다.
각 입력 뷰에 대해 출력 피쳐 맵은 Gaussians 집합으로 변환됩니다.
저희는 단순히 네 개의 뷰 모두에서 이러한 Gaussians을 최종 3D Gaussians로 연결하여 supervision을 위해 새로운 뷰에서 이미지를 렌더링하는 데 사용합니다.
3.4 Robust Training
Data Augmentation.
저희는 Objaverse [12] 데이터 세트에서 렌더링한 멀티뷰 이미지를 학습에 사용합니다.
그러나 추론 시에는 디퓨전 모델에 의해 합성된 멀티뷰 이미지를 사용합니다 [44, 51].
이러한 서로 다른 멀티뷰 이미지 간의 도메인 격차를 완화하기 위해 보다 강력한 학습을 위해 두 가지 유형의 데이터 증강을 설계합니다.
Grid Distortion.
2D 디퓨전 모델을 사용하여 3D 일관된 멀티뷰 이미지를 합성하는 것은 많은 연구에서 탐구되어 왔습니다 [25,43,44,51].
그러나 기본 3D 표현이 없기 때문에 생성된 멀티뷰 이미지는 종종 서로 다른 뷰에 걸쳐 미묘한 불일치로 인해 어려움을 겪습니다.
저희는 그리드 왜곡을 사용하여 이러한 불일치를 시뮬레이션하려고 합니다.
일반적으로 전면 참조 뷰인 첫 번째 입력 뷰를 제외한 나머지 세 개의 입력 뷰는 학습 중에 랜덤 그리드로 랜덤으로 왜곡됩니다.
이를 통해 일관되지 않은 멀티뷰 입력 이미지에 대해 모델이 더 견고해집니다.
Orbital Camera Jitter.
또 다른 문제는 합성된 멀티뷰 이미지가 주어진 카메라 포즈를 정확하게 따르지 않을 수 있다는 것입니다.
[15]에 이어 항상 각 학습 단계에서 카메라 포즈를 정규화하여 첫 번째 뷰의 카메라 포즈가 고정되도록 했습니다.
따라서 학습 중에 마지막 세 개의 입력 뷰에 카메라 지터를 적용합니다.
특히 모델이 부정확한 카메라 포즈와 ray 임베딩에 더 관대하도록 장면 중심을 돌며 카메라 포즈를 랜덤으로 회전시킵니다.
Loss Function.
concat된 가우시안을 supervise하기 위해 [17]의 미분 가능한 렌더러 구현을 사용하여 렌더링합니다.
각 학습 단계에서 4개의 입력 뷰와 4개의 새로운 뷰를 포함하여 8개의 뷰의 RGB 이미지와 알파 이미지를 렌더링합니다.
[15]에 이어 평균 제곱 오차 loss와 VGG 기반 LPIPS loss [60]를 RGB 이미지에 적용합니다:
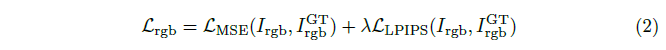
형상의 더 빠른 수렴을 위해 알파 이미지에 평균 제곱 오차 loss를 추가로 적용합니다:
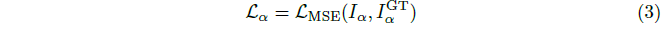
3.5 Mesh Extraction
다각형 메쉬는 여전히 다운스트림 작업에서 가장 널리 사용되는 3D 표현이기 때문에 생성된 Gaussians에서 메쉬를 추가로 추출하기를 희망합니다.
이전 연구 [47]에서는 메쉬 추출을 위해 3D Gaussians의 불투명도 값을 점유 필드로 직접 변환하려고 시도했습니다.
그러나 이 방법은 원활한 점유 필드를 생성하기 위해 3D Gaussians을 최적화하는 동안 공격적인 densification에 의존한다는 것을 발견했습니다.
반대로, 이 방법에서 생성된 Gaussians은 일반적으로 희소하고 적절한 점유 필드를 생성할 수 없어 눈에 보이는 구멍이 있는 불만족스러운 표면으로 이어집니다.
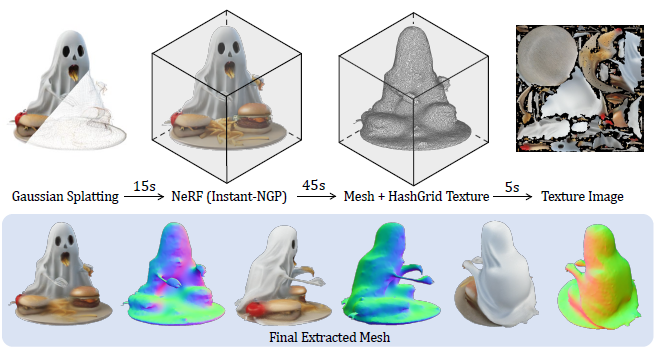
대신, 저희는 그림 4와 같이 3D Gaussians에서 보다 일반적인 메쉬 추출 파이프라인을 제안합니다.
저희는 먼저 3D Gaussians에서 즉석으로 렌더링된 이미지를 사용하여 효율적인 NeRF [34]를 학습한 다음 NeRF를 다각형 메쉬로 변환합니다 [48].
특히, Gaussian 렌더링에서 지오메트리와 외관을 재구성하기 위해 두 개의 해시 그리드를 학습합니다.
Marching Cubes [28]를 적용하여 coarse 메쉬를 추출한 다음, 미분 가능한 렌더링을 사용하여 모양 해시 그리드와 함께 반복적으로 정제합니다.
마지막으로, 텍스처 이미지를 추출하기 위해 외관 필드를 정제된 메쉬에 굽습니다.
자세한 내용은 보충 자료 및 NeRF2Mesh [48]을 참조하십시오.
적절하게 최적화된 구현을 사용하면 이 Gaussian에서 NeRF로 메쉬 변환을 수행하는 데 약 1분밖에 걸리지 않습니다.
4 Experiments
4.1 Implementation Details
Datasets.
저희는 모델을 학습하기 위해 Objaverse [12] 데이터 세트의 필터링된 하위 집합을 사용합니다.
원래 Objaverse 데이터 세트에는 저품질 3D 모델(예: 부분 스캔, 텍스처 누락)이 많기 때문에 데이터 세트를 두 가지 경험적 규칙으로 필터링합니다:
(1) 저희는 Cap3D [30]의 캡션과 렌더링된 이미지를 수동으로 검사하고, 일반적으로 나쁜 모델(예: 'resembling’,‘debris’, ‘frame’)에 나타나는 단어 목록을 큐레이팅한 다음 캡션에 이러한 단어가 포함된 모든 모델을 필터링하는 데 사용합니다.
(2) 저희는 일반적으로 텍스처가 누락된 것을 나타내는 렌더링 후에 대부분 흰색인 모델을 폐기합니다.
이렇게 하면 최종 약 80K 개의 3D 개체 세트가 생성됩니다.
저희는 학습 및 검증을 위해 512 × 512 해상도로 100개의 카메라 뷰에서 RGBA 이미지를 렌더링합니다.
Network Architecture.
저희의 비대칭 U-Net 모델은 6개의 다운 블록, 1개의 미들 블록 및 5개의 업 블록으로 구성되며, 입력 이미지는 256 × 256, 출력 Gaussian 피쳐 맵은 128 × 128입니다.
저희는 4개의 입력 뷰를 사용하므로 출력 Gaussians의 수는 128 × 128 × 4 = 65,536입니다.
모든 블록의 피쳐 채널은 각각 [64, 128, 256, 512, 1024, 1024], [1024, 1024, 512, 256, 128]입니다.
각 블록에는 일련의 잔차 레이어와 선택적인 다운샘플 또는 업샘플 레이어가 포함됩니다.
마지막 3개의 다운 블록, 미들 블록 및 처음 3개의 업 블록에 대해서도 잔차 레이어 다음에 크로스뷰 셀프 어텐션 레이어를 삽입합니다.
최종 피쳐 맵은 1x1 컨볼루션 레이어에서 14채널 픽셀 단위의 Gaussian 피쳐로 처리됩니다.
이전 작업 [39,46]에 이어 U-Net에 대해 Silu 활성화 함수 및 그룹 정규화를 채택합니다.
Training.
저희는 약 4일 동안 32개의 NVIDIA A100 (80G) GPU에서 모델을 학습합니다.
각 GPU에 대해 8개의 배치 크기가 bfloat16 정밀도 하에서 사용되어 256개의 효과적인 배치 크기로 이어집니다.
각 배치에 대해 8개의 카메라 뷰를 랜덤으로 샘플링하고 처음 4개의 뷰를 입력으로, 8개의 뷰를 모두 supervision을 위한 출력으로 사용합니다.
LRM [15]와 유사하게, 저희는 각 배치의 카메라를 변환하여 첫 번째 입력 뷰가 항상 아이덴티티 회전 행렬 및 고정 변환을 통해 앞 뷰가 되도록 합니다.
입력 이미지는 흰색 배경을 가진 것으로 가정됩니다.
출력 3D Gaussians은 평균 제곱 오차 loss를 위해 512 × 512 해상도로 렌더링됩니다.
메모리를 절약하기 위해 LPIPS loss를 위해 이미지의 크기를 256 × 256으로 조정합니다.
AdamW [29] 최적화기는 학습률 4x10-4, 가중치 감쇠 0.05, 베타는 (0.9, 0.95)로 채택됩니다.
학습률은 학습 중에 0으로 코사인 어닐링됩니다.
저희는 최대 norm 1.0으로 그래디언트를 잘라냅니다.
그리드 왜곡과 카메라 jitter에 대한 확률은 50%로 설정됩니다.
Inference.
두 개의 멀티뷰 디퓨전 모델을 포함한 우리의 전체 파이프라인은 추론을 위해 약 10GB의 GPU 메모리만 필요로 하므로 배포에 적합합니다.
멀티뷰 디퓨전 모델의 경우 원본 논문을 따라 ImageDream [51]의 경우 5, MVDream [44]의 경우 7.5의 가이던스 척도를 사용합니다.
DDIM [45] 스케줄러를 사용하여 디퓨전 단계의 수는 30으로 설정됩니다.
생성된 4개의 뷰에 대해 카메라 elevation은 0으로 고정되고 azimuth 각은 [0, 90, 180, 270]도로 고정됩니다.
ImageDream [51]의 경우 텍스트 프롬프트가 항상 비어 있으므로 단일 뷰 이미지만 입력됩니다.
MVDream에서 생성된 이미지에는 다양한 배경이 포함될 수 있으므로 배경 제거[ 37]를 적용하고 흰색 배경을 사용합니다.

4.2 Qualitative Comparisons
Image-to-3D.
저희는 먼저 3D Gaussians을 생성할 수 있는 최근 방법 [47,62]과 비교합니다.
그림 5는 비교를 위해 생성된 3D Gaussians을 렌더링한 이미지를 보여줍니다.
저희 방법으로 생성된 3D Gaussians은 시각적 품질이 더 좋고 입력 뷰에서 콘텐츠를 효과적으로 보존합니다.
저희의 고해상도 3D Gaussians은 대부분의 경우 품질 loss를 최소화하면서 부드러운 질감의 메시로 변환할 수 있습니다.
또한 그림 6의 웹사이트에서 사용할 수 있는 비디오를 사용하여 결과를 LRM [15]와 비교합니다.
특히, 멀티뷰 설정은 블러한 백 뷰와 평평한 지오메트리의 문제를 성공적으로 완화하여 보이지 않는 뷰에서도 세부 정보를 향상시킵니다.

Text-to-3D.
그런 다음 text-to-3D 작업에 대한 최근 방법 [16,47]과 비교합니다.
저희는 이 방법에서 향상된 품질과 효율성을 관찰하여 그림 7과 같이 보다 현실적인 3D 객체를 생성합니다.
멀티뷰 디퓨전 모델로 인해 저희 모델은 멀티페이스 문제에서도 자유롭습니다.

Diversity.
특히 저희 파이프라인은 멀티뷰 디퓨전 모델의 기능으로 인해 3D 생성에서 높은 다양성을 나타냅니다 [44, 51].
그림 8과 같이 다양한 랜덤 시드를 사용하면 동일한 모호한 텍스트 프롬프트 또는 단일 뷰 이미지에서 다양한 실현 가능한 객체를 생성할 수 있습니다.

4.3 Quantitative Comparisons
저희는 주로 image-to-3D Gaussians 생성 성능을 정량적으로 평가하기 위해 사용자 연구를 수행합니다.
30개의 이미지 모음에 대해 DreamGaussian [47](첫 번째 단계만 해당), TriplaneGaussian [62] 및 저희의 3D Gaussians을 360도 회전하는 비디오를 렌더링합니다.
사용자 연구에는 평가를 위한 총 90개의 비디오가 있습니다.
각 지원자는 혼합 랜덤 방법에서 30개의 샘플을 보여주고 이미지 일관성과 전체 모델 품질의 두 가지 측면에서 평가하도록 요청합니다.
저희는 20명의 지원자로부터 결과를 수집하고 총 600개의 유효한 점수를 받습니다.
표 1에서 볼 수 있듯이 저희의 방법은 원래 이미지 콘텐츠와 일치하고 전반적으로 더 나은 품질을 보여주기 때문에 선호됩니다.

4.4 Ablation Study
Number of Views.
저희는 멀티뷰 생성 단계 없이 splatter image [46]와 유사한 입력 뷰를 하나만 사용하여 image-to-3D 모델을 학습합니다.
UNet은 단일 입력 뷰를 셀프 어텐션으로 입력으로 받아 멀티뷰 모델에서와 같이 Gaussian 피쳐를 출력합니다.
Gaussians 수를 보상하기 위해 출력 피쳐 맵의 각 픽셀에 대해 2개의 Gaussians을 예측하여 128x128x2 = 32,768개의 Gaussians을 생성합니다.
그림 9의 왼쪽 상단에 표시된 것처럼 단일 뷰 모델은 충실한 전면 뷰를 재구성할 수 있지만 후면 뷰를 구별하지 못하고 블러함을 초래합니다.
이는 회귀형 U-Net이 재구성 작업에 더 적합하고 실험에서 대규모 데이터 세트로 일반화하기 어렵기 때문에 예상대로입니다.

Data Augmentation.
우리는 효과를 검증하기 위해 데이터 증강을 적용하거나 적용하지 않는 더 작은 모델을 학습합니다.
데이터 증강이 없는 모델의 학습 loss가 더 적지만, 추론 중 도메인 격차로 인해 그림 9의 왼쪽 하단 부분과 같이 더 많은 아티팩트와 더 나쁜 지오메트리가 발생합니다.
데이터 증강 전략을 사용하는 모델은 생성된 멀티뷰 이미지에서 3D 불일치와 부정확한 카메라 포즈를 더 잘 수정할 수 있습니다.
Training Resolution.
마지막으로, 저희는 그림 9의 오른쪽에서와 같이 더 적은 수의 Gaussians과 더 작은 렌더링 해상도를 가진 모델을 학습합니다.
저희는 출력 Gaussians의 수가 64×64×4=16,384가 되도록 U-Net의 마지막 업 블록을 제거하고 supervision을 위해 256×256으로 렌더링합니다.
이 모델은 여전히 수렴하여 성공적으로 3D Gaussians을 재구성할 수 있지만, 세부 사항은 256×256 입력 멀티뷰 이미지에 비해 열악합니다.
이와 대조적으로, 512×512의 큰 해상도 모델은 더 나은 세부 사항을 캡처하고 더 높은 해상도로 Gaussians을 생성할 수 있습니다.
4.5 Limitations
유망한 결과에도 불구하고, 우리의 방법은 여전히 몇 가지 한계가 있습니다.
우리의 모델은 본질적으로 멀티뷰 재구성 모델이기 때문에 3D 생성 품질은 4개의 입력 뷰의 품질에 크게 의존합니다.
그러나 현재의 멀티뷰 디퓨전 모델[44, 51]은 완벽하지 않습니다:
(1) 3D 불일치가 발생하여 재구성 모델이 3D Gaussians에서 floaters를 생성할 수 있습니다.
(2) 합성된 멀티뷰 이미지의 해상도는 256×256으로 제한되어 모델이 해상도를 더욱 향상시키도록 제한합니다.
(3) ImageDream [51] 또한 고도 각도가 큰 입력 이미지를 처리하지 못합니다.
향후 작업에서 더 나은 멀티뷰 디퓨전 모델을 통해 이러한 한계를 완화할 수 있을 것으로 기대합니다.
5 Conclusion
이 작업에서는 고해상도 3D 콘텐츠 생성을 위한 large multi-view Gaussian 모델을 제시합니다.
NeRF 및 트랜스포머에 의존하는 이전 방법과 달리 저희 모델은 고메모리 요구 사항과 저해상도 학습의 문제를 해결하기 위해 Gaussian splatting과 U-Net을 사용합니다.
또한 더 나은 견고성을 위해 데이터 증강을 살펴보고 생성된 3D 가우시안을 위한 메시 추출 알고리즘을 소개합니다.
저희의 접근 방식은 3D 객체 생성을 위한 고해상도와 고효율을 모두 달성하여 다양한 맥락에서 다재다능함과 적용 가능성을 입증했습니다.