2024. 1. 13. 16:41ㆍtext-to-3D
DreamCraft3D: Hierarchical 3D Generation with Bootstrapped Diffusion Prior
Jingxiang Sun, Bo Zhang, Ruizhi Shao, Lizhen Wang, Wen Liu, Zhenda Xie, Yebin Liu
Abstract
저희는 높은 충실도와 일관성 있는 3D 객체를 생성하는 계층적 3D 콘텐츠 생성 방법인 DreamCraft3D를 제시합니다.
저희는 2D 참조 이미지를 활용하여 지오메트리 조각 및 텍스처 부스팅 단계를 가이드함으로써 문제를 해결합니다.
이 작업의 핵심은 기존 작품이 직면하는 일관성 문제를 해결하는 것입니다.
일관성 있게 렌더링하는 지오메트리를 조각하기 위해 뷰 의존 디퓨전 모델을 통해 score distillation sampling을 수행합니다.
이 3D prior는 여러 학습 전략과 함께 지오메트리 일관성에 우선 순위를 두지만 텍스처 충실도를 손상시킵니다.
또한 텍스처를 구체적으로 향상시키기 위해 Bootstrapped Score Distillation을 제안합니다.
저희는 장면의 증강 렌더링에 개인화된 디퓨전 모델인 DreamBooth를 학습시켜 최적화되고 있는 장면에 대한 3D 지식을 제공합니다.
이 3D 인식 디퓨전 prior의 score distillation은 장면에 대한 일관된 가이던스를 제공합니다.
특히, 디퓨전 prior 및 3D 장면 표현의 교대 최적화를 통해 상호 강화된 개선을 달성합니다: 최적화된 3D 장면은 장면별 디퓨전 모델을 학습하는 데 도움이 되며, 이는 3D 최적화를 위한 뷰 일관성 있는 가이던스를 제공합니다.
따라서 최적화는 부트스트랩되어 실질적인 텍스처 부스팅으로 이어집니다.
DreamCraft3D는 계층적 생성 전반에 걸쳐 맞춤화된 3D priors를 통해 사진 현실적 렌더링으로 일관성 있는 3D 객체를 생성하여 3D 콘텐츠 생성에서 SOTA 기술을 발전시킵니다.
1 Introduction
2D 생성 모델링 (Saharia et al., 2022; Ramesh et al., 2022; Rombach et al., 2022; Gu et al., 2022)의 놀라운 성공은 시각적 콘텐츠를 만드는 방식을 크게 변화시켰습니다.
게임, 영화 및 가상 현실과 같은 애플리케이션에 중요한 3D 콘텐츠 제작은 여전히 심층 생성 네트워크에 중요한 과제입니다.
3D 생성 모델링은 특정 범주 (Wang et al., 2023a; Chan et al., 2022; Zhang et al., 2023b)에서 강력한 결과를 보여주었지만, 일반적인 3D 개체를 생성하는 것은 광범위한 3D 데이터 부족으로 인해 여전히 위협적입니다.
최근의 연구 노력은 사전 학습된 text-to-image 생성 모델 (Poole et al., 2022; Lin et al., 2023; Tang et al., 2023)의 가이던스를 활용하고 유망한 결과를 보여주기 위해 노력하고 있습니다.
DreamFusion (Poole et al., 2022)은 3D 생성을 위해 사전 학습된 text-to-image (T2I) 모델을 활용하는 아이디어를 처음 제안했습니다.
score distillation sampling (SDS) loss는 3D 모델을 최적화하기 위해 시행되며, 이는 랜덤 시점에서의 렌더링이 강력한 T2I 디퓨전 모델에 의해 해석되는 텍스트 조건 이미지 분포와 일치하도록 합니다.
DreamFusion은 2D 생성 모델의 상상력을 이어받아 매우 창의적인 3D 자산을 생성할 수 있습니다.
최근 연구는 과포화 및 블러함 문제를 해결하기 위해 단계적 최적화 전략 (Mildenhall et al., 2021)을 채택하거나 개선된 2D distillation loss(Wang et al., 2023b)를 제안하여 사진 현실성을 향상시킵니다.
그러나 현재 대부분의 연구는 2D 생성 모델이 달성한 것처럼 복잡한 콘텐츠를 합성하는 데 부족합니다.
또한 이러한 작업은 종종 "Janus issue"로 골치를 앓는데, 이 문제는 그럴듯하게 보이는 3D 렌더링이 전체론적으로 검토할 때 시맥틱 및 스타일적 불일치를 보여줍니다.
본 논문에서는 전체적인 3D 일관성을 유지하면서 복잡한 3D 자산을 생성하기 위한 접근 방식인 DreamCraft3D를 제안합니다.
저희의 접근 방식은 계층적 생성의 가능성을 탐구합니다.
저희는 수동 예술 프로세스에서 영감을 얻습니다: 먼저 추상적인 개념을 2D 초안으로 굳힌 다음 거친 지오메트리 구조를 조각하고 지오메트리 디테일을 정제하며 고품질 텍스처를 칠하는 작업이 뒤따릅니다.
저희는 어려운 3D 생성을 관리 가능한 단계로 분해하는 유사한 접근 방식을 채택합니다.
텍스트 프롬프트에서 생성된 고품질 2D 참조 이미지에서 시작하여 지오메트리 구조 조각 및 텍스처 부스팅 단계를 거쳐 3D로 리프트합니다.
이전의 접근 방식과 달리 저희의 작업은 각 단계를 신중하게 고려하면 계층적 생성의 잠재력을 최대한 발휘하여 우수한 품질의 3D 생성을 얻을 수 있는지 강조합니다.
지오메트리 조각 단계는 2D 참조 이미지에서 타당하고 일관된 3D 지오메트리를 생성하는 것을 목표로 합니다.
저희는 새로운 뷰와 참조 뷰에서의 photometric loss에 대한 SDS loss를 사용하는 것 외에도 지오메트릭 일관성을 높이기 위한 다양한 전략을 소개합니다.
먼저, 저희는 기존의 시점 조건 이미지 변환 모델인 Zero-1-to-3 (Liu et al., 2023b)을 활용하여 참조 이미지를 기반으로 새로운 뷰의 분포를 모델링합니다.
이 시점 조건 디퓨전 모델은 다양한 3D 데이터 (Deitke et al., 2023)를 기반으로 학습되기 때문에 2D 디퓨전 prior를 보완하는 풍부한 3D prior를 제공합니다.
또한 일관성을 더욱 향상시키기 위해서는 샘플링 시간 단계를 어닐링하고 학습 뷰를 점진적으로 확대하는 것이 중요하다는 것을 알게 되었습니다.
저희는 최적화 동안 coarse-to-fine 지오메트리 정제를 위해 암시적 표면 표현 (Wang et al., 2021)에서 메쉬 표현 (Shen et al., 2021)으로 전환합니다.
지오메트리 조각 단계는 이러한 기술을 통해 대부분의 지오메트릭 아티팩트를 효과적으로 억제하면서 샤프하고 디테일한 지오메트리를 생성합니다.
저희는 텍스처를 실질적으로 향상시키기 위해 bootstrapped score distillation을 제안합니다.
제한된 3D에서 학습된 기존 뷰 조건 디퓨전 모델은 종종 최신 2D 디퓨전 모델의 충실도와 일치하기 위해 애를 먹습니다.
대신, 최적화되는 3D 인스턴스의 멀티뷰 렌더링에 따라 디퓨전 모델을 파인튜닝합니다.
이 개인화된 3D 인식 생성 prior는 뷰 일관성을 보장하면서 3D 텍스처를 향상시키는 데 중요한 역할을 합니다.
중요한 것은, 생성 prior 및 3D 표현을 대안적으로 최적화하면 상호 개선이 가능하다는 것입니다.
디퓨전 모델은 개선된 멀티뷰 렌더링에 대한 학습의 이점을 얻으며, 이는 3D 텍스처를 최적화하기 위한 우수한 가이던스를 제공합니다.
고정된 타겟 분포에서 distill하는 이전 작업 (Poole et al., 2022; Wang et al., 2023b)과 달리 최적화 상태에 따라 점진적으로 진화하는 분포에서 학습합니다.
이 "bootstrapping"을 통해 저희의 접근 방식은 뷰 일관성을 유지하면서 점점 더 자세한 텍스처를 캡처합니다.

그림 1에서 볼 수 있듯이, 우리의 방법은 복잡한 지오메트릭 구조와 360˚에서 일관성 있게 렌더링된 사실적인 텍스쳐로 창의적인 3D 자산을 생성할 수 있습니다.
우리의 방법은 최적화 기반 접근 방식 (Poole et al., 2022; Lin et al., 2023)에 비해 훨씬 향상된 텍스쳐와 복잡성을 제공합니다.
한편, 우리의 작업은 image-to-3D (Tang et al., 2023; Qian et al., 2023) 기법에 비해 360˚ 렌더링에서 전례 없는 사실적인 렌더링을 생성하는 데 탁월합니다.
이러한 결과는 DreamCraft3D가 3D 콘텐츠 제작에서 새로운 창의적 가능성을 가능하게 하는 강력한 잠재력을 시사합니다.
전체 구현은 공개될 것입니다.
2 Related work
3D generative models은 지루한 수동 생성 없이 3D 자산을 생성하기 위해 집중적으로 연구되어 왔습니다.
Generative adversarial networks (GAN) (Chan et al., 2021; 2022; 2021; Xie et al., 2021; Zeng et al., 2022; Skorokhodov et al., 2023; Gao et al., 2022; Tang et al., 2022; Xie et al., 2021; Sun et al., 2023; 2022)는 오랫동안 이 분야에서 중요한 기술이었습니다.
이미지 또는 텍스트를 기반으로 이러한 3D 모양의 분포를 학습하는 Auto-regressive 모델 (Sanghi et al., 2022; Mittal et al., 2022; Yan et al., 2022; Zhang et al., 2022; Yu et al., 2023)이 탐구되었습니다.
디퓨전 모델 (Wang et al., 2023a; Cheng et al., 2023; Li et al., 2023; Nam et al., 2022; Zhang et al., 2023a; Nichol et al., 2022; Jun & Nichol, 2023; Bautista et al., 2022; Gupta et al., 2023)은 또한 텍스트 또는 이미지에서 잠재적인 3D 모양으로의 확률적 매핑을 학습하는 데 최근 상당한 성공을 거두었습니다.
그러나 이러한 방법은 학습을 위해 3D 모양 또는 멀티뷰 데이터가 필요하므로 2D에 비해 다양한 3D 데이터 (Chang et al., 2015; Deitke et al., 2023; Wu et al., 2023)의 부족으로 인해 야생에서 3D 자산을 생성할 때 어려움이 있습니다.
3D-aware image generation은 일정 수준의 3D 일관성을 제공하면서 새로운 뷰로 이미지를 렌더링하는 것을 목표로 합니다.
이러한 작업 (Sargent et al., 2023; Skorokhodov et al., 2023; Xiang et al., 2023)은 종종 사전 학습된 단안 depth 예측 모델에 의존하여 뷰 일관성 이미지를 합성합니다.
이들은 ImageNet의 범주에 대해 사진 사실적 렌더링을 달성하지만 큰 뷰에서 결과를 생성하는 데는 실패합니다.
최근 3D 데이터에 대해 뷰 의존적 디퓨전 모델을 학습하고 오픈 도메인에 대한 유망한 새로운 뷰 합성 능력을 입증하는 몇 가지 시도 (Watson et al., 2022; Liu et al., 2023b)가 있습니다.
그러나 이들은 본질적으로 2D 모델이며 완벽한 뷰 일관성을 보장할 수 없습니다.
Lifting 2D to 3D
접근법은 확립된 2D 텍스트-이미지 기반 모델을 사용하여 가이던스를 모색함으로써 3D 장면 표현을 향상시킵니다. 초기 작업 (Jain et al., 2022; Lee & Chang, 2022; Hong et al., 2022)은 렌더링된 이미지와 텍스트 프롬프트 간의 유사성을 극대화하기 위해 사전 학습된 CLIP (Radford et al., 2021) 모델을 활용합니다. 반면 DreamFusion (Poole et al., 2022)과 SJC (Wang et al., 2022)는 사전 학습된 디퓨전 모델에서 이미지 분포 score를 distill하고 유망한 결과를 보여줄 것을 제안합니다. 최근 작업은 coarse-to-fine 최적화 (Lin et al., 2023; Chen et al., 2023), 개선된 distillation loss (Wang et al., 2023b), 형상 가이던스 (Metzer et al., 2023) 또는 2D 이미지를 3D로 리프팅 (Deng et al., 2023; Tang et al., 2023; Qian et al., 2023; Liu et al., 2023a)을 통해 텍스쳐 현실성을 더욱 향상시키고자 했습니다. 최근 Raj et al. (2023)은 3D 일관된 생성을 위한 개인화된 디퓨전 모델을 파인튜닝하는 것을 제안합니다. 그러나 전 세계적으로 일관된 3D를 생성하는 것은 여전히 어려운 과제입니다. 본 연구에서는 전체 계층 생성 프로세스를 통해 3D priors를 세심하게 설계하여 전례 없는 일관된 3D 생성을 달성합니다.
3 Preliminaries
DreamFusion (Pool et al., 2022)은 θ에 의해 매개변수화된 3D 표현을 최적화하기 전에 사전 학습된 text-to-image 디퓨전 모델 ϕ_ϵ를 이미지로 활용하여 text-to--3D 생성을 달성합니다.
볼륨 렌더러에 의해 랜덤 시점에서 렌더링된 이미지 x = g(θ)는 사전 학습된 디퓨전 모델에 의해 모델링된 텍스트 조건 이미지 분포 p(x|y)에서 추출된 샘플을 나타낼 것으로 예상됩니다.
디퓨전 모델 ϕ은 텍스트 프롬프트 y를 기반으로 노이즈 레벨 t에서 노이즈 이미지 x_t의 샘플링된 노이즈 ϵ_ϕ(x_t; y, t)를 예측하도록 학습됩니다.
score distillation sampling (SDS) loss는 렌더링된 이미지가 디퓨전 모델에 의해 모델링된 분포와 일치하도록 장려합니다.
특히 SDS loss는 그래디언트를 계산합니다:

, 렌더링된 이미지에서 예측된 노이즈와 추가된 노이즈 사이의 픽셀당 차이이며, 여기서 ω(t)는 가중치 함수입니다.
조건부 디퓨전 모델의 생성 품질을 향상시키는 한 가지 방법은 classifier-free guidance (CFG) 기법을 사용하여 샘플링을 무조건적 샘플링에서 약간 멀리 조정하는 것입니다, 즉, ϵ_ϕ(x_t; y, t)+ϵ_ϕ(x_t; y, t)-ϵ_ϕ(x_t, t, ∅), 여기서 ∅는 "empty" 텍스트 프롬프트를 나타냅니다
일반적으로 SDS loss는 고품질 text-to-3D 생성하기 위해 큰 CFG 가이던스 가중치를 필요로 하지만 이는 과도한 포화 및 과도한 평활과 같은 부작용을 초래합니다 (Poole et al., 2022).
최근 Wang et al. (2023b)는 표준 CFG 가이던스 강도에 친화적이고 부자연스러운 텍스쳐를 더 잘 해결하는 variational score distillation (VSD) loss를 제안했습니다.
이 접근법은 단일 데이터 포인트를 찾는 대신 텍스트 프롬프트에 해당하는 솔루션을 랜덤 변수로 간주합니다.
특히, VSD는 텍스트 y에 해당하는 가능한 3D 표현 μ(θ|y)의 분포 q^μ(x_0|y)를 디퓨전 시간 단계 t = 0, p(x_0|y)로 정의된 분포와 KL 발산 측면에서 밀접하게 정렬되도록 최적화합니다:

Wang et al. (2023b)는 또한 이 objective가 각 시간 t에서 노이즈가 많은 실제 이미지의 스코어와 노이즈가 많은 렌더링 이미지의 스코어를 일치시켜 최적화될 수 있음을 보여주므로 L_VSD의 그래디언트는

여기서 ϵ_lora는 LoRA (Low-rank adaptation) (Hu et al., 2021)모델을 사용하여 렌더링된 이미지의 스코어를 추정합니다.
획득한 변형 분포는 충실도가 높은 텍스처로 샘플을 산출합니다.
그러나 이러한 loss는 텍스처 향상에 적용되며 SDS에서 처음에 학습한 coarse 지오메트리에는 속수무책입니다.
또한 SDS와 VSD는 모두 전역 3D 일관성보다는 뷰 단위 신뢰성만 보장하는 고정 대상 2D 분포에서 distill을 시도합니다.
결과적으로 인식된 3D 품질을 방해하는 동일한 외관 및 시멘틱 전환 문제로 어려움을 겪습니다.
4 DreamCraft3D
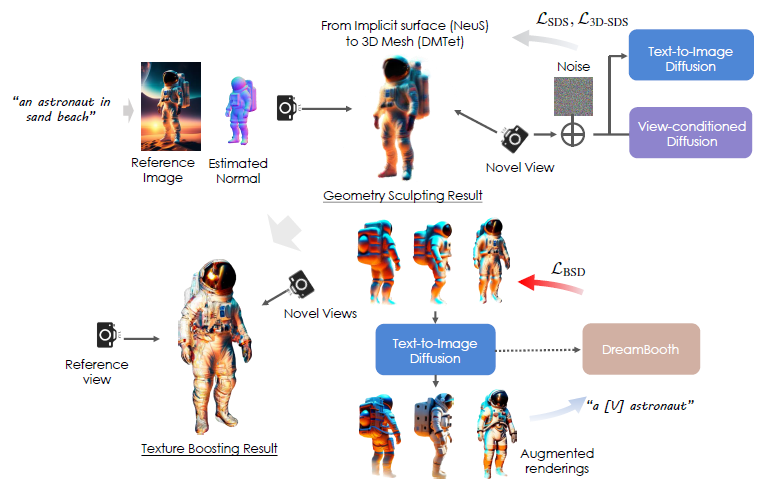
저희는 그림 2와 같이 3D 콘텐츠 생성을 위한 계층적 파이프라인을 제안합니다.
저희의 방법은 먼저 SOTA text-to-image 생성 모델을 활용하여 텍스트 프롬프트에서 고품질의 2D 이미지를 생성합니다.
이를 통해 SOTA 2D 디퓨전 모델의 모든 기능을 활용하여 텍스트에 설명된 복잡한 시각적 의미를 표현하여 2D 모델로서 창의적인 자유를 유지할 수 있습니다.
그런 다음 지오메트릭 조각 및 텍스처 부스팅의 계단식 단계를 통해 이 이미지를 3D로 리프트합니다.
문제를 분해하여 각 단계에서 특수화된 기술을 적용할 수 있습니다.
지오메트리의 경우 멀티뷰 일관성과 전역 3D 구조를 우선시하여 세부 텍스처를 약간 손상시킬 수 있습니다.
그런 다음 지오메트리를 고정한 상태에서 현실적이고 일관된 텍스처 최적화에만 초점을 맞추고 이를 위해 3D 최적화를 부트스트랩하는 3D 인식 디퓨전 prior를 공동으로 학습합니다.
다음으로 두 단계에 대한 주요 설계 고려 사항에 대해 자세히 설명합니다.
4.1 Geometry sculpting
이 단계에서는 다양한 시야각 하에서 신뢰성을 유지하면서 동일한 참조 뷰에서 참조 이미지 ˆx의 외관과 일치하도록 3D 모델을 만드는 것을 목표로 합니다.
이를 위해 사전 학습된 디퓨전 모델로 인식할 수 있는 랜덤으로 샘플링된 각 뷰에 대한 그럴듯한 이미지 렌더링을 권장합니다.
이는 식 1에 정의된 대로 SDS loss L_SDS를 사용하여 달성됩니다.
참조 이미지의 가이던스를 효과적으로 활용하기 위해 참조 뷰 ˆc에서 L_rgb = ∥ˆm ⊙ (ˆx - g(θ; ˆc))∥를 통해 렌더링된 이미지와 참조 사이의 photometric 차이를 벌합니다.
loss는 마스크 ˆm으로 표시되는 전경 영역 내에서만 계산됩니다.
한편, 저희는 장면 희소성을 장려하기 위해 마스크 loss L_mask = ∥ˆm - g_m(θ; ˆc)∥를 구현하며, 여기서 g_m은 실루엣을 렌더링합니다.
또한 (Deng et al., 2023)과 마찬가지로 참조 이미지에서 이전에 추론된 지오메트리를 완전히 활용하고 참조 뷰에 대해 계산된 depth 및 normal 맵과의 일치성을 강화합니다.
해당 depth 및 normal loss는 각각

로 계산되며, 여기서 conv(·)와 σ(·)은 각각 공분산 및 분산 연산자를 나타내고 참조 뷰에서 depth ˆd와 normal ˆn은 기성 단일 뷰 추정기(Eftekhar et al., 2021)를 사용하여 계산됩니다.
depth loss는 depth의 스케일 불일치를 설명하기 위해 음의 피어슨 상관 관계 L_depth 형태를 채택합니다.
그럼에도 불구하고 백뷰 전반에 걸쳐 일관된 시맨틱과 외관을 유지하는 것은 여전히 어려운 과제입니다.
그래서 우리는 일관되고 상세한 지오메트리를 만들기 위해 추가적인 기법을 사용합니다.
3D-aware diffusion prior.
저희는 뷰 단위 supervision만으로는 3D 최적화가 과소 제약된다고 주장합니다.
따라서 저희는 대규모 3D 자산에 대해 학습되고 개선된 시점 인식을 제공하는 뷰 조건 디퓨전 모델인 Zero-1-to-3을 활용합니다.
Zero-1-to-3은 파인튜닝된 2D 디퓨전 모델로, 참조 이미지 ˆx가 주어진 상대 카메라 포즈 c에서 이미지를 환각 상태로 만듭니다.
이 3D 인식 모델을 통해 시각 세계에 대한 보다 풍부한 3D 지식을 인코딩하고, 주어진 참조 이미지에서 뷰를 더 잘 추정할 수 있습니다.
이와 같이 저희는 이 모델에서 확률 밀도를 distill하고 새로운 뷰에 대한 3D-aware SDS loss의 그래디언트를 계산합니다:

이 loss는 Janus 문제와 같은 3D 일관성 문제를 효과적으로 완화합니다.
그러나 렌더링 품질이 떨어지는 제한된 범주의 3D 데이터에 대한 파인튜닝은 디퓨전 모델의 생성 능력을 손상시키기 때문에 일반 이미지를 3D로 리프팅할 때 3D-aware SDS loss만으로는 품질 저하를 유발하기 쉽습니다.
따라서 저희는 2D와 3D 디퓨전 priors를 동시에 통합하는 하이브리드 SDS loss를 사용합니다.
형식적으로 이 하이브리드 SDS loss는

과 같은 그래디언트를 제공하며, 여기서 3D 디퓨전 priors의 가중치를 강조하기 위해 μ = 2를 선택합니다.
L_SDS를 계산할 때 64 × 64 해상도 픽셀 공간에서 작동하며 coarse 지오메트리를 더 잘 포착하는 디퓨전 모델인 DeepFloyd IF base 모델(Shonenkov et al., 2023)을 채택합니다.
Progressive view training.
그러나 360˚에서 자유 뷰를 직접 도출하면 단일 참조 이미지에 내재된 모호성으로 인해 의자 다리 추가와 같은 지오메트릭 아티팩트가 발생할 수 있습니다.
이를 해결하기 위해 저희는 학습 뷰를 점진적으로 확장하고 잘 설정된 지오메트리를 360˚ 결과로 점진적으로 전파합니다.
Diffusion timestep annealing.
3D 최적화의 coarse-to-fine 진행에 맞추기 위해, 저희는 Huang et al. (2023)과 유사한 디퓨전 시간 단계 어닐링 전략을 채택합니다.
최적화를 시작할 때, 저희는 전역 구조를 제공하기 위해 식 6을 계산할 때 범위 [0.7, 0.85]에서 더 큰 디퓨전 시간 단계 t를 샘플링하는 데 우선 순위를 둡니다.
학습이 진행됨에 따라 저희는 t 샘플링 범위를 수백 번 반복하여 [0.2, 0.5]로 선형 어닐링합니다.
이 어닐링 전략을 통해 모델은 구조적 디테일을 개선하기 전에 초기 최적화 단계에서 먼저 그럴듯한 전역 지오메트리를 확립할 수 있습니다.
Detailed structual enhancement.
저희는 처음에 NeuS(Wang et al., 2021)에서와 같이 해당 볼륨 렌더링으로 암시적 표면 표현을 최적화하여 coarse 구조를 확립합니다.
그런 다음 Lin et al.(2023)에 이어 이 결과를 사용하여 고해상도 디테일을 용이하게 하기 위해 변형 가능한 사면체 그리드(DMTet)(Sen et al., 2021)를 사용하여 텍스처 3D 메쉬 표현을 초기화합니다.
또한 이 표현은 지오메트리와 텍스처 학습을 분리합니다.
따라서 이러한 구조적 향상의 끝에서 텍스처만 정제하고 참조 이미지에서 고주파 디테일을 더 잘 보존할 수 있습니다.
4.2 Texture boosting via bootstrapped score sampling
지오메트리 조각 단계에서는 일관되고 디테일한 지오메트리 학습이 우선이지만 텍스쳐는 블러하게 유지됩니다.
이는 coarse 해상도에서 작동하는 2D prior 모델에 의존하고 있으며, 3D-aware 디퓨전 모델이 제공하는 샤프함이 제한적이기 때문입니다.
또한 과도하게 큰 classifier-free guidance는 과평활화 및 과포화와 같은 텍스쳐 문제를 야기합니다.
텍스처 현실성을 높이기 위해 식 3에 자세히 설명된 대로 variational score distillation (VSD) loss를 사용합니다.
저희는 이 단계에서 고해상도 그래디언트를 제공하는 Stable Diffusion 모델(Rombach et al., 2021)로 전환합니다.
저희는 사실적인 렌더링을 촉진하기 위해 사면체 그리드를 고정한 상태에서 메쉬 텍스처를 독점적으로 최적화합니다.
이 학습 단계에서는 텍스처 품질에 악영향을 미치기 때문에 Zero-1-to-3 모델을 3D prior 모델로 활용하지 않습니다.
그럼에도 불구하고 일관되지 않은 텍스처가 다시 돌아와 이상한 3D 결과를 초래할 수 있습니다.
저희는 약간의 블러함에도 불구하고 마지막 단계의 멀티뷰 렌더링이 우수한 3D 일관성을 보이는 것을 관찰했습니다.
한 가지 아이디어는 이러한 렌더링 결과를 사용하여 사전 학습된 2D 디퓨전 모델을 적용하여 모델이 현장 주변 뷰에 대한 개념을 형성할 수 있도록 하는 것입니다.
이를 고려하여 DreamBooth (Ruiz et al., 2023)를 사용하여 멀티뷰 이미지 렌더링 {x}로 디퓨전 모델을 파인튜닝합니다.
구체적으로, 저희는 고유 식별자와 타겟의 클래스 이름(예: 그림 2의 "A [V] astronaut")을 포함하는 텍스트 프롬프트를 통합합니다.
파인튜닝 중에 각 뷰의 카메라 매개변수가 추가 조건으로 도입됩니다.
실제로 저희는 " augmented" 이미지 렌더링인 x_r = r_t'(x)로 DreamBooth를 학습시킵니다.
저희는 디퓨전 시간 단계 t'에 의해 지정된 양으로 가우시안 노이즈를 멀티뷰 렌더링에 도입합니다, 즉, x_t' = α_t' x_0 + σ_t' ϵ(α_t', σ_t' > 0은 하이퍼파라미터)는 디퓨전 모델을 사용하여 복원됩니다.
이러한 증강 이미지는 큰 t'를 선택함으로써 원래 렌더링에 대한 충실도를 희생시키면서 고주파 디테일을 보여줍니다.
이러한 증강 렌더링에 대해 학습된 DreamBooth 모델은 텍스처 개선을 가이드하기 전에 3D 역할을 할 수 있습니다.
또한 부트스트랩 최적화를 용이하게 하기 위해 3D 장면을 대안적으로 최적화할 것을 제안합니다(그림 2).
초기에 3D 메쉬는 블러한 멀티뷰 렌더링을 생성합니다.
저희는 텍스처 품질을 향상시키는 동시에 몇 가지 3D 불일치를 도입하기 위해 대규모 디퓨전 t'를 채택합니다.
이러한 증강 렌더링에 대해 학습된 DreamBooth 모델은 텍스처 개선을 가이드하기 위해 장면의 통합된 3D 개념을 얻습니다.
3D 메쉬가 더 미세한 텍스처를 드러냄에 따라 이미지 렌더링에 도입되는 디퓨전 노이즈를 줄여 DreamBooth 모델은 보다 일관된 렌더링에서 학습하고 진화하는 뷰에 충실한 이미지 분포를 더 잘 캡처합니다.
이 순환 프로세스에서 3D 메쉬와 디퓨전은 부트스트랩 방식으로 상호 개선됩니다.
저희는 공식적으로 다음과 같은 bootstrapped score distillation (BSD) loss를 사용하여 3D 최적화 그래디언트를 도출합니다:

고정된 2D 모델에서 스코어 함수를 distill하는 이전 작업(Pool et al., 2022; Wang et al., 2023b)과 달리, 우리의 BSD loss는 진행 중인 3D 모델에서 피드백을 이끌어냄으로써 점점 더 3D 일관성을 갖게 되는 진화하는 모델에서 학습합니다.
우리의 실험에서, 우리는 두 번의 최적화를 교대하며, 이는 풍부한 세부 사항으로 일관된 텍스쳐를 생성하기에 충분합니다.
5 Experiments
5.1 Implementation Details
Architectural details.
지오메트릭 조각 단계에서는 Neus와 텍스처링된 3D 메쉬 표현을 사용합니다.
저희는 Instant NGP(M ¨uller et al., 2022)를 사용하며 64 해상도에서 384 해상도로 최적화합니다.
텍스처링된 메쉬의 경우 128 그리드 및 512 렌더링 해상도에서 DMTet을 사용합니다.
Optimization.
메쉬 개선 과정에서 저희는 가이드된 normal 맵과 RGB 이미지를 반복적으로 렌더링하여 지오메트릭 디테일을 향상시키고 일관성을 위해 텍스처 예측 네트워크를 최적화합니다.
저희의 접근 방식은 주어진 그럴듯한 전역 지오메트릭 구조를 고려하여 텍스처 최적화 시 3D prior 사용을 피합니다.
저희는 Dreamfusion의 방법론에 맞춰 카메라 반경과 Field of View (FOV) 각도를 랜덤으로 샘플링합니다.
이를 통해 normal 맵과 RGB 이미지를 번갈아 렌더링하여 텍스처와 지오메트릭 디테일을 향상시킵니다.
5.2. Comparisons with the State of the Arts
Baseline.
저희는 다섯 가지 기본 방법과 비교 분석을 수행합니다.
처음 세 가지는 text-to-3D 방법입니다: DreamFusion (Pool et al., 2022), Magic 3D (Lin et al., 2023) 및 ProlificDreamer (Wang et al., 2023b).
또한 저희의 방법을 두 가지 image-to-3d 방법과 비교합니다: Make-it-3D (Tang et al., 2023)와 Magic123 (Qian et al., 2023).
DreamFusion, Magic3D, Magic123 및 ProlificDreamer의 경우 비교를 위해 Threestudio 라이브러리 (Guo et al., 2023)의 구현을 활용합니다.
Make-it-3D의 경우 공식 구현을 사용합니다.
Datasets.
저희는 Stable Diffusion (Rombach et al., 2021)과 Deep Floyd가 제작한 실제 사진을 혼합한 300개의 이미지를 포함하는 테스트 벤치마크를 수립합니다.
이 벤치마크의 각 이미지에는 전경에 대한 알파 마스크, 예측된 depth 맵 및 텍스트 프롬프트가 함께 제공됩니다.
실제 이미지의 경우 텍스트 프롬프트는 이미지 캡션 모델에서 제공됩니다.
저희는 이 테스트 벤치마크를 대중이 액세스할 수 있도록 할 계획입니다.
Quantitative comparison.
정량적 분석을 통해 우리의 기법을 기존의 베이스라인과 비교하여 다양한 관점에서 시멘틱을 일관적으로 전달하고 입력 이미지와 유사한 매력적인 3D 콘텐츠를 생성합니다: 참조 시점에서 충실도 측정을 위한 LPIPS(Zhang et al., 2018) 및 PSNR; 픽셀 수준 일치 평가를 위한 Contextual Distance (Mechrez et al., 2018) 및 시멘틱 일관성 추정을 위한 CLIP score (Radford et al., 2021).
표 1에 표시된 결과는 우리의 접근 방식이 텍스처 일관성과 충실도를 모두 유지하는 데 있어 베이스라인을 크게 능가한다는 것을 나타냅니다.

User study.
제안된 모델의 견고성과 품질을 입증하기 위해 저희는 15개의 개별 프롬프트와 이미지 쌍을 사용하는 사용자 연구를 실행했습니다.
각 참가자는 해당 텍스트 입력과 함께 4개의 자유 뷰 렌더링 비디오를 제공받고 가장 선호하는 3D 모델을 선택하도록 요청했습니다.
이 연구는 총 32명의 참가자로부터 480개의 응답을 수집했으며, 이에 대한 분석은 그림 5에 나와 있습니다.
평균적으로 저희 모델은 대체 모델보다 92%의 사용자가 선호하여 베이스라인을 큰 차이로 능가했습니다.
이 결과는 제안된 방법에 내재된 복원력과 우수한 품질에 대한 강력한 증거를 제공합니다.


Qualitative comparison.
그림 3은 우리의 방법을 베이스라인과 비교합니다.
text-to-3D 모든 방법은 다중 뷰 일관성 문제를 겪습니다.
ProlificDreamer는 현실적인 텍스쳐를 제공하지만 그럴듯한 3D 개체를 형성하지는 못합니다.
Make-it-3D와 같은 image-to-3D 방법은 고품질의 정면 뷰를 생성하지만 지오메트리 구조 문제로 어려움을 겪습니다.
Zero-1-to-3에서 향상된 Magic123은 지오메트리 정규화에서 더 나은 성능을 발휘하지만 지나치게 매끄러운 텍스쳐와 지오메트릭 디테일을 모두 생성합니다.
반면 Bootstrapped Score Distillation 방식은 시멘틱 일관성을 유지하면서 상상력의 다양성을 향상시킵니다.
5.3. Analysis
The effect of 3D prior.
본 논문에서 저희는 3D prior에 의해 제공되는 가이던스가 전역적으로 그럴듯한 지오메트리의 생성을 향상시킨다고 주장합니다.
그 영향을 확인하기 위해 3D prior가 비활성화된 ablation 연구가 수행됩니다.
그림 6은 3D prior가 없는 경우 결과 특성이 다면적인 Janus 문제를 나타내는 경향이 있으며 불규칙한 지오메트리로 인해 어려움을 겪는다는 것을 보여줍니다.
이 관찰은 전역적으로 일관된 모양을 조절하기 전에 시점 인식 3D의 중요성을 강조합니다.

The effect of BSD.
그림 6은 또한 세 가지 텍스처 최적화 기법을 포함하는 ablation 연구를 보여줍니다: (1) 전통적인 stable diffusion 방식의 BSD, (2) VSD 및 (3) score distillation sampling (SDS).
SDS의 적용은 과도하게 부드럽고 과포화된 새로운 시점의 텍스처를 생성하는 것으로 관찰되었습니다.
대조적으로, 표준 stable diffusion을 사용하는 VSD는 현실적인 텍스처를 생성할 수 있지만 현저하게 높은 불일치를 생성합니다.
대조적으로, 저희가 제안한 접근 방식은 사실성과 일관성 사이의 균형을 이루는 텍스처를 성공적으로 생성합니다.

Visualization of multiple stages.
그림 7은 계층적 파이프라인의 각 단계별 중간 렌더링 결과를 시각화한 것입니다.
지오메트릭 조각 단계에서는 Neus를 DMTet로 변환하여 고해상도 지오메트리 디테일을 개선합니다.
그러나 텍스처의 개선은 무시할 수 있습니다.
반대로 텍스처 단계에서는 제안한 BSD로 텍스처 품질을 크게 향상시킵니다.

DreamBooth times.
그림 4는 DreamBooth의 멀티뷰 데이터 세트를 보여줍니다.
초기 단계는 각 이미지에 상당한 노이즈를 도입하여 세부적인 풍부함을 증폭하여 일관성 없는 디노이즈 이미지를 생성합니다.
그러나 텍스처 메쉬가 최적화됨에 따라 생성된 렌더링은 일관성과 포토리얼리즘을 향상시키는 방향으로 진화하여 DreamBooth에 맞게 조정된 입력 데이터 세트의 품질을 향상시킵니다.
6 Conclusion
저희는 복잡한 3D 자산 생성 분야를 발전시키는 혁신적인 접근 방식인 DreamCraft3D를 제시했습니다.
이 작업은 그럴듯하고 일관성 있는 3D 지오메트리를 생성하기 위한 세심한 지오메트릭 조각 단계와 새로운 Bootstrapped Score Distillation 전략을 소개합니다.
후자는 최적화된 3D 인식 디퓨전 prior에 distill하고 최적화된 인스턴스의 멀티뷰 렌더링에 적응함으로써 텍스처 품질과 일관성을 크게 향상시킵니다.
DreamCraft3D는 강력한 텍스쳐 디테일과 멀티뷰 일관성으로 충실도가 높은 3D 자산을 생성합니다.
저희는 이 작업이 3D 콘텐츠 생성의 민주화를 위한 중요한 단계이며 향후 응용 분야에서 큰 가능성을 보여줄 것이라고 믿습니다.