2024. 5. 20. 10:07ㆍtext-to-3D
DreamGaussian4D: Generative 4D Gaussian Splatting
Jiawei Ren, Liang Pan, Jiaxiang Tang, Chi Zhang, Ang Cao, Gang Zeng, Ziwei Liu
Abstract
최근 4D 콘텐츠 생성에서 괄목할 만한 진전이 있었습니다.
그러나 기존 방법은 최적화 시간이 길고, 모션 제어 가능성이 부족하며, 세부 정보 수준이 낮다는 어려움을 겪고 있습니다.
이 논문에서는 4D Gaussian Splatting 표현을 기반으로 하는 효율적인 4D 생성 프레임워크인 DreamGaussian4D를 소개합니다.
저희의 핵심 통찰력은 Gaussian Splatting에서 공간 변환을 명시적으로 모델링하면 암시적 표현에 비해 4D 생성 설정에 더 적합하다는 것입니다.
DreamGaussian4D는 최적화 시간을 몇 시간에서 불과 몇 분으로 단축하고, 생성된 3D 모션을 유연하게 제어할 수 있으며, 3D 엔진에서 효율적으로 렌더링할 수 있는 애니메이션 메시를 생성합니다.

1. Introduction
2D 이미지 (Rombach et al., 2022; Sheynin et al., 2022), 비디오 (Wang et al., 2023; Blattmann et al., 2023) 및 3D 장면 (Jun & Nichol, 2023; Hong et al., 2023; Tang et al., 2023a)과 같은 다양한 디지털 콘텐츠를 생성하는 데 있어 최근의 상당한 발전과 혁신을 보여주는 생성 모델에서 놀라운 진전이 관찰되었습니다.
최근의 몇몇 연구 작업 (Singer et al., 2023; Jiang et al., 2023; Zhao et al., 2023; Bahmani et al., 2023)이 4D 생성에 집중되었지만 동적 4D 장면 생성에서 일관성과 고품질을 달성하는 것은 완전히 해결되지 않았습니다.
4D 동적 장면은 종종 임의의 관점에서 일관된 외관, 지오메트리 및 모션을 보여줄 것으로 예상되는 4D 동적 Neural Radiance Fields (NeRF)를 사용하여 표현됩니다.
MAV3D (Singer et al., 2023)는 비디오 및 3D 생성 모델의 이점을 결합하여 text-to-video 디퓨전 모델을 Hexplane (Cao & Johnson, 2023)에서 distilling하여 text-to-4D 생성을 달성합니다.
Consistent4D (Jiang et al., 2023)는 video-tp-4D 프레임워크를 도입하여 정적으로 캡처된 단안 비디오에서 4D 생성을 위한 Cascaded DyNeRF를 최적화합니다.
다중 디퓨전 priors를 통해 Animate124 (Zhao et al., 2023)는 텍스트 모션 설명을 통해 단일 야생 이미지를 3D 비디오로 애니메이션화할 수 있습니다.
hybrid SDS를 사용하여 4D-fy (Bahmani et al., 2023)는 사전 학습된 여러 디퓨전 모델을 기반으로 강력한 text-to-4D 생성을 달성합니다.
그러나 그들은 (Singer et al., 2023; Jiang et al., 2023; Zhao et al., 2023; Bahmani et al., 2023) 4D NeRF를 생성하는 데 몇 시간이 걸리는 경향이 있으며 생성된 모션도 잘 제어할 수 없습니다.
이 작업에서는 4D Gaussian splatting (4D GS)으로 동적 장면을 단 몇 분 만에 효율적으로 생성할 수 있는 DreamGaussian4D 프레임워크를 소개합니다.
저희의 핵심 통찰력은 Gaussian Splatting에서 공간 변환의 명시적 모델링이 4D 생성에서 동적 최적화를 크게 단순화한다는 것입니다.
저희는 먼저 DreamGaussian (Tang et al., 2023a)에 소개된 image-to-3D 프레임워크를 사용하여 정적 3D Gaussian Splatting (3D GS)을 적합시킵니다.
저희는 DreamGaussian의 과소 최적화 문제를 완화하는 더 나은 학습 레시피인 DreamGaussianHD를 제안합니다.
동적 최적화를 위해 일반적으로 사용되는 비디오 디퓨전 모델의 score distillation을 대신하여 주행 비디오에서 움직임을 학습합니다.
주행 비디오는 image-to-video 디퓨전 모델에서 생성되며 더 나은 제어 가능성과 움직임 다양성을 가능하게 합니다.
마지막으로, 저희는 4D GS를 애니메이션 메시 시퀀스로 내보내고 시간 일관성을 개선하는 video-to-video 파이프라인으로 프레임별 텍스처 맵을 개선합니다.
요약하면 우리의 기여는 다음과 같습니다:
1. 우리는 4D 콘텐츠 생성에서 변형 가능한 Gaussian Splatting 표현을 사용하고, 명시적인 공간 변환 모델링을 통해 최적화 시간이 몇 시간에서 불과 몇 분으로 크게 단축되는 것을 관찰했습니다.
2. 우리는 이미지 조건으로 생성된 비디오에서 움직임을 학습하는 image-to-4D 프레임워크를 설계하여 보다 제어 가능하고 다양한 3D 움직임을 가능하게 합니다.
3. 우리는 내보낸 애니메이션 메시의 품질을 더욱 향상시켜 실제 환경에서 프레임워크를 더 쉽게 배포할 수 있는 video-to-video 텍스처 개선 전략을 제안합니다.
2. Related works
2.1. 4D Representations
동적 3D 장면(4D 장면)을 표현하는 데 있어 짜릿한 진전이 관찰되었습니다.
한 연구 라인은 추가 시간 차원 t 또는 잠재 코드와 함께 x, y, z의 함수로 4D 장면을 직접 표현합니다 (Xian et al., 2021; Gao et al., 2021; Li et al., 2022; 2021).
또 다른 작업 라인은 4D 장면을 정적 canonical 3D 장면과 변형 필드의 조합으로 표현합니다 (Pumarola et al., 2021; Park
et al., 2021a;b; Du et al., 2021; Tretschk et al., 2021; Yuan et al., 2021; Li et al., 2023).
4D 표현의 중요한 병목 현상은 단일 장면에 수십 시간이 걸리는 속도입니다.
이 문제를 해결하기 위해 다양한 접근 방식이 모색되고 있습니다.
특히 명시적 또는 하이브리드 표현을 사용하면 4D 시공간 그리드에 대한 평면 분해 (Cao & Johnson, 2023; Fridovich-Keil et al., 2023; Shao et al., 2023), 해시 표현 (Turki et al., 2023) 및 기타 구조 (Fang et al., 2022; Abou-Chakra et al., 2024; Guan et al., 2022)를 포함한 인상적인 결과가 기록됩니다.
매우 최근에는 Gaussian Splatting (Kerbl et al., 2023)이 만족스러운 속도와 인상적인 재구성 품질을 모두 제공하여 상당한 주목을 받았습니다.
정적 Gaussian Splatting을 동적 버전으로 확장하는 것이 유망한 방향이 됩니다.
Dynamic 3D Gaussian (Luiten et al., 2023)은 동적 정규화를 통해 프레임별 Gaussian Splatting을 최적화하고 크기, 색상 및 불투명도를 공유합니다.
4D Gaussian Splatting (Wu et al., 2023; Yang et al., 2023)은 변형 네트워크를 사용하여 시간에 따른 위치, 규모 및 회전 변형을 예측합니다.
2.2. Image-to-3D Generation
image-to-3D 생성은 단일 참조 이미지에서 3D 자산을 생성하는 것을 목표로 합니다.
디퓨전 모델 (Ho et al., 2020)과 같은 기술을 사용하는 조건적 생성 작업으로 볼 수 있습니다.
Point-E (Nichol et al., 2022) 및 Shap-E (Jun & Nichol, 2023)는 이미지 피쳐에 따라 조건적 3D 포인트 클라우드 또는 Neural Radiance Fields (NeRF) (Mildenhall et al., 2020)를 생성하도록 직접 학습할 수 있지만, 품질은 공간 해상도 및 고품질 3D 데이터 세트로 인해 제한됩니다.
일부 방법 (Melas-Kyriazi et al., 2023; Tang et al., 2023b)은 최근의 성능이 뛰어난 2D 디퓨전 모델을 활용하여 score distillation sampling (SDS) (Poole et al., 2022)을 사용하여 3D로 리프트합니다.
예를 들어 Magic123 (Qian et al., 2023)은 이미지 입력과 텍스트 입력을 모두 결합하여 NeRF를 통해 고품질 3D 모델을 distill합니다.
DreamGaussian (Tang et al., 2023a)은 Gaussian splatiing (Kerbl et al., 2023) 표현을 사용하여 최적화 시간을 더욱 단축합니다.
문제는 단일 뷰 3D 재구성 작업으로도 공식화될 수 있습니다.
많은 작업 (Xu et al., 2019; Chen & Zhang, 2019; Chen et al., 2020; Trevithick & Yang, 2021; Duggal & Pathak, 2022; Szymanowicz et al., 2023)이 이 잘못된 작업에 대해 3D priors를 학습하기 위해 오토인코더 구조를 채택하지만 일반적으로 하나 또는 몇 가지 범주의 합성 개체 (Chang et al., 2015)로 제한됩니다.
최근에는 One-2-3-45 (Liu et al., 2023b;a)가 2D 디퓨전 모델 (Liu et al., 2023c; Shi et al., 2023)을 사용하여 멀티 뷰 이미지를 생성하고 효율적인 멀티 뷰 재구성 모델을 학습합니다.
LRM (Hong et al., 2023)은 트랜스포머 기반 아키텍처를 채택하여 triplane 기반 NeRF를 직접 회귀하여 대규모 데이터 세트 (Deitke et al., 2023b; Yu et al., 2023)에서 작업을 확장합니다.
2.3. 4D Generation
4D 생성은 애니메이션, 게임 및 가상 현실을 포함한 광범위한 그래픽 애플리케이션에 유용한 동적 3D 장면을 생성하는 것을 목표로 합니다.
한 가지 작업은 text-to-video 디퓨전 모델을 활용하여 4D 콘텐츠를 distill하는 것입니다 (Singer et al., 2023).
구체적으로 카메라 궤적을 합성한 다음 렌더링된 비디오에 SDS를 계산하여 Hexplane (Cao & Johnson, 2023) 또는 K-plane (Fridovich-Keil et al., 2023)과 같은 4D 표현을 최적화합니다.
최근 연구는 더 강력한 supervision 신호 (Bahmani et al., 2023; Zheng et al., 2023)를 추구하기 위해 여러 디퓨전 priors를 결합하여 사진 현실성을 더욱 개선하는 데 중점을 둡니다.
그러나 이러한 접근 방식을 실제 세계에 배포하려면 최적화 시간과 계산 비용이 많이 듭니다.
또한 3D 콘텐츠는 모션과 결합하기 때문에 생성된 모션의 다양성과 제어가 부족합니다.
최근 몇 가지 작업에서 입력 이미지에서 4D 모델을 얻는 것이 제안되었습니다 (Zhao et al., 2023).
그러나 여전히 비디오 distillation 프레임워크를 고수하고 있으며 장기간의 최적화 시간과 효과적인 모션 제어 부족으로 어려움을 겪고 있습니다.
핵심적인 것은 Consistent4D (Jiang et al., 2023)는 입력 비디오에서 4D 모델을 얻는 것을 제안한다는 것입니다.
이와 비교하여 동일한 정적 모델에서 다양한 모션을 허용하는 이미지 조건으로 생성된 비디오를 연구합니다.
동시 작업 (Ling et al., 2023)에서는 고품질 4D 생성을 위해 Gaussian Splatting도 탐구하며 우리의 접근 방식은 비교하여 최적화 반복 횟수의 5% 미만이 필요합니다.
3. Approach
DreamGaussian4D는 3단계로 구성됩니다.
초기 단계인 정적 생성에는 입력 이미지에서 3D Gaussians을 생성하기 위해 DreamGaussian (Tang et al., 2023a)의 향상된 변형을 설계하는 것이 포함됩니다.
두 번째 단계인 동적 생성은 입력 이미지에서 구동 비디오를 생성하여 정적 3D Gaussians에 대한 시간 의존적 변형 필드를 최적화합니다(섹션 3.2).
마지막 단계는 4D Gaussians을 애니메이션 메시 시퀀스로 변환하고 video-to-video 파이프라인을 적용하여 텍스처 맵을 일관되게 개선하는 옵션 메시 개선입니다(섹션 3.3).

3.1. DreamGaussianHD for Static Generation
빠른 최적화 속도에도 불구하고 원래의 DreamGaussian (Tang et al., 2023a)은 그림 6과 같이 정적 모델의 보이지 않는 영역에 상당한 블러함을 도입합니다.
이러한 블러함은 후속 동적 최적화 프로세스에 악영향을 미칩니다.
따라서 저희는 먼저 최적화 시간을 합리적으로 늘리는 대신 DreamGaussian의 image-to-3D 생성 품질을 안정적으로 향상시키기 위해 더 나은 구현 관행을 설계합니다.
저희는 이러한 개선된 관행을 DreamGaussianHD로 요약합니다.
3.1.1. Multi-view Optimization
참조 뷰와 별도로 DreamGaussian은 일반적으로 SDS에 대한 각 최적화 반복에서 하나의 랜덤 뷰를 샘플링합니다.
이 접근 방식은 Gaussians의 일부만 다루고 불균형 최적화 및 수렴으로 이어집니다.
이전 연구에서 볼 수 있듯이 각 최적화 단계에서 샘플링된 뷰 수(배치 크기)를 늘리면 이 문제를 크게 완화할 수 있습니다(Poole et al., 2022; Chen et al., 2023).
예를 들어, 16개의 뷰를 샘플링하면 3D Gaussians의 보이지 않는 영역에서 고품질 지오메트리가 생성됩니다.
이 접근 방식은 SDS 계산 중 메모리 사용량이 증가하고 최적화 기간이 길어집니다.
3.1.2. Fixing Background Color
DreamGaussian은 흑백에서 배경 색상을 균일하게 샘플링합니다.
그러나 대부분의 3D-aware 이미지 디퓨전 모델은 학습 객체를 흰색 배경으로 렌더링합니다.
저희는 검은색 배경을 사용한 렌더링이 최적화 프로세스에 추가 노이즈를 도입하여 궁극적으로 블러함을 초래하는 것을 관찰했습니다.
배경 색상을 흰색으로 일관되게 설정함으로써 최적화된 3D GS에서 더 상세하고 정제된 결과를 얻을 수 있습니다.
3.2. Gaussian Deformation for Dynamic Generation
3.2.1. Generating Driving Video
특정 비디오 디퓨전 모델을 사용하여 SDS supervision을 수행하는 다른 방법 (Bahmani et al., 2023)과 달리 입력 이미지를 묘사하는 모든 비디오에서 명시적 supervision을 사용할 것을 제안합니다.
이 비디오는 video-to-4D (Jiang et al., 2023)와 같은 아티스트에 의해 생성되거나 image-to-video 모델에서 자동으로 생성될 수 있습니다.
실제로 우리는 기성품의 Stabel Diffusion Video (Blattmann et al., 2023)를 사용하여 입력 이미지에서 비디오를 생성합니다:
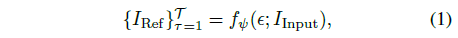
, 여기서 I_Input은 입력 이미지, {I_Ref}_(τ =1)^T는 주행 이미지, ϵ는 랜덤 노이즈, f_ψ는 image-to-video 디퓨전 모델입니다.
저희 방식은 추후 비디오 디퓨전 모델에 의존하지 않기 때문에 서로 다른 랜덤 시드에 의해 생성된 시간적 일관성과 모션이 더 우수한 고품질 비디오를 선택할 수 있어 image-to-4D 생성을 위한 제어성과 다양성이 향상됩니다.
3.2.2. Static-to-Dynamic Initialization
정적 3D Gaussians을 동적 4D Gaussians로 더욱 보강하기 위해 타임스탬프가 주어진 각 Gaussian의 위치, 회전 및 규모 변화를 예측하도록 변형 네트워크를 학습합니다.
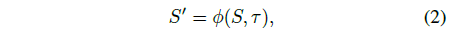
, 여기서 ϕ는 변형 네트워크, S는 위치, 회전 및 스케일링을 포함한 정적 3D GS의 공간 설명, τ는 타임 스탬프, S'는 변형된 3D GS 공간 설명입니다.
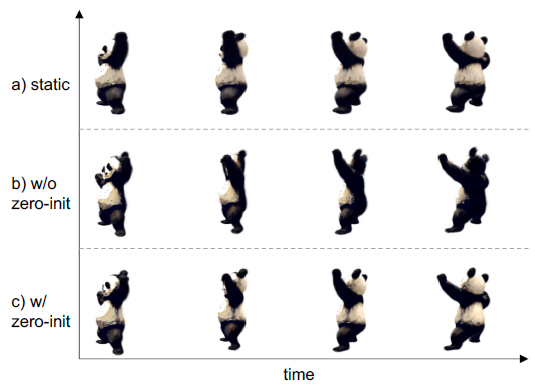
그러나 변형 네트워크를 랜덤으로 초기화하면 동적 모델과 정적 모델 간에 차이가 발생하여 그림 7에 예시된 바와 같이 차선의 모드로 수렴할 수 있습니다.
이를 완화하기 위해 변형 모델을 초기화하여 학습 시작 시 변형을 0으로 예측합니다.
구체적으로, 최종 예측 헤드의 가중치와 편향을 0으로 초기화합니다.
그래디언트 역전파를 가능하게 하기 위해 예측 헤드에 스킵 연결이 도입됩니다.
3.2.3. Deformation Field Optimization
우리는 참조 뷰에서 주행 비디오가 주어진 변형 필드를 최적화합니다.
우리는 카메라를 참조 뷰에 고정하고, 각 타임스탬프에서 렌더링된 이미지와 주행 비디오 프레임 사이의 Mean Squared Error (MSE)를 최소화합니다:
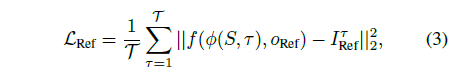
, 여기서 I_Ref^τ는 비디오의 τ번째 프레임이며, o_Ref는 참조 뷰 포인트이고 f는 렌더링 함수입니다.
참조 뷰에서 전체 3D 모델로 모션을 전파하기 위해 Zero-1-to-3-XL (Deitke et al., 2023a)을 활용하여 보이지 않는 부분의 변형을 예측합니다.
이미지 디퓨전 모델은 프레임별 예측만 수행하지만 정적 3D GS의 색상과 불투명도가 고정되어 있기 때문에 시간적 일관성은 대부분 유지될 수 있습니다.
DreamGaussianHD의 학습 관행과 유사하게 각 시간 단계에서 여러 뷰가 샘플링됩니다.
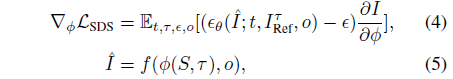
, 여기서 ϵ는 랜덤 노이즈, ϵ_θ는 3D-aware 이미지 디퓨전 모델의 노이즈 예측 변수, o는 랜덤 시점입니다.
정적 모델 초기화 덕분에 우리는 더 낮은 노이즈 레벨에서 SDS를 시작할 수 있습니다.
구체적으로, 우리는 일반적인 관행인 T_max = 0.98보다 낮은 T_max = 0.5로 SDS를 시작합니다.

3.3. Video-to-video Texture Refinement
각 프레임에 대한 메시는 DreamGaussian (Tang et al., 2023a)과 유사하게 추출할 수 있으며, 이는 로컬 밀도 쿼리를 실행하고 색상을 역투영하는 것을 포함합니다.
그러나 이러한 프레임별 메시는 시간적 연관성이 부족하며, 그림 9와 같이 텍스처를 개별적으로 정제하면 깜박임이 발생할 수 있습니다.
시간적 일관성을 유지하면서 UV 공간 텍스처 맵을 향상시키기 위해 video-to-video 파이프라인을 사용합니다.
이 프로세스는 카메라 궤적을 합성하는 것으로 시작되며, 카메라는 랜덤으로 선택된 수평 각도에서 0 고도를 따라 일정한 속도로 이동합니다.
그런 다음 비디오를 렌더링하고 0.7 레벨의 노이즈를 도입합니다.
마지막으로 image-to-video 디퓨전 모델을 사용하여 이 노이즈가 많은 비디오를 디노이즈된 깨끗한 버전으로 변환합니다:
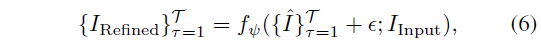
, 여기서 ϵ는 지정된 레벨에서 랜덤 노이즈이고 {ˆI}_(τ=1)^T는 렌더링된 비디오입니다.
MSE loss는 두 비디오 사이에서 계산됩니다:
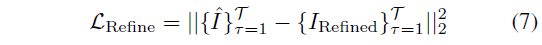
loss는 모든 시간 단계에서 텍스처 맵을 개선하기 위해 역전파됩니다.
4. Experiments
4.1. Implementation Details
저희는 모든 실험을 단일 80GB A100 GPU에서 실행합니다.
저희는 오픈 소스 저장소인 DreamGaussian (Tang et al., 2023a) 및 4D Gaussian Splatting (Wu et al., 2023)에서 DreamGaussian4D 프레임워크를 구현합니다.
비디오 생성을 위해 Stable Video Diffusion을 사용하여 14개의 프레임을 생성합니다.
정적 최적화를 위해 배치 크기가 16인 500번의 반복을 2분 동안 실행합니다.
저희는 T_max를 0.98에서 0.02로 선형 감쇠합니다.
동적 표현을 위해 배치 크기 4로 4.5분 동안 200번의 반복을 실행하고, T_max는 0.5에서 0.02로 선형 감쇠합니다.
옵션 메쉬 개선의 경우 3.5분 동안 일정한 T = 0.7로 50번의 반복을 실행합니다.

4.2. Quantitative Results
저희는 Animate124 (Zhao et al., 2023)에 제공된 예제를 평가합니다.
평가 메트릭의 경우 CLIP-I를 계산합니다.
CLIP-I는 참조 뷰 렌더링과 참조 이미지 간의 CLIP 이미지 임베딩의 코사인 유사성을 측정합니다.
결과는 표 2에 나와 있습니다.
DreamGaussian은 입력 이미지와 가장 좋은 유사성을 달성합니다.
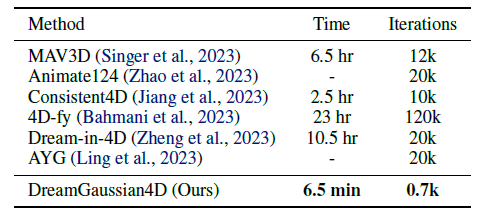
또한 표 1의 실행 속도를 비교합니다.
DreamGaussian4D는 최적화 시간을 몇 시간에서 몇 분으로 단축합니다.


4.3. Qualitative Results
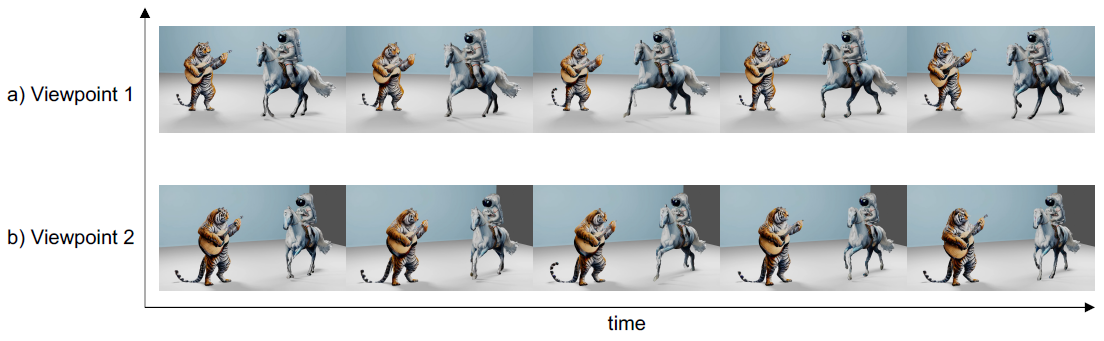
저희는 그림 3에서 정성적인 image-to-4D 결과를 보여줍니다.
결과는 다양한 시간 단계와 카메라 뷰로 렌더링됩니다.
그림 4에서 저희는 저희의 접근 방식을 Animate124와 비교합니다.
저희의 접근 방식은 입력 이미지에 대한 더 나은 충실도, 더 강한 움직임, 지오메트리 및 텍스처의 더 풍부한 디테일을 달성합니다.
저희는 또한 텍스처가 개선된 메쉬에 4D GS를 내보내고 Blender 엔진에서 합성합니다.
저희는 그림 5에서 합성된 장면을 다른 시야각에서 렌더링합니다.
4.4. Ablation
4.4.1. DreamGaussianHD
저희는 그림 6에서 DreamGaussianHD의 image-to-3D 품질 향상을 ablate합니다.
저희는 특히 측면 뷰와 후면 뷰에서 DreamGaussian의 심각한 블러를 관찰합니다.
멀티 뷰 최적화와 배경 고정을 도입함으로써 새로운 뷰 품질이 크게 향상되었습니다.
4.4.2. Zero-Initialization
제로 초기화를 하지 않으면 동적 모델이 최적화를 시작할 때 정적 모델과 약간 다를 수 있고 최적화 과정에서 차이가 의미되어 차선의 결과를 초래할 수 있습니다.
그림 7에서 판다의 등은 정적 단계에서 흑백이었습니다.
그러나 다른 방식으로 초기화하면 동적 최적화 후 등이 완전히 검은색으로 변할 수 있습니다.
이 문제는 제로 초기화를 통해 해결됩니다.
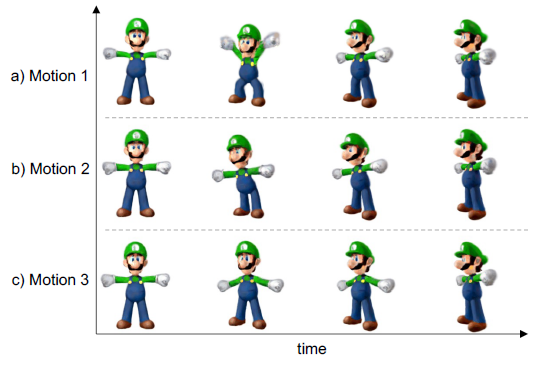
4.4.3. Diverse Motions
SDS를 사용하는 대부분의 기존 4D 생성 접근 방식(Bahmani et al., 2023; Giang et al., 2023)과 달리, 우리의 방법은 더 나은 제어 가능성과 모션의 더 다양성을 허용합니다.
서로 다른 주행 비디오에서 서로 다른 4D 모션을 생성할 수 있습니다.
그림 8에서는 입력 이미지에 대한 세 가지 다른 주행 비디오를 생성하여 세 가지 다른 3D 모션을 생성합니다.
4.4.4. Video-to-video Texture Refinement
프레임별 메쉬는 개별 텍스처 맵이 있으므로 표현에 시간적 일관성 제한이 없습니다.
그림 9와 같이 DreamGaussian 같은 정제를 사용하여 텍스처 맵을 직접 최적화하면 인접한 프레임에서 깜박임이 발생합니다.
대신 비디오 디퓨전 모델은 시간적 일관성을 제공하고 더 부드러운 시간적 변화를 초래합니다.
5. Conclusion
저희는 4D Gaussian Splatting을 사용하여 4D 콘텐츠를 생성하는 프레임워크인 DreamGaussian4D를 제안합니다.
저희는 Gaussian Splatting에서 공간 변환의 명시적 모델링이 4D 생성 작업을 크게 단순화한다는 것을 보여줍니다.
DreamGaussian4D는 최적화 시간을 몇 시간에서 몇 분으로 크게 단축합니다.
또한 생성된 비디오를 사용하여 모션을 구동하면 처음으로 3D 모션을 명시적으로 제어할 수 있습니다.
마지막으로 DreamGaussian4D는 메쉬 추출과 시간적으로 일관된 텍스처 최적화를 가능하게 하여 실제 애플리케이션을 용이하게 합니다.