2024. 9. 16. 16:53ㆍ3D Vision/NeRF with Real-World
Hallucinated Neural Radiance Fields in the Wild
Xingyu Chen, Qi Zhang, Xiaoyu Li, Yue Chen, Ying Feng, Xuan Wang, Jue Wang
Abstract
Neural Radiance Fields (NeRF)는 최근 인상적인 새로운 뷰 합성 능력으로 인기를 얻고 있습니다.
이 논문은 환각 상태의 NeRF 문제를 연구합니다: 즉, 관광 이미지 그룹에서 하루 중 다른 시간에 현실적인 NeRF를 복구하는 것입니다.
기존 솔루션은 다양한 조건에서 새로운 뷰를 렌더링하기 위해 제어 가능한 외관 임베딩을 갖춘 NeRF를 채택하지만, 보이지 않는 외관으로 뷰 일관성 있는 이미지를 렌더링할 수는 없습니다.
이 문제를 해결하기 위해 Ha-NeRF라고 불리는 hallucinated NeRF를 구성하기 위한 종단 간 프레임워크를 제시합니다.
특히 시간에 따라 변하는 외관을 처리하고 새로운 뷰로 전달하기 위한 외관 환각 모듈을 제안합니다.
관광 이미지의 복잡한 폐색을 고려하여 정적 피사체를 정확하게 분해하여 가시성을 확보하기 위해 폐색 방지 모듈을 도입합니다.
합성 데이터와 실제 관광 사진 컬렉션에 대한 실험 결과는 우리의 방법이 원하는 외관을 환각시키고 다양한 뷰에서 폐색이 없는 이미지를 렌더링할 수 있음을 보여줍니다.
1. Introduction
최근 몇 년 동안 뉴럴 렌더링 기술의 급속한 발전과 함께 장면에 대한 사진 사실적인 새로운 뷰를 합성하는 것이 연구의 핫스팟이 되고 있습니다.
베를린의 Brandenberg Gate를 방문하여 다른 시간과 날씨에 풍경을 즐기고 싶지만 코로나바이러스 팬데믹으로 인해 그럴 수 없다고 상상해 보세요.
이 환각 경험이 최대한 매력적이려면 날씨, 시간 및 기타 요인에 따라 달라질 수 있는 다양한 관점의 사진 사실적 이미지가 필요합니다.
이를 달성하기 위해 Neural Radiance Fields (NeRF) [33]와 그 다음 방법 [25,40,58]은 3D 지오메트리와 외관을 복구할 수 있는 놀라운 능력을 보여주어 사용자에게 물리적으로 그곳에 있는 듯한 몰입감을 제공합니다.
그러나 NeRF의 한 가지 중요한 단점은 가변 조명과 움직이는 물체가 없는 이미지 그룹, 즉 장면의 광채가 각 뷰마다 일정하고 볼 수 있다는 것입니다.
안타깝게도 관광 랜드마크의 대부분의 이미지는 서로 다른 시간에 촬영되고 다양한 물체에 의해 가려지는 인터넷 사진입니다.
대부분의 NeRF 기반 방법은 가변 외관과 transient 폐색기가 발생하면 3D 볼륨에 통합하여 볼륨의 실제 장면을 방해합니다.
가변 외관과 폐색기가 있는 이미지에서 폐색이 없는 뷰를 합성하는 방법은 아직 해결해야 할 문제입니다.
Martin-Brualla et al. [28]는 NeRF in the Wild (NeRF-W) 방법을 제안하여 앞서 언급한 문제를 해결하려고 시도합니다.
이들은 각 입력 이미지에 대한 외관 임베딩을 최적화하여 가변 외관을 해결하고 transient 볼륨을 사용하여 정적 구성 요소와 폐색을 분해합니다.
NeRF와 비교하여 NeRF-W는 가변 외관 및 폐색기가 있는 관광 이미지에서 현실적인 세계를 복구하기 위한 한 걸음을 내디뎠습니다.
그러나 NeRF-W는 학습 샘플의 최적화된 임베딩을 통해 제어 가능한 외관을 구현하므로 새로운 이미지가 주어졌을 때 임베딩을 최적화해야 하며 다른 데이터 세트의 외관을 환각할 수 없습니다.
또한 NeRF-W는 transient 임베딩을 입력으로 사용하여 각 입력 이미지에 대한 transient 볼륨을 최적화하려고 시도하는데, 이는 transient 폐색기의 랜덤성으로 인해 매우 ill-posed에 있습니다.
이는 장면의 부정확한 분해로 이어지고 또한 외관과 폐색의 얽힘을 유발하여 예를 들어 transient 볼륨이 일몰 광채를 기억하게 만듭니다.

이러한 한계를 해결하기 위해 그림 1과 같이 다양한 모양과 폐색기를 가진 제약 없는 관광 이미지에서 사실적인 래디언스 필드를 환각할 수 있는 hallucinated NeRF(Ha-NeRF) 프레임워크를 제시합니다.
외관 환각을 위해 CNN 기반 외관 인코더와 뷰 일관성 있는 외관 loss를 제안하여 다양한 뷰에서 일관된 측광 외관을 전송합니다.
이 설계는 학습되지 않은 이미지의 외관을 유연하게 전달할 수 있는 방법을 제공합니다.
폐색 방지를 위해 MLP를 활용하여 학습 중에 정적 구성 요소를 높은 정확도로 자동으로 분리할 수 있는 폐색 방지 loss가 있는 이미지 종속 2D 가시성 마스크를 학습합니다.
여러 랜드마크에 대한 실험을 통해 외관 환각 및 폐색 방지 측면에서 제안된 방법의 우수성을 확인할 수 있습니다.
저희의 기여는 다음과 같이 요약할 수 있습니다:
1. Ha-NeRF는 다양한 외관과 폐색기를 가진 이미지 그룹에서 외관 환각 래디언스 필드를 복구하기 위해 제안되었습니다.
2. 외관 환각 모듈은 뷰 일관성 있는 외관을 새로운 뷰로 전달하기 위해 개발되었습니다.
3. 폐색 방지 모듈은 ray 가시성을 인식하기 위해 이미지에 따라 모델링됩니다.
2. Related Work
Novel View Synthesis.
사진-사실적인 이미지 렌더링은 컴퓨터 비전의 핵심이며 수십 년 동안 연구의 초점이 되어 왔습니다.
전통적으로 뷰 합성은 조밀한 이미지의 암시적 지오메트리 [4, 10, 15, 24, 29] 및 명시적 지오메트리 [5, 11, 17, 18, 36]와 같은 지오메트리 구조 [49]와 결합된 이미지 기반 워핑 작업으로 간주될 수 있습니다.
최근 연구에서는 장면에서 물체의 빛과 반사율을 명시적으로 추론하기 위해 제약이 없는 사진 모음을 사용했습니다[22,48].
다른 작업은 의미 정보를 사용하여 transient 물체를 복원합니다 [39].
딥러닝의 발전으로 많은 접근 방식이 딥러닝 기술을 적용하여 뷰 합성의 성능을 개선하고 있습니다.
연구자들은 컨볼루션 신경망과 장면 지오메트리를 결합하여 새로운 뷰 합성을 위한 depth 또는 평면 호모그래피를 예측하려고 합니다 [7, 19, 26, 35, 56, 61].
레이어드 depth 이미지 [47]에서 영감을 받은 최근 연구는 명시적인 장면 표현 (예: 다중 평면 이미지, 다중 구 이미지)을 활용하고 새로운 뷰 합성을 위해 알파 합성을 사용하여 새로운 뷰를 렌더링합니다 [3, 12, 32, 51, 55, 60].
최근에는 연구자들이 새로운 뷰 합성을 위한 장면을 표현하기 위해 암시적 함수 (예: 인코딩된 피쳐, NeRF)를 학습하는 어려운 문제에 집중하고 있습니다 [33, 44, 45, 58].
Neural Rendering.
Neural Rendering [53]은 밀접한 관련이 있으며 고전적인 컴퓨터 그래픽과 딥러닝의 아이디어를 결합하여 실제 관찰에서 이미지와 재구성 지오메트리를 합성하는 알고리즘을 만듭니다.
여러 연구에서 학습된 잠재 텍스처 [54], 포인트 클라우드 [1, 9], 점유 필드 [31], 부호 거리 함수 [38] 등 학습 구성 요소를 렌더링 파이프라인에 주입하는 다양한 방법을 제시합니다.
이미지 변환 네트워크를 기반으로 Meshry et al. [30]은 뷰 합성을 위해 포인트 클라우드를 복구하기 위해 학습된 잠재 모양 임베딩 모듈을 조건으로 하는 뉴럴 재렌더링 네트워크를 학습했습니다.
그러나 이미지 변환 네트워크를 활용하면 카메라 움직임 아래에서 시간적 아티팩트가 표시됩니다.
볼륨 렌더링 [27, 33, 50]의 개발로 사실적이고 일관된 뷰를 쉽게 렌더링할 수 있습니다.
Mildenhall et al. [33]은 Neural Radiance Fields (NeRF)를 제안하고 multi-layer perceptron (MLP)을 사용하여 래디언스 필드를 복원합니다.
많은 후속 작업은 NeRF를 동적 장면 [6, 25, 40, 58]으로 확장하고 빠른 학습과 렌더링 [8, 13, 43, 57]을 시도하며 장면 편집 [2, 28, 34, 59]을 시도합니다.
Martin-Brualla et al. [28]는 정적 볼륨과 동적 볼륨을 각각 통해 외관을 최적화하고 폐색을 해결하기 위해 NeRF in the Wild (NeRF-W)를 제안하지만 일부 장면에서는 실패했습니다.
동적 볼륨은 종종 시야 의존 조명과 같은 외관의 극적인 변화를 설명하는 데 사용됩니다.
또한 NeRF-W는 제어 가능한 외관을 구현하지만, 한 번도 본 적이 없는 외관에서 일관된 시야를 환각하기 어렵습니다.
Appearance Transfer.
주어진 장면은 다양한 기상 조건과 다른 시간에 극적으로 다양한 모습을 보여줄 수 있습니다.
Grag et al. [14]는 동일한 위치에서 촬영된 관광 이미지에서 장면 출현의 차원이 transient 물체와 같은 이상치를 제외하고는 상대적으로 낮다고 제안합니다.
컬렉션 [22]에서 일관된 알베도를 추정하고, 형상 복구에서 표면 알베도와 장면 조명을 분리하고, 타임스탬프와 지오로케이션을 통해 태양의 위치를 검색하거나, 고정된 뷰 [52]를 가정하여 사진 컬렉션의 외관을 복구할 수 있습니다.
그러나 이러한 방법은 야간 장면 출현에는 적용되지 않는 간단한 조명 모델을 가정합니다.
Radenovic et al. [42]는 낮과 밤의 뚜렷한 재구성을 복원하지만 낮과 밤의 부드러운 외관 눈금을 달성할 수 없습니다.
Park et al. [37]은 일반적인 장면을 묘사하는 이미지 컬렉션의 외관을 최적화하는 효율적인 기술을 제안합니다.
Meshry [30]는 입력 이미지 분포에서 학습한 데이터 기반 암묵적 외관 표현을 사용하며, Martin-Brualla et al. [28]는 데이터 기반 방법을 NeRF로 확장하고 외관 제어 가능한 각 뷰에 대한 외관 잠재 코드를 최적화합니다.
반면, 제안된 방법은 뷰에서 분해된 외관 피쳐를 학습하려고 시도하므로 학습되지 않은 외관에서 일관되게 새로운 시각을 환각할 수 있습니다.
3. Preliminary
먼저 Ha-NeRF가 확장되는 Neural Radiance Fields (NeRF) [33]를 소개합니다.
NeRF는 multilayer perceptron (MLP)으로 모델링된 연속 체적 함수 F_θ을 사용하는 장면을 나타냅니다.
3D 위치 x = (x, y, z) 및 2D 뷰잉 방향 d = (α, β)를 입력으로 받아 방출된 색상 c = (r, g, b) 및 부피 밀도 σ를

로 출력하며, 여기서 θ = (θ_1, θ_2)는 MLP 매개변수, γ_x(·) 및 γ_d(·)는 각각 x 및 d의 값에 적용되는 위치 인코딩 함수입니다.
장면을 통과하는 ray의 색상을 렌더링하기 위해 NeRF는 수치 직교를 사용하여 볼륨 렌더링 적분을 근사화합니다.
r(t) = o + td를 카메라 중심 o에서 이미지 평면의 주어진 픽셀을 통해 방출되는 ray라고 합니다.
픽셀의 색 ^C(r)의 근사치는

이며, 여기서 c_k와 σ_k는 점 r(t_k)의 색과 밀도, δ_k = t_(k+1) - t_k는 두 직교 점 사이의 거리입니다.
계층화 샘플링은 카메라의 근거리 평면과 원거리 평면 사이의 직교 점 {t_k} =1을 선택하는 데 사용됩니다.
직관적으로 알파 값 1 - exp(1-σ_k δ_k)로 합성하는 알파는 해당 위치에서 ray가 종료될 확률로 해석할 수 있으며, 함수 T_k는 가까운 평면에서 r(t_k)까지의 ray를 따라 축적된 투과율에 해당합니다.
MLP 매개변수를 최적화하기 위해 NeRF는 이미지 컬렉션 {I_i}과 해당 렌더링된 출력 사이의 제곱 오차의 합을 최소화합니다.
각 이미지 I_i는 structure-from-motion 알고리즘을 사용하여 추정할 수 있는 intrinsic 및 extrinsic 카메라 매개 변수로 등록됩니다.
NeRF는 이미지 I_i에서 픽셀 j의 카메라 ray {r_ij} 세트를 미리 계산하며, 각 ray r_ij(t) = o_i + td_ij가 방향 d_ij로 3D 위치 o_i를 통과합니다.
모든 매개변수는 다음 loss
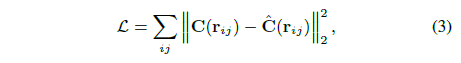
을 최소화하여 최적화되며, 여기서 C(r_ij)는 이미지 I_i에서 ray j의 관찰된 색상입니다.
4. Method
다양한 외관과 transient 폐색기를 가진 장면의 사진 모음이 주어지면, 우리는 폐색을 처리하는 동안 새로운 장면에서 환각을 일으킬 수 있는 장면을 재구성하는 것을 목표로 합니다.
즉, 다른 측광 조건에서 캡처된 새로운 뷰에 따라 전체 3D 장면의 외관을 수정할 수 있다는 것입니다.
보다 구체적으로, 야생에서 사진을 입력으로 촬영하는 것은 섹션 4.1에서 컨볼루션 신경망에 의해 인코딩된 외관 임베딩에 의해 변조된 외관 독립적인 NeRF를 재구성하는 것입니다.
사진의 transient 폐색기를 해결하기 위해 섹션 4.2에서 정적 장면을 자동으로 분리하는 폐색 처리 모듈을 제안합니다.
그림 2는 제안된 아키텍처의 개요를 보여줍니다.
다음으로 각 모듈에 대해 자세히 설명합니다.
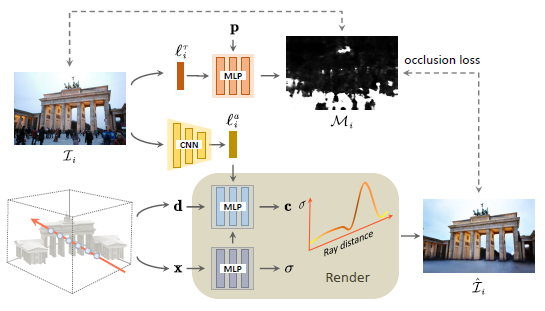
4.1. View-consistent Hallucination
다양한 외관을 가진 입력의 새로운 장면에 따른 3D 장면의 환각을 달성하려면 장면 지오메트리와 외관을 분리하는 방법과 재구성된 장면으로 새로운 외관을 전달하는 방법이 핵심 문제입니다.
NeRF-W [28]는 최적화된 외관 임베딩을 사용하여 입력의 이미지 의존적 외관을 설명하려고 합니다.
그러나 이 임베딩은 학습 중에 최적화되어야 하므로 학습 샘플을 넘어선 새로운 장면에서 장면을 환각하기 위해 임베딩을 최적화해야 하며 다른 데이터 세트의 외관을 환각할 수 없습니다.
따라서 우리는 컨볼루션 신경망 기반 인코더 E_ɸ을 사용하여 분리된 외관 표현을 학습할 것을 제안하며, 이 중 ɸ 매개변수는 입력의 다양한 조명 및 측광 후처리를 설명합니다.
E_ɸ는 각 이미지 I_i를 외관 잠재 벡터 l_i^a로 인코딩합니다.
식 1의 래디언스 c는 외관 의존적 래디언스 c^(l_i^a)로 확장되어 방출되는 색상에 대한 외관 잠재 벡터 l_i^a에 대한 의존성을 도입합니다:

외관 인코더 E_ɸ의 매개변수 ɸ은 레이디언스 필드 F_θ의 매개변수 θ와 함께 학습됩니다.
이 외관 인코더를 통해 우리의 방법은 학습 세트 이상의 이미지 외관을 유연하게 사용할 수 있습니다.
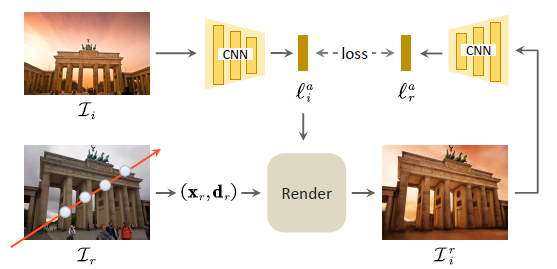
그러나 페어링되지 않은 이미지로 외관과 뷰 방향을 분리하는 문제는 본질적으로 ill-posed이며 추가적인 제약이 필요합니다.
잠재 회귀 loss를 활용하여 이미지 공간과 잠재 공간 간의 반전 매핑을 장려하는 최근 연구 [20, 23, 62]에서 영감을 받아, 외관 인코더 E_ɸ에서 외관 벡터 l_i^(a)를 가져와 외관과 시야의 분리를 달성하기 위해 뷰 일관성 loss L_v를 제안하고
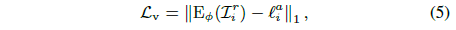
로 공식화된 다양한 뷰에서 재구성을 시도하며, 여기서 I_i^r은 그림 3과 같이 뷰가 랜덤으로 생성되고 이미지 I_i에 외관이 조건화된 렌더링된 이미지입니다.
여기서 우리는 재구성된 외관 벡터 E_ɸ(I_i^r)가 서로 다른 뷰에서 전역적으로 표현되므로 원래 외관 벡터 l_i^a와 동일해야 한다고 가정합니다.
뷰 일관성 loss로 인해 입력과 동일한 외관 벡터가 주어지면 뷰 일관성 있는 모양 렌더링을 수행할 수 있습니다.
또한 동일한 벡터에서 볼륨을 컨디셔닝할 때 서로 다른 뷰 (또한 콘텐츠)의 렌더링 이미지를 동일한 벡터로 인코딩하는 뷰 일관성 loss를 통해 이미지 지오메트리 콘텐츠를 외관 벡터로 인코딩하는 것을 방지합니다.
효율성을 개선하기 위해 학습 중에 전체 이미지를 렌더링하는 대신 ray 그리드를 샘플링하고 이미지 I_i^r로 결합합니다. [46].
이는 랜덤 그리드를 사용하여 샘플링한 후에도 이미지의 전역 외관 벡터가 변경되지 않는다는 가정을 기반으로 합니다.
4.2. Occlusion Handling
3D transient 필드를 사용하여 [28]에서와 같이 개별 이미지에서만 관찰되는 transient 현상을 재구성하는 대신 이미지 종속 2D 가시성 맵을 사용하여 transient 현상을 제거합니다.
이러한 단순화를 통해 우리의 방법은 정적 장면과 transient 물체 사이를 보다 정확하게 세그멘테이션할 수 있습니다.
맵을 모델링하기 위해 2D 픽셀 위치 p = (u, v)와 이미지 의존적 transient 임베딩 l_i^ τ를 가시적인 가능성 M에 매핑하는 암시적 연속 함수 F_ψ을 사용합니다:
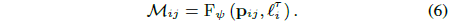
가시성 맵을 학습합니다, 이는 정적 장면에서 발생한 ray가 이미지의 정적 및 transient 현상을 unsupervised 방식으로 분리하여 폐색 loss L_o를 초래한다는 것을 나타냅니다:
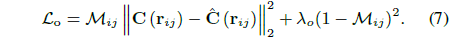
첫 번째 항은 렌더링된 색상과 ground truth 색상 간의 픽셀 가시성을 고려한 재구성 오류입니다.
눈에 보이는 가능성 M의 값이 클수록 정적 현상에 속한다는 가정 하에서 픽셀에 할당된 중요도가 향상됩니다.
첫 번째 항은 보이지 않는 확률에 승수 λ_o를 갖는 정규화기에 해당하는 두 번째 항으로 균형을 맞추고 있으며, 이는 모델이 정적 현상을 외면하는 것을 방지합니다.
4.3. Optimization
Ha-NeRF를 달성하기 위해 앞서 언급한 제약 조건을 결합하고 매개 변수(θ, ɸ, ψ)와 이미지별 transient 임베딩 {l_i^ τ}을 공동으로 학습하여 전체 objective를 최적화합니다:
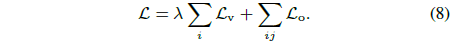
5. Experiments
5.1. Implementation Details
NeRF 및 NeRF-W의 구현은 [41]을 따릅니다.
정적 뉴럴 래디언스 필드 F_θ은 256개의 채널을 가진 8개의 완전 연결 레이어와 ReLU 활성화를 통해 σ을 생성하고 시그모이드 활성화를 통해 1개의 추가 128개의 채널을 완전 연결하여 외관에 의존하는 RGB 색상 c를 출력하는 것으로 구성됩니다.
외관 인코더 E_ɸ는 5개의 컨볼루션 레이어에 이어 적응형 평균 풀링과 48차원의 외관 벡터 l_i^(a)를 얻기 위한 완전 연결 레이어로 구성됩니다.
이미지 의존적 2D 가시성 마스크 F_ψ은 256개 채널로 구성된 5개의 완전 연결 레이어로 모델링된 후 시그모이드 활성화를 통해 128차원의 transient 임베딩 l_i^ τ에 조건을 맞춘 가시적 가능성 M을 생성합니다.
우리는 λ을 1 x 10^-3으로, λ_o를 6 x 10^-3으로 설정했습니다.
야생에서 Ha-NeRF의 성능을 평가하기 위해 문화 랜드마크의 인터넷 사진 컬렉션으로 구성된 Phototourism 데이터 세트를 사용하여 "Brandenburg Gate”, “Sacre Coeur”, “Trevi Fountain”라는 세 가지 데이터 세트를 구축했습니다.
우리는 학습 중에 모든 이미지를 2배 다운샘플링합니다.
5.2. Evaluation
Baselines.
우리는 NeRF, NeRF-W 및 Ha-NeRF의 두 가지 ablations에 대해 제안된 방법을 평가합니다: Ha-NeRF(A) 및 Ha-NeRF(T).
Ha-NeRF(A) (appearance)는 가시성 네트워크 F_ɸ를 제거하여 전체 모델을 구축하는 반면, Ha-NeRF(T) (transient)는 전체 모델에서 외관 인코더 E_ψ를 제거합니다.
Ha-NeRF는 우리 방법의 완전한 모델입니다.
Comparisons.
우리는 새로운 뷰 합성 작업에 대한 방법과 베이스라인을 평가합니다.
각 테스트 이미지의 왼쪽 절반을 사용하여 테스트 세트의 외관 임베딩을 최적화하는 NeRF-W를 제외한 모든 방법은 동일한 입력 뷰 세트를 사용하여 각 장면에 대한 매개 변수와 임베딩을 학습합니다.
시각적 검사를 위해 렌더링된 이미지를 제시하고 PSNR, SSIM, LPIPS를 기반으로 정량적 결과를 보고합니다.

그림 4는 장면 하위 집합에 대한 모든 모델과 베이스라인에 대한 정성적 결과를 보여줍니다.
NeRF는 고스팅 아티팩트와 전역 색상 이동으로 인해 어려움을 겪고 있습니다.
NeRF-W는 보다 정확한 3D 재구성을 생성하고 다양한 광도 효과를 모델링할 수 있습니다.
그러나 여전히 "Brandenburg Gate" 주변의 안개 효과와 같은 블러 아티팩트로 인해 어려움을 겪고 있습니다.
이러한 안개 효과는 transient 현상을 재구성하기 위해 3D transient 필드를 추정하려는 NeRF-W의 시도의 결과이며, transient 물체는 단일 이미지에서만 관찰됩니다.
동시에 NeRF-W의 렌더링도 "Sacre Coeur"의 햇빛과 푸른 하늘, "Trevi Fountain"의 빛 반사와 같이 ground truth와 비교하여 다른 모습을 보이는 경향이 있습니다.
Ha-NeRF(A)는 "Sacre Coeur" 상단의 파란색 하늘과 같이 보다 일관된 모양을 가지고 있습니다.
그러나 폐색으로 인해 고주파 디테일을 재구성할 수 없습니다.
반면, Ha-NeRF(T)는 "Brandenburg Gate"의 정사각형과 같은 폐색이 있는 구조를 재구성할 수 있지만 다양한 광도 효과를 모델링할 수 없습니다.
Ha-NeRF는 두 가지 ablations의 장점이 있으므로 더 나은 외관과 폐색 방지 렌더링을 생성합니다.

정량적 결과는 표 1에 요약되어 있습니다.
야생의 사진 모음에서 NeRF를 최적화하면 NeRF-W와 경쟁할 수 없는 특히 열악한 결과가 초래됩니다.
반면, Ha-NeRF는 모든 데이터 세트에서 LPIPS에서 다른 것보다 성능이 뛰어나면서 NeRF-W에 비해 경쟁력 있는 PSNR 및 SSIM을 달성합니다.
사실 이러한 비교는 불공평합니다.
테스트 이미지에서 외관을 전송하려면 학습 중에 테스트 이미지의 하위 집합에서 외관 벡터를 최적화해야 합니다.
Ha-NeRF는 학습 중에 테스트 이미지를 사용하지 않습니다.
테스트할 때 Ha-NeRF는 학습된 인코더에 의해 이미지 외관을 직접 인코딩할 수 있습니다.
그럼에도 불구하고, 우리의 방법은 NeRF-W에 비해 여전히 경쟁력 있는 결과를 생성할 수 있습니다.
또한 NeRF-W는 시야 불일치를 나타냅니다.
카메라가 이동함에 따라 동일한 외관 임베딩을 조건으로 하는 렌더링은 일관성 없는 외관을 갖는 것으로 보이며, 이는 현재 메트릭으로 반영할 수 없습니다.
그리고 결과를 보충 자료에 넣어 NeRF-W와 Ha-NeRF의 일관성 비교를 위해 노력합니다.
Appearance Hallucination.
잠재 벡터 l_i^(a)의 색상을 컨디셔닝함으로써 기본 3D 지오메트리를 변경하지 않고도 렌더링의 조명과 모양을 수정할 수 있습니다.
한편, 인코더 E_ɸ로 모양을 인코딩하면 프레임워크가 예제 안내 외관 전송을 수행할 수 있습니다.

그림 5에서 예제 이미지에서 추출한 다양한 외관 벡터를 사용하여 Ha-NeRF에서 생성한 렌더링 이미지를 볼 수 있습니다.
또한 학습 중에 외관 벡터가 최적화된 NeRF-W의 결과도 보여줍니다.
Ha-NeRF는 사실적인 이미지를 환각시키는 반면, NeRF-W는 예제 이미지와 비교하여 전역적인 색상 변화를 겪고 있습니다.
또한 그림 6은 Ha-NeRF가 모양의 고주파 정보를 캡처하고 장면의 햇빛과 색광 반사를 환각할 수 있음을 보여줍니다.


Ha-NeRF는 다른 환각을 얻기 위해 외관 벡터를 보간할 수도 있습니다.
그림 7에서는 고정된 카메라 위치에서 렌더링된 5개의 이미지를 제시하며, 여기서 가장 왼쪽 및 오른쪽 이미지에서 인코딩된 외관 벡터를 보간합니다.
렌더링된 이미지의 외관은 Ha-NeRF에 의해 두 평가변수 간에 원활하게 전환된다는 점에 유의하세요.
그러나 보간된 NeRF-W의 결과는 일몰 광채를 완전히 무시합니다.
또한 렌더링 중에 NeRF-W의 transient 필드(NeRF-W w/T)를 추가하여 일몰 광채를 보여줍니다.
이는 NeRF-W가 가변 외관(일몰 광채)과 transient 현상(사람)을 잘 분리하지 못한다는 것을 보여줍니다.

Cross-Appearance Hallucination.
우리는 다른 데이터 세트에서 사용자가 제공한 예제 이미지로 외관 전송을 수행할 수 있습니다.
그림 8과 같이 "Trevi Fountain"의 예제 이미지에서 "Brandenburg Gate" 조건에 대한 새로운 외관을 환각합니다.
우리는 외관 이미지와 장면 사이에 도메인 간격이 큰 그림 9와 같이 근본적으로 다른 장면에서 외관을 전송할 수도 있습니다.
NeRF-W는 동일한 장소를 묘사해야 하는 예제 이미지에서 외관 벡터를 최적화해야 하기 때문에 NeRF-W는 본질적으로 다른 데이터 세트의 외관을 환각할 수 없다는 점에 유의합니다.


Occlusion Handling.
이미지 의존적 2D 가시성 맵을 사용하여 transient 현상을 제거하는 반면, NeRF-W는 3D transient도 필드를 사용하여 transient 객체를 재구성합니다.
그림 10에 나와 있듯이 폐색 처리 방법은 정적 장면과 transient 객체 사이에 정확한 세그멘테이션을 생성하여 폐색 없는 이미지를 렌더링할 수 있습니다.
그러나 NeRF-W는 장면 (예: 보드, 사람, 울타리가 NeRF-W 렌더링에 그대로 남아 있음)을 부정확하게 분해하고 3D transient 필드에서 변수 외관과 transient 폐색을 더욱 얽히게 합니다 (예: transient 볼륨이 "Brandenburg Gate"의 화이트 클라우드를 기억하게 됩니다).
Limitations.
제안된 Ha-NeRF는 예외 없이 대부분의 NeRF 기반 접근 방식과 유사하게 노이지 카메라 extrinsic 매개 변수로 인해 어려움을 겪습니다.
또한 입력 이미지가 모션 블러링되거나 디포커스되는 동안 합성 이미지의 품질이 저하됩니다.
이러한 문제를 처리하기 위해 특정 기술을 개발해야 합니다.
6. Conclusion
NeRF는 점점 더 주목받고 있으며 관광 이미지에서 NeRF를 복구하는 등 다양한 응용 분야에 활용되고 있습니다.
NeRF-W는 학습 데이터에 최적화된 외관 임베딩으로 효과적으로 작동하지만, 학습되지 않은 외관에서 일관되게 새로운 시각을 환각하기는 어렵습니다.
이 어려운 문제를 극복하기 위해 가변적인 외관과 복잡한 폐색 하에서 현실적인 래디언스 필드를 환각할 수 있는 Ha-NeRF를 제시합니다.
특히 시간에 따라 변하는 외관을 처리하고 새로운 시각으로 전달하기 위해 외관 환각 모듈을 제안합니다.
또한 폐색 방지 모듈을 사용하여 정적 피사체를 정확하게 분리할 수 있는 이미지 의존적 2D 가시성 마스크를 학습합니다.
합성 데이터와 관광 사진 컬렉션을 사용한 실험 결과는 우리의 방법이 외관의 자유 폐색 뷰와 환각을 만들 수 있음을 보여줍니다.
코드와 모델은 재현 가능한 연구를 촉진하기 위해 연구 커뮤니티에서 공개적으로 사용할 수 있습니다.
'3D Vision > NeRF with Real-World' 카테고리의 다른 글
| RobustNeRF: Ignoring Distractors with Robust Losses (0) | 2024.10.03 |
|---|---|
| Cross-Ray Neural Radiance Fields for Novel-view Synthesis from Unconstrained Image Collections (0) | 2024.10.02 |
| NeRF-MS: Neural Radiance Fields with Multi-Sequence (0) | 2024.09.28 |
| NeRF for Outdoor Scene Relighting (0) | 2024.09.25 |
| NeRF in the Wild: Neural Radiance Fields for Unconstrained Photo Collections (0) | 2022.04.13 |