2024. 9. 25. 14:54ㆍ3D Vision/NeRF with Real-World
NeRF for Outdoor Scene Relighting
Viktor Rudnev, Mohamed Elgharib, William Smith, Lingjie Liu, Vladislav Golyanik, Christian Theobalt
Abstract
사진에서 실외 장면을 사실적으로 편집하려면 이미지 형성 과정에 대한 깊은 이해와 장면 지오메트리, 반사율 및 조명의 정확한 추정이 필요합니다.
그런 다음 장면 알베도와 지오메트리를 변경하지 않으면서 조명을 섬세하게 조작할 수 있습니다.
뉴럴 래디언스 필드를 기반으로 한 실외 장면 재조명을 위한 최초의 접근 방식인 NeRF-OSR을 제시합니다.
기존 기술과 달리, 이 방법은 제어되지 않은 설정에서 촬영한 실외 사진 모음만 사용하여 조명과 카메라 시점을 동시에 편집할 수 있습니다.
또한 구형 고조파 모델을 통해 정의된 바와 같이 장면 조명을 직접 제어할 수 있습니다.
평가를 위해 여러 시점과 다른 시간에 여러 시점에서 촬영된 여러 실외 sites의 새로운 벤치마크 데이터 세트를 수집합니다.
매번 360˚ 환경 맵이 색상 보정 체커보드와 함께 캡처되어 실제 데이터에 대한 정확한 수치 평가가 가능합니다.
SOTA와의 비교에 따르면 NeRF-OSR은 더 높은 품질과 사실적인 자체 음영 재현으로 제어 가능한 조명 및 시점 편집을 가능하게 합니다.
1 Introduction
사진에서 실제 장면을 제어 가능하게 조명 편집하는 것은 가상 현실과 증강 현실의 여러 응용 분야에서 오랫동안 지속되어 온 어려운 문제입니다 [8,20,21,27,46].
이미지 형성 프로세스의 명시적인 모델링과 재료 특성 및 장면 조명의 정확한 추정이 필요합니다.
이러한 장면 분해를 통해 나머지 장면 구성 요소 (예: 알베도 및 지오메트리)의 무결성을 유지하면서 조명을 개별적으로 조작할 수 있습니다.
제어 가능한 조명 편집을 위한 여러 가지 방법이 존재하지만, 일부 솔루션은 사람의 얼굴 [18,34] 및 사람의 신체 [8,21]와 같은 특정 종류의 물체에만 전용으로 제공됩니다.
다른 솔루션은 실내 [7,20,30,33,45,49] 또는 실외 [1,5,27,44,46] 장면을 처리하도록 설계되었습니다.
실내 데이터와 실외 데이터의 특성이 매우 다르기 때문에 이를 재조명하는 방법은 문헌에서 주로 별도로 취급되었습니다.
이 작업에서는 실외 장면 재조명에 초점을 맞춥니다.
기존 방법 [1,5,27,44,46]과 달리, 우리의 접근 방식은 장면 조명과 카메라 시점을 동시에 편집하는 최초의 접근 방식입니다.
최근 제안된 Neural Radiance Fields (NeRF) [23]는 보정된 단안 카메라 [26, 39, 40, 48]로 기록된 2D 이미지에서 self-supervissd 학습을 할 수 있는 강력한 뉴럴 3D 장면 표현입니다.
테스트 시점에 NeRF는 사실적인 새로운 장면 뷰를 생성할 수 있습니다.
조명 편집을 위해 NeRF를 확장하려는 시도가 몇 차례 있었지만 [3, 19, 33, 35, 49] 기존 접근 방식은 특정 오브젝트 클래스[35]를 위해 설계되었거나, 학습을 위해 알려진 또는 단일 조명 조건이 필요하거나 [33, 49], 주조 그림자와 같은 중요한 실외 조명 효과를 모델링하지 않습니다 [3].
대부분의 기존 NeRF 기반 재조면 방법[3, 33, 35, 49]은 제어되지 않은 설정에서 캡처된 실외 장면을 위해 설계되지 않았습니다.
이에 대한 예외는 언뜻 보기에 제어되지 않은 이미지에서 학습된 NeRF in the Wild (NeRF-W) [19]로, 이미지별 외관을 임베딩 공간에 팩토링합니다.
그러나 NeRF-W와 최근 후속 조치 [4, 37]는 intrinsic 이미지 분해를 수행하지 않으므로 조명, 그림자 또는 심지어 알베도에 대한 의미론적으로 의미 있는 매개변수 제어가 불가능합니다.

이 논문은 기존 방법의 단점을 해결하고 NeRF-OSR, 즉 제어되지 않은 환경에서 촬영된 실외 장면의 조명과 카메라 시점을 고품질의 의미 있는 방식으로 변경할 수 있는 뉴럴 래디언스 필드 기반의 첫 번째 접근 방식을 제시하며, 그림 1을 참조하세요.
우리의 접근 방식은 입력된 이미지를 intrinsic 구성 요소와 장면 조명으로 분리하여 이미지 형성 프로세스를 모델링합니다.
또한 고품질 실외 장면 재조명을 위해 사실적인 재현이 중요한 그림자 학습 전용 네트워크가 포함되어 있습니다.
NeRF-OSR은 서로 다른 시점과 서로 다른 조명 아래에서 촬영된 여러 sites 이미지에 대해 self-supervised 방식으로 학습됩니다.
우리는 다양한 실외 장면에 대해 우리의 방법을 질적, 정량적으로 평가하고 SOTA를 능가한다는 것을 보여줍니다.
우리 작업의 참신성 측면에는 다음이 포함됩니다:
– NeRF-OSR, 즉, 장면 조명 및 카메라 시점의 동시적이고 의미론적으로 의미 있는 편집을 지원하는 야외 장면 재조명을 위해 뉴럴 래디언스 필드를 사용하는 첫 번째 방법입니다.
우리 모델은 로컬 셰이딩, 그림자, 심지어 알베도를 포함한 장면 intrinsic 요소를 명시적으로 제어할 수 있습니다.
– 우리의 방법은 장면을 공간 점유, 조명, 그림자 및 확산 알베도 반사율로 분해하는 신경 장면 표현을 학습합니다.
다양한 관점과 다양한 조명에서 캡처한 실외 데이터에서 self-supervised 방식으로 학습됩니다.
– 야외 장면 재조명을 위한 새롭고 가장 큰 문헌 벤치마크 데이터 세트입니다.
여기에는 3240개 시점과 110개 다른 시간대에서 촬영된 8개의 건물이 포함됩니다.
또한 정확한 수치 평가가 가능한 색상 보정 360˚ 환경 맵이 포함된 최초의 데이터 세트입니다.
2 Related Work
Scene Relighting.
실외 조명 편집에는 여러 가지 방법이 있습니다 [1, 5, 10-12, 27, 36, 44, 46, 47].
그 중 일부는 조명에 일관된 방식으로 물체를 이미지에 통합하는 데 초점을 맞추고[10, 44], 다른 일부는 전체 장면을 처리합니다[1, 5,11,12,27,36,46,47].
Duchene et al. [5]는 고정 조명에서 촬영한 여러 뷰에서 장면 반사율, 음영 및 가시성을 추정합니다.
이들은 움직이는 캐스트 그림자와 같은 새로운 재조명 효과를 생성합니다.
Barron et al. [1]은 통계적 추론을 통해 역 렌더링을 공식화합니다.
물체의 단일 RGB 이미지가 주어졌을 때, 이 방법은 조사된 이미지를 재현할 수 있는 가장 가능성이 높은 모양의 노멀, 반사율, 음영 및 조명을 추정합니다.
이들은 조각별로 매끄럽고 낮은 엔트로피 반사율 이미지와 등방성(흔히 구부러짐) 표면을 가정합니다.
Philip et al. [27]은 멀티뷰 이미지에서 추정된 프록시 지오메트리를 통해 재조명을 가이드합니다.
신경망은 조사된 장면의 이미지 공간 버퍼를 원하는 재조명으로 변환합니다.
버퍼에는 섀도우 마스크(추출된 지오메트리에서 추정), 노멀 맵 및 조명 구성 요소가 포함됩니다.
Philip et al.의 방법은 고품질 합성 데이터로 학습됩니다.
그러나 주로 카메라 시점이 아닌 입력의 조명만 편집하도록 설계되었습니다.
또한 조명 모델은 태양 조명으로 제한되며 흐린 하늘과 같은 다른 경우는 처리할 수 없습니다.
Yu와 Smith [47]는 단일 이미지에서 실외 장면의 알베도, 노멀 및 조명을 추정하고, 통계 모델을 prior로 하여 spherical harmonics (SH)를 통해 조명을 모델링합니다.
그런 다음 재구성된 조명(저주파 모델 사용)을 편집하여 재조명을 달성합니다.
Yu et al. [46]은 제어되지 않은 대규모 실외 이미지 코퍼스에서 주어진 단일 이미지를 self-supervised 방식으로 장면 재조명하는 방법을 학습합니다.
뉴럴 렌더러는 원본 알베도 및 지오메트리, 타겟 셰이딩 및 타겟 그림자를 가져와 장면을 재조명하고 전용 네트워크는 타겟 그림자를 예측합니다.
그런 다음, 역 렌더링의 잔차 장면 세부 정보를 더 잘 캡처하기 위한 입력으로 뉴럴 렌더러에 제공됩니다.
인상적인 결과는 새로운 벤치마크 데이터 세트에서 시각적으로 표시되고 수치적으로 검증됩니다.
우리의 접근 방식과 달리 Yu et al. [46]와 Yu 및 Smith [47]는 카메라 시점을 편집할 수 없습니다.
최근 NeRF 백본 [3, 33, 35, 49]을 사용하여 재조명 방법을 개발하려는 노력이 있었습니다.
이러한 방법의 대부분은 우리와 다른 설정에서 작동합니다, 즉, 단일 조명 조건 [49]을 가진 입력 이미지가 필요하거나, 학습 중 [33] 알려진 조명을 가정하거나, 얼굴 [35]과 같은 특정 종류의 물체를 위해 설계되었습니다.
우리의 기법에 가장 가까운 것은 Boss et al. [3]의 NeRD로, 서로 다른 조명 아래에서 촬영된 동일한 장면의 이미지에서 작동할 수 있다는 점에서 그렇습니다.
여기서 조사된 장면의 공간적으로 변화하는 BRDF는 물리적 기반 렌더링의 도움을 통해 추정됩니다.
임의의 시점과 조명에서 빠른 렌더링을 허용하기 위해 학습된 반사율 볼륨은 조명 가능한 텍스처 메시로 변환됩니다.
NeRF-OSR과 달리 NeRD는 고품질 야외 장면 재조명에 중요한 그림자를 명시적으로 모델링하지 않습니다.
또한 조사된 물체가 모든 뷰에서 비슷한 거리에 있어야 합니다—통제되지 않은 환경에서 촬영한 야외 사진에 대해 쉽게 만족할 수 없는 가정입니다.
Style-based Editing.
장면 재조명 기법은 스타일 기반 외관 편집 방법 범주와 멀리 관련이 있습니다 [4, 15, 17, 19, 22, 24, 31, 37].
재조명 방법과 달리 후자는 장면 조명에 대한 물리적 이해가 없으며 전체 외관을 한 번에 편집하려고 합니다.
따라서 로컬 음영과 그림자에 대한 명시적인 매개 변수 제어가 부족합니다.
반면, NeRF-OSR은 장면 intrinsic 분해를 수행하고 알베도 및 지오메트리와 분리하여 조명을 편집하려고 합니다.
또한 고품질 야외 재조명에 중요한 조명 기반 그림자를 직접 모델링합니다.
다음으로, 우리의 intrinsic 분해는 스타일 기반 방법으로는 불가능한 애플리케이션을 편집할 수 있습니다 (예: 알베도 채널을 별도로 편집하여 객체를 삽입한 다음 전체 합성된 새 장면을 재조명하는 등).
3 Method
NeRF-OSR은 서로 다른 타이밍과 서로 다른 시점에서 촬영된 단일 장면의 여러 RGB 이미지를 입력으로 받습니다.
그런 다음 조사된 장면을 임의의 시점과 다양한 조명 아래에서 렌더링합니다.
우리의 방법은 장면 intrinsic을 명시적으로 추정하고 장면 조명에 직접 액세스할 수 있습니다.
또한 그림자를 예측하기 위한 전용 구성 요소, 즉 야외 장면 조명의 필수 기능도 포함합니다.
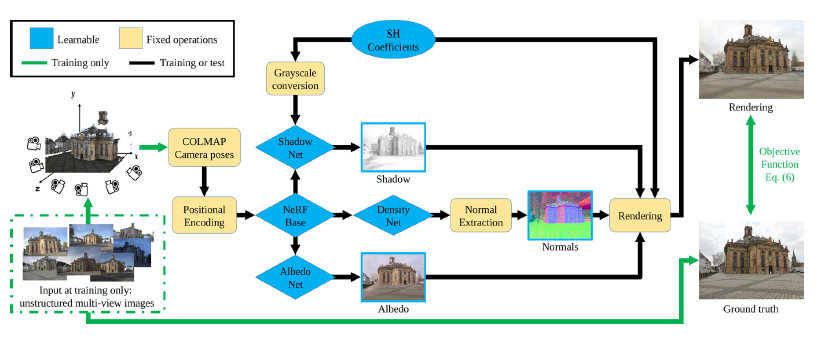
NeRF-OSR의 개요는 그림 2에 나와 있습니다.
그 중심에는 neural radiance fields (NeRF), 즉 체적 렌더링을 위한 신경 암시적 장면 표현이 있습니다.
우리의 방법은 제어되지 않은 설정에서 캡처된 실외 데이터에 대해 self-supervised 방식으로 학습되며 사실적인 뷰를 렌더링할 수 있습니다.
다음으로, 우리는 뷰 종속 효과가 없는 NeRF 모델 [23]을 섹션 3.1에 설명하며, 이를 기반으로 구축합니다.
그런 다음 조명 모델과 섹션 3.2-3.3의 체적 기반 표현에서 조명 모델이 어떻게 적응되는지 논의합니다.
objective 함수는 섹션 3.4에 제시된 후 학습 세부 사항에 대해 논의합니다(섹션 3.5).
3.1 Neural Radiance Fields (NeRF)
3.2 Spherical Harmonics NeRF
(1)은 고품질의 자유 시점 합성을 허용하지만, c(x)는 조명을 인코딩하지 않는 MLP를 통해서만 정의됩니다.
즉, 이러한 공식은 고정 조명 하에서 장면의 Lambertian 모델을 학습합니다.
시야 방향 의존성이 있는 보다 일반화된 모델 [23]은 고정 조명에서 겉보기 BRDF의 일부를 학습합니다.
그럼에도 불구하고 이 학습된 표현은 여전히 기본 장면 intrinsics의 의미론적 의미를 갖지 않으며 조명을 직접 제어할 수 없습니다.
재조명을 허용하기 위해 명시적인 2차 Spherical Harmonics (SH) 조명 모델 [2]을 도입하고 렌더링 식 (1)을 다음
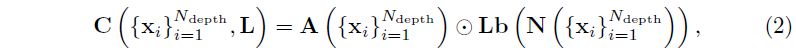
와 같이 재정의하며, 여기서 ⊙는 요소별 곱셈을 나타냅니다.
A(x) ∈ R^3은 (1)과 유사한 방식으로 생성된 축적된 알베도 색상, 즉 알베도 MLP의 출력을 적분하여 생성됩니다.
L ∈ R^(9×3)은 이미지별 학습 가능한 SH 계수이고, b(n) ∈ R^9는 SH 기저입니다.
N(x)은 축적된 ray 밀도로부터 계산된 표면 노멀입니다.
이는
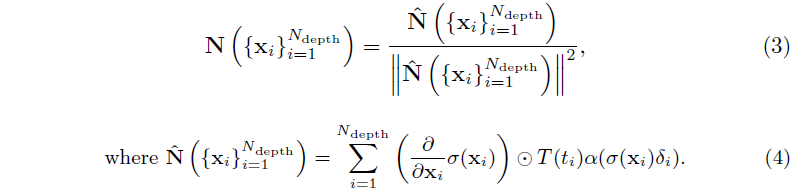
으로 정의됩니다.
N을 추출하기 위해 먼저 ray 샘플의 원래 x-, y-, z- 구성 요소와 관련하여 ray의 점 밀도를 미분하고 가중치 T(t_i)α(σ(x_i)δ_i)로 ray의 모든 N_depth 샘플에 축적한 다음 결과 벡터를 단위 구로 정규화합니다.
(2)에서는 신경 볼륨에서 축적된 화면 공간 알베도와 노멀 분포를 사용하여 화면 공간에서 렌더링합니다.
축적을 통해 알베도 및 표면 노멀 분포 추정치가 덜 시끄럽고 수렴하는 데 도움이 됩니다.
또한 샘플 포인트당 하나의 대안이 아닌 단일 음영 계산만 수행하고 음영 색상을 축적한다는 의미이기도 합니다.
고정된 명시적 모델을 기반으로 하는 SH 기저 b(·)와 노멀 추출 연산자 N(·)을 제외한 (2)의 모든 항은 학습할 수 있습니다.
제안된 조명 모델 통합은 L을 변화시켜 명시적인 조명을 허용한다.
Lambertian 효과를 설명하지만 야외 장면의 모델링 및 후속 재조명에 중요한 직접 그림자 생성이 부족합니다.
3.3 Shadow Generation Network
재조명 시 명시적인 그림자 제어를 허용하기 위해 전용 그림자 모델 S({x_i, L)를 도입하고 렌더링 식 (2)을 확장합니다:
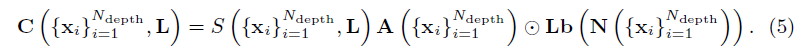
그림자 모델은 MLP s(x, L) ∈[0, 1]에 의해 계산된 스칼라로 정의됩니다.
최종 그림자 값은 (1)과 동일한 방식으로 ray를 따라 S({x_i}, L) ∈[0, 1]에 축적되어 계산됩니다.
그림 2는 제안된 NeRF-OSR의 상위 수준 다이어그램을 보여줍니다.
그림자 예측 네트워크는 회색 스케일 버전, 즉 L ∈ R^(1×9)의 SH 계수를 입력으로 사용하며 R^(3×9)는 입력하지 않습니다.
이는 그림자가 공간 광 분포에만 의존한다는 사실에서 동기가 부여됩니다.
[27, 33]에 사용된 기존의 레이 트레이싱 접근 방식과 달리, 그림자 추정기는 알베도 및 지오메트리와 동일한 단일 순방향 패스를 통해 훨씬 더 효율적으로 작동합니다.
우리는 이 방법을 훨씬 더 계산적으로 확장할 수 있으면서도 완전히 새로운 조명 조건을 사용하여 다시 조명할 수 있기 때문에 강점이라고 주장합니다.
3.4 Objective Function
다음 loss 함수를 최적화합니다:
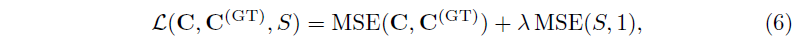
, 여기서 MSE(·, ·)는 평균 제곱 오차입니다.
첫 번째 항은 추정된 색상 C와 해당 ground truth C^(GT)에 정의된 재구성 loss입니다.
두 번째 항은 그림자를 정규화합니다.
그림자 네트워크 S는 SH로 설명할 수 없는 모든 회색조 조명 효과를 흡수합니다.
그림자만 학습하는 것으로 제한하기 위해 재구성된 이미지의 PSNR을 저하시키지 않는 정규화 강도 λ의 가장 큰 값을 선택합니다.
실험에 따르면 정규화기를 제거하면 일반적으로 색도를 제외한 모든 조명 구성 요소를 S가 학습하는 것으로 나타났습니다
—따라서 SH 조명을 쓸모없게 만듭니다.
3.5 Training and Implementation Details
우리의 self-supervised 모델은 다양한 관점에서 다른 조명 아래에서 촬영된 야외 장면의 RGB 이미지로 학습됩니다.
다음으로 우리의 방법과 그 중요성을 학습하기 위한 몇 가지 전략을 설명합니다.
Frequency Annealing.
우리는 모델을 그대로 학습하면 노이즈가 많은 노멀 맵이 생성된다는 것을 경험적으로 발견했습니다.
positional encoding (PE) 주파수의 일부 임계값을 넘으면 (학습 시작 시) 처음에 생성된 노이즈는 조작하기가 매우 어려워지며 올바른 지오메트리로 거의 수렴하지 않습니다.
따라서 Deformable NeRF [26]에서 약간 수정된 어닐링 체계를 사용하여 이를 완화합니다, 즉, 각 PE 구성 요소에 어닐링 계수 β_k(n)를 추가합니다: γ'_k(x) = γ_k(x) β_k(n), 여기서 β_k(n) = 1/2(1-cos(πclamp(α - i + N_f_min, 0, 1)), α(n) = (N_f_max - N_f_min) n/N_anneal, n은 현재 학습 반복, N_f_max는 사용된 PE 주파수의 총 개수(제안된 모델은 12개를 사용함), N_f_min은 시작 시 사용된 PE 주파수의 개수입니다(8개를 사용함), N_anneal은 모든 시퀀스에 대해 경험적으로 3 · 104로 조정됩니다.
이 학습 전략을 통해 지오메트리 예측을 크게 개선할 수 있습니다.
Ray Direction Jitter.
NeRF-OSR의 일반화 가능성을 개선하기 위해 ray 방향에 하위 픽셀 jitter를 적용합니다.
여기서는 픽셀 중심에서 촬영하는 대신 jitter ψ를 다음과 같이 사용합니다: xi = o+t_i(d+ψ).
우리는 균일하게 ψ을 샘플링하여 결과 ray가 여전히 지정된 픽셀의 경계에 국한되도록 합니다.
Shadow Network Input Jitter.
그림자는 직접 기하학적 접근 방식을 사용하는 대신 학습 기반 방식으로 생성되므로 학습 조명에 과적합될 가능성이 남아 있습니다.
이러한 효과를 완화하기 위해 그림자 생성 네트워크의 입력으로 환경 계수에 약간의 노멀 노이즈 ε를 추가합니다:
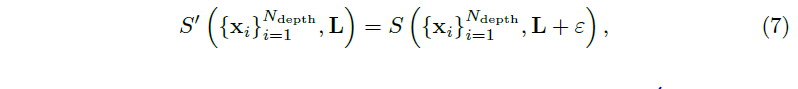
, 여기서 ε ~N(0, 0.025I).
(7)은 로컬성 조건으로 해석할 수 있으며, 즉 유사한 조명 조건에서 그림자가 너무 달라져서는 안 됩니다.
이를 통해 모델은 서로 다른 조명 간의 원활한 전환을 학습할 수 있습니다.
Implementation.
우리는 백그라운드 네트워크가 비활성화된 NeRF++[48]을 코드 베이스로 사용하며 전경 네트워크의 단위 구 경계 내에서 작동합니다.
학습 및 평가를 위해 두 개의 Nvidia Quadro RTX 8000 GPU를 사용합니다.
≈ 2일이 걸리는 2^10 ray 배치 크기를 사용하여 5회 및 10^5회 반복에 대한 모델을 학습합니다.
4 A New Benchmark for Outdoor Scene Relighting
실외 sites에 대한 여러 데이터 세트가 존재합니다 [9, 14, 15, 32, 46].
대부분 [9, 14, 15, 32]은 재조명이 아닌 3D 장면 재구성 작업을 염두에 두고 수집되었습니다.
따라서 대부분 통제되지 않은 설정에서 수집된 공개적으로 사용 가능한 사진이 포함되어 있습니다.
또한 실제 데이터에서 ground truth에 맞서 수치적으로 재조명 기술을 평가하는 데 중요한 환경 맵을 제공하지 않습니다.
이러한 데이터 세트의 예로는 PhotoTourism [9, 32]과 MegaDepth [14]가 있습니다.
MegaDepth 데이터 세트는 처음에 랜드마크10k 데이터 세트 [13]의 일부인 여러 sites의 멀티뷰 이미지로 구성됩니다.
여기서 depth 신호는 COLMAP [29]와 multi-view stereo (MVS) 접근 방식 [28]을 사용하여 추출됩니다.
MegaDepth는 원래 단일 뷰 depth 추출을 위한 벤치마크로 출시되었지만 Yu et al. [46]이 사용했습니다 (가장 최근 재조명 작업 중 하나).
그러나 방법을 정성적으로만 평가할 수 있습니다.
실제 데이터에 대한 ground truth에 대한 수치 평가를 위해 Yu et al. [46]은 환경 맵과 함께 DSLR 카메라를 사용하여 하루 중 서로 다른 시점과 다른 시간에 한 site를 기록했습니다.
안타깝게도 이 벤치마크는 두 가지 방식으로 제한됩니다: 첫째, 단일 site가 포함되어 있습니다.
둘째, 캡처된 환경 맵은 주요 기록의 DSLR 카메라와 관련하여 색상 보정되지 않았습니다.
따라서 이 데이터 세트로 얻은 수치 결과는 알 수 없는 비선형 색상 변환에 의해 항상 ground truth와 다를 수 있습니다.
따라서 모든 오류 메트릭은 먼저 최적의 변환을 계산해야 합니다(Yu et al. [46]은 색상별 채널 선형 스케일링을 사용했습니다).
따라서 조사된 재조명 방법의 동작과 이 정규화의 수정 동작을 분리하기가 어렵습니다.
따라서 야외 장면 재조명을 위한 새로운 벤치마크를 제시합니다.
우리의 데이터 세트는 ground truth에 맞서 실제 데이터에 대한 정확한 수치 평가를 수행할 수 있는 크기와 기능 측면에서 최초의 데이터 세트입니다.
DSLR 카메라 (110개의 서로 다른 녹화 세션에서 캡처한 3240개의 시점)를 사용하여 다양한 관점에서 캡처한 8개의 sites를 포함하는 Yu et al. [46]보다 훨씬 큽니다.
하루 중 서로 다른 시간에 각 site에 대해 여러 번의 녹화 세션이 수행되었으며, 모든 세션은 화창한 날과 흐린 날을 포함한 다양한 날씨를 포함합니다.
또한 각 세션에 대한 환경 맵의 360˚ 샷을 캡처합니다.
Yu et al. [46]와 달리, 우리는 주요 녹화의 환경 맵과 DSLR 카메라 간의 색상 보정을 명시적으로 설명합니다.
이를 위해—테스트 세트의 모든 세션에 대해—DSLR 및 360˚ 카메라를 사용하여 "GreTagMacbeth ColorChecker" 색상 보정 차트도 동시에 캡처합니다.
그런 다음 Finlayson et al. [6]의 2차 방법을 적용하여 해당 DSLR 이미지의 ColorChecker 값을 보정하여 환경 맵을 색상 보정합니다.
마지막으로, 각 site의 COLMAP [29] 재구성을 사용하여 환경 맵을 월드 좌표에 수동으로 정렬합니다.


그림 3은 데이터 세트의 다양한 sites와 해당 환경 맵의 샘플을 보여줍니다.
색상 보정된 환경 맵은 그림 4를 참조하세요.
저희는 벽돌이나 목재 건물과 같이 특정 효과가 최소화된 장면을 대상으로 합니다.
모든 데이터는 DSLR 사진의 경우 -3 ~ +3 EV, 환경 맵의 경우 -2 ~ +2 EV 범위의 5개 사진 노출 브래킷에 캡처되었습니다.
태양이 과도하게 노출되지 않도록 360˚ 환경 맵에 가장 어두운 캡처를 사용했습니다.
DSLR을 사용한 컬러체커 보정의 경우 체커보드의 백색 세포가 과도하게 노출되지 않도록 충분히 어두운 이미지를 사용합니다.
DSLR 이미지 해상도는 5184×3456픽셀이고 환경 맵의 해상도는 5660×2830픽셀입니다.
5 Results
우리는 다양한 실제 sites에서 NeRF-OSR의 성능을 평가합니다.
새로 제안된 데이터 세트의 세 sites와 Phototourism 데이터 세트 [19]의 Trevi Fountain을 살펴봅니다.
이러한 장면에는 다양한 피쳐가 포함됩니다.
여기에는 조각품 (Site 1, Trevi)과 같은 크고 작은 규모의 세부 사항, 나무와 우산과 같은 구조적 세부 사항 (Site 3), 스스로 많은 그림자를 드리우는 조각별로 매끄러운 표면 (Site 2), 물 (Trevi)) 및 주변 건물 (모두)이 포함됩니다.
또한 Trevi Fountain는 크라우드소싱을 통해 인터넷에서 완전히 수집된 데이터에 대한 성능을 보여줍니다.
환경 맵이 없기 때문에 Trevi Fountain에 대한 정성적 평가만 가능하다는 점에 유의하세요.
또한 ablative 연구에서 방법의 다양한 설계 선택 사항을 평가합니다.
기존 장면 relighting 방법 (섹션 2 참조) 중, 우리는 주로 Yu et al. [46] 및 Philip et al. [27]과 유사한 유형의 입력 데이터를 처리하고, 제어되지 않은 설정에서 촬영된 야외 장면과 장면 조명에 대한 직접적인 시맨틱 이해를 가지고 있기 때문에 비교합니다.
그러나 그럼에도 불구하고 Yu et al. [46]과 Philip et al. [27]은 모두 입력 이미지의 조명만 편집하도록 설계되었으며, 우리의 방법은 조명과 시점을 모두 편집할 수 있습니다.
따라서 이 두 가지 방법 [27,46]은 우리 방법의 직접적인 경쟁자가 아니라 여전히 문헌에서 가장 관련성이 높습니다.
NeRV [33]는 설정이 우리 방법과 근본적으로 다르기 때문에 데이터에 적용할 수 없습니다.
우리의 기법은 알 수 없는 조명에서 촬영된 데이터를 사용하는 반면, 학습 장면은 알려진 조명에 의해 조명되어야 합니다.
또한 intrinsic 분해를 수행하지 않고, 장면 조명에 대한 물리적 이해가 없으며, 환경 맵에 따라 조명을 편집할 수 없기 때문에 NeRF-W [19] 또는 기타 스타일 기반 방법과 정량적으로 비교하지 않습니다.
반면, NeRF-OSR의 intrinsic 분해는 스타일 기반 방법으로는 접근할 수 없는 애플리케이션을 가능하게 합니다.
예를 들어, 우리는 조사된 장면의 알베도를 편집하고 결과적으로 합성된 전체 장면을 다시 조명하는 방법을 보여줍니다 (그림 7-가운데).
또한 추출된 메시와 알베도를 사용하여 기존의 컴퓨터 그래픽 방법으로 실시간 렌더링을 달성하는 방법을 보여줍니다 (그림 7-왼쪽).

Boss et al. [3] (NeRD)는 검사 대상이 모든 뷰에서 비슷한 거리에 있어야 한다는 점에 유의합니다 — 통제되지 않은 설정과 데이터에서 캡처된 실외 데이터에 대해 근본적으로 위반되는 가정입니다.
NeRD의 저자들이 확인한 바와 같이, 이로 인해 데이터에 대한 재구성이 거의 불가능합니다.
또한 논문 저자들이 데이터에 NeRD를 실행하려고 시도한 결과 ray당 많은 수의 샘플이 필요한 ray 거리 변화가 발생했습니다.
따라서 NeRD로 데이터를 처리하는 것은 계산적으로 불가능했습니다.
NeRF-OSR은 뉴럴 래디언스 필드를 사용하여 실외 sites의 시점과 조명을 동시에 편집할 수 있는 최초의 방법입니다.
또한 기본 장면 intrinsics를 추출하고 전용 조명 기반 그림자 구성 요소를 갖추고 있으며 사진사실적 결과를 생성하며 SOTA 기술을 크게 능가합니다.
또한 부드러운 그림자만 합성하는 것으로 제한되지 않으며 새로운 하드 그림자도 합성할 수 있습니다 (그림 1 및 5 참조).

Data Pre-Processing.
NeRF-OSR은 동적 물체를 합성하여 학습 단계에서 버리는 것 (예: 자동차, 사람, 자전거)을 목표로 하지 않기 때문입니다.
기록하는 동안 데이터의 존재를 줄이려고 시도했지만, 데이터의 통제되지 않은 특성으로 인해 캡처 중에 데이터를 제거하는 것이 불가능합니다.
따라서 우리는 이러한 객체의 고품질 마스크를 얻기 위해 Tao et al. [38]의 세그멘테이션 방법을 사용합니다.
또한 NeRF-OSR은 하늘과 초목 (예: 나무)을 합성할 수 있지만, 특히 기록 세션이 날씨 시즌에 따라 다를 때 매우 다양한 모양으로 인해 예측을 평가할 수 없습니다.
따라서 이러한 지역의 마스크도 추정하여 평가에서 제외합니다.
Sites 1-3의 경우 5개의 기록 세션을 테스트용으로 보관하고 나머지는 학습용으로 사용합니다.
결과적인 학습/테스트 분할은 다음과 같습니다: Site 1의 160/95 뷰, Site 2의 301/96 뷰, Site 3의 258/96 뷰.
Relighting with Ground-Truth Environments.
우리는 방법의 파라메트릭 조명 제어를 정량적으로 평가하고 환경 맵에서 추출한 조명 계수를 사용하여 새로운 조명을 재현할 수 있음을 보여줍니다.
데이터 세트의 각 기록 세션에서 테스트 세트에서 하나의 사진을 소스로 선택합니다.
Site 1을 사용하면 총 5개의 소스 이미지를 제공합니다.
관찰된 시점과 조명에서 5개의 이미지를 모두 직접 렌더링합니다.
그러나 Philip et al. [27]과 Yu et al. [46]의 경우 주어진 이미지의 조명만 편집할 수 있습니다.
따라서 각 소스 이미지에 대해 동일한 site의 다른 4개 소스 이미지의 조명을 사용하여 다시 조명합니다.
그런 다음 출력을 타겟 조명이 추출된 카메라 시점으로 교차 투사합니다.
이는 COLMAP 재구성을 활용하여 수행됩니다.
우리는 세그멘테이션 마스크를 사용하여 일관된 예측을 할 수있는 영역의 성능을 평가하고 다른 방법에 대해 교차 투영합니다.
이것은 일반적으로 메인 빌딩입니다.
여기서는 MSE, MAE 및 SSIM을 포함한 여러 메트릭을 계산합니다.
SSIM의 경우 scikit-image [41] 구현을 사용하여 세그멘테이션 마스크에 대한 평균을 보고합니다.
여기서는 윈도우 크기가 5인 SSIM 메트릭과 동일한 윈도우 크기에 의해 침식된 세그멘테이션 마스크를 사용하여 마스크 외부의 픽셀이 메트릭 값에 미치는 영향을 제거합니다.
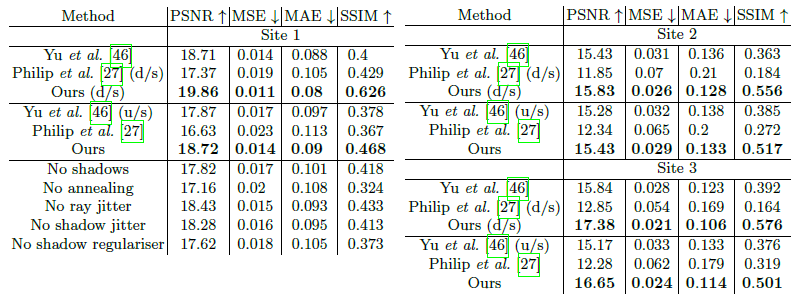

표 1은 이 실험의 결과 (평가된 모든 이미지에 대한 평균)를 보고합니다.
그림 6은 비교된 방법으로 렌더링된 여러 ground truth 이미지와 뷰를 보여줍니다.
NeRF-OSR은 양적, 질적으로 관련 기술을 능가합니다.
우리의 방법과 Philip et al.은 1280x844 픽셀에서 결과를 생성하는 반면, Yu et al.은 303x200 픽셀에서만 결과를 생성할 수 있습니다.
따라서 표 1에서는 방법의 출력을 Yu et al.의 기본 해상도로 다운스케일링하는 설정에서 Yu et al.과 비교하기도 합니다 (표 1의 d/s 참조).
그럼에도 불구하고, 우리의 방법은 여전히 Yu et al.을 능가하며, 이는 출력 해상도의 차이 때문이 아니라는 것을 보여줍니다.
여기서 NeRF-W와 같은 스타일 기반 방법과 비교하는 것은 빛의 의미 표현이 없기 때문에 환경 맵에 따라 빛을 편집할 수 없기 때문에 실현 가능하지 않다는 점에 유의합니다.
Ablation Study.
우리는 ablation 연구를 통해 방법의 설계 선택을 평가합니다.
우리는 relighting 비교와 동일한 평가 절차를 따르고 모든 출력 이미지에 대한 평균으로 결과를 보고합니다.
우리의 접근 방식은 Site 1의 5개 이미지입니다.
Philip et al. [27]의 경우 총 20개의 이미지입니다.
표 1-(아래)은 테스트된 다양한 설정의 PSNR, MSE, MAE 및 SSIM을 보고합니다.
결과는 NeRF-OSR의 전체 버전을 사용하면 최상의 성능을 얻을 수 있음을 보여줍니다.
표 1의 모든 메트릭은 마스킹된 영역에서만 계산되므로 마스킹되지 않은 영역을 검은색으로 채우면서 전체 이미지를 평가한 경우 더 높은 성능을 기대할 수 있습니다.
Real-time Interactive Rendering in VR.
[19]와 같은 스타일 기반 방법과 달리 렌더링은 지오메트리, 알베도, 그림자 및 조명 조건 (식 5 참조)의 명시적인 함수입니다.
우리의 모델은 알베도와 지오메트리에 직접 액세스할 수 있는 기능을 제공합니다.
조명과 그림자는 렌더링 시점에 잠재적으로 미분할 수 없는 여러 조명 모델을 사용하여 지오메트리에서 생성할 수 있습니다.
따라서 충분한 해상도로 지오메트리와 알베도를 추출할 수 있다면 원래 신경 모델에 비해 느린 NeRF ray-marching 없이도 품질 loss 없이 사용할 수 있습니다.
우리는 해상도 1000^3 복셀에서 Marching Cubes [16]를 사용하여 Site 1의 학습된 모델에서 지오메트리와 알베도를 메시로 추출합니다.
그런 다음 C++, OpenGL 및 SteamVR로 구현된 대화형 VR 렌더러에 이를 사용합니다.
조명 모델은 태양과 간단한 지오메트리 기반 그림자 맵 [43]으로 구성됩니다: C_interactive = C_ambient + s ⊙ C_sun max{0,D_sun^T N}, 여기서 C_ambient는 주변 색상, s는 렌더링된 포인트가 가려졌을 때 0, 그렇지 않은 경우 1, 섀도우 맵에 따르면 C_sun은 태양의 색상, D_sun은 태양의 방향, N은 메시의 일반 색상입니다.
사용자는 장면에서 대화형으로 움직이며 컨트롤러로 태양 방향을 제어할 수 있습니다.
이 데모는 Intel i7-4770 CPU, Nvidia GeForce GTX 970 (4GB VRAM) GPU, Oculus Rift S HMD가 탑재된 데스크톱 컴퓨터에서 실시간으로 실행됩니다.
애플리케이션의 시스템 RAM 사용량은 3GB 미만입니다.
추가 비디오에서 광범위한 데모를 제공하고 그림 7-(왼쪽)의 발췌문을 보여줍니다.
Albedo and Shadow Editing.
intrinsic 분해의 또 다른 응용 프로그램은 조명이나 그림자에 영향을 주지 않고 장면 알베도를 편집하는 것입니다.
이러한 적용은 이미지 분해를 수행하지 않기 때문에 스타일 기반 방법 (예: NeRF-W [19])으로는 불가능합니다.
그림 7-(가운데)에서는 Site 3의 안내 포스터를 ECCV 2022 포스터로 대체했습니다.
교체된 포스터가 나머지 장면과 함께 자연스럽게 보이는 방식에 주목하세요.
그림 7-(오른쪽)에서는 렌더링 후 그림자 강도를 편집합니다.
이 실험의 확장된 비디오 결과는 추가 동영상에서 확인할 수 있으며, 합성된 안내 포스터로 relighting 결과도 표시됩니다.
6 Discussion and Conclusion
우리는 2차 SH 조명 모델이 그럴듯한 조명을 생성할 수 있음을 보여주었습니다.
햇볕이 잘 드는 환경에는 2차 SH로 잘 표현되지 않는 그림자가 포함될 수 있지만, 학습된 그림자 구성 요소가 이를 보완한다고 생각합니다 (새로운 하드 섀도우의 예는 그림 7 참조).
그럼에도 불구하고 SH 조명 모델은 고주파 조명, 사양 및 공간적으로 변화하는 조명 측면에서 여전히 제한될 수 있습니다.
이러한 효과를 포착하면 시야 의존적 효과와 야간 조건을 포함한 더 어려운 장면을 재구성할 수 있습니다.
우리의 방법이 수치적으로나 시각적으로 관련 접근 방식을 능가함에도 불구하고 약간의 블러가 존재할 수 있습니다.
우리는 이는 지오메트리 추정의 일부 부정확성 때문이라고 생각합니다.
보다 구체적으로, 우리는 이미지 intrinsics의 분리된 표현을 학습하여 많은 새로운 응용을 허용합니다 (그림 7).
그러나 학습된 지오메트리의 작은 돌출부조차도 표준에 상당한 변화를 초래하여 계산된 조명의 오류를 초래할 수 있기 때문에 정확한 지오메트리가 필요합니다.
따라서 모델은 보다 정확한 조명을 확보하기 위해 지오메트리의 일부를 부드럽게 처리할 수 있습니다.
이는 표 1에 표시된 다른 방법에 비해 전반적으로 더 나은 재조명 결과로 이어집니다.
그럼에도 불구하고 향후 연구는 보다 정교한 지오메트리 모델(예: 하이브리드 볼륨 밀도 또는 암묵적 표면 표현 [25, 42])을 조사함으로써 결과를 더욱 개선할 수 있습니다.
우리의 방법은 서로 다른 시간과 뷰에서 촬영한 야생 사진 세트만 있으면 됩니다.
이를 위해 우리는 새로 수집한 데이터 세트와 [9, 32]의 "Trevi" 장면에 대한 접근 방식을 평가했습니다.
이 장면은 인터넷에서 완전히 수집되었으며 문헌 [15, 19, 22]에서 널리 사용되고 있습니다.
ground truth 환경 맵은 평가에만 사용되며 (섹션 5에서와 같이) 우리의 방법이 작동하는 데 필요하지 않다는 점을 기억하세요.
우리가 조사한 데이터 세트는 우리 방법의 실용적인 사용 사례를 보여주지만, 향후 연구는 테스트 중에 단일 조명 조건만큼 적은 수의 것을 사용하여 조사할 수 있습니다.
마지막으로, 더 많은 사전 실외 장면을 통합하는 것이 흥미로운 미래 연구 방향이 될 수 있습니다.
Concluding Remarks.
우리는 통제되지 않은 설정에서 캡처한 야외 장면의 새로운 뷰와 새로운 조명 생성을 동시에 수행하는 첫 번째 방법을 제시했습니다.
우리는 다양한 조명을 가진 포즈 이미지가 장면 intrinsic의 신경 표현을 학습하고 이미지별 조명을 추정하는 데 충분하다는 것을 보여주었습니다.
우리의 방법은 ground truth 환경 맵이 포함된 새로 수집된 벤치마크 데이터 세트를 포함하여 여러 시퀀스에서 주관적이고 정량적으로 관련 기술을 능가합니다.