2024. 10. 11. 18:12ㆍ3D Vision/NeRF with Real-World
Gaussian in the Wild: 3D Gaussian Splatting for Unconstrained Image Collections
Dongbin Zhang, Chuming Wang, Weitao Wang, Peihao Li, Minghan Qin, Haoqian Wang
Abstract
제약이 없는 야생 이미지에서 새로운 뷰 합성은 의미 있지만 어려운 작업으로 남아 있습니다.
이러한 제약이 없는 이미지의 photometric 변화와 transient occluders로 인해 원래 장면을 정확하게 재구성하는 것이 어렵습니다.
이전 접근 방식은 Neural Radiance Fields (NeRF)에 전역적인 외관 피쳐를 도입하여 문제를 해결합니다.
그러나 실제 세계에서는 장면에서 각 작은 점의 고유한 외관이 독립적인 intrinsic 재료 속성과 받는 다양한 환경 영향에 의해 결정됩니다.
이러한 사실에서 영감을 받아 3D 가우시안 포인트를 사용하여 장면을 재구성하고 각 점에 대해 분리된 intrinsic 및 동적 외관 피쳐를 도입하여 조명 및 날씨와 같은 동적 변화와 함께 변하지 않은 장면 모양을 캡처하는 방법인 Gaussian in the wild (GS-W)를 제안합니다.
또한 각 가우시안 포인트가 로컬 및 세부 정보에 더 효과적으로 집중할 수 있도록 적응형 샘플링 전략이 제시됩니다.
또한 2D 가시성 맵을 사용하여 transient occluders의 영향을 줄입니다.
더 많은 실험에서 더 빠른 렌더링 속도로 NeRF 기반 방법에 비해 GS-W의 재구성 품질과 세부 사항이 더 우수하다는 것이 입증되었습니다.

1 Introduction
새로운 뷰 합성은 2D 이미지 컬렉션에서 장면의 3D 구조를 복구하는 것을 목표로 하는 컴퓨터 비전 분야에서 오랫동안 주목받고 복잡한 작업이었으며 virtual reality (VR) 및 자율 주행과 같은 많은 응용 분야에서 중요한 역할을 해왔습니다.
최근 암시적 표현, 특히 Neural Radiance Field (NeRF)[26]와 그 후속 작업 [1,2,27]은 임의의 관점에서 사실적인 이미지를 렌더링하는 데 인상적인 진전을 보였습니다.
한편, 명시적 표현은 실시간 렌더링 속도 덕분에 점점 더 많은 관심을 받고 있습니다.
3D Gaussian Splatting (3DGS) [16]은 새롭고 유연한 장면 표현으로 3D 가우시안을 도입하고 빠른 미분 가능한 렌더링 접근 방식을 설계하여 뷰 합성을 위해 높은 충실도를 유지하면서 실시간 렌더링을 가능하게 합니다.
그러나 앞서 언급한 이러한 방법은 transient occluders 없이 이미지가 캡처되는 정적 장면과 끊임없이 변화하는 하늘, 날씨, 조명과 같은 동적 외관 변화에만 초점을 맞춥니다.
안타깝게도 실제로 입력 비제약 이미지 컬렉션은 서로 다른 시간에 다른 설정을 가진 카메라에 의해 캡처될 수 있으며 일반적으로 보행자 또는 차량을 포함할 수 있습니다.
정적 장면에서 이미지를 캡처해야 한다는 이전 방법의 가정은 심각하게 위반되어 급격한 성능 저하를 초래합니다 [23, 50].
최근 여러 시도 [6, 19, 23, 41]는 각 이미지에 대해 전역 잠재 임베딩을 채택하여 모델이 이미지 간의 외관 변화를 처리할 수 있는 기능을 제공합니다.
CR-NeRF [50]는 다중 ray의 정보를 활용하여 여러 픽셀의 색상을 얻는 새로운 cross ray 패러다임을 제안하여 보다 사실적이고 효율적인 외관 모델링을 달성합니다.
그럼에도 불구하고 위의 방법은 여전히 세 가지 결함으로 인해 어려움을 겪고 있습니다:
1) Global appearance representation: 동적 외관 변화를 제어하는 데 사용되는 표현은 전체 장면이 공유하므로 로컬 고주파수 변화를 설명하는 데 어려움을 겪을 수 있습니다.
반면, 3D 현실 세계에서는 장면의 모든 지점에 고유한 광택과 질감을 제공하는 외관 피쳐가 있습니다;
2) Blurring intrinsic and dynamic appearance: 물체의 intrinsic 외관은 고유한 재료 및 표면 특성에 의해 결정되며, 동적 외관은 하이라이트 및 그림자와 같은 환경 요인의 영향을 받습니다.
이전 접근 방식은 두 가지 외관을 함께 블러 하여 외관 튜닝과 같은 애플리케이션에 혼란을 야기합니다;
3) High time cost: 볼륨 렌더링 기반 방법과 유사하게 위의 대부분의 NeRF 기반 접근 방식은 많은 양의 네트워크 평가로 인해 높은 학습 비용과 낮은 렌더링 속도로 인해 어려움을 겪습니다.
이러한 과제를 해결하기 위해 제약이 없는 이미지 컬렉션에 대한 고품질의 유연한 장면 재구성을 달성하는 방법인 Gaussian in the wild (GS-W)를 제안합니다.
특히, 먼저 3D 가우시안 포인트를 사용하여 장면을 표현하고 각 지점에 독립적인 외관 피쳐를 도입하여 고유한 외관 표현을 가능하게 합니다.
둘째, intrinsic 외관과 동적 외관을 분리하고 적응형 샘플링 전략을 제시하여 모든 지점이 다양한 세부 동적 외관 정보에 집중할 수 있는 자유를 부여합니다.
또한 타일 기반 래스터라이저 덕분에 장면 렌더링 속도가 크게 빨라졌습니다.
저희의 기여는 다음과 같이 요약할 수 있습니다:
– 우리는 각 가우시안 포인트에 별도의 intrinsic 및 동적 외관 피쳐가 장착되어 제약 없는 이미지 컬렉션에서 보다 유연하게 다양한 외관 모델링을 가능하게 하는 새로운 프레임워크 GS-W를 제안합니다.
– 이미지의 환경 요소를 장면에 더 잘 통합하기 위해 적응형 샘플링을 제안하여 각 지점이 피쳐 맵에서 동적 외관 피쳐를 더 효과적으로 샘플링하여 더 많은 로컬 및 세부 정보에 집중할 수 있도록 합니다.
– 실험 결과에 따르면 우리의 방법은 품질 측면에서 SOTA NeRF 기반 방법을 능가할 뿐만 아니라 렌더링 속도에서도 1000배 이상 능가하는 것으로 나타났습니다.
2 Related Work
2.1 3D representations
3차원 물체 또는 장면의 지오메트릭 및 외관 정보를 표현하기 위해 다양한 3D 표현이 개발되었으며, 그중 암시적 표현과 명시적 표현은 3D 물체 생성 및 장면 재구성과 같은 실제 응용을 위한 두 가지 일반적인 방법입니다.
암시적 표현은 3D 데이터를 점유 필드 [24], 거리 필드 [29], 색상 및 밀도와 같은 연속적인 함수 또는 필드로 표현합니다.
NeRF [26]는 장면을 밀도와 래디언스의 연속적인 필드로 모델링하는 뛰어난 작업입니다.
NeRF는 MLP를 사용하면 볼륨 렌더링의 도움으로 복잡한 장면을 표현하고 새로운 사진 사실적인 뷰를 렌더링할 수 있음을 나타냅니다.
반대로 명시적 표현은 메시 [14,15,45], 포인트 클라우드 [31,32,40], 복셀 [38,47,48] 등의 개별 구조를 사용하여 3D 데이터를 저장하고 조작하여 장면을 묘사합니다.
최근에는 3DGS [16]로 표현되는 방법이 고해상도 합성 품질을 보존하면서 실시간 렌더링 속도로 연구자의 비전에 진입했습니다.
3DGS는 가우시안을 이미지 평면으로 splat하고 이전 방법에 비해 렌더링 속도를 몇 배 가속화하기 위해 효율적인 타일 기반 래스터라이저를 도입했습니다.
많은 연구자들이 다양한 작업으로 확장하여 잠재력을 모색하고 있습니다 [33,46,52].
여러 하이브리드 표현 [3-5,10,39]도 등장하고 있으며 더 많은 가능성을 창출하고 있습니다.
2.2 Novel view synthesis
2D 이미지 세트를 사용하여 장면의 임의의 뷰를 합성하는 것은 컴퓨터 비전의 오랜 문제입니다.
많은 NeRF 기반 방법 [11,12,27,34,53]은 양호한 뷰 일관성과 함께 표현 합성 품질 [1,42,49]을 달성했습니다 [7,28,43].
Mip-NeRF [1]은 ray를 3D 원뿔형 frustum으로 대체하고 안티 앨리어싱에 통합 위치 임베딩을 제안합니다.
Instant-NGP [27]는 더 작은 네트워크를 사용하여 학습 비용을 절감할 수 있는 다중 해상도 해시 인코딩을 도입합니다.
또한 3DGS를 수정하여 이 작업에 기여하는 가우시안 기반 방법 [9,22,51,54]도 있습니다.
예를 들어, 특정 요소가 있는 장면을 처리하기 위해 Spec-Gaussian [51]은 구형 고조파를 사용하는 것에서 벗어나 anisotropic 구형 가우시안 외관 필드를 채택하여 각 지점을 모델링합니다.
앞서 언급한 이러한 방법은 모두 입력 이미지가 정적 장면에서 캡처된다고 가정하기 때문에 제약이 없는 사진 모음에서 재구성할 때 성능이 크게 저하됩니다.
따라서 외관 변형과 transient occluers를 처리하여 이 어려운 야생 작업을 해결하기 위해 여러 시도 [6,19,23,25,36,50]가 제안됩니다. 다른 작업 [20,21]은 시간에 따라 변하는 외관을 가진 장면에 초점을 맞추고 방법 [8,18,55]은 다양한 조명 조건에 대한 물리적 렌더링 모델을 사용합니다.
이 필드는 여전히 몇 가지 남은 문제에 직면해 있으며 발전을 기대합니다.
그 중 하나로, 우리가 제안한 방법은 섹션 4에서 언급한 수정을 통해 더 빠른 렌더링 속도로 더 섬세하고 유연한 합성을 달성함으로써 이 분야를 한 단계 더 발전시키려고 노력합니다.
3. Preliminaries
3D Gaussian Splatting (3DGS) [16]은 카메라 포즈 정보로 정적 이미지에서 3D 장면을 재구성하는 방법입니다.
명시적인 3D 가우시안 포인트 GP를 사용하여 장면을 표현하고 미분 가능한 타일 기반 래스터라이저를 통해 실시간 이미지 렌더링을 달성합니다.
이러한 가우시안 포인트의 위치 X는 이미지 세트에서 SFM [37]이 추출한 포인트 클라우드로 초기화됩니다.
특히 3D 공분산 Σ을 사용하여 각 가우시안 포인트가 주변 영역의 색 anisotropy에 미치는 영향을 모델링합니다:
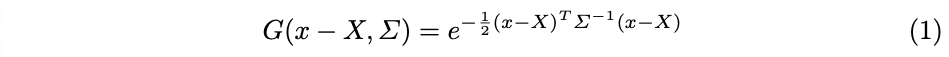
이 방법은 양의 반정확성을 유지하면서 공분산 Σ을 쉽게 최적화하기 위해 각 가우시안 포인트의 공분산을 스케일링 행렬 S와 회전 행렬 R로 분해한 다음 3D 벡터와 쿼터니언을 사용하여 각각 가우시안 포인트 속성 s와 r로 저장합니다.

또한 각 가우시안 포인트에는 두 가지 속성이 더 포함되어 있습니다: 색 속성이 3차 구형 고조파 계수로 표시되는 불투명도 α 및 색 c.
렌더링할 때 각 가우시안 포인트를 이미지 평면의 16×16 타일 그리드에 투영하는 것 외에도 3D 공분산 Σ는 뷰 변환 W와 투영 변환 J의 아핀 근사치의 자코비안을 사용하여 2D Σ'에 투영됩니다:
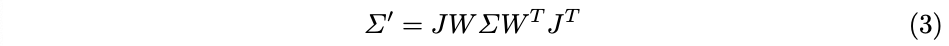
그런 다음 래스터라이저로 정렬된 가우시안 포인트를 기반으로 α-블렌딩을 사용하여 각 픽셀의 색상을 집계합니다:

여기서 px'는 픽셀의 위치를 나타내며 GP_px'는 해당 픽셀과 관련된 정렬된 가우시안 포인트를 나타냅니다.
그런 다음 최종 렌더링된 이미지는 모든 가우시안 속성을 공동으로 최적화하는 학습을 위해 참조 이미지로 loss를 계산하는 데 사용됩니다.
또한 그래디언트와 불투명도를 기반으로 포인트 성장 및 가지치기 전략을 고안합니다.
4 Method
이전 분석에 따르면, 앞서 언급한 NeRF 기반 방법 [6,23,50]은 샘플링 포인트 수가 많기 때문에 상당한 렌더링 비용과 함께 외관상 고주파수 및 로컬 세부 정보에 대한 충분한 주의력이 부족합니다.
이러한 문제를 해결하기 위해 3D 가우시안 포인트를 활용하여 섹션 4.1의 장면을 명시적으로 모델링하고 섹션 4.2의 각 가우시안 포인트에 대한 새로운 외관 모델링 방법을 소개합니다.
intrinsic 외관 및 dynamic 외관 피쳐를 분리한 다음 섹션 4.3에서 융합합니다.
또한 섹션 4.5의 loss들을 계산할 때 섹션 4.4의 transient 물체의 영향을 줄이기 위해 가시성 맵을 사용합니다.
전체 파이프라인은 그림 2와 같이 시각화됩니다.

4.1 3D Gaussian Splatting in the Wild
Appearance.
3DGS [16]는 정적 장면을 재구성하기 위해 설계되었기 때문에 GS-W는 구형 고조파 계수를 사용하는 기존의 색상 모델링 접근 방식을 포기합니다.
대신 다음 섹션에서는 이미지에서 추출한 dynamic 외관 피쳐 df_i와 intrinsic 외관 피쳐 sf_i를 융합하여 참조 이미지의 변화에 적응하는 각 가우시안 포인트에 대한 새로운 외관 피쳐 af_i를 소개합니다.
Transient object.
transient 객체 영역 주변의 가우시안 포인트가 그래디언트를 받아 이동하거나 성장하여 무의미한 플로팅 포인트와 렌더링 아티팩트가 나타날 수 있는 3DGS의 경우 transient 객체를 처리하는 것도 어렵습니다.
따라서 섹션 4.4에서 이 문제를 완화하기 위해 가시성 맵을 사용합니다.
또한, 우리는 초기 포인트 클라우드에 없는 건물을 재구성하기 위해 포인트에 대한 가지치기 및 성장 전략을 유지합니다.
4.2 Dynamic appearance features modeling
실제 물리적 세계에서는 동일한 장면 내에서도 대부분의 물체 지점이 서로 다른 방향에서 오는 빛과 같은 다양한 환경적 영향을 경험합니다.
독특한 intrinsic 재료 특성과 결합하여 각 지점은 서로 다른 색상, 광택 및 텍스쳐를 표시합니다.
NeRF-W [23] 및 Ha-NeRF [6]는 모든 지점에서 균일한 환경 정보를 가정하여 전체 장면의 외관에 참조 이미지에서 전역 피쳐 임베딩을 사용합니다.
CR-NeRF [50]는 참조 이미지 피쳐를 2D 레벨의 렌더링 이미지 피쳐에 통합하여 3D의 동적 환경 정보가 부족합니다.
이러한 방법은 장면의 전역 색상 톤을 대략적으로 복원하고 하이라이트 및 그림자와 같은 로컬 세부 정보를 캡처하는 데 어려움을 겪는 경향이 있습니다.
이를 해결하기 위해 각 지점에 대해 다양한 정보를 도입하여 실제 시나리오와 더 잘 일치시킵니다.
Projection feature map.
이미지 I_gt에서 2D 피쳐를 추출한 다음 각 지점을 2D 공간에 매핑하여 피쳐 샘플링을 수행합니다.
이미지의 알려진 카메라 포즈를 사용하여 3D 지점에서 2D 이미지로의 매핑 관계를 결정할 수 있습니다.
따라서 이미지에서 투영 행렬 P를 사용하여 각 3D 지점을 투영한 다음 아래와 같이 이중 선형 보간 피쳐 샘플링을 수행하는 투영 피쳐 맵 F^P를 추출합니다:

, 여기서 X_i는 i번째 가우시안 포인트의 위치 좌표를 나타내며, f_i^P ∈ R^16은 dynamic 외관 피쳐의 일부를 구성하는 이 가우시안 포인트에 대한 투영 피쳐 맵에서 샘플링된 피쳐를 나타냅니다.
BL이라는 항은 이중 선형 보간 샘플링을 나타냅니다.
이 방법을 사용하면 서로 다른 ray를 따라 가우시안 포인트가 참조 이미지의 해당 위치에 있는 피쳐를 효과적으로 캡처할 수 있습니다.
K feature maps.
단일 뷰 참조 이미지 I_gt에 의해 제한되는 투영 피쳐 맵에서 샘플링된 피쳐는 동일한 ray를 따라 동일하며, 이는 고르지 않은 조명 하에서 불합리합니다.
또한 참조 이미지에는 때때로 장면의 일부만 포함되기 때문에 많은 지점이 유효한 피쳐 샘플을 얻기 위한 유효 영역으로 투영되지 않아 새로운 관점에서 불일치가 발생할 수 있습니다.
이러한 문제를 해결하고 가우시안 포인트가 다양한 정보에 집중할 수 있는 자유를 부여하기 위해 고차원 샘플링 공간을 구성하기 위해 I_gt에서 K개의 피쳐 맵(F^1,F^2...F^K)을 추가로 추출할 것을 제안합니다.
각 가우시안 포인트는 적응형 샘플링을 위해 이러한 맵에 각각 매핑되어 고주파 피쳐에 집중할 수 있습니다.
Adapting sampling.
다양한 정보에 더 잘 집중하려면 가우시안 포인트를 K 피처 맵의 다른 위치에 매핑해야 합니다.
각 가우시안 포인트가 독립적으로 고유한 속성을 학습하는 동기에서 영감을 받아 모든 포인트가 자체 학습을 통해 샘플링 위치를 결정할 수 있는 효율적인 방법이라고 생각합니다.
따라서 우리는 각 가우시안 포인트에 학습 가능한 샘플링 좌표 속성(sc_i^1, sc_i^2 ...sc_i^K)을 K개로 할당하여 집중해야 하는 정보를 적응적으로 선택할 수 있도록 합니다.
K 피처 맵에서 이러한 K 샘플링 좌표를 사용하는 샘플링 프로세스는 다음과 같습니다:

, 여기서 (f_i^1,f_i^2...f_i^K) ∈ R^(K×16)은 i번째 가우시안 포인트에 대한 K개의 피쳐 맵에서 샘플링된 피쳐를 나타냅니다.
다음으로 샘플링된 피쳐를 f_i^P와 연결하여 다음과 같이 가우시안 포인트의 dynamic 외관 피쳐를 공동으로 표현합니다:

학습 중에 샘플링 좌표가 유효 샘플링 범위를 벗어나지 않도록 정규화 항을 도입합니다:

, 여기서 N은 가우시안 포인트의 총 개수를 나타내며 |.|는 절대값을 나타냅니다.
Feature maps extraction.
우리는 투영 피쳐 맵과 K 피쳐 맵을 모두 생성하기 위해 ResNet [13] 백본이 있는 Unet [35] 모델을 활용합니다.
Unet 모델은 참조 이미지 I_gt ∈ R^(3×H×W)를 입력으로 받아 동일한 공간 크기의 2D 피쳐 맵 F ∈ R^(16(K+1)×H×W)을 생성합니다.
그런 다음 이 피쳐 맵은 채널 차원을 따라 (K+1) 피쳐 맵으로 균등하게 나뉘며, 각각 K 피쳐 맵(F^1,F^2...F^K)과 투영 피쳐 맵 F^P 중 하나로 사용됩니다.
동일한 스케일의 이미지에서 피쳐를 추출하는 단순성과 효과 때문에 Unet을 피쳐 추출기로 선택합니다.
4.3 Intrinsic and dynamic appearance
Separation of intrinsic and dynamic appearance.
앞서 언급했듯이 물체의 외관은 intrinsic 재료뿐만 아니라 표면 특성, 동적 환경 요인의 영향을 모두 받습니다.
그러나 Ha-NeRF와 같은 이전 방법은 MLP를 사용하여 외관을 해독하기 위해 주로 이미지 피쳐, 위치 데이터 및 뷰 방향에 의존합니다.
MLP를 통한 장면의 intrinsic 속성에 대한 이러한 암묵적 모델링은 작은 MLP만으로는 고주파수 피쳐를 표현하기 어렵기 때문에 추출된 동적 피쳐에 의존하여 포괄적인 정보를 캡처합니다.
따라서 이러한 피쳐의 블러는 특히 조명 및 기상 조건의 변화와 관련된 시나리오에서 모델이 intrinsic 외관과 dynamic 외관을 정확하게 구별하는 데 방해가 됩니다.
이를 해결하기 위해 장면 외관을 두 가지 형태로 명시적으로 분리합니다: intrinsic이고 dynamic 외관 피쳐.
정적 가우시안 포인트의 위치를 모델링하는 것과 유사하게, 우리는 각 가우시안 포인트에 학습 가능한 새로운 intrinsic 외관 속성 sf_i를 할당합니다.
한편, dynamic 외관 피쳐 df_i는 참조 이미지에서 추출한 피쳐에 의해 얻어집니다.
Fusion of intrinsic and dynamic appearance features.
적응형 샘플링을 통해 각 가우시안 포인트에 대한 독립적인 dynamic 외관 피쳐를 획득한 후, 포괄적인 외관 피쳐 af_i를 생성하려면 해당 intrinsic 외관 피쳐와 결합하는 것이 필수적입니다.
이를 위해 두 개의 외관 피쳐와 위치 정보를 입력으로 사용하고 두 가지 모두의 영향을 받는 전체적인 외관 피쳐를 생성하는 두 개의 MLP로 구성된 융합 네트워크 M_f를 설계합니다.
구체적으로:

이미지 렌더링 시 융합된 외관 피쳐 af_i는 뷰 방향 φ와 함께 MLP M_c에 의해 공동으로 디코딩되어 식 (11)과 같이 i번째 가우시안 포인트의 색상 c_i를 얻습니다.
마지막으로 가우시안 포인트는 미분 가능한 타일 래스터라이저를 사용하여 렌더링되고 색상은 식 (5)에 따라 집계되어 참조 이미지의 외관 피쳐와 함께 이미지 I_r을 생성합니다.

4.4 Transient objects handling
transient 물체의 영향을 완화하고 플로팅 포인트와 같은 아티팩트의 발생을 방지하기 위해 Unet 모델에서 얻은 2D 가시성 맵 VM ∈ R^(1xH×W)을 사용하여 transient 물체와 정적인 물체 사이의 정확한 세그멘테이션을 용이하게 합니다.
가시성 맵을 활용하여 식 (13)과 같이 참조 이미지 I_gt와 렌더링된 이미지 I_r 사이의 loss 계산에 가중치를 부여합니다.
학습 중에 모델은 transient 물체의 지오메트리와 외관을 재구성하는 데 어려움을 겪는 경우가 많으며, 이러한 물체가 포함된 영역에서 loss가 더 커집니다.
따라서 unsupervised 시나리오에서 2D 가시성 맵은 학습 loss를 최소화하기 위해 transient 물체의 가시성을 감소시키는 경향이 있습니다.
그 결과 가시성이 높은 영역은 더 많은 강조를 받는 반면 가시성이 낮은 영역은 무시됩니다.
또한 가시성 맵이 모든 픽셀을 보이지 않게 표시하는 것을 방지하기 위해 가시성 맵에 대한 정규화 loss 항을 도입합니다:

4.5 Optimization
[16]과 유사하게 렌더링된 이미지 I_r과 참조 이미지 I_gt 사이의 픽셀 오류를 계산하기 위해 두 가지 유형의 loss 함수인 L_1 및 L_SSIM [44]을 적용합니다.
다르게는 참조 이미지에 의한 렌더링된 이미지의 supervision을 가이드하기 위해 가시성 맵 VM이 통합됩니다.
또한 지각 loss L_LPIPS [56]를 소개합니다.
따라서 전체 이미지 loss 함수는 식 (13)과 같이 표현되며, 여기서 ⊙는 하다마드 곱을 나타냅니다.
식 (9) 및 식 (12)에 언급된 정규화 loss 항을 결합하면 총 loss 함수는 식 (14)와 같이 공식화되며, 여기서 λ_1, λ_SSIM, λ_LPIPS, λ_sc 및 λ_vm은 각각 0.8, 0.2, 0.001, 0.15입니다.

5 Experiments
5.1 Implementation details
우리는 Pytorch [30]를 사용하여 방법을 구현하고 Adam 옵티마이저 [17]로 네트워크를 학습합니다.
우리는 실험에서 K가 증가함에 따라 의미 없는 계산 비용으로 성능이 향상되지 않기 때문에 K=3으로 설정했습니다.
우리는 70k 스텝 동안 단일 Nvidia RTX 3090 GPU에서 전체 모델을 학습하고 학습 및 평가 중에 약 2시간이 걸리는 모든 이미지를 2번 다운샘플링합니다.
또한 3D 가우시안의 적응형 제어를 수행하고 3DGS [16]와 유사한 다른 하이퍼파라미터 설정을 따릅니다.
5.2 Evaluation
Dataset, metrics, baseline.
우리는 PhotoTourism 데이터 세트의 세 가지 장면에서 제안된 방법을 평가합니다: Brandenburg Gate, Sacre Coeur, and Trevi Fountain로 다양한 외관과 transient 물체를 포함합니다.
정량적 비교를 위해 PSNR, SSIM [44] 및 LPIPS [56]를 메트릭으로 사용하여 방법의 성능을 평가합니다.
또한 시각적 검사를 위해 입력 뷰와 동일한 포즈에서 생성된 렌더링된 이미지를 제시합니다.
우리 방법의 우수성을 입증하기 위해 3DGS [16], NeRF-W [23], Ha-NeRF [6] 및 CR-NeRF [50]에 대해 제안된 방법을 평가합니다.

Quantitative comparison.
정량적 결과는 표 1에 나와 있습니다.
3DGS는 외관 변화와 transient 객체를 명시적으로 모델링하지 않기 때문에 PSNR 및 SSIM 지표 모두에서 저조한 성능을 발휘합니다.
NeRF-W와 Ha-NeRF는 전역 외관 임베딩 및 anti-transient 모듈을 도입하여 중간 정도의 성능을 달성합니다.
NeRF-W는 테스트 이미지의 외관 임베딩을 최적화해야 하므로 NeRF-W와의 비교는 불공평하다는 점에 유의할 필요가 있습니다.
CR-NeRF는 cross-ray 방식으로 인해 경쟁 성능을 달성합니다.
각 지점이 로컬 세부 사항에 집중할 수 있는 적응형 샘플링 전략을 활용하여 PSNR, SSIM 및 LPIPS 측면에서 세 가지 장면의 베이스라인을 능가하는 성능을 발휘하며, 이를 통해 더 많은 세부 사항을 캡처하고 더 높은 품질의 이미지를 렌더링할 수 있는지 확인합니다.
Render speed.
추론 중 다양한 방법의 렌더링 속도를 비교하기 위해 이미지 해상도를 800×800으로 설정하고 단일 RTX 3090 GPU를 사용하여 이미지당 평균 렌더링 시간을 계산하여 세 가지 장면을 실험합니다.
Ha-NeRF, CR-NeRF 및 우리의 방법의 참조 이미지에서 피쳐를 추출하는 데 걸리는 시간은 전체 추론 시간에 포함됩니다.
표 2에 표시된 것처럼, 우리의 방법은 렌더링 속도가 크게 향상되어 이전 NeRF 기반 방법보다 1000배 더 빠릅니다.

우리의 방법은 하나의 피쳐 추출 단계만 필요하고 가우시안 포인트마다 외관 피쳐 af_i를 캐시할 수 있기 때문에 새로운 뷰를 합성할 때 색상 디코딩을 위해 작은 MLP 디코더 M_c만 필요합니다.
이를 통해 GS-W는 3DGS와 비슷한 200FPS 렌더링 속도를 달성할 수 있습니다.

Qualitative comparison.
그림 3은 모든 방법에 대한 정성적 결과를 제시합니다.
NeRF-W와 Ha-NeRF는 전역 외관 임베딩을 도입하여 참조 이미지에서 다양한 외관을 모델링할 수 있습니다.
CR-NeRF는 Ha-NeRF 및 NeRF-W에 비해 더 나은 지오메트리를 재구성하고 외관 변화를 모델링할 수 있습니다.
그러나 모두 Brandenburg의 문 기둥과 멀리 떨어진 탑, Sacre의 공동, Trevi의 멀리 떨어진 건물 등 멀리 떨어진 장면의 세부 사항과 장면의 복잡한 텍스쳐를 재구성하는 데 어려움을 겪고 있습니다.
반면, 고빈도 dynamic 외관 피쳐 덕분에 우리의 방법은 Brandenburg의 말 조각, Sacre의 하늘과 구름, Trevi의 기둥 조명과 같은 보다 정확한 외관 세부 사항을 복구합니다.

5.3 Ablation studies
우리는 표 3의 Brandenburg, Sacre, 및 Trevi 데이터 세트에 대한 방법의 ablation 연구를 요약하고 각 구성 요소의 효과를 검증하기 위해 그림 4 및 그림 5에 정성적 결과를 생성합니다.


Without the visibility map.
transient 객체 처리 모듈을 제거하면 메트릭 성능이 향상되지만 그림 4와 같이 transient 객체의 영향으로 인해 렌더링된 이미지에 아티팩트가 발생합니다.
대부분의 테스트 이미지에는 동적 객체가 없기 때문에 이러한 아티팩트는 메트릭에 큰 영향을 미치지 않을 수 있습니다.
Without K feature maps or projection feature map.
K 피처 맵 또는 프로젝션 피처 맵을 제거하면 성능이 저하됩니다.
특히 K 피처 맵 없이 새로운 뷰를 합성하면 그림 4와 같이 참조 이미지에서 정보를 캡처할 수 있을 뿐만 아니라 뷰 일관성이 없는 모양이 생성됩니다.
Without adaptive sampling.
각 포인트에 대한 샘플링 좌표를 고정하면서 K 피처 맵을 유지하면 성능이 크게 저하됩니다.
이는 K 피처 맵에 대한 적응형 샘플링 전략의 중요성을 강조하여 가우시안 포인트가 로컬 및 세부 피처에 적응적으로 집중할 수 있도록 지원합니다.
Without separation.
우리는 intrinsic 피쳐를 제거하고 dynamic 외관 피쳐로만 가우시안 포인트의 색상을 예측합니다.
표 3의 결과는 인간의 시각 인식과 더 일치하는 LPIPS와 SSIM 모두에서 눈에 띄게 감소한 것으로 나타났습니다.
그림 5에서 dynamic 외관 피쳐가 없으면 장면 외관이 불완전해집니다.
이는 본질적인 장면 특성을 유지하는 데 intrinsic 피쳐의 중요성을 강조합니다.
두 가지 모두 분리가 모델이 샤프한 외관을 정확하게 이해하고 재구성하는 데 도움이 된다는 것을 보여줍니다.
5.4 Appearance tuning experiment
장면의 외관을 변하지 않고 다양한 dynamic 피쳐로 명시적으로 모델링하기 때문에 df_i에 비례 가중치를 곱하여 dynamic 외관 피쳐가 intrinsic 외관에 미치는 영향을 조정할 수 있습니다.
또한 추출된 이미지 피쳐에 동일한 가중치를 적용하여 Ha-NeRF 및 CR-NeRF와 비교합니다.
정성적 결과는 그림 5에 나와 있습니다.
Ha-NeRF와 CR-NeRF는 낮은 가중치에서 하늘과 건물에서 이상한 색상을 보이는 반면, 높은 가중치에서는 세부 하이라이트를 포착하지 못하고 충분한 조명 스타일을 향상시키지 못해 건물 색상이 어두워집니다.
대조적으로, 우리의 방법은 물리적 세계에 대한 인간의 이해와 더 밀접하게 일치합니다.
가중치가 작은 것에서 큰 것으로 증가함에 따라, 우리의 방법은 기둥에 하이라이트를 표시하고 조명을 강화하는 등 추출된 환경 영향을 장면에 점진적으로 적용합니다.
이는 환경 정보를 캡처하고 intrinsic 외관과 dynamic 외관을 명시적으로 분리하는 데 있어 dynamic 피쳐의 중요성을 입증하여 모델이 두 가지를 명확하게 학습하고 구별함으로써 장면 외관에 대해 더 유연한 튜닝을 달성할 수 있도록 지원합니다.
5.5 Limitations
GS-W는 이전 방법보다 성능이 뛰어나지만 여전히 한계가 있습니다.
Brandenburg Gate 장면의 바닥 텍스쳐와 같이 복잡한 조명 변화, 정반사, 자주 가려지는 장면에서 텍스처를 정확하게 재구성하는 데 어려움을 겪습니다.
또한 참조 이미지의 외관 정보를 통합할 때 알려진 이미지 포즈를 가정합니다.
향후 연구에서는 이러한 문제를 해결하기 위해 새로운 외관 모델링 기술을 개발하는 데 집중할 수 있습니다.
6 Conclusion
본 논문에서는 제약이 없는 이미지 컬렉션의 장면을 재구성하는 방법인 GS-W를 소개합니다.
3D 가우시안 포인트를 3D 표현으로 사용하여 장면 모양을 효과적으로 모델링하기 위해 각 포인트에 대해 분리된 intrinsic 및 dynamic 외관 피쳐를 도입합니다.
우리는 하이라이트와 같은 로컬 환경 요소를 캡처하고 가시성 맵을 활용하여 transient 물체를 처리하는 적응형 샘플링 전략을 제안합니다.
우리의 접근 방식은 이미지에서 동적 환경 영향을 더 잘 추출하고 느린 렌더링 속도를 처리함으로써 이전 NeRF 기반 방법을 능가합니다.
실험 결과는 이전 접근 방식과 비교하여 우리 방법의 우수성과 효율성을 입증합니다.