2024. 10. 21. 10:02ㆍ3D Vision/NeRF with Real-World
SpotLessSplats: Ignoring Distractors in 3D Gaussian Splatting
Sara Sabour, Lily Goli, George Kopanas, Mark Mathews, Dmitry Lagun, Leonidas Guibas, Alec Jacobson, David Fleet, Andrea Tagliasacchi
Abstract
3D Gaussian Splatting (3DGS)은 효율적인 학습 및 렌더링 속도를 제공하는 3D 재구성을 위한 유망한 기술로, 실시간 애플리케이션에 적합합니다.
그러나 현재 방법은 3DGS의 인터-뷰 일관성 가정을 충족하기 위해 고도로 제어된 환경—움직이는 사람이나 바람이 부는 요소가 없고 일관된 조명이 필요하지 않다—이 필요합니다.
따라서 실제 캡처를 재구성하는 데 문제가 있습니다.
우리는 사전 학습된 피쳐와 강력한 최적화를 활용하여 transient distractors 요소를 효과적으로 무시하는 접근 방식인 SpotLessSplats를 제시합니다.
우리의 방법은 캐주얼 캡처에서 시각적으로나 정량적으로 SOTA 재구성 품질을 달성합니다.

1 Introduction
neural radiance fields (NeRF) [Mildenhall et al. 2020]를 사용한 2D 이미지의 3D 장면 재구성과 최근에는 3D Gaussian Splatting (3DGS) [Kerbl et al. 2023]을 사용한 3D 장면 재구성은 비전 연구에서 집중적으로 초점을 맞추고 있습니다.
대부분의 현재 방법은 이미지가 동시에 캡처되고 완벽한 포즈를 취하며 노이즈가 없다고 가정합니다.
이러한 가정은 3D 재구성을 단순화하지만 움직이는 물체(예: 사람이나 반려동물), 조명 변화 및 기타 가짜 측광 불일치로 인해 성능이 저하되어 광범위한 적용이 제한되는 실제 세계에서는 거의 유지되지 않습니다.
NeRF 학습에서 이상값에 대한 robustness는 색상 잔차의 크기에 따라 일관성이 없는 관측값의 가중치를 낮추거나 폐기함으로써 통합되었습니다 [Chen et al. 2024; Martin-Brualla et al. 2021b; Sabour et al. 2023; Wu et al. 2022].
3DGS에 적용된 유사한 방법 [Dahmani et al. 2024; Kulhanek et al. 2024; Wang et al. 2024]은 Phototourism [Snavely et al. 2006]과 같은 데이터 세트에서 볼 수 있는 전역적인 외관 변경과 단일 프레임 transient 현상을 해결합니다.
이러한 캡처에는 대부분의 캐주얼 캡처에는 흔하지 않은 몇 주에 걸쳐 발생하는 외관 변경과 하루 중 다른 시간이 포함됩니다.
특히 3DGS의 경우 adaptive densification 프로세스 자체가 색상 잔차의 분산을 도입하여 robust NeRF 프레임워크의 기존 아이디어를 직접 적용할 때 transient 현상 감지를 손상시킵니다.
본 논문에서는 학습 이미지의 이상값을 unsupervised로 감지하여 3DGS로 robust 3D 장면 재구성을 위한 프레임워크인 SpotLessSplats (SLS)를 소개합니다.
RGB 공간에서 이상값을 감지하는 대신 text-to-image 모델에서 더 풍부하고 learned feature space를 활용합니다.
이 피쳐 임베딩의 의미 있는 시맨틱 구조를 통해 예를 들어 단일 객체와 관련된 구조화된 이상값의 공간적 지원을 더 쉽게 감지할 수 있습니다.
이상값 식별을 위해 수동으로 지정된 robust 커널을 사용하는 [Sabour et al. 2023] 대신 이 피쳐 공간에서 적응형 방법을 활용하여 이상값을 감지합니다.
이를 위해 우리는 이 프레임워크 내에서 두 가지 접근 방식을 고려합니다.
첫 번째는 구조화된 이상값의 이미지 영역을 찾는 간단한 방법으로 로컬 피쳐 임베딩의 비모수 클러스터링을 사용합니다.
두 번째는 unsupervised 방식으로 학습된 MLP를 사용하여 distractors와 관련될 가능성이 있는 피쳐 공간의 부분을 예측합니다.
또한, distractors-free 데이터 세트에서도 2~4배 적은 스플랫으로 유사한 재구성 품질을 제공하여 컴퓨팅 및 메모리를 크게 절약할 수 있는 robust 최적화와 호환되는 (보충적이고 일반적인 목적) 희소화 전략을 도입합니다.
자연스럽게 캡처된 장면의 까다로운 벤치마크에 대한 실험 [Ren et al. 2024; Sabour et al. 2023]을 통해 SLS는 재구성 정확도에서 경쟁 방법들을 지속적으로 능가하는 것으로 나타났습니다.
주요 기여 사항은 다음과 같습니다:
• text-to-image 디퓨전 피쳐를 활용하여 인과관계 캡처에서 transient distractors를 안정적으로 식별하여 photometric 오류에 과적합되는 문제를 제거하는 적응적이고 robust loss입니다.
• 가우시안의 수를 크게 줄여 충실도 loss 없이 컴퓨팅과 메모리를 절약할 수 있는 robust loss와 호환되는 새로운 희소화 방법입니다.
• 표준 벤치마크에서 SLS를 종합적으로 평가하여 SOTA의 강력한 재구성을 입증하고 기존 방법을 상당한 차이로 능가합니다.
2 Related work
Neural Radiance Fields (NeRF) [Mildenhall et al. 2020]는 3D 장면의 고품질 재구성과 새로운 뷰 합성으로 인해 광범위한 관심을 받고 있습니다.
NeRF는 장면을 뷰 종속 방출 볼륨으로 나타냅니다.
볼륨 렌더링 식 [Kajiya and Von Herzen 1984]의 흡수-방출 부분을 사용하여 볼륨을 렌더링합니다.
여러 개선 사항이 뒤따랐습니다.
빠른 학습 및 추론 [Chen et al. 2023; Müller et al. 2022; Sun et al. 2022; Yu et al. 2021a], 제한된 또는 단일 뷰(들)를 사용한 학습 [Jain et al. 2021; Rebain et al. 2022; Yu et al. 2021b] 및 동시 포즈 추론 [Levy et al. 2024; Lin et al. 2021; Wang et al. 2021]을 통해 래디언스 필드는 실제 응용 분야에 가까워졌습니다.
최근에는 고품질을 유지하면서 렌더링 속도가 훨씬 빠른 NeRF의 원시 기반 대안으로 3D Gaussian Splatting (3DGS) [Kerbl et al. 2023]이 제안되었습니다.
3D 가우시안은 알파 블렌딩 [Zwicker et al. 2001]을 사용하여 효율적으로 래스터화할 수 있습니다.
이 단순화된 표현은 최신 GPU 하드웨어를 활용하여 실시간 렌더링을 용이하게 합니다.
3DGS의 효율성과 단순성으로 인해 많은 NeRF 개선 사항이 3DGS로 빠르게 포팅되면서 필드 내에서 초점이 변화하고 있습니다 [Charatan et al. 2024; Yu et al. 2024].
Robustness in NeRF.
원본 NeRF 논문은 캡처 설정에 대해 강력한 가정을 세웠습니다: 장면은 완벽하게 정적이어야 하며, 촬영하는 동안 조명은 변하지 않아야 합니다.
최근에는 이러한 제약 조건을 위반하는 비정형 "in-the-wild" 캡처 이미지에 대한 학습을 위해 NeRF가 확장되었습니다.
두 가지 영향력 있는 작업인 NeRF-W [Martin-Brualla et al. 2021a]와 RobustNeRF [Sabour et al. 2023]는 photometric 오류를 가이던스로 사용하여 transient distractors 문제를 해결했습니다.
NeRF-W [Martin-Brualla et al. 2021a]는 2D 이상치 마스크로 렌더링된 3D uncertainty 필드를 모델링하여 픽셀의 loss를 높은 오차로 축소하고 퇴화 솔루션을 방지합니다.
NeRF-W [Martin-Brualla et al. 2021a]는 또한 광범위하게 변화하는 조명 및 대기 조건에서 캡처된 이미지에 유용한 학습된 임베딩을 통해 전역 외관을 모델링합니다.
Urban Radiance Fields (URF) [Rematas et al. 2022]와 Block-NeRF [Tancik et al. 2022]도 학습된 외관 임베딩을 대규모 재구성에 유사하게 적용합니다.
cross-ray 상관 관계를 위해 CNN 또는 트랜스포머를 활용하여 3D 필드 대신 HA-NeRF [Chen et al. 2022] 및 Cross-Ray [Yang et al. 2023]는 2D 이상치 마스크를 모델링합니다.

RobustNeRF [Sabour et al. 2023]는 임계값 렌더링 오류에 의해 결정되는 이진 가중치와 distractors에 속하는 픽셀이 공간적으로 상관관계가 있다는 가정을 반영하는 블러 커널을 통해 robust 추정기 관점에서 문제에 접근했습니다.
그러나 RobustNeRF와 NeRF-W 변형 [Chen et al. 2022; Yang et al. 2023]은 모두 RGB 잔여 오류에만 의존하며, 이로 인해 배경과 유사한 색상으로 transient를 잘못 분류하는 경우가 많습니다; 그림 2의 RobustMask를 참조하세요.
이를 방지하기 위해 이전 방법에서는 하이퍼 파라미터, 즉 RobustNeRF의 블러 커널 크기와 임계값과 NeRF-W의 정규화기 가중치를 신중하게 조정해야 합니다.
반대로, 우리의 방법은 시맨틱 이상치 모델링을 위해 text-to-image 모델의 풍부한 표현을 사용합니다.
이는 클러스터링을 위해 피쳐 공간 유사성에 의존하기 때문에 직접적인 RGB 오류 supervision을 피할 수 있습니다.

NeRF On-the-go [Ren et al. 2024]는 transient occluders가 있는 캐주얼하게 캡처된 비디오 데이터 세트를 출시했습니다.
저희의 방법과 유사하게 DINOv2의 시맨틱 피쳐를 사용하여 작은 MLP를 통해 이상치 마스크를 예측합니다.
그러나 또한 구조 렌더링 오류의 직접적인 supervision에 의존하여 이상치를 과대 또는 과소 마스킹할 가능성이 있습니다.
이는 그림 3에 나와 있는데, 과잉 마스킹으로 인해 호스('Fountain')가 제거되고 카펫이 매끄러워진 반면 ('Spot'), 과소 마스킹으로 인해 distrators 누출과 안개가 낀 아티팩트('Corner' 및 'Spot')가 발생했습니다.
NeRFHUGS [Chen et al. 2024]는 COLMAP의 강력한 희소 포인트 클라우드의 휴리스틱 [Schönberger and Frahm 2016]과 기성 시맨틱 세그멘테이션을 결합하여 distractors를 제거합니다.
두 휴리스틱 모두 [Ren et al. 2024]에서 transient occlusion이 심한 경우 실패하는 것으로 나타났습니다.
Precomputed features.
DINO [Caron et al. 2021; Oquab et al. 2023]와 같이 사전 계산된 비전 피쳐를 사용하면 여러 비전 작업에 일반화할 수 있는 능력이 입증되었습니다.
Denoising Diffusion Probabalistic Models [Ho et al. 2020; Rombach et al. 2022; Song and Ermon 2019]은 텍스트 프롬프트에서 사실적인 이미지 생성 기능으로 유명한 모델 [Ramesh et al. 2022; Rombach et al. 2021; Saharia et al. 2022]은 세그멘테이션 및 키포인트 대응과 같은 많은 작업 [Amir et al. 2022; Hedlin et al. 2024; Luo et al. 2023; Tang et al. 2023; Zhang et al. 2023]에서 일반화하는 데 유사하게 강력한 내부 기능을 가진 것으로 나타났습니다.
Robustness in 3DGS (concurrent works).
여러 개의 동시 작업에서 야생 캡처 데이터에 대한 3DGS 학습을 다룹니다.
SWAG [Dahmani et al. 2024] 및 GS-W [Zhang et al. 2024]는 학습된 전역 및 로컬 원시별 외관 임베딩을 사용하여 외관 변화를 모델링합니다.
마찬가지로 WE-GS [Wang et al. 2024]는 이미지 인코더를 사용하여 이미지별로 각 스플랫의 색상 파라미터에 대한 적응을 학습합니다.
Wild-GS [Xu et al. 2024]는 외관 임베딩을 위한 공간 트라이플레인 필드를 학습합니다.
이러한 모든 방법 [Wang et al. 2024; Xu et al. 2024; Zhang et al. 2024]은 높은 오류 렌더링 픽셀의 가중치를 낮추는 것으로 예측되는 2D 이상치 마스크를 사용하여 NeRF-W [Martin-Brualla et al. 2021a]와 같은 이상치 마스크 예측에 대한 접근 방식을 채택합니다.
SWAG [Dahmani et al. 2024]는 각 가우시안에 대해 이미지별 불투명도를 학습하고 불투명도 분산이 높은 프리미티브를 transients로 나타냅니다.
주목할 만한 것은 추가로 학습된 transient 마스크를 Phototourism 장면 [Snavely et al. 2006]에 적용했을 때 로컬/전역 외관 모델링에 비해 개선되지 않거나 거의 보이지 않는 SWAG [Dahmani et al. 2024] 및 GS-W [Zhang et al. 2024]입니다.
SLS는 "NeRF on-the-go" 데이터 세트와 같은 비디오 캡처에서 흔히 볼 수 있는 더 긴 지속 시간 transient 및 최소한의 외관 변화를 가진 캐주얼 캡처에 중점을 둡니다.
3 Background
우리는 3D anisotropic 가우시안 G={𝑔_𝑖}의 컬렉션으로 3D 장면을 나타내는 3D Gaussian Splatting [Kerbl et al. 2023] 또는 간결성을 위한 3DGS 위에 기술을 구축하며, 이를 이후 스플랫이라고 합니다.
캐주얼하게 캡처된 장면의 포즈 이미지 {I_𝑛}^𝑁_(𝑛=1), I_𝑖 ∈ R^(𝐻×𝑊) 세트가 주어지면 장면의 3DGS 재구성 G를 학습하는 것을 목표로 합니다.
각 스플랫 𝑔_𝑖은 평균 𝜇_𝑖, 양의 semi-definite 공분산 행렬 𝚺_𝑖, 불투명도 𝛼_𝑖로 정의되며 구형 고조파 계수 c_𝑖로 매개변수화된 뷰 종속 색상입니다 [Ramamoorthi and Hanrahan 2001].
3D 장면 표현은 래스터화를 통해 스크린 공간으로 렌더링됩니다.
스플랫 위치/평균은 고전적인 투영 지오메트리를 통해 스크린 좌표로 래스터화되며, 각 스플랫의 공분산 행렬을 래스터화하기 위해 특별한 주의가 필요합니다.
특히 원근 변환 행렬을 W로 표시하면 2D 스크린 공간에 대한 3D 공분산의 투영은 [Zwicker et al. 2001]을 따라 ˜ 𝚺 = JW𝚺W^𝑇 J^𝑇로 근사화할 수 있으며, 여기서 J는 비선형 투영 프로세스에 대한 선형 근사치를 제공합니다.
𝚺이 최적화(즉, 양의 semi-definite) 전반에 걸쳐 공분산을 나타내도록 공분산 행렬은 𝚺 = RSS^𝑇 R^𝑇로 매개변수화되며, 여기서 s ∈ R^3을 사용하는 척도 S=diag(s)와 회전 R은 단위 쿼터니언 𝑞에서 계산됩니다.
스크린 공간의 스플랫 위치와 공분산이 계산되면 이미지 형성 프로세스는 볼륨 렌더링을 알파 블렌딩으로 실행하므로 뷰 방향을 따라 스플랫 정렬이 필요합니다.
한 번에 하나의 픽셀을 렌더링하는 NeRF와 달리 3DSG는 전체 이미지를 단일 순방향 패스로 렌더링합니다.
3.1 Robust optimization of 3DGS
3DGS [Kerbl et al. 2023]의 일반적인 캡처 데이터와 달리, 우리는 포즈 이미지 집합 {I_𝑛}^𝑁_(𝑛=1)을 큐레이션할 것이 아니라 캐주얼하게 캡처할 것으로 가정합니다.
즉, 이미지가 완벽하게 3D 일관되고 정적인 세계를 묘사할 것을 요구하지 않습니다.
이전 작업에 이어, 우리는 이러한 가정을 깨는 이미지의 부분을 (교환적으로) distractors [Sabour et al. 2023] 또는 transient 효과 [Martin-Brualla et al. 2021b]로 표시합니다.
그리고 이전 작업 [Kerbl et al. 2024; Martin-Brualla et al. 2021b; Tancik et al. 2022]과 달리 transient 객체 클래스, 외관 및/또는 모양에 대한 가정은 하지 않습니다.
최적화 과정에서 마스킹해야 할 입력 이미지의 부분을 식별하여 distractors를 제거하는 RobustNeRF에서 [Sabour et al. 2023]의 선구적인 연구에서 영감을 받아 이 문제를 해결합니다.
문제는 각 학습 이미지에 대한 (supervision 없이) 인라이어/아웃라이어 마스크 {M_𝑛}^𝑁_(𝑛=1)를 예측하고 마스크된 L1 loss를 통해 모델을 최적화하는 것으로 축소됩니다:
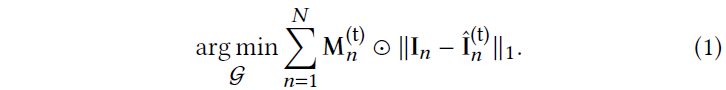
, 여기서 ˆI_𝑛^(t)는 학습 iteration (𝑡)에서 G를 렌더링한 것입니다.
RobustNeRF [Sabour et al. 2023]에서와 마찬가지로 학습 중에 photometric 불일치, 즉 큰 loss 값과 관련된 이미지 영역을 관찰하여 transient 효과를 감지할 수 있습니다.
R_𝑛^(t) = |I_𝑛 -ˆI_𝑛^(t)| 잔차 이미지(1-norm이 픽셀 단위로 실행됨에 따라 색상 채널을 따라 약간의 표기법 남용이 있음)를 표시함으로써 마스크를
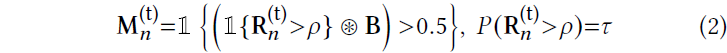
로 계산하고, 여기서 1은 술어가 참이면 1을 반환하는 지시 함수이고, 𝜌은 컷오프 백분위수를 제어하는 하이퍼파라미터인 일반화된 중위수이며, B는 컨볼루션(⊛)을 통해 형태학적 확장을 수행하는 (정규화된) 3×3 박스 필터입니다.
직관적으로 위의 식 (2)로 요약된 RobustNeRF [Sabour et al. 2023]는 공간적으로 상관관계가 있다고 가정하여 트리밍된 robust 추정기를 확장합니다.
그림 2에 묘사된 것과 같이 색상 잔차가 오해의 소지가 있는 경우에 국한되지 않더라도 [Sabour et al. 2023]의 아이디어를 3DGS에 직접 적용해도 이상치를 효과적으로 제거할 수 없다는 것을 발견했습니다.
오히려 3DGS의 표현 및 학습 프로세스의 차이를 수용하기 위해 몇 가지 조정이 필요합니다 (섹션 4.2 참조).
4 Method
식 (2)의 이상값 마스크는 새로운 뷰 합성 프로세스의 photometric 오류만을 기반으로 구축됩니다.
반대로, 우리는 학습 과정에서 발생하는 distractors를 인식하고 시맨틱을 기반으로 그들을 식별할 것을 제안합니다.
우리는 시맨틱을 self-supervised 2D 기반 모델에서 계산된 피쳐 맵으로 간주합니다(예: [Tang et al. 2023]).
그런 다음 학습 이미지에서 distractors를 제거하는 과정은 큰 photometric 오류를 일으킬 가능성이 있는 피쳐의 하위 공간을 식별하는 것 중 하나가 됩니다.
예를 들어, 완벽하게 정적인 장면에서 걸어다니는 개를 고려해 보겠습니다.
각 이미지 (섹션 4.1.1)에서 공간적으로 또는 더 넓게는 데이터 세트 (섹션 4.1.2)에서 시공간적으로 'dog' 픽셀을 재구성 문제의 가능한 원인으로 인식하고 최적화에서 자동으로 제거하는 시스템을 설계하고자 합니다.
우리의 방법은 이상값 감지 및 색상 오류에 과적합하기 위해 로컬 색상 잔차에 대한 의존도를 줄이고 대신 픽셀 간의 시맨틱 피쳐 유사성에 대한 의존도를 강조하도록 설계되었습니다.
따라서 우리는 우리의 방법을 "clustering"이라고 부릅니다.
섹션 4.1에서 우리는 이 objective를 달성하는 방법을 자세히 설명합니다.
그런 다음 섹션 4.2에서 우리는 RobustNeRF [Sabour et al. 2023]에서 3DGS 학습 체제로 아이디어를 조정하기 위한 몇 가지 주요 조정 사항을 자세히 설명합니다; 섹션 4.1.1 및 4.1.2 참조.
4.1 Recognizing distractors
입력 이미지 {I_𝑛}^𝑁_(𝑛=1)가 주어졌을 때, [Tang et al. 2023]에서 제안한 대로 Stable Diffusion [Rombach et al. 2022]을 사용하여 각 이미지에 대한 피쳐 맵을 사전-계산하여 피쳐 맵 {F𝑛}^𝑁_(𝑛=1)을 생성합니다.
이 전처리 단계는 학습 프로세스가 시작되기 전에 한 번 실행됩니다.
그런 다음 이러한 피쳐 맵을 사용하여 인라이어/아웃라이어 마스크 M^(t)을 계산하고; 학습 프로세스에는 배치당 하나의 이미지가 포함되므로 이미지 인덱스 𝑛를 삭제하여 표기를 단순화합니다.
이제 이상값을 감지하는 두 가지 다른 방법을 자세히 설명합니다.
4.1.1 Spatial clustering.
전처리 단계에서는 이미지 영역의 unsupervised 클러스터링을 추가로 수행합니다.
슈퍼 픽셀 기술 [Ibrahim and El-kenawy 2020; Li and Chen 2015]과 마찬가지로 이미지를 공간적으로 연결된 𝐶 구성 요소의 고정 카디널리티 컬렉션으로 오버 세그먼트화하고; 'Clustered Features' 그림 2 참조.
더 자세히 설명하자면, 각 픽셀이 8개의 주변 픽셀에 연결되는 피쳐 맵 F에서 agglomerative clustering [Müllner 2011]을 실행합니다.
클러스터 𝑐에 픽셀 𝑝를 클러스터링 할당하는 것을 C[𝑐, 𝑝]∈{0, 1}로 표시하고, 자체 클러스터의 모든 픽셀에서 클러스터링이 초기화됩니다.
클러스터는 탐욕스럽게 응집되어 붕괴 전후에 클러스터 간 피쳐 분산을 가장 적게 유발하는 클러스터가 붕괴됩니다.
클러스터링은 𝐶=100 클러스터가 남아있을 때 종료됩니다.
그런 다음 식 (2)의 인라이어 픽셀 비율로부터 클러스터 𝑐이 인라이어일 확률을 계산할 수 있습니다:
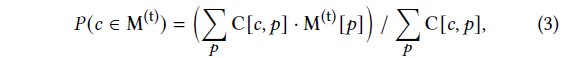
그런 다음 클러스터 레이블을
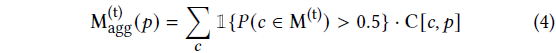
와 같이 픽셀로 다시 전파합니다.
그런 다음 식 (1)에서 3DGS 모델을 학습하기 위해 M^(t)이 아닌 M_agg^(t)를 inlier/outlier 마스크로 사용합니다.
이 모델 구성을 'SLS-agg'로 지정합니다.
4.1.2 Spatio-temporal clustering.
두 번째 접근 방식은 픽셀이 관련된 피쳐를 기반으로 최적화 식 (1)에 포함되어야 하는지 여부를 결정하는 분류기를 학습하는 것입니다.
이를 위해 픽셀 피쳐에서 픽셀별 인라이어 확률을 예측하는 파라미터 𝜃가 있는 MLP를 사용합니다:
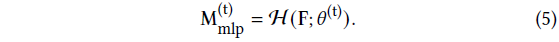
𝜃^(t) 표기법에서 알 수 있듯이 분류기 매개변수는 3DGS 최적화와 동시에 업데이트됩니다.
H는 1×1 컨볼루션으로 구현되므로 픽셀 간에 i.i.d. 방식으로 작동합니다.
MLP와 3DGS 모델의 최적화를 인터리브하여 하나는 고정되고 다른 하나는 최적화되는 방식으로 번갈아 가며 최적화됩니다.
MLP 분류기 loss는
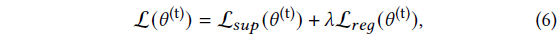
에 의해 주어지며, 𝜆 = 0.5이며, 여기서 L_𝑠𝑢𝑝는 분류기를 supervise합니다:
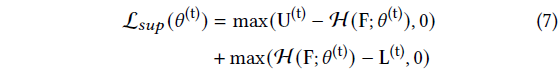
, 그리고 U와 L은 현재 잔차의 마스크에서 계산된 self-supervision 레이블입니다:
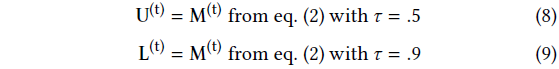
즉, 재구성 잔차를 기반으로 인라이어 상태를 자신 있게 결정할 수 있는 픽셀에만 분류기를 직접 supervise하고, 그렇지 않으면 피쳐 공간의 시맨틱 유사성에 크게 의존합니다; 그림 4를 참조하세요.
유사한 피쳐를 유사한 확률로 매핑하도록 H를 더 정규화하려면 [Liu et al. 2022, 식. (13)]에 자세히 설명된 대로 L_𝑟𝑒𝑔을 통해 Lipschitz 상수를 최소화합니다.
그런 다음 M^(t) 대신 M_mlp^(t)를 사용하여 3DGS를 식 (1)으로 학습시킵니다.
이 구성을 'SLS-mlp'로 지정합니다.
3DGS 모델과 함께 분류기를 공동 학습하기 때문에 구현에 추가적인 주의가 필요합니다; 섹션 4.2.1 참조.

4.2 Adapting 3DGS to robust optimization
robust 마스킹 기술을 3DGS에 직접 적용하면 초기 3DGS 모델에 대한 robust 마스크 과적합 (섹션 4.2.1)이 발생할 수 있으며, 이미지 기반 학습 (섹션 4.2.2) 또는 3DGS의 고밀도화 전술 (섹션 4.2.3)에 의해 인라이어 추정기가 왜곡될 수 있습니다.
우리는 다음과 같은 문제에 대한 해결책을 제안합니다.
4.2.1 Warm up with scheduled sampling.
초기 잔차는 랜덤이기 때문에 마스크를 점진적으로 적용하는 것이 중요하다는 것을 알 수 있습니다.
MLP가 최적화 초기에 수렴하지 않고 랜덤 마스크를 예측하기 때문에 학습된 클러스터링을 마스킹에 사용하는 경우 이는 두 배로 사실입니다.
또한 이상치 마스크를 직접 사용하면 이상치에 빠르게 오버커밋되어 귀중한 오류 역전파를 방지하고 해당 영역에서 학습하는 경향이 있습니다.
우리는 각 픽셀에 대한 마스킹 정책을 마스크를 기반으로 한 Bernoulli 분포에서 샘플링으로 공식화하여 이를 완화합니다:
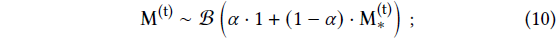
; 𝛼은 계단 지수 스케줄러 (보충 자료 B에 자세히 설명되어 있음)로 1에서 0으로 이동하여 워밍업을 제공합니다.
이를 통해 확신할 수 없는 영역에서 여전히 드문드문 그래디언트를 샘플링할 수 있으므로 이상값을 더 잘 분류할 수 있습니다.
4.2.2 Trimmed estimators in image-based training.
[Sabour et al. 2023]이 트리밍된 추정기를 구현할 때, 기본 가정은 각 미니배치에 (평균적으로) 동일한 비율의 이상치가 포함된다는 것입니다.
이 가정은 각 미니배치가 학습 이미지 세트에서 추출한 랜덤 픽셀 집합이 아닌 전체 이미지인 3DGS 학습 실행에서 깨집니다.
이는 이상치 분포가 이미지 사이에 치우쳐 있기 때문에 식 (2)의 일반화된 중앙값을 구현하는 데 어려움을 초래합니다.
우리는 여러 학습 배치에 대한 잔차 크기를 추적하여 이를 극복합니다.
특히 렌더링 오류의 하한(10^-3)과 동일한 너비의 𝐵 히스토그램 버킷으로 잔차 크기를 이산화합니다.
빠른 중앙값 필터링 접근 방식과 유사하게 버킷 모집단에 대한 할인된 업데이트를 통해 각 반복에서 각 버킷의 가능성을 업데이트합니다 [Perreault and Hebert 2007].
이를 통해 일정한 메모리 소비로 잔차 분포의 이동 추정치를 유지하며, 여기에서 일반화된 중앙값 𝜌을 히스토그램 모집단의 𝜏 분위수로 추출할 수 있습니다.
4.2.3 A friendly alternative to "opacity reset".
[Kerbl et al. 2023]은 모든 𝑀 반복마다 모든 가우시안의 불투명도를 재설정할 것을 제안했습니다.
이 불투명도 재설정은 두 가지 주요 문제를 처리하는 메커니즘입니다.
첫째, 어려운 데이터 세트에서 최적화는 카메라에 가까운 가우시안을 축적하는 경향이 있습니다.
이를 종종 문헌에서 플로터라고 부릅니다.
플로터는 카메라 ray들이 조기에 투과율을 포화시키도록 강요하기 때문에 처리하기 어렵고, 그 결과 그라디언트가 장면의 폐색된 부분을 통과할 기회가 없기 때문입니다.
불투명도 재설정은 모든 가우시안의 불투명도를 낮추어 그라디언트가 전체 ray를 따라 다시 흐를 수 있도록 합니다.
둘째, 불투명도 재설정은 가우시안 수의 제어 메커니즘으로 작용합니다.
불투명도를 낮은 값으로 재설정하면 더 높은 불투명도를 회복하지 못하는 가우시안이 적응형 밀도 제어 메커니즘에 의해 잘릴 수 있습니다 [Kerbl et al. 2023].
그러나 불투명도 리셋은 잔차 분포 추적을 방해하므로 (섹션 4.2.2) 불투명도 리셋 후 반복에서 잔차가 인위적으로 커집니다.
단순히 비활성화하는 것만으로는 최적화가 필요하기 때문에 작동하지 않습니다.
[Goli et al. 2024]에 이어, 대신 utilization-based pruning (UBP)를 제안합니다.
우리는 각 가우시안 𝑔의 투영된 스플랫 위치 𝑥_𝑔와 관련하여 렌더링된 색상의 그래디언트를 추적합니다.
3D 위치와 달리 투영된 위치와 관련하여 도함수를 계산하면 메모리 집약적이지 않은 GPU 구현이 가능하면서도 [Goli et al. 2024]와 유사한 메트릭을 제공할 수 있습니다.
보다 구체적으로, 우리는 활용도를
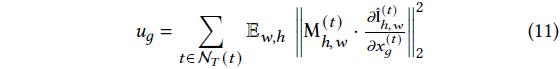
로 정의합니다.
우리는 이 메트릭을 이미지 (𝑊×𝐻)에 걸쳐 평균화하여 이전 |N_𝑇(𝑡)| = 100 이미지 세트에 걸쳐 축적된 모든 𝑇 = 100 단계마다 계산합니다.
우리는 𝑢_𝑔<𝜅, 𝜅 = 10^-8을 사용할 때마다 가우시안 프루닝을 수행합니다.
불투명도 재설정을 활용 기반 프루닝으로 대체하면 불투명도 재설정이라는 원래 목표를 모두 달성하는 동시에 잔차 분포 추적에 대한 간섭을 완화할 수 있습니다.
활용 기반 프루닝은 더 적은 수의 프리미티브를 사용하여 장면 표현을 크게 압축하는 동시에 이상값이 없는 장면에서도 비슷한 재구성 품질을 달성합니다; 섹션 5.2 참조.
또한 플로터를 효과적으로 처리합니다; 그림 10 참조.
플로터는 자연스럽게 매우 적은 수의 뷰 렌더링에 참여하기 때문에 활용도가 낮습니다.
또한 식 (11)과 같이 마스킹된 도함수를 사용하면 웜업 단계에서 robust 마스크를 통해 누출된 스플랫을 제거할 수 있습니다.
4.2.4 Appearance modeling.
[Kerbl et al. 2023]은 장면의 이미지(up to distractors)가 photometrically 완벽하게 일치한다고 가정했지만, 일반적으로 자동 노출과 화이트 밸런스를 사용하는 캐주얼 캡처의 경우는 거의 그렇지 않습니다.
우리는 [Kerbl et al. 2023]의 구형 고조파로 표현되는 뷰 종속 색상에 적응된 [Rematas et al. 2022]의 솔루션을 통합하여 이 문제를 해결합니다.
우리는 입력 카메라 뷰당 잠재 𝑧_𝑛∈R^64를 공동 최적화하고 MLP를 통해 이 잠재 벡터를 고조파 계수 c에 작용하는 선형 변환에 매핑합니다: (12), ⊙은 하다마드 곱이며 b는 밝기 변화를 모델링하고 a는 화이트 밸런스에 대한 표현력을 제공합니다.
최적화 중에 학습 가능한 매개변수에는 𝜃_Q 및 {z_𝑛}도 포함됩니다.
이러한 감소된 모델은 더 간단한 GLO [Martin-Brualla et al. 2021b]에서 발생하는 것처럼 z_𝑛가 분산 요소를 이미지별 조정으로 설명하는 것을 방지할 수 있습니다; 분석은 [Rematas et al. 2022]를 참조하세요.
5 Results
다음으로, 우리는 제안된 방법을 기존의 캐주얼한 distractor로 채워진 캡처 데이터셋 (섹션 5.1)과 비교하여 다른 방법들과 비교합니다.
그런 다음, 제안된 불투명도 리셋 대체 프루닝 (섹션 5.2)의 효과를 조사합니다.
마지막으로, 클러스터링의 다양한 변형에 대한 완전한 분석과 설계 선택에 대한 ablation 연구 (섹션 5.3)를 보고합니다.
Datasets.
우리는 RobustNeRF [Sabour et al. 2023] 및 NeRF on-the-go [Ren et al. 2024] 데이터셋에서 우리의 방법을 평가합니다.
RobustNeRF 데이터셋에는 distractor-filled 학습 분할과 distractor-free 학습 분할이 포함된 네 개의 장면이 포함되어 있어, distractor-free 이미지로 학습된 'clean' 모델과 robust 모델을 비교할 수 있습니다.
모든 모델은 깨끗한 테스트 세트에서 평가됩니다.
'Crab' 및 'Yoda' 장면은 단일 캐주얼 비디오에서 캡처되지 않고 이미지 전반에 걸쳐 가변적인 distractor를 피쳐로 하지만, 쌍둥이 distractor-free와 distractor-filled 이미지를 가진 이러한 정확한 로봇 캡처는 'clean' 모델과 공정한 비교를 가능하게 합니다.
참고로, (원래 공개된) Crab (1) 장면은 학습 세트와 동일한 뷰 세트를 가지고 있었으며, 이는 Crab (2)에 고정되어 있습니다.
우리는 Crab (1)에서 이전 방법들을 비교하고, 섹션 5.3에서 Crab (2)와 보충 자료 C에서 전체 결과를 제시합니다.
NeRF on-the-go 데이터셋에는 세 가지 수준의 transient distractor 폐색 (낮음, 중간, 높음)을 가진 여섯 개의 장면과 정량적 비교를 위한 별도의 깨끗한 테스트 세트가 있습니다.
Baselines.
distractor-free 재구성은 아직 3D 가우시안 스플래팅 방법으로 널리 다루어지지 않았습니다.
기존 방법들은 주로 밝기 변화와 같은 전역적인 외관 변화에 초점을 맞추고 있으며 [Dahmani et al. 2024; Kulhanek et al. 2024; Wang et al. 2024], 이 작업을 위해 큐레이팅된 캐주얼 캡처의 distractor-filled 데이터셋에는 초점을 맞추지 않습니다.
따라서 우리는 vanilla 3DGS 및 robust NeRF 방법과 비교합니다.
우리는 GLO를 활성화한 MipNeRF360 결과와 비교하기 위해 vanilla 3DGS 기준에 GLO를 추가합니다.
우리는 최신 NeRF 방법, NeRF on-the-go [Ren et al. 2024], NeRF-HuGS [Chen et al. 2024] 및 RobustNeRF [Sabour et al. 2023]과 비교합니다.
또한, NeRF의 베이스라인으로 MipNeRF-360 [Barron et al. 2022]을 포함합니다.
Metrics.
우리는 PSNR, SSIM 및 LPIPS의 일반적으로 사용되는 이미지 재구성 지표를 계산합니다.
우리는 LPIPS 지표를 계산할 때 대부분의 경우와 마찬가지로 정규화된 VGG 피쳐를 사용합니다.
NeRF-HuGS [Chen et al. 2024]는 AlexNet 피쳐에서 LPIPS 지표를 보고합니다.
공정한 비교를 위해, 우리는 공개된 렌더링에서 VGG LPIPS 지표를 계산하고 보고합니다.
마지막으로, NeRF는 앞서 언급한 문제 때문에 'Crab'에서 평가하지 않습니다.
Implementation details.
우리는 공식적으로 공개된 코드베이스와 동일한 하이퍼파라미터를 사용하여 3DGS 모델을 학습합니다.
모든 모델은 30k 반복 학습을 위해 학습되었습니다.
우리는 불투명도 재설정을 끄고 8000번째 단계에서 비확산 구형 고조파 계수만 0.001로 재설정합니다.
이를 통해 MLP 학습 초기 단계에서 유출된 distractors가 뷰 종속 효과로 모델링되지 않도록 합니다.
우리는 500번째 단계부터 15,000번째 단계까지 100단계마다 UBP를 실행합니다.
MLP 학습의 경우, 0.001 학습률을 가진 Adam 최적화기를 사용합니다.
Stable diffusion v2.1의 두 번째 업샘플링 레이어에서 이미지 피쳐를 계산하여 261의 시간 단계를 노이즈 제거하고 빈 프롬프트를 표시합니다.
[Tang et al. 2023]은 이 구성이 세그멘테이션 및 키포인트 대응 작업에 가장 효율적임을 발견했습니다.
MLP에 입력되는 피쳐에 20도의 위치 인코딩을 연결했습니다.
5.1 Distractor-free 3D reconstruction
우리는 RobustNeRF 및 NeRF on-the-go 데이터셋에서 3D 재구성을 수행하여 우리의 방법을 평가합니다.
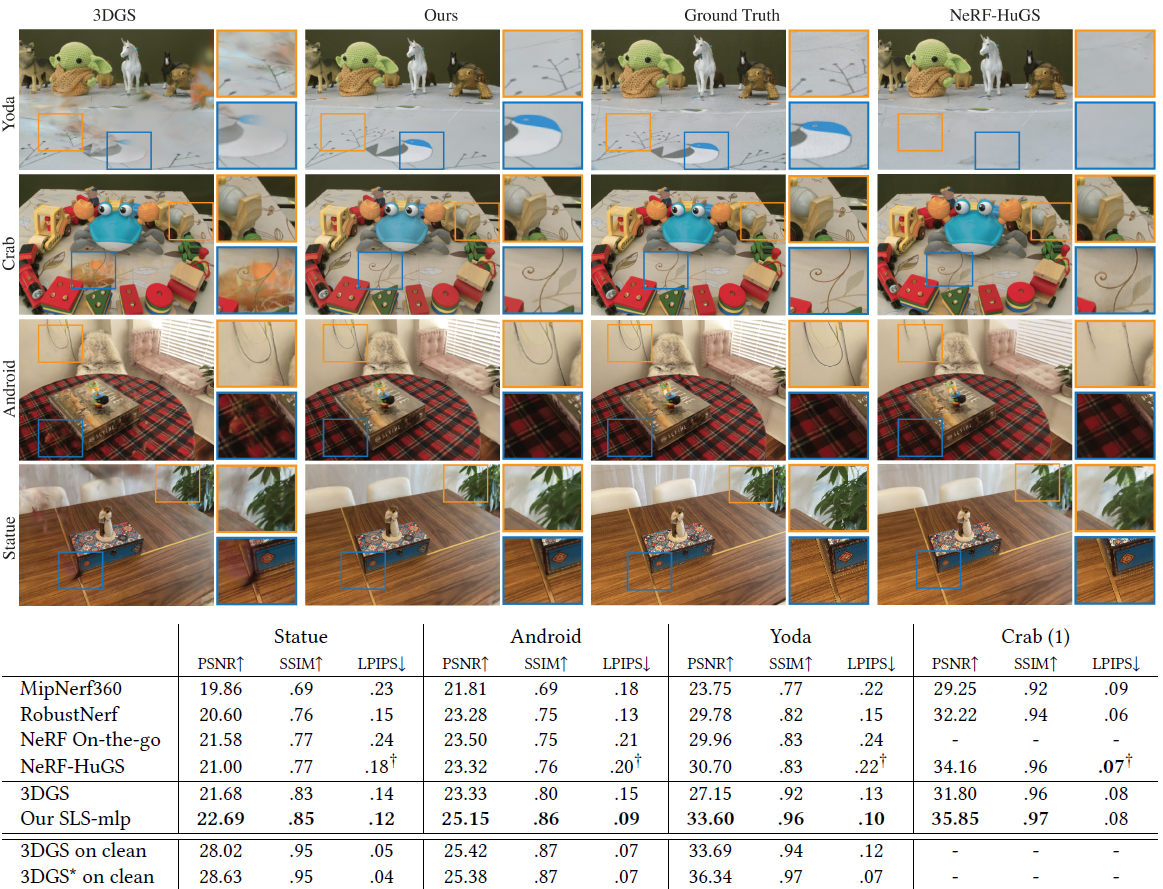
그림 5에서 우리는 SLS-mlp가 RobustNeRF 데이터셋에서 모든 RobustNeRF 기반 베이스라인을 능가한다는 것을 정량적으로 보여줍니다.
결과는 또한 vanilla 3DGS에서 크게 개선되는 동시에 이상적인 클린 모델, 특히 'Yoda'와 'Android'에서 더 가까운 성능을 보인다는 것을 보여줍니다.
또한 vanilla 3DGS 및 NeRF-HuGS와 질적으로 비교합니다.
정성적 결과는 vanilla 3DGS가 distractors를 노이즈가 있는 플로터 스플랫 ('Yoda', 'Statue') 또는 뷰 의존적 효과 ('Android') 또는 이 둘의 혼합물 ('Crab')로 모델링하려고 시도한다는 것을 보여줍니다.
세그멘테이션 기반 마스크를 사용하는 NeRF-HuGS [Chen et al. 2024]는 과도한 마스킹 (네 장면 모두에서 정적인 부분 제거) 또는 transient 객체 ('Crab')에 도전적이고 희소하게 샘플링된 뷰를 허용하는 언더마스크의 징후를 보여줍니다.
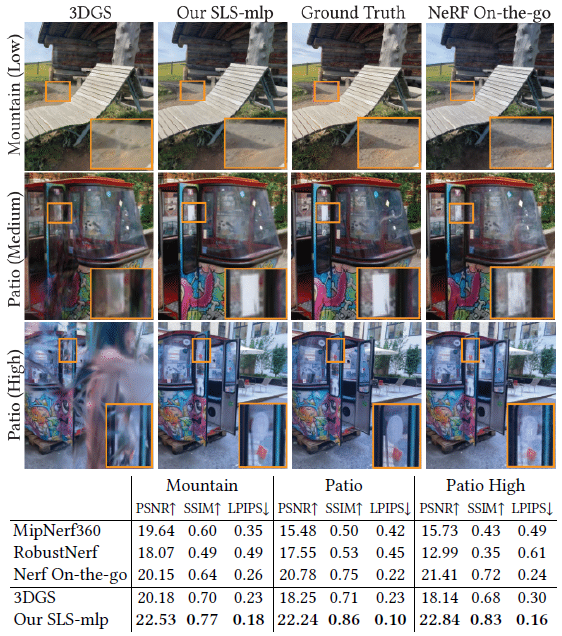
그림 3과 그림 6에서 우리는 NeRF On-the-go [Ren et al. 2024] 데이터셋에 대해 유사한 분석을 수행합니다.
우리는 SOTA robust NeRF 방법들보다 우수한 정량적 결과를 보여주지만, vanilla 3DGS와 비교했을 때도 상당한 성능 향상을 달성했습니다.
또한, 낮은 폐색 장면에서는 COLMAP [Schonberger and Frahm 2016] 포인트 클라우드에서 vanilla 3DGS의 robust 초기화, 특히 RANSAC의 이상치 거부가 좋은 재구성 품질을 제공하기에 충분하다는 것을 보여줍니다.
그러나 distractor 밀도가 증가함에 따라 3DGS 재구성 품질이 떨어지고, distractor transient가 누출되는 정성적 결과가 나타납니다.
추가적으로, 정성적 결과에 따르면 NeRF On-the-go는 학습 초기 단계('Patio', 'Corner', 'Mountain', 'Spot')에 포함된 distractors 중 일부를 제거하지 못해 렌더링 오류에 과적합되는 징후를 보입니다.
이는 미세한 세부 사항 ('Patio High')이나 더 큰 구조물 ('Fountain')이 완전히 제거된 경우에도 나타납니다.
5.2 Effect of utilization-based pruning
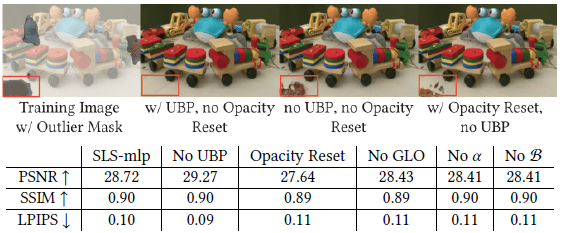
모든 실험에서 제안된 utilization-based pruning (UBP) (섹션 4.2.3)를 활성화하면 가우시안 수가 4배에서 6배로 감소합니다.
이 압축은 UBP를 활성화하면 학습 시간이 최소 2배 단축되고 추론 중에는 3배 단축됩니다.
그림 10은 UBP를 활성화하면 정량적 측정이 약간 저하될 수 있지만, 실제로는 최종 렌더링이 더 깔끔하고 플로터 수가 적습니다 (예: 이미지 왼쪽 하단).
유사한 관찰 결과, PSNR 및 LPIPS와 같은 지표가 렌더링된 비디오만큼 플로터의 존재를 명확하게 반영하지 않을 수 있음을 나타냅니다.
가우시안 수가 크게 감소함에 따라, 우리는 UBP를 복잡한 데이터셋뿐만 아니라 깨끗한 데이터셋에도 적용할 수 있는 압축 기법으로 제안합니다.
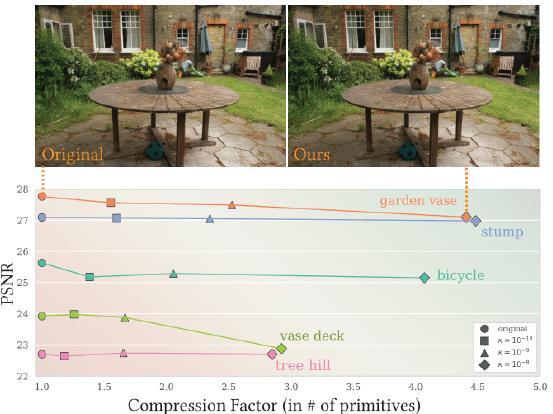
그림 7은 불투명도 재설정 대신 UBP를 사용하면 렌더링 품질을 유지하면서 가우시안 수가 2배에서 4.5배로 줄어든다는 것을 보여줍니다.


5.3 Ablation study
그림 8에서 우리는 SLS의 성능을 다른 robust 마스킹 기술의 발전과 비교합니다.
이러한 발전은 robust 필터 (2)의 나이브한 적용으로 시작하여 SLS-agg의 적용, 마지막으로 SLS-mlp에서 MLP의 사용으로 이어집니다.
우리는 SLS-agg와 SLS-mlp가 재구성된 장면에서 distractors를 효과적으로 제거하면서 장면의 최대 커버리지를 유지할 수 있음을 보여줍니다.
또한, 그림 9와 그림 10에서 우리는 아키텍처 설계와 섹션 4.2에서 제안된 적응 모두에서 선택 사항을 완화합니다.
그림 9는 작은 CNN 대신 MLP (약 30K개의 매개변수와 두 개의 비선형 활성화)를 사용하면 그림자와 같은 미묘한 transient 현상에 더 잘 적응할 수 있음을 보여줍니다.
정규화 가중치 𝜆의 선택은 거의 효과가 없는 것으로 보입니다.
응집 클러스터링에서는 일반적으로 더 많은 클러스터가 더 나은 결과를 가져오며, 100개의 클러스터 이후에는 증가가 감소합니다.
그림 10은 유출된 distractors를 제거하는 데 있어 UBP의 효과를 추가로 보여줍니다.
우리의 다른 적응, GLO, 웜업 단계 및 Bernoulli 샘플링 모두 개선된 결과를 보여줍니다.
6 Conclusion
우리는 3DGS를 위한 transient distractor 억제 방법인 SpotLessSplats를 소개했습니다.
우리는 명시적인 supervision 없이도 transient distractor를 효과적으로 식별하기 위해 시맨틱 피쳐를 활용하는 마스킹 전략의 한 종류를 확립했습니다.
구체적으로, 우리는 빠르고 추가적인 학습이 필요 없는 공간 클러스터링 방법인 'SLS-agg'를 제안했으며, 각 클러스터에 단순히 이상치 분류를 할당했습니다.
그런 다음, 3DGS 모델과 동시에 경량 MLP를 학습하여 시맨틱적으로 연관된 픽셀을 더 높은 정밀도로 그룹화할 수 있는 시공간 학습 클러스터링인 'SLS-mlp'를 제안했습니다.
우리의 방법은 Stable Diffusion 피쳐의 시맨틱 편향과 강력한 기술을 활용하여 transient distractor의 SOTA 억제를 달성합니다.
또한, vanilla 3DGS와 동일한 재구성 품질을 제공하면서도 훨씬 적은 수의 스플랫을 사용하고 distractor 억제 방법과 호환되는 그래디언트 기반 프루닝 방법을 도입했습니다.
우리의 연구는 3DGS를 실제 환경에 널리 적용하는 데 필요한 중요한 기여라고 믿습니다.
Limitations.
text-to-image 피쳐에 의존하는 것은 일반적으로 distractors를 robust 탐지하는 데 도움이 되지만 몇 가지 제한 사항을 부과합니다.
한 가지 제한 사항은 동일한 시맨틱 클래스의 distractor와 non-distractor가 존재하고 근접해 있을 때 우리 모델에 의해 구분되지 않을 수 있다는 점입니다.
자세한 내용은 보충 자료 A에서 자세히 설명합니다.
또한, 이러한 모델이 제공하는 저해상도 피쳐는 그림 8의 풍선 문자열과 같은 얇은 구조를 놓칠 수 있습니다.
특히 클러스터링을 사용할 때 피쳐를 이미지 해상도로 업샘플링하면 부정확한 엣지가 발생합니다.
우리의 프루닝 전략은 원시별 인식적 불확실성 계산을 기반으로 하며, 이는 덜 사용되는 가우시안을 제거하는 데 효과적입니다.
그러나 불확실성이 너무 공격적으로 임계값을 설정하면(예: 그림 7의 'vase deck'), 학습 데이터에서 거의 볼 수 없는 장면의 일부를 제거할 수 있습니다.