2024. 10. 31. 14:42ㆍ3D Vision/NeRF with Real-World
Semantic-aware Occlusion Filtering Neural Radiance Fields in the Wild
Jaewon Lee, Injae Kim, Hwan Heo, Hyunwoo J. Kim
Abstract
우리는 소수의 제약 없는 관광 사진에서 신경 장면 표현을 재구성하기 위한 학습 프레임워크를 제시합니다.
각 이미지에는 transient occluders가 포함되어 있기 때문에 기존 방법에는 많은 학습 데이터가 필요한 야생 사진으로 래디언스 필드를 구성하려면 정적 및 transient 구성 요소를 분해하는 것이 필요합니다.
우리는 주어진 몇 개의 이미지만으로 두 구성 요소를 분리하는 것을 목표로 하는 SF-NeRF를 소개하며, 이는 supervision 없이 시맨틱 정보를 활용합니다.
제안된 방법에는 각 픽셀에 대한 transient 색상과 불투명도를 예측하는 폐색 필터링 모듈이 포함되어 있어 NeRF 모델이 정적 장면 표현만 학습할 수 있습니다.
이 필터링 모듈은 여러 장면에 걸쳐 학습하여 transient 객체의 prior를 학습할 수 있는 학습 가능한 이미지 인코더에서 얻은 픽셀 단위 시맨틱 피쳐에 의해 가이드되는 transient 현상을 학습합니다.
또한 필터링 모듈의 모호한 분해 및 노이즈 결과를 방지하기 위한 두 가지 기술을 제시합니다.
우리는 우리의 방법이 퓨샷 설정에서 Phototourism 데이터 세트에서 SOTA 새로운 뷰 합성 방법을 능가한다는 것을 입증한다.
1. Introduction
최근 몇 년 동안 2D 이미지에서 새로운 뷰를 합성하는 것은 뉴럴 렌더링 기술의 급속한 발전으로 인해 점점 더 많은 관심을 받고 있습니다.
특히 neural radiance fields (NeRF) [1]는 multi-layer perceptron (MLP)을 통해 3D 장면의 체적 밀도와 색상을 암시적으로 인코딩하여 새로운 뷰 합성에서 놀라운 성능을 보여주었습니다.
NeRF의 성공으로 신경망 필드를 확장하여 학습 및 렌더링 속도를 높이고 [2-7], 동적 장면을 처리하고 [8-16], 이미지가 거의 없는 장면 표현을 학습하고 [17-27] 등을 수행하는 여러 후속 작업이 제안되었습니다.
그러나 이러한 접근 방식의 대부분은 모든 이미지에 걸친 장면의 래디언스가 변하지 않고 장면의 모든 콘텐츠가 정적인 제어된 환경에서 시연되었습니다.
실제 이미지(예: 문화 랜드마크의 인터넷 사진)의 경우, 이러한 가정을 따르지 않습니다: 조명은 사진을 촬영한 시간과 날씨에 따라 다르며 구름, 사람 또는 자동차와 같은 움직이는 물체가 나타날 수 있습니다.
photometric 변화와 transient 물체를 처리하기 위해 많은 연구가 수행되었습니다.
이전 연구에서는 주로 각 이미지에 대한 외관 임베딩을 사용하고 최적화하여 일관성 없는 모양을 해결했습니다 [28-30].
우리가 집중할 transient 현상의 경우, NeRF-W [28]와 HA-NeRF [31]는 transient 구성 요소를 장면에서 분리하는 추가 transient 모듈을 활용합니다.
반면에 Block-NeRF [29]와 Mega-NeRF [30]는 일반적으로 이동 가능한 물체로 간주되는 클래스의 객체를 마스킹하기 위해 세그멘테이션 모델을 사용합니다.
그러나 전자는 복잡한 장면의 지오메트리와 외관을 학습하기 위해 모델이 occluders를 제거해야 하고 후자는 그림자와 같은 예외적인 물체를 놓칠 수 있는 미리 정의된 클래스로 제한되기 때문에 많은 수의 이미지가 필요합니다.
이러한 한계를 해결하기 위해 두 개의 추가 모듈을 활용하는 SF-NeRF라는 새로운 프레임워크를 제안합니다: transient occluders의 prior 정보를 학습하는 이미지 인코더와 FilterNet이라는 occlusion 필터링 모듈.
FilterNet은 transient 성분을 예측하여 정적 및 transient 현상을 분해합니다: 인코더에서 제공하는 이미지 피쳐를 조건으로 각 이미지의 색상과 불투명도를 조정합니다.
위의 이전 방법과 달리, 우리의 방법은 미리 정의된 클래스에 국한되지 않으며 일반적으로 transient 물체와 장면을 분리하는 데 사용할 수 있는 피쳐를 학습할 수 있으므로 퓨샷 학습이 가능합니다.
또한 transient 불투명도에 재파라미터화 기법을 이진 콘크리트 랜덤 변수로 모델링하여 transient 물체를 장면에서 완전히 분리합니다.
또한 transient 불투명도에 평활성 제약을 부과하기 위해 정규화 항을 추가합니다.
우리는 문화 랜드마크에서 촬영한 인터넷 사진을 포함하는 Phototourism 데이터 세트 [32]에서 각 랜드마크에 대해 30개의 이미지로 학습하는 방법을 몇 번의 촬영 설정에서 평가합니다.
우리의 실험은 SF-NeRF가 transient occluders의 prior를 학습하여 몇 개의 학습 이미지만으로 장면을 분해할 수 있음을 보여줍니다.
요약하면, 우리의 기여는 다음과 같이 요약할 수 있습니다:
• 우리는 unsupervised 방식으로 이미지의 시맨틱 피쳐를 활용하여 장면의 정적 및 transient 구성 요소를 분해하는 방법을 학습하는 새로운 프레임워크 (SF-NeRF)를 제안합니다.
• 우리는 장면의 모호한 분해를 피하기 위해 학습 중에 FilterNet 내에 재파라미터화 기술을 도입합니다.
• transient 불투명도 필드의 평활성을 보장하기 위해 정규화 항을 도입합니다.
• 제안된 방법은 퓨샷 설정에서 Phototourism 데이터 세트에서 SOTA 새로운 뷰 합성 방법을 능가합니다.
2. Related Works
2.1. Neural Rendering
최근 몇 년 동안 뉴럴 장면 표현은 새로운 뷰 합성 및 3D 재구성 작업을 달성하기 위해 광범위하게 연구되고 있습니다 [1, 33-40].
특히 neural radiance fields (NeRF) [1]는 미분 가능한 볼륨 렌더링을 MLP와 결합하여 3D 장면을 나타내며, 사실적인 새로운 뷰 합성을 달성합니다.
NeRF의 큰 성공 이후, 여러 후속 작업에서 뷰 합성 [3,41,42]의 성능을 개선하거나 생성 작업 [43-47], 빠른 렌더링 [2,4-7,48], 퓨샷 뷰 합성 [17,18,20-23,25,27,49], 포즈 추정 [50-53], 동적 뷰 합성 [8-16], relighting [54-57] 등이 있습니다.
Martin-Brualla et al. [28]과 Chen et al. [31]은 transient occluding 피사체와 가변 조명이 포함된 인터넷 사진 모음으로 뷰 합성을 해결하는 것을 목표로 합니다.
우리의 연구는 퓨 샷 설정에서 이러한 사진으로 학습하는 데 중점을 둡니다.
2.2. 3D scene decomposition
장면 분해에 대한 연구는 다양한 목적으로 수행되어 왔습니다.
여러 연구에서 실외 환경에 대한 무한 장면을 처리하기 위해 전경 및 배경 NeRF 모델을 분리합니다 [30,58,59].
동적 장면의 경우, 여러 작업에서 배경에 대한 정적 NeRF 모델과 장면 내에서 움직이는 물체를 포함하는 전경에 대한 동적 NeRF를 분해합니다 [12-14, 60, 61].
일부 연구에서는 여러 물체로 구성된 장면 [29,30,59,62-68]을 분해하고 세그멘테이션 피쳐 [63] 또는 마스크 [29,30,59,62,64,65]와 같은 외부 지식의 도움으로 해당 물체를 별도로 [62-65] 조작하는 것을 목표로 합니다.
Phototourism 데이터 세트 [32]와 같은 실제 환경에서 촬영한 사진 모음의 3D 장면을 재구성하는 것은 대부분의 이미지에서 다양한 물체에 의해 가려지기 때문에 어렵습니다.
따라서 정적 장면에서 transient 요소를 분리하는 것은 필수적입니다.
NeRF-W [28]는 이미지별 임베딩을 조건으로 하는 고유한 색상과 밀도를 방출하는 NeRF 모델에 "transient" 헤드를 추가하여 이 문제를 해결합니다.
3D transient 필드를 사용하여 transient 물체를 재구성하는 대신, HA-NeRF [31]는 이미지의 transient 부분을 마스킹하는 이미지 종속 2D 가시성 맵으로 대체합니다.
그러나 NeRF-W [28]와 HA-NeRF [31]는 적은 수의 학습 이미지가 주어졌을 때 정적 및 transient 성분을 분해할 수 없습니다.
우리는 이미지가 거의 없는 장면에서 transient 성분을 분리하는 데 집중하는 것을 목표로 합니다.
3. Method
우리는 몇 개의 야생 사진에서만 NeRF 표현을 학습하기 위해 "Semantic-aware Occlusion Filtering Neural Radiance Fields (SF-NeRF)"라는 새로운 학습 프레임워크를 제안합니다.
정적 및 transient 구성 요소를 일관되게 분해하기 위해 섹션 3.2에서 unsupervised 사전 학습된 인코더로 추출한 이미지의 시맨틱 정보를 사용하여 transient 구성 요소를 예측하는 FilterNet이라는 새로운 폐색 처리 모듈을 도입합니다.
그런 다음 한 가지 재파라미터화 트릭을 사용하여 섹션 3.3에서 모호한 분해를 방지합니다.
학습 중에 섹션 3.4에서 FilterNet의 노이즈 결과를 방지하기 위한 사전 조치를 사용합니다.
전체 파이프라인은 그림 1에 나와 있습니다.

3.1. Preliminary
SF-NeRF를 소개하기 전에 먼저 정적 장면을 재구성하는 데 사용하는 NeRF 및 관련 방법을 간략하게 검토합니다.
우리는 방출된 래디언스가 이미지별 잠재 임베딩에 따라 조건부 NeRF 구조를 채택합니다.
또한 단일 지점 대신 공간 영역을 피쳐화되는 Integrated Positional Encoding (IPE)을 사용하여 단일 MLP가 멀티스케일 장면 표현을 학습할 수 있도록 지원합니다.
Neural Radiance Fields (NeRF).
NeRF [1]은 multi-layer perceptron (MLP)을 사용하여 연속적인 체적 래디언스 필드 F_θ을 갖는 장면을 나타냅니다.
3D 위치 x = (x, y, z) ∈ R^3과 뷰 방향 d ∈ S^2가 주어지면, NeRF 네트워크 F_θ는 부피 밀도 σ와 방출된 색 c = (r, g, b)를 반환합니다.
, 여기서 θ = [θ_1, θ_2]는 MLP의 학습 가능한 매개변수이고, γ_x(·)와 γ_d(·)는 각각 공간 위치와 뷰 방향에 대한 사전 정의된 인코딩 함수 [1]입니다.
ray 원점이 o ∈ R^3인 ray r(t) = o+ td을 고려하고, 각각 σ(t)와 c(t)를 점 r(t)에서의 밀도와 색상으로 표시하자.
NeRF는 다음과 같이 수치 직교 [69]로 근사화된 ray를 따라 밀도와 색상의 알파 합성을 사용하여 예상 색상 C(r)을 렌더링합니다:
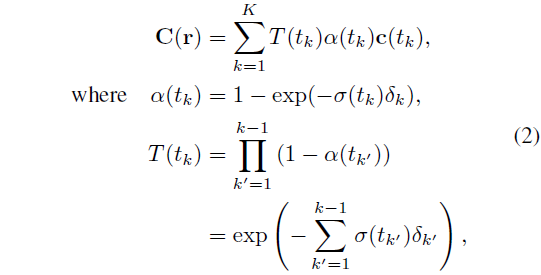
, {t_k}_(k=1)^K는 볼륨 렌더링을 위해 계층화된 샘플링을 사용하여 선택한 샘플링 지점의 집합이며, δ_k = t_(k+1) - t_k는 인접한 샘플링 지점 사이의 거리를 나타냅니다.
샘플링 효율성을 높이기 위해 NeRF는 동일한 구조를 공유하는 두 개의 MLP를 동시에 학습시킵니다: coarse 네트워크가 fine 네트워크에 공급할 샘플링 지점을 결정하는 "Coarse" 및 "fine" 네트워크입니다.
Latent Conditional NeRF.
가변 조명이 있는 사진에서 뷰를 합성하기 위해 이전 방법 [28, 28-30]은 주로 l_i^(a) ∈ R^(n^(a))을 포함하는 외관을 사용하여 NeRF에 각 이미지 I_i에 대해 장면의 방출된 래디언스를 조정할 수 있는 유연성을 부여했습니다.
식 (1)의 래디언스 c와 식 (2)의 렌더링된 색상 C(r)는 다음과 같이 이미지 의존적인 c_i 및 C_i(r)로 대체됩니다:
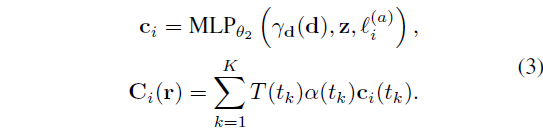
NeRF-W [28, 70]의 프레임워크에 따라 외관 임베딩을 채택하여 각 입력 이미지에 최적화합니다.
Mip-NeRF.
mip-NeRF [3]는 NeRF와 같은 픽셀마다 단일 ray를 캐스팅하는 대신 이미지의 해상도가 변경됨에 따라 반경이 변경되는 cone을 캐스팅합니다.
Mip-NeRF는 위치 인코딩 체계를 무한히 작은 점을 인코딩하는 것에서 ray의 각 섹션에 대한 conical frustum (Integrated Positional Encoding) 내에 통합하는 것으로 변경합니다.
이를 통해 mip-NeRF는 멀티스케일 표현을 학습하여 NeRF의 coarse하고 fine한 MLP를 단일 MLP로 결합할 수 있습니다.
우리는 다양한 카메라 거리와 해상도에서 현장 사진을 촬영하기 때문에 반으로 줄어든 모델 용량과 규모 견고성을 활용하기 위해 이 작업에서 mip-NeRF 구조를 따릅니다.
3.2. Semantic-aware Scene Decomposition
일관된 장면 분해를 달성하기 위해 이미지의 시맨틱 피쳐를 활용하여 transient 구성 요소를 모델링하는 FilterNet이라는 추가 MLP 모듈을 사용합니다.
FilterNet T_ψ은 이미지 의존적 2D 맵을 학습하여 transient 현상을 처리하도록 설계되었습니다: transient RGBA 및 uncertainty 맵.
transient RGBA 이미지는 NeRF에서 생성한 렌더링된 (정적) 이미지와 알파 블렌딩되어 그림 1과 같이 원본 이미지를 재구성합니다.
우리는 각 픽셀에 대해 관찰된 색상의 uncertainty를 추정하여 모델이 신뢰할 수 없는 픽셀을 무시하여 재구성 loss를 조정할 수 있도록 합니다.
이 아이디어는 NeRF-W [28]에서 차용한 것이지만, 차이점은 2D uncertainty 맵을 직접 추정하는 반면 NeRF-W는 ray를 따라 3D 위치의 uncertainies로 값을 렌더링한다는 것입니다.
구체적으로, 우리는 FilterNet T_ψ을 transient 임베딩 l_i^(τ) ∈ R^(n^(τ)), 픽셀 위치 p ∈ R^2 및 해당 인코딩 피쳐 f_i(p) ∈ R^F를 transient 색상 C_i^(τ), 불투명도 α_i^(τ) ∈ [0, 1] 및 불확실성 β_i ∈ R^+ 값을
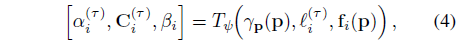
로 매핑하는 암묵적 연속 함수로 모델링하며, 여기서 γ_p : R^2 → R^4L은 각 픽셀 좌표에 적용되는 위치 인코딩 함수입니다.
피쳐 맵 f_i는 다른 실제 데이터 세트에서 사전 학습될 수 있는 인코더 E : R^(H x W X 3) → R^(H x W F)를 사용하여 입력 이미지 I_i에서 추출됩니다.
C_i^(τ) (p_r), α_i^(τ) (p_r), β_i(p_r)를 각각 ray r에 해당하는 픽셀의 transient 색상, 불투명도 및 불확실성 값으로 표시합니다.
그런 다음 최종 예측 픽셀 색상 ^C_i(r)은 다음과 같이 transient 색상 C_i^(p_r)과 정적 색상 C_i(r)를 알파 블렌딩과 결합하여 구합니다:
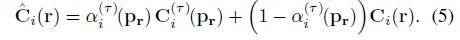
이미지 I_i의 각 ray r에 대해 FilterNet을 학습하여 loss L_t^(i)로 transient 성분을 장면에서 unsupervised 방식으로 분리합니다:
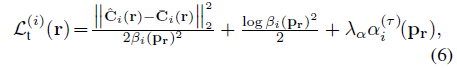
, 여기서 C는 ground truth 색상입니다.
첫 번째와 두 번째 항은 평균 ^C_i(r) 및 분산 β_i(p_r)^2 [28]를 갖는 isotropic 정규 분포를 따르는 것으로 가정되는 C_i(r)의 음의 log-likelihood로 볼 수 있습니다.
세 번째 항은 FilterNet이 정적 현상을 설명하지 못하도록 합니다.
3.3. Transient Opacity Reparameterization
우리는 FilterNet을 나이브하게 채택하면 모호한 transient 불투명도 값, 즉 시그모이드 활성화 함수를 통해 MLP의 출력을 전달하여 예측하도록 학습된 경우 0 또는 1에 가깝지 않은 값이 생성된다는 것을 경험적으로 발견했습니다.
이러한 모호한 분해는 정적 장면에서 블러한 아티팩트로 이어집니다.
우리는 α_i^(τ)를 베르누이 랜덤 변수의 연속적인 이완인 Binary Concrete random variable [71]로 모델링하고 그 확률을 예측함으로써 transient 이미지가 완전히 불투명하거나 비어 있도록 권장합니다.
이진 콘크리트 분포는 일반적으로 이산 랜덤 변수를 근사하는 데 사용되는 Gumbel-Softmax distribution [72]라고도 알려진 콘크리트 분포의 특별한 경우입니다.
우리는 위치 매개 변수 ~α_i ∈ (0, ∞)를 가진 이진 콘크리트 분포에서 α_i^(τ)를 샘플링하고, FilterNet은 다음
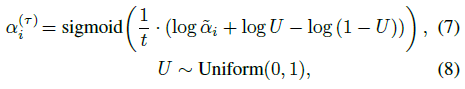
과 같이 불투명도 값을 직접 예측하는 대신 예측할 것이며, 여기서 t ∈ (0, ∞)는 하이퍼파라미터입니다.
이 샘플링 체계는 역전파를 허용하면서 모델이 구간 [0, 1]의 경계에 집중된 불투명도 값을 예측하도록 장려합니다.
평가하는 동안 U를 0.5로 고정합니다.
3.4. Transient Opacity Smoothness Prior
FilterNet의 입력: 인코딩된 픽셀(PE 피쳐) γ_p(p), 이미지 피쳐 f(p), 임베딩 l^(τ)은 고주파 정보를 포함합니다.
이는 자연스럽게 픽셀의 색상을 예측하는 데 적합하지만 transient 불투명도에 대한 노이즈 예측을 유발할 수 있는 고주파 출력으로 이어집니다.
따라서 우리는 transient 불투명도 필드에 대한 평활도 loss를 (9)와 같이 추가하며, 여기서 γ_k(p) = [cos(2^kπp), sin(2^kπp)]은 p의 k번째 주파수 인코딩입니다.
loss 항에 상수 값을 곱한 값은 픽셀 좌표, 즉
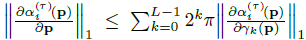
에 대한 α_i^(τ) 도함수의 L1-norm의 상한이며, 이는 본질적으로 transient 불투명도 필드에 평활성을 강제합니다.
우리는 정규화 항에 대한 모델의 민감도를 줄이기 위해 이 간접적인 접근 방식을 취했습니다.
위의 부등식은 체인 규칙과 삼각형 부등식을 사용하여 간단히 도출할 수 있습니다.
3.5. Optimization
전체 loss를 최소화하여 모델 매개변수 (θ, ɸ , ψ), 이미지별 외관 임베딩 {l_i^(a)}_(i=1)^N 및 transient 임베딩 {l_i^(τ)}_(i=1)^N을 공동으로 최적화합니다:
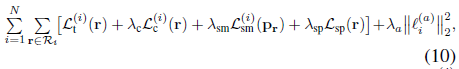
, 여기서 λ_c, λ_sm, λ_sp 및 λ_a는 하이퍼파라미터이고 L_c^(i)는 coarse 샘플 t^c = {t_k^c}_(k=1)^K로 합성된 렌더링 이미지의 재구성 loss이며, L_sp는 희소성 loss라는 정규화 항입니다:
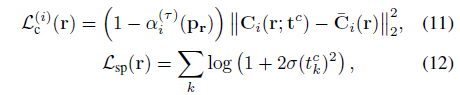
, 여기서 t_c = {t_k^c}_(k=1)^K는 계층화 샘플링으로 생성된 coarse 샘플입니다.
희소성 loss L_sp는 정적 장면이 관찰되지 않은 영역에서 밀도가 0이 되도록 장려합니다.
transient 물체는 정적 장면을 숨기기 때문에 정적 모델은 해당 영역에서 장면 표현을 학습할 수 없습니다.
충분한 학습 이미지가 주어지면 다른 이미지가 누락된 영역을 관찰할 수 있는 기회를 제공하기 때문에 이러한 장애물은 무시할 수 있습니다.
그러나 몇 번의 촬영 설정에서는 이를 보장할 수 없으며 모델이 관찰되지 않은 영역에서 임의의 지오메트리를 자유롭게 생성할 수 있습니다.
따라서 우리는 Cauchy loss [5, 73]이라고도 알려진 이 희소성 prior를 사용하여 NeRF의 불투명도 필드의 희소성을 장려합니다.
4. Experiments
이 섹션에서는 SF-NeRF라고 하는 우리의 방법이 양적으로나 질적으로 이전의 SOTA 접근 방식을 능가한다는 것을 보여줍니다.
그런 다음 광범위한 ablation 연구와 시각화를 제공하여 SF-NeRF의 구성 요소의 효과를 검증합니다.
Datasets.
Phototourism 데이터 세트 [32]의 문화 랜드마크 인터넷 사진 모음으로 구성된 네 가지 학습 세트에 대한 접근 방식을 시연합니다: “Brandenburg Gate”, “Sacre Coeur”, “Trevi Fountain” 및 “Taj Mahal”.
우리는 HA-NeRF [31]에서 사용한 분할을 따르고 이미지를 HA-NeRF보다 2배 다운샘플링합니다.
각 랜드마크에 대해 700~1700개의 이미지 중 15개와 30개의 이미지를 샘플링하여 퓨 샷 설정에서 방법을 평가합니다.
Baselines.
우리는 우리의 방법을 NeRF [1], NeRF-W [28], HA-NeRF [31] 및 NeRF-AM이라고 부르는 NeRF-W의 한 변형과 비교합니다.
NeRF-AM은 transient 헤드가 제거된 NeRF-W와 동일한 구조 (일명 NeRF-A)를 공유하고 사전 학습된 시맨틱 세그멘테이션 모델을 사용하여 transient 물체를 제거합니다.
NeRF-AM은 Cityscapes 데이터 세트 [75]에서 학습된 DeepLabv3+ [74]를 사용하고 사람 (person, rider) 및 차량 ((rider, car, truck, bus, train, motorcycle, bicycle)과 같은 이동 가능한 물체를 마스킹합니다.
공정한 비교를 위해 모든 모델은 밀도 σ을 생성하기 위한 256개의 숨겨진 단위 8개 레이어와 색상 c의 경우 128개의 숨겨진 단위 1개 레이어로 구성된 동일한 정적 NeRF 모델 아키텍처를 공유합니다.
Implementation details.
모든 방법은 새로운 뷰 합성 작업에 대해 평가됩니다.
우리는 모든 평가에 대해 표준 이미지 품질 메트릭, Peak Signal to Noise Ratio (PSNR), Structural Similarity Index Measure (SSIM) [77] 및 Learned Perceptual Image Patch Similarity (LPIPS) [78]을 AlexNet과 함께 보고합니다.
외관 임베딩은 세트 이미지 학습에만 최적화되므로 각 테스트 이미지에 대한 외관 임베딩을 얻는 절차는 필수적입니다.
우리는 평가 체계에 따라 각 베이스라인을 평가하며, 여기서 NeRF-W는 각 테스트 이미지의 왼쪽 절반에 임베딩을 최적화하고 오른쪽 절반에 메트릭을 보고하며, HA-NeRF는 학습된 인코더를 통해 외관 임베딩을 얻습니다.
여기서는 NeRF-W의 체계를 사용하여 우리의 접근 방식을 평가합니다.

4.1. Results
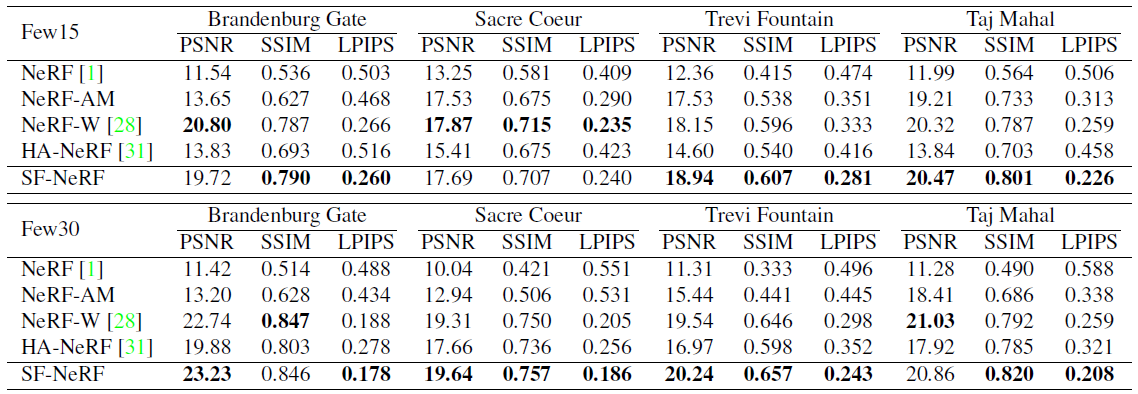
전체 정량적 결과는 표 1에 나와 있으며, SF-NeRF는 퓨샷 설정에서 대부분 베이스라인을 능가합니다.
SF-NeRF는 전반적으로 성능이 향상되지만 그 격차는 극적이지 않습니다.
이는 Phototourism 데이터 세트의 테스트 세트를 보면 설명할 수 있습니다.
그림 5와 같이 대부분의 테스트 이미지에는 학습 중에 랜드마크의 가시적인 부분, 즉 transient occluders에 의해 숨겨져 있지 않은 부분만 포함되어 있습니다.
따라서 이러한 이미지를 평가하는 것은 정적 및 transient 구성 요소를 분해하는 능력을 반영하지 않을 수 있습니다.
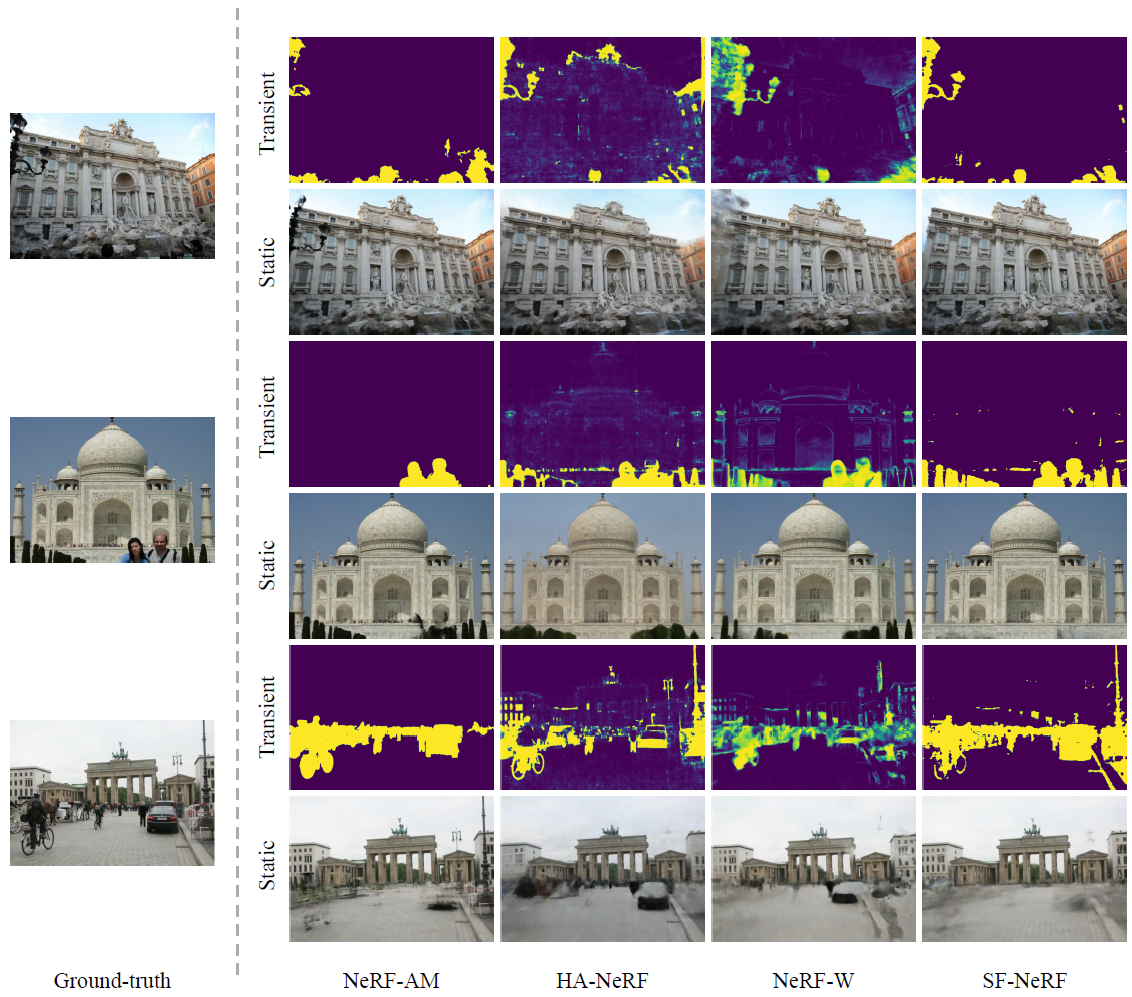
정성적 결과는 베이스라인에 비해 SF-NeRF가 명확하게 개선되었음을 보여줍니다.

그림 2는 모델의 정성적 결과와 데이터 세트의 일부 예에 대한 베이스라인을 보여줍니다.
NeRF로 렌더링하면 종종 전역 색상 이동과 고스팅 아티팩트가 발생합니다.
이는 섹션 1에서 설명한 NeRF 가정의 직접적인 결과이며, 장면은 모든 이미지에서 일정하고 장면의 모든 콘텐츠는 정적입니다.
NeRF-AM, HA-NeRF 및 NeRF-W는 외관 임베딩을 사용하여 다양한 photometric 효과를 모델링할 수 있지만 아티팩트로 인해 어려움을 겪기도 합니다.
특히 세 가지 베이스라인은 "Taj Mahal"과 "Brandenburg Gate" (특히 NeRF-AM에서)의 고스팅 아티팩트와 "Trevi Fountain"의 블러 아티팩트를 보여줍니다.
대부분의 아티팩트는 transient occluders로부터 종종 숨겨져 있는 영역에 배치되어 정적 및 transient 구성 요소를 분해하는 능력이 부족하다는 것을 알 수 있습니다.
이러한 관찰은 NeRF-AM, HA-NeRF 및 NeRF-W가 일부 transient 객체를 제거하지 못하는 경우가 많은 그림 3을 통해 뒷받침됩니다.
반대로 SF-NeRF는 정적 장면에서 transient 요소를 일관되게 분리하여 시맨티-가이드 필터링 모듈의 효과를 입증합니다.
4.2. Ablations Studies
우리는 제안된 방법에서 각 구성 요소의 개별 기여도를 분석하기 위해 ablation 연구를 수행합니다.
"w/o Concrete"는 transient 불투명도 재파라미터화 트릭을 제거하고 소프트플러스에서 시그모이드로 ~α_i의 활성화를 대체하며, "w/o Smooth"는 transient 불투명도 평활도 정규화 항 L_sm^(i)을 제거합니다.
우리는 "Brandenburg Gate" 데이터 세트에서 평가하고 그 결과를 표 2와 그림 4에 제공합니다.
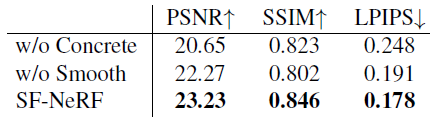

표 2와 같이 모든 구성 요소 (콘크리트 재파라미터화 및 스무스 prior)를 사용하면 SF-NeRF의 ablation에 비해 상당한 개선 효과를 얻을 수 있습니다: PSNR은 "w/o Concrete" 및 "w/o Smooth"에 비해 각각 평균 2.6dB 및 1.0dB 개선되었습니다.
그림 4는 두 구성 요소에 대한 정성적 ablation 결과를 보여줍니다.
섹션 3.3에서 언급했듯이 콘크리트 재파라미터화 트릭 ("w/o Concrete")을 제거하면 FilterNet은 모호한 transient 불투명도 값을 생성하여 블러하고 고스팅이 발생합니다.
transient 불투명도 스무스 prior의 경우, "w/o Smooth"는 노이즈 transient 불투명도를 예측하며, 다시 말해 불투명도는 희박하게 예측됩니다.
불투명도의 누락된 부분도 이러한 아티팩트를 유발할 수 있으며, 이는 그림 4에 나와 있습니다.
4.3. Limitations and Future Work
SF-NeRF는 야생 사진에서 퓨샷 새로운 뷰 합성을 해결하기 위해 transient 현상을 잘 제거하는 데에만 집중합니다.
더 개선하기 위해서는 퓨샷 설정에서 정적 장면의 지오메트리와 다양한 외관을 잘 학습하는 접근 방식이 필요합니다.
또한, structure-from-motion [79]를 사용하여 얻은 각 이미지에 대한 카메라 매개 변수가 완전히 정확하지는 않습니다.
우리는 적은 이미지로 학습하기 때문에 SF-NeRF는 카메라 보정 오류에 민감하며, 이는 블러 재구성으로 이어집니다.
따라서 카메라 포즈 개선을 동시에 수행하는 것이 하나의 해결책이 될 수 있습니다.
5. Conclusion
우리는 "Semantic-aware Occlusion Filtering Neural Radiance Fields (SF-NeRF)"라는 이름의 소수의 야생 사진에서 신경 표현을 학습하는 새로운 학습 프레임워크를 제안합니다.
SF-NeRF는 transient 현상과 정적 현상을 분해하여 FilterNet이라는 추가 MLP 모듈로 각 이미지의 transient 구성 요소를 예측하는 데 중점을 둡니다.
FilterNet은 unsupervised 방식으로 사전 학습된 이미지 인코더가 제공하는 시맨틱 정보를 활용하며, 이는 퓨샷 학습을 달성하는 데 핵심적인 역할을 합니다.
또한, 모호한 분해를 방지하고 transient 불투명도에 대한 스무스 prior를 사용하기 위해 재파라미터화 기술을 적용합니다.
우리는 SF-NeRF가 퓨샷 설정에서 Phototourism 데이터 세트에서 전반적으로 SOTA 새로운 뷰 합성 방법을 능가한다는 것을 촬영했습니다.