2025. 1. 10. 15:20ㆍRobotics
Cosmos World Foundation Model Platform for Physical AI
NVIDIA
Abstract
Physical AI는 먼저 디지털로 학습되어야 합니다.
이를 위해서는 그 자체의 디지털 트윈인 policy 모델과 월드의 디지털 트윈인 world 모델이 필요합니다.
본 논문에서는 개발자들이 Physical AI 설정을 위한 맞춤형 월드 모델을 구축할 수 있도록 돕는 Cosmos World Foundation Model 플랫폼을 제시합니다.
우리는 다운스트림 애플리케이션을 위한 맞춤형 월드 모델로 파인튜닝할 수 있는 범용 월드 모델로서 월드 파운데이션 모델을 제안합니다.
우리의 플랫폼은 비디오 큐레이션 파이프라인, 사전 학습된 월드 파운데이션 모델, 사전 학습된 월드 파운데이션 모델의 사후 학습 예시, 비디오 토크나이저 등을 다룹니다.
Physical AI 구축자들이 우리 사회의 가장 중요한 문제를 해결할 수 있도록 돕기 위해, 우리는 NVIDIA Cosmos를 통해 사용 가능한 허가 라이선스를 통해 플랫폼 오픈 소스와 모델을 오픈-가중치를 제공합니다.
1. Introduction
Physical AI는 센서와 액추에이터가 장착된 AI 시스템입니다: 센서를 통해 세상을 관찰할 수 있고, 액추에이터를 통해 세상과 상호작용하고 수정할 수 있습니다.
이 시스템은 위험하거나 힘들거나 지루한 물리적 작업에서 인간 노동자를 해방시킬 수 있는 약속을 담고 있습니다.
최근 10년 동안 데이터와 컴퓨팅 확장 덕분에 여러 AI 분야가 크게 발전했지만, Physical AI는 불과 몇 인치 앞으로 나아가고 있습니다.
이는 주로 Physical AI를 위한 학습 데이터를 확장하는 것이 훨씬 더 어렵기 때문입니다, 원하는 데이터에는 일련의 관찰과 액션이 포함되어야 하기 때문입니다.
이러한 액션은 물리적 세계를 교란시키고 시스템과 세계에 심각한 손상을 초래할 수 있습니다.
특히 AI가 아직 탐색적 액션이 필수적인 초기 단계에 있을 때 더욱 그렇습니다.
Physical AI가 안전하게 상호작용할 수 있는 물리적 세계의 디지털 트윈인 World Foundation Model (WFM)은 데이터 확장 문제에 대한 오랫동안 기다려온 해결책이었습니다.

이 논문에서는 Physical AI 구축을 위한 Cosmos World Foundation Model (WFM) 플랫폼을 소개합니다.
우리는 주로 시각 월드 파운데이션 모델에 중점을 두며, 관찰 결과는 비디오로 제공되며, 교란은 다양한 형태로 존재할 수 있습니다.
그림 2에 나타난 바와 같이, 우리는 WFM을 사전 학습된 WFM과 사후 학습된 WFM으로 나누는 사전-학습-및-사후-학습 패러다임을 제시합니다.
사전 학습된 WFM을 구축하기 위해 대규모 비디오 학습 데이터셋을 활용하여 모델을 다양한 시각적 경험에 노출시켜 일반론자가 될 수 있도록 합니다.
사후 학습된 WFM을 구축하기 위해, 우리는 사전 학습된 WFM이 특정 Physical AI 환경에서 수집된 데이터셋을 사용하여 전문화된 WFM에 도달하도록 파인튜낭합니다.
그림 1은 사전 학습된 WFM과 사후 학습된 WFM의 예시 결과를 보여줍니다.

데이터는 AI 모델의 한계를 결정합니다.
우리는 높은 수준의 사전 학습된 WFM을 구축하기 위해 비디오 데이터 큐레이션 파이프라인을 개발합니다.
우리는 이 파이프라인을 사용하여 시각적 콘텐츠에 인코딩된 물리학 학습을 용이하게 하는 풍부한 동적 특성과 높은 시각적 품질을 가진 비디오의 일부를 찾습니다.
우리는 이 파이프라인을 사용하여 2에서 60초에 이르는 약 100M개의 비디오 클립을 20M 시간 분량의 비디오 컬렉션에서 추출합니다.
각 클립에 대해 visual language model (VLM)을 사용하여 256프레임당 비디오 캡션을 제공합니다.
비디오 처리는 계산 집약적입니다.
우리는 디코딩 및 트랜스코딩을 위해 최신 GPU에서 사용 가능한 H.264 비디오 인코더와 디코더의 하드웨어 구현을 활용합니다.
우리의 비디오 데이터 큐레이션 파이프라인은 많은 사전 학습된 이미지/비디오 이해 모델을 활용합니다.
이러한 모델들은 서로 다른 처리량을 가지고 있습니다.
학습 가능한 비디오 데이터를 생성하기 위한 전체 처리량을 최대화하기 위해, 우리는 Ray 기반 오케스트레이션 파이프라인 (Moritz et al., 2017)을 구축합니다.
자세한 내용은 섹션 3에 설명되어 있습니다.
우리는 섹션 5에서 논의된 사전 학습된 WFM을 구축하기 위한 두 가지 확장 가능한 접근 방식을 탐구합니다.
이러한 접근 방식은 트랜스포머 기반 디퓨전 모델과 트랜스포머 기반 자기회귀 모델입니다.
디퓨전 모델은 가우시안 노이즈 비디오에서 노이즈를 점진적으로 제거하여 비디오를 생성합니다.
자기회귀 모델은 사전 설정된 순서에 따라 과거 생성을 조건으로 비디오를 하나씩 생성합니다.
두 접근 방식 모두 어려운 비디오 생성 문제를 더 쉬운 하위 문제로 분해하여 더 다루기 쉽게 만듭니다.
우리는 최신 트랜스포머 아키텍처를 활용하여 확장성을 높였습니다.
섹션 5.1에서는 강력한 월드 생성 능력을 발휘하는 트랜스포머 기반 디퓨전 모델 설계를 제시합니다.
섹션 5.2에서는 월드 생성을 위한 트랜스포머 기반 자기회귀 모델 설계를 제시합니다.
트랜스포머 기반 디퓨전 모델과 트랜스포머 기반 자기회귀 모델 모두 비디오의 표현으로 토큰을 사용하는데, 전자는 벡터 형태의 연속 토큰을 사용하고 후자는 정수 형태의 이산 토큰을 사용합니다.
우리는 비디오에 대한 토큰화—비디오를 토큰 집합으로 변환하는 과정—가 매우 간단하지 않다는 점에 주목합니다.
비디오는 시각적 월드에 대한 풍부한 정보를 포함하고 있습니다.
그러나 WFM의 학습을 용이하게 하기 위해서는 토큰 수가 증가함에 따라 월드 파운데이션 모델 학습의 계산 복잡도가 증가함에 따라 비디오의 원본 내용을 최대한 보존하면서 비디오를 압축하여 압축해야 합니다.
여러 면에서 비디오 토크나이저를 구축하는 것은 비디오 코덱을 구축하는 것과 유사합니다.
우리는 섹션 4에서 설명한 연속 토큰과 이산 토큰 모두에 대한 비디오 토큰화를 학습하기 위해 어텐션 기반 인코더-디코더 아키텍처를 개발했습니다.
섹션 6에서는 다양한 Physical AI 작업을 위해 사전 학습된 WFM을 사후 학습된 WFM에 도착하도록 파인튜닝합니다.
섹션 6.1에서는 사전 학습된 디퓨전 WFM을 카메라 포즈로 조정합니다.
이 사후 학습은 사용자가 가상 시점을 이동시켜 생성된 월드를 탐색할 수 있는 탐색 가능한 가상 월드를 만듭니다.
섹션 6.2에서는 비디오-액션 시퀀스로 구성된 다양한 로봇 작업에 대해 WFM을 파인튜닝합니다.
사전 학습된 WFM을 활용함으로써 로봇이 취한 액션을 바탕으로 미래 월드의 상태를 더 잘 예측할 수 있음을 보여줍니다.
섹션 6.3에서는 사전 학습된 WFM이 다양한 자율 주행 관련 작업에 대해 어떻게 파인튜닝될 수 있는지 시연합니다.
개발된 WFM의 의도된 사용 목적은 Physical AI 빌더입니다.
월드 기반 모델을 사용할 때 개발자를 더 잘 보호하기 위해, 우리는 유해한 입력을 차단하는 프리 가드와 유해한 출력을 차단하는 포스트 가드로 구성된 강력한 가드레일 시스템을 개발했습니다.
자세한 내용은 섹션 7에 설명되어 있습니다.
우리는 Physical AI 구축자들이 시스템을 발전시킬 수 있도록 돕기 위해 월드 파운데이션 모델 플랫폼을 구축하는 것을 목표로 합니다.
이 목표를 달성하기 위해, 우리는 사전 학습된 월드 파운데이션 모델과 토크나이저를 각각 NVIDIA Cosmos와 NVIDIA Cosmos Tokenizer의 NVIDIA 오픈 모델 라이선스 하에 제공합니다.
사전 학습 스크립트와 사후 학습 스크립트는 NVIDIA Nemo Framework에서 비디오 데이터 큐레이션 파이프라인과 함께 제공되어 구축자들이 파인튜닝 데이터셋을 제작하는 데 도움을 줄 것입니다.
이 논문은 월드 파운데이션 모델 설계에서 몇 가지 개선을 이루었지만, 월드 파운데이션 모델 문제는 아직 해결되지 않았습니다.
SOTA 기술을 더 발전시키기 위해서는 추가 연구가 필요합니다.
2. World Foundation Model Platform
𝑥_(0:𝑡)를 시간 0에서 𝑡까지 실제 월드를 시각적으로 관측한 시퀀스라고 합시다.
𝑐_𝑡를 월드에 대한 교란이라고 합시다.
그림 3에서 볼 수 있듯이, WFM은 과거 관측 𝑥_(0:𝑡)와 현재 섭동 𝑐_𝑡를 기반으로 시간 𝑡+1, ˆ𝑥_(𝑡+1)에서 미래 관측을 예측하는 모델 𝒲입니다.
우리의 경우, 𝑥_(0:𝑡)는 RGB 비디오이며, 𝑐_𝑡는 다양한 형태를 취할 수 있는 교란입니다.
이는 Physical AI가 취하는 앤션, 랜덤 교란, 교란에 대한 텍스트 설명 등이 될 수 있습니다.

2.1. Future Cosmos
우리는 WFM이 Physical AI 구축자들에게 여러 가지 면에서 유용하다고 믿습니다, 여기에는 다음이 포함됩니다 (이에 국한되지 않습니다)
• Policy 평가.
이는 Physical AI 시스템에서 policy 모델의 품질을 평가하는 것을 의미합니다.
학습된 policy를 실제 월드에서 작동하는 Physical AI 시스템에 배포하여 평가하는 대신, Physical AI 시스템의 디지털 복사본이 월드 파운데이션 모델과 상호작용하도록 할 수 있습니다.
WFM 기반 평가는 더 비용 효율적이고 시간 효율적입니다.
WFM을 통해 빌더는 사용할 수 없는 보이지 않는 환경에서 policy 모델을 배포할 수 있습니다.
WFM은 빌더들이 무능한 policy들을 신속하게 배제하고 물리적 자원을 몇 가지 유망한 정책에 집중할 수 있도록 도울 수 있습니다.
• Policy 초기화.
policy 모델은 현재 관찰과 주어진 작업을 기반으로 Physical AI 시스템이 취할 조치를 생성합니다.
입력된 교란을 기반으로 월드의 동적 패턴을 모델링하는 잘 학습된 WFM은 policy 모델의 좋은 초기화 역할을 할 수 있습니다.
이는 Physical AI의 데이터 부족 문제를 해결하는 데 도움이 됩니다.
• Policy 학습.
reward 모델과 결합된 WFM은 강화 학습 설정에서 물리적 세계가 policy 모델에 피드백을 제공하는 대리인이 될 수 있습니다.
agent는 WFM과 상호 작용하여 작업 해결 능력을 향상시킬 수 있습니다.
• Planning 또는 모델 예측 제어.
WFM은 Physical AI 시스템이 수행한 다양한 action 시퀀스를 따라 다양한 미래 상태를 시뮬레이션하는 데 사용할 수 있습니다.
그런 다음 cost/reward 모듈을 사용하여 결과에 따라 이러한 다양한 action 시퀀스의 성능을 정량화할 수 있습니다.
Physical AI는 계획 알고리즘이나 모델 예측 제어와 같이 전체 시뮬레이션 결과를 기반으로 최상의 action 시퀀스를 실행하거나 후퇴하는 지평선 방식으로 실행할 수 있습니다.
월드 모델의 정확성은 이러한 의사 결정 전략의 성능을 상한선으로 설정합니다.
• 합성 데이터 생성.
WFM은 학습용 합성 데이터를 생성하는 데 사용할 수 있습니다.
또한 뎁스나 시맨틱 맵과 같은 렌더링 메타데이터에 맞게 파인튜닝할 수도 있습니다.
Sim2Real 사용 사례에서는 조건부 WFM을 사용할 수 있습니다.
이 논문에서는 가능성을 나열하면서 Cosmos WFM을 적용한 실증 결과는 포함하지 않았습니다.
향후 연구에서 이러한 주장을 검증하고자 합니다.

2.2. Current Cosmos
그림 4는 비디오 큐레이터, 비디오 토큰화, 월드 파운데이션 모델 사전 학습, 월드 파운데이션 모델 사후 학습, 가드레일을 포함하여 이 논문에 포함된 Cosmos WFM 플랫폼에서 제공되는 기능을 시각화한 것입니다.
비디오 큐레이터.
우리는 확장 가능한 비디오 데이터 큐레이션 파이프라인을 개발합니다.
각 비디오는 장면 변경 없이 개별 장면으로 분할됩니다.
그런 다음 일련의 필터링 단계를 클립에 적용하여 고품질의 동적 정보가 풍부한 하위 집합을 찾아 학습합니다.
이러한 고품질 장면은 VLM을 사용하여 주석을 달았습니다.
그런 다음 시맨틱 중복 제거를 수행하여 다양하지만 컴팩트한 데이터셋을 구성합니다.
비디오 토큰화.
우리는 다양한 압축 비율을 가진 비디오 토크나이저 제품군을 개발합니다.
이러한 토크나이저는 인과적입니다.
현재 프레임에 대한 토큰 계산은 미래 관찰을 기반으로 하지 않습니다.
이러한 인과적 설계에는 여러 가지 이점이 있습니다.
학습 측면에서는 입력이 단일 이미지일 때 인과적 비디오 토크나이저도 이미지 토크나이저이기 때문에 이미지와 비디오 공동 학습이 가능합니다.
이는 비디오 모델이 이미지 데이터셋을 활용하여 학습하는 데 중요하며, 이 데이터셋은 월드의 풍부한 외관 정보를 포함하고 있으며 더 다양한 경향이 있습니다.
응용 측면에서는 인과적 비디오 토크나이저가 인과적 월드에 존재하는 Physical AI 시스템과 더 잘 일치합니다.
WFM 사전 학습.
우리는 사전 학습된 월드 파운데이션 모델을 구축하기 위한 두 가지 확장 가능한 접근 방식을 탐구합니다—디퓨전 모델과 autoregressive 모델.
우리는 확장성을 위해 트랜스포머 아키텍처를 사용합니다.
디퓨전 기반 WFM의 경우, 사전 학습은 두 단계로 구성됩니다: 1) Text2World generation pre-training 및 2) Video2World generation pre-training.
구체적으로, 우리는 입력 텍스트 프롬프트를 기반으로 비디오 월드를 생성하도록 모델을 학습시킵니다.
그런 다음, 이를 파인튜닝하여 과거 비디오와 입력 텍스트 프롬프트를 기반으로 미래 비디오 월드를 생성합니다, 이를 Video2World 생성 작업이라고 합니다.
autoregressive 기반 WFM의 경우, 사전 학습은 두 단계로 구성됩니다: 1) vanilla next token generation과 2) text-conditioned Video2World generation.
먼저 과거 비디오의 입력을 기반으로 미래 비디오 월드를 생성하도록 모델을 학습시킵니다—예견 생성.
그런 다음 과거 비디오와 텍스트 프롬프트를 기반으로 미래 비디오 월드를 생성하도록 파인튜닝합니다.
Video2World 생성 모델은 현재 관찰 (과거 비디오)과 제어 입력 (프롬프트)을 기반으로 미래를 생성하는 사전 학습된 월드 모델입니다.
디퓨전 기반 WFM과 autoregressive 기반 WFM 모두에서 서로 다른 용량을 가진 모델군을 구축하고 다양한 다운스트림 응용 분야에서 그 효과를 연구합니다.
또한 사전 학습된 디퓨전 WFM을 디퓨전 디코더에 도달하도록 파인튜닝하여 autoregressive 모델의 생성 결과를 향상시켰습니다.
WFM을 더 잘 제어하기 위해 Large Language Model (LLM)을 기반으로 한 프롬프트 업샘플러도 구축했습니다.
월드 모델 사후 학습.
우리는 여러 다운스트림 Physical AI 애플리케이션에서 사전 학습된 WFM의 응용을 보여줍니다.
카메라 포즈를 입력 프롬프트로 사용하여 사전 학습된 WFM을 파인튜닝합니다.
이를 통해 생성된 월드에서 자유롭게 탐색할 수 있습니다.
또한, 사전 학습된 WFM이 휴머노이드 및 자율 주행 작업에 어떻게 파인튜닝될 수 있는지 시연합니다.
가드레일.
개발된 월드 파운데이션 모델을 안전하게 사용하기 위해 유해한 입력과 출력이 차단되는 가드레일 시스템을 개발했습니다.
3. Data Curation
우리는 토큰라이저와 WFM을 위한 고품질 학습 데이터셋을 생성하는 비디오 큐레이션 파이프라인에 대해 설명합니다.
그림 5에서 볼 수 있듯이, 우리의 파이프라인은 크게 5단계로 구성되어 있습니다: 1) 분할, 2) 필터링, 3) 주석, 4) 중복 제거, 5) 샤딩.
모든 단계는 데이터 품질을 향상시키고 모델 학습의 요구 사항을 충족하도록 맞춤화되어 있습니다.
먼저 raw 데이터셋을 제시한 다음 각 단계를 자세히 설명합니다.
3.1. Dataset
우리는 독점 비디오 데이터셋과 공개적으로 이용 가능한 오픈 도메인 인터넷 비디오를 모두 사용하여 모델을 학습합니다.
우리의 목표는 Physical AI 개발자를 지원하는 것입니다.
이를 위해 다양한 Physical AI 응용 프로그램을 다룰 수 있도록 비디오 학습 데이터셋을 큐레이션하고 다음 비디오 카테고리를 타겟팅합니다:
1. 운전 (11%),
2. 손동작 및 물체 조작(16%),
3. 인간의 움직임과 활동(10%),
4. 공간 인식 및 내비게이션(16%),
5. 1인칭 시점 (8%),
6. 자연 역학 (20%),
7. 동적 카메라 움직임(8%),
8. 합성 렌더링 (4%) 및
9. 기타 (7%).
이 비디오들은 다양한 시각적 객체와 동작에 대한 광범위한 커버리지를 제공합니다.
이러한 비디오의 다양성은 WFM의 일반화를 개선하고 모델이 다양한 다운스트림 작업을 처리하는 데 도움을 줍니다.
이러한 비디오의 비정형적인 특성과 방대한 양은 알고리즘적 관점과 인프라적 관점에서 효율적으로 처리하는 데 많은 어려움을 초래합니다.
비디오는 다양한 코덱으로 인코딩될 수 있으며, 다양한 화면 비율, 해상도, 길이 등을 가질 수 있습니다.
또한 많은 비디오가 후처리되거나 다양한 시각적 효과로 편집되어 생성된 비디오에서 원치 않는 아티팩트를 유발하고 적절하게 처리되지 않으면 월드 모델의 성능을 저하시킬 수 있습니다.
총 해상도가 720p에서 4k에 이르는 약 2천만 시간의 raw 비디오를 축적합니다.
그러나 상당한 양의 비디오 데이터는 시맨틱적으로 중복되거나 세상의 물리학을 학습하는 데 유용한 정보를 포함하지 않습니다.
따라서 우리는 raw 비디오에서 가장 가치 있는 부분을 찾기 위해 일련의 데이터 처리 단계를 설계합니다.
또한 이미지와 비디오의 공동 학습이 생성된 비디오의 시각적 품질을 향상시키고 모델 학습을 가속화함에 따라 이미지 데이터를 수집합니다.
데이터 큐레이션 파이프라인의 모듈식 설계 덕분에 이미지와 비디오 데이터를 모두 처리하고 사전 학습과 파인튜닝을 위한 데이터셋을 생성할 수 있습니다.
우리는 사전 학습을 위해 약 10^8개의 비디오 클립을 생성하고, 파인튜닝을 위해 약 10^7개의 비디오 클립을 생성합니다.
3.2. Splitting
우리의 비디오는 임의의 길이를 가지고 있으며, 최신 딥러닝 모델은 매우 긴 비디오를 직접 소비할 수 없습니다.
또한 많은 비디오에는 샷 전환이 포함되어 있습니다.
한 장면에서 시작하여 두 장면을 완전히 분리할 수 있는 다른 장면으로 전환할 수 있습니다, 예를 들어, 뉴욕시의 현대 주방에서 두 사람이 대화하는 장면부터 아프리카 사바나에서 사자가 얼룩말을 쫓는 장면 등이 있습니다.
각 비디오를 샷 변화에 따라 세그멘트하고 시각적으로 일관된 비디오 클립을 생성하여 모델이 인위적으로 편집하는 대신 물리적으로 그럴듯한 시각적 콘텐츠 전환을 학습할 수 있도록 하는 것이 중요합니다.
3.2.1. Shot Detection
분할은 임의의 길이의 raw 비디오를 샷 변경 없이 클립으로 시간적으로 세그멘트하는 것을 목표로 합니다.
raw 비디오를 입력으로 받아 각 샷의 시작 및 끝 프레임 인덱스를 생성합니다.
2초보다 짧은 클립은 샷 전환 또는 시각적 효과일 수 있으므로 폐기됩니다.
60초보다 긴 클립은 최대 길이가 60초가 되도록 추가로 분할합니다.
이후 필터링 단계를 통해 클립에 세계의 물리학을 학습하는 데 유용한 정보가 포함되어 있는지 여부를 확인할 수 있습니다.
샷 경계 감지는 고전적인 컴퓨터 비전 문제입니다.
기존 방법들은 시각적 피쳐 공간의 변화를 기반으로 샷 경계를 감지하지만, 비디오 프레임에서 시각적 피쳐를 학습하는 방법에는 차이가 있습니다.
우리는 표 1에서 이 작업을 위한 여러 알고리즘을 평가합니다: PySceneDetect (Castellano, 2024), Panda70M (Chen et al., 2024), TransNetV2 (Soucek and Lokoc, 2024), 그리고 AutoShot (Zhu et al., 2023).
PySceneDetect는 HSV 공간에서 색상 히스토그램의 시간적 변화를 임계값으로 설정하여 샷 변화를 감지하는 인기 있는 라이브러리입니다.
이 라이브러리는 최근 MovieGen 연구 (Polyak et al., 2024)에서도 채택되었습니다.
Panda70M은 CLIP 임베딩 기반 스티칭 및 필터링을 통해 PySceneDetect를 증강합니다.
반면 TransNetV2와 AutoShot은 신경망 기반으로, 100프레임 롤링 입력 창이 주어졌을 때 각 프레임이 전이 프레임일 확률을 예측합니다.
많이 편집된 동영상은 복잡한 샷 변화와 다양한 시각적 효과가 복합적으로 작용하는 경우가 많기 때문에 잘 처리할 수 있는 알고리즘을 선택하는 것이 중요합니다.
이를 통해 이 방법이 동영상에서 깨끗한 샷 컷으로 클립을 생성할 수 있는지 평가하기 위한 전용 벤치마크를 구축할 수 있습니다.
우리의 벤치마크 (ShotBench^2라는 이름)에는 RAI, BBC Planet Earth (AI Image Lab, Modena University, 2016), ClipShots(Tang et al., 2018), SHOT(Zhu et al., 2023)와 같은 기존 데이터셋이 포함됩니다.
ClipShots의 경우, 각 샷 주석의 시작과 끝을 다른 데이터셋과 일치하도록 전이 프레임으로 정의합니다.
표 1은 ShotBench에서 다양한 방법을 비교한 것입니다.
우리는 TransNetV2와 AutoShot 모두에 대해 신뢰 임계값을 0.4로 설정했습니다.
Panda70M의 경우, 필터링 단계를 제외한 분할 구현 방식을 따르며 공정한 비교를 위해 노력했습니다.
종단 간 학습 기반 접근 방식 (예: TransNetV2와 AutoShot)은 수작업으로 만든 피쳐나 휴리스틱 규칙을 사용하는 방법 (예: PysSceneDetect 및 Panda70M)보다 훨씬 우수한 성능을 보였습니다.
TransNetV2와 AutoShot은 기존 데이터셋에서 비슷한 성능을 보였지만, TransNetV2가 더 어려운 샷 변경에서도 더 잘 작동한다는 것을 발견했습니다.
종단 간 신경망 (예: TransNetV2)을 사용하면 복잡한 논리를 사용하여 PySceneDetect와 ImageBind 임베딩을 결합하는 하이브리드 접근 방식 (예: Panda70M)의 장애물 없이 최신 GPU를 활용하여 가속화함으로써 분할 처리량을 늘릴 수 있습니다 (Girdhar et al., 2023).
3.2.2. Transcoding
저희 비디오는 다양한 설정을 가진 다양한 코덱을 사용하므로 데이터 큐레이션에 어려움을 겪습니다.
촬영 감지부터 각 비디오 클립을 일관된 고품질 mp4 형식으로 재인코딩합니다.
이를 통해 후속 데이터 큐레이션 프로세스가 간소화됩니다.
통합된 비디오 코덱을 통해 모델 학습을 위한 데이터 로더의 안정성과 효율성도 크게 향상되었습니다.
우리는 빠른 움직임과 고주파 텍스처를 갖춘 비디오를 사용하여 빠른 비트레이트와 고주파 텍스처를 갖춘 h264_nvenc 코덱을 사용하여 눈에 띄는 시각적 저하를 방지하기 위해 설정을 테스트합니다.
우리는 표 2에서 처리량을 최대화하기 위해 트랜스코딩을 위한 다양한 하드웨어 및 소프트웨어 구성을 철저히 평가합니다.
최신 GPU는 하드웨어 가속 비디오 인코딩 및 디코딩 기능을 제공합니다.
NVIDIA L40S는 디코딩 (NVDEC)과 인코딩 (NVENC) 모두를 위한 하드웨어 가속기를 가지고 있는 반면, NVIDIA H100은 NVDEC만 가지고 있습니다.
우리는 표 2에서 L40S와 공정하게 비교하기 위해 최대 사용 가능한 CPU 코어 (1이 아닌 28개)로 H100을 보상합니다.
L40S는 H100보다 처리량이 약 17% 높습니다 (0.0674 vs. 0.0574).
소프트웨어 구성의 경우 libx264에서 h264_nvenc로 전환하고 동일한 비디오의 여러 클립을 일괄적으로 트랜스코딩하면 처리량이 크게 증가합니다.
특히 다중 GPU 노드에서 NVDEC/NVENC 가속기를 완전히 활용하는 fffmpeg 문제를 관찰했습니다.
비디오 스트림 트랜스코딩을 위해 fffmpeg를 PynVideoCodec로 대체하면 가속기 이용률이 훨씬 높아지고 처리량이 가장 크게 향상됩니다 (0.3702 vs. 0.1026).
오디오 리믹스를 위해 fffmpeg만 유지하고 GPU의 컴퓨팅 성능을 더 잘 활용하기 위해 PynVideoCodec을 사용합니다.
모든 개선 사항을 결합하면 처리량이 약 ~6.5배 증가합니다.
3.3. Filtering
분할 단계에서 생성된 비디오 클립은 노이즈가 많으며, 다양한 주제를 포괄하는 품질이 크게 다릅니다.
우리는 필터링 단계를 설계하여 1) 시각적 품질이 최소 요구 사항을 충족하지 못하는 비디오 클립을 제거하고, 2) 파인튜닝에 적합한 고품질 비디오 클립을 선택하며, 3) WFM을 구축하기 위한 데이터 분포를 맞춤화합니다.
우리는 모션 필터링, 시각적 품질 필터링, 텍스트 필터링 및 비디오 유형 필터링을 수행하여 위의 목표를 달성합니다.
3.3.1. Motion Filtering
모션 필터링에는 두 가지 주요 목표가 있습니다: 1) 정적이거나 갑작스러운 카메라 움직임이 있는 비디오 (일반적으로 휴대용 카메라에서)와 2) 다양한 유형의 카메라 움직임 (예: 팬, 줌, 기울기 등)이 있는 태그 비디오를 제거하여 모델 학습을 안내하는 데 추가 정보를 제공할 수 있습니다.
우리는 모션 필터링을 위한 경량 분류기를 구축합니다.
분류기에 입력되는 것은 비디오 클립에서 추출한 일련의 모션 벡터 또는 optical flow입니다.
이 분류기는 ViT 아키텍처를 기반으로 하며 레이블이 지정된 비디오로 학습됩니다.
우리는 h264 코덱, Farneback optical flow 알고리즘 (Farnebäck, 2003), 그리고 NVIDIA TensorRT-accelerated optical flow 추정 네트워크의 모션 벡터를 실험합니다.
우리는 NVIDIA TensorRT-accelerated optical flow 추정을 기반으로 구축된 분류기가 모션 필터링에 대해 높은 분류 정확도를 제공하여 가장 잘 작동한다는 것을 발견했습니다.
3.3.2. Visual Quality Filtering
우리는 시각적 품질 기반 필터링을 위해 왜곡과 외관 품질이라는 두 가지 기준을 고려합니다.
첫째, 아티팩트, 노이즈, 블러, 낮은 선명도, 과다 노출, 과소 노출 등 왜곡이 있는 비디오 클립을 제거합니다.
우리는 DOVER (Wu et al., 2023)를 기반으로 인간 등급의 비디오로 학습된 비디오 품질 평가 모델을 사용합니다.
이를 통해 클립당 지각 품질 점수를 부여하고, 그 점수를 사용하여 하위 15%에 해당하는 클립을 제거합니다.
둘째, 외관 품질이 낮은 비디오 클립을 필터링합니다.
입력 클립에서 샘플링된 프레임에 이미지 미적 모델 (Schuhmann, 2022)을 적용합니다.
우리는 미적 요소가 Physical AI에 덜 중요하기 때문에 보수적인 임계값인 3.5를 설정했습니다.
3.3.3. Text Overlay Filtering
일부 동영상은 시청자를 위한 추가 정보를 포함하기 위해 텍스트를 추가하도록 후처리됩니다.
또한 텍스트는 다양한 시각적 효과와 함께 발생하는 경향이 있다는 사실도 발견했습니다.
우리의 목표는 세상의 물리학을 배우는 것입니다.
이러한 과도한 텍스트가 있는 동영상은 삭제하는 것이 중요합니다.
운전 동영상의 도로명과 같이 동영상이 생성되는 원본 장면의 텍스트 대신 후처리에서 추가된 텍스트에 중점을 둡니다.
우리는 이러한 비디오를 감지하기 위해 MLP 기반 이진 분류기를 학습시킵니다.
분류기의 입력은 InterVideo2 (Wang et al., 2025)를 사용하여 추출된 비디오 임베딩입니다.
우리는 독점적인 VLM을 사용하여 긍정적인 비디오와 부정적인 비디오를 라벨링하기 위한 학습 세트를 구축합니다.
학습된 모델은 검증 세트에서 높은 예측 정확도를 달성합니다.
3.3.4. Video Type Filtering
학습 데이터 분포를 조정하고 원치 않는 비디오 유형을 걸러내기 위해, 우리는 비디오를 콘텐츠 유형과 시각적 스타일에 따라 분류하는 포괄적인 분류 체계를 설계합니다.
분류기를 학습시켜 각 비디오 클립을 분류 체계에서 카테고리로 분류합니다.
추상적인 시각 패턴, 비디오 게임 영상, 애니메이션 콘텐츠 등 생성 품질이 떨어지거나 비현실적인 동적 특성을 초래할 수 있는 특정 비디오 유형을 제외하여 데이터를 정제합니다.
또한, WFM과 더 관련성이 높은 카테고리 (예: 인간 행동, 인간 및 객체 상호작용 등)에서 업샘플링하고 덜 중요한 카테고리 (예: 자연 또는 풍경 비디오)에서 다운샘플링하여 데이터 분포를 조정합니다.
기존 라벨링된 데이터셋이 우리의 분류 체계와 일치하지 않는 상황에서, 우리는 독점적인 VLM을 활용하여 분류기에 대한 학습 및 평가 데이터를 생성합니다.
각 비디오 클립에 대해, 우리는 8개의 균일하게 샘플링된 프레임으로 VLM을 프롬프트하고 가장 적합한 분류 체계 라벨을 조회합니다.
주석이 달린 데이터를 사용하여 텍스트 필터링에서 동일한 InterVideo2 임베딩에 대해 MLP 분류기를 학습시킵니다.
3.4. Annotation
텍스트 설명은 일반적으로 이미지 및 비디오 데이터와 결합하여 월드 모델 학습을 위한 supervision 및 조건을 제공합니다.
우리는 VLM을 사용하여 각 비디오 클립에 대해 고품질의 일관된 캡션을 생성합니다.
우리는 비디오의 중요한 사실과 세부 사항에 초점을 맞추도록 VLM을 구성합니다.
Alt 텍스트에 의존하지 않고 이 접근 방식을 사용하여 비디오 설명을 제공함으로써 학습 중에 다양한 텍스트 스타일이나 형식에 적응할 필요가 없기 때문에 월드 모델의 학습 부담을 덜어줍니다.
우리는 비디오에서 캡션 생성을 위해 여러 SOTA 방법 (예: VFC (Ge et al., 2024), Qwen2-VL (Wang et al., 2024), VILA (Lin et al., 2024; Xue et al., 2024))을 테스트한 결과, VILA가 소규모 인간 평가를 기반으로 더 정확한 설명을 생성한다는 것을 발견했습니다.
우리는 비디오 캡션을 위해 파인튜닝된 13B 매개변수를 가진 내부 VILA 모델을 사용합니다.
이 모델은 최대 입력 및 출력 토큰 길이가 각각 5904와 256인 긴 멀티프레임 컨텍스트를 처리하기에 적합한 확장된 컨텍스트 창을 가지고 있습니다.
추론 효율성을 향상시키기 위해, 우리는 FP8 양자화된 TensorRT-LLM 엔진을 사용하여 PyTorch 반정밀 기준 모델에 비해 처리량을 10배 빠르게 증가시켰습니다 (표 3).
우리는 VILA에 "Elaborate on the visual and narrative elements of the video in detail"고 프롬프트하고 입력 클립에서 8개의 균일하게 샘플링된 프레임을 제공합니다.
캡션의 평균 길이는 559자 또는 97단어입니다.
3.5. Deduplication
동영상의 양이 방대하기 때문에 학습 세트에 중복되거나 거의 중복될 수 있는 샘플이 있을 수 있습니다.
보다 균형 잡힌 다양한 데이터 분포를 만들기 위해서는 데이터 중복 제거가 중요합니다.
또한 학습의 효율성을 높이고 특정 학습 샘플을 암기할 기회를 줄입니다.
우리는 확장 가능한 시맨틱 중복 제거를 위해 SemDeDup (Abbas et al., 2023)과 DataComp (Gadre et al., 2024)의 접근 방식을 채택합니다.
필터링 중에 계산된 InterVideo2 임베딩을 재사용하고, 𝑘 = 10,000인 k-means (RAPIDS, 2023)의 다중 노드 GPU 가속 구현을 사용하여 임베딩을 클러스터링합니다.
각 임베딩 클러스터 내에서 쌍별 거리를 계산하여 중복을 식별합니다.
중복된 비디오가 감지되면, 중복 제거로 인해 품질이 저하되지 않도록 최고 해상도의 비디오를 선택합니다.
GPU 메모리에 전체 쌍별 거리 행렬을 저장하지 않기 위해 필요한 상위 triang 행렬과 256개의 블록에서 argmax 감소를 즉시 계산합니다.
중복 제거 중에 약 30%의 학습 데이터를 제거합니다.
또한 추출된 InterVideo2 임베딩 및 클러스터링 결과를 활용하여 전체 학습 데이터셋을 자유 형식의 텍스트와 비디오로 쿼리할 수 있는 시각적 검색 엔진을 구축합니다.
이 검색 엔진은 데이터의 문제를 디버깅하고 사전 학습 데이터셋과 다운스트림 애플리케이션 간의 격차를 이해하는 데 유용합니다.
3.6. Sharding
이 단계는 처리된 비디오 클립을 모델 트레이너가 직접 사용할 수 있는 웹 데이터셋으로 패키징하는 것을 목표로 합니다.
우리는 비디오의 해상도, 화면 비율, 길이에 따라 비디오를 공유하여 학습 커리큘럼에 맞게 조정합니다.
사전 학습 데이터셋 외에도 위에서 설명한 다양한 필터를 활용하여 더욱 높은 품질의 파인튜닝 데이터셋을 생성합니다.
3.7. Infrastructure
우리의 데이터 처리 인프라는 AnyScale Ray (Moritz et al., 2017)를 사용하여 지리적으로 분산된 클러스터를 위한 스트리밍 파이프라인 시스템을 구현하여 대규모 ML 워크플로우에서 두 가지 주요 과제를 해결합니다: 동질적인 노드 간의 효율적인 자원 활용과 데이터 소스에 대한 고지연 연결을 통한 견고한 운영.
데이터 전송을 계산에서 분리함으로써 파이프라인은 원격 데이터 저장소와 효율적으로 작동하면서 데이터셋 크기가 아닌 파이프라인 복잡성에 따라 확장되는 메모리 요구 사항을 유지하여 무제한 스트림 처리를 가능하게 합니다.
우리의 아키텍처는 병렬 파이프라인 단계를 통해 상호 보완적인 하드웨어 자원을 동시에 활용할 수 있게 합니다, 예를 들어, 데이터 수집을 위해 네트워크 대역폭을 사용하고, 비디오 디코딩을 위해 NVDEC 유닛을 사용하며, 컴퓨팅 집약적인 변환을 위해 GPU를 사용합니다.
우리는 이 다중 자원 할당을 최적화하기 위해 Fragmentation Gradient Descent 알고리즘 (Weng et al., 2023)을 확장하였으며, 우리의 스케줄러는 개별 단계를 자동으로 확장하여 특수 하드웨어 가속기 간의 균형 잡힌 처리량을 유지합니다.
4. Tokenizer
토큰라이저는 현대 대규모 모델의 기본 구성 요소입니다.
그들은 unsupervised 방식으로 발견된 병목 잠재 공간을 학습하여 raw 데이터를 더 효율적인 표현으로 변환합니다.
특히, 시각적 토큰화기는 raw 및 중복 시각 데이터—이미지 및 비디오와 같이—를 압축된 시맨틱 토큰으로 매핑하여 고차원 시각 데이터를 처리하는 데 중요합니다.
이 기능은 대규모 트랜스포머 모델의 효율적인 학습을 가능하게 할 뿐만 아니라 제한된 계산 자원에 대한 추론을 민주화합니다.
그림 6은 인코더와 디코더를 학습시켜 병목 토큰 표현이 입력의 시각적 정보를 최대한 보존하도록 하는 것이 목표인 토큰화 학습 파이프라인을 개략적으로 보여줍니다.
토큰라이저는 두 가지 유형으로 제공됩니다: 연속적이고 이산적 (그림 7 참조).
연속 토큰라이저는 Stable Diffusion (Rombach et al., 2022) 또는 VideoLDM (Blattmann et al., 2023)과 같은 잠재 확산 모델에서와 같이 시각적 데이터를 연속 잠재 임베딩으로 인코딩합니다.
이러한 임베딩은 연속 분포에서 샘플링하여 데이터를 생성하는 모델에 적합합니다.
이산 토큰화기는 시각적 데이터를 이산 잠재 코드로 인코딩하여 VideoPoet (Kondratyuk et al., 2024)과 같은 자기회귀 트랜스포머에서 볼 수 있듯이 양자화된 인덱스로 매핑합니다.
이 이산 표현은 교차 엔트로피 loss로 학습된 GPT와 같은 모델에 필요합니다.
그림 7은 두 가지 유형의 토큰을 보여줍니다.
토큰라이저의 성공은 주로 후속 시각적 재구성 품질을 저하시키지 않으면서 높은 압축률을 제공하는 능력에 달려 있습니다.
한편으로는 높은 압축률로 인해 저장 및 계산 요구가 감소합니다.
다른 한편으로는 과도한 압축으로 인해 필수적인 시각적 세부 사항이 손실될 수 있습니다.
이러한 절충안은 토큰라이저 설계에 상당한 도전 과제를 제시합니다.
Cosmus Tokenizer를 소개합니다, 이는 이미지와 비디오를 위한 연속 및 이산 토큰라이저를 모두 포함하는 시각적 토큰라이저 모음입니다.
Cosmus Tokenizer는 뛰어난 시각적 재구성 품질과 추론 효율성을 제공합니다.
다양한 계산 제약과 애플리케이션 요구를 수용할 수 있는 다양한 압축률을 제공합니다.
표 4는 다양한 시각적 토큰라이저와 그 기능을 비교한 것입니다.
우리는 시간적 인과 메커니즘을 갖춘 가볍고 계산 효율적인 아키텍처를 사용하여 Cosmos Tokenizer를 설계합니다.
구체적으로, 우리는 비디오 프레임의 자연스러운 시간 순서를 보존하기 위해 인과 시간 컨볼루션 레이어와 인과 시간 어텐션 레이어를 사용하여 단일 통합 네트워크 아키텍처를 사용하여 이미지와 비디오의 원활한 토큰화를 보장합니다.
저희는 카테고리나 종횡비를 제한하지 않고 고해상도 이미지와 장기 동영상을 통해 직접 토큰라이저를 학습합니다.
특정 데이터 카테고리와 크기에 초점을 맞춘 기존 토큰라이저와 달리, Cosmos Tokenizer는 다양한 종횡비에서 작동합니다—1:1, 3:4, 4:3, 9:16, 16:9를 포함합니다.
추론 중에는 시간적으로 길이에 구애받지 않으며, 학습된 시간 길이를 초과하는 토큰화가 가능합니다.
우리는 또한 MS-COCO 2017 (Lin et al., 2014), ImageNet-1K (Deng et al., 2009), 그리고 DAVIS (Perazzi et al., 2016)를 포함한 표준 이미지 및 비디오 벤치마킹 데이터셋에서 우리의 토큰라이저를 평가합니다.
Physical AI 응용을 위한 비디오 토큰화 연구를 용이하게 하기 위해, 우리는 fish-eye, 로봇 공학, 운전, 인간 활동, 그리고 공간 내비게이션에 이르기까지 다양한 Physical AI를 위한 비디오 카테고리를 포함하는 비디오 데이터셋을 큐레이션합니다.
그림 8에 나타난 바와 같이, 우리의 평가 결과는 Cosmos Tokenizer가 기존 토큰라이저를 큰 폭으로 능가한다는 것을 보여줍니다—예를 들어, DAVIS 비디오에서 +4 dB PSNR 향상을 달성했습니다.
최대 12배 더 빠르게 실행되며, 80GB 메모리를 갖춘 단일 NVIDIA A100 GPU에서 메모리 부족 없이 한 번의 촬영으로 1080p에서 최대 8초, 720p에서 최대 10초까지 비디오를 인코딩할 수 있습니다.
공간 압축이 8배 및 16배인 사전 학습된 모델 모음입니다,
4.1. Architecture
Cosmos Tokenizer는 인코더-디코더 아키텍처로 설계되었습니다.
입력 비디오 𝑥_0: 𝑇 ∈ R^(((1+𝑇)×𝐻×𝑊×3)가 주어졌을 때, 𝐻, 𝑊, 𝑇는 프레임의 높이, 너비, 개수입니다, 인코더(ℰ)는 입력을 토큰 비디오 𝑧_0: 𝑇' ∈ R^(((1+𝑇'))×𝐻'×𝑊'×𝐶')로 토큰화하며, 공간 압축 계수는 𝑠_𝐻𝑊=𝐻/𝐻'=𝑊/𝑊'이고 시간 압축 계수는 𝑠_𝑇 =𝑇/𝑇'입니다.
디코더(𝒟)는 이러한 토큰으로부터 입력 비디오를 재구성하여

에 의해 수학적으로 주어진 재구성된 비디오 ˆ𝑥_0:𝑇 ∈ R^((1+𝑇)×𝐻×𝑊×3)를 생성합니다.
우리의 아키텍처는 시간적 인과 설계를 사용하여 각 단계가 미래 프레임과 무관하게 현재 프레임과 과거 프레임만 처리하도록 보장합니다.
일반적인 접근 방식과 달리, 우리의 토큰라이저는 입력이 먼저 2단계 웨이블릿 변환에 의해 처리되는 웨이블릿 공간에서 작동합니다.
구체적으로, 웨이블릿 변환은 입력 비디오 𝑥_0:𝑇를 그룹별로 매핑하여 입력을 𝑥, 𝑦, 𝑡에 따라 4배씩 다운샘플링합니다.
그룹은 다음과 같이 구성됩니다: {𝑥_0, 𝑥_1:4, 𝑥_5:8, ..., 𝑥_(𝑇−3):𝑇} → {𝑔_0, 𝑔_1, 𝑔_2, ..., 𝑔_𝑇/4}.
후속 인코더 단계에서는 프레임을 {𝑔_0, 𝑔_0:1, 𝑔_0:2, ...} → {𝜉_0, 𝜉_1, 𝜉_2, ...}와 같이 시간적으로 인과적인 방식으로 처리합니다.
연속적인 인코더 단계는 유사한 방식을 따르며, 마지막으로 토큰 𝑧_0:𝑇′를 출력합니다.
인과 설계는 토큰라이저 위에 구축된 모델을 시간적 인과 설정에서 작동하는 다운스트림 Physical AI 애플리케이션에 적용하는 데 도움이 됩니다.
웨이블릿 변환을 통해 픽셀 정보의 중복을 제거하고 남은 레이어가 더 의미적 압축에 집중할 수 있는 더 간결한 비디오 표현을 사용할 수 있습니다.
인코더 단계 (웨이브릿 후 변환)는 다운샘플링 블록과 인터리브된 일련의 잔여 블록을 사용하여 구현됩니다.
각 블록에서 우리는 시공간 인수분해 3D 컨볼루션을 사용합니다, 먼저 공간 정보를 포착하기 위해 커널 크기가 1 × 𝑘 × 𝑘인 2D 컨볼루션을 적용하고, 이어서 커널 크기가 𝑘 × 1 × 1 인 시간 컨볼루션을 적용하여 시간 역학을 포착합니다.
인과관계를 보장하기 위해 𝑘 - 1의 왼쪽 패딩을 사용합니다.
장기적인 의존성을 포착하기 위해, 우리는 전역 지원 지역과 함께 시공간적으로 요인화된 인과적 셀프 어텐션을 활용합니다—예를 들어, 마지막 인코더 블록에 대해 1 + 𝑇′입니다.
우리는 비선형성을 위해 Swish activation function (Ramachandran et al., 2017)를 사용합니다, 우리는 Group Normalization (GroupNorm) (Wu and He, 2018) 대신 Layer Normalization (LayerNorm) (Lei Ba et al., 2016)를 활용합니다, 잠재 공간의 특정 영역이나 재구성된 출력에서 큰 규모가 나타나는 것을 방지합니다 (Karras et al., 2020; Sadat et al., 2024).
디코더는 인코더를 미러링하여 다운샘플링 블록을 업샘플링 블록으로 대체합니다.
그림 9는 전체 Cosmos Tokenizer 아키텍처의 개요를 보여줍니다.
우리는 연속 토큰리저의 잠재 공간을 모델링하기 위해 vanilla autoencoder (AE) 공식을 사용합니다.
이산 토큰라이저의 경우, 우리는 Finite-Scalar-Quantization (FSQ) (Mentzer et al., 2023)를 잠재 공간 양자화기로 채택합니다.
연속 토큰라이저의 잠재 차원은 16인 반면, 이산 토큰라이저의 경우 6으로, FSQ 레벨의 수 (8, 8, 8, 5, 5, 5)를 나타냅니다.
이 구성은 64,000개의 어휘 크기에 해당합니다.
4.2. Training Strategy
우리는 미리 설정된 빈도로 이미지와 비디오의 미니 배치를 번갈아 가며 공동 학습 전략을 사용합니다.
저희는 토큰라이저 디코더의 최종 출력만 supervise합니다.
우리는 약속이나 KL prior loss들과 같은 잠재 공간에 활용되는 auxiliary loss들을 사용하지 않습니다.
예를 들어, VAE (Kingma, 2013) 공식이 vanilla AE 대신 연속 토큰화에 사용된다면, KL prior loss들이 있어야 할 것입니다.
FSQ 대신 VQ-VAE (van den Oord et al., 2017)를 이산 양자화에 사용한다면, commitment loss가 발생해야 할 것입니다.
저희는 2단계 학습 방식을 채택하고 있습니다.
첫 번째 단계에서는 입력 비디오와 재구성 비디오 (ˆ𝑥_0: 𝑇) 간의 픽셀 단위 RGB 차이를 최소화하는 L1 loss,
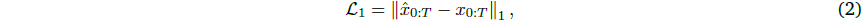
에 의해 주어진, 그리고 VGG-19 피쳐 (Simonyan and Zisserman, 2014)에 기반한 지각 loss를 최적화합니다,
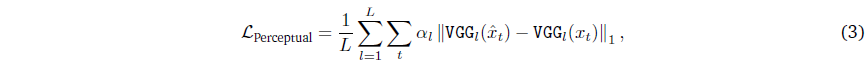
에 의해 주어졌습니다, 여기서 VGG_𝑙(·) ∈ R^(𝐻×𝑊×𝐶)는 사전 학습된 VGG-19 네트워크의 𝑙번째 레이어에서 나온 피쳐들이고, 𝐿_𝑙는 𝑙번째 레이어의 가중치입니다.
두 번째 단계에서는 optical flow (OF) loss (Teeed and Deng, 2020)을 사용하여 재구성된 비디오의 시간적 매끄러움을 처리합니다,

, 그리고 재구성된 이미지의 선명도를 높이기 위해 Gram-matrix (GM) loss (Gatys et al., 2016)를 사용합니다,

또한, 파인튜닝 단계에서 적대적 loss를 사용하여 특히 큰 압축률에서 재구성 세부 사항을 더욱 향상시킵니다.
우리는 이미지 토큰라이저 (CI와 DI로 표시됨)를 두 가지 압축 속도로 학습합니다: 8 × 8 및 16 × 16.
마찬가지로, 우리는 비디오 토큰라이저 (CV 및 DV로 표시됨)를 세 가지 압축 속도로 학습합니다: 4 × 8 × 8, 8 × 8 × 8, 8 × 16 × 16으로 압축률을 나타냅니다.
여기서 압축률은 이미지의 경우 𝐻 × 𝑊, 동영상의 경우 𝑇 × 𝐻 × 𝑊로 표현되며, 여기서 𝑇는 시간 차원을 나타내고 𝐻와 𝑊는 공간 차원을 나타냅니다.
비디오 토큰라이저의 경우 두 가지 변형을 생성합니다:
1. Cosmos-0.1-Tokenizer: 더 적은 수의 비디오 프레임 (CV는 49 프레임, DV는 17 프레임)을 샘플링하는 미니 배치를 사용하여 학습되었습니다.
2. Cosmos-1.0-Tokenizer: 더 많은 수의 비디오 프레임 (CV는 121 프레임, DV는 49 프레임)을 샘플링하는 미니 배치를 사용하여 학습되었습니다.
이 접근 방식은 이미지 및 비디오 데이터의 다양한 시간 및 공간 해상도를 유연하게 처리할 수 있도록 보장합니다.
4.3. Results
우리는 다양한 이미지 및 비디오 벤치마크 데이터셋에서 Cosmos Tokenizer 제품군을 광범위하게 평가합니다.
이미지 토큰라이저 평가를 위해 선행 기술을 따라 MS-COCO 2017(Lin et al., 2014)과 ImageNet-1K (Deng et al., 2009)를 평가합니다.
이미지 평가 벤치마크로 MS-COCO 2017 검증 서브셋 5,000개 이미지와 ImageNet-1K 검증 서브셋 50,000개 이미지를 사용합니다.
TokenBench.
비디오 토큰라이저 평가를 위해 고해상도 및 장기 동영상에 대한 표준 벤치마크는 아직 없습니다.
이를 위해 로봇 조작, 운전, 자기중심적, 웹 동영상 등 다양한 영역을 포괄하는 TokenBench라는 벤치마크를 도입하고 평가를 표준화합니다.
우리는 BDD100K (Yu et al., 2020), EgoExo-4D (Grauman et al., 2024), BridgeData V2 (Walke et al., 2023), Panda-70M (Chen et al., 2024) 등 다양한 작업에 일반적으로 사용되는 기존 비디오 데이터셋을 활용합니다.
각 데이터셋에서 랜덤으로 100개의 비디오를 샘플링하고 처음 10초 동안 짧은 크기를 1080으로 조정하여 전처리합니다.
Panda-70M의 경우, 저품질 콘텐츠와 작은 동작으로 비디오를 수동으로 필터링합니다.
EgoExo-4D의 경우, 랜덤으로 100개의 장면을 선택하여 자기중심적인 비디오 1개와 자기외중심적인 비디오 1개를 샘플링합니다.
그 결과 총 500개의 비디오가 생성됩니다.
TokenBench의 일부 예는 그림 10에서 확인할 수 있습니다.
TokenBench 외에도, 우리는 1080p 해상도로 DAVIS 데이터셋에서 비디오 토큰라이저를 평가합니다.
Baselines and evaluation metrics.
우리는 다양한 압축률로 토큰라이저를 평가하여 다양한 계산 요구에 대한 효과를 보여줍니다.
우리는 이러한 토큰라이저를 각각 SOTA 이미지 및 비디오 토큰라이저와 비교합니다.
표 4는 다양한 설정에서 비교한 특정 SOTA 토큰라이저를 보여줍니다.
평가 지표에는 Peak Signal-to-Noise Ratio (PSNR), Structural Similarity (SSIM), 이미지의 경우 reconstruction Fréchet Inception Distance (rFID) (Heussel et al., 2017), 비디오의 경우 econstruction Fréchet Video Distance (rFVD) (Unterthiner et al., 2019)가 포함됩니다.
Quantitative results.
표 5와 6은 다양한 벤치마크에서 연속 및 이산 비디오 토큰라이저의 평균 정량 지표를 요약한 것입니다.
두 표에서 볼 수 있듯이 Cosmos Tokenizer는 DAVIS 비디오 데이터셋과 토큰벤치 모두에서 기존 기술과 비교하여 모든 지표에서 4 × 8 × 8의 공간-시간 압축 비율로 SOTA 성능을 달성했습니다.
또한, 2× 및 8× 더 높은 압축 비율 (즉, 8×8×8 및 8×16×16)에서도 Cosmos Tokenizer는 여전히 기존 기술보다 더 나은 품질을 달성하여 우수한 압축 품질 절충안을 보여줍니다.
표 7과 8은 다양한 이미지 벤치마크에서 연속 및 이산 이미지 토큰라이저의 평균 정량적 지표를 요약한 것으로, 다양한 이미지 유형을 다룹니다.
보시다시피, 이전 기술들과 비교했을 때 Cosmos Tokenizer는 압축비 8 × 8로 일관되게 SOTA 결과를 달성합니다.
더 중요한 것은 4배 더 큰 압축 비율인 16 × 16에서 Cosmos Tokenizer의 이미지 품질이 8 × 8 압축 비율에서 이전 기술과 비슷하거나 더 나은 경우가 많다는 점입니다, 이는 표 7과 8에서 볼 수 있습니다.
다양한 이미지 및 비디오 벤치마크 데이터셋에 대한 이러한 정량적 결과는 Cosmos Tokenizer가 큰 공간-시간 압축으로 시각적 콘텐츠를 더 잘 표현할 수 있음을 확인시켜줍니다.
Runtime performance.
표 9는 단일 A100 80GB GPU에서 측정된 매개변수 수와 이미지 또는 비디오 프레임당 평균 인코딩 및 디코딩 시간을 보여줍니다.
이와 비교하여 이전 SOTA 토큰라이저의 매개변수와 평균 속도도 나열합니다.
그림과 같이, 이미지 및 비디오 토큰라이저 모두에서 Cosmos Tokenizer는 기존 기술에 비해 모델 크기를 최소화하면서도 2배 ~ 12배 더 빠르며, Cosmos Tokenizer가 시각적 콘텐츠 인코딩 및 디코딩에 높은 효율성을 가지고 있음을 보여줍니다.
5. World Foundation Model Pre-training
사전 학습된 WFM은 실제 물리학과 자연스러운 행동에 대한 일반적인 지식을 포착하는 일반론자입니다.
우리는 디퓨전 모델과 자기회귀 모델이라는 두 가지 확장 가능한 딥러닝 패러다임을 활용하여 두 가지 WFM 계열을 구축합니다.
디퓨전 모델과 자기회귀 모델 모두 어려운 생성 문제를 더 쉬운 하위 문제의 연속으로 분해하고 생성 모델 개발에 박차를 가하고 있습니다.
디퓨전 모델의 경우, 어려운 생성 문제는 일련의 디노이징 문제로 나뉩니다.
자기회귀 모델의 경우, 어려운 생성 문제는 일련의 다음 토큰 예측 문제로 나뉩니다.
우리는 사전 학습된 WFM을 구축하기 위해 현대 GPU에 맞춘 다양한 병렬화 기법을 사용하여 이러한 딥러닝 패러다임을 확장하는 방법을 논의합니다.
우리는 논문에 보고된 모든 WFM 모델을 10,000개의 NVIDIA H100 GPU 클러스터를 사용하여 3개월 동안 학습시킵니다.
표 10에서 우리는 사전 학습된 WFM과 그 동료들의 맵을 제시합니다.
디퓨전 기반 WFM 제품군의 경우, 각각 Cosmos-1.0-Diffusion-7B-Text2World와 Cosmos-1.0-Diffusion-14B-Text2World를 렌더링하는 7B와 14B의 두 가지 Text2World 모델을 구축하는 것으로 시작합니다.
이러한 모델은 텍스트 프롬프트를 시각적 세계의 비디오에 매핑할 수 있습니다.
그런 다음 Text2World 모델을 파인튜닝하여 현재 관찰을 나타내는 추가 비디오 입력을 받습니다.
그 결과 현재 관찰 (입력 비디오)과 교란 (텍스트 프롬프트)을 기반으로 미래 비디오를 예측하는 Video2World 모델이 탄생했습니다.
이러한 디퓨전 모델은 연속적인 토큰을 사용하는 잠재 디퓨전 모델입니다.
우리는 Cosmos-1.0-Tokenizer-CV8x8x8을 사용하여 시각적 토큰을 생성합니다.
WFM의 학습 텍스트 프롬프트는 비디오 설명 생성을 통해 VLM에 의해 생성됩니다.
이러한 설명은 비디오에 대한 인간 설명의 다양한 분포를 따릅니다.
도메인 격차를 완화하기 위해, 우리는 Mistral-NeMo-12B-Instruction 모델 (Mistral 및 NVIDIA, 2024)을 기반으로 Cosmos-1.0-PromptUpsAmpler-12B-Text2World를 구축하여 인간 텍스트 프롬프트를 디퓨전 기반 WFM이 선호하는 텍스트 프롬프트로 변환하는 데 도움을 줍니다.
자기회귀 기반 WFM 제품군의 경우, 먼저 현재 비디오 관찰만을 기반으로 미래 비디오를 예측하기 위해 각각 4B와 12B 크기의 두 가지 기본 모델을 구축합니다.
이 모델들을 각각 Cosmos-1.0-Autoregressive-4B와 Cosmos-1.0-Autoregressive-12B로 명명합니다.
이 모델들은 비디오 예측 작업을 위해 처음부터 학습된 Llama3 스타일의 GPT 모델로, 언어 이해가 필요하지 않습니다.
자기회귀 기반 WFM이 텍스트 정보를 활용하여 다음 토큰 예측을 할 수 있도록 하기 위해, 우리는 트랜스포머 블록에 추가된 크로스 어텐션 레이어를 통해 입력 텍스트 프롬프트의 T5 임베딩을 WFM에 통합합니다.
이러한 자기회귀 WFM은 Cosmos-1.0-Tokenizer-DV8x16x16을 사용하며, 이는 입력 비디오를 몇 개의 정수로 매핑합니다.
토큰라이저를 과도하게 압축하면 때때로 원치 않는 왜곡을 초래할 수 있습니다.
이 문제를 해결하기 위해, 우리는 Cosmos-1.0-Diffusion-7B-Decoder-DV8x16x16ToCV8x8x8을 구축하여 Cosmos-1.0-Diffusion-7B-Text2World 모델을 파인튜닝하여 CV8x8 공간의 연속 토큰으로 이산 토큰을 매핑합니다.
5.1. Diffusion-based World Foundation Model
우리의 디퓨전 기반 WFM은 학습된 토큰라이저의 잠재 공간 내에서 작동하는 잠재 디퓨전 모델로, 비디오를 간결하고 축소된 차원으로 표현할 수 있게 합니다.
이 설계 선택은 여러 가지 장점을 제공합니다: 학습과 추론 모두에서 계산 비용을 줄이면서 디노이징 작업을 단순화합니다 (Hoogeboom et al., 2024; Rombach et al., 2022).
비디오를 잠재 표현으로 토큰화하기 위해, 우리는 Cosmos-1.0-Tokenizer-CV8x8x8을 사용합니다.
5.1.1. Formulation
디퓨전 WFM을 학습시키기 위해 우리는 EDM (Karras et al., 2022, 2024)에 명시된 접근 방식을 채택합니다.
노이즈 레벨 𝜎에서 평가된 디노이저 𝐷_𝜃의 디노이징 스코어 매칭 loss는

로 정의되며, 여기서 x_(0~𝑝_data)는 학습 세트에서 샘플링된 깨끗한 이미지 또는 비디오이고, n ~ 𝒩(︀0, 𝜎^2I) ︀는 독립적이고 동일하게 분포된 가우시안 노이즈이며, 𝐷_𝜃는 손상된 샘플 x_0 + n을 디노이징하는 임무를 맡은 노이즈 조건 신경망입니다.
우리는 𝐷_𝜃을 매개변수화하기 위해 EDM에 도입된 전처리 설계를 준수합니다.
전체 학습 loss는 노이즈 레벨에 대한 ℒ(𝐷_𝜃; 𝜎)의 가중 기대치로 정의됩니다:

, 노이즈 레벨 𝜎의 분포는 하이퍼파라미터 𝑃_mean과 𝑃_std에 의해 제어됩니다.
𝜎_data는 학습 데이터의 표준 편차이며, 가중치 함수 𝜆(𝜎)은 학습 초기에 각 노이즈 레벨의 기여도를 동일하게 보장합니다.
그러나 학습이 진행됨에 따라 이러한 균형이 악화될 수 있습니다.
이 문제를 완화하기 위해 우리는 다양한 노이즈 레벨에 대한 최적화를 멀티 태스크 학습의 한 형태로 취급합니다.
우리는 노이즈 레벨 𝜎에서 디노이징 objective ℒ(𝐷_𝜃, 𝜎)의 불확실성을 정량화하는 연속 불확실성 함수로 𝑢(𝜎)을 도입하여 불확실성 기반 가중치 접근 방식을 활용합니다.
우리는 간단한 MLP를 사용하여 𝑢(𝜎)을 매개변수화하고 학습 중 전체 loss ℒ(𝐷_𝜃)을 최소화합니다.
직관적으로, 모델이 작업에 대해 불확실한 경우, 즉 𝑢(𝜎)가 높은 경우 노이즈 레벨 𝜎에서 손실 기여도를 가중치로 적용합니다.
동시에, 이 불확실성에 대해 모델이 페널티를 부여하여 𝑢(𝜎)를 가능한 한 낮게 유지하도록 장려합니다.
최근 Gaussian flow matching formulation을 채택한 비디오 생성 모델 (Kong et al., 2024; Polyak et al., 2024)과 비교했을 때, 우리의 연구는 디퓨전 스코어 매칭 관점 (Ho et al., 2020; Song et al., 2020)에서 도출되었습니다.
그러나 Gao et al. (2024)이 보여준 바와 같이, 이러한 프레임워크는 이론적으로 동등하며 objectives와 학습 절차에서 근본적인 유사점을 공유합니다.
우리의 EDM 기반 공식은 이러한 통찰력과 일치하며, 주로 전처리 설계와 하이퍼파라미터의 선택에서 차이가 있습니다.
실제로, 우리는 EDM 공식과 아무런 성능 제한을 겪지 않았습니다.
5.1.2. Architecture
이 섹션에서는 라벨 조건부 이미지 생성을 위해 설계된 DiT (Peebles and Xie, 2023)를 기반으로 한 디노이징 네트워크 𝐷_𝜃의 설계에 대해 설명합니다.
우리는 제어 가능한 비디오 생성이라는 목표에 더 잘 맞도록 그 아키텍처를 조정합니다.
그림 11에서 전체 네트워크 설계를 시각화합니다.
3D patchification.
우리 네트워크에 입력된 것은 이미지와 비디오 데이터 모두에 대한 형태 𝑇 × 𝐶 × 𝐻 × 𝑊의 잠재적 표현으로, 이미지는 단일 프레임을 가진 비디오로 구분됩니다.
디노이징 네트워크를 위한 입력을 준비하기 위해 먼저 선형 레이어를 사용하여 상태를 "patchify"한 다음 평탄화합니다.
이 과정은 겹치지 않는 형태의 큐브 (𝑝_𝑡, 𝑝_ℎ, 𝑝_𝑤)를 네트워크의 개별 토큰 입력에 투영하는 것을 포함합니다.
따라서 패치화 후 이미지 또는 비디오는 길이가 𝑇𝐻𝑊/(𝑝_𝑡 𝑝_ℎ 𝑝_𝑤)인 1차원 시공간 시퀀스로 재구성됩니다.
우리는 디노이징 네트워크를 위해 𝑝_𝑡=1, 𝑝_ℎ=𝑝_𝑤=2를 사용합니다.
Hybrid positional embedding with FPS-aware 3D RoPE and learnable embedding.
우리는 임의의 크기, 종횡비, 비디오 길이를 생성할 수 있도록 3D 팩터화된 Rotary Position Embedding (RoPE) (Su et al., 2024)을 사용합니다.
구체적으로, 피쳐 차원을 세 개의 대략 동일한 청크로 분할하고, 각각 시간 축, 높이 축, 너비 축을 따라 위치 정보를 가진 RoPE를 적용합니다.
실제로, 이는 각 블록에서 주파수 임베딩을 각 축에 연결하고 Large Language Models (LLM)에 최적화된 RoPE 커널을 재사용함으로써 분할 및 concatenation 없이 효율적으로 구현할 수 있습니다.
다양한 프레임 속도로 비디오 합성을 더욱 지원하기 위해, 우리는 학습 비디오의 Frames Per Second (FPS)를 기반으로 시간 주파수를 재조정합니다.
RoPE의 상대적인 위치 인코딩 특성과 3D 팩터화 설계 덕분에 FPS 인식 설계는 우리의 공동 이미지-비디오 학습과 호환됩니다.
해상도나 비디오 길이를 변경할 때 RoPE의 추가적인 이점은 점진적인 학습 중에 분명해집니다.
Neural Tangent Kernel (NTK)-RoPE (Peng and Quesnelle, 2023)을 활용하여, 우리는 5,000개의 학습 단계 내에서도 합리적인 성능을 달성하며 빠른 모델 수렴을 관찰했습니다.
추가적으로, 임베딩 블록당 학습 가능한 절대 위치를 추가하면 모델을 더욱 향상시키고, 학습 loss를 줄이며, 생성된 비디오에서 변형 아티팩트를 줄일 수 있음을 발견했습니다.
Cross-attention for text conditioning.
우리는 언어 정보를 통합하기 위해 네트워크의 크로스 어텐션 레이어에 의존합니다.
각 트랜스포머 블록은 순차적인 셀프 어텐션, 크로스 어텐션, 피드포워드 레이어로 구성됩니다.
셀프 어텐션은 시공간 토큰을 통해 작동하지만, 크로스 어텐션은 T5-XXL (Raffel et al., 2020) 임베딩을 키와 값으로 사용하여 시맨틱 맥락을 통합하여 효과적인 텍스트 조건화를 가능하게 합니다.
Query-key normalization.
학습 초기 단계에서는 어텐션 로짓의 성장이 불안정해져 어텐션 엔트로피가 붕괴되는 것을 관찰합니다.
우리는 기존 문헌 (Dehhgani et al., 2023; Esser et al., 2024; Wortsman et al., 2023)을 따라 어텐션 연산 전에 쿼리 𝑄와 키 𝐾를 정규화합니다.
우리는 네트워크 내의 모든 셀프 어텐션 및 크로스 어텐션 레이어에 대해 학습 가능한 척도를 가진 Root Mean Square Normalization (RMSNorm) (Zhang and Sennrich, 2019)를 사용합니다.
AdaLN-LoRA.
우리는 DiT의 adaptive layer normalization (AdaLN) layers (Peebles and Xie, 2023; Xu et al., 2019)이 모델 매개변수의 상당 부분을 차지하면서도 FLOPs 측면에서 계산 복잡성에는 거의 기여하지 않는다는 것을 발견했습니다.
W.A.L.T (Gupta et al., 2024)에서 영감을 받아, 우리는 Low-Rank Adaptation (LoRA) (Hu et al., 2022)을 구현하여 이러한 레이어의 밀집 선형 투영을 저차원 근사로 분해합니다.
Cosmos-1.0-Diffusion-7B의 경우, 이 아키텍처 최적화는 모든 평가 지표에서 성능 패리티를 유지하면서 매개변수 수를 36% 감소시켜 매개변수 효율적인 설계의 효과를 입증합니다.
5.1.3. Training Strategy
이 섹션에서는 멀티 모달리티, 해상도, 종횡비 및 조건 입력에 걸친 데이터셋에서 모델을 학습하는 데 사용되는 방법론을 개략적으로 설명합니다.
Joint image and video training.
모델 학습에서 고품질의 다양한 이미지 데이터셋의 방대한 양을 활용하기 위해, 우리는 이미지와 비디오 데이터 배치를 통합하는 교대 최적화 전략을 구현합니다.
이미지 도메인과 비디오 도메인 간의 크로스-모달 지식 전달을 용이하게 하기 위해, 이미지와 비디오 데이터에 대해 독립적으로 추정된 충분한 통계를 사용하여 잠재 분포를 정렬하는 도메인별 정규화 방식을 채택합니다.
이 접근 방식은 이미지와 비디오 잠재 표현 간의 분포 이동을 줄이는 것이 생성 품질을 향상시킨다는 관찰에서 영감을 받았습니다.
또한, 비디오 잠재 표현에서 시간 및 채널 차원에 걸쳐 비정상 통계를 관찰합니다.
이러한 이질성을 해결하기 위해, 우리는 비디오 잠재 표현에 프레임 단위 및 채널 단위 표준화를 적용하는 정규화 전략을 사용하여, 이들이 isotropic 가우시안 사전 분포를 더 잘 근사하도록 효과적으로 장려합니다.
크로스 모달리티 지식 전달 외에도, 우리의 정규화 방식은 중요한 이론적 이점을 제공합니다: 학습 중 신호 대 잡음비의 스케일 불변성.
스케일이 다른 두 가지 0-평균 잠재 표현을 고려합니다: 하나는 단위 분산으로 표준화되고, 다른 하나는 분산 4로 표준화됩니다.
표준화된 표현에 대해 원하는 신호 대 잡음비를 달성하기 위해 가우시안 노이즈 𝒩(0, 𝜎^2)를 추가할 때, 동일한 비율을 유지하기 위해 비정규화된 표현에 대해 노이즈를 𝒩(0, 4 𝜎^2)로 스케일링해야 합니다.
모든 잠재 표현을 표준화함으로써, 우리는 다양한 스케일에서 일관된 신호 대 잡음비를 보장하며, 기본 토큰라이저가 학습 중에 업데이트되더라도 모델 적응을 용이하게 합니다.
계산 효율성을 유지하기 위해, 우리는 이미지와 비디오 배치 크기를 균형 있게 조정하여 GPU 간에 비교 가능한 메모리 활용을 보장합니다.
그러나 비디오 배치 디노이징 loss는 이미지 배치 loss에 비해 수렴 속도가 느리다는 것을 관찰했습니다.
이는 비디오 프레임의 고유한 시간적 중복성 때문이며, 이로 인해 비디오 배치의 그래디언트 크기가 작아집니다.
최근 멀티-해상도 이미지 학습의 발전 (Atzmon et al., 2024; Chen, 2023; Hoogeboom et al., 2023)에서 영감을 받아, 우리는 비디오 배치 노이즈 레벨을 이미지 배치 노이즈 레벨에 비해 프레임 수의 제곱근으로 스케일링하여 이러한 수렴 불일치를 해결합니다.
Progressive training.
우리는 점진적인 학습 전략을 채택하고 있으며, 각 단계의 세부 사항은 표 12에 자세히 나와 있습니다.
초기 단계는 57 프레임으로 구성된 비디오를 사용하여 512 픽셀 해상도의 비디오와 이미지를 학습하는 것입니다.
그 후 목표 해상도인 720 픽셀로 전환하여 비디오 길이를 121 프레임으로 늘립니다.
방대한 데이터에 대한 사전 학습 후, 선형적으로 감소하는 학습 속도로 𝒪(10𝑘) 반복에 대한 고품질 하위 집합에서 모델을 파인튜닝합니다.
Dai et al. (2023)의 연구 결과와 일치하게, 파인튜닝이 생성된 비디오의 품질을 향상시킬 수 있음을 발견했습니다.
Multi-aspect training.
다양한 종횡비를 가진 콘텐츠를 수용하기 위해 데이터를 1:1, 3:4, 4:3, 9:16, 16:9의 비율에 해당하는 5개의 서로 다른 버킷으로 구성하여 각 이미지 또는 비디오를 가장 가까운 종횡비를 가진 버킷에 할당합니다.
학습 중에 각 데이터 병렬 프로세스 그룹은 하나의 버킷에서 샘플링하여 서로 다른 병렬 프로세스 그룹 간에 서로 다른 버킷을 허용합니다.
프롬프트에 설명된 원본 콘텐츠 정보를 최대한 보존하기 위해 최장 측 크기 조정을 구현합니다.
일괄 처리를 위해 누락된 픽셀에 반사 패딩을 적용하고 디퓨전 백본에 패딩 마스크를 공급하여 추론 중에 정밀한 제어가 가능합니다.
Mixed-precision training.
우리는 모델 가중치의 두 복사본을 유지합니다: 하나는 BF16에 있고 다른 하나는 FP32에 있습니다.
전방 및 후방 패스 동안, BF16 가중치는 학습 효율성을 향상시키기 위해 사용되며, 이는 BF16 형식으로도 그래디언트와 활성화를 초래합니다.
매개변수 업데이트의 경우, 가중치는 수치적 안정성을 보장하기 위해 FP32에서 업데이트됩니다.
그런 다음 업데이트된 FP32 매개변수는 다음 반복을 위해 BF16에 복사되고 캐스팅됩니다.
학습을 더욱 안정화하기 위해, 우리는 식. (5)에서 디노이징 스코어 매칭의 loss를 10배로 스케일링합니다.
또한 AdamW에서 베타 및 주당순이익 계수가 낮을수록 loss 스파이크가 현저히 감소한다는 것을 발견했습니다.
14B 디퓨전 모델 학습에서는 loss 스파이크를 거의 발견하지 못했으며, 회복 불가능한 loss 스파이크도 없었습니다.
Text conditioning.
Text2World 모델에서는 텍스트 인코더로 T5-XXL (Raffel et al., 2020)을 사용합니다.
우리는 고정된 시퀀스 길이인 512를 유지하기 위해 제로패드 T5 임베딩을 사용합니다.
텍스트-컨텍스트 정렬을 강화하기 위해 classifier-free guidance (Ho and Salimans, 2022)를 채택합니다.
이전 연구들 (Balaji et al., 2022; Saharia et al., 2022)이 텍스트 임베딩을 랜덤으로 제로화하는 것과 달리, 우리는 추론 중 부정적인 프롬프트의 효과로 인해 이 단계를 생략합니다.
특히, text-to-image 생성기로서, 우리의 모델은 가이던스 없이도 높은 충실도의 이미지를 생성하는 데 탁월하며, 이는 고품질 학습 데이터셋에 기인합니다.
classifier-free guidance는 일반적으로 선호되는 시각적 콘텐츠에 대해 모드 탐색 행동을 촉진하지만, 신중한 데이터 선택이 유사한 효과를 달성한다는 것을 발견했습니다.
그러나 비디오 생성의 경우, 비교 가능한 고품질 데이터의 부족으로 인해 낮은 가이던스 설정에서 최적의 결과를 얻지 못합니다.
따라서 비디오 생성 작업에서 만족스러운 콘텐츠를 생성하기 위해서는 더 높은 가이던스 값이 필요합니다.
Image and video conditioning.
우리는 Text2World 모델을 확장하여 생성 과정에 이전 프레임을 통합하여 이미지 및 비디오 컨디셔닝을 지원하는 Video2World 모델을 구축합니다.
구체적으로, 조건부 프레임은 시간 차원을 따라 생성된 프레임과 연결됩니다.
추론 중 입력 프레임의 변화에 대한 견고성을 향상시키기 위해, 우리는 학습 중에 조건부 프레임에 증강 노이즈를 도입합니다.
이 증강 노이즈의 시그마 값은 𝑃_mean = -3.0, 𝑃_std = 2.0으로 샘플링됩니다.
또한, 디퓨전 모델의 입력은 채널 차원을 따라 조건부 프레임과 생성된 프레임을 구별하는 이진 마스크로 연결됩니다.
loss 함수는 생성된 출력에만 초점을 맞추어 조건부 프레임의 위치에서 기여를 배제합니다.
일반화를 개선하기 위해, 학습 중에 조건부 프레임의 수를 랜덤으로 변경합니다.
추론 중에 모델은 단일 조건부 프레임 (이미지) 또는 여러 이전 프레임을 입력으로 사용하여 유연하게 작동할 수 있습니다.
5.1.4. Scaling Up
여기에서는 디퓨전 WFM을 효율적으로 확장할 수 있는 기술을 개략적으로 설명합니다.
모델의 메모리 요구 사항을 분석하고 병렬 처리 전략을 논의하며, 다른 비디오 디퓨전 모델 및 SOTA LLM과 학습 설정을 비교합니다.
Memory requirements.
GPU 메모리를 소비하는 네 가지 주요 구성 요소는 다음과 같습니다:
• 모델 매개변수: 매개변수당 10바이트. 우리의 혼합 정밀 학습은 모델 매개변수를 FP32와 BF16에 저장하고, Exponential Moving Average (EMA) 가중치를 FP32에 저장합니다.
• 그라디언트: 매개변수당 2바이트. 그라디언트를 BF16에 저장합니다.
• 옵티마이저 상태: 매개변수당 8바이트. 우리는 AdamW (Loshchilov and Hutter, 2019)를 옵티마이저로 사용하고, 옵티마이저 상태 (즉, 첫 번째 및 두 번째 모멘트)를 FP32에 저장합니다.
• 활성화: (2×number_of_layers×15×seq_len×batch_size×d_model) 바이트. 우리는 활성화를 BF16에 저장합니다. 표 13은 네트워크 내 주요 작업에 대한 저장된 활성화에 대한 세부 정보를 제공합니다. 메모리 사용량을 최적화하기 위해, 우리는 선택적 활성화 체크포인트 (Chen et al., 2016; Korthikanti et al., 2023)를 구현하여 정규화 함수와 같은 메모리 제한 계층에 대한 활성화를 재계산합니다.
예를 들어, 우리의 14B 모델 (Cosmos-1.0-Diffusion-14B-Text2World)은 모델 매개변수, 그래디언트 및 최적화 상태에 약 280GB가 필요하며, 고해상도 사전 학습 중 활성화에는 310GB가 필요합니다.
NVIDIA H100 GPU의 HBM3 한계가 80GB이므로, 우리는 메모리 요구 사항을 여러 GPU에 분산시키기 위해 Full Sharded Data Parallelism (FSDP)과 Context Parallelism (CP)을 사용합니다.
Fully Sharded Data Parallelism (FSDP).
FSDP는 모델 매개변수, 그래디언트 및 옵티마이저 상태를 장치 간에 공유함으로써 메모리 효율성을 향상시킵니다.
계산 중에 필요한 경우에만 매개변수를 수집하고 이후에 이를 해제합니다.
표준 데이터 병렬 처리가 장치 간에 매개변수를 중복하는 것과 달리, FSDP는 매개변수, 그래디언트 및 옵티마이저 상태를 분배하며 각 장치는 샤드만 관리합니다.
이 접근 방식은 매개변수, 그래디언트 및 옵티마이저 상태의 공유와 함께 최대 일시적으로 샤드되지 않은 매개변수 집합에 대한 메모리 사용량을 최소화합니다.
구현을 위해, 우리는 메모리와 통신 지연 시간의 균형을 맞추기 위해 7B 모델에는 32, 14B 모델에는 64의 샤드 팩터를 사용합니다.
Context Parallelism (CP).
긴 컨텍스트 설정을 위한 확장 트랜스포머는 FLOP 및 활성화 메모리 증가와 관련된 문제를 야기합니다.
CP는 여러 GPU에 계산과 활성화를 분산시킴으로써 이러한 문제를 해결합니다.
이는 쿼리 𝑄와 키 값 (𝐾, 𝑉)을 시퀀스 차원에 따라 CP_SIZE 청크로 분할하는 방식으로 작동하며, 여기서 CP_SIZE는 CP 그룹 내 GPU의 수입니다.
각 GPU는 하나의 𝑄 청크를 처리하고 동일한 CP 그룹에 저장된 (𝐾, 𝑉) 블록을 사용하여 부분 어텐션 출력을 반복적으로 축적합니다.
CP의 다양한 구현 방식은 all-gather (Dubey et al., 2024), P2P (Liu et al., 2023), all-to-all (Jacobs et al., 2023) 등 다양한 통신 프리미티브를 활용합니다.
우리는 TransformerEngine (NVIDIA, 2024)의 P2P 변형 모델을 사용하여 GPU 간에 블록을 전송하면서 동시에 어텐션을 처리하여 계산과 통신을 겹칩니다.
블록 크기를 신중하게 선택하면 이 중첩은 데이터 전송 지연 시간을 효과적으로 숨깁니다.
우리는 NVLink에 연결된 GPU 내에서 CP 그룹을 구성하고 최적의 활용을 위해 FSDP 랭크와 CP 랭크를 겹칩니다.
컨텍스트가 짧은 이미지 반복의 경우 처리량을 개선하기 위해 CP를 비활성화합니다.
크로스-어텐션 레이어는 (𝐾, 𝑉)의 시퀀스 길이가 짧아 통신 지연 시간을 마스킹하기에 충분한 계산이 필요하지 않습니다.
Cosmos-1.0-Diffusion-14B를 예로 사용하면 샤딩 팩터가 64인 FSDP를 사용하면 파라미터, 그래디언트 및 옵티마이저 상태에 대한 메모리 요구 사항이 줄어들어 GPU당 280GB에서 약 280/64 ≈ 4GB로 감소합니다.
마찬가지로 CP_SIZE = 8인 CP를 사용하면 활성화 메모리가 GPU당 310GB에서 약 310/8 ≈ 40GB로 감소합니다.
이러한 계산은 과소평가라는 점에 유의하는 것이 중요하며, 실제로는 토큰라이저와 샤딩되지 않은 파라미터에 의해 추가 메모리가 소비됩니다.
CP에서 통신과 계산이 중복되면 각 GPU는 여러 개의 청크 (𝐾, 𝑉)를 유지해야 합니다.
Comparison with other video generative models.
우리의 병렬화 전략은 Tensor Parallelism (TP)와 그 확장인 Sequence Parallelism (SP)를 통합한 HunyuanVideo (Kong et al., 2024)와 MovieGen (Polyak et al., 2024)에 제시된 접근 방식과 비교하여 의도적으로 간소화됩니다.
TP/SP를 제외하더라도, 우리의 설정은 유사한 Model FLOPs Utilization (MFU)를 달성합니다.
TP/SP는 더 큰 모델이나 대체 네트워크 토폴로지와 같은 특정 시나리오에서는 여전히 가치가 있지만, 절충안에 대한 자세한 분석은 향후 연구를 위해 남겨두었습니다.
Comparison with large language models.
일반적으로 더 짧은 컨텍스트 길이로 사전 학습되는 LLM과 달리, 긴 컨텍스트 설정은 셀프 어텐션의 이차 비용으로 인해 FLOP를 크게 증가시킵니다.
LLM의 FLOP는 일반적으로 6 × seq_len × 𝑃으로 계산되지만, 여기서 𝑃는 매개변수의 수입니다 (Kaplan et al., 2020), 우리는 이 공식이 디퓨전 WFM에 대해 부정확하다는 점에 주목합니다.
우리는 표 13에서 각 주요 작업의 순방향 통과 FLOP를 제공합니다.
5.1.5. Prompt Upsampler
학습 중에 WFM은 상세한 비디오 설명을 입력 텍스트 프롬프트로 사용하여 고품질 비디오를 생성합니다.
그러나 추론 중에 사용자 프롬프트는 길이, 구조, 스타일이 다를 수 있으며, 종종 훨씬 짧습니다.
학습 텍스트 프롬프트와 추론 텍스트 프롬프트 사이의 이러한 격차를 해소하기 위해, 우리는 원래 입력 프롬프트를 더 자세하고 풍부한 버전으로 변환하는 프롬프트 업샘플러를 개발했습니다.
이는 더 많은 세부 사항을 추가하고 일관된 설명 구조를 유지함으로써 프롬프트를 개선할 수 있으며, 이는 더 높은 품질의 출력으로 이어집니다.
프롬프트 업샘플러의 주요 요구 사항은 다음과 같습니다:
• 입력 프롬프트에 충실도: 업샘플링된 프롬프트는 주요 캐릭터, 액션 또는 모션, 주요 속성 및 전체 의도를 포함한 원래 사용자 입력의 주요 요소를 충실히 보존해야 합니다.
• 학습 분포와의 일치: 업샘플링된 프롬프트는 길이, 언어 구조, 스타일 측면에서 WFM의 학습 프롬프트 분포와 매우 유사해야 합니다.
• 향상된 시각적 세부 사항: 업샘플링된 프롬프트는 WFM이 더 정확한 이미지를 생성하도록 유도하도록 설계되어야 합니다.
Prompt upsampler for Text2World model.
우리는 Mistral-NeMo-12B-Instrument (Mistral and NVIDIA, 2024)을 파인튜닝하여 프롬프트 업샘플러를 구축합니다.
사용자 입력을 시뮬레이션하는 짧은 프롬프트와 학습 프롬프트 분포를 반영하는 긴 프롬프트를 쌍으로 구성한 데이터를 얻기 위해, 우리는 VLM을 사용하여 학습 긴 프롬프트와 해당 비디오를 기반으로 짧은 캡션을 생성합니다.
이 긴 데이터 생성 전략은 (1) WFM의 세부 학습 프롬프트로부터 실제 비디오 콘텐츠와 분포를 보존하고 (2) 짧은 프롬프트와 긴 프롬프트 간의 충실도를 보장하는 데 효과적입니다.
그 결과 생성된 프롬프트 업샘플러는 Cosmos-1.0-PromptUpsampler-12B-Text2World라고 불립니다.
Prompt upsampler for Video2World model.
Video2World 모델의 경우, 입력은 비디오 조건과 사용자 텍스트 프롬프트로 구성됩니다.
사용자 프롬프트를 향상시키기 위해, 우리는 제로샷 프롬프트 엔지니어링과 결합된 오픈 소스 VLM인 Pixtral-12B (Agrawal et al., 2024)를 사용하여 프롬프트를 비디오 조건과 사용자 프롬프트를 모두 고려한 상세한 설명으로 업샘플링합니다.
우리는 기본적으로 Pixtral-12B 모델이 잘 작동하며 위에서 설명한 유사한 파인튜닝을 수행하지 않는다는 것을 발견했습니다.
5.1.6. Results
그림 12에서는 Cosmos-1.0-Diffusion-7B-Text2World 및 Cosmos-1.0-Diffusion-14B-Text2World 모델에서 생성된 정성적 결과를 제시합니다.
두 모델 모두 높은 시각적 품질, 모션 다이내믹스, 텍스트 정렬을 갖춘 비디오를 생성합니다.
7B 모델에 비해 14B 모델은 더 복잡한 시각적 세부 사항과 복잡한 모션을 포착하는 비디오를 생성할 수 있습니다.
우리는 그림 13에 Video2World 7B 및 14B 모델에서 생성된 비디오를 보여줍니다.
Video2World 모델은 이미지와 비디오 컨디셔닝을 모두 지원하며 자기회귀 방식으로 확장된 비디오를 생성할 수 있습니다.
그림 13에서 보여준 바와 같이, 우리의 Video2World 모델은 좋은 모션 다이내믹스와 시각적 충실도로 사실적인 비디오를 생성합니다.
14B 모델은 장면의 풍부함과 모션 안정성 측면에서 더 나은 비디오를 생성합니다.
5.2. Autoregressive-based World Foundation Model
자기회귀 WFM에서 우리는 언어 모델링과 유사한 다음 token 예측 작업으로 월드 시뮬레이션 생성을 공식화합니다.
먼저, 섹션 4에서 소개한 Cosmos Discrete Tokenizer를 사용하여 비디오를 일련의 이산 비디오 토큰 𝒱 = {𝑣_1, 𝑣_2, . . , 𝑣_𝑛}로 변환합니다.
그런 다음, Transformer 디코더 (Vaswani et al., 2017)를 학습시켜 large language models (LLMs) (Brown et al., 2020; Dubey et al., 2024; Jiang et al., 2023)과 유사하게 과거 비디오 토큰을 컨텍스트로 사용하여 다음 비디오 토큰을 예측합니다.
구체적으로, 학습 objective는 다음과 같은 negative log-likelihood (NLL) loss를 최소화하는 것입니다:

, 예측된 다음 비디오 토큰 𝑣_𝑖의 조건부 확률 𝑃는 매개변수 θ를 가진 트랜스포머 디코더로 모델링됩니다.
5.2.1. Architecture
우리의 자기회귀 기반 WFM 아키텍처는 그림 14에 나와 있습니다.
우리는 비디오 생성 작업에 맞춘 표준 트랜스포머 모델 아키텍처에 여러 가지 수정을 가했습니다, 여기에는 1) 3D 인식 위치 임베딩 추가, 2) 텍스트 입력을 더 나은 제어를 가능하게 하는 크로스-어텐션 추가, 3) QK-Normalization (Wortsman et al., 2023) 등이 포함됩니다.
3D positional embeddings.
디퓨전 기반 WFM (섹션 5.1.2)과 유사하게, 우리는 두 가지 상호 보완적인 위치 임베딩 메커니즘을 통합합니다: 상대 위치에 대한 3D 분해 Rotary Position Embedding (RoPE)과 절대 좌표에 대한 3D 분해 absolute positional embedding (APE).
이러한 메커니즘은 네트워크 전반에 걸쳐 포괄적인 공간 및 시간 정보를 제공하기 위해 협력합니다.
• 3D Rotary Position Embedding (RoPE).
우리는 모델에 3D RoPE를 적용하여 시간적, 높이 및 너비 차원에서 상대적인 위치 정보를 인코딩합니다. 학습 중에는 학습이 진행됨에 따라 비디오의 시퀀스 길이가 증가하는 다단계 학습 전략을 채택합니다. 변화하는 시간적 지속 시간에 맞춰 3D RoPE를 적응시키기 위해, 우리는 RoPE의 컨텍스트 창을 확장하도록 설계된 계산 효율적인 기법인 YaRN (Peng et al., 2023)을 사용합니다. 비디오 시퀀스 길이가 시간적 차원을 따라 증가함에 따라 YaRN 확장을 시간 축을 따라만 적용합니다. YaRN을 활용함으로써, 우리의 모델은 초기 학습 단계에서 경험한 것보다 더 긴 컨텍스트 길이로 외삽할 수 있습니다.
• 3D Absolute Positional Embedding (APE).
3D RoPE 외에도 각 트랜스포머 블록 내에 3D APE를 통합하여 상대 위치 인코딩을 보완합니다. 이 APE는 시간, 높이 및 너비 차원에 걸쳐 인수분해된 사인파 임베딩을 사용하여 위치 정보를 인코딩하여 모델이 절대 위치를 인식할 수 있도록 합니다. 임베딩은 각 단계에서 입력 텐서에 직접 추가되어 트랜스포머의 위치 컨텍스트를 풍부하게 합니다. 절대 위치 인코딩과 상대 위치 인코딩을 결합하면 생성된 비디오에서 모델 성능이 향상되고 학습 loss가 줄어들며 변형 아티팩트를 최소화할 수 있음을 발견했습니다. 특히, 디퓨전 기반 WFM (섹션 5.1.2)은 학습 가능한 임베딩을 사용하지만, 자기회귀 기반 WFM에서는 APE를 위한 사인파 기반 임베딩을 채택했습니다.
Vocabulary.
토큰화는 입력된 텍스트를 large language models (LLM)에서 일련의 이산 토큰으로 변환하는 중요한 단계입니다.
LLM에서 가능한 토큰의 어휘는 LLM의 토큰라이저 (예: OpenAI (2022)에서 도입한 tiktoken)에 의해 결정되며, 이는 Byte Pair Encoding (BPE) (Gage, 1994)과 같은 알고리즘을 사용하여 대규모 텍스트 코퍼스에서 학습됩니다.
자기회귀 모델에서는 Cosmos-1.0-Tokenizer-DV8x16x16을 토큰라이저로 사용합니다.
섹션 4에서 소개한 바와 같이, 우리는 Finite-Scalar-Quantization (FSQ) (Mentzer et al., 2023)를 활용하여 6차원 잠재 공간을 (8, 8, 8, 5, 5) 수준으로 양자화합니다.
이 양자화를 통해 어휘 크기는 8×8×8×5×5 = 64,000이 됩니다.
Cross-attention for text conditioning.
트랜스포머 아키텍처에 존재하는 셀프 어텐션 블록 외에도, 모델이 입력 텍스트를 조건으로 할 수 있도록 크로스 어텐션 레이어를 추가합니다.
디퓨전 기반 WFM (섹션 5.1.2)과 유사하게, 트랜스포머 모델의 피쳐와 사전 학습된 텍스트 인코더 (T5-XXL)에서 얻은 텍스트 임베딩 간에 크로스 어텐션이 적용됩니다.
실험에서는 모든 셀프 어텐션 레이어 후에 크로스 어텐션 블록을 추가합니다.
Query-key normalization.
학습 안정성을 높이기 위해 Query-Key Normalization (QKNorm) (Wortsman et al., 2023)를 통합했습니다.
QKNorm은 도트 곱을 계산하기 전에 쿼리(𝑄)와 키(𝐾) 벡터를 정규화하여 어텐션 메커니즘의 불안정성을 해결함으로써 소프트맥스 함수가 포화되는 것을 방지하고 보다 효과적인 학습을 보장합니다.
정규화 후, 도트 곱은 고정된 1/√𝑑_𝑘 대신 학습 가능한 매개변수 𝛾에 의해 스케일링됩니다.
이 학습 가능한 스케일링 팩터를 통해 모델은 어텐션 스코어의 크기를 적응적으로 제어할 수 있으며, 유연성과 표현력을 향상시킵니다.
Z-loss.
학습 안정성을 더욱 향상시키기 위해, 우리는 학습 objective에 z-loss (de Brebisson and Vincent, 2016)이라는 안정화 항을 도입했습니다.
z-loss는 로짓이 0에서 벗어나는 것을 방지하여, 모델이 수치적 불안정성이나 그래디언트 폭발을 초래할 수 있는 지나치게 큰 로짓 값을 생성하는 것을 효과적으로 방지합니다.
z-loss는 제곱 로짓의 합으로 정의되며, 이는 ℒ_z-loss = 𝜆 · Σ︀𝑧_𝑖^2입니다.
우리는 z-loss가 특히 다수의 GPU 노드로 학습을 확장할 때, 그래디언트 노름을 건강한 범위로 유지하는 데 중요하다는 것을 발견했습니다.
실험적으로, z-loss 계수 𝜆 = 3 × 10-4가 최적의 균형에 도달하여 모델 성능에 부정적인 영향을 미치지 않으면서 학습을 효과적으로 안정화시킨다는 것을 발견했습니다.
5.2.2. Scaling Up
이 섹션에서는 자기회귀 WFM을 효율적으로 확장할 수 있는 기술에 대해 설명합니다.
우리는 모델의 메모리 소비를 간단히 분석하고, 병렬 처리 전략을 논의하며, 다른 자기회귀 모델과 학습 설정을 비교합니다.
Memory requirements.
학습 중 GPU 메모리는 주로 다음에 의해 소비됩니다:
• 모델 매개변수: 매개변수당 6바이트. BF16과 FP32 모두에 모델 매개변수를 저장합니다.
• 그라디언트: 매개변수당 2바이트. 그라디언트를 BF16에 저장합니다.
• 옵티마이저 상태: 매개변수당 8바이트. AdamW (Loshchilov와 Hutter, 2019)의 첫 번째와 두 번째 모멘트를 모두 FP32에 저장합니다.
• 활성화: 약 (2 × number_of_layer × 17 × seq_len × batch_size × d_model) 바이트. SOTA 자기회귀 모델의 활성화 메모리에 대한 자세한 분석을 위해 Korthikanti et al. (2023)을 참고합니다.
예를 들어, 우리의 12B 모델 (Cosmos-1.0-Autoregressive-12B)은 매개변수, 그래디언트 및 최적화 상태를 결합하여 약 192GB의 메모리를 필요로 합니다.
이는 단일 NVIDIA H100 GPU의 80GB HBM3 용량을 초과하므로, 우리는 tensor parallelism (TP) (Shoeybi et al., 2019)와 그 확장인 sequence parallelism (SP) (Korthikanti et al., 2023)를 활용하여 메모리 요구 사항과 계산을 여러 GPU에 분산시킵니다.
Tensor Parallelism (TP).
Tensor Parallelism (TP) (Shoeybi et al., 2019)는 입력 또는 출력 피쳐 차원을 따라 선형 레이어의 가중치를 분할하며, 선택은 GPU 간 통신을 최소화하는 것을 목표로 합니다.
예를 들어, 2계층 피드포워드 네트워크에서는 첫 번째 레이어의 가중치는 출력 피쳐 차원을 따라 분할되고, 두 번째 레이어의 가중치는 입력 피쳐 차원을 따라 분할됩니다.
이 배열은 GPU 간의 통신 없이 중간 활성화를 로컬에서 처리할 수 있게 합니다.
최종 출력은 올-리듀스 통신을 사용하여 결합됩니다.
TP를 사용하면 각 GPU는 선형 레이어의 가중치 중 일부, 특히 1/TP_SIZE만 저장합니다.
그러나 TP의 기본 구현은 LayerNorm과 같은 작업에 대해서는 여전히 시퀀스 차원을 따라 활성화를 복제하여 중복성을 초래합니다.
Sequence Parallelism (SP).
SP (Korthikanti et al., 2023)는 시퀀스 차원을 따라 컨텍스트를 더 세분화하여 텐서 병렬 처리를 확장합니다.
이 접근 방식은 셀프 어텐션 레이어의 LayerNorm 및 Dropout과 같은 연산자에 적용할 수 있으며, 시퀀스의 각 요소를 독립적으로 처리할 수 있습니다.
SP가 활성화된 상태에서. 각 GPU는 활성화의 일부, 특히 1 / TP_SIZE만 저장합니다.
Comparison with other autoregressive models.
인기 있는 LLM과 비교했을 때, 우리 모델은 MQA나 GQA와 같은 메모리 절약 어텐션 변형을 활용하지 않습니다.
그렇지 않으면, 우리의 자기회귀 모델은 LLM의 아키텍처와 매우 유사하도록 의도적으로 설계되었습니다 (Adler et al., 2024; Brown et al., 2020; Dubey et al., 2024; Jiang et al., 2023; Team, 2024; Yang et al., 2024).
이 정렬은 유연성과 확장성을 제공하기 때문입니다.
모델 크기와 컨텍스트 길이를 더욱 확장하기 위해 컨텍스트 병렬 처리와 파이프라인 병렬 처리와 같은 더 많은 병렬 처리를 활용하는 실험은 향후 연구에 남아 있습니다.
5.2.3. Training Strategy
우리는 자기회귀 WFM의 사전 학습을 여러 단계로 수행합니다.
• 1단계: 첫 번째 단계에서는 비디오 예측 목표를 사용하여 모델을 학습시킵니다. 첫 번째 프레임이 입력 조건으로 주어지면 모델은 미래의 비디오 프레임을 예측하도록 학습됩니다. 이 작업에는 17프레임의 컨텍스트 길이가 사용되며, 즉 모델은 첫 번째 프레임을 입력으로 하여 16개의 미래 프레임을 예측합니다.
• 1.1단계: 이 단계에서는 비디오 예측을 수행하지만 컨텍스트 길이가 34프레임으로 증가합니다. 우리는 RoPE의 컨텍스트 길이를 늘리기 위해 시간 차원에서 YaRN 확장을 사용합니다.
• 2단계: 학습의 2단계에서는 모델에 텍스트 컨디셔닝을 도입합니다. 텍스트 임베딩은 새로 초기화된 크로스 어텐션 레이어를 사용하여 통합됩니다. 모델은 34 프레임 컨텍스트로 학습됩니다. text-to-video 생성 능력을 향상시키기 위해 섹션 5.1.3에 설명된 대로 이미지와 비디오 데이터를 결합하여 모델을 학습합니다. 이미지 배치를 사용할 때는 이미지의 컨텍스트 길이가 비디오보다 훨씬 작기 때문에 더 큰 배치 크기를 사용합니다.
모든 모델은 640 × 1024의 고정된 공간 해상도로 학습됩니다.
Cooling down.
사전 학습 후, 우리는 고품질 데이터를 사용하여 "cooling down" 단계를 수행합니다.
이는 LLM 학습 방식 (Dubey et al., 2024)과 유사합니다.
이 단계에서는 고품질 이미지-비디오 쌍을 학습하는 동안 학습률을 선형적으로 0으로 감소시킵니다.
쿨링다운 단계는 30,000번 이상의 반복으로 수행됩니다.
우리는 두 세트의 자기회귀 기반 WFM을 학습합니다.
먼저 두 가지 base 모델을 구축합니다: 하나는 4B 용량이고 다른 하나는 12B 용량입니다.
이 모델들은 텍스트 프롬프트를 입력으로 받지 않는 순수한 다음 비디오 토큰 예측기입니다.
그런 다음 각 기본 모델에서 Video2World 버전을 도출하고, 여기에 크로스 어텐션 레이어를 추가하여 다음 비디오 토큰 예측을 위한 텍스트 프롬프트 입력을 활용합니다.
• Cosmos-1.0-Autoregressive-4B: 다음 비디오 토큰 예측을 위한 4B 트랜스포머 모델. 이 모델은 다단계 학습 objective의 1단계와 1.1단계를 사용하여 학습됩니다.
• Cosmos-1.0-Autoregressive-5B-Video2World: Cosmos-1.0-Autoregressive-4B에서 파생된 5B 트랜스포머 모델로, 다단계 학습 objective의 2단계로 추가 학습되었습니다.
• Cosmos-1.0-Autoregressive-12B: 다음 비디오 토큰 예측을 위한 12B 트랜스포머 모델. 이 모델은 다단계 학습 objective의 1단계와 1.1단계를 사용하여 학습됩니다.
• Cosmos-1.0-Autoregressive-13B-Video2World: Cosmos-1.0-Autoregressive-12B에서 파생된 13B 트랜스포머 모델로, 다단계 학습 objective의 2단계로 추가 학습되었습니다.
5.2.4. Inference Optimization Towards Real-Time Generation
Cosmos Autoregressive WFM은 LLM과 아키텍처 유사성을 공유하므로 기존의 LLM 추론 최적화 기법을 활용하여 순차적 디코딩 병목 현상을 해결할 수 있습니다.
우리는 PyTorch에서 gpt-fast (Paszke et al., 2019) 구현을 따라 키-값 캐싱, 텐서 병렬 처리, 그리고 torch.compile의 조합을 구현합니다.
Speculative decoding.
자기회귀 WFM을 더욱 가속화하기 위해, 우리는 Medusa speculative decoding framework (Cai et al., 2024)를 적용합니다.
별도의 초안 모델 (Leviathan et al., 2023)이나 제한된 속도 향상을 위한 학습 없는 방법 (Teng et al., 2024)을 필요로 하는 일반적인 사변 디코딩 접근 방식과 달리, Medusa는 트랜스포머 백본을 추가 디코딩 헤드와 함께 확장하여 여러 후속 토큰을 병렬로 예측합니다.
그런 다음, 이러한 사변 토큰을 거부 샘플링을 통해 검증합니다.
따라서 추론은 한 번에 한 토큰씩 처리되는 병목 현상을 완화함으로써 가속화됩니다.
우리는 생성된 출력의 품질을 저하시키지 않으면서 시각적 자기회귀 가속에서 Medusa 기법의 잠재력을 입증합니다.
우리의 구현에서는 메두사 헤드를 아키텍처에 도입하여 사전 학습된 자기회귀 WFM을 파인튜닝합니다.
이러한 헤드는 모든 백본 매개변수와 최종 비임베딩 레이어가 서로 다른 헤드에 걸쳐 공유되는 마지막 트랜스포머 숨겨진 상태 이후에 전략적으로 삽입됩니다.
각 메두사 헤드는 SiLU 활성화와 잔여 연결이 있는 단층 FFN입니다.
또한 여러 메두사 헤드의 가중치 행렬을 통합 FFN으로 병합하여 토큰 예측 시 병렬성을 극대화합니다.
Cai et al. (2024)의 트리 기반 어텐션 메커니즘을 사용하지 않습니다.
자기회귀 WFM을 위한 최적의 메두사 설정을 조사하기 위해 두 가지 측면에서 심층 연구를 수행합니다: (1) 파인튜닝할 트랜스포머 레이어와 (2) 추가할 메두사 헤드의 수를 비교합니다.
첫 번째 문제에서는 전체 파인튜닝과 선택적 레이어 동결을 비교합니다.
메두사 헤드를 파인튜닝할 때만 멀티 토큰 예측이 잘 되지 않는 반면, 전체 파인튜닝은 품질 저하를 초래한다는 것을 관찰했습니다.
마지막 두 트랜스포머 레이어와 마지막 언임베딩 레이어를 동결 해제하면서 백본을 동결하는 것이 최고의 성능을 발휘한다는 것을 실험적으로 확인했습니다.
이 전략은 메두사 학습이 치명적인 망각을 겪지 않으면서도 적절한 추측 디코딩 정확도를 달성할 수 있도록 보장합니다.
최적의 메두사 헤드 수를 탐색하기 위해, 우리는 다양한 메두사 헤드 수를 사용하여 모델 토큰 처리량과 순방향 패스 횟수를 계산합니다.
ablation 연구는 8 × H100 GPU에서 수행되었으며, 640 × 1024 해상도의 50개의 보이지 않는 테스트 비디오를 대상으로 평가되었습니다.
표 15의 결과는 우리의 메두사 프레임워크가 4B 모델의 경우 최대 2.0배의 토큰 처리량과 4.6배의 순방향 패스, 5B 모델의 경우 최대 3.2배의 토큰 처리량과 6.1배의 순방향 패스로 추론을 효과적으로 가속화할 수 있음을 시사합니다.
우리는 메두사 헤드 수가 많을수록 생성에 필요한 순방향 패스 수를 줄일 수 있지만, 전체 토큰 처리량을 늦출 수 있음을 보여줍니다.
우리는 9개의 메두사 헤드가 계산 효율성과 모델 성능 사이에서 가장 좋은 균형을 이룬다는 것을 발견했습니다.
표 16에서는 메두사 통합이 적용된 자기회귀 WFM의 성능 분석을 보여줍니다.
이 분석은 H100 GPU에서 수행되었으며, BF16 정밀도에서 640 × 1024 해상도의 테스트 비디오에서 평가되었습니다.
결과에 따르면 메두사 구현은 다양한 GPU 구성 하에서 4B 모델과 5B 모델 모두에 대한 추론을 일관되게 가속화합니다.
Low-resolution adaptation for real-time inference.
우리는 320×512의 낮은 공간 해상도로 모델을 조정하여 실시간 추론을 추구하며, 이로 인해 비디오당 토큰 수가 줄어듭니다.
구체적으로, 먼저 타겟 Physical AI 도메인의 비디오를 사용하여 320p 저해상도 비디오에서 이산 비디오 토큰라이저(Cosmos-1.0-Tokenizer-DV8×16×16)를 파인튜닝합니다.
그런 다음, 타겟 Physical AI 도메인의 320×512 해상도 비디오에서 640 × 1024 해상도 (Cosmos-1.0-Autoregressive-4B in Sec. 5.2.3)로 사전 학습된 자기회귀 WFM을 파인튜닝합니다.
마지막으로, 파인튜닝된 저해상도 자기회귀 WFM에 Medusa 헤드를 추가합니다.
우리는 BF16 정밀도에서 torch.compile의 "max-autotune" 모드를 사용하여 8 × H100 GPU에 대한 추론 벤치마킹을 수행했으며, 타겟 Physical AI 도메인의 10-FPS 입력 비디오로 평가했습니다.
표 17에서는 이 설정에서 달성한 평균 토큰 처리량과 프레임 생성 속도를 보고합니다.
우리의 모델이 1초 이내에 10개의 비디오 프레임을 생성할 수 있음을 관찰하여, 10 FPS에서 실시간 비디오 생성을 달성할 수 있음을 입증했습니다.
5.2.5. Diffusion Decoder
Cosmos tokenizer는 경량 인코더-디코더 아키텍처를 사용하여 공격적인 압축을 수행하므로 WFM 학습에 필요한 토큰 수가 줄어듭니다.
공격적인 압축의 결과로 인해 비디오 생성 시 블러와 가시적인 아티팩트가 발생할 수 있으며, 특히 소수의 정수만 사용하여 이산 토큰화를 통해 풍부한 비디오를 표현하는 자기회귀 WFM 환경에서는 더욱 그렇습니다.
우리는 이러한 한계를 해결하기 위해 디퓨전 디코더 설계 (OpenAI, 2024; Ramesh et al., 2022)에 의존합니다.
구체적으로, 우리는 섹션 5.1에서 Cosmos-1.0-Diffusion-7B-Text2Video를 파인튜닝하여 더 강력한 토큰라이저 디코더를 구축합니다.
그림 15는 자기회귀 WFM을 위한 디퓨전 디코더를 학습하는 방법을 보여줍니다.
각 학습 비디오에 대해 Cosmos-1.0-Tokenizer-CV8x8x8과 Cosmos-1.0-Tokenizer-DV8x16x16을 사용하여 각각 연속 토큰 비디오와 해당 이산 토큰 비디오를 계산합니다.
우리는 Cosmos-1.0-Tokenizer-CV8x8x8이 더 부드러운 연속 토큰화 과정과 덜 공격적인 압축 방식 (8×16×16 대신 8×8×8) 덕분에 Cosmos-1.0-Tokenizer-DV8x16보다 더 높은 품질의 비디오 출력을 생성할 수 있음을 주목합니다.
이산 토큰 비디오는 Cosmos-1.0-Diffusion-7B 모델의 디노이저에 대한 조건부 입력으로 취급됩니다.
조건부 입력을 계산하기 위해 먼저 이산 토큰 비디오의 각 이산 토큰을 학습 가능한 어휘 임베딩 레이어를 기반으로 16차원 벡터에 임베딩합니다.
그런 다음 𝑥 및 𝑦 방향으로 임베딩을 2x 업샘플링하여 조건부 입력이 연속 토큰 비디오의 디노이저에 대한 노이즈 입력과 동일한 크기가 되도록 합니다.
우리는 노이즈가 있는 연속 입력을 채널 차원을 따라 조건부 입력과 concat하여 디퓨전 디노이저에 대한 입력이 됩니다.
디노이저의 첫 번째 레이어는 새로운 입력 모양을 수용하도록 확장된 채널 차원입니다.
우리는 추가된 노이즈를 제거하여 업데이트된 Cosmos-1.0-Diffusion-7B를 파인튜닝합니다.
이산 토큰 비디오가 노이즈에 의해 손상되지 않기 때문에, 디노이저는 디노이징을 위해 조건부 입력에 있는 상주 정보를 활용하는 방법을 배웁니다.
그 결과, 예비 디퓨전 문제를 해결하여 이산 토큰을 디코딩하는 토큰라이저의 고품질 디코더가 됩니다.
그림 16은 추론을 보여줍니다.
자기회귀 WFM에서 출력된 이산 토큰 비디오 (8×16×16 이산 압축 하에서)는 두 단계를 거쳐 비디오로 디코딩됩니다.
먼저, 조건부 디노이저를 롤아웃하여 자기회귀 WFM 출력을 기반으로 연속 토큰 비디오 (8×8×8 연속 압축 하에서)를 생성합니다.
다음으로, 연속 토큰 비디오는 Cosmos-1.0-Tokenizer-CV8x8x8에 의해 디코딩되어 결과 RGB 비디오를 생성합니다.
5.2.6. Results
그림 17에서는 다양한 모델 크기를 사용한 자기회귀 WFM의 정성적 결과를 보여줍니다.
프롬프트되지 않은 설정에서 Cosmos-1.0-Autoregressive-4B 모델과 Cosmos-1.0-Autoregressive-12B 모델을 비교한 결과, 12B 모델이 더 나은 움직임과 더 선명한 디테일을 가진 비디오를 생성하는 것을 관찰할 수 있었습니다.
마찬가지로, 프롬프트된 설정에서 Cosmos-1.0-Autoregressive-5B-Video2World와 Cosmos-1.0-Autoregressive-13B-Video2World를 비교한 결과, 13B 모델이 5B 모델보다 더 나은 움직임을 보인다는 것을 알 수 있었습니다.
그림 18에서는 디퓨전 디코더를 사용할 때 얻은 향상된 성능을 보여줍니다.
자기회귀 모델의 출력은 주로 이산 토큰라이저의 손실 압축으로 인해 블러해집니다.
디퓨전 디코더를 사용하면 콘텐츠를 보존하면서 세부 사항을 향상시킬 수 있습니다.
우리는 경험적으로 섹션 5.1.5에서 논의된 프롬프트 업샘플러에서 업샘플링된 프롬프트로 인해 자기회귀 기반 Text2World WFM의 출력이 개선되지 않는다는 것을 발견했습니다.
이는 이러한 WFM이 대부분의 학습 동안 순수 비디오 생성 작업으로 사전 학습되었기 때문일 수 있다고 가정합니다.
텍스트 입력을 활용할 만큼 충분히 강제되지 않습니다.
5.2.7. Limitations
생성된 자기회귀 WFM 비디오에서 관찰된 주목할 만한 실패 사례 중 하나는 아래에서 예기치 않게 나타나는 객체입니다.
그림 19는 이 문제의 예를 보여줍니다.
모델의 실패율을 이해하기 위해, 우리는 자기회귀 WFM에 대한 100개의 Physical AI 입력 평가 세트를 생성하여 체계적인 연구를 수행합니다.
우리는 두 가지 입력 모드를 사용하여 모든 모델과 함께 비디오를 생성합니다—이미지 (단일 프레임) 컨디셔닝 및 비디오 (9 프레임) 컨디셔닝.
생성된 모든 비디오에 대해 수동으로 고장 사례를 검사하고 고장률을 표 18에 보고합니다.
우리는 작은 모델인 Cosmos-1.0-Autoregressive-4B와 Cosmos-1.0-Autoregressive-5B-Video2World가 단일 프레임 컨디셔닝에서 더 높은 손상률을 보이는 반면, 큰 모델인 Cosmos-1.0-Autoregressive-12B와 Cosmos-1.0-Autoregressive-13B-Video2World가 더 견고하다는 것을 관찰했습니다.
9 프레임 비디오 컨디셔닝을 사용한 생성은 모든 모델에서 안정적이며, 고장률은 2% 미만입니다.
5.3. Evaluation
사전 학습된 WFM은 시각적 월드 시뮬레이션의 일반론자입니다.
그들의 능력은 여러 측면에서 측정되어야 합니다.
여기서 우리는 두 가지 측면에서 모델을 평가합니다.
첫째, 생성된 비디오의 3D 일관성을 평가합니다.
이상적인 WFM은 기하학적으로 그럴듯한 3D 월드로부터 비디오 시뮬레이션을 생성해야 합니다.
둘째, 생성된 비디오의 물리적 정렬을 평가합니다.
렌더링된 동역학이 물리 법칙을 얼마나 잘 준수하는지 계산합니다.
WFM의 평가는 매우 중요한 작업입니다.
우리는 평가를 위해 몇 가지 다른 중요한 측면이 필요하다는 것을 인정합니다.
우리는 더 포괄적인 평가를 향후 작업으로 남깁니다.
5.3.1. 3D Consistency
WFM은 비디오 생성을 통해 3D 월드를 시뮬레이션하도록 설계되었으며, 생성된 비디오가 시각적 세계의 3D 구조와 얼마나 잘 일치하는지 평가하는 것이 필수적입니다.
생성된 비디오는 현실적으로 보일 뿐만 아니라 시간이 지남에 따라 장면의 물리적 원리와 일관성을 유지해야 하며, 이는 다운스트림 Physical AI 애플리케이션의 핵심 요구 사항입니다.
Test data and baseline model.
우리는 멀티뷰 지오메트리 기반의 기존 도구를 사용하여 비디오의 3D 일관성을 효과적으로 측정하기 위해 정적 장면 시나리오에 중점을 둡니다.
RealEstate10K 데이터셋의 테스트 세트에서 랜덤으로 선택된 500개의 비디오 데이터셋을 큐레이션합니다 (Zhou et al., 2018).
또한 독점적인 VLM을 사용하여 비디오에 캡션을 부여하여 비디오를 정적 장면으로 설명하는 텍스트 프롬프트를 얻으므로 메트릭 계산을 위해 장면 동작을 고려할 필요가 없습니다.
우리는 VideoLDM (Blattmann et al., 2023)과의 기본 방법을 비교합니다.
Metrics.
생성된 비디오는 기본 3D 시각 월드의 2D 투영입니다.
우리는 생성된 비디오의 3D 일관성을 측정하기 위해 다음과 같은 지표를 설계합니다.
1. 지오메트릭 일관성.
우리는 생성된 월드의 3D 일관성을 평가하며, 생성된 비디오에서 Sampson error (Hartley and Ziserman, 2003; Sampson, 1982)와 카메라 포즈 추정 알고리즘의 성공률 (Schönberger et al., 2016; Schönberger and Framh, 2016)을 포함하여 에피폴라 지오메트리 제약 조건이 어떻게 충족되는지 정량화합니다.
2. 합성 뷰 일관성.
우리는 기본 3D 구조와의 일관성을 유지하면서 보간된 새로운 관점에서 이미지를 합성하는 월드 파운데이션 모델의 능력을 평가합니다.
Sampson error는 한 관심 지점에서 다른 관점의 해당 에피폴라 라인까지의 거리를 1차 근사한 것입니다.
주어진 프레임 쌍에서 𝑁 포인트 대응(균질 좌표로 표시) {(¯x_𝑖, ¯y_𝑖)}이 주어졌을 때, 우리는 Sampson error를

으로 정의하고, F는 대응으로부터 추정된 기본 행렬입니다.
우리는 오차 함수의 제곱근 버전을 사용하여 픽셀 단위로 메트릭을 더 직관적으로 만듭니다.
우리는 SuperPoint (DeTone et al., 2018)와 LightGlue (Lindenberger et al., 2023)의 조합을 사용하여 프레임 쌍에서 키포인트 대응을 감지하고 일치시키며 OpenCV의 8 포인트 RANSAC 알고리즘을 사용하여 F를 추정합니다.
우리는 평균 오차를 960 × 540 캔버스에 대한 프레임의 대각선 길이로 정규화합니다.
우리는 또한 생성된 비디오의 3D 일관성과 새로운 관점을 자체적으로 합성할 수 있는 능력을 평가합니다.
새로운 뷰 합성 문헌 (Mildenhall et al., 2020)의 일반적인 관행에 따라, 우리는 8개의 프레임을 테스트 프레임으로 사용하고 나머지 학습 프레임과 함께 3D Gaussian splatting 모델 (Kerbl et al., 2023)을 Nerfstudio 라이브러리 (Tancik et al., 2023)의 기본 설정을 사용하여 피팅합니다.
우리는 합성된 테스트 뷰의 품질을 정량화하기 위한 지표로 Peak Signal-to-Noise Ratio (PSNR), Structural Similarity (SSIM), LPIPS (Zhang et al., 2018)를 보고합니다.
Results.
우리는 표 19에 정량적 평가 결과를 제시합니다.
Cosmos WFM은 지오메트릭 및 뷰 합성 일관성 측면에서 우리의 베이스라인 모델보다 훨씬 더 나은 3D 일관성을 달성합니다.
Cosmos WFM의 관심 지점이 3D 일관성을 가질 뿐만 아니라, 카메라 포즈 추정 성공률도 현저히 높아 전체 품질이 향상되고 3D 일관성이 향상되어 실제 비디오 수준에 도달하기도 합니다.
카메라 포즈가 성공적으로 추정된 경우 중, 합성된 홀드아웃 뷰는 모든 이미지 합성 지표에서 더 높은 품질을 보여줍니다.
이러한 결과는 Cosmos WFM이 3D 일관성 비디오를 생성하여 효과적인 월드 시뮬레이터로 자리매김할 수 있는 능력을 강조합니다.
5.3.2. Physics Alignment
이상적인 WFM은 물리 법칙에 대한 강한 이해를 보여주고 이를 존중하는 미래의 관측 결과를 제공해야 합니다.
사전 학습된 WFM은 일정 수준의 물리학적 이해를 보여주고 SOTA 기술을 발전시키지만, 물리 법칙을 따르지 않는 예제를 쉽게 생성할 수 있습니다.
우리는 물리적으로 믿기 어려운 비디오를 제거하는 데이터 큐레이션의 추가 단계와 모델 설계의 개선이 필요하다고 믿습니다.
강력한 물리학적 정렬이 가능한 WFM을 향후 연구 과제로 남겨두지만, 대규모 데이터 기반 사전 학습에서 물리학이 얼마나 자연스럽게 나타나는지 측정하는 데 여전히 관심이 있습니다.
이를 탐구하기 위해, 우리는 물리 시뮬레이션 엔진을 사용하여 제어된 벤치마크 데이터셋을 설계합니다 (Kang et al., 2024).
우리는 물리 기반 시뮬레이션을 생성하여 사전 학습된 WFM이 뉴턴 물리학 및 강체 동역학에 얼마나 잘 부합하는지 테스트합니다.
구체적으로, 시뮬레이션을 사용하여 물리적으로 관심 있는 법칙에 특화된 테스트 시나리오의 물리적으로 정확한 포토리얼리즘 비디오를 생성합니다.
그런 다음, 이러한 참조 "ground truth" 비디오를 공유된 맥락 (과거 관찰 및 섭동)에서 WFM이 제작한 "predicted" 비디오와 비교합니다.
Synthetic data generation.
PhysX (NVIDIA, 2024)와 Isaac Sim (NVIDIA, 2024)을 사용하여 다양한 물리적 효과를 평가하기 위한 8가지 3D 시나리오를 설계했습니다:
1. 자유 낙하 물체: 비행기에 떨어지는 물체 (중력, 충돌 등)
2. 기울어진 평면 경사: 경사면을 따라 굴러가는 물체 (중력, 관성 모멘트 등)
3. U자형 경사: U자형 경사를 따라 굴러가는 물체 (위치, 운동 에너지 등)
4. 안정적인 스택: 평형 상태에 있는 물체들의 스택 (균형 잡힌 힘)
5. 불안정한 스택: 불균형 상태에 있는 물체들의 스택 (중력, 충돌 등)
6. 도미노: 직사각형 벽돌이 순차적으로 떨어지는 순서 (운동량 전달, 충돌 등)
7. 시소: 시소 양쪽에 있는 물체 (토크, 회전 관성 등)
8. 자이로스코프: 평평한 표면에서 회전하는 팽이 (각운동량, precession, 등)
각 시나리오마다 동적 객체 (다양한 크기, 질감, 모양)의 수와 유형을 랜덤으로 지정하여 Omniverse 자산 (NVIDIA, 2024)과 배경 외관을 선택합니다.
우리는 시간 경과에 따른 객체의 운동학적 상태를 시뮬레이션하고 4가지 다른 정적 카메라 뷰에서 출력된 비디오를 렌더링합니다.
총 100프레임 길이의 1080p 비디오 800개를 렌더링합니다.
각 시뮬레이션 롤아웃의 객체는 존재 모호성을 피하기 위해 첫 번째 프레임에서 모두 보이도록 배치됩니다.
Metrics.
우리는 시뮬레이션된 실제 비디오를 WFM이 직접 생성한 출력과 비교하여 물리 법칙을 준수하는지 평가하는 데 관심이 있습니다.
따라서 향후 관측 결과를 생성하기 위해, 우리는 실제 비디오의 처음 몇 프레임 (1프레임 또는 9프레임)에 대해 WFM을 조건화합니다.
해당되는 경우, 텍스트 프롬프트 (조건화 프레임에 캡션을 붙여 독점 VLM을 사용하여 얻은)에 추가적으로 WFM을 조건화합니다.
시뮬레이션된 시나리오와 예측된 시나리오의 몇 가지 예는 그림 20을 참조하세요.
평가를 위해 다음과 같은 지표를 사용합니다:
1. 픽셀 레벨 메트릭.
픽셀 레벨의 비교를 위해, 우리는 WFM 출시에서 예측된 프레임을 실제 비디오의 참조 프레임과 비교하기 위해 Peak Signal-to-Noise Ratio (PSNR)와 Structural Similarity Index Measure (SSIM)을 계산합니다.
2. 피쳐 레벨 메트릭.
약간 더 높은 수준의 시맨틱 비교를 위해, 우리는 예측된 프레임과 참조 프레임 간의 피쳐 유사성 지표인 DreamSim 유사성 점수 (Fu et al., 2023)를 계산합니다.
3. 객체 레벨 메트릭.
마지막으로, 우리는 관심 있는 객체가 지속적인 물리적 현상에 의해 어떻게 영향을 받는지에 가장 신경 쓰기 때문에, 추적을 사용하여 혼란 요소 (배경 변화, 시각적 품질 등)를 제거하는 객체 레벨 메트릭을 계산합니다.
테스트 조건이 합성적으로 생성되기 때문에, 우리는 장면 내 동적 객체의 실제 인스턴스 세그멘테이션 마스크에 접근할 수 있습니다.
SAMURAI (Yang et al., 2024)를 사용하여, 우리는 첫 번째 프레임에서 실제 인스턴스 마스크를 나머지 예측된 비디오 프레임을 통해 전파하여 트랙을 추출하고, 객체 레벨 메트릭을 정량화할 수 있게 합니다.
우리는 각 프레임과 관심 객체에 대해 실제 데이터와 예측된 객체 마스크 간의 intersection-over-union (IoU)을 계산합니다.
우리는 이러한 지표를 비디오의 프레임, 평가 세트의 비디오, 롤아웃을 위한 네 개의 랜덤 시드에 걸쳐 평균화합니다.
PSNR과 SSIM은 조건화에 사용된 것을 제외한 모든 프레임에서 계산됩니다.
Results.
물리적 정렬에 대한 정량적 결과는 표 20에 요약되어 있습니다.
정량적 및 정성적 결과를 바탕으로 다음과 같은 관찰을 수행합니다.
당연히 모델은 더 많은 프레임을 조건 입력으로 사용하여 전체 물체 운동학을 더 잘 예측할 수 있으며, 이를 통해 속도와 가속도와 같은 1차 및 2차 양을 더 잘 추론할 수 있습니다.
표에서 우리는 디퓨전 WFM이 9 프레임 조건부 설정에서 자기회귀 WFM보다 픽셀 레벨 예측에서 더 나은 성능을 보인다는 것을 발견했습니다.
이는 디퓨전 기반 WFM이 더 높은 시각적 품질로 비디오를 렌더링한다는 우리의 시각적 관찰과 상관관계가 있습니다.
또한, 우리의 결과가 더 큰 모델이 물리적 정렬에서 더 나은 성능을 보인다는 것을 시사하지 않는다는 점에도 주목합니다.
더 큰 모델이 더 높은 시각적 품질로 비디오를 렌더링하는 것을 관찰하지만, 모든 WFM은 물리적 준수에 어려움을 겪으며 더 나은 데이터 큐레이션과 모델 설계가 필요합니다.
더 일반적으로, 위에서 설명한 강체 시뮬레이션은 이미 WFM의 한계를 테스트하여 특정 고장 사례를 식별하는 데 유용한 도구로 사용된다는 것을 관찰할 수 있습니다.
이러한 문제는 객체의 무상성 (자발적 출현 및 소멸) 및 변형 (형태 변화)과 같은 저수준 문제부터 불가능한 운동학, 중력 위반 등과 같은 더 복잡한 문제에 이르기까지 다양합니다.
우리는 이러한 구조화된 시뮬레이션이 물리학적 정렬을 테스트하는 데 유용한 방법론을 제공한다고 믿습니다.
따라서 우리는 더 복잡한 시나리오를 통합하고, 실제 비디오로 구성된 WFM 사전 학습 데이터를 통해 시뮬레이션과 실제 간의 격차를 해소하기 위해 포토리얼리즘을 강화하며, 물리적 이해를 보다 포괄적으로 평가하기 위해 평가 지표를 개선함으로써 시간이 지남에 따라 이를 개선하고자 합니다.
6. Post-trained World Foundation Model
'Robotics' 카테고리의 다른 글
| Open X-Embodiment: Robotic Learning Datasets and RT-X Models (0) | 2025.03.24 |
|---|---|
| PaLM-E: An Embodied Multimodal Language Model (0) | 2025.03.20 |
| RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control (0) | 2025.03.17 |
| RT-1: Robotics Transformer for Real-World Control at Scale (0) | 2025.03.10 |
| π0: A Vision-Language-Action Flow Model for General Robot Control (0) | 2025.02.20 |