2025. 2. 20. 12:07ㆍRobotics
π0: A Vision-Language-Action Flow Model for General Robot Control
Physical Intelligence
Abstract
로봇 학습은 유연하고 일반적이며 손재주가 뛰어난 로봇 시스템의 잠재력을 최대한 발휘할 수 있을 뿐만 아니라 인공지능의 가장 깊은 질문들을 해결할 수 있는 엄청난 가능성을 가지고 있습니다.
그러나 효과적인 실제 시스템에 필요한 일반성 수준으로 로봇 학습을 발전시키는 것은 데이터, 일반화 및 견고성 측면에서 큰 장애물에 직면해 있습니다.
이 논문에서는 일반적인 로봇 정책 (즉, 로봇 파운데이션 모델)이 이러한 문제를 어떻게 해결할 수 있는지, 그리고 복잡하고 손재주가 뛰어난 작업을 위한 효과적인 일반적인 로봇 정책을 어떻게 설계할 수 있는지 논의합니다.
우리는 인터넷 규모의 시맨틱 지식을 계승하기 위해 사전 학습된 vision-language model (VLM)을 기반으로 한 새로운 플로우 매칭 아키텍처를 제안합니다.
그런 다음 이 모델이 단일 팔 로봇, 이중 팔 로봇, 모바일 매니퓰레이터를 포함한 여러 손재주 로봇 플랫폼의 대규모 및 다양한 데이터셋에서 어떻게 학습될 수 있는지 논의합니다.
우리는 우리의 모델이 직접 프롬프트를 통해 작업을 수행하고, 사람들과 고급 VLM 정책의 언어 지시를 따르며, 파인튜닝을 통해 새로운 기술을 습득할 수 있는 능력 측면에서 평가합니다.
우리의 결과는 세탁 접기, 테이블 청소, 조립 상자와 같은 다양한 작업을 다룹니다.
Ⅰ. Introduction
인공지능 시스템은 단백질의 형태를 예측하는 [21] 등 인간의 마음에 접근할 수 없는 복잡한 문제를 해결하는 고도로 전문화된 시스템부터 텍스트 프롬프트를 기반으로 실제와 같은 고해상도 이미지나 동영상을 생성할 수 있는 시스템에 이르기까지 다양한 형태와 크기로 제공됩니다 [40].
그러나 인간 지능이 기계 지능을 가장 앞지르는 축은 다재다능함입니다: 환경 제약, 언어 명령, 예상치 못한 교란에 지능적으로 대응하면서 다양한 물리적 환경에서 다양한 작업을 해결할 수 있는 능력.
이러한 유형의 인공지능의 다재다능성을 향한 가장 가시적인 진전은 대형 언어- 및 비전- 언어 모델에서 볼 수 있습니다 [1, 48]: 웹에서 가져온 이미지와 텍스트의 크고 다양한 말뭉치에 대해 사전 학습된 후, 원하는 행동 패턴과 반응성을 유도하기 위해 보다 신중하게 조정된 데이터셋을 사용하여 파인튜닝된 ("aligned") 시스템입니다.
이러한 모델은 광범위한 명령어 준수 및 문제 해결 능력을 보이는 것으로 나타났지만 [53, 27], 사람들이 실제로 존재하는 물리적 세계에 위치하지 않으며, 물리적 상호작용에 대한 이해는 전적으로 추상적인 설명에 기반하고 있습니다.
이러한 방법이 사람들이 가지고 있는 물리적으로 위치한 다재다능함을 보여주는 AI 시스템으로 실질적인 진전을 이루려면, 우리는 물리적으로 위치한 데이터를 사용하여 AI 시스템을 학습시켜야 할 것입니다 — 즉, 임바디드 로봇 에이전트의 데이터입니다.
다양한 로봇 행동을 수행할 수 있는 유연하고 범용적인 모델은 엄청난 실질적인 영향을 미칠 수 있지만, 데이터의 가용성, 일반화 및 견고성과 같은 오늘날 로봇 학습이 직면한 가장 어려운 과제들에 대한 해결책을 제공할 수도 있습니다.
자연어 [1]과 컴퓨터 비전 [39]에서는 다양한 멀티태스크 데이터로 사전 학습된 범용 파운데이션 모델이 좁은 맞춤형 및 전문화된 솔루션을 능가하는 경향이 있습니다.
예를 들어, 사진에서 새를 인식하는 것이 목표라면, 새 인식 데이터만으로 학습하는 것보다 다양한 이미지-언어 연관성을 사전 학습한 후, 새 인식 작업을 위해 파인튜닝 또는 프롬프트하는 것이 더 편리할 가능성이 높습니다.
마찬가지로, 효과적인 전문 로봇 시스템을 위해서는 매우 다양한 로봇 데이터로 먼저 사전 학습한 후, 원하는 작업을 파인튜닝하거나 프롬프트하는 것이 더 효과적일 수 있습니다.
이는 데이터 부족 문제를 해결할 수 있습니다, 왜냐하면 일반 모델 — 다른 작업, 다른 로봇, 심지어 비로봇 소스의 데이터 포함 — 이 더 많은 데이터 소스를 이용할 수 있기 때문입니다, 또한, 다양한 데이터가 더 넓은 관찰 및 행동 범위를 나타내어 더 좁은 전문화된 데이터에서는 존재하지 않을 수 있는 다양한 장면, 수정 및 복구 동작을 제공하기 때문에 견고성 및 일반화 문제를 해결할 수 있습니다.
따라서 로봇 학습에 대규모 사전 학습 접근 방식을 채택하면 이 분야의 많은 도전 과제를 해결하고 실용적인 학습 기반 로봇을 현실화하는 동시에, 인공지능의 가장 깊은 문제에 대한 이해를 증진시킬 수 있는 잠재력을 가지고 있습니다.
그러나 이러한 일반주의적 로봇 정책 — 즉, 로봇 파운데이션 모델 — 을 개발하는 것은 여러 주요 과제를 수반합니다.
첫째, 대규모 사전 학습의 완전한 이점이 소규모에서는 종종 존재하지 않기 때문에 이러한 연구는 매우 대규모로 수행되어야 합니다 [54].
둘째, 다양한 데이터 소스를 효과적으로 활용할 수 있는 올바른 모델 아키텍처를 개발하는 동시에 복잡한 물리적 장면과 상호작용하는 데 필요한 복잡하고 미묘한 행동을 표현할 수 있어야 합니다.
셋째, 올바른 학습 레시피가 필요합니다.
이는 아마도 가장 중요한 요소일 것입니다, 최근 NLP 및 컴퓨터 비전 분야의 대규모 모델에 대한 진전이 사전 학습 및 사후 학습 데이터 큐레이션을 위한 섬세한 전략에 크게 의존해 왔기 때문입니다[35].

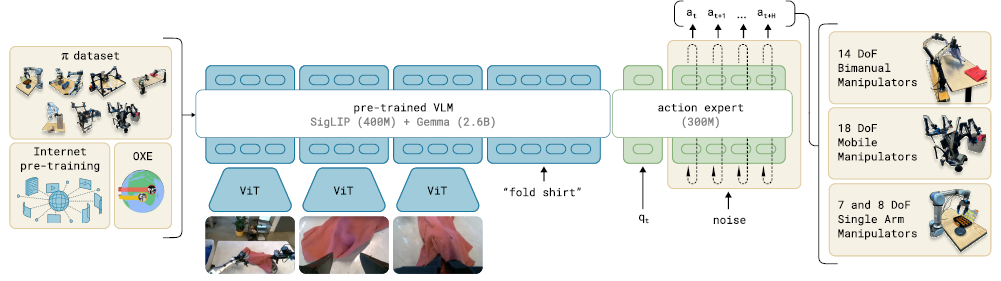
이 논문에서는 이 세 가지 병목 현상을 각각 어떻게 해결할 수 있는지 설명하는 프로토타입 모델 및 학습 프레임워크인 π_0을 제시합니다.
우리는 그림 1에 모델과 시스템을 설명합니다.
다양한 데이터 소스를 통합하기 위해 먼저 사전 학습된 vision-language model (VLM)을 활용하여 인터넷 규모의 경험을 가져옵니다.
우리의 모델을 VLM에 기반함으로써, 언어- 및 비전- 언어 모델의 일반적인 지식, 의미론적 추론, 문제 해결 능력을 계승합니다.
그런 다음 로봇 액션을 통합하도록 모델을 학습하여 vision-language-action (VLA) 모델로 전환합니다 [7].
다양한 로봇 데이터 소스를 활용할 수 있도록 하기 위해, 우리는 다양한 로봇 유형의 데이터를 동일한 모델로 결합하는 cross-embodiment training [10]을 사용합니다.
이러한 다양한 로봇 유형은 단일 및 이중 팔 시스템뿐만 아니라 모바일 매니퓰레이터를 포함한 다양한 구성 공간과 동작 표현을 가지고 있습니다.
또한, 매우 능숙하고 복잡한 물리적 작업을 수행할 수 있도록 하기 위해, 복잡한 연속 동작 분포를 나타내기 위해 플로우 매칭 (디퓨전의 변형)이 있는 액션 청킹 아키텍처 [57]를 사용합니다 [28, 32].
이를 통해 세탁 접기와 같은 능숙한 작업을 위해 최대 50Hz의 주파수로 로봇을 제어할 수 있습니다 (그림 1 참조).
VLM과의 플로우 매칭을 결합하기 위해, 우리는 표준 VLM을 플로우 기반 출력으로 보강하는 새로운 action expert를 사용합니다.
언어 모델과 마찬가지로, 우리 모델의 아키텍처도 우리 방법의 일부에 불과합니다.
복잡한 작업을 유연하고 견고하게 수행하기 위해서는 올바른 학습 레시피가 필요합니다.
우리의 레시피는 엑사스케일 언어- 및 이미지- 언어 모델 [1, 48]에서 흔히 볼 수 있는 사전 학습/사후 학습 분리를 반영합니다, 여기서 모델은 먼저 매우 크고 다양한 말뭉치에 대해 사전 학습된 후, 더 좁고 신중하게 선별된 데이터에 대해 파인튜닝되어 원하는 행동 패턴을 유도합니다 — 우리의 경우 손재주, 효율성, 견고성이 중요합니다.
직관적으로 고품질 데이터로만 학습한다고 해서 모델에게 실수를 복구하는 방법을 가르쳐주지는 않습니다, 왜냐하면 이러한 데이터에서는 실수가 거의 보이지 않기 때문입니다.
저품질 사전 학습 데이터로만 학습한다고 해서 모델이 효율적이고 견고하게 행동하도록 가르치는 것은 아닙니다.
두 가지를 결합하면 원하는 동작을 얻을 수 있습니다: 모델은 가능한 한 고품질 데이터와 유사한 방식으로 행동하려고 시도하지만, 실수 시 배포할 수 있는 복구 및 수정 레퍼토리를 여전히 가지고 있습니다.
우리 작업의 기여는 VLM 사전 학습과 플로우 매칭을 기반으로 한 새로운 일반주의 로봇 정책 아키텍처와 이러한 로봇 파운데이션 모델에 대한 사전 학습/사후 학습 레시피에 대한 실증적 조사로 구성됩니다.
우리는 언어 명령, 다운스트림 작업에 대한 파인튜닝, 중간 언어 명령을 출력하여 복잡하고 시간적으로 확장된 작업을 수행하는 고급 시맨틱 정책과 결합하여 우리의 모델을 처음부터 평가합니다.
우리의 모델과 시스템은 최근 연구에서 제시된 다양한 아이디어를 활용하지만, 구성 요소의 조합은 참신하며, 실증적 평가는 이전에 입증된 로봇 파운데이션 모델을 훨씬 뛰어넘는 수준의 손재주와 일반성을 보여줍니다.
우리는 10,000시간 이상의 로봇 데이터를 사전 학습하고 세탁 접기 (그림 2 참조), 테이블 정리, 전자레인지에 접시 넣기, 상자에 계란 쌓기, 상자 조립, 식료품 포장 등 다양한 손재주 작업에 대한 파인튜닝을 통해 우리의 접근 방식을 평가합니다.
Ⅱ. Related Work
우리의 연구는 최근 제안된 대규모 로봇 학습 방법과 멀티모달 언어 모델을 기반으로 합니다.
우리의 연구는 로봇 제어를 위해 파인튜닝된 사전 학습된 VLM을 사용하는 최근 제안된 vision-language action (VLA) 모델과 가장 밀접한 관련이 있습니다 [7, 24, 55].
이러한 모델은 텍스트 토큰과 유사한 방식으로 행동을 표현하기 위해 autoregressive 이산화를 사용합니다.
대조적으로, 우리 모델은 VLM을 파인튜닝하여 디퓨전의 변형 [20, 46]인 플로우 매칭 [32, 28]을 통해 액션을 생성하는 새로운 설계를 사용합니다.
이를 통해 고주파 행동 청크 [57] (최대 50Hz)와 매우 능숙한 작업을 처리할 수 있으며, 이는 이전의 autoregressive VLA [7]에게 큰 도전 과제임을 보여줍니다.
이는 액션 생성 [9, 60]을 위한 디퓨전 모델에 대한 최근의 여러 연구와 유사합니다.
이러한 연구와 달리, 우리의 모델은 사전 학습된 VLM 백본 [5]을 사용합니다.
우리의 기여는 또한 근본적으로 통합적이며, 모델 아키텍처 자체뿐만 아니라 사전 학습 레시피, 사전 학습 및 사후 학습 단계, 다양한 실제 실험을 포함한 로봇 파운데이션 모델을 위한 프레임워크에 중점을 둡니다.
로봇 제어 외에도 사전 학습된 언어 모델과 디퓨전 [40, 41, 14]을 결합한 많은 모델이 제안되었습니다, 여기에는 디퓨전과 autoregressive large language models [19, 29, 59]가 포함됩니다.
이러한 모델은 일반적으로 이미지 생성과 관련이 있지만, 우리의 액션 생성 모델은 이전에 제안된 여러 개념을 기반으로 합니다.
Zhou et al. [59]과 마찬가지로, 우리는 디코더 전용 트랜스포머에 대한 표준 크로스 엔트로피 loss 대신 개별 시퀀스 요소에 적용된 디퓨전 스타일 (플로우 매칭) loss를 통해 모델을 학습시킵니다.
Liu et al. [29]과 마찬가지로, 우리는 디퓨전에 해당하는 토큰에 대해 별도의 가중치 집합을 사용합니다.
이러한 개념을 VLA 모델에 통합하여, 우리가 아는 바로는 고주파 액션 청크를 생성하여 능숙한 제어를 가능하게 하는 최초의 플로우 매칭 VLA를 소개합니다.
우리의 연구는 또한 대규모 로봇 학습에 관한 이전 연구들의 풍부한 역사를 바탕으로 하고 있습니다.
이 분야의 초기 연구는 종종 self-supervised 또는 자율 데이터 수집 [26, 22, 8]을 활용하여 잡기 [18, 37]나 밀기 [56]와 같은 간단한 작업에 적합한 데이터 소스를 제공했지만, 더 손재주 있는 행동의 복잡성 없이도 처리할 수 있었습니다.
최근에는 로봇 제어를 위해 광범위한 일반화를 가능하게 하는 고품질 데이터셋이 다수 수집되었지만 [23, 10, 52, 33, 34, 43, 13, 6], 일반적으로 객체 재배치 및 기본적인 가구 조작 (예: 서랍 열기)과 같은 간단한 작업을 위해 수집되었습니다 [31, 15].
더 손재주 있는 작업들은 소규모로 연구되었으며, 일반적으로 10시간 또는 100시간의 학습 궤적 [57]이 10시간 이하에 해당합니다.
우리의 목표 중 하나는 복잡하고 손재주 있는 행동을 연구하는 것이기 때문에, 우리는 오픈 소스 OXE 데이터셋 [10]으로 보완된 약 10,000시간의 시연을 통해 훨씬 더 큰 데이터셋을 활용합니다.
우리가 아는 한, 이는 로봇 데이터의 양 측면에서 단연코 가장 큰 로봇 학습 실험을 나타냅니다.
이 규모에서 우리는 더 정교한 사전 학습/사후 학습 레시피가 매우 효과적임을 보여줍니다 — 대규모 언어 모델에 사용되는 레시피와 유사하게, 사전 학습 단계는 우리 모델에 광범위한 지식을 제공하며, 이는 학습 후 단계에서 더 높은 품질의 큐레이팅된 데이터로 정제되어 원하는 액션을 달성합니다.
우리가 설명하는 작업의 복잡성은 이전 연구를 훨씬 뛰어넘습니다.
최근 연구에서는 신발끈 묶기 [58]나 새우 요리 [17]와 같은 더 복잡하고 손재주가 많은 동작을 설명했지만, 우리의 프레임워크는 물리적 손재주와 조합적 복잡성을 모두 결합한 동작을 위해 매우 긴 작업, 때로는 수십 분 길이의 작업을 학습할 수 있음을 보여줍니다.
예를 들어, 우리의 세탁 접기 작업은 로봇이 어떤 구성에서든 시작할 수 있는 다양한 의류 품목을 조작하고 여러 품목을 순차적으로 접어야 합니다.
우리의 테이블 치우기 작업은 새로운 객체 (쓰레기나 접시)의 클래스를 식별해야 합니다.
우리는 단일 cross-embodiment 모델이 이러한 작업의 base 모델로 사용될 수 있음을 보여줍니다.
우리가 아는 한, 우리의 작업은 종단 간 로봇 학습 문헌에서 가장 긴 손재주 작업을 보여줍니다.
Ⅲ. Overview
우리는 모델과 학습 절차에 대한 개요를 그림 3에 제공합니다.
학습 프레임워크에서는 먼저 68개의 다양한 작업에 대해 7가지 다른 로봇 구성에서 수집된 자체 손재주 조작 데이터셋 (섹션 V-C)과 22개의 로봇 데이터를 포함하는 전체 OXE 데이터셋 [10]의 가중치 조합으로 구성된 사전 학습 혼합물을 조립합니다.
또한 사전 학습 단계 (섹션 V-A)에서는 작업 이름과 세그먼트 주석 (일반적으로 약 2초 길이의 하위 궤적에 대한 세분화된 레이블)을 결합하여 다양한 언어 레이블을 사용합니다.
사전 학습 단계의 목적은 광범위한 능력과 일반화를 나타내지만 반드시 한 작업의 고성능에 특화된 base 모델을 학습시키는 것입니다.
이 base 모델은 언어 명령을 따르고 다양한 작업을 초보적인 숙련도로 수행할 수 있습니다.
복잡하고 손재주가 많은 작업의 경우 고품질 큐레이팅 데이터를 사용하여 특정 다운스트림 작업에 모델을 적응시키는 사후 학습 절차 (섹션 V-A)를 사용합니다.
우리는 소량에서 중간 정도의 데이터를 사용하는 효율적인 사후 학습과 세탁 접기 및 모바일 조작과 같은 복잡한 작업에 대해 더 큰 데이터셋을 사용하는 고품질 사후 학습을 모두 연구합니다.
우리가 섹션 IV에서 설명하는 우리의 모델은 PaliGemma vision-language model [5]을 기반으로 하며, 이 모델은 데이터 혼합을 통해 추가로 학습됩니다.
base PaliGemma VLM을 π_0으로 변환하기 위해, 연속적인 액션 분포를 생성하기 위해 플로우 매칭 [32, 28]을 사용하는 액션 출력을 추가합니다.
우리는 이 디자인을 다음 섹션에서 자세히 설명합니다.
편의상 PaliGemma를 사용하며, 이는 비교적 작은 크기 (실시간 제어에 유용함) 때문입니다, 그러나 우리의 프레임워크는 사전 학습된 모든 base VLM과 호환됩니다.
Ⅳ. The π_0 Model
그림 3에 나와 있는 π_0 모델은 주로 언어 모델 트랜스포머 백본으로 구성되어 있습니다.
표준 후기 융합 VLM 레시피 [3, 11, 30]를 따라 이미지 인코더는 로봇의 이미지 관찰을 언어 토큰과 동일한 임베딩 공간에 임베딩합니다.
우리는 또한 로봇 공학에 특화된 입력 및 출력으로 이 백본을 보강합니다 — 즉, 고유 수용 상태와 로봇 액션입니다.
π_0는 조건부 플로우 매칭 [28, 32]을 사용하여 액션의 연속 분포를 모델링합니다.
플로우 매칭은 우리 모델에 높은 정밀도와 멀티모달 모델링 능력을 제공하여 특히 고주파 손재주 작업에 적합합니다.
우리의 아키텍처는 Transfusion [59]에서 영감을 받았습니다, 그것은 여러 objective들을 사용하여 단일 트랜스포머를 학습시키며, 연속 출력에 해당하는 토큰은 플로우 매칭 loss를 통해 supervise되고 이산 출력에 해당하는 토큰은 크로스 엔트로피 loss를 통해 supervise됩니다.
Transfusion을 기반으로, 우리는 로봇 공학 특유의 (action 및 state) 토큰에 대해 별도의 가중치 집합을 사용하는 것이 성능 향상을 가져온다는 것을 추가로 발견했습니다.
이 설계는 두 가지 혼합 요소를 가진 expert [45, 25, 12, 16]의 혼합과 유사하며, 첫 번째 요소는 이미지 및 텍스트 입력에 사용되고 두 번째 요소는 로봇 공학 특유의 입력 및 출력에 사용됩니다.
우리는 두 번째 가중치 집합을 action expert라고 부릅니다.
형식적으로, 우리는 데이터 분포 p(A_t|o_t)를 모델링하고자 합니다, 여기서 A_t = [a_t, a_(t+1), ..., a_(t+H-1)]는 미래 액션의 액션 청크에 해당하며 (우리는 작업에 H = 50을 사용합니다), o_t는 관측치입니다.
관찰은 여러 RGB 이미지, 언어 명령, 그리고 로봇의 고유 수용 상태로 구성됩니다, 여기서 o_t = [I_t^1 , ..., I_t^n , ℓ_t, q_t], 여기서 I_t^i는 i^번째 이미지 (로봇당 2개 또는 3개의 이미지 포함), ℓ_t는 언어 토큰 시퀀스, 그리고 q_t는 관절 각도 벡터입니다.
이미지 I_t^i와 상태 q_t는 해당 인코더를 통해 인코딩된 다음 선형 투영 레이어를 통해 언어 토큰과 동일한 임베딩 공간에 투영됩니다.
액션 청크 A_t의 각 액션 a_t′에 대해 액션 전문가를 통해 제공되는 해당 액션 토큰이 있습니다.
학습 중에는 조건부 플로우 매칭 loss [28, 32],
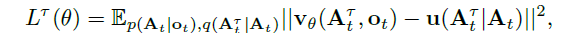
을 사용하여 이러한 액션 토큰을 supervise합니다, 여기서 아래첨자는 로봇 시간 단계를 나타내고 위첨자는 플로우 매칭 시간 단계를 나타내며, τ ∈는 [0, 1]입니다.
고해상도 이미지 [14]와 비디오 [38] 합성에 대한 최근 연구에 따르면 플로우 매칭은 q(A_t^ τ|A_t) = N(τA_t, (1 - τ )I)로 주어진 간단한 선형 가우시안 (또는 최적 수송) 확률 경로 [28]와 결합할 때 강력한 경험적 성능을 달성할 수 있습니다.
실제로 네트워크는 랜덤 노이즈 ϵ ~ N(0, I)을 샘플링하여 "noisy actions" A_t^ τ = τ A_t + (1 - τ )ϵ을 계산한 다음 디노이징 벡터 필드 u(A_t^ τ|A_t) = ϵ - A_t와 일치하도록 네트워크 출력 v_θ(A_t^ τ, o_t)을 학습합니다.
액션 전문가는 모든 액션 토큰이 서로를 주목할 수 있도록 전체 양방향 어텐션 마스크를 사용합니다.
학습 중에, 우리는 더 낮은 (noisier) 시간 단계를 강조하는 베타 분포에서 플로우 매칭 시간 단계 τ를 샘플링합니다.
자세한 내용은 부록 B를 참조하세요.
추론 시간에 우리는 랜덤 노이즈 A_t^0 ~ N(0, I)부터 시작하여 τ = 0에서 τ = 1까지 학습된 벡터 필드를 적분하여 액션을 생성합니다.
우리는 순방향 오일러 적분 규칙을 사용합니다:
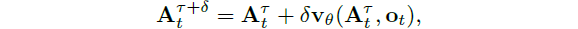
, δ는 적분 단계 크기입니다.
우리는 실험에서 10단계의 적분 단계 (δ =0.1에 해당)를 사용합니다.
접두사 o_t에 대한 어텐션 키와 값을 캐싱하고 각 적분 단계에 대해 액션 토큰에 해당하는 접미사만 다시 계산하면 추론을 효율적으로 구현할 수 있다는 점에 유의하세요.
모델의 각 부분에 대한 추론 시간을 포함한 추론 절차에 대한 자세한 내용은 부록 D에 나와 있습니다.
원칙적으로 우리의 모델은 처음부터 초기화하거나 VLM 백본에서 파인튜닝할 수 있지만, 실제로는 PaliGemma [5]를 base 모델로 사용합니다.
PaliGemma는 크기와 성능 간의 편리한 절충을 제공하는 오픈 소스 30억 개의 매개변수 VLM입니다.
우리는 액션 전문가를 위해 3억 개의 매개변수를 추가했으며, (이는 처음부터 초기화된 것입니다) 총 33억 개의 매개변수를 포함합니다.
우리는 부록 B에서 모델 아키텍처에 대한 전체 설명을 제공합니다.
Non-VLM baseline model.
우리의 주요 VLA 모델 외에도, 우리는 ablation 실험을 위해 VLM 초기화를 사용하지 않은 유사한 base 모델을 학습시켰습니다.
우리가 π_0-small이라고 부르는 이 모델은 470M 매개변수를 가지고 있으며, VLM 초기화를 사용하지 않으며, 우리가 VLM 초기화 없이 데이터를 학습하는 데 도움이 되는 몇 가지 작은 차이점이 있습니다, 이 모델은 부록 C에 요약되어 있습니다.
우리의 비교에서 VLM 통합의 이점을 평가하는 데 사용됩니다.
Ⅴ. Data Collection and Training Recipe
광범위하게 능력 있는 로봇 파운데이션 모델은 표현력이 뛰어나고 강력한 아키텍처뿐만 아니라 올바른 데이터셋, 그리고 더 중요한 것은 올바른 학습 레시피도 필요합니다.
LLM 학습이 일반적으로 사전 학습 단계와 사후 학습 단계로 나뉘는 것처럼, 우리는 모델에 다단계 학습 절차를 적용합니다.
사전 학습 단계의 목표는 모델이 광범위하게 적용 가능하고 일반적인 물리적 능력을 습득할 수 있도록 다양한 작업에 노출시키는 것이며, 사후 학습 단계의 목표는 모델에게 원하는 다운스트림 작업을 능숙하고 유창하게 수행할 수 있는 능력을 제공하는 것입니다.
이로 인해 사전 학습과 사후 학습 데이터셋에 대한 요구 사항은 다릅니다: 사전 학습 데이터셋은 가능한 한 많은 작업을 포함해야 하며, 각 작업 내에서 다양한 액션을 포함해야 합니다.
대신 사후 학습 데이터셋은 효과적인 작업 실행에 도움이 되는 행동을 포함해야 하며, 이는 일관되고 유창한 전략을 보여야 합니다.
직관적으로, 다양하지만 품질이 낮은 사전 학습 데이터는 모델이 실수로부터 회복하고 고품질 사후 학습 데이터에서는 발생하지 않을 수 있는 매우 다양한 상황을 처리할 수 있게 해주며, 사후 학습 데이터는 모델이 작업을 잘 수행하도록 가르칩니다.
A. Pre-training and post-training
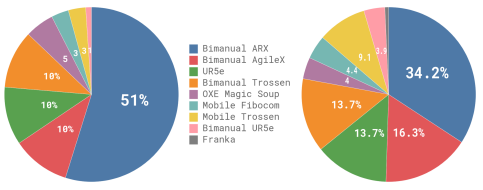
우리는 그림 4에서 사전 학습 혼합물에 대한 개요를 제공합니다.
각 학습 예제는 타임스텝 — 즉, 튜플(o_t, A_t) — 에 해당하므로, 이 논의에서는 데이터를 타임스텝으로 정량화할 것입니다.
학습습 혼합물의 9.1%는 OXE [10], Bridge v2 [52], DROID [23]를 포함한 오픈 소스 데이터셋으로 구성되어 있습니다.
이 데이터셋의 로봇과 작업은 일반적으로 한두 대의 카메라를 가지고 있으며 2에서 10Hz 사이의 저주파 제어를 사용합니다.
그러나 이러한 데이터셋은 다양한 객체와 환경을 다룹니다.
손재주가 많고 복잡한 작업을 배우기 위해, 우리는 또한 단일 팔 로봇에서 106M 단계, 이중 팔 로봇에서 797M 단계의 데이터를 자체 데이터셋에서 수집한 903M 단계의 데이터를 사용합니다.
이 데이터에는 68개의 작업이 있으며, 각 작업은 복잡한 동작으로 구성되어 있습니다 — 예를 들어, "bussing" 작업은 다양한 종류의 접시, 컵, 식기를 버스킹 쓰레기통에 넣고, 다양한 쓰레기를 쓰레기통에 넣는 것을 포함합니다.
이 작업의 정의는 일반적으로 명사와 동사의 조합(예: "pick up the cup" vs. "pick up the plate")을 사용하여 별개의 작업을 구성하는 이전 작업과는 상당히 다르다는 점에 유의하세요.
따라서, 우리 데이터셋의 실제 행동 범위는 이 "tasks"의 수보다 훨씬 더 넓습니다.
우리는 데이터셋의 특정 로봇과 작업에 대해 섹션 V-C에서 더 자세히 논의합니다.
데이터셋의 크기가 다소 불균형하기 때문에 (예: 세탁 접기 작업이 과도하게 표현될수록), 각 작업-로봇 조합에 n^0.43의 가중치를 부여합니다, 여기서 n은 해당 조합의 샘플 수이므로 과도하게 표현된 조합은 가중치가 낮아집니다.
구성 벡터 q_t와 액션 벡터 a_t는 항상 데이터셋에서 가장 큰 로봇의 차원을 갖습니다 (우리의 경우, 두 개의 6-DoF 팔, 두 개의 그리퍼, 이동 베이스, 그리고 수직으로 작동하는 몸통을 수용할 수 있는 18개).
저차원 구성 및 동작 공간을 가진 로봇의 경우, 구성 및 동작 벡터를 제로패드로 처리합니다.
이미지가 세 개 미만인 로봇의 경우, 누락된 이미지 슬롯도 마스킹합니다.
학습 후 단계에서는 특정 다운스트림 애플리케이션에 특화하기 위해 더 작은 작업별 데이터 세트로 모델을 파인튜닝합니다.
앞서 언급했듯이 "task"에 대한 정의는 상당히 광범위합니다 — 예를 들어, "bussing" 작업은 다양한 객체를 조작해야 합니다.
작업마다 매우 다른 데이터셋이 필요하며, 가장 간단한 작업은 5시간만 소요되고 가장 복잡한 작업은 100시간 이상의 데이터를 사용합니다.
B. Language and high-level policies
시맨틱 추론과 고수준 전략이 필요한 더 복잡한 작업들, 예를 들어 table bussing과 같은 고급 작업들은 고수준 작업들 (예: "bus the table")을 더 즉각적인 하위 작업들 (예: "pick up the napkin" 또는 "throw the napkin into the trash")로 분해하는 고수준급 정책의 혜택을 받을 수 있습니다.
우리 모델은 언어 입력을 처리하도록 학습되었기 때문에, SayCan [2]과 같은 LLM/VLM 계획 방법과 유사한 방법인 고수준 VLM을 사용하여 이러한 의미론적 추론을 할 수 있습니다.
우리는 이러한 고수준 정책을 사용하여 여러 실험 과제에 대한 고수준 전략을 통해 모델을 지원합니다.
이는 섹션 VI에서 논의할 내용입니다.

C. Robot system details
우리의 능숙한 조작 데이터셋에는 7가지 로봇 구성과 68가지 작업이 포함되어 있습니다.
우리는 이 플랫폼들을 그림 5에 요약하고, 아래에서 논의합니다:
UR5e.
평행 턱 그립퍼가 있는 암, 손목에 착용하고 어깨 위에 카메라가 있는 암으로, 총 두 개의 카메라 이미지와 7차원 구성 및 동작 공간을 제공합니다.
Bimanual UR5e.
두 개의 UR5e 설정, 총 세 개의 카메라 이미지와 14차원 구성 및 액션 공간.
Franka.
Franka 설정에는 두 대의 카메라와 8차원 구성 및 액션 공간이 있습니다.
Bimanual Trossen.
이 설정은 ALOHA 설정을 기반으로 한 구성으로 두 개의 6-DoF Trossen ViperX 암을 가지고 있으며 [4, 57], 두 개의 손목 카메라와 기본 카메라, 그리고 14차원 구성 및 액션 공간을 갖추고 있습니다.
Bimanual ARX & bimanual AgileX.
이 설정은 두 개의 6-DoF 암을 사용하며, ARX 또는 AgileX 암을 지원합니다, 세 개의 카메라 (두 개의 손목과 하나의 베이스)와 14차원 구성 및 액션 공간이 있습니다.
이 클래스는 두 개의 서로 다른 플랫폼을 포함하지만, 유사한 운동학적 특성 때문에 함께 분류합니다.
Mobile Trossen & mobile ARX.
이 설정은 Mobile ALOHA [57] 플랫폼을 기반으로 하며, 모바일 베이스에는 ARX 암 또는 Trossen ViperX 암인 두 개의 6-DoF 암이 있습니다.
비홀로노믹 베이스는 14차원 구성과 16차원 행동 공간을 위해 두 가지 행동 차원을 추가합니다.
손목 카메라 두 대와 기본 카메라 한 대가 있습니다.
이 클래스는 두 개의 서로 다른 플랫폼을 포함하지만, 유사한 운동학적 특성 때문에 함께 분류합니다.
Mobile Fibocom.
홀로노믹 베이스 위에 두 개의 6-DoF ARX 암이 있습니다.
베이스는 14차원 구성과 17차원 액션 공간을 위해 세 가지 액션 차원 (이동용 2개, 방향용 1개)을 추가합니다.
그림 4에 각 로봇의 데이터 세트 비율을 요약했습니다.
VI. Experimental Evaluation
우리의 실험 평가는 base (사전 학습된) 모델을 직접 프롬프트가 있는 대체 모델 설계와 비교하는 즉시 사용 가능한 평가 실험과, 도전적인 다운스트림 작업에서 우리의 모델을 평가하는 세부적인 파인튜닝 실험으로 구성되며, 이를 손재주 있는 조작을 위해 제안된 다른 방법들과 비교합니다.
우리는 다음 연구 질문들을 연구합니다:
π_0는 사전 학습 데이터에 포함된 다양한 작업에 대해 사전 학습 후 얼마나 잘 수행됩니까?
우리는 이 질문을 다른 로봇 파운데이션 모델과의 비교를 통해 π_0을 직접 평가하여 연구합니다.
π_0는 언어 명령을 얼마나 잘 따르나요?
이 실험들은 VLM 초기화가 없는 우리 모델의 작은 버전인 π_0와 π_0-small을 비교하여 다음 언어 명령어에 대한 성능을 평가합니다.
우리는 섹션 V-B에서 논의된 바와 같이 인간이 제공한 명령과 고수준 VLM 정책에 의해 지정된 명령을 모두 사용하여 평가합니다.
π_0는 손재주 있는 조작 작업을 해결하기 위해 특별히 제안된 방법들과 어떻게 비교됩니까?
이 실험들은 사전 학습된 초기화에서 모델을 파인튜닝하거나, 작업별 데이터를 바탕으로 처음부터 학습할 수 있는 다운스트림 작업을 연구합니다, 이는 손재주 있는 조작을 위해 제안된 이전 방법들과 비교됩니다.
저희는 아키텍처와 사전 학습 절차의 장점을 모두 평가하는 것을 목표로 합니다.
π_0를 복잡하고 다단계인 작업에 적용할 수 있습니까?
마지막 실험 세트에서는 세탁물 접기와 테이블 정리를 포함한 매우 복잡한 작업 세트에 맞춰 π_0을 파인튜닝합니다.
이 작업들은 완료하는 데 5분에서 20분 정도 걸립니다.
일부는 고수준의 정책이 필요합니다.
A. Evaluating the base model
첫 번째 실험 세트에서는 사전 학습 없이 전체 혼합물에 대해 사전 학습 후 모델을 평가하여 base 모델이 다양한 작업을 얼마나 잘 수행할 수 있는지 평가합니다.
문헌에 나와 있는 다른 로봇 파운데이션 모델과 비교합니다: 동일한 사전 학습 혼합물에서 처음부터 학습된 VLA와 작은 모델 모두.
우리는 그림 6에 시각화된 다음 작업들을 평가하며, 각 작업은 언어 명령을 통해 동일한 base 모델에 명령됩니다.

Shirt folding:
로봇은 평평하게 시작되는 티셔츠를 접어야 합니다.
Bussing easy:
로봇은 테이블을 청소하고 쓰레기통에 쓰레기를 넣고 접시를 접시통에 넣어야 합니다.
점수는 올바른 리셉터클에 배치된 객체의 수를 나타냅니다.
Bussing hard:
더 많은 객체와 더 도전적인 구성, 예를 들어 쓰레기 객체 위에 의도적으로 놓인 도구, 서로를 방해하는 객체, 그리고 사전 학습 데이터셋에 없는 일부 객체와 같은 더 많은 객체가 포함된 더 어려운 버전의 bussing 작업입니다.
Grocery bagging:
로봇은 감자칩, 마시멜로, 고양이 사료와 같은 모든 식료품을 포장해야 합니다.
Toast out of toaster:
로봇이 토스터기에서 토스트를 제거합니다.
이 실험들에 대한 비교를 제공하는 것은 매우 어려운 일입니다, 왜냐하면 이 규모에서 작동할 수 있는 이전 모델이 거의 없기 때문입니다.
우리는 원래 OXE 데이터셋 [10]에서 학습된 7B 매개변수 VLA 모델인 OpenVLA [24]와 비교합니다.
저희는 전체 혼합물에 대해 OpenVLA를 학습합니다.
이것은 액션 청킹이나 고주파 제어를 지원하지 않는 OpenVLA에게 매우 어려운 혼합물입니다.
우리는 또한 더 작은 93M 매개변수 모델인 Octo [50]과 비교합니다.
Octo는 VLA는 아니지만 디퓨전 과정을 사용하여 액션을 생성하므로 플로우가 일치하는 VLA에 대한 귀중한 비교 지점을 제공합니다.
우리는 또한 모델과 동일한 혼합물에 대해 Octo를 학습시킵니다.
시간 제약으로 인해 전체 모델과 동일한 수의 에포크에 대해 OpenVLA와 Octo를 학습할 수 없었습니다.
따라서 우리는 또한 (주 모델의 70k 단계가 아닌) 160k 단계만 학습된 "compute parity" 버전과 비교합니다, 베이스라인에 제공되는 단계 수 (OpenVLA의 경우 160k 개, Octo의 경우 320k 개)와 같거나 낮습니다.
우리는 또한 UR5e 작업에 대한 더 강력한 베이스라인을 제공하기 위해 교차 구현 학습 없이 UR5e 데이터에만 파인튜닝한 OpenVLA 모델의 버전도 포함하고 있습니다.
마지막으로, 섹션 IV에서 설명한 π_0-small 모델과의 비교를 포함합니다, 이 모델은 VLM 사전 학습 없이 축소된 버전으로 볼 수 있습니다.
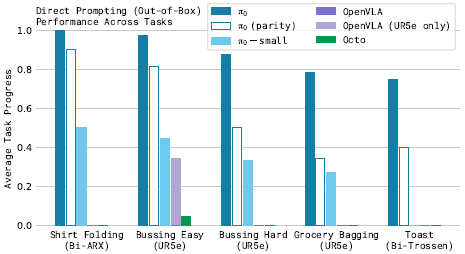
평가 지표는 과제와 방법당 10개의 에피소드에 대해 평균화된 정규화 점수를 사용하며, 에피소드가 전체 성공을 거두면 1.0점, 부분 성공을 하면 단편적인 점수를 받습니다.
예를 들어, bussing 점수는 적절한 receptacle에 올바르게 배치된 객체의 비율입니다.
우리는 부록 E에서 점수 rubrics을 설명합니다.
그림 7에 표시된 결과에 따르면 π_0는 셔츠 접기와 더 쉬운 bussing 작업에서 거의 완벽한 성공률을 보였으며, 모든 베이스라인에서 큰 개선을 이루었습니다.
π_0의 "parity" 버전은 160k 단계만 학습되어 여전히 모든 베이스라인을 능가하며, 심지어 π_0-small도 OpenVLA와 Octo를 능가합니다.
OpenVLA는 자기회귀 이산화 아키텍처가 액션 청크를 지원하지 않기 때문에 이러한 작업에서 어려움을 겪고 있습니다.
UR5e 전용 OpenVLA 모델은 더 나은 성능을 보이지만 여전히 π_0의 성능에는 훨씬 못 미칩니다.
Octo는 액션 청크를 지원하지만, 비교적 제한된 표현 능력을 가지고 있습니다.
이 비교는 플로우 매칭이나 디퓨전을 통해 복잡한 분포를 모델링할 수 있는 능력과 크고 표현력이 뛰어난 아키텍처를 결합하는 것의 중요성을 보여줍니다.
또한, π_0-small과의 비교는 VLM 사전 학습 통합의 중요성을 보여줍니다.
안타깝게도 이 마지막 비교를 공정하게 만드는 것은 어렵습니다:
π_0-small은 더 적은 매개변수를 사용하지만, 더 큰 모델은 사전 학습 없이는 사용하기 어렵습니다.
전반적으로, 이 실험들은 π_0이 다양한 로봇으로 다양한 작업을 효과적으로 수행할 수 있는 강력한 사전 학습된 모델을 제공하며, 이전 모델들보다 훨씬 더 나은 성능을 보인다는 것을 보여줍니다.
B. Following language commands
다음 실험 세트에서는 평가 도메인 세트에서 언어 명령을 따르도록 base π_0 모델을 파인튜닝합니다.
우리는 이 파인튜닝된 π_0 모델을 이전 섹션에서 가장 강력한 베이스라인으로 밝혀진 섹션 IV에서 설명한 π_0-small 모델과 비교합니다.
π_0-small은 VLM 초기화를 사용하지 않는다는 점을 기억하세요.
따라서 이 실험은 VLM 사전 학습이 우리 모델의 언어 지침 준수 능력을 얼마나 향상시키는지 측정하는 것을 목표로 합니다.
π_0-small도 상당히 작은 모델입니다 — 안타깝게도 VLM 초기화는 과적합 없이 훨씬 더 큰 모델을 학습하는 것을 실용적으로 만들고 언어 학습을 따르는 것을 개선하는 데 도움이 되기 때문에 이 혼란을 제거하기는 어렵습니다.
그럼에도 불구하고, 우리는 이 실험이 π_0의 언어 능력에 대한 통찰을 제공하기를 바랍니다.
각 작업의 언어 지침은 픽업할 객체와 해당 객체를 배치할 위치로 구성되며, 약 2초 길이의 언어 라벨 세그먼트가 있습니다.
각 전체 작업은 수많은 이러한 세그먼트로 구성됩니다.
이 평가의 작업은 다음과 같이 구성됩니다:
Bussing:
로봇은 테이블을 청소하고 접시와 식기를 쓰레기통에 넣고 쓰레기통에 버려야 합니다.
Table setting:
로봇은 테이블을 세팅하기 위해 쓰레기통에서 물건들을 꺼내야 합니다, 여기에는 장소 매트, 접시, 은식기, 냅킨, 컵 등이 포함되며, 언어 지침에 따라 조절해야 합니다.
Grocery bagging:
로봇은 커피 원두, 보리, 마시멜로, 해초, 아몬드, 스파게티, 캔 등 식료품을 가방에 넣어야 합니다.

그림 8에서 우리는 평가에서 언어 조건 과제를 보여주고 평가 결과를 제시합니다.
우리는 다섯 가지 다른 조건을 평가합니다.
π_0-flat (및 π_0-small-flat)은 중간 언어 명령 없이 작업 설명(예: "bag the groceries")으로 모델을 직접 명령하는 것에 해당합니다.
π_0-human (및 π_0-small-human)은 전문가 인간 사용자로부터 중간 단계 명령 (예: 어떤 객체를 선택하고 어디에 배치할지)을 제공합니다.
이러한 조건들은 각 모델이 더 자세한 언어 명령을 따를 수 있는 능력을 평가합니다:
이러한 중간 명령어는 작업을 수행하는 방법에 상당한 정보를 제공하지만, 모델은 이러한 명령어를 이해하고 따를 수 있어야만 이를 통해 이점을 얻을 수 있습니다.
마지막으로, π_0-HL은 섹션 V-B에서 논의된 바와 같이 고수준 VLM에서 제공하는 고수준 명령으로 π_0을 평가합니다.
이 조건은 또한 인간 전문가 없이 자율적입니다.
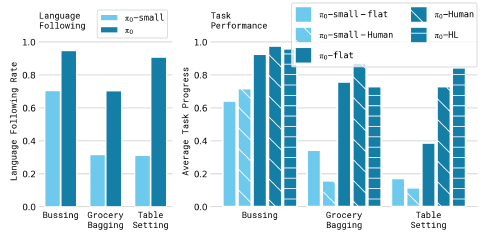
그림 9의 결과는 작업당 평균 10번 이상의 시도를 통해 π_0의 정확도를 따르는 언어가 π_0-small의 정확도보다 훨씬 우수하다는 것을 보여줍니다.
이는 대규모 사전 학습된 VLM 초기화보다 크게 개선되었음을 시사합니다.
이 기능은 전문가의 인간 지침 (π_0-human)과 고수준 모델 지침 (π_0-HL)을 통해 성능 향상으로 이어집니다.
결과는 π_0의 언어 추종 능력이 고수준의 지침을 통해 복잡한 작업에서 더 나은 자율적 성능으로 직접적으로 변환된다는 것을 나타냅니다.

C. Learning new dexterous tasks
다음 실험 세트에서는 사전 학습 데이터와 크게 다른 새로운 작업에 대해 모델을 평가하여 완전히 새로운 행동이 필요합니다.
이러한 평가를 위해 각 새로운 작업에 대해 다양한 양의 데이터를 사용하여 모델을 파인튜닝합니다.
각 작업은 새롭지만, 사전 학습 데이터의 작업과 얼마나 다른지에 따라 작업을 "tiers"로 나눕니다.
그림 10에 표시된 작업은 다음과 같습니다:
UR5e stack bowls.
이 작업은 서로 다른 크기의 네 개의 그릇으로 그릇을 쌓아야 합니다.
이 작업은 사전 학습 데이터에서 bussing 작업과 같은 접시를 잡고 이동해야 하므로, 우리는 이를 "easy" 단계에 배치합니다.
학습 데이터에는 다양한 그릇이 포함되어 있으며, 평가는 보이는 그릇과 보이지 않는 그릇을 혼합하여 사용합니다.
Towel folding.
이 작업은 수건을 접어야 합니다.
이것은 사전 학습에서 볼 수 있는 셔츠 접기와 유사하기 때문에, 우리는 그것을 "easy" 티어에 배치합니다.
Tupperware in microwave.
이 작업은 전자레인지를 열고, 그 안에 플라스틱 용기를 넣고, 닫아야 합니다.
용기는 다양한 모양과 색상으로 제공되며, 평가는 보이는 용기와 보이지 않는 용기를 혼합하여 사용합니다.
컨테이너 조작은 사전 학습 데이터와 유사하지만, 사전 학습에서는 전자레인지를 찾을 수 없습니다.
Paper towel replacement.
이 작업은 홀더에서 오래된 판지 종이 타월 튜브를 제거하고 새 종이 타월 롤로 교체해야 합니다.
사전 학습에서는 이러한 항목이 발견되지 않기 때문에, 우리는 이것을 "hard"라고 생각합니다
Franka items in drawer.
이 작업은 서랍을 열고 물건을 서랍에 포장한 다음 닫아야 합니다.
사전 학습에서 Franka 로봇과 유사한 작업이 없기 때문에, 우리는 이것을 "hard"라고 생각합니다
우리는 사전 학습 및 파인튜닝 레시피를 사용하는 Open-VLA [24]와 Octo [50]을 모두 파인튜닝한 후 모델을 비교합니다.
우리의 목표는 아키텍처가 아닌 특정 모델을 평가하는 것이기 때문에, 이러한 모델에 대해 공개적으로 사용 가능한 사전 학습된 체크포인트를 사용하여 OXE [10]로 학습한 후 각 작업에 맞게 파인튜닝합니다.
우리는 또한 작은 데이터셋에서 손재주 있는 작업을 학습하기 위해 특별히 설계된 ACT [57] 및 디퓨전 정책 [9]과 비교합니다.
ACT 및 디퓨전 정책은 ACT 및 디퓨전 정책 실험에 사용된 개별 데이터 세트와 유사한 크기의 파인튜닝 데이터 세트에 대해서만 학습됩니다 [9, 57].
우리는 사전 학습된 base 모델에서 파인튜닝을 통해 π_0을 평가하고, 처음부터 다시 학습하여 평가합니다.
이 비교는 π_0 아키텍처와 사전 학습 절차의 개별적인 이점을 평가하기 위한 것입니다.
우리는 VLM 초기화가 적용된 π_0 아키텍처가 이미 개별 작업에 더 강력한 출발점을 제공할 것이며, 사전 학습 절차는 특히 더 작은 파인튜닝 데이터셋을 통해 성능을 더욱 향상시킬 것이라고 가정합니다.
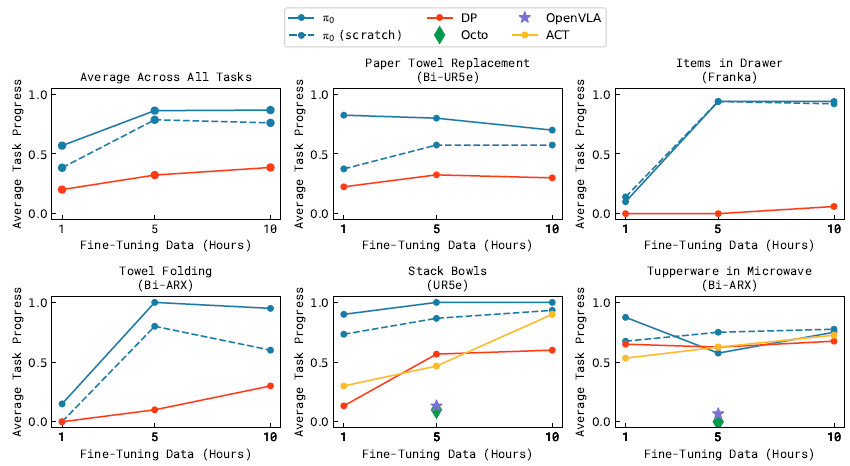
그림 11은 다양한 방법에 대한 모든 작업의 성능을 보여줍니다, 각 작업마다 평균 10번 이상의 시도가 있으며, 각 작업에 대한 파인튜닝 데이터의 양이 다릅니다.
stack bowls과 Tupperware in microwave 작업에 모든 베이스라인을 포함합니다.
OpenVLA와 Octo는 성능이 현저히 저하되기 때문에, 현실 세계에서 수많은 모델을 평가하는 데 드는 시간 비용 때문에 데이터셋 크기 중 하나에 대해서만 이를 실행합니다.
결과는 π_0이 일반적으로 다른 방법들보다 우수하다는 것을 보여줍니다.
흥미롭게도 가장 강력한 prioi 모델은 목표 작업에 대해 완전히 처음부터 학습된 모델로, 이러한 도메인에서 사전 학습을 활용하는 것이 이전 접근 방식에 큰 도전 과제임을 시사합니다.
Tupperware 작업에서 π_0에 대한 5시간 정책은 베이스라인과 유사한 성능을 보이지만, 1시간 버전이 훨씬 더 좋습니다.
예상대로, 사전 학습은 사전 학습 데이터와 더 유사한 작업에 대해 더 큰 개선을 가져옵니다, 그러나 사전 학습된 모델은 종종 사전 학습되지 않은 모델보다 최대 2배 더 나은 경우가 많습니다.

D. Mastering complex multi-stage tasks
마지막 실험 세트에서는 파인튜닝과 언어의 조합을 통해 다양한 도전적인 다단계 작업에 도전합니다.
이러한 작업 중 일부의 경우 사전 학습 시 데이터가 존재하지만 숙달을 달성하려면 파인튜닝이 필요합니다.
일부에게는 사전 학습에 데이터가 없습니다.
그림 12에 표시된 이 평가의 작업은 다음과 같습니다:
Laundry folding:
이 작업은 의류 제품을 접기 위해 정적인 (비이동식) 양방향 시스템이 필요합니다.
의류 품목은 쓰레기통에 랜덤으로 구겨진 상태로 시작하며, 목표는 해당 품목을 꺼내서 접은 다음 이전에 접힌 품목 더미 위에 올려놓는 것입니다.
구겨진 세탁물의 랜덤 초기 구성은 정책이 어떤 구성에도 일반화되어야 하기 때문에 큰 도전 과제를 제시합니다.
이 작업은 사전 학습에 포함되어 있습니다.
Mobile laundry:
여기서 그림 5의 Fibocom 모바일 로봇은 방향과 이동을 제어하면서 많은 동일한 문제에 직면하여 세탁물을 접어야 합니다.
이 작업은 사전 학습에 포함되어 있습니다.
Dryer unloading:
여기서 Fibocom 이동 로봇은 건조기에서 빨래를 꺼내 바구니에 넣어야 합니다.
이 작업은 사전 학습에 포함되어 있습니다.
Table bussing:
이 작업은 어수선한 장면에서 다양한 새로운 객체가 포함된 테이블 치우기로 연결해야 하므로, 우리의 기본 평가에서 벤치마크보다 훨씬 더 큰 도전 과제를 제시합니다:
정책은 다양한 모양과 크기의 보이지 않는 물체에 일반화하고 그립퍼를 비틀어 큰 접시를 집어 들고 안경과 같은 얇고 섬세한 물건을 조심스럽게 잡는 등 복잡한 손재주 동작을 수행해야 합니다.
로봇은 밀집된 어수선함을 처리하고 다양한 액션을 지능적으로 시퀀싱해야 합니다 — 예를 들어, 쓰레기로 접시를 닦으려면 먼저 접시를 집어 들고 내용물을 쓰레기통에 흔든 다음 접시를 쓰레기통에 넣어야 합니다.
이 작업은 사전 학습에는 포함되지 않습니다.
Box building:
로봇은 평평한 상태에서 시작하는 골판지 상자를 조립해야 합니다.
이 작업은 여러 주요 과제를 제시합니다:
상자는 올바른 방향으로 구부러져야 하며, 로봇은 상자의 일부를 누른 상태에서 다른 부분을 접으면서 양쪽 팔과 테이블 표면까지 활용하여 접는 동작을 할 때 보조해야 합니다.
로봇은 몇 번의 접힘을 다시 시도해야 할 수도 있으며, 이를 위해서는 반응적이고 지능적인 전략이 필요합니다.
이 작업은 사전 학습에 포함되지 않습니다.
To-go box:
이 작업은 여러 음식을 접시에서 포장 상자로 옮기는 작업을 필요로 하며, 음식이 튀어나오지 않도록 상자에 포장한 다음 양팔로 상자를 닫아야 합니다.
이 작업은 사전 학습에 포함되지 않습니다.
Packing eggs:
로봇은 그릇에서 달걀 여섯 개를 꺼내 달걀 상자에 포장한 다음 상자를 닫아야 합니다.
달걀은 그릇 안에서 자세에 맞게 잡고 상자 안의 열린 공간에 넣어야 합니다.
이것은 달걀 모양, 미끄러움, 그리고 신중한 배치의 필요성 때문에 어려움을 초래합니다.
상자를 닫으려면 양쪽 팔을 사용해야 합니다.
이 작업은 사전 학습에 포함되지 않습니다.
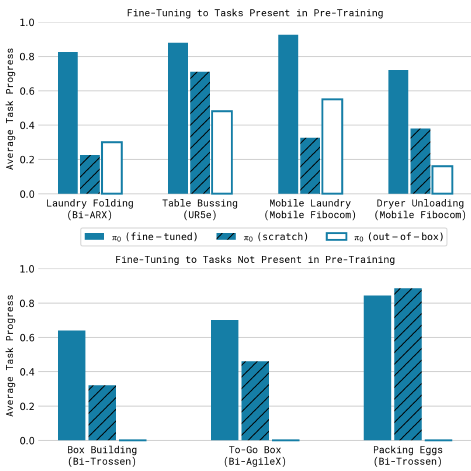
10번의 시험에서 과제당 평균 점수를 보여주는 결과는 그림 13에 나와 있습니다.
점수 rubrics은 부록 E에 나와 있습니다.
점수 1.0은 완벽한 실행을 의미하며, 부분 점수는 부분적으로 완료된 작업에 해당합니다 (예: 0.5는 객체의 절반이 올바르게 bussed되었음을 나타냅니다).
이 작업들은 매우 어려워서 다른 방법으로는 해결할 수 없었습니다.
따라서 우리는 이러한 작업을 우리의 접근 방식의 ablation과 비교하기 위해 사용합니다, 사전 학습과 파인튜닝 후 π_0을 평가하고, 사전 학습만 한 후 ("out-of-box"), 사전 학습 없이 파인튜닝 데이터에 대한 학습 ("scratch")을 수행합니다.
결과에 따르면 π_0는 이러한 작업 중 많은 부분을 해결할 수 있으며, 전체 사전 학습 및 파인튜닝 레시피가 전반적으로 가장 우수한 성능을 발휘합니다.
이러한 더 어려운 작업 중 많은 부분이 사전 학습된 모델을 사용했을 때 매우 큰 개선을 보여주며, 이는 사전 학습이 특히 더 어려운 작업에서 유용하다는 것을 나타냅니다.
π_0의 절대 성능은 과제마다 다를 수 있으며, 이는 과제 난이도와 과제가 사전 학습에 반영되는 정도의 차이 때문일 수 있습니다.
첨부된 웹사이트에서 작업 동영상을 시청하여 이러한 작업과 그 복잡성에 대한 보다 완벽한 인상을 받을 것을 권장합니다.
우리는 이러한 도전적인 작업에서 이러한 수준의 자율적인 성능이 학습된 정책을 통해 손재주 있는 로봇 조작의 새로운 SOTA 기술을 나타낸다고 믿습니다.
VII. Discussion, Limiations, and Future Work
우리는 로봇 파운데이션 모델을 학습시키기 위한 프레임워크를 제시했습니다, 이 프레임워크는 매우 다양한 데이터에 대한 사전 학습을 거친 후, 기본적인 평가나 복잡한 다운스트림 작업에 대한 파인튜닝을 포함합니다.
우리의 경험적 평가는 손재주, 일반화, 그리고 시간적으로 확장된 다단계 행동을 결합한 과제를 연구합니다.
우리 모델은 복잡한 고주파 액션 청크를 표현하기 위해 플로우 매칭과 함께 인터넷 규모의 vision-language model (VLM) 사전 학습을 통합합니다.
우리의 사전 학습 혼합물은 OXE [10], DROID [23], Bridge [52]에서 수집된 대량의 로봇 조작 데이터 외에도 7가지 다른 로봇 구성과 68개의 작업에서 10,000시간 분량의 능숙한 조작 데이터로 구성되어 있습니다.
우리가 아는 한, 이것은 로봇 조작 모델에 사용된 가장 큰 사전 학습 혼합물입니다.
우리의 파인튜닝 실험에는 20개 이상의 작업이 포함되어 있으며, 여기서 우리의 모델이 이전의 VLA 모델 [24]과 손재주 있는 조작을 위해 특별히 설계된 모델 [57, 9]을 포함한 다양한 베이스라인을 능가한다는 것을 보여줍니다.
또한 학습 후 레시피가 임의의 초기 구성에서 여러 의류를 접거나 상자를 조립하는 등 매우 복잡한 작업을 어떻게 가능하게 할 수 있는지 살펴봅니다.
우리의 프레임워크는 대규모 언어 모델에 사용되는 학습 절차와 대체로 유사합니다, 이 절차는 일반적으로 웹에서 스크랩된 매우 큰 데이터셋에서 base 모델을 사전 학습한 다음, 모델이 지침을 따르고 사용자 명령을 수행할 수 있도록 "align"하는 것을 목표로 하는 사후 학습 절차로 구성됩니다.
일반적으로 이러한 모델의 대부분의 "knowledge"은 사전 학습 단계에서 습득되는 것으로 알려져 있으며, 사후 학습 단계에서는 모델이 사용자 명령을 수행하기 위해 그 지식을 어떻게 활용해야 하는지 알려주는 역할을 합니다.
우리의 실험은 로봇 파운데이션 모델에서도 유사한 현상이 발생할 수 있음을 시사합니다, 모델에서는 사전 학습된 모델이 일부 제로샷 기능을 가지고 있지만, 세탁 후 작업과 같은 복잡한 작업은 고품질 데이터로 파인튜닝이 필요합니다.
이 고품질 데이터만으로 학습하면 실수로부터 안정적으로 회복되지 않는 취약한 모델이 생성되지만, 사전 학습된 모델을 제로 샷으로 실행한다고 해서 항상 학습 후 데이터에서 입증된 유창한 전략이 나타나는 것은 아닙니다.
우리의 결과가 일반적이고 광범위하게 적용 가능한 로봇 파운데이션 모델을 향한 디딤돌이 되기를 바랍니다.
우리의 실험은 이러한 모델이 곧 현실이 될 수 있음을 시사하지만, 여러 가지 한계와 향후 연구를 위한 충분한 여지가 있습니다.
첫째, 우리의 실험은 아직 사전 학습 데이터셋이 어떻게 구성되어야 하는지에 대한 포괄적인 이해를 제공하지 않습니다: 우리는 이용 가능한 모든 데이터를 결합했지만, 어떤 유형의 데이터를 추가하는 것이 더 도움이 되는지, 그리고 그것을 어떻게 가중치를 부여해야 하는지에 대한 이해는 여전히 미해결 문제로 남아 있습니다.
평가의 모든 작업이 안정적으로 작동하는 것은 아니며, 거의 완벽한 성능을 달성하기 위해 얼마나 많은 데이터와 어떤 종류의 데이터가 필요한지 예측하는 방법도 여전히 불분명합니다.
마지막으로, 특히 다양한 작업과 로봇의 매우 다양한 데이터를 결합할 때 얼마나 긍정적인 전이가 있는지는 아직 지켜봐야 합니다: 우리의 결과는 보편적인 사전 학습된 로봇 파운데이션 모델이 현실이 될 수 있음을 시사하지만, 이러한 보편성이 자율 주행, 내비게이션, 다리 이동과 같은 훨씬 더 다양한 영역으로 확장되는지는 향후 연구에 맡겨야 합니다.
'Robotics' 카테고리의 다른 글
| Open X-Embodiment: Robotic Learning Datasets and RT-X Models (0) | 2025.03.24 |
|---|---|
| PaLM-E: An Embodied Multimodal Language Model (0) | 2025.03.20 |
| RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control (0) | 2025.03.17 |
| RT-1: Robotics Transformer for Real-World Control at Scale (0) | 2025.03.10 |
| Cosmos World Foundation Model Platform for Physical AI (0) | 2025.01.10 |