2025. 3. 24. 15:41ㆍRobotics
Open X-Embodiment: Robotic Learning Datasets and RT-X Models
Open X-Embodiment Collaboration
Abstract
다양한 데이터셋으로 학습된 대용량 모델은 다운스트림 애플리케이션을 효율적으로 처리하는 데 있어 놀라운 성공을 거두었습니다.
NLP에서 Computer Vision에 이르는 도메인에서 이는 사전 학습된 모델의 통합으로 이어졌으며, 일반적인 사전 학습된 백본이 많은 응용 프로그램의 출발점이 되었습니다.
로보틱스에서 이러한 통합이 일어날 수 있을까요?
전통적으로 로봇 학습 방법은 모든 애플리케이션, 모든 로봇, 심지어 모든 환경에 대해 별도의 모델을 학습시킵니다.
대신 새로운 로봇, 작업 및 환경에 효율적으로 적응할 수 있는 "generalist" X-robot policy를 학습할 수 있을까요?
이 논문에서는 효과적인 X-robot policy의 예를 제공하는 실험 결과와 함께 로봇 조작의 맥락에서 이러한 가능성을 탐구할 수 있도록 표준화된 데이터 형식과 모델의 데이터셋을 제공합니다.
우리는 21개 기관 간의 협업을 통해 수집된 22개의 서로 다른 로봇 데이터셋을 조립하여 527개의 기술 (160266개의 작업)을 입증했습니다.
우리는 이 데이터로 학습된 고용량 모델, 즉 RT-X가 긍정적인 전이를 보이며 다른 플랫폼의 경험을 활용하여 여러 로봇의 능력을 향상시킨다는 것을 보여줍니다.

Ⅰ. Introduction
머신러닝과 인공지능의 발전에서 중요한 교훈은 다양한 데이터셋에서 대규모 학습을 통해 범용 사전 학습 모델을 제공함으로써 유능한 AI 시스템을 구현할 수 있다는 점입니다.
사실, 일반적으로 크고 다양한 데이터셋으로 학습된 대규모 범용 모델은 작지만 더 작업별 데이터로 학습된 좁은 타겟 모델보다 종종 더 나은 성능을 발휘할 수 있습니다.
예를 들어, 웹에서 스크래핑된 대규모 데이터셋에서 학습된 오픈 어휘 분류기 (예: CLIP [1])는 제한된 데이터셋에서 학습된 고정 어휘 모델보다 성능이 우수한 경향이 있으며, 대규모 텍스트 말뭉치에서 학습된 대규모 언어 모델 [2, 3]은 좁은 작업별 데이터셋에서만 학습된 시스템보다 성능이 우수한 경향이 있습니다.
점점 더 좁은 과제 (예: 비전 또는 자연어 처리)를 해결하는 가장 효과적인 방법은 범용 모델을 적응시키는 것입니다.
그러나 이러한 교훈은 로보틱스에 적용하기 어렵습니다: 모든 단일 로봇 도메인은 너무 좁을 수 있으며, 컴퓨터 비전과 NLP는 웹에서 가져온 대규모 데이터셋을 활용할 수 있지만, 로봇 상호작용을 위한 비교적 크고 넓은 데이터셋은 구하기 어렵습니다.
대규모 데이터 수집 노력에도 불구하고 비전 (5-18M) [4, 5] 및 NLP (1.5B-4.5B) [6, 7]에서 벤치마크 데이터셋의 크기와 다양성에 비하면 미미한 수준에 불과한 데이터셋이 여전히 존재합니다.
더 중요한 것은 이러한 데이터셋이 단일 환경, 단일 객체 세트 또는 좁은 범위의 작업에 초점을 맞추는 등 여전히 일부 변동 축을 따라 좁은 경우가 많다는 점입니다.
로보틱스 분야에서 이러한 도전 과제를 극복하고 로봇 학습 분야를 다른 분야에서 큰 성공을 거둔 대규모 데이터 체제로 전환하려면 어떻게 해야 할까요?
다양한 데이터에 대해 대규모 비전 또는 언어 모델을 사전 학습함으로써 가능해진 일반화에서 영감을 받아, 우리는 일반화 가능한 로봇 policy를 학습하기 위해서는 여러 로봇 플랫폼의 데이터를 사용한 X-embodiment training이 필요하다는 관점을 취합니다.
각 개별 로봇 학습 데이터셋은 너무 좁을 수 있지만, 이러한 모든 데이터셋의 결합은 환경과 로봇의 다양성을 더 잘 다룰 수 있게 해줍니다.
일반화 가능한 로봇 policy를 학습하려면 많은 실험실, 로봇 및 환경의 데이터셋을 활용하여 X-embodiment 데이터를 활용할 수 있는 방법을 개발해야 합니다.
현재 크기와 커버리지에서 이러한 데이터셋이 대규모 언어 모델에서 입증된 인상적인 일반화 결과를 얻기에는 충분하지 않더라도, 미래에는 이러한 데이터의 결합이 잠재적으로 이러한 종류의 커버리지를 제공할 수 있습니다.
이 때문에, 우리는 현재 시점에서 X-embodiment 로봇 학습에 대한 연구를 가능하게 하는 것이 중요하다고 믿습니다.
이 논리에 따르면, 우리는 두 가지 목표를 가지고 있습니다:
(1) 다양한 로봇과 환경의 데이터로 학습된 policy가 긍정적인 전이의 이점을 누리고 있는지 평가하여 각 평가 설정의 데이터로만 학습된 policy보다 더 나은 성능을 얻도록 합니다.
(2) 대규모 로봇 데이터셋을 조직하여 X-embodiment 모델에 대한 향후 연구를 가능하게 합니다.
우리는 로봇 조작에 집중합니다.
목표 (1)을 해결하기 위해, 우리의 경험적 기여는 최소한의 수정으로 여러 최신 로봇 학습 방법이 X-embodiment 데이터를 활용하고 긍정적인 전이를 가능하게 할 수 있음을 입증하는 것입니다.
구체적으로, 우리는 9개의 서로 다른 로봇 조작기를 사용하여 RT-1 [8] 및 RT-2 [9] 모델을 학습시킵니다.
우리는 RT-X라고 부르는 결과 모델이 평가 도메인의 데이터로만 학습된 policy보다 개선되어 더 나은 일반화와 새로운 기능을 보여줄 수 있음을 보여줍니다.
(2)에 대해 설명하자면, 우리는 21개의 다른 기관에서 온 22개의 서로 다른 로봇 구현 데이터셋을 포함하는 Open X-Embodiment (OXE) 저장소를 제공합니다, 이 데이터셋은 로봇 커뮤니티가 X-Embodiment 모델에 대한 추가 연구를 진행할 수 있도록 도와주며, 이러한 연구를 촉진하기 위한 오픈 소스 도구도 포함하고 있습니다.
우리의 목표는 특정 아키텍처와 알고리즘 측면에서 혁신하는 것이 아니라, 함께 학습한 모델을 데이터와 도구와 함께 제공하여 X-Embodiment 로봇 학습에 대한 연구에 활력을 불어넣는 것입니다.
Ⅱ. Related Work
Transfer across embodiments.
이전의 여러 연구들은 시뮬레이션 [10–22]과 실제 로봇 [23–29]에서 로봇 embodiments 간의 전이 방법을 연구했습니다.
이러한 방법들은 종종 서로 다른 로봇 간의 embodiment 격차를 해결하기 위해 특별히 설계된 메커니즘을 도입합니다, 예를 들어, 공유 행동 표현 [14, 30], 표현 학습 목표 [17, 26], 학습된 embodiment 정보 policy [11, 15, 18, 30, 31], 그리고 로봇과 환경 표현 분리 [24]가 있습니다.
이전 연구에서는 트랜스포머 모델을 사용한 X-embodiment 학습 [27]과 전이 [25, 29, 32]의 초기 시연을 제공했습니다.
우리는 보완적인 아키텍처를 조사하고 보완적인 분석을 제공하며, 특히 X-embodiment 전이와 웹 스케일 사전 학습 간의 상호작용을 연구합니다.
마찬가지로, 인간과 로봇 embodiment 간의 전이 방법도 embodiment 격차를 줄이기 위한 기술을 사용합니다, 예를 들어, 도메인 간의 이동이나 전이 가능한 표현 학습 [33–43]이 그것입니다.
또한, 일부 연구는 인간 비디오 데이터에서 전이 가능한 리워드 함수 [17, 44–48], 목표 [49, 50], 동역학 모델 [51] 또는 시각적 표현 [52–59]을 학습하는 것과 같은 문제의 하위 측면에 중점을 둡니다.
대부분의 이전 연구와 달리, 우리는 embodiment 격차를 줄이기 위한 메커니즘 없이 X-embodiment 데이터에 대한 policy를 직접 학습하고, 그 데이터를 활용하여 긍정적인 전이를 관찰합니다.
Large-scale robot learning datasets.
로봇 학습 커뮤니티는 grasping [60–71], pushing interactions [23, 72–74], 객체 및 모델 세트 [75–85], 원격 조작 시연 [8, 86–95] 등의 오픈 소스 로봇 학습 데이터셋을 만들었습니다.
RoboNet [23]을 제외하고, 이러한 데이터셋에는 동일한 유형의 로봇 데이터가 포함되어 있는 반면, 우리는 여러 embodiments에 걸친 데이터에 중점을 둡니다.
우리 데이터 저장소의 목표는 이러한 노력을 보완하는 것입니다: 우리는 많은 이전 데이터셋을 처리하고 통합하여 Open X-Embodiment라는 단일 표준화된 저장소로 만듭니다, 이 저장소는 로봇 학습 데이터셋이 어떻게 의미 있고 유용한 방식으로 공유될 수 있는지 보여줍니다.
Language-conditioned robot learning.
이전 연구는 로봇과 다른 에이전트들에게 언어 지침을 이해하고 따를 수 있는 능력을 부여하는 것을 목표로 했습니다 [96–101], 종종 언어 조건 policy를 학습함으로써 이루어졌습니다 [8, 40, 45, 102-106].
우리는 이전의 많은 연구들처럼 모방 학습을 통해 언어 조건부 policy를 학습시키지만, 대규모 멀티-embodiment 시연 데이터를 사용하여 이를 수행합니다.
로봇 모방 학습에서 사전 학습된 언어 임베딩 [8, 40, 45, 103, 107–112]과 사전 학습된 비전-언어 모델 [9, 113–115]을 활용한 이전 연구들에 이어, 우리는 실험에서 두 가지 형태의 사전 학습을 연구합니다, 특히 RT-1 [8]과 RT-2 [9]의 레시피를 따릅니다.
Ⅲ. The Open X-Embodiment Repository
Open X-Embodiment 저장소를 소개합니다 – 대규모 데이터와 X-embodied 로봇 학습 연구를 위한 사전 학습된 모델 체크포인트를 포함하는 오픈 소스 저장소.
보다 구체적으로, 우리는 더 넓은 커뮤니티에 다음과 같은 오픈 소스 자원을 제공하고 유지합니다:
• Open X-Embodiment 데이터셋: 22개의 로봇 embodiments에서 1M 이상의 로봇 궤적을 가진 로봇 학습 데이터셋.
• 사전 학습된 체크포인트: 추론 및 파인튜닝을 위한 RT-X 모델 체크포인트 선택.
우리는 이러한 자원들이 로봇 학습에서 X-Embodiment 연구의 파운데이션을 형성하기 위해 노력하고 있지만, 그것들은 단지 시작에 불과합니다.
Open X-Embodiment는 현재 전 세계 21개 기관이 참여하고 있는 커뮤니티 주도의 노력으로, 시간이 지남에 따라 참여 범위를 더욱 넓히고 초기 Open X-Embodiment 데이터셋을 확장할 수 있기를 기대합니다.
이 섹션에서는 데이터셋과 X-Embodiment 학습 프레임워크를 요약한 후, 데이터셋과 실험 결과를 평가하는 데 사용하는 특정 모델에 대해 논의합니다.
A. The Open X-Embodiment Dataset
Open X-Embodiment 데이터셋에는 단일 로봇 팔부터 이중 수동 로봇 및 사족보행에 이르기까지 22개의 로봇 embodiment에 걸친 1M 이상의 실제 로봇 궤적이 포함되어 있습니다.
이 데이터셋은 전 세계 34개 로봇 연구소에서 60개의 기존 로봇 데이터셋을 풀링하여 쉽게 다운로드하고 사용할 수 있도록 일관된 데이터 형식으로 변환하여 구축되었습니다.
우리는 RLDS 데이터 형식 [119]을 사용하여 데이터를 직렬화된 tfrecord 파일에 저장하고, 다양한 수의 RGB 카메라, 뎁스 카메라 및 포인트 클라우드와 같은 다양한 로봇 설정의 다양한 액션 공간과 입력 방식을 수용합니다.
또한 모든 주요 딥러닝 프레임워크에서 효율적이고 병렬화된 데이터 로딩을 지원합니다.
데이터 저장 형식에 대한 자세한 내용과 60개의 모든 데이터셋 분석은 프로젝트 페이지를 참조하세요.

B. Dataset Analysis
그림 2는 Open X-Embodiment 데이터셋을 분석한 것입니다.
그림 2(a)는 로봇 embodiment에 따른 데이터셋 분석을 보여주며, Franka 로봇이 가장 일반적입니다.
이는 Franka가 지배적인 embodiment당 장면 수 (데이터셋 메타데이터 기반)에 반영됩니다 (그림 2(b)).
그림 2(c)는 embodiment당 궤적 분석을 보여줍니다.
다양성을 더 분석하기 위해 데이터에 있는 언어 주석을 사용합니다.
우리는 PaLM 언어 모델 [3]을 사용하여 지침에서 객체와 행동을 추출합니다.
그림 2(d,e)는 기술과 객체의 다양성을 보여줍니다.
대부분의 기술은 pick-place 계열에 속하지만, 데이터셋의 긴 꼬리에는 "wiping" 또는 "assembling"과 같은 기술이 포함되어 있습니다.
또한, 데이터는 가전제품부터 식품 및 식기류에 이르기까지 다양한 가정용품을 다룹니다.
Ⅳ. RT-X Design
X-embodiment 학습이 개별 로봇에서 학습된 policy의 성능을 얼마나 향상시킬 수 있는지 평가하기 위해, 우리는 이러한 크고 이질적인 데이터셋을 생산적으로 활용할 수 있는 충분한 능력을 갖춘 모델이 필요합니다.
이를 위해, 우리의 실험은 최근에 제안된 두 가지 트랜스포머 기반 로봇 policy를 기반으로 할 것입니다: RT-1 [8] 및 RT-2 [9].
이 섹션에서는 이러한 모델의 설계를 간략하게 요약하고, 실험에서 X-embodiment 설정에 어떻게 적용했는지 논의합니다.
A. Data format consolidation
X-embodiment 모델을 만드는 데 있어 한 가지 도전 과제는 로봇마다 관찰 공간과 행동 공간이 크게 다르다는 점입니다.
우리는 데이터셋 간에 coarse하게 정렬된 액션 및 관찰 공간을 사용합니다.
이 모델은 최근 이미지와 언어 지침의 이력을 관측값으로 받아 엔드 이펙터(x, y, z, roll, pitch, yaw, gripper 개구부 또는 이러한 양의 비율)를 제어하는 7차원 액션 벡터를 예측합니다.
각 데이터셋에서 하나의 canonical 카메라 뷰를 입력 이미지로 선택하고, 이를 공통 해상도로 크기를 조정한 후 원래 액션 세트를 7 DoF 엔드 이펙터 액션으로 변환합니다.
이산화하기 전에 각 데이터셋의 작업을 정규화합니다.
이와 같이, 모델의 출력은 사용된 embodiment 방식에 따라 다르게 해석될 수 있습니다 (비정규화).
이러한 대략적인 정렬에도 불구하고 로봇에 대한 카메라 포즈가 다르거나 카메라 특성이 다르기 때문에 카메라 관측값은 여전히 데이터 세트마다 상당히 다르다는 점에 유의해야 합니다, 그림 3 참조.
마찬가지로, 액션 공간의 경우 엔드 이펙터가 제어되는 데이터셋 간에 좌표 프레임을 정렬하지 않으며, 각 로봇에 대해 선택된 원래 제어 방식에 따라 액션 값이 절대적 또는 상대적 위치 또는 속도를 나타낼 수 있도록 허용합니다.
따라서 동일한 액션 벡터가 로봇마다 매우 다른 동작을 유도할 수 있습니다.
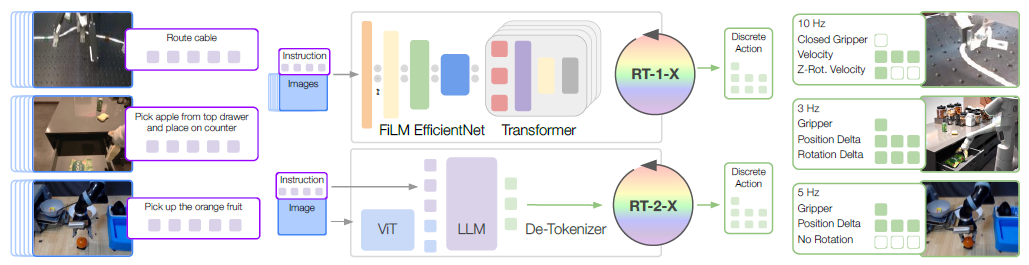
B. Policy architectures
우리는 실험에서 두 가지 모델 아키텍처를 고려합니다: (1) 로봇 제어를 위해 설계된 효율적인 트랜스포머 기반 아키텍처인 RT-1 [8]과 (2) 로봇 액션을 자연어 토큰으로 출력하도록 공동 파인튜닝된 대형 비전-언어 모델인 RT-2 [9].
두 모델 모두 작업을 설명하는 시각적 입력과 자연어 지시를 받아 토큰화된 액션을 출력합니다.
각 모델에 대해 액션은 8차원을 따라 균일하게 분포된 256개의 빈으로 토큰화됩니다; 에피소드 종료를 위한 1차원과 엔드-이펙터 움직임을 위한 7차원.
두 아키텍처 모두 원래 논문 [8, 9]에 자세히 설명되어 있지만, 아래에 각각의 간략한 요약을 제공합니다:
RT-1 [8] 은 트랜스포머 아키텍처 [118]를 기반으로 구축된 35M 매개변수 네트워크로, 그림 3과 같이 로봇 제어를 위해 설계되었습니다.
자연어와 함께 15개의 이미지의 역사를 담고 있습니다.
각 이미지는 ImageNet으로 사전 학습된 EfficientNet [117]을 통해 처리되며, 자연어 명령어는 USE [120] 임베딩으로 변환됩니다.
시각적 및 언어적 표현은 FiLM [116] 레이어를 통해 혼합되어 81개의 시각-언어 토큰을 생성합니다.
이 토큰들은 디코더 전용 트랜스포머에 입력되어 토큰화된 액션을 출력합니다.
RT-2 [9]는 로봇 제어 데이터와 함께 인터넷 규모의 비전 및 언어 데이터로 학습된 대규모 비전-언어-행동 모델 (VLA) 계열입니다.
RT-2는 토큰화된 액션을 텍스트 토큰에 적용합니다, 예를 들어, 가능한 액션은 "1 128 91 241 5 101 127"일 수 있습니다.
따라서 사전 학습된 비전-언어 모델 (VLM [121–123])은 로봇 제어를 위해 파인튜닝될 수 있으며, 따라서 VLM의 백본을 활용하고 일부 일반화 속성을 이전할 수 있습니다.
이 연구에서는 시각적 모델인 ViT [124]와 언어 모델인 UL2 [125]의 백본을 기반으로 구축된 RT-2-PaLI-X 변형 [121]에 중점을 두고 있으며, 주로 WebLI [121] 데이터셋에서 사전 학습되었습니다.
C. Training and inference details
두 모델 모두 출력 공간에서 표준 범주형 크로스 엔트로피 objective (RT-1의 경우 개별 버킷, RT-2의 경우 모든 가능한 언어 토큰)를 사용합니다.
모든 실험에서 사용된 로봇 데이터 혼합물을 9개의 매니퓰레이터 데이터로 정의하고, RT-1 [8], QT-Opt [66], Bridge [95], Task Agnostic Robot Play [126, 127], Jaco Play [128], Cable Routing [129], RoboTurk [86], NYU VINN [130], Austin VILA [131], Berkeley Autolab UR5 [132], TOTO [133] 및 Language Table [91] 데이터셋에서 가져왔습니다.
RT-1-X는 위에서 정의한 로보틱스 혼합 데이터만으로 학습되는 반면, RT-2-X는 원래 RT-2 [9]와 유사하게 원래 VLM 데이터와 로보틱스 데이터 혼합의 대략 1:1 분할을 통해 공동 파인튜닝을 통해 학습됩니다.
실험에 사용된 로봇 데이터 혼합물에는 전체 Open X-Embodiment 데이터셋 (22)보다 적은 9개의 embodiment가 포함되어 있습니다 – 이 차이의 실질적인 이유는 우리가 시간이 지남에 따라 데이터셋을 계속 확장해왔기 때문이며, 실험 당시에는 위의 데이터셋이 모든 데이터를 대표했기 때문입니다.
앞으로 우리는 확장된 버전의 데이터셋에 대한 학습 policy를 계속할 계획이며, 로봇 학습 커뮤니티와 함께 데이터셋을 계속 성장시킬 것입니다.
추론 시점에 각 모델은 로봇에 필요한 속도 (3-10Hz)로 실행되며, RT-1은 로컬에서 실행되고 RT-2는 클라우드 서비스에서 호스팅되며 네트워크를 통해 쿼리됩니다.
Ⅴ. Experimental Results
우리의 실험은 X-embodiment 학습의 효과에 대한 세 가지 질문에 답합니다:
(1) 우리의 X-embodiment 데이터셋에서 학습된 policy가 긍정적인 전이를 효과적으로 가능하게 하여, 여러 로봇에서 수집된 데이터에 대한 공동 학습이 학습 작업의 성능을 향상시킬 수 있을까요?
(2) 여러 플랫폼과 작업의 데이터에 대한 모델을 공동 학습하면 새로운 미지의 작업에 대한 일반화가 향상됩니까?
(3) 모델 크기, 모델 아키텍처 또는 데이터셋 구성과 같은 다양한 디자인 차원이 결과 policy의 성능 및 일반화 능력에 미치는 영향은 무엇입니까?
이러한 질문에 답하기 위해 6개의 다른 로봇에 걸쳐 총 3600건의 평가 시험을 실시합니다.
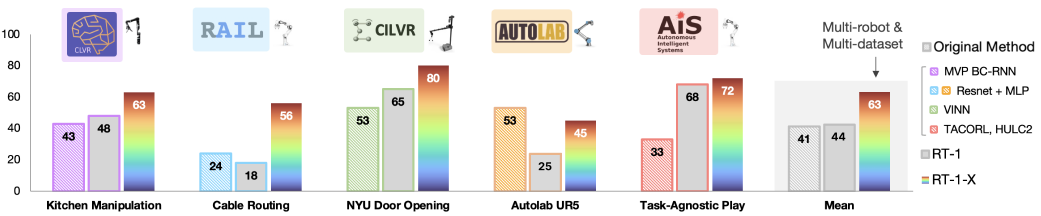
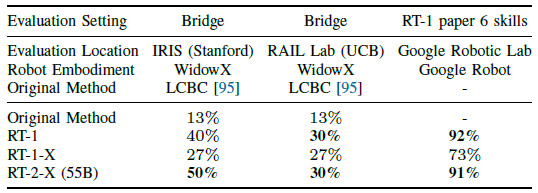
A. In-distribution performance across different embodiments
RT-X 모델이 X-embodiment 데이터로부터 학습할 수 있는 능력을 평가하기 위해, 우리는 분포 내 작업에서의 성능을 평가합니다.
우리는 평가를 두 가지 유형으로 나눕니다: 소규모 데이터셋이 있는 도메인에 대한 평가 (그림 4)에서는 대규모 데이터셋에서 성능이 크게 향상될 것으로 예상하고, 대규모 데이터셋이 있는 도메인에 대한 평가 (표 I)에서는 추가 개선이 더 어려울 것으로 예상됩니다.
이 섹션에 제시된 모든 평가에 대해 동일한 로봇 데이터 학습 혼합물 (섹션 IV-C에 정의됨)을 사용한다는 점에 유의하세요.
소규모 데이터셋 실험에서는 Kitchen Manipulation [128], Cable Routing [129], NYU Door Opening [130], AUTOLab UR5 [132], 그리고 Robot Play [134]를 사용합니다.
우리는 각각의 출판물과 동일한 평가와 로봇 embodiment을 사용합니다.
대규모 데이터셋 실험을 위해, 우리는 Bridge [95]와 RT-1 [8]을 분포 내 평가에 고려하고 각각의 로봇을 사용합니다: WidowX와 Google Robot.
각 소규모 데이터셋 도메인에 대해 RT-1-X 모델의 성능을 비교하고, 각 대규모 데이터셋에 대해 RT-1-X 모델과 RT-2-X 모델을 모두 고려합니다.
모든 실험에서 모델은 전체 X-embodiment 데이터셋에서 공동 학습됩니다.
이 평가에서 우리는 두 가지 기본 모델과 비교합니다:
(1) 데이터셋 제작자들이 개발한 모델은 해당 데이터셋에서만 학습되었습니다.
이 모델이 관련 데이터와 잘 작동하도록 최적화되었을 것으로 예상되는 한, 이는 합리적인 베이스라인 모델을 구성합니다; 우리는 이 베이스라인 모델을 원래 방법 모델이라고 부릅니다.
(2) 데이터셋에서 개별적으로 학습된 RT-1 모델; 이 베이스라인을 통해 RT-X 모델 아키텍처가 여러 다른 로봇 플랫폼에 대한 policy를 동시에 표현할 수 있는 충분한 용량을 가지고 있는지, 그리고 멀티-embodiment 데이터에 대한 공동 학습이 더 높은 성능으로 이어지는지 평가할 수 있습니다.
Small-scale dataset domains (그림 4).
RT-1-X는 5개의 데이터셋 중 4개의 데이터셋에서 각각의 로봇 전용 데이터셋으로 학습된 오리지널 메서드보다 성능이 뛰어나며, 평균적으로 큰 개선이 이루어졌으며, 데이터가 제한된 도메인이 X-embodiment 데이터에 대한 공동 학습을 통해 상당한 이점을 가지고 있음을 보여줍니다.
Large-scale dataset domains (표 Ⅰ).
대규모 데이터셋 설정에서 RT-1-X 모델은 embodiment-특정 데이터셋에서만 학습된 RT-1 베이스라인을 능가하지 않으며, 이는 해당 모델 클래스에 적합하지 않음을 나타냅니다.
그러나 더 큰 RT-2-X 모델은 오리지널 방법과 RT-1을 모두 능가하여 X-로봇 학습이 데이터가 풍부한 도메인에서 성능을 향상시킬 수 있지만, 충분히 높은 용량의 아키텍처를 활용할 때만 가능하다는 것을 시사합니다.
B. Improved generalization to out-of-distribution settings
이제 X-embodiment 학습이 어떻게 분포 외 설정과 더 복잡하고 새로운 지침에 대한 더 나은 일반화를 가능하게 할 수 있는지 살펴봅니다.
이 실험들은 고데이터 도메인에 초점을 맞추고 있으며, RT-2-X 모델을 사용합니다.

Unseen objects, backgrounds and environments.
먼저 [9]에서 제안한 것과 동일한 일반화 속성 평가를 수행하여 보이지 않는 환경과 보이지 않는 배경에서 보이지 않는 물체를 조작할 수 있는 능력을 테스트합니다.
RT-2와 RT-2-X가 대략 동등한 성능을 보인다는 것을 발견했습니다 (표 II, 행 (1)과 (2), 마지막 열).
이는 예상치 못한 일이 아닙니다, RT-2는 VLM 백본 덕분에 이미 이러한 차원에서 잘 일반화되어 있기 때문입니다 ([9] 참조).

Emergent skills evaluation.
로봇 간 지식 전달을 조사하기 위해, 우리는 Google Robot을 사용하여 실험을 수행하고, 그림 5와 같은 작업에서 성능을 평가합니다.
이러한 작업에는 RT-2 데이터셋에는 없지만 다른 로봇 (WidowX 로봇)의 Bridge 데이터셋 [95]에는 존재하는 객체와 기술이 포함됩니다.
결과는 표 II, Emergent Skills Evaluation 열에 나와 있습니다.
행 (1)과 (2)를 비교한 결과, RT-2-X가 RT-2보다 약 3배 더 우수한 성능을 보인다는 것을 발견했습니다, 이는 다른 로봇의 데이터를 학습에 통합하면 이미 많은 양의 데이터를 사용할 수 있는 로봇도 수행할 수 있는 작업 범위가 향상된다는 것을 시사합니다.
우리의 결과는 다른 플랫폼의 데이터와 공동 학습을 통해 RT-2-X 컨트롤러가 해당 플랫폼의 원래 데이터셋에 없는 추가 기술을 습득할 수 있음을 시사합니다.
다음 ablation은 RT-2-X 학습에서 Bridge 데이터 세트를 제거하는 것입니다: 행 (3)은 Bridge 데이터셋을 제외한 RT-2-X에 사용된 모든 데이터를 포함하는 RT-2-X의 결과를 보여줍니다.
이 변형은 보류 작업의 성능을 크게 저하시키며, 이는 WidowX 데이터의 전송이 실제로 Google Robot을 사용하여 RT-2-X가 수행할 수 있는 추가 기술에 책임이 있을 수 있음을 시사합니다.
C. Design decisions
마지막으로, 표 II에 제시된 가장 성능이 뛰어난 RT-2-X 모델의 일반화 능력에 대한 다양한 설계 결정의 영향을 측정하기 위해 ablation을 수행합니다.
짧은 이미지 기록을 포함하면 일반화 성능이 크게 향상된다는 점에 유의합니다 (행 (4) vs 행 (5)).
RT-2 논문 [9]의 결론과 유사하게, 모델의 웹 기반 사전 학습은 대형 모델 (행(4) vs 행(6))에서 높은 성능을 달성하는 데 매우 중요합니다.
우리는 또한 55B 모델이 5B 모델 (행 (2) vs 행 (4))에 비해 이머전트 스킬에서 훨씬 더 높은 성공률을 보인다는 점을 주목하며, 더 높은 모델 용량이 로봇 데이터셋 간의 더 높은 전송 수준을 가능하게 한다는 것을 보여줍니다.
이전 RT-2 연구 결과와 달리, 공동 파인튜닝과 파인튜닝은 이머전트 스킬 및 일반화 평가 (행 (4) vs 행 (7)) 모두에서 유사한 성능을 보입니다, 이는 RT-2-X에 사용된 로봇 데이터가 이전에 사용된 로봇 데이터셋보다 훨씬 더 다양하기 때문입니다.
Ⅵ. Discussion, Future Work, and Open Problems
우리는 21개 기관 간의 협업을 통해 수집된 22개의 로봇 embodiments 데이터를 결합한 통합 데이터셋을 제시하여 527개의 기술 (160266개의 작업)을 입증했습니다.
우리는 또한 이 데이터를 기반으로 학습된 트랜스포머 기반 policy가 데이터셋 내 다른 로봇들 간에 상당한 양의 전이를 보일 수 있다는 실험적 시연을 제시했습니다.
우리의 결과에 따르면 RT-1-X policy를 서로 다른 협력 기관에서 기여한 기존 SOTA 방법보다 50% 더 높은 성공률을 보였으며, 더 큰 비전-언어 모델 기반 버전 (RT-2-X)은 평가 embodiment 데이터만으로 학습된 모델에 비해 약 3배의 일반화 개선을 보였습니다.
또한, 우리는 로봇 커뮤니티가 X-embodiment 로봇 학습 연구를 탐구할 수 있도록 여러 자원을 제공했습니다: 통합된 X-robot 및 X-institution 데이터셋, 데이터 사용 방법을 보여주는 샘플 코드, 그리고 미래 탐사를 위한 파운데이션이 될 RT-1-X 모델.
RT-X는 X-embodied 로봇 일반화를 향한 한 걸음을 내딛는 모습을 보여주지만, 이 미래를 현실로 만들기 위해서는 더 많은 단계가 필요합니다.
우리의 실험은 감지 및 작동 방식이 매우 다른 로봇을 고려하지 않습니다.
그들은 새로운 로봇에 대한 일반화를 연구하지 않으며, 긍정적인 전이가 발생하거나 발생하지 않는 시점에 대한 결정 기준을 제공합니다.
이 질문들을 연구하는 것은 중요한 미래 작업 방향입니다.
이 연구는 X-로봇 학습이 실현 가능하고 실용적일 뿐만 아니라, 앞으로 이러한 방향으로 연구를 발전시킬 수 있는 도구를 제공합니다.
'Robotics' 카테고리의 다른 글
| PaLM-E: An Embodied Multimodal Language Model (0) | 2025.03.20 |
|---|---|
| RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control (0) | 2025.03.17 |
| RT-1: Robotics Transformer for Real-World Control at Scale (0) | 2025.03.10 |
| π0: A Vision-Language-Action Flow Model for General Robot Control (0) | 2025.02.20 |
| Cosmos World Foundation Model Platform for Physical AI (0) | 2025.01.10 |