2025. 6. 25. 10:51ㆍRobotics
Navigation World Models
Amir Bar, Gaoyue Zhou, Danny Tran, Trevor Darrell, Yann LeCun
Abstract
내비게이션은 비주얼-모터 능력을 갖춘 에이전트의 기본 기술입니다.
우리는 과거의 관찰과 내비게이션 동작을 기반으로 미래의 시각적 관찰을 예측하는 제어 가능한 비디오 생성 모델인 Navigation World Model (NWM)을 소개합니다.
복잡한 환경 역학을 포착하기 위해 NWM은 Conditional Diffusion Transformer (CDiT)를 사용하여 인간 및 로봇 에이전트의 다양한 자기 중심적 비디오 컬렉션을 학습하고 최대 10억 개의 매개변수로 확장했습니다.
익숙한 환경에서 NWM은 내비게이션 경로를 시뮬레이션하고 원하는 목표를 달성했는지 평가하여 경로를 계획할 수 있습니다.
고정된 동작을 사용하는 supervised 내비게이션 policy와 달리, NWM은 계획 중에 동적으로 제약 조건을 통합할 수 있습니다.
실험은 궤적을 처음부터 계획하거나 외부 policy에서 샘플링한 궤적의 순위를 매기는 데 효과적임을 보여줍니다.
또한, NWM은 학습된 시각적 priors를 활용하여 단일 입력 이미지를 통해 낯선 환경에서의 궤적을 상상할 수 있어 차세대 내비게이션 시스템을 위한 유연하고 강력한 도구입니다.
1. Introduction
내비게이션은 시력을 가진 모든 유기체에게 기본적인 기술로, 에이전트가 먹이를 찾고, 은신하며, 포식자를 피할 수 있도록 함으로써 생존에 중요한 역할을 합니다.
스마트 에이전트는 환경을 성공적으로 탐색하기 위해 주로 시각에 의존하며, 이를 통해 주변 환경의 표현을 구성하여 거리를 평가하고 환경의 랜드마크를 포착할 수 있으며, 이는 모두 탐색 경로를 계획하는 데 유용합니다.
인간 에이전트는 계획을 세울 때 제약 조건과 반사실적을 고려하여 미래의 궤적을 상상하는 경우가 많습니다.
반면, 현재 SOTA 로봇 내비게이션 policy [53, 55]는 "hard-coded"되어 있으며, 학습 후에는 새로운 제약 조건을 쉽게 도입할 수 없습니다 (예: "no left turns").
현재 supervised 시각 내비게이션 모델의 또 다른 한계는 어려운 문제를 해결하기 위해 더 많은 계산 자원을 동적으로 할당할 수 없다는 점입니다.
우리는 이러한 문제를 완화할 수 있는 새로운 모델을 설계하는 것을 목표로 합니다.

이 연구에서는 과거 프레임 표현과 액션을 기반으로 비디오 프레임의 미래 표현을 예측하도록 학습된 Navigation World Model (NWM)을 제안합니다 (그림 1(a) 참조).
NWM은 다양한 로봇 에이전트로부터 수집한 비디오 영상과 내비게이션 액션을 학습합니다.
학습 후 NWM은 잠재적인 내비게이션 계획을 시뮬레이션하고 타겟 목표에 도달했는지 확인하여 새로운 내비게이션 경로를 계획하는 데 사용됩니다 (그림 1(b) 참조).
내비게이션 기술을 평가하기 위해, 우리는 알려진 환경에서 NWM을 테스트하고, 독립적으로 새로운 경로를 계획하거나 외부 내비게이션 policy를 순위 매김으로써 NWM의 능력을 평가합니다.
계획 설정에서는 Model Predictive Control (MPC) 프레임워크에서 NWM을 사용하여 NWM이 타겟 목표에 도달할 수 있도록 액 순서를 최적화합니다.
순위 설정에서 우리는 NoMaD [55]와 같은 기존 내비게이션 policy에 접근할 수 있다고 가정합니다, 이 궤적을 샘플링하고, NWM을 사용하여 시뮬레이션하며, 최적의 경로를 선택할 수 있게 해줍니다.
저희 NWM은 기존 방법과 결합하여 SOTA 독립형 성능과 경쟁력 있는 결과를 달성합니다.
NWM은 개념적으로 DIAMOND [1] 및 GameNGen [66]과 같은 오프라인 모델 기반 강화 학습을 위한 최신 디퓨전 기반 월드 모델과 유사합니다.
그러나 이러한 모델과 달리 NWM은 로봇 및 인간 에이전트의 다양한 내비게이션 데이터를 활용하여 다양한 환경과 embodiments에 걸쳐 학습됩니다.
이를 통해 모델 크기와 데이터를 효과적으로 확장하여 여러 환경에 적응할 수 있는 대형 디퓨전 트랜스포머 모델을 학습할 수 있습니다.
우리의 접근 방식은 NeRF [40], Zero-1-2-3 [38], GDC [67]과 같은 Novel View Synthesis (NVS) 방법과도 유사하며, 이를 통해 영감을 얻습니다.
그러나 NVS 접근 방식과 달리, 우리의 목표는 다양한 환경에서 내비게이션을 위한 단일 모델을 학습하고, 3D priors에 의존하지 않고 자연 비디오를 통해 시간 역학을 모델링하는 것입니다.
NWM을 학습하기 위해, 우리는 과거 이미지 상태와 액션을 맥락으로 하여 다음 이미지 상태를 예측하도록 학습된 새로운 Conditional Diffusion Transformer (CDiT)를 제안합니다.
DiT[44]와 달리, CDiT의 계산 복잡성은 컨텍스트 프레임 수에 비례하여 선형적이며, 다양한 환경과 embodiments에서 최대 1B 매개변수까지 학습된 모델에 유리하게 확장됩니다, 이는 표준 DiT에 비해 4배 적은 FLOP을 요구하면서도 더 나은 미래 예측 결과를 달성합니다.
알 수 없는 환경에서, 우리의 결과는 NWM이 Ego4D의 라벨이 없는, 액션 및 리워드 없는 비디오 데이터에 대한 학습을 통해 이점을 얻는다는 것을 보여줍니다.
질적으로 단일 이미지에서 향상된 비디오 예측 및 생성 성능을 관찰했습니다 (그림 1(c) 참조).
정량적으로, 라벨이 없는 추가 데이터를 통해 NWM은 held-out Standford Go [24] 데이터셋에서 평가할 때 더 정확한 예측을 제공합니다.
우리의 기여는 다음과 같습니다.
Navigation World Model (NWM)을 소개하고 표준 DiT에 비해 계산 요구 사항을 크게 줄이면서 최대 1B 매개변수까지 효율적으로 확장할 수 있는 새로운 Conditional Diffusion Transformer (CDiT)를 제안합니다.
우리는 다양한 로봇 에이전트의 비디오 영상과 내비게이션 액션에 대해 CDiT를 학습시켜, 내비게이션 계획을 독립적으로 또는 외부 내비게이션 policy와 함께 시뮬레이션하여 계획을 수립할 수 있게 하여 SOTA 시각적 내비게이션 성능을 달성합니다.
마지막으로, Ego4D와 같은 액션 및 리워드 없는 비디오 데이터를 기반으로 NWM을 학습함으로써 보이지 않는 환경에서 향상된 비디오 예측 및 생성 성능을 입증합니다.
2. Related Work
목표 조건 시각 내비게이션은 로봇 공학에서 지각과 계획 능력을 모두 요구하는 중요한 작업입니다 [8, 13, 15, 41, 43, 51, 55].
맥락 이미지와 내비게이션 목표를 지정하는 이미지가 주어지면, 목표 조건부 시각 내비게이션 모델 [51, 55]은 환경이 알려져 있을 때 목표를 향해 실행 가능한 경로를 생성하거나 다른 방식으로 탐색하는 것을 목표로 합니다.
최근의 시각적 내비게이션 방법인 NoMaD [55]는 조건부 설정에서 목표를 따르거나 무조건적인 설정에서 새로운 환경을 탐색하기 위해 행동 복제와 시간적 거리 objective를 통해 디퓨전 policy를 학습시킵니다.
이전 접근 방식인 Active Neural SLAM [8]은 3D 환경에서 궤적을 계획하기 위해 분석 계획자와 함께 Neural SLAM을 사용했으며, 다른 접근 방식인 [9]는 강화 학습을 통해 policy를 학습합니다.
여기서 우리는 월드 모델이 탐색 데이터를 사용하여 기존 내비게이션 policy를 계획하거나 개선할 수 있음을 보여줍니다.
policy를 학습하는 것과는 달리, 월드 모델 [19]의 목표는 환경을 시뮬레이션하는 것입니다, 예를 들어, 현재 상태와 다음 상를 예측하는 액션 및 관련 리워드가 주어집니다.
이전 연구들은 policy와 월드 모델을 공동으로 학습하는 것이 Atari [1, 20, 21], 시뮬레이션된 로봇 환경 [50], 그리고 실제 로봇에 적용될 때에도 샘플 효율성을 향상시킬 수 있음을 보여주었습니다 [71].
최근에 [22]는 작업과 작업 임베딩을 도입하여 작업 간에 공유되는 단일 월드 모델을 사용할 것을 제안했으며, [37, 73]은 언어로 작업을 설명하고, [6]은 잠재적인 작업을 학습할 것을 제안했습니다.
월드 모델들도 게임 시뮬레이션의 맥락에서 탐구되었습니다.
DIAMOND [1]와 GameNGen [66]은 디퓨전 모델을 사용하여 Atari와 Doom과 같은 컴퓨터 게임의 게임 엔진을 학습할 것을 제안합니다.
우리의 작업은 이러한 작업에서 영감을 받았으며, 다양한 환경과 다양한 embodiments에서 공유할 수 있는 단일 일반 디퓨전 비디오 트랜스포머를 학습하는 것을 목표로 합니다.
컴퓨터 비전에서 비디오를 생성하는 것은 오랜 도전 과제였습니다 [3, 4, 17, 29, 32, 62, 74].
가장 최근에는 Sora [5]와 MovieGen [45]와 같은 방법으로 text-to-video 합성에 엄청난 진전이 있었습니다.
과거 연구들은 구조화된 액션-객체 클래스 카테고리 [61] 또는 Action Graphs [2]가 주어졌을 때 비디오 합성을 제어할 것을 제안합니다.
비디오 생성 모델은 이전에 강화 학습에서 리워드 [10], 사전 학습 방법 [59], 조작 액션 시뮬레이션 및 계획 [11, 35], 실내 환경에서 경로 생성 [26, 31]으로 사용되었습니다.
흥미롭게도 디퓨전 모델 [28, 54]은 생성 [69] 및 예측 [36]과 같은 비디오 작업뿐만 아니라 뷰 합성 [7, 46, 63]에도 유용합니다.
다르게, 우리는 명시적인 3D 표현이나 priors 없이 계획을 위한 궤적을 시뮬레이션하기 위해 조건부 디퓨전 트랜스포머를 사용합니다.
3. Navigation World Models
3.1. Formulation
다음으로, 우리는 NWM 공식에 대해 설명하겠습니다.
직관적으로 NWM은 현재 월드의 상태 (예: 이미지 관찰)와 이동 위치 및 회전 방법을 설명하는 내비게이션 action을 수신하는 모델입니다.
그런 다음 모델은 에이전트의 관점에서 다음 월드 상를 생성합니다.
자기중심적인 비디오 데이터셋과 에이전트 내비게이션 액션 D = {(x_0, a_0, ..., x_T, a_T)}가 주어졌습니다, x_i ∈ R^(H×W×3)는 이미지이고, a_i = (u, ϕ)는 순방향/역방향 및 오른쪽/왼쪽 움직임의 변화를 제어하는 변환 매개변수 u ∈ R^2에 의해 주어지는 내비게이션 명령이며, yaw 회전 각도의 변화를 제어하는 ϕ ∈ R입니다.
내비게이션 액션 a_i는 완전히 관찰될 수 있습니다 (Habitat [49]에서와 같이), 예를 들어, 벽을 향해 앞으로 나아가는 것은 물리학에 기반한 환경의 반응을 유발하여 에이전트가 제자리에 머무르게 할 것입니다, 반면, 다른 환경에서는 에이전트의 위치 변화를 기반으로 내비게이션 액션을 근사화할 수 있습니다.
우리의 목표는 월드 모델 F를 학습하는 것입니다, 이는 이전의 잠재적 관찰 s_τ와 액션 a_τ에서 미래의 잠재 상태 표현 s_(t+1)로의 확률적 매핑입니다:

여기서 s_τ = (s_τ , ..., s_(τ-m))는 사전 학습된 VAE [4]를 통해 인코딩된 과거 m개의 시각적 관측값입니다.
VAE를 사용하면 압축된 잠재 변수를 처리할 수 있어 예측을 픽셀 공간으로 디코딩하여 시각화할 수 있다는 장점이 있습니다.
이 공식의 단순성 덕분에 여러 환경에서 자연스럽게 공유할 수 있으며 로봇 팔을 제어하는 것과 같은 더 복잡한 액션 공간으로 쉽게 확장할 수 있습니다.
[20]과 달리, 우리는 [22]와 같은 작업이나 액션 임베딩을 사용하지 않고 환경과 embodiments에 걸쳐 단일 월드 모델을 학습하는 것을 목표로 합니다.
식 1의 공식은 맥션을 모델링하지만 시간적 역학을 제어할 수는 없습니다.
우리는 이 공식을 시간 이동 입력 k ∈ [T_min, T_max]로 확장하여 a_τ = (u, ϕ, k)를 설정합니다, 따라서 이제 a_τ는 모델이 미래 (또는 과거)로 이동해야 할 단계 수를 결정하는 데 사용되는 시간 변화 k를 지정합니다.
따라서 현재 상태 s_τ가 주어졌을 때, 우리는 임의로 시간 이동 k를 선택하고 해당 시간 이동 비디오 프레임을 다음 상태 s_(τ+1)로 사용할 수 있습니다.
내비게이션 액션은 시간 τ에서 m = τ + k - 1까지의 합으로 근사할 수 있습니다:
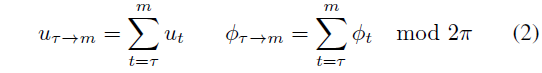
이 공식은 내비게이션 액션뿐만 아니라 환경 시간 역학도 학습할 수 있게 해줍니다.
실제로 우리는 최대 ±16초의 시간 이동을 허용합니다.
발생할 수 있는 한 가지 도전 과제는 액션과 시간의 얽힘입니다.
예를 들어, 특정 위치에 항상 도달하는 것이 특정 시간에 발생하는 경우, 모델은 시간에만 의존하고 후속 조치를 무시하는 방법을 배울 수 있으며, 그 반대의 경우도 마찬가지입니다.
실제로 데이터에는 자연스러운 반사실적이 포함될 수 있습니다—다른 시간에 같은 지역에 도달하는 것과 같은.
이러한 자연스러운 반사실적을 장려하기 위해, 우리는 학습 중에 각 상태 여러 목표를 샘플링합니다.
우리는 섹션 4에서 이 접근 방식을 더 탐구합니다.
3.2. Diffusion Transformer as World Model
이전 섹션에서 언급했듯이, 우리는 확률적 환경을 시뮬레이션할 수 있도록 F_θ을 확률적 매핑으로 설계합니다.
이는 다음에 설명하는 Conditional Diffusion Transformer (CDiT) 모델을 사용하여 달성됩니다.

Conditional Diffusion Transformer Architecture.
우리가 사용하는 아키텍처는 효율적인 CDiT 블록 (그림 2 참조)을 활용한 시간적 자기회귀 트랜스포머 모델로, 입력 액션 조건이 있는 잠재 변수의 입력 시퀀스에 대해 ×N 번 적용됩니다.
CDiT는 첫 번째 어텐션 블록의 어텐션을 디노이즈되는 타겟 프레임의 토큰으로만 제한하여 시간 효율적인 자기회귀 모델링을 가능하게 합니다.
과거 프레임의 토큰을 조건으로 하기 위해, 우리는 크로스-어텐션 레이어를 통합하여 현재 타겟의 모든 query 토큰이 과거 프레임의 토큰을 key와 value로 사용하도록 합니다.
크로스-어텐션은 그런 다음 스킵 연결 레이어를 사용하여 표현을 맥락화합니다.
내비게이션 액션 a ∈ R^3을 조건으로 하기 위해, 먼저 사인-코사인 피쳐를 추출한 다음 2-레이어 MLP를 적용하여 각 스칼라를 R^(d/3)로 매핑하고, 이를 단일 벡터 ψ_a ∈ R^d로 concat합니다.
우리는 유사한 과정을 따라 시간 이동 k ∈ R을 ψ_k ∈ R^d로, 디퓨전 시간 단계 t ∈를 ψ_k ∈ R^d로 매핑합니다.
마지막으로 모든 임베딩을 조건화에 사용되는 단일 벡터로 합산합니다:
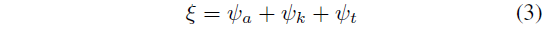
그런 다음 ξ를 AdaLN [72] 블록에 공급하여 레이어 정규화 [34] 출력과 어텐션 레이어 출력을 변조하는 스케일 및 시프트 계수를 생성합니다.
라벨이 없는 데이터를 학습하기 위해 ξ를 계산할 때 명시적인 내비게이션 액션을 생략하기만 하면 됩니다 (식 3 참조).
다른 접근 방식은 단순히 DiT를 사용하는 것이지만 [44], 전체 입력에 DiT를 적용하는 것은 계산 비용이 많이 듭니다.
프레임당 입력 토큰의 수를 n으로 나타내고, 프레임 수를 m으로 하며, 토큰 차원을 d로 표시합니다.
Scaled Multi-head Attention Layer [68] 복잡도는 컨텍스트 길이에 따라 이차적인 어텐션 항 O(m^2 n^2 d)에 의해 지배됩니다.
반면, 우리의 CDiT 블록은 컨텍스트에 대해 선형적인 크로스-어텐션 레이어 복잡도 O(m n^2 d)에 의해 지배되므로 더 긴 컨텍스트 크기를 사용할 수 있습니다.
우리는 섹션 4에서 이 두 가지 설계 선택 사항을 분석합니다.
CDiT는 컨텍스트 토큰에 비싼 셀프 어텐션을 적용하지 않고도 원래 트랜스포머 블록 [68]과 유사합니다.
Diffusion Training.
순방향 프로세스에서는 랜덤으로 선택된 시간 단계 t ∈ {1, ..., T}에 따라 타겟 상태 s_(τ+1)에 노이즈가 추가됩니다.
노이즈 상태 s_(τ+1)^(t)은 다음과 같이 정의할 수 있습니다: s_(τ+1)^(t) = √α_t s_(τ+1)+ √(1 - α_t) ϵ, 여기서 ϵ ~ N(0, I)는 가우시안 노이즈이고 {α_t}는 분산을 제어하는 노이즈 스케줄입니다.
t가 증가함에 따라 s_(τ+1)^(t)는 순수 노이즈로 수렴합니다.
역 과정은 문맥 s_τ, 현재 액션 a_τ, 디퓨전 시간 단계 t에 따라 노이즈 버전 s_(τ+1)^(t)에서 원래 상태 표현 s_(τ+1)을 복원하려고 시도합니다.
우리는 F_θ(s_(τ+1)|s_τ, a_τ, t)를 θ에 의해 매개변수화된 디노이징 신경망 모델로 정의합니다.
우리는 DiT [44]의 동일한 노이즈 스케줄과 하이퍼파라미터를 따릅니다.
Training Objective.
이 모델은 디노이징 과정을 학습하기 위해 깨끗한 타겟과 예측된 목표 사이의 평균 제곱을 최소화하도록 학습되었습니다:
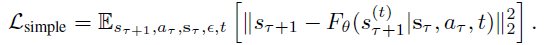
이 objective에서는 모델이 다양한 수준의 손상에서 프레임 디노이즈하는 방법을 학습하도록 시간 단계 t를 랜덤으로 샘플링합니다.
이 loss를 최소화함으로써, 모델은 s_τ와 액션 a_τ를 조건으로 하여 노이즈 버전 s(τ+1)^(t)에서 s_(τ+1)을 재구성하는 방법을 학습하여 현실적인 미래 프레임을 생성할 수 있습니다.
[44]에 이어, 우리는 노이즈의 공분산 행렬을 예측하고 variational lower bound loss L_vlb [42]로 이를 supervise합니다.
3.3. Navigation Planning with World Models
여기에서는 학습된 NWM을 사용하여 내비게이션 경로를 계획하는 방법을 설명합니다.
직관적으로, 우리의 월드 모델이 환경에 익숙하다면, 그것을 사용하여 항해 경로를 시뮬레이션하고 목표에 도달하는 경로를 선택할 수 있습니다.
알려지지 않은 배포 환경에서는 장기 계획이 상상력에 의존할 수 있습니다.
형식적으로, 잠재 인코딩 s_0와 내비게이션 타겟 s∗가 주어졌을 때, 우리는 s∗에 도달할 가능성을 최대화하는 일련의 액션 (a_0, ..., a_(T-1))을 찾습니다.
S(s_T, s∗)를 초기 조건 s_0, 액션 a = (a_0, . . , a_(T-1)), 상태 s = (s_1, ..., s_T)가 주어졌을 때 상태 s∗에 도달하기 위한 비정규화 점수를 나타낸다고 가정해 보겠습니다: s ~ F_θ(·|s_0, a).
우리는 에너지 함수 E(s_0, a_0, . . , a_(T-1), s_T)를 정의하여, 에너지를 최소화하는 것이 비정규화된 지각 유사성 점수를 최대화하고 상태와 액션에 대한 잠재적 제약을 따르는 것과 일치하도록 합니다:
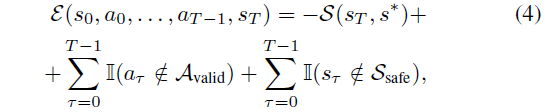
유사성은 사전 학습된 VAE 디코더를 사용하여 s∗ 및 s_T를 픽셀로 디코딩한 다음 지각적 유사성을 측정하여 계산됩니다 [14, 75].
"never go left then right"와 같은 제약 조건은 a_τ가 유효한 액션 세트 A_valid에 있도록 제약함으로써 인코딩할 수 있으며, s_τ가 S_safe에 있는지 확인함으로써 "never explore the edge of the cliff"고 할 수 있습니다.
I(·)는 어떤 액션이나 상태 제약이 위반될 경우 큰 벌금을 부과하는 지시 함수를 나타냅니다.
문제는 이 에너지 함수를 최소화하는 액션을 찾는 것으로 귀결됩니다:
이 objective는 Model Predictive Control (MPC) 문제로 재구성할 수 있으며, 최근 월드 모델과 함께 계획에 사용된 간단한 파생상품 없는 인구 기반 최적화 방법인 크로스 엔트로피 방법 [48]을 사용하여 최적화합니다 [77].
우리는 부록 7에 교차 엔트로피 방법의 개요와 전체 최적화 기술 세부 사항을 포함하고 있습니다.
Ranking Navigation Trajectories.
기존 내비게이션 정책인 π(a|s_0, s∗)가 있다고 가정하면, NWM을 사용하여 샘플링된 궤적의 순위를 매길 수 있습니다.
여기서는 로봇 내비게이션을 위한 SOTA 내비게이션 정책인 NoMaD [55]를 사용합니다.
궤적을 순위 매기기 위해, 우리는 π에서 여러 개의 샘플을 추출하고, 식 5와 같이 에너지가 가장 낮은 샘플을 선택합니다.
4. Experiments and Results
실험 설정, 설계 선택 사항을 설명하고 NWM을 이전 접근 방식과 비교합니다.
추가 결과는 보충 자료에 포함되어 있습니다.
4.1. Experimental Setting
Datasets.
모든 로봇 데이터셋 (SCAND [30], TartanDrive [60], RECON [52], HuRoN [27])에 대해 로봇의 위치와 회전에 접근할 수 있으므로 현재 위치와 비교하여 상대적인 액션을 추론할 수 있습니다 (식 2 참조).
에이전트 간의 스텝 크기를 표준화하기 위해, 우리는 에이전트들이 프레임 간 이동하는 거리를 평균 스텝 크기를 미터 단위로 나누어 작업 공간이 서로 비슷하도록 합니다.
우리는 NoMaD [55]를 따라 역방향 움직임을 추가로 필터링합니다.
또한 라벨이 없는 Ego4D [18] 동영상을 사용하는데, 여기서 고려하는 유일한 액션은 시간 이동입니다.
SCAND는 다양한 환경에서 사회적 규정을 준수하는 내비게이션의 비디오 영상을 제공하고, TartanDrive는 오프로드 주행에 중점을 두며, RECON은 오픈 월드 내비게이션을 다루고, HuRoN은 소셜 상호작용을 캡처합니다.
우리는 레이블이 없는 Ego4D 비디오로 학습하며, GO Stanford [24]는 미지의 평가 환경으로 작용합니다.
자세한 내용은 부록 8.1을 참조하세요.
Evaluation Metrics.
우리는 정확성을 위해 Absolute Trajectory Error (ATE)를 사용하고 포즈 일관성을 위해 Relative Pose Error (RPE)를 사용하여 예측된 내비게이션 궤적을 평가합니다 [57].
월드 모델 예측이 실제 이미지와 얼마나 시맨적으로 유사한지 확인하기 위해, 우리는 LPIPS [76]와 DreamSim [14]을 적용하여 심층 피쳐를 비교하여 지각적 유사성을 측정하고, 픽셀 수준의 품질을 위해 PSNR을 적용합니다.
이미지 및 비디오 합성 품질을 위해 생성된 데이터 분포를 평가하는 FID [23]와 FVD [64]를 사용합니다.
자세한 내용은 부록 8.1을 참조하세요.
Baselines.
다음 모든 베이스라인을 고려합니다.
• DIAMOND [1]은 UNet [47] 아키텍처를 기반으로 한 디퓨전 월드 모델입니다.
우리는 공개 코드를 따르는 오프라인 강화 학습 환경에서 DIAMOND를 사용합니다.
디퓨전 모델은 업샘플러와 함께 56x56 해상도에서 자기회귀적으로 예측하도록 학습되어 224x224 해상도 예측을 방해합니다.
연속적인 액션을 조건으로 하기 위해 선형 임베딩 레이어를 사용합니다.
• GNM [53]은 완전히 연결된 궤적 예측 네트워크를 갖춘 로봇 내비게이션 데이터셋의 데이터셋 수프에서 학습된 일반적인 목표 조건부 내비게이션 정책입니다.
GNM은 SCAND, TartanDrive, GO Stanford, RECON을 포함한 여러 데이터셋에서 학습됩니다.
• NoMaD [55]는 로봇 탐사 및 시각적 내비게이션을 위한 경로 예측을 위한 디퓨전 정책을 사용하여 GNM을 확장합니다.
NoMaD는 GNM에서 사용하는 동일한 데이터셋과 HuRoN에서 학습됩니다.
Implementation Details.
디폴트 실험 설정에서는 컨텍스트 4프레임, 총 배치 크기 1024, 그리고 4가지 다른 탐색 목표를 가진 1B 매개변수의 CDiT-XL을 사용하여 최종 총 배치 크기 4096을 도출합니다.
우리는 DiT [44]에서와 유사하게 Stable Diffusion [4] VAE 토큰라이저를 사용합니다.
우리는 학습률이 8e^-5인 AdamW [39] 옵티마이저를 사용합니다.
학습 후, 우리는 각 모델에서 5번씩 샘플링하여 평균 및 표준 결과를 보고합니다.
XL 사이즈 모델은 각각 8개의 GPU를 갖춘 8대의 H100 머신으로 학습됩니다.
달리 언급되지 않는 한, 우리는 DiT-*/2 모델에서와 동일한 설정을 사용합니다.
4.2. Ablations
모델은 알려진 환경 RECON에서 검증 세트 궤적에 대한 단일 단계 4초 미래 예측을 통해 평가됩니다.
우리는 LPIPS, DreamSim, PSNR을 측정하여 ground truth 프레임에 대한 성능을 평가합니다.
우리는 그림 3에 정성적인 예시를 제공합니다.


Model Size and CDiT.
CDiT(섹션 3.2 참조)를 모든 컨텍스트 토큰이 입력으로 제공되는 표준 DiT와 비교합니다.
우리는 알려진 환경을 탐색할 때 모델의 용량이 가장 중요하다고 가정하며, 그림 5의 결과는 CDiT가 최대 1B 매개변수 모델에서 2배 미만의 FLOP을 소비하면서 실제로 더 나은 성능을 발휘한다는 것을 나타냅니다.
놀랍게도, 동일한 양의 매개변수(예: DiT-XL과 비교했을 때 CDiT-L)를 사용하더라도 CDiT는 4배 더 빠르고 성능이 더 뛰어납니다.
Number of Goals.
우리는 고정된 맥락에서 목표 상태의 수가 가변적인 모델을 학습시키며, 목표 수를 1개에서 4개로 변경합니다.
각 목표는 현재 상태를 기준으로 ±16초 간격으로 랜덤으로 선택됩니다.
표 1에 보고된 결과는 4가지 목표를 사용하면 모든 지표에서 예측 성능이 크게 향상된다는 것을 나타냅니다.
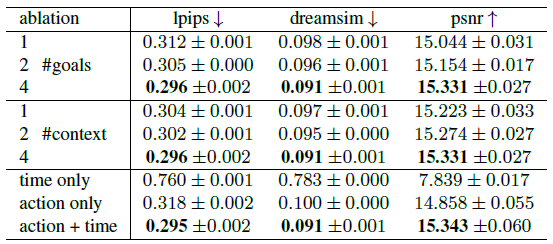
Context Size.
우리는 조건화 프레임의 수를 1에서 4까지 변화시키면서 모델을 학습합니다 (표 1 참조).
당연히 더 많은 맥락이 도움이 되며, 짧은 맥락에서는 모델이 종종 "lose track" 잘못된 예측으로 이어집니다.
Time and Action Conditioning.
우리는 시간과 액션 조건을 모두 갖춘 모델을 학습시키고 각 입력이 예측 성능에 얼마나 기여하는지 테스트합니다 (표 1에 결과를 포함합니다).
시간이 지남에 따라 모델을 실행하면 성능이 저하되는 반면, 시간을 조건으로 하지 않으면 성능 저하가 적다는 것을 발견했습니다.
이는 두 입력이 모두 모델에 유익하다는 것을 확인시켜줍니다.
4.3. Video Prediction and Synthesis
우리는 우리의 모델이 실제 액션을 얼마나 잘 따르고 미래 상태를 예측하는지 평가합니다.
모델은 첫 번째 이미지와 컨텍스트 프레임을 기반으로 조건화된 후, 실제 액션을 사용하여 다음 상태를 자기회귀적으로 예측하고 각 예측에 피드백을 제공합니다.
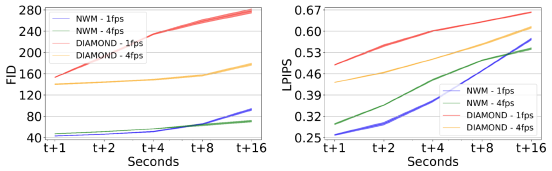
우리는 RECON 데이터셋에서 FID와 LPIPS를 보고하면서 예측을 1초, 2초, 4초, 8초, 16초의 실제 이미지와 비교합니다.
그림 4는 시간 경과에 따른 성능을 4 FPS와 1 FPS에서 DIAMOND와 비교하여 보여주며, NWM 예측이 DIAMOND보다 훨씬 더 정확하다는 것을 보여줍니다.
처음에는 NWM 1 FPS 변형이 더 나은 성능을 발휘하지만, 8초 후에는 누적된 오류와 문맥 loss로 인해 예측이 저하되고 4 FPS가 더 우수해집니다.
그림 3의 정성적 예시를 참조하세요.
Generation Quality.
비디오 품질을 평가하기 위해, 우리는 4 FPS에서 16초 동안 비디오를 자동 회귀적으로 예측하여 비디오를 생성하는 동시에 실제 액션을 조건으로 합니다.
그런 다음 FVD를 사용하여 생성된 비디오의 품질을 DIAMOND [1]과 비교하여 평가합니다.
그림 6의 결과는 NWM이 더 높은 품질의 비디오를 출력한다는 것을 나타냅니다.

4.4. Planning Using a Navigation World Model
다음으로, 우리는 NWM을 사용하여 얼마나 잘 탐색할 수 있는지를 측정하는 실험들을 설명합니다.
실험의 전체 기술적 세부 사항은 부록 8.2에 포함되어 있습니다.
Standalone Planning.
우리는 NWM이 목표 조건 내비게이션에 독립적으로 효과적으로 사용될 수 있음을 입증합니다.
우리는 과거 관측값과 목표 이미지를 기반으로 이를 조건화하고, 크로스-엔트로피 방법을 사용하여 마지막 예측 이미지와 목표 이미지의 LPIPS 유사성을 최소화하는 궤적을 찾습니다 (식 5 참조).
행동 순서를 순위 매기기 위해, 우리는 NWM을 실행하고 마지막 상태와 목표 사이의 LPIPS를 3번 측정하여 평균 점수를 얻습니다.
우리는 k = 0.25의 시간적 이동이 있는 길이 8의 궤적을 생성합니다.
우리는 표 2에서 모델 성능을 평가합니다.
우리는 NWM을 계획에 사용하면 SOTA 정책으로 경쟁력 있는 결과를 얻을 수 있다는 것을 발견했습니다.

Planning with Constraints.
월드 모델은 제약 조건 하에서 계획을 가능하게 합니다—예를 들어, 직선 운동이나 한 번의 회전이 필요합니다.
우리는 NWM이 제약 조건 인식 계획을 지원한다는 것을 보여줍니다.
전진 우선순위에서 에이전트는 5단계 동안 앞으로 이동한 다음 3단계로 전환합니다.
좌우 우선순위에서 3단계 동안 회전한 다음 앞으로 이동합니다.
직진하다가 앞으로 나아가면 3단계 동안 직진한 다음 앞으로 이동합니다.
제약 조건은 특정 액션을 제로화하여 적용됩니다; 예를 들어, 왼쪽에서 오른쪽으로 먼저 이동할 때는 전진 액션을 제로화하고, 나머지는 독립형 계획이 최적화합니다.
우리는 제약 없는 계획에 비해 최종 위치와 요의 차이에 대한 규범을 보고합니다.
결과 (표 3)는 제약 조건 하에서 NWM 계획을 효과적으로 보여주며, 성능 저하는 미미합니다 (그림 9의 예시 참조).


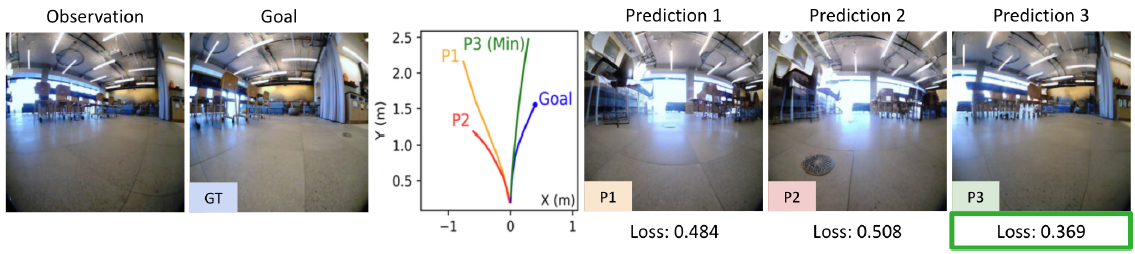
Using a Navigation World Model for Ranking.
NWM은 목표 조건 내비게이션에서 기존 내비게이션 정책을 개선할 수 있습니다.
과거 관측값과 목표 이미지에 NoMaD를 조건으로 하여, 우리는 길이 8의 n ∈ {16, 32}개의 궤적을 샘플링하고, NWM을 사용하여 액션을 자기회귀적으로 따라 평가합니다.
마지막으로, 목표 이미지와의 LPIPS 유사성을 측정하여 각 궤적의 최종 예측 순위를 매깁니다 (그림 7 참조).
우리는 모든 도메인 내 데이터셋 (표 2)에서 ATE와 RPE를 보고한 결과, NWM 기반 궤적 순위가 내비게이션 성능을 향상시키며, 더 많은 샘플이 더 나은 결과를 낳는다는 것을 발견했습니다.
4.5. Generalization to Unknown Environments
여기서 우리는 라벨이 없는 데이터를 추가하는 실험을 하고, NWM이 상상력을 사용하여 새로운 환경에서 예측을 할 수 있는지 여부를 묻습니다.
이 실험에서는 모든 도메인 내 데이터 세트와 Ego4D의 라벨이 없는 비디오 하위 집합에 대해 모델을 학습합니다, 여기서 우리는 시간 이동 액션에만 접근할 수 있습니다.
우리는 CDiT-XL 모델을 학습시키고 Go Stanford 데이터셋과 다른 랜덤 이미지에서 이를 테스트합니다.
우리는 표 4에 결과를 보고하며, 라벨이 없는 데이터에 대한 학습이 생성 품질 향상을 포함한 모든 지표에 따라 비디오 예측을 크게 향상시킨다는 것을 발견했습니다.
우리는 그림 8에 정성적인 예시를 포함하고 있습니다.
인도메인 (그림 3)과 비교했을 때, 이 모델은 상상된 환경의 횡단을 생성할 때 더 빠르게 돌파하고 예상대로 경로를 환각시킵니다.



5. Limitations
우리는 여러 가지 한계를 식별합니다.
먼저, 분포 외 데이터에 적용하면 모델은 서서히 맥락을 잃고 학습 데이터와 유사한 다음 상태를 생성하는 경향이 있으며, 이는 이미지 생성에서 관찰되었으며 모드 붕괴로 알려져 있습니다 [56, 58].
우리는 그림 10에 그러한 예를 포함하고 있습니다.
둘째, 모델은 계획을 세울 수는 있지만 보행자의 움직임과 같은 시간적 역학을 시뮬레이션하는 데 어려움을 겪습니다 (일부 경우에는 그렇게 하기도 합니다).
두 가지 한계는 더 긴 맥락과 더 많은 학습 데이터로 해결될 가능성이 높습니다.
또한, 이 모델은 현재 3개의 DoF 내비게이션 액션을 활용하고 있지만, 6개의 DoF 내비게이션 및 잠재적으로 로봇 팔의 관절을 제어하는 것과 같은 더 많은 액션도 가능하므로 향후 연구를 위해 남겨두겠습니다.
6. Discussion
우리가 제안한 Navigation World Model (NWM)은 시각적 내비게이션을 위한 확장 가능하고 데이터 기반의 학습 월드 모델 접근 방식을 제공합니다;
그러나 우리의 NWM은 환경의 구조화된 맵을 명시적으로 활용하지 않기 때문에 어떤 표현이 이를 가능하게 하는지 아직 정확히 알 수 없습니다.
한 가지 아이디어는 자기중심적 관점에서의 다음 프레임 예측이 할당 중심 표현의 출현을 촉진할 수 있다는 것입니다 [65].
궁극적으로 우리의 접근 방식은 비디오, 시각적 내비게이션, 모델 기반 계획을 통한 학습을 연결하며, 액션을 인식할 뿐만 아니라 계획할 수 있는 self-supervised 시스템의 문을 열 수 있습니다.
'Robotics' 카테고리의 다른 글
| Octo: An Open-Source Generalist Robot Policy (0) | 2025.07.03 |
|---|---|
| OpenVLA: An Open-Source Vision-Language-Action Model (0) | 2025.06.30 |
| 3D-VLA: A 3D Vision-Language-Action Generative World Model (0) | 2025.06.09 |
| NoMaD: Goal Masked Diffusion Policies for Navigation and Exploration (ICRA 2024 Best Paper) (0) | 2025.04.14 |
| Open X-Embodiment: Robotic Learning Datasets and RT-X Models (0) | 2025.03.24 |