2022. 2. 15. 18:27ㆍ3D Vision
PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation
Charles R. Qi, Hao Su, Kaichun Mo, Leonidas J. Guibas
Abstract
포인트 클라우드는 기하학적 데이터 구조의 중요한 유형이다.
불규칙한 형식 때문에 대부분의 연구자들은 이러한 데이터를 일반 3D 복셀 그리드 또는 이미지 모음으로 변환한다.
그러나 이로 인해 불필요하게 많은 양의 데이터가 생성되어 문제가 발생합니다.
본 논문에서, 우리는 입력에 있는 점의 순열 불변성을 잘 존중하는 포인트 클라우드를 직접 소비하는 새로운 유형의 신경망을 설계한다.
PointNet이라는 이름의 네트워크는 객체 분류, 부품 분할, 장면 의미 파싱에 이르는 애플리케이션을 위한 통합 아키텍처를 제공한다.
PointNet은 간단하지만 매우 효율적이고 효과적입니다.
경험적으로, 그것은 최첨단 기술과 동등하거나 심지어 더 나은 성능을 보여줍니다.
이론적으로, 우리는 네트워크가 학습한 내용과 입력 섭동 및 손상과 관련하여 네트워크가 강력한 이유를 이해하기 위한 분석을 제공한다.
1. Introduction
이 논문에서 우리는 포인트 클라우드 또는 메쉬와 같은 3D 기하학적 데이터에 대해 추론할 수 있는 딥 러닝 아키텍처를 탐구한다.
일반적인 컨볼루션 아키텍처는 가중치 공유 및 기타 커널 최적화를 수행하기 위해 이미지 그리드 또는 3D 복셀의 형식과 같은 매우 규칙적인 입력 데이터 형식을 필요로 한다.
포인트 클라우드 또는 메시가 정규 형식이 아니기 때문에 대부분의 연구자들은 일반적으로 이러한 데이터를 딥 넷 아키텍처에 제공하기 전에 일반 3D 복셀 그리드 또는 이미지 모음(예: 뷰)으로 변환한다.
그러나 이러한 데이터 표현 변환은 결과 데이터를 불필요하게 대량으로 만듭니다-또한 데이터의 자연적인 불변성을 가릴 수 있는 정량화 아티팩트를 도입한다.
이러한 이유로 우리는 단순히 포인트 클라우드를 사용하는 3D 지오메트리에 대한 다른 입력 표현에 초점을 맞추고 결과적인 심층 네트의 이름을 PointNets로 지정합니다.
점 구름은 메시의 조합적 불규칙성과 복잡성을 피하는 단순하고 통합된 구조이므로 배우기 쉽다.
그러나 PointNet은 여전히 포인트 클라우드가 단지 포인트 집합이기 때문에 멤버의 순열에 불변하므로 네트워크 계산에서 특정 대칭화가 필요하다는 사실을 존중해야 한다.
경직된 동작에 대한 추가적인 불변도 고려될 필요가 있다.
PointNet은 포인트 클라우드를 직접 입력으로 사용하고 전체 입력에 대한 클래스 레이블 또는 입력의 각 지점에 대한 포인트 세그먼트/부품 레이블 중 하나를 출력하는 통합 아키텍처이다.
우리 네트워크의 기본 아키텍처는 초기 단계에서 각 지점이 동일하고 독립적으로 처리되기 때문에 놀라울 정도로 간단하다.
기본 설정에서 각 점은 세 개의 좌표(x, y, z)로 표시됩니다.
추가 차원은 노멀과 다른 로컬 또는 글로벌 특성을 계산하여 추가할 수 있습니다.
우리의 접근 방식의 핵심은 단일 대칭 함수인 최대 풀링을 사용하는 것이다.
네트워크는 포인트 클라우드의 흥미롭거나 유익한 지점을 선택하고 선택 이유를 인코딩하는 일련의 최적화 함수/기준을 효과적으로 학습한다.
네트워크의 최종 full connected layer는 위에서 언급한 바와 같이 전체 형상에 대해 학습된 최적 값을 전역 설명자로 집계하거나(형상 분류) 포인트 레이블당 예측에 사용된다(형상 분할).
우리의 입력 형식은 각 점이 독립적으로 변환되기 때문에 견고하거나 아핀 변환을 적용하기 쉽다.
따라서 우리는 결과를 더욱 개선하기 위해 PointNet이 데이터를 처리하기 전에 데이터를 정규화하려는 데이터 의존적 공간 변압기 네트워크를 추가할 수 있다.
우리는 우리의 접근 방식에 대한 이론적 분석과 실험적 평가를 모두 제공한다.
우리는 우리의 네트워크가 연속적인 모든 세트 함수에 근접할 수 있다는 것을 보여준다.
더욱 흥미로운 것은 우리 네트워크가 입력 포인트 클라우드를 시각화에 따라 객체의 골격에 대략적으로 해당하는 희박한 핵심 지점 집합으로 요약하는 방법을 배운다는 것이다.
이론적 분석은 PointNet이 포인트 삽입(외부) 또는 삭제(데이터 누락)를 통한 손상뿐만 아니라 입력 포인트의 작은 동요에도 매우 강력한 이유를 이해한다.
형상 분류, 부분 분할, 장면 분할에 이르는 여러 벤치마크 데이터 세트에서 PointNet을 다중 뷰 및 체적 표현을 기반으로 한 최첨단 접근 방식과 실험적으로 비교한다.
통합된 아키텍처에서 PointNet은 속도가 훨씬 빠를 뿐만 아니라 최첨단 기술과 동등하거나 심지어 더 나은 성능을 보여준다.
저희 작업의 주요 기여 사항은 다음과 같습니다:
· 우리는 주문되지 않은 포인트 세트를 3D로 소비하기에 적합한 새로운 딥 넷 아키텍처를 설계한다.
· 3D 형상 분류, 형상 부품 분할 및 장면 의미 구문 분석 작업을 수행하기 위해 그러한 네트를 훈련하는 방법을 보여준다.
· 우리는 방법의 안정성과 효율성에 대한 철저한 경험적, 이론적 분석을 제공한다.
· 우리는 네트에서 선택된 뉴런에 의해 계산된 3D 특징을 설명하고 그 성능에 대한 직관적인 설명을 개발한다.
신경망에 의해 순서가 정해져 있지 않은 세트를 처리하는 문제는 매우 일반적이고 근본적인 문제이다 - 우리는 우리의 아이디어가 다른 영역으로도 전달될 수 있을 것으로 기대한다.
2. Related Work
Point Cloud Features
포인트 클라우드의 기존 기능은 대부분 특정 작업을 위해 수작업으로 제작된다.
점 특징은 종종 점의 특정 통계적 특성을 인코딩하며 일반적으로 본질적 [2, 24, 3] 또는 외적 [20, 19, 14, 10, 5]로 분류되는 특정 변환에 불변하도록 설계된다.
로컬 기능과 전역 기능으로 분류할 수도 있습니다.
특정 작업의 경우 최적의 기능 조합을 찾는 것이 간단하지 않다.
Deep Learning on 3D Data
3D 데이터는 여러 가지 대중적인 표현을 가지고 있어 학습을 위한 다양한 접근법으로 이어진다.
Volumetric CNNs:
[28, 17, 18]은 복셀화된 형태에 3D 컨볼루션 신경망을 적용하는 선구자이다.
그러나 볼륨 표현은 데이터 희소성과 3D 컨볼루션의 계산 비용으로 인해 해상도에 의해 제약을 받는다.
FPNN [13] 및 Boit3D [26]는 희소성 문제를 처리하기 위한 특별한 방법을 제안했다. 그러나 해당 작업은 여전히 희소 볼륨에서 수행되므로 매우 큰 포인트 클라우드를 처리하기가 어렵다.
Multiview CNNs:
[23, 18]은 3D 포인트 클라우드 또는 형상을 2D 이미지로 렌더링한 다음 2D 컨볼루션 네트를 적용하여 분류하려고 시도했다.
잘 설계된 이미지 CNN을 통해 이 방법의 라인은 형상 분류 및 검색 작업에서 지배적인 성능을 달성했다[21].
그러나 장면 이해 또는 점 분류 및 형상 완성 같은 다른 3D 작업으로 확장하는 것은 중요하지 않다.
Spectral CNNs:
일부 최신 연구[4, 16]는 메시에 스펙트럼 CNN을 사용한다.
그러나 이러한 방법은 현재 유기물 같은 매니폴드 메시에 제한되어 있으며 가구와 같은 비등방적 형태로 확장하는 방법은 명확하지 않다.
Feature-based DNNs:
[6, 8]은 먼저 기존의 형상 특징을 추출하여 3D 데이터를 벡터로 변환한 다음 완전히 연결된 망을 사용하여 형상을 분류한다.
우리는 그것들이 추출된 특징의 표현력에 의해 제약을 받는다고 생각한다.
Deep Learning on Unordered Sets
데이터 구조의 관점에서 포인트 클라우드는 순서가 정해져 있지 않은 벡터 집합이다.
딥러닝의 대부분의 작업이 시퀀스(음성 및 언어 처리), 이미지 및 볼륨(비디오 또는 3D 데이터)과 같은 규칙적인 입력 표현에 초점을 맞추고 있지만 포인트 세트에 대한 딥러닝에서는 많은 작업이 수행되지 않았다.
Oriol Vinyals 등의 최근 연구[25]는 이 문제를 조사한다.
이들은 순서 없는 입력 세트를 소비하고 네트워크가 숫자를 정렬할 수 있다는 것을 보여주기 위해 주의 메커니즘이 있는 읽기-프로세스-쓰기 네트워크를 사용한다.
그러나 이들의 작업은 일반 세트와 NLP 애플리케이션에 초점을 맞추고 있기 때문에 세트 내 기하학의 역할이 부족하다.
3. Problem Statement
우리는 순서가 지정되지 않은 포인트 세트를 입력으로 직접 소비하는 딥러닝 프레임워크를 설계한다.
포인트 클라우드는 3D 점 {P_i | i = 1, ..., n}의 집합으로 표현되며, 여기서 각 점 P_i는 그것의 (x, y, z) 좌표와 색상, 정규 등과 같은 추가 형상 채널의 벡터이다.
별도의 언급이 없는 한 단순성과 명확성을 위해 우리는 점의 채널로 (x, y, z) 좌표만 사용합니다.
객체 분류 작업의 경우 입력 점 구름은 쉐이프에서 직접 샘플링되거나 장면 점 구름에서 사전 세그먼트화됩니다.
우리가 제안한 심층 네트워크는 모든 k 후보 클래스에 대해 k 점수를 출력한다.
의미 분할의 경우 입력은 부분 영역 분할을 위한 단일 객체이거나 객체 영역 분할을 위한 3D 장면의 하위 볼륨일 수 있다.
우리의 모델은 각 n개의 점과 각 m개의 의미 하위 범주에 대해 n x m 점수를 출력할 것이다.
4. Deep Learning on Point Sets
네트워크 아키텍처(섹션 4.2)는 R^n(섹션 4.1)의 포인트 세트 속성에서 영감을 받았다.
4.1. Properties of Point Sets in R^n
우리의 입력은 유클리드 공간에서 점들의 하위 집합이다.
세 가지 주요 특성이 있다:
· 순서 없음.
이미지의 픽셀 배열 또는 볼륨 그리드의 복셀 배열과 달리 포인트 클라우드는 특정 순서가 없는 점 집합입니다.
즉, N개의 3D 포인트 세트를 소비하는 네트워크는 데이터 공급 순서로 입력 세트의 N! 순열에 불변해야 한다.
· 점 간의 교호작용입니다.
점은 거리 메트릭이 있는 공간에서 나옵니다.
이것은 점들이 분리되어 있지 않고, 이웃한 점들이 의미 있는 부분 집합을 형성한다는 것을 의미합니다.
따라서 이 모델은 인근 지점에서 국소 구조와 국소 구조 간의 조합 상호작용을 캡처할 수 있어야 한다.
· 변환 시 불변성.
기하학적 객체로서, 포인트 세트의 학습된 표현은 특정 변환에 불변해야 한다.
예를 들어 점을 모두 회전 및 변환하면 전역 포인트 클라우드 범주나 점의 분할이 수정되어서는 안 됩니다.
4.2. PointNet Architecture

우리의 전체 네트워크 아키텍처는 그림 2에서 시각화되며, 여기서 분류 네트워크와 분할 네트워크는 구조의 상당 부분을 공유한다.
파이프라인은 그림 2의 캡션을 읽어주세요.
네트워크에는 세 가지 핵심 모듈이 있습니다:
모든 점의 정보를 집계하는 대칭 함수로써의 최대 풀링 도면층, 로컬 및 전역 정보 조합 구조, 입력점과 점 피쳐를 모두 정렬하는 두 개의 공동 선형 네트워크.
우리는 아래의 별도 단락에서 이러한 디자인을 선택한 이유에 대해 논의할 것입니다.
Symmetry Function for Unordered Input
모델을 입력 순열에서 불변으로 만들기 위해, 세 가지 전략이 존재한다:
1) 입력을 표준 순서로 정렬합니다;
2) 입력을 RNN을 훈련시키기 위한 시퀀스로 취급하지만 모든 종류의 순열로 훈련 데이터를 증가시킨다.
3) 간단한 대칭 함수를 사용하여 각 점의 정보를 집계합니다.
여기서 대칭 함수는 n개의 벡터를 입력으로 사용하고 입력 순서에 변하지 않는 새로운 벡터를 출력한다.
예를 들어 + 및 * 연산자는 대칭 이진 함수입니다.
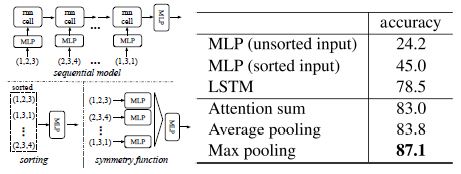
정렬은 간단한 해결책처럼 들리지만, 고차원 공간에서는 사실 일반적인 의미에서 안정적인 w.r.t. 포인트 섭동이 존재하지 않는다.
이것은 모순으로 쉽게 드러날 수 있습니다.
그러한 순서 전략이 존재하는 경우, 고차원 공간과 1d 실선 사이의 투영 맵을 정의한다.
안정적인 w.r.t 포인트 섭동을 요구하는 것은 일반적인 경우 달성할 수 없는 작업인 치수가 감소함에 따라 이 지도가 공간 근접성을 보존해야 하는 것과 동일하다는 것을 쉽게 알 수 있다.
따라서 정렬한다고 해서 정렬 문제가 완전히 해결되는 것은 아니며, 정렬 문제가 지속되면 네트워크가 입력에서 출력까지 일관된 매핑을 학습하기 어렵습니다.
실험(그림 5)에서 볼 수 있듯이 정렬된 포인트 세트에 직접 MLP를 적용하는 것이 정렬되지 않은 입력을 직접 처리하는 것보다 약간 더 낫지만 성능이 떨어진다는 것을 발견했다.
RNN을 사용하는 아이디어는 포인트 세트를 순차 신호로 간주하고 무작위로 순열된 시퀀스로 RNN을 훈련시킴으로써 RNN이 입력 순서에 불변하게 되기를 바란다.
그러나 "OrderMatters"[25]에서 저자들은 순서가 중요하며 완전히 생략할 수 없다는 것을 보여주었다.
RNN은 작은 길이(도젠)의 시퀀스에 대한 입력 순서에는 비교적 양호한 편이지만, 포인트 세트의 일반적인 크기인 수천 개의 입력 요소로 확장하기는 어렵다.
경험적으로, 우리는 또한 RNN을 기반으로 한 모델이 우리가 제안한 방법만큼 잘 수행되지 않는다는 것을 보여주었다(그림 5).
우리의 아이디어는 세트의 변환된 요소에 대칭 함수를 적용하여 점 집합에 정의된 일반 함수를 근사화하는 것이다:
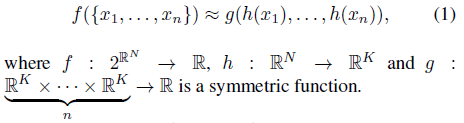
경험적으로 우리의 기본 모듈은 매우 간단하다:
우리는 다층 퍼셉트론 네트워크에 의한 h와 단일 변수 함수와 최대 풀링 함수의 구성에 의한 g에 근사한다.
이것은 실험에 의해 잘 작동하는 것으로 밝혀졌습니다.
h의 모음을 통해, 우리는 집합의 다른 속성을 포착하기 위해 많은 f를 배울 수 있다.
우리의 핵심 모듈은 단순해 보이지만 흥미로운 특성(섹션 5.3 참조)을 가지고 있으며 몇몇 다른 애플리케이션에서 강력한 성능(섹션 5.1 참조)을 달성할 수 있다.
우리 모듈의 단순성 때문에 섹션 4.3과 같이 이론적 분석도 제공할 수 있습니다.
Local and Global Information Aggregation
위 절의 출력은 입력 집합의 전역 시그니처인 벡터 [f_1, ..., f_K]를 형성합니다.
우리는 분류를 위한 쉐이프 전역 특징에 대한 SVM 또는 다층 퍼셉트론 분류기를 쉽게 훈련시킬 수 있다.
그러나 점 분할에는 로컬 및 글로벌 지식의 조합이 필요하다.
우리는 단순하면서도 매우 효과적인 방법으로 이것을 달성할 수 있습니다.
우리의 솔루션은 그림 2(세그먼트 네트워크)에서 확인할 수 있다.
전역 포인트 클라우드 피쳐 벡터를 계산한 후 전역 피쳐와 각 점 피쳐를 연결하여 점별 피쳐로 피드백한다.
그런 다음 결합된 포인트 피쳐를 기반으로 새로운 포인트 피쳐를 추출합니다 - 이번에는 포인트 피쳐가 로컬 및 전역 정보를 모두 인식합니다.
이 수정을 통해 네트워크는 로컬 지오메트리와 글로벌 의미론 모두에 의존하는 포인트당 양을 예측할 수 있다.
예를 들어, 우리는 네트워크가 점의 로컬 이웃으로부터 정보를 요약할 수 있음을 검증하면서 포인트당 규범(보충 그림)을 정확하게 예측할 수 있다.
실험 세션에서, 우리는 또한 우리의 모델이 형상 부분 분할 및 장면 분할에서 최첨단 성능을 달성할 수 있다는 것을 보여준다.
joint Alignment Network
포인트 클라우드의 의미적 레이블링은 포인트 클라우드가 견고한 변환과 같은 특정 기하학적 변환을 겪는 경우 불변이어야 한다.
따라서 우리는 포인트 세트에 의한 학습된 표현이 이러한 변환에 불변일 것으로 기대한다.
자연스러운 해결책은 피쳐 추출 전에 모든 입력 세트를 표준 공간에 정렬하는 것이다.
제이더버그 외 연구진. [9] GPU에 구현된 특정 맞춤형 레이어에 의해 달성된 샘플링 및 보간법을 통해 2D 이미지를 정렬하는 공간 변압기 아이디어를 소개한다.
포인트 클라우드의 입력 형태를 통해 [9]에 비해 훨씬 더 간단한 방법으로 이 목표를 달성할 수 있습니다.
우리는 새로운 레이어를 개발할 필요가 없으며 이미지 케이스처럼 별칭이 도입되지 않습니다.
우리는 미니 네트워크(그림 2의 T-net)를 통해 아핀 변환 매트릭스를 예측하고 이 변환을 입력 지점의 좌표에 직접 적용한다.
미니 네트워크 자체는 빅 네트워크와 유사하며 포인트 독립 기능 추출, 최대 풀링 및 완전 연결 레이어의 기본 모듈로 구성된다.
T-net에 대한 자세한 내용은 부록에 있습니다.
이 아이디어는 피쳐 공간의 정렬로도 확장될 수 있습니다.
점 형상에 다른 선형 네트워크를 삽입하고 형상 변환 매트릭스를 예측하여 다른 입력 포인트 클라우드에서 형상을 정렬할 수 있습니다.
그러나 형상 공간의 변환 행렬은 공간 변환 행렬보다 차원이 훨씬 높아 최적화의 난이도가 크게 높아진다.
따라서 우리는 소프트맥스 훈련 손실에 정규화 항을 추가한다.
형상 변환 행렬을 직교 행렬에 가깝게 제한한다:
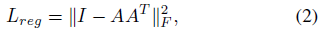
여기서 A는 미니 네트워크에 의해 예측된 형상 정렬 행렬이다.
직교 변환은 입력에서 정보를 잃지 않으므로 원하는 바입니다.
정규화 항을 추가하면 최적화가 더 안정화되고 모델이 더 나은 성능을 달성한다는 것을 발견했다.
4.3. Theoretical Analysis
Universal approzimation
먼저 연속적인 설정 기능에 대한 신경망의 보편적 근사 능력을 보여준다.
집합 함수의 연속성에 의해, 직관적으로 입력 포인트 집합에 대한 작은 동요가 분류 또는 분할 점수와 같은 함수 값을 크게 변경하지 않아야 한다.
공식적으로, 모든 S에 대해 X = {S : S ⊆ [0, 1]^m and |S| = n}, f : X → R을 X w.r.t에서 하우스도르프 거리 d_H(·, ·), 즉 ∀ε > 0, ∃δ > 0에 대한 연속 집합 함수이다.
우리의 정리는 f가 최대 풀링 층에 충분한 뉴런이 주어지면 네트워크에 의해 임의로 근사될 수 있다고 말한다. 즉, (1)의 K는 충분히 크다.
Theorem 1.
f : X → R이 hausdorff 거리 d_H(·, ·)인 연속 집합 함수라고 가정하자.
∀ε > 0, ∃ a 연속 함수 h와 대칭 함수 g(x_1, ..., x_n) = γ º MAX, 즉, 임의의 S ∈ X에 대해,
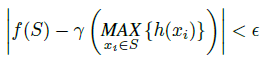
여기서 x_1, ..., x_n은 임의의 순서로 정렬된 S의 원소의 전체 리스트이고, γ는 연속 함수이며, MAX는 n개의 벡터를 입력으로 취하고 원소별 최대값의 새로운 벡터를 반환하는 벡터 최대 연산자이다.
이 정리의 증명은 보충 자료에서 찾을 수 있다.
핵심 아이디어는 최악의 경우 네트워크가 공간을 동일한 크기의 복셀로 분할하여 포인트 클라우드를 체적 표현으로 변환하는 방법을 배울 수 있다는 것이다.
그러나 실제로 네트워크는 포인트 함수 시각화에서 볼 수 있듯이 공간을 탐색하는 훨씬 더 현명한 전략을 학습한다.
Bottleneck dimension and stability
이론적으로 그리고 실험적으로 우리는 네트워크의 표현성이 최대 풀링 계층의 차원, 즉 (1)의 K에 의해 크게 영향을 받는다는 것을 발견한다.
여기서 우리는 모델의 안정성과 관련된 속성도 보여주는 분석을 제공한다.
우리는 u = MAX {h(x_i)}를 [0, 1]^m에 설정된 점을 K차원 벡터에 매핑하는 f의 하위 네트워크로 정의한다.
다음 정리는 입력 세트의 작은 손상이나 추가 노이즈 포인트가 네트워크의 출력을 변경하지 않을 것이라는 것을 알려줍니다:
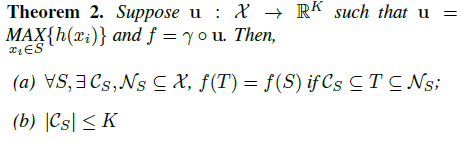
우리는 그 정리의 함축성을 설명한다.
(a) 는 C_S의 모든 포인트가 보존될 경우 입력 손상까지 f(S)가 변경되지 않으며 N_S까지의 추가 노이즈 포인트도 변경되지 않는다고 말합니다.
(b) 는 C_S가 (1)의 K에 의해 결정되는 한정된 수의 점만 포함한다고 말한다.
즉, f(S)는 사실상 K 원소와 같거나 작은 유한 부분 집합 C_S ≤ S에 의해 완전히 결정된다.
따라서 우리는 C_S를 S와 K의 임계점 집합이라고 부른다.
h의 연속성과 결합하여, 이것은 우리 모델의 강건성을 설명한다, w.r.t 포인트 섭동, 손상 및 추가 노이즈 포인트.
견고성은 머신러닝 모델의 희소성 원리와 유사하여 얻어진다.
직관적으로, 우리 네트워크는 희박한 주요 포인트 세트별로 모양을 요약하는 방법을 배운다.
실험 부분에서 우리는 핵심점들이 물체의 골격을 형성한다는 것을 볼 수 있다.
5. Experiment
실험은 네 가지 부분으로 나뉩니다.
먼저 PointNets가 여러 3D 인식 작업에 적용될 수 있음을 보여준다(섹션 5.1).
둘째, 네트워크 설계를 검증하기 위한 자세한 실험을 제공한다(섹션 5.2).
마지막으로 네트워크가 학습하는 것을 시각화(섹션 5.3)하고 시간과 공간의 복잡성(섹션 5.4)을 분석한다.
5.1. Applications
이 섹션에서는 네트워크가 3D 객체 분류, 객체 부분 분할 및 의미 장면 분할을 수행하도록 훈련되는 방법을 보여준다.
새로운 데이터 표현(포인트 세트)을 작업하고 있지만, 여러 작업에 대해 벤치마크에서 비슷한 성능을 달성하거나 훨씬 더 나은 성능을 얻을 수 있습니다.
3D Object Classification
우리 네트워크는 객체 분류에 사용할 수 있는 전역 포인트 클라우드 기능을 학습한다.
우리는 ModelNet40[28] 형상 분류 벤치마크에서 모델을 평가한다.
40개의 인공 객체 범주에서 12,311개의 CAD 모델이 있으며 교육을 위한 9,843개와 테스트를 위한 2,468개로 나뉩니다.
이전 방법은 볼륨 및 다중 뷰 이미지 표현에 초점을 맞춘 반면 원시 포인트 클라우드에서 직접 작업한 것은 우리가 처음이다.
6. Conclusion
본 연구에서는 포인트 클라우드를 직접 소비하는 새로운 심층 신경망 PointNet을 제안한다.
우리의 네트워크는 객체 분류, 부분 분할 및 의미 분할을 포함한 여러 3D 인식 작업에 대한 통일된 접근 방식을 제공하는 동시에 표준 벤치마크에서 최신 기술과 동등하거나 더 나은 결과를 얻는다.
우리는 또한 네트워크에 대한 이해를 위한 이론적 분석과 시각화를 제공한다.