2022. 10. 18. 14:34ㆍtext-to-3D
DreamFusion: Text-to-3D using 2D Diffusion
Ben Poole, Ajay Jain, Jonathan T. Barron, Ben Mildenhall
Abstract
text-to-image 합성의 최근 돌파구는 수십억 개의 image-text 쌍에 대해 학습된 diffusion 모델에 의해 주도되었다.
이 접근 방식을 3D 합성에 적응하려면 레이블이 지정된 3D 데이터의 대규모 데이터 세트와 디노이징 3D 데이터를 위한 효율적인 아키텍처가 필요한데, 현재 이 두 가지 모두 존재하지 않는다.
본 연구에서는 사전 학습된 2D text-to-image diffusion 모델을 사용하여 text-to-3D 합성을 수행함으로써 이러한 한계를 극복한다.
우리는 파라메트릭 이미지 생성기의 최적화를 위한 prior로 2D diffusion 모델을 사용할 수 있는 확률 밀도 distillation에 기반한 loss를 소개한다.
DeepDream과 유사한 절차에서 이 loss를 사용하여 랜덤 각도에서 2D 렌더링이 낮은 loss를 달성하도록 그레디언트 강하를 통해 랜덤으로 초기화된 3D 모델(Neural Radiance Field 또는 NeRF)을 최적화한다.
주어진 텍스트의 결과 3D 모델은 임의의 각도에서 볼 수 있고, 임의의 조명에 의해 재조명되거나, 임의의 3D 환경에서 합성될 수 있다.
우리의 접근 방식은 3D 학습 데이터와 이미지 diffusion 모델에 대한 수정이 필요하지 않으므로 사전 학습된 이미지 diffusion 모델의 효과를 priors와 같이 입증합니다.
1 Introduction
텍스트를 조건으로 한 생성 이미지 모델은 이제 충실도가 높고 다양하며 제어 가능한 이미지 합성을 지원한다 (Nichol et al., 2022; Ramesh et al., 2021; 2022; Saharia et al., 2022; 2021a; Yu et al., 2022; Saharia et al., 2021b).
이러한 품질 향상은 정렬된 대규모 이미지-텍스트 데이터 세트 (Schuhmann et al., 2022)와 확장 가능한 생성 모델 아키텍처에서 비롯되었다.
diffusion 모델은 안정적이고 확장 가능한 디노이징 objective를 가진 고품질 이미지 생성기를 학습하는 데 특히 효과적이다 (Ho et al., 2020; Sohl-Dickstein et al., 2015; Song et al., 2021).
다른 모달리티에 diffusion 모델을 적용하는 것은 성공적이었지만, 많은 양의 모달리티 별 학습 데이터가 필요하다 (Chen et al., 2020; Ho et al., 2022; Kong et al., 2021).
본 연구에서는 사전 학습된 2D image-text diffusion 모델을 3D 데이터 없이 3D 객체 합성으로 전송하는 기술을 개발한다(그림 1 참조).
2D 이미지 생성은 널리 적용 가능하지만, 비디오 게임이나 영화와 같은 시뮬레이터와 디지털 미디어는 풍부한 대화형 환경을 구현하기 위해 수천 개의 상세한 3D 자산을 요구합니다.
3D 자산은 현재 Blender와 Maya3D와 같은 모델링 소프트웨어를 통해 직접 설계되고 있으며, 이 프로세스에는 많은 시간과 전문 지식이 필요합니다.
text-to-3D 생성 모델은 초보자의 진입 장벽을 낮추고 숙련된 예술가의 작업 흐름을 개선할 수 있다.

3D 생성 모델은 복셀 (Wu et al., 2016; Chen et al., 2018) 및 포인트 클라우드 (Yang et al., 2019; Cai et al., 2020; Zhou et al., 2021)와 같은 구조의 explicit 표현에 대해 학습될 수 있지만, 필요한 3D 데이터는 풍부한 2D 이미지에 비해 상대적으로 부족하다.
우리의 접근 방식은 이미지에 대해 학습된 2D diffusion 모델만 사용하여 3D 구조를 학습하고 이 문제를 회피한다.
GAN은 출력 3D 객체 또는 장면의 2D 이미지 렌더링에 적대적 loss를 배치함으로써 단일 객체 범주의 사진에서 제어 가능한 3D 생성기를 학습할 수 있다 (Henzler et al., 2019; Nguyen-Phuoc et al., 2019; Or-El et al., 2022).
이러한 접근 방식은 얼굴과 같은 특정 객체 범주에 대해 유망한 결과를 산출했지만, 아직 임의의 텍스트를 지원하는 것으로 입증되지 않았다.
Neural Radience Fields 또는 NeRF는 공간 좌표에서 색 및 체적 밀도에 이르는 신경 매핑과 결합된 역 렌더링에 대한 접근법이다.
NeRF는 신경 역 렌더링을 위한 중요한 도구가 되었다 (Tewari et al., 2022).
원래 NeRF는 "classic" 3D 재구성 작업에 잘 작동하는 것으로 밝혀졌다: 많은 장면의 이미지가 모델에 입력으로 제공되며, NeRF는 특정 장면의 기하학적 구조를 복구하도록 최적화되어 관찰되지 않은 각도에서 해당 장면의 새로운 뷰를 합성할 수 있다.
많은 3D 생성 접근 방식은 NeRF-like 모델을 더 큰 생성 시스템 내에서 구성 요소로 통합하는 데 성공했다 (Schwarz et al., 2020; Chan et al., 2021b;a; Gu et al., 2021; Liu et al., 2022).
그러한 접근 방식 중 하나는 CLIP의 frozen image-text joint 임베딩 모델과 NeRF를 학습시키기 위한 최적화 기반 접근 방식을 사용하는 Dream Fields (Jain et al., 2022)이다.
이 연구는 사전 학습된 2D image-text 모델이 3D 합성에 사용될 수 있음을 보여주었지만, 이 접근법으로 생성된 3D 물체는 사실성과 정확성이 부족한 경향이 있다.
CLIP은 복셀 그리드 및 메시를 기반으로 한 다른 접근 방식을 안내하는 데 사용되었다 (Sanghi et al., 2022; Jetchev, 2021; Wang et al., 2022).
우리는 Dream Fields와 유사한 접근 방식을 채택하지만 CLIP을 2D diffusion 모델의 distillation에서 파생된 loss로 대체한다.
우리의 loss는 probability density distillation을 기반으로 diffusion의 전진 프로세스에 기반한 공유 수단을 가진 가우시안 분포 계열과 사전 학습된 diffusion 모델에 의해 학습된 score 함수 사이의 KL divergence를 최소화한다.
결과적인 Score Distillation Sampling (SDS) 방법은 미분 가능한 이미지 매개 변수화에서 최적화를 통한 샘플링을 가능하게 한다.
DreamFusion은 SDS를 이 3D 생성 작업에 맞게 조정된 NeRF 변형과 결합하여 사용자가 제공한 다양한 텍스트 프롬프트 세트에 대한 충실도가 높은 일관된 3D 개체와 장면을 생성한다.
2 Diffusion Models and Score Distillation Sampling
Diffusion 모델은 샘플을 다루기 쉬운 노이즈 분포에서 데이터 분포로 점진적으로 변환하는 방법을 배우는 잠재 변수 생성 모델이다 (Sohl-Dickstein et al., 2015; Ho et al., 2020).
Diffusion 모델은 노이즈를 추가하여 데이터 x에서 구조를 천천히 제거하는 forward 프로세스 q와 노이즈 z_t에서 시작하여 구조를 천천히 추가하는 reverse 프로세스 또는 생성 모델 p로 구성된다.
forward 프로세스는 일반적으로 시간 단계 t에서 이전의 덜 노이즈 잠재에서 시간 단계 t+1에서 더 노이즈 잠재로 전환되는 가우시안 분포입니다.
중간 시간 단계를 통합하여 초기 데이터 지점 x가 주어진 시간 단계 t에서 잠재 변수의 한계 분포를 계산할 수 있습니다: q(z_t|x) = N(α_t x, σ_t^2 I).
데이터 밀도 q(x)를 통합하는 한계값은 q(z_t) = ∫q(z_t|x) q(x) dx이며, 데이터 분포의 평활 버전에 해당합니다.
계수 α_t와 σ_t는 q(z_t)가 프로세스 시작 시 데이터 밀도에 가깝고(σ_0 ≈ 0), forward 프로세스 종료 시 가우시안(σ_T ≈ 1)에 가깝도록 선택되며, 분산 보존을 위해 α_t^2 = 1 - σ_t^2가 선택된다 (Kingma et al., 2021; Song et al., 2021).
생성 모델 p는 transitions p_ɸ(z_(t-1)|z_t)로 랜덤 노이즈 p(z_T) = N(0, I)에서 시작하여 구조를 천천히 추가하도록 학습된다.
이론적으로, 충분한 시간 단계를 거치면, 최적의 reverse 프로세스 단계는 또한 가우시안이며 최적의 MSE 디노이저 (Sohl-Dickstein et al., 2015)와 관련이 있다.
transitions는 일반적으로 p_ɸ(z_(t-1)|z_t) = q(z_(t-1)|z_t, x = ^x_ɸ(z_t; t))로 매개 변수화됩니다, 여기서 q(z_(t-1)|z_t, x)는 forward 프로세스에서 파생된 사후 분포이고 ^x_ɸ(z_t; t)는 최적의 디노이저의 근사치입니다.
Ho et al. (2020)은 ^x_ɸ를 직접 예측하는 대신 잠재 z_t: E[x|z_t] = ^x_ɸ(z_t; t) = (z_t - σ_t ε_ɸ(z_t; t) / α_t의 노이즈 내용을 예측하는 image-to-image U-Net ε_ɸ(z_t; t)를 학습시킨다.
예측된 노이즈는 Tweedie의 공식(Robbins, 1992)을 통해 평활 밀도 ∇_z_t log p(z_t)에 대한 예측 score 함수와 관련될 수 있다: ε_ɸ(z_t; t) = -σ_t s_ɸ(z_t; t)
(가중된) evidence lower bound (ELBO)를 사용하여 생성 모델을 학습하면 매개 변수 ɸ에 대한 가중된 디노이징 score matching objective로 단순화된다:

, 여기서 w(t)는 시간 단계 t에 따라 달라지는 가중치 함수이다.
따라서 diffusion 모델 학습은 잠재 변수 모델 (Sohl-Dickstein et al., 2015; Ho et al., 2020)을 학습하거나 데이터의 더 노이즈 버전 (Vincent, 2011; Song & Ermon, 2019; Song et al., 2021)에 해당하는 일련의 score 함수를 학습하는 것으로 볼 수 있다.
우리는 p_ɸ(z_t; t)를 사용하여 score 함수가 s_ɸ(z_t; t) = -ε_ɸ(z_t; t) / σ_t에 의해 주어지는 대략적인 한계 분포를 나타낼 것이다.
우리의 작업은 텍스트 임베딩 y를 조건으로 하는 ε_ɸ(z_t; t, y)를 학습하는 text-to-image diffusion 모델을 기반으로 한다 (Saharia et al., 2022; Ramesh et al., 2022; Nichol et al., 2022).
이러한 모델은 classifier-free guidance (CFG, Ho & Salimans, 2022)를 사용하며, guidance 척도 매개 변수 ω를 통해 더 높은 품질의 생성을 가능하게 하는 무조건적인 모델을 공동으로 학습한다: ^ε_ɸ(z_t; y, t) = (1 + ω)ε_ɸ(z_t; y, t) - ω ε_ɸ(z_t; t).
CFG는 무조건적 밀도에 대한 조건적 밀도의 비율이 큰 영역을 선호하도록 score 함수를 변경한다.
실제로 ω > 0으로 설정하면 다양성 비용으로 샘플 충실도가 향상됩니다.
우리는 노이즈 예측과 한계 분포의 guided 버전을 나타내기 위해 전체적으로 ^ε과 ^p를 사용한다.
2.1 How can we sample in parameter space, not pixel space?
Diffusion 모델의 샘플링에 대한 기존의 접근법은 모델이 (Song et al., 2021; 2020)에 대해 학습된 관측 데이터와 동일한 유형 및 차원의 샘플을 생성합니다.
조건부 diffusion 샘플링이 상당한 유연성(예: 인페인팅)을 가능하게 하지만 픽셀에 대해 학습된 diffusion 모델은 전통적으로 픽셀만 샘플링하는 데 사용되었다.
우리는 픽셀 샘플링에 관심이 없다; 대신 랜덤 각도에서 렌더링할 때 좋은 이미지처럼 보이는 3D 모델을 만들고 싶다.
이러한 모델은 differentiable image parameterization (DIP, Mordvintseve et al, 2018)로 지정할 수 있으며, 여기서 미분 가능한 생성기 g는 매개 변수 θ를 변환하여 이미지 x = g(θ)를 생성한다.
DIP를 사용하면 제약 조건을 표현하거나, 더 컴팩트한 공간(예: 임의 해상도 좌표 기반 MLP)에서 최적화하거나, 픽셀 공간을 가로지르는 더 강력한 최적화 알고리즘을 활용할 수 있다.
3D의 경우 θ를 3D 볼륨 및 g를 볼륨 렌더러의 매개 변수가 되도록 합니다.
이러한 매개 변수를 학습하기 위해서는 diffusion 모델에 적용할 수 있는 loss 함수가 필요하다.
우리의 접근 방식은 diffusion 모델의 구조를 활용하여 최적화를 통해 다루기 쉬운 샘플링을 가능하게 한다 — 이는 최소화되면 샘플을 산출하는 loss 함수이다.
우리는 x = g(θ)가 frozen diffusion 모델의 샘플처럼 보이도록 매개 변수 θ에 대해 최적화한다.
이러한 최적화를 수행하려면 DeepDream (Mordvintseev et al, 2015)과 유사한 스타일로 그럴듯한 이미지의 loss는 적고, 신뢰할 수 없는 이미지의 loss는 높은 미분 가능한 loss 함수가 필요하다.
우리는 먼저 학습된 조건부 밀도 p(x|y)의 모드를 찾기 위해 diffusion 학습 loss(식. 1)를 재사용하는 것을 조사했다.
고차원의 생성 모델의 모드는 종종 일반적인 샘플과 멀리 떨어져 있지만(Nalisnick et al, 2018), diffusion 모델 학습의 다중 스케일 특성은 이러한 병리를 피하는 데 도움이 될 수 있다.
생성된 데이터 포인트 x = g(θ)에 대한 diffusion 학습 loss를 최소화하면 θ* = arg min_θ L_Diff(ɸ, x = g(θ))가 주어진다.
실제로, 우리는 이 loss 함수가 x = θ인 아이덴티티 DIP를 사용하는 경우에도 현실적인 샘플을 생성하지 않는다는 것을 발견했다.
Graikos et al. (2022)의 동시 연구는 이 방법이 신중하게 선택된 시간 단계 스케줄과 함께 작동할 수 있음을 보여주지만, 우리는 이 객관적인 취약성과 그것의 시간 단계 스케줄이 조정하기 어렵다는 것을 발견했다.
이 접근법의 어려움을 이해하려면 L_Diff의 그래디언트를 고려하십시오:

, 여기서 우리는 상수 α_t I = ∂z_t / ∂x를 ω(t)로 흡수한다.
실제로 U-Net Jacobian 항은 계산 비용이 많이 들고(diffusion 모델 U-Net을 통해 역전파 필요), 한계 밀도의 스케일링된 헤시안 근사치를 학습하기 때문에 작은 노이즈 레벨에 대해 제대로 조정되지 않는다.
우리는 U-Net Jacobian 항을 생략하면 diffusion 모델을 사용하여 DIP를 최적화하는 데 효과적인 그래디언트로 이어진다는 것을 발견했다:
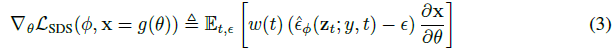
직관적으로, 이 loss는 시간 단계 t에 해당하는 임의의 양의 노이즈로 x를 교란하고, 더 높은 밀도 영역으로 이동하기 위해 diffusion 모델의 score 함수를 따르는 업데이트 방향을 추정한다.
diffusion 모델을 사용하여 DIP를 학습하기 위한 이 그래디언트는 임시로 나타날 수 있지만, 부록 A.4에서는 diffusion 모델에서 학습된 score 함수를 사용하여 가중된 probability density distillation loss의 그래디언트 (van den Oord et al., 2018)임을 보여준다:

우리는 샘플링 접근 방식의 이름을 distillation과 관련이 있기 때문에 SDS(Score Distillation Sampling)라고 명명하지만 밀도 대신 score 함수를 사용한다.
variational 계열 q(z_t|. . .)의 노이즈가 t → 0으로 사라지고 변동 분포 g(θ)의 평균 매개 변수가 관심 있는 샘플이 되기 때문에 우리는 그것을 샘플러라고 부른다.
우리의 loss는 구현하기 쉽고(그림 8 참조), 가중치 ω(t) 선택에 비교적 강하다.
diffusion 모델이 업데이트 방향을 직접 예측하기 때문에 diffusion 모델을 통해 역전파할 필요가 없다; 모델은 단순히 이미지 공간 편집을 예측하는 효율적이고 frozen 비평가처럼 행동한다.

L_SDS의 모드 탐색 특성을 고려할 때, 이 loss를 최소화하면 좋은 샘플을 생성할 수 있을지 확실하지 않을 수 있다.
그림 2에서, 우리는 SDS가 합리적인 품질로 제한된 이미지를 생성할 수 있음을 보여준다.
경험적으로, 우리는 classifier-free guidance를 위해 guidance 가중치 ω 값을 큰 값으로 설정하면 품질이 향상된다는 것을 발견했다(부록 표 9).
SDS는 조상 샘플링에 버금가는 디테일을 생성하지만 매개 변수 공간에서 작동하기 때문에 새로운 전이 학습 애플리케이션이 가능하다.
3 The DreamFusion Alogrithm
이제 샘플을 생성하기 위해 일반적인 연속 최적화 문제 내에서 diffusion 모델이 loss로 사용될 수 있는 방법을 시연했으므로 텍스트에서 3D 자산을 생성할 수 있는 특정 알고리즘을 구성할 것이다.
diffusion 모델의 경우 텍스트에서 이미지를 합성하도록 학습된 Saharia et al. (2022)의 Imagen 모델을 사용한다.
우리는 64x64 base 모델(더 높은 해상도의 이미지를 생성하기 위한 초해상도 캐스케이드가 아님)만 사용하고, 이 사전 학습된 모델을 수정 없이 그대로 사용한다.
텍스트의 장면을 합성하기 위해 랜덤 가중치로 NeRF-like 모델을 초기화한 다음 이러한 렌더링을 Imagen을 감싸는 score distillation loss 함수의 입력으로 사용하여 랜덤 카메라 위치와 각도에서 해당 NeRF의 뷰를 반복적으로 렌더링한다.
우리가 시연할 것처럼, 이 접근 방식을 사용한 단순한 그래디언트 하강은 결국 텍스트와 유사한 3D 모델(NeRF로 매개 변수화됨)을 초래한다.
우리의 접근 방식에 대한 개요는 그림 3을 참조하십시오.

3.1 Neural Rendering of a 3D Model
NeRF는 체적 raytracer와 multilayer perceptron (MLP)으로 구성된 신경 역 렌더링 기술이다.
NeRF에서 이미지를 렌더링하는 것은 카메라의 투영 중심에서 이미지 평면의 픽셀 위치를 통해 world로 각 픽셀에 대한 ray를 투사하는 것이다.
각 ray를 따라 샘플링된 3D 점 μ는 MLP를 통과하여 출력으로 4개의 스칼라 값을 생성합니다: 체적 밀도 τ(3D 좌표에서 장면 지오메트리가 얼마나 불투명한지)와 RGB 색상 c.
이러한 밀도와 색상은 ray의 뒤쪽에서 카메라를 향해 알파 합성되어 픽셀에 대한 최종 렌더링 RGB 값을 생성한다:

기존의 NeRF 사용 사례에서 우리는 입력 이미지 및 관련 카메라 위치의 데이터 세트를 제공하고 NeRF MLP는 각 픽셀의 렌더링된 색과 입력 이미지의 해당 ground truth 색 사이의 평균 제곱 오류 loss 함수를 사용하여 랜덤 초기화로부터 학습된다.
이는 이전에 볼 수 없었던 뷰에서 사실적인 렌더링을 생성할 수 있는 3D 모델(MLP 가중치로 매개 변수 지정)을 산출한다.
우리의 모델은 앨리어싱을 줄이는 NeRF의 개선된 버전인 mip-NeRF 360을 기반으로 한다.
mip-NeRF 360은 원래 이미지에서 3D 재구성을 위해 설계되었지만, 개선 사항은 생성 text-to-3D 작업에도 도움이 된다 (자세한 내용은 부록 참조).
Shading.
전통적인 NeRF 모델은 3D 지점이 관찰되는 ray 방향에 따라 RGB 색상으로 조절된 radiance를 방출한다.
대조적으로, 우리의 MLP는 표면 자체의 색을 매개 변수화하며, 이는 우리가 제어하는 조명(일반적으로 "shading"이라고 불리는 과정)에 의해 조명된다.
NeRF-like 모델을 사용한 생성적 또는 다중 시점 3D 재구성에 대한 이전 연구는 다양한 반사 모델을 제안했다 (Bi et al., 2020; Boss et al., 2021; Srinivasan et al., 2021; Pan et al., 2022).
우리는 τ가 부피 밀도인 각 점에 RGB albedo ρ(재료 색상)를 사용한다:
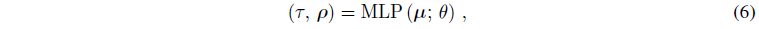
3D 포인트에 대한 최종 음영 출력 색상을 계산하려면 객체 지오메트리의 로컬 방향을 나타내는 normal 벡터가 필요합니다.
이 표면 normal 벡터는 3차원 좌표 μ에 대한 밀도 τ의 음의 그래디언트를 정규화하여 계산할 수 있다: n = -∇_μ τ / |∇_μ τ| (Yariv et al., 2020; Srinivasan et al., 2021).
각 normal n 및 재료 albedo ρ에서 3D 좌표 l_ρ 색상과 주변 ray l_a를 갖는 점 광원을 가정하고, 우리는 diffusion 반사율을 사용하여 각 점을 ray를 따라 렌더링하여 각 점에 대한 색상 c를 생성한다:

이러한 색상과 이전에 생성된 밀도로 표준 NeRF(식 5)에 사용된 것과 동일한 렌더링 가중치 ω_i로 볼륨 렌더링 적분을 근사한다.
text-to-3D 생성에 대한 이전 작업에서와 같이 albedo 색상 ρ를 랜덤으로 흰색(1, 1, 1)으로 대체하여 "textureless" 음영 출력을 생성하는 것이 유리하다는 것을 발견했다.
이는 모델이 텍스트 조건을 만족시키기 위해 장면 콘텐츠를 평면 기하학으로 그리는 퇴화 솔루션을 생성하는 것을 방지한다.
예를 들어, 이것은 특정 시야각과 조명 조건에서 모두 동일하게 보일 수 있는 다람쥐의 이미지를 포함하는 평평한 표면 대신 3D 다람쥐를 생성하는 최적화를 장려한다.
Scene Structure.
우리의 방법은 일부 복잡한 장면을 생성할 수 있지만, 고정된 경계 영역 내에서 NeRF 장면 표현만 쿼리하고, 배경색을 계산하기 위해 입력으로 위치 인코딩된 ray 방향을 취하는 두 번째 MLP에서 생성된 환경 맵을 사용하는 것이 도움이 된다는 것을 발견했다.
우리는 누적된 알파 값을 사용하여 이 배경색 위에 렌더링된 ray 색상을 합성한다.
이것은 NeRF 모델이 생성된 장면 뒤에 적절한 색상이나 배경을 그릴 수 있게 하면서 카메라에 매우 가까운 밀도로 공간을 채우는 것을 방지한다.
장면 대신 단일 객체를 생성하는 경우 경계 구를 줄이는 것이 유용할 수 있습니다.
Geometry regularizers,
우리가 구축한 mip-NeRF 360 모델에는 간결성을 위해 생략한 다른 세부 사항이 많이 포함되어 있다.
불필요하게 빈 공간을 채우는 것을 방지하기 위해 Jain et al. (2022)과 유사한 각 ray를 따라 불투명도에 대한 정규화 페널티를 포함한다.
노멀 벡터가 카메라에서 뒤로 향하는 밀도 분야의 병리를 방지하기 위해 Ref-NeRF에서 제안된 방향 loss의 수정된 버전을 사용한다.
이 패널티는 텍스처가 없는 음영을 포함할 때 중요합니다, 밀도 필드가 그렇지 않으면 음영이 더 어두워지도록 카메라에서 멀어지는 노멀의 방향을 지정하려고 하기 때문입니다.
이러한 정규화기 및 NeRF의 추가 하이퍼 파라미터에 대한 자세한 내용은 부록 A.2에 제시되어 있다.
3.2 Text-to-3D Synthesis
사전 학습된 text-to-image diffusion 모델, NeRF 형태의 미분 가능한 이미지 매개 변수화, 최소값이 좋은 샘플인 loss 함수를 고려할 때, 우리는 3D 데이터를 사용하지 않고 text-to-3D 합성에 필요한 모든 구성 요소를 가지고 있다.
각 텍스트 프롬프트에 대해 랜덤으로 초기화된 NeRF를 처음부터 학습한다.
DreamFusion 최적화의 각 반복은 다음을 수행합니다: (1) 카메라와 빛을 랜덤으로 샘플링하고 (2) 그 카메라에서 NeRF 이미지를 렌더링하고 빛으로 음영 처리히며 (3) NeRF 매개 변수에 대한 SDS loss의 그레디언트를 계산하고, (4) 최적화 도구를 사용하여 NeRF 매개 변수를 업데이트합니다.
아래에서는 이러한 각 단계를 자세히 설명하고 부록 8에 pseudocode를 제시합니다.
1. Random camera and light sampling.
각 반복에서 카메라 위치는 구면 좌표로 랜덤으로 샘플링되며, elevation 각도 ɸ_cam ∈ [-10°, 90°], azimuth 각도 θ_cam ∈ [0°, 360°], 원점으로부터의 거리는 [1, 1.5]이다.
참고로, 앞서 설명한 장면 바운딩 구체는 반지름이 1.4이다.
우리는 또한 원점과 "up" 벡터를 중심으로 "look-at" 지점을 샘플링하고, 이것들을 카메라 위치와 결합하여 카메라 포즈 행렬을 만든다.
우리는 또한 초점 거리가 λ_focal ω가 되도록 초점 거리 multiplier λ_focal ∈ U(0.7, 1.35)를 샘플링한다, 여기서 ω = 64는 픽셀 단위의 이미지 폭이다.
포인트 조명 위치 l은 카메라 위치를 중심으로 한 분포로부터 샘플링된다.
우리는 광범위한 카메라 위치를 사용하는 것이 일관된 3D 장면을 합성하는 데 중요하며, 광범위한 카메라 거리는 학습된 장면의 해상도를 향상시키는 데 도움이 된다는 것을 발견했다.
2. Rendering.
카메라 포즈와 조명 위치를 고려하여 섹션 3.1에서 설명한 대로 64x64 해상도로 음영 처리된 NeRF 모델을 렌더링합니다.
우리는 조명된 컬러 렌더, 텍스처가 없는 렌더, 음영 없는 albedo의 렌더링 중에서 랜덤으로 선택한다.
3. Diffusion loss with view-dependent conditioning.
텍스트 프롬프트는 종종 다른 뷰를 샘플링할 때 좋은 설명이 아닌 객체의 표준 뷰를 설명합니다.
따라서 랜덤으로 샘플링된 카메라의 위치를 기반으로 제공된 입력 텍스트에 뷰 종속 텍스트를 추가하는 것이 유리하다는 것을 발견했다.
elevation 각도가 ɸ_cam > 60° 이상인 경우 "overhead view"를 추가합니다.
ɸ_cam ≤ 60°의 경우, 우리는 azimuth 각도 θ_cam의 값에 따라 "front view", "side view" 또는 "back view"를 추가하기 위해 텍스트 임베딩의 가중치 조합을 사용한다(자세한 내용은 부록 A.2 참조).
우리는 Saharia et al. (2022)의 사전 학습된 64x64 base text-to-image 모델을 사용한다.
이 모델은 대규모 web-image-text 데이터에 대해 학습되었으며 T5-XXL 텍스트 임베딩을 조건으로 한다.
우리는 ω(t) = σ_t^2의 가중치 함수를 사용하지만 균일한 가중치가 유사하게 수행된다는 것을 발견했다.
수치 불안정성으로 인한 매우 높고 낮은 노이즈 레벨을 피하여 t ~ U(0.02, 0.98)를 샘플링한다.
classifier-free guidance를 위해, 우리는 ω = 100을 설정하여, 더 높은 guidance 가중치가 향상된 샘플 품질을 제공한다는 것을 발견했다.
이는 이미지 샘플링 방법보다 훨씬 크며, 작은 guidance 가중치에서 과도한 평활을 초래하는 objective의 모드 탐색 특성 때문에 필요할 수 있다(부록 표 9 참조).
렌더링된 이미지와 샘플링된 시간 단계 t를 고려하여 노이즈 ε을 샘플링하고 식. 3에 따라 NeRF 매개 변수의 그래디언트를 계산합니다.
4. Optimization.
우리의 3D 장면은 4개의 칩이 있는 TPUv4 기계에 최적화되어 있다.
각 칩은 별도의 뷰를 렌더링하고 장치당 배치 크기가 1인 diffusion U-Net을 평가한다.
우리는 약 1.5시간이 걸리는 15,000번의 반복을 최적화한다.
컴퓨팅 시간은 NeRF 렌더링과 diffusion 모델 평가 간에 균등하게 분할된다.
매개 변수는 Distributed Shampoo Optimizer를 사용하여 최적화됩니다(Anil et al., 2020).
최적화 설정은 부록 A.2를 참조하십시오.
4 Experiments
우리는 다양한 텍스트 프롬프트에서 일관된 3D 장면을 생성하는 DreamFusion의 능력을 평가한다.
기존의 제로샷 텍스트에서 3D 생성 모델과 비교하고 정확한 3D 지오메트리를 가능하게 하는 모델의 핵심 구성 요소를 식별하고 그림 4에 표시된 구성 생성과 같은 DreamFusion의 정성적 기능을 탐색한다.
우리는 3D 자산, 확장된 비디오 및 메시의 대형 갤러리를 선보인다.

3D 재구성 작업은 일반적으로 복구된 지오메트리를 일부 ground truth와 비교하는 Chamfer 거리와 같은 참조 기반 메트릭을 사용하여 평가된다.
뷰 합성 문헌은 렌더링된 뷰를 보류된 사진과 비교하기 위해 종종 PSNR을 사용한다.
이러한 참조 기반 메트릭은 텍스트 프롬프트에 해당하는 "true" 3D 장면이 없기 때문에 제로샷 text-to-3D 생성에 적용하기 어렵다.
Jain et al.(2022)에 따라, 우리는 입력 캡션과 관련하여 렌더링된 이미지의 일관성을 위한 자동화된 메트릭인 CLIP R-Precision을 평가한다.
R-Precision은 CLIP(Radford et al., 2021)이 장면의 렌더링이 주어진 산만함 집합 중에서 올바른 캡션을 검색하는 정확도입니다.
우리는 Dream Fields의 객체 중심 COCO 검증 하위 집합에서 153개의 프롬프트를 사용한다.
또한 기존 메트릭이 지오메트리의 품질을 포착하지 못하기 때문에 텍스처가 평평한 지오메트리에 그려질 때 종종 높은 값을 산출하기 때문에 텍스처 없는 렌더링에 대한 R-Precision를 측정하여 지오메트리를 평가한다.

표 1은 DreamFusion에 대한 CLIP R-Precision 및 몇 가지 베이스라인을 보고합니다.
여기에는 Dream Fields, CLIP-Mesh(CLIP로 메시를 최적화하는), MS-COCO에서 원래 캡션 이미지 쌍을 평가하는 오라클이 포함된다.
우리는 또한 우리의 3D 표현을 사용하는 Dream Fields의 향상된 재구현과 비교한다(섹션 3.1).
이번 평가는 CLIP를 기반으로 하기 때문에 Dream Fields와 CLIP-Mesh는 학습 중 CLIP를 사용하기 때문에 불공평한 이점이 있다.
그럼에도 불구하고 DreamFusion은 컬러 이미지에서 두 베이스라인을 모두 능가하고 실제 이미지 성능에 접근한다.
Dream Fields의 구현은 텍스처가 없는 렌더링을 사용하여 지오메트리(Geo)를 평가할 때 거의 우연히 수행되지만 DreamFusion은 58.5%의 캡션과 일치한다.
실험 설정에 대한 자세한 내용은 부록 A.3을 참조한다.
Ablations.
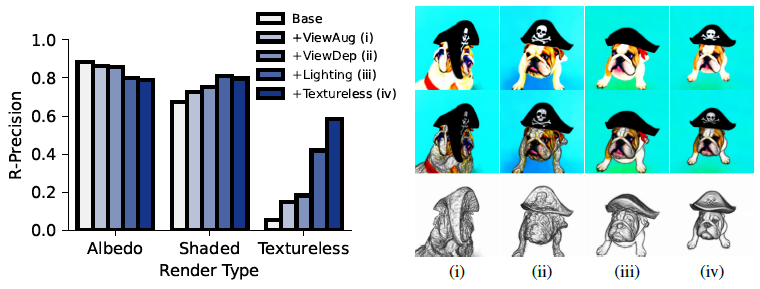
그림 6은 단순화된 DreamFusion ablation를 위한 CLIP R-Precision을 보여주고 최적화 선택지를 점진적으로 추가한다: 넓은 범위의 관점(ViewAug), 뷰 종속 프롬프트(ViewDep), 조명이 없는 albedo 컬러 렌더링(조명), 텍스처가 없는 음영 지오메트리 이미지(Textureless) 최적화.
우리는 기하학적 품질을 확인하기 위해 베이스라인(왼쪽), 전체 음영 렌더(중간) 및 텍스처가 없는 렌더(오른쪽)에서 albedo 렌더에 대한 R-Precision을 측정한다.
이러한 선택에 따라 지오메트리가 크게 개선되고 전체 렌더링이 +12.5% 개선됩니다.
그림 6은 albation에 대한 정성적 결과를 보여줍니다.
이 ablation은 또한 albedo 렌더링이 어떻게 기만적일 수 있는지 강조합니다.
우리의 기본 모델은 가장 높은 점수를 달성하지만 열악한 기하학적 구조를 보여줍니다(개는 여러 개의 머리를 가지고 있습니다).
정확한 형상을 복구하려면 뷰에 의존하는 프롬프트, 조명 및 텍스처가 없는 렌더링이 필요하다.
5 Discussion
우리는 광범위한 텍스트 프롬프트에 대한 text-to-3D 합성에 효과적인 기술인 DreamFusion을 제시했다.
DreamFusion은 새로운 score distillation sampling 접근 방식과 새로운 NeRF 유사 렌더링 엔진을 사용하여 확장 가능한 고품질 2D 이미지 확산 모델을 3D 도메인으로 전송함으로써 작동한다.
DreamFusion은 3D 또는 다중 뷰 학습 데이터가 필요하지 않으며, 3D 합성을 수행하기 위해 사전 학습된 2D 확산 모델(2D 영상으로만 학습됨)만 사용한다.
DreamFusion은 이 작업에 대한 이전 작업을 능가하고 설득력 있는 결과를 산출하지만 여전히 몇 가지 한계가 있다.
SDS는 이미지 샘플링에 적용될 때 완벽한 손실 함수가 아니며 종종 조상 샘플링에 비해 과포화 및 과평활 결과를 생성한다.
동적 임계치(Saharia et al., 2022)는 이미지에 SDS를 적용할 때 이 문제를 부분적으로 개선하지만, NeRF 맥락에서 이 문제를 해결하지는 못했다.
또한 SDS를 사용하여 생성된 2D 이미지 샘플은 조상 샘플링에 비해 다양성이 부족한 경향이 있으며, 우리의 3D 결과는 랜덤 시드 간에 거의 차이를 보이지 않는다.
이것은 변형 추론과 확률 밀도 distillation의 맥락에서 모드 탐색 특성을 갖는 것으로 이전에 지적된 역 KL 발산을 사용하는 데 기본적일 수 있다.
DreamFusion은 64x64 Imagen 모델을 사용하므로 3D 합성 모델은 세세한 디테일이 부족한 경향이 있습니다.
더 높은 해상도의 확산 모델과 더 큰 NeRF를 사용하면 아마도 이를 해결할 수 있지만, 합성은 비실용적으로 느려질 것이다.
향후 확산 및 신경 렌더링의 효율성이 향상되면 고해상도로 다루기 쉬운 3D 합성이 가능해질 것으로 기대된다.
2D 관측에서 3D 재구성 문제는 매우 ill-posed로 널리 이해되며, 이러한 모호성은 3D 합성 맥락에서 결과를 가져온다.
기본적으로, 우리의 작업은 역 렌더링이 어렵다는 것과 같은 이유로 어렵다: 동일한 2D 이미지를 생성하는 가능한 3D 세계가 많이 있다.
따라서 우리 작업의 최적화 지형은 매우 비볼록적이며, 이 작업의 많은 세부 사항은 이러한 로컬 최소값을 피하도록 특별히 설계되었다.
그러나 최선의 노력에도 불구하고 우리는 여전히 모든 장면 콘텐츠가 단일 평면 위에 "painted"되는 3D 재구성 같은 로컬 최소값을 관찰한다.
본 연구에서 제시된 기술은 효과적이지만, 2D 관찰을 3D 세계로 "리프팅"하는 이 작업은 본질적으로 모호하며, 더 강력한 3D 이전으로부터 이익을 얻을 수 있다.
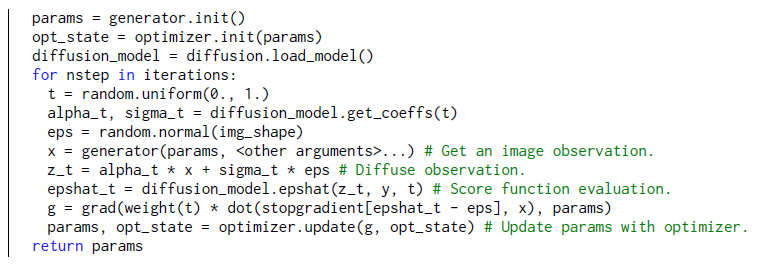
A.1 Pseudocode for Ancenstral Sampling and Our Score Distillation Sampling

A.2 NeRF Details and Training Hyperparameters
우리 모델은 mip-NeRF 360(Barron et al, 2022)을 기반으로 구축된다. (공식적으로 사용 가능한 구현 2022부터), 이는 NeRF의 개선된 버전이다(Mildenhall et al, 2020).
이 모델이 NeRF에 적용하는 주요 수정은 3D 포인트 정보가 NeRF MLP로 전달되는 방법이다.
NeRF에서 각 3D 입력 포인트는 사인파 위치 인코딩 함수를 사용하여 더 높은 차원의 공간에 매핑된다(Vaswani et al, 2017).
mip-NeRF에서, 이것은 렌더링되는 레이의 "폭"과 (이미지 평면의 픽셀 발자국을 기반으로) 레이를 따라 샘플링된 각 간격 [d_i, d_(i+1)]의 길이를 설명하는 통합 위치 인코딩으로 대체된다(Barron et al., 2021).
이를 통해 레이를 따른 각 간격은 간격의 3D 볼륨에 근사하는 평균 μ 및 공분산 행렬 Σ를 사용하여 가우시안 분포로 표현될 수 있습니다.
Mip-NeRF covariance annealing.
mip-NeRF에서와 같이, 각 평균 μ는 레이 간격의 중심부의 3D 좌표이지만, mip-NeRF와 달리 우리는 카메라 기하학에서 파생된 공분산을 사용하지 않고 대신 각 Σ를

로 정의한다.
여기서 λ_Σ는 학습 중 큰 값에서 작은 값으로 선형 어닐링되는 스케일 파라미터이다.
λ_Σ의 초기 및 최종 값에 대한 5 x 10^-2 및 2 x 10^-3의 대표적인 설정은 최적화 첫 번째 5k 단계에 대해 선형 어닐링된 것입니다(총 15k 중).
이러한 스케일 파라미터의 "coarse to fine" 어닐링은 Park et al(2021)에 의해 사용되는 어닐링과 유사한 효과를 가지지만, 기존의 위치 부호화 대신 통합 위치 부호화를 사용한다.
기본 사인파 위치 인코딩 함수는 주파수 2^0, 2^1, ..., 2^(L-1)을 사용하며 여기서 L = 8을 설정합니다.
MLP architecture changes.
우리의 NeRF MLP는 128개의 숨겨진 유닛이 있는 5개의 ResNet 블록(He et al, 2016), Swish/SiLU 활성화(Hendrycks & Gimpel, 2016), 블록 간의 레이어 정규화(Ba et al, 2016)로 구성된다.
우리는 밀도 τ를 생성하기 위해 exp 활성화를 사용하고 RGB 알베도 ρ를 생성하기 위해 시그모이드 활성화를 사용한다.
Shading hyperparameters.
최적화 첫 1k 단계의 경우 주변 레이 색상 l_a를 1로, 확산 레이 색상 l_ρ를 0으로 설정하여 확산 음영을 효과적으로 비활성화한다.
나머지 단계에 대해서는 l_a = [0.1, 0.1, 0.1] 및 l_ρ = [0.9, 0.9, 0.9] 확률을 설정하고, 그렇지 않으면 l_a = 1, l_ρ = 0으로 75%의 확산 음영을 사용합니다.
음영이 켜져 있을 때(l_ρ > 0), 우리는 0.5의 확률로 질감이 없는 음영(ρ = 1)을 선택합니다.
Spatial density bias.
최적화 초기 단계에 도움을 주기 위해, 우리는 MLP의 출력에 원점 주변의 작은 밀도 "blob"을 추가한다.
이렇게 하면 샘플링된 카메라 바로 옆에 있는 것이 아니라 3D 좌표 공간의 중심에 장면 컨텐츠에 초점을 맞출 수 있습니다.
가우시안 PDF를 사용하여 추가된 밀도를 매개 변수화합니다:

대표적인 설정은 스케일 파라미터의 경우 λ_τ = 5이고 width 파라미터의 경우 σ_τ = 0.2입니다.
이 밀도는 NeRF MLP의 τ 출력에 추가됩니다.
Additional camera and light sampling details.
각 공간에서 카메라 elevation ɸ_cam을 균일하게 샘플링하는 것은 구 표면에 균일한 샘플을 생성하지 않는다 - 극 주변 영역이 과도하게 샘플링되었습니다
우리는 이 편향이 실제로 도움이 된다는 것을 알았기 때문에, 우리는 확률 0.5로 이 편중 분포에서 ɸ_cam을 샘플링하고, 그렇지 않으면 반구체의 진정한 면적 균일 분포에서 샘플링한다.
샘플링된 카메라 위치는 작고 균일한 오프셋 U(-0.1, 0.1)^3에 의해 교란된다.
"look-at" 점은 N(0, 0.2I)에서 샘플링됩니다, 그리고 default "up" 벡터는 N(0, 0.02I)에서 샘플링된 노이즈에 의해 교란된다.
이 노이즈는 추가적인 증강으로 작용하며 학습 중에 더 다양한 관점을 볼 수 있도록 한다.
우리는 광 위치 벡터 l의 방향과 norm을 별도로 샘플링한다.
방향을 샘플링하기 위해, 우리는 p_cam이 카메라 위치인 N(p_cam, I)에서 샘플링한다(이것은 점광이 보통 카메라와 같은 쪽의 물체에 도달하도록 보장한다).
norm |l|은 U(0.8, 1.5)에서 샘플링되는 반면 |p_cam| ~ U(1.0, 1.5)에서는 샘플링됩니다.
Regularizer hyperparameters.
우리는 Ref-NeRF(Verbin et al, 2022)가 제안한 방향 손실을 사용하여 밀도 필드의 normal 벡터가 보일 때 카메라를 향하도록 장려한다(그래서 카메라가 음영 처리될 때 "backwards"를 향하는 것처럼 보이는 형상을 관찰하지 않는다).
우리는 렌더링 가중치 w_i에 스탑-그래디언트를 배치하여 생성된 개체가 축소되거나 사라지는 의도하지 않은 로컬 최소값을 방지하는 데 도움이 된다:

, 여기서 v는 레이의 방향(뷰 방향)이다.
우리는 또한 각 레이를 따라 누적된 알파 값(불투명도)에 작은 정규화를 적용한다: L_opacity = √((∑_i w_i)^2 + 0.01).
이는 최적화가 불필요하게 빈 공간을 채우는 것을 방지하고 전경/배경 분리를 개선한다.
방향 손실 L_orient의 경우 [10^-1, 10^-3]에 놓일 합리적인 가중치를 찾는다.
방향 손실이 너무 크면 표면이 지나치게 매끄러워집니다.
대부분의 실험에서, 우리는 가중치를 10^-2로 설정한다.
이 가중치는 처음 5k(15k 중) 단계에서 10^-4에서 시작하여 어닐링됩니다.
누적된 알파 손실 L_opacity의 경우 [10^-3, 5 x 10^-3]에 놓일 합리적인 가중치를 찾는다.
View-dependent prompting.
샘플링된 azimuth θ_cam을 포함하는 quadrant를 기반으로 전면/측면/후면 뷰 프롬프트 증강 사이에 보간한다.
우리는 텍스트 임베딩을 보간하는 다양한 방법을 실험했지만, 샘플링된 azimuth와 가장 가까운 텍스트 임베딩을 단순히 취하는 것이 잘 작동한다는 것을 발견했다.
Optimizer.
Distributed Shampoo (Anil et al., 2020)를 β_1 = 0.9, β_2 = 0.9, exponent_override = 2, block_size = 128, graft_type = SQRT_N, ε = 10^-6, 코사인 붕괴 후 10^6까지 3000단계에 걸쳐 학습률을 선형 워밍업한다.
우리는 이 긴 예열 기간이 생성된 기하학의 일관성을 개선하는 데 도움이 된다는 것을 발견했다.
A.3 Experiment setup
R-Precision에 대한 우리의 계산은 베이스라인과 약간 다르다.
언급한 바와 같이 CLIP 기반 text-to-3D 시스템은 학습에 사용되는 모델이 평가 모델과 유사하기 때문에 평가 CLIP R-Precision 메트릭을 과적합하기 쉽다.
이 문제를 최소화하기 위해 Dream Fields(Jain et al, 2022)와 CLIP-Mesh(Khalid et al, 2022)는 학습 중 보이는 것보다 높은 45˚ 고도에서 단일 돌출 뷰에서 렌더링을 평가한다(최대 30˚).
DreamFusion은 이 문제가 발생하기 쉽기 때문에 30˚로 평가하지만 분산을 줄이기 위해 여러 azimuth에서 메트릭을 평균합니다.
표 1의 주요 결과에서 달리 명시되지 않는 한 2세대 시드로 모든 캡션을 평가한다.