2023. 7. 24. 11:53ㆍtext-to-3D
Zero-1-to-3: Zero-shot One Image to 3D Object
Ruoshi Liu, Rundi Wu, Basile Van Hoorick, Pavel Tokmakov, Sergey Zakharov, Carl Vondrick
Abstract
우리는 단일 RGB 이미지만 주어진 객체의 카메라 시점을 변경하기 위한 프레임워크인 Zero-1-to-3을 소개합니다.
이러한 제약이 적은 환경에서 새로운 뷰 합성을 수행하기 위해 대규모 디퓨전 모델이 자연 이미지에 대해 학습하는 기하학적 priors를 활용합니다.
우리의 조건적 디퓨전 모델은 합성 데이터 세트를 사용하여 상대적 카메라 관점의 제어를 학습하여, 이를 통해 지정된 카메라 변환 하에서 동일한 개체의 새로운 이미지를 생성할 수 있습니다.
합성 데이터 세트에 대해 학습되었지만, 우리 모델은 인상주의 그림을 포함한 야생 이미지뿐만 아니라 배포되지 않은 데이터 세트에 대한 강력한 제로샷 일반화 능력을 유지합니다.
우리의 관점-조건적 디퓨전 접근법은 단일 이미지에서 3D 재구성 작업에 추가로 사용될 수 있습니다.
정성 및 정량적 실험에 따르면 우리의 방법은 인터넷 규모의 사전 학습을 활용하여 SOTA 단일 뷰 3D 재구성 및 새로운 뷰 합성 모델을 크게 능가합니다.
1. Introduction
하나의 카메라 뷰만으로, 인간은 종종 물체의 3D 모양과 외관을 상상할 수 있습니다.
이 능력은 복잡한 환경에서 물체 조작[17] 및 탐색[7]과 같은 일상적인 작업에 중요하지만 그림[32]과 같은 시각적 창의성에도 중요합니다.
이 능력은 대칭과 같은 기하학적 prior에 의존함으로써 부분적으로 설명될 수 있지만, 우리는 물리적, 기하학적 제약을 쉽게 깨는 훨씬 더 도전적인 물체로 일반화할 수 있는 것 같습니다.
실제로 물리적 세계에 존재하지 않거나 존재할 수 없는 물체의 3D 모양을 예측할 수 있습니다(그림 1의 세 번째 열 참조).
이 정도의 일반화를 달성하기 위해 인간은 평생의 시각적 탐구를 통해 축적된 prior 지식에 의존합니다.

대조적으로, 3D 이미지 재구성을 위한 대부분의 기존 접근 방식은 값비싼 3D 주석(예: CAD 모델) 또는 카테고리별 prior에 의존하기 때문에 폐쇄적인 환경에서 작동합니다 [37, 21, 36, 67, 68, 66, 25, 24].
최근 몇 가지 방법이 CO3D[43, 30, 36, 15]와 같은 대규모의 다양한 데이터 세트에 대한 사전 학습을 통해 개방형 3D 재구성 방향으로 큰 진전을 이루었습니다.
그러나 이러한 접근 방식은 여전히 스테레오 뷰 또는 카메라 포즈와 같은 학습을 위해 기하학 관련 정보를 필요로 합니다.
결과적으로, 그들이 사용하는 데이터의 규모와 다양성은 대규모 디퓨전 모델의 성공을 가능하게 하는 최근의 인터넷 규모 텍스트 이미지 컬렉션[47]에 비해 미미한 수준으로 남아 있습니다 [45, 44, 33].
인터넷 규모의 사전 학습은 이러한 모델에 풍부한 semantic priors를 부여하지만 기하학적 정보를 포착하는 정도는 여전히 탐구되지 않은 것으로 나타났습니다.
본 논문에서, 우리는 제로샷 새로운 뷰 합성과 3D 형상 재구성을 수행하기 위해 Stable Diffusion [44]과 같은 대규모 디퓨전 모델에서 카메라 시점을 조작하는 제어 메커니즘을 배울 수 있음을 보여줍니다.
단일 RGB 이미지가 주어지면, 이 두 작업은 모두 심각하게 제한됩니다.
그러나 현대의 생성 모델(50억 개 이상의 이미지)이 사용할 수 있는 학습 데이터의 규모로 인해 디퓨전 모델은 자연 이미지 분포에 대한 SOTA 표현이며, 다양한 관점에서 방대한 수의 객체를 포괄하는 지원을 제공합니다.
카메라 대응 없이 2D 단안 이미지에 대해 학습되지만, 생성 과정에서 상대적인 카메라 회전 및 변환에 대한 제어를 학습하기 위해 모델을 파인튜닝할 수 있습니다.
이러한 제어를 통해 선택한 다른 카메라 시점으로 디코딩되는 임의 이미지를 인코딩할 수 있습니다.
그림 1은 결과의 몇 가지 예를 보여줍니다.
이 논문의 주요 기여는 대규모 디퓨전 모델이 2D 이미지에 대해서만 학습되었음에도 불구하고 시각적 세계에 대해 풍부한 3D priors에 학습했다는 것을 보여주는 것입니다.
또한 단일 RGB 이미지에서 새로운 뷰 합성을 위한 SOTA 결과와 객체의 제로샷 3D 재구성을 위한 SOTA 결과를 시연합니다.
우리는 섹션 2에서 관련 작업을 간략하게 검토하는 것으로 시작합니다.
섹션 3에서는 대규모 디퓨전 모델을 파인튜닝하여 카메라 extrinsics에 대한 제어를 학습하는 접근 방식을 설명합니다.
마지막으로 섹션 4에서는 단일 이미지에서 제로샷 뷰 합성과 기하학적 및 외관의 3D 재구성을 평가하기 위한 몇 가지 정량적 및 정성적 실험을 제시합니다.
2. Related Work
3D generative models.
대규모 이미지-텍스트 데이터 세트[47]와 결합된 생성 이미지 아키텍처의 최근 발전으로 다양한 장면과 객체의 고충실도 합성이 가능해졌습니다[33, 40, 45].
특히, 디퓨전 모델은 디노이징 objective를 사용하여 확장 가능한 이미지 생성기를 학습하는 데 매우 효과적인 것으로 나타났습니다 [6, 48].
그러나 3D 도메인으로 확장하려면 주석이 달린 많은 양의 3D 데이터가 필요합니다.
대신, 최근의 접근 방식은 사전 학습된 대규모 2D 디퓨전 모델을 ground truth 3D 데이터를 사용하지 않고 3D로 전송하는 데 의존합니다.
Neural Radiance Fields 또는 NeRFs [31]는 높은 충실도로 장면을 인코딩하는 능력 덕분에 강력한 표현으로 부상했습니다.
일반적으로 NeRF는 단일 장면 재구성에 사용됩니다, 여기서는 전체 장면을 커버하는 많은 포즈 이미지가 제공됩니다.
그런 다음 관찰되지 않은 각도에서 새로운 뷰를 예측하는 것이 과제입니다.
DreamFields [22]는 NeRF가 3D 생성 시스템의 주 구성요소로도 사용될 수 있는 보다 다용도의 도구임을 보여주었습니다.
다양한 후속 작업 [38, 26, 53]은 텍스트 입력에서 충실도가 높은 3D 객체와 장면을 생성하기 위해 용도가 변경된 2D 디퓨전 모델의 distillation loss를 CLIP으로 대체합니다.
우리의 작업은 디퓨전 모델을 사용하여 시점 조건 image-to-image 변환 작업으로 모델링하여 새로운 뷰 합성에 대한 비전통적인 접근 방식을 탐구합니다.
학습된 모델은 3D distillation과 결합하여 단일 이미지에서 3D 모양을 재구성할 수도 있습니다.
이전 연구 [56]는 유사한 파이프라인을 채택했지만 제로샷 일반화 기능을 입증하지 못했습니다.
동시 접근법 [9, 29, 61]은 language-guided priors 및 textual inversion [14]을 사용하여 image-to-3D 생성을 수행하기 위한 유사한 기술을 제안했습니다.
이에 비해, 우리의 방법은 합성 데이터 세트를 통해 시점 제어를 학습하고 야생 이미지에 대한 제로샷 일반화를 보여줍니다.
Single-view object reconstruction.
단일 뷰에서 3D 객체를 재구성하는 것은 강력한 priors가 필요한 매우 어려운 문제입니다.
한 작업 라인은 메시 [58, 62], 복셀 [16, 60] 또는 포인트 클라우드 [12, 30]로 표시되는 3D primitives 모음에 의존하여 priors를 구축하고 조건화를 위해 이미지 인코더를 사용합니다.
이러한 모델은 사용되는 3D 데이터 수집의 다양성에 의해 제약을 받고 이러한 유형의 조건화의 전역적 특성으로 인해 일반화 기능이 좋지 않습니다.
또한 추정된 형상과 입력 사이의 정렬을 보장하기 위해 추가 포즈 추정 단계가 필요합니다.
반면, 로컬 조건적 모델 [46, 63, 54, 51, 52]은 장면 재구성에 직접 로컬 이미지 피쳐를 사용하고 일반적으로 근접 뷰 재구성에 제한되지만 더 큰 교차 도메인 일반화 기능을 보여주는 것을 목표로 합니다.
최근, MCC [59]는 RGB-D 뷰에서 3D 재구성을 위한 범용 표현을 학습하고 객체 중심 비디오의 대규모 데이터 세트에 대해 학습됩니다.
우리의 연구에서, 우리는 사전 학습된 Stable Diffusion 모델에서 풍부한 기하학적 정보를 직접 추출할 수 있어 추가 depth 정보의 필요성을 완화할 수 있음을 보여줍니다.
3. Method
객체의 단일 RGB 이미지 x ∈ R^(H x W x 3)이 주어지면, 우리의 목표는 다른 카메라 관점에서 객체의 이미지를 합성하는 것입니다.
R ∈ R^(3x3)와 T ∈ R^3을 각각 원하는 시점의 상대적 카메라 회전 및 변환이라고 합니다.
우리는 이 카메라 변환에서 새로운 이미지를 합성하는 모델 f를 배우는 것을 목표로 합니다:

, 여기서 우리는 합성된 이미지로서 ^x_(R,T)를 나타냅니다.
우리는 우리의 추정된 ^x_(R,T)가 진정하지만 관찰되지 않은 새로운 뷰 x_(R,T)과 지각적으로 유사하기를 원합니다.
단안 RGB 이미지에서 새로운 뷰 합성은 심각하게 제한됩니다.
우리의 접근 방식은 텍스트 설명에서 다양한 이미지를 생성할 때 비정상적인 제로샷 능력을 보이기 때문에 이 작업을 수행하기 위해 Stable Diffusion과 같은 대규모 디퓨전 모델을 활용할 것입니다.
학습 데이터의 규모[47]로 인해, 사전 학습된 디퓨전 모델은 오늘날 자연 이미지 분포에 대한 SOTA 표현입니다.
하지만 f를 만들기 위해서는 우리가 극복해야 할 두 가지 과제가 있습니다.
첫째, 대규모 생성 모델은 서로 다른 관점에서 다양한 객체에 대해 학습되지만, 표현은 관점 간의 대응을 명시적으로 인코딩하지 않습니다.
둘째, 생성 모델은 인터넷에 반영된 관점 편향을 상속합니다.
그림 2에서 볼 수 있듯이, Stable Diffusion은 표준 포즈로 정면을 향한 chair의 이미지를 생성하는 경향이 있습니다.
이 두가지 문제는 능력을 크게 방해합니다

3.1. Learning to Control Camera Viewpoint
디퓨전 모델은 인터넷 규모 데이터에 대해 학습되었기 때문에 자연 이미지 분포에 대한 지원은 대부분의 객체에 대한 대부분의 관점을 포함할 가능성이 높지만, 이러한 관점은 사전 학습된 모델에서 제어될 수 없습니다.
일단 우리가 모델에게 사진이 캡처되는 카메라 extrinsics를 제어하는 메커니즘을 teach할 수 있게 되면, 우리는 새로운 뷰 합성을 수행할 수 있는 기능을 해제합니다.
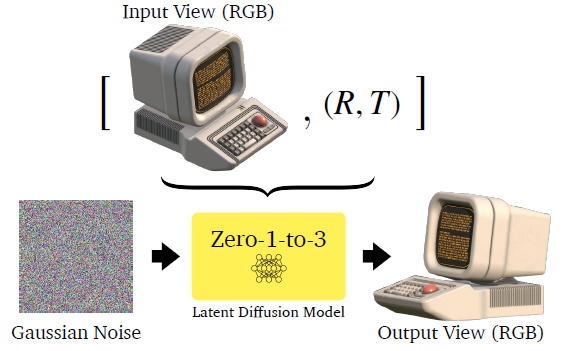
이를 위해, 쌍을 이룬 이미지의 데이터 세트와 그 상대적인 카메라 extrinsic {(x, x_(R,T), R, T)}가 주어지면, 그림 3에 나온 우리의 접근 방식은 나머지 표현을 파괴하지 않고 카메라 매개 변수에 대한 제어를 학습하기 위해 사전 학습된 디퓨전 모델을 파인튜닝합니다.
[44]에 이어 인코더 E, 디노이저 U-Net ε_θ 및 디코더 D가 있는 latent diffusion 아키텍처를 사용합니다.
디퓨전 시간 단계 t ~ [1, 1000]에서 c(x,R,T)를 입력 뷰 및 상대 카메라 extrinsic을 임베딩합니다.
그런 다음 모델을 파인튜닝하기 위해 다음 objective를 해결합니다:
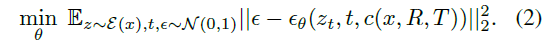
모델 ε_θ가 학습된 후, 추론 모델 f는 c(x,R,T)에 조건화된 가우시안 노이즈 이미지 [44]에서 반복 디노이징을 수행하여 이미지를 생성할 수 있습니다.
본 논문의 주요 결과는 이러한 방식으로 사전 학습된 디퓨전 모델을 파인튜닝하면 카메라 시점을 제어하기 위한 일반적인 메커니즘을 학습할 수 있으며, 이는 파인튜닝 데이터 세트에서 볼 수 있는 객체의 외부를 추론합니다.
다시 말해, 이 파인튜닝을 통해 컨트롤을 "bolted on"할 수 있고 디퓨전 모델은 시점을 제어하는 경우를 제외하고 사실적인 이미지를 생성할 수 있는 기능을 유지할 수 있습니다.
이 구성성은 모델에서 제로샷 기능을 설정하여 최종 모델이 3D 자산이 부족하고 파인튜닝 세트에 나타나지 않는 객체 클래스에 대한 새로운 뷰를 합성할 수 있습니다.
3.2. View-Conditioned Diffusion
단일 이미지에서 3D 재구성에는 낮은 레벨의 인식(깊이, 음영, 질감 등)과 높은 레벨의 이해(유형, 기능, 구조 등)가 모두 필요합니다.
따라서 하이브리드 컨디셔닝 메커니즘을 채택합니다.
하나의 스트림에서, 입력 이미지의 CLIP [39] 임베딩은 (R, T)와 연결되어 c(x, R, T)를 포함하는 "posed CLIP"을 형성합니다.
우리는 입력 이미지의 높은 레벨의 semantic 정보를 제공하는 디노이징 U-Net을 조건화하기 위해 크로스 어텐션을 적용합니다.
다른 스트림에서는 입력 이미지가 디노이즈된 이미지와 채널 연결되어 모델이 합성되는 개체의 ID와 세부 정보를 유지하는 데 도움이 됩니다.
classifier-free guidance [19]을 적용할 수 있도록 [3]에서 제안된 유사한 메커니즘을 따르며, 입력 이미지와 제안된 CLIP 임베딩을 임의로 null 벡터로 설정하고 추론 중에 조건부 정보를 스케일링합니다.
3.3. 3D Reconstruction
많은 응용 프로그램에서 객체의 새로운 뷰를 합성하는 것만으로는 충분하지 않습니다.
개체의 모양과 형상을 모두 캡처하는 전체 3D 재구성이 필요합니다.
최근 오픈 소스 프레임워크인 Score Jacobian Chaining (SJC) [53]을 채택하여 text-to-image 디퓨전 모델의 priors로 3D 표현을 최적화합니다.
그러나 디퓨전 모델의 확률적 특성으로 인해 그레디언트 업데이트는 매우 확률적입니다.
DreamFusion [38]에서 영감을 받아 SJC에서 사용되는 중요한 기술은 classifier-free guidance 값을 평소보다 상당히 높게 설정하는 것입니다.
이 방법론은 각 샘플의 다양성을 감소시키지만 재구성의 충실도를 향상시킵니다.
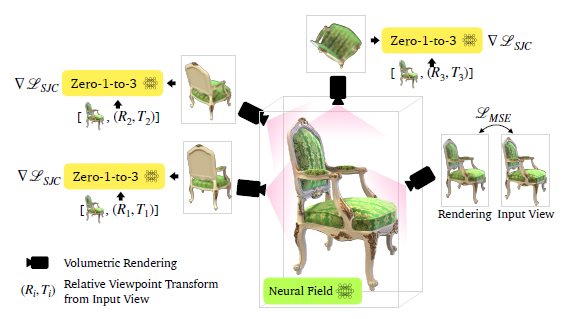
그림 4와 같이 SJC와 유사하게 시점을 랜덤으로 샘플링하여 볼륨 렌더링을 수행합니다.
그런 다음 가우시안 노이즈 ε ~ N(0, 1)으로 결과 이미지를 교란하고, 노이즈가 없는 입력 x_π를 향해 score를 근사화하기 위해 입력 이미지 x, posed CLIP 임베딩 c(x,R,T) 및 타임스텝 t에 조건화된 U-Net ε_t를 적용하여 디노이징합니다:
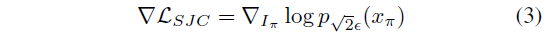
, 여기서 ∇L_SJC는 [53]에 의해 도입된 PAAS score입니다.
또한 MSE loss로 입력 뷰를 최적화합니다.
NeRF 표현을 더욱 정규화하기 위해, 우리는 또한 모든 샘플링된 관점에 depth smoothness loss을 적용하고 근거리 consistency loss를 적용하여 주변 관점 간의 외관 변화를 정규화합니다.
3.4. Dataset
우리는 파인튜닝을 위해 최근 출시된 Objaverse [8] 데이터 세트를 사용하는데, 이는 100K+ 아티스트가 만든 800K+ 3D 모델이 포함된 대규모 오픈 소스 데이터 세트입니다.
ShapeNet [4]과 같은 명시적인 클래스 레이블은 없지만 Objaverse는 풍부한 기하학적 구조를 가진 고품질 3D 모델의 다양성을 구현하며, 그 중 많은 모델은 세밀한 세부 사항과 재료 특성을 가지고 있습니다.
데이터 세트의 각 객체에 대해 객체의 중심을 가리키는 12개의 카메라 extrinsics 행렬 M_을 랜덤으로 샘플링하고 ray-tracing 엔진으로 12개의 뷰를 렌더링합니다.
학습 시간에 각 개체에 대해 두 개의 뷰를 샘플링하여 이미지 쌍(x,x_(R,T))을 형성할 수 있습니다.
두 관점 사이의 매핑을 정의하는 해당 상대 관점 변환(R,T)은 두 외부 행렬에서 쉽게 파생될 수 있습니다.
4. Experiments
제로샷 새로운 뷰 합성 및 3D 재구성에 대한 모델의 성능을 평가합니다.
Objaverse의 저자가 확인한 바와 같이, 본 논문에서 사용한 데이터 세트와 이미지는 Objaverse 데이터 세트 외부에 있으므로 제로샷 결과로 간주할 수 있습니다.
우리는 복잡성 수준이 다른 합성 물체 및 장면에 대한 SOTA 모델과 정량적으로 비교합니다.
또한 일상적인 물건을 찍은 사진부터 그림까지 다양한 야생 이미지를 사용하여 정성적인 결과를 보고합니다.
4.1. Tasks
우리는 단일 뷰 RGB 이미지를 입력으로 사용하는 밀접하게 관련된 두 가지 작업을 설명하고 제로샷을 적용합니다.
Novel view synthesis.
새로운 뷰 합성은 컴퓨터 비전에서 오래된 3D 문제로, 모델이 물체의 깊이, 질감 및 모양을 암묵적으로 학습해야 합니다.
단일 뷰의 입력 정보가 극도로 제한되기 때문에 prior 지식을 활용하기 위한 새로운 뷰 합성 방법이 필요합니다.
최근의 인기 있는 방법은 랜덤으로 샘플링된 뷰에서 CLIP 일관성 objective를 사용하여 암시적 신경 필드를 최적화하는 데 의존했습니다 [23].
그러나 3D 재구성 및 새로운 뷰 합성의 순서를 반전시키면서 입력 이미지에 표시된 객체의 정체성을 유지하기 때문에 뷰 조건적 이미지 생성에 대한 우리의 접근 방식은 직교입니다.
이러한 방식으로, 자기 폐색으로 인한 우연적 불확실성은 물체 주변에서 회전할 때 확률론적 생성 모델에 의해 모델링될 수 있으며, 대규모 디퓨전 모델에 의해 학습된 의미론적 및 기하학적 priors를 효과적으로 활용할 수 있습니다.
3D Reconstruction.
또한 SJC [53] 또는 DreamFusion [38]과 같은 확률적 3D 재구성 프레임워크를 적용하여 가장 가능성이 높은 3D 표현을 만들 수 있습니다.
우리는 이것을 voxel radiance field [5, 49, 13]로 매개 변수화한 다음 밀도 필드에서 marching 큐브를 수행하여 메시를 추출합니다.
3D 재구성을 위한 뷰 조건적 디퓨전 모델의 적용은 디퓨전 모델에서 학습한 풍부한 2D 외관을 3D 기하학으로 전환할 수 있는 실행 가능한 경로를 제공합니다.
4.2. Baselines
우리 방법의 범위와 일치하기 위해 제로샷 설정에서 동작하는 방법과 비교하고 단일 뷰 RGB 이미지를 입력으로 사용합니다.
새로운 뷰 합성을 위해 여러 SOTA 단일 이미지 알고리즘과 비교합니다.
특히 시점 간 CLIP image-to-image 일관성 loss로 NeRF를 정규화하는 DietNeRF[23]를 벤치마크합니다.
또한 텍스트 프롬프트 대신 이미지에서 조정되도록 파인튜닝된 Stable Diffusion 모델이며 Stable Diffusion을 사용하는 의미론적 가장 가까운 이웃 검색 엔진으로 볼 수 있는 Image Variants (IV) [1]과 비교합니다.
마지막으로, 원래 텍스트 조건적 디퓨전 모델을 이미지 조건적 디퓨전 모델로 대체하는 디퓨전 기반 text-to-3D 모델인 SJC [53]를 적용했으며, 이 모델을 SJC-I라고 명명했습니다.
3D 재구성을 위해 두 가지 SOTA 단일 뷰 알고리즘을 베이스라인으로 사용합니다: (1) RGB-D 관찰을 3D 표현으로 완료하는 신경 필드 기반 접근 방식인 Multi view Compressive Coding (MCC) [59]와 (2) 컬러화된 포인트 클라우드에 대한 디퓨전 모델인 Point-E[34].
MCC는 CO3Dv2[43]에 대해 학습된 반면, Point-E는 특히 훨씬 더 큰 OpenAI의 내부 3D 데이터 세트에 대해 학습되었습니다.
또한 SJC-I와 비교합니다.
MCC는 깊이 입력을 필요로 하기 때문에 depth 추정을 위해 기성품인 MiDaS [42, 41]를 사용합니다.
우리는 전체 테스트 세트에 걸쳐 합리적으로 보이는 표준 스케일 및 시프트 값을 가정함으로써 획득된 상대적 disparity 맵을 절대 pseudo-metric depth 맵으로 변환합니다.
4.3. Benchmarks and Metrics
우리는 고품질 스캔 가정용품 데이터 세트인 Google Scanned Objects (GSO)[10]와 각각 20개의 랜덤 객체로 구성된 복잡한 장면으로 구성된 RTMV[50]에서 두 작업을 모두 평가합니다.
모든 실험에서 각각의 ground truth 3D 모델은 3D 재구성을 평가하는 데 사용됩니다.
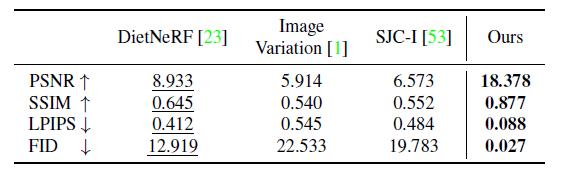
새로운 뷰 합성을 위해, 우리는 이미지 유사성의 다양한 측면을 다루는 네 가지 측정 기준으로 우리의 방법과 베이스라인을 수치적으로 평가합니다: PSNR, SSIM [55], LPIPS [64] 및 FID [18].
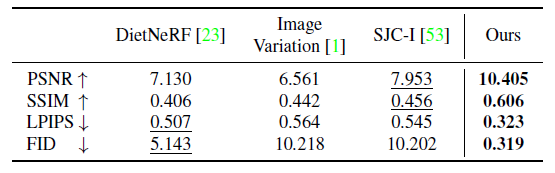
3D 재구성을 위해 Chamfer Distance와 Volume IoU를 측정합니다.


4.4. Novel View Synthesis Results
우리는 표 1과 표 2에 수치 결과를 보여줍니다.
그림 5는 GSO의 모든 베이스라인에 비해 우리의 방법이 ground truth와 밀접하게 일치하는 매우 사실적인 이미지를 생성할 수 있음을 보여줍니다.
이러한 경향은 그림 6의 RTMV에서도 찾을 수 있는데, Objaverse 데이터 세트에 비해 장면이 분포를 벗어남에도 불구하고 말입니다.
베이스라인 중에서 Point-E는 인상적인 제로 샷 일반화 가능성을 유지하면서 다른 베이스라인보다 훨씬 더 나은 결과를 달성하는 경향이 있음을 관찰했습니다.
그러나 생성된 포인트 클라우드의 작은 크기는 새로운 뷰 합성에 대한 Point-E의 적용 가능성을 크게 제한합니다.

그림 7에서는 객체 유형, 아이덴티티 및 낮은 레벨의 세부 정보를 유지하면서 높은 충실도의 시점을 합성하는 능력뿐만 아니라 까다로운 기하학적 구조와 질감을 가진 객체에 대한 모델의 일반화 성능을 추가로 보여줍니다.
Diversity across samples.
단일 이미지에서 새로운 뷰 합성은 심각하게 제한된 작업이며, 이는 디퓨전 모델을 근본적인 불확실성을 포착하는 측면에서 NeRF에 비해 아키텍처를 특히 적절하게 선택하도록 만듭니다.
입력 이미지는 2D이기 때문에 항상 객체의 부분적인 뷰만을 묘사하며 많은 부분이 관찰되지 않습니다.
그림 8은 새로운 관점에서 샘플링된 그럴듯한 고품질 이미지의 다양성을 예시합니다.




4.5. 3D Reconstruction Results
우리는 표 3과 표 4에 수치 결과를 보여줍니다.
그림 9는 우리의 방법이 사실과 일치하는 충실도 높은 3D 메쉬를 재구성하는 것을 정성적으로 보여줍니다.
MCC는 입력 뷰에서 보이는 표면을 잘 추정하는 경향이 있지만 종종 물체 뒤쪽의 기하학을 정확하게 추론하지 못합니다.
SJC-I는 또한 의미 있는 기하학을 재구성할 수 없는 경우가 많습니다.
반면, Point-E는 인상적인 제로 샷 일반화 능력을 가지고 있으며 객체 기하학의 합리적인 추정치를 예측할 수 있습니다.
그러나 4,096 포인트의 불균일한 희소 포인트 클라우드를 생성하여 때때로 재구성된 표면에 구멍으로 이어집니다(제공된 메쉬 변환 방법에 따라).
따라서 좋은 CD score를 얻지만 부피 IoU에는 미치지 못합니다.
우리의 방법은 뷰 조건적 디퓨전 모델에서 학습된 다중 뷰 priors를 활용하고 NeRF 스타일 표현의 장점과 결합합니다.
두 요인 모두 표 3과 4에서 알 수 있듯이 이전 작업에 비해 CD 및 부피 IoU 측면에서 개선됩니다.
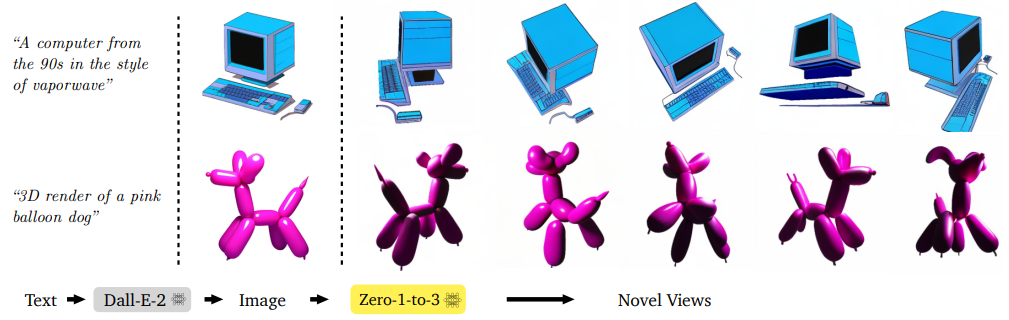
4.6. Text to Image to 3D
야생 이미지 외에도 Dall-E-2 [40]와 같은 txt2img 모델에서 생성된 이미지에 대한 방법을 테스트했습니다.
그림 10에서 보는 바와 같이, 우리의 모델은 객체의 동일성을 보존하면서 이러한 이미지의 새로운 뷰를 생성할 수 있습니다.
우리는 이것이 많은 text-to-3D 생성 응용에서 매우 유용할 수 있다고 믿습니다.
5. Discussion
이 연구에서, 우리는 제로샷, 단일 이미지 새로운-뷰 합성 및 3D 재구성을 위한 새로운 접근법인 Zero-1-to-3를 제안했습니다.
우리의 방법은 인터넷 규모 데이터에 대해 사전 학습을 받고 풍부한 semantic 및 기하학적 priors를 포착하는 Stable Diffusion 모델을 활용합니다.
이 정보를 추출하기 위해 합성 데이터에 대한 모델을 미세 조정하여 카메라 관점에 대한 제어를 학습했습니다.
결과적인 방법은 Stable Diffusion에 의해 학습된 priors의 강력한 객체 모양을 활용할 수 있는 능력으로 인해 여러 벤치마크에서 SOTA 결과를 입증했습니다.
5.1. Future Work
From objects to scenes.
우리의 접근 방식은 평범한 배경에서 단일 객체의 데이터 세트에 대해 학습됩니다.
RTMV 데이터 세트에서 여러 개체가 있는 장면에 대한 강력한 일반화 정도를 입증했지만 GSO의 배포 내 샘플에 비해 품질이 여전히 저하됩니다.
따라서 복잡한 배경을 가진 장면에 대한 일반화는 우리 방법의 중요한 과제로 남아 있습니다.
From scenes to videos.
단일 관점에서 동적 장면의 기하학적 구조에 대해 추론할 수 있는 것은 폐색 이해[52, 27] 및 동적 객체 조작과 같은 새로운 연구 방향을 열 것입니다.
디퓨전 기반 비디오 생성을 위한 몇 가지 접근 방식이 최근 제안되었습니다 [20, 11].
이를 3D로 확장하는 것이 이러한 기회를 여는 열쇠가 될 것입니다.
Combining graphics pipelines with Stable Diffusion.
이 논문에서, 우리는 Stable Diffusion으로부터 물체에 대한 3D 지식을 추출하기 위한 프레임워크를 보여줍니다.
Stable Diffusion과 같은 강력한 자연 이미지 생성 모델에는 조명, 음영, 질감 등에 대한 다른 암묵적인 지식이 포함되어 있습니다.
향후 작업에서는 장면 재조명과 같은 전통적인 그래픽 작업을 수행하기 위해 유사한 메커니즘을 탐구할 수 있습니다.
C. Finetuning Stable Diffusion
렌더링된 데이터 세트를 사용하여 새로운 뷰 합성을 수행하기 위해 사전 학습된 Stable Diffusion 모델을 파인튜닝합니다.
원래 Stable Diffusion 네트워크는 멀티모달 텍스트 임베딩에 조건이 없으므로 이미지에서 조건 정보를 가져올 수 있도록 원래 Stable Diffusion 아키텍처를 조정하고 파인튜닝해야 합니다.
이 작업은 [1]에서 수행되며, 해제된 체크포인트를 사용합니다.
상대적인 카메라 포즈와 함께 이미지의 조건 정보를 수용하도록 모델을 추가로 조정하기 위해 이미지 CLIP 임베딩(차원 768)과 포즈 벡터(차원 4)를 concatenate하고 다른 fully-connected layer (772 → 768)를 초기화하여 디퓨전 모델 아키텍처와의 호환성을 보장합니다.
이 레이어의 학습률은 다른 레이어보다 10배 더 크게 확장됩니다.
나머지 네트워크 아키텍처는 원래 Stable Diffusion과 동일하게 유지됩니다.
C.1. Training Details
우리는 학습률이 10^-4인 AdamW[28]를 학습에 사용합니다.
먼저, 학습을 위해 원래 해상도(이미지 차원 512x512, 잠재 차원 64x64)를 유지하면서 배치 크기 192를 시도했습니다.
그러나 이로 인해 배치 간의 수렴 속도가 느리고 분산이 높다는 것을 발견했습니다.
원래 Stable Diffusion 학습 절차는 3072의 배치 크기를 사용했기 때문에 배치 크기를 1536으로 늘릴 수 있도록 이미지 크기를 256x256으로 줄였습니다(따라서 해당 잠재 차원을 32x32로 줄였습니다).
이러한 배치 크기의 증가는 더 나은 학습 안정성과 수렴 속도를 크게 향상시켰습니다.
우리는 7일 동안 8 x A100-80GB 기계에서 모델을 파인튜닝했습니다.
C.2. Inference Details
새로운 뷰를 생성하기 위해 RTX A6000 GPU에서 Zero-1-to-3은 2초밖에 걸리지 않습니다.
이전 작업에서는 일반적으로 NeRF가 새로운 뷰를 렌더링하기 위해 학습되는데, 이는 상당히 오래 걸립니다.
이에 비해 우리의 접근 방식은 3D 재구성과 새로운 뷰 합성의 순서를 뒤집어서 새로운 뷰 합성 프로세스가 빠르고 불확실성 하에서 다양성을 포함하게 합니다.
본 논문에서는 3D 객체에 대한 단일 이미지 문제를 다루기 때문에 추론 중에 야생 이미지가 사용될 때 모든 이미지에 기성 배경 제거 도구 [35]를 적용한 후 Zero-1-to-3 입력으로 사용합니다.
D. 3D Reconstruction
원래 Score Jacobian Chaining (SJC) 구현과 달리 "emptiness loss" 및 "center loss"를 제거했습니다.
VoxelRF 표현을 정규화하기 위해 depth 맵을 차등적으로 렌더링하고 depth 맵에 smoothness loss를 적용합니다.
이는 일반적으로 객체의 기하학적 구조가 텍스처보다 고주파 정보를 덜 포함한다는 prior 지식에 기초합니다.
객체 표현의 구멍을 제거하는 데 특히 도움이 됩니다.
또한 한 뷰에서 렌더링된 이미지와 근처의 랜덤으로 샘플링된 뷰에서 렌더링된 다른 이미지 간의 차이를 정규화하기 위해 근거리 일관성 loss를 적용합니다.
이는 객체 텍스처의 교차 뷰 일관성을 향상시키는 데 매우 도움이 된다는 것을 발견했습니다.
모든 구현 세부 사항은 부록의 일부로 제출된 코드에서 확인할 수 있습니다.
이미지에서 전체 3D 재구성을 실행하는 데 RTX A6000 GPU에서 약 30분이 소요됩니다.
'text-to-3D' 카테고리의 다른 글
| DreamGaussian: Generative Gaussian Splatting for Efficient 3D Content Creation (0) | 2023.10.29 |
|---|---|
| Magic3D: High-Resolution Text-to-3D Content Creation (0) | 2023.10.26 |
| Magic123: One Image to High-Quality 3D Object Generation Using Both 2D and 3D Diffusion Priors (0) | 2023.07.17 |
| DreamBooth3D: Subject-Driven Text-to-3D Generation (0) | 2023.05.24 |
| DreamFusion: Text-to-3D using 2D Diffusion (0) | 2022.10.18 |