2023. 10. 26. 12:02ㆍtext-to-3D
Magic3D: High-Resolution Text-to-3D Content Creation
Chen-Hsuan Lin, Jun Gao, Luming Tang, Towaki Takikawa, Xiaohui Zeng, Xun Huang, Karsten Kreis, Sanja Fidler, Ming-Yu Liu, Tsung-Yi Lin
Abstract
DreamFusion [33]은 최근 Neural Radiance Fields (NeRF)[25]를 최적화하기 위해 사전 학습된 text-to-image diffusion 모델의 유용성을 입증하여 주목할 만한 text-to-3D 합성 결과를 달성했습니다.
그러나 이 방법에는 두 가지 고유한 한계가 있습니다: (a) NeRF의 극도로 느린 최적화와 (b) NeRF에 대한 저해상도 이미지 공간 supervision으로 인해 처리 시간이 긴 저화질 3D 모델로 이어집니다.
본 논문에서는 2단계 최적화 프레임워크를 활용하여 이러한 한계를 해결합니다.
먼저, 저해상도 diffusion prior를 사용하여 coarse 모델을 얻고 희소 3D 해시 그리드 구조로 가속화합니다.
coarse 표현을 초기화로 사용하여 고해상도 잠재 diffusion 모델과 상호 작용하는 효율적인 미분 가능 렌더러로 질감이 있는 3D 메쉬 모델을 추가로 최적화합니다.
Magic3D라고 불리는 우리의 방법은 40분 만에 고품질 3D 메쉬 모델을 만들 수 있는데, 이는 DreamFusion보다 2배 빠른 속도이며(평균 1.5시간이 걸린다는 보고가 있음), 고해상도를 달성합니다.
사용자 연구는 61.7%의 평가자가 DreamFusion보다 우리의 접근 방식을 선호하는 것을 보여줍니다.
이미지 조건 생성 기능과 함께 사용자에게 3D 합성을 제어할 수 있는 새로운 방법을 제공하여 다양한 창의적인 응용 프로그램에 새로운 길을 열어줍니다.
1. Introduction
3D 디지털 콘텐츠는 게임, 엔터테인먼트, 아키텍처, 로봇 시뮬레이션 등 다양한 응용 분야에 대한 수요가 높아 왔습니다.
가능한 거의 모든 영역에 서서히 진입하고 있습니다: 소매업, 온라인 회의, 가상 사회적 존재감, 교육 등등.
그러나 전문적인 3D 컨텐츠를 만드는 것은 누구를 위한 것이 아닙니다 — 3D 모델링 전문 지식과 함께 엄청난 예술적, 미적 학습이 필요합니다.
이러한 스킬 세트를 개발하는 데는 상당한 시간과 노력이 필요합니다.
자연어로 3D 컨텐츠 제작을 강화하면 초보자와 전문 아티스트를 위한 3D 컨텐츠 제작 민주화에 상당한 도움이 될 수 있습니다.
텍스트 프롬프트 [2, 30, 35, 38]에서 이미지 콘텐츠 생성은 이미지 생성 모델링을 위한 diffusion 모델 [13, 43, 44]의 발전과 함께 상당한 발전을 이루고 있습니다.
주요 활성화 요인은 인터넷에서 스크랩된 수십억 개의 샘플(텍스트가 포함된 이미지)과 방대한 양의 컴퓨팅으로 구성된 대규모 데이터 세트입니다.
이에 반해 3D 콘텐츠 생성은 훨씬 더 느린 속도로 진행되었습니다.
기존 3D 객체 생성 모델 [4,9,49]은 대부분 범주형 모델입니다.
학습된 모델은 단일 클래스에 대한 객체를 합성하는 데만 사용될 수 있으며, 최근 Zeng et al. [49]이 보여준 여러 클래스로의 확장 초기 징후가 있습니다.
따라서 사용자가 이러한 모델로 할 수 있는 작업은 극히 제한적이며 예술적인 창작을 할 준비가 아직 되지 않았습니다.
이 한계는 주로 다양한 대규모 3D 데이터 세트의 부족에 기인합니다 — 이미지와 비디오 컨텐츠에 비해 3D 컨텐츠는 인터넷에서 훨씬 덜 접근할 수 있습니다.
따라서 강력한 text-to-image 생성 모델을 활용하여 3D 생성 기능을 달성할 수 있는지에 대한 의문이 자연스럽게 제기됩니다.
최근, DreamFusion [33]은 강력한 이미지 prior로 이미지를 생성하는 사전 학습된 text-to-image diffusion 모델 [38]을 활용하여 텍스트 조건 3D 콘텐츠 생성에 탁월한 능력을 입증했습니다.
diffusion 모델은 기본 3D 표현을 최적화하기 위한 비평가 역할을 합니다.
최적화 프로세스는 Neural Radiance Fields (NeRF) [25]로 표시되는 3D 모델의 렌더링된 이미지가 입력 텍스트 프롬프트가 주어지면 서로 다른 시점에서 사실적인 이미지의 분포와 일치하도록 보장합니다.
DreamFusion의 supervision 신호는 매우 낮은 해상도의 이미지(64 × 64)에서 작동하기 때문에 DreamFusion은 고주파 3D 기하학적 및 텍스처 세부 정보를 합성할 수 없습니다.
NeRF 표현에 비효율적인 MLP 아키텍처를 사용하기 때문에 필요한 메모리 풋프린트와 해상도에 따라 계산 예산이 빠르게 증가함에 따라 실제적인 고해상도 합성이 불가능할 수도 있습니다.
64 × 64의 해상도에서도 최적화 시간은 몇 시간(TPUv4를 사용하여 프롬프트당 평균 1.5시간)입니다.
본 논문에서는 단축된 계산 시간 내에 텍스트 프롬프트에서 매우 상세한 3D 모델을 합성할 수 있는 방법을 제시합니다.
구체적으로, 우리는 서로 다른 해상도에서 다중 diffusion priors를 사용하여 3D 표현을 최적화하는 coarse-to-fine 최적화 접근 방식을 제안하여 뷰 일관된 기하학적 구조와 고해상도 세부 정보를 모두 생성할 수 있도록 합니다.
첫 번째 단계에서는 DreamFusion과 유사한 coarse 신경 필드 표현을 최적화하지만 해시 그리드 [27]를 기반으로 메모리 및 계산 효율적인 장면 표현을 사용합니다.
두 번째 단계에서는 최대 512 × 512의 높은 해상도에서 diffusion priors를 활용할 수 있는 중요한 단계인 메쉬 표현 최적화로 전환합니다.
3D 메쉬는 실시간으로 고해상도 이미지를 렌더링할 수 있는 빠른 그래픽 렌더러에 적용할 수 있기 때문에 효율적인 미분 가능한 래스터라이저 [9, 28]를 활용하고 카메라 클로즈업을 사용하여 기하학 및 텍스처의 고주파 세부 정보를 복구합니다.
그 결과, 우리의 접근 방식은 표준 그래픽 소프트웨어로 편리하게 가져오고 시각화할 수 있는 충실도 높은 3D 콘텐츠(그림 1 참조)를 생성하고 DreamFusion의 2배 속도로 그렇게 합니다.
또한 text-to-image 편집 애플리케이션을 위해 개발된 고급 기술을 활용하여 3D 합성 프로세스에 대한 다양한 창의적 제어를 보여줍니다 [2, 37].
Magic3D라고 불리는 우리의 접근 방식은 사용자가 원하는 3D 객체를 텍스트 프롬프트와 참조 이미지로 제작하는 데 전례 없는 제어력을 제공하여 이 기술을 3D 콘텐츠 생성 민주화에 한 걸음 더 다가가게 합니다.

요약하면, 우리의 업적은 다음과 같습니다:
• DreamFusion에서 선택한 몇 가지 주요 설계 사항을 개선하여 텍스트 프롬프트를 이용한 고품질 3D 컨텐츠 합성 프레임워크인 Magic3D를 제안합니다.
타겟 컨텐츠의 3D 표현을 학습하기 위해 저해상도와 고해상도 diffusio priors를 모두 활용하는 coarse-to-fine 전략으로 구성되어 있습니다.
8배 높은 해상도 supervision으로 3D 컨텐츠를 합성하는 Magic3D는 DreamFusion보다 2배 빠릅니다.
우리의 접근 방식으로 합성된 3D 컨텐츠는 사용자(61.7%)가 매우 선호합니다.
• text-to-image 모델을 위해 개발된 다양한 이미지 편집 기술을 3D 객체 편집으로 확장하고 제안된 프레임워크에서 응용 프로그램을 보여줍니다.
2. Related Work
Text-to-image generation.
우리는 최근 몇 년 동안 diffusion 모델을 사용하여 text-to-image 생성에서 상당한 발전을 목격했습니다.
모델링 및 데이터 큐레이션의 개선으로 diffusion 모델은 텍스트 설명(명사, 형용사, 예술 스타일 등)에서 복잡한 의미 개념을 구성하여 객체 및 장면의 고품질 이미지를 생성할 수 있습니다 [2, 35, 36, 38].
diffusion 모델에서 이미지를 샘플링하는 데는 많은 시간이 소요됩니다.
고해상도 이미지를 생성하기 위해 이러한 모델은 일련의 초해상도 모델 [2, 38]을 사용하거나 저해상도 잠재 공간에서 샘플을 추출하고 잠재 상태를 고해상도 이미지로 디코딩합니다 [36].
고해상도 이미지 생성의 발전에도 불구하고 3D에서 일관성을 유지하면서 3D 속성(예: 카메라 시점)을 설명하고 제어하기 위해 언어를 사용하는 것은 여전히 열려 있고 도전적인 문제로 남아 있습니다.
3D generative models.
3D 생성 모델링에 대한 많은 연구가 있으며, 3D 복셀 그리드 [7, 12, 22, 42, 47], 포인트 클라우드 [1, 23, 26, 48, 49, 51], 메쉬 [9, 50], 암시적 [6, 24] 또는 옥트리 [15] 표현과 같은 다양한 유형의 3D 표현을 탐구합니다.
이러한 접근 방식의 대부분은 규모 면에서 획득하기 어려운 3D 자산 형태의 학습 데이터에 의존합니다.
신경 볼륨 렌더링 [25]의 성공에 영감을 받아 최근 작업은 3D 인식 이미지 합성에 투자하기 시작했습니다 [4, 5, 10, 11, 29, 31, 32, 40], 이미지에서 직접 3D 생성 모델을 학습할 수 있는 이점을 가지고 있습니다 — 보다 광범위하게 액세스할 수 있는 리소스.
그러나 볼륨 렌더링 네트워크는 일반적으로 쿼리 속도가 느려서 긴 학습 시간 [5, 31]과 다중 뷰 일관성 [10] 사이의 트레이드 오프를 초래합니다.
EG3D [4]는 이중 판별기를 사용하여 이 문제를 부분적으로 완화합니다.
유망한 결과를 얻으면서 이러한 작업은 자동차, 의자 또는 사람의 얼굴과 같은 단일 객체 범주 내의 모델링 객체로 제한되어 있으므로 확장성과 3D 콘텐츠 생성에 필요한 창의적인 제어가 부족합니다.
본 논문에서는 텍스트 프롬프트를 기반으로 장면의 3D 렌더링 가능한 표현을 생성하는 것을 목표로 text-to-3D 합성에 중점을 둡니다.
Text-to-3D generation.
최근 몇 년 동안 text-to-image 생성 모델링이 성공하면서 text-to-3D 생성은 학습 커뮤니티의 관심도 급증했습니다.
CLIP-Forge [39]와 같은 이전 작업은 텍스트 입력에서 모양 임베딩을 샘플링하기 위한 normalizing flow 모델을 학습하여 객체를 합성합니다.
그러나 학습 중에 복셀 표현에 3D 자산이 필요하여 데이터로 확장하기가 어렵습니다.
DreamField [16] 및 CLIPmesh [17]는 사전 학습된 image-text 모델 [34]에 의존하여 기본 3D 표현(NeRF 및 메시)을 최적화함으로써 모든 2D 렌더링이 높은 text-image 정렬 score에 도달하도록 함으로써 학습 데이터 문제를 완화합니다.
이러한 접근 방식은 값비싼 3D 학습 데이터의 요구를 피하고 대부분 사전 학습된 대규모 image-text 모델에 의존하지만, 덜 현실적인 2D 렌더링을 생성하는 경향이 있습니다.
최근, DreamFusion [33]은 강력한 이미지 prior로 강력한 사전 학습된 text-to-image diffusion 모델 [38]을 활용하여 text-to-3D 합성에서 인상적인 기능을 선보였습니다.
우리는 이 작업을 기반으로 하고 몇 가지 설계 선택 사항을 개선하여 생성 시간을 훨씬 단축한 사용자에게 훨씬 더 높은 충실도의 3D 모델을 제공합니다.
3. Background: DreamFusion
DreamFusion [33]은 두 가지 주요 구성 요소로 text-to-3D로 생성합니다: 장면 모델이라고 하는 신경 장면 표현 및 사전 학습된 text-to-image diffusion 기반 생성 모델.
장면 모델은 파라메트릭 함수 x = g(θ)로서, 원하는 카메라 포즈에서 이미지 x를 생성할 수 있습니다.
여기서, g는 선택한 볼륨 렌더링자이고, θ는 3D 볼륨을 나타내는 좌표 기반 MLP입니다.
diffusion 모델 ϕ에는 노이즈 이미지 x_t, 노이즈 레벨 t, 텍스트 임베딩 y가 주어졌을 때 샘플링된 노이즈 ϵ을 예측하는 학습된 디노이징 함수 ϵ_ϕ(x_t; y, t)가 함께 제공됩니다.
모든 렌더링된 이미지가 diffusion prior에 텍스트 임베딩된 조건의 높은 확률 밀도 영역으로 푸시되도록 θ 업데이트를 위한 그래디언트 방향을 제공합니다.
구체적으로, DreamFusion은 그래디언트를 계산하는 Score Distillation Sampling (SDS)를 도입합니다:
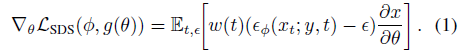
여기서 ω(t)는 가중치 함수입니다.
우리는 장면 모델 g와 diffusion 모델 ϕ를 선택할 수 있는 프레임워크의 모듈 구성 요소로 봅니다.
실제로 디노이징 함수 ϵ_ϕ는 종종 classifier-free guidance [14]를 사용하는 다른 함수 ˜ϵ_ϕ 로 대체되는데, 이를 통해 텍스트 조정의 강도를 신중하게 측정할 수 있습니다(섹션 6 참조).
DreamFusion은 더 나은 품질의 결과를 얻기 위해 큰 classifier-free guidance 가중치에 의존합니다.
DreamFusion은 장면 모델에 대한 명시적 shading 모델과 Imagen[38]을 diffusion 모델로 하는 Mip-NeRF 360[3]의 변형을 채택합니다.
이러한 선택은 두 가지 주요 제한을 초래합니다.
첫째, diffusion 모델이 64×64 이미지에서만 작동하기 때문에 고해상도 기하학적 구조나 텍스처를 얻을 수 없습니다.
둘째, 볼륨 렌더링을 위한 대규모 전역 MLP의 유용성은 계산 비용이 많이 들 뿐만 아니라 메모리 집약적이므로 이미지의 해상도가 증가함에 따라 이 접근 방식의 스케일이 좋지 않습니다.
4. High-Resolution 3D Generation
Magic3D는 고해상도 text-to-3D 합성을 가능하게 하는 효율적인 장면 모델을 사용하는 2단계 coarse-to-fine 프레임워크입니다(그림 2).
본 섹션에서는 DreamFusion[33]과의 방법 및 주요 차이점에 대해 설명합니다.
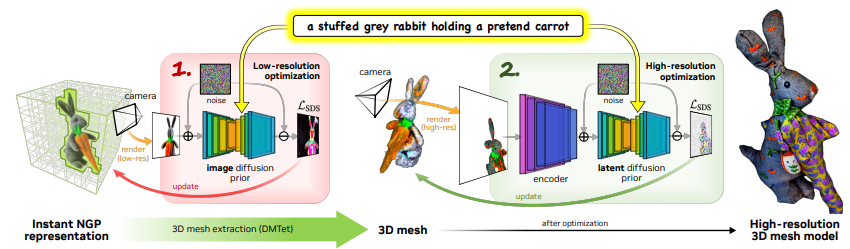
4.1. Coarse-to-fine Diffusion Priors
Magic3D는 고해상도 기하학 및 텍스처를 생성하기 위해 두 개의 서로 다른 diffusion priors를 coarse-to-fine 방식으로 사용합니다.
첫 번째 단계에서는 DreamFusion에서 사용되는 Imagen [38]의 기본 diffusion 모델과 유사한 eDiff-I [2]에 설명된 기본 diffusion 모델을 사용합니다.
이 diffusion prior는 낮은 해상도 64 × 64로 렌더링된 이미지에 정의된 loss를 통해 장면 모델의 그래디언트를 계산하는 데 사용됩니다.
두 번째 단계에서는 높은 해상도 512 × 512로 렌더링된 이미지로 역전파 그라디언트를 허용하는 latent diffusion model (LDM) [36]을 사용합니다; 실제로 공개적으로 사용 가능한 Stable Diffusion 모델 [36]을 사용합니다.
고해상도 이미지를 생성함에도 불구하고 LDM의 계산은 diffusion prior가 해상도 64 × 64의 잠재 z_t에 작용하기 때문에 관리할 수 있습니다:
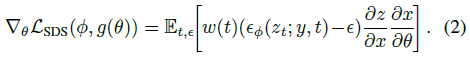
계산 시간의 증가는 주로 ∂x/∂θ(고해상도 렌더링 이미지의 그래디언트)와 ∂z/∂x(LDM에서 인코더의 그래디언트)를 계산하는 것에서 비롯됩니다.
4.2. Scene Models
다음과 같이 논의되는 고해상도 priors 입력을 위해 렌더링된 이미지의 해상도 증가를 수용하기 위해 두 개의 서로 다른 3D 장면 표현을 coarse와 fine 해상도에서 두 개의 서로 다른 diffusion priors에 전달합니다.
Neural fields as coarse scene models.
최적화의 초기 대략적인 단계는 처음부터 기하학과 텍스처를 찾아야 합니다.
이것은 3D 기하학의 복잡한 위상 변화와 2D supervision 신호의 depth 모호성을 수용해야 하기 때문에 어려울 수 있습니다.
DreamFusion [33]에서 장면 모델은 알베도와 밀도를 예측하는 Mip-NeRF 360[3] 기반의 신경망(좌표 기반 MLP)입니다.
이것은 신경망이 위상 변화를 부드럽고 연속적인 방식으로 처리할 수 있기 때문에 적합한 선택입니다.
그러나 Mip-NeRF 360 [3]은 대규모 전역 좌표 기반 MLP를 기반으로 하므로 계산 비용이 많이 듭니다.
볼륨 렌더링은 고주파 기하학과 음영을 정확하게 렌더링하기 위해 ray를 따라 조밀한 샘플이 필요하기 때문에 모든 샘플 지점에서 대규모 신경망을 평가해야 하는 비용이 빠르게 쌓입니다.
이러한 이유로, 우리는 훨씬 더 낮은 계산 비용으로 고주파 세부 정보를 나타낼 수 있는 Instant NGP [27]의 해시 그리드 인코딩을 사용하기로 선택했습니다.
우리는 두 개의 싱글 레이어 신경망으로 하나는 알베도와 밀도를 예측하고 다른 하나는 normals를 예측하는 해시 그리드를 사용합니다.
또한 장면 점유를 인코딩하고 빈 공간 건너뛰기를 활용하는 공간 데이터 구조를 유지합니다 [20, 45].
특히 옥트리 기반 ray 샘플링 및 렌더링 알고리즘 [46]을 사용하여 Instant NGP [27]의 밀도 기반 복셀 가지치기 접근법을 사용합니다.
이러한 설계 선택을 통해 품질을 유지하면서 coarse 장면 모델의 최적화를 대폭 가속화합니다.
Textured meshes as fine scene models.
최적화의 fine 단계에서, 우리는 고해상도 diffusion priors로 장면 모델을 파인튜닝하기 위해 매우 고해상도 렌더링된 이미지를 수용할 수 있어야 합니다.
초기 coarse 최적화 단계에서 동일한 장면 표현(신경 필드)을 사용하는 것은 모델의 가중치가 직접 전달될 수 있기 때문에 자연스러운 선택일 수 있습니다.
이 전략은 어느 정도 효과가 있을 수 있지만(그림 4 및 5), 합리적인 메모리 제약 및 계산 예산 내에서 매우 고해상도(예: 512 × 512) 이미지를 렌더링하는 데 어려움이 있습니다.


이 문제를 해결하기 위해 텍스처링된 3D 메쉬를 최적화의 fine 단계를 위한 장면 표현으로 사용합니다.
신경 필드에 대한 볼륨 렌더링과는 대조적으로, 미분 가능한 래스터화를 가진 텍스처링 메쉬를 매우 높은 해상도에서 효율적으로 수행할 수 있으므로, 메쉬를 고해상도 최적화 단계에 적합한 선택으로 만들 수 있습니다.
coarse 단계의 신경 필드를 메쉬 기하학에 대한 초기화로 사용하면 메쉬의 큰 위상 변화를 학습하는 어려움을 피할 수도 있습니다.
형식적으로 변형 가능한 사면체 그리드 (V_T, T)를 사용하여 3D 모양을 표현하며, 여기서 V_T는 그리드 T의 꼭지점입니다 [8, 41].
각 꼭지점 v_i ⊂ V_T ∈ R^3은 signed distance field (SDF) 값 s_i ∈ R과 초기 표준 좌표로부터 꼭지점의 변형 ∆v_i ∈ R^3을 포함합니다.
그런 다음, 미분 가능한 마칭 테트라 알고리즘 [41]을 사용하여 SDF에서 표면 메시를 추출합니다.
텍스처의 경우, 우리는 체적 텍스처 표현으로 신경 색상 필드를 사용합니다.
4.3. Coarse-to-fine Optimiztion
우리는 먼저 coarse 신경 필드 표현에 대해 작동하고 그 후 고해상도 텍스처 메시에 대해 작동하는 coarse-to-fine 최적화 절차를 설명합니다.
Neural field optimization.
Instant NGP [27]과 마찬가지로 최적화의 초기 단계에서 모양이 커지도록 하기 위해 해상도 256^3의 점유 그리드를 20으로 초기화합니다.
우리는 10번의 반복마다 그리드를 업데이트하고 빈 공간 건너뛰기를 위한 옥트리를 생성합니다.
우리는 업데이트할 때마다 점유 그리드를 0.6씩 붕괴시키고 동일한 업데이트 및 임계값 매개 변수로 Instant NGP를 따릅니다.
밀도 차이로부터 정규식을 추정하는 대신 MLP를 사용하여 정규식을 예측합니다.
이는 표면 렌더링 대신 볼륨 렌더링을 사용하므로 기하학적 특성을 위반하지 않습니다.
따라서 연속적인 위치에서 입자의 방향을 레벨 집합 표면에 맞출 필요가 없습니다.
이는 유한 차분의 사용을 피하여 대략적인 모델을 최적화하는 계산 비용을 크게 줄이는 데 도움이 됩니다.
실제 표면 렌더링 모델을 사용할 때 정확한 정규식을 최적화의 fine 단계에서 얻을 수 있습니다.
DreamFusion과 유사하게 RGB 색상을 ray 방향의 함수로 예측하는 환경 맵 MLP를 사용하여 배경을 모델링하기도 합니다.
희소 표현 모델은 Mip-NeRF 360 [3]에서와 같이 장면 재파라미터화를 지원하지 않기 때문에 최적화는 배경 환경 맵을 사용하여 객체의 본질을 학습함으로써 "cheat"하는 경향이 있습니다.
따라서 환경 맵에 대해 작은 MLP(숨겨진 차원 크기 16)를 사용하고 모델이 신경 필드 기하학에 더 집중할 수 있도록 학습률을 10배로 낮춥니다.
Mesh optimization.
신경 필드 초기화에서 메쉬를 최적화하기 위해, 초기 s_i를 산출하는 0이 아닌 상수로 빼서 (coarse) 밀도 필드를 SDF로 변환합니다.
우리는 또한 coarse 스테이지에서 최적화된 컬러 필드로 볼륨 텍스처 필드를 직접 초기화합니다.
최적화 동안, 우리는 미분 가능한 래스터라이저를 사용하여 추출된 표면 메쉬를 고해상도 이미지로 렌더링합니다[19,28].
우리는 고해상도 SDS 그라디언트(Eq. 2)를 사용하여 역전파를 통해 각 정점 v_i에 대해 s_i와 ∆v_i를 모두 최적화합니다.
메쉬를 이미지로 렌더링할 때, 우리는 또한 공동 최적화를 위해 해당 텍스처 필드에서 색상을 쿼리하는 데 사용될 각 해당 픽셀 투영의 3D 좌표를 추적합니다.
메시를 렌더링할 때 초점 거리를 늘려 객체 세부 정보를 확대하여 고주파 세부 정보를 복구하는 중요한 단계입니다.
우리는 대략적인 최적화 단계부터 동일한 사전 학습된 환경 맵을 유지하고 미분 가능한 안티엘리어싱을 사용하여 렌더링된 배경을 렌더링된 전경 객체와 합성합니다 [19].
표면의 평활성을 장려하기 위해 메시의 인접 면 사이의 각도 차이를 더 정규화합니다.
이를 통해 SDS 그래디언트 ∇_ θ L_SDS와 같이 분산이 높은 supervision 신호에서도 잘 동작하는 기하학을 얻을 수 있습니다.
5. Experiments
우리는 DreamFusion 웹사이트에서 가져온 397개의 텍스트 프롬프트에서 우리의 방법을 DreamFusion [33]과 비교하는 데 중점을 둡니다.
우리는 모든 텍스트 프롬프트에 대해 Magic3D를 학습하고 웹사이트에 제공된 결과와 비교합니다.
Speed evaluation.
특별한 언급이 없는 한, coarse 스테이지는 배치 크기가 32인 ray를 따라 1024개의 샘플(이후 희소 옥트리에 의해 필터링됨)로 5000번의 반복에 대해 학습되며, 배치 크기는 약 15분(8번의 반복/초 이상, 희소성 차이로 인한 변수)입니다.
fine 스테이지는 배치 크기가 32인 3000번의 반복에 대해 학습되며, 총 런타임은 25분(2번의 반복/초)입니다.
두 런타임을 모두 합하면 40분입니다.
모든 런타임은 8개의 NVIDIA A100 GPU에서 측정되었습니다.

Qualitative comparisons.
우리는 그림 3에 질적인 예를 제시합니다.
질적으로, 우리 모델은 기하학과 질감 면에서 훨씬 더 높은 3D 품질을 달성합니다.
우리 모델은 candies on ice cream cones, highly detailed sushi-like cars, vivid strawberries, 그리고 birds를 생성할 수 있습니다.
또한 우리는 우리의 결과물 3D 모델을 표준 그래픽 소프트웨어로 직접 가져와 시각화할 수 있다는 것에 주목합니다.
User studies.
우리는 Amazon MTurk에서 사용자 선호도를 기반으로 다른 방법을 평가하기 위한 사용자 연구를 수행합니다.
우리는 사용자에게 동일한 텍스트 프롬프트를 사용하여 두 개의 다른 알고리즘에 의해 표준 뷰에서 나란히 렌더링된 두 개의 비디오를 보여줍니다.
우리는 사용자에게 더 현실적이고 상세한 것을 선택하도록 요청합니다.
각 프롬프트는 3명의 다른 사용자에 의해 평가되어 1191개의 쌍별 비교 결과가 도출되었습니다.
표 1에서 보는 바와 같이 Magic3D에서 생성된 3D 모델을 선호하는 사용자가 61.7%로 우리의 결과를 더 높은 품질로 고려하고 있습니다.

Can single-stage optimization work with LDM prior?
우리는 단일 단계 최적화 설정에서 고해상도 LDM으로 최적화된 장면 모델을 축소합니다.
우리는 장면 모델과 같은 3D 메시가 처음부터 최적화되면 고품질 결과를 생성하지 못한다는 것을 발견합니다.
따라서 메모리 효율적인 희소 3D 표현이 장면 모델에 대한 이상적인 후보로 남습니다.
그러나 512 x 512 이미지를 렌더링하는 것은 여전히 메모리 집약적이어서 최신 GPU에 맞지 않습니다.
따라서 장면 모델에서 저해상도 이미지를 렌더링하고 LDM에 입력할 때 512 x 512로 업샘플링합니다.
우리는 그것이 더 나쁜 모양의 객체를 생성한다는 것을 발견했습니다.
그림 4는 장면 렌더링 해상도 64 × 64 및 256 × 256(맨 위 행)을 사용한 두 가지 예를 보여줍니다.
털로 덮인 세부 정보를 생성하지만 모양은 coarse 모델보다 더 좋지 않습니다.
Can we use NeRF for the fine model?
예.
NeRF를 처음부터 최적화하는 것은 잘 작동하지 않지만 coarse-to-fine 프레임워크를 따르되 2단계 장면 모델을 NeRF로 대체할 수 있습니다.
그림 4의 오른쪽 하단에 coarse 모델로 왼쪽에 초기화되고 256 × 256 렌더링 이미지로 파인튜닝된 fine NeRF 모델의 결과를 나타냅니다.
2단계 접근 방식은 초기 모델에서 양호한 기하학적 구조를 유지하고 더 많은 세부 정보를 추가하여 1단계 대응 모델보다 우수한 품질을 보여줍니다.
Coarse models vs. fine models.
그림 5는 coarse와 fine 모델을 대조하여 더 많은 시각적 결과를 제공합니다.
장면 모델에 대해 NeRF와 메쉬를 모두 시도하고 위의 동일한 coarse 모델에서 파인튜닝합니다.
NeRF와 메쉬 모델 모두에서 상당한 품질 향상을 볼 수 있으며, 이는 일반 장면 모델에 대한 coarse-to-fine 접근 방식의 작동을 시사합니다.
6. Controllable 3D Generation
특정 스타일과 개념은 단어로 표현하기 어렵지만 이미지로 쉽게 표현하기 때문에 이미지로 text-to-3D 모델 생성에 영향을 주는 메커니즘을 갖는 것이 바람직합니다.
우리는 사용자에게 3D 생성 출력에 대한 더 많은 제어를 제공하기 위해 다양한 이미지 컨디셔닝 기술과 신속한 기반 편집 접근법을 탐구합니다.
Personalized text-to-3D.
DreamBooth [37]에서는 피사체의 여러 이미지에 대해 사전 학습된 모델을 파인튜닝하여 text-to-image diffusion 모델을 개인화하는 방법을 설명했습니다.
파인튜닝된 모델은 [V]로 표시되는 고유 식별자 문자열에 피사체를 묶는 방법을 학습하고 [V]가 텍스트 프롬프트에 포함될 때 피사체의 이미지를 생성할 수 있습니다.
text-to-3D 생성의 맥락에서 피사체의 3D 모델을 생성하고자 합니다.
이것은 먼저 DreamBooth 접근법으로 diffusion prior 모델을 파인튜닝한 다음 [V] 식별자를 사용하여 3D 모델을 최적화할 때 학습 신호를 제공함으로써 달성할 수 있습니다.
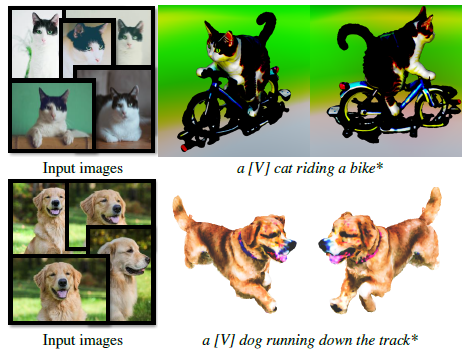
프레임워크에서 DreamBooth의 적용 가능성을 입증하기 위해 고양이 한 마리의 이미지 11개와 개 한 마리의 이미지 4개를 수집합니다.
eDiff-I [2] 및 LDM [36]을 파인튜닝하여 텍스트 식별자 [V]를 지정된 제목에 바인딩합니다.
그런 다음 텍스트 프롬프트에서 [V]로 3D 모델을 최적화합니다.
모든 파인튜닝에는 배치 크기 1을 사용합니다.
eDiff-I의 경우 1,500번의 반복에 대해 학습률 1 × 10-5의 Adam Optimizer를 사용합니다; LDM의 경우 800번의 반복에 대해 학습률 1 × 10-6으로 파인튜닝합니다.
그림 6은 개인화된 text-to-3D 결과를 보여줍니다: 우리는 주어진 입력 이미지에서 피사체를 보존하는 3D 모델을 성공적으로 수정할 수 있습니다.
Prompt-based editing through fine-tuning.
생성된 3D 콘텐츠를 제어하는 또 다른 방법은 학습된 coarse 모델을 새로운 프롬프트로 파인튜닝하는 것입니다.
프롬프트 기반 편집에는 세 단계가 포함됩니다.
(a) 기본 프롬프트로 coarse 모델을 학습합니다.
(b) 기본 프롬프트를 수정하고 LDM으로 coarse 모델을 파인튜닝합니다.
이 단계는 다음 단계를 위해 잘 초기화된 NeRF 모델을 제공합니다.
새로운 프롬프트에 메시 최적화를 직접 적용하면 매우 상세한 텍스처가 생성되지만 기하학적 구조를 약간 변형시킬 수 있습니다.
(c) 수정된 텍스트 프롬프트로 메시를 최적화합니다.
프롬프트 기반 편집은 모양의 텍스처를 수정하거나 텍스트에 따라 기하학적 구조와 텍스처를 변환할 수 있습니다.
결과 장면 모델은 layer-out 구조와 전체 구조를 보존합니다.
이러한 편집 기능은 Magic3D로 3D 콘텐츠 생성을 보다 제어 가능하게 만듭니다.
그림 7에서는 "bunny" 및 "squirrel"에 대한 기본 프롬프트로 학습된 두 개의 coarse NeRF 모델을 보여줍니다.
기본 프롬프트를 수정하고 NeRF 모델을 고해상도로 파인튜닝하며 메시를 최적화합니다.
결과는 "baby bunny"를 "stained glass bunny" 또는 "metal bunny"로 변경하는 등 프롬프트에 따라 장면 모델을 조정할 수 있음을 보여줍니다.

7. Conclusion
우리는 빠르고 고품질의 text-to-3D 생성 프레임워크인 Magic3D를 제안합니다.
우리는 효율적인 장면 모델과 coarse-to-fine 접근 방식의 고해상도 diffusion prior의 두 가지 이점을 모두 누릴 수 있습니다.
특히 3D 메쉬 모델은 이미지 해상도로 잘 확장되며 속도를 희생하지 않고 잠재 diffusion 모델이 제공하는 고해상도 supervision의 이점을 누릴 수 있습니다.
텍스트 프롬프트에서 그래픽 엔진에 사용할 수 있는 고품질 3D 메쉬 모델까지 40분이 소요됩니다.
광범위한 사용자 연구와 질적 비교를 통해 우리는 Magic3D가 DreamFusion에 비해 평가자가 더 선호하는(61.7%) 동시에 2배 속도 향상을 즐긴다는 것을 보여줍니다.
마지막으로, 우리는 3D 생성에서 스타일과 콘텐츠를 더 잘 제어할 수 있는 일련의 도구를 제안합니다.
우리는 Magic3D로 3D 합성을 민주화하고 3D 콘텐츠 제작에 있어 모든 사람의 창의력을 개방할 수 있기를 바랍니다.