2023. 7. 17. 11:52ㆍtext-to-3D
Magic123: One Image to High-Quality 3D Object Generation Using Both 2D and 3D Diffusion Priors
Guocheng Qian, Jinjie Mai, Abdullah Hamdi, Jian Ren, Aliaksandr Siarohin, Bing Li, Hsin-Ying Lee, Ivan Skorokhodov, PeterWonka, Sergey Tulyakov, Bernard Ghanem
Abstract
우리는 2D 및 3D priors의 이미지를 모두 사용하여 야생에서 배치되지 않은 단일 이미지에서 고품질의 질감의 3D 메시 생성을 위한 2단계 coarse-to-fine 접근법인 "Magic123"을 제시합니다.
첫 번째 단계에서, 우리는 coarse 지오메트리를 생성하기 위해 neural radiance field를 최적화합니다.
두 번째 단계에서는 시각적으로 매력적인 질감을 가진 고해상도 메시를 생성하기 위해 메모리 효율적인 미분 가능한 메시 표현을 채택합니다.
두 단계 모두 참조 뷰 supervision과 2D 및 3D diffusion priors의 조합에 의해 가이드되는 새로운 뷰를 통해 3D 콘텐츠를 학습합니다.
우리는 생성된 지오메트리의 탐색(더 창의적)과 이용(더 정확)을 제어하기 전에 2D와 3D priors 사이의 단일 절충 매개 변수를 소개합니다.
또한, 우리는 textual inversion 및 단안 depth 정규화를 사용하여 뷰 전체에서 일관된 모습을 장려하고 퇴화 솔루션을 방지합니다.
Magic123은 합성 벤치마크 및 다양한 실제 이미지에 대한 광범위한 실험을 통해 검증된 이전의 image-to-3D 기술에 비해 상당한 개선을 보여줍니다.

1 Introduction
2D로 세상을 관찰했음에도 불구하고, 인간은 3D 환경을 탐색하고, 추론하고, 참여할 수 있는 놀라운 능력을 가지고 있습니다.
이것은 3D 세계의 특징과 행동에 대한 깊이 있는 인지적 이해를 지향합니다 - 인간 본성의 진정한 인상적인 측면입니다.
이러한 능력은 단일 이미지에서 상세한 3D 복제본을 생성할 수 있는 예술가들에 의해 한 차원 더 높아졌습니다.
반대로, 컴퓨터 비전의 관점에서 볼 때, - 기하학 및 텍스처의 생성을 포함하는 - unposed 이미지에서 3D 재구성 작업은 수십 년간의 탐색 및 개발에도 불구하고 해결되지 않은 ill-posed 문제로 남아 있습니다 [89, 59, 69, 25].
최근 딥러닝[23, 37, 55, 71]의 발전으로 점점 더 많은 3D 생성 작업이 학습 기반이 될 수 있게 되었습니다.
딥러닝이 이미지 인식[27, 15] 및 생성[23, 37, 71]에서 상당한 발전을 이루었음에도 불구하고, 야생에서 단일 이미지 3D 재구성의 특정 작업은 여전히 뒤쳐져 있습니다.
우리는 인간과 기계 사이의 3D 재구성 능력의 상당한 차이를 두 가지 주요 요인에 기인한다고 생각합니다: (i) 3D 기하학의 대규모 학습을 방해하는 대규모 3D 데이터 세트의 결함, 그리고 (ii) 3D 데이터 작업 시 세부 수준과 계산 리소스 간의 트레이드오프.
이 문제를 해결하기 위한 한 가지 가능한 접근법은 2D priors를 사용하는 것입니다.
온라인에서 사용할 수 있는 사실적인 2D 이미지 데이터의 풀은 방대합니다.
가장 광범위한 텍스트-이미지 쌍 데이터 세트 중 하나인 LAION [75]은 CLIP [63] 및 Stable Diffusion [71]과 같은 현대 이미지 이해 및 생성 모델을 학습하는 데 도움이 됩니다.
2D 생성 모델의 일반화 기능이 증가함에 따라 3D 콘텐츠를 생성하기 전에 2D 모델을 사용하는 접근 방식이 눈에 띄게 증가했습니다.
DreamFusion [62]는 텍스트에서 3D 생성을 위한 2D priors 기반 방법론의 선구자 역할을 합니다.
이 기술은 제로샷 설정에서 새로운 뷰를 안내하고 neural radiance field (NeRF)[55]를 최적화할 수 있는 탁월한 능력을 보여줍니다.
DreamFusion을 기반으로 RealFusion [51] 및 NeuralLift [93]과 같은 최근 작업은 단일 이미지 3D 재구성을 위해 이러한 2D priors를 적용하기 위해 노력했습니다.
또 다른 접근 방식은 3D priors 버전을 사용하는 것입니다.
3D 재구성에 대한 이전의 시도는 토폴로지 제약 조건과 같은 3D priors의 시도를 활용하여 3D 생성을 지원했습니다 [88, 53, 59, 24].
그러나 수동으로 제작된 이러한 3D priors 버전은 고품질 3D 콘텐츠를 생성하기에는 부족합니다.
최근, Zero-1-to-3[46] 및 3Dim[91]과 같은 접근 방식은 2D diffusion 모델[71]을 적용하여 뷰 의존적이 되었고 이 뷰 의존적 diffusion을 3D prior로 활용했습니다.

2D priors와 3D priors 모두의 행동을 분석한 결과 장점과 단점이 모두 있는 것으로 나타났습니다.
2D priors는 3D priors로는 달성할 수 없는 3D 생성에 대한 인상적인 일반화를 보여줍니다(예: 그림 2의 용상 사례).
그러나 2D priors에만 의존하는 방법은 제한된 3D 지식으로 인해 불가피하게 3D 충실도와 일관성을 손상시킵니다.
이는 다중 면(Janus 문제), 크기 불일치, 일관되지 않은 질감 등과 같은 비현실적인 기하학적 구조로 이어집니다.
그림 2의 테디베어의 예에서는 실패 사례를 관찰할 수 있습니다.
반면, 3D priors에만 엄격하게 의존하는 것은 제한된 3D 학습 데이터로 인해 야생 재구성에 적합하지 않습니다.
결과적으로 그림 2에 표시된 것처럼 3D priors 기반 솔루션은 일반적인 객체(예: 맨 위 줄의 테디 베어 예제)를 효과적으로 처리하지만, 일반적이지 않은 객체와 씨름하여 지나치게 단순화된, 때로는 평평한 3D 기하학적 구조(예: 왼쪽 하단의 용 조각상)를 산출합니다.
본 논문에서는 2D 또는 3D prior에만 의존하는 것이 아니라 image-to-3D 생성으로 새로운 관점을 안내하기 위해 두 가지 priors를 동시에 사용할 것을 지지합니다.
2D와 3D priors의 잠재력 사이의 간단하지만 효과적인 트레이드오프 매개 변수를 조정함으로써 생성된 3D 지오메트리에서 탐색과 이용 사이의 균형을 관리할 수 있습니다.
2D의 우선 순위를 지정하면 상상력이 풍부한 3D 기능을 향상시켜 단일 2D 이미지에 내재된 불완전한 3D 정보를 보완할 수 있지만, 이는 3D 지식 부족으로 인해 정확도가 떨어지는 3D 지오메트리를 초래할 수 있습니다.
대조적으로, 3D prior에 우선 순위를 매기는 것은 더 많은 3D 제약 솔루션으로 이어질 수 있으며, 상상력이 떨어지고 도전적이고 흔치 않은 사례에 대한 그럴듯한 솔루션을 발견하는 능력이 줄어들기는 하지만 더 정확한 3D 지오메트리를 생성할 수 있습니다.
우리는 2D 및 3D priors 단계를 모두 활용하는 2단계 coarse-to-fine 최적화 프로세스를 통해 고품질 3D 출력을 산출하는 새로운 image-to-3D 파이프라인인 Magic123을 소개합니다.
coarse 단계에서, 우리는 neural radiance field (NeRF)을 최적화합니다 [55].
NeRF는 암시적 볼륨 표현을 학습하여 복잡한 기하학 학습에 매우 효과적입니다.
그러나 NeRF는 상당한 메모리를 요구하여 저해상도 렌더링된 이미지가 diffusion 모델로 전달되어 image-to-3D 작업의 출력을 저품질로 만듭니다.
더 자원 효율적인 NeRF 대안인 Instant-NGP[57]도 16GB 메모리 GPU의 image-to-3D 파이프라인에서 128×128 해상도에 도달할 수 있습니다.
따라서 3D 콘텐츠의 품질을 향상시키기 위해 Deep Marching Tetrahedra (DMTet)로 알려진 메모리 효율적이고 텍스처 분해된 SDF-Mesh 하이브리드 표현을 사용하는 두 번째 단계를 소개합니다[78].
이 접근 방식을 사용하면 해상도를 최대 1K까지 높이고 NeRF의 형상과 질감을 별도로 개선할 수 있습니다.
두 단계 모두 2D와 3D priors의 조합을 활용하여 새로운 뷰를 안내합니다.
우리는 우리의 기여를 다음과 같이 요약합니다:
• 우리는 고품질 고해상도 3D 지오메트리 및 텍스처를 생성하기 위해 2단계 coarse-to-fine 최적화 프로세스를 사용하는 새로운 image-to-3D 파이프라인인 Magic123을 소개합니다.
• 주어진 이미지에서 충실한 3D 콘텐츠를 생성하기 위해 2D 및 3D priors 버전을 동시에 사용할 것을 제안합니다. priors의 강도 매개 변수는 기하학적 탐색과 이용 사이의 균형을 허용합니다. 따라서 사용자는 이 절충 매개 변수를 사용하여 원하는 3D 콘텐츠를 생성할 수 있습니다.
• 또한, 우리는 2D priors와 3D priors 사이의 균형 잡힌 트레이드오프를 찾아 합리적으로 현실적이고 상세한 3D 재구성으로 이어집니다. 추가 재구성 없이 모든 예제에 대해 동일한 매개 변수 세트를 사용하는 Magic123은 실제 시나리오와 합성 시나리오 모두에서 배치되지 않은 단일 이미지에서 3D 재구성의 SOTA 결과를 달성합니다.

2 Methodology
우리는 그림 3과 같이 단일 참조 이미지에서 coarse-to-fine 방식으로 3D 콘텐츠를 생성하는 2단계 프레임워크인 Magic123을 제안합니다.
coarse 단계에서 Magic123은 NeRF를 최적화하여 coarse 지오메트리와 텍스쳐를 학습합니다.
fine 단계에서 Magic123은 고해상도 렌더링을 통해 메모리 효율적인 미분 가능한 메시 표현을 직접 최적화하여 3D 콘텐츠의 품질을 향상시킵니다.
두 단계 모두 Magic123은 지오메트리 탐색과 지오메트리 활용을 절충하기 위해 joint 2D 및 3D diffusion priors를 사용하여 일반화 가능성이 높은 신뢰할 수 있는 3D 콘텐츠를 생성합니다.
2.1 Magic123 pipeline
Image preprocessing.
Magic123은 객체 수준의 이미지를 3D로 생성하기 위한 파이프라인입니다.
배경이 있는 이미지가 지정된 경우 Magic123은 전경 객체를 추출하기 위한 전처리 단계가 필요합니다.
기성 세그멘테이션 모델인 Dense Prediction Transformer [67]를 활용하여 객체를 세그먼트합니다.
추출된 마스크, M으로 표시됨, 는 이진 분할 마스크이며 최적화에 사용됩니다.
플랫 지오메트리 붕괴를 방지하기 위해, 즉 모델은 실제 기하학적 세부 사항을 캡처하지 않고 표면에만 나타나는 텍스처를 생성합니다, 우리는 사전 학습된 MiDaS[68]에 의해 참조 뷰에서 depth 맵을 추가로 추출합니다.
전경 이미지는 입력으로 사용되고 마스크와 depth 맵은 정규화 전 최적화에 사용됩니다.
이러한 참조 이미지에는 전면 뷰로 가정한 고정 카메라 포즈가 할당됩니다.
카메라 설정에 대한 자세한 내용은 섹션 3.2에서 확인할 수 있습니다.
2.1.1 Coarse stage
Magic123의 coarse 단계는 참조 이미지를 존중하는 근본적인 지오메트리를 학습하는 것을 목표로 합니다.
복잡한 위상 변화를 원활하고 지속적인 방식으로 처리하는 강력한 능력으로 인해 이 단계에서 NeRF를 채택합니다.
Instant-NGP and its optimization.
우리는 빠른 추론과 복잡한 기하학적 구조를 복구할 수 있는 능력 때문에 Instant-NGP[57]를 NeRF 구현으로 활용합니다.
단일 이미지에서 3D를 충실하게 재구성하려면 NeRF를 최적화에는 다음과 같은 두 가지 이상의 loss 함수가 필요합니다: (i) reference view reconstruction supervision 및 (ii) novel view guidance.
Reference view reconstruction loss
L_rec는 참조 시점(v^r, 정면 뷰로 가정)에서 렌더링된 이미지가 참조 이미지 I^r에 최대한 근접하도록 보장하기 위한 주요 loss 함수 중 하나로 파이프라인에 부과됩니다.
참조 이미지와 해당 마스크 모두에 대해 다음과 같이 평균 제곱 오차(MSE) loss를 채택합니다:
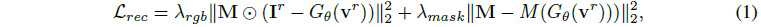
, 여기서 θ는 최적화할 NeRF 파라미터, ⊙는 Hadamard 곱, G_θ(v^r)는 v^r 시점에서 NeRF 렌더링 뷰, M()은 각 픽셀의 ray를 따라 볼륨 밀도를 적분하여 얻은 전경 마스크입니다.
전경 객체가 입력으로 추출되기 때문에, 우리는 어떠한 배경도 모델링하지 않고 모든 실험에 대한 배경 렌더링에 순백색을 사용합니다.
λ_rgb, λ_mask는 전경 RGB 및 마스크의 가중치입니다.
Novel view guidance
NeRF를 학습하기 위해서는 여러 뷰가 필요하기 때문에 L_g가 필요합니다.
우리는 텍스트/이미지-to-3D로의 선구적인 작업[62, 93]을 따르고 diffusion priors를 사용하여 새로운 뷰 생성을 안내합니다.
이전 작업과의 중요한 차이점으로, 우리는 2D prior 또는 3D prior에만 의존하지 않고 두 가지 모두를 사용하여 NeRF의 최적화를 가이드합니다.
자세한 내용은 § 2.2를 참조하십시오.
Depth prior
L_d는 지나치게 평평하거나 함몰된 3D 콘텐츠를 방지하기 위해 사용됩니다.
외관 재구성 loss만 사용하면 2D 이미지에서 3D 콘텐츠를 재구성해야 하는 본질적인 모호성으로 인해 형상이 불량해질 수 있습니다: 3D의 내용은 거리에 상관없이 동일한 이미지로 렌더링될 수 있습니다.
이러한 모호성으로 인해 이전 연구에서 언급한 것처럼 평면 또는 곡면 기하학이 발생할 수 있습니다 [93].
depth 정규화를 활용하여 이 문제를 완화합니다.
사전 학습된 단안 depth 추정기[68]를 활용하여 참조 이미지에서 pseudo depth d^r을 획득합니다.
참조 관점에서 NeRF 모델에서 출력되는 depth는 depth prior에 가까워야 합니다.
그러나 서로 다른 두 깊이 depth 소스의 값 불일치로 인해 MSE loss는 이상적인 loss 함수가 아닙니다.
정규화된 음의 피어슨 상관 관계를 depth 정규화로 사용합니다:
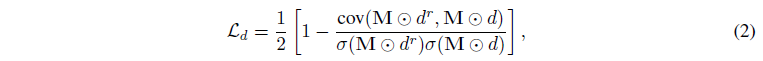
, 여기서 cov(·)는 공분산을 나타내고 σ(·)는 표준 편차를 측정합니다.
Normal smoothness
L_n.
NeRF 제한 사항 중 하나는 물체 표면에 고주파 아티팩트를 생성하는 경향입니다.
이를 위해 [51]에 따라 생성된 3D 모델에 대한 지오메트리의 normal 맵의 평활도를 적용합니다.
depth의 유한한 차이를 사용하여 각 점의 normal 벡터를 추정하고, normal 벡터에서 2D normal 맵 n을 렌더링하고, 다음과 같이 loss를 부과합니다:
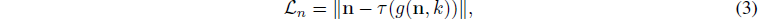
, 여기서 τ(·)는 스탑그래디언트 연산을 나타내고 g(·)는 가우시안 블러입니다.
블러링 k의 커널 크기는 9 × 9로 설정됩니다.
전체적으로 coarse 단계는 다음과 같은 loss 조합에 의해 최적화됩니다:
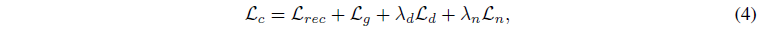
, 여기서 λ_d, λ_n은 깊이 및 정규화의 가중치입니다.
2.1.2 Fine stage
coarse 단계는 저해상도 3D 모델을 제공하며, 고주파 아티팩트를 생성하는 NeRF의 경향으로 인해 노이즈가 있을 수 있습니다.
우리의 fine 단계는 3D 모델을 개선하고 고해상도로 분리된 지오메트리와 텍스처를 얻는 것을 목표로 합니다.
이를 위해 하이브리드 SDF-Mesh 표현인 DMTet[78]을 채택하고 메모리 효율성이 높아 고해상도 3D 형상을 생성할 수 있습니다.
fine 단계는 3D 표현 및 렌더링을 제외하고 coarse 단계와 동일합니다.
DMTet는 변형 가능한 사면체 그리드(V_T, T)의 관점에서 3D 모양을 나타내며, 여기서 T는 사면체 그리드를 나타내고 V_T는 정점입니다.
정점 v_i ∈ V_T가 주어지면, Signed Distance Function (SDF) s_i ∈ R과 삼각형 변형 벡터 Δv_i ∈ R^3은 미분 가능한 메시를 추출하기 위해 최적화하는 동안 학습해야 할 매개 변수입니다 [78].
SDF는 coarse 단계의 밀도 필드를 변환하여 초기화되고 삼각형 변형은 0으로 초기화됩니다.
텍스처의 경우, 우리는 Magic3D[43]를 따라 coarse 단계의 색상 필드에서 초기화된 신경 색상 필드를 사용합니다.
미분 가능한 래스터화는 매우 높은 해상도에서 효율적으로 수행될 수 있기 때문에, 우리는 항상 coarse 단계의 8배 해상도를 사용하는데, 이는 coarse 단계와 비슷한 메모리 소비를 갖는 것으로 밝혀졌습니다.
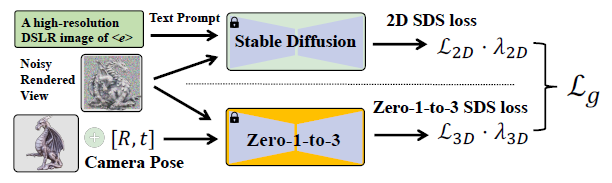
2.2 Joint 2D and 3D priors for image-to-3D generation
2D priors.
단일 참조 이미지를 사용하는 것은 priors의 어떤 것도 없이 완전한 NeRF 모델을 학습시키기에 충분하지 않습니다 [99, 45].
이 문제를 해결하기 위해 DreamFusion [62]은 제안된 score distillation sampling (SDS) loss를 통해 새로운 뷰를 가이드하기 위한 prior로 2D diffusion 모델을 사용할 것을 제안합니다.
SDS는 2D text-to-image diffusion 모델[72]을 활용하여 렌더링된 뷰를 잠재로 인코딩하고 노이즈를 추가한 다음 입력 텍스트 프롬프트에 의해 가이드되는 깨끗한 새로운 뷰를 추측합니다.
SDS는 대략적으로 렌더링된 뷰를 렌더링된 뷰와 프롬프트의 내용을 모두 존중하는 이미지로 변환합니다.
SDS loss는 그림 4의 상부에 도시되어 있고 (5)로 공식화되어 있으며, 여기서 I는 렌더링된 뷰이며, z_t는 I의 잠재에 시간 단계 t의 랜덤 가우시안 노이즈를 추가하여 잠재 노이즈입니다.
ϵ, ϵ_ϕ, ϕ, θ는 추가된 노이즈, 예측된 노이즈, 2D diffusion prior의 매개 변수 및 3D 모델의 매개 변수입니다.
θ는 coarse 단계의 경우 NeRF의 MLP이거나, fine 단계의 경우 SDF, 삼각 변형 및 색상 필드일 수 있습니다.
DreamFusion [62]는 또한 식 (5)에서 이미지 인코더 ∂z/∂I의 야코비안 항을 더욱 제거하여 속도와 메모리 측면에서 SDS loss를 훨씬 더 효율적으로 만들 수 있다고 지적합니다.
우리의 실험에서, 우리는 Stable Diffusion [71] v1.5를 2D prior로 사용한 SDS loss를 활용합니다.
렌더링된 이미지는 [71]의 이미지 인코더에서 요구하는 대로 512x512로 보간됩니다.
Textual inversion.
각 참조 이미지에 사용하는 프롬프트 e는 지루한 프롬프트 엔지니어링에서 선택한 순수 텍스트가 아닙니다.
image-to-3D 생성에 순수 텍스트를 사용하면 인간 언어의 제한된 표현력으로 인해 일관성 없는 텍스쳐와 지오메트리가 발생할 가능성이 높습니다.
예를 들어, "A high-resolution DSLR image of a colorful teapot"를 사용하면 참조 이미지를 존중하지 않는 다양한 형상과 색상이 생성됩니다.
따라서 RealFusion [51]을 따라 동일한 textual inversion [20] 기술을 활용하여 참조 이미지에서 개체를 나타내는 특수 토큰 <e>를 획득합니다.
모든 예에 대해 동일한 프롬프트를 사용합니다: "A high-resolution DSLR image of <e>".
우리는 Stable Diffusion이 없는 결과에 비해 textual inversion 기법으로 참조 이미지와 더 유사한 질감과 스타일로 teapot를 생성할 수 있다는 것을 발견했습니다.
전반적으로, 2D diffusion prior [62, 52, 43]는 지오메트리의 공간을 탐색할 수 있는 놀라운 능력을 보여줌으로써 높은 상상력으로 다양한 기하학적 표현의 생성을 용이하게 합니다.
이 탁월한 상상력은 단일 2D 이미지에서 불완전한 3D 정보의 가용성과 관련된 고유한 한계를 보완합니다.
또한 3D 재구성을 위한 2D prior 기반 기술의 활용은 10억 개 이상의 이미지로 구성된 광범위한 데이터 세트에 대한 학습으로 인해 특정 시나리오에서 과적합될 가능성을 줄입니다.
그러나 2D prior에 대한 의존은 생성된 3D 표현에 부정확성을 초래하여 잠재적으로 진정한 충실도에서 벗어날 수 있다는 것을 인정하는 것이 중요합니다.
이러한 저충실도 생성은 2D prior 버전이 3D 지식이 부족하기 때문에 발생합니다.
예를 들어, 2D prior 버전의 활용은 그림 2와 8에 표시된 Janus 문제 및 일치하지 않는 크기와 같은 부정확한 기하학적 구조를 산출할 수 있습니다.
2.2.1 3D prior
2D prior만 사용하는 것만으로는 상세하고 일관된 3D 형상을 포착하기에 충분하지 않습니다.
따라서 Zero-1-to-3 [46]은 3D prior 솔루션을 제안합니다.
Zero-1-to-3는 818K 모델로 구성된 최대 오픈 소스 3D 데이터 세트인 Objaverse [14]에서 뷰 의존 버전으로 Stable Diffusion을 fine-tune합니다.
Zero-1-to-3는 참조 이미지와 시점을 입력으로 사용하며 주어진 시점에서 새로운 뷰를 생성할 수 있습니다.
따라서 Zero-1-to-3는 3D 재구성에 강력한 3D prior로 사용할 수 있습니다.
SDS loss [62]를 사용하는 image-to-3D 생성 파이프라인에서 Zero-1-to-3의 사용은
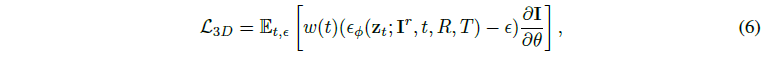
으로 공식화되며, 여기서 R, T는 뷰 의존적 diffusion 모델인 Zero-1-to-3에 전달된 카메라 포즈입니다.
3D prior과 2D prior 사용의 차이는 그림 4에 설명되어 있는데, 여기서 우리는 2D prior는 텍스트 임베딩을 가이던스로 사용하는 반면 3D prior는 새로운 뷰 카메라 포즈가 있는 참조 뷰 I^r을 가이던스로 사용한다는 것을 보여줍니다.
3D prior는 카메라 포즈를 활용하여 3D 일관성을 장려하고 2D prior에 비해 더 많은 3D 정보를 사용할 수 있습니다.
전반적으로, 3D prior의 활용은 광범위한 기하학적 영역을 효과적으로 활용할 수 있는 우수한 용량을 보여주며, 그 결과 2D prior에 비해 훨씬 정확한 기하학적 표현이 생성됩니다.
이렇게 높아진 정밀도는 특히 사전 학습된 3D 데이터 세트 내에서 일반적으로 마주치는 물체를 다룰 때 적용됩니다.
그러나 3D prior의 일반화 기능이 2D prior보다 상대적으로 낮으므로 불가능해 보일 수 있는 기하학적 구조가 생성될 가능성이 있다는 점을 인정해야 합니다.
이러한 낮은 일반화는 특히 고품질 real-scanned 개체의 경우 사용 가능한 3D 데이터 세트의 제한된 규모에서 비롯됩니다.
예를 들어, 흔치 않은 물체의 경우, Zero-1-to-3의 사용은 종종 지나치게 단순화된 기하학적 구조를 산출하는 경향이 있습니다, 예를 들어, 백 뷰에서 세부 사항이 없는 평평한 표면입니다(그림 2 및 8 참조).
2.2.2 Joint 2D and 3D priors
우리는 2D와 3D prior가 서로 보완적이라는 것을 발견했습니다.
2D 또는 3D prior에만 의존하는 대신 3D 생성에서 두 가지 prior를 모두 사용할 것을 제안합니다.
2D prior는 높은 상상력을 선호하여 지오메트리 공간을 탐색하는 데 사용되지만 부정확한 지오메트리로 이어질 수 있습니다.
우리는 기하학적 탐사로 2D prior의 이러한 특성을 명명합니다.
반면, 3D prior는 기하학 공간을 활용하는 데 사용되어 생성된 3D 콘텐츠가 기본 기하학의 암묵적 요구 사항을 충족하도록 제한하여 정확한 기하학을 선호하지만 일반화 가능성은 낮습니다.
일반적이지 않은 물체의 경우 3D prior의 경우 기하학적 구조가 지나치게 단순화될 수 있습니다.
우리는 3D prior를 사용하는 이 기능을 지오메트리 활용이라고 이름 붙입니다.
image-to-3D로의 파이프라인에서, 우리는 2D와 3D prior를 모두 결합하는 새로운 뷰 supervision에 대한 새로운 prior loss를 제안합니다:
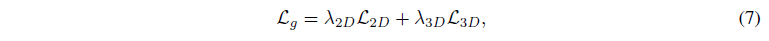
, 여기서 λ_2D와 λ_3D는 각각 2D와 3D prior의 강도를 먼저 결정합니다.
λ_2D에 더 많은 가중치를 부여하면 더 많은 기하학적 탐색이 가능하고, λ_3D에 더 많은 가중치를 부여하면 더 많은 기하학적 이용이 가능합니다.
그러나 두 매개 변수를 동시에 조정하는 것은 사용자에게 친숙하지 않습니다.
흥미롭게도, 정성적 실험과 정량적 실험을 모두 통해 우리는 우리가 사용한 3D prior인 Zero-1-to-3이 λ_2D로의 Stable Diffusion보다 λ_3D에 훨씬 더 내성이 있다는 것을 발견했습니다.
3D prior만 사용하는 경우(예: λ_2D = 0, 0-1-to-3), λ_3D에 대해 10부터 60까지의 일관된 결과가 생성됩니다.
반대로 Stable Diffusion은 λ_2D에 다소 민감합니다.
λ_3D를 0으로 설정하고 2D prior만 사용할 때 λ_2D가 1에서 2로 변경될 때 생성되는 지오메트리가 많이 달라집니다.
이 관찰을 통해 λ_3D를 수정하고 λ_2D를 튜닝하여 기하학적 탐색과 이용을 절충할 수 있습니다.
따라서, 우리는 식 (7)을
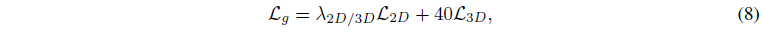
로 재구성하고, 여기서 2D loss 가중치 항의 이름을 λ_(2D/3D)로 바꿉니다.
우리는 논문 전체의 모든 결과에 대해 λ_(2D/3D) = 1.0을 설정했지만, 이 값은 사용자의 취향에 따라 조정할 수 있습니다.
2D 및 3D prior 가중치 선택에 대한 자세한 내용과 논의는 섹션 3.4절에서 확인할 수 있습니다.
3 Experiments
3.1 Datasets
NeRF4.
synthetic NeRF 데이터 세트 [55]의 8가지 테스트 예 중 chair, drums, ficus 및 microphone의 4가지 시나리오에서 수집한 NeRF4 데이터 세트를 소개합니다.
이 네 가지 시나리오에서는 복잡한 물체(drums 및 ficus), 하드 케이스(chair의 후면도) 및 간단한 케이스(microphone)를 다룹니다.
다른 네 가지 예는 전면 뷰 가정의 대상이 아니므로 제거되며, 추가 카메라 포즈 추정 또는 카메라 포즈의 수동 조정이 필요하며, 이 작업의 범위를 벗어납니다.
RealFusion15.
우리는 또한 RealFusion [51]이 수집하고 공개한 데이터 세트를 사용하며 bananas, birds, cacti, barbie cakes, cat statues, teapots, microphones, dragon statues, fishes, cherries, and watercolor paintings 등을 포함한 15개의 자연 이미지로 구성됩니다.
3.2 Implementation details
Optimizing the pipeline.
우리는 모든 실험에 동일한 하이퍼 파라미터 세트를 사용하며 객체별 하이퍼 파라미터 최적화를 수행하지 않습니다.
coarse 단계와 fine 단계 모두 Adam을 사용하여 최적화되었으며 0.001 학습률과 5,000회 반복에 대한 가중치 감소가 없습니다.
두 단계 모두에서 λ_rgb, λ_mask, λ_d가 5, 0.5, 0.001로 설정됩니다.
λ_2D 및 λ_3D는 1단계에서는 1, 40으로 설정하고 2단계에서는 0.001 및 0.01로 낮춰 과포화 텍스처를 완화합니다.
우리는 V1.5의 Stable Diffusion [80] 모델을 2D prior로 채택합니다.
[62]에 이어 2D prior의 지침 스케일이 100으로 설정됩니다.
3D prior의 경우 Zero-1-to-3 [46](105,000회 반복 finetuned 버전)이 활용됩니다.
Zero-1-to-3의 지침 척도는 [46]에 이어 5로 설정됩니다.
NeRF 백본은 64개의 숨겨진 차원이 있는 3개의 다층 퍼셉트론에 의해 구현됩니다.
조명 및 음영에 관해서는 [62]와 거의 동일하게 유지합니다.
차이점은 기하학 학습에 초점을 맞추기 위해 첫 단계에서 처음 3,000번의 반복을 일반적인 음영으로 설정했다는 것입니다.
fine 단계뿐만 아니라 다른 반복의 경우 확률 0.75의 diffusion 음영과 확률 0.25의 텍스처리스 음영을 사용합니다.
coarse 단계와 fine 단계의 경우 렌더링 해상도가 각각 128×128 및 1024×1024로 설정됩니다.
Camera setting.
참조 이미지가 배치되지 않았기 때문에 카메라 매개 변수는 다음과 같습니다.
먼저 참조 이미지는 전면 뷰기, 즉 polar 각도 90˚, azimuth 각도 0˚에서 촬영된 것으로 가정합니다.
둘째, 카메라는 좌표 원점에서 1.8m 떨어진 곳에 배치됩니다, 즉, 반경 거리는 1.8입니다.
셋째, 카메라의 시야(FOV)는 40˚입니다.
우리는 3D 재구성 성능이 카메라 매개 변수(예: FOV 20~60 사이, 방사 거리 1~4m)에 민감하지 않다는 것을 강조합니다.
이 카메라 설정은 정면도 가정에 따른 이미지에 적용됩니다.
전면 뷰에서 벗어나 촬영된 이미지의 경우 수동으로 편광 각도를 변경하거나 카메라 추정이 필요합니다.
3.3 Results
Evaluation metrics.
종합적인 평가를 위해, 우리는 prior 연구에 사용된 메트릭 [93, 51], 즉 PSNR, LPIPS [103] 및 CLIP-similarity [63]를 준수합니다.
PSNR과 LPIPS는 재구성 품질과 지각적 유사성을 측정하기 위해 참조 뷰에서 측정됩니다.
CLIP-similarity는 렌더링된 이미지와 참조 이미지 간의 평균 CLIP 거리를 계산하여 새로운 뷰와 참조 뷰 간의 모양 유사성을 통해 3D 일관성을 측정합니다.

Quantitative and qualitative comparisons.
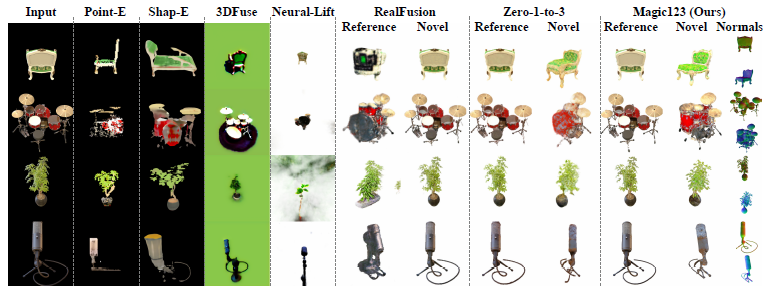
Magic123을 NeRF4 및 RealFusion15 데이터 세트 모두에서 SOTA PointE [58], Shap-E [34], 3Duse [77], NeuralLift [93], RealFusion [51] 및 Zero-1-to-3 [46]과 비교합니다.
Zero-1-to-3의 경우, 우리는 여기서 구현을 채택합니다 [84], 이는 원래 구현보다 더 나은 성능을 산출합니다.
다른 작품들은 공식적으로 공개된 코드를 사용합니다.
표 1에서 볼 수 있듯이 Magic123은 이전 접근 방식과 비교했을 때 두 데이터 세트의 모든 메트릭에서 상위 1위 성능을 달성합니다.
PSNR 및 LPIPS 결과는 Magic123의 탁월한 재구성 성능을 강조하면서 베이스라인에 비해 상당한 개선을 보여준다는 점에 주목할 필요가 있습니다.
CLIP-similarity의 개선은 참조 뷰와 관련하여 3D 일관성을 크게 반영합니다.
정성적 비교는 그림 5에서 확인할 수 있습니다.
Magic123은 기하학적 구조와 질감 모두에서 최고의 결과를 달성합니다.
Magic123이 특히 처음 두 줄의 dragon statue와 colorful teapot과 같은 복잡한 물체에서 3D 기반 Zero-1-to-3[46]을 크게 능가하는 동시에 모든 예에서 2D 기반 RealFusion[51]을 크게 능가하는 것에 주목하십시오.
이 성능은 SOTA Magic123보다 우수한 성능과 고품질 3D 컨텐츠를 생성하는 능력을 보여줍니다.

3.4 Ablation and analysis
Magic123은 단일 이미지 재구성을 위한 coarse-to-fine 파이프라인과 새로운 뷰 안내를 위한 Joint 2D 및 3D를 도입합니다.
우리는 그 효과를 보여주기 위해 분석 및 ablation 연구를 제공합니다.

The effect of two stages.
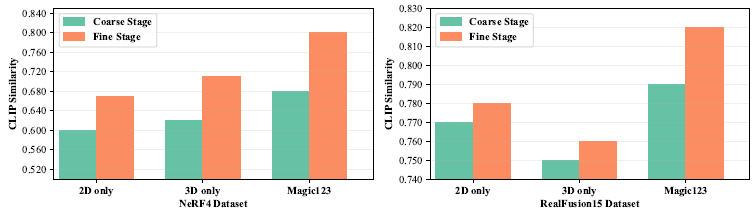
우리는 그림 6과 그림 7에서 파이프라인의 fine 단계를 사용하는 것이 Magic123의 성능에 미치는 영향을 연구합니다.
우리는 fine 단계가 coarse 단계와 결합될 때 다양한 설정에 걸쳐 질적 및 양적 성능 측면에서 일관된 개선이 관찰된다는 점에 주목합니다.
질감이 있는 메시 DMTet 표현을 사용하면 목표에 맞는 고품질 3D 콘텐츠를 사용할 수 있으며, 보다 매력적이고 고해상도의 3D 일관된 시각 자료를 생성할 수 있습니다.
3D priors only.
우리는 먼저 λ_2D = 0을 설정하여 2D의 안내를 꺼서 3D prior의 Zero-1-to-3 [46]만 안내로 사용합니다.
우리는 λ_3D를 10, 20, 40, 60으로 설정하여 효과를 연구합니다.
흥미롭게도, 우리는 Zero-1-to-3이 λ_3D의 변화에 매우 강하다는 것을 발견했습니다.
표 2는 상이한 λ_3D가 일관된 정량적 결과로 이어진다는 것을 보여줍니다.
따라서 다른 값보다 약간 더 나은 CLIP-similarity 점수를 얻기 때문에 우리는 실험 내내 단순히 λ_3D = 40을 설정합니다.

2D priors only.
그런 다음 3D prior를 먼저 끄고 image-to-3D 작업에서 λ_2D의 효과를 연구합니다.
표 2에 나타난 바와 같이, λ_2D의 증가와 함께 CLIP-similarity의 증가가 관찰됩니다.
이는 2D prior 가중치가 클수록 더 많은 상상력이 발생하지만 불행히도 Janus 문제가 발생할 수 있기 때문입니다.
Combining both 2D and 3D priors and the trade off factor λ_(2D/3D).
Magic123에서는 2D와 3D prior를 모두 사용할 것을 제안합니다.
그림 6은 image-to-3D 생성의 정량적 성능에 대한 2D 및 3D prior 결합의 효과를 보여줍니다.
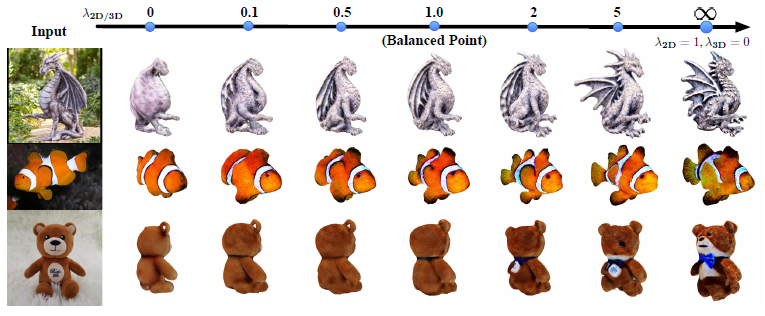
그림 8에서, 우리는 식 (8)로부터의 트레이드오프 하이퍼 파라미터 λ_(2D/3D)를 추가로 분석합니다.
λ_(2D/3D) = 0에서 시작하여 3D prior의 λ_(2D/3D)만 사용하고 점차 0.1, 0.5, 1.0, 2, 5, 마지막으로 λ_2D = 1, λ_3D = 0의 2D prior만 사용합니다.
주요 관찰 사항은 다음과 같습니다:
(1) 3D prior의 결과에만 의존하면 정밀한 기하학적 구조를 얻을 수 있지만(teddy bear에서 관찰된 바와 같이) 복잡하고 흔치 않은 물체를 생성하는 데에는 어려움이 있으며, 종종 최소한의 세부 사항으로 과도하게 단순화된 기하학적 구조를 렌더링합니다(dragon statue에서 본 바와 같이);
(2) 2D prior에만 의존하면 dragon staute와 같은 복잡한 장면을 묘사할 때 성능이 크게 향상되지만 teddy bear와 같은 간단한 예에서는 야누스 문제가 동시에 발생합니다;
(3) λ_(2D/3D)가 상승함에 따라 Magic123의 상상력이 향상되고 세부 사항이 더 분명해 지지만 3D 일관성을 훼손하는 경향이 있습니다.
모든 예제의 기본값으로 λ_(2D/3D) = 1을 지정합니다.
그러나 이 매개 변수는 특정 입력에서 훨씬 더 나은 결과를 얻기 위해 fine-tune될 수도 있습니다.
4 Related work
Multi-view 3D reconstruction.
다중 뷰 3D 재구성은 서로 다른 카메라 위치에서 캡처된 2D RGB 이미지에서 장면의 3D 구조를 복구하는 것을 목표로 합니다 [18, 1].
일반적으로 고전적인 접근 방식은 SIFT 기반 [49] point matching [73, 74]을 사용하여 장면의 지오메트리를 포인트 클라우드로 복구합니다.
더 최근의 방법은 피쳐 추출을 위해 신경망에 의존함으로써 그것들을 향상시킵니다(예: [95, 30, 96, 100]).
Neural Radiance Fields (NeRF)의 개발[55, 47]은 3D를 볼륨 radiance [83]로 재구성하는 방향으로 전환하여 사진 현실적인 새로운 뷰의 합성을 가능하게 했습니다 [85, 3, 4].
후속 연구는 또한 퓨샷(예: [32, 39, 16]) 및 원샷(예: [99, 9]) 설정에서 NeRF의 최적화를 탐구했습니다.
NeRF는 3D 지오메트리를 명시적으로 저장하지 않으며(밀도 필드만), 몇몇 연구에서는 signed distance funstion을 사용하여 장면의 표면을 복구할 것을 제안합니다(예: [101, 102]).
In-domain single-view 3D reconstruction.
단일 뷰에서 3D 재구성은 그러한 설정에서 에피폴라 제약 조건[26]조차도 부과될 수 없기 때문에 객체 기하학에 대한 강력한 priors 준비가 필요합니다.
3D 모양 또는 키포인트 형태의 직접 supervision은 사람의 얼굴 [5, 6], 머리 [42, 87], 손 [61] 또는 전신 [48, 50]과 같은 특정 영역에 이러한 제약을 부과하는 강력한 방법입니다.
이러한 supervision을 위해서는 값비싼 3D 주석과 수동 3D prior 생성이 필요합니다.
따라서 여러 연구는 객체 중심 데이터 세트(예: [35, 17, 38, 82, 22, 41, 79])에서 3D 기하학의 비지도 학습을 탐구합니다.
이러한 방법은 일반적으로 후드 아래에서 명시적인 3D 분해가 있는 auto-encoders [92, 36, 44] 또는 generators [7, 81]로 구성됩니다.
대규모 3D 데이터가 부족하기 때문에 이러한 방법은 단순한 모양(예: chairs, cars)으로 제한되며 더 복잡하거나 흔치 않은 물체(예: dragons, statues)로 일반화할 수 없습니다.
Zero-shot single-view 3D reconstruction.
기본적인 멀티 모달 네트워크[63, 8, 71]는 다양한 제로샷 3D 합성 작업을 가능하게 했습니다.
이전 연구에서는 3D 생성 [31, 29, 56, 94] 및 텍스트 프롬프트의 조작 [60, 40, 21]을 위한 CLIP [63] 지침을 사용했습니다.
현대의 제로샷 text-to-image 생성기[66, 71, 65, 72, 2, 19]는 더 강력한 합성 priors를 제공함으로써 이러한 결과를 개선할 수 있었습니다 [62, 86, 52, 10, 12].
DreamFusion [62]는 주어진 텍스트 쿼리에 대해 기성 diffusion 모델 [72]을 NeRF [55, 4]로 증류할 것을 제안한 중요한 작업입니다.
text-to-3D 합성(예: [43, 11]) 및 image-to-3D 재구성(예: [76, 51, 46])을 위한 수많은 후속 접근법을 촉발했습니다.
후자는 전면 카메라 위치에서 추가 재구성 loss [46] 및/또는 피사체 주도 diffusion 지침 [64, 43]을 통해 달성됩니다.
개발된 방법은 supervision[46, 77]의 기본적인 3D 표현[43, 11, 84]과 3D 일관성을 개선했습니다; 작업별 prior [28, 33, 70]과 추가 제어 [54].
최근의 3D 이미지 생성기[46, 51]와 유사하게, 우리는 또한 DreamFusion [62] 파이프라인을 따르지만, 저해상도에서만 supervise될 수 있는 radiance 필드 대신 고해상도 질감의 3D 메시를 재구성하는 데 중점을 둡니다 [43].
5 Conclusion and discussion
이 작업은 배치되지 않은 단일 이미지에서 고품질 질감의 3D 메시를 생성하기 위한 2단계 coarse-to-fine 솔루션인 Magic123을 제시합니다.
우리의 접근 방식은 2D 및 3D priors를 모두 활용함으로써 기존 연구의 한계를 극복하고 이미지에서 3D로의 재구성에서 SOTA 결과를 달성합니다.
2D와 3D priors 사이의 트레이드오프 매개 변수를 사용하면 생성된 형상의 탐색과 이용 사이의 균형을 제어할 수 있습니다.
우리의 방법은 실제 이미지와 합성 벤치마크에 대한 광범위한 실험을 통해 입증된 것처럼 사실성과 세부 수준 측면에서 이전 기술을 능가합니다.
우리의 연구 결과는 3D 추론에서 인간의 능력과 기계의 능력 사이의 격차를 줄이는 데 기여하고 단일 이미지 3D 재구성에서 미래의 발전을 위한 길을 열어줍니다.
코드, 모델 및 생성된 3D 자산의 가용성은 이 분야의 연구 및 응용을 더욱 용이하게 할 것입니다.
Limitations.
제한 사항 중 하나는 참조 이미지가 전면 뷰에서 가져온 것으로 가정한다는 것입니다.
이러한 가정은 참조 이미지가 전면적인 가정(예: 테이블 위의 요리 사진)과 일치하지 않을 때 좋지 않은 기하학적 구조로 이어집니다.
대신 우리의 방법은 접시 기하학적 구조 자체 대신 접시와 테이블의 바닥을 생성하는 데 초점을 맞출 것입니다.
이러한 제한은 수동 기준 카메라 포즈 조정 또는 카메라 추정을 통해 완화할 수 있습니다.
우리 연구의 또 다른 한계는 전처리된 세그멘테이션 [67]과 단안 깊이 추정 모델 [68]에 대한 의존성입니다.
이러한 모듈에서 발생하는 모든 오류는 이후 단계로 슬금슬금 이동하여 전체 생성 품질에 영향을 참조하십시오.
이전 작업과 마찬가지로 Magic123은 SDS loss 사용으로 인해 과포화 텍스처를 생성하는 경향이 있습니다.
두 번째 단계에서는 고해상도로 인해 과포화도 문제가 더욱 심각해집니다.
'text-to-3D' 카테고리의 다른 글
| DreamGaussian: Generative Gaussian Splatting for Efficient 3D Content Creation (0) | 2023.10.29 |
|---|---|
| Magic3D: High-Resolution Text-to-3D Content Creation (0) | 2023.10.26 |
| Zero-1-to-3: Zero-shot One Image to 3D Object (0) | 2023.07.24 |
| DreamBooth3D: Subject-Driven Text-to-3D Generation (0) | 2023.05.24 |
| DreamFusion: Text-to-3D using 2D Diffusion (0) | 2022.10.18 |