2024. 6. 15. 11:11ㆍDiffusion
Projected GANs Converge Faster
Axel Sauer, Kashyap Chitta, Jens Müller, Andreas Geiger
Abstract
Generative Adversarial Networks (GAN)은 고품질 이미지를 생성하지만 학습하기가 어렵습니다.
신중한 정규화, 방대한 양의 계산 및 값비싼 하이퍼 파라미터 스위프가 필요합니다.
저희는 생성된 실제 샘플을 고정된 사전 학습된 피쳐 공간에 투영하여 이러한 문제를 크게 발전시켰습니다.
판별기가 사전 학습된 모델의 더 깊은 레이어의 피쳐를 완전히 활용할 수 없다는 발견에 영감을 받아 채널과 해상도에 걸쳐 피쳐를 혼합하는 보다 효과적인 전략을 제안합니다.
저희의 Projected GAN은 이미지 품질, 샘플 효율성 및 수렴 속도를 향상시킵니다.
최대 1메가픽셀의 해상도와 더욱 호환되며 22개의 벤치마크 데이터 세트에서 SOTA Fréchet Inception Distance(FID)를 발전시킵니다.
중요한 것은 Projected GAN이 이전에 가장 낮은 FID를 최대 40배 더 빠르게 일치시켜 동일한 계산 리소스가 주어지면 월 클럭 시간을 5일에서 3시간 미만으로 단축한다는 것입니다.
1 Introduction
Generative Adversarial Network (GAN)은 생성기와 판별기로 구성됩니다.
이미지 합성을 위해 생성기의 작업은 RGB 이미지를 생성하는 것입니다; 판별기는 실제 샘플과 가짜 샘플을 구별하는 것을 목표로 합니다.
자세히 살펴보면 판별기의 작업은 두 가지입니다: 첫째, 실제 샘플과 가짜 샘플을 의미 있는 공간에 투영합니다, 즉, 입력 공간의 표현을 학습합니다.
둘째, 이 표현을 기반으로 판별합니다.
안타깝게도 생성기와 함께 판별기를 학습하는 것은 매우 어려운 작업으로 악명 높습니다.
판별기 정규화 기술은 적대적 게임 [43]의 균형을 맞추는 데 도움이 되지만, 그래디언트 패널티 [50]와 같은 표준 정규화 방법은 하이퍼파라미터 선택 [33]에 취약하고 성능이 크게 저하될 수 있습니다 [5].
이 논문에서는 GAN 학습을 개선하고 안정화하기 위해 사전 학습된 표현의 유용성을 살펴봅니다.
사전 학습된 표현을 사용하는 것은 컴퓨터 비전 [40, 41, 62]과 자연어 처리 [24, 59, 61]에서 어디에나 있게 되었습니다.
사전 학습된 지각 네트워크 [73]와 imaget-to-image 변환을 위한 GAN을 결합하면 인상적인 결과가 나오긴 했지만 [19, 63, 75, 81], 이 아이디어는 무조건적인 noise-to-image 합성을 위해 아직 구체화되지 않았습니다.
실제로, 저희는 강력한 사전 학습된 피쳐로 인해 판별자가 2인용 게임을 지배할 수 있으므로 이 아이디어의 나이브한 적용이 SOTA 결과로 이어지지 않음을 확인합니다 (섹션 4).
이 작업에서는 이러한 문제를 어떻게 극복할 수 있는지 보여주고 GAN 학습을 위한 사전 학습된 지각 피쳐 공간의 잠재력을 최대한 활용하기 위한 두 가지 주요 구성 요소를 식별합니다 [2]: 여러 판별기로 다중 스케일 피드백이 가능하도록 피쳐 피라미드 그리고 사전 학습된 네트워크의 더 깊은 레이어를 더 잘 활용하기 위한 랜덤 투영.

저희는 최대 1024^2 픽셀의 해상도를 가진 소형 및 대형 데이터 세트에 대해 광범위한 실험을 수행합니다.
모든 데이터 세트에서 학습 시간이 크게 단축된 상태에서 SOTA 이미지 합성 결과를 보여줍니다 (그림 1).
또한 Projected GAN은 데이터 효율성을 높이고 추가 정규화의 필요성을 방지하여 고가의 하이퍼파라미터 스위프가 불필요하다는 것을 발견했습니다.
2 Related Work
우리는 관련 작업을 크게 두 가지 영역으로 분류합니다: GAN 및 판별기 설계를 위한 사전 학습.
Pretrained Models for GAN Training.
GAN에 대한 사전 학습된 표현을 활용하는 작업은 다음 두 가지 범주로 나눌 수 있습니다: 첫째, GAN의 일부를 새로운 데이터 세트 [21, 52, 82, 88]로 전송하고, 둘째, 사전 학습된 모델을 사용하여 GAN을 제어하고 개선합니다.
후자는 사전 학습이 적대적일 필요가 없기 때문에 유리합니다.
저희의 작업은 이 두 번째 범주에 속합니다.
사전 학습된 모델은 인과적 생성 요소 [69]를 분리하는 가이딩 메커니즘으로, 텍스트 기반 이미지 조작 [58]을 위해 생성기 활성화를 역 분류기 [25, 71]에 일치시키거나 생성기의 잠재 공간에서 그래디언트 상승을 통해 이미지를 생성하는 데 사용할 수 있습니다.
[68]의 비적대적 접근 방식은 사전 학습된 모델에서 모멘트 일치를 사용하여 생성 모델을 학습하지만; 그 결과는 표준 GAN과 경쟁하는 것과는 거리가 멀습니다.
확립된 방법은 적대적 loss와 지각적 loss의 조합입니다 [28].
일반적으로 loss는 추가로 결합됩니다 [15, 19, 45, 67, 81].
그러나 추가 조합은 재구성 타겟을 사용할 수 있는 경우, 예를 들어 쌍으로 구성된 image-to-image 변환 설정 [92]에서만 가능합니다.
사전 학습된 네트워크에 재구성 타겟을 제공하는 대신 Sungatullina et al. [75]은 frozen VGG 피쳐에서 적대적 loss를 최적화할 것을 제안합니다 [73].
그들은 그들의 접근 방식이 이미지 변환 작업에서 CycleGAN [92]을 개선한다는 것을 보여줍니다.
유사한 맥락에서 [63]은 최근 다른 지각 판별기를 제안했습니다.
그들은 사전 학습된 VGG를 사용하고 그 피쳐를 사전 학습된 세그멘테이션 네트워크의 예측과 연결합니다.
결합된 피쳐는 서로 다른 스케일에서 여러 판별기에 공급됩니다.
마지막 두 가지 접근 방식은 image-to-image 변환 작업에 특화되어 있습니다.
저희는 이러한 방법이 전체 이미지 콘텐츠가 랜덤 잠재 코드에서 합성되는 더 까다로운 무조건 설정에서는 잘 작동하지 않는다는 것을 보여줍니다.
Discriminator Design.
GAN에 대한 많은 작업은 새로운 생성기 아키텍처 [5,33,34,86]에 초점을 맞추고 있는 반면, 판별기는 종종 vanilla 컨볼루션 신경망에 가깝게 유지되거나 생성기를 미러링합니다.
주목할 만한 예외는 인코더-디코더 판별기 아키텍처를 사용하는 [70,87]입니다.
그러나 저희와는 달리 사전 학습된 피쳐나 랜덤 투영을 사용하지 않습니다.
다른 작업 라인은 생성된 RGB 이미지 [13,18] 또는 [1,54]의 저차원 투영에 적용된 여러 판별기가 있는 설정을 고려합니다.
여러 판별기를 사용하면 샘플 다양성, 학습 속도 및 학습 안정성이 향상됩니다.
그러나 이러한 접근 방식은 증가된 계산 노력에 비해 수익률이 감소하기 때문에 현재 SOTA 시스템에서는 활용되지 않습니다.
하나 또는 여러 판별기로 다중 스케일 피드백을 제공하는 것은 이미지 합성 [30,31]과 이미지 간 변환 [57,81]에 모두 도움이 되었습니다.
이러한 작업은 서로 다른 해상도에서 RGB 이미지를 보간하는 반면, 저희의 연구 결과는 객체 감지를 위한 피라미드 네트워크의 성공과 유사점을 보여주는 다중 스케일 피쳐 맵의 중요성을 나타냅니다.
마지막으로, 판별기의 과적합을 방지하기 위해 최근에 미분 가능한 증강 방법이 제안되었습니다 [32,79,89,90].
저희는 이러한 전략을 채택하는 것이 GAN 학습을 위한 사전 학습된 표현의 잠재력을 최대한 활용하는 데 도움이 된다는 것을 발견했습니다.
3 Projected GANs
GAN은 주어진 학습 데이터 세트의 분포를 모델링하는 것을 목표로 합니다.
생성기 G는 단순 분포 P_z(일반적으로 정규 분포)에서 샘플링된 잠재 벡터 z를 해당 생성된 샘플 G(z)에 매핑합니다.
그런 다음 판별기 D는 실제 샘플 x ~ P_x를 생성된 샘플 G(z) ~ P_G(z)를 구별하는 것을 목표로 합니다.
이 기본 아이디어는 다음과 같은 미니맥스 objective

를 낳습니다.
실제 이미지와 생성된 이미지를 판별기의 입력 공간에 매핑하는 피쳐 투영기 {P_l} 집합을 소개합니다.
따라서 Projected GAN 학습은 다음
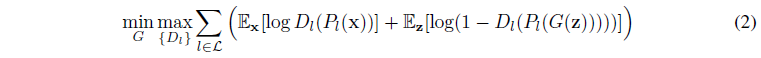
와 같이 공식화할 수 있으며, 여기서 {D_l}은 서로 다른 피쳐 투영에서 작동하는 독립적인 판별기 집합입니다.
{P_l}은(3)에서 고정된 상태로 유지하고 G와 {D_l}의 매개 변수만 최적화합니다.
피쳐 투영기 {P_l}은(는) 두 가지 필요한 조건을 만족해야 합니다: 미분 가능할 수 있어야 하며 입력에 대한 충분한 통계를 제공해야 합니다, 즉, 중요한 정보를 보존해야 합니다.
또한 (1)의 (최적화하기 어려운) objective를 그래디언트 기반 최적화에 더 적합한 objective로 변환하는 피쳐 프로젝터 {P_l}을 찾는 것을 목표로 합니다.
이제 피쳐 프로젝터의 세부 정보를 지정하기 전에 Projected GAN이 실제로 투영된 피쳐 공간의 분포와 일치한다는 것을 보여줍니다.
3.1 Consistency
(3)의 Projected GAN objective는 더 이상 실제 분포 P_T와 일치하도록 직접 최적화하지 않습니다.
이상적인 조건에서 학습 속성을 이해하기 위해 [54]의 일관성 theorem의 보다 일반화된 형태를 고려합니다:

theorem에 대한 증명은 부록에 제공됩니다.
이 theorem에서 관련 판별기 D_l을 사용하는 피쳐 프로젝터 P_l이 생성기가 P_l을 통해 한계를 따라 실제 분포와 일치하도록 장려한다는 결론을 내렸습니다.
따라서 수렴 시 G는 피쳐 공간에서 생성된 분포와 실제 분포와 일치합니다.
이 theorem은 결정론적 투영 P_l 이전에 stochastic data augmentations [32]을 사용할 때도 유지됩니다.
3.2. Model Overview
사전 학습된 피쳐 공간에 투영하고 학습하면 아래에서 다루는 새로운 질문의 영역이 열립니다.
이 섹션에서는 일반적인 시스템에 대한 개요를 제공하고 각 설계 선택에 대한 광범위한 ablation이 이어집니다.
피쳐 투영이 판별기에 영향을 미치기 때문에 이 섹션에서는 P_l과 D_l에 초점을 맞추고 생성기 아키텍처에 대한 논의를 섹션 5로 미룹니다.
Multi-Scale Discriminators.
저희는 해상도(L_1 = 64^2; L_2 = 32^2; L_3 = 16^2; L_4 = 8^2)에서 사전 학습된 피쳐 네트워크의 네 개의 레이어 L_l에서 피쳐를 얻습니다.
저희는 별도의 판별기 D_l을 레이어 L_l의 피쳐와 각각 연관시킵니다.
각 판별기 D_l은 각 컨볼루션 레이어에서 스펙트럼 정규화 [51]가 있는 간단한 컨볼루션 아키텍처를 사용합니다.
저희는 모든 판별기가 동일한 해상도에서 로짓을 출력하는 경우 더 나은 성능을 관찰합니다 (4^2).
따라서 저희는 저해상도 입력에 더 적은 수의 다운샘플링 블록을 사용합니다.
일반적인 관행에 따라 전체 loss를 계산하기 위해 모든 로짓을 합산합니다.
생성기 패스의 경우 모든 판별기의 loss를 합산합니다.
더 복잡한 전략 [1, 18]은 실험에서 성능을 향상시키지 못했습니다.
Random Projections.
저희는 섹션 4의 실험에서 입증된 바와 같이 더 깊은 레이어의 피쳐는 다루기가 훨씬 더 어렵다는 것을 관찰했습니다.
저희는 판별자가 다른 부분을 완전히 무시하면서 피쳐 공간의 하위 집합에 초점을 맞출 수 있다고 가정합니다.
이 문제는 특히 더 깊고 의미론적인 레이어에서 두드러질 수 있습니다.
따라서 저희는 판별자가 사용 가능한 모든 정보를 동등하게 활용하도록 장려하면서 두드러진 피쳐를 희석하기 위한 두 가지 전략을 제안합니다.
두 전략의 공통점은 고정된 미분 가능한 랜덤 투영을 사용하여 피쳐를 혼합한다는 것입니다, 즉, 랜덤 초기화 후에는 이러한 레이어의 매개 변수가 학습되지 않는다는 것입니다.
Cross-Channel Mixing (CCM).
경험적으로 우리는 다음 두 가지 속성이 바람직하다는 것을 발견했습니다: (i) 랜덤 투영은 F의 완전한 표현력을 활용하기 위해 보존되는 정보여야 하며, (ii) 사소한 반전성이 없어야 합니다.
채널 간에 혼합하는 가장 쉬운 방법은 1x1 컨볼루션입니다.
동일한 수의 출력 채널과 입력 채널이 있는 1x1 컨볼루션은 순열의 일반화이며 [38] 결과적으로 입력에 대한 정보를 보존합니다.
실제로, 우리는 매핑이 주입식으로 남아 있으므로 더 많은 출력 채널이 더 나은 성능으로 이어지고 따라서 정보가 보존된다는 것을 발견했습니다.
Kingma et al. [38]은 최적화를 위한 좋은 시작점으로 컨볼루션 레이어를 랜덤 회전 행렬로 초기화합니다.
우리는 (ii)를 위반하기 때문에 이것이 GAN 성능을 향상시키는 것을 찾지 못했습니다 (부록 참조).
따라서 우리는 Kaiming 초기화 [22]를 통해 컨볼루션 레이어의 가중치를 랜덤으로 초기화합니다.
우리는 활성화 함수를 추가하지 않습니다.
우리는 이 랜덤 투영을 네 개의 척도 각각에 적용하고 그림 2에 표시된 것처럼 변환된 피쳐를 판별기에 공급합니다.


Cross-Scale Mixing (CSM).
스케일 간의 피쳐 혼합을 장려하기 위해 CSM은 랜덤 3x3 컨볼루션과 이중 선형 업샘플링으로 CCM을 확장하여 U-Net [65] 아키텍처를 생성합니다, 그림 3을 참조하십시오.
그러나 CSM 블록은 vanilla U-Net [65]보다 간단합니다: 우리는 각 스케일에서 단일 컨볼루션 레이어만 사용합니다.
CCM의 경우 모든 가중치에 대해 Kaiming 초기화를 사용합니다.
Pretrained Feature Networks.
저희는 다양한 피쳐 네트워크를 ablate합니다.
첫째, 모델 크기 대 성능을 직접 제어할 수 있는 다양한 버전의 EfficientNet을 조사합니다.
EfficientNet은 ImageNet [10]에서 학습된 이미지 분류 모델이며, 정확도와 계산의 균형을 유리하게 제공하도록 설계되었습니다.
둘째, 다양한 크기의 ResNet을 사용합니다.
ImageNet 피쳐에 대한 의존성을 분석하기 위해 (섹션 4.3), 4억 개의 (image, text) 쌍으로 구성된 데이터 세트에서 대조적인 언어-이미지 objective로 최적화된 ResNet인 R50-CLIP [60]도 고려합니다.
마지막으로, 저희는 비전 트랜스포머 아키텍처 (ViT-Base) [14]와 효율적인 후속 조치(DeiT-small distilled) [78]를 활용합니다.
저희는 평가 메트릭 FID [23]와 강한 상관 관계를 피하기 위해 inception 네트워크 [76]를 선택하지 않습니다.
부록에서는 상관 관계를 배제하기 위해 다른 여러 신경 및 비신경 메트릭도 평가합니다.
이러한 추가 메트릭은 FID에서 얻은 순위를 반영합니다.
다음에서는 SOTA 기술과 비교하기 전에 Projected GAN 모델에서 각 구성 요소의 중요도와 최상의 구성을 분석하기 위해 체계적인 ablation 연구를 수행합니다.
4 Ablation Study
판별기, 혼합 전략 및 사전 학습된 피쳐 네트워크의 최상의 구성을 결정하기 위해 256^2 픽셀의 해상도를 사용하여 중간 크기(126k 이미지)이고 시각적으로 상당히 복잡한 LSUN-Church [84]에 대한 실험을 수행합니다.
생성기 G의 경우 여러 업샘플링 블록으로 구성된 FastGAN [49]의 생성기 아키텍처와 추가 스킵-레이어-excitation 블록을 사용합니다.
hinge loss [47]를 사용하여 실제 이미지가 판별기에 100만 개가 나타날 때까지 배치 크기가 64인 상태로 학습하며, 이는 G가 수렴에 가까운 값에 도달하기에 충분한 양입니다.
달리 지정되지 않은 경우 이 섹션에서는 EfficientNet-Lite1 [77] 피쳐 네트워크를 사용합니다.
저희는 판별기 증강 [32,79,89,90]이 모든 방법의 성능을 일관되게 향상시키며 SOTA 성능에 도달하는 데 필요하다는 것을 발견했습니다.
저희는 FastGAN 생성기와 결합하여 최상의 결과를 얻을 수 있는 것으로 밝혀진 미분 가능한 데이터 증강 [89]을 활용합니다.
4.1 Which feature network layers are most informative?
저희는 먼저 독립적인 멀티 스케일 판별기의 관련성을 조사합니다.
이 실험에서는 피쳐 혼합을 사용하지 않습니다.
G가 특정 피쳐 공간에 얼마나 잘 맞는지 측정하기 위해 레이어 i에 FD_i로 표시된 공간적으로 풀링된 피쳐에 Fréchet Distance (FD)[17]를 사용합니다.
서로 다른 피쳐 공간에 걸친 FD는 직접 비교할 수 없습니다.
따라서 저희는 표준 RGB 판별기로 GAN 베이스라인을 학습하고 각 레이어에서 FD_i^RGB를 기록하고 분수 rel-FD_i = FD_i / FD_i^RGB를 통해 상대적 개선을 정량화합니다.
저희는 또한 단일 로짓을 예측하기 위해 피쳐 맵이 동일한 판별기의 서로 다른 레이어에 공급되는 지각 판별기 [75]도 조사합니다.

표 1(투영 없음)의 결과는 두 개의 판별기가 하나보다 낫고 vanilla RGB 베이스라인보다 향상되었음을 보여줍니다.
놀랍게도 심층 레이어에 판별기를 추가하면 성능이 손상됩니다.
저희는 이러한 더 많은 시맨틱 피쳐가 직접적인 적대적 loss에 잘 반응하지 않는다는 결론을 내렸습니다.
저희는 또한 원본 이미지의 크기가 조정된 버전에서 판별기를 사용하여 실험했지만 단일 이미지 베이스라인보다 향상된 하이퍼파라미터 및 아키텍처 설정을 찾을 수 없었습니다.
얕은 피쳐에 대한 판별기를 생략하면 성능이 저하되는데, 이는 이러한 레이어에 원본 이미지에 대한 대부분의 정보가 포함되어 있기 때문에 예상됩니다.
피쳐 반전 [16]에 대해서도 유사한 효과가 관찰되었습니다 – 레이어가 깊어질수록 입력을 재구성하기가 더 어려워집니다.
마지막으로 우리는 독립적인 판별자가 지각적인 판별자보다 상당한 차이로 더 뛰어나다는 것을 관찰했습니다.
4.2 How can we best utilize the pretrained features?
이전 섹션의 통찰력을 감안할 때, 저희는 심층 피쳐의 활용도를 향상시키는 것을 목표로 합니다.
이 실험을 위해 저희는 고해상도에서 판별기를 포함하는 구성만 조사합니다.
표 1(CCM 및 CCM + CSM)에는 두 가지 혼합 전략에 대한 결과가 나와 있습니다.
CCM은 모든 설정에서 FD를 적당히 감소시켜 채널을 혼합하면 생성기에 대한 더 나은 피드백을 얻을 수 있다는 가설을 확인했습니다.
CSM을 추가하면 모든 구성에서 또 다른 눈에 띄는 개선을 달성할 수 있습니다.
특히 심층 레이어의 rel-FD_i가 크게 감소하여 심층 시맨틱 피쳐를 활용하는 CSM의 유용성을 보여줍니다.
흥미롭게도 저희는 이제 네 가지 판별기를 모두 결합하여 최고의 성능을 얻을 수 있음을 관찰했습니다.
지각 판별기는 다시 여러 판별기보다 성능이 떨어집니다.
저희는 독립적인 판별기 또는 CCM 또는 CSM을 통해 원본 이미지를 통합하면 항상 성능이 더 나빠진다는 점에 주목합니다.
이 실패는 투영되지 않은 적대적 최적화와 나이브하게 결합하면 학습 역학이 손상된다는 것을 시사합니다.

4.3 Which feature network architecture is most effective?
위의 실험에 의해 결정된 최상의 설정 (4개의 판별자가 있는 CCM + CSM)을 사용하여 Projected GAN 학습을 위한 다양한 지각 피쳐 네트워크 아키텍처의 효과를 연구합니다.
수렴을 보장하기 위해 더 큰 아키텍처의 경우에도 천만 개의 이미지를 학습합니다.
표 2는 LSUN-Church에서 달성한 FID를 보고합니다.
놀랍게도, 저희는 ImageNet 정확도와 상관관계가 없다는 것을 발견했습니다.
반대로, 저희는 더 작은 모델(예: EfficientNetslite)의 경우 더 낮은 FID를 관찰했습니다.
이 관찰은 더 간결한 표현이 유익하면서 동시에 계산 오버헤드와 결과적으로 학습 시간을 단축한다는 것을 나타냅니다.
R50-CLIP는 R50 대응물을 약간 능가하여 ImageNet 피쳐가 낮은 FID를 달성하는 데 필요하지 않음을 나타냅니다.
완전성을 위해 저희는 랜덤으로 초기화된 피쳐 네트워크로도 학습하지만 훨씬 더 높은 FID 값으로 수렴합니다(부록 참조).
다음에서는 EfficientNet-Lite1을 피쳐 네트워크로 사용합니다.
5 Comparison to State-of-the-Art
이 섹션에서는 최신 모델과 관련하여 Projected GAN의 장점을 보여주는 포괄적인 분석을 수행합니다.
우리의 실험은 세 가지 섹션으로 구성됩니다: 수렴 속도 및 데이터 효율성 평가 (5.1), 대규모 (5.2) 및 소규모 (5.3) 벤치마크 데이터 세트에 대한 비교.
크기(수억 ~ 수백만 샘플), 해상도(256^2 ~ 1024^2), 시각적 복잡성(클립 아트, 그림 및 사진) 측면에서 다양한 데이터 세트를 다룹니다.
Evaluation Protocol.
저희는 Fréchet Inception Distance (FID)[23]를 사용하여 이미지 품질을 측정합니다.
[33, 34]에 이어 생성된 5만 개의 실제 이미지와 모든 실제 이미지 사이의 FID를 보고합니다.
저희는 각 방법에 대해 가장 좋은 FID를 가진 스냅샷을 선택합니다.
이미지 품질 외에도 수렴을 평가하기 위한 메트릭을 포함합니다.
[32]에서와 같이 판별기(Imgs)에 표시된 실제 이미지 수를 기반으로 학습 진행률을 측정합니다.
저희는 FID가 학습 시 가장 좋은 FID의 5% 이내의 값에 도달하는 데 모델에 필요한 이미지 수를 보고합니다.
부록에서 GAN 문헌에서 벤치마킹이 덜 된 다른 메트릭도 보고합니다: KID [4], SwAV-FID [53], precision 및 recall [66].
달리 명시되지 않는 한, 공정한 비교를 용이하게 하기 위해 [26]의 평가 프로토콜을 따릅니다.
특히, 저희는 동일한 고정된 이미지 수(1000만 개)가 주어진 모든 접근 방식을 비교합니다.
이 설정을 통해 각 실험은 NVIDIA V100에서 약 100-200 GPU 시간이 소요되며, 자세한 내용은 부록을 참조하십시오.
Baselines.
저희는 StyleGAN2-ADA [32]와 FastGAN [49]을 베이스라인으로 사용합니다.
StyleGAN2-ADA는 샘플 품질 측면에서 대부분의 데이터 세트에서 가장 강력한 모델인 반면, FastGAN은 학습 속도에서 탁월합니다.
저희는 이러한 베이스라인과 저희의 Projected GAN을 StyleGAN2-ADA [32]의 저자가 제공한 코드베이스 내에 구현합니다.
각 모델에 대해 두 가지 종류의 데이터 증강을 실행했습니다: 미분 가능한 데이터 증강 [89] 및 적응형 판별기 증강 [32].
저희는 모델당 더 나은 성능의 증강 전략을 선택합니다.
모든 베이스라인과 데이터 세트에 대해 x-플립을 통해 데이터 증폭을 수행합니다.
Projected GAN은 모든 실험에 동일한 생성기 및 판별기 아키텍처를 사용하고 하이퍼파라미터(학습 속도 및 배치 크기)를 학습합니다.
고해상도 이미지 생성을 위해 원하는 출력 해상도와 일치하도록 생성기에 추가 업샘플링 블록이 포함됩니다.
저희는 최상의 결과를 위해 두 베이스라인 모두에 대한 모든 하이퍼파라미터를 신중하게 조정합니다: FastGAN은 배치 크기 선택에 민감하고 StyleGAN2-ADA는 학습률 및 R1 페널티에 민감하다는 것을 발견했습니다.
부록에서는 각 실험에 사용된 추가 구현 세부 정보를 문서화합니다.
5.1 Convergence Speed and Data Efficiency
[26] 및 [85]에 이어 256^2 픽셀의 이미지 해상도와 70k CLEVR 데이터 세트 [29]에서 LSUN-Church의 Projected GAN의 학습 속성을 분석합니다.
이 섹션에서는 수렴 속성에 관심이 있기 때문에 필요한 경우 10M 이상의 이미지도 학습합니다.
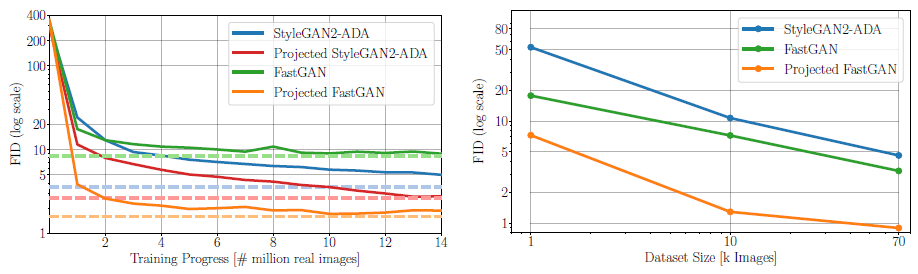
Convergence Speed.
저희는 StyleGAN2의 스타일 기반 생성기와 FastGAN의 단일 입력 노이즈 벡터를 사용하는 표준 생성기 모두에 대해 Projected GAN 학습을 적용합니다.
그림 4(왼쪽)와 같이 FastGAN은 빠르게 수렴하지만 높은 FID에서 포화됩니다.
StyleGAN2는 더 느리게 수렴하지만(88M 이미지) 더 낮은 FID에 도달합니다.
Projected GAN 학습은 두 생성기 모두를 개선합니다.
특히 FastGAN의 경우 수렴 속도와 최종 FID 모두의 개선이 중요하지만 StyleGAN2의 개선은 덜 두드러집니다.
놀랍게도, Projected FastGAN은 88M의 StyleGAN2에 비해 1.1M 이미지만 경험한 후 이전에 StyleGAN2의 최고 FID에 도달합니다.
월 클럭 시간에서 이는 5일이 아닌 3시간 미만에 해당합니다.
따라서 지금부터는 FastGAN 생성기를 활용하고 이 모델을 간단히 Project GAN이라고 부릅니다.

그림 5는 LSUN-Church에서 학습하는 동안 고정 노이즈 벡터 z에 대한 샘플을 보여줍니다.
FastGAN과 StyleGAN 모두에서 텍스처 패치가 점차 전역 구조로 형성됩니다.
Projected GAN의 경우 시간이 지남에 따라 더 자세히 설명되는 구조의 출현을 직접 관찰합니다.
흥미롭게도 Projected GAN 잠재 공간은 매우 변동성이 큰 것으로 보이며, 즉 고정 z의 경우 이미지가 학습 중에 상당한 지각 변화를 겪습니다.
투영되지 않은 경우 이러한 변화는 더 점진적입니다.
저희는 이러한 유도된 변동성이 기존 RGB loss에 비해 더 많은 의미론적 피드백을 제공하는 판별기 때문일 수 있다고 가정합니다.
이러한 의미론적 피드백은 학습 중에 더 많은 확률성을 도입할 수 있으며, 이는 결과적으로 수렴과 성능을 향상시킵니다.
또한 판별기의 signed 실제 로짓이 학습 중에도 동일한 수준으로 유지되는 것을 관찰했습니다(부록 참조).
안정적인 signed 로짓은 판별기가 과적합으로 인해 고통받지 않는다는 것을 나타냅니다.
Sample Efficiency.
사전 학습된 모델을 사용하는 것은 일반적으로 샘플 효율성 향상과 연결됩니다.
이 속성을 평가하기 위해 70k CLEVR 데이터 세트에서 각각 10k 및 1k 이미지를 랜덤으로 서브샘플링하여 두 개의 하위 집합을 만들었습니다.
그림 4(오른쪽)에 표시된 바와 같이 Projected GAN은 모든 데이터 세트 분할에서 두 베이스라인 모두에서 크게 향상됩니다.
5.2 Large Datasets
CLEVR과 LSUN-Church 외에도 다른 세 가지 대규모 데이터 세트에서 다양한 SOTA 모델과 비교하여 Projected GAN을 벤치마킹합니다: LSUN-Bedroom [84] (3M 실내 침실 장면), FFHQ [33] (7만 개의 얼굴 이미지) 및 Cityscape [9] (차량에서 캡처한 2만 5천 개의 운전 장면).
모든 데이터 세트에 대해 256^2 픽셀의 이미지 해상도를 사용합니다.
Cityscape과 CLEVR 이미지는 종횡비가 1:1이 아니기 때문에 학습을 위해 256^2로 크기를 조정합니다.
StyleGAN2-ADA 및 FastGAN 외에도 SAGAN [86] 및 GANsformer [26]과 비교합니다.
모든 모델은 10M 이미지에 대해 학습되었습니다.
대규모 데이터 세트의 경우 10M 이상의 이미지에 대해 학습된 StyleGAN2의 수를 보고하여 이전 문헌에서 달성한 가장 낮은 FID 값을 보고합니다(StyleGAN2*로 표시됨).
부록에서는 9개의 더 큰 데이터 세트에 대한 결과를 보고합니다.

표 3은 Projected GAN이 모든 데이터 세트의 FID 값 측면에서 모든 SOTA 모델을 큰 차이로 능가한다는 것을 보여줍니다.
예를 들어, LSUN-Bedroom에서 이 설정에서 이전에 최고의 모델이었던 GANsformer의 6.15와 비교하여 1.52의 FID 값을 달성합니다.
Projected GAN은 LSUN-church에서 SOTA FID 값을 현저하게 빠르게 달성합니다.
예를 들어, LSUN-church에서 1.1M Imgs 후 FID 값 3.18을 달성합니다.
StyleGAN2는 Projected GAN에 의해 필요한 것의 80배인 88M Imgs 후에 이전에 가장 낮은 FID 값인 3.39를 얻었습니다.
표 3과 같이 다른 모든 대규모 데이터 세트에서도 유사한 속도 향상이 실현됩니다.
흥미롭게도 FFHQ (39M Imgs)에서 더 오래 학습할 때 Projected GAN이 FID 2.2로 추가 개선되는 것을 관찰할 수 있습니다.
다섯 개의 데이터 세트 모두 다양한 장면에서 매우 다른 객체를 나타냅니다.
이는 피쳐 네트워크가 ImageNet에서만 학습되지만 데이터 세트의 선택에 강력하다는 것을 보여줍니다.
주요 개선 사항은 부록에 보고한 리콜에서 알 수 있듯이 향상된 샘플 다양성을 기반으로 한다는 점에 유의하는 것이 중요합니다.
다양성의 개선은 이미지 충실도가 StyleGAN과 유사한 것으로 보이는 LSUN church와 같은 대규모 데이터 세트에서 가장 두드러집니다.
5.3 Small Datasets
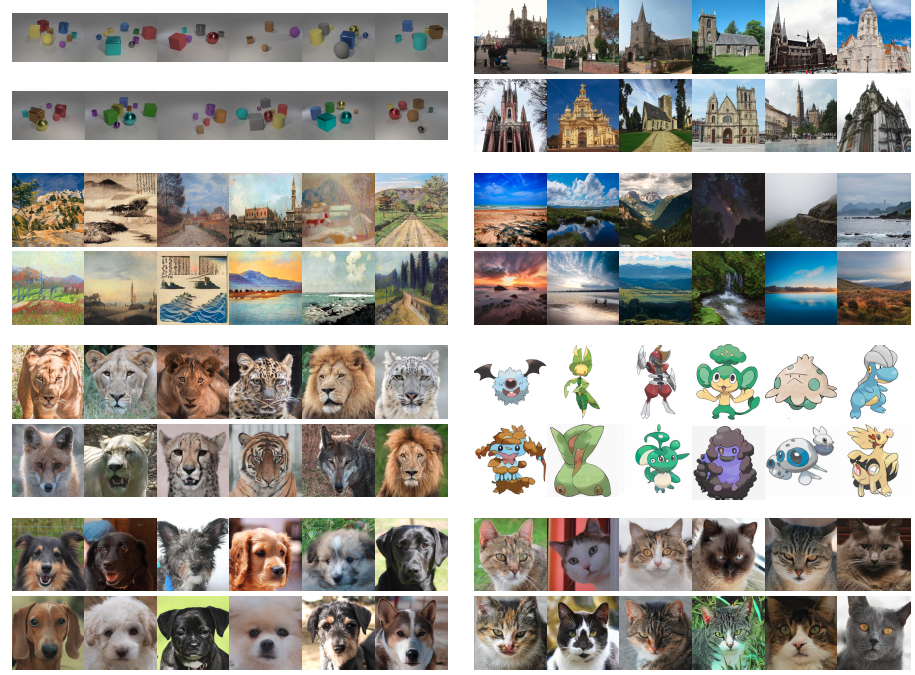
몇 번의 촬영 설정에서 우리의 방법을 추가로 평가하기 위해, 우리는 WikiArt (1000개의 이미지; wikiart.org ), Oxford Flowers (1360개의 이미지) [56], photographs of landscapes (4319개의 이미지; flickr.com ), AnimalFace-Dog (389개의 이미지)[72], Pokemon (833개의 이미지; pokemon.com )의 아트 페인팅에 대한 StyleGAN2-ADA 및 FastGAN과 비교합니다.
또한, 우리는 포켓몬과 아트-페인팅 (1024^2)의 고해상도 버전에 대한 결과를 보고합니다.
마지막으로, 우리는 AFHQ-Cat, -Dog 및 -Wild에 대해 512^2 [7]로 평가합니다.
AFHQ 데이터 세트에는 고양이, 개 또는 야생 동물당 ~5,000개의 클로즈업이 포함되어 있습니다.
우리는 이러한 데이터 세트를 재배포로 변환할 수 있는 라이센스가 없지만, [49]와 유사하게 재현성을 가능하게 하는 URL을 제공합니다.
Projected GAN은 표 3과 같이 모든 데이터 세트와 모든 해상도에서 FID 값 측면에서 모든 베이스라인을 크게 능가합니다.
놀랍게도, 저희 모델은 60만 개 미만의 이미지를 관찰한 후 모든 데이터 세트(256^2)에서 이전의 SOTA를 능가합니다.
AnimalFace-Dog의 경우 Projected GAN은 단 20,000개의 이미지 후에 이전의 최고 FID를 능가합니다.
EfficientNet이 많은 동물 클래스 (예: 개 품종의 경우 120개 클래스)를 포함하는 ImageNet에서 학습되기 때문에 피쳐 네트워크로 사용되는 EfficientNet이 동물 데이터 세트에 대한 데이터 생성을 용이하게 한다고 주장할 수 있습니다.
그러나 이러한 데이터 세트는 ImageNet과 크게 다르지만 Projected GAN은 포켓몬과 아트 페인팅에서도 SOTA FID를 달성한다는 것이 흥미롭습니다.
이는 ImageNet 피쳐의 일반성을 증명합니다.
고해상도 데이터 세트의 경우 Projected GAN은 AFHQCat의 StyleGAN2-ADA보다 10배 또는 Pokemon의 FastGAN보다 4배 빠르게 동일한 FID 값을 달성합니다.
F와 D_l은 완전히 컨볼루션되기 때문에 모든 해상도로 일반화됩니다.

6 Discussion and Future Work
모든 데이터 세트에서 낮은 FID를 달성하는 반면, 우리는 두 가지 체계적인 실패 사례도 식별합니다: 그림 7에서 볼 수 있듯이, 우리는 때때로 AFHQ에서 "floating heads"를 관찰합니다.
몇 가지 샘플에서 동물은 고품질로 보이지만 블러하거나 밋밋한 배경에서 잘라낸 것과 유사합니다.
우리는 눈에 띄는 물체가 이미 묘사되었을 때 현실적인 배경과 이미지 구성을 생성하는 것이 덜 중요하다고 가정합니다.
이 가설은 배경이 제거된 물체의 이미지에 적용될 때 정확도가 약간만 감소하는 것으로 나타난 투영에 이미지 분류 모델을 사용했다는 사실에서 비롯됩니다 [83].
FFHQ에서 투영된 GAN은 때때로 SOTA FID에서도 잘못된 비율과 아티팩트로 불량한 품질의 샘플을 생성합니다(그림 8 참조).

생성기 측면에서 StyleGAN은 조정하기가 더 어렵고 예측된 학습을 통해 많은 이익을 얻지 못합니다.
FastGAN 생성기는 최적화 속도가 빠르지만 동시에 잠재 공간의 일부 부분에서 비현실적인 샘플을 생성합니다 – StyleGAN과 유사한 매핑 네트워크로 해결할 수 있는 문제입니다.
따라서, 저희는 두 아키텍처의 강점을 예측된 학습과 결합하여 통합하면 성능이 더욱 향상될 수 있다고 추측합니다.
또한, 다양한 사전 학습된 네트워크에 대한 저희의 연구는 효율적인 모델이 Projected GAN 학습에 특히 적합하다는 것을 보여줍니다.
이 연결을 심층적으로, 그리고 일반적으로 바람직한 피쳐 공간 속성을 결정하는 것은 흥미로운 새로운 연구 기회를 열어줍니다.
마지막으로, 저희의 작업은 생성 모델에 대한 효율성을 발전시킵니다.
보다 효율적인 모델은 실제 이미지를 생성하는 데 필요한 계산 노력의 장벽을 낮춥니다.
장벽이 낮아지면 생성 모델(예: "deep fakes")의 악성 사용이 용이해지는 동시에 이 분야의 연구가 민주화됩니다.